
A Comparative Study of the Use of Stratified Cross-Validation and Distribution-Balanced Stratified Cross-Validation in Imbalanced Learning



Abstract
1. Introduction
2. Materials and Methods
2.1. Validation Methods
2.1.1. SCV
| Algorithm 1 Fold generation of SCV (based on Ref. [20]) | |||
| Require: k // number of folds | |||
| Require: // classes | |||
| Ensure: // generated folds | |||
| for to n do | |||
| if mod k) then | |||
| end if | |||
| for to k do | |||
| randomly select n samples from | |||
| \S | |||
| end for | |||
| end for | |||
2.1.2. DOB-SCV
| Algorithm 2 Fold generation of DOB-SCV (based on Ref. [20]) | |||
| Require: k // number of folds | |||
| Require: // classes | |||
| Ensure: // generated folds | |||
| for to n do | |||
| while do | |||
| randomly select sample from | |||
| \ | |||
| for to k do | |||
| select the nearest neighbour of from | |||
| \ | |||
| if then | |||
| // end for j | |||
| end if | |||
| end for | |||
| end while | |||
| end for | |||
2.2. Classifiers
2.2.1. kNN
2.2.2. SVM
2.2.3. MLP
2.2.4. DTree
2.3. Oversamplers
2.4. Data Sets
2.5. Measures
3. Experiments and Results
3.1. Analysis 1: Comparison of the Validation Methods
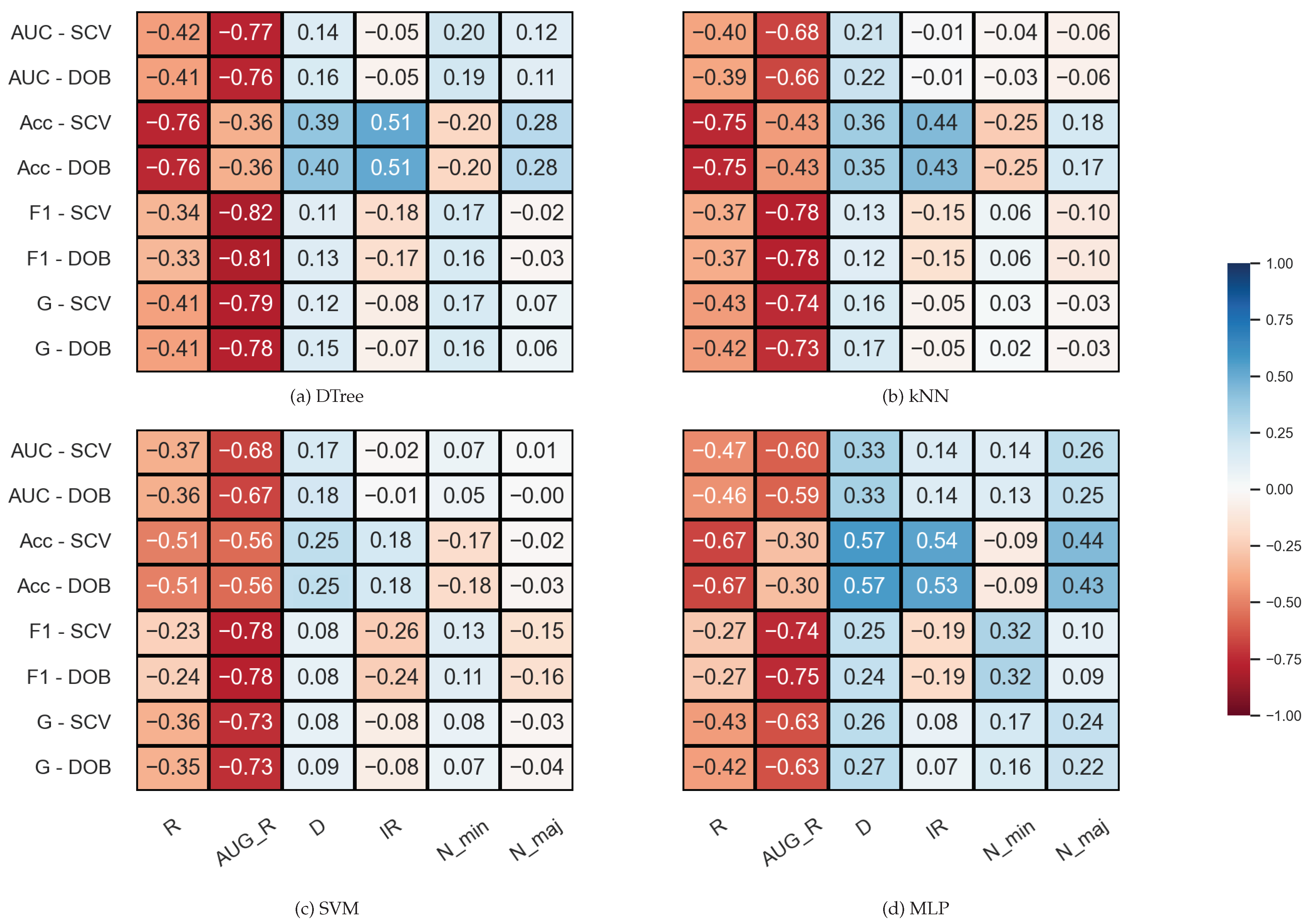
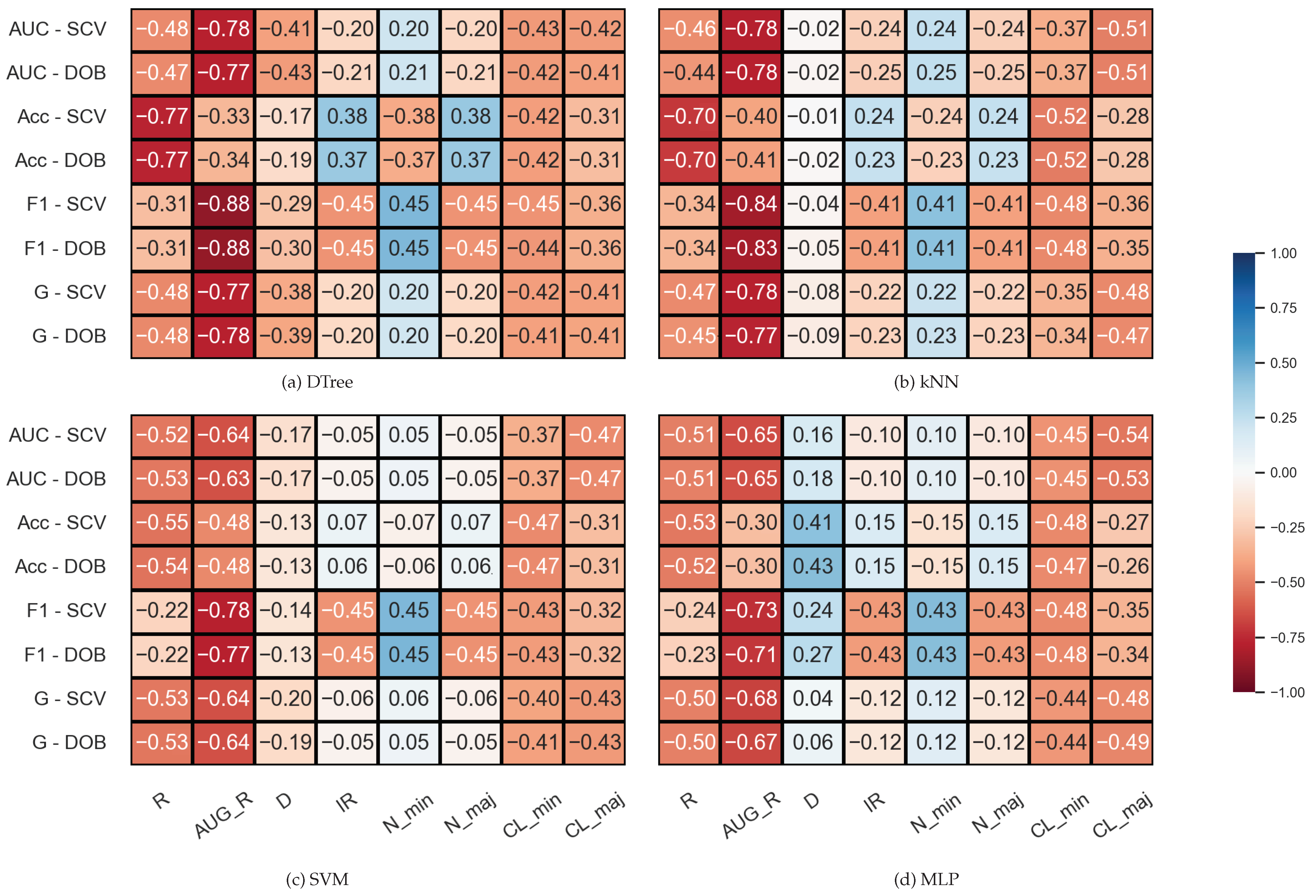
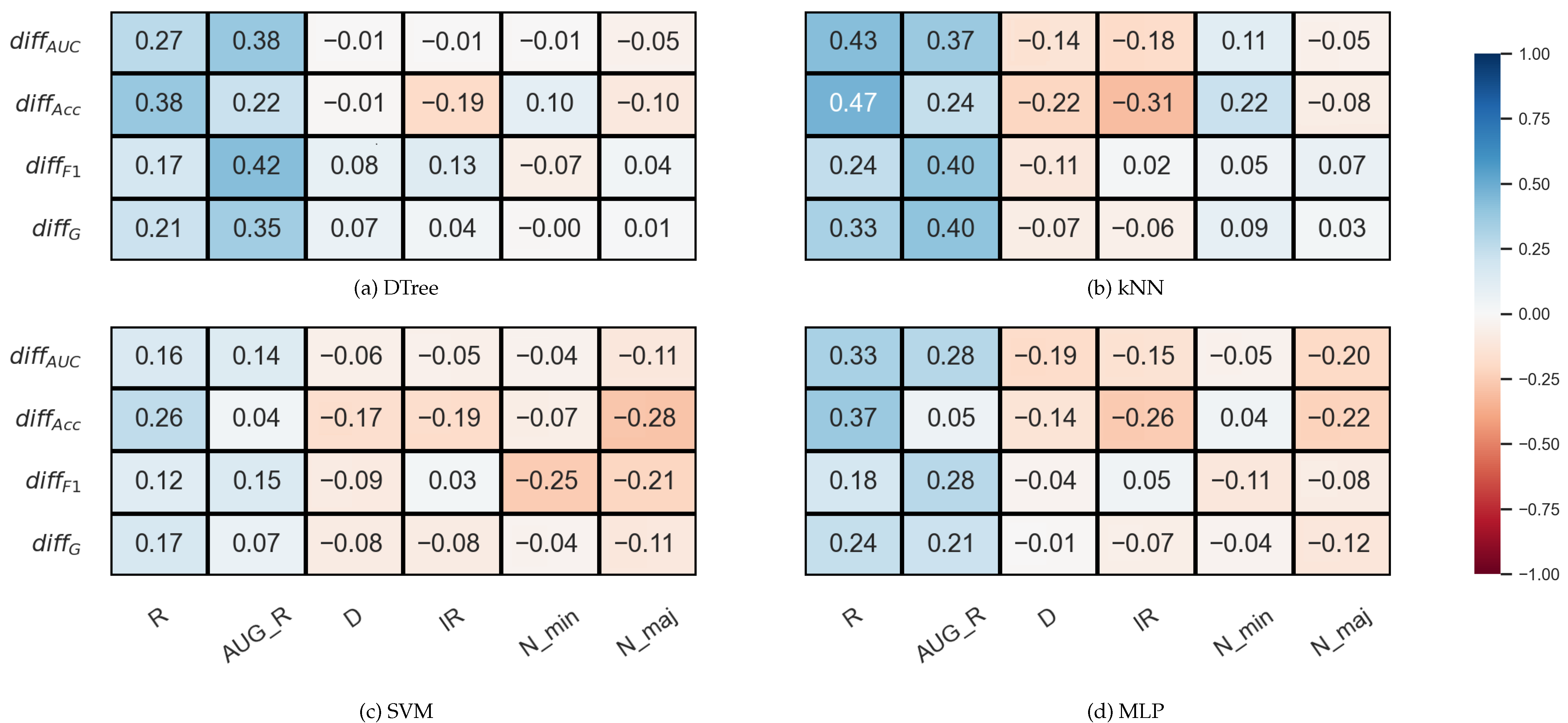
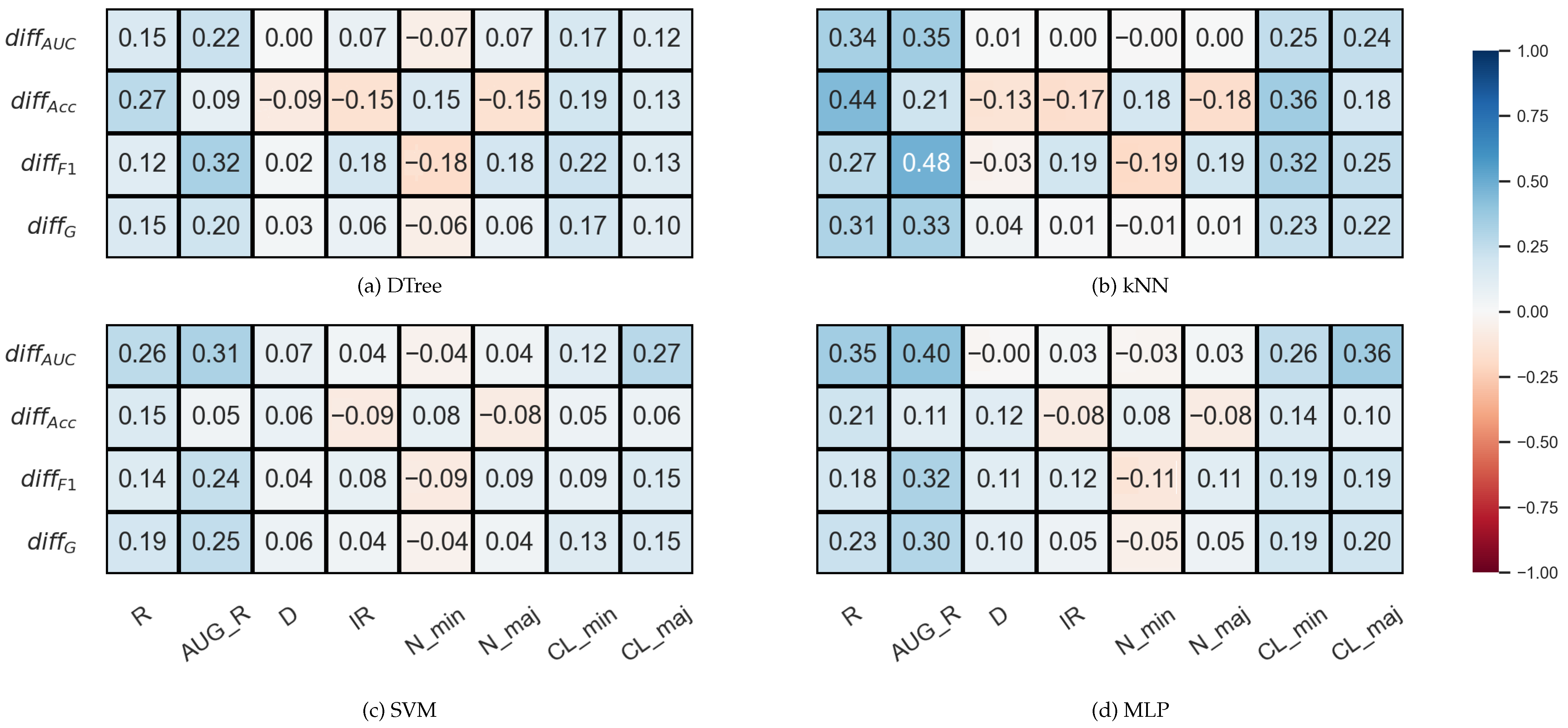
3.2. Correlation Analysis
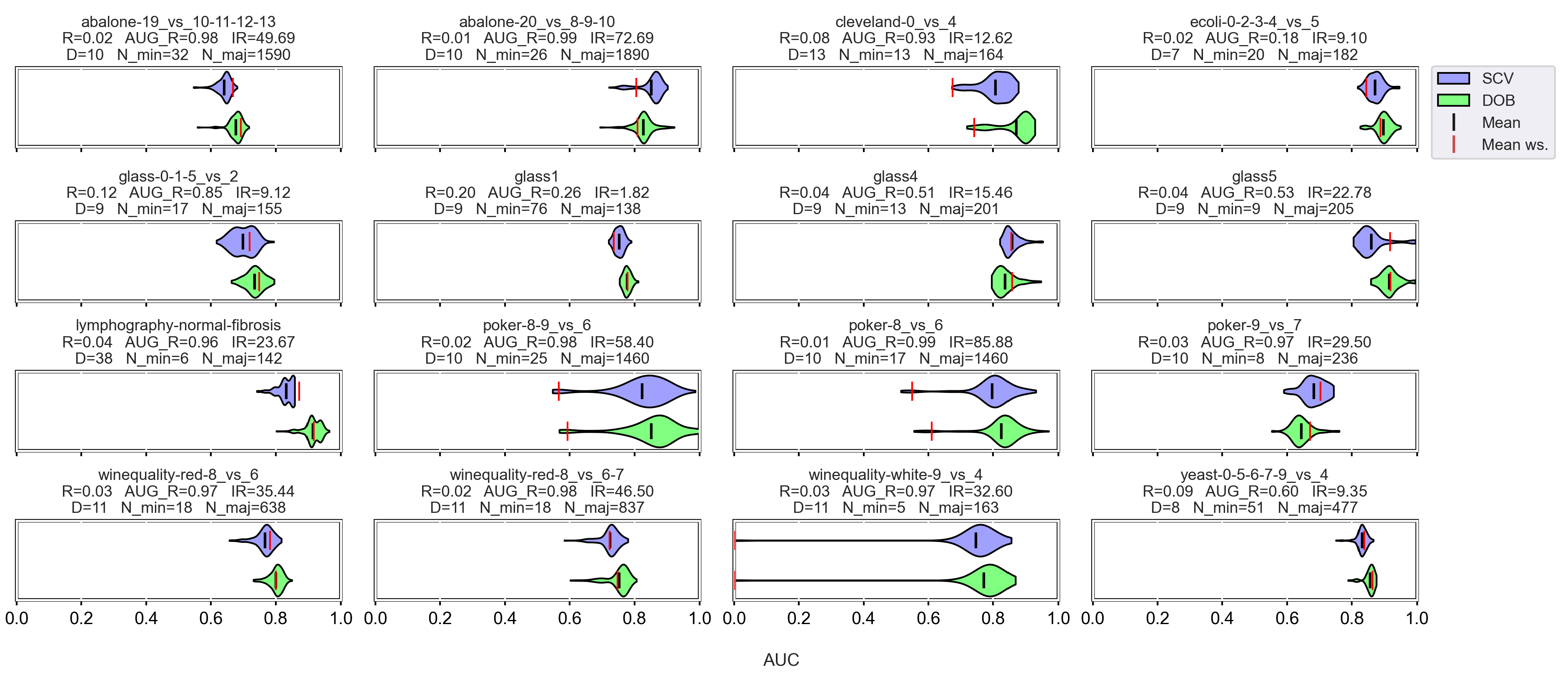
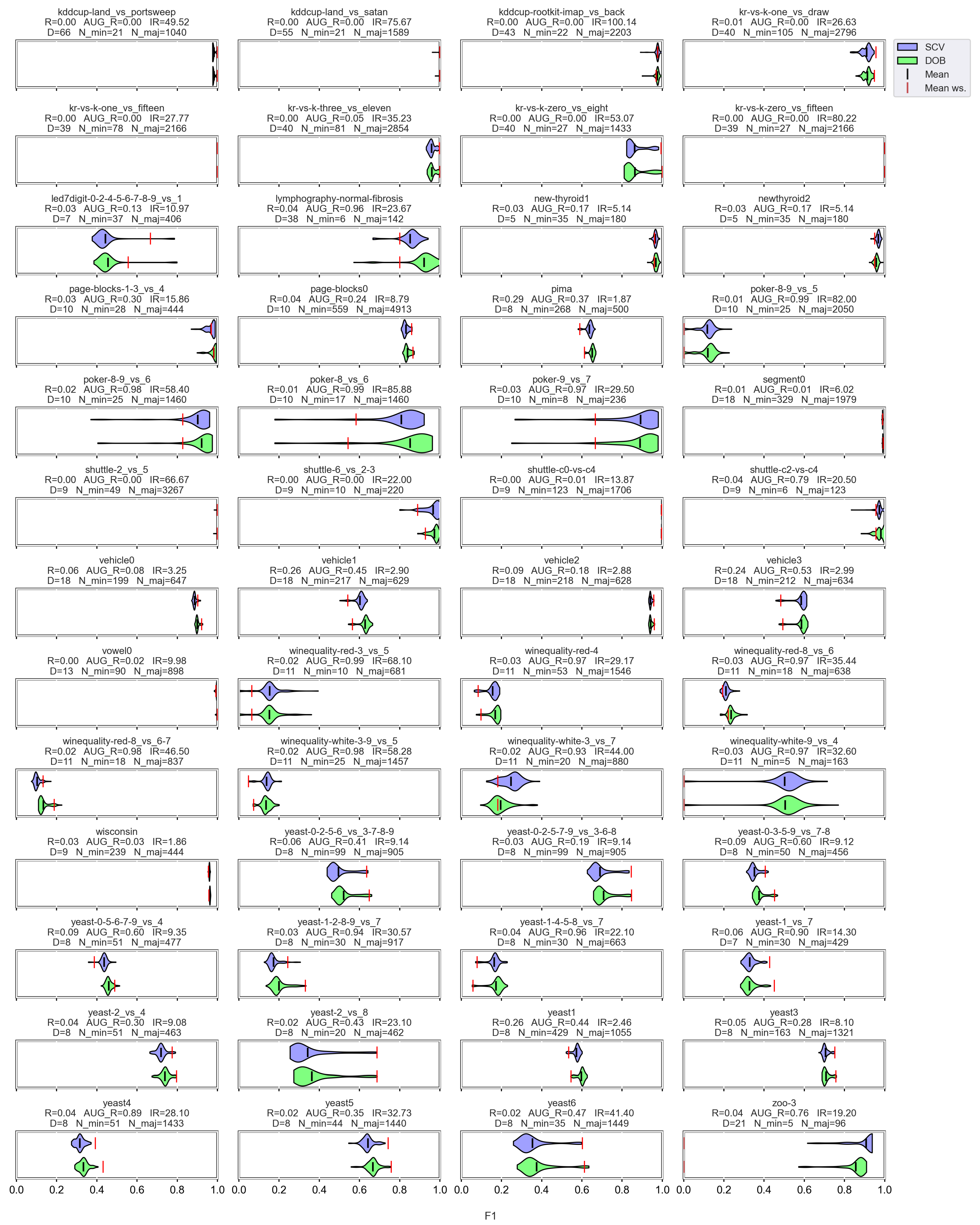
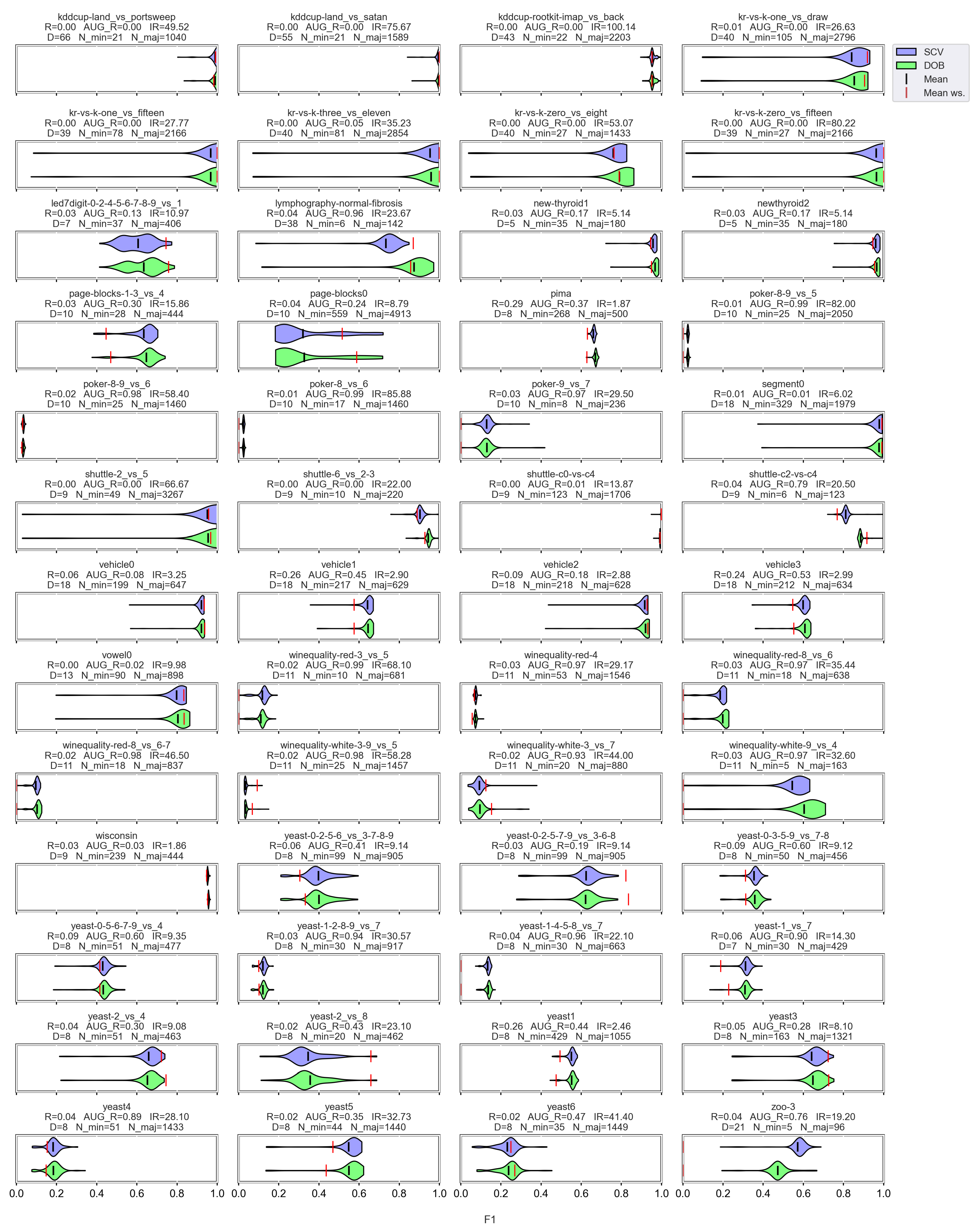
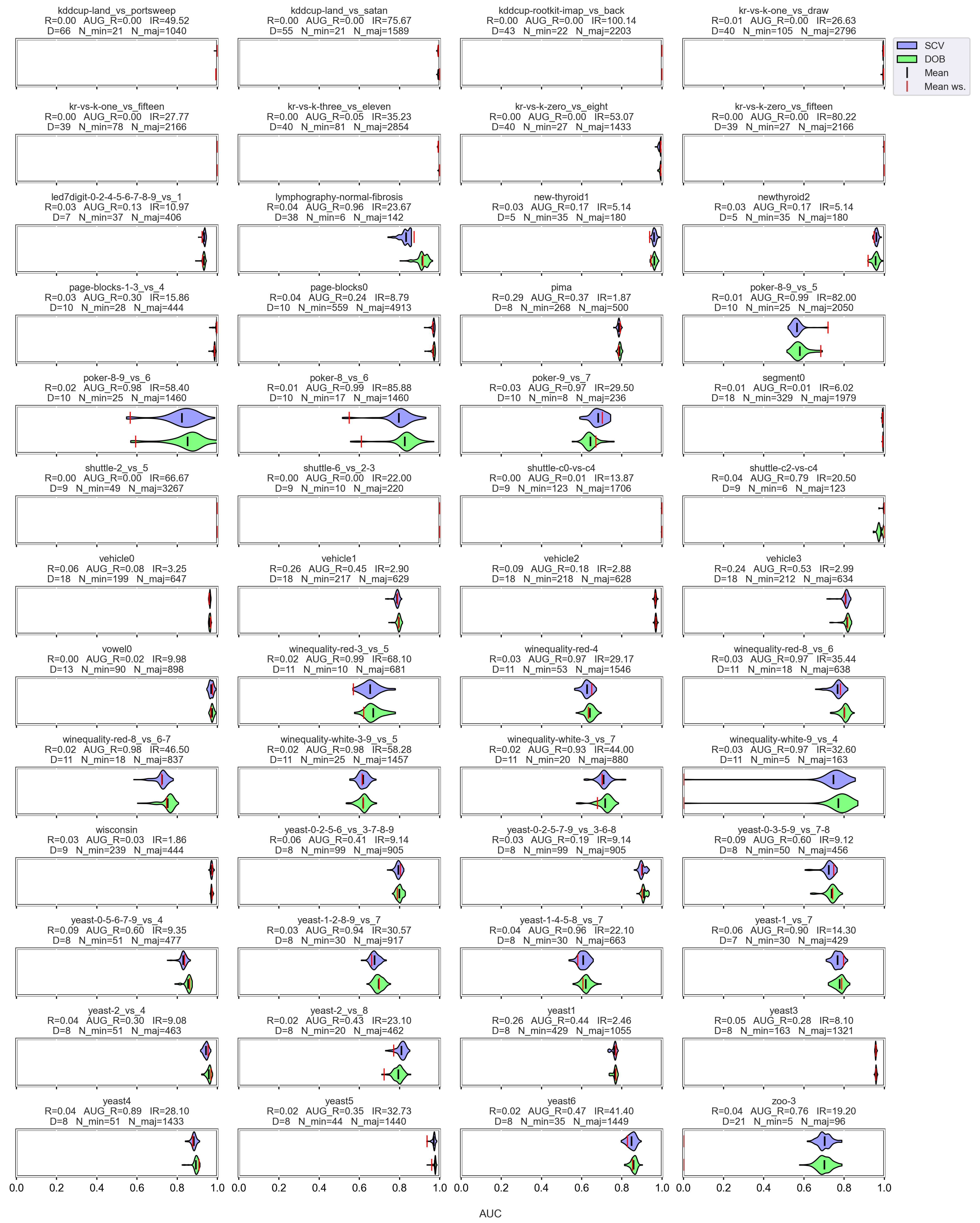
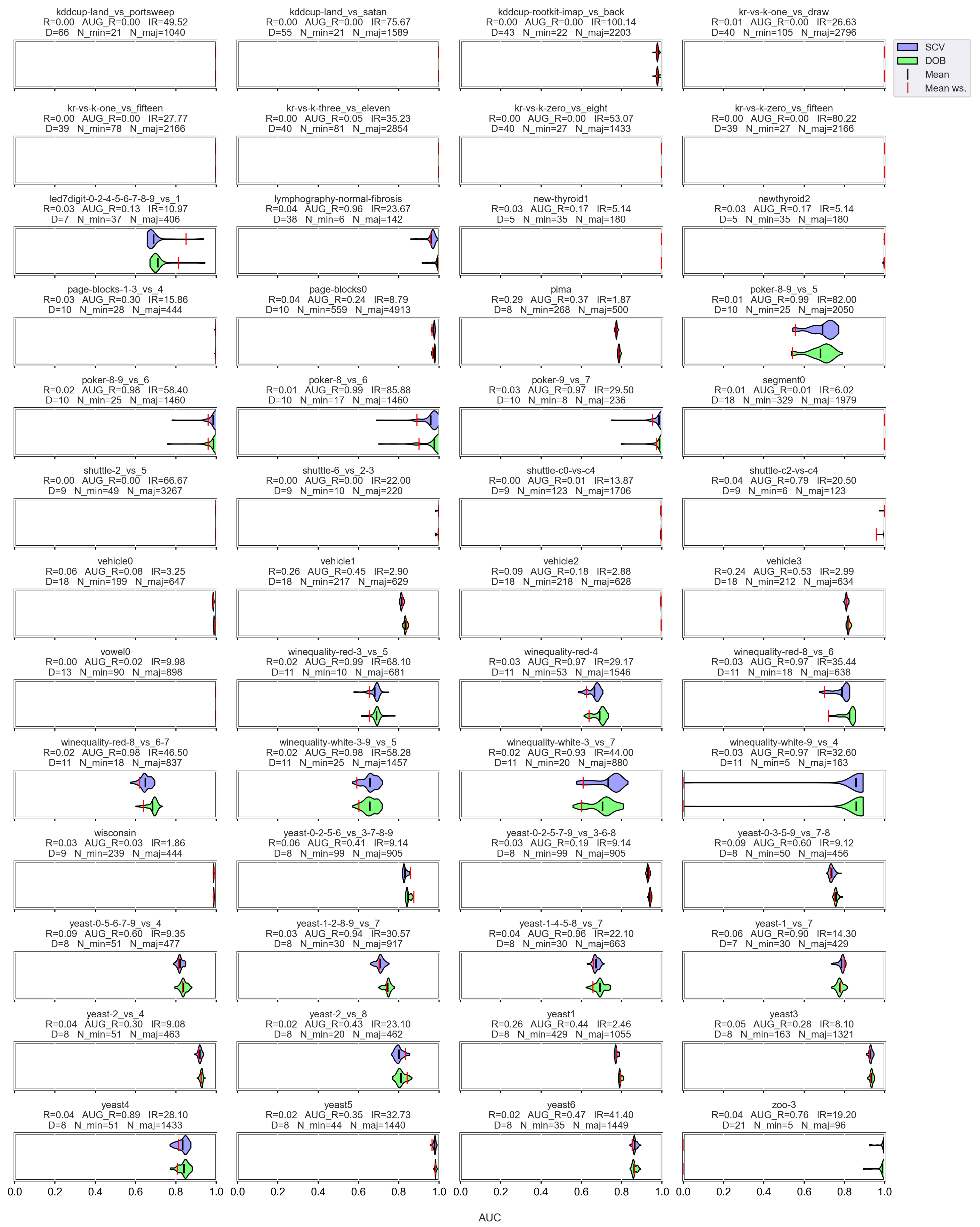
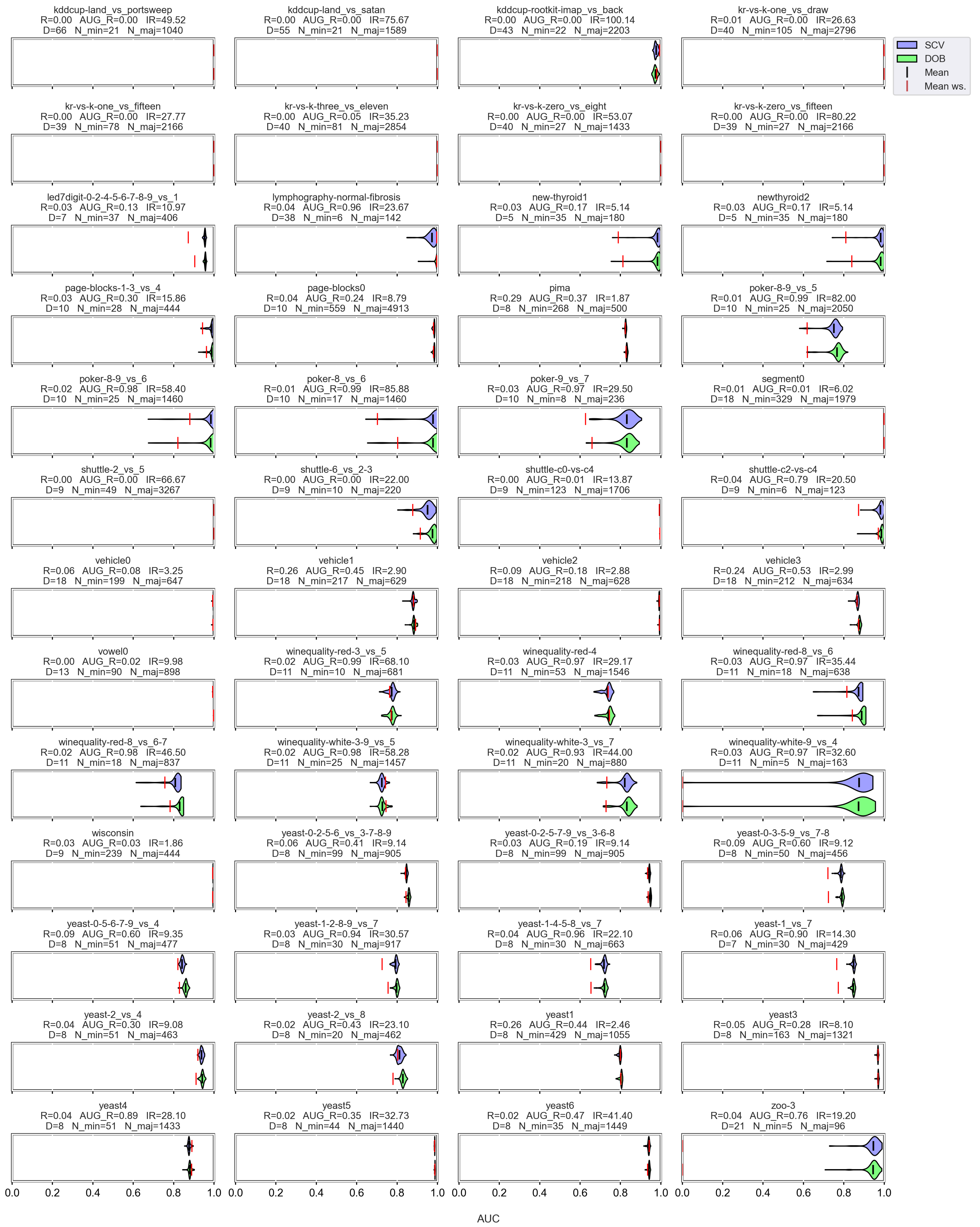
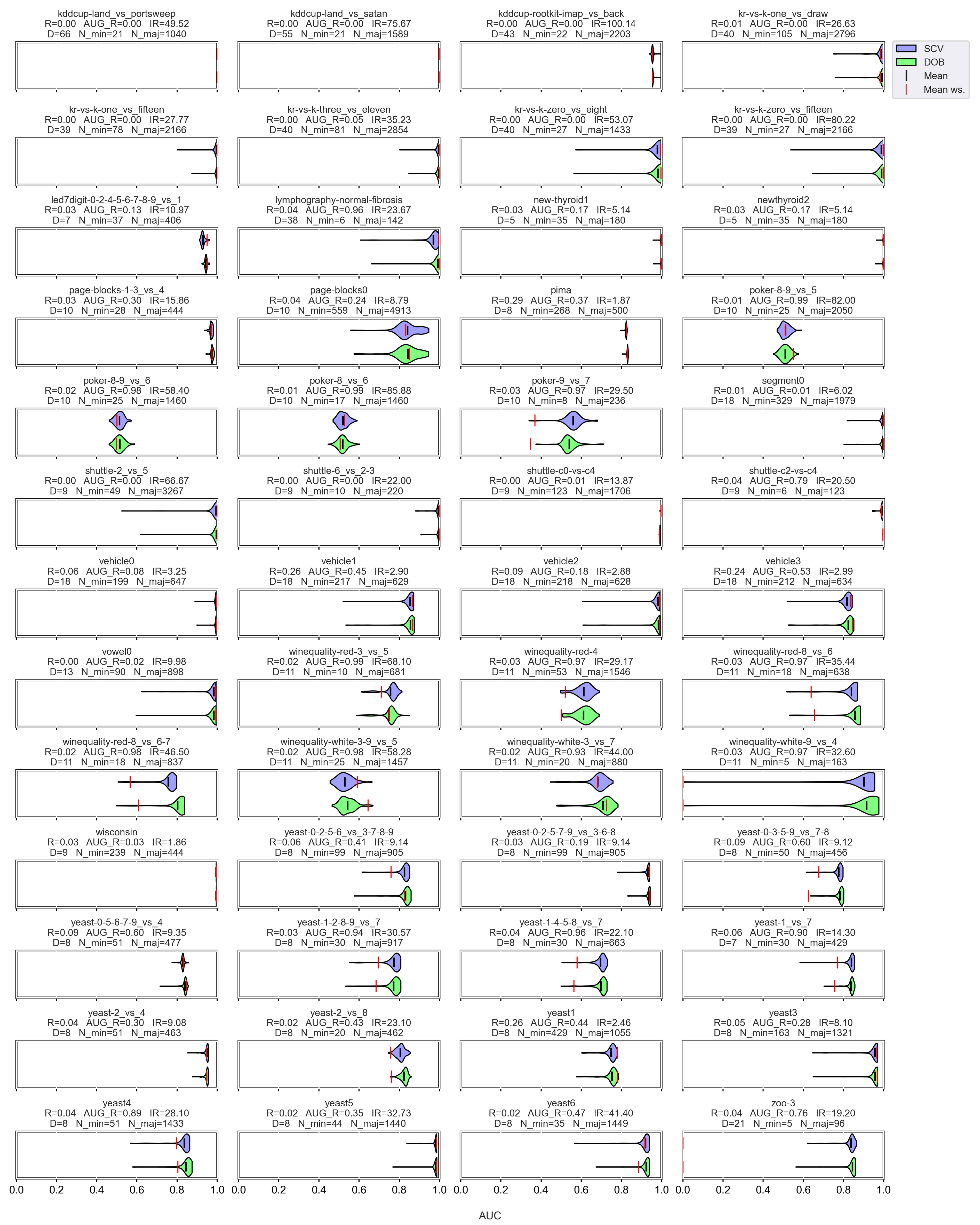
3.3. Graphical Analysis per Data Set
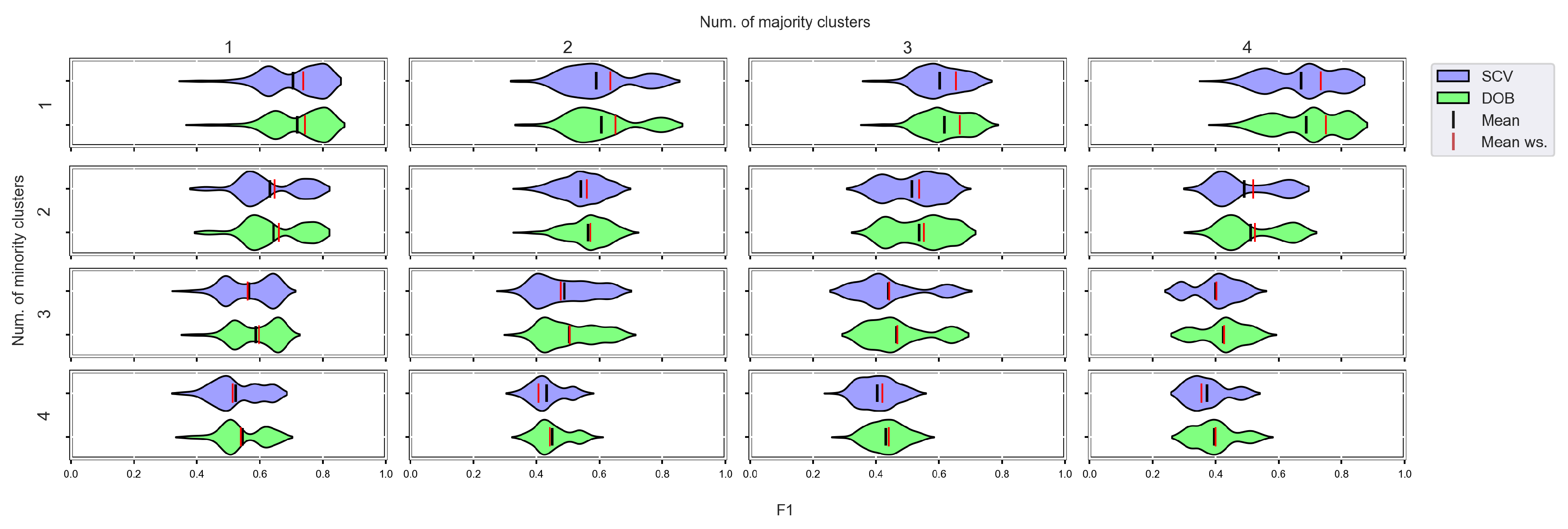
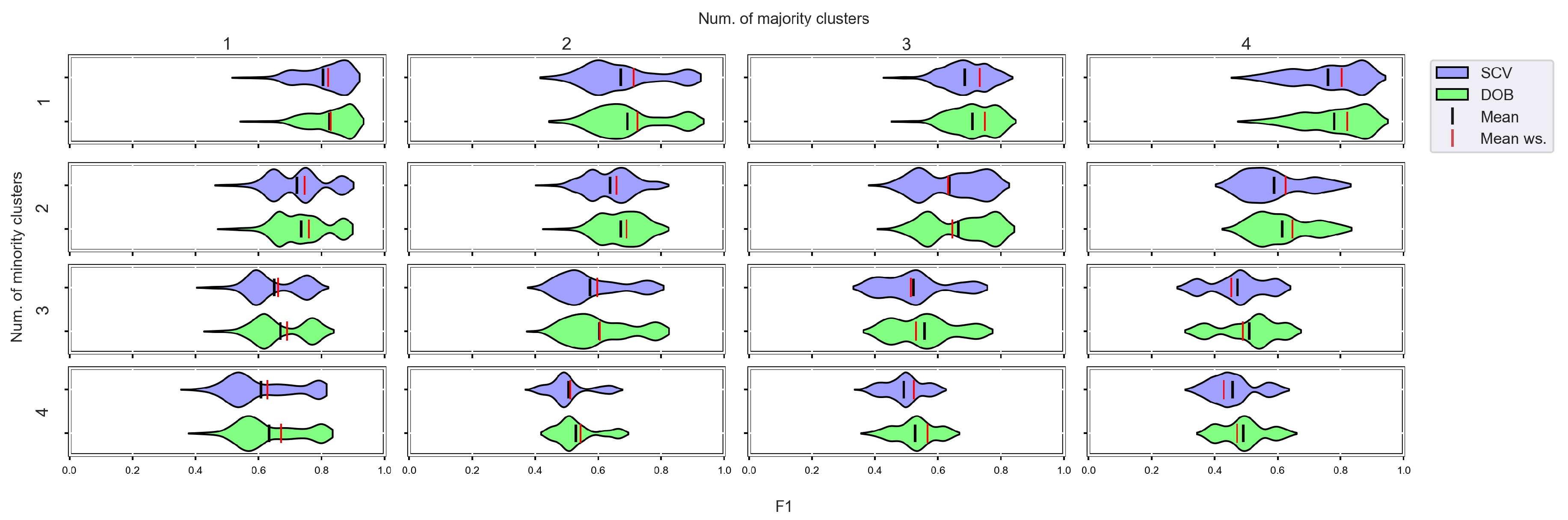
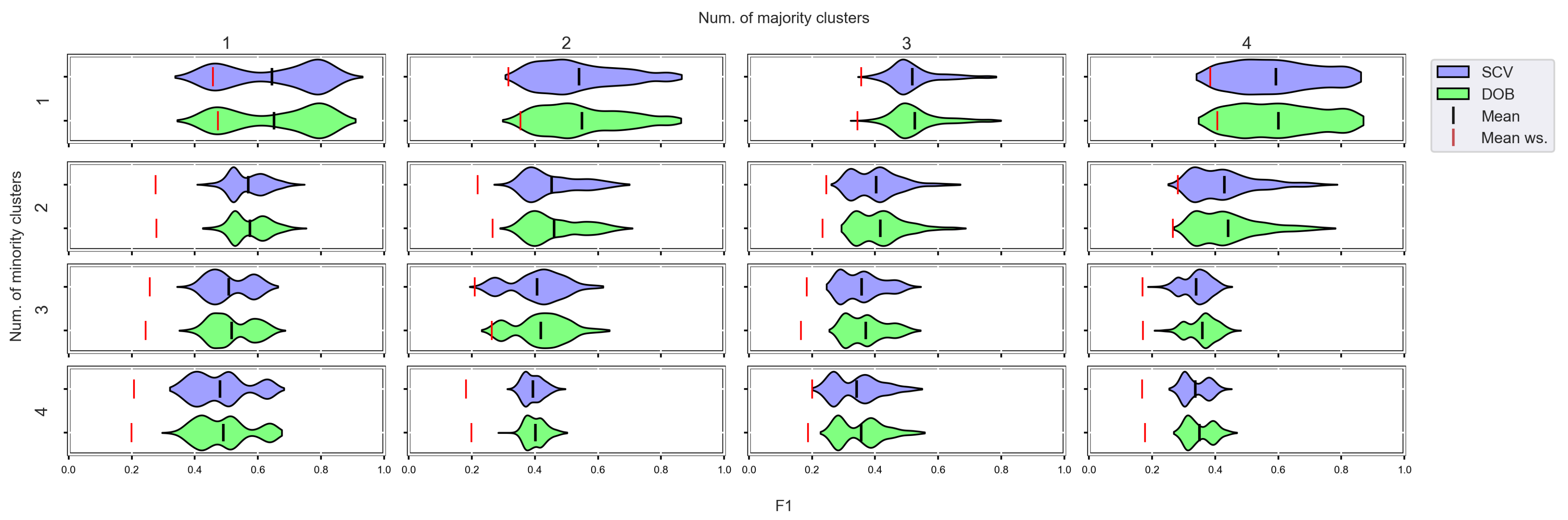
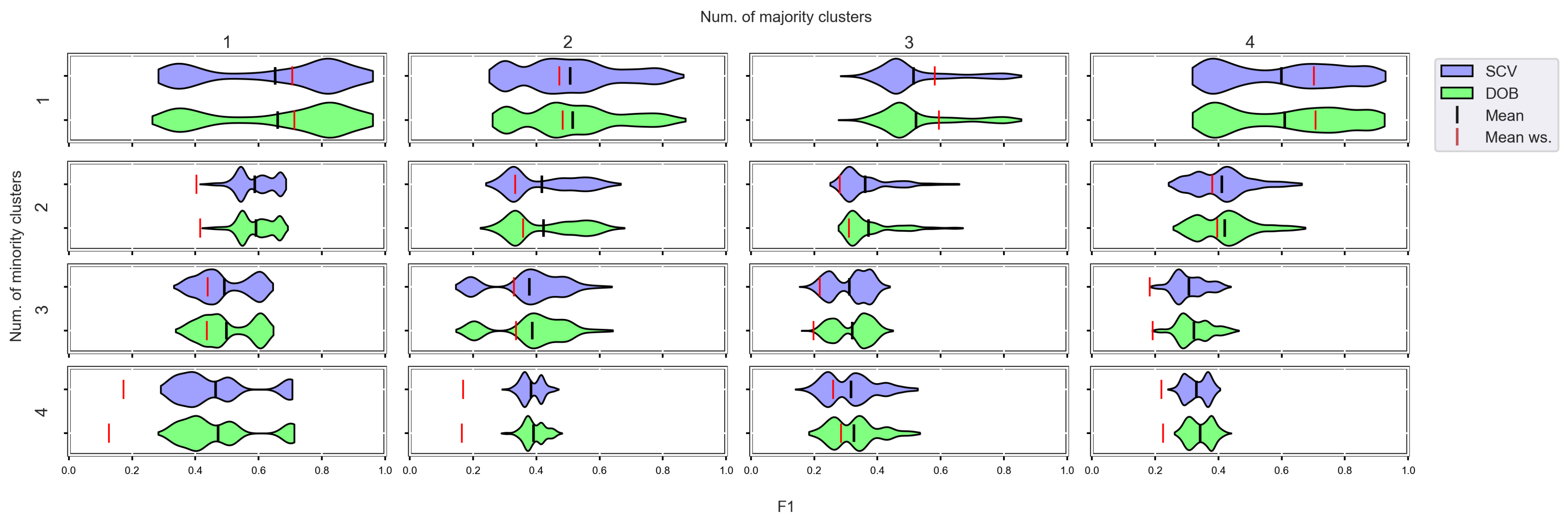
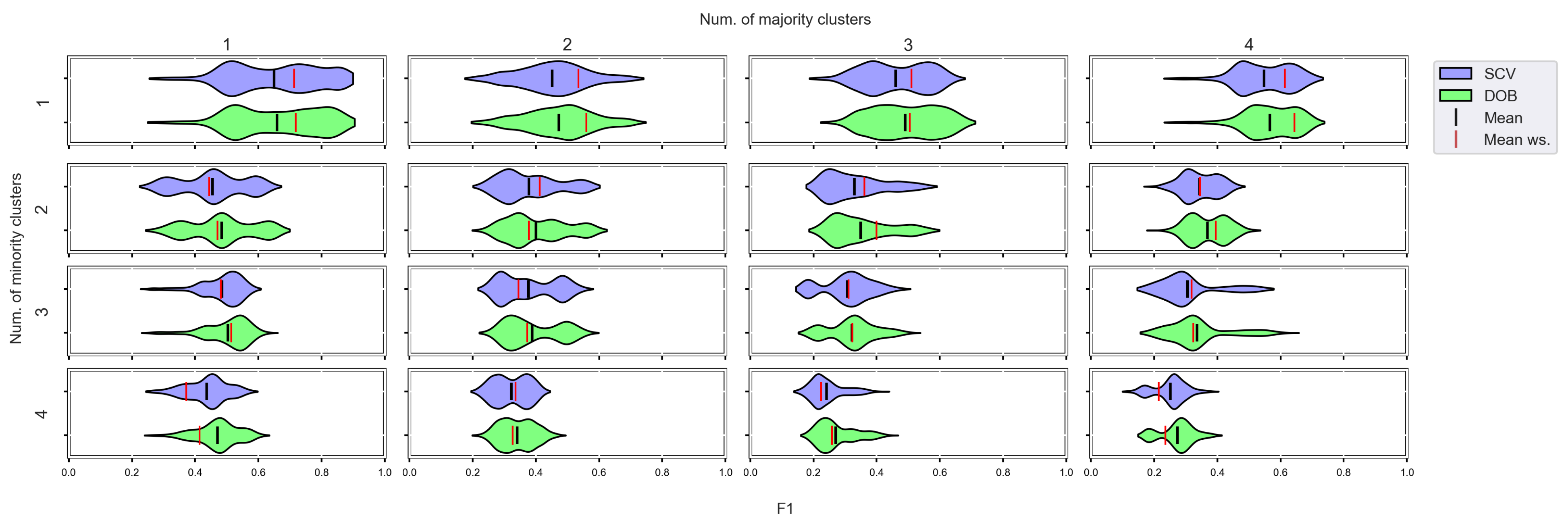
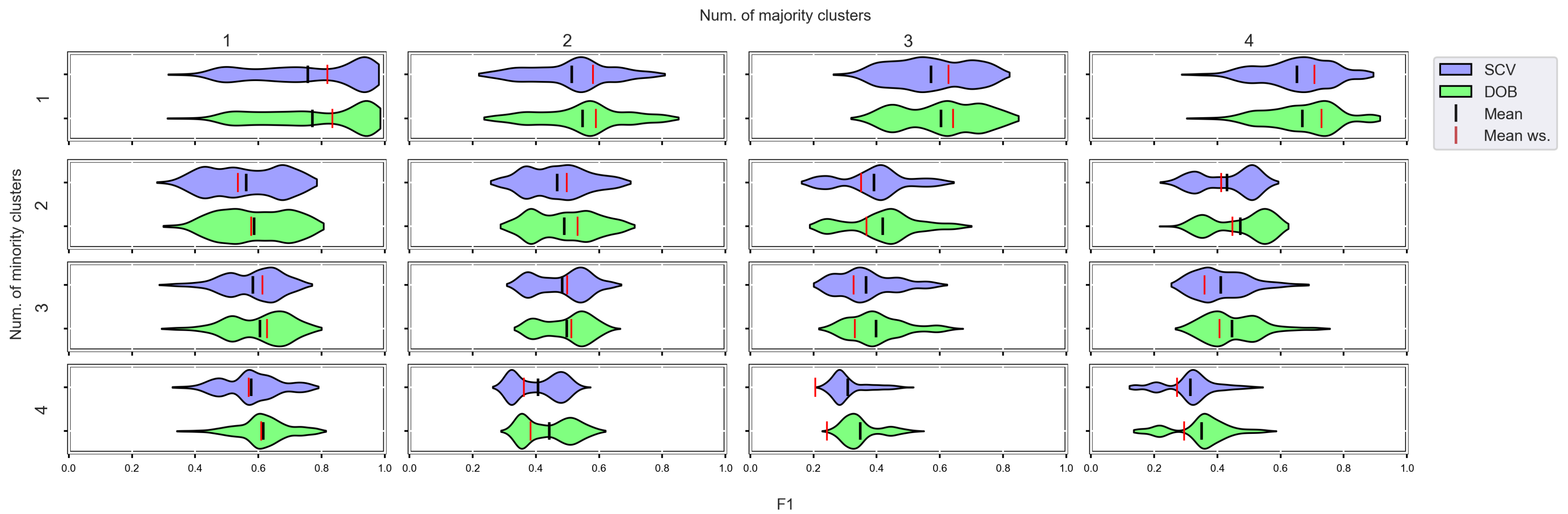
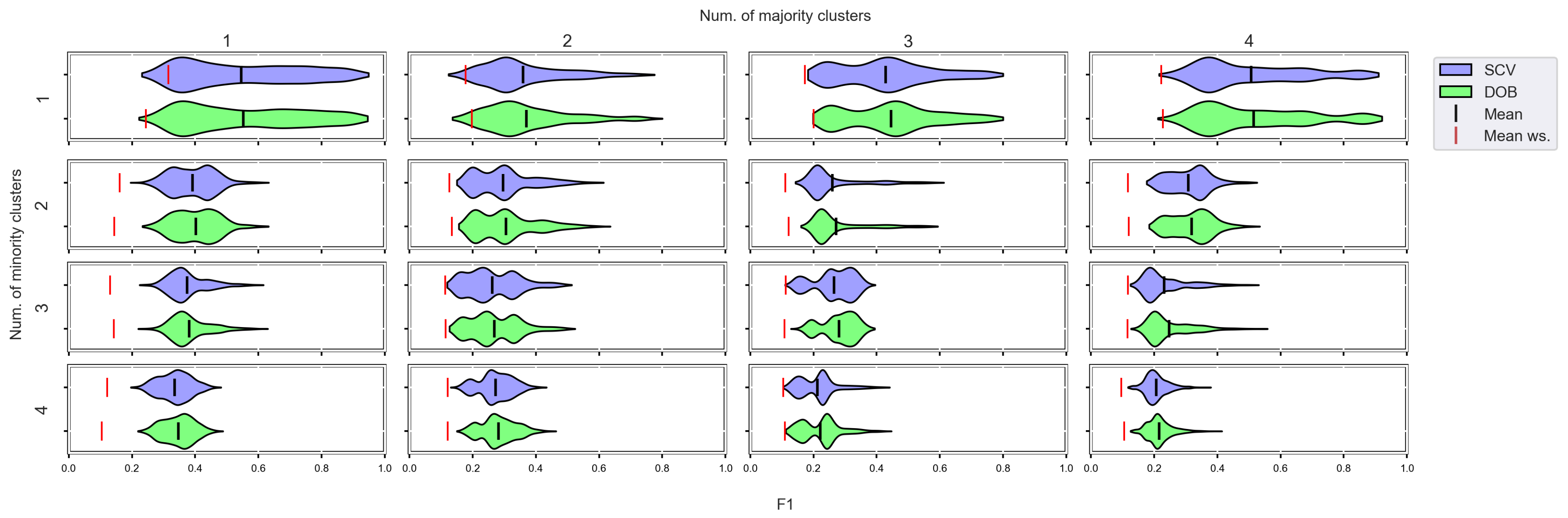
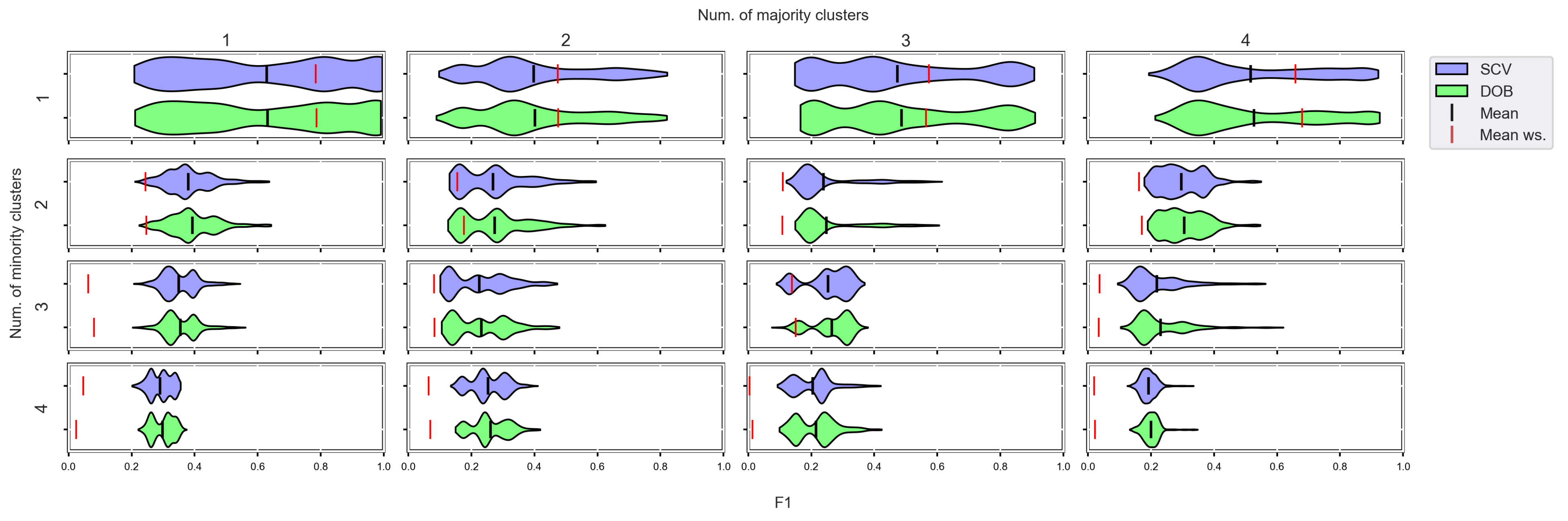
3.4. Graphical Analysis for Clusters
4. Conclusions
- In general, slightly higher F1, AUC G, Acc values can be achieved with DOB-SCV than SCV in combination oversamplers and classifiers;
- Based on our experiments, we can not confirm the statement [19] that the difference between the two verification techniques involved in our tests (SCV, DOB-SCV) increases when the imbalance ratio of the data sets increases;
- We can state that there is a difference between SCV and DOB-SCV in favor of DOB-SCV when the number of clusters within the classes or the volume of overlapping between the clusters increases;
- The selection of the sampler–classifier pair is much more critical for the classification performance than the choice between these two validation techniques.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A




Appendix B




Appendix C




Appendix D

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DTree | kNN | |||||||
|---|---|---|---|---|---|---|---|---|
| Sampler | % | % | % | % | % | % | % | % |
| Assembled-SMOTE | 0.79 | 0.21 | 1.16 | 0.65 | 0.89 | 0.36 | 1.65 | 0.97 |
| CCR | 0.70 | 0.14 | 1.36 | 0.96 | 1.02 | 0.29 | 1.93 | 1.21 |
| G-SMOTE | 1.05 | 0.26 | 1.91 | 1.10 | 0.89 | 0.34 | 1.83 | 1.09 |
| LVQ-SMOTE | 0.57 | 0.27 | 1.49 | 0.58 | 0.89 | 0.39 | 2.27 | 1.32 |
| Lee | 0.98 | 0.26 | 1.71 | 0.87 | 0.87 | 0.38 | 1.61 | 0.97 |
| ModularOverSampler | 0.71 | 0.26 | 1.49 | 0.92 | 0.96 | 0.39 | 2.06 | 1.37 |
| ProWSyn | 0.93 | 0.23 | 1.27 | 0.95 | 0.86 | 0.43 | 1.73 | 1.00 |
| Polynomial fitting SMOTE | 0.80 | 0.14 | 1.47 | 1.11 | 0.95 | 0.31 | 2.09 | 1.31 |
| SMOBD | 0.86 | 0.23 | 1.44 | 0.82 | 0.85 | 0.35 | 1.47 | 0.89 |
| SMOTE | 0.96 | 0.28 | 1.69 | 0.79 | 0.86 | 0.34 | 1.57 | 0.96 |
| SMOTE-IPF | 0.92 | 0.24 | 1.21 | 0.86 | 0.85 | 0.37 | 1.54 | 0.90 |
| SMOTE-TomekLinks | 0.91 | 0.19 | 1.21 | 0.94 | 0.90 | 0.35 | 1.61 | 0.99 |
| SVM | MLP | |||||||
| Assembled-SMOTE | 0.48 | 0.29 | 1.70 | 0.54 | 0.52 | 0.18 | 1.16 | 0.53 |
| CCR | 0.64 | 0.26 | 1.19 | 0.56 | 0.65 | 0.18 | 1.00 | 0.64 |
| G-SMOTE | 0.48 | 0.24 | 1.73 | 0.73 | 0.51 | 0.18 | 1.15 | 0.68 |
| LVQ-SMOTE | 0.46 | 0.12 | 1.04 | 0.48 | 0.50 | 0.21 | 1.00 | 0.56 |
| Lee | 0.46 | 0.18 | 1.61 | 0.65 | 0.51 | 0.19 | 1.19 | 0.55 |
| ModularOverSampler | 0.41 | 0.25 | 1.70 | 0.63 | 0.59 | 0.27 | 1.42 | 0.69 |
| ProWSyn | 0.45 | 0.24 | 1.49 | 0.54 | 0.55 | 0.25 | 1.36 | 0.68 |
| Polynomial fitting SMOTE | 0.45 | 0.14 | 1.44 | 0.50 | 0.58 | 0.27 | 1.46 | 0.64 |
| SMOBD | 0.43 | 0.11 | 1.49 | 0.48 | 0.49 | 0.23 | 1.34 | 0.68 |
| SMOTE | 0.38 | 0.28 | 1.54 | 0.49 | 0.83 | 0.37 | 1.54 | 0.78 |
| SMOTE-IPF | 0.44 | 0.32 | 1.50 | 0.42 | 0.61 | 0.29 | 1.24 | 0.57 |
| SMOTE-TomekLinks | 0.45 | −0.06 | 1.69 | 0.53 | 0.59 | 0.23 | 1.23 | 0.79 |
| DTree | kNN | |||||||
|---|---|---|---|---|---|---|---|---|
| Sampler | % | % | % | % | % | % | % | % |
| Assembled-SMOTE | 1.77 | 0.61 | 4.49 | 1.73 | 1.43 | 0.81 | 4.62 | 1.85 |
| CCR | 1.58 | 0.55 | 4.09 | 1.52 | 1.58 | 0.78 | 4.93 | 2.01 |
| G-SMOTE | 1.86 | 0.54 | 4.68 | 1.86 | 1.53 | 0.70 | 4.61 | 1.98 |
| LVQ-SMOTE | 1.48 | 0.64 | 4.02 | 1.49 | 1.46 | 0.74 | 4.35 | 1.77 |
| Lee | 1.80 | 0.61 | 4.49 | 1.77 | 1.44 | 0.79 | 4.53 | 1.86 |
| ModularOverSampler | 1.80 | 0.59 | 4.59 | 1.97 | 1.65 | 0.82 | 4.97 | 2.24 |
| ProWSyn | 1.80 | 0.71 | 4.19 | 1.77 | 1.45 | 0.98 | 4.57 | 1.79 |
| Polynomial Fitting SMOTE | 1.49 | 0.41 | 4.33 | 1.97 | 1.54 | 0.56 | 4.70 | 2.33 |
| SMOBD | 1.79 | 0.61 | 4.46 | 1.74 | 1.44 | 0.80 | 4.52 | 1.83 |
| SMOTE | 1.86 | 0.63 | 4.68 | 1.77 | 1.42 | 0.77 | 4.49 | 1.86 |
| SMOTE-IPF | 1.79 | 0.65 | 4.74 | 1.74 | 1.46 | 0.80 | 4.55 | 1.87 |
| SMOTE-TomekLinks | 1.77 | 0.62 | 4.65 | 1.83 | 1.48 | 0.81 | 4.60 | 1.86 |
| SVM | MLP | |||||||
| Assembled-SMOTE | 1.55 | 0.47 | 2.44 | 1.42 | 1.45 | 0.56 | 3.13 | 1.62 |
| CCR | 1.43 | 0.41 | 2.11 | 1.16 | 1.25 | 0.49 | 2.58 | 1.36 |
| G-SMOTE | 1.50 | 0.43 | 2.41 | 1.35 | 1.40 | 0.41 | 3.05 | 1.52 |
| LVQ-SMOTE | 1.32 | 0.47 | 2.10 | 1.14 | 1.26 | 0.45 | 2.69 | 1.28 |
| Lee | 1.55 | 0.47 | 2.46 | 1.46 | 1.43 | 0.44 | 2.95 | 1.60 |
| ModularOverSampler | 1.61 | 0.44 | 2.53 | 1.47 | 1.56 | 0.49 | 3.34 | 1.70 |
| ProWSyn | 1.48 | 0.41 | 2.27 | 1.29 | 1.36 | 0.52 | 2.88 | 1.46 |
| Polynomial Fitting SMOTE | 1.42 | 0.24 | 2.38 | 1.35 | 1.43 | 0.39 | 2.95 | 1.36 |
| SMOBD | 1.51 | 0.40 | 2.32 | 1.36 | 1.41 | 0.48 | 2.97 | 1.58 |
| SMOTE | 1.56 | 0.50 | 2.41 | 1.45 | 1.48 | 0.53 | 2.93 | 1.55 |
| SMOTE-IPF | 1.58 | 0.45 | 2.39 | 1.43 | 1.40 | 0.47 | 3.06 | 1.67 |
| SMOTE-TomekLinks | 1.54 | 0.34 | 2.31 | 1.38 | 1.55 | 0.69 | 3.11 | 1.57 |
References
- El-Naby, A.; Hemdan, E.E.D.; El-Sayed, A. An efficient fraud detection framework with credit card imbalanced data in financial services. Multimed. Tools Appl. 2023, 82, 4139–4160. [Google Scholar] [CrossRef]
- Singh, A.; Ranjan, R.K.; Tiwari, A. Credit card fraud detection under extreme imbalanced data: A comparative study of data-level algorithms. J. Exp. Theor. Artif. Intell. 2022, 34, 571–598. [Google Scholar] [CrossRef]
- Gupta, S.; Gupta, M.K. A comprehensive data-level investigation of cancer diagnosis on imbalanced data. Comput. Intell. 2022, 38, 156–186. [Google Scholar] [CrossRef]
- Liu, S.; Zhang, J.; Xiang, Y.; Zhou, W.; Xiang, D. A study of data pre-processing techniques for imbalanced biomedical data classification. Int. J. Bioinform. Res. Appl. 2020, 16, 290–318. [Google Scholar] [CrossRef]
- Liu, J. A minority oversampling approach for fault detection with heterogeneous imbalanced data. Expert Syst. Appl. 2021, 184, 115492. [Google Scholar] [CrossRef]
- Chen, Y.; Chang, R.; Guo, J. Effects of data augmentation method borderline-SMOTE on emotion recognition of EEG signals based on convolutional neural network. IEEE Access 2021, 9, 47491–47502. [Google Scholar] [CrossRef]
- Li, J.; Shrestha, A.; Le Kernec, J.; Fioranelli, F. From Kinect skeleton data to hand gesture recognition with radar. J. Eng. 2019, 2019, 6914–6919. [Google Scholar] [CrossRef]
- Ige, A.O.; Mohd Noor, M.H. A survey on unsupervised learning for wearable sensor-based activity recognition. Appl. Soft Comput. 2022, 127, 109363. [Google Scholar] [CrossRef]
- De-La-Hoz-Franco, E.; Ariza-Colpas, P.; Quero, J.M.; Espinilla, M. Sensor-based datasets for human activity recognition—A systematic review of literature. IEEE Access 2018, 6, 59192–59210. [Google Scholar] [CrossRef]
- Link, J.; Perst, T.; Stoeve, M.; Eskofier, B.M. Wearable sensors for activity recognition in ultimate frisbee using convolutional neural networks and transfer learning. Sensors 2022, 22, 2560. [Google Scholar] [CrossRef]
- Guglielmo, G.; Blom, P.M.; Klincewicz, M.; Čule, B.; Spronck, P. Face in the game: Using facial action units to track expertise in competitive video game play. In Proceedings of the 2022 IEEE Conference on Games (CoG), Beijing, China, 21–24 August 2022; pp. 112–118. [Google Scholar]
- Xingyu, G.; Zhenyu, C.; Sheng, T.; Yongdong, Z.; Jintao, L. Adaptive weighted imbalance learning with application to abnormal activity recognition. Neurocomputing 2016, 173, 1927–1935. [Google Scholar] [CrossRef]
- Zhang, J.; Li, J.; Wang, W. A class-imbalanced deep learning fall detection algorithm using wearable sensors. Sensors 2021, 21, 6511. [Google Scholar] [CrossRef] [PubMed]
- García, V.; Sánchez, J.; Marqués, A.; Florencia, R.; Rivera, G. Understanding the apparent superiority of over-sampling through an analysis of local information for class-imbalanced data. Expert Syst. Appl. 2020, 158, 113026. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; Galar, M.; Prati, R.C.; Krawczyk, B.; Herrera, F. Learning from Imbalanced Data Sets; Springer: Berlin/Heidelberg, Germany, 2018; Volume 10. [Google Scholar]
- Quinonero-Candela, J.; Sugiyama, M.; Schwaighofer, A.; Lawrence, N.D. Dataset Shift in Machine Learning; MIT Press: Cambridge, MA, USA, 2022. [Google Scholar]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the 14th International Joint Conference on Artificial Intelligence (IJCAI’95), Montreal, QC, Canada, 20–25 August 1995; Volume 2, pp. 1137–1145. [Google Scholar]
- Sammut, C.; Webb, G.I. Encyclopedia of Machine Learning; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- López, V.; Fernández, A.; Herrera, F. On the importance of the validation technique for classification with imbalanced datasets: Addressing covariate shift when data is skewed. Inf. Sci. 2014, 257, 1–13. [Google Scholar] [CrossRef]
- Moreno-Torres, J.G.; Sáez, J.A.; Herrera, F. Study on the impact of partition-induced dataset shift on k-fold cross-validation. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 1304–1312. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity Analysis of k-Fold Cross Validation in Prediction Error Estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 569–575. [Google Scholar] [CrossRef]
- Zeng, X.; Martinez, T.R. Distribution-balanced stratified cross-validation for accuracy estimation. J. Exp. Theor. Artif. Intell. 2000, 12, 1–12. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Zhou, Z.H. Machine Learning; Springer: Singapore, 2021. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Murtagh, F. Multilayer perceptrons for classification and regression. Neurocomputing 1991, 2, 183–197. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kaufmann: San Mateo, CA, USA, 2014. [Google Scholar]
- Kovács, G. An empirical comparison and evaluation of minority oversampling techniques on a large number of imbalanced datasets. Appl. Soft Comput. 2019, 83, 105662. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM Sigkdd Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Sáez, J.A.; Luengo, J.; Stefanowski, J.; Herrera, F. SMOTE–IPF: Addressing the noisy and borderline examples problem in imbalanced classification by a re-sampling method with filtering. Inf. Sci. 2015, 291, 184–203. [Google Scholar] [CrossRef]
- Lee, J.; Kim, N.R.; Lee, J.H. An over-sampling technique with rejection for imbalanced class learning. In Proceedings of the 9th International Conference on Ubiquitous Information Management and Communication, Bali, Indonesia, 8–10 January 2015; pp. 1–6. [Google Scholar]
- Koziarski, M.; Woźniak, M. CCR: A combined cleaning and resampling algorithm for imbalanced data classification. Int. J. Appl. Math. Comput. Sci. 2017, 27, 727–736. [Google Scholar] [CrossRef]
- Zhou, B.; Yang, C.; Guo, H.; Hu, J. A quasi-linear SVM combined with assembled SMOTE for imbalanced data classification. In Proceedings of the 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–7. [Google Scholar]
- Barua, S.; Islam, M.; Murase, K. ProWSyn: Proximity weighted synthetic oversampling technique for imbalanced data set learning. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Gold Coast, Australia, 14–17 April 2013; pp. 317–328. [Google Scholar]
- Cao, Q.; Wang, S. Applying over-sampling technique based on data density and cost-sensitive SVM to imbalanced learning. In Proceedings of the 2011 International Conference on Information Management, Innovation Management and Industrial Engineering, Shenzhen, China, 26–27 November 2011; Volume 2, pp. 543–548. [Google Scholar]
- Nakamura, M.; Kajiwara, Y.; Otsuka, A.; Kimura, H. Lvq-smote—learning vector quantization based synthetic minority over-sampling technique for biomedical data. Biodata Min. 2013, 6, 16. [Google Scholar] [CrossRef]
- Kovács, G. Smote-variants: A python implementation of 85 minority oversampling techniques. Neurocomputing 2019, 366, 352–354. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the KDD’96: Second International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Szeghalmy, S.; Fazekas, A. A Highly Adaptive Oversampling Approach to Address the Issue of Data Imbalance. Computers 2022, 11, 73. [Google Scholar] [CrossRef]
- Fernández, A.; García, S.; del Jesus, M.J.; Herrera, F. A study of the behaviour of linguistic fuzzy rule based classification systems in the framework of imbalanced data-sets. Fuzzy Sets Syst. 2008, 159, 2378–2398. [Google Scholar] [CrossRef]
- Fernández, A.; del Jesus, M.J.; Herrera, F. Hierarchical fuzzy rule based classification systems with genetic rule selection for imbalanced data-sets. Int. J. Approx. Reason. 2009, 50, 561–577. [Google Scholar] [CrossRef]
- Abalone. UCI Machine Learning Repository. 1995. Available online: https://archive.ics.uci.edu/ml/datasets/abalone (accessed on 18 December 2022).
- Nakai, K. Ecoli. UCI Machine Learning Repository. 1996. Available online: https://archive.ics.uci.edu/ml/datasets/ecoli (accessed on 18 December 2022).
- Ilter, N.; Guvenir, H. Dermatology. UCI Machine Learning Repository. 1998. Available online: https://archive.ics.uci.edu/ml/datasets/dermatology (accessed on 18 December 2022).
- Car Evaluation. UCI Machine Learning Repository. 1997. Available online: https://archive.ics.uci.edu/ml/datasets/car+evaluation (accessed on 18 December 2022).
- Cortez, P.; Cerdeira, A.; Almeida, F.; Matos, T.; Reis, J. Wine Quality. UCI Machine Learning Repository. 2009. Available online: https://archive.ics.uci.edu/ml/datasets/wine+quality (accessed on 18 December 2022).
- Statlog (Vehicle Silhouettes). UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/datasets/Statlog+%28Vehicle+Silhouettes%29 (accessed on 18 December 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Forman, G.; Scholz, M. Apples-to-apples in cross-validation studies: Pitfalls in classifier performance measurement. ACM Sigkdd Explor. Newsl. 2010, 12, 49–57. [Google Scholar] [CrossRef]
- Wardhani, N.W.S.; Rochayani, M.Y.; Iriany, A.; Sulistyono, A.D.; Lestantyo, P. Cross-validation metrics for evaluating classification performance on imbalanced data. In Proceedings of the 2019 international conference on computer, control, informatics and its applications (IC3INA), Tangerang, Indonesia, 23–24 October 2019; pp. 14–18. [Google Scholar]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Nemenyi, P. Distribution-Free Multiple Comparisons; Princeton University: Princeton, NJ, USA, 1963. [Google Scholar]
- Weaver, K.F.; Morales, V.; Dunn, S.L.; Godde, K.; Weaver, P.F. An Introduction to Statistical Analysis in Research: With Applications in the Biological and Life Sciences; Wiley: Hoboken, NJ, USA, 2017. [Google Scholar]
- Gu, Q.; Zhu, L.; Cai, Z. Evaluation measures of the classification performance of imbalanced data sets. In Proceedings of the International Symposium on Intelligence Computation and Applications, Huangshi, China, 23–25 October 2009; pp. 461–471. [Google Scholar]
- Bansal, M.; Goyal, A.; Choudhary, A. A comparative analysis of K-Nearest Neighbour, Genetic, Support Vector Machine, Decision Tree, and Long Short Term Memory algorithms in machine learning. Decis. Anal. J. 2022, 3, 100071. [Google Scholar] [CrossRef]
- Abdualgalil, B.; Abraham, S. Applications of machine learning algorithms and performance comparison: A review. In Proceedings of the 2020 International Conference on Emerging Trends in Information Technology and Engineering (ic-ETITE), Vellore, India, 24–25 February 2020; pp. 1–6. [Google Scholar]










| R | AUG_R | D | IR | N_min | N_maj | |
|---|---|---|---|---|---|---|
| KEEL | 0.0000–0.2851 | 0.0000–0.9923 | 3–66 | 1.8157–129.4375 | 5–559 | 83–4913 |
| Synthetic | 0.0083–0.1083 | 0.1305–0.9403 | 4; 8 | 7.9552; 15.6667 | 36; 67 | 533; 564 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Szeghalmy, S.; Fazekas, A. A Comparative Study of the Use of Stratified Cross-Validation and Distribution-Balanced Stratified Cross-Validation in Imbalanced Learning. Sensors 2023, 23, 2333. https://doi.org/10.3390/s23042333
Szeghalmy S, Fazekas A. A Comparative Study of the Use of Stratified Cross-Validation and Distribution-Balanced Stratified Cross-Validation in Imbalanced Learning. Sensors. 2023; 23(4):2333. https://doi.org/10.3390/s23042333
Chicago/Turabian StyleSzeghalmy, Szilvia, and Attila Fazekas. 2023. "A Comparative Study of the Use of Stratified Cross-Validation and Distribution-Balanced Stratified Cross-Validation in Imbalanced Learning" Sensors 23, no. 4: 2333. https://doi.org/10.3390/s23042333
APA StyleSzeghalmy, S., & Fazekas, A. (2023). A Comparative Study of the Use of Stratified Cross-Validation and Distribution-Balanced Stratified Cross-Validation in Imbalanced Learning. Sensors, 23(4), 2333. https://doi.org/10.3390/s23042333