Abstract
This paper considers the appearance of indications of useful acoustic signals in the signal/noise mixture. Various information characteristics (information entropy, Jensen–Shannon divergence, spectral information divergence and statistical complexity) are investigated in the context of solving this problem. Both time and frequency domains are studied for the calculation of information entropy. The effectiveness of statistical complexity is shown in comparison with other information metrics for different signal-to-noise ratios. Two different approaches for statistical complexity calculations are also compared. In addition, analytical formulas for complexity and disequilibrium are obtained using entropy variation in the case of signal spectral distribution. The connection between the statistical complexity criterion and the Neyman–Pearson approach for hypothesis testing is discussed. The effectiveness of the proposed approach is shown for different types of acoustic signals and noise models, including colored noises, and different signal-to-noise ratios, especially when the estimation of additional noise characteristics is impossible.
1. Introduction
Since Shannon [1] introduced information and information entropy, these concepts have attracted significant attention from scientists, as evidenced by the large number of articles devoted to the development of information theory in relation to various theoretical and practical aspects. Many different information criteria, metrics, and methods for their calculation that are based, one way or another, on the concepts of Shannon entropy have been proposed and investigated [2]. These metrics can be used quite successfully in signal processing, which eventually led to the emergence of a separate section of this scientific area, called entropic signal analysis [3].
For signals described by time series, the information entropy can be calculated on the basis of both signal representation in the time domain [4] and its representation in the frequency domain [5], i.e., using the signal spectrum. The convenience of the second approach comes from the fact that white noise, which is usually used to model background noise in these problem statements, has a uniform frequency distribution. This allows us to simplify its mathematical description and separate useful signals more effectively.
Decision theory considers change-point detection problems, which are closely related to the problems discussed above: often, in such problems, the moment of change in the parameters of a random process registered in discrete time must be determined. In [6,7], many probabilistic-statistical methods of solving such problems are considered. The Neyman–Pearson approach to this problem was used in [8]. Additionally, one cannot ignore the so-called Anomaly Detection Problems, where detection of anomalies in time series is required [9,10,11], i.e., the moment at which the behavior of the system begins to qualitatively differ from normal for various reasons, in particular, due to unwanted external interference. The electrocardiogram (ECG) is one example of such a time series, and ECGs have been analyzed in a large number of articles, for example, [12]. The presence of an anomaly in this case can indicate health problems, and detection at an early stage may save the life of the patient.
Of particular interest is the processing of acoustic signals, which can be useful, for example, in Voice Activity Detection (VAD) problems [13] related to voice assistants. The task is usually to separate speech segments from background environmental noise. Related articles [5,14,15] present a method for endpoint detection, i.e., the determination of the limits of a speech signal in a mixture of this signal and background noise based on the calculation of the spectral entropy. The general idea of methods based on information criteria is that their values experience a sharp jump when a useful signal appears in the noise.
In a series of articles [16,17,18,19,20,21], researchers introduced the concept of a statistical measure of signal complexity, which they called statistical complexity. In [22,23], statistical complexity and information entropy were used to classify various underwater objects of animate and inanimate nature from recorded sound. In the present article, we use this measure to indicate the appearance of an useful acoustic signal in a highly noisy mixture. It should be noted that the positive side of the proposed method is that it does not require any a priori knowledge about the signal to be detected. However, a priori information, such as the approximate frequency range of the signal is known, its detection will be even more accurate.
The structure of the paper is as follows. Section 2 provides a brief theoretical summary of the information criteria used in various known signal detection methods. In Section 3, entropy variation is investigated and statistical complexity is introduced. In Section 4, the connection between statistical complexity and the Neyman–Pearson criterion for hypothesis testing is also discussed to justify the proposed approach. Section 5 is provides a variety of examples, gives a comparison of different information criteria, and discussed the results, which allows us to make an educated choice about a suitable rule for the detection of signals in a noisy mixture. Section 6 summarizes the conducted research and provides the direction for future work.
2. Information Criteria
2.1. Information Entropy and Other Information Criteria
In information theory, the entropy of a random variable is the average level of ”surprise” or ”uncertainty” inherent in the possible outcomes of the variable. For a discrete random variable X that takes values in the alphabet and has a distribution density of p, the entropy, according to Shannon [1], is defined as
where denotes the sum across all possible values of the variable. When computing the sum (1), it is agreed that , and this assumption holds for all future equations. From the Formula (1), it follows that entropy reaches its maximum value when all states of the system are equally probable.
There are several definitions of information divergences, i.e., the statistical distances between two distributions. The Kullback–Leibler divergence (or mutual entropy) between two discrete probability distributions and on an event set is defined as
This measure is a statistical distance and distinguishes statistical processes by indicating how much differs from by the maximum likelihood hypothesis test when the actual data obey the distribution . It is easy to see that
where is a cross-entropy between p and q:
where is an operator of the mathematical expectation relative to the distribution p.
The symmetrized Kullback–Leibler distance [13] is often used in studies:
However, the Jensen–Shannon divergence, which symmetrizes the Kullback–Leibler divergence and is often a more convenient information measure for practical applications, is used more often:
It is symmetric and always has a finite value. The square root of the Jensen–Shannon divergence is a metric that is often called the Jensen–Shannon distance.
It is easy to see that
Another quantity related to the complexity of the system is the ”disequilibrium,” denoted by D, which shows the deviation of a given probability distribution from a uniform one. The concept of the statistical complexity of a system can be considered a development of the concept of entropy. In [16,17,18,19,20,21], it is defined as
where C is the statistical complexity, H is the information entropy, and D is a measure of the disequilibrium of the distribution relative to the uniform one.
The measure of statistical complexity reflects the relationship between the amount of information and its disequilibrium in the system. As a parameter D, according to the authors of [16], one can choose any metric that determines the difference between the maximum entropy and the entropy of the studied signal. The simplest example of disequilibrium is the square of the Euclidean distance in between the original distribution and the uniform distribution, but often, the Jensen–Shannon divergence [22,23] is also used.
2.2. Time Entropy
Now let us consider the information characteristics mentioned above in relation to time series. The Shannon entropy for systems with unequal probability states is defined as follows: Let the i-th state of the system have a probability of , where N is a sample volume and is the amount of filling at the i-level. Then, the entropy , according to the Formula (1), equals
From here, we consider discrete probability distributions with the following properties:
There are different ways to calculate probabilities from the time series. The simplest one is as follows: First, the maximum and minimum values are found for the considered time series with N data points. Then, the interval () is divided into n subintervals (levels) so that the value of the interval is not less than the confidence interval of the observations. The resulting sample is treated as a “message”, and the i subintervals are treated as an “alphabet”. Then, we find the number of sample values that fall into each of the subintervals and determine the relative population level (the probability of a value from the sample falling into a subinterval i, that is, the relative frequency of occurrence of the “letter” in the “message”):
The elementary entropy of the sampling is defined as the Shannon entropy (9) on a given set , and this is normalized to the total number of states n so that its values belong to the interval :
This approach is known as the first sampling entropy [4] and is used, for example, in [24] to detect the hydroacoustic signals emitted by an underwater source.
On the other hand, the second sampling entropy can be defined as
In this case, the signal samples themselves are considered “letters”, which are distributed across the time axis in contrast to the amplitude axis from (12), and the “alphabet” is the whole set of amplitudes.
2.3. Spectral Entropy
In addition to the time domain, the entropy can be calculated based on the representation of the signal in the frequency domain, i.e., can be calculated with the spectrum of the signal. Spectral entropy is a quantitative assessment of the spectral complexity of the signal in the frequency domain from an energy point of view.
Consider the time series and its spectral decomposition in the frequency domain with frequency components, obtained using the Fast Fourier Transform (FFT). The spectral power density is estimated as follows:
Then, the probability distribution of the spectral power density can be written in the form
where is the spectral energy for the spectral component with a frequency of , is the corresponding probability density, is the number of spectral components in the FFT, and the upper index s shows that the distribution refers to the signal spectrum. The resulting function is a spectrum distribution density function.
Finally, the spectral entropy can be determined with the Equation (9) and normalized by the size of the spectrum:
The Spectral Information Divergence () method [25] was recently added to the Matlab mathematical package, and is calculated according to Formula (5) according to the similarity of two signals based on the divergence between the probability distributions of their spectra:
where r and t are the reference and test spectra, respectively, and the values of the probability distribution and for these spectra are determined according to (15).
3. Entropy Variation and Related Information Criteria
The purpose of this section is to determine the most appropriate formulas for calculating the information criteria that are responsible for the differences between distributions. Let us consider an entropy variation with respect to the variation in the probability distribution. The following lemma is valid:
Lemma 1.
For small variations in the discrete distribution , such as , there is also some discrete distribution (10), and the decomposition of the entropy variation in the case of series convergence by powers has the form
The first summand of the entropy variation decomposition is the difference between cross-entropy and entropy, and the second depends on the weighted squares of the variation of the distribution:
The proof of the Lemma 1 is given in Appendix A.
Remark 1.
If q is the uniform distribution, i.e., for , when
and the disequilibrium is proportional to variance of the distribution p relative to the uniform one and is equal to
Equation (21) coincides with the disequilibrium definition from [16].
According to Lemma 1 and Remark 1, we can introduce a new definition.
Definition 1.
In the case where q is the uniform distribution statistical complexity, as defined in [16], it is proportional to the first nonzero member of the row of square entropy variation, namely,
Remark 2.
In general cases, the statistical complexity is defined as
where is an entropy maximum.
It follows from Remark 1 that the disequilibrium (21) and the complexity (22) concelts must be applied when evaluating and comparing signals with background noise that has a spectral distribution close to uniform.
The formula for disequilibrium (21) proposed in [16] is derived from entropy variation, but most papers use the Jensen–Shannon divergence [22] for disequilibrium:
where . The statistical complexity, correspondingly, is expressed as
Further on in the article, a comparison of the complexity graphs calculated for these two values and is presented.
Considering the signal distribution in the frequency and time domains, it can be observed that the spectral distribution does not require any additional estimation of the signal variance, whereas when calculating entropy in the time domain, variance estimation is required, since for white noise (Gauss distribution), the following formula is valid:
where is the Gaussian distribution.
Remark 3.
For the case of two continuous distributions , the disequilibrium is equivalent to the f-divergence [26] with the quadratic function f:
if an integral exists.
Remark 4.
The Formulas (28) and (29) are obtained by calculating the integrals (27) and (26) for continuous distributions. These are also applicable for discrete ones.
The problem addressed here is the determination of the most informative methods for calculating entropy and other information criteria. In our opinion, the answer can only be obtained in the presence of additional knowledge about the phenomenon under study. Indeed, when measuring the amplitude of the signal , initially there is only knowledge of the time series samples , i.e., we know the values of amplitudes in the increasing sequence of time samples , . Setting the distribution density using the Formula (11) itself allows some random variable to be defined.
Let us calculate the entropy by applying grouping (11) and considering the fact that the entropy does not change as the summation order changes. Thus, the following chain of equations is valid:
where
so that
Thus, we have obtained that
If is now a uniform distribution, then (33) takes the form
The Formula (33) shows the relationship between the entropy calculated from the time samples and the Kullback–Leibler distance between the distributions obtained by alphabetical grouping along the amplitude and time coordinate axes. Therefore, the next statement is valid.
Corollary 1.
The value of is approximately a constant value, independent of the method of grouping when the number of letters of the alphabet is large enough when their number is in some interval of values.
The following observation considering distribution is true.
Remark 5.
If the sequence of samples has the property of ergodicity and the signal is represented by white noise, then if the number of letters of the alphabet from (31) is large enough, the density will be close to Gaussian.
Remark 5 allows us to estimate using Equation (26) for the Gaussian .
Now, there are four distribution densities at our disposal: three of them, , , and , are related to the time domain and are determined by the Formulas (13), (31), and (32), and one, , is related to the signal spectrum, calculated by the Formula (15).
With the presence of four distribution densities, the following criteria are considered simultaneously: the normalized information entropy H, defined by Formulas (12) and (16); the statistical complexity C, computed by (22) with a disequilibrium D (21); the Jenson–Shannon divergence (6); the spectral information divergence (17); and the cross-entropy and entropy difference (19).
Since the spectral density is used to compare the signal/noise mixture with white noise, i.e., with a uniform distribution, all of the proposed criteria are applicable for this density. In the case of temporal distributions, the normalized information entropy H, which depends only on the distribution under study, and the difference of cross-entropy and entropy , calculated explicitly by the Formula (29) for , are estimated.
On the basis of the numerical experiments performed, a conclusion is made about the quality of the criteria used and the limits of their applicability in the presence of the noise component of the signal.
4. Hypothesis Testing
The classical probabilistic approach to the study of the considered problem of the detection of useful signals against background noise is called binary hypothesis testing. The binary problem associated with the decision to receive only noise (hypothesis ) or to receive a mixture of a useful signal and noise (hypothesis ) is solved [8].
In the statistical decision theory [6], it is shown that, in signal detection in the presence of noise, the optimal decisive rule is based on a comparison of the likelihood ratio with some threshold. The Neyman–Pearson criterion is used to select the threshold in the absence of a priori probabilities of the presence and absence of a useful signal. The efficiency of the detection procedure using the Neyman–Pearson criterion is characterized by the probability of correct detection with a fixed probability of false alarms.
The solution to the problem of distinguishing between two hypotheses can be derived from the following variant of the Neyman–Pearson lemma.
Lemma 2
(Neyman-Pearson). Let there be a measurable function, called a decisive rule,
based on which
The decisive rule is optimal if
where is called an error function.
In the problem of the detection of a useful signal, is known as the probability of a false alarm occurring, and is known as the probability of missing a useful signal.
The error function can be calculated precisely through the variation of the measure (with a sign) by the following formula from [6]:
where is the multivariate distribution function of observational statistics under hypothesis , and is the multivariate distribution function of observational statistics under hypothesis , and is the full variation .
The peculiarity of the Formula (37) is that if the carriers on which the hypothesis measures and are concentrated are different, then . If the measures and are similar, then , and then .
For the problem of detecting a deterministic useful signal, the case and the possibility of a reasonable estimate of this value is interesting.
The estimated constraints are known from thed estimate , which is used to compute the statistical complexity . Both and are metrics related to the probability distribution space, but in the Euclidean space, (21) serves as this metric. Since the problem of detecting a deterministic signal in the presence of background noise is considered, it is reasonable to additionally take into account this ”determinism” by multiplying by the entropy H, which is associated with the introduction and use of statistical complexity in the form of (22) and (25).
5. Modelling and Discussion
5.1. The Calculation Algorithm and Presentation of the Simulation Results
In all experiments, graphs of the information characteristics are presented as functions of time. The characteristics are calculated from the signal according to the following algorithm:
- After being digitized with the sampling rate, the audio signal is divided into short segments containing W digital samples.
- The discrete densities (15) are calculated from the time or frequency domains.
- The information criterion is calculated using .
- The sequence of values is displayed together with the signal on the time axis (each of the obtained values is extended by W counts).
When a certain threshold of the information criterion is exceeded, this indicates the appearance of a useful signal in the mixture.
The signal processing results according to this algorithm are presented below. For different acoustic signals, a comparison of the quality of indication of the appearance of a useful signal by different information criteria at different levels of added white noise is demonstrated. In addition, Section 5.5 shows a comparison of two methods for calculating the statistical complexity and draws conclusions about the usefulness of both.
The first acoustic signal chosen was an audio recording of a humpback whale song recorded underwater. A large set of such recordings is available from the Watkins Marine Mammal Sound Database collected by Woods Hole Oceanographic Institution and the New Bedford Whaling Museum. The ability to separate such signals from strong sea noise may be useful for research biologists for further classification and study. In addition, these signals are similar in structure to the human voice with separate words, the extraction of which could be useful, for example, in tasks of voice activity detection and speech recognition.
In all of the graphs presented below, the signal is marked with a blue line, and the corresponding information metric is marked with a red line. The left vertical axis corresponds to the values of the signal amplitude, and the right vertical axis corresponds to the values of the information metric. All horizontal axes represent the timeline in seconds. The signal is shown without added noise for better comprehension, but the variable parameter of the standard deviation of the white noise is marked with a dashed line. All information metrics are normalized for the convenience of presentation. All calculations and visualizations were performed using Python. White, brown, and pink noises, which were artificially added to audio recordings, were also generated numerically.
5.2. Time Information Criteria
First, we consider the behavior of the information entropies and , calculated from the time samples of the signal .
Figure 1 shows that as noise increases, there is serious degradation of the time entropy graph for both calculation methods, so that for (SNR ≈ 1.5 dB), these information criteria can no longer serve as reliable indicators of the appearance of a useful signal in the mixture. We note an interesting feature of the behavior of and : the value of the first characteristic is maximal for the uniform distribution and decreases with the appearance of a useful signal in the mixture, while, in contrast, the value of the second is minimal in the absence of a signal and increases with its appearance. This obviously follows on from the formulas for calculating the distributions and entropies (11), (13), (12).
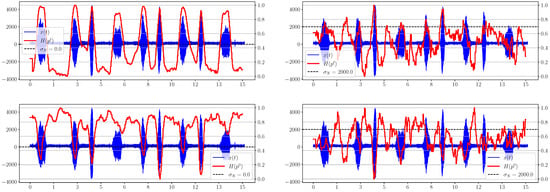
Figure 1.
Graphs of and for different levels of added noise.
The information characteristic stands out favorably from the time entropies, as demonstrated above.
In Figure 2, the for the noise level shows the appearance of a useful signal and works sufficiently, even for the double noise value. However, it should be noted that this is true only for stationary noise, whose average value does not change over time. Otherwise, this metric will react to changes in noise as well, which follows on from the formula (29). Moreover, initial estimation of is required for the correct functioning of this criterion.
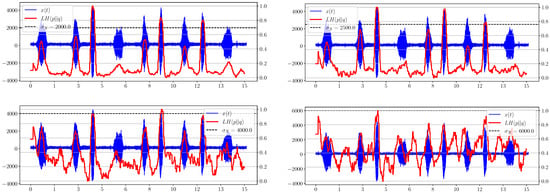
Figure 2.
Graphs of for different levels of added noise.
5.3. Time Entropy
The time entropy associated with another grouping of the ”alphabet” derived from the signal samples is considered separately and the graphs for different number of letters are shown in Figure 3 and Figure 4.

Figure 3.
The entropy for the number of letters of the alphabet equal to 64.
Changing the alphabet partitioning negatively affects the effectiveness of entropy in this representation:

Figure 4.
The entropy for the number of letters of the alphabet equal to 8.

5.4. Spectral Information Criteria
Information criteria based on the spectral distribution of are deprived of the disadvantages of the time criteria.
Figure 5 shows the dependence of the spectral entropy on time. We can see a significant improvement in the maximum allowable noise level, at which the indication of the appearance of a useful signal is still possible, with respect to the graphs presented in Figure 2.
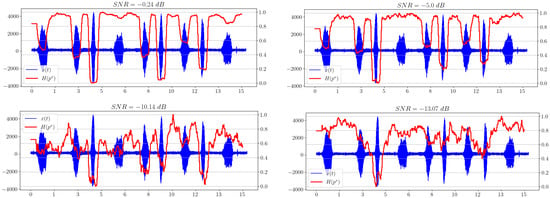
Figure 5.
Spectral entropy plots for different SNRs.
The point that we want to make is that the white noise in a signal in spectral representation has quite a definite uniform probability distribution, which greatly facilitates the calculation of entropy and saves us from the necessity of estimating the variance of this noise. Moreover, even if the noise is not stationary, i.e., its parameters change over time, in a small window W, it can still be considered white, and the above statement is still true.
The distribution can be used as the basis for a number of information divergences (17), (24), (22), (25):
Figure 6 shows that the separability of information metrics decreases along with the signal-to-noise ratio (SNR). However, the statistical complexity performs better than all other criteria, because it still allows a useful signal to be distinguished when other metrics behave irregularly and no longer show significantly excess levels compared to areas without a signal. Thus, it is the most promising characteristic in our opinion.
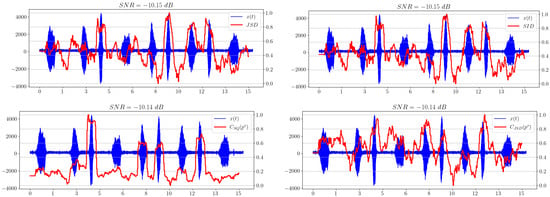
Figure 6.
Information divergence plots based on spectral distribution.
5.5. Comparison of Different Ways of Calculating the Statistical Complexity
Of separate interest is the comparison of the behavior of the statistical complexities and , which essentially correspond to different methods of calculating the same value of statistical complexity. Figure 7 illustrates this comparison.
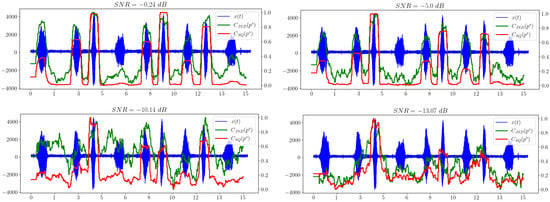
Figure 7.
Comparison of statistical complexities and .
We can see that shows a better result when used as an indicator of the appearance of a useful signal in white noise compared to the Jensen–Shannon divergence.
5.6. Hydroacoustic Signal Model of an Underwater Marine Object
The second signal is a modelled hydroacoustic signal of an underwater marine object. The study of such signals is important in military and civilian applications, because it can automate the process of analyzing the hydroacoustic scene and identifying potential threats. In Figure 8, spectral entropy dependencies for different levels of added noise are shown.
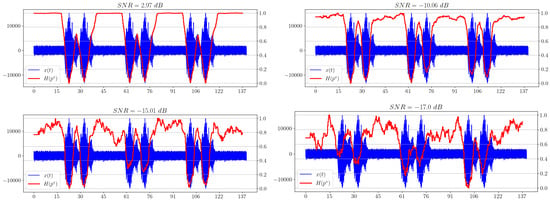
Figure 8.
Spectral entropy plots for different SNRs.
Figure 9 shows the dependencies of statistical complexity for a given signal. It is worth noting that the selected information metric shows the presence of a useful signal, even for a very small SNR ( dB) in the last example.
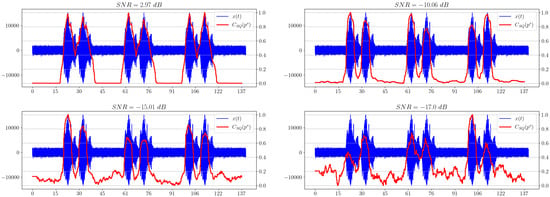
Figure 9.
Graphs of statistical complexity for different SNRs.
It can be observed that, in comparison with all other information metrics, the statistical complexity shows the best result in terms of indicating the presence of a useful signal in the mixture, because it remains effective for small SNRs, while all other characteristics can no longer detect a useful signal in noisy receiving channels.
5.7. Hydroacoustic Signal Model with Pink Noise
Now let us change the additive noise model and use pink noise instead of white noise. As can be observed in Figure 10, the spectral entropy shows an unsatisfactory result for the chosen low SNR.
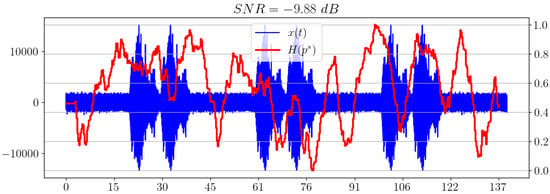
Figure 10.
Spectral entropy for pink noise model.
Figure 11 shows that, along with the spectral entropy, the statistical complexity performs poorly, but confidently shows the presence of a signal.
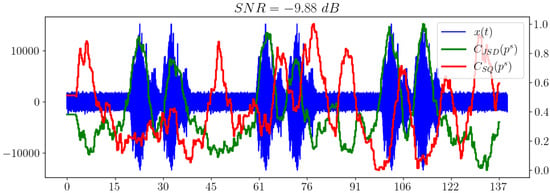
Figure 11.
Statistical complexities and for pink noise model.
5.8. Hydroacoustic Signal Model with Brown Noise
In this example, brown noise is used as the noise model. As in the previous subsection, spectral entropy fails in the task of signal extraction, as shown in Figure 12.
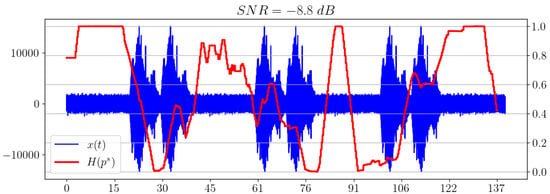
Figure 12.
Spectral entropy for brown noise model.
However, Figure 13 shows that the statistical complexity with the Jensen–Shannon disbalance exhibits a satisfactory performance.
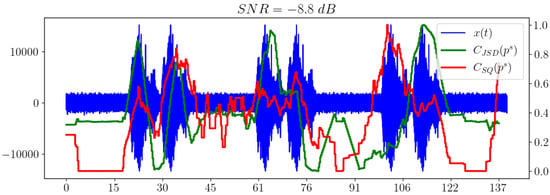
Figure 13.
Statistical complexities and for brown noise model.
The results are summarized in Table 1. The checkmark indicates the possibility of confident indication of the useful signal, and x indicates the lack of this.

Table 1.
Comparison of information criteria for different noise models and SNRs.
6. Conclusions
The article proposed a method for indicating the appearance of a useful signal in a heavily noisy mixture based on the statistical complexity. The analytical formulas used to determine the disequilibrium and statistical complexity were obtained using entropy variation. The effectiveness of the proposed approach for two types of acoustic signals in comparison with other information metrics was shown for different models of added noise. For white noise, the appearance of deterministic signal was shown to be reliably detected for a very small SNR ( dB) when the statistical complexity based on the spectral distribution variance was used as the criterion. However, for more complex noise models, the use of the statistical complexity with the Jensen–Shannon disequilibrium was shown to have better efficiency. Both the time and frequency domains were considered for the entropy calculation. The criteria for signal detection in a heavy noise mixture based on time distributions were shown to be less informative than those based on spectral distribution. The connection between the statistical complexity criterion and the Neyman–Pearson approach for hypothesis testing was also discussed. Future work will be devoted to research on the information criteria based on two- and multidimensional distributions, and acoustic signals with realistic background noise will be considered.
Author Contributions
Conceptualization, A.G. and P.L.; methodology, A.G. and P.L.; software, P.L.; validation, L.B. and P.L.; formal analysis, P.L., L.B. and A.G.; investigation, L.B., A.G. and P.L.; writing—original draft preparation, P.L. and A.G.; writing—review and editing, L.B., A.G. and P.L.; visualization, P.L.; supervision, A.G.; project administration, A.G.; funding acquisition, A.G. All authors have read and agreed to the published version of the manuscript.
Funding
The work of A.G. and P.L. was partially supported by the Russian Science Foundation under grant no 23-19-00134.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The humpback whale song example was downloaded from https://cis.whoi.edu/science/B/whalesounds/bestOf.cfm?code=AC2A (accessed on 25 September 2022).
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| FFT | Fast Fourier Transform |
| SNR | Signal-to-noise ratio |
Appendix A
Proof of Lemma 1.
The difference between entropies for the distributions and gives the entropy variation :
The property of the logarithm of the product and the regrouping of the summands allows the chain of equations to continue as follows:
The first sum is equal to the difference between cross-entropy and entropy. The next transformation is decomposed into an infinite logarithm series, and the resulting sum is divided into two parts:
One summand corresponding to is removed from the first sum, and summation continues with .
The resulting summand is zero. Shifting the summation index of the first summation results in in the following form:
Another shift of the summation index leads to the Equation (18), which ends the proof of the Lemma. □
References
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Ribeiro, M.; Henriques, T.; Castro, L.; Souto, A.; Antunes, L.; Costa-Santos, C.; Teixeira, A. The Entropy Universe. Entropy 2021, 23, 222. [Google Scholar] [CrossRef] [PubMed]
- Gray, R.M. Entropy and Information Theory; Springer: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Delgado-Bonal, A.; Marshak, A. Approximate Entropy and Sample Entropy: A Comprehensive Tutorial. Entropy 2019, 21, 541. [Google Scholar] [CrossRef]
- Shen, J.L.; Hung, J.W.; Lee, L.S. Robust entropy-based endpoint detection for speech recognition in noisy environments. In Proceedings of the 5th International Conference on Spoken Language Processing (ICSLP 1998), Sydney, Australia, 30 November–4 December 1998. [Google Scholar]
- Shiryaev, A.N.; Spokoiny, V.G. Statistical Experiments and Decisions; WORLD SCIENTIFIC: Singapore, 2000. [Google Scholar] [CrossRef]
- Johnson, P.; Moriarty, J.; Peskir, G. Detecting changes in real-time data: A user’s guide to optimal detection. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2017, 375, 16. [Google Scholar] [CrossRef]
- Ship detection using Neyman-Pearson criterion in marine environment. Ocean Eng. 2017, 143, 106–112. [CrossRef]
- Mehrotra, K.G.; Mohan, C.K.; Huang, H. Anomaly Detection Principles and Algorithms; Terrorism, Security, and Computation; Springer International Publishing: Cham, Switzerland, 2017. [Google Scholar] [CrossRef]
- Howedi, A.; Lotfi, A.; Pourabdollah, A. An Entropy-Based Approach for Anomaly Detection in Activities of Daily Living in the Presence of a Visitor. Entropy 2020, 22, 845. [Google Scholar] [CrossRef] [PubMed]
- Bereziński, P.; Jasiul, B.; Szpyrka, M. An Entropy-Based Network Anomaly Detection Method. Entropy 2015, 17, 2367–2408. [Google Scholar] [CrossRef]
- Horie, T.; Burioka, N.; Amisaki, T.; Shimizu, E. Sample Entropy in Electrocardiogram During Atrial Fibrillation. Yonago Acta Medica 2018, 61, 049–057. [Google Scholar] [CrossRef] [PubMed]
- Ramirez, J.; Segura, J.; Benitez, C.; de la Torre, A.; Rubio, A. A new Kullback-Leibler VAD for speech recognition in noise. IEEE Signal Process. Lett. 2004, 11, 266–269. [Google Scholar] [CrossRef]
- Wu, B.F.; Wang, K.C. Robust Endpoint Detection Algorithm Based on the Adaptive Band-Partitioning Spectral Entropy in Adverse Environments. Speech Audio Process. IEEE Trans. 2005, 13, 762–775. [Google Scholar] [CrossRef]
- Weaver, K.; Waheed, K.; Salem, F. An entropy based robust speech boundary detection algorithm for realistic noisy environments. In Proceedings of the International Joint Conference on Neural Networks, Portland, OR, USA, 20–24 July 2003; Volume 1, pp. 680–685. [Google Scholar] [CrossRef]
- López-Ruiz, R. Shannon information, LMC complexity and Rényi entropies: A straightforward approach. Biophys. Chem. 2005, 115, 215–218. [Google Scholar] [CrossRef] [PubMed]
- Catalán, R.G.; Garay, J.; López-Ruiz, R. Features of the extension of a statistical measure of complexity to continuous systems. Phys. Rev. E 2002, 66, 011102. [Google Scholar] [CrossRef] [PubMed]
- Calbet, X.; López-Ruiz, R. Tendency towards maximum complexity in a nonequilibrium isolated system. Phys. Rev. E 2001, 63, 066116. [Google Scholar] [CrossRef] [PubMed]
- Rosso, O.; Larrondo, H.; Martin, M.; Plastino, A.; Fuentes, M. Distinguishing Noise from Chaos. Phys. Rev. Lett. 2007, 99, 154102. [Google Scholar] [CrossRef] [PubMed]
- Lamberti, P.; Martin, M.; Plastino, A.; Rosso, O. Intensive entropic non-triviality measure. Phys. A Stat. Mech. Its Appl. 2004, 334, 119–131. [Google Scholar] [CrossRef]
- Zunino, L.; Soriano, M.C.; Rosso, O.A. Distinguishing chaotic and stochastic dynamics from time series by using a multiscale symbolic approach. Phys. Rev. E 2012, 86, 046210. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Li, Y.; Zhang, K. A Feature Extraction Method of Ship-Radiated Noise Based on Fluctuation-Based Dispersion Entropy and Intrinsic Time-Scale Decomposition. Entropy 2019, 21, 693. [Google Scholar] [CrossRef] [PubMed]
- Dai, Y.; Zhang, H.; Mao, X.; Shang, P. Complexity–entropy causality plane based on power spectral entropy for complex time series. Phys. A: Stat. Mech. Its Appl. 2018, 509, 501–514. [Google Scholar] [CrossRef]
- Quazi, A.H. Method for Detecting Acoustic Signals from an Underwater Source. U.S. Patent US5668778A, 16 September 1997. [Google Scholar]
- Chang, C.-I. An information-theoretic approach to spectral variability, similarity, and discrimination for hyperspectral image analysis. IEEE Trans. Inf. Theory 2000, 46, 1927–1932. [Google Scholar] [CrossRef]
- Sason, I. On f-Divergences: Integral Representations, Local Behavior, and Inequalities. Entropy 2018, 20, 383. [Google Scholar] [CrossRef] [PubMed]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).