Abstract
To extract the phase information from multiple receivers, the conventional sound source localization system involves substantial complexity in software and hardware. Along with the algorithm complexity, the dedicated communication channel and individual analog-to-digital conversions prevent an increase in the system’s capability due to feasibility. The previous study suggested and verified the single-channel sound source localization system, which aggregates the receivers on the single analog network for the single digital converter. This paper proposes the improved algorithm for the single-channel sound source localization system based on the Gaussian process regression with the novel feature extraction method. The proposed system consists of three computational stages: homomorphic deconvolution, feature extraction, and Gaussian process regression in cascade. The individual stages represent time delay extraction, data arrangement, and machine prediction, respectively. The optimal receiver configuration for the three-receiver structure is derived from the novel similarity matrix analysis based on the time delay pattern diversity. The simulations and experiments present precise predictions with proper model order and ensemble average length. The nonparametric method, with the rational quadratic kernel, shows consistent performance on trained angles. The Steiglitz–McBride model with the exponential kernel delivers the best predictions for trained and untrained angles with low bias and low variance in statistics.
1. Introduction
The delivered signal over the space contains the spatial information due to the limited propagation speed. The walls and/or obstacles in the field may provide multipath patterns on the received signal. In the isotropic and open environment, the multiple receivers create numerous arrivals on the received signal. The propagated signal can be analyzed by the sound source localization (SSL) system to estimate the angle of arrival (AoA) for the signal source. The first engineering approaches for the SSL system utilized the unidirectional sound collection structure with steering for localizing. To avoid the physical movement, the extensive processing over the multichannel signals is required to understand the spatial information. The mathematical modeling of the propagation and arrival of the sound is important for processing in terms of sound directions.
The conventional method for SSL is beamforming [1,2], which uses the phase information from the multiple receivers for the spatial filtering. The accuracy of the beamforming localization is proportional to the receiver numbers along with the processing power; therefore, the significant computing power as well as data rate are involved in the precise sound localization. Certain natural creatures, including humans, can accurately localize sound sources in three-dimensional (3D) space by using the binaural correlation and structure profile [3]. The reflections and diffractions on the receiver structure provide additional features to derive the AoA for the sound sources. The human hearing for localization has been imitated by the SSL system based on the monaural [4] and binaural [5] configurations. With reduced receivers and computation, the researchers are continuously conducting investigations to understand the complex propagation of the physical structure for precise and feasible SSL systems [6,7,8,9,10,11].
The recently developed autonomous driving systems comprehend their surroundings through camera vision and active sensors, which deliver pinpoint accuracy for localization. The general driving conditions frequently present the situations beyond the immediate hazards and warnings above the direct detection and estimation. The acoustic information can be employed for elevating the safety of the autonomous system further due to the acoustic signal properties [12]. The sound source can be identified and localized by the SSL system based on the reflected and diffracted propagation for the extended ranges. Therefore, upon the detection of the direct or indirect endangerment, the system may activate the pre-emptive safety procedures to reduce the possibility of the imminent accidents. Obviously, the sound is complementary information to the vision for navigating with mobile and immobile objects. We, as humans, completely perceive the importance of hearing for everyday navigation and communication. The loss of sound localization capability makes a person unable to understand the environment via visual information.
The SSL system demands the multiple arrival information in the form of a time delay in the received signal. The beamforming algorithms explicitly obtain the time delays from multiple and independent receiver channels [1,2]. Therefore, the dedicated and synchronized communication channels should be designed to avoid temporal contamination. The biomimetic-inspired SSL systems, such as monaural and binaural methods, figure out the AoA based on the structure around the receiver to implement the subtle time delays in the received signal [4,5]. The dedicated communication as well as additional structure prevent the realization of the SSL system in the mobile objects due to the complexity and safety. Additionally, the receivers installed over the 3D surface create further complexity to derive the sound propagation model, which is the fundamental component of the conventional SSL system. For the autonomous mobile system, the novel SSL method should be developed to achieve optimal, scalable, and feasible performance.
Continuously, numerous novel SSL systems have widely utilized machine/deep learning algorithms to improve their performance and adaptation in various deployment environments. SongGong et al. [13] present the frequency-invariant circular harmonic features for the convolutional neural network to obtain an accurate AoA estimation. Nguyen et al. [14] suggest the feature based on the multichannel log-spectrograms and normalized principal eigenvector of the spatial covariance matrix for the convolutional recurrent neural network to estimate and detect the AoA and event, simultaneously. In the spherical microphone array, the spherical map representation with a dual-branched convolutional autoencoder is proposed for the multiple sound source localization [15]. Tan-Hsu, Yu-Tang, Yang-Lang, and Mohammad provide the convolutional neural network with a regression model to estimate the sound source angle and distance based on the interaural phase difference [16]. To improve SSL performance in noisy and reverberant environments, the steering vector phase difference enhancement is realized by the deep neural network [17]. The SSL system invariant to the configuration was developed by Chun et al. based on the azimuth-frequency representation and convolutional neural networks [18].
The machine/deep learning-based SSL system extends the application to a specific area. The flying drone localizes the sound source from ambient noise and frequent movement [19]. The low-power device with a microphone array derives the AoA for the sound source in the application of various human interaction [20]. The complex environment from the indoor condition is challenged for the SSL system by Machhamer [21] and Zhang [22]. The sound source-specific classification and localization are accomplished for the gunshot [23], acoustic alarm [24], and multispeaker [25]. The underwater SSL system is implemented by comprehending the complicated sound propagation based on the convolutional neural networks [26], artificial neural networks [27], and deep neural networks [28]. Grumiaux, Kitić, Girin, and Guérin organized the survey on deep learning methods for single and multiple SSL in indoor/domestic environments with an exhaustive topography [29].
This paper proposes a single analog-to-digital converter (ADC) channel SSL system with multiple receivers. The multiple arrivals in the received signal are superimposed into one data flow for single-channel processing. The receiver locations are configured to maximize the pattern diversity in a time-delay distribution. The deconvolution procedure from the single channel data extracts the time delays, which are produced by the receiver configuration for direction-wise time delays. The time delays can be represented by the nonparametric and parametric features of the machine learning algorithm. The supervised machine learning for the regression predicts the AoA based on feature learning. The benefits of the proposed single-channel sound source localization (SCSSL) system can be described as scalability and feasibility. The increased number of receivers in the SCSSL system contributes to the enhanced prediction accuracy without expanding the data rate or computation requirements. The proposed SCSSL system demonstrates the constant computational complexity in terms of receiver number due to the unique data and computation flow. Additionally, the SCSSL system does not require an explicit mathematical model for the temporal arrival information due to supervised machine learning. In all practicality, the receivers can be placed and attached at any place as long as the receivers are located within the common wire extension range. Note that all receivers are connected based on the bus topology using a simple analog network with the analog mixer.
The SCSSL system consists of three computational stages: homomorphic deconvolution (HD), feature extraction, and machine learning stage, as shown in Figure 1. The sound source emits the acoustic waves in spherical shape, and the wavefronts arrive at the receiver module in plane format with far field provision. According to the AoA , the inter-receiver time delays are determined and fused as independent arrivals on the analog microphone network. The single ADC transforms the mixed analog signal into digital format for further processing. The HD separates the time delays (or impulse responses) of the receiver module from the single-channel received signal. The previous paper confirmed the performance of time of flight (ToF) estimation by utilizing the nonparametric and parametric HD algorithms [30]. The nonparametric HD presents the raw distribution of time delays, and parametric HDs show the parametrized rational function of the time delays. Therefore, the feature extraction stage isolates the representative information from the given HD outcome by selecting the proper domain. The Gaussian process regression (GPR) in the machine learning stage performs the stochastic process on the supervised learning to define the likelihood distribution over functions. Proper parameter estimation and Bayesian function modeling can predict the accurate arrival angle based on the given features. The increased number of receivers is expected to produce improved accuracy in the prediction; however, this paper uses the minimum number of receivers as three in the horizontal space.
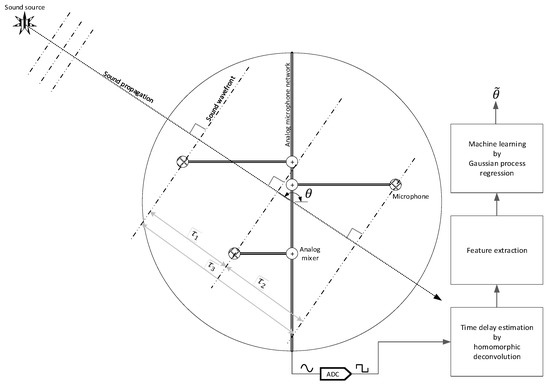
Figure 1.
Functional diagram of the overall SCSSL system. The big circle indicates that the object installed three microphones with an analog microphone network. is the real arrival angle for the sound and is the estimated angle.
This paper justifies the author’s continuous research activities on the SSL system for decades. The novel underwater SSL systems based on the beamforming had been presented for rapid and scalable systems [31,32,33,34,35,36]. The sparsely distributed wireless sensor network localized the targets by capturing the acoustic energy from the moving vehicle [37]. The unique binaural [38] and monaural [39,40,41] SSL systems were proposed for feasible systems over the airborne sound propagation. The human aggressively exploits the binaural and monaural methods for better localization by using the magnitude, phase, and frequency variations over the two ears as well as the pinna/head structure [3]. The binaural and monaural SSL systems are possible because of the extensive use of the structure to overcome the receiver number limitation. In general, the conventional sensing modules are required to be installed on the target system without modifying the overall structure and configuration. Additionally, the computation and communication complexity should be maintained at a low level for system feasibility. The single-channel multiple-receiver SSL was suggested in the previous papers [30,42] to challenge the binaural/monaural method without the external structure and to include the beamforming performance with reduced computation/communication burden. The paper established the promising performance with a simple machine learning algorithm, linear regression. This paper extends the single-channel, multiple-receiver SSL method with an advanced machine learning algorithm called GPR and novel feature extraction. Additionally, the simulation and experiment are diversified by including the further hold-out dataset for extensive angles. Therefore, this paper investigates the prediction performance along with the complex inference of the angles not shown in the learning process. Note that the identical anechoic chamber [43] has been operated for the acoustic experiments and evaluations to maintain consistency.
This paper is organized as follows: Section 2 introduces HD and explains how the time delays are extracted and represented. Section 3 presents the feature extraction methods for nonparametric/parametric HDs and the GPR for machine learning. Section 4 presents the computer simulations for the optimal receiver position and prominent localization parameters. The similarity matrix is employed for evaluating the various receiver positions with reduced computation. The simulation also demonstrates the performance of localization for the numerous parameters and models. The prediction performances on the training and hold-out datasets are illustrated and analyzed for extensive directions. Section 5 describes the performance of the actual dataset produced by the anechoic chamber experiments. The best parameters and model benefits are observed and arranged for the conclusion.
2. Nonparametric and Parametric Homomorphic Deconvolution
This section is presented by summarizing the previous papers [30,42] to provide access to the reader while maintaining concept integrity. For further information, the readers are suggested to follow the article for finding detailed explanation about the nonparametric and parameter HD. The homomorphic filtering method is a comprehensive method for signal processing, comprising a nonlinear transformation to a counterpart domain in which linear filters are performed, followed by an inverse transformation back to the original domain [44,45,46]. The HD is one application of homomorphic filtering to separate the convoluted signals by using the logarithm and exponential operations. The forward homomorphic system based on the logarithm converts the multiplicative functions into an additive format. The simple window operation performs the separation based on a signal property. The backward homomorphic system with exponentials reverts to the original time domain. The HD uses two homomorphic systems in a cascade to derive the propagation function, which indicates ToFs between the receivers.
The nonparametric HD produces the conventional raw distribution of time delay information based on multiple discrete Fourier transforms (DFT) or fast Fourier transforms (FFT). The propagation function model realizes the parametric ToF estimation in the last HD stage by employing Yule–Walker [47,48], Prony [48,49], and Steiglitz–McBride [48,50]. Note that the parametric method computes model coefficients and the nonparametric technique delivers the numerical distribution. Figure 2 illustrates the complete computational procedure for the nonparametric and parametric HD algorithms. The ensemble average in stage ③ and conjugate in stage ⑦ are inserted to conduct the signal-to-noise ratio (SNR) improvement and parametric modeling, respectively.
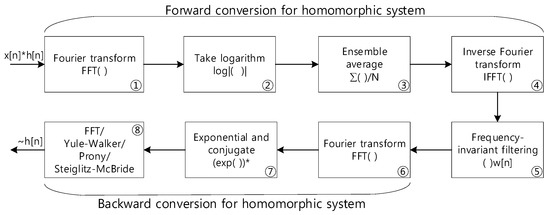
Figure 2.
Computational procedure for the parametric and nonparametric homomorphic deconvolution. The * in stage ⑦ indicates the conjugate operation.
In Figure 2, the system receives the single channel signal, which contains the impulse response (or propagation function) of the receiver configuration based on the convolution sum. Note that the star operation in in Figure 2 indicates a convolution sum operation. The FFT (stage ①) and inverse FFT (stage ④) pair with the absolute logarithm (stage ②), which corresponds to the real cepstrum of the forward conversion of the homomorphic system. The previous paper [42] showed that the ensemble average (stage ③) after the logarithm (stage ②) denotes the inverse proportionality in noise variance. Therefore, the longer ensemble average length induces higher SNR due to the lower noise power. The window function in frequency invariant filtering (stage ⑤) actually executes the separation of impulse response . The is allowed to pass beyond the specified time sample, which controls the minimum time delay in . The other FFT (stages ⑥ and ⑧) pairs with exponential functions (stage ⑦) reconstitutes and estimates the nonparametric propagation impulse response . The FFT in the last stage essentially performs the inverse FFT because the conjugate to the FFT provides the conjugated inverse FFT outcome according to the DFT/FFT property.
The choice of the last computation stage in Figure 2 is divided between the nonparametric and parametric HD. The Yule–Walker, Prony, and Steiglitz–McBride method are devised to provide the parametric HD. The following equations show the conventional regressive signal models in the time and z domains.
The model parameters below are estimated by the Yule–Walker algorithm to describe the propagation function of the given time signal. The Yule–Walker algorithm is classified as the autoregressive (AR) model; hence, the algorithm derives the coefficients of the denominator in Equation (2).
The model coefficients below are computed by the Prony and Steiglitz–McBride algorithms to represent . The Prony and Steiglitz–McBride algorithms belong to the autoregressive moving average (ARMA) model; therefore, the algorithms are required to compute the numerator and denominator coefficients in Equation (2).
Note that the complex number input for the Yule–Walker, Prony, and Steiglitz–McBride algorithm provide the complex number coefficients which disengage the pole/zero location constrains. Without the constraints, further estimation accuracy is obtained from the numerical expansion [30].
In Equation (3), the estimated time delays are properly indicated by the derived coefficients from the parametric methods. The is the rational function shown in Equation (2), and L is the consistent FFT length in the HD algorithm. Observe that the samples n corresponding to the maximum propagation function specify the time delays.
Figure 3 illustrates the normalized for 50, 100, and 150 samples in time delay for the nonparametric and parametric HD algorithms. The window length for all HDs is 25 samples, with a 200 ensemble average length. The order for the parametric HDs is 9 in constant. The data is generated from the recorded audio signal from the anechoic chamber [43] with postprocessing (convolution sum) for dedicated time delays. The HDs demonstrate the statistical performance based on the SNR, ensemble average length, and order (only for parametric HDs). The nonparametric HD and Steiglitz–McBride methods provide consistent estimation with low variance and bias in general. The Yule–Walker and Prony methods are prone to the performance degradation in low SNR and short ensemble average length overall. Further statistical performances were analyzed for time delay estimation in the previous paper [30] based on the various conditions.
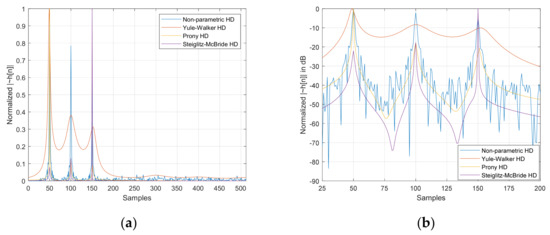
Figure 3.
Estimated distribution (normalized), with 200 ensemble average lengths for 50, 100, and 150 sample delays. The order for the parametric HDs is 9 and the window length for all HDs is 25 samples. (a) Magnitude distribution; (b) decibel distribution. is represented by .
3. Methodology
The previous section introduced the methods to derive the time delay information, which is induced by the receiver structure. The process is known as the deconvolution for reversing the convolution between the original sound and produced delays. Based on the delay distribution, the AoA is estimated by the machine learning algorithm, the GPR with proper information format. The GPR predicts the AoA based on the supervised learning process, which computes the optimal function from the statistical procedure. The nonparametric and parametric HD algorithms produce distinctive numerical distribution for the time delay; therefore, the appropriate feature extraction is necessary for the GPR. The following subsections demonstrate the feature extraction and GPR methods for accurate predictions.
3.1. Feature Extraction
Machine learning algorithms classified as supervised require labeled examples with feature input. The regression problem predicts a real-valued label from the feature learning process for the given unlabeled feature input. The GPR is one of the supervised and regression algorithms; therefore, a representative feature dataset as well as accurate labels are necessary for the learning process. The features and labels are arranged as follows:
The lower case presents the scalar and the bold lower case denotes the vector for the L dataset in the above equation. The subscript indicates the i-th dataset. The label is produced by the feature vector . The individual vector xi is organized as follows:
The n-th feature in the vector is described by the superscript number n in parenthesis in the above equation. Note that there are M features in the vector. The choice of is distinctive for the nonparametric and parametric HD algorithms in terms of domain as well as length.
The nonparametric HD utilizes the direct method for feature extraction. The raw distribution of nonparametric HD output immediately illustrates the time delay information with likelihood. The higher value in the sample location shows the stronger possibility of time delay in the sample location. The range of the distribution follows the time delay information from the given receiver configuration. The lower bound W is specified by the window function in Figure 2 stage ⑤ since the window function prunes the time delay below the cutoff W to separate the ToF from the received signal.
Equation (6) shows the feature extraction from the nonparametric HD output. The is the maximum time delay possibly derived from the receiver configuration. The time locations from the W + 1 to of the nonparametric HD output are organized for the feature sequentially. Note that the nonparametric HD output is normalized for consistency.
The parametric HDs employ the parameter-based extraction method known as pole angle method for feature extraction. The parametric HDs can produce the same raw distribution as the nonparametric HD output by using Equation (3); however, the benefits of the parametric HDs are lost with the extra computation. All parametric HDs establish the rational function as shown in Equation (2), and the poles of the function are the dominant components to create the peaky response in the time delay distribution. Especially, the phases of the poles correspond to the time delay in HD distribution [30]. The denominator of the rational function in Equation (2) is shown below, and the solution of the polynomial provides the poles of the given regressive model.
The polynomial coefficients in the above equation are estimated parameters by using the Yule–Walker, Prony, and Steiglitz–McBride methods with the given order N. The s are complex numbers, and the solutions of the polynomial are also complex numbers. The phase of the individual pole is assigned to the feature vector, as shown below.
The operator computes the angle of the complex number by using the simple trigonometric calculation in radians.
The direct method is the simplest method to extract the feature from the HD output. The method simply extracts the portion of the output and cast it on the feature vector. The length of the feature vector from the direct method is likely to be extensive due to the maximum time delay collected by the receiver configuration. The pole angle method requires further computation to calculate the poles and phases. However, the length of the feature vector from the pole angle method is expected to be concise because of the parametric model order. Observe that the parameter order is considerably smaller than the HD length, and the model parameters represent the time delay based on the dedicated computation introduced in Section 2.
3.2. Gaussian Process Regression
The Gaussian process regression contains two methods: the Gaussian process and regression. By definition, a Gaussian process is a collection of random variables, any finite number of which have a joint Gaussian distribution. Therefore, the Gaussian process generalizes the Gaussian distribution to an uncountably infinite set of possible dimensions. The regression is a problem of predicting a real-valued output given a feature vector by establishing a model from a learning algorithm. The GPR assumes that the regression outputs are infinite and latent function variables and the finite collection of the function variables obeys the multivariate Gaussian distribution. The Bayesian modeling of functions allows us to train the model and predict the target, especially in applications where data is limited.
The GPR is an extensive research area for the machine learning algorithm utilized for various purposes [51,52,53]. The diverse approaches have explained the GPR in numerous papers [54,55] and web documentation [56,57] in mathematical and technical terms, respectively. Note that the following equations and descriptions provide the GPR for the given application/structure in a concise and deliverable style. The function below is specified by the Gaussian process with zero mean and input variance. Observe that the function variance is computed by the input variance [58,59].
The explicit basis function is a method to denote a nonzero mean over the function. The equation below represents the zero-order mean basis function 1 and coefficient with the given mean and variance for the coefficient. The higher order mean function can be realized by the mean function matrix with vector .
The GPR output in the equation below shows the Gaussian process with the new mean and variance for the linear combination in Equation (10).
The scalar output of Equation (11) is extended to the vector output in the equation below. The bold font in the function name presents the vector output. The corresponds to the basis function and one vector for the zero order.
The matrix/vector format and dimension are demonstrated in below equation. Note that the s in below equation are the feature vectors specified at Equation (5).
The joint distribution between the observed and predicted function values derives the conditional distribution with mean and covariance, as shown below. is the identity matrix for L size.
The dimensions of the predicted output and basis function are shown in the equation below. The actual prediction of the GPR is the mean of the conditional distribution, equivalently . is the length of the test dataset.
The computation of the prediction requires hyperparameters as covariance matrix, , and . Note that the is a noise variance from the data measurement. The covariance matrix consists of covariance values defined by the covariance function or kernel. The covariance matrix for the training set is presented in the equation below with the parameter vector . The covariance matrix between the training and test sets is illustrated in the equation below as well.
The kernel (or covariance function) denotes the similarity between two latent function variables and equivalently between data points and by a kernel trick [59]. The kernel develops the similarity model with parameters for the signal standard deviation , and characteristic length-scale . Both parameters control the horizontal and vertical relationships between the points. Table 1 provides the conventional kernel functions with corresponding parameters.

Table 1.
Conventional kernel functions and corresponding parameters [53].
After establishing the covariance matrix with the kernel function, the parameters are necessary to be estimated from the given training dataset to complete Equation (14). The maximum posteriori estimate of the parameter occurs when the conditional probability distribution of the parameter is at its highest. With insufficient prior knowledge about the parameter, the highest corresponds to the maximizing point from the marginal log likelihood shown in the equation below.
The multivariate optimization algorithm [60,61,62] over Equation (19) executes the following equation to find the respecting parameters in a numerical way.
Once the kernel is selected, the parameters are estimated by the training process, and the predictions are performed by Equation (14) from the parameters. The prediction for a single point can be realized with the equation below.
The GPR training and prediction require intensive computation as due to the inversion of the covariance matrix. To release the complexity, numerous methods are possible, such as subsets of data point approximation [53,63], subsets of regressor approximation [53,64], etc. This paper applied the GPR without any approximation on training and prediction to remove any uncertainties caused by the information reduction. However, the optimized matrix inversion algorithms are used, such as LU decomposition [65] and Cholesky decomposition [66].
The explained GPR is utilized for the predictions from the 3D sinc function in Figure 4. The original 3D sinc plot is depicted by the one million x and y grid points in Figure 4a. The GPR is trained by the randomly chosen 300 data points (* in Figure 4a), and the measurement is observed in the immaculate situation of the noise-free input data. The GPR with exponential, squared exponential, and Matern 3/2 kernels predicts the rest of the figure based on the estimated parameters in Figure 4b, Figure 4c, and Figure 4d, respectively. The GPR prediction performance suggests the significance of the kernel selection. If possible, prior knowledge of the data model leads to a better choice of the kernel function.
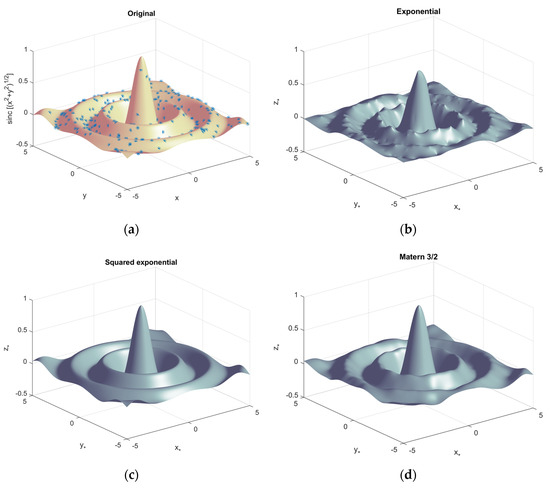
Figure 4.
Gaussian process regression example by 3D sinc function. (Trained by 300 data points) (a) Original sinc function with one million data points. The * indicates training data points; (b) predictions by GPR with exponential kernel; (c) predictions by GPR with squared exponential kernel; (d) predictions by GPR with Matern 3/2 kernel.
4. Simulations
In the previous section, the SCSSL algorithm is implemented by the HD, feature extraction, and GPR in consecutive order. This section realizes and performs the SCSSL algorithm over the computer-generated data. The performances are evaluated over the various parameters, such as kernels, orders, and ensemble lengths to determine the optimal choices for the actual experiments. Prior to the discuss of the SCSSL system simulation, the performance of the SCSSL system depends on the receiver configuration due to the derived time delay patterns from the receiver locations. The pattern diversity contributes to the prediction accuracy, and massive choices on the receiver configuration engage in the complex decision. This section initiates the simulation with the receiver configuration.
4.1. Receiver Locations
The HD algorithms compute the time delay between the receivers; hence, the receiver locations provide the performance fluctuation based on the temporal information quality. At least three receivers are required to resolve the angles for the (180°) range. The higher numbers of receivers produce better performance in accuracy; however, the prediction range is still limited to . The ambiguity originated from the HD algorithms, which introduced the range constraint. Observe that the time delays from the HDs are arranged for the positive values and cannot be distinguished between and in the given algorithm structure. Therefore, the receiver configuration comprises three receivers for range observation.
Figure 5 shows the arbitrary receiver configuration and corresponding time delay distribution. The receivers are placed on the particular grids (tiny blank circles in Figure 5a), which are located over the plane circle with a 32-cm radius. The distance between the adjacent grids is 4 cm in the horizontal and vertical directions for the total of 197 grids. Note that the discrete grids are applied to limit the number of combinations. The three receivers are located at , , and positions, and the resultant vectors are shown at , , and directions in Figure 5a. The receiver positions and vectors are represented by complex numbers in the Cartesian complex plane. Using the conventional angle notation, the arrivals from the east, north, and west directions correspond to the for 0, , and , respectively. For the individual vector , the actual time delay in samples can be calculated by the following equation.
The is the arrival angle in radians, is the sound speed (34,613 cm/s), is the sampling period (1/48,000 s), is the imaginary number, and is the operator for extracting the real part from the complex number. Note that the in Equation (22) represents the round to the nearest integer function.
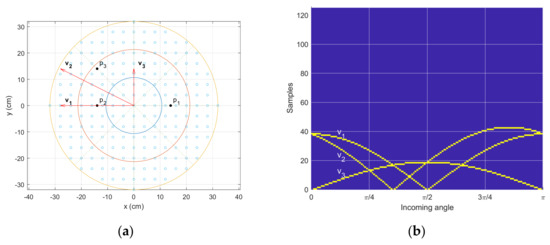
Figure 5.
Receiver configuration and time delay distribution. (a) Receiver grid—black circles indicate one example receiver location, and red arrows show the vectors between the receivers in the given configuration. (b) Time delay distribution for the given incoming angles. The yellow points provide the actual time delay (samples) created by the corresponding vectors .
The equation below generates Figure 5b for the time delay distribution, where the time delay locations are identified with yellow points. The T matrix represents the time delay distribution, and the t vector indicates the time delays for individual angles.
The is the Kronecker delta function with time on a sample unit, A is the number of discrete angles, V is the number of time delay vectors, and is the maximum time delay on a sample for all configurations. Figure 5b casts the n for vertical and for horizontal axis.
The optimal receiver configuration can be obtained by employing the brute force method which systematically enumerates all feasible configurations for the least prediction error. The extensive computations are necessary for searching for the best receiver positions since each configuration realizes the entire SCSSL procedure for possible angles. By understanding the machine learning characteristics, the feature discrimination significantly mitigates the computational burden for evaluating the receiver configurations. The optimal receiver configuration should provide distinctive time delays on every assessing angle for information diversity. Observe that the GPR requires the unique feature for individual angles.
The diversity pattern can be analyzed by creating the similarity matrix S in the equation below. The multiplication in the equation below is the inner product between vectors.
The t vector is from Equation (23), and the S matrix is illustrated in Figure 6a. According to the Cauchy–Schwarz inequality [67], the inner product with itself or the same pattern produces the highest values. Figure 6a demonstrates the highest values of the diagonal axis, which indicate the auto-inner products. The off-diagonal element should yield lower values than the diagonal elements; otherwise, the GPR delivers the confusion decision.
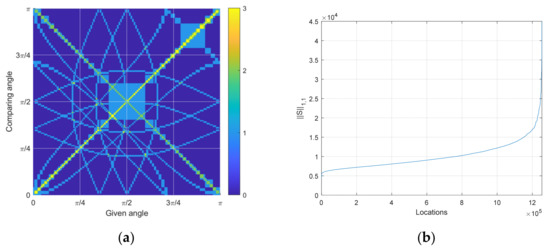
Figure 6.
Similarity analysis. (a) The similarity matrix for the given receiver configuration shown is Figure 5a. The higher value indicates the higher similarity between the given and comparing angle; (b) The sorted distribution of similarity matrix norm for all possible combinations of three receiver configurations.
The S matrix is established for one receiver configuration. The norm of the S matrix shown below presents the overall similarity of the given configuration.
The norm is the simple sum of all absolute elements. The lower value in denotes the higher diversity and equivalently, the lower similarity in time delay pattern since the off-diagonal elements are decreased overall. Note that the diagonal elements are predetermined by the auto-inner products as constants. Figure 6b illustrates the sorted norm of the S matrix for all receiver configurations. The combination of the three receiver positions resulting in 197 grid points is 1,254,890, which describes the x axis of Figure 6b.
The optimal receiver configuration is chosen from the least norm and is shown in Figure 7a. Multiple configurations provide identical minimum norm values due to the geometric symmetry of rotated structures. The receiver positions are located at the edge of the circle so that they can deliver the widest range of time delays in the pattern. Additionally, the asymmetricity is observed in the receiver positions to discriminate the east and west directions. Note that the symmetric receiver configuration provides the prediction of up to the range. The corresponding similarity matrix is depicted in Figure 7b. In contrast to Figure 6a, the optimal similarity matrix presents a substantially low distribution in Figure 7b. Fewer highest values are detected in the off-diagonal axis area in Figure 7b; therefore, improved accuracy is expected from the GPR prediction in the Figure 7a receiver configuration. The angle ambiguity is expected to be reduced for the wider receiver position with an increased receiver number.
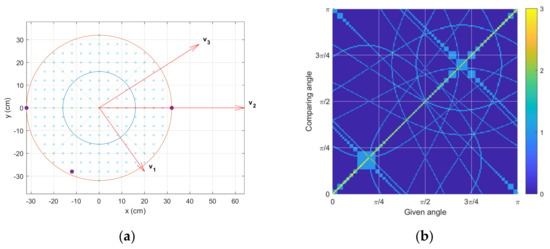
Figure 7.
Optimal similarity outcome, which shows the lowest similarity matrix norm. (a) One of the best configurations for the three-receiver structure. (b) The corresponding similarity matrix.
Figure 8a presents the time delay distribution for the optimal receiver configuration shown in Figure 7a. The dynamic range and the diversity pattern of the delay are further expanded and improved than in the example case, respectively. Corresponding to the similarity matrix in Figure 7b, minor pattern overlaps are observed in the distribution in Figure 8a. Figure 8b illustrates the estimated time delay distribution by using the nonparametric HD algorithm on the simulated data. The data is generated from the receiver’s perspective in the time domain with a 20 dB SNR. The estimated time delay precisely visualizes the theoretical time delay with trivial shadows caused by the DFT length limitation and noise interference [30]. Additionally, note that the minimum detectable time delay is determined by the window function in stage ⑤ of the HD algorithms shown in Figure 2. Figure 8b initiates the time delay axis (y axis) from six samples due to the five samples in the window length.
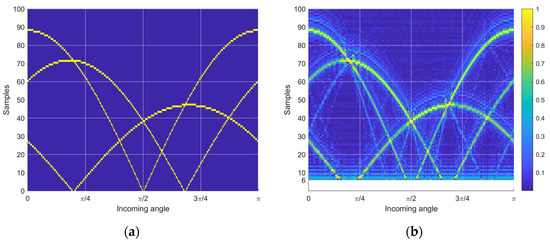
Figure 8.
Time delay distribution from optimal similarity configuration. (a) Theoretical time delay distribution. (b) Estimated time delay distribution with nonparametric HD.
The optimal receiver configuration is justified by the similarity matrix and its corresponding norm. This process significantly reduces the computation of evaluating the receiver configuration. The previous paper [42] performed the 680-combination evaluation, the prediction error analysis, on 14 computers (intel i7-7700/32GB memory) with 25-h execution time. This paper assesses the 1,254,890 combinations of the single computer (inter i7-10700k/32GB memory) for less than half hour. The maximum diversity on the time delay pattern is provided with the receiver configuration and is interpreted properly with feature extraction and GPR.
4.2. Localization Performance
The SCSSL system sequentially executes HD, feature extraction, and GPR for prediction based on the provided receiver configuration. The performance of the SCSSL depends on the prediction accuracy and the independent variables are listed as ensemble length, parametric order, kernel functions, and incoming angles. The length of ensemble average controls the depth of average for enhancing the SNR in HD. The parametric order determines the pole and/or zero number to adjust peaks and valleys of the time delays to follow the distribution. The kernel functions define the relationship between the feature vectors to establish the prediction model. The incoming angle selects the training and evaluating angles for the performance analysis. This subsection analyzes the performance in terms of prediction accuracy with described independent parameters.
The GPR produces the continuous output of the angle prediction because of the regression property; however, training and analyzing the system require discrete angles. The SCSSL system is trained by the seen angles from to with resolution. Note that the opposite direction angles should be avoided to remove the confusion due to the ambiguity in the HD algorithms. The angles between the adjacent seen angles are organized as the unseen angles to characterize the inference performance of the SCSSL system. The vocabulary ‘seen’ and ‘unseen’ is adopted to distinguish the included and excluded angles for learning, respectively, and both types of angles are shown in Figure 9a. The SCSSL system performance is numerated by root mean square error (RMSE), as shown below.
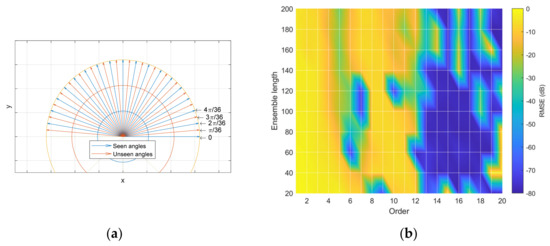
Figure 9.
Incoming angles and RMSE distribution. (a) The angle distribution for learning is classified as seen angles (blue arrows) and the angles between the adjacent seen angles are organized as unseen angles (orange arrows). (b) One example of RMSE distribution in decibel scale for various orders and ensemble lengths.
The is the real output (label) and is the predicted output. For the given kernel function, the RMSE for the parametric HD method is illustrated by the colormap surface plot (shown in Figure 9b), with parametric order and an ensemble length parameter. The RMSE of the nonparametric HD is depicted by the conventional plot with ensemble length only.
The simulation parameters and corresponding values are arranged in Table 2. For one prediction, the SCSSL algorithm requires the ensemble length frames with overlapping between frames. Each frame consists of 1024 samples; however, the frame progresses only for the nonoverlapped samples, 256. The number of seen angles is equal to the number of unseen angle, and 0– angles are called the angle set. The SCSSL algorithm is trained by the 111 angle sets with 1998 iterations. The validation process is performed by two angle sets of the training as 222 angle set and 3996 iterations. Note that one iteration is one angle training, and the training/validation are operated by the separated dataset.
Table 2.
Simulation parameters and values.
Figure 10 demonstrates the empirical cumulative distribution function (CDF) for simulated RMSE with kernel functions, HD algorithms, and angle classification on training and validation. The empirical CDF is constructed from the sorted RMSE in decibel and cumulated up to the individual RMSE for probability. The empirical CDF shown earlier, equivalently further left, indicates better performance in prediction because the reduced RMSEs are dominant. Eventually, all empirical CDF approaches the unit value due to the probability property. The speed represents the performance of the SCSSL algorithm. The left and right figures are divided into training and validation sets. Each row of the figure matrix is organized for the individual HD algorithms. The colored legend plots in the figure are designed to identify the kernel functions.
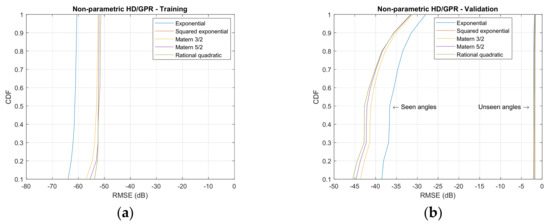
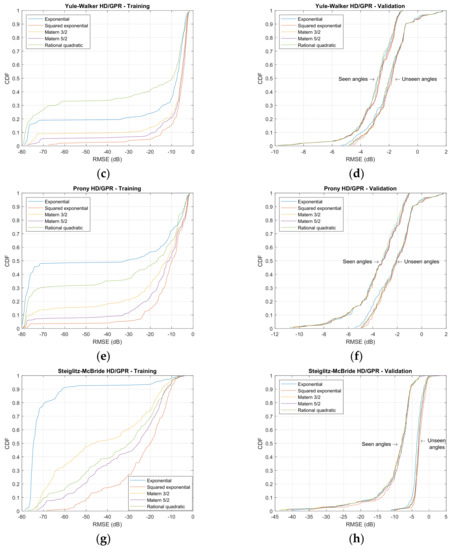
Figure 10.
Empirical cumulative distribution function (CDF) distributions for simulated RMSE from GPR kernel functions. (Training: 1998 iterations; validation seen-angle: 3996 iterations; and validation unseen-angle: 3996 iterations.) (a) Nonparametric HD/GPR—Training. (b) Nonparametric HD/GPR—Validation; (c) Yule–Walker HD/GPR—Training; (d) Yule–Walker HD/GPR—Validation; (e) Prony HD/GPR—Training; (f) Prony HD/GPR—Validation; (g) Steiglitz–McBride HD/GPR—Training; (h) Steiglitz–McBride HD/GPR—Validation.
The nonparametric HD/GPR shows the consistent RMSE values for the training set in Figure 10a. The exponential kernel delivers the least RMSE distribution in the training set; however, the rational quadratic kernel is narrowly located on the left of the other kernels in validation and seen angles shown in Figure 10b. The unseen angles produce nearly identical distributions for all kernels. The Yule–Walker HD/GPR provides the distinguished empirical CDFs for individual kernels in training set in Figure 10c, and the rational quadratic kernel exhibits the optimal performance. According to the CDF slopes, the majority of the RMSEs are located at the edges of the performance graph. The validation in Figure 10d provides approximately duplicated performance for all kernels in seen and unseen angles. Unlike the training CDFs, the RMSEs are gathered at the center of the RMSE distribution by analyzing the slopes.
On Figure 10e, the Prony HD/GPR demonstrates the comparable performance to the Yule–Walker HD/GPR outcome for training. The steeper slopes are measured on low RMSE values for all kernels and the exponential kernel denotes the best performance in training. The validation in Figure 10f stays in Figure 10d for all kernels and seen/unseen angles; however, the Prony HD/GPR initiates the RMSE distribution slightly earlier. The Steiglitz–McBride HD/GPR delivers the prominent performance in training set, as shown in Figure 10g. The exponential kernel quickly increases the empirical CDF in low RMSE range for optimal performance and the other kernels consistently distributed the RMSE values based on the slope analysis. The validation in Figure 10h indicates the least RMSE distributions among the parametric HDs. The unseen angle performance is outstanding against all HD/GPR algorithms. Based on the investigation described above, the nonparametric HD/GPR, Yule–Walker HD/GPR, Prony HD/GPR, and Steiglitz–McBride HD/GPR chose the rational quadratic, rational quadratic, exponential, and exponential kernel, respectively.
Figure 11 provides the RMSE distribution for ensemble length and/or parametric order based on the selected kernel function from Figure 10. Each row of the figure matrix shows the individual HD/GPR, and each column specifies the training, validation for seen angles, and validation for unseen angles. The red circle in each figure corresponds to the lowest RMSE position to indicate the best parameters. The nonparametric HD/GPR is a function of the ensemble length only; therefore, the first row of Figure 11 is a conventional 2D plot. The parametric HD/GPR RMSEs are determined by the ensemble length as well as parametric order; hence, the figures except the first row are described by the 3D surface plot with color bars. Note that the surface plots are generated by the interpolation, and the grids crossed by the white lines represent the original simulated and noninterpolated positions. The depth of RMSE in decibels is equalized with Figure 10 simulation.
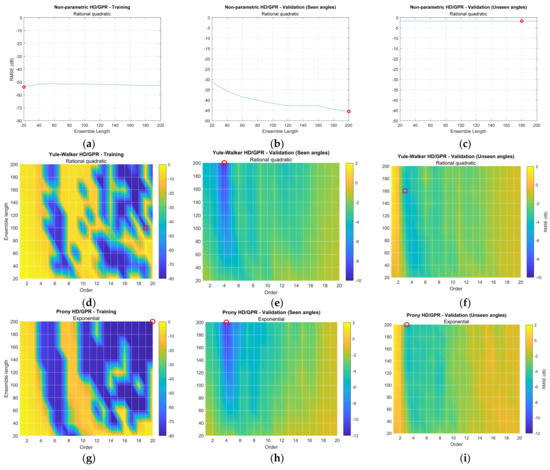
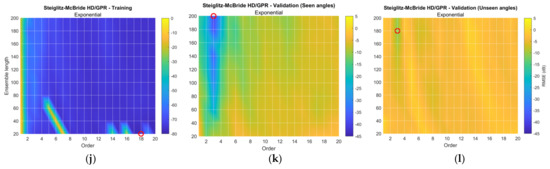
Figure 11.
Simulated RMSE distribution for selected GPR kernel function. The red circle indicates the minimum RMSE location. (Training: 1998 iterations; validation seen-angle: 3996 iterations; and validation unseen-angle: 3996 iterations.) (a–c) Non-parametric HD/GPR—Training and validations; (d–f) Yule–Walker HD/GPR—Training and validations; (g–i) Prony HD/GPR—Training and validations; (j–l) Steiglitz–McBride HD/GPR—Training and validations.
Figure 11a–c collect the RMSEs for non-parametric HD/GPR. Relatively consistent distributions were observed in all plots, and the validation for seen angles in Figure 11b provides the least RMSE on 200 ensemble lengths, which indicates the best parameter. Note that the best parameters should be evaluated during the validation process based on the hold-out dataset. Figure 11d–f arrange the RMSEs for Yule–Walker HD/GPR. The training RMSE distribution in Figure 11d illustrates the performance fluctuation in column-wise patterns. The high orders and around order 6 designate the low RMSE contributions. The validation RMSE for seen angles in Figure 11e shows the RMSE valley in order 4 and long ensemble length, which are recognized as the best parameters. Figure 11f for unseen angles includes the overall high RMSE distribution.
Figure 11g–i organizes the RMSEs for Prony HD/GPR. The overall distributions for training and validation resemble the Yule–Walker HD/GPR counterparts with a lower bias. Observe that the blue area in Figure 11g and the colorbar in Figure 11h,i correspond to the blue area in Figure 11d and the colorbar in Figure 11e,f, respectively. The best parameters for the Prony HD/GPR are order 4 and ensemble length 200 as well. Figure 11j–l consolidates the RMSEs for the Steiglitz–McBride HD/GPR. The training RMSE distribution in Figure 11j provides a low RMSE distribution for wide parameter combinations except for minor high glitches at certain spots. The validation RMSEs for seen and unseen angles in Figure 11k,l yield the RMSE valley at the order 3 column for higher ensemble length. The optimal parameters for Steiglitz–McBride HD/GPR are order 3 and ensemble length 200.
Table 3 summarizes the RMSE performance for the selected kernel function. The first column shows the SCSSL methods with kernel function in parentheses. The second column presents the best parameter values and corresponding RMSE in decibel for validation on seen angles. The third and fourth column collect the training and validation (unseen angles) RMSE on the determined best parameters, respectively. Note that the arrows in the column title indicate the source of the parameter. The RMSEs in squared brackets represent the best RMSE values which belong to the column simulation.
Table 3.
The RMSE values for the selected kernel function and parameters.
Figure 12 demonstrates the predictions from the HD/GPR algorithms for training and validation. The rows of the figure matrix specify the individual HD/GPR algorithms and the columns divide the training and validation. Figure 12 realizes the individual coordinate by axis with real angles and axis with predicted angles. The solid orange diagonal line in the figures indicates the perfect prediction. The 18 angular positions are isolated by radian distance with equiprobable possibility for all iterations in training. The 36 angles are evaluated on validation for seen and unseen angles with radian away from the adjacent angles. Note that the unseen angles (even sequence in validation angles) did not participate in the training process and seen angles are identified by the green vertical lines in validation plots. The single points in the plot are the cumulated predictions with very low prediction variance.
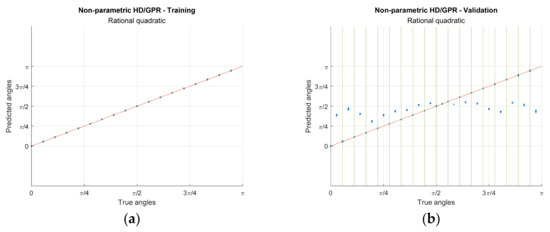
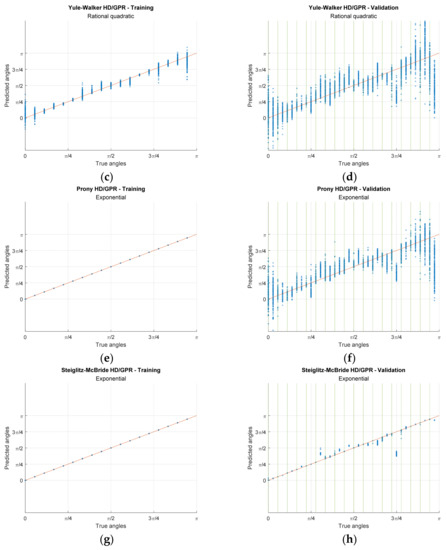
Figure 12.
Actual predictions for training and validation from simulation. The iteration numbers are identical to Figure 9 and Figure 10 caption. The green vertical lines show the seen angles. (a,b) Non-parametric HD/GPR—Training and Validation; (c,d) Yule–Walker HD/GPR—Training and Validation; (e,f) Prony HD/GPR—Training and Validation; (g,h) Steiglitz–McBride HD/GPR—Training and Validation.
The non-parametric HD/GPR shows the coherent predictions for training and validation in Figure 12a,b, respectively. The calculated RMSEs for training and validation (seen angles) are −52.43 dB and −45.52 dB, individually, as shown in Table 3 with given optimal parameter. Therefore, the non-parametric HD/GPR predicts the seen angles with high accuracy and low variance. However, the unseen angle predictions in Figure 12b present the high bias and low variance in statistics. The predictions are located at approximately for all unseen angles with inferior RMSE performance −1.74 dB. The Yule–Walker HD/GPR provides the wide range of the predictions for training and validation in Figure 12c,d, respectively. The computed RMSEs for training and validation (seen angles) are −15.90 dB and −9.77 dB, individually, as shown in Table 3 with given best parameters. The Yule–Walker HD/GPR predicts the seen angles with low accuracy even for the training process because of the Yule–Walker estimator property [30]. The validation for seen angles denotes the wider prediction distribution than the training counterparts. The unseen angle predictions produce the RMSE as −3.99 dB which lends the better performance than the non-parametric HD/GPR since the prediction mean follows the true angles in Figure 12d.
The Prony HD/GPR derives the mixed prediction characteristics for training and validation in Figure 12e,f correspondingly. The evaluated RMSEs for training and validation (seen angles) are −71.69 dB and −10.79 dB, respectively, as shown in Table 3 with given best parameters. The Prony HD/GPR predicts the seen angles with high accuracy and low variance for the training in Figure 12e. The seen angle predictions in validation on Figure 12f generate the performance degradation with low accuracy and high variance which is comparable to the Yule–Walker HD/GPR equivalent. The unseen angle predictions provide the RMSE as −4.71 dB which offer the similar performance with the Yule–Walker HD/GPR because the prediction averages pursue the real angles as well in Figure 12f. The Steiglitz–McBride HD/GPR introduces the neat predictions for training and validation in Figure 12g,h, respectively. The calculated RMSEs for training and validation (seen angles) are −63.48 dB and −39.91 dB, individually, as shown in Table 3 with given best parameters. The Steiglitz–McBride HD/GPR estimates the seen angles with high accuracy and low variance for the training in Figure 12g. Additionally, the seen angle predictions in validation on Figure 12h deliver the consistent high precision arranged nearby the perfect prediction line. Notable property of the prediction is that the unseen angles are distinctly estimated for the true angles with low variation and −10.73 dB RMSE. The unseen angles approximately and demonstrate the biased estimation due to the duplication in the time delay pattern. The similarity matrix in Figure 7b validates the duplication by inspecting the off-diagonal high values nearby and angle. The Steiglitz–McBride HD/GPR provides the best performance for all angle situations with accurate inference.
This simulation section investigates the optimal receiver configuration and localization performance analysis based on the computer-generated dataset. The similarity matrix significantly reduces the computational complexity for finding the best configuration from numerous combinations. Based on the optimal receiver configuration, the localization performance is evaluated for kernel functions, ensemble length, parametric order, and directional angles. The Steiglitz–McBride HD/GPR with exponential kernel demonstrates the best performance for seen and unseen angles with various dataset. The hold-out dataset for unseen angles can be predicted with −10.73 dB RMSE. The minor prediction glitches are observed due to the receiver configuration limitation.
5. Results
The acoustic experiments are implemented and evaluated in an anechoic chamber, which is proved to show limited conformance with ISO 3745 [68] for the 1 kHz–16 kHz 1/3 octave band in a hemi-free-field mode and for the 250 Hz–16 kHz 1/3 octave band in a free-field mode [43]. The SCSSL methods are analyzed in the free-field mode which requires completely shielded surfaces for all directions with acoustic wedges. The acoustic experimentation demands three microphones with predetermined locations (shown in Figure 7a) and single speaker with far-field provision. The directional angle between receivers and speaker are guided by the line laser (GLL 3–80 P, Bosch, Gerlingen, Germany) located above the speaker. The far-field provision is preserved by maintaining a one-meter minimum distance for all possible signal propagations.
The microphones are positioned at the receiver frame composed of lumbers with plastic supports. The structure retains the receiver shape and microphone height for circular movements. Note that the speaker and receiver level should be identical for unimpeded horizontal propagation. The circular movements for incoming angles involve the pair of saw-toothed wheels with engraved and intagliated shape for (10°) rotations. As photographed in Figure 13, the three receivers are placed in the radial pattern with concentric circles; hence, the circle center provides the angular movement center which is designed for the saw-toothed wheel pair. The general experiment arrangement is presented in Figure 13a and the receiver center is depicted in Figure 13b for the circular movement engager. The plastic accessories are realized by the 3D printer (Replicator 2, MakerBot, Brooklyn, NY, USA) from the polylactic acid (PLA) filament.

Figure 13.
Acoustic experiment in the anechoic chamber: (a) three microphones and one speaker configuration with laser guidance; (b) top-view of the receiver structure and angular movement engager (the center pole).
The analog mixer (MX-1020, MPA Tech, Seoul, Republic of Korea) combines the microphones (C-2, Behringer, Tortola, British Virgin Islands) for establishing the single channel signal. The computer-connected audio interface (Quad-Capture, Roland, Hamamatsu, Japan) quantizes the single-channel signal for SCSSL algorithms. The speaker (HS80M, Yamaha, Hamamatsu, Japan) is also connected to the audio interface to produce the wideband acoustic signal. The generation and reception of real-time audio are managed by the MATLAB system object with the audio stream input/output (ASIO) driver. The audio is recorded for 5 min in every appointed angles. The first and last one second of data are excluded to decrease the interruptions by transition conditions. Consequently, the experiment for individual angles utilizes approximately 5 min of recorded data. Each data frame is built by 1024 samples and the frame progresses to the further time by non-overlapped samples 256 for information consistency. The angular movement engager (shown in Figure 13b) is designed to rotate the receiver structure for every degree with the given 3D printer resource. Hence, the experiment angles are reduced by half for seen and unseen angle datasets. The experiment parameters are organized in Table 4.
Table 4.
Experiment parameters and values.
Figure 14 shows the experimented RMSE distributions with a selected kernel function which is derived from the simulation. The validation is performed with 9 seen angles for 999 training iterations and 999 validation iterations. The range of the RMSE is equalized to the previous RMSE distribution plots, such as in Figure 10 and Figure 11. The red circle on each figure corresponds to the lowest RMSE position to indicate the best parameters. The non-parametric HD/GPR demonstrates the gradually decreasing distribution from −35 dB to −48 dB. The improved SNR from the longer ensemble length contributes to the lower RMSE. The Yule–Walker HD/GPR indicates the enhanced RMSE on the area for longer ensemble length and low parametric order. The low RMSE area is wide and clustered. The Prony HD/GPR introduces the analogous RMSE distribution to the Yule–Walker HD/GPR counterpart. The low RMSE area is narrower than the lower parametric order. The Steiglitz–McBride HD/GPR delivers the low RMSE area on the small region with fragmented pattern. The orders 2, 3, and 4 with certain ensemble lengths produce very low RMSE values.
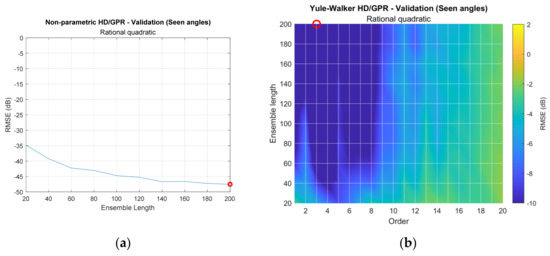
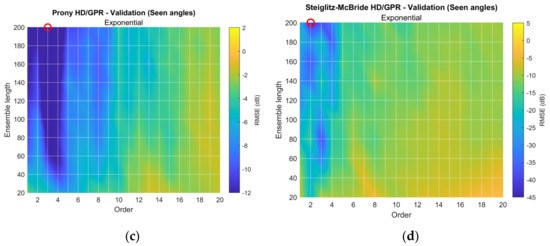
Figure 14.
Experimented RMSE distribution for selected kernel functions. The red circle indicates the minimum RMSE location. (Training: 999 iterations; and validation seen-angle: 999 iterations.) (a) Nonparametric HD/GPR—Validation (seen angles); (b) Yule–Walker HD/GPR—Validation (seen angles); (c) Prony HD/GPR—Validation (seen angles); (d) Steiglitz–McBride HD/GPR –Validation (seen angles).
Table 5 organizes the best parameter values and corresponding RMSE from the validation process. The longer ensemble length achieves the lowest RMSE values for all HD/GPR algorithms. Observe that the optimal parametric orders are increased by one from the order chosen from the experimental RMSE distribution (seen angles) in Figure 14. The shifted orders are selected from the balance between the seen and unseen angle performance. Additionally, the parameter values are equal to the values from the simulation results shown in Table 3. The nonparametric HD/GPR produces the leading prediction accuracy for the seen angles according to the RMSE values. However, the unseen angle performance is significantly decreased, as expected from the prediction simulation shown in Figure 12b. The Steiglitz–McBride HD/GPR provides the lowest RMSE value for the unseen angles and the second RMSE performance for seen angles with least parametric order. The Yule–Walker and Prony HD/GPR methods show the overall performance deterioration for seen and unseen angles.
Table 5.
Minimum RMSE values for HD/GPR experiments and corresponding parameters.
Along with the previous simulations and experiments, this paper arrives at the final phase of investigating the actual prediction distribution based on the selected kernel function, ensemble length, and parametric order. Figure 15 shows the predictions from the individual HD/GPR algorithms for seen and unseen angles. The number of predictions is described in Table 4 as 999/999 iterations for seen/unseen angles. Note that the seen angles are indicated by the green vertical lines in the plots. In Figure 15a, the nonparametric HD/GPR represents the accurate predictions on seen angles with −47.54 dB RMSE; however, the predictions on unseen angles are consistent but biased with −1.95 dB RMSE. In Figure 15b, the Yule–Walker HD/GPR presents a wide variance on all predictions with −15.75 dB/−3.04 dB RMSE for seen/unseen angles. The means of the distribution seem to be following the perfect prediction line except for unseen angles around west end arrivals. In Figure 15c, the Prony HD/GPR provides a similar performance pattern to the Yule–Walker HD/GPR with −15.50 dB/−0.24 dB RMSE for seen/unseen angles. The performance glitches on the unseen angles are observed around west end and north-east arrivals. In Figure 15d, the Steiglitz–McBride HD/GPR demonstrates the overall best performance in terms of bias and variance with −37.56 dB/−9.11 dB RMSE for seen/unseen angles. The unseen angles around north-east () arrivals provide the biased estimations due to the duplication in the time delay pattern shown in Figure 7b.
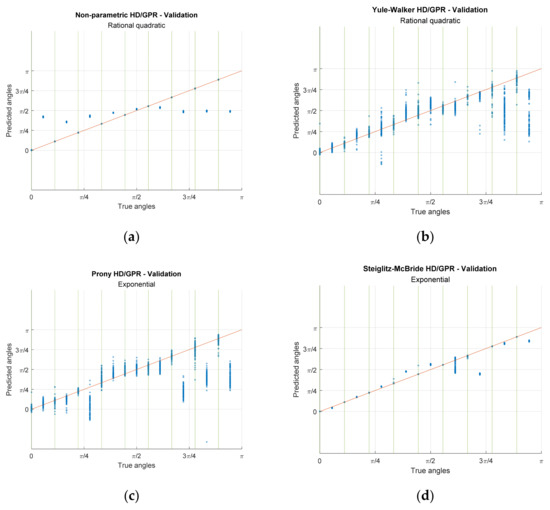
Figure 15.
Actual predictions for validation from experiment. The iteration numbers are identical to Figure 13 caption. The green vertical lines show the seen angles. (a) Non-parametric HD/GPR—Validation; (b) Yule–Walker HD/GPR—Validation; (c) Prony HD/GPR—Validation; (d) Steiglitz–McBride HD/GPR—Validation.
This results section performs the actual experiments with the optimal receiver configuration over the recorded audio from the anechoic chamber. With a wideband sound source, the three receivers are connected by the audio analog mixer and wired to the audio interface to collect data for individual angles. The HD/GPR algorithms show better performance with longer ensemble lengths and lower parametric orders, overall. The minimum RMSE value for each HD/GPR algorithm denotes the comparable performance outline to the simulation RMSE counterpart with minor discrepancy. The non-parametric HD/GPR and Steiglitz–McBride HD/GPR show the good performance on seen angles. The Steiglitz–McBride HD/GPR provides high prediction accuracy at unseen angles. The other HD/GPR algorithms generate marginal prediction performance for seen or unseen angles with high variance and/or high bias. Therefore, the Steiglitz–McBride homomorphic deconvolution, the pole angle method (feature extraction), and Gaussian process regress (exponential kernel) are combined as the SCSSL algorithm for optimal prediction on extensive incoming angles.
6. Conclusions
This paper provides the novel method to localize the angle of arrival based on the deconvolution with Gaussian process regression. The forward and backward homomorphic systems in cascade realize the deconvolution to extract the propagation function, which contains the time of flight between receivers. The nonparametric method is represented by the raw distribution of homomorphic deconvolution. The Yule–Walker, Prony, and Steiglitz–McBride from the spectral estimation technique are employed in the last stage of homomorphic deconvolution for model- and parameter-based propagation representation as a parametric method. The Gaussian process regression with a kernel (covariance) function calculates the mean and covariance of the updated function to predict the output based on the given training data. The Gaussian process regression predicts the angle from the given feature input once the learning process is completed. For feature extraction, the direct method and pole angle method are used for the nonparametric and parametric homomorphic deconvolutions, respectively. The optimal receiver configuration for a three-receiver structure is derived from the proposed similarity matrix analysis based on the time delay pattern diversity. The extensive simulations that present specific model order and longer ensemble length produce the least root mean square error. The Steiglitz–McBride model with an exponential kernel demonstrates the best performance for trained and untrained angles with various datasets. The experiments in the anechoic chamber present precise predictions with proper model order and ensemble length. The nonparametric method with a rational quadratic kernel shows good performance on trained angles. The Steiglitz–McBride model with an exponential kernel delivers the best predictions for trained and untrained angles based on the reduced model order.
This paper broadens the single-channel sound source localization system of the previous article to improve the comprehensive prediction performance by using Gaussian process regression with novel feature extraction. The foundation of the single channel sound source localization system was constructed by the time delay estimation using nonparametric and parametric homomorphic deconvolutions which was shown in prior independent article. The advantages of the system involve reduced system complexity because of the single analog receiver network with a single analog-to-digital converter for serving multiple receivers. The second benefit includes moderate modeling of machine learning algorithms to derive the estimation algorithm. Without using the complex propagation model, the training process of Gaussian process regression from the selected kernel function provides proper functioning for the sound source localization. Contrary to linear regression in the previous paper, the outcome of this paper proved that the Gaussian process regression with noble feature extraction realized the highest accuracy prediction for a wide range of the angles even for the untrained directions. Another enhancement of this system is introduced by the consistent algorithm complexity against receiver numbers. With fixed parameter values, the computational requirement is invariant to the receiver number. Observe that the conventional sound source localization systems show the same proportional complexity in terms of receiver numbers. The statistical analysis in simulation and experimentation demonstrates the feasibility of sound localization based on homomorphic deconvolution and Gaussian process regression. This paper contributes to increasing the possibility for the realization of a deployable and feasible sound source localization system by improving scalability and complexity. Currently, machine and deep learning techniques present aggressive progress for providing further accuracy in predictions and decisions with sparse or no datasets. The proposed system is expected to be improved by the use of advanced learning algorithms. Future work may aim to enhance the proposed system in complex situations, such as receiver failure and indirect propagation, etc. In addition, the future paper will explore the localization performance in the field using data collected by the mobile robot in a conventional environment. Due to the flexibility and expandability of deconvolution and machine learning, the use of the proposed method is not limited to sound source localization. From any sequential signals, the phase information on the multiple receivers can be extracted by the proposed algorithm. The future work will assist in finding additional utilizations other than sound source localization in succession.
Author Contributions
Conceptualization, K.K.; methodology, K.K.; software, K.K.; validation, K.K.; formal analysis, K.K.; investigation, K.K.; resources, K.K.; data curation, K.K. and Y.H.; writing—original draft preparation, K.K.; writing—review and editing, K.K. and Y.H.; visualization, K.K.; supervision, K.K.; project administration, K.K.; funding acquisition, K.K. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The acoustic data collected in the anechoic chamber for various angles are available upon request.
Acknowledgments
This work was supported by the Dongguk University Research Fund of 2022.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript (listed in order of appearance in the text).
| SSL | Sound source localization |
| AoA | Angle of arrival |
| 3D | Three-dimensional |
| ADC | Analog-to-digital converter |
| SCSSL | Single-channel sound source localization |
| HD | Homomorphic deconvolution |
| ToF | Time of flight |
| GPR | Gaussian process regression |
| DFT | Discrete Fourier transform |
| FFT | Fast Fourier transform |
| SNR | Signal-to-noise ratio |
| AR | Autoregressive |
| ARMA | Autoregressive moving average |
| RMSE | Root mean square error |
| CDF | Cumulative distribution function |
| PLA | Polylactic acid |
| ASIO | Audio stream input/output |
References
- Veen, B.D.V.; Buckley, K.M. Beamforming: A versatile approach to spatial filtering. IEEE ASSP Mag. 1988, 5, 4–24. [Google Scholar] [CrossRef]
- Krim, H.; Viberg, M. Two decades of array signal processing research: The parametric approach. IEEE Signal Process. Mag. 1996, 13, 67–94. [Google Scholar] [CrossRef]
- Blauert, J. Spatial Hearing: The Psychophysics of Human Sound Localization; Revised Edition; Massachusetts Institute of Technology: Cambridge, MA, USA, 1997. [Google Scholar]
- Wightman, F.L.; Kistler, D.J. Monaural sound localization revisited. J. Acoust. Soc. Am. 1997, 101, 1050–1063. [Google Scholar] [CrossRef] [PubMed]
- Stecker, G.; Gallun, F. Binaural hearing, sound localization, and spatial hearing. Transl. Perspect. Audit. Neurosci. Norm. Asp. Hear. 2012, 383, 433. [Google Scholar]
- Yang, B.; Liu, H.; Li, X. Learning Deep Direct-Path Relative Transfer Function for Binaural Sound Source Localization. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 3491–3503. [Google Scholar] [CrossRef]
- Ding, J.; Li, J.; Zheng, C.; Li, X. Wideband sparse Bayesian learning for off-grid binaural sound source localization. Signal Process. 2020, 166, 107250. [Google Scholar] [CrossRef]
- Badawy, D.E.; Dokmanić, I. Direction of Arrival with One Microphone, a Few LEGOs, and Non-Negative Matrix Factorization. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 2436–2446. [Google Scholar] [CrossRef]
- Pang, C.; Liu, H.; Zhang, J.; Li, X. Binaural sound localization based on reverberation weighting and generalized parametric mapping. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1618–1632. [Google Scholar] [CrossRef]
- Kim, U.-H.; Nakadai, K.; Okuno, H.G. Improved sound source localization in horizontal plane for binaural robot audition. Appl. Intell. 2015, 42, 63–74. [Google Scholar] [CrossRef]
- Baumann, C.; Rogers, C.; Massen, F. Dynamic binaural sound localization based on variations of interaural time delays and system rotations. J. Acoust. Soc. Am. 2015, 138, 635–650. [Google Scholar] [CrossRef]
- King, E.A.; Tatoglu, A.; Iglesias, D.; Matriss, A. Audio-visual based non-line-of-sight sound source localization: A feasibility study. Appl. Acoust. 2021, 171, 107674. [Google Scholar] [CrossRef]
- SongGong, K.; Wang, W.; Chen, H. Acoustic Source Localization in the Circular Harmonic Domain Using Deep Learning Architecture. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 2475–2491. [Google Scholar] [CrossRef]
- Nguyen, T.N.T.; Watcharasupat, K.N.; Nguyen, N.K.; Jones, D.L.; Gan, W.S. SALSA: Spatial Cue-Augmented Log-Spectrogram Features for Polyphonic Sound Event Localization and Detection. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 1749–1762. [Google Scholar] [CrossRef]
- Lee, S.Y.; Chang, J.; Lee, S. Deep Learning-Enabled High-Resolution and Fast Sound Source Localization in Spherical Microphone Array System. IEEE Trans. Instrum. Meas. 2022, 71, 2506112. [Google Scholar] [CrossRef]
- Tan, T.-H.; Lin, Y.-T.; Chang, Y.-L.; Alkhaleefah, M. Sound Source Localization Using a Convolutional Neural Network and Regression Model. Sensors 2021, 21, 8031. [Google Scholar] [CrossRef]
- Cheng, L.; Sun, X.; Yao, D.; Li, J.; Yan, Y. Estimation Reliability Function Assisted Sound Source Localization with Enhanced Steering Vector Phase Difference. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 421–435. [Google Scholar] [CrossRef]
- Chun, C.; Jeon, K.M.; Choi, W. Configuration-Invariant Sound Localization Technique Using Azimuth-Frequency Representation and Convolutional Neural Networks. Sensors 2020, 20, 3768. [Google Scholar] [CrossRef]
- Wang, L.; Cavallaro, A. Deep-Learning-Assisted Sound Source Localization from a Flying Drone. IEEE Sens. J. 2022, 22, 20828–20838. [Google Scholar] [CrossRef]
- Ko, J.; Kim, H.; Kim, J. Real-Time Sound Source Localization for Low-Power IoT Devices Based on Multi-Stream CNN. Sensors 2022, 22, 4650. [Google Scholar] [CrossRef]
- Machhamer, R.; Dziubany, M.; Czenkusch, L.; Laux, H.; Schmeink, A.; Gollmer, K.U.; Naumann, S.; Dartmann, G. Online Offline Learning for Sound-Based Indoor Localization Using Low-Cost Hardware. IEEE Access 2019, 7, 155088–155106. [Google Scholar] [CrossRef]
- Zhang, X.; Sun, H.; Wang, S.; Xu, J. A New Regional Localization Method for Indoor Sound Source Based on Convolutional Neural Networks. IEEE Access 2018, 6, 72073–72082. [Google Scholar] [CrossRef]
- Qureshi, S.A.; Hussain, L.; Alshahrani, H.M.; Abbas, S.R.; Nour, M.K.; Fatima, N.; Khalid, M.I.; Sohail, H.; Mohamed, A.; Hilal, A.M. Gunshots Localization and Classification Model Based on Wind Noise Sensitivity Analysis Using Extreme Learning Machine. IEEE Access 2022, 10, 87302–87321. [Google Scholar] [CrossRef]
- Marchegiani, L.; Newman, P. Listening for Sirens: Locating and Classifying Acoustic Alarms in City Scenes. IEEE Trans. Intell. Transp. Syst. 2022, 23, 17087–17096. [Google Scholar] [CrossRef]
- He, W.; Motlicek, P.; Odobez, J.M. Neural Network Adaptation and Data Augmentation for Multi-Speaker Direction-of-Arrival Estimation. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1303–1317. [Google Scholar] [CrossRef]
- Komen, D.F.V.; Howarth, K.; Neilsen, T.B.; Knobles, D.P.; Dahl, P.H. A CNN for Range and Seabed Estimation on Normalized and Extracted Time-Series Impulses. IEEE J. Oceanic. Eng. 2022, 47, 833–846. [Google Scholar] [CrossRef]
- El-Banna, A.A.A.; Wu, K.; ElHalawany, B.M. Application of Neural Networks for Dynamic Modeling of an Environmental-Aware Underwater Acoustic Positioning System Using Seawater Physical Properties. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, J.; Gong, Z.; Wang, H.; Yan, Y. Multiple Source Localization in a Shallow Water Waveguide Exploiting Subarray Beamforming and Deep Neural Networks. Sensors 2019, 19, 4768. [Google Scholar] [CrossRef]
- Grumiaux, P.-A.; Kitić, S.; Girin, L.; Guérin, A. A survey of sound source localization with deep learning methods. J. Acoust. Soc. Am. 2022, 152, 107–151. [Google Scholar] [CrossRef]
- Park, Y.; Choi, A.; Kim, K. Parametric Estimations Based on Homomorphic Deconvolution for Time of Flight in Sound Source Localization System. Sensors 2020, 20, 925. [Google Scholar] [CrossRef]
- George, A.D.; Kim, K. Parallel Algorithms for Split-Aperture Conventional Beamforming. J. Comput. Acoust. 1999, 7, 225–244. [Google Scholar] [CrossRef]
- George, A.D.; Garcia, J.; Kim, K.; Sinha, P. Distributed Parallel Processing Techniques for Adaptive Sonar Beamforming. J. Comput. Acoust. 2002, 10, 1–23. [Google Scholar] [CrossRef]
- Sinha, P.; George, A.D.; Kim, K. Parallel Algorithms for Robust Broadband MVDR Beamforming. J. Comput. Acoust. 2002, 10, 69–96. [Google Scholar] [CrossRef]
- Kim, K.; George, A.D. Parallel Subspace Projection Beamforming for Autonomous, Passive Sonar Signal Processing. J. Comput. Acoust. 2003, 11, 55–74. [Google Scholar] [CrossRef]
- Cho, K.; George, A.D.; Subramaniyan, R.; Kim, K. Parallel Algorithms for Adaptive Matched-Field Processing on Distributed Array Systems. J. Comput. Acoust. 2004, 12, 149–174. [Google Scholar] [CrossRef]
- Cho, K.; George, A.D.; Subramaniyan, R.; Kim, K. Fault-Tolerant Matched-Field Processing in the Presence of Element Failures. J. Comput. Acoust. 2006, 14, 299–319. [Google Scholar] [CrossRef]
- Kim, K. Lightweight Filter Architecture for Energy Efficient Mobile Vehicle Localization Based on a Distributed Acoustic Sensor Network. Sensors 2013, 13, 11314–11335. [Google Scholar] [CrossRef]
- Kim, K.; Choi, A. Binaural Sound Localizer for Azimuthal Movement Detection Based on Diffraction. Sensors 2012, 12, 10584–10603. [Google Scholar] [CrossRef]
- Kim, K.; Kim, Y. Monaural Sound Localization Based on Structure-Induced Acoustic Resonance. Sensors 2015, 15, 3872–3895. [Google Scholar] [CrossRef]
- Kim, Y.; Kim, K. Near-Field Sound Localization Based on the Small Profile Monaural Structure. Sensors 2015, 15, 28742–28763. [Google Scholar] [CrossRef]
- Park, Y.; Choi, A.; Kim, K. Monaural Sound Localization Based on Reflective Structure and Homomorphic Deconvolution. Sensors 2017, 17, 2189. [Google Scholar] [CrossRef]
- Park, Y.; Choi, A.; Kim, K. Single-Channel Multiple-Receiver Sound Source Localization System with Homomorphic Deconvolution and Linear Regression. Sensors 2021, 21, 760. [Google Scholar] [CrossRef] [PubMed]
- Kim, K. Design and analysis of experimental anechoic chamber for localization. J. Acoust. Soc. Korea 2012, 31, 10. [Google Scholar] [CrossRef]
- Oppenheim, A.V.; Schafer, R.W.; Stockham, T.G. Nonlinear filtering of multiplied and convolved signals. Proc. IEEE 1968, 56, 1264–1291. [Google Scholar] [CrossRef]
- Oppenheim, A.V.; Schafer, R.W. Discrete-Time Signal Processing; Prentice Hall: Upper Saddle River, NJ, USA, 1989. [Google Scholar]
- Rabiner, L.R.; Schafer, R.W. Theory and Applications of Digital Speech Processing; Pearson: San Antonio, TX, USA, 2011. [Google Scholar]
- Yule, G.U. VII. On a method of investigating periodicities disturbed series, with special reference to Wolfer’s sunspot numbers. Philos. Trans. R. Soc. Lond. Ser. A Contain. Pap. Math. Phys. Character 1927, 226, 267–298. [Google Scholar]
- Kim, K. Conceptual Digital Signal Processing with MATLAB, 1st ed.; Signals and Communication Technology; Springer Nature: Singapore, 2021; p. 690. [Google Scholar]
- Parks, T.W.; Burrus, C.S. Digital Filter Design; Wiley: New York, NY, USA, 1987. [Google Scholar]
- Steiglitz, K.; McBride, L. A technique for the identification of linear systems. IEEE Trans. Autom. Control 1965, 10, 461–464. [Google Scholar] [CrossRef]
- Rasmussen, C.E. Evaluation of Gaussian Processes and Other Methods for Non-Linear Regression; University of Toronto: Toronto, ON, Canada, 1997. [Google Scholar]
- Rasmussen, C.E. Gaussian Processes in Machine Learning. In Advanced Lectures on Machine Learning: ML Summer Schools 2003, Canberra, Australia, February 2–14, 2003, Tübingen, Germany, August 4–16, 2003; Revised Lectures; Bousquet, O., von Luxburg, U., Rätsch, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 63–71. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Williams, C.K.I. Prediction with Gaussian Processes: From Linear Regression to Linear Prediction and Beyond. In Learning in Graphical Models; Jordan, M.I., Ed.; Springer: Dordrecht, The Netherlands, 1998; pp. 599–621. [Google Scholar]
- Ebden, M. Gaussian processes: A quick introduction. arXiv 2015, arXiv:1505.02965. [Google Scholar]
- Fonnesbeck, C. Fitting Gaussian Process Models in Python. Available online: https://www.dominodatalab.com/blog/fitting-gaussian-process-models-python (accessed on 17 March 2022).
- Görtler, J.; Kehlbeck, R.; Deussen, O. A Visual Exploration of Gaussian Processes. Available online: https://distill.pub/2019/visual-exploration-gaussian-processes/ (accessed on 10 April 2022).
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Schölkopf, B.; Smola, A.J. Learning with Kernels: Support Vector Machines, Regularization, Optimization, and Beyond; MIT Press: Cambridge, MA, USA; London, UK, 2002. [Google Scholar]
- Liu, D.C.; Nocedal, J. On the limited memory BFGS method for large scale optimization. Math. Program. 1989, 45, 503–528. [Google Scholar] [CrossRef]
- Lagarias, J.C.; Reeds, J.A.; Wright, M.H.; Wright, P.E. Convergence properties of the Nelder—Mead simplex method in low dimensions. SIAM J. Optim. 1998, 9, 112–147. [Google Scholar] [CrossRef]
- Nocedal, J.; Wright, S.J. Numerical Optimization, 2nd ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Lawrence, N.; Seeger, M.; Herbrich, R. Fast sparse Gaussian process methods: The informative vector machine. Adv. Neural Inf. Process. Syst. 2002, 15. [Google Scholar]
- Smola, A.; Schölkopf, B. Sparse Greedy Matrix Approximation for Machine Learning. In Proceedings of the Seventeenth International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000. [Google Scholar]
- Gilbert, J.R.; Peierls, T. Sparse Partial Pivoting in Time Proportional to Arithmetic Operations. SIAM J. Sci. Stat. Comput. 1988, 9, 862–874. [Google Scholar] [CrossRef]
- Vetterling, W.T.; Press, W.H.; Press, W.H.; Teukolsky, S.A.; Flannery, B.P. Numerical Recipes: Example Book C, 2nd ed.; Cambridge University Press: Cambridge, UK, 1992. [Google Scholar]
- Steele, J.M. The Cauchy-Schwarz Master Class: An Introduction to the Art of Mathematical Inequalities; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- ISO 3745:2003; International Organization for Standardization. Acoustics—Determination of Sound Power Levels of Noise Sources Using Sound Pressure—Precision Methods for Anechoic and Hemi-Anechoic Rooms. ISO: Geneva, Switzerland, 2003.



















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).