
Cross-Domain Open Set Fault Diagnosis Based on Weighted Domain Adaptation with Double Classifiers


Abstract
:1. Introduction
2. Related Work
2.1. TL Methods Applied to Closed Set Fault Diagnosis
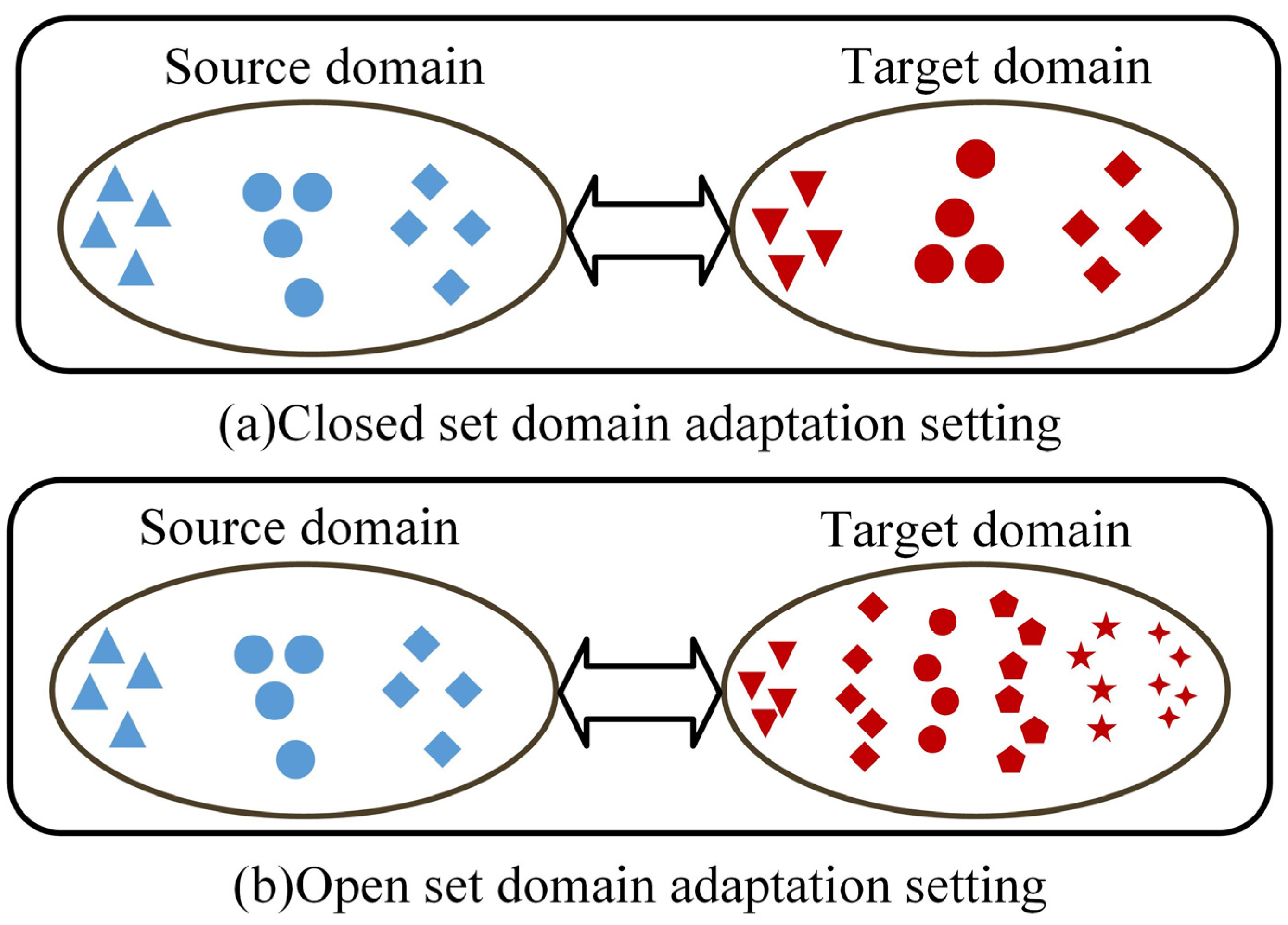
2.2. TL Methods Applied to Open Set Fault Diagnosis
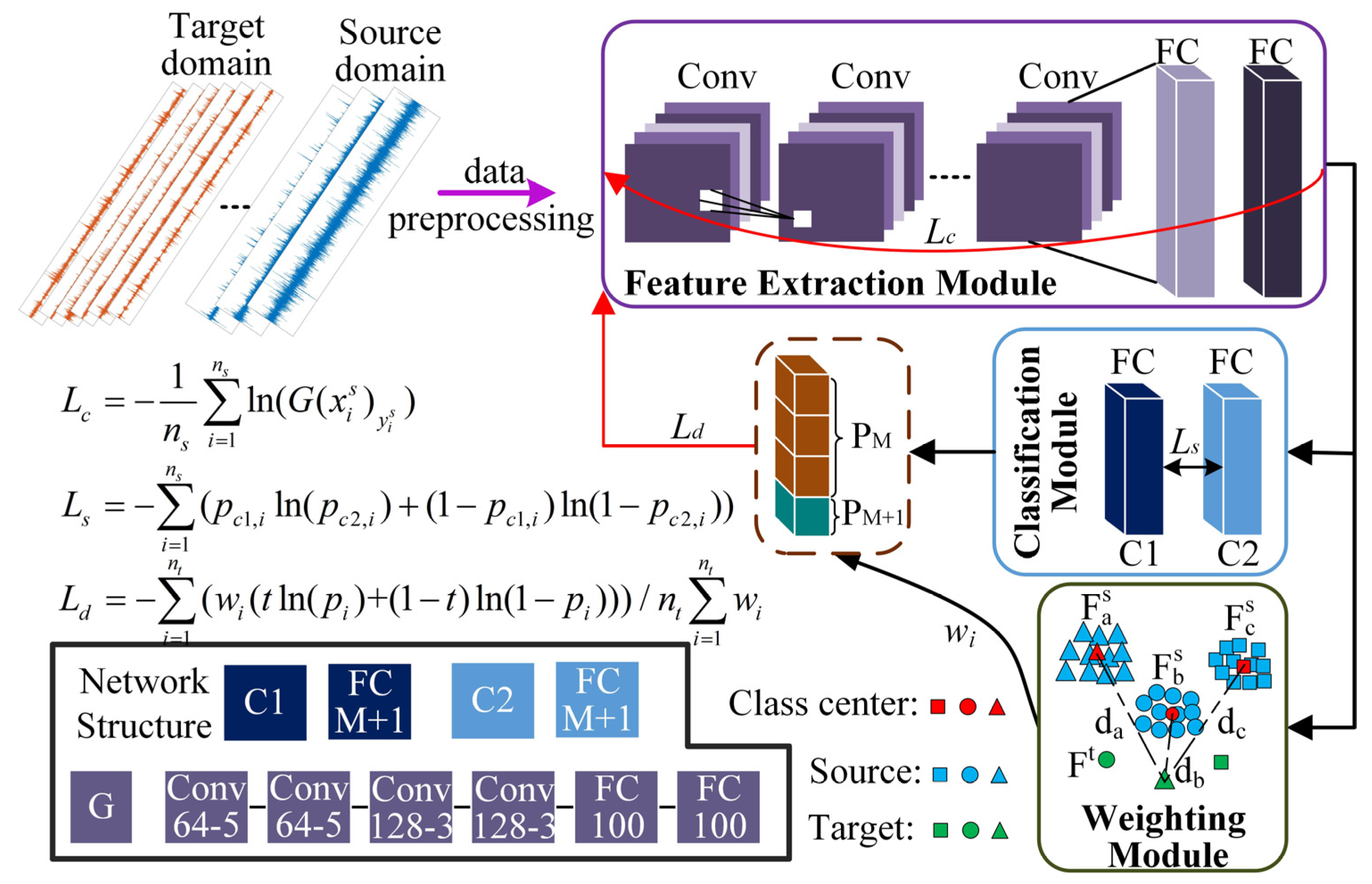
3. Proposed Method
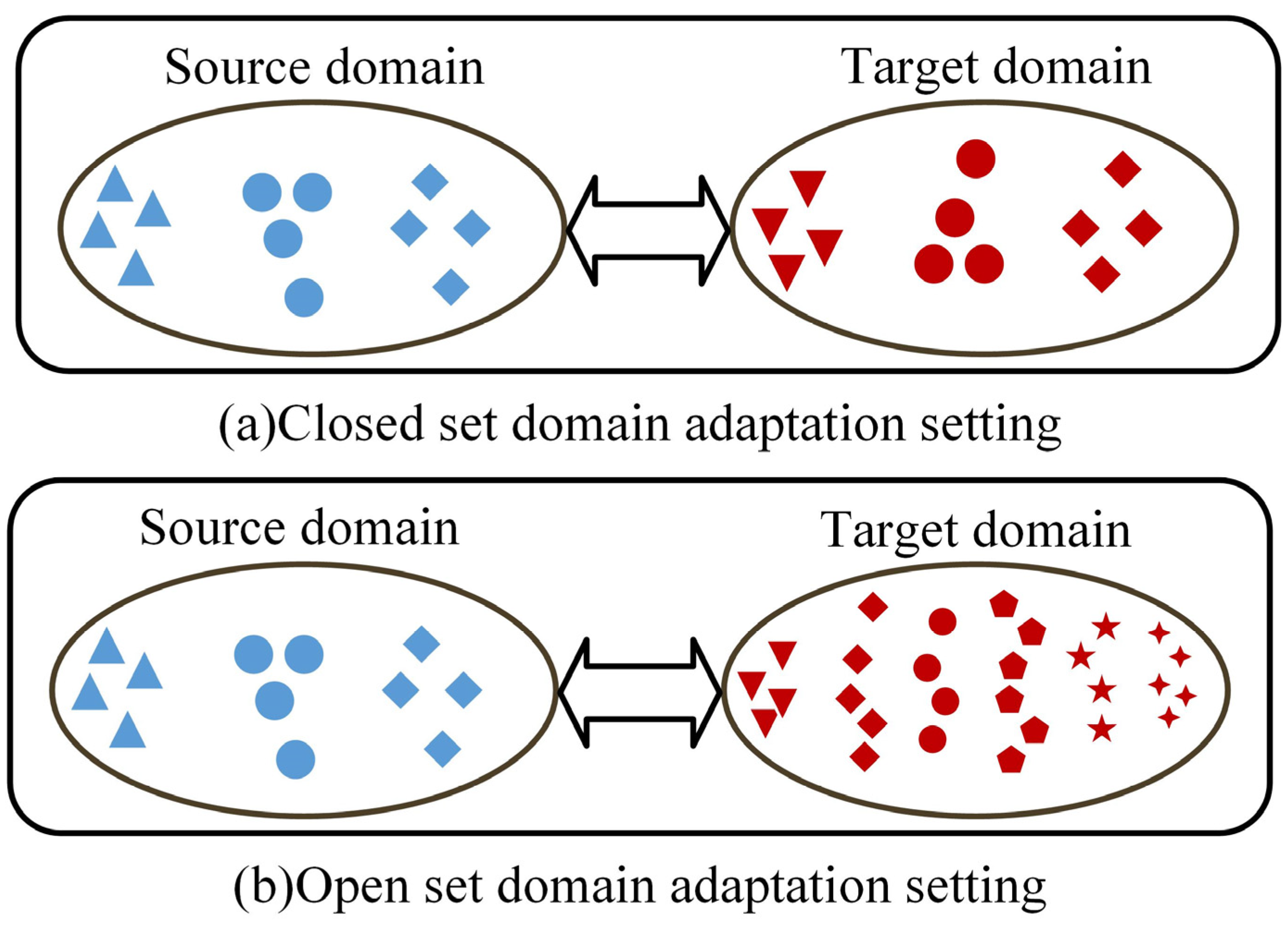
3.1. Problem Description
3.2. OSBP
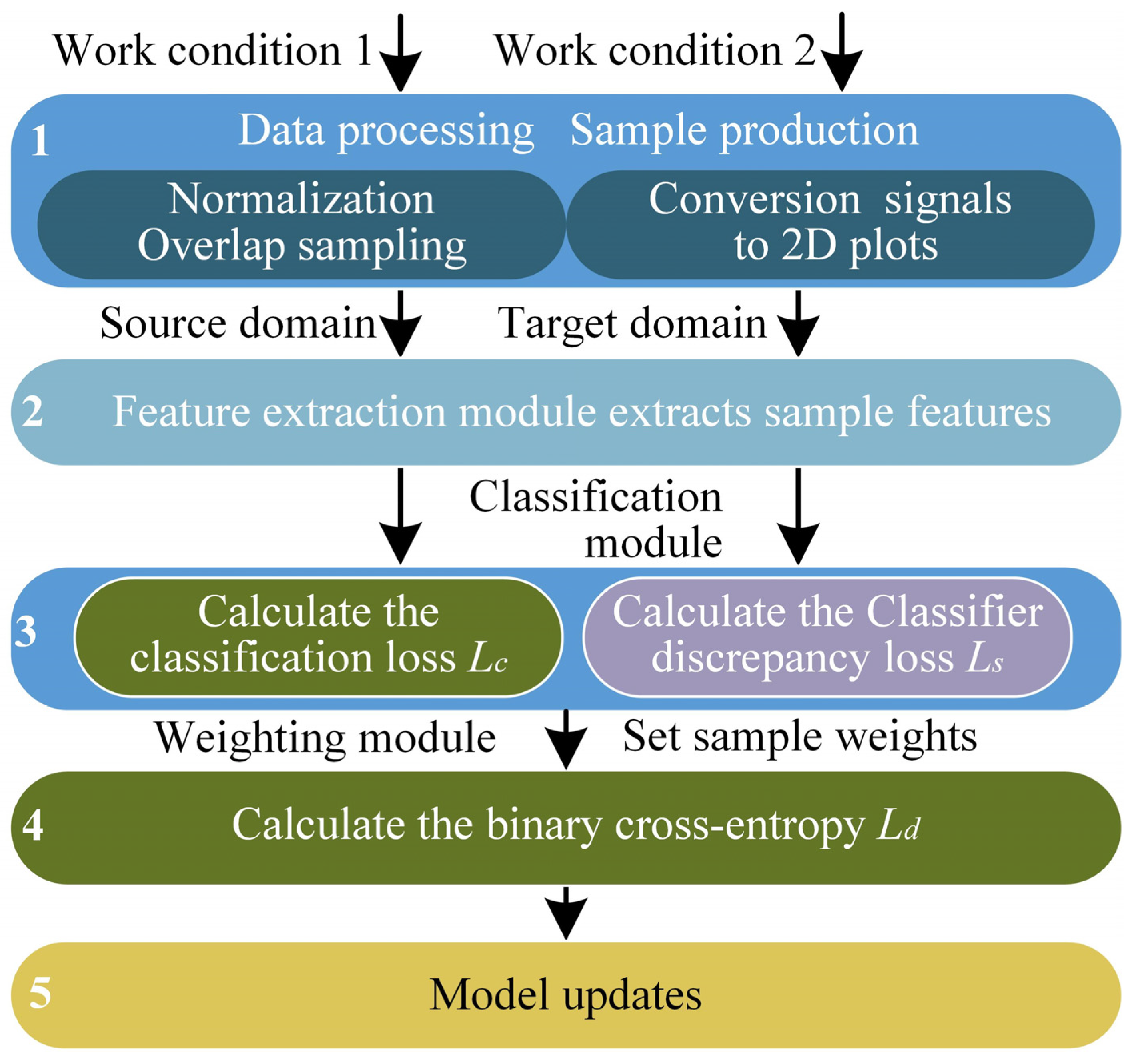
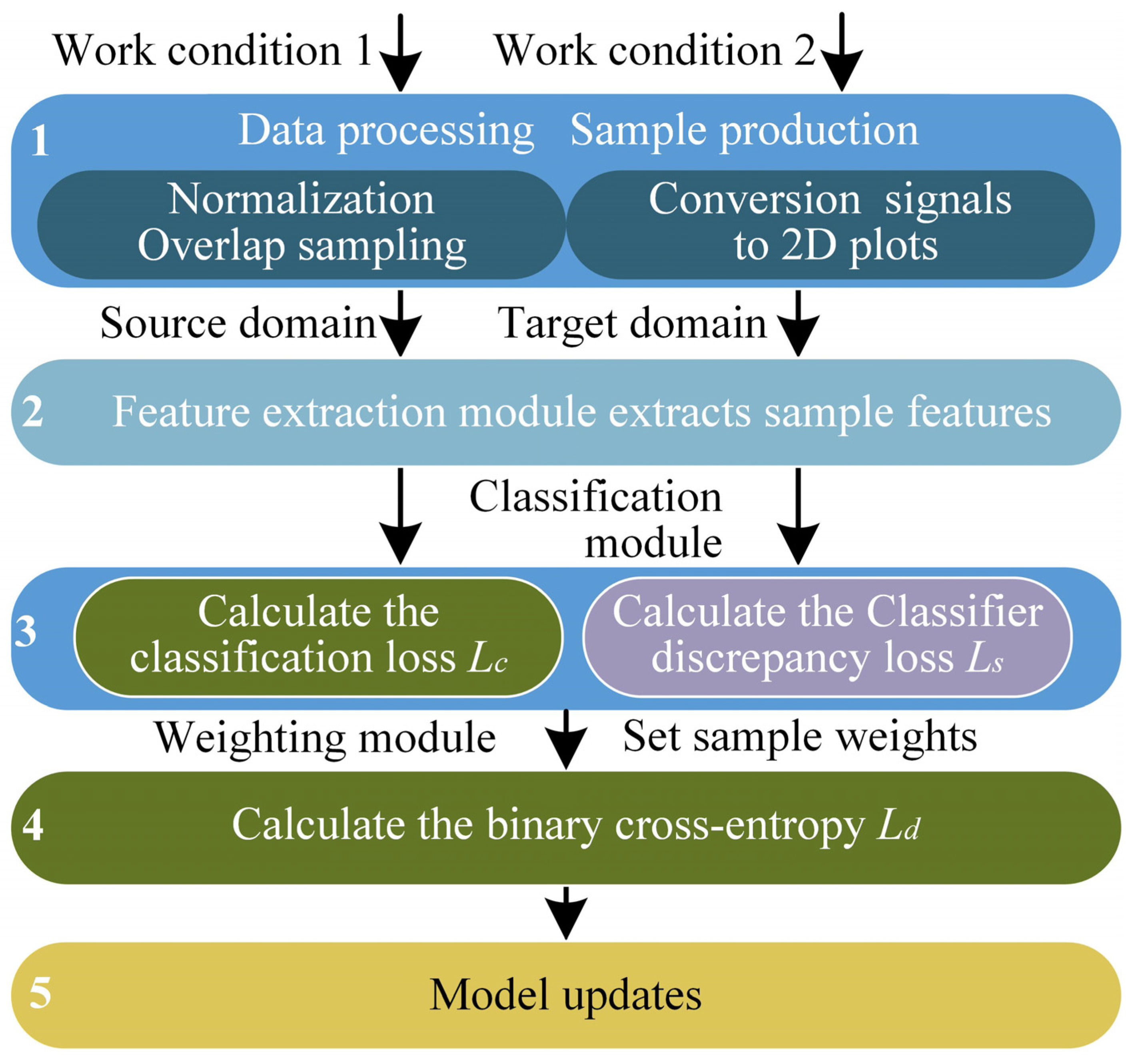
3.3. Proposed Method
4. Experimental Methods
4.1. Datasets Description
4.2. Experiment Settings for Transfer Tasks
4.2.1. The Transfer Tasks between the Same Equipment
4.2.2. The Transfer Tasks between the Different Equipment
4.3. Data Preprocessing
4.4. Competitors
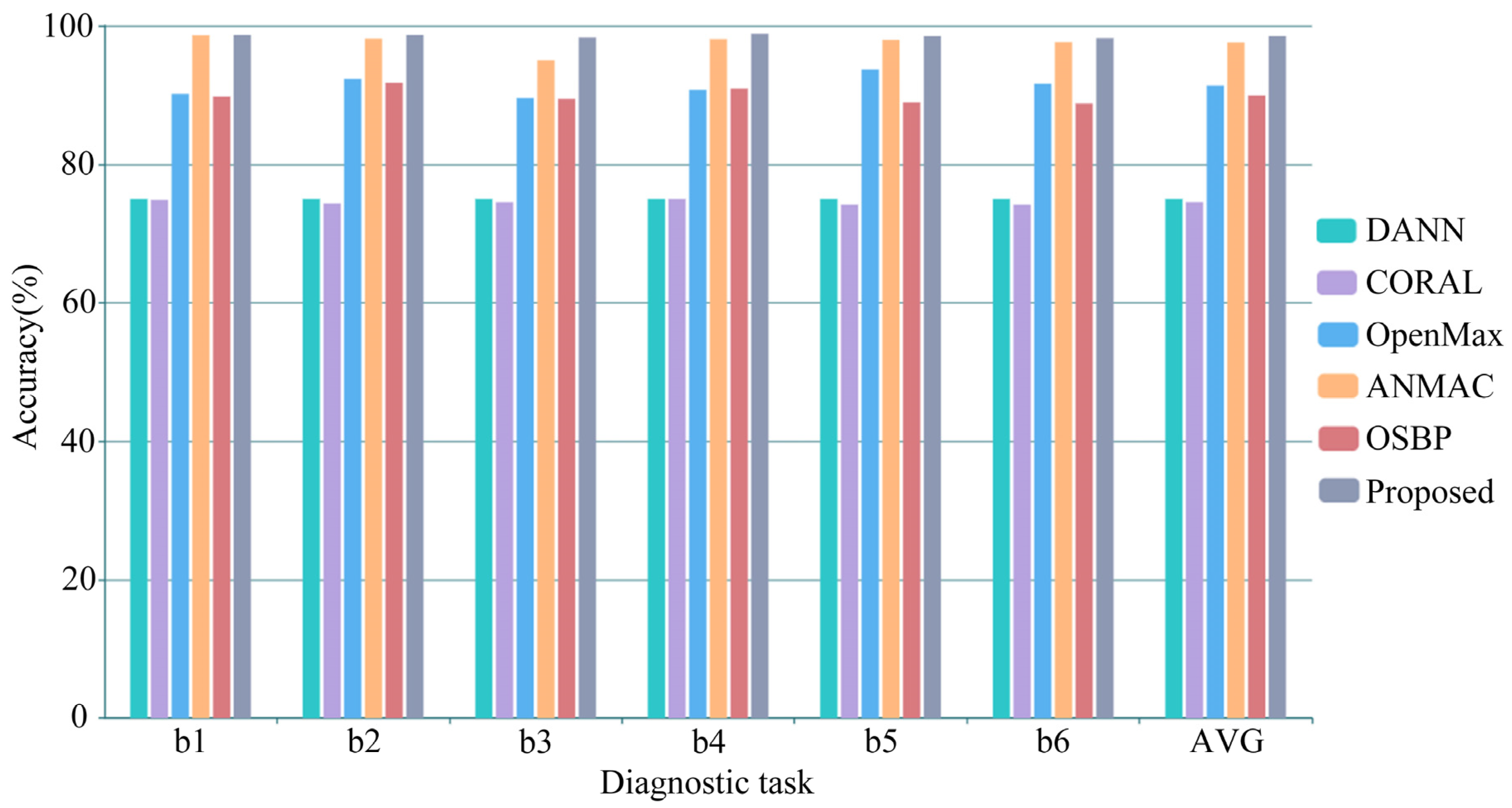
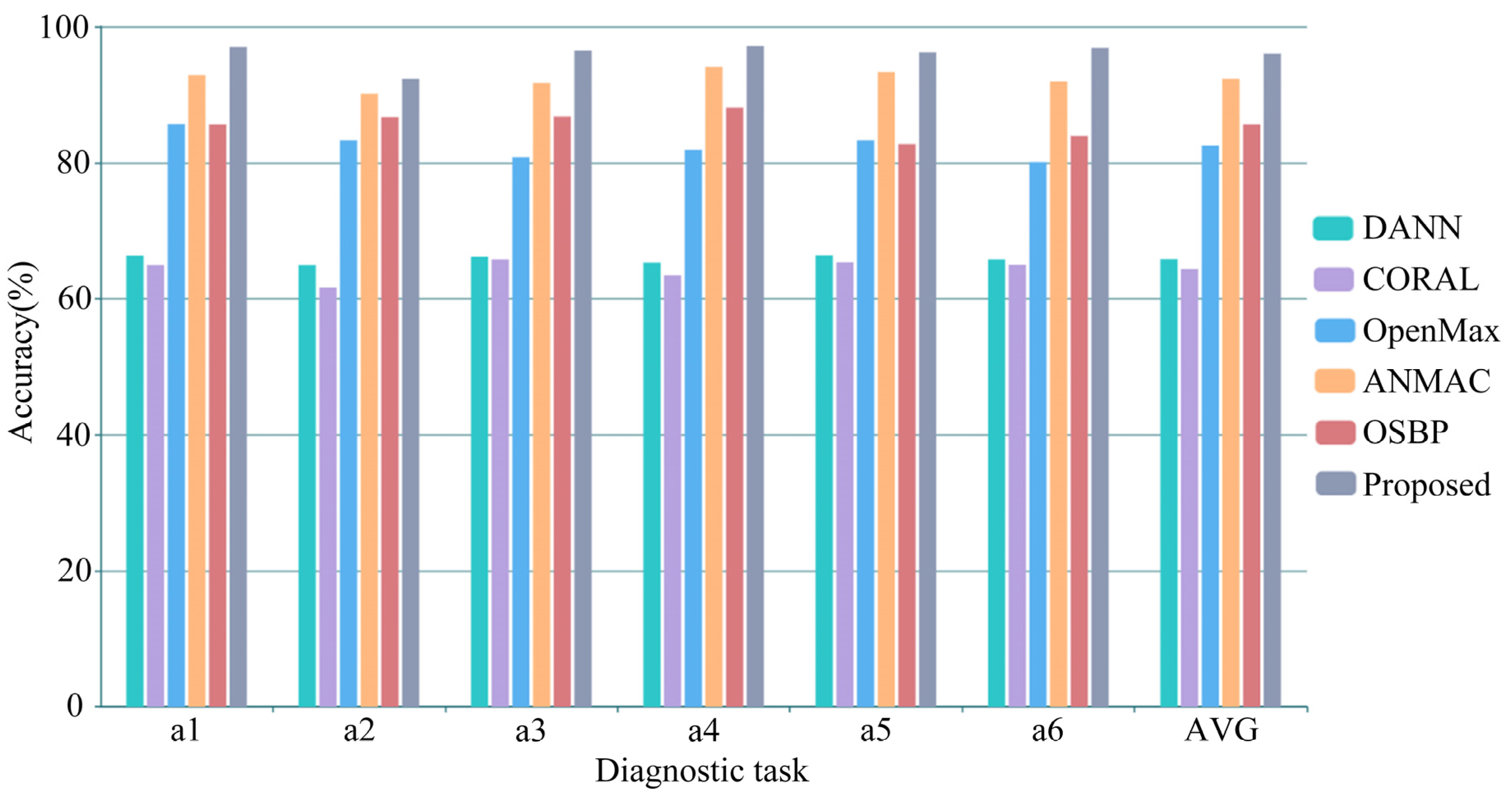
4.5. Experimental Results and Analysis of the Same Equipment
4.5.1. Experimental Results
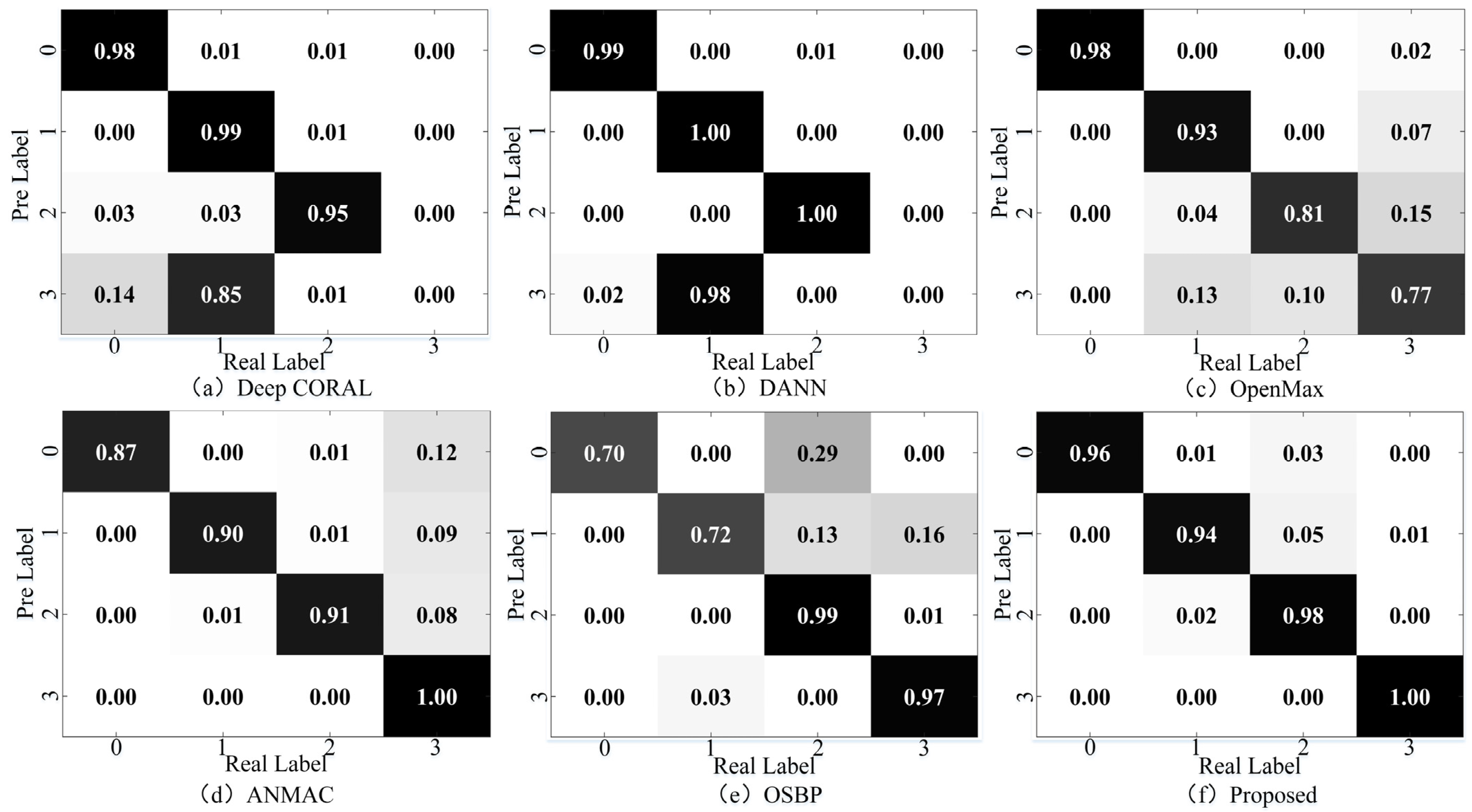
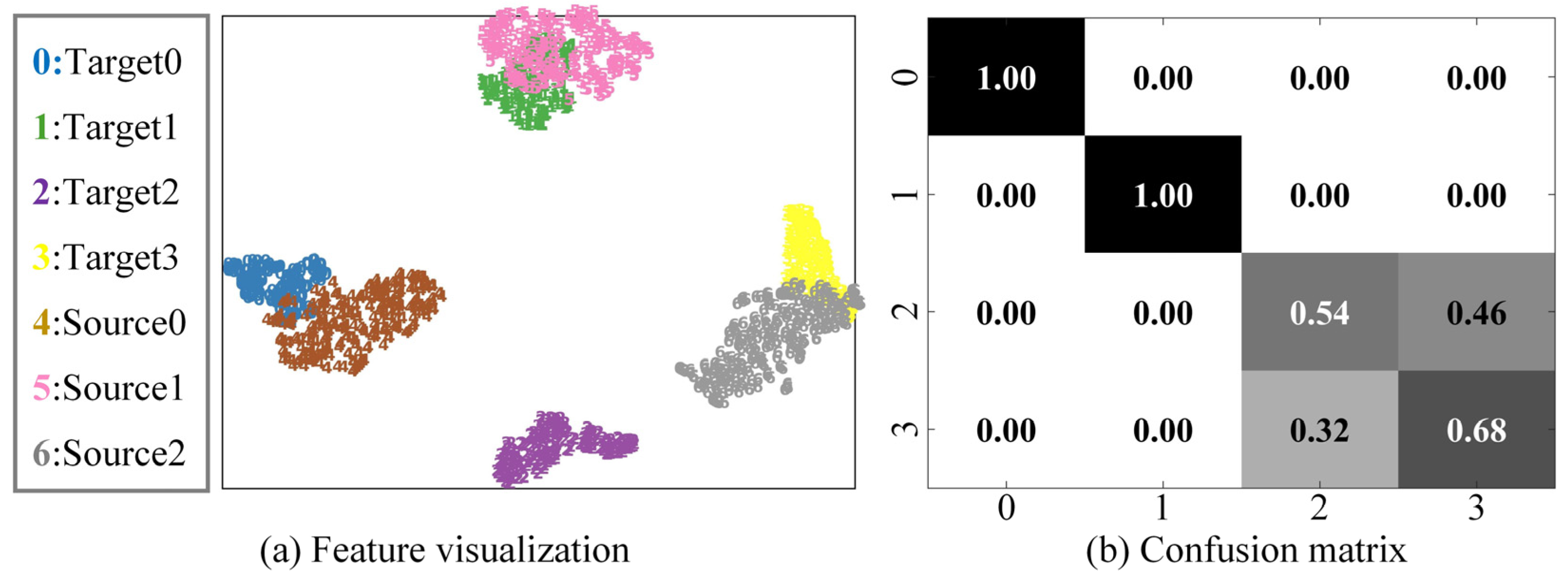
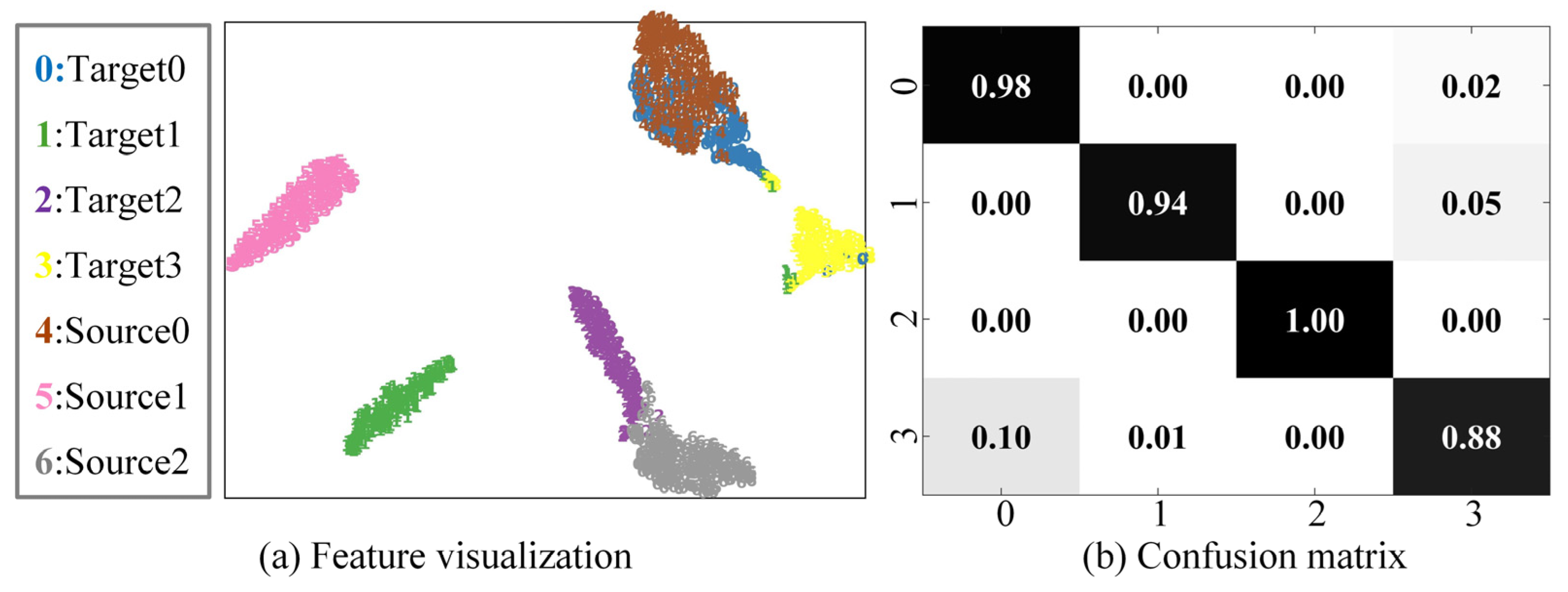
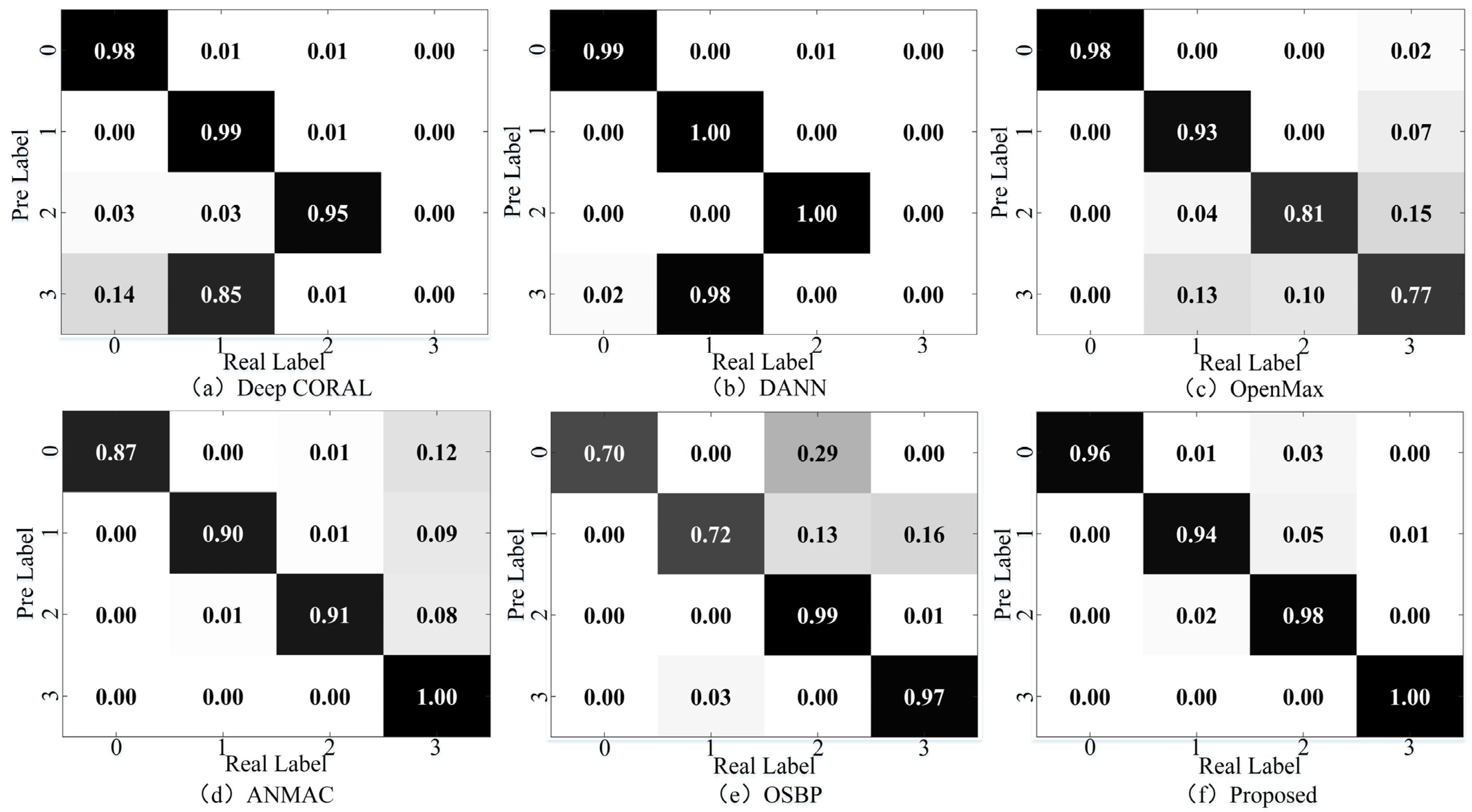
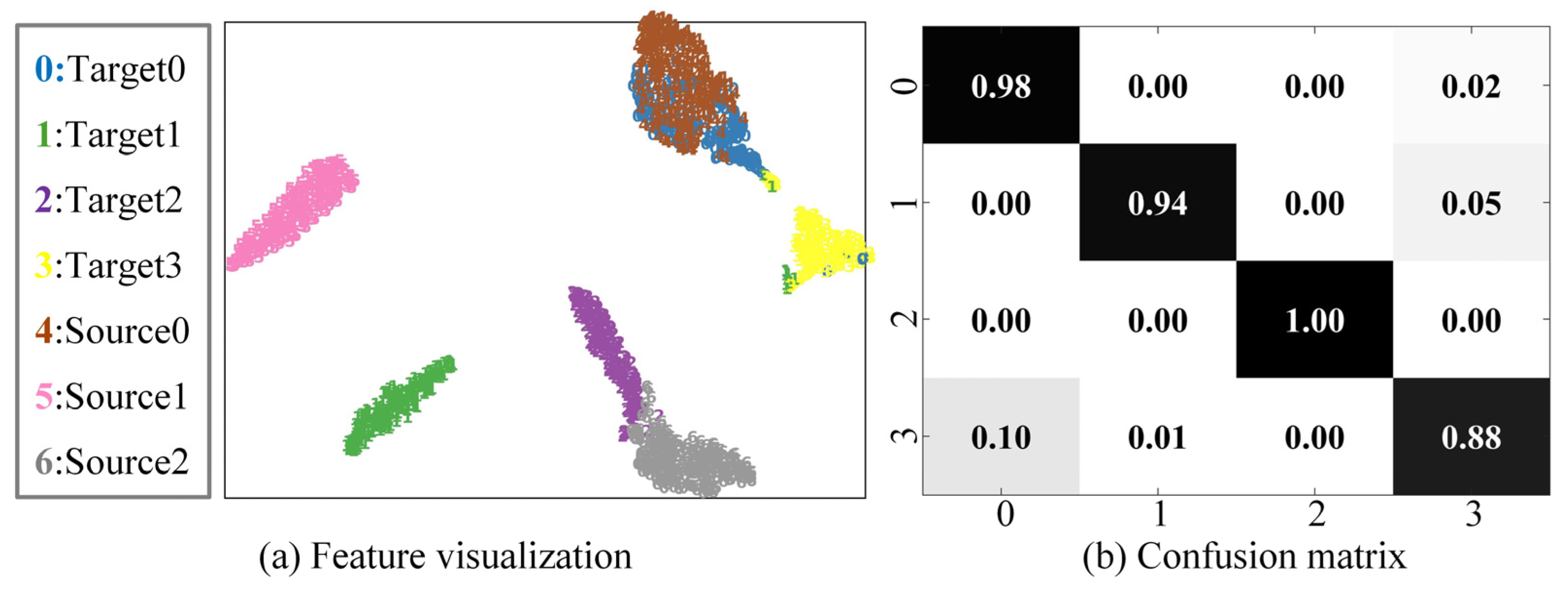
4.5.2. Feature Visualization and Confusion Matrix
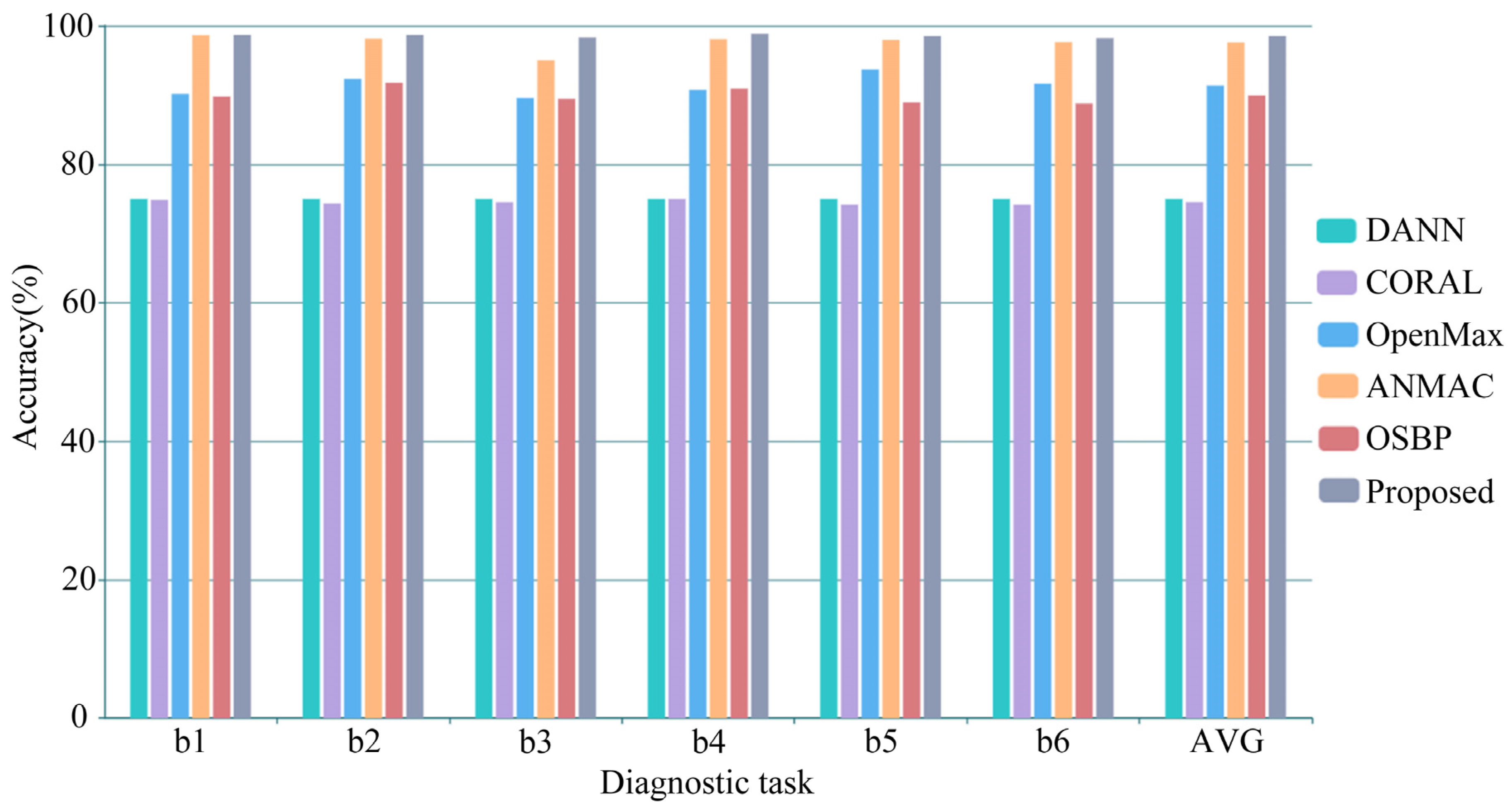
4.6. Experimental Results and Analysis of the Different Equipment
4.7. Test on Adaptability
4.8. The Limitations and Scope
5. Conclusions and Prospects
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| C | Classification module |
| Ca | Class center of the a-th class |
| Di | Distance between the sample and class center |
| DJS | Jensen–Shannon divergence |
| DKL | Kullback–Leibler divergence |
| Features of the i-th target domain sample | |
| Features of the i-th source domain sample | |
| G | Feature extraction module |
| LCE | the cross-entropy loss |
| Ld | the total loss |
| Ls | Discrepancy loss of classifiers |
| the binary cross-entropy loss of the i-th target domain sample | |
| M | Number of fault classes in the source domain |
| ns | Number of labeled samples |
| nt | Number of unlabeled samples |
| na | Number of a-th class samples |
| Probability that the i-th sample is recognized as a non-shared class. | |
| pc1 | Probability distribution of classifier 1’s output |
| pc2 | Probability distribution of classifier 2’s output |
| t | Threshold |
| v | Dimension of the Feature extraction module’s output |
| W | Weighting module |
| wi | Weight of the i-th sample |
| The i-th sample in the source domain | |
| The i-th sample in the target domain | |
| Label of the i-th sample in the source domain | |
| Label of the i-th sample in the target domain |
References
- Han, C.; Lu, W.; Wang, H.; Song, L.; Cui, L. Multistate fault diagnosis strategy for bearings based on an improved convolutional sparse coding with priori periodic filter group. Mech. Syst. Signal Process 2023, 188, 109995. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, S.; Yang, Z.; Chen, Y. A reliable data-driven state-of-health estimation model for lithium-ion batteries in electric vehicles. Front. Energy Res. 2022, 10, 1013800. [Google Scholar] [CrossRef]
- Zhuang, D.; Liu, H.; Zheng, H.; Xu, L.; Gu, Z.; Cheng, G.; Qiu, J. The IBA-ISMO Method for Rolling Bearing Fault Diagnosis Based on VMD-Sample Entropy. Sensors 2023, 23, 991. [Google Scholar] [CrossRef] [PubMed]
- Peyrano, O.G.; Vignolo, J.; Mayer, R.; Marticorena, M. Online Unbalance Detection and Diagnosis on Large Flexible Rotors by SVR and ANN trained by Dynamic Multibody Simulations. J. Dyn. Monit. Diagn. 2022, 1, 139–147. [Google Scholar] [CrossRef]
- Li, J.; Wang, H.; Song, L. A novel sparse feature extraction method based on sparse signal via dual-channel self-adaptive TQWT. Chin. J. Aeronaut. 2021, 34, 157–169. [Google Scholar] [CrossRef]
- Ye, X.; Hu, Y.; Shen, J.; Chen, C.; Zhai, G. An Adaptive Optimized TVF-EMD Based on a Sparsity-Impact Measure Index for Bearing Incipient Fault Diagnosis. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar] [CrossRef]
- Han, C.; Lu, W.; Wang, P.; Song, L.; Wang, H. A recursive sparse representation strategy for bearing fault diagnosis. Measurement 2022, 187, 110360. [Google Scholar] [CrossRef]
- Wang, H.; Jing, W.; Li, Y.; Yang, H. Fault Diagnosis of Fuel System Based on Improved Extreme Learning Machine. Neural Process. Lett. 2021, 53, 2553–2565. [Google Scholar] [CrossRef]
- Zhang, C.; Zhao, S.; He, Y. An Integrated Method of the Future Capacity and RUL Prediction for Lithium-Ion Battery Pack. IEEE Trans. Veh. Technol. 2022, 71, 2601–2613. [Google Scholar] [CrossRef]
- Lin, L.; Pang, X.; Zhang, J.; Sun, X.; Zhang, L. System Performance and Empathetic Design Enhance User Experience for Fault Diagnosis Expert System. In Proceedings of the Engineering Psychology and Cognitive Ergonomics: 18th International Conference, EPCE 2021, Held as Part of the 23rd HCI International Conference, HCII 2021, Virtual Event, 24–29 July 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 357–367. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Lin, T.; Cui, L.; Ma, B.; Dong, Z.; Song, L. Multitask learning-based self-attention encoding atrous convolutional neural network for remaining useful life prediction. IEEE Trans. Instrum. Meas. 2022, 71, 1–8. [Google Scholar] [CrossRef]
- Qian, C.; Zhu, J.; Shen, Y.; Jiang, Q.; Zhang, Q. Deep Transfer Learning in Mechanical Intelligent Fault Diagnosis: Application and Challenge. Neural Process. Lett. 2022, 54, 2509–2531. [Google Scholar] [CrossRef]
- Lin, T.; Wang, H.; Guo, X.; Wang, P.; Song, L. A novel prediction network for remaining useful life of rotating machinery. Int. J. Adv. Manuf. Technol. 2023, 124, 4009–4018. [Google Scholar] [CrossRef]
- Wang, P.; Song, L.; Guo, X.; Wang, H.; Cui, L. A High-Stability Diagnosis Model Based on a Multiscale Feature Fusion Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2021, 70, 1–9. [Google Scholar] [CrossRef]
- Zhao, S.; Zhang, C.; Wang, Y. Lithium-ion battery capacity and remaining useful life prediction using board learning system and long short-term memory neural network. J. Energy Storage 2022, 52, 104901. [Google Scholar] [CrossRef]
- Lei, Y.; Wang, W.; Yan, T.; Li, N.; Nandi, A. Residual Convolution LSTM Network for Machines Remaining Useful Life Prediction and Uncertainty Quantification. J. Dyn. Monit. Diagn. 2021, 1, 2–8. [Google Scholar] [CrossRef]
- Sun, J.; Gu, X.; He, J.; Yang, S.; Tu, Y.; Wu, C. A Robust Approach of Multi-sensor Fusion for Fault Diagnosis Using Convolution Neural Network. J. Dyn. Monit. Diagn. 2022, 1, 103–110. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, K.; Ren, Z.; Zhou, S. Joint Domain Alignment and Class Alignment Method for Cross-Domain Fault Diagnosis of Rotating Machinery. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Zhang, G.; Li, Y.; Jiang, W.; Shu, L. A fault diagnosis method for wind turbines with limited labeled data based on balanced joint adaptive network. Neurocomputing 2022, 481, 133–153. [Google Scholar] [CrossRef]
- Zhu, J.; Huang, C.-G.; Shen, C.; Shen, Y. Cross-Domain Open-Set Machinery Fault Diagnosis Based on Adversarial Network With Multiple Auxiliary Classifiers. IEEE Trans. Ind. Informatics 2022, 18, 8077–8086. [Google Scholar] [CrossRef]
- Lee, K.; Han, S.; Pham, V.; Cho, S.; Choi, H.-J.; Lee, J.; Noh, I.; Lee, S. Multi-Objective Instance Weighting-Based Deep Transfer Learning Network for Intelligent Fault Diagnosis. Appl. Sci. 2021, 11, 2370. [Google Scholar] [CrossRef]
- Zhao, B.; Cheng, C.; Zhang, G.; Lin, M.; Peng, Z.; Meng, G. An Instance and Feature-Based Hybrid Transfer Model for Fault Diagnosis of Rotating Machinery With Different Speeds. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Li, Q.; Shen, C.; Chen, L.; Zhu, Z. Knowledge mapping-based adversarial domain adaptation: A novel fault diagnosis method with high generalizability under variable working conditions. Mech. Syst. Signal Process. 2021, 147, 107095. [Google Scholar] [CrossRef]
- Shao, X.; Kim, C.-S. Unsupervised Domain Adaptive 1D-CNN for Fault Diagnosis of Bearing. Sensors 2022, 22, 4156. [Google Scholar] [CrossRef]
- Zhong, H.; Lv, Y.; Yuan, R.; Yang, D. Bearing fault diagnosis using transfer learning and self-attention ensemble lightweight convolutional neural network. Neurocomputing 2022, 501, 765–777. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, W.; Wu, H.; Zhou, J. Improved bilayer convolution transfer learning neural network for industrial fault detection. Can. J. Chem. Eng. 2022, 100, 1814–1825. [Google Scholar] [CrossRef]
- Li, J.; Huang, R.; He, G.; Liao, Y.; Wang, Z.; Li, W. A Two-Stage Transfer Adversarial Network for Intelligent Fault Diagnosis of Rotating Machinery With Multiple New Faults. IEEE/ASME Trans. Mechatronics 2021, 26, 1591–1601. [Google Scholar] [CrossRef]
- Kuang, J.; Xu, G.; Tao, T.; Wu, Q. Class-Imbalance Adversarial Transfer Learning Network for Cross-Domain Fault Diagnosis With Imbalanced Data. IEEE Trans. Instrum. Meas. 2022, 71, 1–11. [Google Scholar] [CrossRef]
- He, W.; Chen, J.; Zhou, Y.; Liu, X.; Chen, B.; Guo, B. An Intelligent Machinery Fault Diagnosis Method Based on GAN and Transfer Learning under Variable Working Conditions. Sensors 2022, 22, 9175. [Google Scholar] [CrossRef]
- Zhao, X.; Shao, F.; Zhang, Y. A Novel Joint Adversarial Domain Adaptation Method for Rotary Machine Fault Diagnosis under Different Working Conditions. Sensors 2022, 22, 9007. [Google Scholar] [CrossRef]
- Jung, D. Data-Driven Open-Set Fault Classification of Residual Data Using Bayesian Filtering. IEEE Trans. Control. Syst. Technol. 2020, 28, 2045–2052. [Google Scholar] [CrossRef]
- Schmidt, S.; Heyns, P.S. An open set recognition methodology utilising discrepancy analysis for gear diagnostics under varying operating conditions. Mech. Syst. Signal Process. 2019, 119, 1–22. [Google Scholar] [CrossRef]
- Sun, X.; Ling, K.-V.; Sin, K.-K.; Liu, Y. Air Leakage Detection of Pneumatic Train Door Subsystems Using Open Set Recognition. IEEE Trans. Instrum. Meas. 2021, 70, 1–9. [Google Scholar] [CrossRef]
- Wang, C.; Xin, C.; Xu, Z. A novel deep metric learning model for imbalanced fault diagnosis and toward open-set classification. Knowledge-Based Syst. 2021, 220, 106925. [Google Scholar] [CrossRef]
- Zhao, C.; Shen, W. Dual adversarial network for cross-domain open set fault diagnosis. Reliab. Eng. Syst. Saf. 2022, 221, 108358. [Google Scholar] [CrossRef]
- Yu, X.; Zhao, Z.; Zhang, X.; Zhang, Q.; Liu, Y.; Sun, C.; Chen, X. Deep-Learning-Based Open Set Fault Diagnosis by Extreme Value Theory. IEEE Trans. Ind. Informatics 2021, 18, 185–196. [Google Scholar] [CrossRef]
- Geng, C.; Huang, S.-J.; Chen, S. Recent Advances in Open Set Recognition: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3614–3631. [Google Scholar] [CrossRef]
- Saito, K.; Yamamoto, S.; Ushiku, Y.; Harada, T. Open Set Domain Adaptation by Backpropagation. Lect. Notes Comput. Sci. 2018, 11209, 156–171. [Google Scholar] [CrossRef]
- Zhang, X.; Delpha, C.; Diallo, D. Incipient fault detection and estimation based on Jensen–Shannon divergence in a data-driven approach. Signal Process. 2020, 169, 107410. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Problems | Types | Papers | |
|---|---|---|---|
| Transfer Learning for fault diagnosis | Closed set | Instance-based | [22,23] |
| Mapping-based | [24,25] | ||
| Model-based | [26,27] | ||
| Adversary-based | [28,29,30,31] | ||
| Open set | Discriminate-based | [32,33,34,35] | |
| Generation-based | [36,37] |
| Task | Source | Target | Shared Class |
|---|---|---|---|
| a1 | 1800 | 1500 | IR, IT, I |
| a2 | 1500 | 1800 | IR, IT, I |
| a3 | 1800 | 1200 | IR, OT, I |
| a4 | 1200 | 1800 | IR, OT, I |
| a5 | 1500 | 1200 | OT, IT, I |
| a6 | 1200 | 1500 | OT, IT, I |
| Task | Source | Target | Task | Source | Target |
|---|---|---|---|---|---|
| b1 | 0 | 1 | b4 | 2 | 1 |
| b2 | 1 | 0 | b5 | 0 | 2 |
| b3 | 1 | 2 | b6 | 2 | 0 |
| Task | DANN | CORAL | OpenMax | ANMAC | OSBP | Proposed |
|---|---|---|---|---|---|---|
| a1 | 66.31 ± 0.17 | 64.93 ± 0.33 | 85.67 ± 0.79 | 92.87 ± 0.35 | 85.62 ± 0.75 | 97.02 ± 0.34 |
| a2 | 64.93 ± 0.51 | 61.60 ± 0.79 | 83.27 ± 0.83 | 90.13 ± 0.34 | 86.67 ± 0.31 | 92.33 ± 0.53 |
| a3 | 66.18 ± 0.33 | 65.76 ± 0.42 | 80.80 ± 0.34 | 91.73 ± 0.26 | 86.76 ± 0.58 | 96.49 ± 0.21 |
| a4 | 65.31 ± 0.38 | 63.44 ± 0.67 | 81.87 ± 0.51 | 94.07 ± 0.87 | 88.07 ± 0.69 | 97.16 ± 0.07 |
| a5 | 66.35 ± 0.25 | 65.36 ± 0.43 | 83.27 ± 0.87 | 93.31 ± 0.09 | 82.71 ± 0.52 | 96.20 ± 0.13 |
| a6 | 65.76 ± 0.23 | 64.96 ± 0.57 | 80.07 ± 0.21 | 91.93 ± 0.87 | 83.91 ± 0.39 | 96.87 ± 0.30 |
| AVG | 65.81 | 64.34 | 82.49 | 92.34 | 85.62 | 96.01 |
| Task | DANN | CORAL | OpenMax | ANMAC | OSBP | Proposed |
|---|---|---|---|---|---|---|
| b1 | 75.00 ± 0 | 74.87 ± 0.32 | 90.15 ± 0.25 | 98.63 ± 0.23 | 89.80 ± 0.45 | 98.67 ± 0.26 |
| b2 | 75.00 ± 0 | 74.33 ± 0.27 | 92.34 ± 0.18 | 98.13 ± 0.31 | 91.77 ± 0.37 | 98.67 ± 0.17 |
| b3 | 75.00 ± 0 | 74.50 ± 0.08 | 89.57 ± 0.49 | 95.03 ± 0.77 | 89.43 ± 0.74 | 98.30 ± 0.22 |
| b4 | 75.00 ± 0 | 75.00 ± 0 | 90.73 ± 0.39 | 98.07 ± 0.34 | 90.93 ± 0.23 | 98.83 ± 0.24 |
| b5 | 75.00 ± 0 | 74.17 ± 0.41 | 93.70 ± 0.09 | 97.97 ± 0.37 | 88.93 ± 0.59 | 98.53 ± 0.11 |
| b6 | 75.00 ± 0 | 74.17 ± 0.21 | 91.63 ± 0.12 | 97.63 ± 0.65 | 88.77 ± 0.47 | 98.20 ± 0.34 |
| AVG | 75.00 | 74.51 | 91.35 | 97.58 | 89.94 | 98.53 |
| Task | DANN | CORAL | OpenMax | ANMAC | OSBP | Proposed |
|---|---|---|---|---|---|---|
| IMS → CWRU | 45.93 ± 2.30 | 38.33 ± 1.66 | 47.54 ± 3.03 | 69.87 ± 1.91 | 65.50 ± 1.30 | 80.53 ± 1.02 |
| CWRU → IMS | 40.03 ± 2.35 | 36.83 ± 1.85 | 39.33 ± 1.54 | 64.15 ± 1.33 | 58.40 ± 1.74 | 79.93 ± 0.91 |
| AVG | 42.98 | 37.58 | 43.44 | 67.01 | 60.45 | 80.23 |
| Task | DANN | CORAL | OpenMax | ANMAC | OSBP | Proposed |
|---|---|---|---|---|---|---|
| c1 | 75.00 ± 0 | 72.53 ± 1.08 | 72.87 ± 1.68 | 90.13 ± 1.79 | 82.67 ± 1.41 | 95.13 ± 0.88 |
| c2 | 74.86 ± 0.32 | 73.2 ± 1.17 | 79.61 ± 3.94 | 92.13 ± 1.07 | 83.46 ± 0.81 | 97.00 ± 0.54 |
| AVG | 74.93 | 72.87 | 76.24 | 91.13 | 83.07 | 96.07 |
| Method | Training Time (s) | Parameter Count | Params Size (MB) |
|---|---|---|---|
| DANN | 3.49 | 660,742 | 2.52 |
| CORAL | 2.11 | 660,136 | 2.52 |
| OpenMax | 2.27 | 660,136 | 2.52 |
| ANMAC | 4.28 | 669,183 | 2.55 |
| OSBP | 2.79 | 660,540 | 2.52 |
| Proposed | 4.52 | 660,944 | 2.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Xu, Z.; Tong, X.; Song, L. Cross-Domain Open Set Fault Diagnosis Based on Weighted Domain Adaptation with Double Classifiers. Sensors 2023, 23, 2137. https://doi.org/10.3390/s23042137
Wang H, Xu Z, Tong X, Song L. Cross-Domain Open Set Fault Diagnosis Based on Weighted Domain Adaptation with Double Classifiers. Sensors. 2023; 23(4):2137. https://doi.org/10.3390/s23042137
Chicago/Turabian StyleWang, Huaqing, Zhitao Xu, Xingwei Tong, and Liuyang Song. 2023. "Cross-Domain Open Set Fault Diagnosis Based on Weighted Domain Adaptation with Double Classifiers" Sensors 23, no. 4: 2137. https://doi.org/10.3390/s23042137
APA StyleWang, H., Xu, Z., Tong, X., & Song, L. (2023). Cross-Domain Open Set Fault Diagnosis Based on Weighted Domain Adaptation with Double Classifiers. Sensors, 23(4), 2137. https://doi.org/10.3390/s23042137