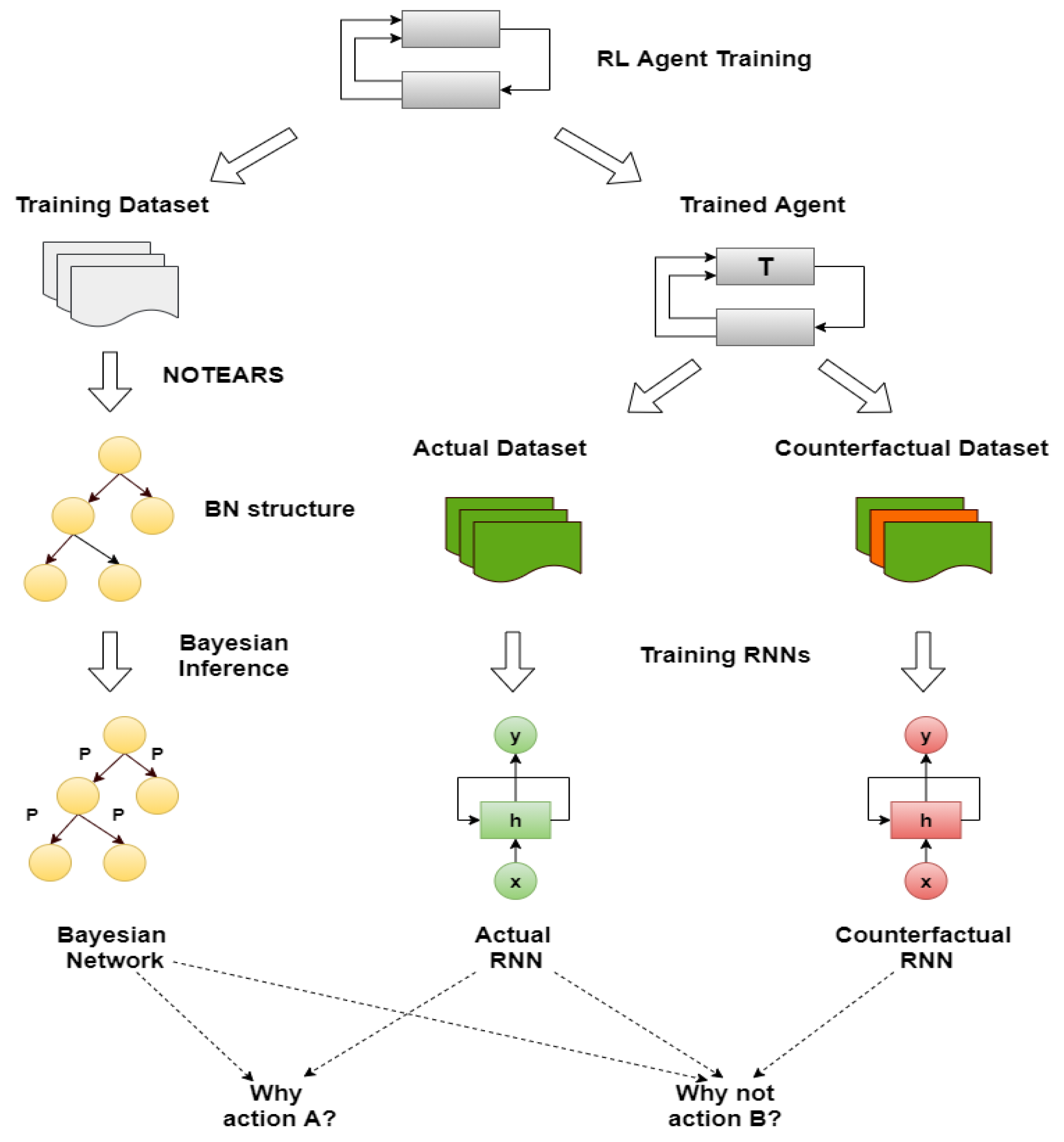
4. Our Method
The proposed method consists of four components, illustrated together with the complete pipeline of the methodology in
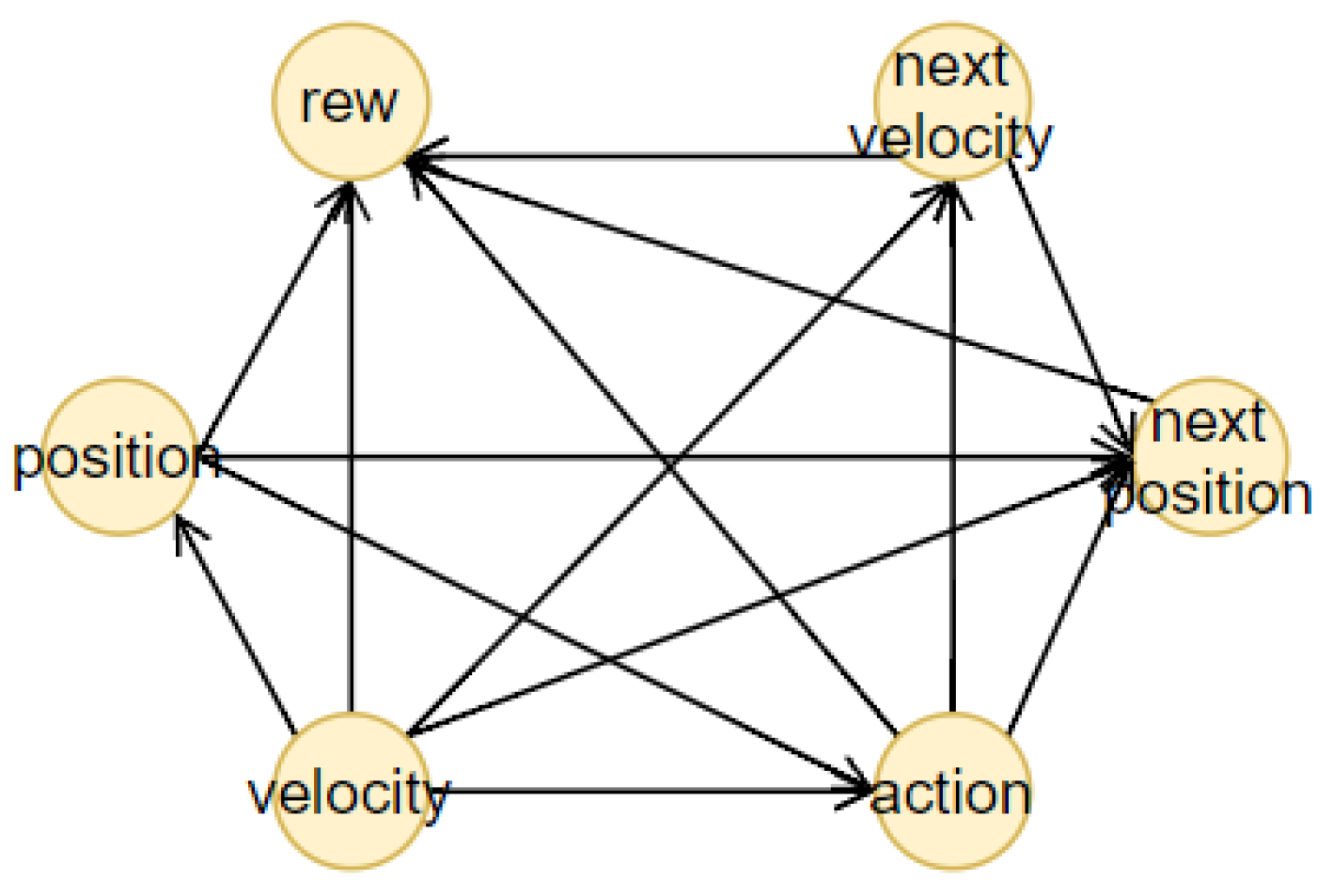
Figure 2. The first one is an RL agent, trained with a model-free method. During the training, the state-action pairs are saved in a dataset, the memory, to build the BN (the second component). The memory is composed of all the actual states, the action chosen by the agent, the next states and the reward obtained. From this dataset, we generated different causal graphs using different algorithms, represented in
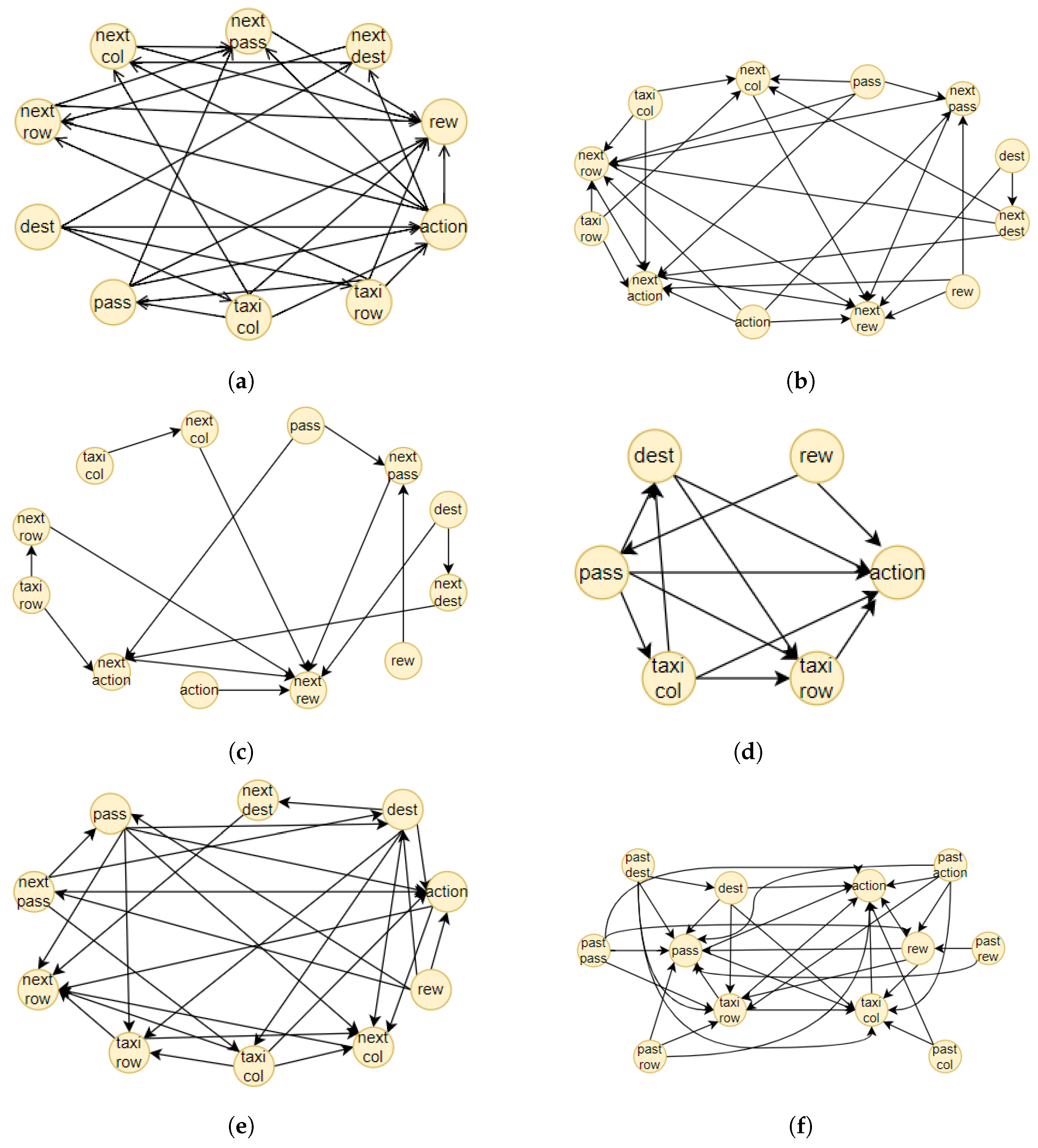
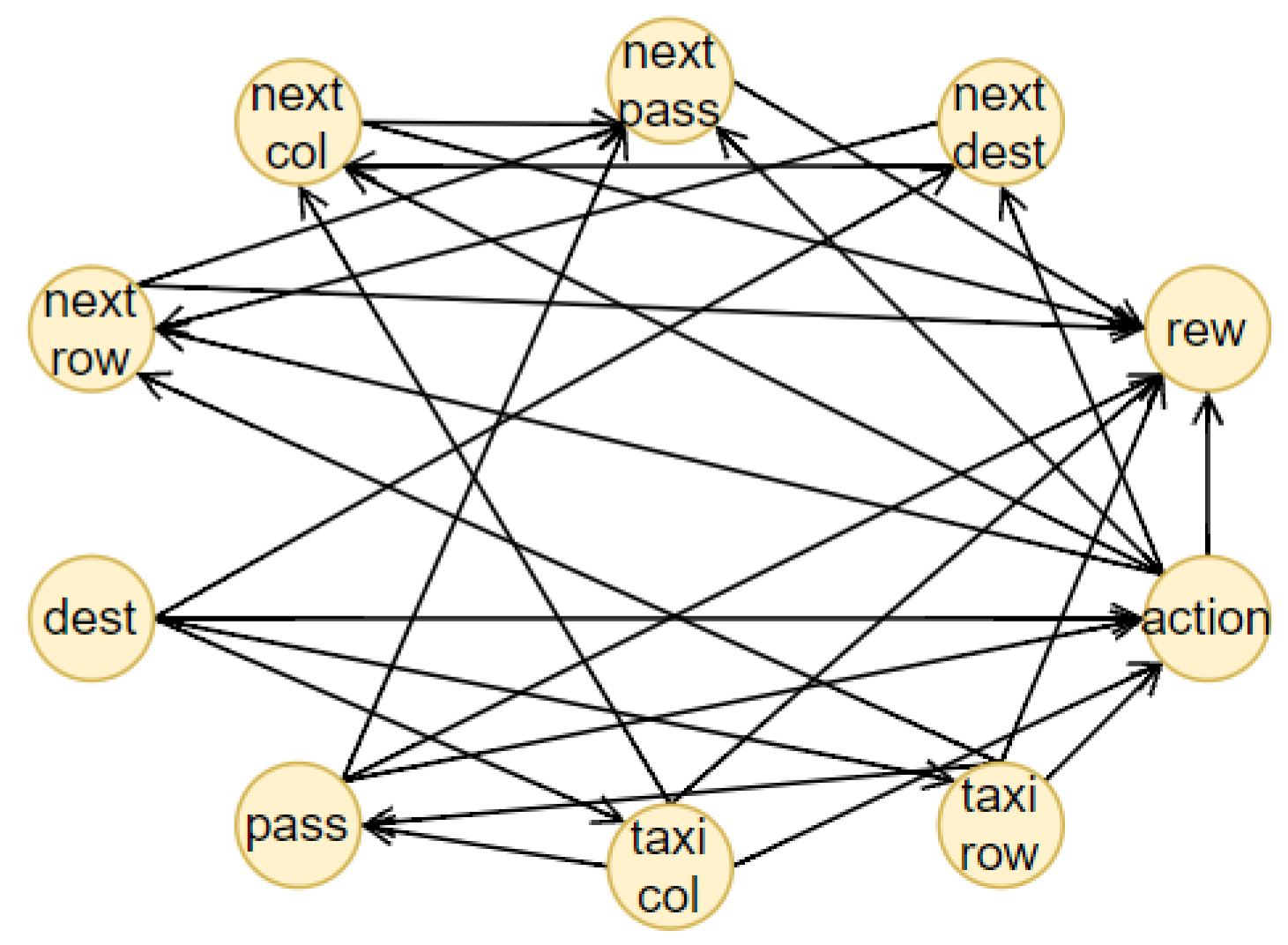
Figure 3. We decided to adopt our final methodology after a comparison of the different results obtained using approaches well known in the literature. In the first case,
Figure 3a, we created a causal structure that is in between a BN and a DBN. In fact, for each of the memory’s characteristics, we consider a node in the BN. To create the structure of this BN, the NOTEARS algorithm, as discussed in
Section 2.6, is utilized. The obtained graph is similar to a DBN but it does not present all the features in the next time step. In fact, we do not use any future information for the reward and action. Furthermore, during the last step of the NOTEARS algorithm (the thresholding), we include some assumptions to obtain a more realistic structure. The conditions are the following:
Causality: all the state features influence their corresponding future values (so no future feature can influence current states or there will be a cycle that is not allowed);
Stationarity of dependencies between variables: if there is a dependency between features at a one-time step, then it will be in every time step;
Importance of the action: all the values of the actual state will be used to obtain the action and the action node is connected to all the future features.
These assumptions are justified by the observation of the other graphs. The first two hypotheses come from the DBN since they are fundamental conditions for generating this kind of graph. The third one is, instead, derived from the relations obtained using the Direct LiNGAM [
43] and VARLiNGAM [
44]. In the last graphs presented in
Figure 3e,f, it is possible to see how all the state variables are connected to the action. This is also justified by the fact that the RL agent is trained to consider the state values and choose the best action in that particular instantiation. The resulting final graph is the closest to the ground truth compared to the others.
For the other tests, we generated two DBNs using the equivalent algorithm for DBNs to NOTEARS, i.e., DYNOTEARS [
45]. As we can see from
Figure 3b,c, the result is only satisfying when we use a small threshold parameter, i.e.,
, which means that the structural equations of the causal graphs considered are shallow and therefore subjected to higher fluctuation given different datasets (
Figure 3b). If we increase this parameter to
, many connections will be erased, resulting in a sparse graph (
Figure 3c). For the remaining tests, we used Direct LiNGAM [
43], which is a method applied for learning causal structures from data without any further assumption, relying only on the statistical method known as independent component analysis, and VARLiNGAM [
44], which corresponds to the previous algorithm for studying time series. We first derived the structural equations by studying only the features at one-time step through the LiNGAM method. The resulting graph is presented in
Figure 3d. As we can see, we have some contradictory results since it seems that the reward influences the passenger’s position and, most importantly, the action, while it is well known that the action causes the reward. This error is shown in the next graph in
Figure 3e, where, in this case, all the features of the memory dataset were used as different characteristics. Lastly, we generate the causal graph using VARLiNGAM, with threshold parameters for the relations between actual state features fixed at
and threshold for the next state features
. The obtained structure is shown in
Figure 3f. The causal graph obtained presents the same problem with the causality of the reward, but, on the other hand, it can understand the relationship between the state features. In fact, it is the only graph, together with the initial one, to recognize the destination as a root node. Moreover, if we compare the graph obtained with the algorithm NOTEARS considering also the next time step state features, in
Figure 3a and the one generated through VARLiNGAM, in
Figure 3f, we can notice that the relations discovered are principally the same. For these reasons, we consider the structure obtained using the NOTEARS algorithm correct and the best in this set of different models.
After the creation of the DAG for the BN, it is possible to learn the probabilities using inference. To this end, the dataset must be discrete. The discretization of the features depends on the particular environment that is studied. In our case, we will focus on three RL benchmarks (Taxi, Cartpole and Mountaincar) that will be explained in detail in the next section. In a discrete environment, e.g., Taxi, every feature is ready for inference, while in a continuous one, e.g., Cartpole and Mountaincar, we have to find the best clusters for each characteristic using the K-means algorithm. Usually, for the discretization of RL environments, tile coding is applied, which consists in dividing the continuous space into different tiles and then for each point evaluating if it is in a particular tile (1) or not (0). In this way, it is possible to obtain a vector of 0s and 1s as a discrete representation of each value. This process, the One-Hot-Encoding, is completely independent of the values that will be used during the simulation. To avoid this, we used the K-means clustering algorithm thus we have a better differentiation between each cluster considering the information gathered during the training. More information about the creation of the clusters for each environment is given in the following section. After the discretization, we applied the Bayesian estimators’ method assuming a Dirichlet distribution prior to learning the probabilities of the BN.
Consequently, it is possible to forecast the next state values using the freshly created BN. In fact, by giving to the network the state information and the actual (counterfactual) action, the prediction for the future time step will be the output of the BN. Following this concept, we enunciate the definition of the actual (counterfactual) prediction.
Definition 7 (Actual/Counterfactual Prediction).Given an initial vector of the state at a time t, and the actual (counterfactual) action , the actual (counterfactual) prediction of the Bayesian Network () is defined as the state values with the maximum probability, given and , i.e.: This definition will be used later for the description of how an explanation is generated.
Now, we can focus on distal predictions. The idea of distal actions was first presented in [
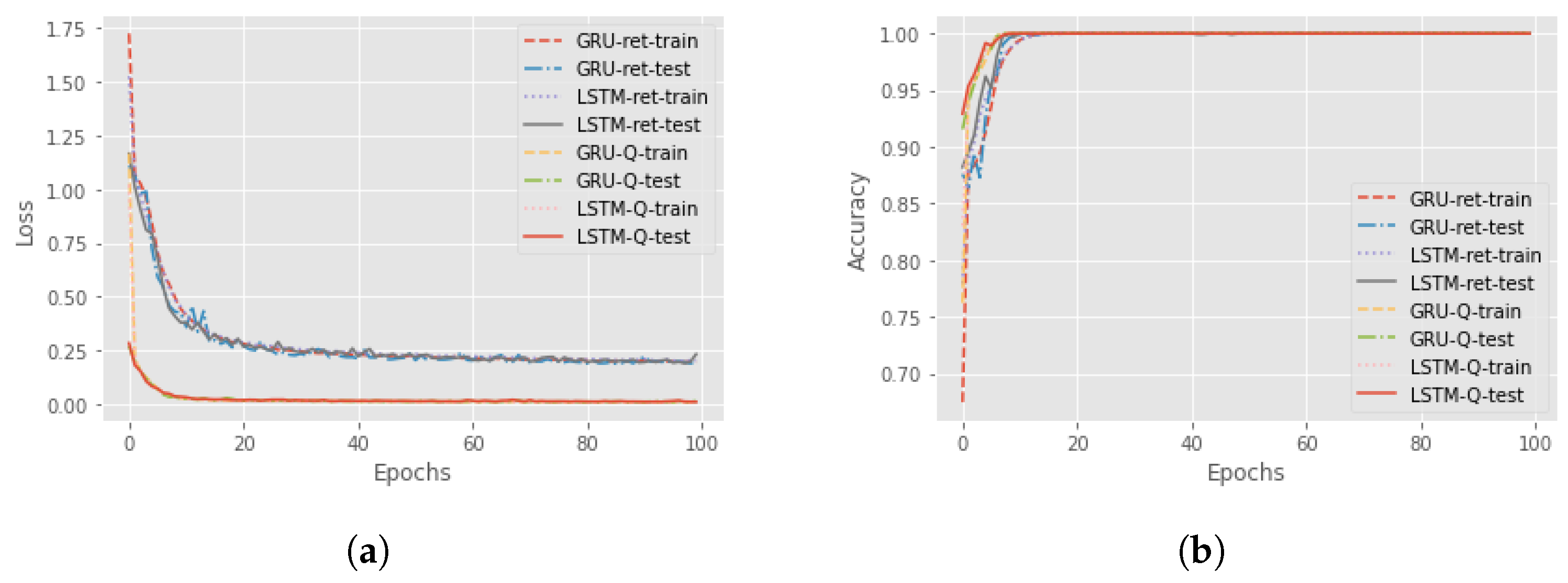
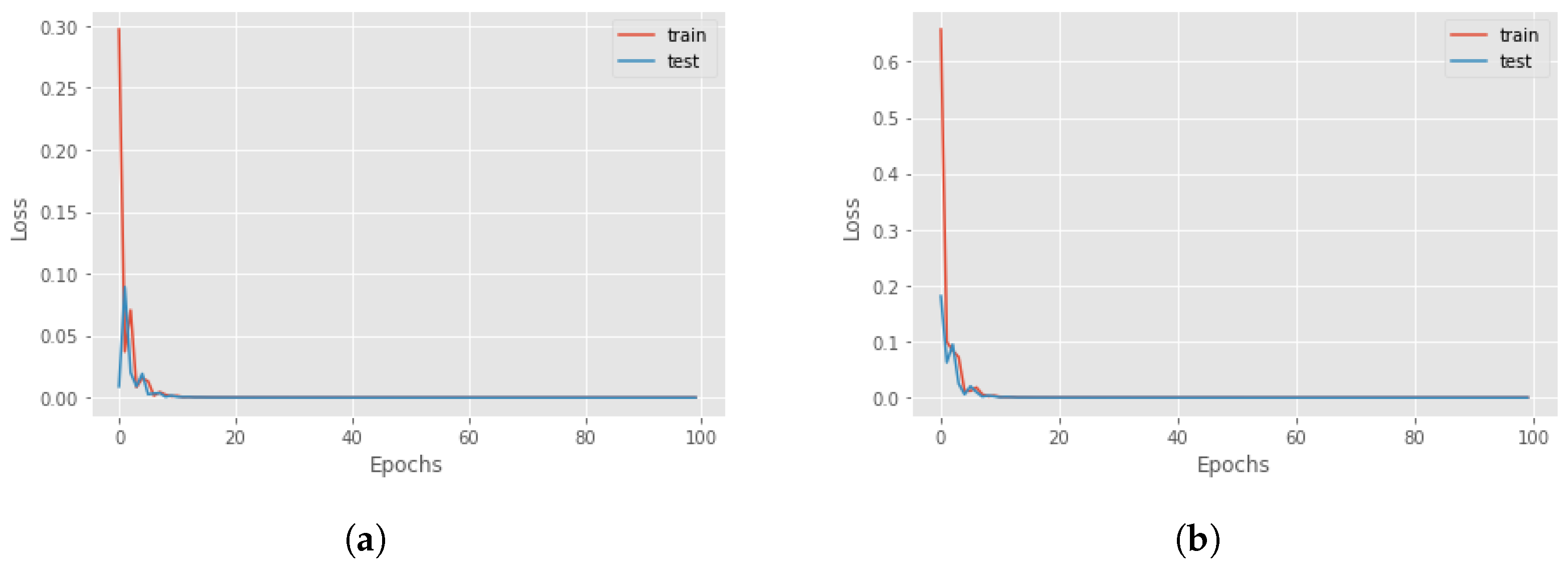
8], where a distal action is one of the most significant actions that is enabled if the agent realizes a particular sequence of actions. However, there is also different influential distal information which is valuable for a more detailed explanation. An example could be the final return of the episode. The third and fourth components of the proposed methodology are RNNs for the actual and counterfactual distal predictions. The third component aims to predict the distal return and action/state following the correct policy, and the fourth component to forecast the distal values if, at a particular time step, an action different from the correct one is executed. For these networks, we compared the performance of Long-short term memory (LSTM) cells and Gated Recurrent Units (GRUs) to find the better option. The features involved in the training of the network were the state characteristics, the actions executed and the actual accumulated returns or the Q-values. Four different RNNs were created to understand the best choice: using LSTM cells or GRU and if it is better to consider the actual return or if it is sufficient to only use the Q-value. In
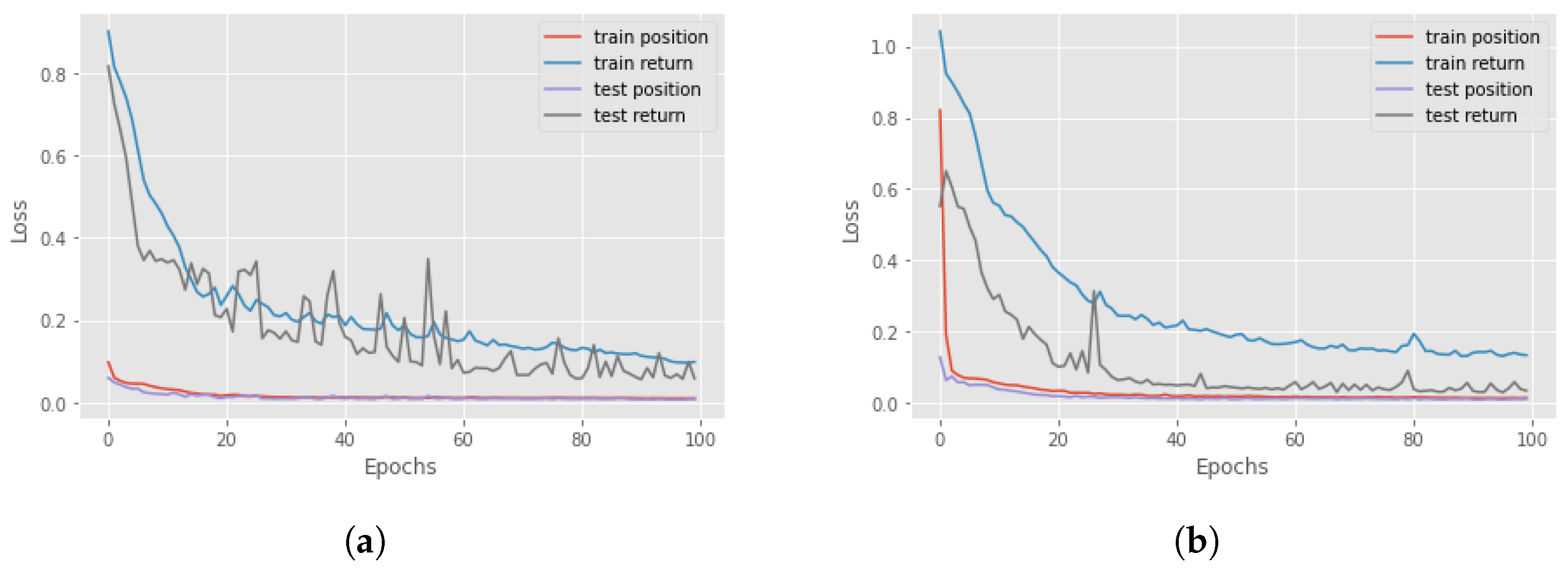
Figure 4, there is a comparison between all four different networks in terms of loss and accuracy during the training and test session over 100 epochs, for the Taxi environment. It can be seen that the best choice is to use the GRU network with Q-value, but in general, there are no significant differences with the GRU network that used the return. For this reason, in an environment where we have the Q-value, it is better to use it as a feature, while, if the Q-function is not known, it is possible to accomplish the same result using the actual accumulated returns.
The main difference between the RNNs for the actual prediction and the counterfactual one is how the memory for their training is composed. The actual RNN data are created following the optimal policy and saving all the information of each step. Meanwhile, for the counterfactual, the agent will always choose the optimal action following the trained RL agent until a “why not” question is asked. In that case, the counterfactual action is chosen and saved in the same way as indicated before. The final return and the distal state/action are given by following the correct actions after the counterfactual one. In both cases, it is fundamental to pre-process data: for the actions, One-Hot-Encoding is applied, while for the return it was beneficial to standardize the values to reduce the time of the training and the loss.
Another important problem is that each data point is a time series of potentially different lengths. At the start of the episode, the saved values
v are only the one of the initial time step, so
(where
f represents the number of the features), while at the end, the saved data are composed of all the values of each previous step, i.e., if the episode length is
l we have
. However, each data point must have the same dimensions. To this end, it is possible to evaluate the maximum length of the episodes
m. Then, all the elements that have a lower dimension than
m will be filled with vectors of 0. This technique (
Padding) is a well known method used in message [
46] or image recognition [
47].
Figure 5 represents the pipeline of the creation of the dataset for the RNN training. Now, we introduce a definition of distal prediction that will be useful for creating the final explanation.
Definition 8 (Distal Actual/Counterfactual Prediction).Given an initial vector of the state at a time t, , the one-hot-encoded actual (counterfactual) action () and the corresponding Q-value , the distal actual (counterfactual) prediction () is defined as the output of the actual (counterfactual) RNN given and as input.
All the information obtained from the previous components is fundamental for the explanation: the next state values prediction through the BN, the causal structure and the distal values obtained from the RNNs. However, the first step is to define what is the center of the explanation, i.e., the central variable.
Definition 9 (Actual central variable/node for “why” question).Given the state and , the vector of predicted values by the Bayesian Network at time step t, an actual central variable or node D in a Bayesian Network for the “why” question explanation is a node such that , where and are, respectively, the D components of the state vector and the predicted vector .
After this introductory part, it is possible to talk about the explanation for “why” questions. The following definition shows in detail how to use the information obtained previously to create an explanation.
Definition 10 (Explanation for “why” question).Given the state and an action , the explanation for the “why” question is a tuple:where is the predicted values through the Bayesian Network, is the distal actual prediction through the actual RNN, is the parent set and the children set of the actual central node D and the reward node connected to D, which are the variables in the chain that are directly linked to the reward node. Principally, we give the user all the information obtained through the BN and RNN predictions, connecting all of them and analyzing the structure of the DAG.
Similar to the previous definitions, there are almost identical definitions for the counterfactual case.
Definition 11 (Counterfactual central variable/node for “why not” question).Assume the state and let be the vector of the counterfactual predicted values by the Bayesian Network at a time step t. A central variable or node C in a Bayesian Network for a “why not” question explanation is the node such that , where and are, respectively, the C components of the actual vector and the counterfactual predicted vector .
Definition 12 (Explanation for “why not” question).Given the state , an actual action and a counterfactual action , the explanation for a “why not” question is a tuple:where are, respectively, the vectors of predicted actual and counterfactual values through the Bayesian Network, are, respectively, the distal prediction through the actual and counterfactual RNNs, C is the counterfactual central variable/node, the parent set and the children set of the actual central node D and the reward node connected to D. For the explanation of the “why not” question, the main idea is the same as the actual one: give to the user all the predicted information, linking them with each other through the central variables and the structure of the BN. In this way, it is also possible to directly compare the results of actual and counterfactual forecasting. Therefore, human awareness of the correctness of the agent will increase. An interesting event is when we have more than one central variable. In these scenarios, we will compute the chain for all the nodes that satisfy the properties described above.
In the next section, all these definitions are practically used to clearly explain what the results of the model will be.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}