ESVIO: Event-Based Stereo Visual-Inertial Odometry


Abstract
1. Introduction
- We present a direct event-based stereo VIO method for the first time, which uses the sliding window tightly coupled optimization method to directly estimate the optimal state of the system based on the event and IMU data without feature tracking.
- We propose a semi-joint event-inertial initialization method to estimate initialization parameters, including scale, gravity direction, initial velocities, accelerometer, and gyroscope biases, in two steps (event-only initialization and event-inertial initial optimization).
- We implement the event-based stereo VIO system, ESVIO, in C++ and evaluate it on four public datasets [25,26,27,28]. The results demonstrate that our system achieves good accuracy and robust performance when compared with the state-of-the-art, and, at the same time, with no compromise to real-time performance.
2. Related Work
2.1. Visual-Inertial Odometry Methods
2.2. Event-Based Visual Odometry and SLAM
2.3. Event-Based Visual-Inertial Odometry
2.4. Visual-Inertial Initialization Methods
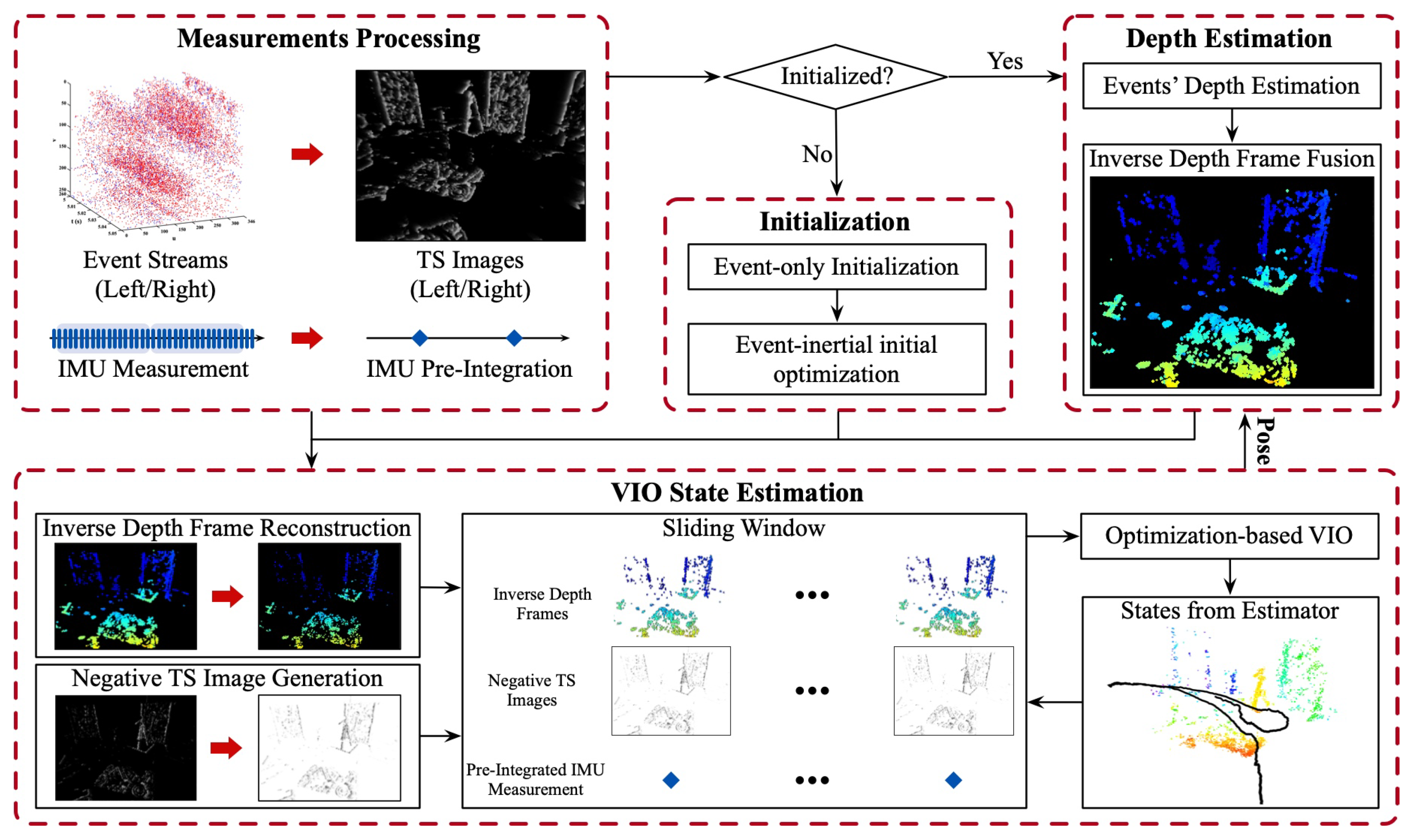
3. System Overview of ESVIO
4. Preliminaries
4.1. Notations
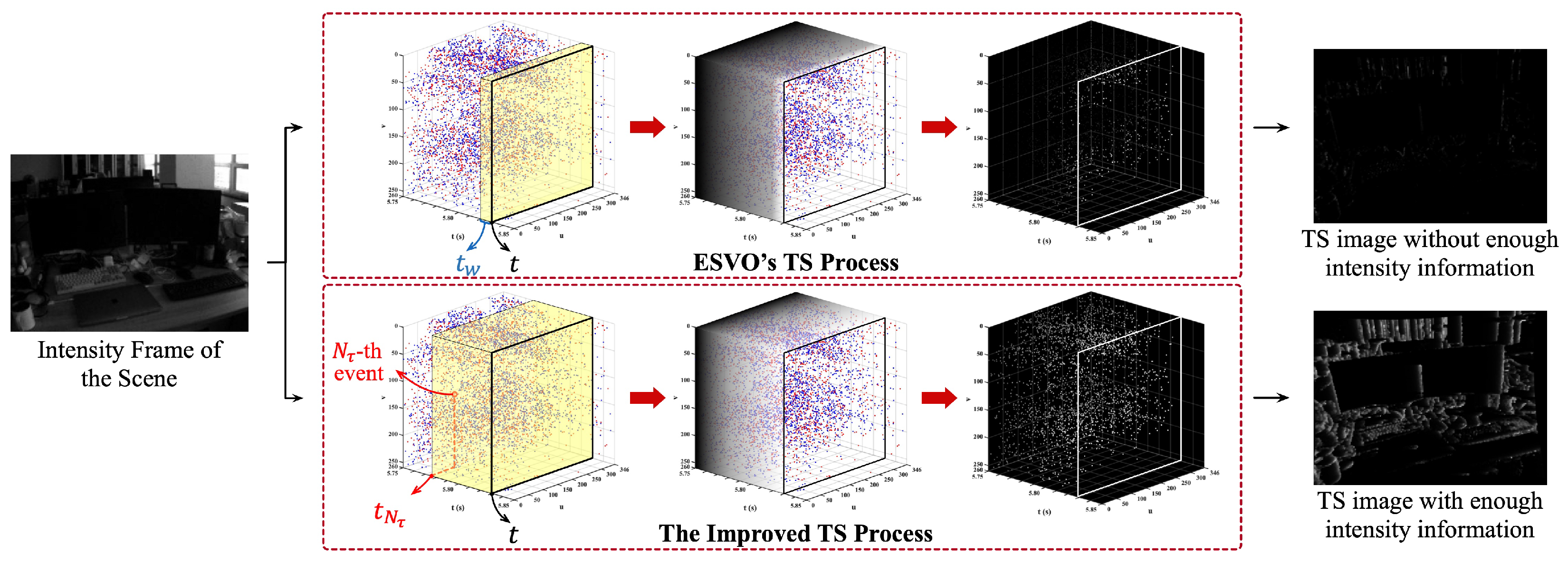
4.2. Event Presentation Based on Time-Surface
4.3. IMU Pre-Integration
4.4. Depth Estimation Based on Time-Surface
5. Event-Inertial Initialization Method
5.1. Event-Only Initialization
5.2. Event-Inertial Initial Optimization
6. Direct Event-Based VIO Method
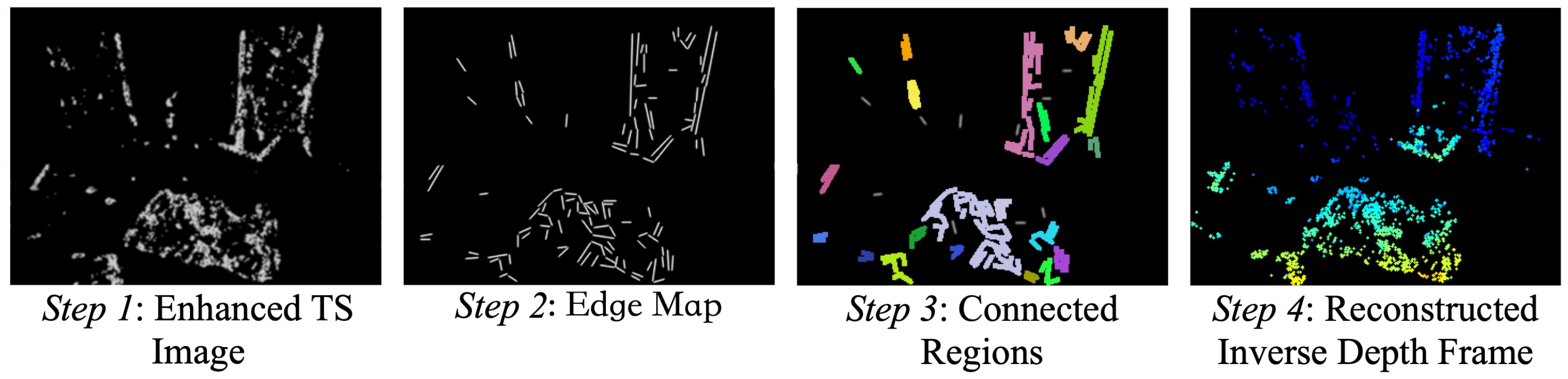
6.1. Inverse Depth Frame Reconstruction
- Step 1: Project all depth points of the inverse depth frame to its corresponding TS image (same timestamp) to enhance the intensity information in this TS image.
- Step 3: Extract connected regions in the edge map based on the contour retrieval algorithm [60]. According to the connected regions and projected coordinates in the TS image, cluster the depth points into each connected region.
- Step 4: According to the proportion of the number of depth points in each connected region to the total number of depth points, determine the number of points to select in each connected region, and then randomly select this number of depth points from each connected region to reconstruct the inverse depth frame.
6.2. Negative TS Image Generation
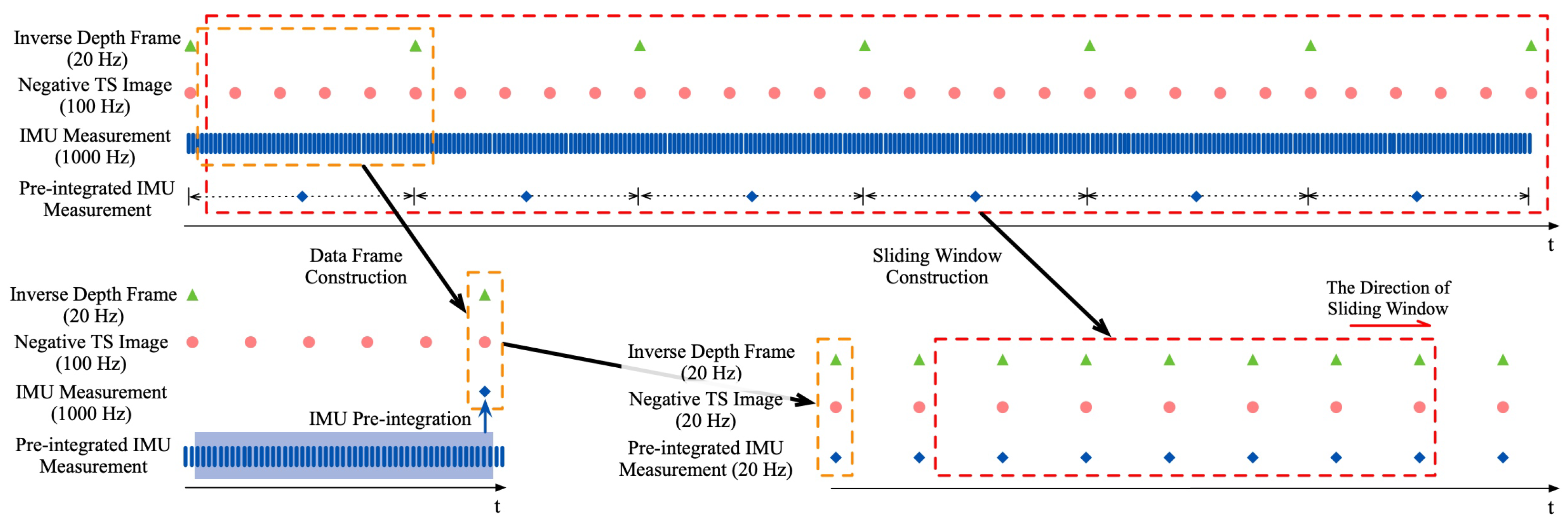
6.3. Direct VIO State Estimation Based on Event Data and IMU Measurement
7. Experimental Evaluation
7.1. Performance of the Event-Inertial Initialization
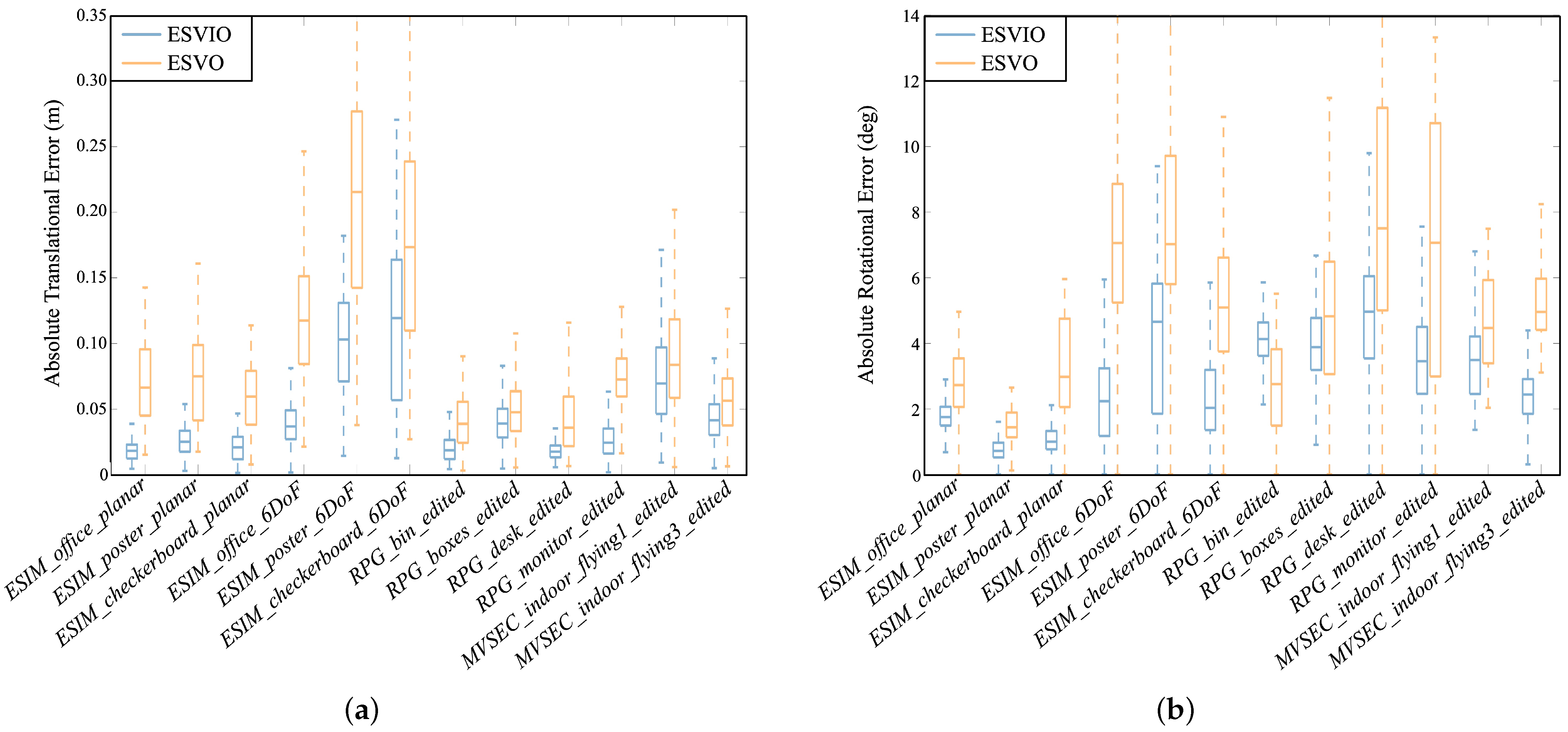
7.2. Evaluation of the VIO State Estimation Accuracy for ESVIO
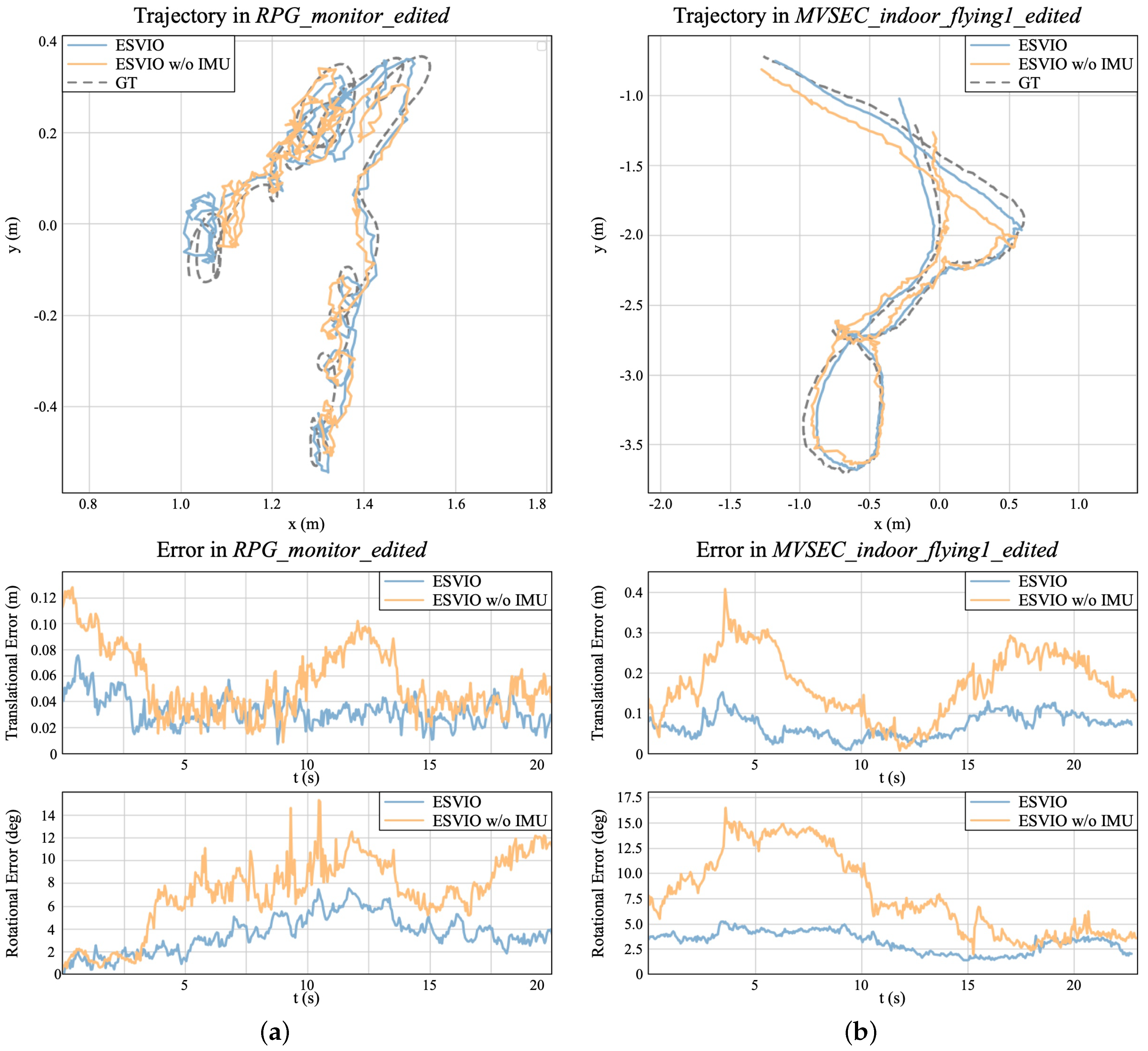
7.3. Evaluation of the Impact of Adding IMU to ESVIO
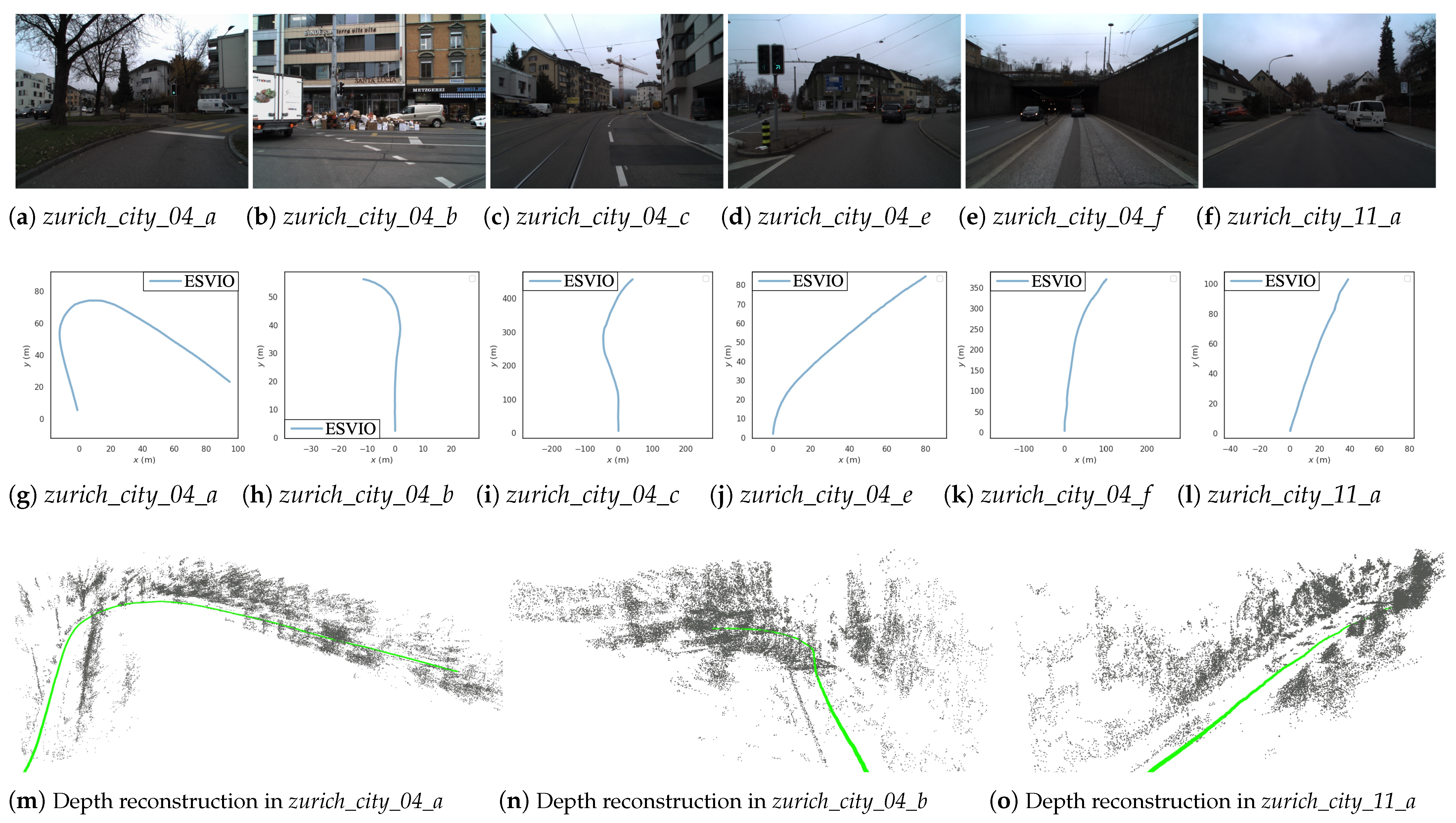
7.4. Experiments on DSEC Dataset
7.5. Real-Time Performance Analysis
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Jacobian Matrices in Initialization
Appendix A.2. Jacobian Matrices in State Estimation
Appendix A.2.1. Jacobian Matrices of IMU Measurement Residual
Appendix A.2.2. Jacobian Matrices of Event Data Residual
References
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Gomez-Ojeda, R.; Moreno, F.A.; Zuñiga-Noël, D.; Scaramuzza, D.; Gonzalez-Jimenez, J. PL-SLAM: A stereo SLAM system through the combination of points and line segments. IEEE Trans. Robot. 2019, 35, 734–746. [Google Scholar] [CrossRef]
- Wang, R.; Schworer, M.; Cremers, D. Stereo DSO: Large-scale direct sparse visual odometry with stereo cameras. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3903–3911. [Google Scholar]
- Huang, H.; Yeung, S.K. 360vo: Visual odometry using a single 360 camera. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 5594–5600. [Google Scholar]
- Fontan, A.; Civera, J.; Triebel, R. Information-driven direct rgb-d odometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4929–4937. [Google Scholar]
- Gallego, G.; Delbruck, T.; Orchard, G.; Bartolozzi, C.; Taba, B.; Censi, A.; Leutenegger, S.; Davison, A.; Conradt, J.; Daniilidis, K.; et al. Event-based vision: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 154–180. [Google Scholar] [CrossRef]
- Mostafavi, M.; Wang, L.; Yoon, K.J. Learning to reconstruct HDR images from events, with applications to depth and flow prediction. Int. J. Comput. Vis. 2021, 129, 900–920. [Google Scholar] [CrossRef]
- Zhou, Y.; Gallego, G.; Shen, S. Event-based stereo visual odometry. IEEE Trans. Robot. 2021, 37, 1433–1450. [Google Scholar] [CrossRef]
- Mueggler, E.; Huber, B.; Scaramuzza, D. Event-based, 6-DoF pose tracking for high-speed maneuvers. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Chicago, IL, USA, 14–18 September 2014; pp. 2761–2768. [Google Scholar]
- Kim, H.; Leutenegger, S.; Davison, A.J. Real-time 3D reconstruction and 6-DoF tracking with an event camera. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 349–364. [Google Scholar]
- Rebecq, H.; Horstschäfer, T.; Gallego, G.; Scaramuzza, D. EVO: A geometric approach to event-based 6-DoF parallel tracking and mapping in real time. IEEE Robot. Autom. Lett. 2016, 2, 593–600. [Google Scholar] [CrossRef]
- Bryner, S.; Gallego, G.; Rebecq, H.; Scaramuzza, D. Event-based, direct camera tracking from a photometric 3D map using nonlinear optimization. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 325–331. [Google Scholar]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-based visual–inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef]
- Bloesch, M.; Omari, S.; Hutter, M.; Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots And Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 298–304. [Google Scholar]
- Qin, T.; Li, P.; Shen, S. VINS-Mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 2018, 34, 1004–1020. [Google Scholar] [CrossRef]
- Von Stumberg, L.; Usenko, V.; Cremers, D. Direct sparse visual-inertial odometry using dynamic marginalization. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2510–2517. [Google Scholar]
- Usenko, V.; Demmel, N.; Schubert, D.; Stückler, J.; Cremers, D. Visual-inertial mapping with non-linear factor recovery. IEEE Robot. Autom. Lett. 2019, 5, 422–429. [Google Scholar] [CrossRef]
- Von Stumberg, L.; Cremers, D. DM-VIO: Delayed Marginalization Visual-Inertial Odometry. IEEE Robot. Autom. Lett. 2022, 7, 1408–1415. [Google Scholar] [CrossRef]
- Zihao Zhu, A.; Atanasov, N.; Daniilidis, K. Event-based visual inertial odometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5391–5399. [Google Scholar]
- Rebecq, H.; Horstschaefer, T.; Scaramuzza, D. Real-time visual-inertial odometry for event cameras using keyframe-based nonlinear optimization. In Proceedings of the British Machine Vision Conference, London, UK, 4–7 September 2017. [Google Scholar]
- Vidal, A.R.; Rebecq, H.; Horstschaefer, T.; Scaramuzza, D. Ultimate SLAM? Combining events, images, and IMU for robust visual SLAM in HDR and high-speed scenarios. IEEE Robot. Autom. Lett. 2018, 3, 994–1001. [Google Scholar] [CrossRef]
- Mueggler, E.; Gallego, G.; Rebecq, H.; Scaramuzza, D. Continuous-time visual-inertial odometry for event cameras. IEEE Trans. Robot. 2018, 34, 1425–1440. [Google Scholar] [CrossRef]
- Le Gentil, C.; Tschopp, F.; Alzugaray, I.; Vidal-Calleja, T.; Siegwart, R.; Nieto, J. Idol: A framework for imu-dvs odometry using lines. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October–24 January 2021; pp. 5863–5870. [Google Scholar]
- Chen, P.; Guan, W.; Lu, P. ESVIO: Event-based Stereo Visual Inertial Odometry. arXiv 2022, arXiv:2212.13184. [Google Scholar]
- Zhou, Y.; Gallego, G.; Rebecq, H.; Kneip, L.; Li, H.; Scaramuzza, D. Semi-dense 3D reconstruction with a stereo event camera. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 235–251. [Google Scholar]
- Jiao, J.; Huang, H.; Li, L.; He, Z.; Zhu, Y.; Liu, M. Comparing Representations in Tracking for Event Camera-based SLAM. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Virtual Conference, 19–25 June 2021; pp. 1369–1376. [Google Scholar]
- Zhu, A.Z.; Thakur, D.; Özaslan, T.; Pfrommer, B.; Kumar, V.; Daniilidis, K. The multivehicle stereo event camera dataset: An event camera dataset for 3D perception. IEEE Robot. Autom. Lett. 2018, 3, 2032–2039. [Google Scholar] [CrossRef]
- Gehrig, M.; Aarents, W.; Gehrig, D.; Scaramuzza, D. Dsec: A stereo event camera dataset for driving scenarios. IEEE Robot. Autom. Lett. 2021, 6, 4947–4954. [Google Scholar] [CrossRef]
- Corke, P.; Lobo, J.; Dias, J. An introduction to inertial and visual sensing. Int. J. Robot. Res. 2007, 26, 519–535. [Google Scholar] [CrossRef]
- Weiss, S.; Achtelik, M.W.; Lynen, S.; Chli, M.; Siegwart, R. Real-time onboard visual-inertial state estimation and self-calibration of MAVs in unknown environments. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, St. Paul, MN, USA, 14–18 May 2012; pp. 957–964. [Google Scholar]
- Lynen, S.; Achtelik, M.W.; Weiss, S.; Chli, M.; Siegwart, R. A robust and modular multi-sensor fusion approach applied to MAV navigation. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 3923–3929. [Google Scholar]
- Mourikis, A.I.; Roumeliotis, S.I. A multi-state constraint Kalman filter for vision-aided inertial navigation. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, Roma, Italy, 10–14 April 2007; pp. 3565–3572. [Google Scholar]
- Yang, Y.; Geneva, P.; Eckenhoff, K.; Huang, G. Visual-Inertial Odometry with Point and Line Features. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, 4–8 November 2019; pp. 2447–2454. [Google Scholar]
- Yang, Z.; Shen, S. Monocular visual–inertial state estimation with online initialization and camera–IMU extrinsic calibration. IEEE Trans. Autom. Sci. Eng. 2016, 14, 39–51. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Visual-inertial monocular SLAM with map reuse. IEEE Robot. Autom. Lett. 2017, 2, 796–803. [Google Scholar] [CrossRef]
- Liu, Z.; Shi, D.; Li, R.; Qin, W.; Zhang, Y.; Ren, X. PLC-VIO: Visual-Inertial Odometry Based on Point-Line Constraints. IEEE Trans. Autom. Sci. Eng. 2021, 19, 1880–1897. [Google Scholar] [CrossRef]
- Mo, J.; Sattar, J. Continuous-time spline visual-inertial odometry. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 9492–9498. [Google Scholar]
- He, Y.; Zhao, J.; Guo, Y.; He, W.; Yuan, K. PL-VIO: Tightly-coupled monocular visual–inertial odometry using point and line features. Sensors 2018, 18, 1159. [Google Scholar] [CrossRef]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Xu, B.; Wang, P.; He, Y.; Chen, Y.; Chen, Y.; Zhou, M. Leveraging structural information to improve point line visual-inertial odometry. IEEE Robot. Autom. Lett. 2022, 7, 3483–3490. [Google Scholar] [CrossRef]
- Huang, G. Visual-inertial navigation: A concise review. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 9572–9582. [Google Scholar]
- Usenko, V.; Engel, J.; Stückler, J.; Cremers, D. Direct visual-inertial odometry with stereo cameras. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1885–1892. [Google Scholar]
- Eckenhoff, K.; Geneva, P.; Huang, G. Direct visual-inertial navigation with analytical preintegration. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 1429–1435. [Google Scholar]
- Hidalgo-Carrió, J.; Gallego, G.; Scaramuzza, D. Event-aided Direct Sparse Odometry. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5781–5790. [Google Scholar]
- Kueng, B.; Mueggler, E.; Gallego, G.; Scaramuzza, D. Low-latency visual odometry using event-based feature tracks. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Republic of Korea, 9–14 October 2016; pp. 16–23. [Google Scholar]
- Nguyen, A.; Do, T.T.; Caldwell, D.G.; Tsagarakis, N.G. Real-time 6-DoF pose relocalization for event cameras with stacked spatial LSTM networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Zhou, Y.; Li, H.; Kneip, L. Canny-VO: Visual Odometry with RGB-D Cameras Based on Geometric 3D-2D Edge Alignment. IEEE Trans. Robot. 2018, 35, 184–199. [Google Scholar] [CrossRef]
- Campos, C.; Montiel, J.M.; Tardós, J.D. Inertial-only optimization for visual-inertial initialization. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 51–57. [Google Scholar]
- Martinelli, A. Closed-form solution of visual-inertial structure from motion. Int. J. Comput. Vis. 2014, 106, 138–152. [Google Scholar] [CrossRef]
- Kaiser, J.; Martinelli, A.; Fontana, F.; Scaramuzza, D. Simultaneous state initialization and gyroscope bias calibration in visual inertial aided navigation. IEEE Robot. Autom. Lett. 2016, 2, 18–25. [Google Scholar] [CrossRef]
- Campos, C.; Montiel, J.M.; Tardós, J.D. Fast and robust initialization for visual-inertial SLAM. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 1288–1294. [Google Scholar]
- Liu, H.; Qiu, J.; Huang, W. Integrating Point and Line Features for Visual-Inertial Initialization. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 9470–9476. [Google Scholar]
- Qin, T.; Shen, S. Robust initialization of monocular visual-inertial estimation on aerial robots. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 4225–4232. [Google Scholar]
- Huang, W.; Liu, H. Online initialization and automatic camera-IMU extrinsic calibration for monocular visual-inertial SLAM. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 5182–5189. [Google Scholar]
- Li, J.; Bao, H.; Zhang, G. Rapid and robust monocular visual-inertial initialization with gravity estimation via vertical edges. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macao, 4–8 November 2019; pp. 6230–6236. [Google Scholar]
- Huang, W.; Wan, W.; Liu, H. Optimization-based online initialization and calibration of monocular visual-inertial odometry considering spatial-temporal constraints. Sensors 2021, 21, 2673. [Google Scholar] [CrossRef]
- Lupton, T.; Sukkarieh, S. Visual-inertial-aided navigation for high-dynamic motion in built environments without initial conditions. IEEE Trans. Robot. 2011, 28, 61–76. [Google Scholar] [CrossRef]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 328–341. [Google Scholar] [CrossRef]
- Akinlar, C.; Topal, C. EDLines: A real-time line segment detector with a false detection control. Pattern Recognit. Lett. 2011, 32, 1633–1642. [Google Scholar] [CrossRef]
- Suzuki, S. Topological structural analysis of digitized binary images by border following. Comput. Vision, Graph. Image Process. 1985, 30, 32–46. [Google Scholar] [CrossRef]
- Huber, P.J. Robust estimation of a location parameter. In Breakthroughs in Statistics; Springer: Cham, Switzerland, 1992; pp. 492–518. [Google Scholar]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3, p. 5. [Google Scholar]
- Rebecq, H.; Gehrig, D.; Scaramuzza, D. ESIM: An open event camera simulator. In Proceedings of the Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2018; pp. 969–982. [Google Scholar]
- Umeyama, S. Least-squares estimation of transformation parameters between two point patterns. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 376–380. [Google Scholar] [CrossRef]
- Mueggler, E.; Rebecq, H.; Gallego, G.; Delbruck, T.; Scaramuzza, D. The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and SLAM. Int. J. Robot. Res. 2017, 36, 142–149. [Google Scholar] [CrossRef]
- Ghosh, S.; Gallego, G. Multi-Event-Camera Depth Estimation and Outlier Rejection by Refocused Events Fusion. Adv. Intell. Syst. 2022, 4, 2200221. [Google Scholar] [CrossRef]
- Sola, J. Quaternion kinematics for the error-state Kalman filter. arXiv 2017, arXiv:1711.02508. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Event Camera | Resolution (Pixel) | IMU | IMU Freq. (Hz) | IMU Noise Specs |
|---|---|---|---|---|---|
| RPG [25] | DAVIS240C | 240 × 180 | MPU-6150 | 1000 | total RMS noise of gyr: 0.2/s-rms power spectral density of acc: 400 μg/ |
| MVSEC [27] | DAVIS346 | 346 × 260 | MPU-6150 | 1000 | |
| ESIM [26] | Simulator [63] | 346 × 260 | Simulator [63] | 1000 | gyr noise density: 1.86 × 10 rad/s gyr random walk: 2.66 × 10 rad/s acc noise density: 1.86 × 10 m/s acc random walk: 4.33 × 10 m/s |
| DSEC [28] | PPS3MVCD | 640 × 480 | MPU-9250 | 1000 | gyr noise density: 5.07 × 10 rad/s gyr random walk: 5.69 × 10 rad/s acc noise density: 7.81 × 10 m/s acc random walk: 1.33 × 10 m/s |
| Sequence | Duration (s) | Method | Scale Error (%) | Mean ATE (cm) | |
|---|---|---|---|---|---|
| 5s | End | ||||
| RPG_bin_edited | 16.995 | ESVIO | 1.8 | 0 | 2.0 |
| ESVIO_w/o_initialization | 8.2 | 0.1 | 2.2 | ||
| RPG_boxes_edited | 14.995 | ESVIO | 8.7 | 2.2 | 4.0 |
| ESVIO_w/o_initialization | 15.8 | 4.0 | 4.7 | ||
| RPG_desk_edited | 12.995 | ESVIO | 2.0 | 1.7 | 1.8 |
| ESVIO_w/o_initialization | 2.9 | 2.2 | 2.5 | ||
| RPG_monitor_edited | 22.985 | ESVIO | 2.3 | 0.2 | 2.6 |
| ESVIO_w/o_initialization | 15.3 | 2.6 | 3.8 | ||
| MVSEC_indoor _flying1_edited | 25.976 | ESVIO | 8.7 | 5.1 | 7.7 |
| ESVIO_w/o_initialization | 9.8 | 5.9 | 9.4 | ||
| MVSEC_indoor _flying3_edited | 24.984 | ESVIO | 6.4 | 3.8 | 4.3 |
| ESVIO_w/o_initialization | 9.6 | 3.6 | 7.1 | ||
| Mean | 19.822 | ESVIO | 5.0 | 2.2 | 3.7 |
| ESVIO_w/o_initialization | 10.3 | 3.1 | 5.0 | ||
| Sequence | Duration (s) | Length (m) | ESVO | ESVO | ESVO | ESVO | ESVO | ESVO | ESVIO |
|---|---|---|---|---|---|---|---|---|---|
| ESIM_ office_ planar | 15.999 | 5.014 | 4.7 | 4.0 | 3.9 | 3.7 | 4.1 | 4.9 | 1.8 |
| ESIM_ poster_ planar | 15.999 | 5.014 | 4.7 | 3.7 | 4.3 | 4.6 | 5.0 | 5.2 | 2.5 |
| ESIM_ checkerboard_ planar | 15.999 | 5.014 | 4.2 | 2.9 | 2.2 | 2.3 | 2.4 | 3.5 | 2.0 |
| ESIM_ office_ 6DoF | 29.999 | 15.003 | 9.1 | 25.3 | 21.0 | 16.6 | 15.8 | 9.4 | 3.8 |
| ESIM_ poster_ 6DoF | 29.999 | 15.003 | 18.2 | 15.4 | 16.3 | 16.8 | 17.4 | 17.8 | 10.2 |
| ESIM_ checkerboard_ 6DoF | 29.999 | 15.003 | 23.0 | 17.0 | 14.0 | 15.1 | 13.4 | 22.4 | 11.5 |
| RPG_ bin_ edited | 16.995 | 4.923 | 3.4 | 22.4 | 16.6 | 8.0 | 14.1 | 3.5 | 2.0 |
| RPG_ boxes_ edited | 14.995 | 6.686 | 6.5 | 5.3 | 17.1 | 13.7 | 9.8 | 22.1 | 4.0 |
| RPG_ desk_ edited | 12.995 | 3.926 | 3.4 | 2.9 | 3.3 | 3.2 | 2.9 | 3.6 | 1.8 |
| RPG_ monitor_ edited | 22.985 | 6.251 | 7.2 | 5.3 | 5.2 | 7.4 | 7.3 | 7.3 | 2.6 |
| MVSEC_ indoor_ flying1_ edited | 25.976 | 11.761 | 18.5 | 22.0 | 16.7 | 16.0 | 22.1 | 14.9 | 7.7 |
| MVSEC_ indoor_ flying3_ edited | 24.984 | 10.646 | 20.9 | 10.8 | 11.9 | 14.0 | 15.0 | 10.6 | 4.3 |
| Mean | 21.41 | 8.687 | 10.3 | 11.4 | 11.0 | 10.1 | 10.8 | 10.4 | 4.5 |
| Sequence | ESVIO | Ultimate SLAM | Ultimate SLAM |
|---|---|---|---|
| (E + I) | (E + I + Fr) | ||
| ESIM_office_planar | 1.8 | - | 9.2 |
| ESIM_poster_planar | 2.5 | 5.8 | 7.3 |
| ESIM_checkerboard_planar | 2.0 | - | 7.0 |
| ESIM_office_6DoF | 3.8 | - | - |
| ESIM_poster_6DoF | 10.2 | - | - |
| ESIM_checkerboard_6DoF | 11.5 | - | - |
| RPG_bin_edited | 2.0 | 2.5 | 2.8 |
| RPG_boxes_edited | 4.0 | - | - |
| RPG_desk_edited | 1.8 | - | - |
| RPG_monitor_edited | 2.6 | 3.8 | 3.8 |
| MVSEC_indoor_flying1_edited | 7.7 | - | - |
| MVSEC_indoor_flying3_edited | 4.3 | - | - |
| Sequence | Scale Error (%) | Mean ATE (cm) | ||||
|---|---|---|---|---|---|---|
| ESVIO | ESVIO_w/o_IMU | ESVO | ESVIO | ESVIO_w/o_IMU | ESVO | |
| ESIM_office_planar | 2.4 | 7.9 | 13.1 | 1.8 | 6.5 | 4.1 |
| ESIM_poster_planar | 1.6 | 12.4 | 11.0 | 2.5 | 6.7 | 4.7 |
| ESIM_checkerboard_planar | 3.3 | 10.7 | 13.0 | 2.0 | 5.3 | 4.9 |
| ESIM_office_6DoF | 1.7 | 11.6 | 24.3 | 3.8 | 9.1 | 11.5 |
| ESIM_poster_6DoF | 2.0 | 24.8 | 21.7 | 10.2 | 21.5 | 15.6 |
| ESIM_checkerboard_6DoF | 10.7 | 17.2 | 14.0 | 11.5 | 17.8 | 19.7 |
| RPG_bin_edited | 0.0 | 11.8 | 16.4 | 2.0 | 3.9 | 3.1 |
| RPG_boxes_edited | 2.2 | 11.1 | 24.7 | 4.0 | 5.0 | 8.8 |
| RPG_desk_edited | 1.7 | 6.7 | 7.7 | 1.8 | 3.2 | 3.6 |
| RPG_monitor_edited | 0.2 | 8.1 | 9.9 | 2.6 | 5.2 | 7.2 |
| MVSEC_indoor_flying1_edited | 5.1 | 9.5 | 12.7 | 7.7 | 13.1 | 14.1 |
| MVSEC_indoor_flying3_edited | 3.8 | 9.8 | 12.8 | 4.3 | 9.7 | 27.8 |
| Mean | 2.9 | 11.8 | 15.1 | 4.5 | 8.9 | 10.4 |
| Thread | Method | Times (ms) | Rate (Hz) |
|---|---|---|---|
| time_surface | Event processing | 12.0 | 83.3 |
| depth_estimation | Depth estimation | 45.8 | 21.8 |
| VIO | IMU pre-integration | 0.4 | 41.5 |
| Data preprocessing | 2.1 | ||
| Nonlinear optimization | 21.6 |
| Size of Sliding Window | State Estimation Accuracy (cm) | Computation Cost of VIO Thread (ms) |
|---|---|---|
| 4 | 10.2 | 16.9 |
| 6 | 7.7 | 24.1 |
| 8 | 7.5 | 36.5 |
| 10 | 8.3 | 44.2 |
| Number of Depth Points | State Estimation Accuracy (cm) | Computation Cost of VIO Thread (ms) |
|---|---|---|
| 300 | 9.9 | 16.4 |
| 500 | 7.7 | 24.1 |
| 1000 | 7.8 | 43.8 |
| 1500 | 7.3 | 66.5 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Shi, D.; Li, R.; Yang, S. ESVIO: Event-Based Stereo Visual-Inertial Odometry. Sensors 2023, 23, 1998. https://doi.org/10.3390/s23041998
Liu Z, Shi D, Li R, Yang S. ESVIO: Event-Based Stereo Visual-Inertial Odometry. Sensors. 2023; 23(4):1998. https://doi.org/10.3390/s23041998
Chicago/Turabian StyleLiu, Zhe, Dianxi Shi, Ruihao Li, and Shaowu Yang. 2023. "ESVIO: Event-Based Stereo Visual-Inertial Odometry" Sensors 23, no. 4: 1998. https://doi.org/10.3390/s23041998
APA StyleLiu, Z., Shi, D., Li, R., & Yang, S. (2023). ESVIO: Event-Based Stereo Visual-Inertial Odometry. Sensors, 23(4), 1998. https://doi.org/10.3390/s23041998