

Learning 3D Bipedal Walking with Planned Footsteps and Fourier Series Periodic Gait Planning

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- By introducing the periodic and symmetrical gait phase function of bipedal robot walking, this paper allows the robot to learn human-like motion without relying on dynamic capture information.
- Omnidirectional locomotion on stairs and the ground is implemented, based on the footstep planner and orientation control. The landing point tracking locomotion is learned by reinforcement learning and leads to 3D walking based on the landing point planner.
2. Materials and Methods
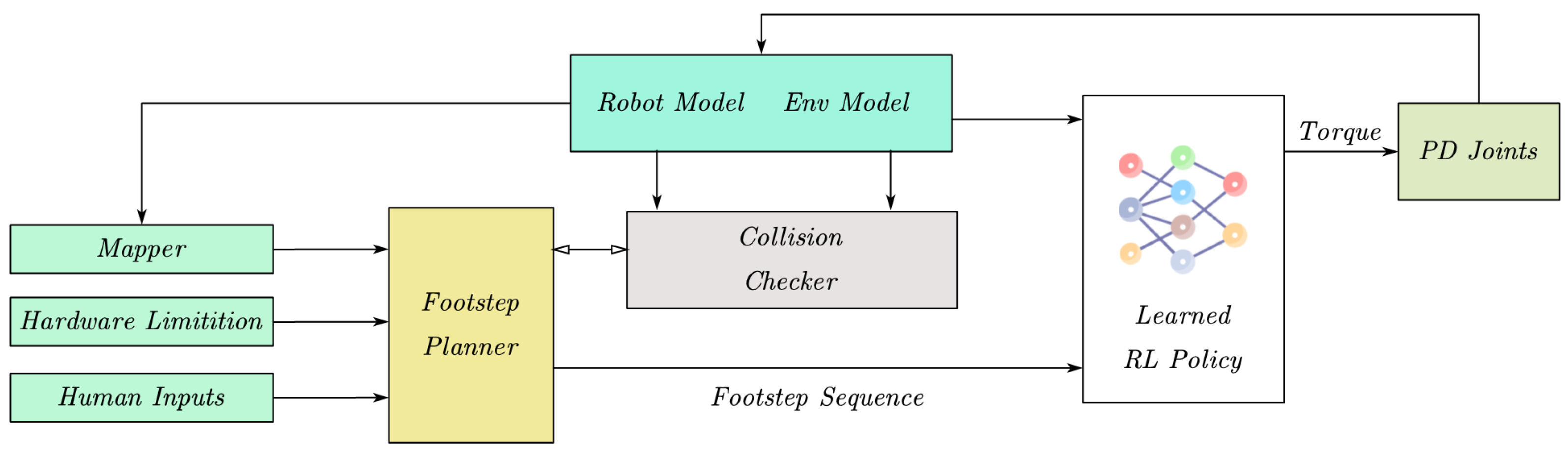
2.1. Control Model Overview
2.2. Planning System
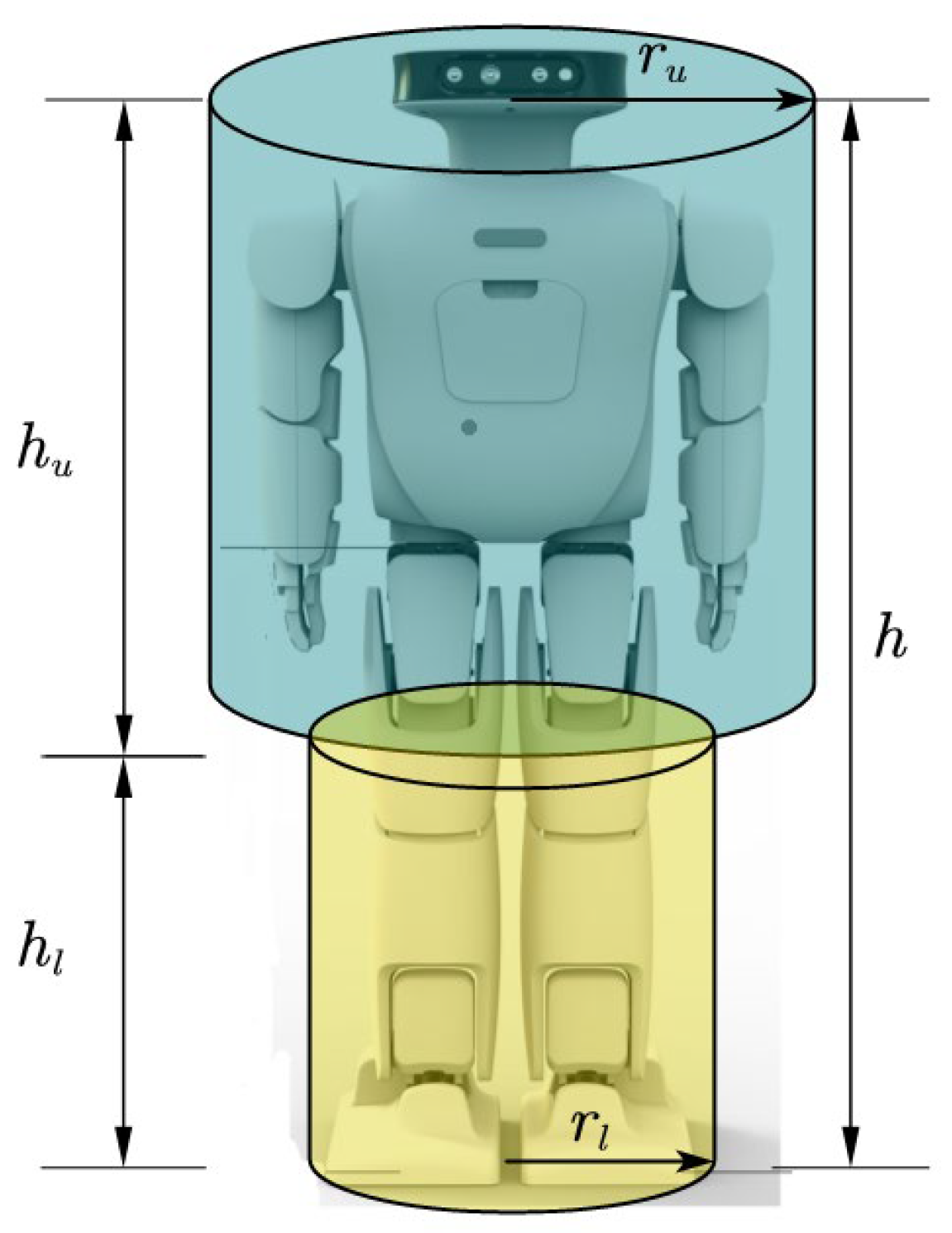
2.2.1. Map Grid
- The working ground environment of the robot is divided into a floor that can be stepped on and obstacles;
- The floor is horizontal and will not be tilted, and other obstacles are treated as obstacles;
- There will be no more than one floor at the same location; and
- The robot can distinguish between the floor and obstacles through its own sensors.
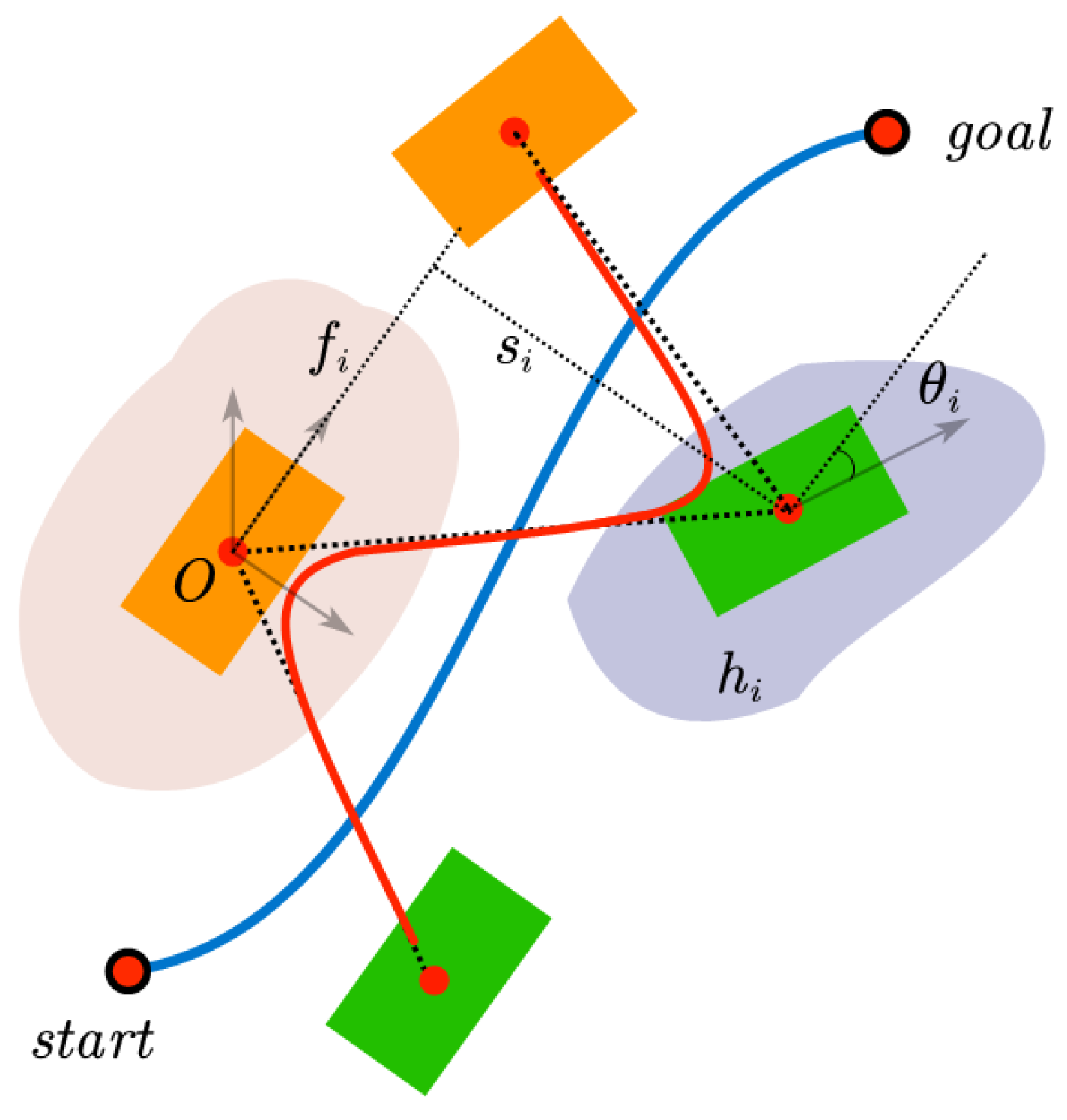
2.2.2. Path Planning
2.3. Walking Pattern Generation Based on Reinforcement Learning
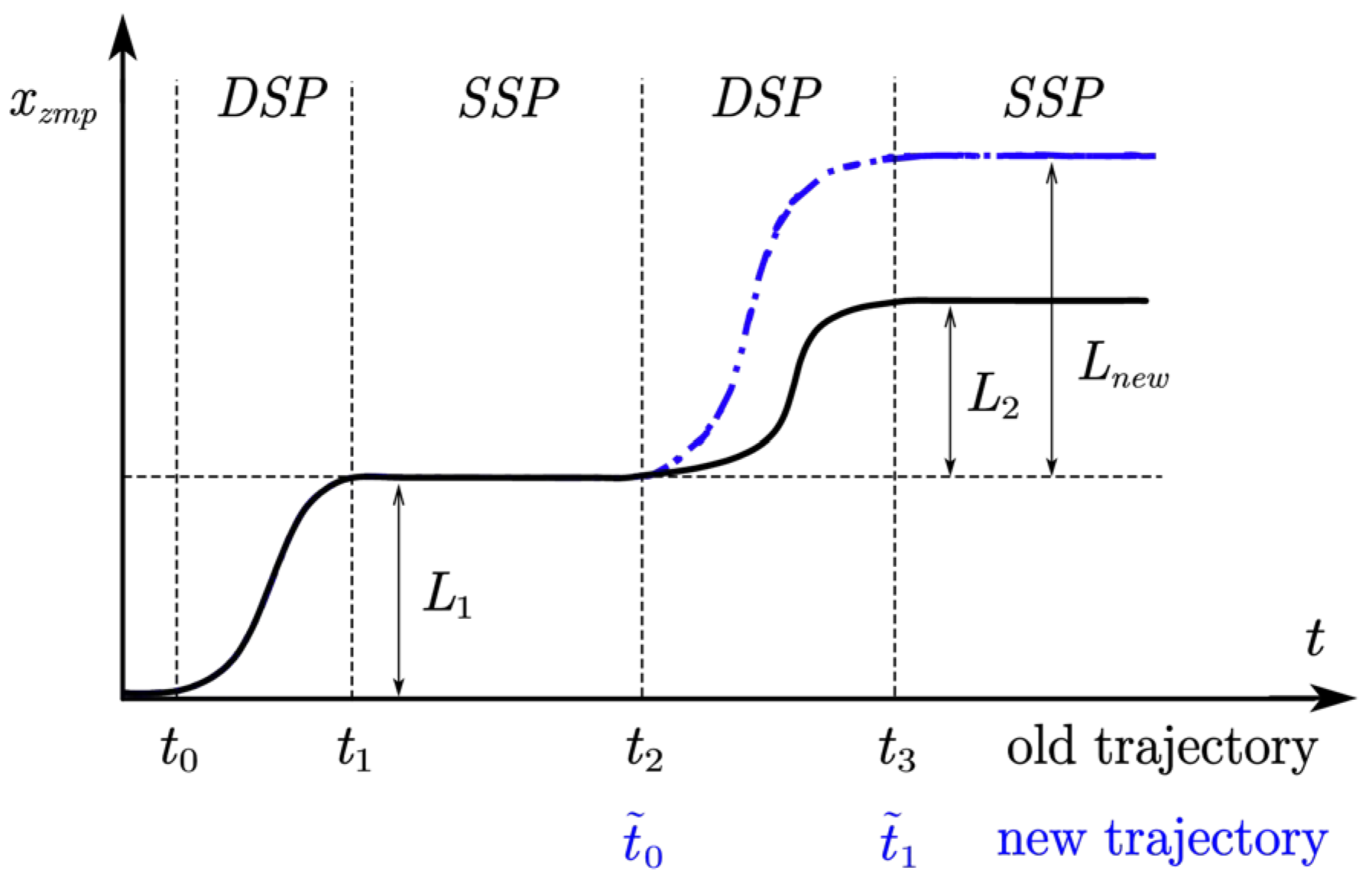
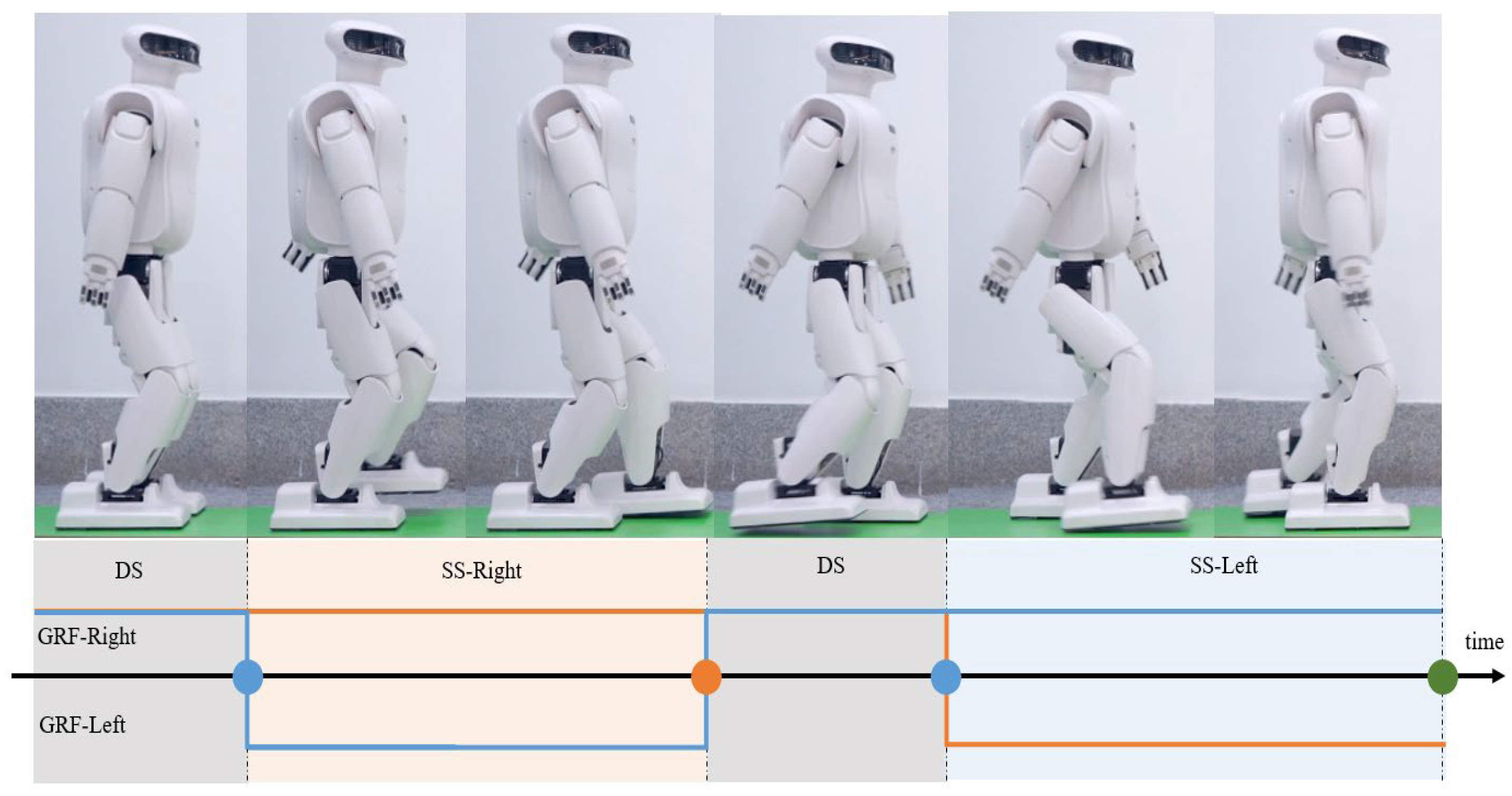
2.4. Gait Period Segmentation Based on Fourier Series
2.5. Observation Space and Action Space
2.6. Reward Function Design
2.7. Curriculum Learning Strategy
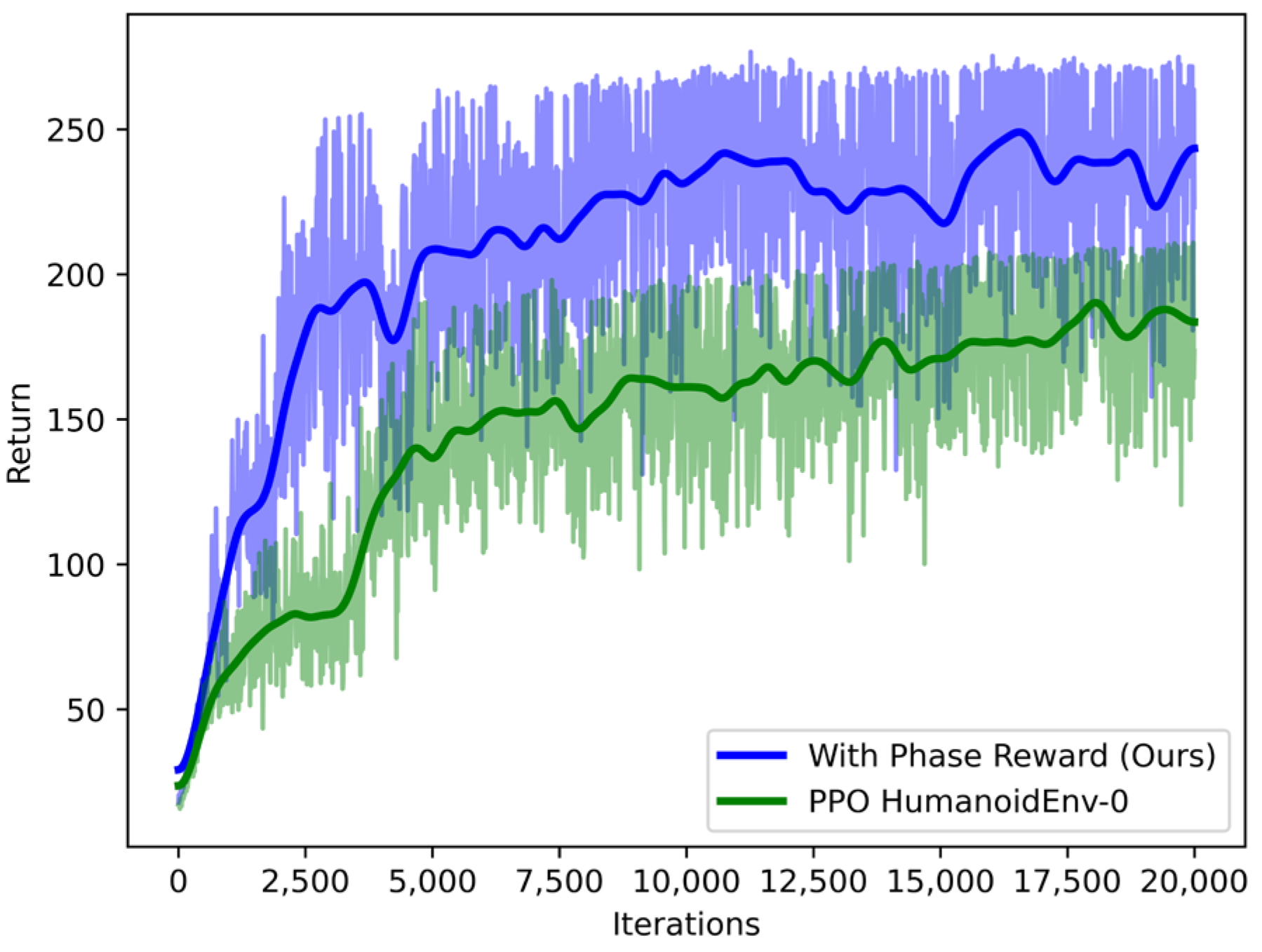
3. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Stumpf, A.; Kohlbrecher, S.; Conner, D.C.; von Stryk, O. Open Source Integrated 3D Footstep Planning Framework for Humanoid Robots. In Proceedings of the 2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), Cancun, Mexico, 15–17 November 2016; pp. 938–945. [Google Scholar]
- Reher, J.; Ames, A.D. Dynamic Walking: Toward Agile and Efficient Bipedal Robots. Annu. Rev. Control Robot. Auton. Syst. 2021, 4, 535–572. [Google Scholar] [CrossRef]
- Karkowski, P.; Oßwald, S.; Bennewitz, M. Real-Time Footstep Planning in 3D Environments. In Proceedings of the 2016 IEEE-RAS 16th International Conference on Humanoid Robots (Humanoids), Cancun, Mexico, 15–17 November 2016; pp. 69–74. [Google Scholar]
- Garimort, J.; Hornung, A.; Bennewitz, M. Humanoid Navigation with Dynamic Footstep Plans. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3982–3987. [Google Scholar]
- Hildebrandt, A.-C.; Wittmann, R.; Sygulla, F.; Wahrmann, D.; Rixen, D.; Buschmann, T. Versatile and Robust Bipedal Walking in Unknown Environments: Real-Time Collision Avoidance and Disturbance Rejection. Auton. Robot. 2019, 43, 1957–1976. [Google Scholar] [CrossRef]
- Teixeira, H.; Silva, T.; Abreu, M.; Reis, L.P. Humanoid Robot Kick in Motion Ability for Playing Robotic Soccer. In Proceedings of the 2020 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Ponta Delgada, Portugal, 15–17 April 2020; pp. 34–39. [Google Scholar]
- Kasaei, M.; Lau, N.; Pereira, A. An Optimal Closed-Loop Framework to Develop Stable Walking for Humanoid Robot. In Proceedings of the 2018 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Torres Vedras, Portugal, 25–27 April 2018; pp. 30–35. [Google Scholar]
- Carpentier, J.; Tonneau, S.; Naveau, M.; Stasse, O.; Mansard, N. A Versatile and Efficient Pattern Generator for Generalized Legged Locomotion. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 3555–3561. [Google Scholar]
- Fox, J.; Gambino, A. Relationship Development with Humanoid Social Robots: Applying Interpersonal Theories to Human–Robot Interaction. Cyberpsychol. Behav. Soc. Netw. 2021, 24, 294–299. [Google Scholar] [CrossRef] [PubMed]
- Tsuru, M.; Escande, A.; Tanguy, A.; Chappellet, K.; Harad, K. Online Object Searching by a Humanoid Robot in an Unknown Environment. IEEE Robot. Autom. Lett. 2021, 6, 2862–2869. [Google Scholar] [CrossRef]
- Li, Q.; Yu, Z.; Chen, X.; Zhou, Q.; Zhang, W.; Meng, L.; Huang, Q. Contact Force/Torque Control Based on Viscoelastic Model for Stable Bipedal Walking on Indefinite Uneven Terrain. IEEE Trans. Autom. Sci. Eng. 2019, 16, 1627–1639. [Google Scholar] [CrossRef]
- Zhang, T.; Nakamura, Y. Hrpslam: A Benchmark for Rgb-d Dynamic Slam and Humanoid Vision. In Proceedings of the 2019 Third IEEE International Conference on Robotic Computing (IRC), Naples, Italy, 25–27 February 2019; pp. 110–116. [Google Scholar]
- Yu, J.; Wen, Y.; Yang, L.; Zhao, Z.; Guo, Y.; Guo, X. Monitoring on triboelectric nanogenerator and deep learning method. Nano Energy 2022, 92, 106698. [Google Scholar] [CrossRef]
- Bergamin, K.; Clavet, S.; Holden, D.; Forbes, J.R. DReCon: Data-Driven Responsive Control of Physics-Based Characters. ACM Trans. Graph. (TOG) 2019, 38, 1–11. [Google Scholar] [CrossRef]
- Rodriguez, D.; Behnke, S. DeepWalk: Omnidirectional Bipedal Gait by Deep Reinforcement Learning. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 3033–3039. [Google Scholar]
- Gangapurwala, S.; Geisert, M.; Orsolino, R.; Fallon, M.; Havoutis, I. Rloc: Terrain-Aware Legged Locomotion Using Reinforcement Learning and Optimal Control. IEEE Trans. Robot. 2022, 38, 2908–2927. [Google Scholar] [CrossRef]
- Rai, A.; Sutanto, G.; Schaal, S.; Meier, F. Learning Feedback Terms for Reactive Planning and Control. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 2184–2191. [Google Scholar]
- Gao, Z.; Chen, X.; Yu, Z.; Zhu, M.; Zhang, R.; Fu, Z.; Li, C.; Li, Q.; Han, L.; Huang, Q. Autonomous Navigation with Human Observation for a Biped Robot. In Proceedings of the 2021 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 15–17 October 2021; pp. 780–785. [Google Scholar]
- Xie, Z.; Ling, H.Y.; Kim, N.H.; van de Panne, M. Allsteps: Curriculum-Driven Learning of Stepping Stone Skills. Comput. Graph. Forum 2020, 39, 213–224. [Google Scholar] [CrossRef]
- Deits, R.; Tedrake, R. Footstep Planning on Uneven Terrain with Mixed-Integer Convex Optimization. In Proceedings of the 2014 IEEE-RAS International Conference on Humanoid Robots, Madrid, Spain, 18–20 November 2014; pp. 279–286. [Google Scholar]
- Harada, K.; Kajita, S.; Kaneko, K.; Hirukawa, H. An Analytical Method on Real-Time Gait Planning for a Humanoid Robot. In Proceedings of the 4th IEEE/RAS International Conference on Humanoid Robots, Santa Monica, CA, USA, 10–12 November 2004; Volume 2, pp. 640–655. [Google Scholar] [CrossRef]
- Park, I.W.; Kim, J.Y. Fourier Series-Based Walking Pattern Generation for a Biped Humanoid Robot. In Proceedings of the 2010 10th IEEE-RAS International Conference on Humanoid Robots, Nashville, TN, USA, 6–8 December 2010; pp. 461–467. [Google Scholar]
- Siekmann, J.; Godse, Y.; Fern, A.; Hurst, J. Sim-to-Real Learning of All Common Bipedal Gaits via Periodic Reward Composition. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 7309–7315. [Google Scholar] [CrossRef]
- Duan, Y.; Chen, X.; Houthooft, R.; Schulman, J.; Abbeel, P. Benchmarking Deep Reinforcement Learning for Continuous Control. In Proceedings of the 33rd International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1329–1338. [Google Scholar]
- Zhao, W.; Queralta, J.P.; Westerlund, T. Sim-to-Real Transfer in Deep Reinforcement Learning for Robotics: A Survey. In Proceedings of the 2020 IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, ACT, Australia, 1–4 December 2020; pp. 737–744. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Piao, S.; Leng, X.; He, Z. Learning 3D Bipedal Walking with Planned Footsteps and Fourier Series Periodic Gait Planning. Sensors 2023, 23, 1873. https://doi.org/10.3390/s23041873
Wang S, Piao S, Leng X, He Z. Learning 3D Bipedal Walking with Planned Footsteps and Fourier Series Periodic Gait Planning. Sensors. 2023; 23(4):1873. https://doi.org/10.3390/s23041873
Chicago/Turabian StyleWang, Song, Songhao Piao, Xiaokun Leng, and Zhicheng He. 2023. "Learning 3D Bipedal Walking with Planned Footsteps and Fourier Series Periodic Gait Planning" Sensors 23, no. 4: 1873. https://doi.org/10.3390/s23041873
APA StyleWang, S., Piao, S., Leng, X., & He, Z. (2023). Learning 3D Bipedal Walking with Planned Footsteps and Fourier Series Periodic Gait Planning. Sensors, 23(4), 1873. https://doi.org/10.3390/s23041873