1. Introduction
The growth in online child exploitation and abuse material is a significant challenge for European Law Enforcement Agencies (LEAs). Currently, the revision of online material about child abuse exceeds the capacity of LEAs to respond in a practical and timely manner. One of the most important sources of information that needs to be analyzed to find evidence about child abuse corresponds to audiovisual material from multimedia content. With the aims of safeguarding victims, prosecuting offenders and limiting the spread of online child abuse related material, LEAs need a next-generation AI-powered platform to process multimedia data from online sources. One of the main goals of the GRACE project (
https://www.grace-fct.eu/ accessed on 1 February 2023) is to develop robust AI-based technology to equip LEAs with the aforementioned platform. Two of the core applications to be incorporated in order to accurately transcribe audiovisual online material and to detect the presence of specific keywords about child abuse in the transcriptions are automatic speech recognition (ASR) and keyword spotting (KWS).
Within this context, ASR technology has been applied in various forensic scenarios—for instance, to collect evidence via the examination of electronic devices [
1] or to analyze multimedia content related to specific threats [
2,
3]. Nevertheless, the successful implementation of an ASR system in forensics introduces a series of issues to be solved, which are not present in other domains where ASR is applied. For instance, it is common to find audio coming from different sources, which are highly affected by background noise, overlapping speakers, and audio reverberation, among other factors. All these aspects affect the quality of the obtained transcription and the capability of the system to detect specific keywords.
Despite the aforementioned problems, recent advances in ASR have introduced novel end-to-end architectures [
4] that have shown to be accurate enough in those adverse conditions. The core idea of end-to-end models is to directly map the input speech signal to character sequences and therefore greatly simplify training, fine-tuning, and inference making [
5,
6,
7,
8,
9]. Two main approaches are distinguished in the literature to train end-to-end ASR systems: fully supervised or self-supervised models. Regarding the first group, NVIDIA proposed Quartznet [
10] with the aim of building a competitive but lighter end-to-end ASR model. The architecture consists of multiple blocks of 1D convolutions stacked with residual connections. The model has been trained and tested on the Common Voice corpus, achieving word error rates (WERs) between
and
, depending on the language [
11]. A Quartznet model also produced WERs of
and
in French and Spanish language multimedia data, respectively, from the MediaSpeech corpus [
12]. Researchers from NVIDIA recently proposed Citrinet [
13] as an evolution of Quartznet. The model consists of a residual network formed by 1D time-channel separable convolutions combined with a sub-word encoding and a squeeze-and-excitation mechanism [
14]. The authors reported a WER of
on the TEDLIUMv2 corpus. Another architecture that has proven to be accurate in many ASR benchmark scenarios is the recurrent neural network transducer (RNN-T) [
15]. The RNN-T is formed by three main blocks: (1) an encoder network that receives input acoustic frames and produces high-level speech representations, (2) a predictor that acts as a decoder by processing the previous produced token, and (3) a joint network that combines the outputs from the two previous blocks and produces the distribution of the next predicted token or blank symbol. Recent models based on RNN-T achieved a WER 14.0% in the TEDLIUMv2 corpus [
16].
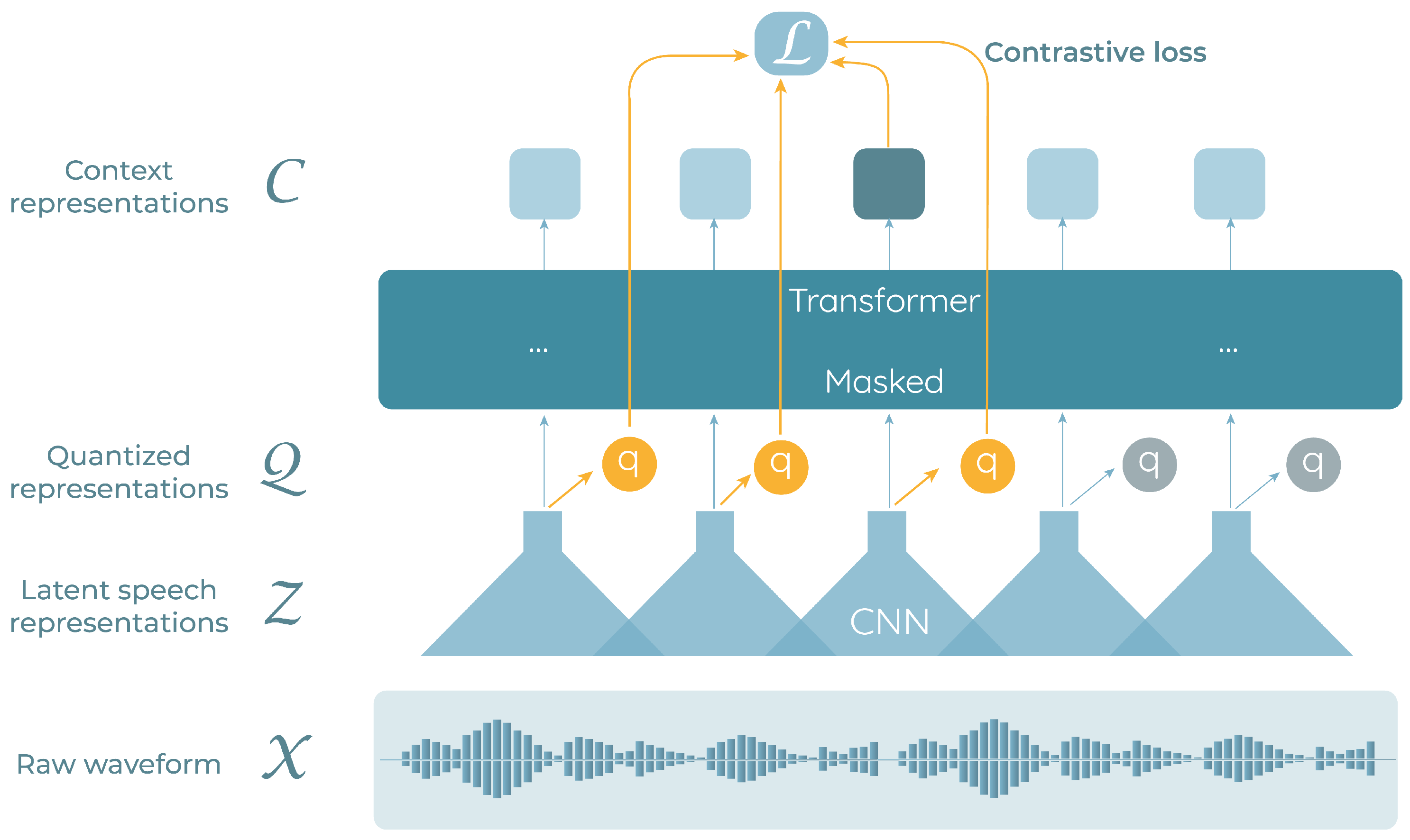
Contrary to fully supervised models, recent studies are focused on the use of big acoustic models trained with self-supervised learning methods and a large amount of unlabeled data. Researchers from Meta AI demonstrated the capabilities of models of this type by introducing Wav2Vec2.0 [
17]. This system outperformed many benchmark results, especially when considering ASR for low-resource languages in the Common Voice corpus [
18]. Particularly, the authors in [
19] considered a Wav2vec2.0 model combined with their proposed language modeling approach and achieved state-of-the-art results in the German Common Voice corpus, with a WER of
. Wav2Vec2.0-based models have also been successfully tested in more adverse acoustic environments, such as in multimedia Portuguese data from the CORAA database [
20]. Due to these reasons, Wav2Vec2.0 has become one of the most often considered neural-based models for ASR. Self-supervised approaches such as Wav2Vec2.0 are challenging because there is not a predefined lexicon for the input sound units during the pre-training phase. Moreover, sound units have variable length with no explicit segmentation [
21]. With the aim of solving such issues, Meta AI released HuBERT as a new approach to learn self-supervised speech representations [
22]. The combination of convolutional and transfomer networks from Wav2Vec2.0 and HuBERT has achieved state-of-the-art results in many ASR scenarios. With the aim of combining the best features from both type of networks in a single neural block, researchers from Google introduced the “convolutional augmented transfomer” or Conformer [
23]. A Conformer network achieved a WER of
in the TEDLIUMv2 corpus [
24].
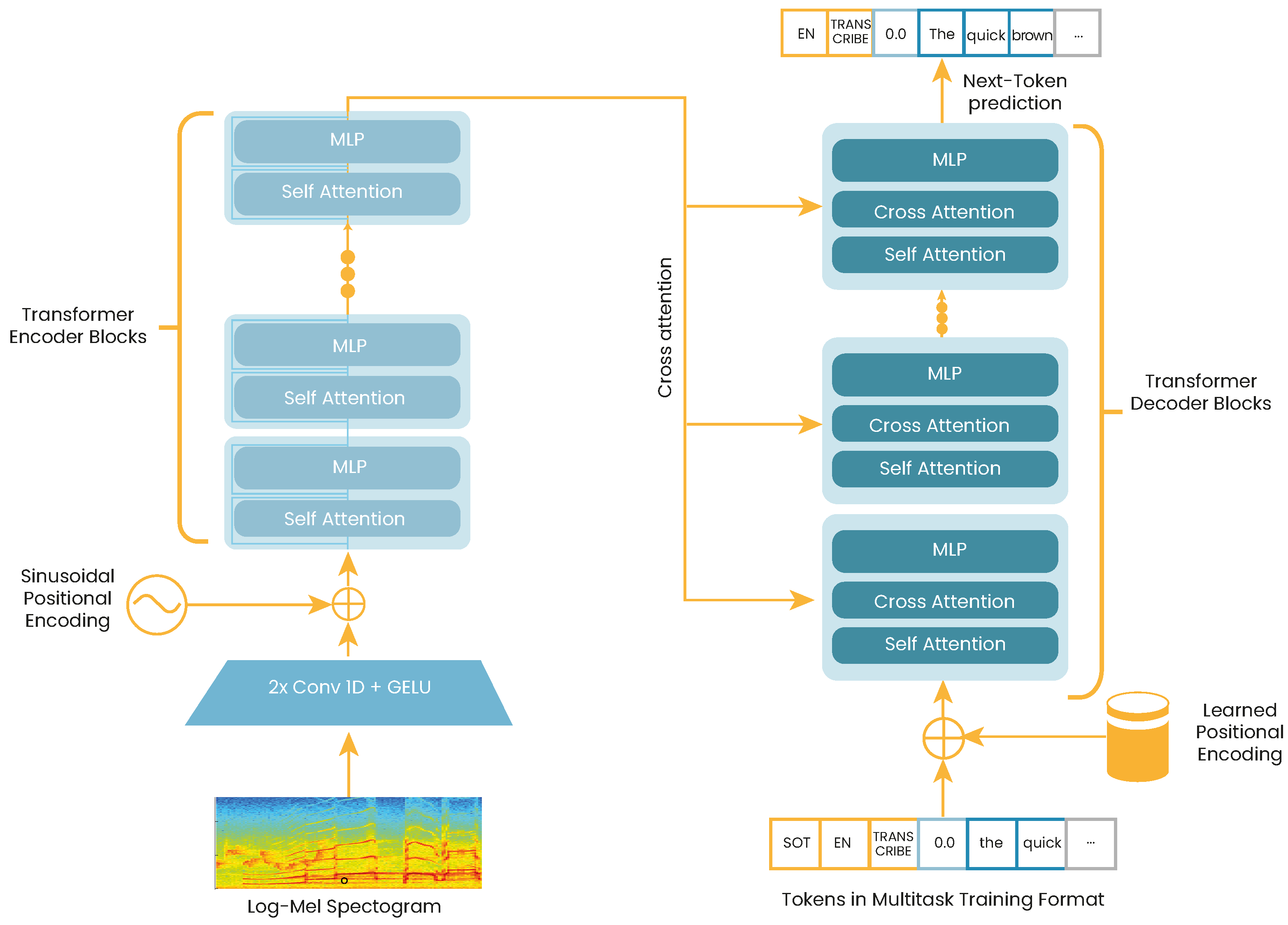
Self-supervised audio encoders like Wav2Vec2.0, HuBERT, and Conformers learn high quality audio representations. However, due to its unsupervised pre-training nature, they lack a proper decoding to transform such representations into usable outputs. This is why a fine-tuning stage is always necessary in order to accurately implement models for ASR or audio classification. With the aim of solving the aforementioned issue, researchers from OpenAI recently proposed “Whisper” [
25]. Whisper is a sequence-to-sequence transformer trained in a fully supervised manner, using up to 680,000 h of labeled audio from the Internet. The model has achieved state-of-the-art WER results on many benchmark datasets for ASR, including librispeech, TEDLIUM, and Common Voice, among others.
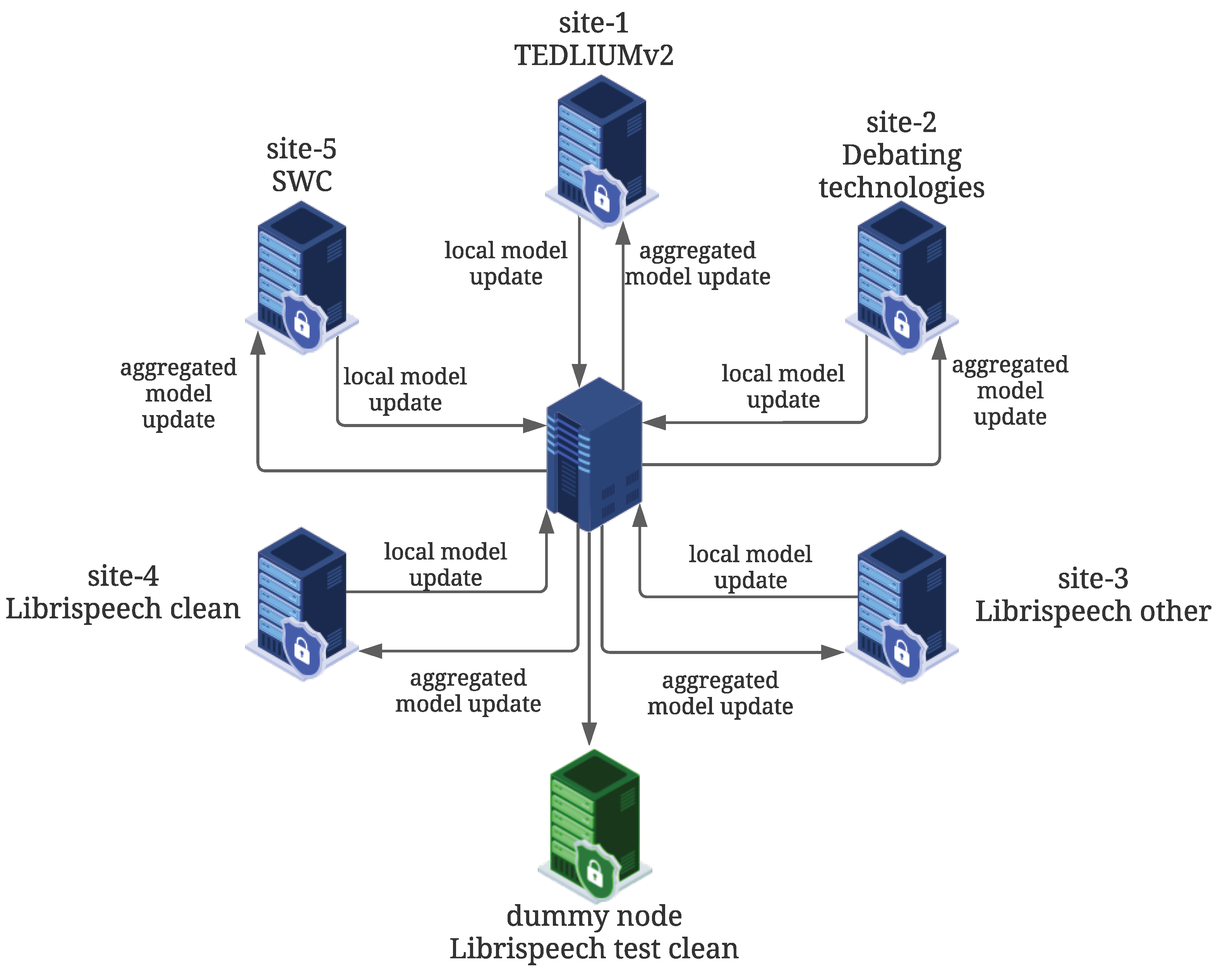
There are two main issues that appear when designing ASR solutions for forensic scenarios: The first one is related to find the most appropriate neural architecture from the ones previously described in order to deal with different acoustic environments. The second one is related to data privacy and protection [
26]. Generally, obtaining operative data from LEAs for the addressed scenario is not possible. In this context, federated learning (FL) has emerged as an alternative with which to train machine learning models on remote devices, such as mobile phones and remote data-centers in a non-centralized manner, preserving data privacy [
27,
28,
29,
30]. The procedure is as follows: LEAs’ operative data are stored in on-premise data servers. Then, FL strategies aim to transfer only local model updates to a central server, keeping LEAs’ data private. The central server aggregates information obtained from multiple clients, i.e., LEAs, and updates a central model that is transmitted back to the clients for their consumption. FL has been applied to train robust federated acoustic models for ASR [
31,
32,
33] and KWS [
34]. In [
32], the authors proposed a client-adaptive federated training scheme to mitigate data heterogeneity when training ASR models. The proposed system achieved a similar WER with respect to the obtained one using fully centralized training. In [
33], the authors proposed a strategy to compensate non-independent and identically distributed (non-IID) data in federated training of ASR systems. The proposed strategy involved random client data sampling, which resulted in a cost-quality trade-off. The optimization of such a trade-off led to obtaining ASRs with similar WERs to the obtained by training-centralized systems. The authors in [
34] demonstrated the capabilities of federated training to obtain robust KWS systems locally trained on edge devices such as smartphones, reaching similar accuracies when compared with centralized trained models.
According to the reviewed literature, the two main paradigms and solutions for ASR to date include self-supervised models based on Wav2Vec2.0 and fully supervised models such as Whisper. This work considered and compared these two approaches to test their capabilities to perform robust ASR and KWS in a large set of test scenarios. We also evaluated the use of FL in the context where different LEAs can share a common ASR and KWS system, keeping the privacy of their data. In summary, the main contributions of this paper are four-fold:
We performed an extensive comparison between two of the most accurate neural-based ASR architectures to date: a fine-tuned version of Wav2Vec2.0 and Whisper. The evaluation was performed in many scenarios, but paying special attention to corpora coming from multimedia content. The models were tested on data from seven indo-European Languages, including English, Spanish, German, French, Italian, Portuguese, and Polish. This evaluation can be useful in other domains besides ASR forensics, making our contribution open and viable for other scenarios.
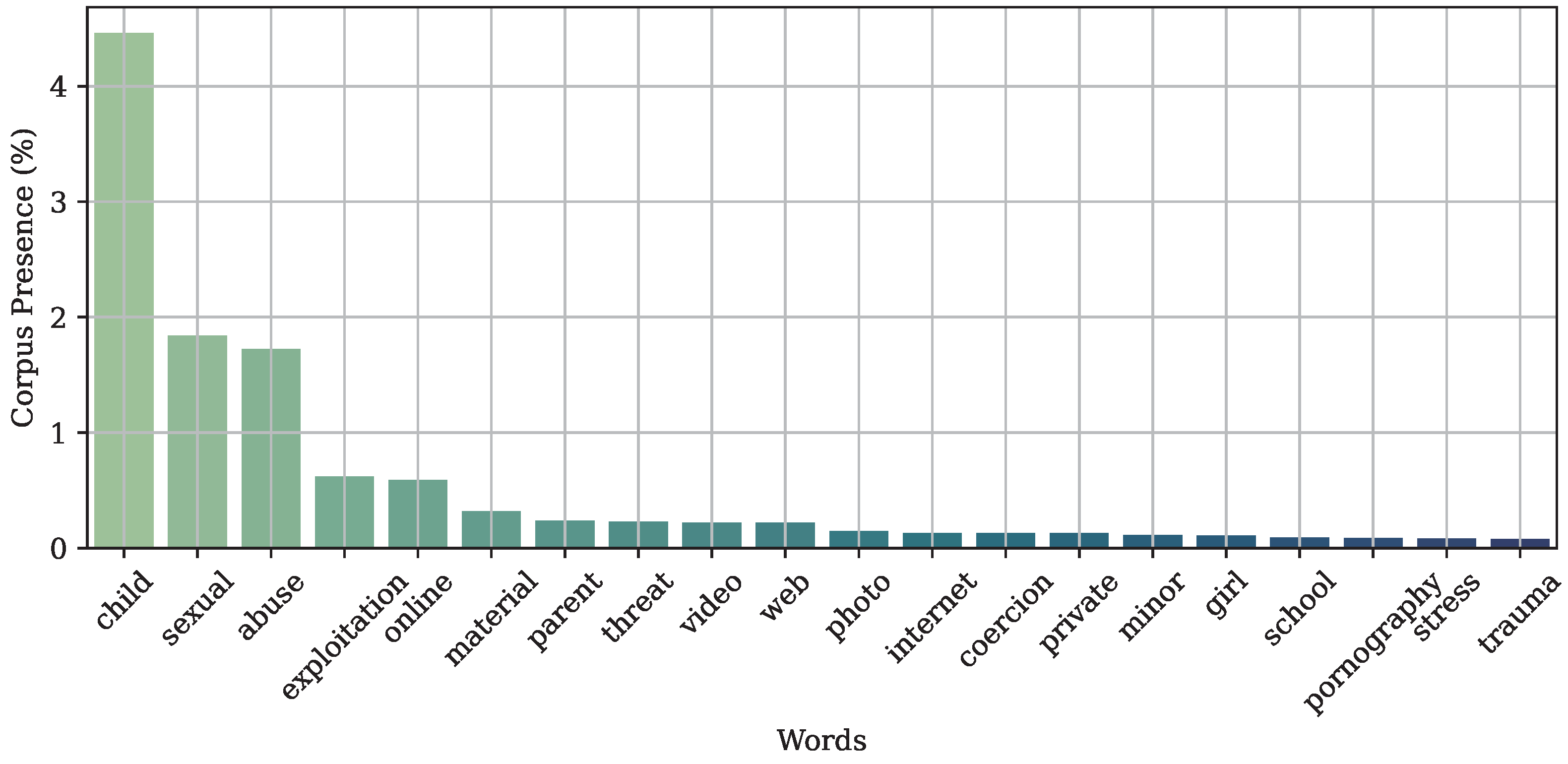
We created and released an in domain corpus that includes specific keywords of the child abuse domain, and a set of accompanying audio files where the keywords are present. The included audio was selected from open available corpora used in the literature. The created corpus can be used as a benchmark to test ASRs in uncontrolled acoustic conditions.
The two neural architectures are compared as well in the created corpora within the scope of child abuse forensics. To the best of our knowledge, this is the first study to comprise the use of open ASR solutions and their capabilities to recognize specific words within a forensic domain.
We validated the use of FL strategies to train ASR systems in the context of forensic applications. The core idea is that different LEAs can share a common model while keeping the privacy of their data.
The rest of the paper is distributed as follows.
Section 2 details different technical aspects of Wav2Vec2.0 and Whisper architectures for ASR.
Section 3 describes the considered corpora to test the ASR systems, and the process to deliver an in domain corpus for KWS in the context of forensics.
Section 4 describes the pilot study on the use of FL for the addressed application.
Section 5 displays the main results obtained regarding ASR, KWS, and FL.
Section 6 discusses the main insights obtained from the results. Finally,
Section 7 shows the main conclusion derived from this work.
6. Discussion
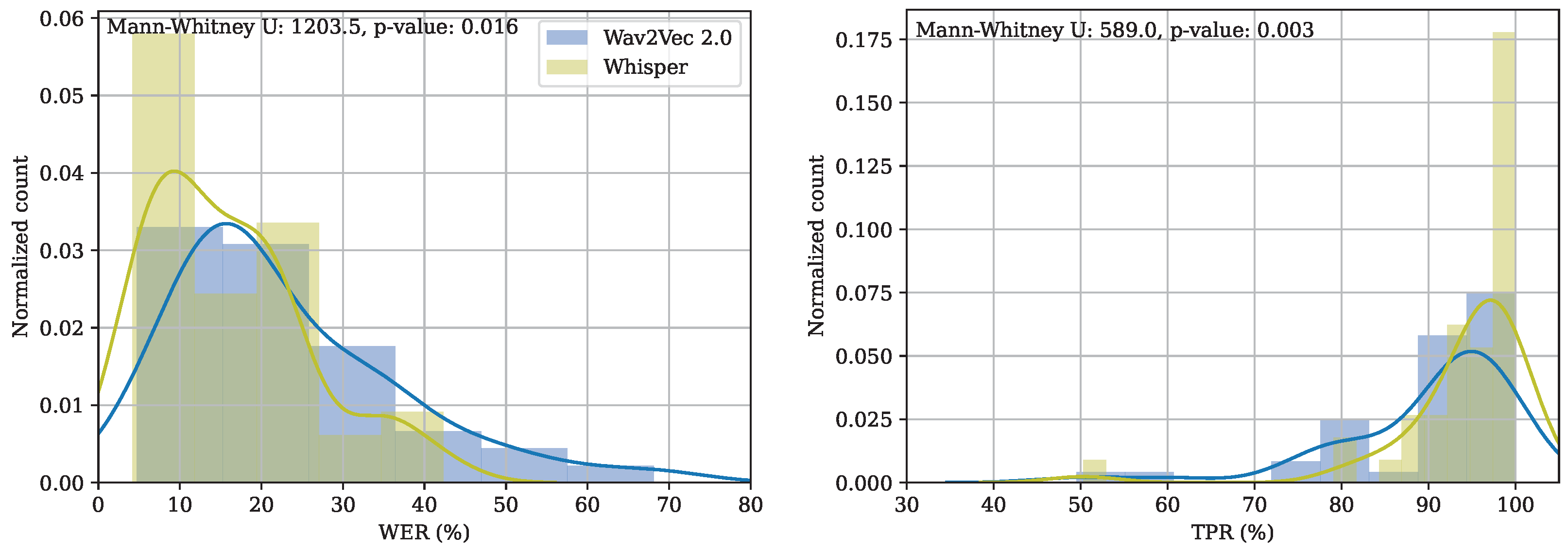
The evaluation of Wav2Vec2.0 and Whisper-based ASR systems was performed in a large set of different scenarios, including one specifically designed for forensic applications within the child abuse domain. On average, Whisper is more accurate than the Wav2Vec2.0-based system. Whisper achieved WERs ranging from to , depending on the language, compared with Wav2Vec2.0’s WERs of between and . The difference between the two models was even larger when using languages trained with fewer resources, such as Portuguese or Italian. Despite these differences, Wav2vec2.0 is competitive with Whisper when the number of hours for fine-tuning is large, e.g, for English, Spanish, or French.
Results using the GRACE dataset showed relatively similar WERs between Wav2Vec2.0 and Whisper when considering the clean version of the corpus: the average WER was for Whisper and was for Wav2Vec2.0. However, the difference between the two models greatly increased with the noisy version of the corpus: the average WER was for Whisper and for Wav2Vec2.0. This is a great indicator of the ability of Whisper to perform accurate transcriptions under uncontrolled and noisy acoustic conditions, by keeping similar WERs in the two versions of the GRACE corpus. Despite the differences between the two types of models, there are some surprising results where Wav2Vec2.0 outperformed Whisper, and which should be considered with special attention—for instance, when evaluating the GRACE clean corpus in languages such as English, French, and Spanish. The models for these three languages were fine-tuned with more data, which likely explains the lower WER for Wav2Vec2.0 compared to that of Whisper.
Our systems achieved state-of-the art results on several of the considered benchmark corpora. We reported state-of-the-art results for some of the languages in the Common Voice corpus. State-of-the-art results were also achieved for almost all languages ib the MTEDx and MediaSpeech corpora. These results are good indicators if the ability of the considered systems to accurately recognize speech under more natural and spontaneous scenarios, closer to the expected in forensic domains.
The KWS evaluation indicated that both Wav2Vec2.0 and Whisper were accurate enough to recognize the considered child-abuse-related keywords in the seven languages. TPRs obtained for Wav2Vec2.0 ranged from 82.9% to 94.9%, depending on the language. Results using Whisper ranged from 80.3% to 98.2%. The particular evaluation of KWS in the GRACE dataset also showed that both models are equally accurate at recognizing the selected keywords under controlled acoustic conditions. On the contrary, when considering the noisy version of the corpus, the results for Wav2Vec2.0 were reduced by 20%, and the results for Whisper were only reduced by 3%. This fact again indicates the ability of Whisper to accurately process speech recordings in uncontrolled acoustic conditions.
The last experiment involved a pilot study on the use of FL to train ASR systems. The results indicated that an ASR trained in a federated way maintains and in some cases outperforms the performance of individual ASRs trained in a centralized manner by each LEA. In addition to the performance, the most important aspect of FL is that the ASR training does not involve any data sharing among LEAs, since only updates of the network parameters are transferred to a central server in charge of aggregating the model. These results are indicators of the potential use of FL to obtain a joint (and potentially richer) model combining sources of data that could not be otherwise combined. Despite the benefits of using FL, it is important to consider external factors that may degrade the performance and reliability of the system. For instance, there is evidence of FL attacks that are able to retrieve speaker information from the transferred weights [
60] and data poisoning attacks inside LEA servers. Different strategies can be considered to mitigate attacks of these kinds, such as the use of differential privacy algorithms [
61] or the use of trusted execution environments.
7. Conclusions
This paper proposed the use of speech recognition and keyword spotting technologies to be applied in forensic scenarios, particularly in child exploitation settings. The aim is to provide LEAs with technology to detect the presence of offensive online audiovisual material related to child abuse. State-of-the art ASR systems based on Wav2Vec2.0 and Whisper were considered for the addressed application. The performance of both models was tested on a large set of open benchmark corpora from the literature. Therefore, the results obtained can be extended to other ASR domains. We additionally created an in-domain corpus using different open source datasets from the research community. The aim was to test the models in more realistic and operative conditions.
The ASR and KWS models were evaluated in corpora from seven Indo-European languages, including English, German, French, Spanish, Italian, Portuguese, and Polish. We obtained overall WERs ranging from 11.3% to 24.9%, depending on the language. The performance of the KWS model for the different languages ranged from 81.5% to 98.4%. The most accurate results were obtained from models trained with more data, such as English or German. The comparison between Wav2Vec2.0 and Whisper models indicated that the second one was the most accurate system in the majority of cases, especially when considering utterances in uncontrolled acoustic conditions.
We also proposed a strategy for using FL to train robust ASR systems in the context of the addressed application. This is a suitable approach considering that collecting operational data from LEAs is not possible. FL approaches allow LEAs to build a common technological platform without the need to share their operational data. The results of the FL pilot indicated that similar WERs were achieved when comparing the model trained in a federated way to individual models trained in a centralized manner, even considering non-IID conditions, which has been shown to be one of the main drawbacks in FL.
For future work, the considered approaches can be extended to other forensic applications where there is a need to monitor audiovisual material from online sources. In addition, the considered technology can be combined with other speech processing methods, such as speaker and language identification, age and gender recognition, and speaker diarization. The ultimate goal is to provide LEAs with accurate tools to monitor audio from online sources, allowing them to respond in a practical and timely manner.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}