
Water Surface Targets Detection Based on the Fusion of Vision and LiDAR


Abstract
:1. Introduction
2. Related Work
2.1. Water Surface Targets Detection Based on the Vision
2.2. Water Surface Targets Detection Based on LiDAR
3. Proposed Approach for Target Detection Based on LiDAR and Vision Fusion
3.1. Overview of the Proposed System
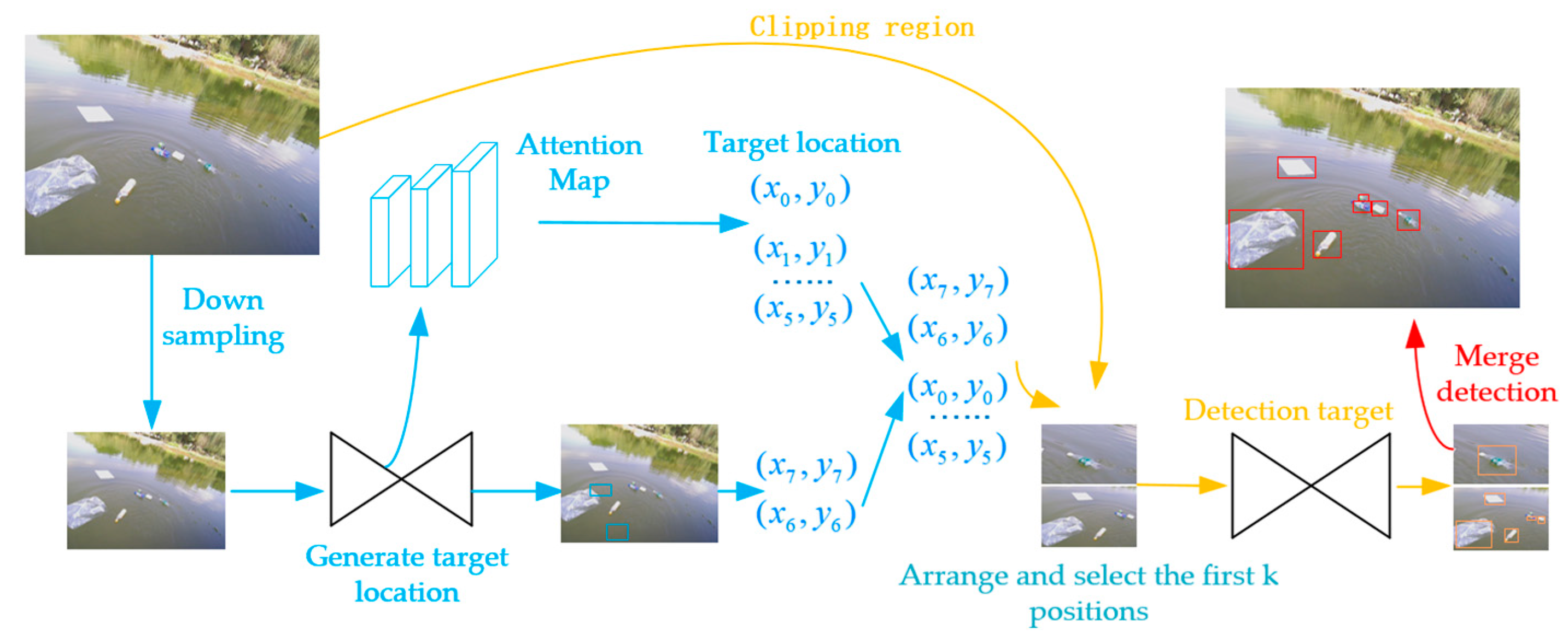
3.2. Detection of the Water Surface Target Based on CornerNet-Lite
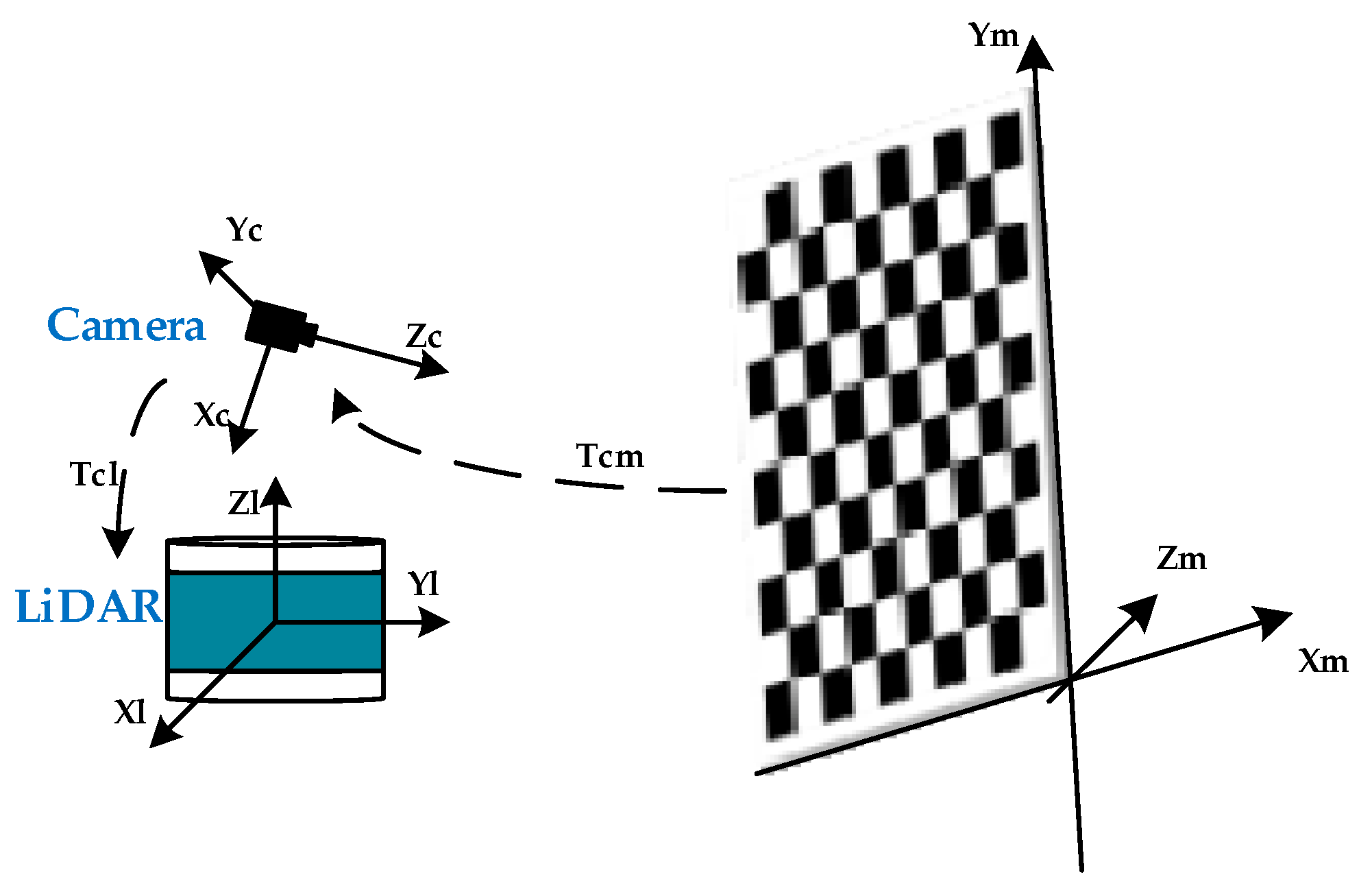
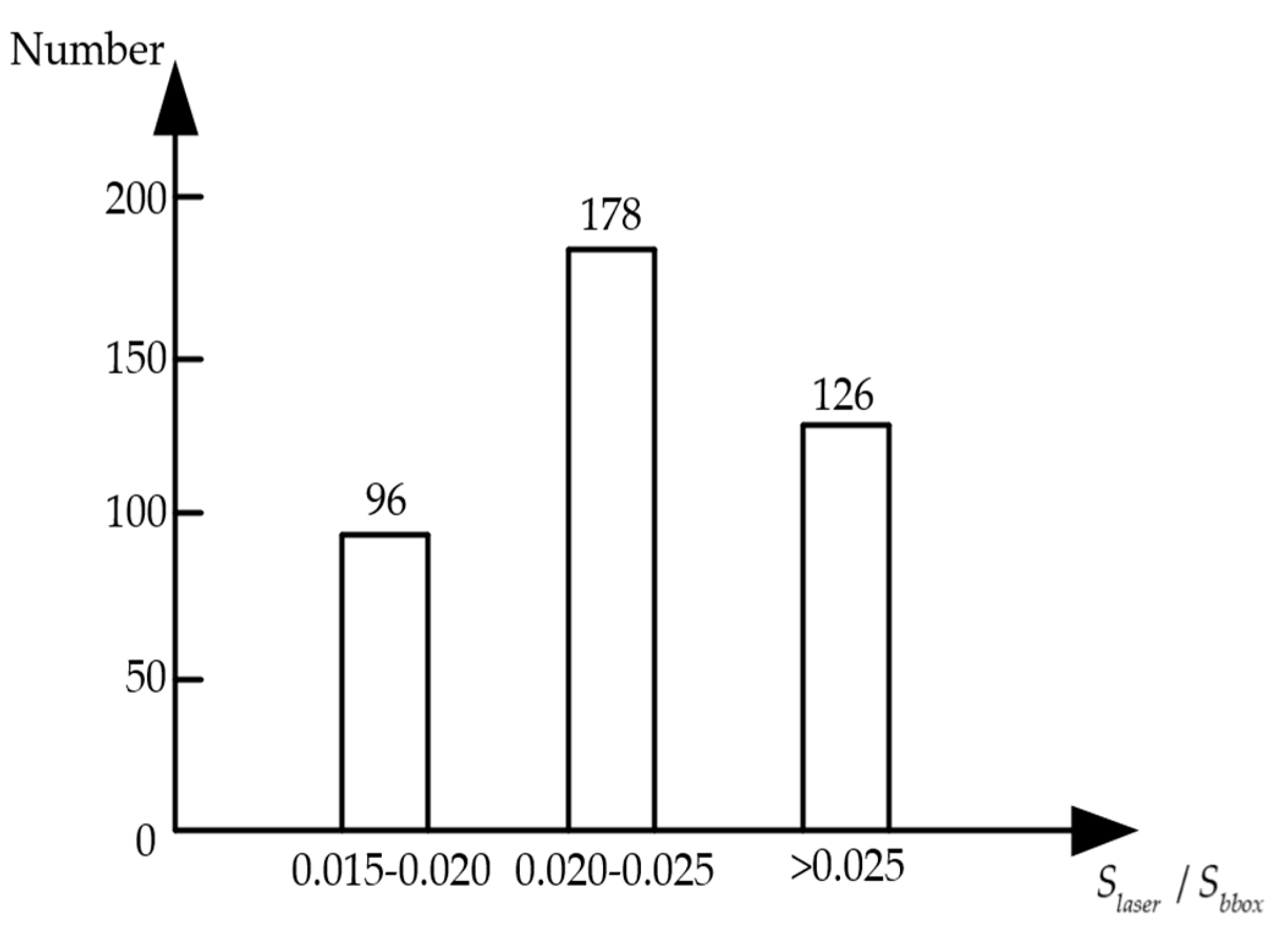
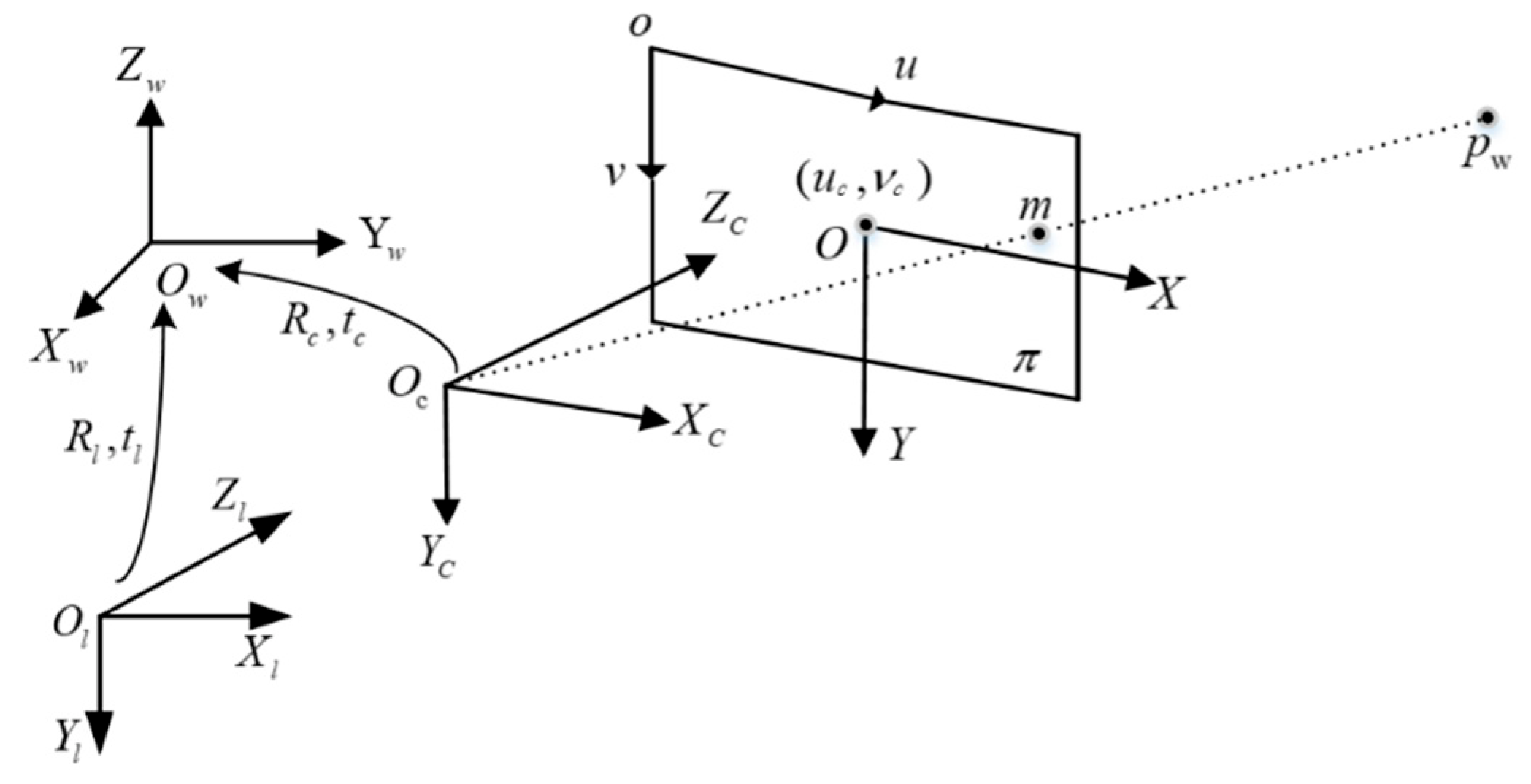
3.3. Camera and LiDAR Data Fusion for Target Detection
| Algorithm 1: Fusion detection of LiDAR and camera |
| Input: Input a picture and the corresponding PCD Output: Fusion detection results Target box diagonal coordinates 1: Get the result of CornerNet-Lite 2: Have 3: For all in do 4: For all point 3d in point 2d, do 5: Get I (x, y) 6: End for 7: Statistical points quantity in 8: 9: Fusion confidence: 10: End for |
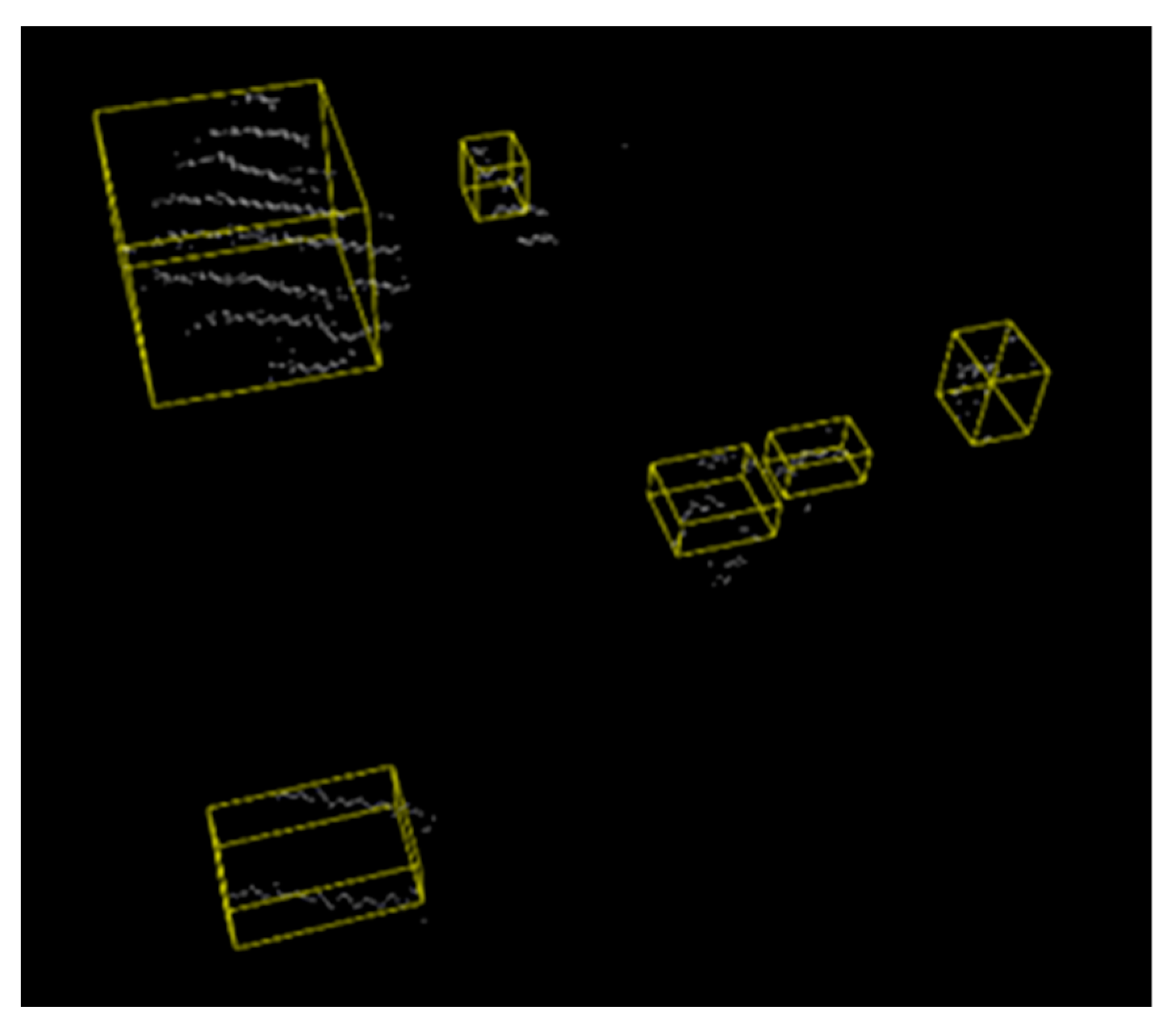
3.4. Creation of the 3D Minimum Wraparound Box
4. Experimental Results
4.1. Surface Target Detection
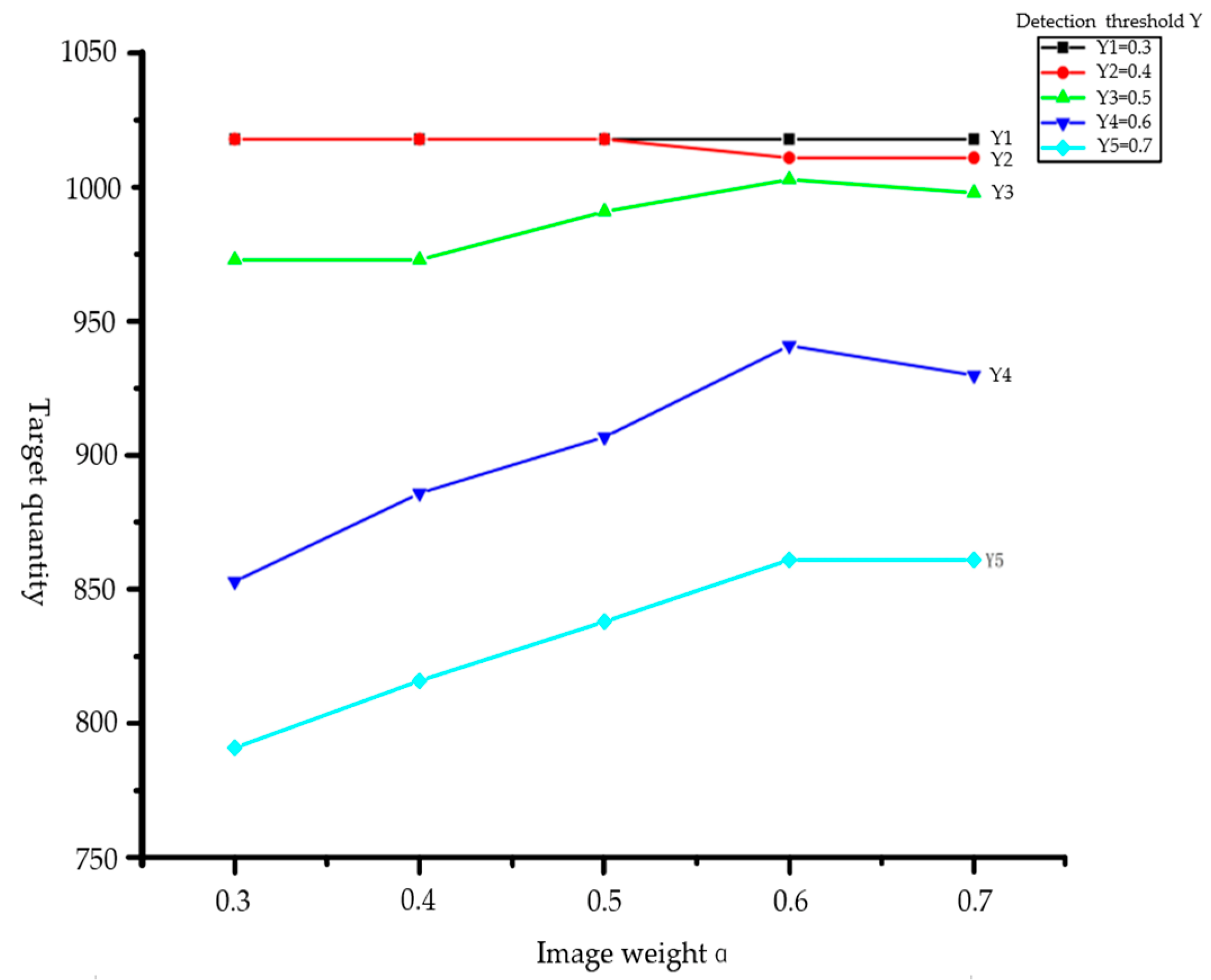
4.2. Positioning of the Target AABB Bounding Box
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, J.; Nam, D.W.; Lee, J.; Moon, S.; Oh, A.; Yoo, W. A Study on the Composition of Image-Based Ship-type/class Identification System. In Proceedings of the 2020 22nd International Conference on Advanced Communication Technology (ICACT), Pyeongchang, South Korea, 16–19 February 2020; pp. 203–206. [Google Scholar] [CrossRef]
- Song, X.; Jiang, P.; Zhu, H. Research on Unmanned Vessel Surface Object Detection Based on Fusion of SSD and Faster-RCNN. In Proceedings of the 2019 Chinese Automation Congress (CAC), Hangzhou, China, 22–24 November 2019; pp. 3784–3788. [Google Scholar] [CrossRef]
- Yao, W.; Ming, H. An integration method for detection and classification of sea surface targets. In Proceedings of the IET International Radar Conference (IET IRC 2020), Online, 4–6 November 2020; pp. 990–993. [Google Scholar] [CrossRef]
- Zhou, Z.; Li, Y.; Cao, J.; Di, S.; Zhao, W.; Ailaterini, M. Research on Surface Target Detection Algorithm Based on 3D Lidar. In Proceedings of the 2021 International Conference on Security, Pattern Analysis, and Cybernetics (SPAC), Chengdu, China, 18–20 June 2021; pp. 489–494. [Google Scholar] [CrossRef]
- Wang, P.; Liu, C.; Wang, Y.; Yu, H. Advanced Pedestrian State Sensing Method for Automated Patrol Vehicle Based on Multi-Sensor Fusion. Sensors 2022, 22, 4807. [Google Scholar] [CrossRef] [PubMed]
- Law, H.; Teng, Y.; Russakovsky, O.; Deng, J. Cornernet-lite: Efficient keypoint based object detection. arXiv 2019, arXiv:1904.08900. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Suykens JA, K.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, Z.; Ji, K.; Leng, X.; Kuang, G. Squeeze and excitation rank faster R-CNN for ship detection in SAR images. IEEE Geosci. Remote Sens. Lett. 2018, 16, 751–755. [Google Scholar] [CrossRef]
- Cheng, L.; Deng, B.; Yang, Y.; Lyu, J.; Zhao, J.; Zhou, K.; Yang, C.; Wang, L.; Yang, S.; He, Y. Water Target Recognition Method and Application for Unmanned Surface Vessels. IEEE Access 2022, 10, 421–434. [Google Scholar] [CrossRef]
- Ma, Z.; Zeng, Y.; Wu, L.; Zhang, L.; Li, J.; Li, H. Water Surface Targets Recognition and Tracking Based on Improved YOLO and KCF Algorithms. In Proceedings of the 2021 IEEE International Conference on Mechatronics and Automation (ICMA), Takamatsu, Japan, 8–11 August 2021; pp. 1460–1465. [Google Scholar] [CrossRef]
- Qi, C.R.; Yi, L.; Su, H.; Leonidas, J. Guibas Pointnet++: Deep hierarchical feature learning on point sets in a metric space. Adv. Neural Inf. Process. Syst. 2017, 30, 5105–5114. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Maturana, D.; Scherer, S. Voxnet: A 3d convolutional neural network for real-time object recognition. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 922–928. [Google Scholar]
- Zhou, Y.; Tuzel, O. Voxelnet: End-to-end learning for point cloud based 3d object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Stateczny, A.; Kazimierski, W.; Gronska-Sledz, D.; Motyl, W. The empirical application of automotive 3D radar sensor for target detection for an autonomous surface vehicle’s navigation. Remote Sens. 2019, 11, 1156. [Google Scholar] [CrossRef]
- Zhiguo, Z.; Yiyao, L.; Jiangwei, C.; Shunfan, D. Research on algorithm of surface target detection based on 3D lidar. Prog. Laser Optoelectron. 2022, 59, 278–287. [Google Scholar]
- Sheng, Y.; Haixiang, X.; Hui, F. Laser Radar Surface Target Detection Based on Improved DBSCAN Algorithm. J. Wuhan Univ. Technol. 2022, 46, 89–93. [Google Scholar]
- Zhang, W.; Yang, C.-F.; Jiang, F.; Gao, X.-Z.; Yang, K. A water surface moving target detection based on information fusion using deep learning. J. Phys.: Conf. Ser. 2020, 1606, 012020. [Google Scholar] [CrossRef]
- Chen, Z.; Huang, T.; Xue, Z.; Zhu, Z.; Xu, J.; Liu, Y. A Novel Unmanned Surface Vehicle with 2D3D Fused Perception and Obstacle Avoidance Module. In Proceedings of the 2021 IEEE International Conference on Robotics and Biomimetics (ROBIO), Sanya, China, 27–31 December 2021; p. 18041809. [Google Scholar] [CrossRef]
- Wu, R.; Dong, J.; Wang, M. Wearable Polarization Conversion Metasurface MIMO Antenna for Biomedical Applications in 5 GHz WBAN. Biosensors 2023, 13, 73. [Google Scholar] [CrossRef] [PubMed]
- Pan, Y.; Dong, J. Design and Optimization of an Ultrathin and Broadband Polarization-Insensitive Fractal FSS Using the Improved Bacteria Foraging Optimization Algorithm and Curve Fitting. Nanomaterials 2023, 13, 191. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Number of Correct Identification | Number of Misidentifications | Accuracy/% |
|---|---|---|---|
| CornerNet-Lite | 17 | 4 | 73.9 |
| YOLO v3 | 13 | 1 | 65.0 |
| YOLO v5 | 11 | 0 | 57.9 |
| Our algorithm | 17 | 0 | 89.4 |
| Target Serial No. | True 3D Position (m) | Estimated 3D Position (m) | Error (m) |
|---|---|---|---|
| Object 1 | (2.01, −0.53, 0.02) | (1.964, −0.462, −0.04) | 0.084 |
| Object 2 | (1.92, −0.11, 0.20) | (1.948, −0.037, 0.137) | 0.100 |
| Object 3 | (1.52, 0.35, −0.31) | (1.395, 0.290, −0.230) | 0.160 |
| Object 4 | (1.31, 0.88, −0.24) | (1.345, 0.761, −0.143) | 0.157 |
| Object 5 | (2.22, 0.94, 0.63) | (2.196, 0.845, 0.585) | 0.097 |
| Object 6 | (1.85, −0.12, 0.09) | (1.959, −0.147, 0.070) | 0.198 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, L.; Xiao, Y.; Zhang, B.; Liu, R.; Zhao, B. Water Surface Targets Detection Based on the Fusion of Vision and LiDAR. Sensors 2023, 23, 1768. https://doi.org/10.3390/s23041768
Wang L, Xiao Y, Zhang B, Liu R, Zhao B. Water Surface Targets Detection Based on the Fusion of Vision and LiDAR. Sensors. 2023; 23(4):1768. https://doi.org/10.3390/s23041768
Chicago/Turabian StyleWang, Lin, Yufeng Xiao, Baorui Zhang, Ran Liu, and Bin Zhao. 2023. "Water Surface Targets Detection Based on the Fusion of Vision and LiDAR" Sensors 23, no. 4: 1768. https://doi.org/10.3390/s23041768
APA StyleWang, L., Xiao, Y., Zhang, B., Liu, R., & Zhao, B. (2023). Water Surface Targets Detection Based on the Fusion of Vision and LiDAR. Sensors, 23(4), 1768. https://doi.org/10.3390/s23041768