

A Graph-Attention-Based Method for Single-Resident Daily Activity Recognition in Smart Homes



Abstract
1. Introduction
- A novel representation method incorporates sensor location information and time-slice information in smart homes and generates features for each sensor event through an embedding process;
- We first apply the time-encoding method and vector operation to automatically capture the correlations between the sensor events relying on their timestamps;
- Two novel parallel modules based on graph attention (GAT), namely a location-oriented GAT module and a time-oriented GAT module, are proposed to capture the correlations between different sensor events based on location information and the activated time information. These modules automatically improve the feature representation of the sensor event sequences;
- A new end-to-end novel framework, namely the time-oriented and location-oriented graph attention (TLGAT) network, is established to address HAR issues. The experimental results reveal that such a model achieves superior performance on public datasets compared with other state-of-the-art methods.
2. Related Work
2.1. Human Activity Recognition
2.2. Deep Learning Algorithms
2.3. Graph Attention Network
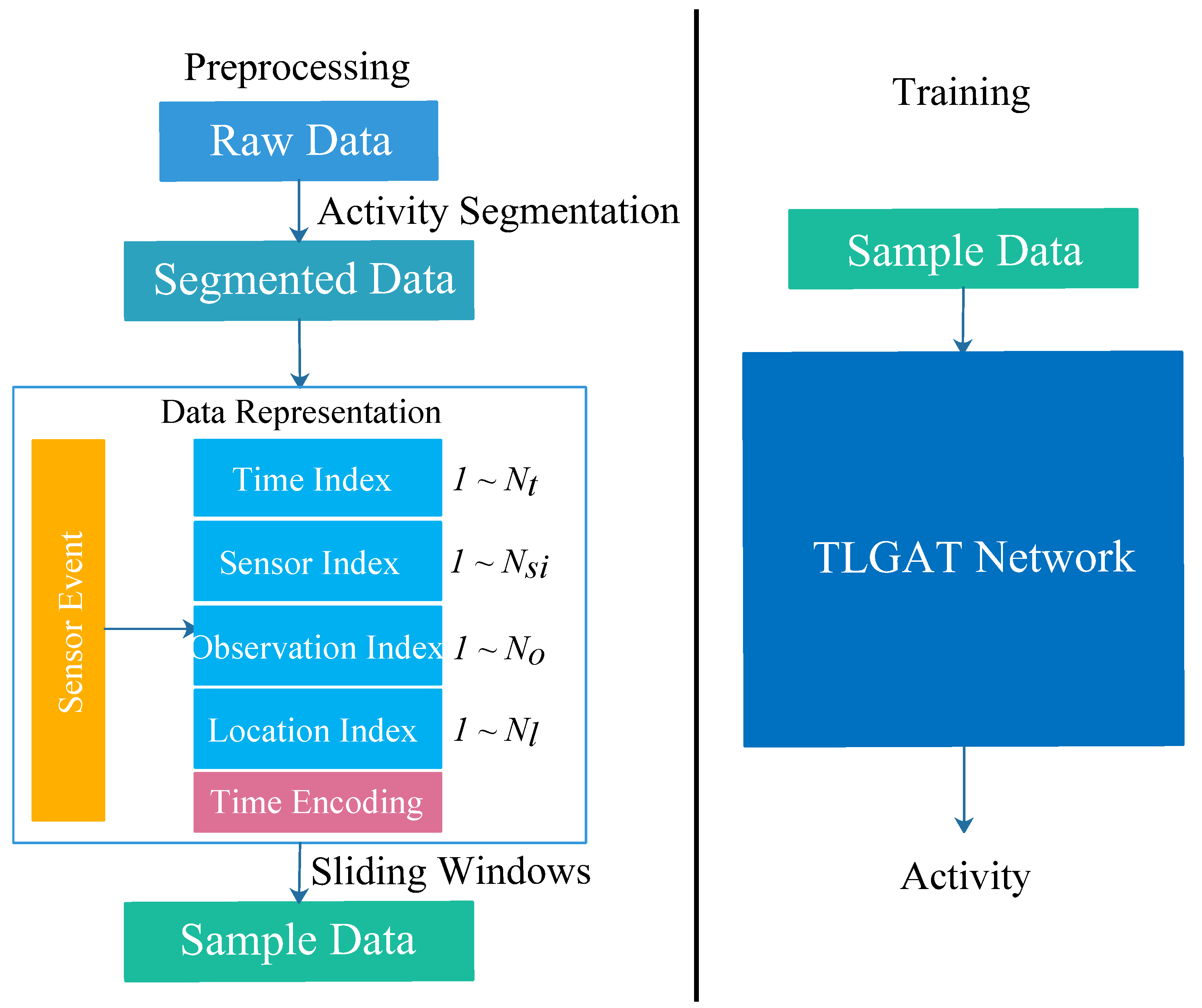
3. Methodology
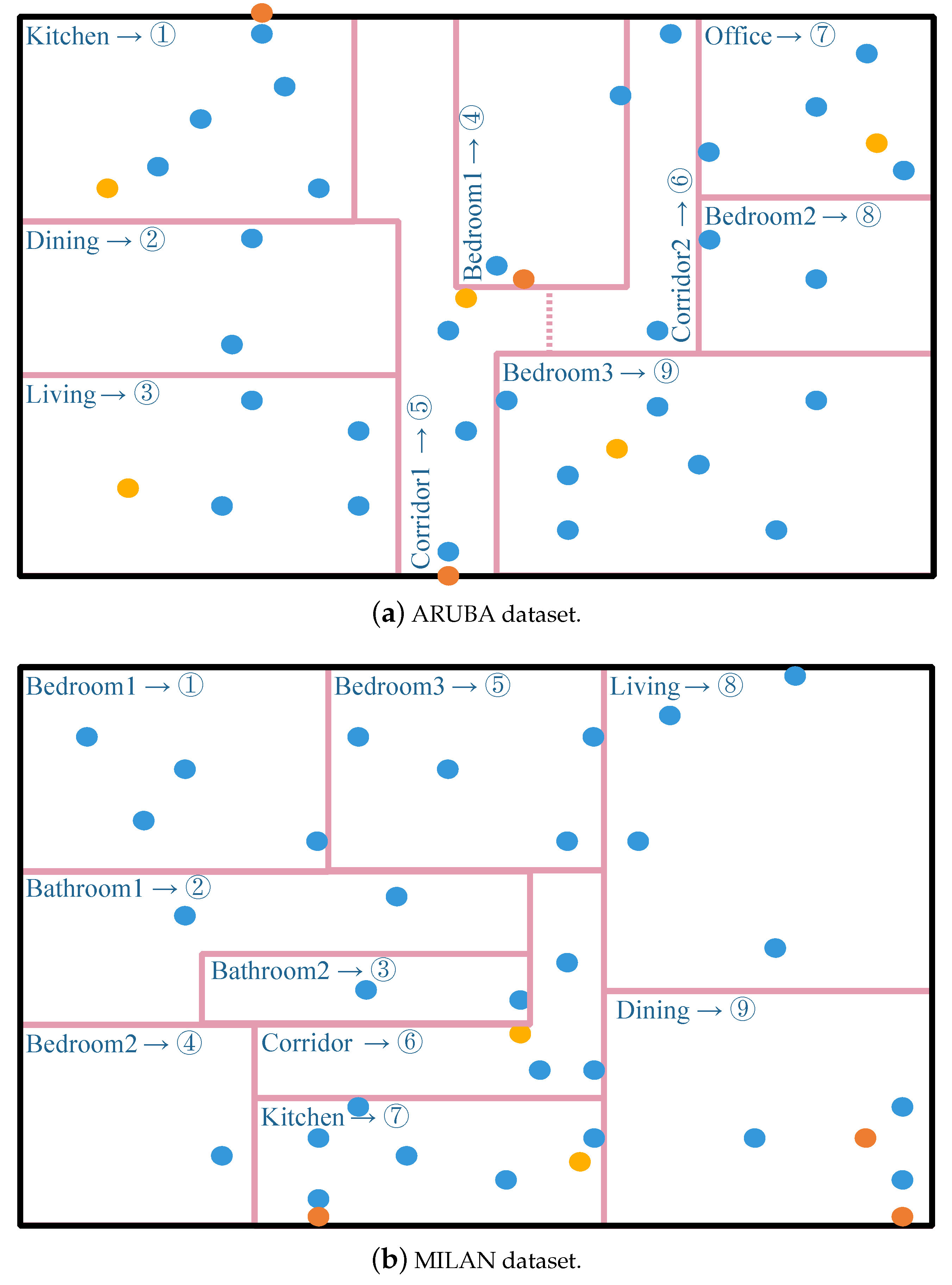
3.1. Dataset Description
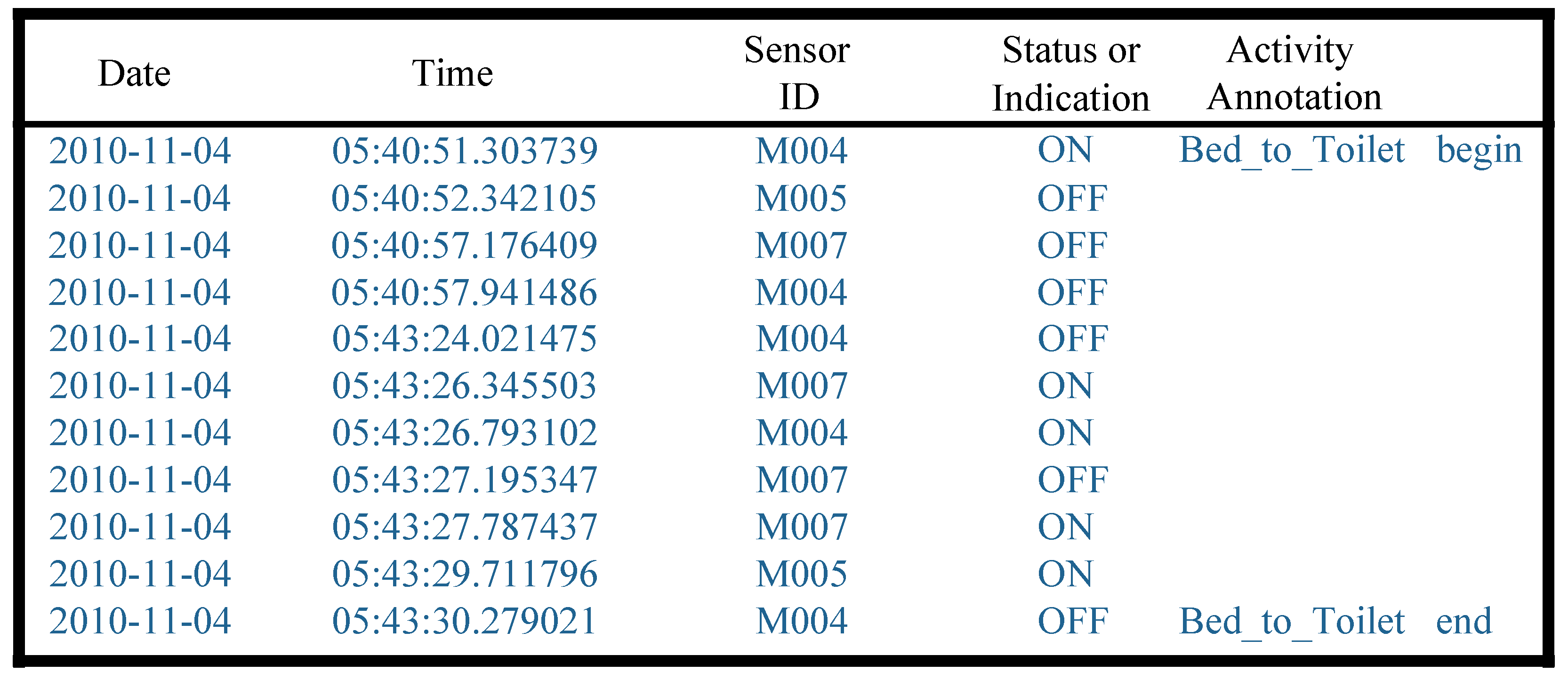
3.2. Data Preprocessing
3.2.1. Activity Segmentation
3.2.2. Data Representation
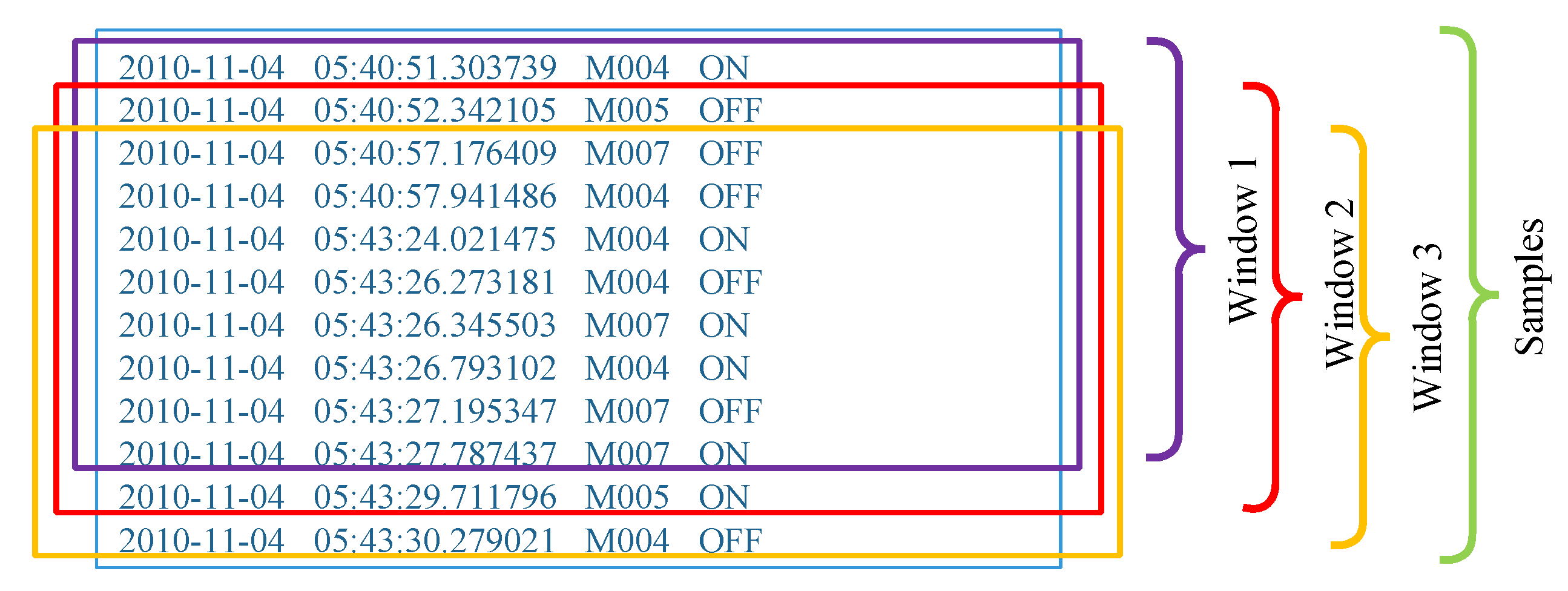
3.2.3. Sliding Windows
3.3. Model Architecture
3.3.1. Embedding Layer
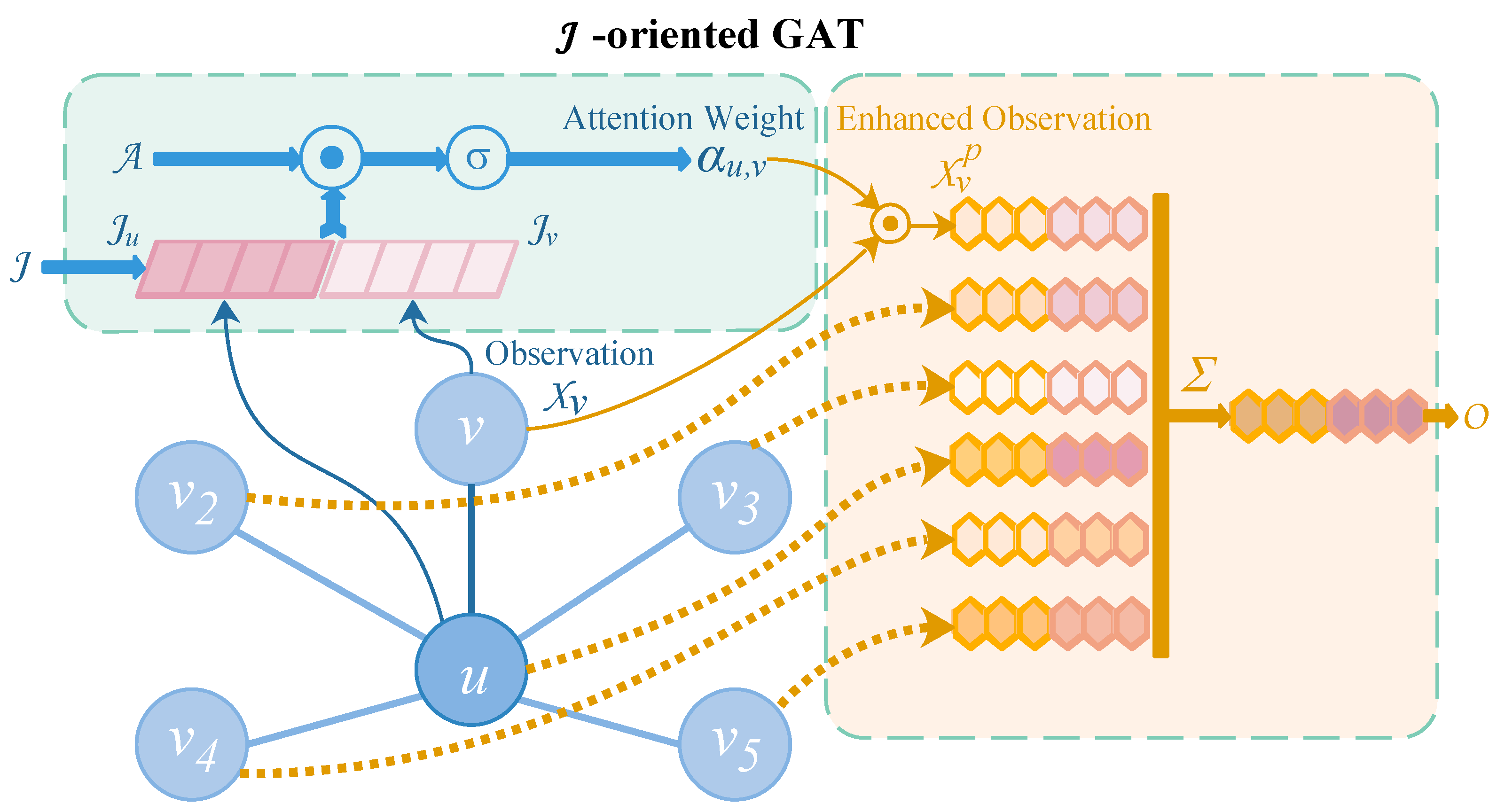
3.3.2. Graph Attention Layer
3.4. Overall Network Architecture
- The proposed method applies a total of four embedding layers in the first layer, each of which converts each index representation into a 32-dimensional vector;
- The original embedding representation of sensor ID and sensor observation is processed with two parallel multiple GAT layers, which automatically optimise the characteristic of sensor events considering time-wise and location-wise specificity;
- The outputs of two parallel multiple GAT layers are connected with the location representation and time-slice representation. Then, they are passed through a four-layer 1-D convolution layer with a kernel size of 5, followed by an average pooling layer to capture the high-level features of the sensor event sequence for the inference of daily activities;
- The outputs of the average pooling layer are fed to the fully connected layer to infer activity categories.
3.5. Model Complexity Analysis
4. Experiments
4.1. Experimental Setups
4.2. Training and Evaluation
4.3. Comparison with State-of-the-Art Models
4.4. Ablation Experiments
5. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lotfi, A.; Langensiepen, C.; Mahmoud, S.M.; Akhlaghinia, M.J. Smart homes for the elderly dementia sufferers: Identification and prediction of abnormal behaviour. J. Ambient Intell. Humaniz. Comput. 2012, 3, 205–218. [Google Scholar] [CrossRef]
- Ye, J.; Stevenson, G.; Dobson, S. Detecting abnormal events on binary sensors in smart home environments. Pervasive Mob. Comput. 2016, 33, 32–49. [Google Scholar] [CrossRef]
- Rocha Filho, G.P.; Brandão, A.H.; Nobre, R.A.; Meneguette, R.I.; Freitas, H.; Gonçalves, V.P. HOsT: Towards a Low-Cost Fog Solution via Smart Objects to Deal with the Heterogeneity of Data in a Residential Environment. Sensors 2022, 22, 6257. [Google Scholar] [CrossRef] [PubMed]
- Ziadeh, A.; Abualigah, L.; Elaziz, M.A.; Şahin, C.B.; Almazroi, A.A.; Omari, M. Augmented grasshopper optimization algorithm by differential evolution: A power scheduling application in smart homes. Multimed. Tools Appl. 2021, 80, 31569–31597. [Google Scholar] [CrossRef]
- Ramlee, R.; Tang, D.; Ismail, M. Smart home system for disabled people via wireless bluetooth. In Proceedings of the 2012 International Conference on System Engineering and Technology (ICSET), Bandung, Indonesia, 11–12 September 2012; pp. 1–4. [Google Scholar]
- Torres Neto, J.R.; Rocha Filho, G.P.; Mano, L.Y.; Villas, L.A.; Ueyama, J. Exploiting offloading in IoT-based microfog: Experiments with face recognition and fall detection. Wirel. Commun. Mob. Comput. 2019, 2019, 2786837. [Google Scholar] [CrossRef]
- Gochoo, M.; Tan, T.H.; Liu, S.H.; Jean, F.R.; Alnajjar, F.S.; Huang, S.C. Unobtrusive activity recognition of elderly people living alone using anonymous binary sensors and DCNN. IEEE J. Biomed. Health Inform. 2018, 23, 693–702. [Google Scholar] [CrossRef]
- Lee, S.M.; Yoon, S.M.; Cho, H. Human activity recognition from accelerometer data using Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Republic of Korea, 13–16 February 2017; pp. 131–134. [Google Scholar]
- Murad, A.; Pyun, J.Y. Deep recurrent neural networks for human activity recognition. Sensors 2017, 17, 2556. [Google Scholar] [CrossRef]
- Cook, D.J.; Crandall, A.S.; Thomas, B.L.; Krishnan, N.C. CASAS: A smart home in a box. Computer 2012, 46, 62–69. [Google Scholar] [CrossRef]
- Bouchabou, D.; Nguyen, S.M.; Lohr, C.; LeDuc, B.; Kanellos, I. A survey of human activity recognition in smart homes based on IoT sensors algorithms: Taxonomies, challenges, and opportunities with deep learning. Sensors 2021, 21, 6037. [Google Scholar] [CrossRef]
- Gu, F.; Chung, M.H.; Chignell, M.; Valaee, S.; Zhou, B.; Liu, X. A survey on deep learning for human activity recognition. ACM Comput. Surv. (CSUR) 2021, 54, 1–34. [Google Scholar] [CrossRef]
- Tapia, E.M.; Intille, S.S.; Larson, K. Activity recognition in the home using simple and ubiquitous sensors. In Proceedings of the International Conference on Pervasive Computing, Linz/Vienna, Austria, 21–23 April 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 158–175. [Google Scholar]
- Van Kasteren, T.; Englebienne, G.; Kröse, B.J. Activity recognition using semi-Markov models on real world smart home datasets. J. Ambient Intell. Smart Environ. 2010, 2, 311–325. [Google Scholar] [CrossRef]
- Wu, H.; Pan, W.; Xiong, X.; Xu, S. Human activity recognition based on the combined SVM&HMM. In Proceedings of the 2014 IEEE International Conference on Information and Automation (ICIA), Hailar, China, 28–30 July 2014; pp. 219–224. [Google Scholar]
- Nazerfard, E.; Das, B.; Holder, L.B.; Cook, D.J. Conditional random fields for activity recognition in smart environments. In Proceedings of the 1st ACM International Health Informatics Symposium, Arlington, VA, USA, 11–12 November 2010; pp. 282–286. [Google Scholar]
- Demrozi, F.; Pravadelli, G.; Bihorac, A.; Rashidi, P. Human activity recognition using inertial, physiological and environmental sensors: A comprehensive survey. IEEE Access 2020, 8, 210816–210836. [Google Scholar] [CrossRef]
- Singh, D.; Merdivan, E.; Hanke, S.; Kropf, J.; Geist, M.; Holzinger, A. Convolutional and recurrent neural networks for activity recognition in smart environment. In Towards Integrative Machine Learning and Knowledge Extraction; Springer: Berlin/Heidelberg, Germany, 2017; pp. 194–205. [Google Scholar]
- Bouchabou, D.; Nguyen, S.M.; Lohr, C.; Leduc, B.; Kanellos, I. Fully convolutional network bootstrapped by word encoding and embedding for activity recognition in smart homes. In Proceedings of the International Workshop on Deep Learning for Human Activity Recognition, Kyoto, Japan, 8 January 2020; Springer: Singapore, 2021; pp. 111–125. [Google Scholar]
- Tan, T.H.; Gochoo, M.; Huang, S.C.; Liu, Y.H.; Liu, S.H.; Huang, Y.F. Multi-resident activity recognition in a smart home using RGB activity image and DCNN. IEEE Sens. J. 2018, 18, 9718–9727. [Google Scholar] [CrossRef]
- Mohmed, G.; Lotfi, A.; Pourabdollah, A. Employing a deep convolutional neural network for human activity recognition based on binary ambient sensor data. In Proceedings of the 13th ACM International Conference on PErvasive Technologies Related to Assistive Environments, Virtual, 30 June–3 July 2020; pp. 1–7. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Arifoglu, D.; Bouchachia, A. Activity recognition and abnormal behaviour detection with recurrent neural networks. Procedia Comput. Sci. 2017, 110, 86–93. [Google Scholar] [CrossRef]
- Liciotti, D.; Bernardini, M.; Romeo, L.; Frontoni, E. A sequential deep learning application for recognising human activities in smart homes. Neurocomputing 2020, 396, 501–513. [Google Scholar] [CrossRef]
- Bouchabou, D.; Nguyen, S.M.; Lohr, C.; LeDuc, B.; Kanellos, I. Using language model to bootstrap human activity recognition ambient sensors based in smart homes. Electronics 2021, 10, 2498. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Hu, S.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. AI Open 2020, 1, 57–81. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.S. Kgat: Knowledge graph attention network for recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 950–958. [Google Scholar]
- Kosaraju, V.; Sadeghian, A.; Martín-Martín, R.; Reid, I.; Rezatofighi, H.; Savarese, S. Social-bigat: Multimodal trajectory forecasting using bicycle-gan and graph attention networks. arXiv 2019, arXiv:1907.03395. [Google Scholar]
- Wu, Y.; Lian, D.; Xu, Y.; Wu, L.; Chen, E. Graph convolutional networks with markov random field reasoning for social spammer detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1054–1061. [Google Scholar]
- Li, L.; Gan, Z.; Cheng, Y.; Liu, J. Relation-aware graph attention network for visual question answering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10313–10322. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Cook, D.J. Learning setting-generalized activity models for smart spaces. IEEE Intell. Syst. 2010, 2010, 1. [Google Scholar] [CrossRef] [PubMed]
- Cook, D.J.; Schmitter-Edgecombe, M. Assessing the quality of activities in a smart environment. Methods Inf. Med. 2009, 48, 480–485. [Google Scholar] [PubMed]
- Horn, M.; Moor, M.; Bock, C.; Rieck, B.; Borgwardt, K. Set functions for time series. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 4353–4363. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Hamad, R.A.; Hidalgo, A.S.; Bouguelia, M.R.; Estevez, M.E.; Quero, J.M. Efficient activity recognition in smart homes using delayed fuzzy temporal windows on binary sensors. IEEE J. Biomed. Health Inform. 2019, 24, 387–395. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | The Kind of Sensors | The Number of Residents | The Number of Raw Sensor Events | The Number of Activity Categories |
|---|---|---|---|---|
| ARUBA | D/M/T | 1 | 1,719,558 | 11 |
| MILAN | D/M/T | 1+pet | 433,665 | 15 |
| Training Hyperparameters | Values |
|---|---|
| Batch size | 256 |
| Dropout rate | 0.2 |
| Channels of embedding layers | 32 |
| Channels of convolutional layers | 128 |
| Learning rate | |
| Iterations | ARUBA: 90; MILAN: 40 |
| Decayed epochs of LR | ARUBA: 24/48/72; MILAN: 20 |
| Decayed rate of LR | 5 |
| Number of replications | 30 |
| Model | N = 20 | N = 25 | N = 30 | N = 35 |
|---|---|---|---|---|
| ELMoBiLSTM [25] | 85.307 ± 0.805 | 86.867 ± 0.805 | 89.564 ± 2.217 | 90.515 ± 2.855 |
| ImageDCNN [7,20] | 84.668 ± 1.864 | 87.618 ± 2.605 | 92.453 ± 2.984 | 95.711 ± 1.654 |
| E-FCNs [19] | 96.987 ± 0.436 | 98.463 ± 0.250 | 99.108 ± 0.098 | 99.442 ± 0.128 |
| TLGAT | 97.651 ± 0.254 | 98.942 ± 0.104 | 99.514 ± 0.062 | 99.760 ± 0.199 |
| Model | N = 20 | N = 25 | N = 30 | N = 35 |
|---|---|---|---|---|
| ELMoBiLSTM [25] | 76.847 ± 1.685 | 85.357 ± 2.228 | 89.975 ± 2.156 | 92.476 ± 1.706 |
| ImageDCNN [7,20] | 67.382 ± 1.696 | 76.408 ± 2.780 | 84.932 ± 2.589 | 90.857 ± 1.726 |
| E-FCNs [19] | 92.901 ± 0.252 | 94.656 ± 0.212 | 95.621 ± 0.257 | 96.445 ± 0.154 |
| TLGAT | 97.569 ± 0.134 | 98.081 ± 0.181 | 98.465 ± 0.174 | 98.736 ± 0.165 |
| ID | Activity | N = 20 | N = 25 | N = 30 | N = 35 |
|---|---|---|---|---|---|
| 1 | Eating | 95.167 ± 2.266 | 98.138 ± 0.653 | 98.984 ± 0.367 | 99.328 ± 0.211 |
| 2 | Housekeeping | 94.397 ± 1.265 | 98.088 ± 0.855 | 98.613 ± 0.741 | 99.593 ± 0.422 |
| 3 | Meal Preparation | 95.384 ± 0.890 | 97.813 ± 1.141 | 98.940 ± 0.216 | 99.524 ± 0.320 |
| 4 | Other | 98.021 ± 1.247 | 99.143 ± 0.237 | 99.591 ± 0.103 | 99.835 ± 0.037 |
| 5 | Relax | 98.877 ± 0.465 | 99.564 ± 0.136 | 99.811 ± 0.074 | 99.925 ± 0.011 |
| 6 | Respirate | 100.000 | 99.978 ± 0.018 | 99.578 ± 0.034 | 100.000 |
| 7 | Sleeping | 99.611 ± 0.056 | 99.852 ± 0.043 | 99.914 ± 0.012 | 99.980 ± 0.021 |
| 8 | Wash Dishes | 84.513 ± 3.264 | 92.104 ± 2.157 | 96.745 ± 1.490 | 98.266 ± 1.873 |
| 9 | Work | 96.786 ± 0.344 | 98.901 ± 0.021 | 99.443 ± 0.187 | 99.780 ± 0.054 |
| ID | Activity | N = 20 | N = 25 | N = 30 | N = 35 |
|---|---|---|---|---|---|
| 1 | Chores | 99.653 ± 0.212 | 99.751 ± 0.102 | 99.671 ± 0.048 | 99.888 ± 0.011 |
| 2 | Desk Activity | 99.768 ± 0.203 | 99.817 ± 0.012 | 99.864 ± 0.101 | 99.944 ± 0.024 |
| 3 | Dining Rm Activity | 99.687 ± 0.164 | 99.342 ± 0.187 | 99.795 ± 0.105 | 100.000 |
| 4 | Guest Bathroom | 99.909 ± 0.158 | 99.594 ± 0.248 | 99.805 ± 0.124 | 99.827 ± 0.233 |
| 5 | Kitchen Activity | 97.999 ± 0.129 | 97.994 ± 0.153 | 98.403 ± 0.620 | 98.535 ± 0.311 |
| 6 | Leave Home | 99.900 ± 0.089 | 99.730 ± 0.180 | 100.000 | 99.893 ± 0.071 |
| 7 | Master Bathroom | 98.098 ± 0.375 | 97.681 ± 0.947 | 97.708 ± 1.185 | 97.794 ± 0.674 |
| 8 | Master Bedroom | 96.945 ± 0.763 | 96.432 ± 0.125 | 96.822 ± 0.417 | 97.113 ± 0.312 |
| 9 | Meditate | 100.000 | 100.000 | 100.000 | 100.000 |
| 10 | Morning Meds | 94.480 ± 4.162 | 94.881 ± 2.964. | 97.992 ± 1.765 | 95.928 ± 1.178 |
| 11 | Other | 98.277 ± 0.111 | 98.140 ± 0.223 | 98.493 ± 0.189 | 98.641 ± 0.126 |
| 12 | Read | 98.702 ± 0.219 | 98.576 ± 0.367 | 99.018 ± 0.169 | 99.162 ± 0.155 |
| 13 | Sleep | 99.514 ± 0.110 | 99.286 ± 0.087 | 99.573 ± 0.061 | 99.630 ± 0.127 |
| 14 | Watch TV | 98.806 ± 0.188 | 98.431 ± 0.217 | 98.590 ± 0.266 | 98.785 ± 0.235 |
| Model | N = 20 | N = 25 | N = 30 | N = 35 |
|---|---|---|---|---|
| baseline | 96.999 ± 0.154 | 98.694 ± 0.229 | 99.262 ± 0.145 | 99.524 ± 0.076 |
| LGAT | 97.519 ± 0.249 | 98.834 ± 0.199 | 99.469 ± 0.136 | 99.710 ± 0.246 |
| TGAT | 97.496 ± 0.479 | 98.979 ± 0.266 | 99.491 ± 0.140 | 99.737 ± 0.242 |
| TLGAT | 97.651 ± 0.254 | 98.942 ± 0.104 | 99.514 ± 0.062 | 99.760 ± 0.199 |
| Model | N = 20 | N = 25 | N = 30 | N = 35 |
|---|---|---|---|---|
| baseline | 96.381 ± 0.202 | 97.211 ± 0.211 | 97.758 ± 0.207 | 98.161 ± 0.184 |
| LGAT | 97.233 ± 0.125 | 97.826 ± 0.115 | 98.239 ± 0.176 | 98.439 ± 0.151 |
| TGAT | 97.149 ± 0.287 | 97.843 ± 0.152 | 98.404 ± 0.107 | 98.620 ± 0.161 |
| TLGAT | 97.569 ± 0.134 | 98.081 ± 0.181 | 98.465 ± 0.174 | 98.736 ± 0.065 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, J.; Jiang, H.; Zhong, J. A Graph-Attention-Based Method for Single-Resident Daily Activity Recognition in Smart Homes. Sensors 2023, 23, 1626. https://doi.org/10.3390/s23031626
Ye J, Jiang H, Zhong J. A Graph-Attention-Based Method for Single-Resident Daily Activity Recognition in Smart Homes. Sensors. 2023; 23(3):1626. https://doi.org/10.3390/s23031626
Chicago/Turabian StyleYe, Jiancong, Hongjie Jiang, and Junpei Zhong. 2023. "A Graph-Attention-Based Method for Single-Resident Daily Activity Recognition in Smart Homes" Sensors 23, no. 3: 1626. https://doi.org/10.3390/s23031626
APA StyleYe, J., Jiang, H., & Zhong, J. (2023). A Graph-Attention-Based Method for Single-Resident Daily Activity Recognition in Smart Homes. Sensors, 23(3), 1626. https://doi.org/10.3390/s23031626