
Speeding up Smartphone-Based Dew Computing: In Vivo Experiments Setup Via an Evolutionary Algorithm

 , , and
, , and
Abstract
1. Introduction
- (1)
- Define a workload;
- (2)
- Define the initial conditions for the testbed;
- (3)
- For each load balancing algorithm within the set of load balancing algorithms under evaluation:
- (a)
- Assure initial conditions for the testbed;
- (b)
- Run the workload on the testbed using the current load balancing algorithm;
- (c)
- Collect results for further analysis.
- –
- Inclusion of a multi-device battery preparation stage as an optimization problem that uses time-related battery (dis)charging events as input;
- –
- Proposal of an evolutionary algorithm to automate and minimize the battery preparation time, evaluated using real smartphone battery traces and several combinations of smartphone cluster sizes and target battery levels;
- –
- Publicly available evolutionary algorithm and simulation engine code, experiment configuration and battery traces for reuse and modification.
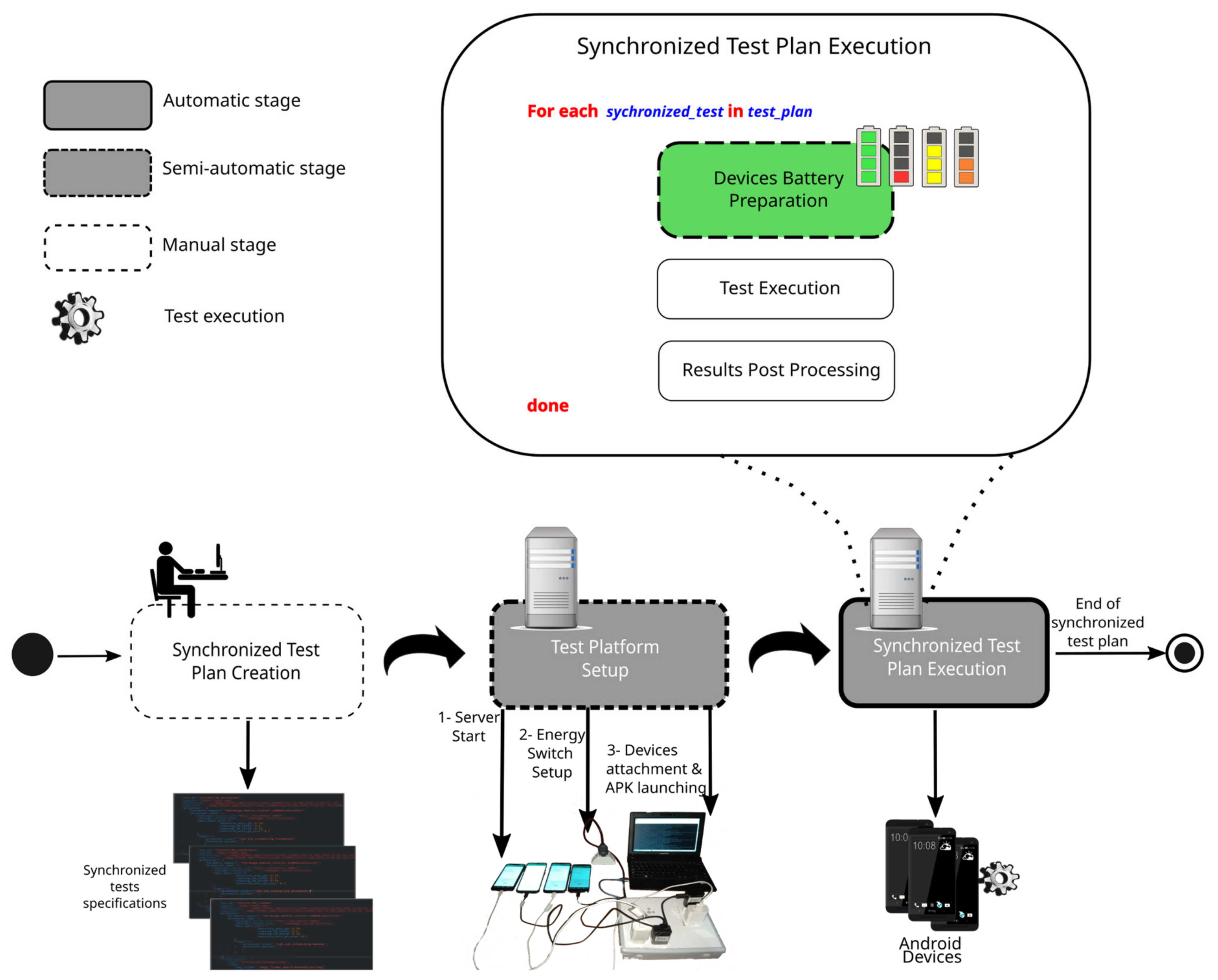
2. The Motrol Platform: Background on the Architecture and Basic Concepts
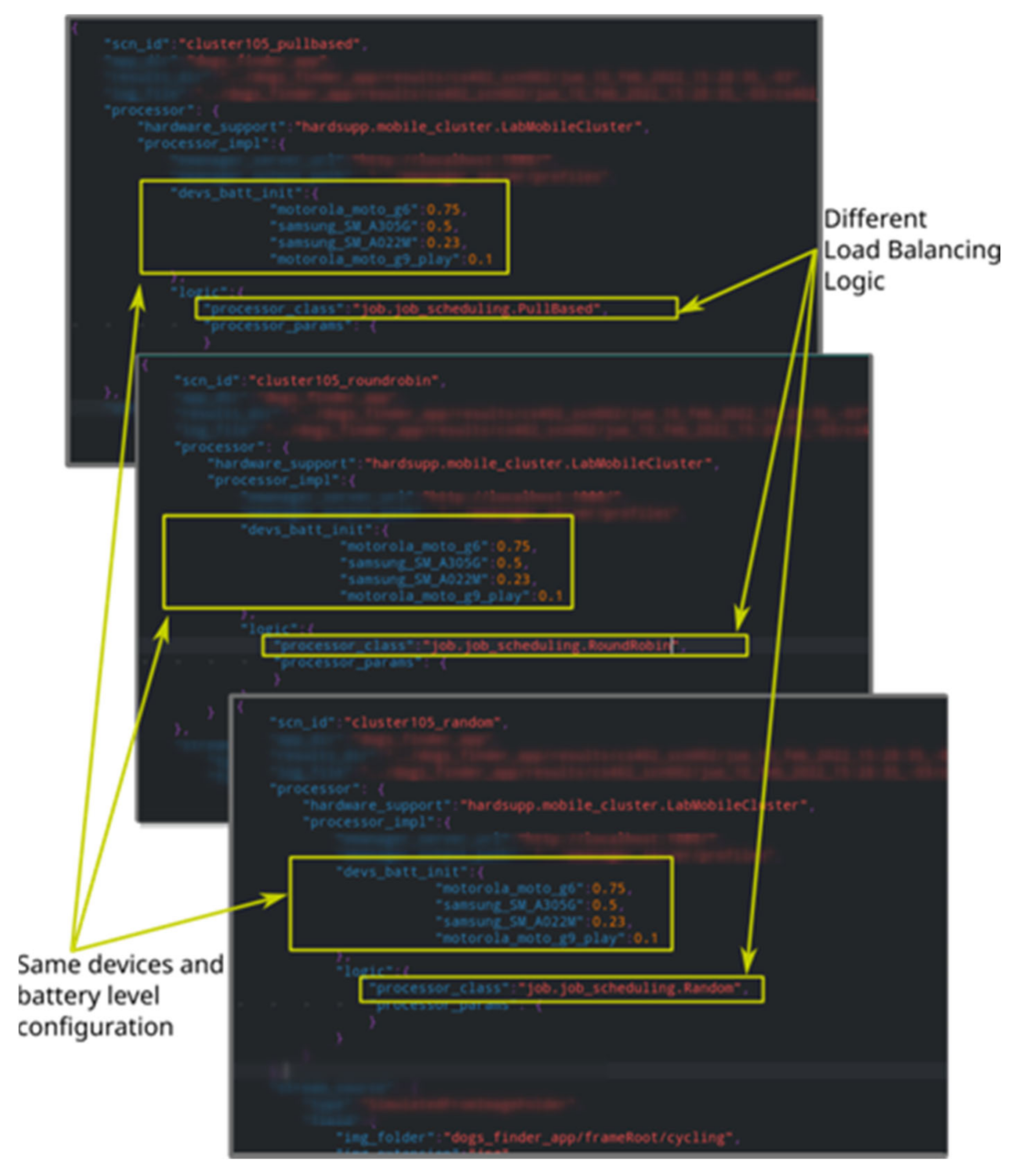
The Battery Preparation Problem for Running Synchronized Tests
3. Evolutionary-based Preparation of Smartphones for Synchronized Test Plans
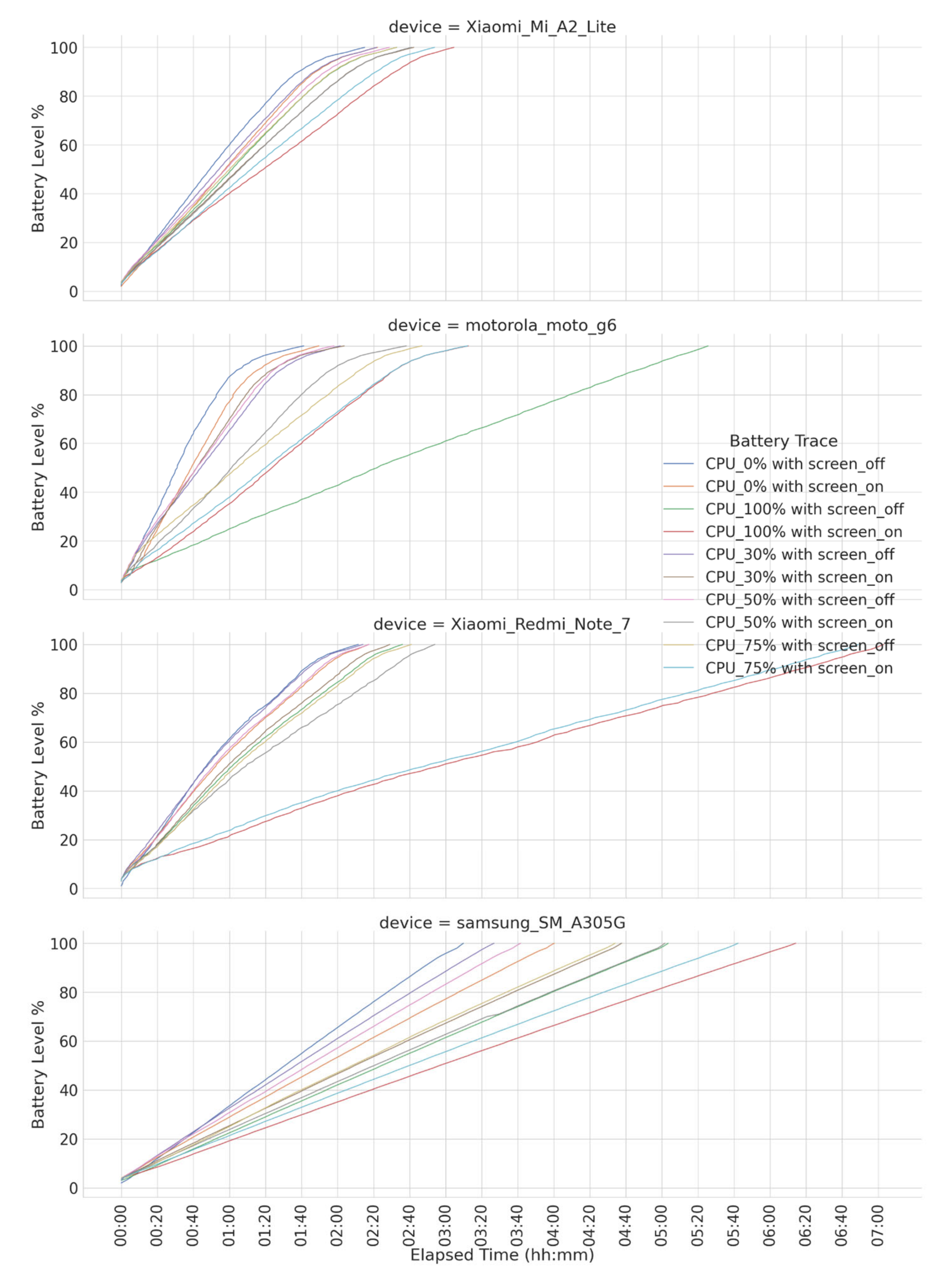
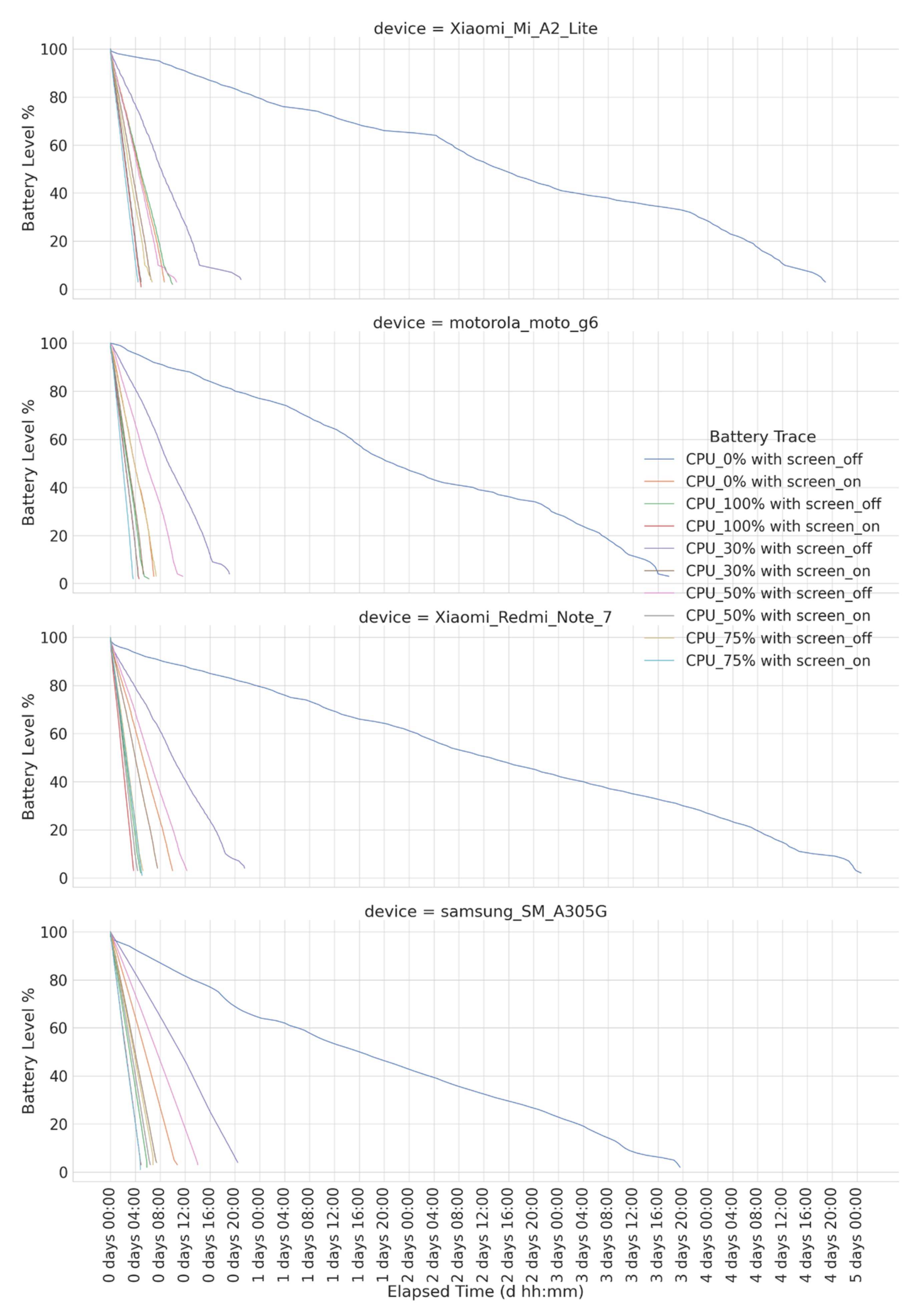
3.1. Input Data of the Component and Pre-Condition Considered
3.2. The Designed Evolutionary Algorithm
3.2.1. Encoding of Solutions
3.2.2. Fitness Evaluation Process
3.2.3. Crossover Process
3.2.4. Mutation Process
4. Computational Experiments
4.1. Instance Sets
4.2. Experimental Setting
4.3. Current Method to Prepare Smartphones in the Context of Motrol
4.4. Experimental Results
5. Related Work
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ray, P.P. Minimizing dependency on internetwork: Is dew computing a solution? Trans. Emerg. Telecommun. Technol. 2018, 30, e3496. [Google Scholar] [CrossRef]
- Hirsch, M.; Mateos, C.; Zunino, A.; Majchrzak, T.A.; Grønli, T.M.; Kaindl, H. A simulation-based performance evaluation of heuristics for dew computing. In Proceedings of the 54th Hawaii International Conference on System Sciences, Grand Wailea, Maui, HI, USA, 5 January 2021; pp. 7207–7216. [Google Scholar]
- Mateos, C.; Hirsch, M.; Toloza, J.; Zunino, A. Motrol 2.0: A Dew-oriented hardware/software platform for batch-benchmarking smartphones. In Proceedings of the IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 12–16 July 2021; pp. 1772–1777. [Google Scholar]
- Hirsch, M.; Mateos, C.; Zunino, A.; Toloza, J. A platform for automating battery-driven batch benchmarking and profiling of Android-based mobile devices. Simul. Modell. Pract. Theory 2021, 109, 102266. [Google Scholar] [CrossRef]
- Hirsch, M.; Mateos, C.; Zunino, A. Augmenting computing capabilities at the edge by jointly exploiting mobile devices: A survey. Future Gener. Comput. Syst. 2018, 88, 644–662. [Google Scholar] [CrossRef]
- Eiben, A.E.; Smith, J.E. Introduction to Evolutionary Computing, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2015. [Google Scholar]
- Toloza, J.M.; Hirsch, M.; Mateos, C.; Zunino, A. Motrol: A hardware-software device for batch benchmarking and profiling of in-lab mobile device clusters. HardwareX 2022, 12, e00340. [Google Scholar] [CrossRef] [PubMed]
- Hirsch, M.; Mateos, C.; Rodriguez, J.M.; Zunino, A. DewSim: A trace-driven toolkit for simulating mobile device clusters in Dew computing environments. Softw. Pract. Exper. 2020, 50, 688–718. [Google Scholar] [CrossRef]
- Chen, J.; Ran, X. Deep learning with edge computing: A review. Proc. IEEE 2019, 107, 1655–1674. [Google Scholar] [CrossRef]
- Mednieks, Z.R.; Dornin, L.; Meike, G.B.; Nakamura, M. Programming Android; O’Reilly Media, Inc.: Newton, MA, USA, 2012. [Google Scholar]
- Keur, C.; Hillegass, A. iOS Programming: The Big Nerd Ranch Guide; Pearson Technology Group: London, UK, 2016. [Google Scholar]
- Raspberry Pi Model 4B. Available online: https://www.raspberrypi.com/products/raspberry-pi-4-model-b/ (accessed on 1 August 2022).
- Ferrer, A.J.; Marquès, J.M.; Jorba, J. Towards the decentralised cloud: Survey on approaches and challenges for mobile, ad hoc, and edge computing. ACM Comput. Surv. 2019, 51, 1–36. [Google Scholar] [CrossRef]
- Yousefpour, A.; Fung, C.; Nguyen, T.; Kadiyala, K.; Jalali, F.; Niakanlahiji, A.; Kong, J.; Jue, J.P. All one needs to know about fog computing and related edge computing paradigms: A complete survey. J. Syst. Archit. 2019, 98, 289–330. [Google Scholar] [CrossRef]
- Mobile Operating Systems’ Market Share Worldwide. Available online: https://www.statista.com/statistics/272698/global-market-share-held-by-mobile-operating-systems-since-2009/ (accessed on 1 August 2022).
- Hirsch, M.; Mateos, C.; Zunino, A.; Majchrzak, T.A.; Grønli, T.M.; Kaindl, H. A Task Execution Scheme for Dew Computing with State-of-the-Art Smartphones. Electronics 2021, 1016, 2–22. [Google Scholar] [CrossRef]
- Markus, A.; Biro, M.; Skala, K.; Šojat, Z.; Kertesz, A. Modeling Dew Computing in DISSECT-CF-Fog. Appl. Sci. 2022, 12, 8809. [Google Scholar] [CrossRef]
- Javadzadeh, G.; Rahmani, A.M.; Kamarposhti, M.S. Mathematical model for the scheduling of real-time applications in IoT using Dew computing. J. Supercomput. 2022, 78, 7464–7488. [Google Scholar] [CrossRef]
- Roy, A.; Midya, S.; Majumder, K.; Phadikar, S. Distributed resource management in dew based edge to cloud computing ecosystem: A hybrid adaptive evolutionary approach. Trans. Emerg. Telecommun. Technol. 2020, 31, e4018. [Google Scholar] [CrossRef]
- Farkhana, M.; Hanan, A.A. Mobility in mobile ad-hoc network testbed using robot: Technical and critical review. Rob. Autom. Syst. 2018, 108, 153–178. [Google Scholar] [CrossRef]
- Alvanou, A.G.; Zervopoulos, A.; Papamichail, A.; Bezas, K.; Vergis, S.; Stylidou, A.; Tsipis, A.; Komianos, V.; Tsoumanis, G.; Koufoudakis, G.; et al. CaBIUs: Description of the enhanced wireless campus testbed of the Ionian University. Electronics 2020, 9, 454. [Google Scholar] [CrossRef]
- Appavoo, P.; William, E.K.; Chan, M.C.; Mohammad, M. Indriya2: A heterogeneous wireless sensor network (wsn) testbed. In Proceedings of the International Conference on Testbeds and Research Infrastructures, Shanghai, China, 16–18 November 2018; pp. 3–19. [Google Scholar]
- Falcón-Cardona, J.G.; Hernández-Goméz, R.; Coello, C.A.; Catillo Tapia, M.G. Parallel Multi-Objective Evolutionary Algorithms: A Comprehensive Survey. Swarm Evol. Comput. Computation 2021, 67, 100960. [Google Scholar] [CrossRef]
- Normapp. Available online: https://github.com/matieber/livedewstream/tree/main/src/emanager_server/Normapp (accessed on 1 October 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Instance Set | S | A | V (%) | Nr. of Instances |
|---|---|---|---|---|
| S4_LA_LV | 4 | [4, 160] | [0, 10] | 10 |
| S4_LA_MV | 4 | [4, 160] | (10, 50] | 10 |
| S4_LA_HV | 4 | [4, 160] | (50, 100] | 10 |
| S4_MA_LV | 4 | [164, 280] | [0, 10] | 10 |
| S4_MA_MV | 4 | [164, 280] | (10, 50] | 10 |
| S4_MA_HV | 4 | [164, 280] | (50, 100] | 10 |
| S4_HA_LV | 4 | [284, 400] | [0, 10] | 10 |
| S4_HA_MV | 4 | [284, 400] | (10, 50] | 10 |
| S4_HA_HV | 4 | [284, 400] | (50, 100] | 10 |
| S8_LA_LV | 8 | [8, 320] | [0, 10] | 10 |
| S8_LA_MV | 8 | [8, 320] | (10, 50] | 10 |
| S8_LA_HV | 8 | [8, 320] | (50, 100] | 10 |
| S8_MA_LV | 8 | [328, 560] | [0, 10] | 10 |
| S8_MA_MV | 8 | [328, 560] | (10, 50] | 10 |
| S8_MA_HV | 8 | [328, 560] | (50, 100] | 10 |
| S8_HA_LV | 8 | [568, 800] | [0, 10] | 10 |
| S8_HA_MV | 8 | [568, 800] | (10, 50] | 10 |
| S8_HA_HV | 8 | [568, 800] | (50, 100] | 10 |
| S16_LA_LV | 16 | [16, 640] | [0, 10] | 10 |
| S16_LA_MV | 16 | [16, 640] | (10, 50] | 10 |
| S16_LA_HV | 16 | [16, 640] | (50, 100] | 10 |
| S16_MA_LV | 16 | [656, 1120] | [0, 10] | 10 |
| S16_MA_MV | 16 | [656, 1120] | (10, 50] | 10 |
| S16_MA_HV | 16 | [656, 1120] | (50, 100] | 10 |
| S16_HA_LV | 16 | [1136, 1600] | [0, 10] | 10 |
| S16_HA_MV | 16 | [1136, 1600] | (10, 50] | 10 |
| S16_HA_HV | 16 | [1136, 1600] | (50, 100] | 10 |
| Parameter | Value |
|---|---|
| Population size | 100 |
| k (tournament selection) | 10 |
| Pc (crossover) | 1.0 |
| Pm (mutation) | 1/L |
| r (steady-state selection) | 50% |
| Number of generations or iterations | 2000 |
| Parameter | Values Considered |
|---|---|
| Population size | {100, 200} |
| k (tournament selection) | {2, 5, 10} |
| Pc (crossover) | {0.7, 0.8, 0.9, 1.0} |
| Pm (mutation) | {1/L} U {0.1, 0.2, 0.3} |
| r (steady-state selection) | {25%, 50%} |
| Number of generations or iterations | {1000, 2000, 3000, 4000, 5000} |
| MAPE (%) | ||||||
|---|---|---|---|---|---|---|
| Instance Set | Average | Maximum | Minimum | |||
| EA | M | EA | M | EA | M | |
| S4_LA_LV | 17.09 | 46.66 | 64.11 | 70.56 | 3,E-04 | 22.31 |
| S4_LA_MV | 12.19 | 48.07 | * 33.26 | 66.73 | 0.01 | 34.58 |
| S4_LA_HV | 26.30 | 52.14 | 53.49 | 68.72 | 4.63 | 26.70 |
| S4_MA_LV | 5.05 | 33.53 | * 12.51 | 43.64 | 2,E-05 | 19.13 |
| S4_MA_MV | 8.26 | 37.48 | 25.96 | 47.53 | 1,E-04 | 21.26 |
| S4_MA_HV | 17.99 | 50.37 | 36.87 | 65.05 | 1,E-03 | 34.56 |
| S4_HA_LV | 3.80 | 31.43 | * 10.22 | 45.21 | 2,E-05 | 13.45 |
| S4_HA_MV | 5.14 | 35.93 | * 19.95 | 48.84 | 1,E-04 | 22.49 |
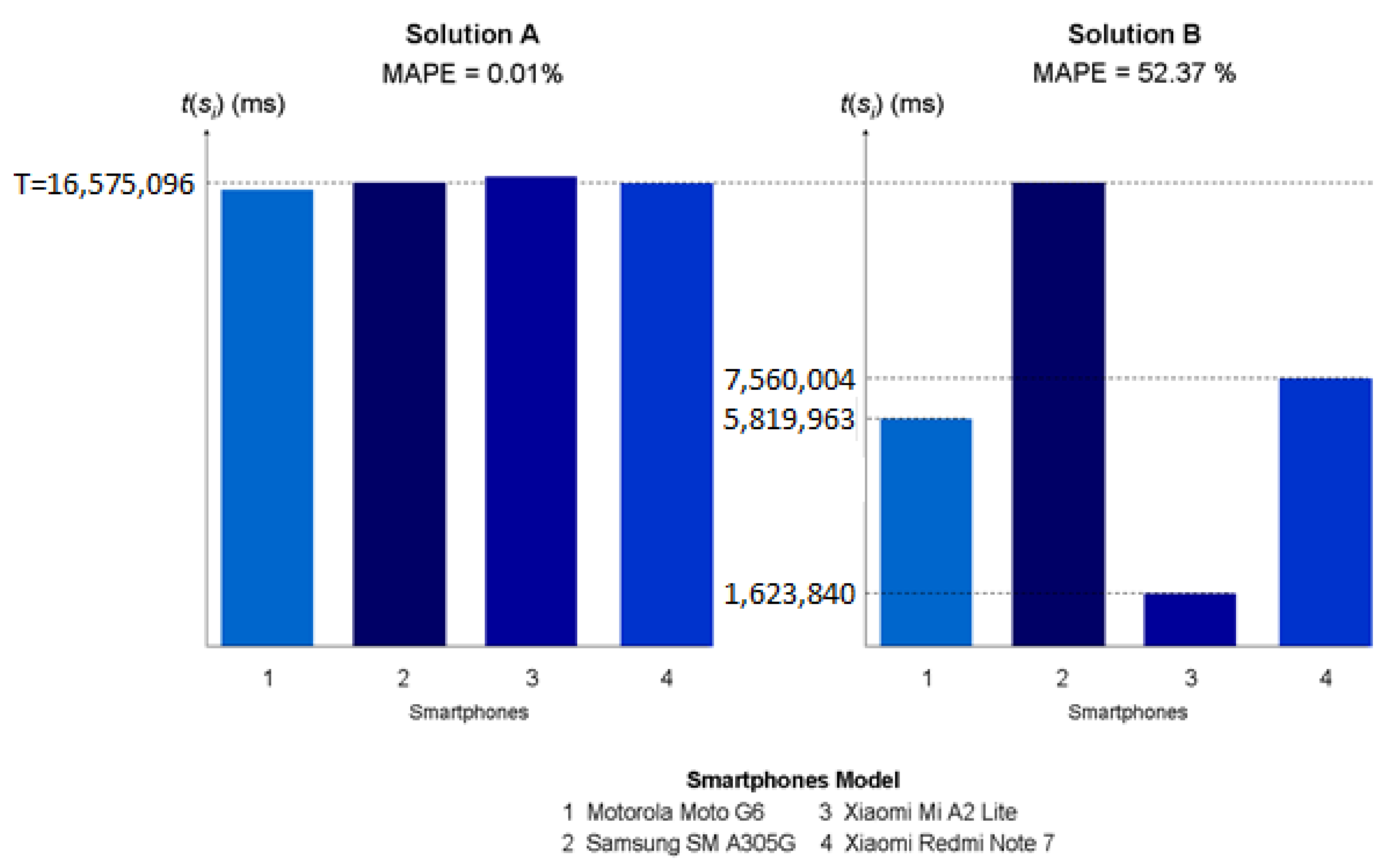
| S4_HA_HV | 10.74 | 45.25 | * 23.86 | 52.37 | 0.01 | 36.29 |
| S8_LA_LV | 20.07 | 50.23 | 53.35 | 73.70 | 4.19 | 28.71 |
| S8_LA_MV | 11.62 | 52.40 | * 27.99 | 62.00 | 2.32 | 38.80 |
| S8_LA_HV | 15.75 | 57.88 | * 24.92 | 71.31 | 4.15 | 41.10 |
| S8_MA_LV | 5.76 | 33.66 | * 11.30 | 45.77 | 3,E-04 | 19.21 |
| S8_MA_MV | 16.15 | 49.84 | * 30.59 | 58.13 | 1.47 | 36.37 |
| S8_MA_HV | 13.81 | 48.21 | * 27.63 | 55.87 | 0.01 | 36.78 |
| S8_HA_LV | 5.72 | 40.60 | * 15.69 | 52.64 | 7,E-05 | 32.41 |
| S8_HA_MV | 6.39 | 40.93 | * 19.22 | 57.58 | 0.01 | 29.26 |
| S8_HA_HV | 16.51 | 49.29 | * 30.29 | 57.37 | 2.34 | 37.24 |
| S16_LA_LV | 6.22 | 35.24 | *8.59 | 43.22 | 2.50 | 24.87 |
| S16_LA_MV | 18.83 | 58.69 | * 25.76 | 65.45 | 9.37 | 54.63 |
| S16_LA_HV | 25.45 | 61.99 | * 46.31 | 75.78 | 14.60 | 51.59 |
| S16_MA_LV | 4.42 | 34.97 | * 10.38 | 50.27 | 2,E-03 | 24.70 |
| S16_MA_MV | 15.42 | 55.39 | * 23.81 | 64.78 | 7.56 | 48.38 |
| S16_MA_HV | 23.41 | 61.45 | * 36.31 | 67.81 | 14.75 | 53.77 |
| S16_HA_LV | 4.87 | 35.31 | * 7.75 | 42.60 | 0.14 | 28.25 |
| S16_HA_MV | 12.70 | 46.82 | * 22.34 | 52.11 | 7.57 | 37.75 |
| S16_HA_HV | 16.99 | 49.82 | * 24.05 | 57.52 | 11.00 | 38.72 |
| Instance Set | RPD (%) | ||
|---|---|---|---|
| Average | Maximum | Minimum | |
| S4_LA_LV | 32.81 | 75.00 | 25.00 |
| S4_LA_MV | 45.00 | 75.00 | 25.00 |
| S4_LA_HV | 33.10 | 75.00 | 25.00 |
| S4_MA_LV | 50.00 | 75.00 | 25.00 |
| S4_MA_MV | 49.54 | 75.00 | 18.75 |
| S4_MA_HV | 50.83 | 75.00 | 35.42 |
| S4_HA_LV | 56.25 | 75.00 | 25.00 |
| S4_HA_MV | 52.50 | 75.00 | 25.00 |
| S4_HA_HV | 50.21 | 75.00 | 25.00 |
| S8_LA_LV | 31.40 | 62.50 | 12.50 |
| S8_LA_MV | 51.98 | 87.50 | 25.00 |
| S8_LA_HV | 50.17 | 77.08 | 12.50 |
| S8_MA_LV | 41.25 | 56.25 | 29.17 |
| S8_MA_MV | 50.73 | 68.75 | 19.79 |
| S8_MA_HV | 41.87 | 62.50 | 18.75 |
| S8_HA_LV | 61.98 | 81.25 | 50.00 |
| S8_HA_MV | 58.44 | 75.00 | 25.00 |
| S8_HA_HV | 52.50 | 71.88 | 37.50 |
| S16_LA_LV | 12.95 | 15.63 | 12.50 |
| S16_LA_MV | 53.93 | 68.75 | 29.69 |
| S16_LA_HV | 53.58 | 68.75 | 33.33 |
| S16_MA_LV | 44.69 | 65.63 | 31.25 |
| S16_MA_MV | 61.05 | 83.33 | 49.48 |
| S16_MA_HV | 53.31 | 71.46 | 25.63 |
| S16_HA_LV | 53.39 | 65.63 | 31.25 |
| S16_HA_MV | 58.88 | 67.19 | 50.00 |
| S16_HA_HV | 54.36 | 69.27 | 41.07 |
| Instance Set | Computing Time (in Seconds) | ||
|---|---|---|---|
| Average | Maximum | Minimum | |
| S4_LA_LV | 5.00 | 7.20 | 2.00 |
| S4_LA_MV | 5.96 | 7.60 | 3.60 |
| S4_LA_HV | 5.64 | 7.60 | 3.20 |
| S4_MA_LV | 9.92 | 13.20 | 5.60 |
| S4_MA_MV | 9.64 | 13.20 | 6.80 |
| S4_MA_HV | 7.88 | 10.00 | 6.00 |
| S4_HA_LV | 13.16 | 16.40 | 10.00 |
| S4_HA_MV | 11.96 | 14.80 | 9.60 |
| S4_HA_HV | 11.60 | 13.60 | 9.60 |
| S8_LA_LV | 10.32 | 14.80 | 3.60 |
| S8_LA_MV | 11.84 | 14.80 | 8.00 |
| S8_LA_HV | 11.48 | 14.80 | 8.80 |
| S8_MA_LV | 19.80 | 25.60 | 13.60 |
| S8_MA_MV | 18.12 | 24.40 | 10.80 |
| S8_MA_HV | 15.24 | 21.60 | 10.80 |
| S8_HA_LV | 26.88 | 35.20 | 19.20 |
| S8_HA_MV | 23.92 | 30.00 | 18.80 |
| S8_HA_HV | 22.64 | 26.80 | 18.80 |
| S16_LA_LV | 20.58 | 22.60 | 18.60 |
| S16_LA_MV | 20.80 | 22.40 | 19.20 |
| S16_LA_HV | 20.36 | 22.80 | 18.00 |
| S16_MA_LV | 29.88 | 40.00 | 23.20 |
| S16_MA_MV | 33.64 | 36.80 | 29.60 |
| S16_MA_HV | 28.92 | 34.80 | 23.60 |
| S16_HA_LV | 49.04 | 59.60 | 41.60 |
| S16_HA_MV | 42.32 | 45.20 | 41.20 |
| S16_HA_HV | 41.60 | 42.80 | 40.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yannibelli, V.; Hirsch, M.; Toloza, J.; Majchrzak, T.A.; Zunino, A.; Mateos, C. Speeding up Smartphone-Based Dew Computing: In Vivo Experiments Setup Via an Evolutionary Algorithm. Sensors 2023, 23, 1388. https://doi.org/10.3390/s23031388
Yannibelli V, Hirsch M, Toloza J, Majchrzak TA, Zunino A, Mateos C. Speeding up Smartphone-Based Dew Computing: In Vivo Experiments Setup Via an Evolutionary Algorithm. Sensors. 2023; 23(3):1388. https://doi.org/10.3390/s23031388
Chicago/Turabian StyleYannibelli, Virginia, Matías Hirsch, Juan Toloza, Tim A. Majchrzak, Alejandro Zunino, and Cristian Mateos. 2023. "Speeding up Smartphone-Based Dew Computing: In Vivo Experiments Setup Via an Evolutionary Algorithm" Sensors 23, no. 3: 1388. https://doi.org/10.3390/s23031388
APA StyleYannibelli, V., Hirsch, M., Toloza, J., Majchrzak, T. A., Zunino, A., & Mateos, C. (2023). Speeding up Smartphone-Based Dew Computing: In Vivo Experiments Setup Via an Evolutionary Algorithm. Sensors, 23(3), 1388. https://doi.org/10.3390/s23031388