Multi-Type Missing Imputation of Time-Series Power Equipment Monitoring Data Based on Moving Average Filter–Asymmetric Denoising Autoencoder


Abstract
:1. Introduction
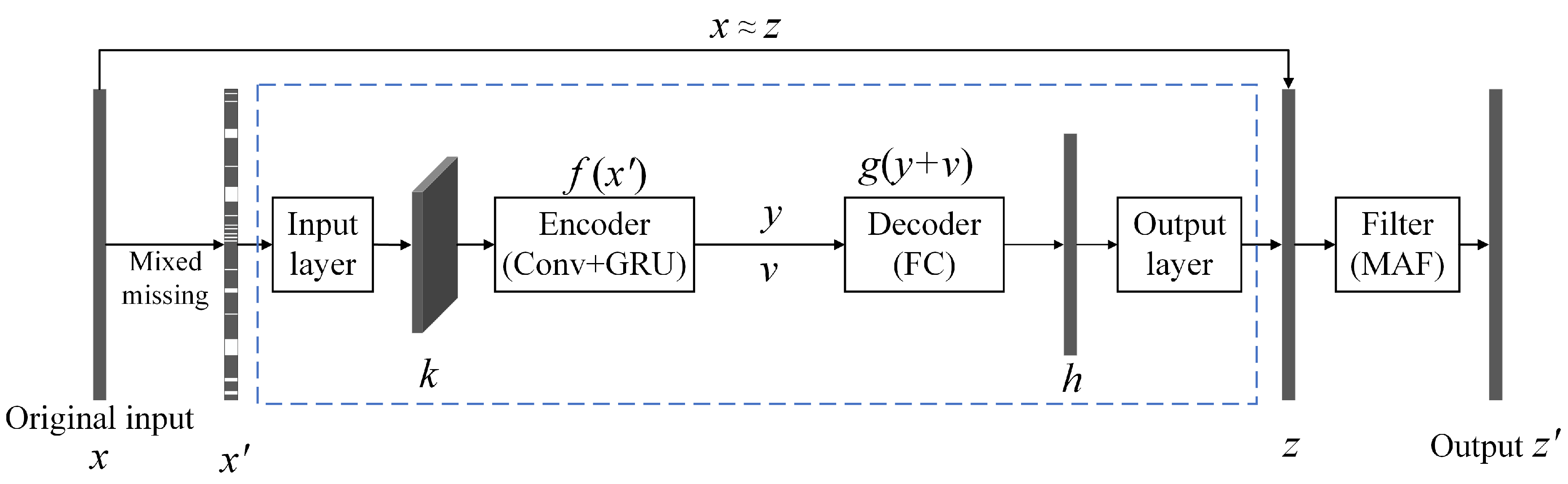
2. Multi-Type Missing Data Imputation by the ADAE
2.1. Problem Formulation
2.2. Asymmetric Denoising Autoencoder
2.3. Improved Loss Function
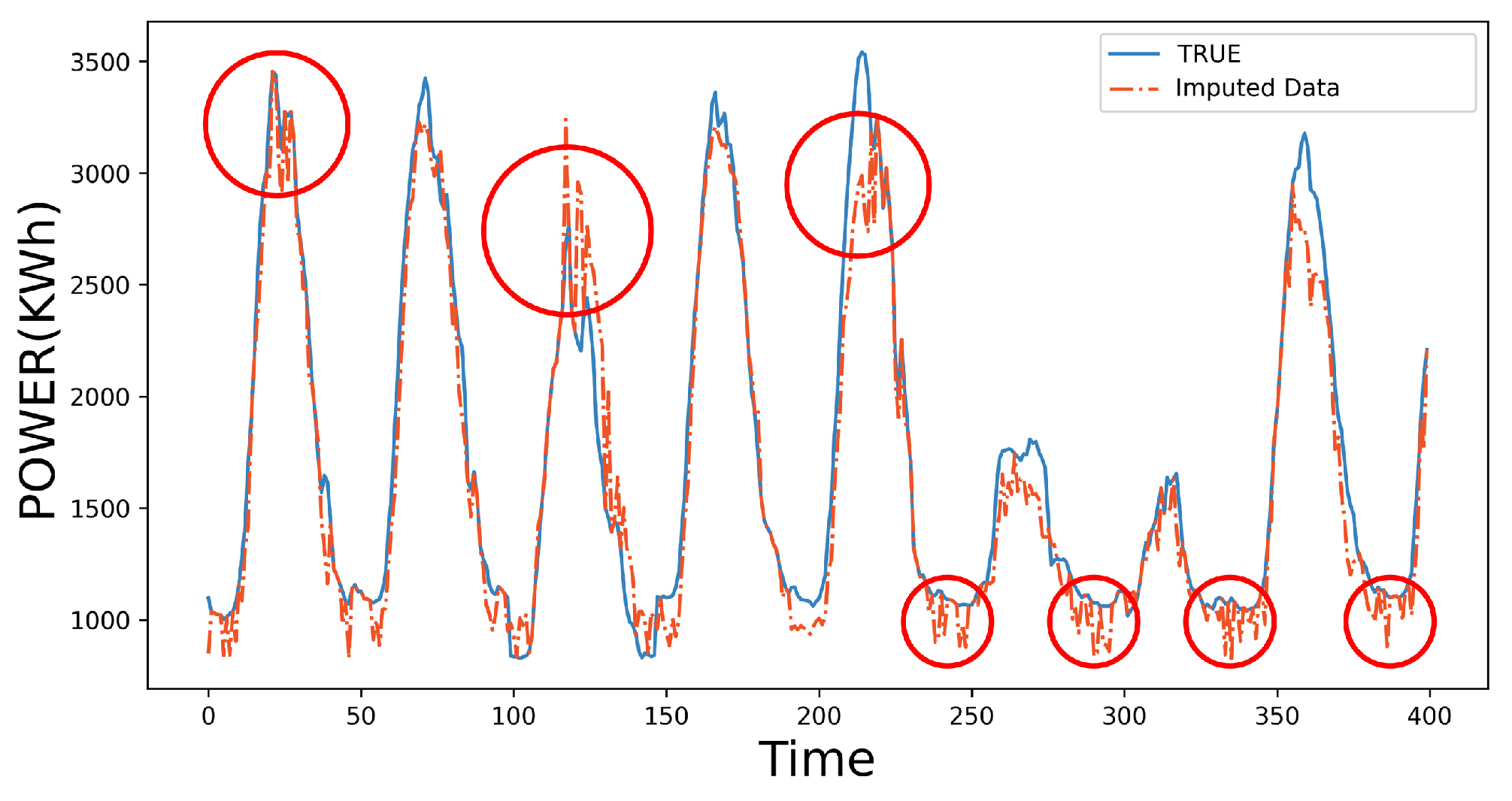
3. Imputed Data Optimization by the MAF
4. Case Studies
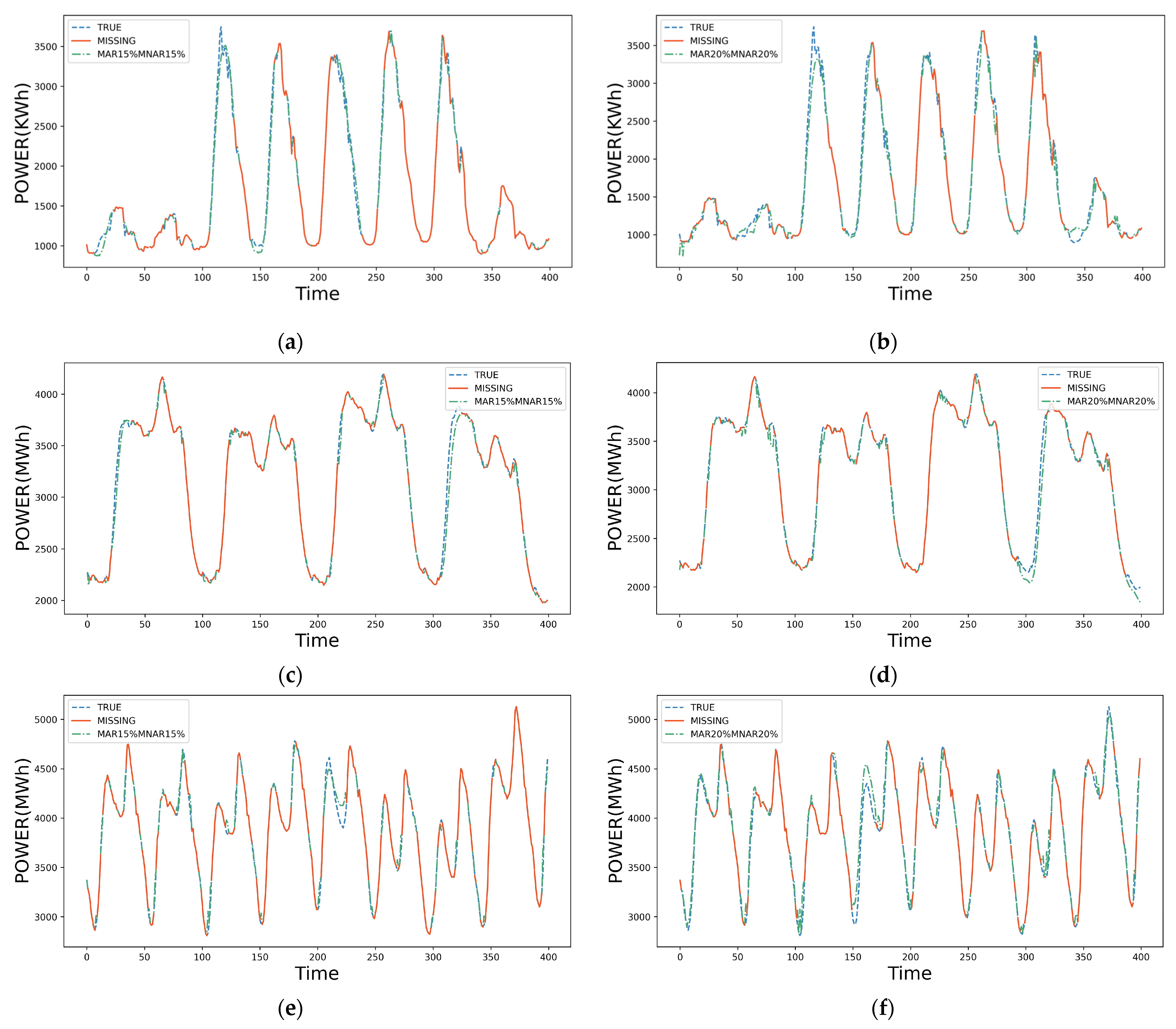
4.1. Datasets Description
- Randomly generate the MAR’s rate and the MNAR’s rate within the range of 0~30% to ensure that the total missing rate does not exceed 60%;
- According to the missing rate, randomly generate a corresponding number of missing locations in the underlying data, and set the value of the position to 0 to form missing data;
- Repeat steps (1) and (2) 192 times to generate 192 groups of multi-type missing data with different missing rates to form the training set.
- Cardiff conference building energy consumption data (C). They contain power consumption data (KWh) of more than 300 buildings at the Cardiff Conference from 2014 to 2016 in 30 min intervals. The training set contains data from 712 days in 2014–2015. The validation set contains data from 365 days in 2016. The training set size is 192 × 712 × 48. The validation set size is 4 × 365 × 48;
- Northern Ireland power energy system data (N). They contain electricity demand (MWh) at 15 min intervals in part of Northern Ireland from 2016 to 2018. The training set contains data from 480 days in 2016–2017. The validation set contains data from 240 days in 2018–2019. The training set size is 192 × 480 × 96. The validation set size is 4 × 240 × 96;
- Australian power load data (A). They contain the electricity demands (MWh) in part of Australia at 30 min intervals from 2006 to 2011. The training set contains data from 1460 days in 2006–2010. The validation set contains data from 365 days in 2010–2011. The training set size is 192 × 1460 × 48. The validation set size is 4 × 365 × 48.
4.2. Imputation Results and Accuracy
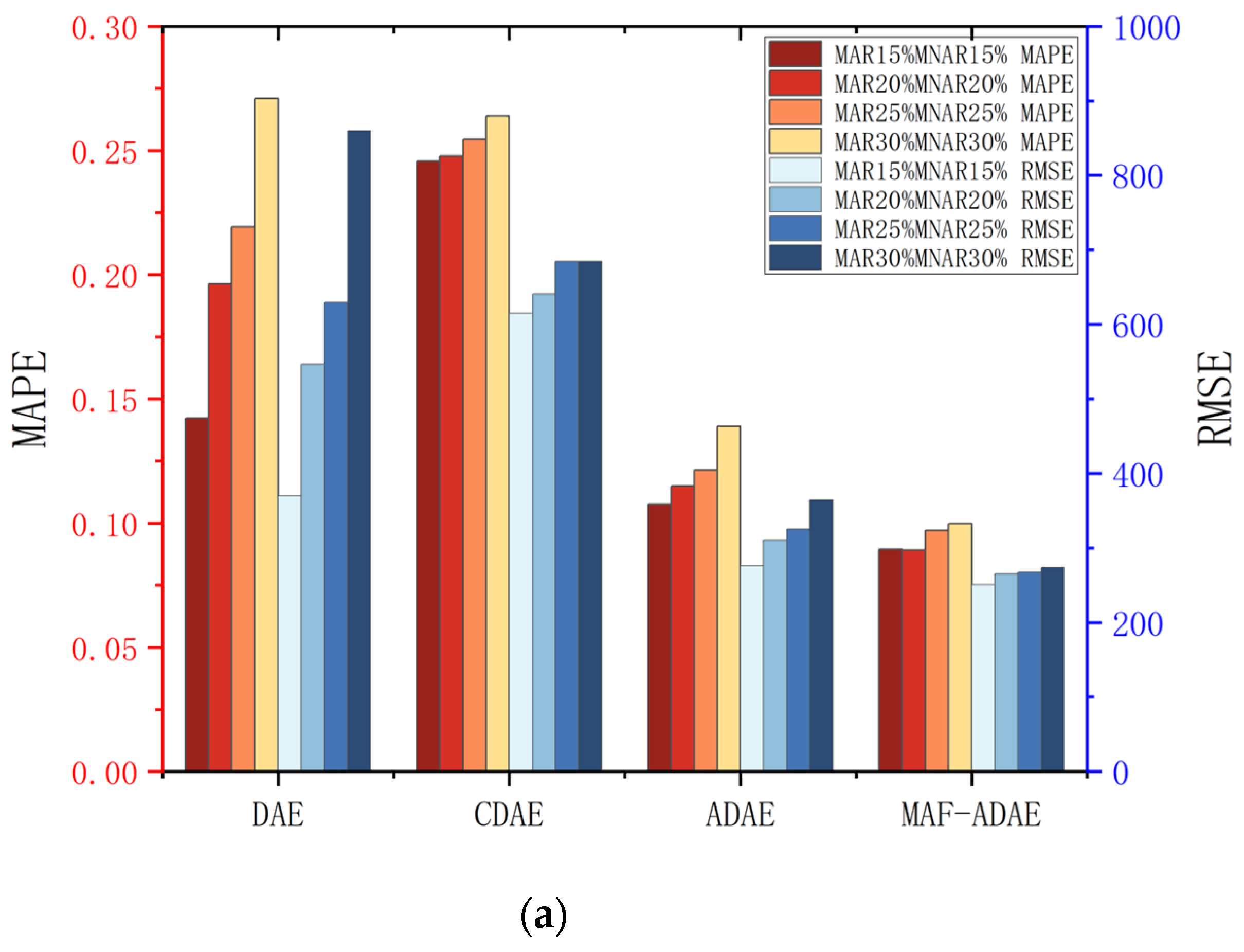
4.3. Ablation Experiment
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Montanari, G.C.; Hebner, R.; Seri, P.; Ghosh, R. Self-Assessment of Health Conditions of Electrical Assets and Grid Components: A Contribution to Smart Grids. IEEE Trans. Smart Grid 2020, 12, 1206–1214. [Google Scholar] [CrossRef]
- Cui, B.; Srivastava, A.K.; Banerjee, P. Synchrophasor-based condition monitoring of instrument transformers using clustering approach. IEEE Trans. Smart Grid 2019, 11, 2688–2698. [Google Scholar] [CrossRef]
- Yao, W.; Liu, Y.; Zhou, D.; Pan, Z.; Till, M.J.; Zhao, J.; Zhu, L.; Zhan, L.; Tang, Q.; Liu, Y. Impact of GPS signal loss and its mitigation in power system synchronized measurement devices. IEEE Trans. Smart Grid 2016, 9, 1141–1149. [Google Scholar] [CrossRef]
- Wang, Q.; Kundur, D.; Yuan, H.; Liu, Y.; Lu, J.; Ma, Z. Noise suppression of corona current measurement from HVdc transmission lines. IEEE Trans. Instrum. Meas. 2016, 65, 264–275. [Google Scholar] [CrossRef]
- Hussein, R.; BashirShaban, K.; El-Hag, A.H. Denoising of acoustic partial discharge signals corrupted with random noise. IEEE Trans. Dielectr. Electr. Insul. 2016, 23, 1453–1459. [Google Scholar] [CrossRef]
- Bhaskaran, K.; Smeeth, L. What is the difference between missing completely at random and missing at random? Int. J. Epidemiol. 2014, 43, 1336–1339. [Google Scholar] [CrossRef] [PubMed]
- Liao, W.; Bak-Jensen, B.; Pillai, J.R.; Yang, D.; Wang, Y. Data-driven missing data imputation for wind farms using context encoder. J. Mod. Power Syst. Clean Energy 2021, 10, 964–976. [Google Scholar] [CrossRef]
- Wan, C.; Chen, H.; Guo, M.; Liang, Z. Wrong data identification and correction for WAMS. In Proceedings of the 2016 IEEE PES Asia-Pacific Power and Energy Engineering Conference, Xi’an, China, 25–28 October 2016; pp. 1903–1907. [Google Scholar]
- Huang, C.; Li, F.; Zhan, L.; Xu, Y.; Hu, Q. Data quality issues for synchrophasor applications Part II: Problem formulation and potential solutions. J. Mod. Power Syst. Clean Energy 2016, 4, 353–361. [Google Scholar] [CrossRef]
- Gao, P.; Wang, M.; Ghiocel, S.G.; Chow, J.H.; Fardanesh, B.; Stefopoulos, G. Missing data recovery by exploiting Low-dimensionality in power system synchrophasor measurements. IEEE Trans. Power Syst. 2015, 31, 1006–1013. [Google Scholar] [CrossRef]
- Hu, Y.; Zhang, D.; Ye, J.; Li, X.; He, X. Fast and accurate matrix completion via truncated nuclear norm regularization. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 2117–2130. [Google Scholar] [CrossRef]
- Liao, M.; Shi, D.; Yu, Z.; Yi, Z.; Wang, Z.; Xiang, Y. An Alternating Direction Method of Multipliers Based Approach for PMU Data Recovery. IEEE Trans. Smart Grid 2018, 10, 4554–4565. [Google Scholar] [CrossRef]
- Konstantinopoulos, S.; De Mijolla, G.M.; Chow, J.H.; Lev-Ari, H.; Wang, M. Synchrophasor missing data recovery via data-driven filtering. IEEE Trans. Smart Grid 2020, 11, 4321–4330. [Google Scholar] [CrossRef]
- Jones, K.D.; Pal, A.; Thorp, J.S. Methodology for performing synchrophasor data conditioning and validation. IEEE Trans. Power Syst. 2014, 30, 1121–1130. [Google Scholar] [CrossRef]
- Chen, X.; Yang, J.; Sun, L. A nonconvex low-rank tensor completion model for spatiotemporal traffic data imputation. Transp. Res. Part C-Emerg. Technol. 2020, 117, 102673. [Google Scholar] [CrossRef]
- James, J.Q.; Lam, A.Y.S.; Hill, D.J.; Hou, Y.; Victor, O.K. Delay aware power system synchrophasor recovery and prediction framework. IEEE Trans. Smart Grid 2018, 10, 3732–3742. [Google Scholar]
- Jeong, D.; Park, C.; Ko, Y.M. Missing data imputation using mixture factor analysis for building electric load data. Appl. Energy 2021, 304, 117655. [Google Scholar] [CrossRef]
- Jung, S.; Moon, J.; Park, S.; Rho, S.; Baik, S.W.; Hwang, E. Bagging ensemble of multilayer perceptrons for missing electricity consumption data imputation. Sensors 2020, 20, 1772. [Google Scholar] [CrossRef] [PubMed]
- Ren, C.; Xu, Y. A fully data-driven method based on generative adversarial networks for power system dynamic security assessment with missing data. IEEE Trans. Power Syst. 2019, 34, 5044–5052. [Google Scholar] [CrossRef]
- Dai, J.; Song, H.; Sheng, G.; Jiang, X. Cleaning method for status monitoring data of power equipment based on stacked denoising autoencoders. IEEE Access 2017, 5, 22863–22870. [Google Scholar] [CrossRef]
- Li, S.; He, H.; Zhao, P.; Cheng, S. Data cleaning and restoring method for vehicle battery big data platform. Appl. Energy 2022, 320, 119292. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Pintelas, E.; Livieris, I.E.; Pintelas, P.E. A convolutional autoencoder topology for classification in high-dimensional noisy image datasets. Sensors 2021, 21, 7731. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.; Chen, G. An accurate GRU-based power time-series prediction approach with selective state updating and stochastic optimization. IEEE Trans. Cybern. 2021, 52, 13902–13914. [Google Scholar] [CrossRef] [PubMed]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Hong, S.; Song, S.K. Kick: Shift-N-Overlap cascades of transposed convolutional layer for better autoencoding reconstruction on remote sensing imagery. IEEE Access 2020, 8, 107244–107259. [Google Scholar] [CrossRef]
- Syed, M.A.; Khalid, M. Moving Regression Filtering with Battery State of Charge Feedback Control for Solar PV Firming and Ramp Rate Curtailment. IEEE Access 2021, 9, 13198–13211. [Google Scholar] [CrossRef]
- Meng, Q.; Xiong, C.; Mourshed, M.; Wu, M.; Ren, X.; Wang, W.; Li, Y.; Song, H. Change-point multivariable quantile regression to explore effect of weather variables on building energy consumption and estimate base temperature range. Sustain. Cities Soc. 2020, 53, 101900. [Google Scholar] [CrossRef]
- Irish Electricity Energy System Monitoring Data. Available online: https://smartgriddashboard.com (accessed on 1 December 2023).
- Australian Electricity Load Data. Available online: https://www.aemo.com.au/energy-systems/electricity/national-electricity-market-nem/data-nem (accessed on 1 December 2023).
- Yu, H.; Rao, N.; Dhillon, I.S. Temporal regularized matrix factorization for high-dimensional time series prediction. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Sun, C.; He, Z.; Lin, H.; Cai, L.; Cai, H.; Gao, M. Anomaly detection of power battery pack using gated recurrent units based variational autoencoder. Appl. Soft. Comput. 2023, 132, 109903. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Imputation Cases | LI | TRMF | LRTC-TNN | SDAE | VAE | MAF-ADAE |
|---|---|---|---|---|---|---|
| MAR15%MNAR15%, C | 0.246/1134.53 | 0.259/798.44 | 0.071/310.94 | 0.142/370.16 | 0.23/581.78 | 0.080/244.48 |
| MAR20%MNAR20%, C | 0.29/1440.74 | 0.269/886.74 | 0.115/538.92 | 0.196/546.27 | 0.242/615.7 | 0.088/265.16 |
| MAR25%MNAR25%, C | 0.478 /3455 | 0.398/796.05 | 0.158/675.88 | 0.219/629.57 | 0.243/584.46 | 0.094/267.52 |
| MAR30%MNAR30%, C | 0.809/8528.04 | 0.487/1133.82 | 0.207/806.99 | 0.271/859.35 | 0.212/553.69 | 0.101/276.05 |
| MAR15%MNAR15%, N | 0.104/227.06 | 0.117/274.4 | 0.078/103.94 | 0.084/101.62 | 0.128/148.88 | 0.038/52.59 |
| MAR20%MNAR20%, N | 0.115/239.23 | 0.12/288 | 0.088/115 | 0.096/121.41 | 0.135/157.93 | 0.04/52.21 |
| MAR25%MNAR25%, N | 0.169/398.67 | 0.228/336.88 | 0.099/179.78 | 0.1/120.96 | 0.146/160.14 | 0.040/53.55 |
| MAR30%MNAR30%, N | 0.248/585.67 | 0.248/335.49 | 0.117/197.29 | 0.135/211.2 | 0.212/235.5 | 0.045/56.91 |
| MAR15%MNAR15%, A | 0.093/2883.07 | 0.086/2373.8 | 0.021/339.04 | 0.054/609.46 | 0.086/1067.05 | 0.023/287.31 |
| MAR20%MNAR20%, A | 0.129/2551.59 | 0.112/2485.79 | 0.029/383.65 | 0.07/788.45 | 0.086/999.56 | 0.029/351.39 |
| MAR25%MNAR25%, A | 0.177/3120.04 | 0.132/2543.06 | 0.039/447.88 | 0.074/887.78 | 0.09/1034.15 | 0.031/370.24 |
| MAR30%MNAR30%, A | 0.212/3525.93 | 0.147/2630.68 | 0.04/536.02 | 0.086/1042.08 | 0.092/1052.86 | 0.032/379.33 |
| Datasets | Models | MAR20%MNAR20% | MAR30%MNAR30% | ||
|---|---|---|---|---|---|
| SD of MAPE | SD of RMSE | SD of MAPE | SD of RMSE | ||
| C | LI | 0.0518 | 362.111 | 0.0538 | 367.634 |
| TRMF | 0.0318 | 68.942 | 0.0406 | 135.750 | |
| LRTC-TNN | 0.0096 | 53.569 | 0.0141 | 58.766 | |
| SDAE | 0.0228 | 43.951 | 0.0244 | 79.984 | |
| VAE | 0.0276 | 85.733 | 0.0345 | 79.721 | |
| MAF-ADAE | 0.0054 | 30.716 | 0.0120 | 41.269 | |
| N | LI | 0.0078 | 41.278 | 0.0235 | 166.059 |
| TRMF | 0.0046 | 28.955 | 0.0177 | 54.697 | |
| LRTC-TNN | 0.0084 | 24.471 | 0.0227 | 69.323 | |
| SDAE | 0.0062 | 9.804 | 0.0093 | 48.262 | |
| VAE | 0.0047 | 11.779 | 0.0130 | 12.231 | |
| MAF-ADAE | 0.0014 | 5.162 | 0.0019 | 7.034 | |
| A | LI | 0.0065 | 120.037 | 0.0248 | 450.984 |
| TRMF | 0.0051 | 49.448 | 0.0219 | 175.664 | |
| LRTC-TNN | 0.0008 | 34.595 | 0.0025 | 45.020 | |
| SDAE | 0.0028 | 44.113 | 0.0083 | 99.060 | |
| VAE | 0.0023 | 51.724 | 0.0109 | 68.564 | |
| MAF-ADAE | 0.0019 | 22.659 | 0.0018 | 38.285 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, L.; Gu, J.; Zhang, X.; Hua, L.; Cai, Y. Multi-Type Missing Imputation of Time-Series Power Equipment Monitoring Data Based on Moving Average Filter–Asymmetric Denoising Autoencoder. Sensors 2023, 23, 9697. https://doi.org/10.3390/s23249697
Jiang L, Gu J, Zhang X, Hua L, Cai Y. Multi-Type Missing Imputation of Time-Series Power Equipment Monitoring Data Based on Moving Average Filter–Asymmetric Denoising Autoencoder. Sensors. 2023; 23(24):9697. https://doi.org/10.3390/s23249697
Chicago/Turabian StyleJiang, Ling, Juping Gu, Xinsong Zhang, Liang Hua, and Yueming Cai. 2023. "Multi-Type Missing Imputation of Time-Series Power Equipment Monitoring Data Based on Moving Average Filter–Asymmetric Denoising Autoencoder" Sensors 23, no. 24: 9697. https://doi.org/10.3390/s23249697
APA StyleJiang, L., Gu, J., Zhang, X., Hua, L., & Cai, Y. (2023). Multi-Type Missing Imputation of Time-Series Power Equipment Monitoring Data Based on Moving Average Filter–Asymmetric Denoising Autoencoder. Sensors, 23(24), 9697. https://doi.org/10.3390/s23249697