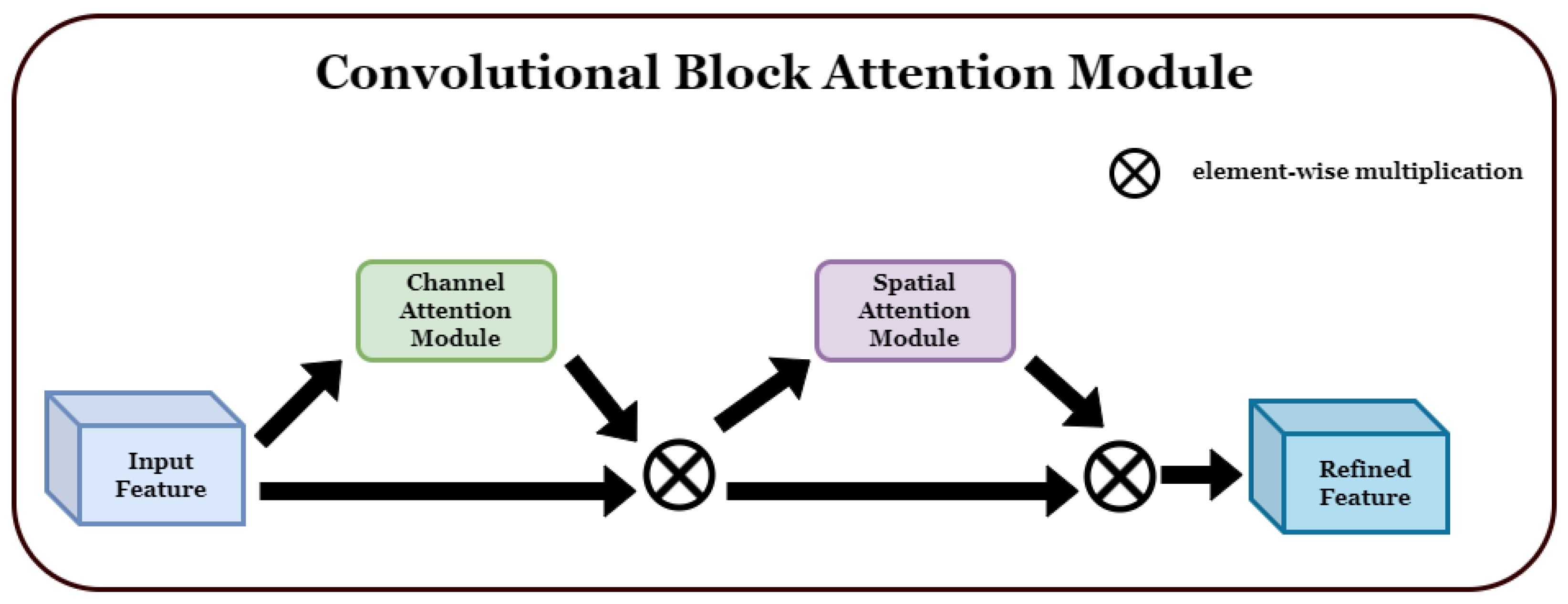
In this section, we propose a network architecture that correctly classifies violent situations by using the spatial and temporal features of each video to detect abnormal situations, particularly violent ones, and achieves state-of-the-art performance. The proposed architecture adds a convolutional block attention module (CBAM) [
3], an attention module that includes the channel attention and spatial attention modules, to a residual neural network (ResNet) [
61] in the form of a 3D convolution.
3.1. CBAM (Convolutional Block Attention Module)
CBAM is a network module used to highlight the channel and spatial information within a convolutional block. This improves the performance of CNNs and is commonly used in image classification and various computer vision tasks, highlighting important information. It comprises two attention modules.
1. Channel attention: Channel attention determines the importance of each channel and plays a role in emphasizing the relationships between channels. Thus, important features can be emphasized, and unnecessary noise can be suppressed. Channel attention is usually implemented by using the average value of each channel, calculated via global average pooling, to learn the relationships between channels. 2. Spatial attention: Spatial attention plays an important role in understanding the spatial structure of feature maps by emphasizing one area and suppressing another. To this end, the importance of the feature map calculated for each channel was determined, and a spatial weight was generated and multiplied by the feature map. If the input feature map
F is multiplied by
, which is the channel attribute map,
is obtained. If it is multiplied by
, which is the spatial attribute map,
is obtained, which is the final feature map.
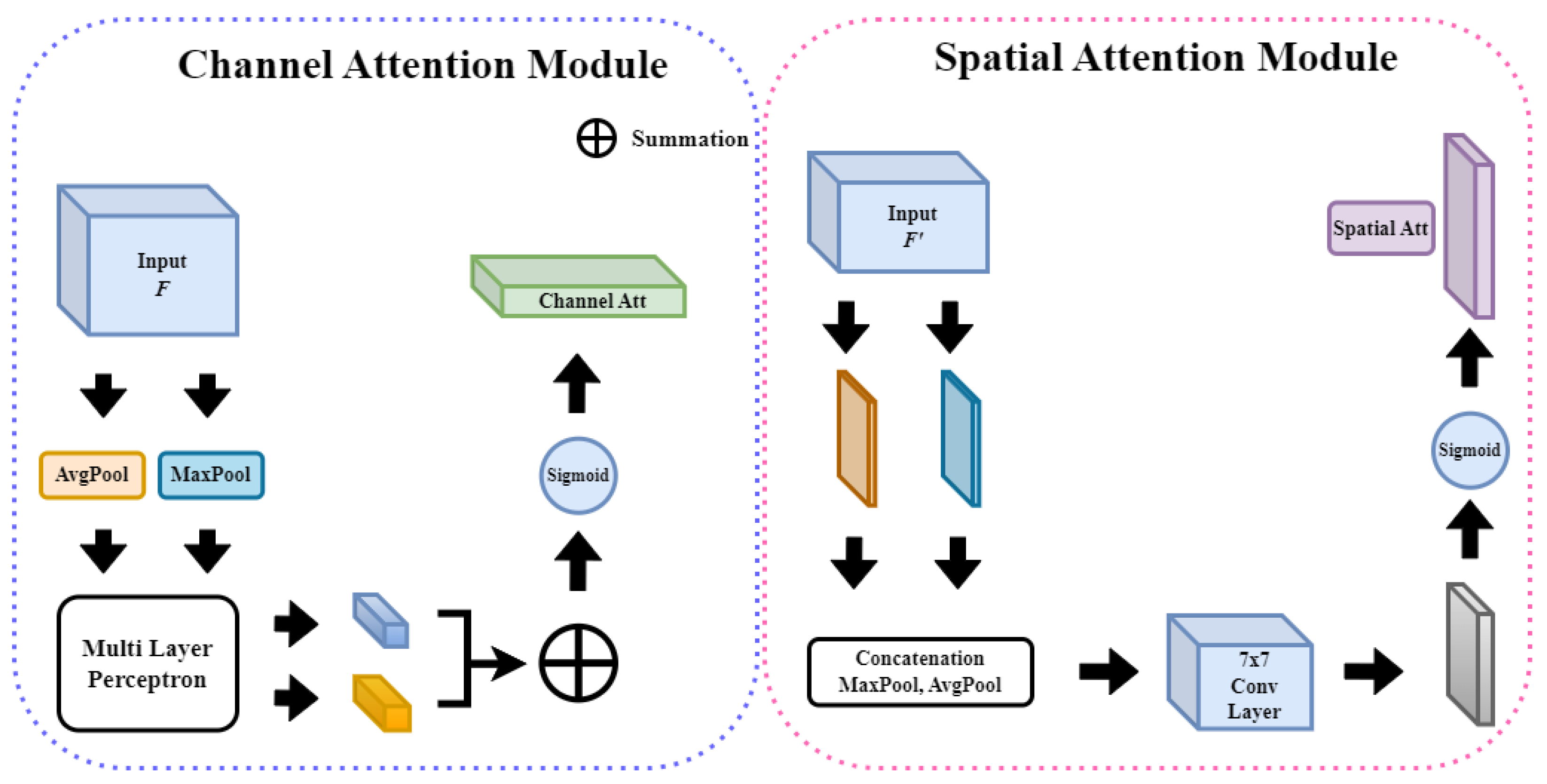
Figure 1 shows the structure of the detailed sub-module of CBAM, and the formulas for obtaining
and
, which are the channel attention map and spatial attention map, respectively, are shown as below Equations (
1) and (
2) in below.
Figure 2 shows the structure of each attention sub-module of CBAM.
The channel attention map calculates the importance of each channel of an input feature map and extracts the relationships between the channels. After calculating the attention score and passing through average and max pooling, two vectors are produced, which are input into the shared multilayer perceptron to add nonlinearity. This is then encoded with a probabilistic value between zero and one using a sigmoid function to generate an
, one-dimensional
channel attention map. If the input feature map
F is multiplied by
,
, which is a feature map to which the channel attachment is applied, is generated. A spatial attention map is created by encoding the pixels to be focused on per
pixels throughout the channel. Up until the pooling process and concatenation, it is the same as channel attention. This information is gathered for comprehensiveness because both pooling methods are carried out to extract spatial information and calculate the importance of location. Additionally, this value is placed in the
conv2d layer and a 2D spatial attention map is generated via a sigmoid function. The feature map generated in this manner is of size
. When the resulting
is multiplied by
, the final attention map is obtained, that is,
is produced. The formulae for
and
as follows Equations (
3) and (
4):
We introduce the proposed method by transforming the attention-based approach proposed in [
62,
63]. In this paper, we describe how the output of a linear classification layer can be influenced in addition to a popular CNN pipeline that has excellent feature extraction capabilities. CBAM influences the feature extraction process of the model and serves to weigh the network output for improved feature extraction.
3.2. Grid Frame
In this section, we describe how to create a grid frame for each dataset and how to assign labels accordingly.
In this study, we propose a method to improve the input data processing methods of existing 2D and 3D CNNs. In general, 2D CNNs adopt a method of processing one image at a time. Consequently, each image is processed independently by considering only the spatial features and thus does not consider the correlation between images. Therefore, to detect abnormalities using 2D CNNs, an RNN such as LSTM or a neural network structure such as ConvLSTM should be added. However, the proposed method of processing multiple images of 3D CNNs at once includes temporal and spatial features. Thus, this method has the advantage of considering correlations between images.
Additionally in this section, we present an approach that extends beyond these image-processing methods, where for each dataset, several images are processed in a single group. This group consists of continuous frames, and each image is processed considering its interrelationship with other images in the group, rather than being processed independently. This enables the model to extract more information and meaningful patterns than a single image of a 2D CNN or multiple images of a 3D CNN, thereby enabling accurate prediction and analysis. This approach aims to capture and use complex relationships between multiple images in a group (this can include, for example, multiple groups corresponding to a video) and finally detect abnormalities by identifying spatial and temporal patterns via the continuity of images in and between groups. This approach addresses complex interactions between images and groups, enabling the derivation of more accurate and meaningful results. Furthermore, this study opens up the possibility of new methods in the field of anomaly detection using an input method conceptually similar to Lightfield and ViT. In this study, we propose inputs of sizes , , , and .
For the UBI-Fights dataset, each annotation file marked fighting or nonfighting frames with a 1 or 0, respectively. Therefore, when preprocessing videos identified as fights, the annotation file was loaded and frame indices with a value of 1 were saved. The frame indices were read at intervals of 5. For example, if frames 1–20 had a value of 1, then frames 1, 6, 11, and 16 were accessed. As the video has a frame rate of 30 fps, without this interval, significant action changes may not be captured; hence, spacing between frames is necessary. Once sufficient frames were gathered for the intended composite image size (9 frames for , 15 frames for , and so on), they were combined into a single composite image. Owing to memory constraints, only ten composite images were generated per video. These ten merged images served as the input data, and depending on the size of the composite image, 90–150 frames were used from a single video. Data corresponding to the normal class were processed in the same manner to generate the input data. This method was adopted and used on all datasets, including UBI-Fights.
The UBI-Fights dataset showed an imbalance between the fight (216) and normal (784) class data. Therefore, experiments were conducted not only at the existing data ratio fight:normal = 216:784 but also by equalizing the data to fight:normal = 216:216, resulting in two experiments. Furthermore, experiments were conducted separately using ResNet depths of 10, 18, 34, and 50, with the data split in an 80:15:5 ratio for training:validation:test datasets.
The RWF-2000 dataset was balanced, and because the training to validation split was already at an 8:2 ratio, only one experiment was conducted. This dataset does not have separate annotations; therefore, the Violence and NonViolence categories were arbitrarily assigned values of 1 and 0, respectively, for experimentation. In contrast to the UBI-Fights dataset, given that the videos were 5 s long with 30 fps, after reading the video, the frames were extracted in the flow of the video to create merged images. This was performed under the assumption that sufficient actions corresponding to the classes were contained within.
UCSD Ped1 originally contained normal data in the training set and anomalous data in the test set; however, they were arbitrarily mixed for use. Similarly, Ped2 was mixed arbitrarily. For both datasets, the ratio of the training and test sets was the same as that in the original datasets, and the test set was used for validation. Furthermore, only a randomly selected 30% of the test set was used for testing. For the UCSD Ped1 and Ped2 datasets, we used all the data. A sample of each input data is described in
Figure 3.
3.3. Model Architecture
Recently, various studies have been conducted on abnormal detection using CBAM, such as [
62,
63,
64]. However, most research has been conducted on structures such as 2D CNN-based generative models. This study employs a different approach to propose a more effective anomaly detection model. Our work differs from other studies because it effectively combines 3D CNN and CBAM for anomaly detection. Additionally, instead of using an autoencoder structure, our approach optimizes the characteristics of 3D CNN and the effects of CBAM and proposes a more sophisticated and robust anomaly detection model. Thus, our study presents an original perspective as compared with previous studies.
3.3.1. Backbone Architecture
In this study, ResNet [
61] was used as the backbone architecture. This is a suitable choice for its efficacy in learning deep neural networks. Particularly, the problem of gradient loss can be solved despite the depth of the model using the advantages of residual blocks. Residual blocks assist in the effective transfer of gradients via residual connections between inputs and outputs and minimize the loss of information, even in deep networks. Furthermore, deeper and more complex models can be developed. Subsequently, the detailed structure of the model and connections between the layers are described.
3.3.2. Proposed Architecture
The model architecture proposed in this study was constructed by adding CBAM after each bottleneck (or basic block) of 3D ResNet. This configuration may improve anomaly detection performance by effectively combining the feature extraction capabilities of the existing 3D CNN with the information emphasis capabilities of CBAM. CBAM can be placed behind each bottleneck, and the model can be extended to include additional residual blocks as required. This increases the expressiveness of the model and aids in capturing complex temporal relationships.
CBAM is an attention mechanism designed primarily for 2D data. However, as this study dealt with 3D data, the code was appropriately modified. First, 2D pooling (AvgPool2d and MaxPool2d) was replaced with AdaptiveAvgPool3d and AdaptiveMaxPool3d, which perform pooling by automatically adjusting kernel and stride sizes to fit the target output tensor sizes. They also work with inputs of various sizes and produce the same output. As channel attention aims to calculate the mean and maximum values for the entire spatial dimension, using adaptive pooling to obtain the outputs of (1, 1, 1) is appropriate. Adaptive pooling also performs pooling to the desired output size without a fixed kernel size or stride, which can help optimize the computing resources. Finally, the overall information in the input feature map was averaged to minimize information loss while maintaining a consistent output size.
- (1)
Channel Attention (designed to recognize and learn the importance of each channel)
- (a)
Adaptive average and max pooling: This module aggregates the spatial information of 3D data. Average and max pooling each return a tensor with a size of , where C is the number of channels in the input tensor.
- (b)
MLP with Conv3d: Importantly, the kernel sizes of both the first and second Conv3d layers are . The first Conv3d layer serves to reduce the number of channels from C to . Conversely, the second Conv3d layer increases the number of channels from the to C again.
- (2)
Spatial attention (designed to learn the importance of each 3D location)
- (a)
Max and min pooling: Extracts the maximum and minimum values of the channel at each location of the input data. This results in a tensor of size . Here, D, H, and W are depth, height, and area, respectively.
- (b)
Three-dimnsional convolution: The tensor generated above passes through the 3D convolution layer, which has a kernel size of and a number of output filters (channels) of 1. A larger kernel size accounts for more amount of spatial information in convolutional operations, with a size kernel accounting for a large area of its surroundings at each 3D location, which aids in capturing a broader context. The output channel is 1 to generate a spatial attention map. This attention map has the same spatial dimension as the original input tensor but only represents the importance (or attention score) of each position. Therefore, the number of output filters is 1, which is multiplied by the original input tensor and element-wise to apply spatial attention. In summary, the setting with a kernel size of and a number of output channels of 1 aims to recognize a wide range of contexts, save parameters, and create a clear spatial attention map.
When the input data are provided, 3D convolution is performed, and the CBAM layer is passed through batch normalization, rectified linear unit (ReLU), and dropout. After passing through all the reserved blocks, the feature map undergoes global average pooling through avgpool. This leaves only the average value for each feature map, and the feature after pooling is a 1D vector, which passes through the fully connected layer (fc layer) and outputs the final predicted value to perform anomaly detection.
In detail, the input data go through convolution, batch normalization, ReLU, and MaxPooling, and they are then input to the bottleneck layer (in the case of ResNet50) or basic block (in case of ResNet 10, 18, and 34). Here, after going through convolution, batch normalization, ReLU, convolution, batch normalization, ReLU, convolution, and batch normalization, and lastly, reduction in computational complexity when the output and input sizes of the bottleneck are different owing to the difference in stride or number of input and output channels. Downsampling (stride = 2) is then performed for high-level feature extraction. Subsequently, CBAM is applied and channel attention and spatial attention proceed. Layers containing bottlenecks or basic blocks are repeated four times from layers 1 to 4, and CBAM is applied to each bottleneck block or basic block. In the case of ResNet 10, 18, and 34, there are (1, 1, 1, 1), (2, 2, 2, 2), and (3, 4, 6, 3), respectively, basic block layers in layer 1. In the case of ResNet50, there are 3, 4, 6, and 3 bottleneck layers in layer 1 to layer 4, respectively. After the input data have executed all the network structures, classification for anomaly detection is performed in the fully connected layer.
In the architecture of the proposed network, when an input arrives, it passes through Conv3d, batch normalization, ReLU, and AdaptiveMaxPool3d and then through the convolutional block (there are
,
, and
depending on the depth of the model) and the basic block (or bottleneck block). Subsequently, the process of going through CBAM is repeated four times before proceeding with the classification. In
Figure 4, it is labeled as “BottleNeck” based on ResNet50, but for shallower depths (10, 18, 34), it changes to “BasicBlock”.
3.4. Dataset
In this section, we describe datasets that we used for experiments. When looking at existing datasets for anomalous behavior detection, few datasets contain violent actions. While there are numerous datasets like UMN [
65], UCSD Ped1 and Ped2 [
66,
67], Subway Entrances and Exits [
68], and CUHK Avenue [
69], the anomalous behaviors they designate refer to actions like walking in a different direction from the majority in a crowd or riding bicycles and inline skates. There are also datasets such as [
70] that occur in public transportation, especially buses. However, these datasets contain many obstacles in public transportation and there are many cases where these obstacles obscure human actions. Because we only tested frames where human actions were clearly visible, we also excluded this dataset from the experiments. Hence, a dataset that clearly distinguishes between violent and nonviolent behaviors is required. Therefore, this study used UBI-Fights [
71] and three other datasets.
3.4.1. UBI-Fights
The UBI-Fights dataset was divided into fight and normal classes, consisting of 216 and 784 videos, respectively, gathered from YouTube and LiveLeak based on extensive text search results of violent incidents. The data were collected at the frame level with annotations totaling 80 h in length; however, the length of each video varied and had a frame rate of 30.00 frames per second with a fixed resolution of . A drawback of the videos in the fight class is that the entire duration of the video does not show fighting; hence, scenes that should be categorized as normal were included.
3.4.2. RWF-2000
Another dataset used was the RWF-2000 [
72]. This dataset consists of 2000 video clips filmed in the real world by surveillance cameras, each 5 s long at 30.00 frames per second. They were also sourced from YouTube and divided into violent and nonviolent classes. Unlike in [
71], the training and test sets were divided in an 8:2 ratio. The resolution of the videos varied, including 240p, 320p, 720p, and 1080p. An advantage of this dataset was that the actions were aligned with their respective classes throughout the video. Therefore, this assumption was more intuitive. The violence class included fights, robberies, explosions, shootings, bleeding, and assaults, enabling a more detailed categorization depending on the situation and purpose. However, because the resolutions varied, preprocessing through resizing could alter the original size of videos, potentially leading to a loss of information.
3.4.3. UCSD Ped1 and Ped2
We included the UCSD Ped1 and Ped2 datasets in our experiment, which considered behaviors, such as walking in the opposite direction to the majority in a crowd, riding a bicycle, or using inline skates, as anomalous. The ground truths of UCSD Ped1 and Ped2 are provided in the form of a segmentation map in which objects exhibiting anomalous behaviors are highlighted in white. The UCSD Ped1 dataset consists of images from 70 videos: 34 for training and 36 for testing. Each set contains 200 images of size . The training set comprises normal behaviors, whereas the testing set contains 10 anomalous behaviors. The UCSD Ped2 dataset comprises images from 28 videos, with 16 for training and 12 for testing. Similar to UCSD Ped1, each image contains 200 images of size . Consequently, any area in the segmentation map with a value of 1, is interpreted as representing abnormal behavior and assigned a label of 1; otherwise, it is assigned a label of 0.
3.5. Details of Training
In this section, we describe the optimizer and loss function used and the hardware and software environments and so on. As this study is a binary classification, the loss function used was BCEWithLogitsLoss. The equation for BCEWithLogitsLoss is as follows in Equation (
5):
where
represents the sigmoid function,
stands for the weight for each input sample, and
y indicates the actual label value (0 or 1). The loss of
(positive class) measures the accuracy of the model prediction using the cross-entropy term, whereas the loss of
(negative class) measures the inaccuracy of the model prediction. In both cases, the closer the prediction is to the actual label, the closer the loss becomes to 0. This function takes the logits (that is, the outputs before passing through the sigmoid activation function) and actual label values as inputs. This effectively combines a two-step operation (sigmoid activation function and binary cross-entropy loss). This merging method was used to achieve computational efficiency and numerical stability.
In this study, the ResNet architectures with 10, 18, 34, and 50 layers were utilized as the foundational backbones. Following the addition of the Convolutional Block Attention Module (CBAM) on four occasions within each architecture, the total number of layers increased to 14, 22, 38, and 54, respectively. For optimization, AdamW was used. AdamW, a variant of the Adam optimization algorithm, implements weight decay separately. This is particularly beneficial in preventing overfitting and enhancing the generalization performance in deep neural networks. The combination of 3D ResNet and CBAM, which forms a profound network architecture, benefits from AdamW for efficient learning and regularization. An initial learning rate of 5 was adopted. In complex tasks such as anomaly detection, setting the appropriate learning rate is crucial. A starting learning rate of 5 is high enough to facilitate rapid convergence, yet it is not so high as to risk overfitting or training instability. And the learning rate was adjusted using the ReduceLROnPlateau scheduler. This scheduler reduces the learning rate automatically when there is no improvement in validation loss. Learning rate can be optimized through training and adjusted. This prevents the model from becoming trapped in local minima during training and aids in fine-tuning performance through more delicate adjustments. Adjusting the learning rate during training is especially crucial in complex tasks like anomaly detection. Callback functions (Early Stopping) were also employed to prevent overfitting by halting the training if the validation loss did not decrease for a certain period. While the epoch count was initially configured to 100, the actual number is different due to the activation of callback functions. Owing to memory constraints, the batch size was set to one. Experiments were conducted on a Windows 10 operating system with hardware specifications of an 11th Gen Intel(R) Core(TM) i7-11700K with a 3.60 GHz CPU, 48.0 GB RAM, and an NVIDIA GeForce RTX 4090 GPU. All the proposed architectures were implemented using PyTorch.







{kind=link}
{kind=link}
{kind=link}
{kind=link}