This section provides an initial solution to classify the human postures in the datasets. Our goal is to evaluate the capacity of the testbed to support experimentation in human posture recognition through a simple but effective classification methodology. We describe the roadmap followed to create, combine, and select the features computed from the acquired data that achieved the best performance for distinguishing the three classes of human postures. The classification methods are also described.
3.1. Classification Process Overview
The solutions proposed in this work consider that the classification algorithms take advantage of an initial stage of calibration, where the user is asked to pose according to each posture class, and labeled data are acquired for learning purposes. In the methodology, the datasets are split into calibration and test. The calibration data are used to extract knowledge that is further used to classify the test data. The calibration data are used to compute a set of features (presented in
Section 3.2) and to identify a subset of features that better discriminate the calibration data. Note that different datasets, with different calibration data, can produce different feature selections. We also propose labeling the calibration data in order to follow a supervised learning approach in the classification process.
An overview of the classification process is presented in the block diagram depicted in
Figure 6, which summarizes the approach followed in this work. The top right dataset block is constructed by merging the calibration data (green color) from each class into the calibration portion and merging the test data (blue color) from each class into the test portion while maintaining the order of each class. As depicted, the calibration data are used to define which features should be computed and, in this way, the combination of the selected features is dynamically chosen. Then, the information regarding the selection of the features and the labeled data from the calibration portion are sent to the classification algorithm to predict the data in the test portion.
The datasets lasting 90 s and 180 s are split into calibration and test portions. The calibration portion has a total duration of 18 s, which represents 6 s of data (or 1.5 MS) for each class. For a 90 s dataset, the test portion would have a total of
= 60 s of data (15 MS), and for each 180 s dataset, the test portion would have a total of
= 150 s of data (37.5 MS). Taking into consideration all the 90 s and 180 s datasets, different slices of 6 s can be chosen for each class of the calibration portion. To avoid the feature selection and classification steps being biased, different combinations of 6 s slices are considered for each of the three classes. The process is described in
Figure 7 for datasets lasting 90 s. The Class 0 is divided into 4 slices of 6 s with 2 s remaining. The division is equal for every other class when considering 90 s datasets. Consequently, 4 different calibration portions are considered by randomly selecting one slice from each class until all the slices are used. Each calibration portion and sequence of slices is presented in
Table 9. To give an example of how to read the information presented in
Table 9 concerning the 90 s datasets, the first calibration portion is composed of slice 1 of Class 0, slice 0 of Class 1, and slice 1 of Class 2. It is also important to note that each calibration portion has a respective test portion, which corresponds to the missing data from the dataset when the calibration portion is removed.
With regard to a 180 s dataset, the division of each class follows the same reasoning depicted in
Figure 7, where every class contains 9 slices of 6 s with 2 s remaining. For every 180 s dataset, 9 different calibration portions were considered by randomly selecting one slice from each class until all slices were used. Each calibration portion and sequence of slices are presented in
Table 9 as well.
Table 9 exemplifies how information is used. For datasets lasting 180 s, the first calibration portion is composed of slice 4 for Class 0, slice 8 for Class 1, and slice 2 for Class 2.
3.2. Feature Selection
To select the best features to represent the acquired data, we computed various features, and their performance was first visually analyzed considering all collected datasets. From the multiple features initially identified as hypothetical candidates, we selected 15 features of interest. The selection of the features was based on a quantitative benchmark (variance of the samples) to evaluate their capacity to discriminate the three classes in the datasets.
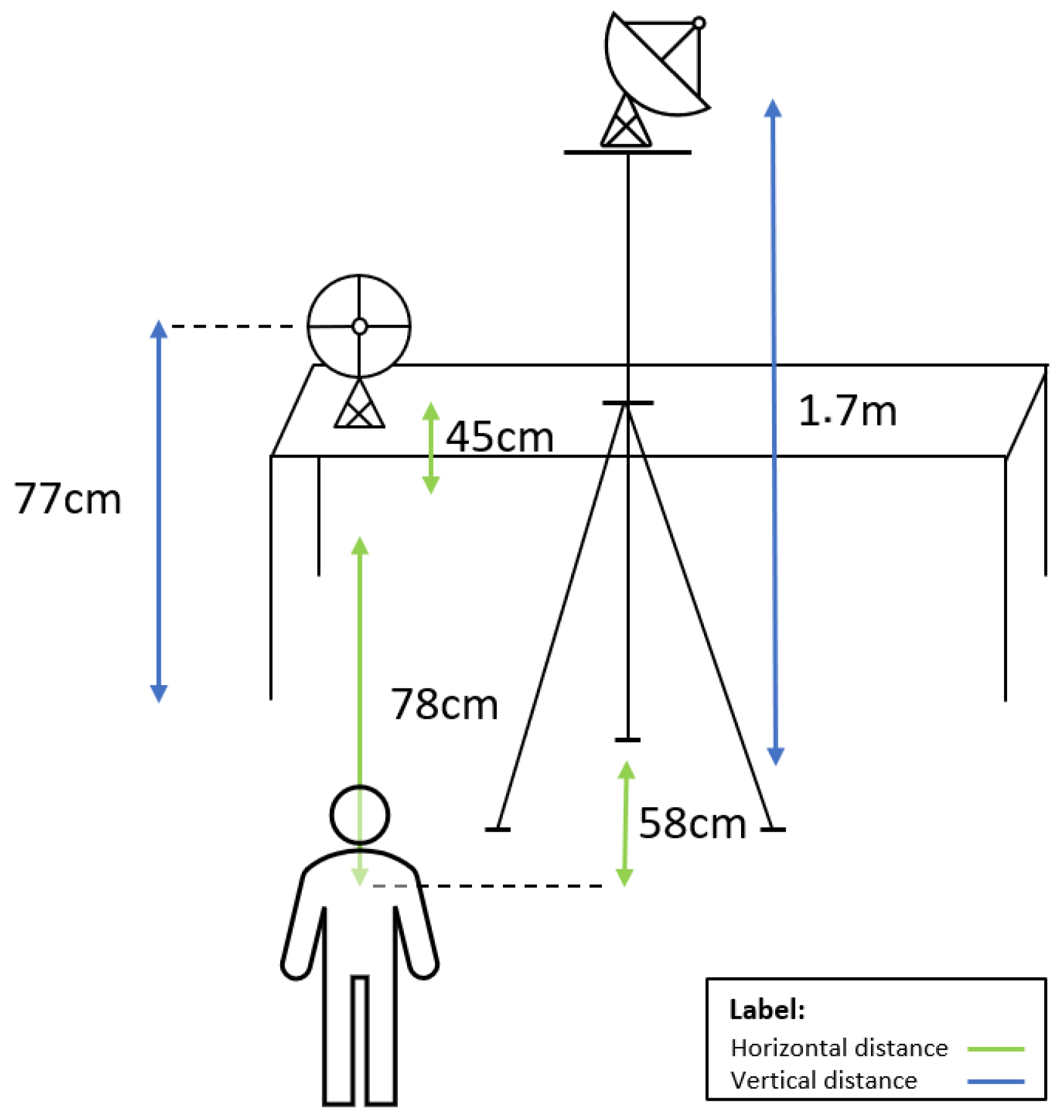
Let
be the matrix that contains the complex values collected by the reference antenna and
the matrix that contains the complex values collected by the surveillance antenna. Both
and
contain
N columns and
M rows, where
N denotes the number of classes and
M represents the number of samples per class.
Table 10 identifies the 15 features adopted in the evaluation process. Note that when computing the Median Absolute Deviation (MAD), the central point used is the median.
Given the sample rate of 250 kS/s adopted in all datasets, we computed each feature for a sliding window of 25 kS. In each second of real-time acquisition, we were able to compute 10 feature outputs, which allowed 10 posture prediction outputs when neglecting the time required to compute each feature. The number of feature outputs for every dataset is described in
Table 11.
To decrease the overall computation time of the classification process, only 2 of the 15 features were dynamically selected and used in the classification algorithm. It is important to highlight that some features are strongly correlated with others (e.g., Feature1 and Feature9); thus, the selection of such features would not add much information. First, we visually tested different combinations of two features with the datasets in
Table 5 by performing a scatter of the two chosen features for each class.
The next step regarding feature selection relies on the identification of the two features that maximize the classification detection probability. In other words, the goal is to identify the two features that provide better separation between the sample clusters of the different classes. To evaluate the combinations of the features to be selected, we adopted the Analysis of Variance (ANOVA) method [
18] for the calibration data from the 90 s and 180 s datasets. The ANOVA method is an efficient and simple feature selection technique that evaluates features through the variance between and within classes. The features achieving the highest F-statistic score can better discriminate the sampled data.
Taking into consideration the datasets lasting 90 s and 180 s,
Table 12 and
Table 13 present the mean, median, dissimilarity measure, and normalized variance of the 10 features obtaining the highest F-statistic values. The mean represents the average performance of a particular feature considering all datasets. The median, on the other hand, indicates the overall performance while ignoring the effect of outliers. The dissimilarity is computed as
and represents the relative difference between the mean and the median value of a particular feature. The normalized variance is computed as
, where Max is the maximum variance value from all 15 features and Min is the minimum variance value from all 15 features. The normalized variance indicates how distant the F-statistic values are from the mean value.
Each feature represented in
Table 12 and
Table 13 is color-labeled, and each color identifies which element was used to compute the feature. The blue color represents a feature computed from data acquired from the reference antenna, the yellow color represents a feature computed from data acquired from the surveillance antenna, and the orange color represents a feature that was computed using the data that resulted from the difference between the complex values acquired by the reference antenna (reference signal) and the complex values acquired by the surveillance antenna (surveillance signal).
Regarding the reference signal, Feature1 and Feature5 are the two features containing the lowest mean and median values. Comparing them, Feature5 exhibits lower mean and median values and higher dissimilarity and normalized variance values. For this reason, Feature1 is preferred. The features Feature9 and Feature14 are very similar in terms of their performance, both having a higher mean and median value than Feature1. Nonetheless, their dissimilarity and normalized variance values are significantly higher than Feature1. Given that a robust and consistent system is desired, Feature1 is preferred as a discriminant of the data obtained from the reference antenna.
Regarding the data obtained from the surveillance antenna, although Feature10 and Feature15 are the features that contain the highest mean value of all features, they also have the highest normalized variance values. Thus, Feature2 is preferred to describe the data obtained from the surveillance antenna.
Lastly, considering the features computed from the difference between the reference and surveillance data, Feature11 achieves the highest dissimilarity and normalized variance values of the three candidate features, and hence, it is discarded. The features Feature3 and Feature6 are very similar: Feature6 achieves a higher dissimilarity value and Feature3 has a higher normalized variance. Feature6 is chosen as the preferred one because we consider the variance as a more important metric in terms of measuring the overall performance of the system.
The two features to be used in the real-time classification process, out of Feature1, Feature2, and Feature6, are dynamically selected from the ones achieving the best ANOVA F-statistic.
3.3. Classification Methods
Regarding the classification methodologies, we exploited three different classification techniques:
The sum of distances to all clusters’ points;
Support Vector Machine (SVM);
K-Nearest Neighbors (KNN).
In the first classification method, for each value pair obtained from the two selected features, we compute the total distance as the sum of all distances between that input and all points of the class cluster in the calibration dataset. Then, the method outputs the total distances for all clusters, and the cluster achieving the smallest total distance is considered as the predicted class. We used a total of 9 different distance metrics to compute this method: city block (or Manhattan), Euclidean, standardized Euclidean, squared Euclidean, cosine, Chebyshev (or infinite norm), Canberra, Bray–Curtis, and Mahalanobis.
Regarding the SVM classification technique, we used three different kernel types in the algorithm: linear, polynomial ( degree), and Radial Basis Function (RBF).
The KNN method is adopted using number of neighbors and, additionally, exploiting six distance metrics, namely city block, euclidean, cosine, Chebyshev, Canberra, and Bray–Curtis. For each distance metric, we computed the KNN for every different N.
For both the SVM and KNN classifiers, we used the
Scikit-learn Python free software ML library [
19] to train and classify the data.
Considering the offline classification step, only the 180 s datasets were used. This means that we used the data from 22 different datasets for this particular step. We performed an offline classification in which each classifier was trained with the labeled data received from the calibration data. The two selected features are computed for each 25 kS sliding window of each test portion. After computing the two features, a 2D feature output was constructed by placing the value of one feature on one axis and the value of the other feature on the other axis, as shown in
Figure 8.
As described in
Table 11, for a 180 s dataset, 560 feature outputs can be computed for each class. However, since only the test portions of each dataset are considered for the classification step, 560 − 60 = 500 feature outputs are computed for each class. Note that the 500 feature outputs are used to obtain 500 system classifications. Sample averaging was adopted, and 10 2D feature outputs were stored before feeding the classifier. This means that the classifier was fed with the 2D median of the accumulated feature outputs. Therefore, the total number of classifier predictions for each class can be summarized as described in
Table 14.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}