
Multi-Objective Optimization in Air-to-Air Communication System Based on Multi-Agent Deep Reinforcement Learning


Abstract
:1. Introduction
1.1. Background and Related Works
1.2. Motivations and Contribution
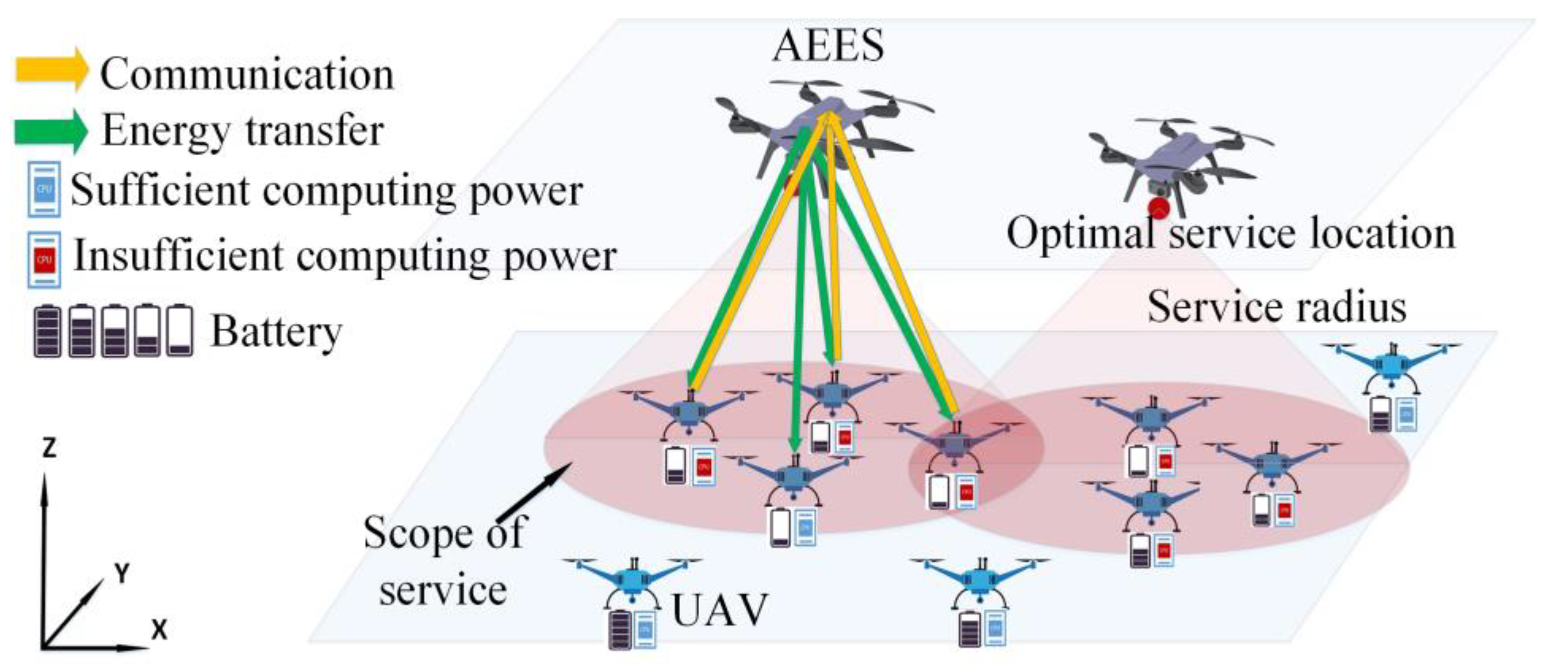
- We propose a novel full-duplex A2ACS model combining WPT with MEC technology. This system uses AEESs to provide wireless charging services and edge computing for airborne UAVs. It can effectively reduce the computational delay and energy consumption of the UAVs, while ensuring that the UAVs will not interrupt the mission or leave the work area due to insufficient energy.
- We construct a MOO model for optimizing AEESs’ service location and energy transmit power. The model fully considers multiple objectives such as mission offloading, energy transfer, prioritization of UAVs, and energy consumption. We formulate four optimization objectives, including maximizing system throughput, minimizing the number of low-power UAV alarms, minimizing system energy consumption, and maximizing the energy transfer efficiency. The optimization objective weights can be adjusted according to the needs of real scenarios.
- We propose a decision-making algorithm as multi-objective deep deterministic policy gradient (MODDPG) based on the DDPG algorithm to achieve multi-objective optimization. We also propose a K-MAU (K-means for AEESs and UAVs) algorithm based on K-means clustering algorithm to determine the association between AEESs and UAVs, to ensure the fairness of the service.
2. System Model and Problem Formulation
2.1. Channel Model
2.1.1. Energy Transfer Channel
2.1.2. Communication Channel
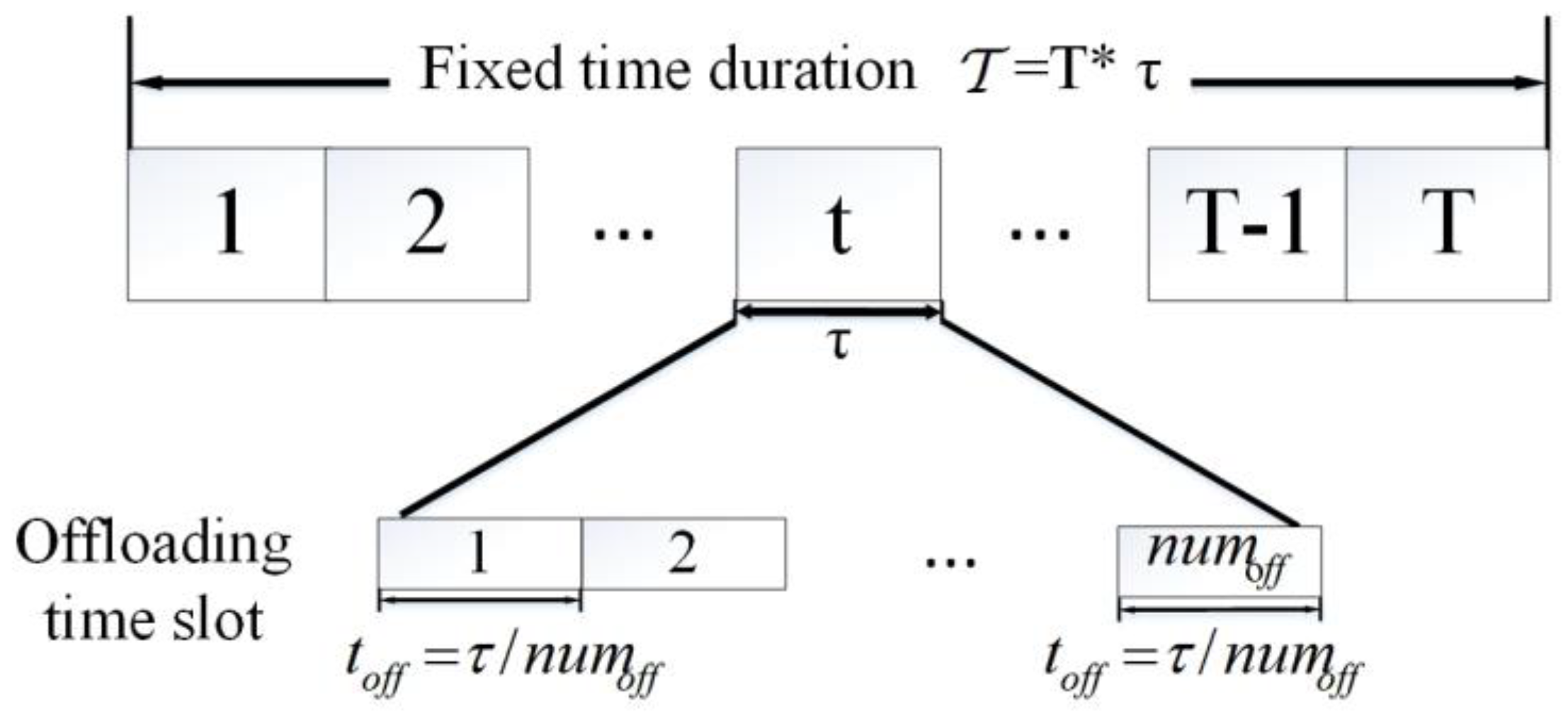
2.2. Computing and Offloading Model
2.3. Wireless Power Transfer and Energy Harvesting Model
2.4. Energy Consumption Model
2.4.1. Changes in the Energy of Unmanned Aerial Vehicles
2.4.2. Changes in the Energy of Air-Edge Energy Servers
2.5. Problem Formulation
- Optimization objective 1:
- Optimization objective 2:
- Optimization objective 3:
- Optimization objective 4:
3. Deep Deterministic Policy Gradient-Based Method for Air-to-Air Multi-Objective Optimization Problem
3.1. Problem Transformation
3.1.1. State Space
3.1.2. Action Space
3.1.3. Reward and Penalty
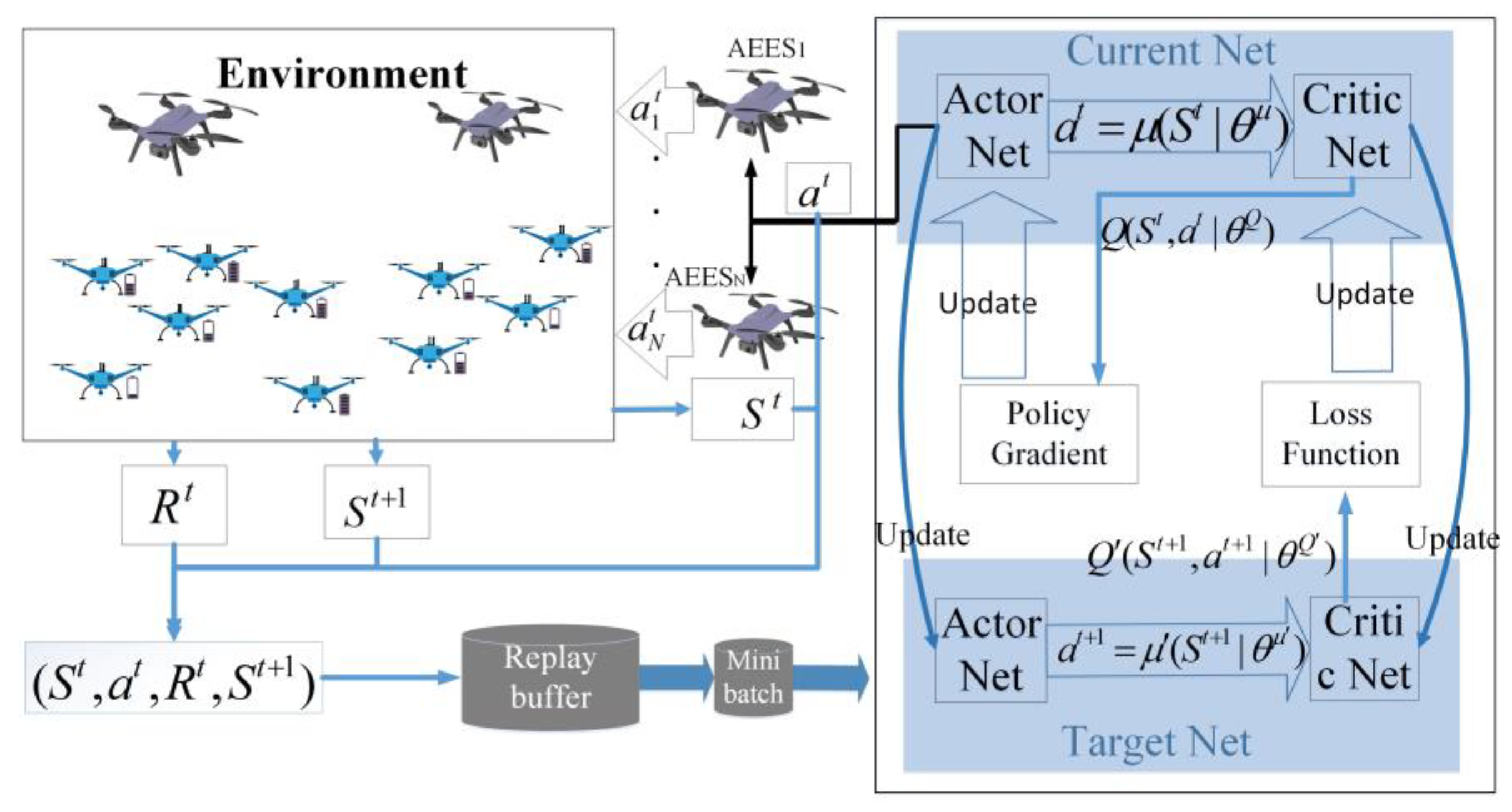
3.2. Multi-Objective Deep Deterministic Policy Gradient Algorithm
| Algorithm 1: MODDPG Algorithm |
| Input:. |
| Initialize: |
| and the number of training steps T. |
| ); |
| ; |
| ; |
| ; |
| do |
| 6: ; |
| 7: for t ← 1…T do |
| 8: Gradually reducing exploration probability: ; |
| 9: ; |
| 10: get b[n][m] according to Algorithm 2; |
| 11: ; |
| 12: ; |
| 13: ; |
| 14: If updated then |
| 15: ; |
| 16: by minimizing its loss function according to Equation (30); |
| 17: by using the policy gradient approach according to Equation (31); |
| 18: by Equations (32) and (33); |
| 19: end for |
| 20: end for |
| Algorithm 2: K-means for AEESs-UAVs (KMID) |
| Input:). |
| output: The relation matrix b[n][m] of AEESs and UAVs. |
| Begin |
| 1: Initialize: b[n][m]=0 |
| 3: for i ← 1 : Iterations do |
| 4: for n ← 1 : N do |
| 5: for m ← 1 : M do |
| 6: ← Calculate the energy transfer channel gain and communication channel gain between AEESn and UAVm |
| 7: end for |
| 8: end for |
| 9: for m ← 1 : M do |
| 10: UAVm joins the cluster of AEESn that is closer in energy transfer channel gain and communication channel gain: |
| 11: end for |
| 12: for n ← 1 : N do |
| 13: |
| 14: end for |
| 15: If no longer changes then end the loop. |
| 16: for n ← 1 : N do |
| 17: for m ← 1 : M do |
| 18: If UAVn∈ and |
| 19: Else : |
| 20: end for |
| 21: end for |
3.3. K-means for Air-Edge Energy Servers and Unmanned Aerial Vehicles (K-MAU)
4. Simulation Results
4.1. Simulation Settings
4.2. Results and Analysis
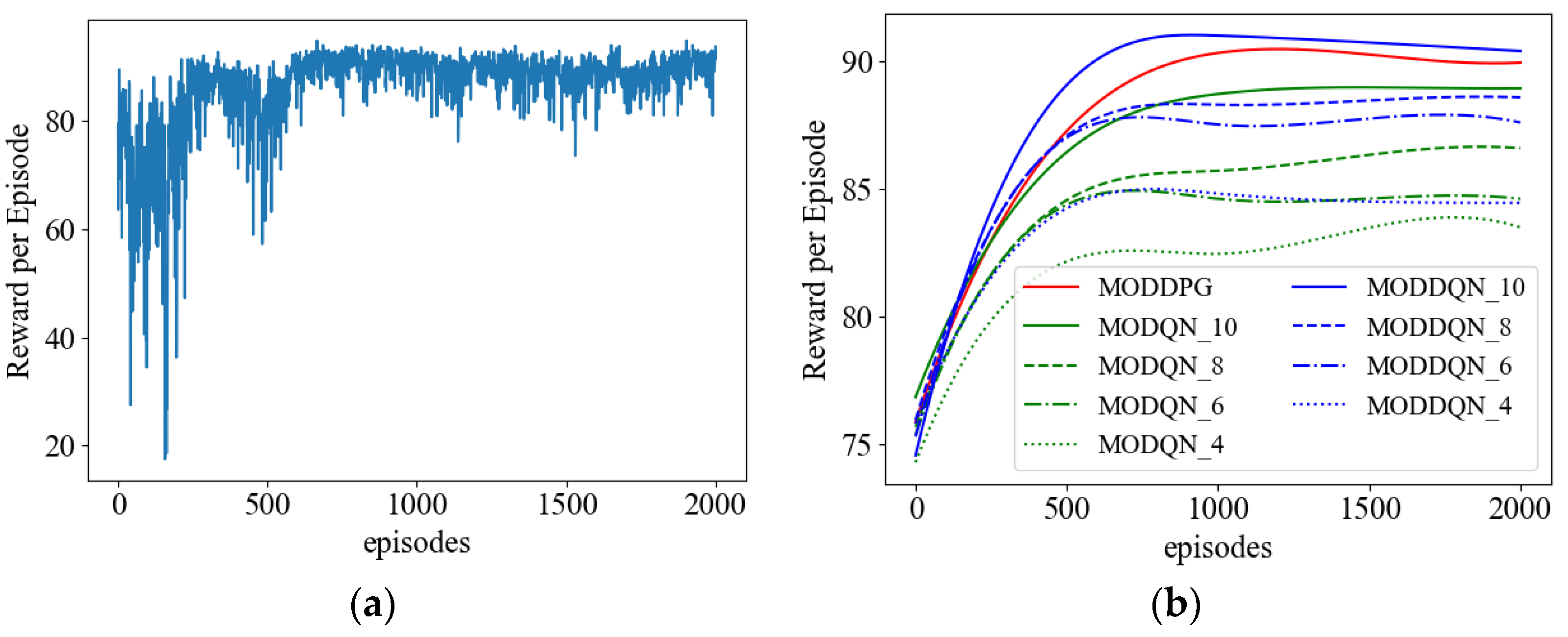
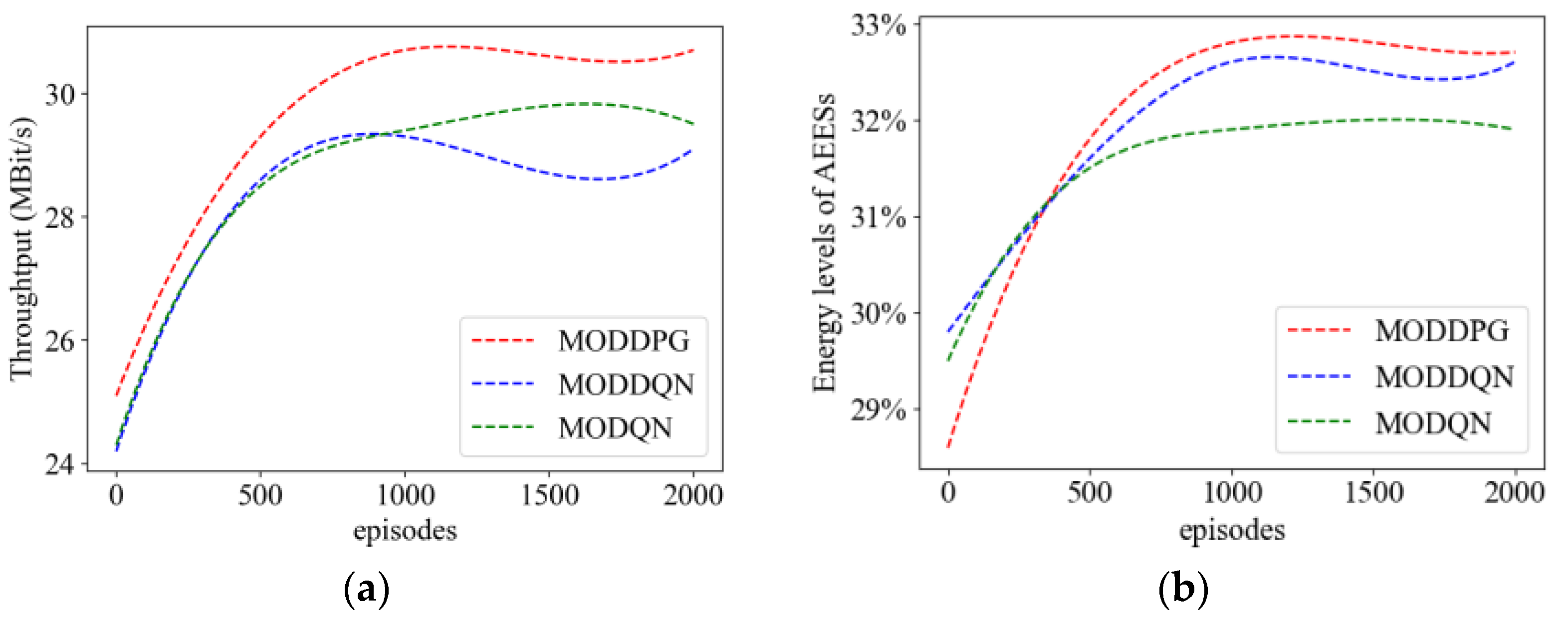
4.2.1. Convergence Analysis
4.2.2. Comparison of Training Time and Model Size
4.2.3. Comparison of Metrics during the Training Process
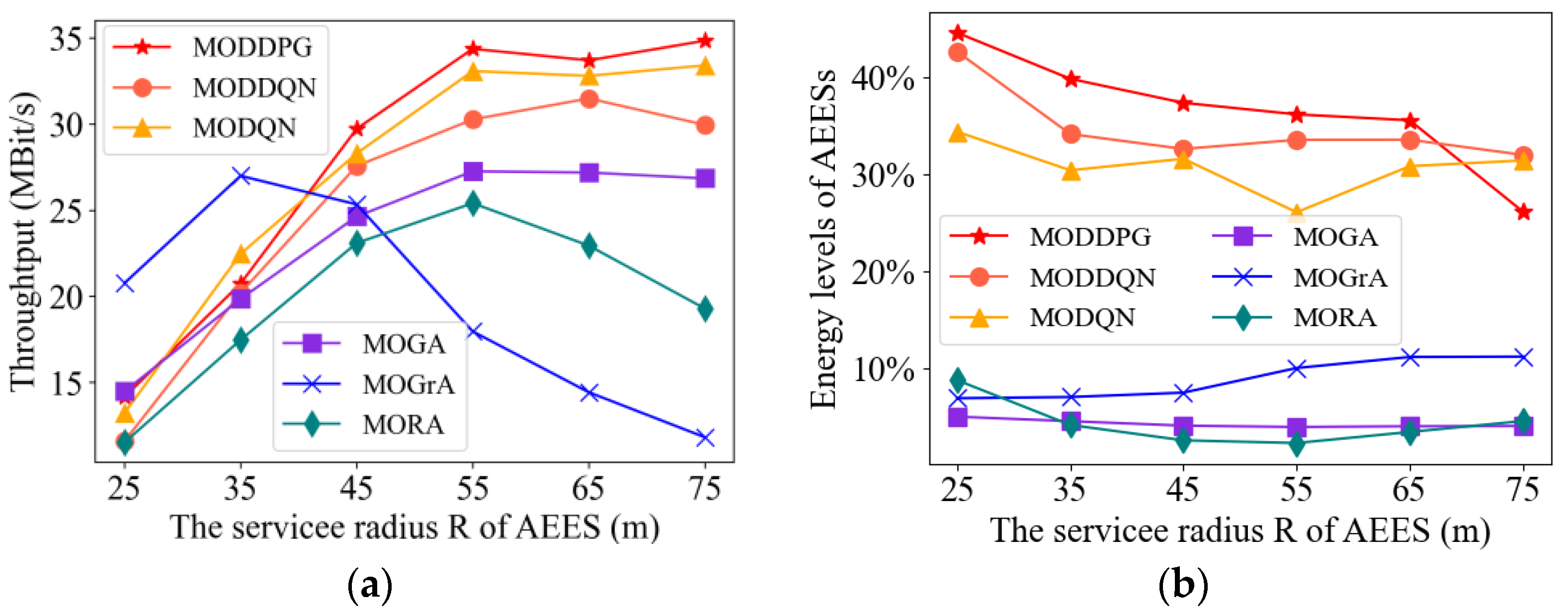
4.2.4. Impact of Air-Edge Energy Server Coverage
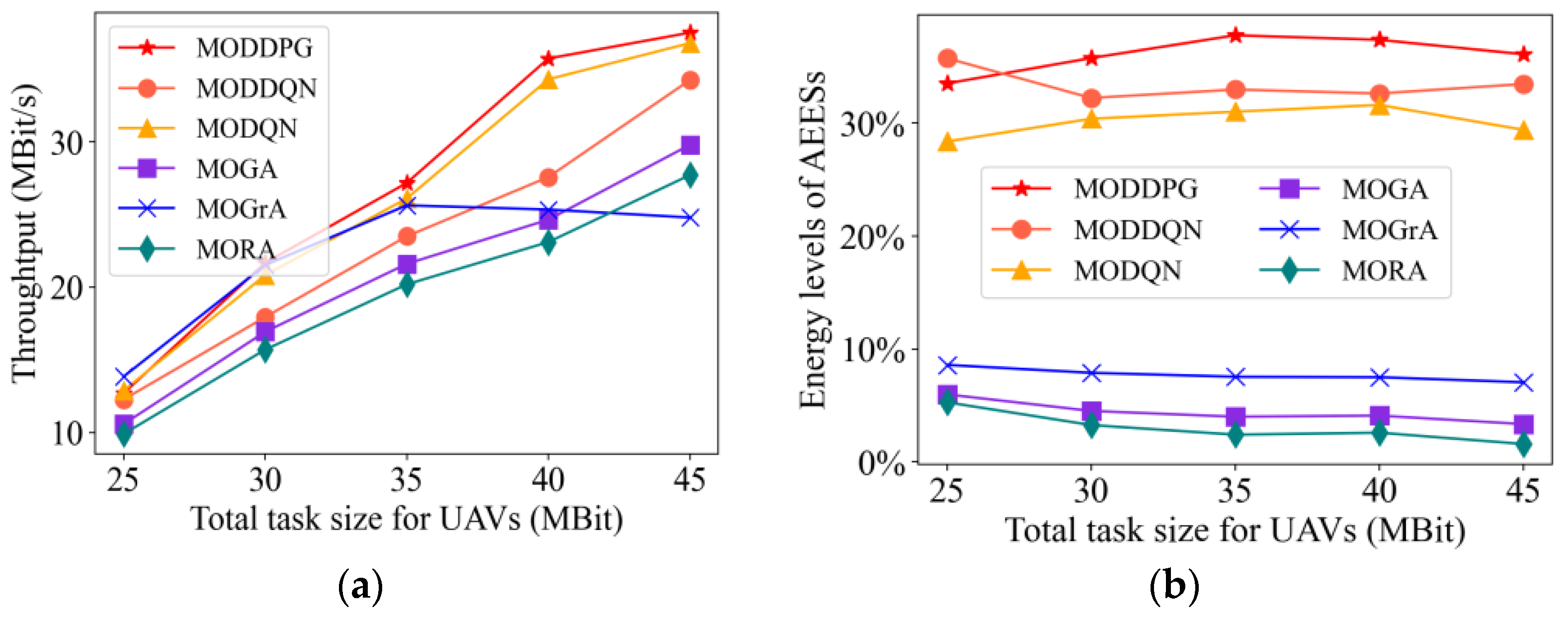
4.2.5. Impact of Total Task Size
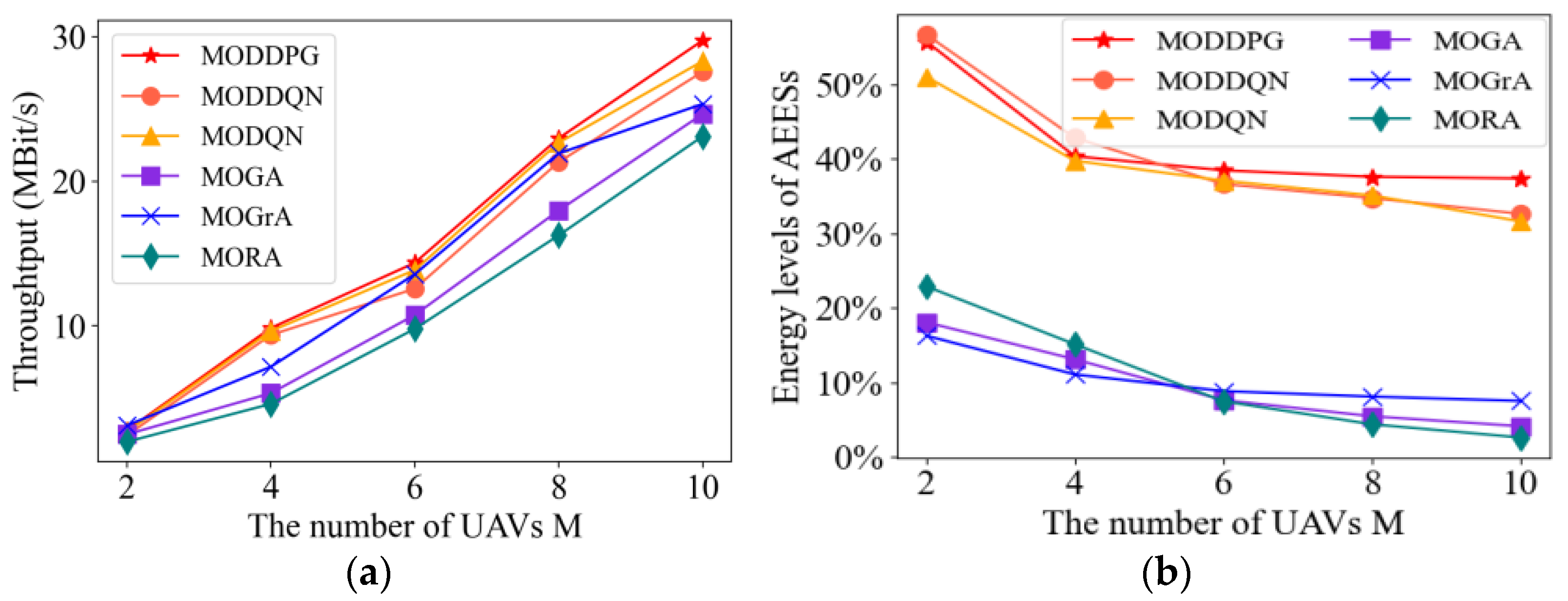
4.2.6. Impact of Unmanned Aerial Vehicle Numbers
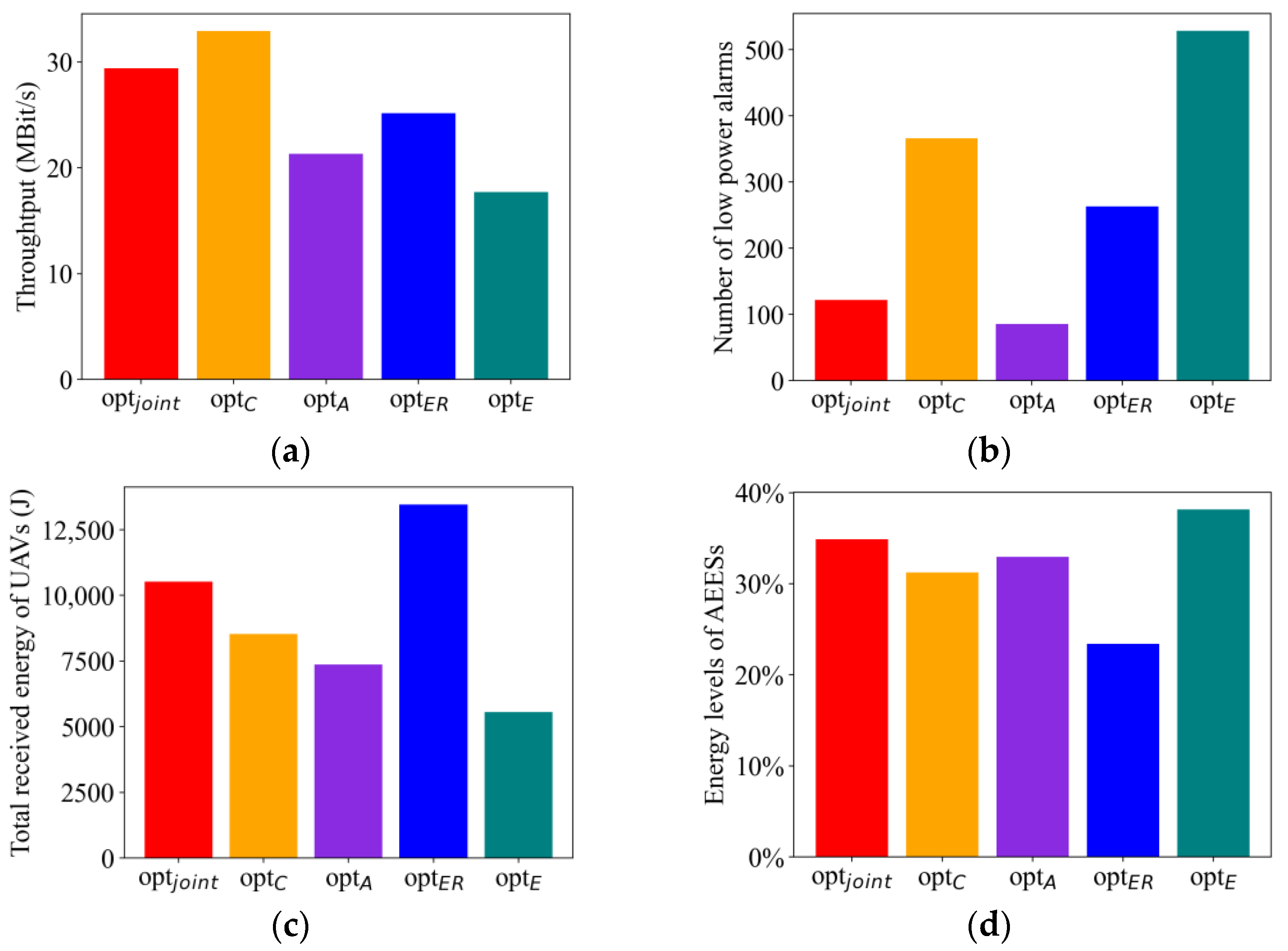
4.2.7. Comparison of Optimization Goals
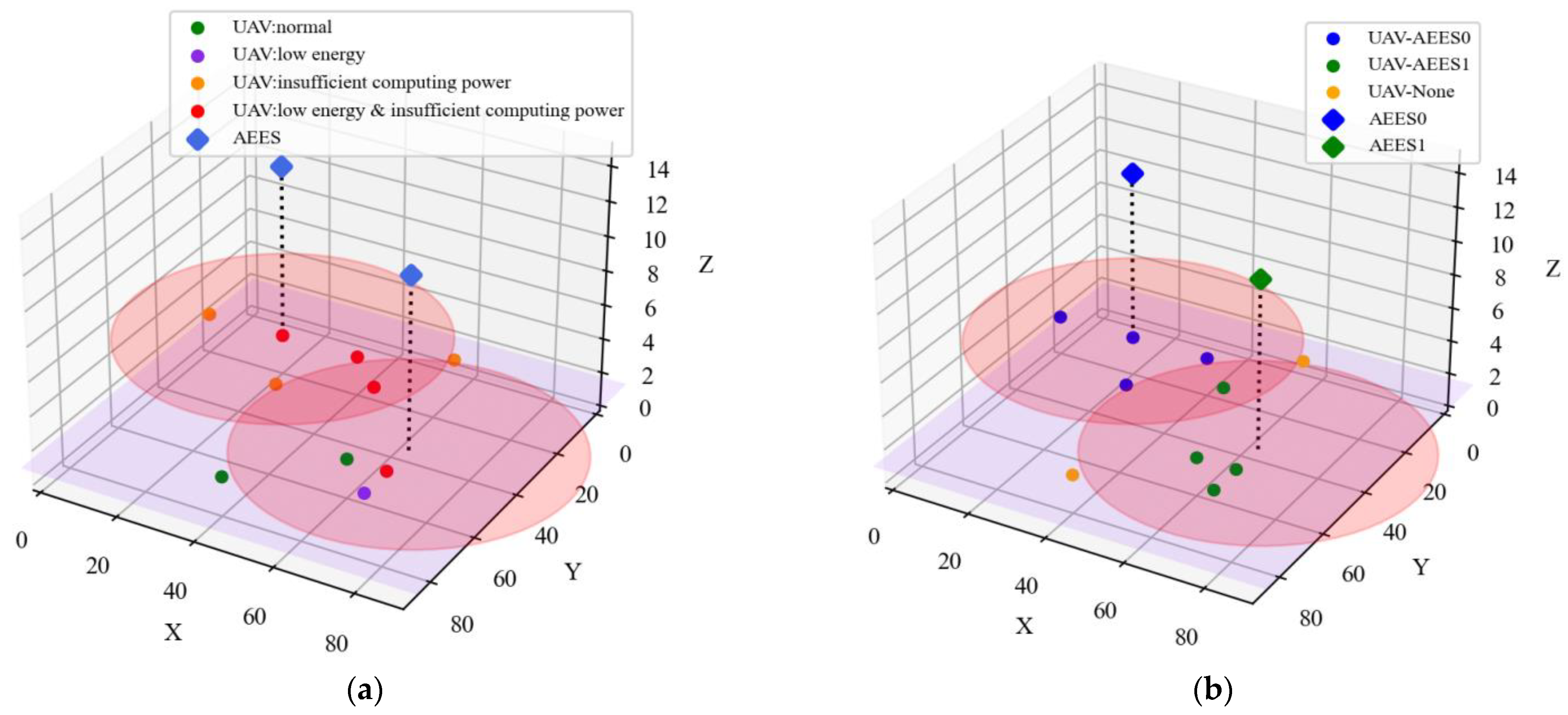
4.2.8. Performance of K-MAU Algorithm
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kouadio, L.; El Jarroudi, M.; Belabess, Z.; Laasli, S.-E.; Roni, M.Z.K.; Amine, I.D.I.; Mokhtari, N.; Mokrini, F.; Junk, J.; Lahlali, R. A Review on UAV-Based Applications for Plant Disease Detection and Monitoring. Remote Sens. 2023, 15, 4273. [Google Scholar] [CrossRef]
- Srivastava, K.; Patel, D.; Jha, A.K.; Jha, M.K.; Singh, J.; Sarvadevabhatla, R.K.; Ramancharla, P.K.; Kandath, H.; Krishna, K.M. UAV-Based Visual Remote Sensing for Automated Building Inspection. In Computer Vision–ECCV 2022 Workshops; Karlinsky, L., Michaeli, T., Nishino, K., Eds.; Springer Nature Switzerland: Cham, Switzerland, 2023; pp. 299–316. [Google Scholar]
- Ou, Q.; Wu, K. Overview and Key Technology Summary of Drone Swarm Operation. In Proceedings of the 2022 International Conference on Autonomous Unmanned Systems (ICAUS 2022), Xi’an, China, 23–25 September 2022; Fu, W., Gu, M., Niu, Y., Eds.; Springer Nature: Singapore, 2023; pp. 3825–3833. [Google Scholar]
- Li, W.; Wu, G.; Sun, H.; Bai, C.; Bao, W. Dim and Small Target Detection in Unmanned Aerial Vehicle Images. In Proceedings of the 2022 International Conference on Autonomous Unmanned Systems (ICAUS 2022), Xi’an, China, 23–25 September 2022; Fu, W., Gu, M., Niu, Y., Eds.; Springer Nature: Singapore, 2023; pp. 3143–3152. [Google Scholar]
- Mehrabi, M.; You, D.; Latzko, V.; Salah, H.; Reisslein, M.; Fitzek, F.H.P. Device-Enhanced MEC: Multi-Access Edge Computing (MEC) Aided by End Device Computation and Caching: A Survey. IEEE Access 2019, 7, 166079–166108. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Yu, K.; Budhiraja, A.K.; Tokekar, P. Algorithms for Routing of Unmanned Aerial Vehicles with Mobile Recharging Stations. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 5720–5725. [Google Scholar]
- Morton, S.; D’Sa, R.; Papanikolopoulos, N. Solar Powered UAV: Design and Experiments. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 2460–2466. [Google Scholar]
- Zhang, H.; Guo, Y.; Zhong, Z.; Wu, W. Cooperative Integration of RF Energy Harvesting and Dedicated WPT for Wireless Sensor Networks. IEEE Microw. Wirel. Compon. Lett. 2019, 29, 291–293. [Google Scholar] [CrossRef]
- Fallahpour, S.A.; Karimian, S.; Mehrshahi, E. Design of a High-Efficiency RF Energy Harvesting System. In Proceedings of the 2022 30th International Conference on Electrical Engineering (ICEE), Tehran, Iran, 17–19 May 2022; pp. 920–925. [Google Scholar]
- Xu, J.; Zeng, Y.; Zhang, R. UAV-Enabled Wireless Power Transfer: Trajectory Design and Energy Optimization. IEEE Trans. Wirel. Commun. 2018, 17, 5092–5106. [Google Scholar] [CrossRef]
- Xie, L.; Cao, X.; Xu, J.; Zhang, R. UAV-Enabled Wireless Power Transfer: A Tutorial Overview. IEEE Trans. Green Commun. Netw. 2021, 5, 2042–2064. [Google Scholar] [CrossRef]
- Shu, Y.; Yousefi, H.; Cheng, P.; Chen, J.; Gu, Y.J.; He, T.; Shin, K.G. Near-Optimal Velocity Control for Mobile Charging in Wireless Rechargeable Sensor Networks. IEEE Trans. Mob. Comput. 2016, 15, 1699–1713. [Google Scholar] [CrossRef]
- Yuan, X.; Sun, G.; Hu, Y.; Wu, L.; Wang, H.; Schmeink, A. UAV Trajectory Design on Completion Time Minimization of WPT Task in UAV-Enabled Multi-User Network. In Proceedings of the 2022 IEEE International Conference on Communications Workshops (ICC Workshops), Seoul, Republic of Korea, 16–20 May 2022; pp. 1047–1052. [Google Scholar]
- He, X.; Zhao, Y.; Xu, Z.; Chen, Y. Resource Allocation Strategy for UAV-Assisted Non-Linear Energy Harvesting MEC System. In Proceedings of the 2022 IEEE 95th Vehicular Technology Conference: (VTC2022-Spring), Helsinki, Finland, 19–22 June 2022; pp. 1–7. [Google Scholar]
- Liu, Y.; Xiong, K.; Ni, Q.; Fan, P.; Letaief, K.B. UAV-Assisted Wireless Powered Cooperative Mobile Edge Computing: Joint Offloading, CPU Control, and Trajectory Optimization. IEEE Internet Things J. 2020, 7, 2777–2790. [Google Scholar] [CrossRef]
- Xu, H.; Pan, C.; Wang, K.; Chen, M.; Nallanathan, A. Resource Allocation for UAV-Assisted IoT Networks with Energy Harvesting and Computation Offloading. In Proceedings of the 2019 11th International Conference on Wireless Communications and Signal Processing (WCSP), Xi’an, China, 23–25 October 2019; pp. 1–7. [Google Scholar]
- Yu, Y.; Tang, J.; Huang, J.; Zhang, X.; So, D.K.C.; Wong, K.-K. Multi-Objective Optimization for UAV-Assisted Wireless Powered IoT Networks Based on Extended DDPG Algorithm. IEEE Trans. Commun. 2021, 69, 6361–6374. [Google Scholar] [CrossRef]
- Oubbati, O.S.; Lakas, A.; Guizani, M. Multiagent Deep Reinforcement Learning for Wireless-Powered UAV Networks. IEEE Internet Things J. 2022, 9, 16044–16059. [Google Scholar] [CrossRef]
- Shi, X.; Wang, A.; Sun, G.; Li, J.; Zheng, X. Air to Air Communications Based on UAV-Enabled Virtual Antenna Arrays: A Multi-Objective Optimization Approach. In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; pp. 878–883. [Google Scholar]
- Nie, Y.; Zhao, J.; Liu, J.; Jiang, J.; Ding, R. Energy-Efficient UAV Trajectory Design for Backscatter Communication: A Deep Reinforcement Learning Approach. China Commun. 2020, 17, 129–141. [Google Scholar] [CrossRef]
- Wu, Q.; Xu, J.; Zeng, Y.; Ng, D.W.K.; Al-Dhahir, N.; Schober, R.; Swindlehurst, A.L. A Comprehensive Overview on 5G-and-Beyond Networks with UAVs: From Communications to Sensing and Intelligence. IEEE J. Sel. Areas Commun. 2021, 39, 2912–2945. [Google Scholar] [CrossRef]
- Zhang, Z.; Xiao, Y.; Ma, Z.; Xiao, M.; Ding, Z.; Lei, X.; Karagiannidis, G.K.; Fan, P. 6G Wireless Networks: Vision, Requirements, Architecture, and Key Technologies. IEEE Veh. Technol. Mag. 2019, 14, 28–41. [Google Scholar] [CrossRef]
- Liu, C.H.; Chen, Z.; Tang, J.; Xu, J.; Piao, C. Energy-Efficient UAV Control for Effective and Fair Communication Coverage: A Deep Reinforcement Learning Approach. IEEE J. Sel. Areas Commun. 2018, 36, 2059–2070. [Google Scholar] [CrossRef]
- Liu, C.H.; Dai, Z.; Zhao, Y.; Crowcroft, J.; Wu, D.; Leung, K.K. Distributed and Energy-Efficient Mobile Crowdsensing with Charging Stations by Deep Reinforcement Learning. IEEE Trans. Mob. Comput. 2021, 20, 130–146. [Google Scholar] [CrossRef]
- Peng, Y.; Liu, Y.; Zhang, H. Deep Reinforcement Learning Based Path Planning for UAV-Assisted Edge Computing Networks. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar]
- Ouamri, M.A.; Barb, G.; Singh, D.; Adam, A.B.M.; Muthanna, M.S.A.; Li, X. Nonlinear Energy-Harvesting for D2D Networks Underlaying UAV with SWIPT Using MADQN. IEEE Commun. Lett. 2023, 27, 1804–1808. [Google Scholar] [CrossRef]
- Wang, L.; Wang, K.; Pan, C.; Xu, W.; Aslam, N.; Hanzo, L. Multi-Agent Deep Reinforcement Learning-Based Trajectory Planning for Multi-UAV Assisted Mobile Edge Computing. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 73–84. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, J.; Zhao, X. Deep Reinforcement Learning Based Latency Minimization for Mobile Edge Computing with Virtualization in Maritime UAV Communication Network. IEEE Trans. Veh. Technol. 2022, 71, 4225–4236. [Google Scholar] [CrossRef]
- Do, Q.T.; Hua, D.T.; Tran, A.T.; Cho, S. Energy Efficient Multi-UAV Communication Using DDPG. In Proceedings of the 2022 13th International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 19–21 October 2022; pp. 1071–1075. [Google Scholar]
- Bi, S.; Zhang, Y.J. Computation Rate Maximization for Wireless Powered Mobile-Edge Computing with Binary Computation Offloading. IEEE Trans. Wirel. Commun. 2018, 17, 4177–4190. [Google Scholar] [CrossRef]
- Yang, Z.; Bi, S.; Zhang, Y.-J.A. Stable Online Offloading and Trajectory Control for UAV-Enabled MEC with EH Devices. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 01–07. [Google Scholar]
- Yang, Z.; Xu, W.; Shikh-Bahaei, M. Energy Efficient UAV Communication with Energy Harvesting. IEEE Trans. Veh. Technol. 2020, 69, 1913–1927. [Google Scholar] [CrossRef]
- Yang, Z.; Bi, S.; Zhang, Y.-J.A. Dynamic Offloading and Trajectory Control for UAV-Enabled Mobile Edge Computing System with Energy Harvesting Devices. IEEE Trans. Wirel. Commun. 2022, 21, 10515–10528. [Google Scholar] [CrossRef]
- Wang, X.; Chen, H.; Liu, T.; He, K.; Ding, D.; Yong, E. Application of Improved K-Means Clustering Algorithm in UAV Reconnaissance Mission Planning. In Proceedings of the 2021 China Automation Congress (CAC), Beijing, China, 22–24 October 2021; pp. 2744–2748. [Google Scholar]
- Luo, J.; Song, J.; Zheng, F.-C.; Gao, L.; Wang, T. User-Centric UAV Deployment and Content Placement in Cache-Enabled Multi-UAV Networks. IEEE Trans. Veh. Technol. 2022, 71, 5656–5660. [Google Scholar] [CrossRef]
- Yue, X.; Zhang, W. UAV Path Planning Based on K-Means Algorithm and Simulated Annealing Algorithm. In Proceedings of the 2018 37th Chinese Control Conference (CCC), Wuhan, China, 25–27 July 2018; pp. 2290–2295. [Google Scholar]
- Singh, A.; Redhu, S.; Hegde, R.M. UAV Altitude Optimization for Efficient Energy Harvesting in IoT Networks. In Proceedings of the 2022 National Conference on Communications (NCC), Mumbai, India, 24–27 May 2022; pp. 350–355. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value | Parameters | Value |
|---|---|---|---|
| Altitude of AEESn | 90 m | Flight speed of AEESn | 5 m/s |
| Altitude of UAVm | 100 m | Flight speed of UAVm | 5 m/s |
| Number of AEESs N | 2 | Battery capacity of AEESn | 8000 J |
| Number of UAVs M | 10 | Battery capacity of UAVm | 50 J |
| Time duration | 100 s | Transmit power of UAVm | 1.5 W |
| Number of time slots T | 100 | The speed of light c | 3 × 108 m/s |
| Length of time slot | 1 s | Reference channel gain | −30 dB |
| Length of area x | 100 m | Communication bandwidth W | 5 × 106 Hz |
| Width of area y | 100 m | Energy loss factor | 0.6 |
| Service radius of AEESs R | 50 m | CPU frequency of AEESn | 10 GHz |
| Minimum transmit power for AEESs | 40 W | CPU frequency of UAVm | 500 MHz |
| Maximum transmit power of AEESs | 50 W | CPU consumption factor | 10−27 |
| Path loss index | 2.2 | Process density | 103 cycles/bit |
| Transmission frequency of AEESs q | 500 MHz |
| Parameters | Value | Parameters | Value |
|---|---|---|---|
| Memory size | 20,000 | Actor learning rate | 0.001 |
| Mini-batch size | 128 | Maximum exploration rate | 0.99 |
| Steps for updating target | 100 | Reward decay rate | 0.9 |
| Steps for learning | 30 | Decreasing rate of exploration | 0.0002 |
| Optimizer method | Adam | Target soft update | 0.25 |
| Optimizer method | RMSProp | Number of neurons of hidden layer in the actor | [128, 256] |
| Critic learning rate | 0.001 | Number of neurons of hidden layer in the critic | [128, 256] |
| Name | MODDPG | MODDQN_10 | MODDQN_8 | MODDQN_6 | MODDQN_4 | MODQN_10 | MODQN_8 | MODQN_6 | MODQN_4 |
|---|---|---|---|---|---|---|---|---|---|
| Action Space Size | 6 | ||||||||
| Training Time (min) | 18 | 52 | 28 | 22 | 20 | 43 | 37 | 22 | 23 |
| Model Size (M) | 0.71 | 247.97 | 65.01 | 11.05 | 1.03 | 247.97 | 65.01 | 11.05 | 1.03 |
| Name | |
|---|---|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, S.; Chen, Y.; Li, S. Multi-Objective Optimization in Air-to-Air Communication System Based on Multi-Agent Deep Reinforcement Learning. Sensors 2023, 23, 9541. https://doi.org/10.3390/s23239541
Lin S, Chen Y, Li S. Multi-Objective Optimization in Air-to-Air Communication System Based on Multi-Agent Deep Reinforcement Learning. Sensors. 2023; 23(23):9541. https://doi.org/10.3390/s23239541
Chicago/Turabian StyleLin, Shaofu, Yingying Chen, and Shuopeng Li. 2023. "Multi-Objective Optimization in Air-to-Air Communication System Based on Multi-Agent Deep Reinforcement Learning" Sensors 23, no. 23: 9541. https://doi.org/10.3390/s23239541
APA StyleLin, S., Chen, Y., & Li, S. (2023). Multi-Objective Optimization in Air-to-Air Communication System Based on Multi-Agent Deep Reinforcement Learning. Sensors, 23(23), 9541. https://doi.org/10.3390/s23239541