
Automatic Roadside Camera Calibration with Transformers


Abstract
:1. Introduction
- We have introduced a camera self-calibration model for vanishing point detection in traffic scenes called “TLCalib”, which is, to our knowledge, the first Transformer-based approach for this purpose. This model combines road and vehicle features to infer vanishing points, incorporating a broader range of features for enhanced accuracy. Additionally, it integrates both semantic and geometric features to improve adaptability across diverse scenarios.
- To simplify the detection process for the second vanishing point while improving its accuracy, we adopt an approach that bypasses edge detection. Instead, we directly employ Line Segment Detector (LSD) to detect vehicle line segments in each frame and accumulate them. This process eliminates the need for designing edge-background models and utilizes the Transformer to predict line segment classification, achieving comparable results. This operation not only reduces manual parameter settings but also operational complexity and the potential for errors.
- Our method has been tested in both real-world and dataset scenarios. Experimental results indicate that our approach outperforms traditional methods and deep learning-based methods in both traffic scenes and our dataset, achieving promising results.
2. Related Work
2.1. Transformers in Vision
2.2. Camera Calibration
2.2.1. Direct Linear Transform (DLT)-Based
2.2.2. Zhang’s Method
2.2.3. Vanishing Point-Based
2.2.4. Deep Learning Based
2.3. Traffic Camera Calibration
2.3.1. Road-Based Vanishing Point Detection
2.3.2. Vehicle-Based Vanishing Point Detection
2.3.3. Deep Learning-Based Camera Calibration in Traffic Scenes
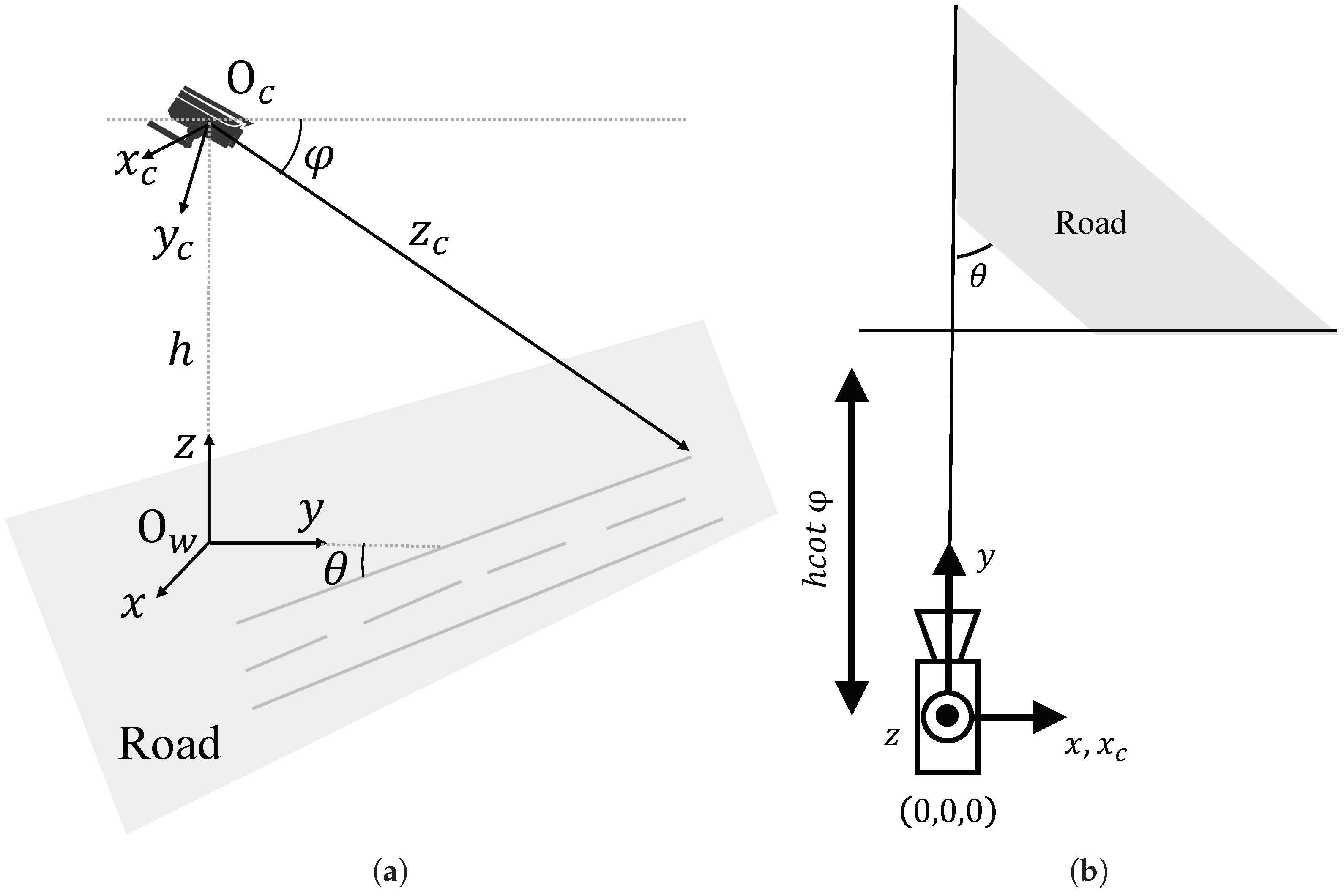
3. Auto Calibration Principle of Traffic Camera
Auto-Calibration Model
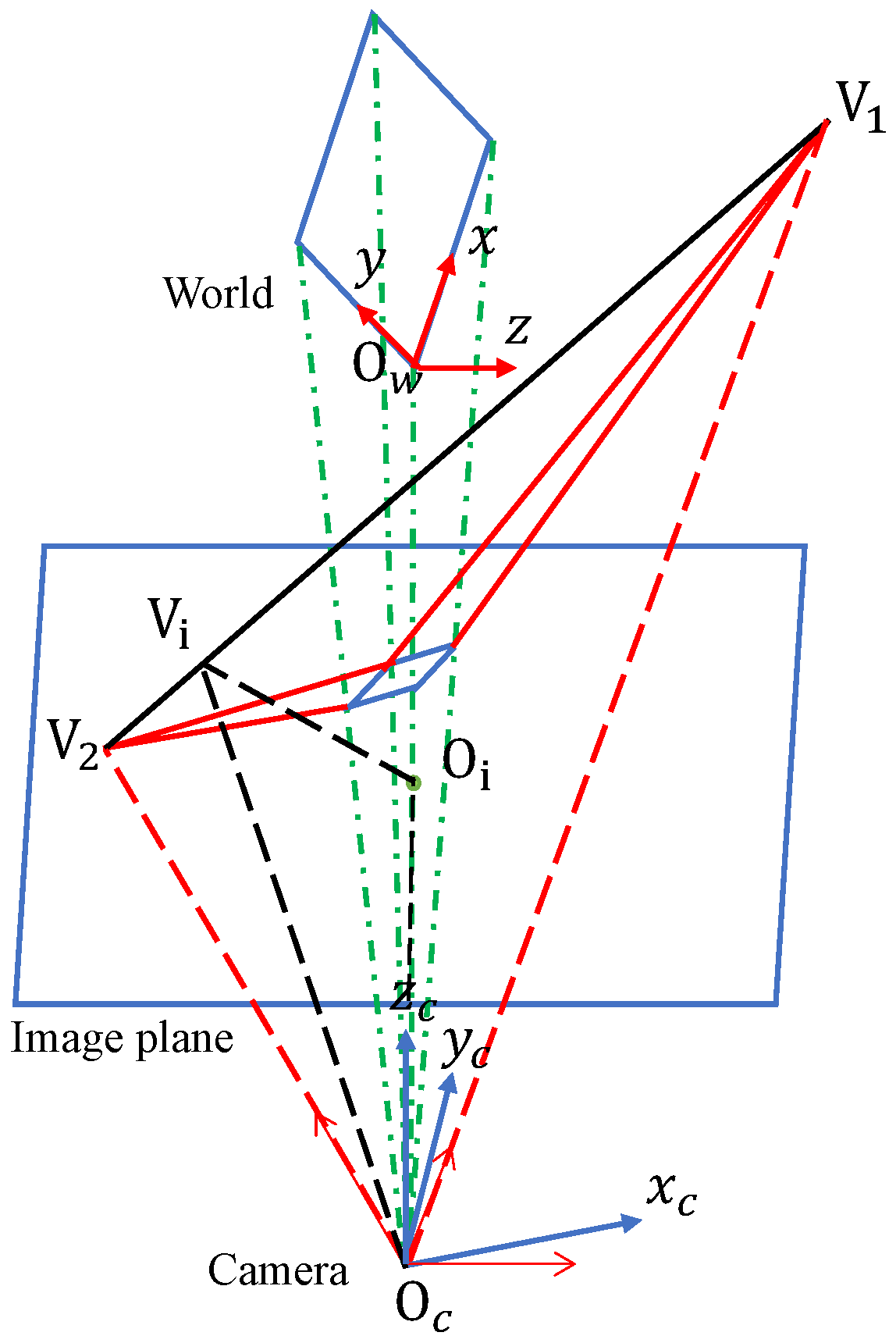
4. Vanishing Point Detection Network
4.1. Representation of the Vanishing Points
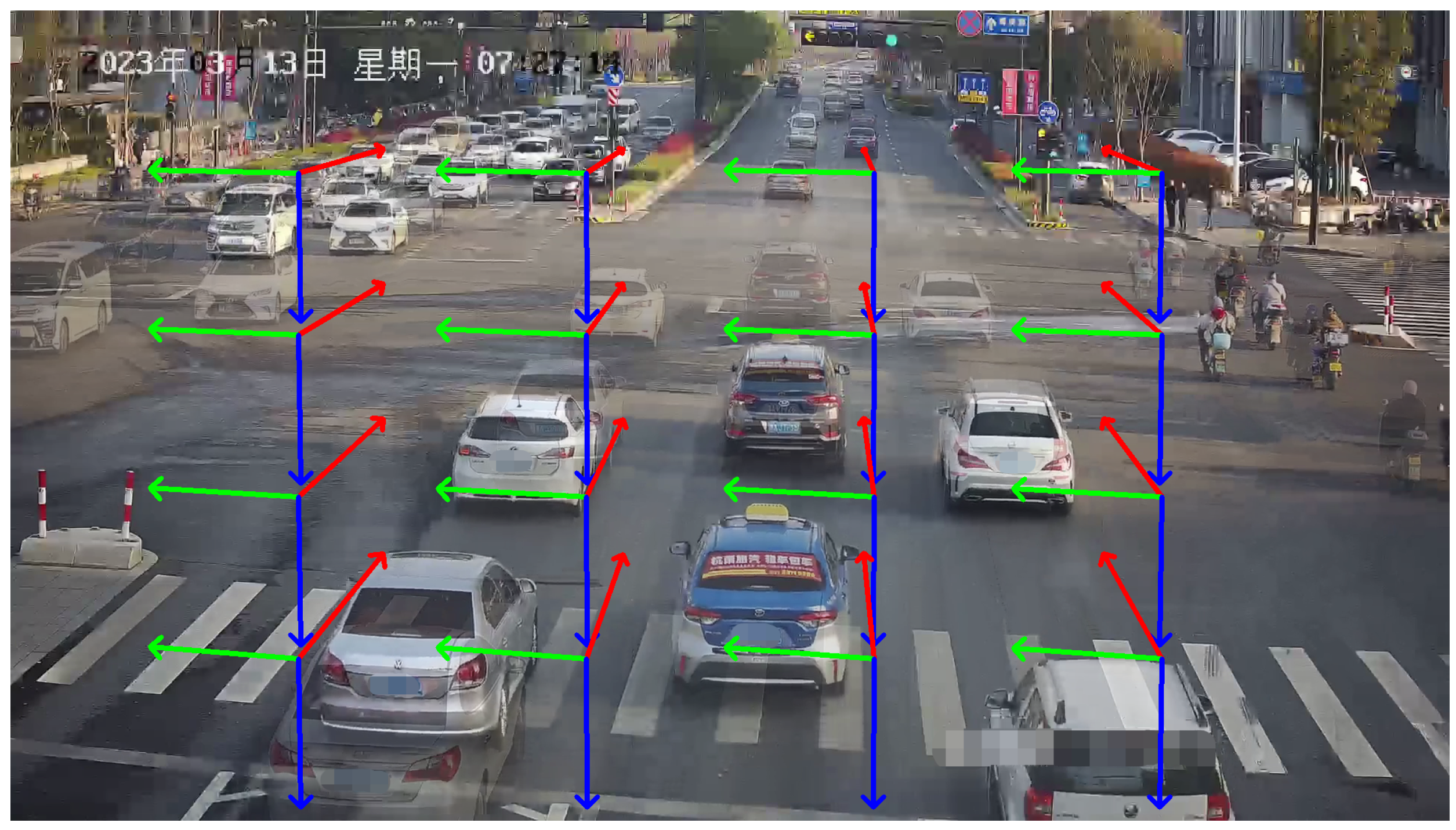
- Firstly, we use an object detector to detect vehicles. Considering the inference speed for traffic scenes and real-time requirements for large-scale deployment, YOLO V7 [54] is employed, which offers high detection accuracy and FPS.
- Feature points are extracted within the bounding boxes, and optical flow is employed to track the vehicles, obtaining a collection of trajectories, denoted as , where represents the optical flow tracking results.
- In real-world scenarios, roads have curved sections. To stably acquire the first vanishing point, it is necessary to eliminate trajectories in set T that do not satisfy linear conditions, i.e., for , .
- If some sets do not satisfy the linear conditions, they are excluded, resulting in , and a new set of trajectories is obtained, denoted as .
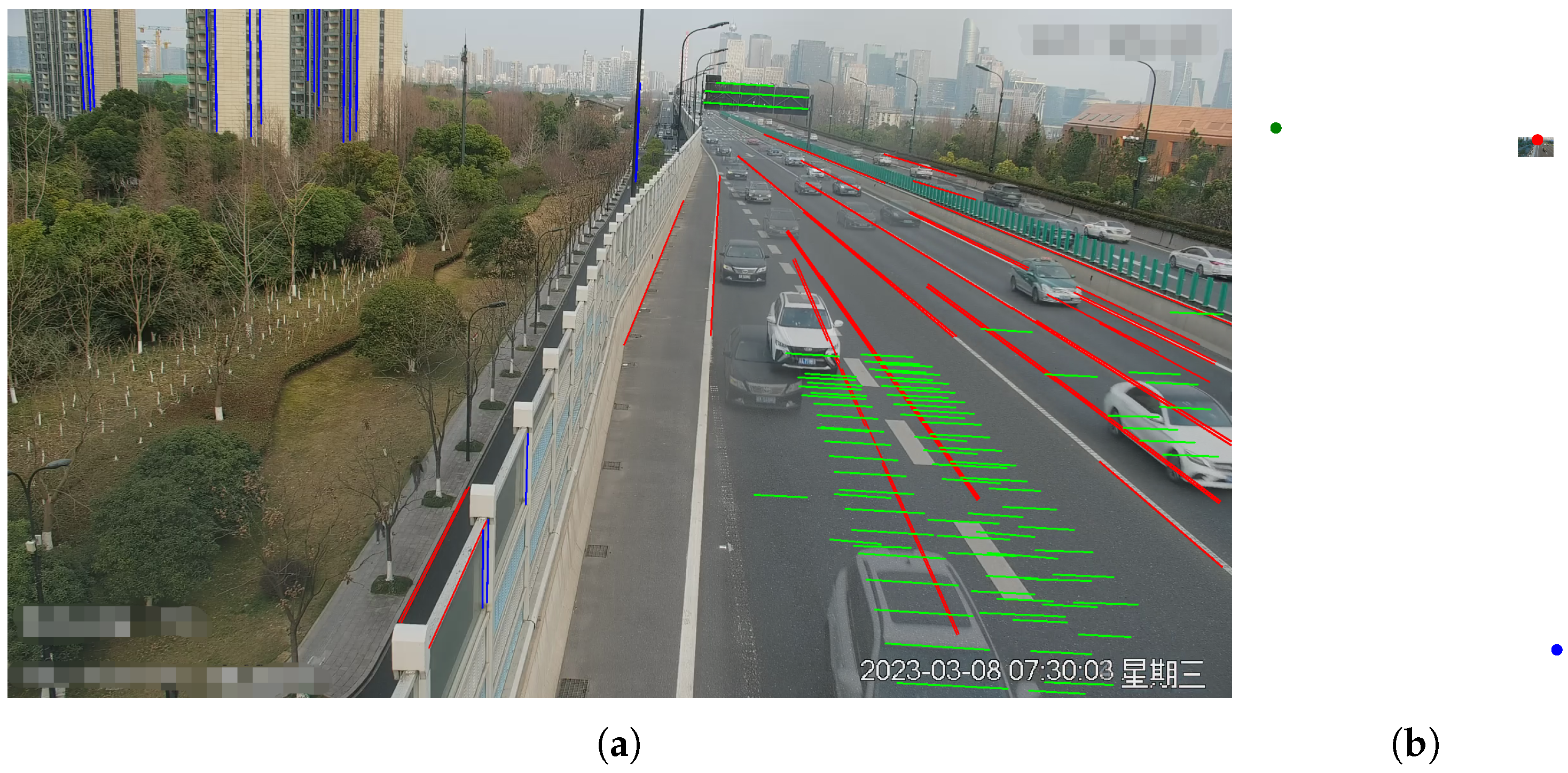
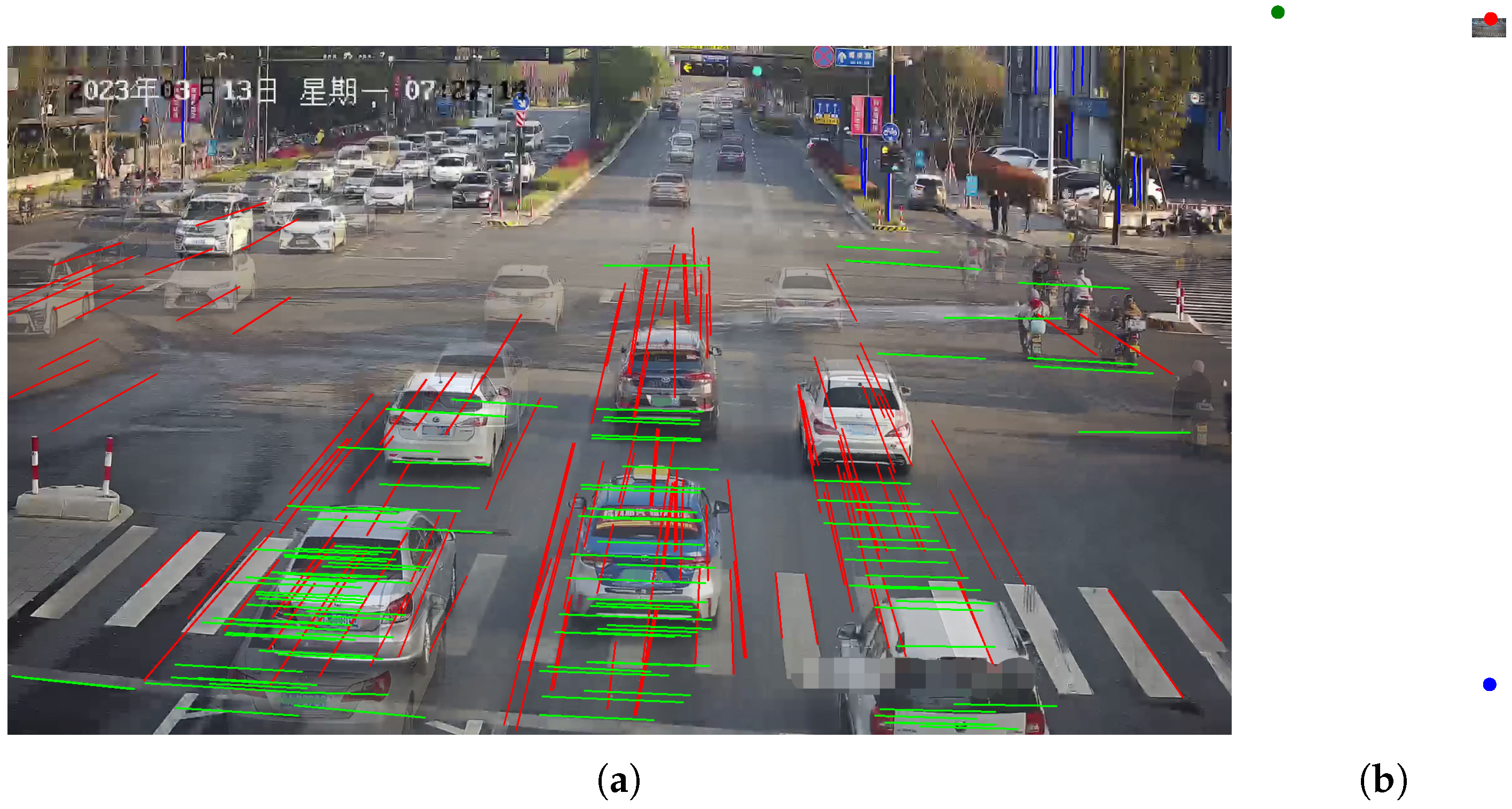
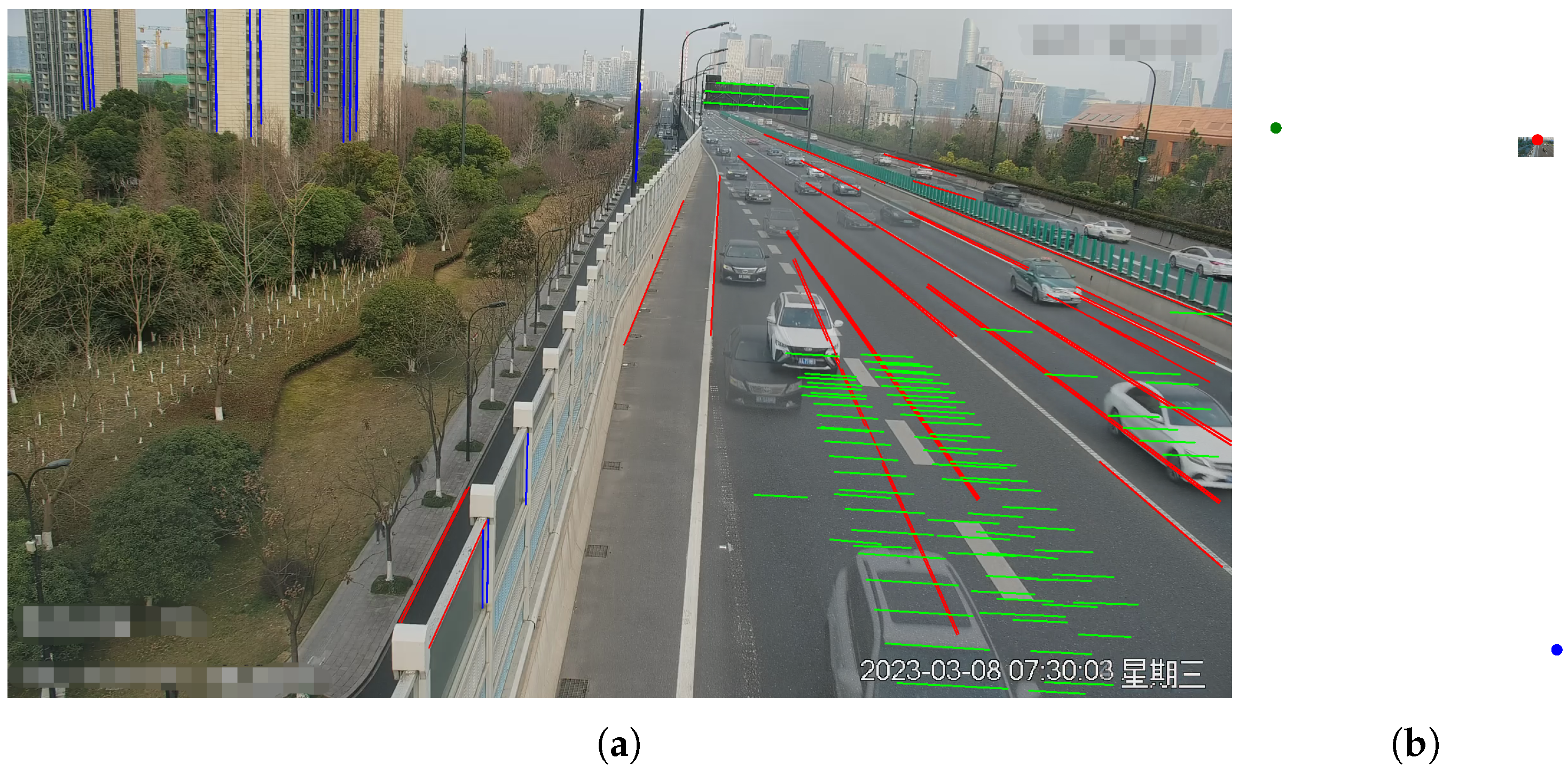
- As shown in Figure 3: the direction indicated by the red lines corresponds to the first vanishing point.
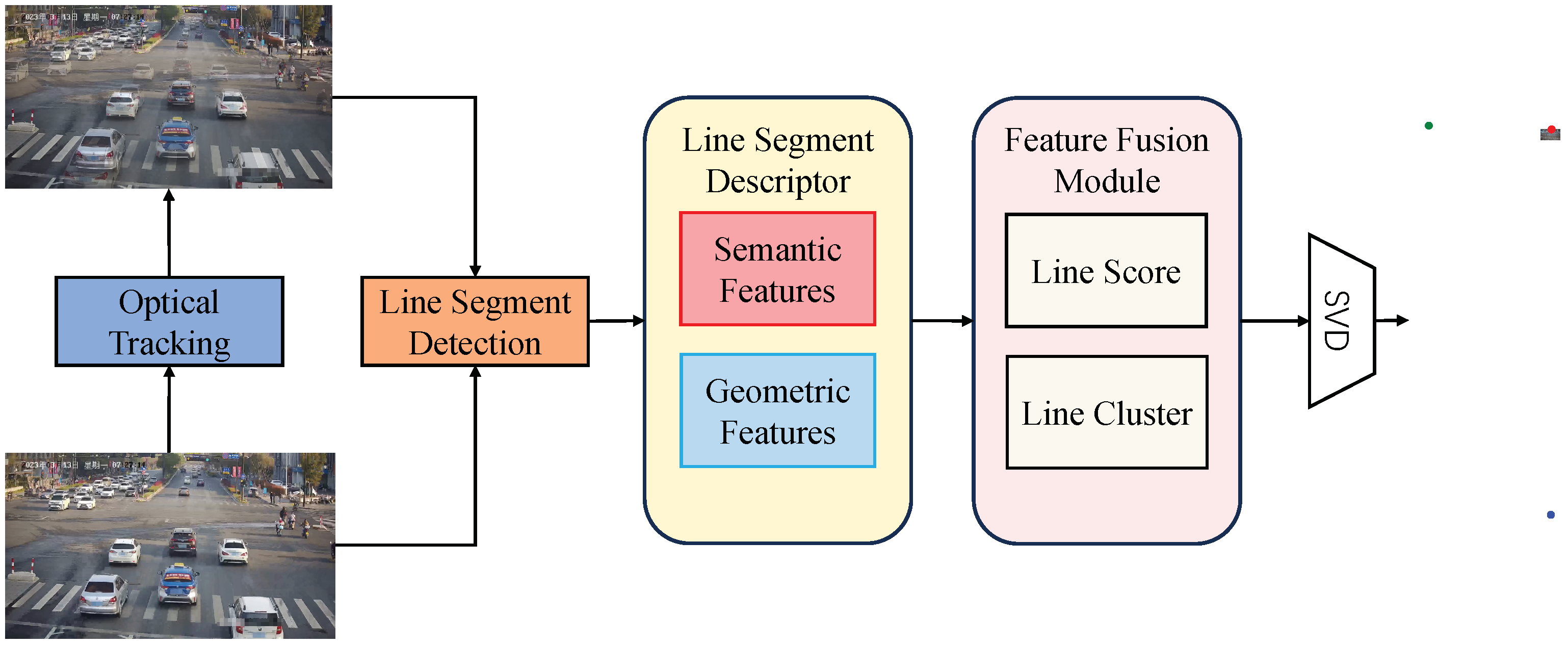
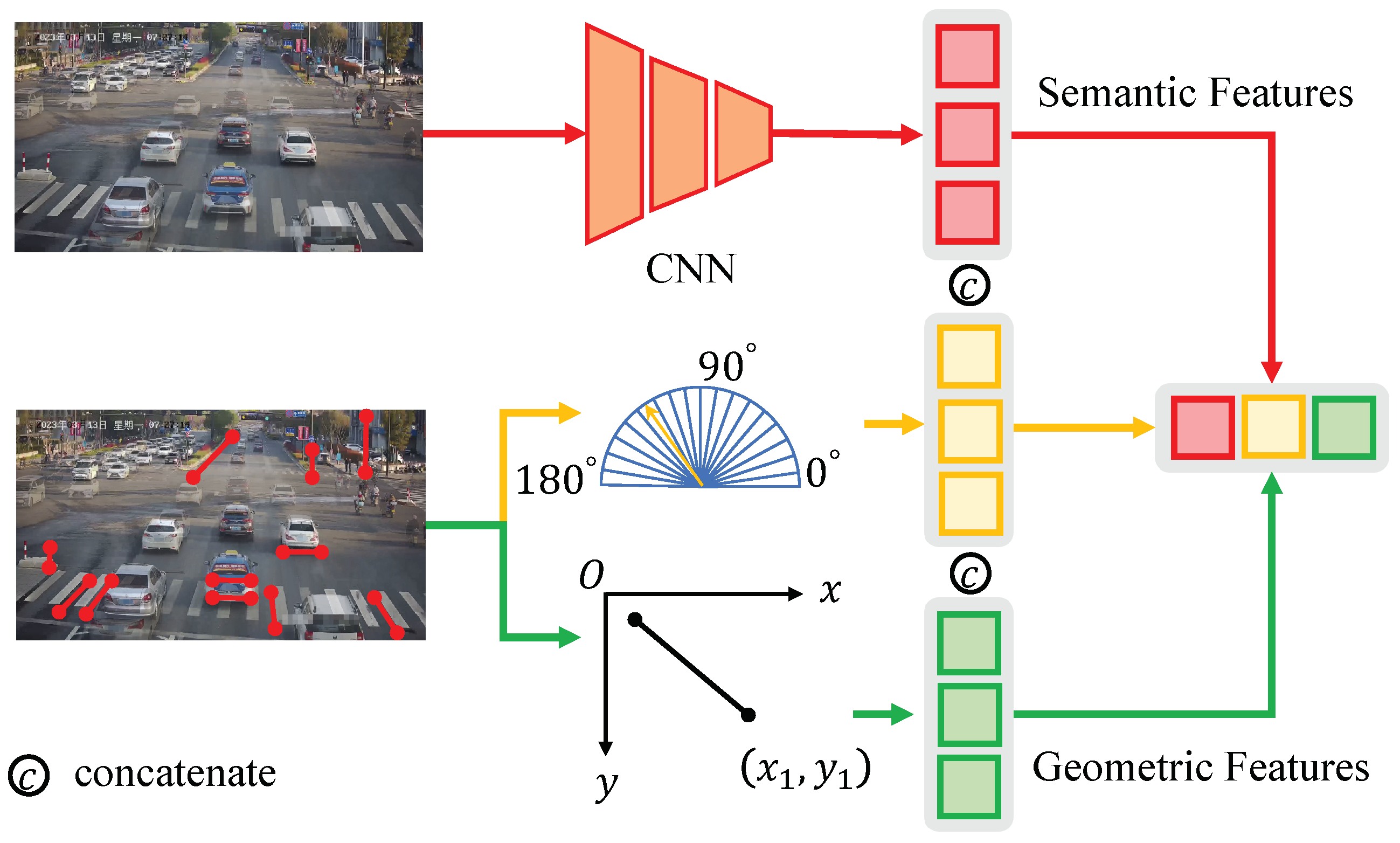
4.2. Line Segment Module
4.3. Feature Fusion Module
4.4. Losses and Vanishing Points Estimation
5. Experimental Results
5.1. Experiment Setup
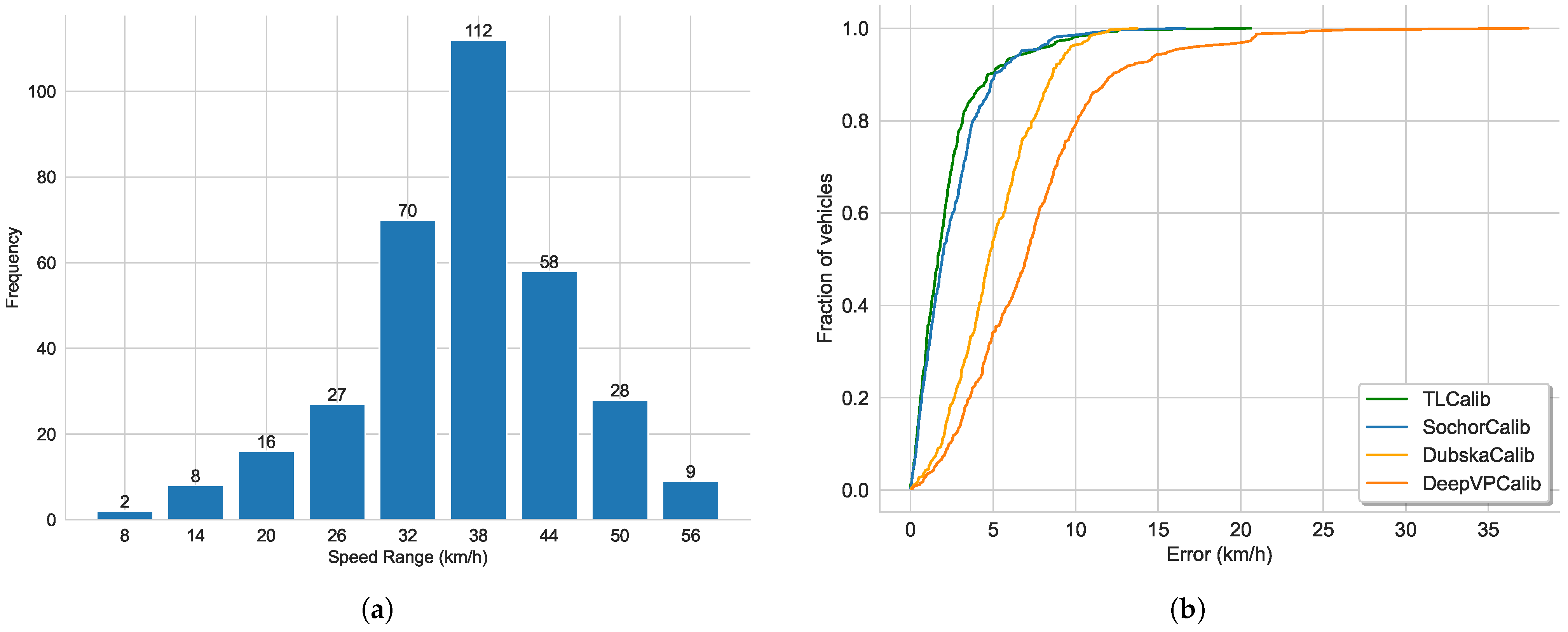
5.2. Error Metric for Comparison to Other Methods
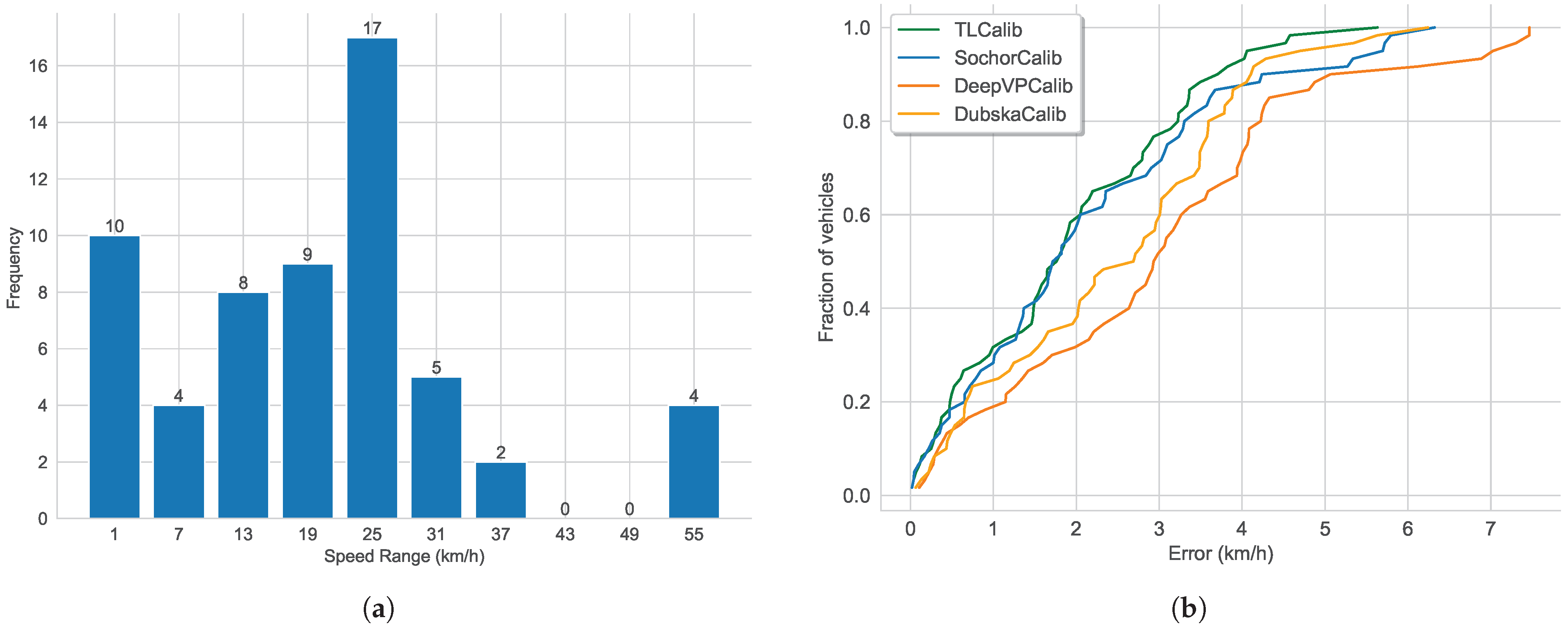
5.3. Speed Error Results in Three Standard Experimental Traffic Scenes
5.3.1. The Scene1 Results
5.3.2. The Scene2 Results
5.3.3. The Scene3 Results
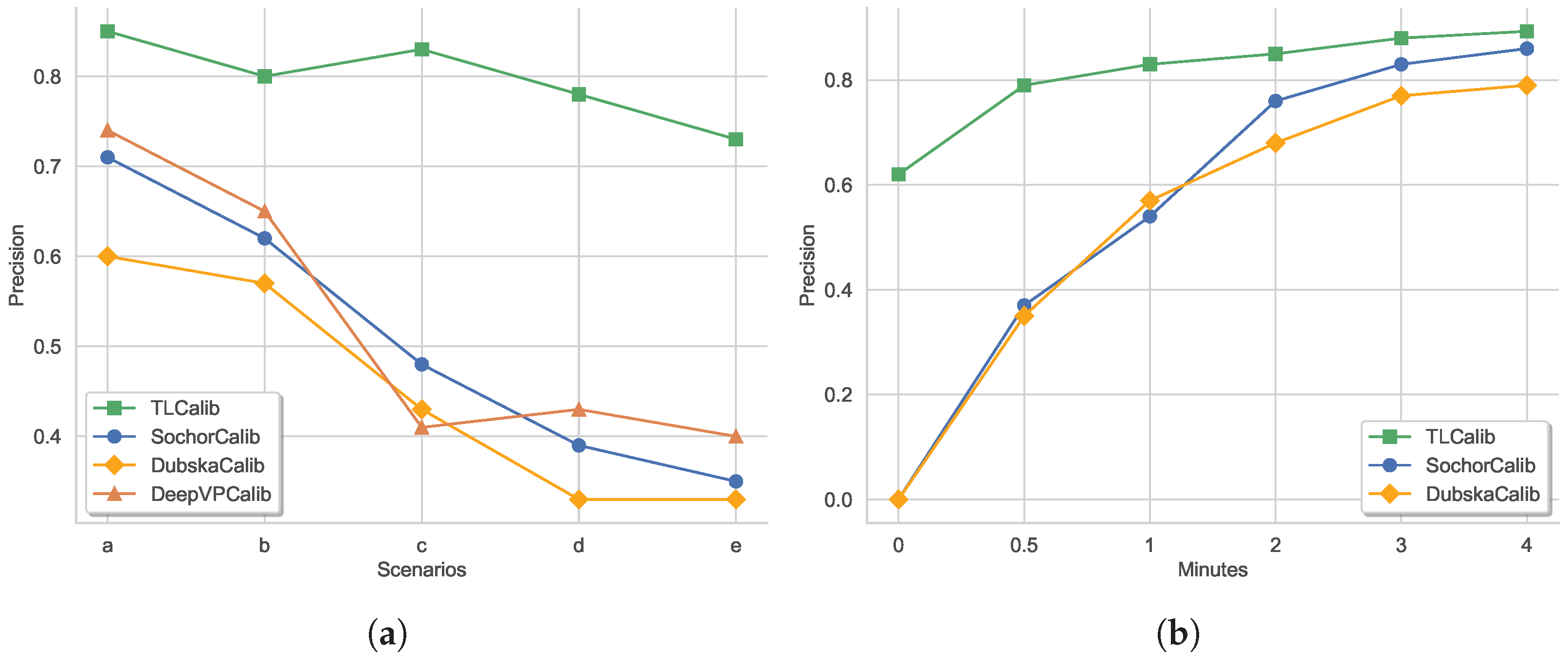
5.4. Further Comparison of the Results of More Complex Traffic Scenarios
5.5. The Speed Errors in Different Sampling Time
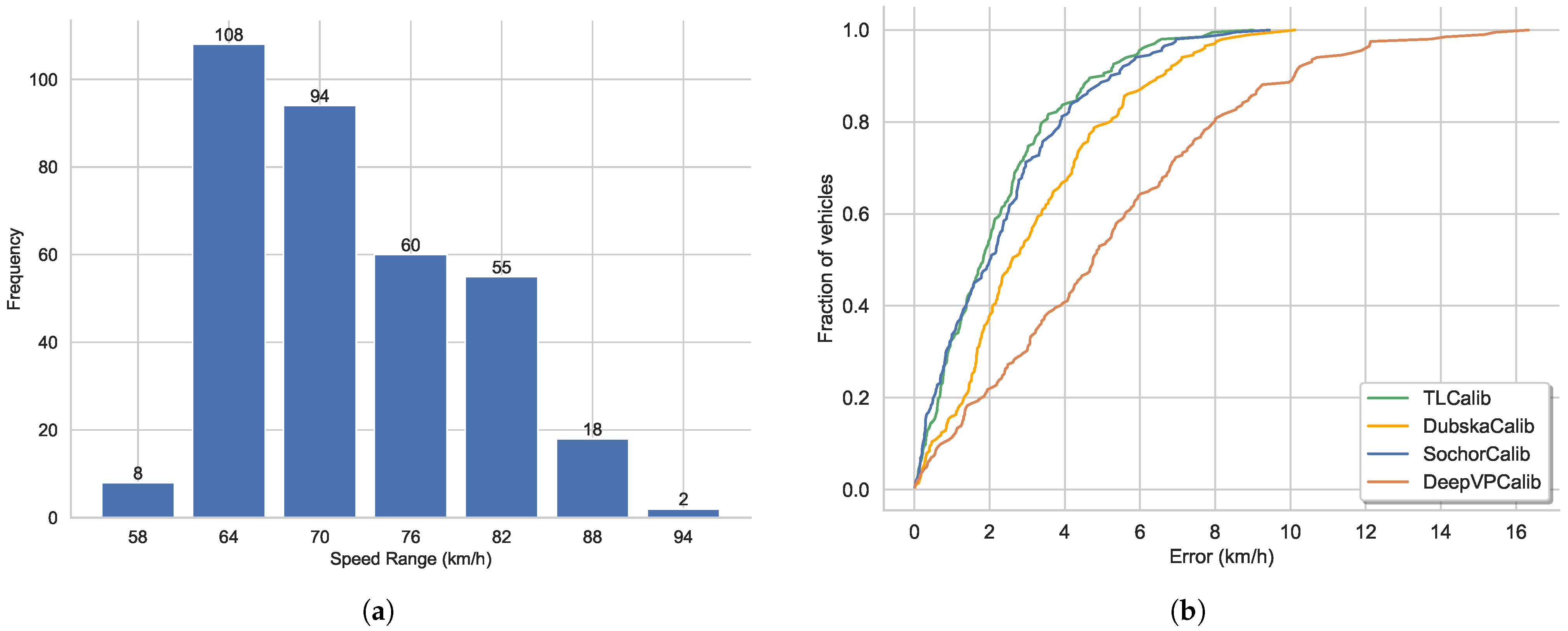
5.6. Comparison to Other Calibration Methods on Public Dataset
5.7. Ablation Study
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PTZ | pan-till-zoom |
| CCS | camera coordinate system |
| WCS | world coordinate system |
| ICS | image coordinate system |
| SGD | stochastic gradient descent |
| SVD | singular value decomposition |
| RANSAC | random sample consensus |
| km/h | kilometers per hour |
References
- Kanhere, N.K.; Birchfield, S. A Taxonomy and Analysis of Camera Calibration Methods for Traffic Monitoring Applications. IEEE Trans. Intell. Transp. Syst. 2010, 11, 441–452. [Google Scholar] [CrossRef]
- Zhang, X.; Feng, Y.; Angeloudis, P.; Demiris, Y. Monocular Visual Traffic Surveillance: A Review. IEEE Trans. Intell. Transp. 2022, 23, 14148–14165. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Q.; Cheng, H.H.; Peng, W.; Xu, W. A Review of Vision-Based Traffic Semantic Understanding in ITSs. IEEE Trans. Intell. Transp. Syst. 2022, 23, 19954–19979. [Google Scholar] [CrossRef]
- Hu, X.; Cao, Y.; Sun, Y.; Tang, T. Railway Automatic Switch Stationary Contacts Wear Detection Under Few-Shot Occasions. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14893–14907. [Google Scholar] [CrossRef]
- Sochor, J.; Juránek, R.; Špaňhel, J.; Maršík, L.; Široký, A.; Herout, A.; Zemčík, P. Comprehensive Data Set for Automatic Single Camera Visual Speed Measurement. IEEE Trans. Intell. Transp. Syst. 2017, 20, 1633–1643. [Google Scholar] [CrossRef]
- Zhang, Z. A Flexible New Technique for Camera Calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef]
- Abdel-Aziz, Y.I.; Karara, H.M. Direct Linear Transformation from Comparator Coordinates into Object Space Coordinates in Close-Range Photogrammetry. Photogramm. Eng. Remote Sens. 2015, 81, 103–107. [Google Scholar] [CrossRef]
- Bas, E.; Crisman, J.D. An easy to install camera calibration for traffic monitoring. In Proceedings of the Conference on Intelligent Transportation Systems, Boston, MA, USA, 12 November 1997; pp. 362–366. [Google Scholar]
- Zheng, Y.; Peng, S. A Practical Roadside Camera Calibration Method Based on Least Squares Optimization. IEEE Trans. Intell. Transp. 2014, 15, 831–843. [Google Scholar] [CrossRef]
- Dawson, D.N.; Birchfield, S. An Energy Minimization Approach to Automatic Traffic Camera Calibration. IEEE Trans. Intell. Transp. 2013, 14, 1095–1108. [Google Scholar] [CrossRef]
- Dubská, M.; Herout, A.; Juránek, R.; Sochor, J. Fully Automatic Roadside Camera Calibration for Traffic Surveillance. IEEE Trans. Intell. Transp. Syst. 2015, 16, 1162–1171. [Google Scholar] [CrossRef]
- Sochor, J.; Juránek, R.; Herout, A. Traffic surveillance camera calibration by 3D model bounding box alignment for accurate vehicle speed measurement. Comput. Vis. Image Underst. 2017, 161, 87–98. [Google Scholar] [CrossRef]
- Bhardwaj, R.; Tummala, G.; Ramalingam, G.; Ramjee, R.; Sinha, P. Autocalib: Automatic traffic camera calibration at scale. In Proceedings of the 4th ACM International Conference on Systems for Energy-Efficient Built Environments, Delft, The Netherlands, 8–9 November 2017. [Google Scholar]
- Kocur, V.; Ftácnik, M. Traffic Camera Calibration via Vehicle Vanishing Point Detection. In Proceedings of the Artificial Neural Networks and Machine Learning—ICANN 2021, Bratislava, Slovakia, 14 September 2021. [Google Scholar]
- Zhang, W.; Song, H.; Liu, L.; Li, C.; Mu, B.; Gao, Q. Vehicle localisation and deep model for automatic calibration of monocular camera in expressway scenes. IET Intell. Transp. Syst. 2022, 16, 459–473. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning texture transformer network for image super-resolution. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5790–5799. [Google Scholar]
- Lee, J.; Go, H.Y.; Lee, H.; Cho, S.; Sung, M.; Kim, J. CTRL-C: Camera calibration TRansformer with Line-Classification. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 16208–16217. [Google Scholar]
- Zeng, Y.; Fu, J.; Chao, H. Learning joint spatial-temporal transformations for video inpainting. arXiv 2020, arXiv:2007.10247. [Google Scholar]
- Chen, X.; Yan, B.; Zhu, J.; Wang, D.; Yang, X.; Lu, H. Transformer tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8122–8131. [Google Scholar]
- Wang, N.; Zhou, W.g.; Wang, J.; Li, H. Transformer meets tracker: Exploiting temporal context for robust visual tracking. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1571–1580. [Google Scholar]
- Li, Z.; Li, S.; Luo, X. An overview of calibration technology of industrial robots. IEEE/CAA J. Autom. Sin. 2021, 8, 23–36. [Google Scholar] [CrossRef]
- Guindel, C.; Beltrán, J.; Martín, D.; García, F.T. Automatic extrinsic calibration for lidar-stereo vehicle sensor setups. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–6. [Google Scholar]
- Caprile, B.; Torre, V. Using vanishing points for camera calibration. Int. J. Comput. Vis. 1990, 4, 127–139. [Google Scholar] [CrossRef]
- Canny, J.F. A Computational Approach to Edge Detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, PAMI-8, 679–698. [Google Scholar] [CrossRef]
- von Gioi, R.G.; Jakubowicz, J.; Morel, J.M.; Randall, G. LSD: A Fast Line Segment Detector with a False Detection Control. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 722–732. [Google Scholar] [CrossRef]
- Lutton, E.; Maître, H.; López-Krahe, J. Contribution to the Determination of Vanishing Points Using Hough Transform. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 430–438. [Google Scholar] [CrossRef]
- Bolles, R.C.; Fischler, M.A. A ransac-based approach to model fitting and its application to finding cylinders in range data. In Proceedings of the 7th International Joint Conference on Artificial Intelligence—Volume 2, ser. IJCAI’81, San Francisco, CA, USA, 24–28 August 1981; pp. 637–643. [Google Scholar]
- Wu, J.; Zhang, L.; Liu, Y.; Chen, K. Real-time Vanishing Point Detector Integrating Under-parameterized RANSAC and Hough Transform. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 3712–3721. [Google Scholar]
- Tardif, J.P. Non-iterative approach for fast and accurate vanishing point detection. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 1250–1257. [Google Scholar]
- Denis, P.; Elder, J.H.; Estrada, F.J. Efficient edge-based methods for estimating manhattan frames in urban imagery. In Proceedings of the Computer Vision–ECCV 2008: 10th European Conference on Computer Vision, Marseille, France, 12–18 October 2008; pp. 197–210. [Google Scholar]
- Lezama, J.; von Gioi, R.G.; Randall, G.; Morel, J.M. Finding Vanishing Points via Point Alignments in Image Primal and Dual Domains. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 509–515. [Google Scholar]
- Orghidan, R.; Salvi, J.; Gordan, M.; Orza, B. Camera calibration using two or three vanishing points. In Proceedings of the 2012 Federated Conference on Computer Science and Information Systems (FedCSIS), Wroclaw, Poland, 9–12 September 2012; pp. 123–130. [Google Scholar]
- Liao, K.; Nie, L.; Huang, S.; Lin, C.; Zhang, J.; Zhao, Y.; Gabbouj, M.; Tao, D. Deep Learning for Camera Calibration and Beyond: A Survey. arXiv 2023, arXiv:2303.10559. [Google Scholar]
- Zhai, M.; Workman, S.; Jacobs, N. Detecting Vanishing Points Using Global Image Context in a Non-Manhattan World. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 5657–5665. [Google Scholar]
- Chang, C.K.; Zhao, J.; Itti, L. DeepVP: Deep Learning for Vanishing Point Detection on 1 Million Street View Images. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 1–8. [Google Scholar]
- Zhou, Y.; Qi, H.; Huang, J.; Ma, Y. NeurVPS: Neural Vanishing Point Scanning via Conic Convolution. arXiv 2019, arXiv:1910.06316. [Google Scholar]
- Tong, X.; Ying, X.; Shi, Y.; Wang, R.; Yang, J. Transformer Based Line Segment Classifier with Image Context for Real-Time Vanishing Point Detection in Manhattan World. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 6083–6092. [Google Scholar]
- Workman, S.; Zhai, M.; Jacobs, N. Horizon Lines in the Wild. arXiv 2016, arXiv:1604.02129. [Google Scholar]
- Hold-Geoffroy, Y.; Piché-Meunier, D.; Sunkavalli, K.; Bazin, J.C.; Rameau, F.; Lalonde, J.F. A Perceptual Measure for Deep Single Image Camera Calibration. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2354–2363. [Google Scholar]
- Xiao, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. Recognizing scene viewpoint using panoramic place representation. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 2695–2702. [Google Scholar]
- Lee, J.; Sung, M.; Lee, H.; Kim, J. Neural Geometric Parser for Single Image Camera Calibration. arXiv 2020, arXiv:2007.11855. [Google Scholar]
- Dong, R.; Li, B.; Chen, M.Q. An Automatic Calibration Method for PTZ Camera in Expressway Monitoring System. In Proceedings of the 2009 WRI World Congress on Computer Science and Information Engineering, Los Angeles, CA, USA, 31 March–2 April 2009; Volume 6, pp. 636–640. [Google Scholar]
- Song, K.; Tai, J.C. Dynamic calibration of pan–tilt–zoom cameras for traffic monitoring. IEEE Trans. Syst. Man Cybern. Part B 2006, 36, 1091–1103. [Google Scholar] [CrossRef]
- Fung, G.S.K.; Yung, N.H.C.; Pang, G. Camera calibration from road lane markings. Opt. Eng. 2003, 42, 2967–2977. [Google Scholar] [CrossRef]
- Kanhere, N.K.; Birchfield, S.; Sarasua, W.A. Automatic Camera Calibration Using Pattern Detection for Vision-Based Speed Sensing. Transp. Rec. 2008, 2086, 30–39. [Google Scholar] [CrossRef]
- Zhang, Z.; Tan, T.; Huang, K.; Wang, Y. Practical Camera Calibration from Moving Objects for Traffic Scene Surveillance. IEEE Trans. Circuitsand Syst. Video Technol. 2013, 23, 518–533. [Google Scholar] [CrossRef]
- Schoepflin, T.N.; Dailey, D.J. Dynamic camera calibration of roadside traffic management cameras for vehicle speed estimation. IEEE Trans. Intell. Transp. Syst. 2003, 4, 90–98. [Google Scholar] [CrossRef]
- Dubská, M.; Herout, A.; Havel, J. PClines—Line detection using parallel coordinates. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition—CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1489–1494. [Google Scholar]
- Dubská, M.; Herout, A.; Sochor, J. Automatic Camera Calibration for Traffic Understanding. In Proceedings of the British Machine Vision Conference, BMVC 2014, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Song, H.; Li, C.; Wu, F.; Dai, Z.; Wang, W.; Zhang, Z.; Fang, Y. 3D vehicle model-based PTZ camera auto-calibration for smart global village. Sustain. Cities Soc. 2019, 46, 101401. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2022; pp. 7464–7475. [Google Scholar]
- Shi, J.; Tomasi, C. Good features to track. In Proceedings of the 1994 Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600. [Google Scholar]
- Tomasi, C. Detection and Tracking of Point Features. Tech. Rep. 1991, 91, 9795–9802. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- You, X.; Zheng, Y. An accurate and practical calibration method for roadside camera using two vanishing points. Neurocomputing 2016, 204, 222–230. [Google Scholar] [CrossRef]
- Zhou, Y.; Qi, H.; Zhai, Y.; Sun, Q.; Chen, Z.; Wei, L.-Y.; Ma, Y. Learning to Reconstruct 3D Manhattan Wireframes From a Single Image. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7697–7706. [Google Scholar]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.A.; Nießner, M. ScanNet: Richly-Annotated 3D Reconstructions of Indoor Scenes. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2432–2443. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| BrnoCompSpeed | Ours | |||||
|---|---|---|---|---|---|---|
| Method | Mean | Median | 99% | Mean | Median | 99% |
| DubskaCalib [11] | 8.59 | 8.76 | 14.78 | 5.06 | 4.75 | 13.73 |
| SochorCalib [12] | 3.88 | 3.35 | 5.47 | 2.46 | 2.30 | 6.24 |
| DeepVPCalib [14] | 13.96 | 10.58 | 20.75 | 8.23 | 7.63 | 19.01 |
| TLCalib-ScanNet | 4.54 | 4.01 | 9.91 | 3.13 | 2.96 | 7.44 |
| TLCalib-SU3 | 3.61 | 3.67 | 8.55 | 2.29 | 1.66 | 5.95 |
| GT | - | - | - | 1.58 | 1.62 | 4.25 |
| Scene | Mean | Median | 99% |
|---|---|---|---|
| Static Traffic Scene Only | 6.72 | 6.12 | 12.54 |
| Dynamic Optical Flow | 3.48 | 3.32 | 7.43 |
| Static Scene + Dynamic Optical Flow | 2.81 | 2.36 | 4.55 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Zhao, Z.; Chen, Y.; Zhang, X.; Tian, R. Automatic Roadside Camera Calibration with Transformers. Sensors 2023, 23, 9527. https://doi.org/10.3390/s23239527
Li Y, Zhao Z, Chen Y, Zhang X, Tian R. Automatic Roadside Camera Calibration with Transformers. Sensors. 2023; 23(23):9527. https://doi.org/10.3390/s23239527
Chicago/Turabian StyleLi, Yong, Zhiguo Zhao, Yunli Chen, Xiaoting Zhang, and Rui Tian. 2023. "Automatic Roadside Camera Calibration with Transformers" Sensors 23, no. 23: 9527. https://doi.org/10.3390/s23239527
APA StyleLi, Y., Zhao, Z., Chen, Y., Zhang, X., & Tian, R. (2023). Automatic Roadside Camera Calibration with Transformers. Sensors, 23(23), 9527. https://doi.org/10.3390/s23239527