1. Introduction
With the emergence of intelligent algorithms, various industries are actively incorporating intelligent technologies to enhance efficiency and generate greater value. As artificial intelligence technology advances, there will be a means to connect individual agents with distinct functions, thereby augmenting system performance in terms of intelligence. In a multi-agent system, each agent possesses specific perceptions, interactions, and execution capabilities [
1]. To collectively accomplish specific tasks, the multi-agent control method serves as a coordination approach that guides the behavior of each agent while considering inter-agent interactions and achieving common objectives. Recently, the utilization of multi-agent group control algorithms has become prevalent in domains such as cluster control [
2] of unmanned aerial vehicles (uavs), distribution logistic path planning [
3], distribution network optimization [
4], and intelligent decision-making [
5].
Currently, three types of decision support methodologies primarily exist; one is the expert system-based decision approach. An expert system refers to a computer software system developed within a specific domain by leveraging expert knowledge and experience [
6]. The emulation of the cognitive process employed by human experts in a specific field enables commanders to receive more precise recommendations, thereby enhancing their decision-making efficiency. In an intelligent decision-making environment, expert system technology proves invaluable for optimizing command plans, improving situational awareness, and ultimately facilitating efficient decision-making. Sun, L. et al. introduced a joint decision system based on an expert system [
7], which encompasses knowledge and rules from multiple fields and leverages the knowledge representation and reasoning capabilities of expert systems to support effective decision-making. The expert system possesses automatic characteristics [
8] and requires minimal manual intervention. However, due to its limited self-learning ability, the expert system remains constrained by human-defined rules during operation, serving as a computer-based substitute for repetitive and rudimentary tasks. The second approach involves model-based swarm intelligent decision algorithms with numerous representative studies available. For instance, Ma, Y. et al. [
9] employed an enhanced swarm algorithm in UAS teamwork defense scenarios that significantly improved task success rates while Hu, Z.Z. et al. [
10], based on an optimized particle swarm algorithm, effectively obtained opponent target strategies and maximized their utilization. Li, J. et al. [
11] successfully achieved an efficient optimal solution for the confrontation strategy by employing an enhanced ant colony algorithm. In terms of situational awareness during confrontations, a swarm intelligence algorithm is utilized to accurately identify and locate the opponent’s position and actions. As scientific and technological advancements continue to progress, intelligent decision-making scenarios necessitate the consideration of exponentially increasing factors, thereby demanding extensive data processing and analysis [
12]. Consequently, researchers have recently been exploring a third approach that integrates AI technology into autonomous decision-making processes in order to address these challenges effectively. The third approach involves an autonomous decision-making method that leverages artificial intelligence technology. This innovative technique integrates machine learning algorithms [
13] to enable self-learning and self-optimization, surpassing the limitations imposed by known rules and models. By effectively processing vast amounts of data, this methodology extracts valuable insights to make precise decisions even in complex environments. However, it is important to note that this method is currently at the research and experimental stage and has not yet reached full maturity or widespread adoption.
In recent years, deep reinforcement learning has become an important research topic in the field of artificial intelligence. Because it allows agents to extract relevant state information directly from the environment and due to its excellent perceptual exploration ability, it can optimally adapt to complex and dynamic environments, so it has been widely used in real-time strategies. Popular multi-agent reinforcement learning algorithms integrate value-learning and strategy-learning structures. It is worth noting that reference [
14] uses the multi-agent depth strategy gradient algorithm to solve the challenges brought by the complex and uncertain dynamic environment encountered in the UAV cluster confrontation process. Reference [
15] proposes a multi-agent cooperative combat simulation algorithm based on reinforcement learning to achieve a balanced decision-making method. Reference [
16] introduces a valuable multi-agent reinforcement learning algorithm for training flight controllers in aircraft simulators to improve their performance in air confrontation. Reference [
17] proposes a multi-agent reinforcement learning algorithm, combining Q-learning and attention mechanisms to solve path-planning problems. However, the mature reinforcement learning algorithms used so far in complex environments are mainly based on the integration of value-learning and strategy-learning methods, so this algorithm inherits some limitations of value-based reinforcement learning methods.
Based on the challenges encountered in current mature algorithm research and engineering practices, it has been identified that existing research exhibits the following limitations:
- (1)
The complexity of simulation environments leads to an expanded observation space and action space for agents, resulting in issues such as subpar experience quality collected by the experience playback pool, inefficient sampling, and challenging algorithm convergence.
- (2)
With an increasing number of agents and environmental complexities, classical algorithm evaluation modules require substantial computational resources and are susceptible to problems like imprecise evaluations, reduced adaptability of classical algorithms, low task completion rates, and arduous convergence.
Although the aforementioned challenges have been effectively addressed in single-agent reinforcement learning, there are limited approaches available to tackle these issues within the intricate multi-agent domain. DeepMind introduced the DQN algorithm in 2013 [
18], which emphasized that the value function typically represents the state value function for assessing the agent’s action quality based on a specific strategy within the current state. In this study, deep learning neural network technology is employed to estimate the Q-value function, while experiential replay and target network technology are utilized to enhance the traditional Q-learning algorithm. Despite significant advancements achieved by the DQN algorithm, notable errors in value estimation still persist. The double DQN algorithm [
19], proposed by Hado et al. in 2016, effectively mitigates the loss caused by overestimation inherent in the DQN algorithm and further enhances the performance of DQN. In 2018, Scott et al. introduced the TD3 algorithm [
20], which successfully addresses the issue of Q overestimation in the DDPG algorithm and significantly stabilizes its training process within continuous action spaces. To enhance cooperative capabilities in multi-UAV aerial countermeasures, Zhang, D. et al. devised a collaborative maneuver decision method based on a multi-agent double delay depth deterministic strategy gradient [
21].
In this paper, we propose the adversarial discriminant network based on the multi-agent depth strategy gradient to accurately and effectively analyze the relative contribution of the agent’s input state and action. To optimize the accuracy of value function estimation, we introduce two critical networks for estimating the action value function jointly. Additionally, we propose a preferential experience replay mechanism based on cluster stratification to enable agents to fully leverage experience information, thereby enhancing algorithmic learning efficiency and stability. Experimental results demonstrate that our improved algorithm exhibits superior convergence effects and task completion compared to other reinforcement learning algorithms.
2. Related Work
Reinforcement learning excels in handling sequential decision tasks, with its fundamental modeling tool being the Markov decision process (MDP). An MDP typically comprises the current state space, action space, reward function, and next state space. The state space (S) represents the set of all feasible states. The action space (A), on the other hand, denotes the collection of all possible actions. The reward function (R) quantifies the value that an environment provides to an agent upon performing a specific action. Ultimately, reinforcement learning aims to maximize this reward (u) by optimizing its expectations. The return can be calculated using Formula (1); in this formula, t represents the time step:
In MDP, the discount return is usually used and is calculated as follows:
In this formula,
represents the discount rate.
In both single-agent and multi-agent cooperative and adversarial environments, the commonly employed and effective algorithms in reinforcement learning can be broadly categorized into three groups: value-based reinforcement learning algorithms, exemplified by DQN; policy gradient-based reinforcement learning algorithms, represented by DDPG; and actor–critic-based reinforcement learning algorithms, such as MADDPG.
2.1. Basic Algorithm of Value-Based Reinforcement Learning
DQN
The DQN algorithm represents an advancement of the Q-learning algorithm and exhibits proficiency in handling intricate discrete environment tasks. The estimation of the Q-value function is accomplished through a neural network capable of processing extensive high-dimensional information, while its parameters are continually optimized during training to gradually approximate the actual Q-value function. During the training process of the DQN algorithm, two crucial techniques are employed that have a profound impact on subsequent reinforcement learning algorithms: the experiential replay mechanism and target network.
The replay mechanism, commonly known as the replay buffer, serves multiple purposes in facilitating smooth training by reducing sample correlation, enhancing data utilization, and mitigating data imbalances. The size of the buffer is typically determined as a hyperparameter denoted by b. It should be noted that the buffer can only retain a maximum of b experiences, which are derived from distinct strategies independent of each other; consequently, when the buffer reaches its capacity, the oldest experiences are automatically removed.
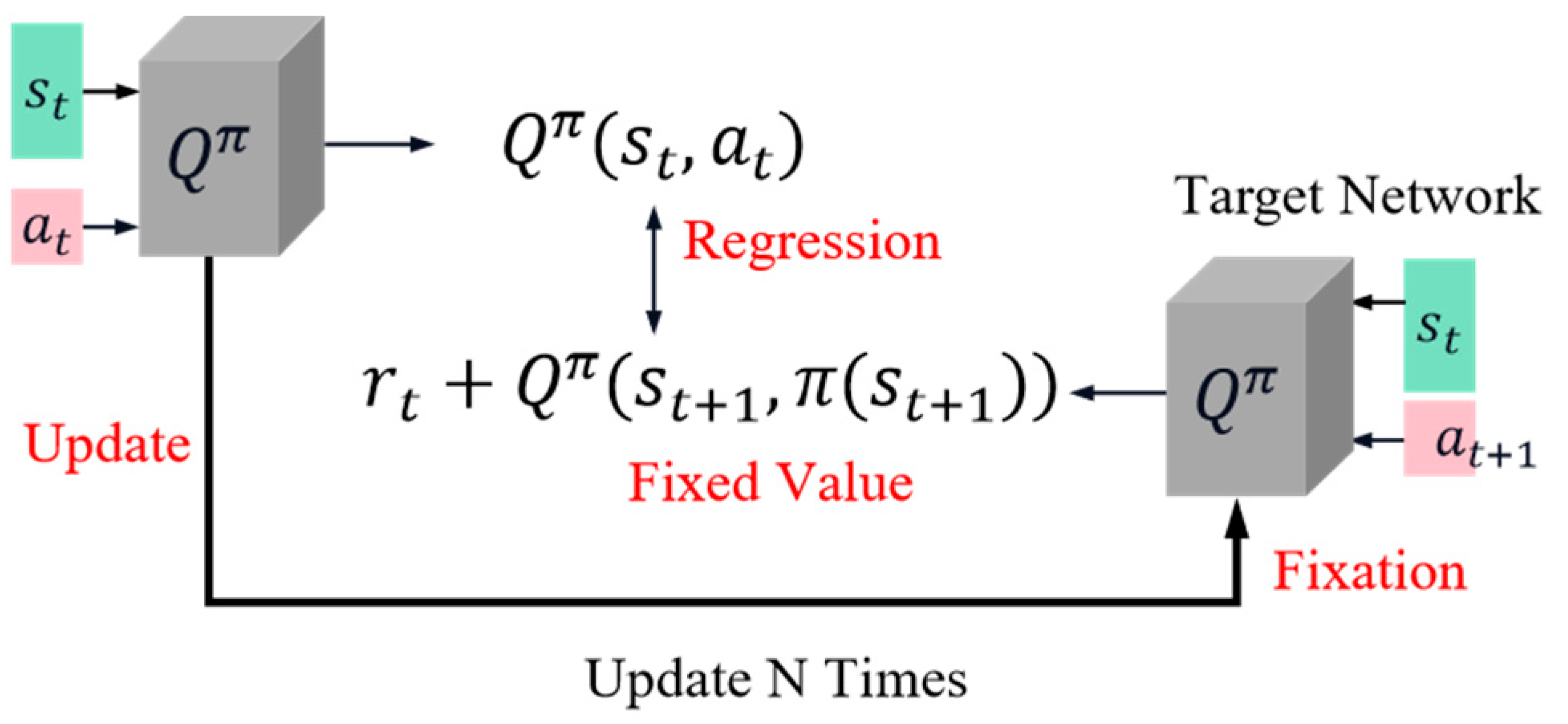
The ‘Target’ function plays a crucial role in guiding the algorithm towards convergence to a stable state during the training process, thereby facilitating the acquisition of an improved strategy. When training the value network, it becomes essential to sample multiple batches of experience samples from the buffer and subsequently update the network parameters using a difference method, as described by Formula (3):
Here,
represents the current policy. However, due to potential changes in TD targets, this can introduce instability into the training process. To address this issue,
Figure 1 illustrates the objective function of DQN, which incorporates a Q network (Figure right) responsible for generating and fixing the target throughout training while only updating parameters on the left side. This configuration ensures that both target and Q networks remain fixed, enabling stable training.
2.2. Basic Algorithm of Strategy-Based Reinforcement Learning
2.2.1. Deep Deterministic Policy Gradient
In the field of continuous control, the deep deterministic policy gradient (DDPG) is a renowned algorithm that utilizes neural networks to generate deterministic actions. DDPG extends the concept of DQN to accommodate continuous action spaces and shares similarities in training with DQN. However, unlike DQN, DDPG incorporates a policy network alongside the value network for action output and necessitates training both networks. The depicted structure in
Figure 2 represents the architecture of the action-discriminant network. In this figure, state (s) serves as input for the policy network that outputs an action (a), while both the action (a) and state (s) are fed into the Q network as inputs, resulting in an output of action value.
The DDPG algorithm also adopts the target function method. As shown in the left part of
Figure 3, there are four networks in the DDPG algorithm, namely the Q network, target Q network, policy network, and alongside target policy network. In the DDPG algorithm, the target Q network is responsible for generating the target Q-value, denoted as Target_Q, denoted as
, which is calculated using Formula (4). In this formula,
is the parameter of the network.
Target policy network, Target_A, noted as
. Calculate the next action
using Formula (5):
The Q network calculates the current valuation using Formula (6):
The policy network calculates the actions
a to be taken in the current state using Formula (7):
When training the DDPG algorithm, both loss functions should be optimized simultaneously. Equation (
8) can calculate the loss function (
) of the target Q network and Q network, and the Q network is optimized by the mean-variance between the Q_target and Q_target.
Equation (
9) calculates the loss function (
) of the policy network:
In Formula (9), can be calculated using Formula (7).
2.2.2. Multi-Agent Deep Deterministic Policy Gradient
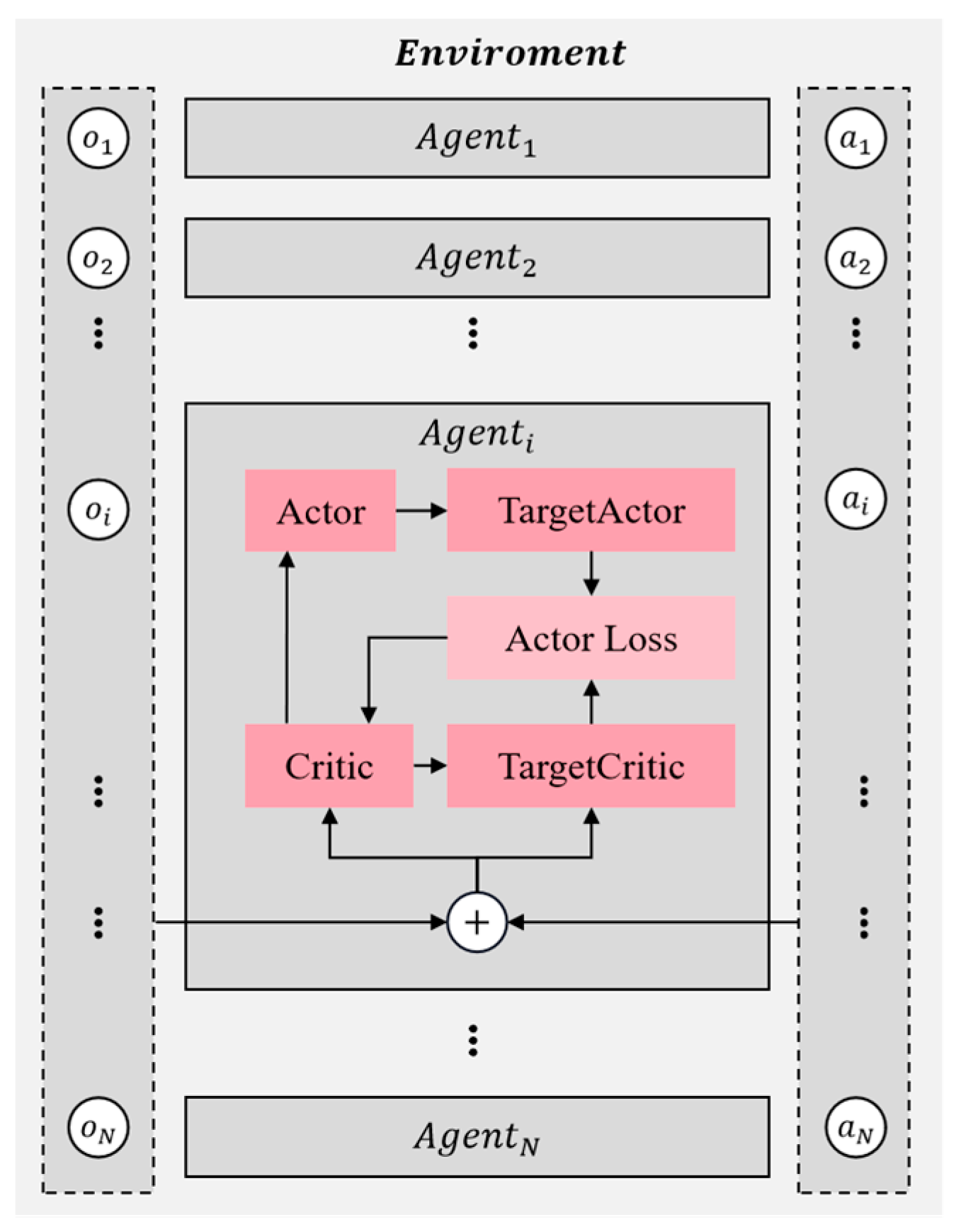
The multi-agent deep deterministic policy gradient (MADDPG) algorithm is an extension of the DDPG algorithm designed specifically for multi-agent environments, incorporating adaptive improvements. This algorithm can be categorized as an actor–critic approach due to its utilization of both action and discriminant networks. As depicted in
Figure 4, MADDPG employs individual action and discriminant networks for each agent, which bear resemblance to those used in DDPG.
Take , for example: the agent has additional information in addition to its state action data, like actions and states of other agents. In addition, MADDPG also uses the empirical pooling mechanism to store the data generated by each agent interacting with the environment. Whenever new data are generated, these data are stored in the replay buffer, denoted as D. The training process takes the form of centralized training with decentralized execution, i.e., each agent, according to their strategy, obtains the current state of action and interacts with the environment to gain experience in their own experience buffer pool D. For all agents, after interacting with the environment, each agent randomly selects experiences from the pool to train their neural network. To accelerate the agent’s learning process, the critic network includes inputs of the other agents’ observation states and actions, updating the critic network parameters by minimizing the loss. Then, the parameters of the action network are calculated via the gradient descent method, finally realizing centralized training.
2.2.3. Overvaluation Based on DDPG
This paper is based on the DDPG algorithm. In the DDPG algorithm, there are two main issues that need to be addressed. Firstly, during the training process, the estimation of the value function tends to be inaccurate, leading to instability in strategy updates and overestimation of Q-value functions. Secondly, essential noises exist in the target strategy which aids in exploring the state space but also contributes to high estimation errors in Q-value functions and affects estimator accuracy. Consequently, utilizing imprecise estimates in each update results in an accumulation of errors. This accumulated error can cause any unfavorable state to be erroneously estimated as favorable, ultimately resulting in suboptimal performance during strategy updates.
Scott et al., in their paper [
20] (TD3), demonstrated that the action-discriminant approach updates the agent’s strategy based on an approximate estimation of the discriminant network, resulting in an overestimation of its value. Through a comparison between the actual and estimated Q-values obtained from different environments, they successfully confirmed the previous algorithm’s tendency to overvalue outcomes. Additionally, they provide Formula (10) for accurately calculating the true Q value:
where
is the cumulative return reward. Then the Formula (10) deformation is as follows:
where
is exactly
. Therefore, the true Q-value is calculated as follows:
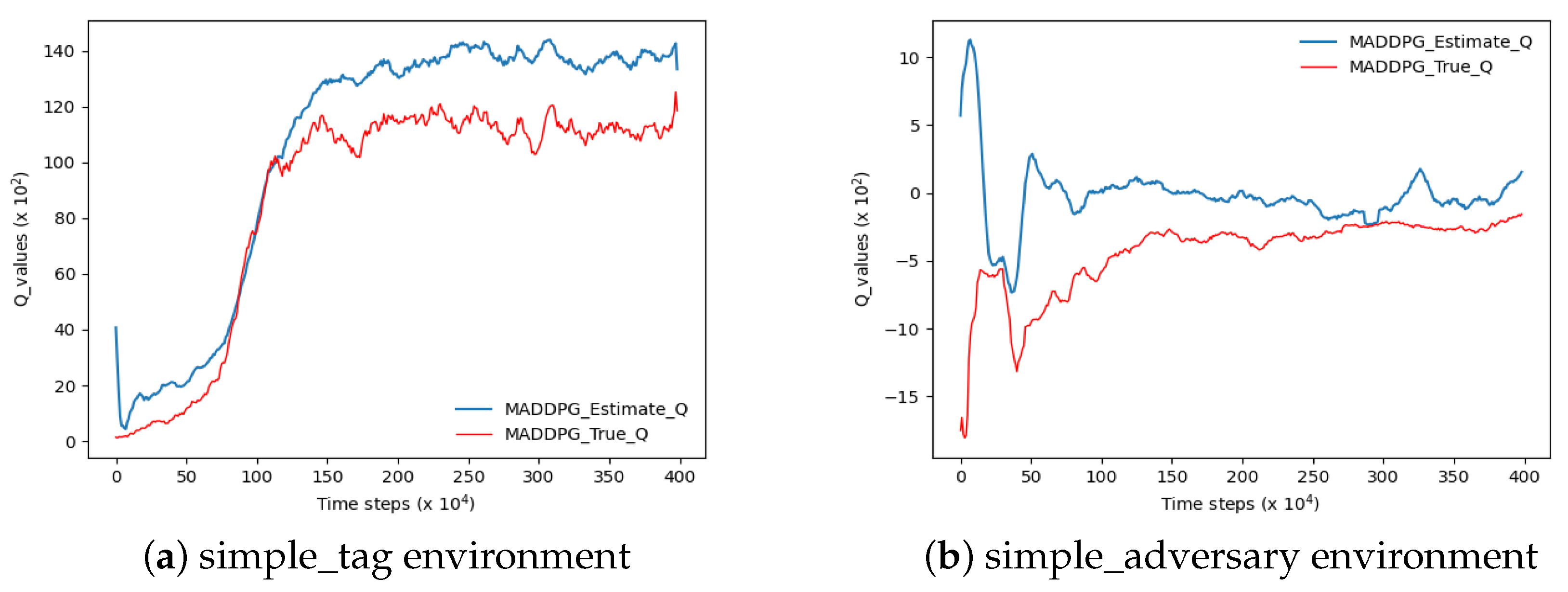
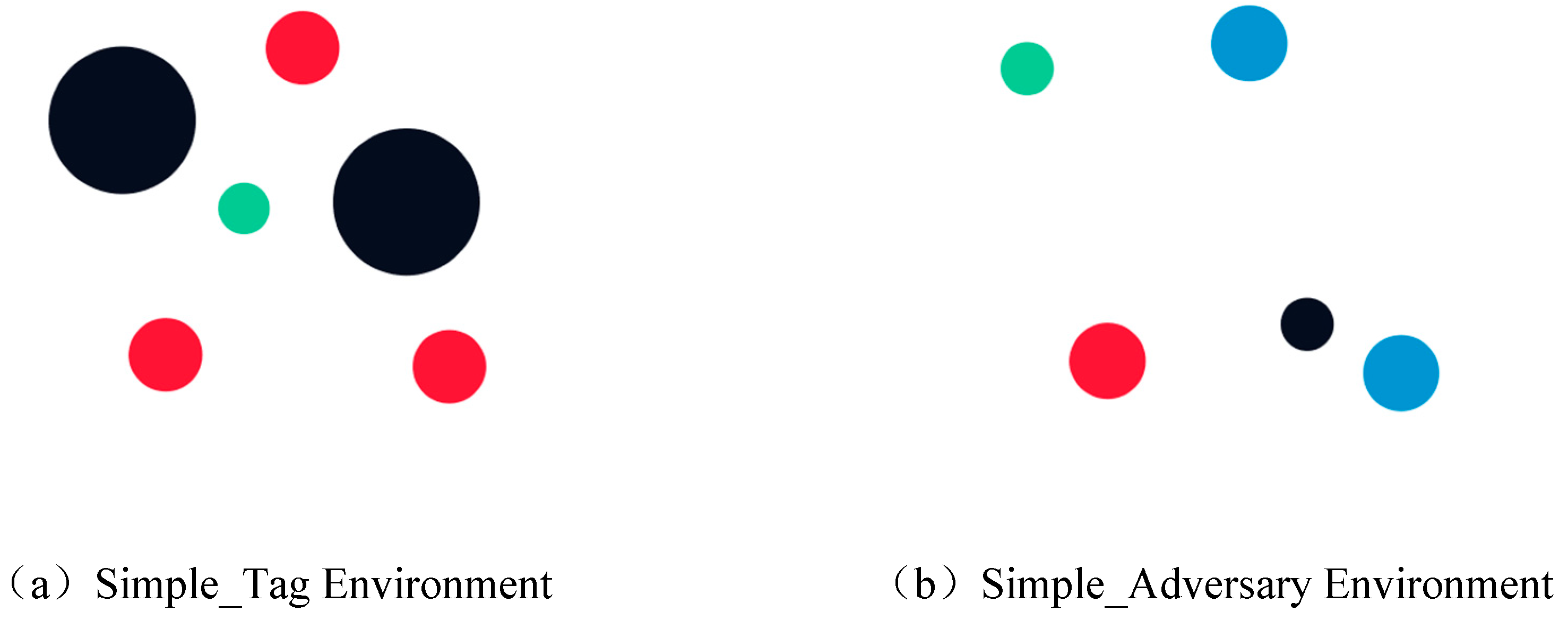
Based on the methodologies employed in previous studies, this paper adopts the MADDPG algorithm to evaluate the Q estimation within a highly authoritative experimental environment pertaining to multi-agent reinforcement learning, as depicted in
Figure 5. In accordance with Scott et al.’s research, if the agent’s estimated Q-value surpasses the actual Q-value at any given step size under a uniform time step size, it signifies an overestimation of the algorithm’s Q-value. In the two figures depicted in
Figure 5, the blue curve denotes the estimated Q-value while the red curve represents its actual counterpart. Notably, both curves exhibit a significant disparity with the blue curve surpassing the red one, indicating an evident overestimation of Q-values.
As shown in
Figure 5a, the experiment was performed in the simple_tag environment. In
Figure 5b, the experiment is shown in the simple_adversary environment.
3. Proposed Algorithm
The multi-agent reinforcement learning environment is characterized by instability, high dimensionality, and continuous space, which pose challenges for Q estimation in this complex setting. Multi-agent reinforcement learning algorithms often require updating numerous parameters and utilizing significant computing resources, leading to cumulative bias. Additionally, issues such as the low correlation between state and action and sparse experience can arise in the experience playback pool, making it difficult to determine sampling points that are uniform enough or sufficient in number to affect algorithmic efficacy. To address these problems, we propose the multi-agent dual dueling policy gradient algorithm based on the empirical clustering layer (ECL-MAD3PG) algorithm as an improvement over MADDPG with three key enhancements.
3.1. The Dueling-Critic Network
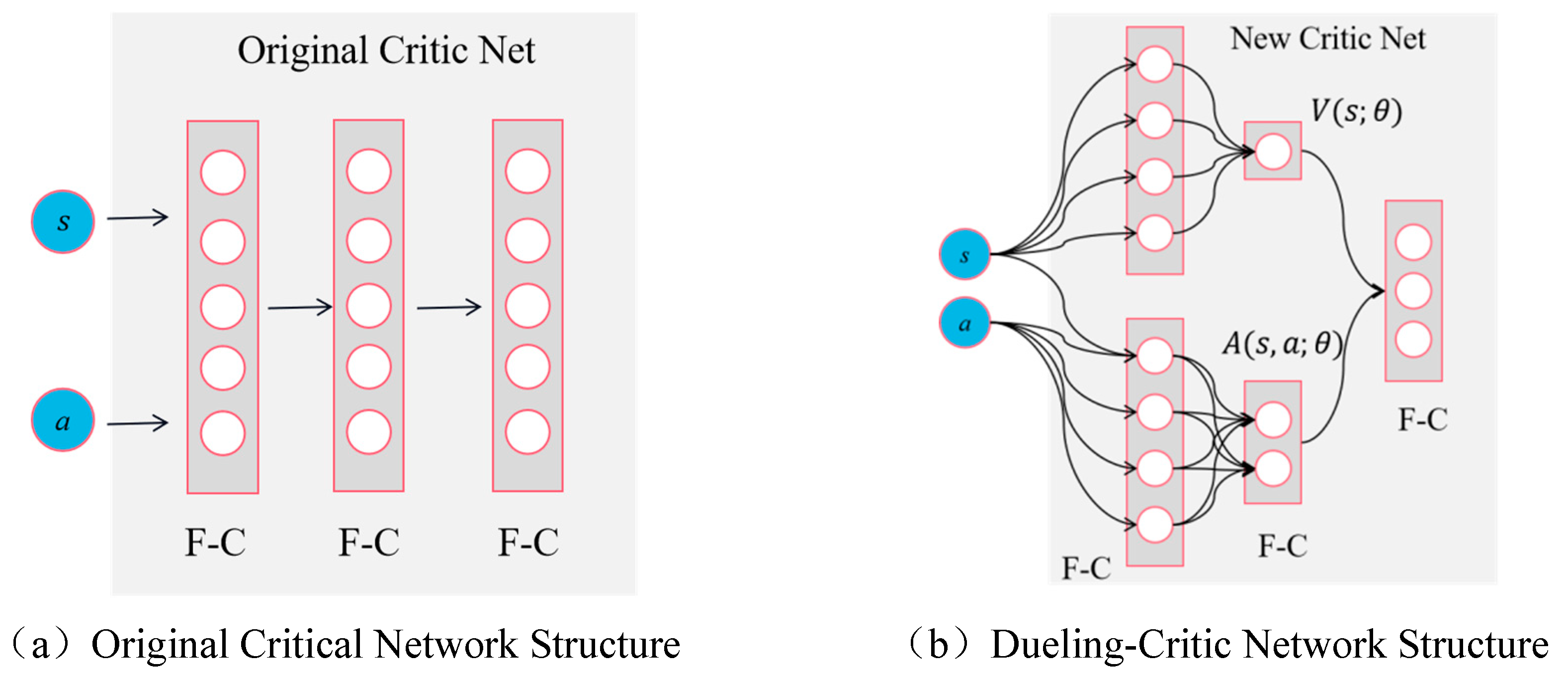
As depicted in
Figure 6a, the input of the critic network in the MADDPG algorithm is compressed into multiple layers of parallel, fully connected networks. However, this structure fails to accurately and effectively analyze the relative contributions of each state and action. Additionally, due to the mixing of state value and action value, when processing high-dimensional state spaces, a large number of parameters need to be learned by the critic network to evaluate the action network’s strategy. Consequently, this leads to substantial computational costs and overestimation issues. To address these limitations and precisely assess the relative contribution of each action by the critical network, we propose introducing an advantage function. This involves dividing the critic network into two components: an advantage function and a value function, thereby forming an adversarial discrimination network structure. The specific splitting process is as follows:
- (1)
Define the optimal advantage function
is defined as the optimal action value function,
is the optimal state value function, and their calculation formula is as follows:
The formula for calculating the optimal advantage function is as follows:
In the context where assesses the quality of the state(s) and evaluates the quality of the agent’s action within that state(s), Formula(20) can be considered as equivalent to utilizing as a reference point, while represents the superiority of action(a) compared to baseline .
- (2)
Properties of the Advantage function
In the field of reinforcement learning theory, function
maximizes function
with respect to
a, as given by Equation (
15):
Taking the maximum of the action
a on both sides of Equation (
14) results in Equation (
16):
Substituting Equation (
15) into Equation (
16) yields Equation (
17):
- (3)
Dueling-Critic function
According to the definition of the optimal advantage function, i.e., Equation (
14), it can be transformed into the following equation:
Substituting Equation (
17) into Equation (
18) yields the formula for the optimal value function, as shown in Equation (
19):
Equation (
19) serves as the theoretical foundation for the modification and decomposition of the critic network.
Figure 6b represents the schematic diagram, illustrating the improvement made to the original critic network structure in this paper through Equation (
19):
Figure 6a illustrates the original critic network structure of the MADDPG algorithm, which comprises fully connected layers.
Figure 6b presents the novel architecture for this problem, referred to as ‘dueling-critic’. In this configuration, the input of the critic network remains unchanged, consisting of state (s) and action (a). However, there is a modification in the transmission mode: both state (s) and action (a) vectors are initially gathered by a fully connected layer before being separately transmitted to the baseline value network
. The data undergoes compression in the dominant network
and ultimately undergoes vector splicing through another layer of fully connected networks. In this structural framework, the critic network effectively maintains state value functions and action value functions, respectively. This dual-value function approach enhances the discriminant capability of the agent’s network during the learning process, thereby strengthening the correlation between state value and action value estimations. Consequently, it leads to more accurate Q-value estimation while also mitigating any imbalance that may exist between state and action values.
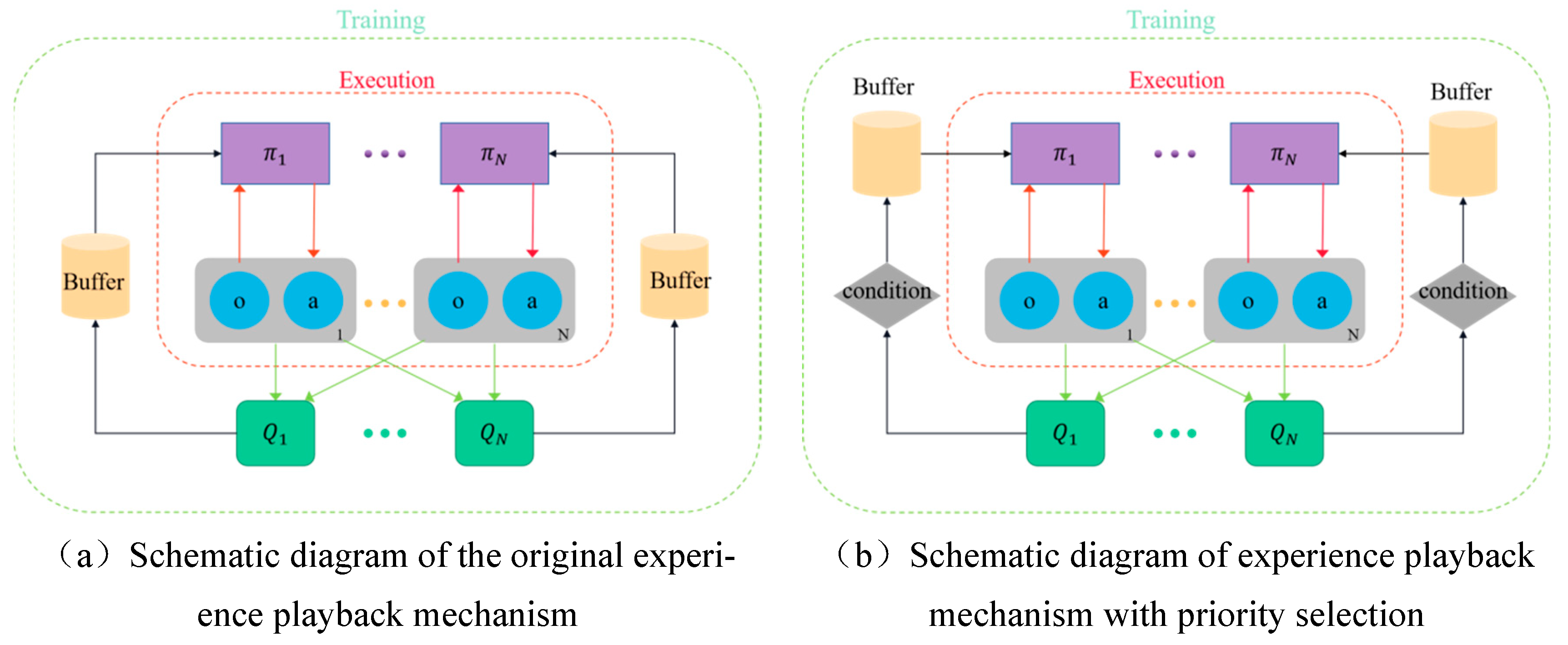
3.2. Priority Experience Replay Mechanism with Conditional Constraints
As the complexity of the experimental environment in the reinforcement learning algorithms increases, it leads to a rise in the number of agents within the system and an expansion in the dimensions of states and observations. This severely impacts the efficiency and quality of algorithm training. Wu Mingxi et al. [
22] have proposed that traditional experience replay methods store all experiences obtained from agent–environment interactions, directly into the experience pool. During training, experiences are randomly sampled from this pool for learning. The original experience replay mechanism does not distinguish which experiences are more valuable. Storing every experience without discernment means that while high-quality experiences can be beneficial for further training of the algorithm, the sampling process may select a large number of low-quality experiences. This leads to a reduced training efficiency, consuming significant time. PER (proposed by Yang, S. et al. [
23]) alleviates the aforementioned problems. The basic idea behind PER is just to adopt one replay buffer for the sake of conserving experiences, assigning a priority level to each one, replacing uniform sampling with non-uniform sampling. In this mechanism, the priority level is represented by the absolute value of the temporal difference error, i.e.,
. A larger
indicates that the algorithm’s evaluation of the state action value at that moment is inaccurate, so that experience should be given a higher weight. During sampling, there are two methods to compute the sampling probability. The first method calculates the probability using Formula (20):
In this formula,
is defined as a small number to inhibit the sampling possibility from reaching 0, ensuring that the overall specimens are plotted via a non-zero probability. The second sampling method sorts
in descending order, and then calculates the sampling probability using Formula (21):
In this expression,
is the index of
, and the larger
is, the smaller
becomes. The principles behind the two sampling methods mentioned above are consistent: the larger
is, the higher the probability of the sample being selected. Because this is non-uniform sampling, different samples have different sampling probabilities, leading to a bias in the algorithm’s prediction. At this point, the learning rate should be adjusted to offset the bias caused by different sampling probabilities. The structure of the priority experience replay is presented in
Table 1.
In
Table 1,
b represents the array size, which must be manually set. If the number of samples exceeds
b, the oldest samples in the replay pool need to be removed. Using this approach, as the algorithm learns, it can sequentially select experiences for training from the replay buffer in order of priority, from highest to lowest, thereby maximizing the utilization of experience information and enhancing both learning efficiency and stability. This grants the algorithm several advantages: it retains essential experiences in the replay buffer, ensuring that these experiences still have a high priority under the current policy, and can be learned first, preventing the propagation of erroneous information. In traditional experience replay processes, since the sampled experiences are entirely random, some critical experiences may not be selected, leading to learning outcomes that fall short of expectations. In contrast, priority experience replay maintains the diversity of the experience pool by setting priorities, ensuring that experiences with greater variance and representativeness are reused more frequently, thereby enhancing the stability of learning. However, when multi-agent reinforcement learning algorithms are applied to relatively complex real-world tasks, they face intricate state and observation dimensions. This places a high demand on the efficiency of the algorithm’s training. Although the priority experience replay mechanism can prioritize the extraction of high-quality experiences, it suffers from high time complexity. As a result, in practice, the algorithm efficacy improvement is often not significant, and it heavily consumes the system’s computational power.
The conventional method of experience playback is limited by its random sampling approach, which occasionally results in the omission of crucial experiences and even yields subpar-quality recovered experiences. Consequently, this hampers the anticipated learning outcomes. In order to enhance the quality of experiences stored in the experience playback pool, it is imperative to investigate the recycling mechanism and experience sampling mechanism that governs this pool. Building upon the original experience replay pool depicted in
Figure 7a, this paper proposes a preferential replay mechanism based on experience clustering and stratification. This is achieved by incorporating a condition module prior to the retrieval of experiences from the original experience pool, as illustrated in
Figure 7b. The purpose of the condition module is to effectively cluster the array of experiences, wherein batches of experiences are grouped based on their priority and subsequently evaluated for their eigenvalues. These eigenvalues are then stored within the experience pool in descending order, ensuring that experiences with higher values take precedence over those with lower values. In this manner, during the interactive learning phase with the environment, the algorithm can effectively prioritize experiences from the condition module in a hierarchical order based on their significance. Additionally, by employing clustering techniques, it can further establish hierarchical priorities to fully leverage experience information and enhance both learning efficiency and stability.
The specific workflow of the priority playback mechanism based on empirical clustering stratification is as follows:
Step 1: The agent interacts with the environment to obtain a collection of empirical data, and the algorithm assigns priority to the data based on the magnitude of the TD error it exhibits. This prioritized list of data is represented as .
Step 2: Cache multiple sets of experience data lists in the ‘Condition’ module and conduct clustering operations to group experiences and calculate the lambda value for each group.
Step 3: According to the characteristic value (), the experiential data are stored in the playback pool (buffer) in ascending order of magnitude.
Step 4: In the sampling stage, experience is selectively sampled based on its value(), enabling the agent to prioritize experiences from groups with higher eigenvalues.
Step 5: The modified algorithm employs empirical data to enhance the optimization of network parameters.
5. Discussion
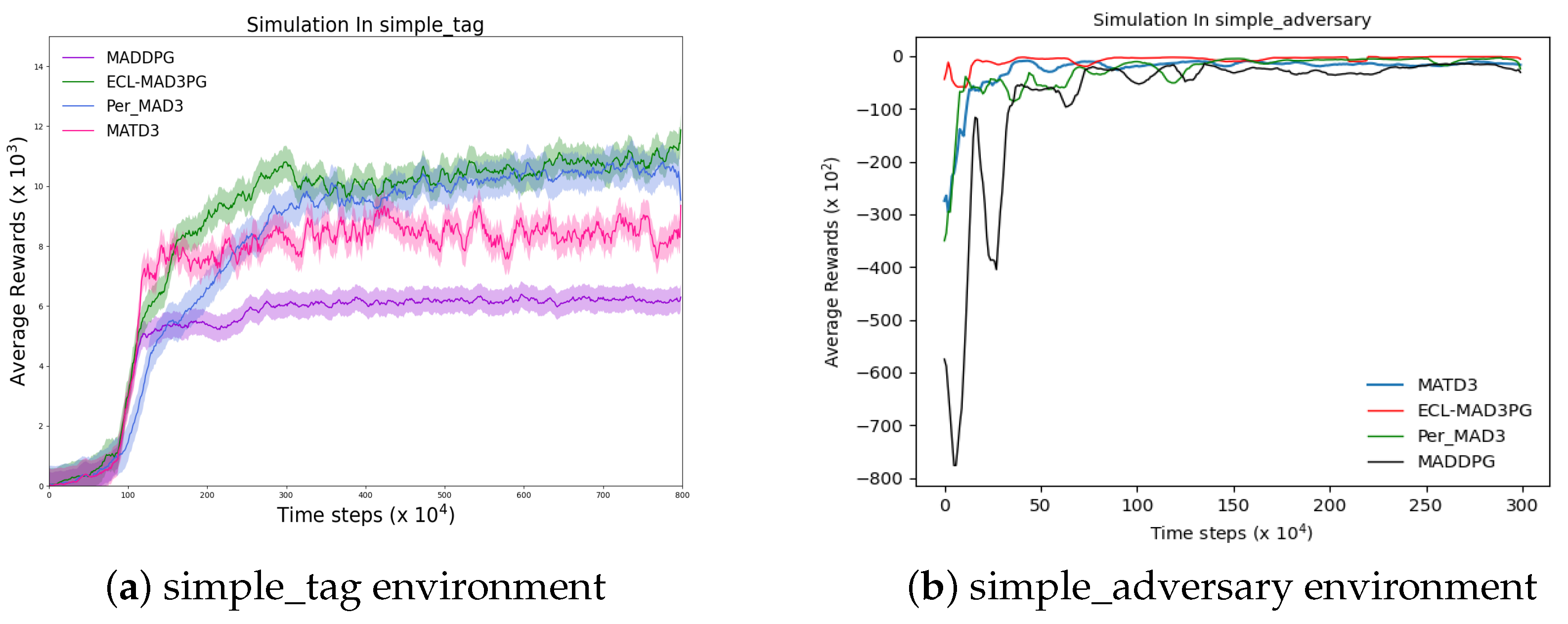
In this study, we compare three algorithms: ECL-MAD3PG (our proposed algorithm), PER-MADDPG, MADDPG, and MATD3, in three different environments. We calculate the average reward value for each algorithm in these environments and plot a curve to illustrate the trend of change in these values. As our work builds upon MADDPG, the algorithm is still influenced by certain hyperparameters, which may require multiple adjustments to achieve convergence.
Notably, we find that the learning rate of the discriminant network significantly impacts training effectiveness. However, other parameters such as the policy network learning rate, experience replay pool size, and noise can be set to commonly used values without significant impact on results. Taking the “simple_tag” environment in the MPE platform as an example,
Figure 13 presents the experimental results of two groups of discriminant network learning rates using the ECL-MAD3PG algorithm. Comparing these results with those depicted by the ECL-MAD3PG curve in
Figure 10a, it can be inferred that while the average reward value of the algorithm increases with an augmented discriminant network learning rate, convergence becomes challenging. Subsequent experiments demonstrate that within this environment, a learning rate ranging from
to
yields relatively favorable outcomes. Beyond this range, excessively large learning rates lead to heightened volatility in algorithmic results and even failure to converge. The default values for parameters such as the policy network’s learning rate, experience playback pool size, and noise exhibit minimal influence on experimental outcomes.
By employing operations akin to fine-tuning the learning rate of the discriminant network, this study successfully determined the optimal experimental parameters through a series of rigorous experiments conducted in three distinct environments. The obtained results are meticulously documented and are presented in
Table 16 for reference.
After conducting multiple experiments in three different environments, the obtained results were documented in this table. The findings indicate that ECL-MAD3PG exhibits superior performance in relatively simple environments when employing a smaller discriminant network learning rate. Conversely, in more complex environments, ECL-MAD3PG demonstrates enhanced efficacy with the utilization of a larger discriminant network learning rate.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}