1. Introduction
Seismic surveys are designed to balance cost, logistics, and a spatial sampling interval, which is crucial for recording a seismic wavefield. The proper (alias-free) spatial sampling of the seismic wavefield is achieved when the distance between adjacent sources (or receivers)
does not exceed the Nyquist sampling criterion
:
, where
is the minimum velocity of the media and
is the maximum frequency of the source [
1]. Depending on
and
, the Nyquist criterion may be very small, e.g., 1 m. The sampling theorem can be expanded to relax the Nyquist criterion, but these expansions require measurements of the wavefield gradient [
2,
3]. Even so, the successful application of the sampling theorem and its expansions may be challenging when the knowledge of
over the area of interest is limited.
The alias-free sampling of a seismic wavefield in all spatial directions is rarely satisfied in practice due to the cost constraints of the survey. Various solutions have been adopted and developed to overcome the issue of spatial aliasing. For instance, in typical exploration survey layouts, at least one or two out of four spatial coordinates are densely sampled to facilitate the proper removal of unwanted linear noise [
4]. This type of noise is usually represented by the surface waves that are suffering the most from the sparse aliasing sampling intervals. On the data processing side, different algorithms can be applied to mitigate the aliasing in the data, for instance, reconstruction methods based on the prediction error filter [
5,
6]. In addition to a long-standing dilemma of shooting a dense survey or working with aliased seismic gathers, the ideal regular seismic layout can be compromised by field deployment circumstances: obstacles and areas without access, equipment malfunction, zones with poor recording conditions, logistical constraints, and surface topography. These long-standing, common, and persistent seismic acquisition challenges motivate us to consider non-regular and non-dense survey layouts.
Recent advances in signal processing have paved the way for a new cost-effective acquisition paradigm called compressive sensing (CS) [
7]. The foundation of CS is the concept of signal sparsity, which is when almost all the energy of a signal is contained in a few transform coefficients of the signal. The key elements of the CS framework include the sampling scheme, sparse transform, and the reconstruction algorithm. Together, they form a framework that can solve undetermined problems, especially those that are common in seismic data processing. One of the earliest works on the application of compressive sensing for seismic signals was published by [
8]. The field implementation of CS-based acquisition has been pioneered by [
9] and further practiced by [
10]. It is worth pointing out that, even before the first applications of the CS framework for the problems of seismic data interpolation, a vast amount of techniques for data reconstruction and dealiasing of spatial wavenumbers has been developed [
6]. These techniques are being continuously improved [
11]. The CS framework stands out from these methods because it constrains in a direct manner the type of sampling pattern needed for the CS reconstruction workflow to succeed.
We focus on CS-based sampling schemes and the application of these schemes for seismic CS. Different CS-based sampling methods can be found in the literature. However, the authors of these methods do not assess the robustness of the prepared CS-based schemes to sample perturbations or reallocations. The latter is an essential consideration for seismic CS-based design since the prepared layout of sources and receivers can be disturbed during the field deployment. In addition, only a few of the proposed CS-based sampling methods are supplemented with complete instructions for generating a proposed sampling scheme.
We organize our study as follows. Firstly, we formulate the criteria for CS-based sampling schemes and analyze the strengths and weaknesses of the available sampling methods. Secondly, guided by the theory of the CS framework, we introduce and implement our two-step sampling approach. We evaluate the performance of two-step sampling schemes through CS reconstruction and compare them with the results obtained for the jittered schemes. We also compare the sensitivity of two-step and jittered sampling schemes for sample reallocations. This comparison demonstrates that the two-step scheme is more robust in the face of perturbations in the sampling scheme.
A mathematical formulation of the CS framework for seismic applications is provided in
Appendix A. Furthermore, in
Appendix B, we summarize different tools that can be used to analyze the CS-based schemes.
2. Overview of Sampling Methods
Important characteristics of CS-based sampling schemes include the following: CS theoretical guarantees, tolerance to perturbations of scheme samples, and flexibility to incorporate geophysical parameters and logistical constraints. Many methods have been proposed for generating CS-based sampling schemes for seismic applications. We briefly describe these methods by clustering them into five main groups based on sampling mechanisms.
The first group of methods includes schemes with random source (receiver) spacing. The random samples may be generated by taking
M samples out of
N uniformly at random (
). Consequently, the maximum distance between adjacent samples in such schemes is not constrained and can vary in a wide range. For sparse signals in the Fourier domain, the restricted isometry property guarantees successful CS reconstruction with random samples [
12]. However, for sparse signals under a transform with localized basis functions (e.g., curvelet transform), the large distance between adjacent sources (or receivers) deteriorates the CS reconstruction results [
13]. Therefore, the random sampling schemes are not recommended due to implied limitations on the sparse transforms. In addition to that consideration, the maximum distance between adjacent sources (or receivers) is constrained by the size of the Fresnel zone: the Fresnel zone should be adequately sampled to ensure that CS-reconstructed data represent the subsurface of interest [
14,
15,
16].
The second group includes methods that generate sampling schemes by solving an optimization problem. In most of these methods, the objective functions are related to the Fourier spectrum of a sampling scheme: a maximum non-DC component of the spectrum, also known as coherence [
17], a weighted sum of the non-DC amplitudes of the spectrum [
18], an average coherence [
19], and a coherence map [
20]. These methods minimize (or maximize) the objective function, assuming that the largest distance between adjacent sources (or receivers) is fixed and relatively small. The performance of these methods is not discussed when the obstructions limit access to a survey area, and consequently, the largest distance assumption is violated. Also, the coherence does lend itself to CS theoretical guarantees [
12], but the assumptions for these guarantees rarely hold in practice. Moreover, the proposition that sampling schemes with smaller coherence promote better reconstruction results is uncertain since some studies support this proposition [
21,
22,
23,
24,
25] and others disprove it [
26,
27,
28,
29,
30,
31]. Finally, coherence computation includes a sparse transform (e.g., the Fourier transform), making these methods computationally expensive for large-scale 3D surveys.
The third group uses the difference sets from combinatorial number theory to define CS-based schemes [
24,
31,
32]. A difference set with parameters
contains
elements taken from the bigger set
,
, such that each element of the set
can be written as the difference of two elements of this set in exactly
ways. The difference sets may be excellent candidates for CS-based schemes from a mathematical point of view. For example, these sampling schemes achieve the smallest coherence when the Fourier transform is taken as the sparse transform. In addition, all non-DC amplitudes of the Fourier spectrum of a difference set are equal. The disadvantages of using the difference set for seismic survey design start with the absence of control of the distances between adjacent sources (or receivers). Second, the difference set limits the survey parameters, such as the number of sources (or receivers) used in the field, because the difference sets exist only for specific combinations of parameters
,
, and
. Finally, the difference sets are sensitive to any changes in the scheme: the smallest coherence may no longer be achieved with a few reallocated samples. Such sampling schemes impose additional restrictions on the field implementations of CS-based surveys.
The methods in the fourth group are based on a sub-interval strategy [
8,
33,
34,
35]. Implementations of this strategy include (i) splitting a source (or receiver) line into sub-intervals and (ii) taking samples within each sub-interval based on a probability distribution. This strategy is devised to control the distance between adjacent sources (or receivers). A recent study by [
36] can be used to theoretically investigate the CS reconstruction performance of these methods. One of the disadvantages of sub-interval methods is that repetitive sampling patterns may appear due to the independent choice of the samples in each sub-interval. In addition, the sub-interval strategy may limit the choice of survey parameters. For example, in the jittered sampling, the number of acquired data points
M should be a sub-multiple of the number of data points after reconstruction
N [
8]. In other methods from the sub-interval group [
33,
35], the relationship between
M and
N has been made more flexible by randomly varying the number of samples in each subinterval
and the length of each subinterval
. Consequently, two additional parameters are introduced in the sampling scheme generation process. The relationship between these four parameters (
M,
N,
, and
) has to be analyzed to understand how to generate a sampling scheme once specific
M and
N are given.
Low-discrepancy sequences define the fifth group of sampling approaches for building CS-based schemes. In seismic exploration, these sequences were first applied as an optimum discretization scheme for migration algorithms. In particular, ref. [
37] used the Halton and Hammersley points to provide a near-optimal discretization for the prestack Kirchhoff migration. As for the CS application, the low-discrepancy sequences may be good candidates because these sequences avoid clusters of sources (or receivers) and large distances between adjacent sources (or receivers). On the other hand, the disadvantages of these sequences include (i) the absence of known CS recovery guarantees and (ii) a logistically challenging implementation of these schemes in the field due to off-grid locations of sources (or receivers). Furthermore, the numerical studies on CS reconstruction with the Hammersley points demonstrate discouraging results [
38] and, finally, low-discrepancy sequences may require additional transformation to reduce aliasing [
39].
The two-step sampling method was initially proposed by [
40]. This paper describes this method in detail and performs different numerical experiments with the two-step sampling schemes. The two-step sampling approach provides sampling schemes with the CS theoretical background, the controlled distance between adjacent sources (or receivers), and the flexible choice of seismic survey parameters. The method combines two types of sampling: random and designated. Random samples are needed to achieve a CS theoretically compliant sampling. The designated samples are purposefully added to the random scheme to control the maximum distance between adjacent sources (or receivers). The random and designated samples are generated sequentially, one after the other. Two-step sampling can be applied in the presence of obstructions in the field and does not limit the choice of seismic survey parameters. In addition, our approach generates schemes that are robust to modifications in a prepared layout of sources (or receivers). The theoretical considerations for the two-step sampling are built based on the Fourier basis. However, the use of this sampling method is not limited to the Fourier sparse transform. In fact, the numerical CS reconstruction experiments are performed with the curvelet sparse transform.
4. Numerical Experiments
4.1. Generating and Modifying Sampling Schemes
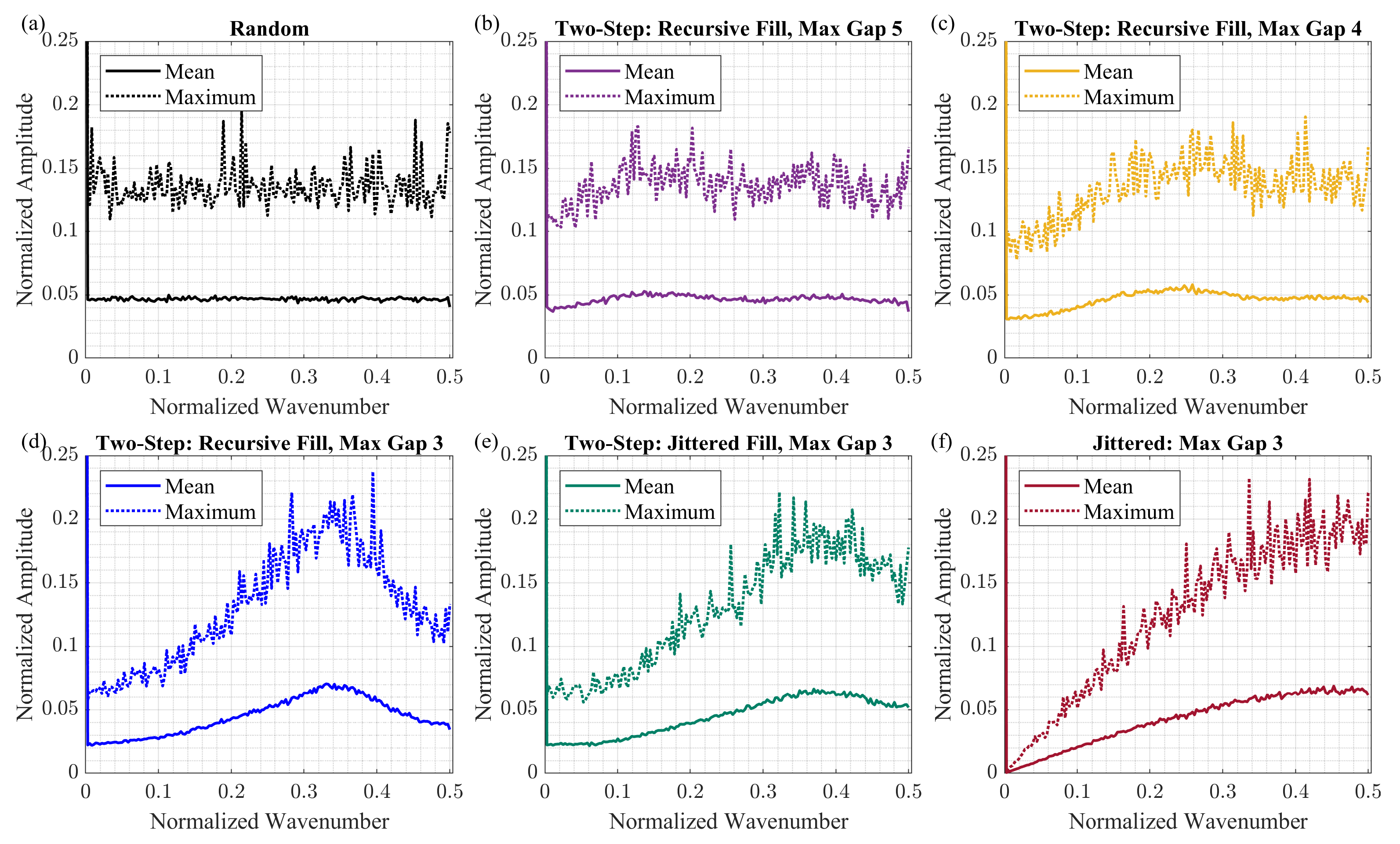
In this section, we describe the sampling schemes further analyzed with the average Fourier spectrum, CS reconstruction tests, fold maps, and rose diagrams of an orthogonal survey. We define the initial sampling schemes as those generated by a sampling method without applying additional subsequent changes. Three types of initial sampling schemes are considered. One of them is generated by the jittered sampling method. The two-step approach with recursive and jittered gap-filling options generates two other types. Each scheme has 360 samples (), and 180 out of 360 samples are active (). Thus, other 180 samples are omitted (), which implies a decimation ratio of . The maximum gap size in these schemes equals 3 grid steps.
In our experiments, we are also interested in evaluating the performance of different sampling schemes whose several initial sample locations have been changed. We define the modified sampling schemes as those generated by a sampling method and subsequently modified by a specific algorithm. Studying the modified sampling schemes is particularly important for seismic CS applications because unforeseen physical obstructions in the field may lead to changes in the prepared survey layout. Also, some sources (or receivers) can be classified as unacceptable for processing and removed from the recorded data, introducing additional distortions to the initial acquisition layout.
We constructed the following modification process to imitate distortions that may happen with a sampling scheme during its field deployment:
- (i)
Identify vacant positions in an initial scheme;
- (ii)
Modify the initial scheme by moving K samples from their old positions to new positions from step (i);
- (iii)
Repeat the modification process times for each K and each scheme to consider different scenarios of new positions.
In this modification algorithm, the new positions of K samples are chosen from the vacant positions such that the maximum gap size in the modified scheme remains the same as in the initial scheme. Also, this procedure avoids creating large gaps because it is known that sampling schemes with large gaps are not desirable for seismic surveys.
As the samples are reallocated, the old positions of K samples cannot be considered as the new locations for any reallocated sample. This setting intends to imitate obstacles that may block the prepared positions of the sources (receivers) in the field. Every input scheme will have modified versions, and each of them can be stored for further analysis. It is also possible to choose one modified version among all modification trials using a criterion for the sampling scheme characterization.
The modified sampling schemes for our numerical tests have been generated for each of the three considered scheme types: jittered sampling, two-step sampling with recursive gap-filling option, and two-step sampling with jittered gap-filling option. The parameters of modified schemes include the number of all samples N, the number of active samples , the maximum gap size, and the number of modified samples . The first three parameters are taken the same as in the initial sampling schemes described above. In the modification algorithm, was set as 100, and coherence was computed for every modified version. For further analysis, modified schemes with the largest coherence value were selected.
4.2. Average Fourier Spectra
In this section, we analyze the influence of reallocated samples in a scheme on the shape of the average Fourier spectra. In the case of the initial sampling schemes, we consider 500 realizations for each type with the parameters described in
Section 4.1. The modified schemes are also built with considerations outlined in
Section 4.1. We consider two cases of the number of modified samples
K: a mild number of reallocated samples
and a more substantial number of reallocated samples
.
Figure 5 shows the average Fourier spectra for each group of schemes before and after modifications. We observe that, for two-step schemes, the average spectra are slightly affected by the reallocated samples for both the gap-filling options: recursive (
Figure 5b) and jittered (
Figure 5c). However, for the jittered schemes, as the number of modified samples increases, deviations from the initial average Fourier spectrum appear for the entire range of the wavenumbers (
Figure 5a). Even with a small number of modified samples (
), the new jittered schemes are no longer featured by the small values of the average Fourier spectrum at the low wavenumbers (<0.1). As for the case of
, the average Fourier spectrum of modified jittered schemes has the spike at the largest normalized wavenumber
. This spike indicates that the modified schemes contain a relatively long aliasing sampling pattern—a portion of a sampling scheme wherein active and omitted samples are regularly alternated. The aliasing sampling patterns occur in the jittered schemes since samples within each sub-interval are chosen independently from neighboring sub-intervals. Although these patterns may be short in the initially populated jittered schemes, several short aliasing patterns may accidentally merge into one long pattern due to the reallocation of the samples.
4.3. Reconstruction Test
The reconstruction test aims to assess the performance of the two-step schemes in the CS reconstruction experiments. In these experiments, a seismic signal is decimated in the spatial direction according to different schemes, and no decimation is applied along the time axis of the signal. For this test, the initial sampling schemes have the parameters outlined in
Section 4.1. For each type of the initial scheme, we consider 50 realizations. The modified schemes were generated with
for every initial scheme according to the instructions in
Section 4.1. We do not change the parameters of the CS reconstruction workflow in order to exclude the parameterization bias and highlight differences due to specific sampling patterns in the sampling schemes.
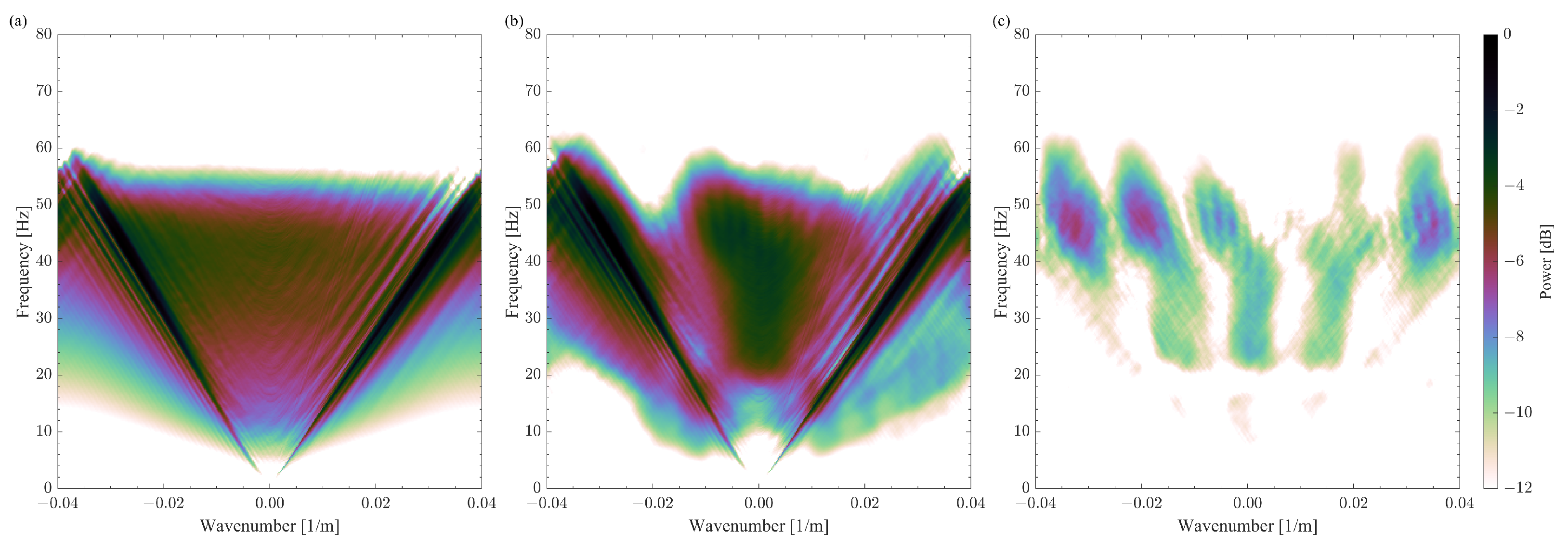
We consider a shot gather as a seismic signal from the SEAM Barrett model dataset [
41]. The shot gather contains 360 receivers spaced by
m and has a wide range of amplitudes (
Figure 6a). Namely, the amplitudes of the surface waves range from
to 500, while the amplitudes of the reflected waves are within
. None of the following is applied to the signal: amplitude correction, clipping, zero-padding, and smoothing functions at the edges. Also, no noise is added to the synthetic data. The Fourier spectrum of the shot gather shows that a
m spacing provides the alias-free sampling of the seismic signal (
Figure 7a). The curvelet transform is used to obtain a sparse representation of the seismic signal [
42]. The SPGL1 solver is used as an algorithm for CS data reconstruction [
43]. For each reconstruction experiment, the solver runs until the predefined tolerance level is achieved, leading to a slightly different number of iterations for each reconstruction experiment.
Figure 6b shows an example of the CS-reconstructed signal. In this case, the initial two-step scheme with the recursive gap-filling option decimates the signal prior to the CS reconstruction step. We do not display the reconstruction results obtained with other sampling schemes since they appear to perform very similarly to the one in
Figure 6b. The difference between the original and the reconstructed signals shows that the reconstruction algorithm cannot correctly recover all features of the signal (
Figure 6c). One can notice the reconstruction noise after 4 s. This noise is related to the wraparound effect of the Fourier transform, which is used in the curvelet to decompose the signal. This effect can be mitigated by extending the signal with zeros along the time axis. This shot gather does not have events of interest after 4 s. Consequently, this wraparound artifact, in this case, is not considered a significant issue.
The CS reconstruction workflow struggles significantly with the portion of the signal outlined in the black rectangle. The seismic shot gather has a huge spike in the amplitude at the very first arrivals for the traces with offsets smaller than 100 m. We make an analogy with a delta function to rationalize the adverse effects of such an amplitude spike on the reconstruction results. It is known that a delta function in the time and space domain would spread over the entire frequency-wavenumber spectrum. In the context of the curvelet transform, which we use as a sparse transform in these experiments, a delta function in the time and space domain will assign rather large values for all curvelet coefficients whose basis functions pass through this location. Some of these strong coefficients will correspond to the basis functions with orientation parallel to the time axis. The proper coefficients of such vertically oriented curvelets are very hard to reconstruct precisely because we decimate the traces in our numerical experiment. The authors in [
13] demonstrated that, once the gap in the signal exceeds the size of the curvelet basis function, the corresponding coefficients will not be recovered correctly. Thus, obtaining all coefficients needed to describe the amplitude spike is challenging for the CS reconstruction algorithm. Consequently, the quality of the reconstructing signal around that amplitude spike is also compromised. We may achieve better results by applying, for instance, a median filter. Instead, we performed the CS reconstruction of the seismic signal as it was generated by a seismic wavefield modeling tool without altering the signal in any way.
The Fourier spectra of the reconstructed and difference signals are also affected by the incorrect reconstruction of the curvelet coefficients (
Figure 7b,c). Namely, the largest difference in
Figure 7c is at the frequency bands of 40–80 Hz and 20–40 Hz. These frequency bands correspond to the scales at which the vertically oriented curvelet basis functions are very thin and may be missed entirely due to the gap size of 3 grid steps. Furthermore, we analyze the CS reconstruction results quantitatively by computing the trace reconstruction error
as follows:
where
and
are the
i-th traces in the reconstructed and original shot gathers, respectively. The smaller the error, the better the CS reconstruction. We use the time window of 1.4–1.8 s, which mainly contains the reflected events, to compute the trace reconstruction error (the yellow rectangle in
Figure 6c).
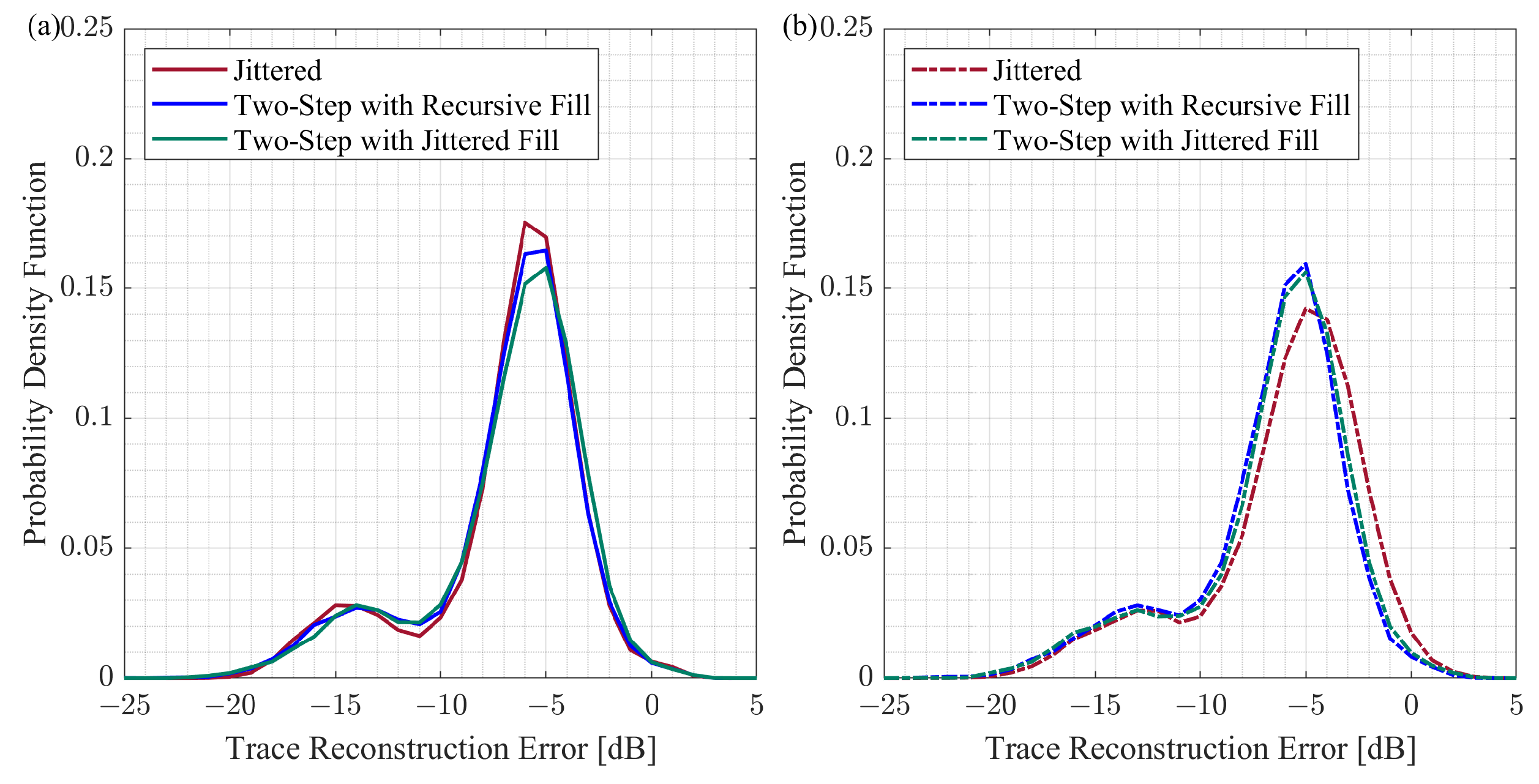
We build the histograms of the trace reconstruction error based on 50 CS reconstruction trials per group, and each trial has 180 reconstructed traces. We use the kernel distribution for each histogram to obtain a non-parametric representation of the probability density function of a trace reconstruction error.
Figure 8 summarizes the probability density functions for the CS reconstruction experiments with initial and modified schemes generated by the different approaches.
The probability density functions have two peaks. For the traces that include the surface waves, the trace reconstruction error is within the range from
dB to
dB. As for the traces that have reflected events, the trace reconstruction error ranges from
dB to 0 dB. The probability density functions are very close for the initial and modified two-step sampling schemes (
Figure 8b,c). In the case of the jittered approach, the probability density function is shifted to the right for the modified schemes compared to the initial schemes (
Figure 8a), implying that the reconstruction results deteriorate for the modified jittered schemes. The comparison between different methods for initial and modified schemes is shown in
Figure 9. This comparison reveals that the probability density functions are very similar for all three groups of initial schemes (
Figure 9a). However, the probability density function for the modified jittered schemes is shifted to the right compared to the probability density functions of the modified two-step schemes (
Figure 9b). It is important to note that, in this experiment, we are considering the change in the reconstruction error due to sampling scheme modification. As for the absolute values of the reconstruction error, these values can change if we consider a different signal or apply another CS reconstruction workflow. Further discussion of the CS reconstruction error is provided in
Section 5.
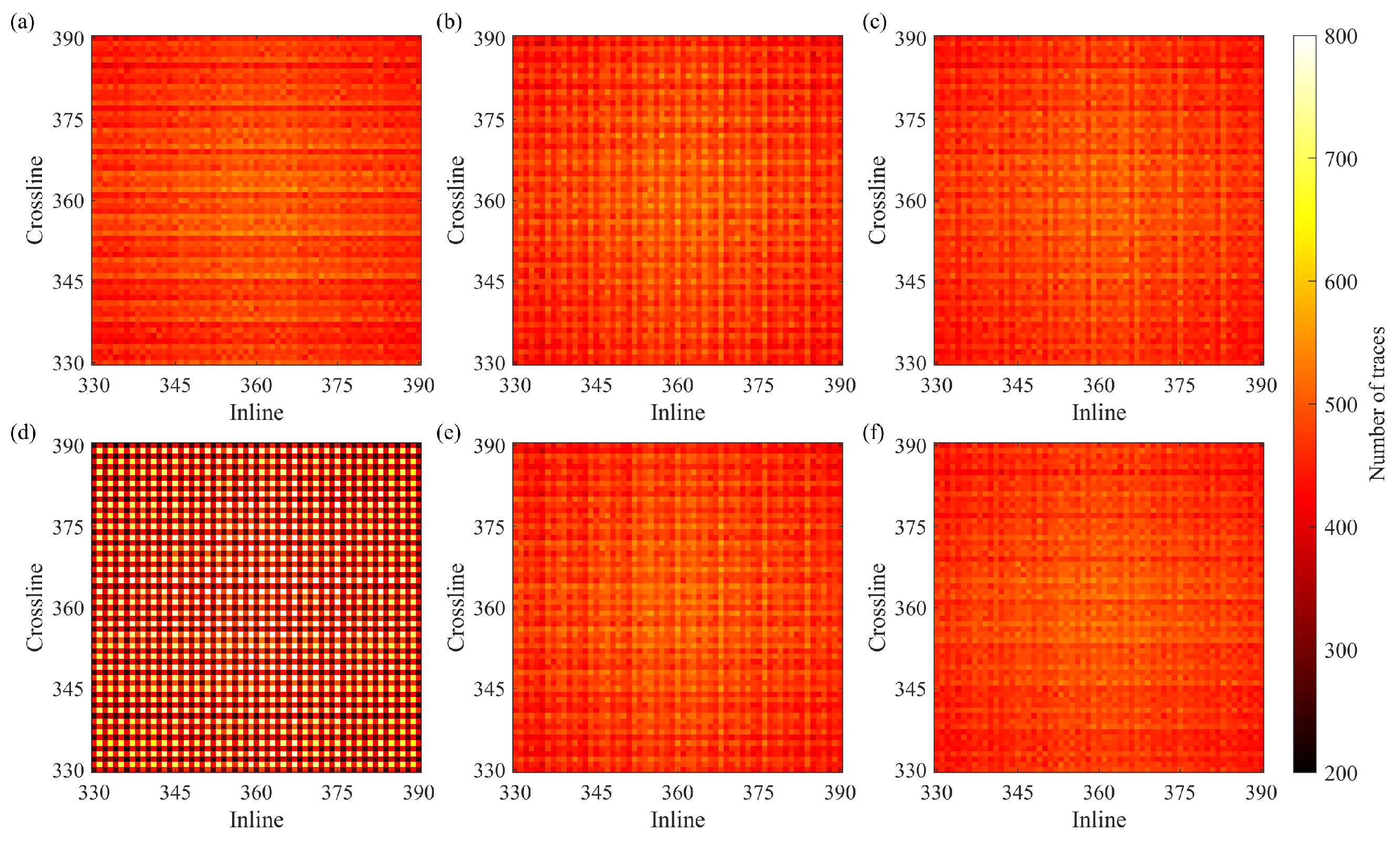
4.4. Three-Dimensional Orthogonal Survey Layout
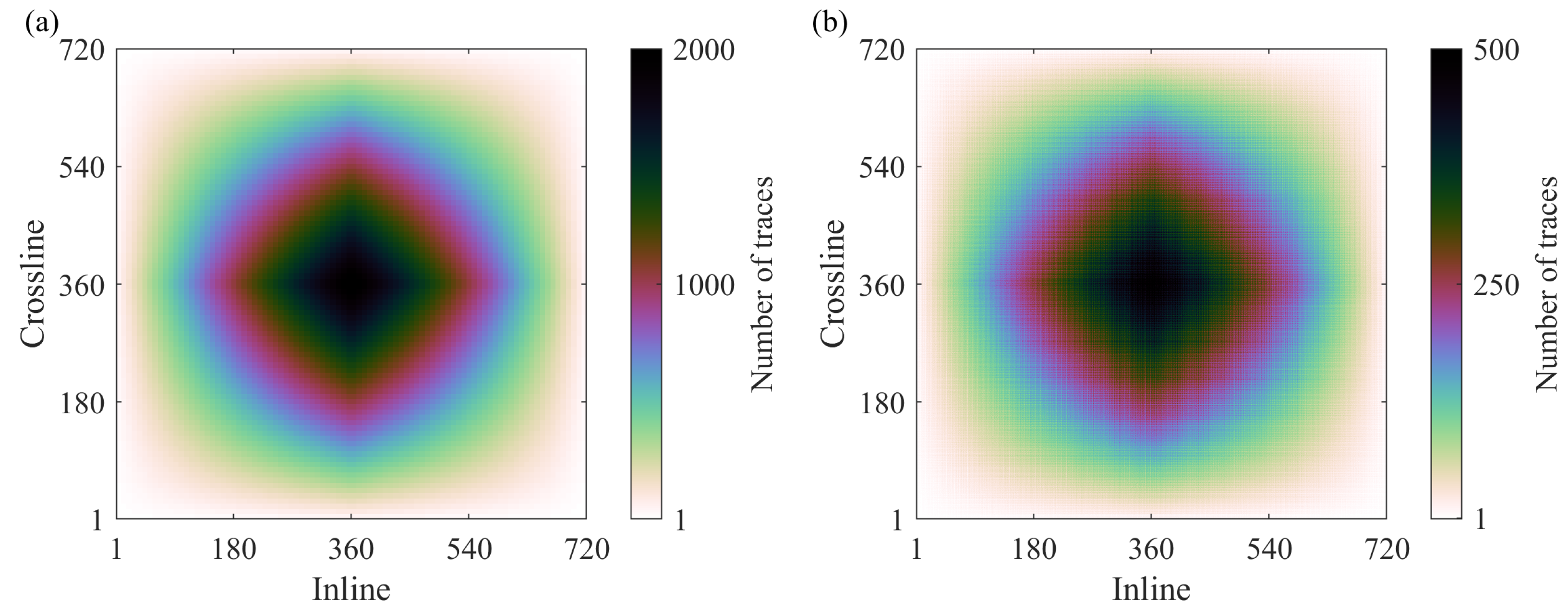
The 3D orthogonal survey layout is considered to analyze the influence of different sampling approaches on the distribution of traces within bins, offsets, and azimuths. The layout has the following parameters: 81 square km covered by 46 source lines orthogonal to 46 receiver lines with 200 m spacing between the lines. Each receiver (or source) line has 360 receivers (or sources), and the distance between adjacent receivers (or sources) is 25 m. The receiver patch covers all 81 square km, which means that each receiver listens to all sources. In addition, the source and receiver lines are shifted by m to avoid reciprocal traces.
The full 3D survey is decimated according to the CS-based schemes to build a CS-based survey layout. After decimation, each source (or receiver) line contains only half of the sources (or receivers), which decreases the total number of traces by four compared to the full survey. The CS-based schemes were generated according to the details in
Section 4.1. Thus, the CS-based survey layout is evaluated for three groups of initial schemes and three groups of modified schemes with
.
We calculate the fold maps with
m by
m bins for each survey.
Figure 10 shows the fold maps of the full survey and the CS-based survey created according to the initial two-step schemes with the recursive gap-filling option. The full fold of the CS-based survey is about four times smaller than the full fold of the full survey, but the distributions of the traces within bins have very similar patterns for both surveys.
Figure 11 shows zoomed portions of the fold maps for the CS-based surveys built with the initial and modified schemes. We observe that the reallocated sources and receivers do not change the distributions of the traces in the case of the two-step sampling schemes (
Figure 11b,c,e,f). However, the modified jittered schemes lead to a less even distribution of traces within the bins than the distribution of traces achieved by using the initial jittered schemes (
Figure 11a,d). In
Figure 11d, the bins with more traces regularly alternate those with fewer traces.
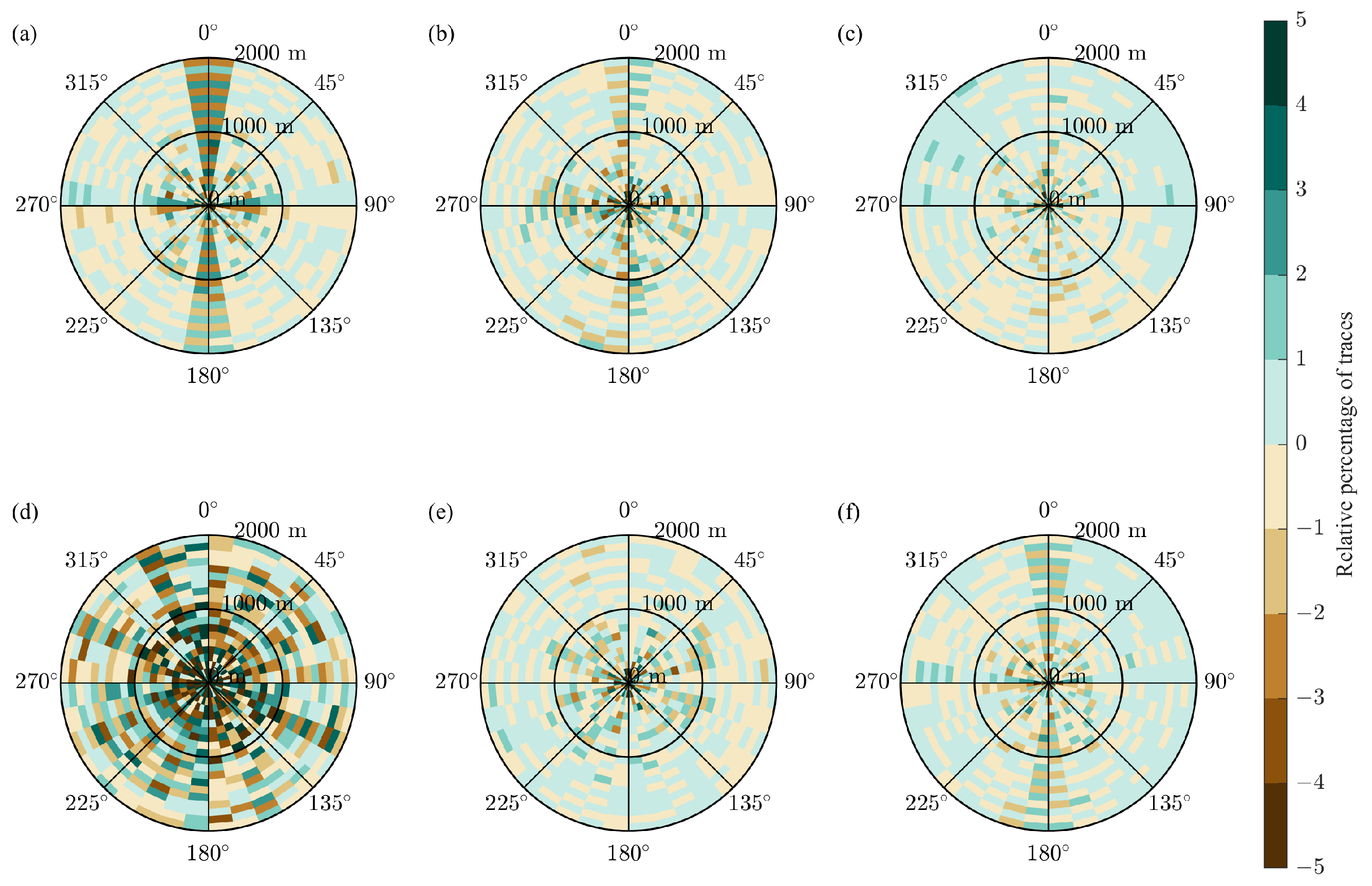
The rose diagrams are computed with bins that have a 10 degree step in azimuth and a 100 m step in offset.
Figure 12 shows the rose diagrams for the full survey and the CS-based survey built with the initial two-step schemes with the recursive gap-filling option. Like the fold maps in
Figure 10, the rose diagrams are different by the trace count and similar in the trace distribution across the bins. To analyze the subtle changes in the distribution of traces due to the CS-based sampling, we computed the relative rose diagram
as
where the factor
is due to the reduction in the number of sources and receivers in each line by the factor of two, the index
i enumerates the bins in the rose diagram, and
and
are the rose diagrams for the full and CS-based surveys, respectively. We observe that the relative percentage of traces ranges from
to 2 for all bins at different azimuths for the initial and modified two-step schemes (
Figure 13b,c,e,f). In contrast to that, the initial jittered schemes produce the relative rose diagram in which bins at the azimuths of 0 degrees and 180 degrees have greater variations in the relative percentage of traces than bins at all other azimuths (
Figure 13a). As for the modified jittered schemes, the uneven distribution of traces across the relative rose diagram spreads for other azimuth directions (
Figure 13d).
5. Discussion
In the literature, CS-based seismic acquisition is referred to as sparse, irregular, nonuniform, or randomized acquisition. However, using these terms interchangeably may be confusing because these terms also describe survey layouts not necessarily designed by CS sampling methods. For example, a sparse acquisition may refer to a Nyquist-based layout with coarsely spaced receivers (or sources). As for an irregular acquisition, even a conventional survey may be called irregular due to different obstructions in the field that cause arbitrary deviations in the planned layout. Moreover, regular sampling in one domain (source and receiver coordinates) may be considered irregular or nonuniform in another domain (midpoint coordinates, offset, and azimuth). Therefore, to avoid confusion, we exclusively use the term “CS-based” while referring to sampling schemes built for seismic CS applications.
The current formulation of the two-step sampling method is built based on the CS reconstruction guarantees available in the literature for the Fourier basis. Our formulation can be generalized. For instance, during the first stage, one can use a sampling scheme other than random as long as it satisfies the restricted isometry property. Possible candidates for the first-step scheme can be found in [
36]. Such potential generalization of the two-step sampling can help to resolve one of the inconsistencies of the current sampling method. Although the theoretical guarantees we considered are valid for the Fourier basis, the CS reconstruction with such a basis can be poor for complex seismic signals. More suitable basis functions, such as the curvelet transform, do not have known theoretical guarantees on which we can rely to build a sampling method.
In our method, the null space property does not impose any restrictions on the locations of the designated samples. Thus, the second-step samples can be used to incorporate other high-priority constraints on the survey layout. For instance, instead of considering the fixed maximum gap size, one can vary the maximum allowed gap size over the area. This strategy can be effective for surveys with variable near-surface conditions and different levels of background noise caused by external factors.
One may be interested in filling in large gaps in the first-step scheme with a sampling strategy that does not have any element of random sampling. One of the simplest strategies is to place additional samples within large gaps equidistantly. In this case, second-step samples will be separated regularly by small gaps of the same size. Such sampling schemes are not recommended since they are known to contribute to aliasing artifacts that contaminate CS-reconstructed signals. Another possible strategy is to distribute second-stage samples within large gaps based on a certain criterion of sampling scheme quality. In this situation, depending on the implementation and complexity of an objective function, the elements of random sampling can still be involved in finding a set of samples that minimize or maximize the considered criterion.
Lastly, we may consider using the first-stage random scheme itself to fill in large gaps. For instance, if we are interested in reducing the size of the large gap from 20 to 3 grid steps, then the first-stage schemes can be searched for a section of length 20 with a gap not exceeding 3 grid steps, and if this section is found, it can be inserted into the considered gap. If this section is not found, then one needs to come up with further considerations. If the first-stage scheme contains several sections of length 20 with a gap not exceeding 3 grid steps, then the choice becomes non-unique. Consequently, unless specific preferences are imposed on the choice, one section can be chosen uniformly at random from the other detected sections with the same length and maximum gap size. This strategy can be intriguing because it can make the first-stage schemes self-sufficient for gap-filling purposes, which in turn reduces the reliance on supplemental sampling strategies for the second step.
We propose our sampling method as a two-step design process, which implies that random and designated samples are not distinguished during the executing stage of the survey project. Yet, we provide here our reasoning for the circumstances when the separation between random and designated samples during the field implementation can be beneficial. For example, in simultaneous source acquisition, seismic vibrators that shoot at random locations may be separated by a time delay (several hours) from the seismic vibrators that shoot at locations strategically chosen based on previous random samples. This scenario may be beneficial when the surface terrain and obstacles disturb a typical time and offset separation scheme required to ease the deblending process.
The overview section highlights the differences between several CS-based sampling methods. At the same time, all methods we consider in this paper have one common characteristic. They do not impose or require prior knowledge of the subsurface either in the form of a velocity model or recorded wavefield over the area. These methods can be in demand when the details of the velocity model or legacy data are limited, e.g., exploration surveys. Once more information about subsurface geology is available, model-based methods and machine learning can be applied to take advantage of this information for survey design [
44,
45]. These methods can be valuable for designing monitoring time-lapse surveys. It is not excluded that different sampling methods will be used over the same survey area in case there will be multiple survey campaigns. Consequently, it may be worth comparing and understanding the differences between sampling schemes generated by general sampling methods and ones that utilize and rely on prior information about the subsurface.
We analyzed the average Fourier spectra and showed that different sampling schemes have different noise patterns in the wavenumber domain. The presence of the spike at the normalized wavenumber of may indeed negatively affect the CS reconstruction results since such a spike indicates the presence of aliasing in the sampling scheme. Although we do not observe a strong relationship between the shape average Fourier spectra and the CS reconstruction results, the role of the average Fourier spectra of the sampling scheme on other processing steps may be interesting to investigate.
We used the trace reconstruction error to assess the CS reconstruction results qualitatively with different sampling schemes. Even though this measure is often used in the CS literature, its usefulness for seismic CS application is uncertain. Firstly, measuring reconstruction errors in the shot or receiver gather domains is not straightforwardly translated into the final products of the seismic interpretation and analysis. The reconstructed gathers will go through a comprehensive processing workflow with a number of steps. The choice of the parameters for the processing steps depends on both data quality and processor decision-making. Consequently, it may be hard to predict how the features of the reconstruction noise are mapped into the final results.
The direct comparison of reconstruction error values reported in different publications should be conducted carefully, considering various factors. One factor contributing to the reconstruction error is the sparsity level (Equation (
A7)). Sparsity levels of the seismic signals are not quantified in many publications. Thus, one can only make qualitative assumptions on the sparsity level based on the visual appearance of the seismic signal. Reprocessing of the seismic gathers is another factor that can challenge the comparison of the reconstruction error values. The prepossessing of the data can be conducted with slightly different parameters, and such procedures are not always reported in an explicit manner.
In this paper, we restricted our reconstruction experiments to a commonly used CS-reconstruction workflow, which uses the curvelet transform and the basis pursuit algorithm (the solver). Such a choice was made since, for this interpolation workflow, the interaction of the user with the solver is minimal, which helps to remove the parameterization bias of a specific user and reveal differences associated with specific sampling patterns. Many other interpolation techniques available in the literature can potentially be explored, some of which can be less sensitive to specific sampling patterns. One of the commonly used seismic data interpolation techniques is the 5D interpolation method [
46]. This technique has been found to be effective for preparing the data for subsequent seismic data processing steps such as migration. For this purpose, the input signal of the 5D interpolation workflow is a denoised common midpoint gather. In other words, linear noise, such as surface wave energy, will be suppressed before interpolation. As for our reconstruction experiments, the workflow was able to handle the recorded wavefield in the shot gather domain, which includes the surface wave energy.
We studied the application of CS-based sampling for seismic surveys with the orthogonal layout. In our examples, we considered decimating source (or receiver) stations within the source (or receiver) lines along the densely sampled direction. Decimating the survey lines may not be favorable for CS reconstruction because the seismic wavefield may be sampled too coarsely in the direction perpendicular to the lines. The two-step sampling may be applied to the other survey layouts. It is worth noting that CS-based surveys may not be necessarily built by decimating the regular layout. In CS, the number of successfully reconstructed samples is constrained by the sparsity level of a signal and the number of active measurements.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












