
Dynamic and Real-Time Object Detection Based on Deep Learning for Home Service Robots



Abstract
:1. Introduction
- (1)
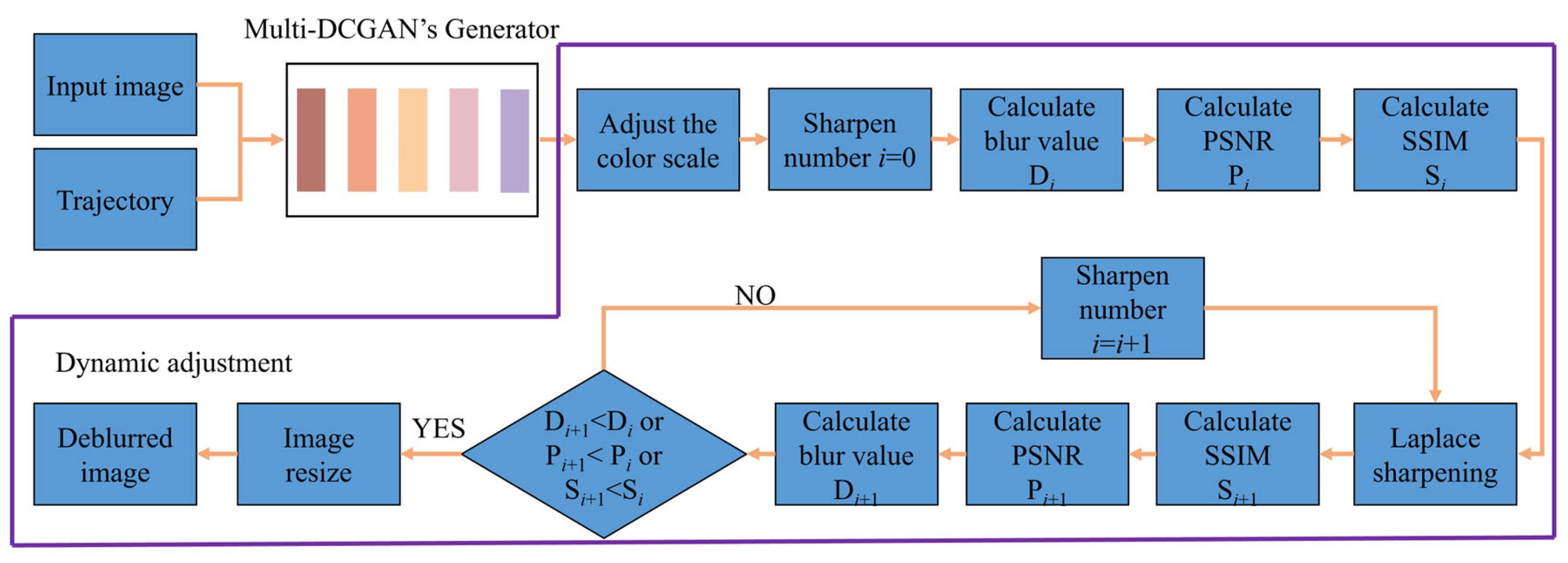
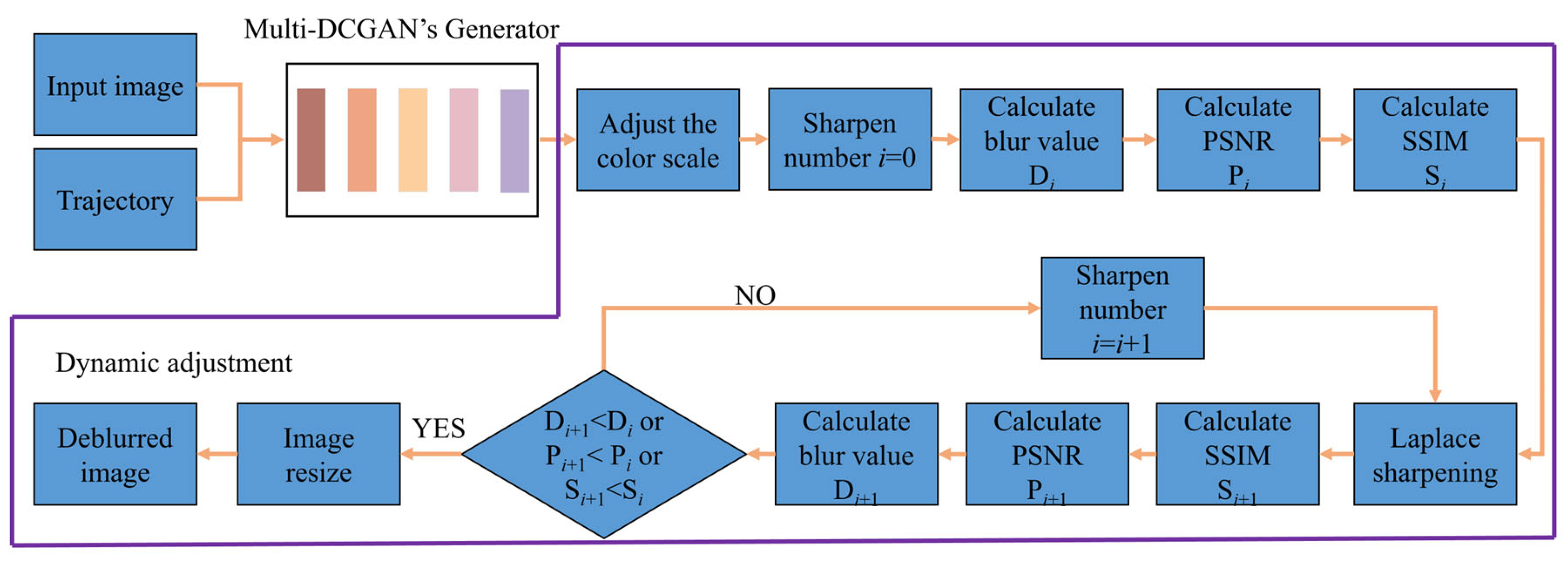
- A DA-Multi-DCGAN with a dynamic adjustment mechanism combining PSNR, SSIM, and sharpness and a multimodal multiscale fusion structure taking robot motion and the surrounding environment information into account is proposed, which can realize the deblurring of the acquired images under different motion states and enhance the efficiency.
- (2)
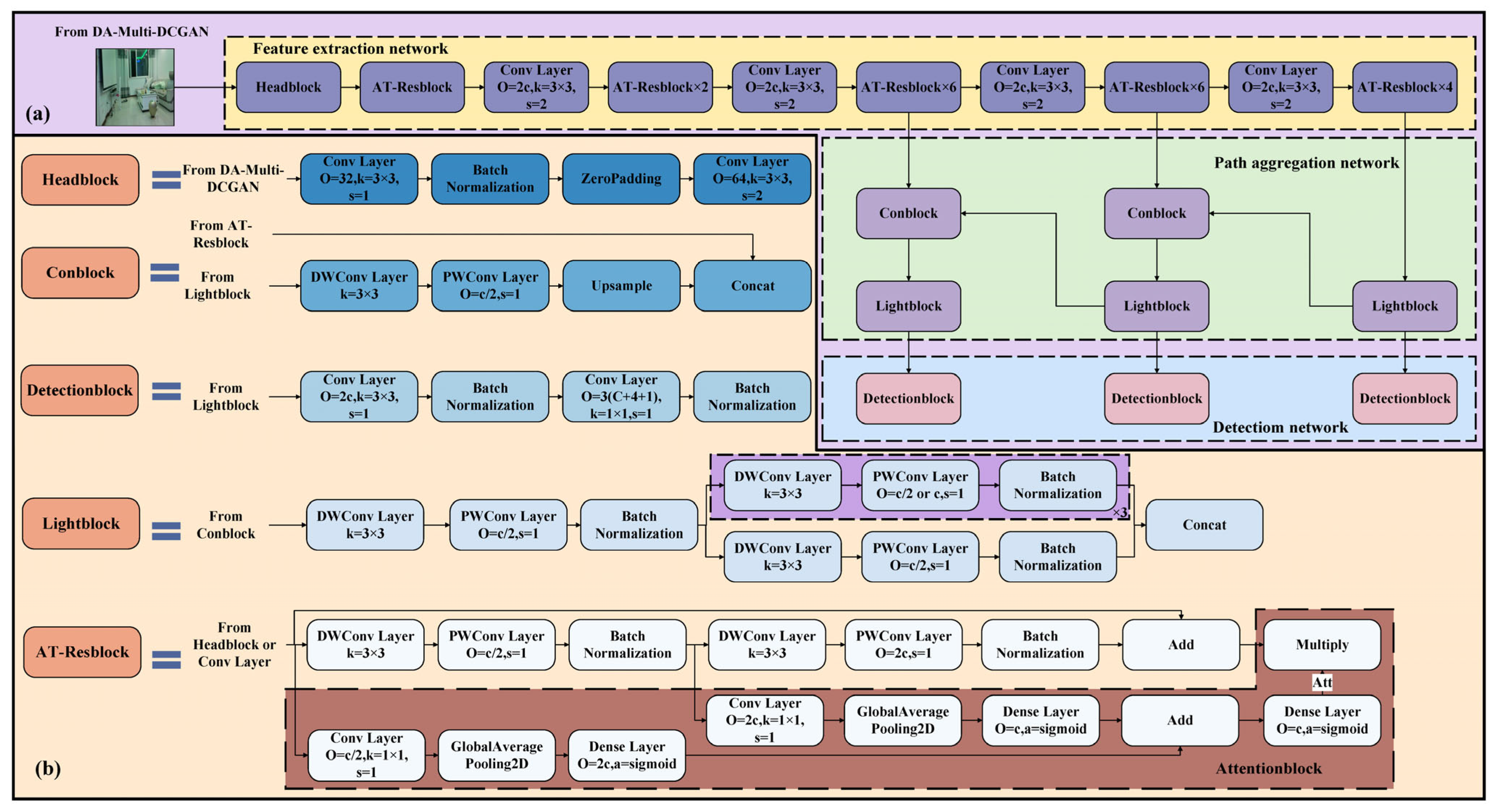
- An AT-Resblock embedded with an attention module is designed, which can fully extract features such as color and texture contours of objects, highlight key areas, integrate salient features, and improve the sensitivity and precision of small and partially occluded objects. Based on a partial depthwise separable convolution that replaces the standard convolution to improve model detection speed, a lightweight network unit named Lightblock is developed, which reduces the number of network parameters and computational complexity, and improves computational efficiency.
- (3)
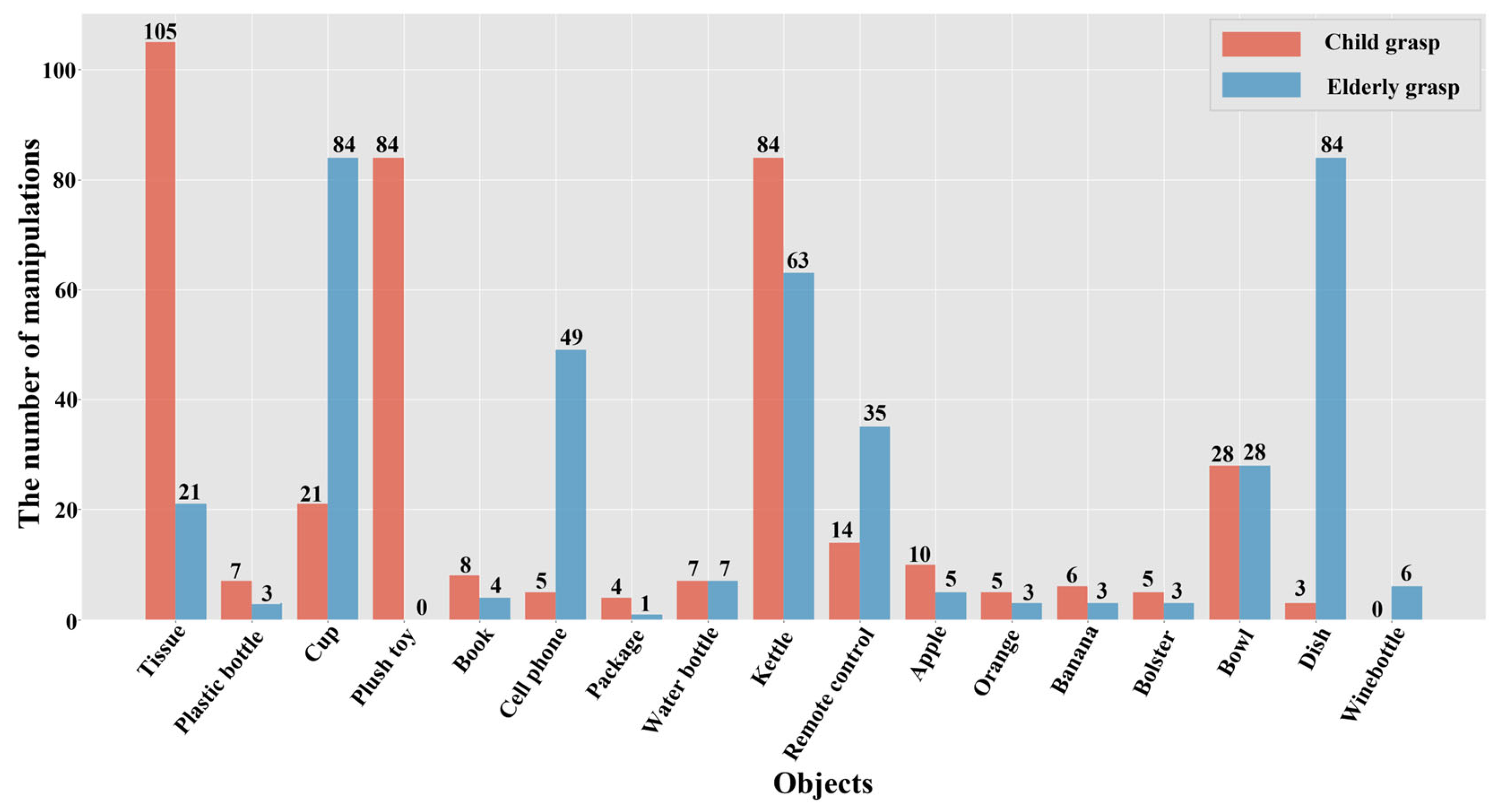
- We analyzed the daily manipulating tasks of older people and children, summarized 17 kinds of frequently used daily necessities, and constructed a dataset named Grasp-17 for object detection of service robots.
- (4)
- The TensorRT neural network inference engine was run on the home service robot prototype equipped with NVIDIA Jeston AGX Xavier, and the inference efficiency was improved by three times under the same model, which achieved the dynamic object detection time of 29 ms, demonstrating the real-time nature of the proposed method in service robots during motion.
2. Materials and Methods
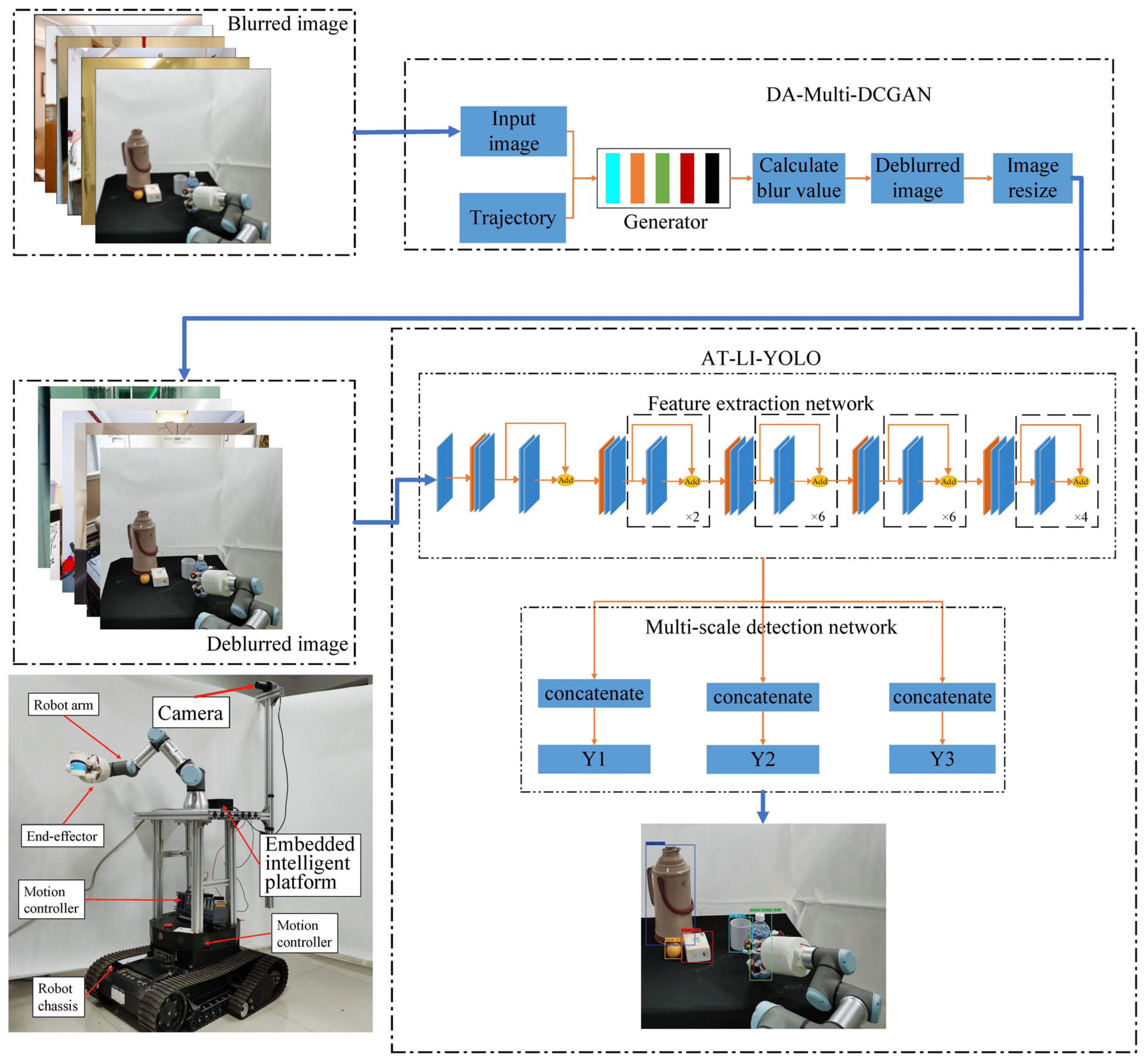
2.1. Framework of the Proposed Method
2.2. DA-Multi-DCGAN Algorithm
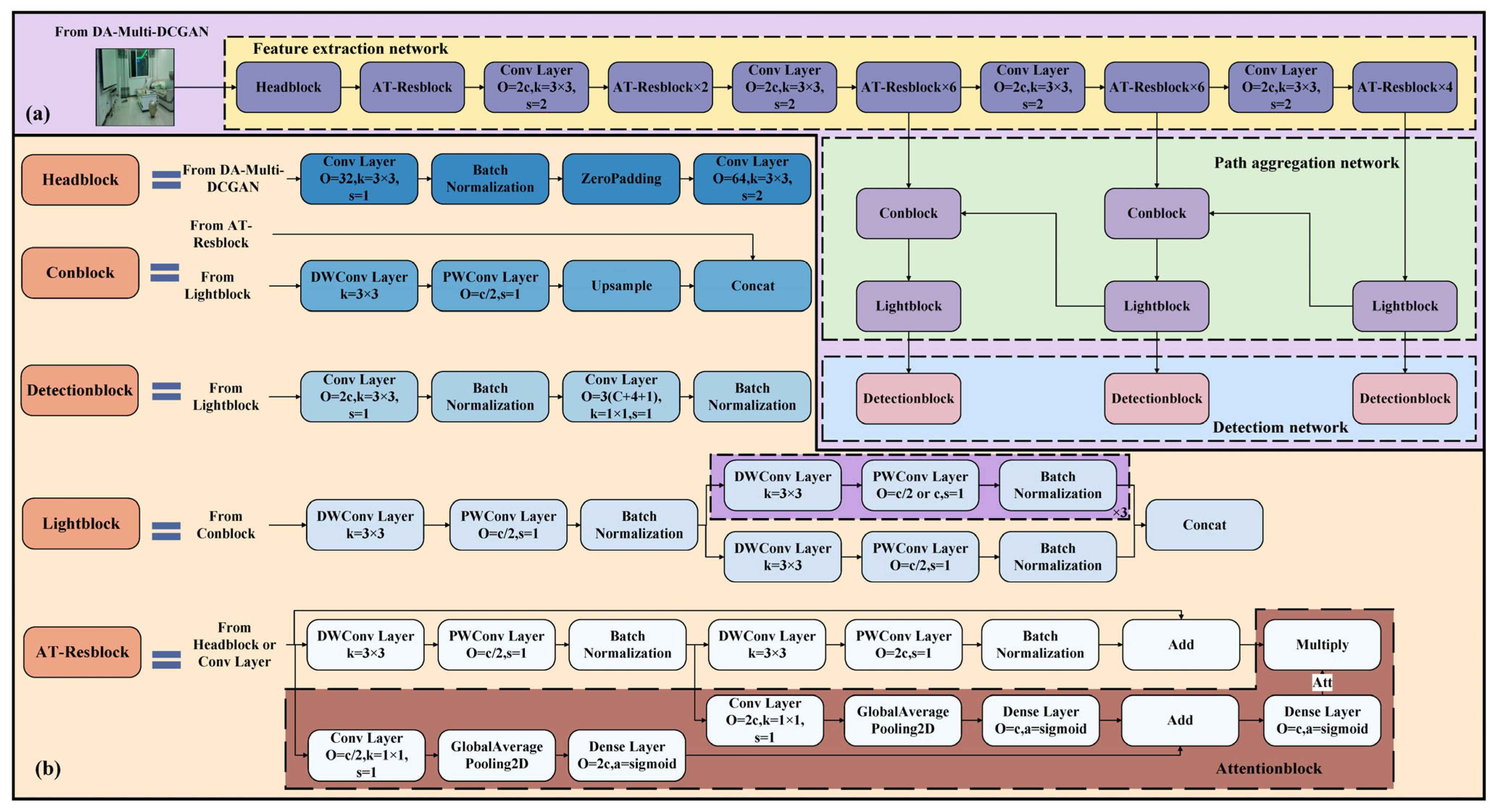
2.3. Structure of AT-LI-YOLO
3. Experimental Section
3.1. Experimental Setup
3.2. Dataset Preparation
3.3. Design of Experiments
4. Results
4.1. Deblurring Performance of DA-Multi-DCGAN
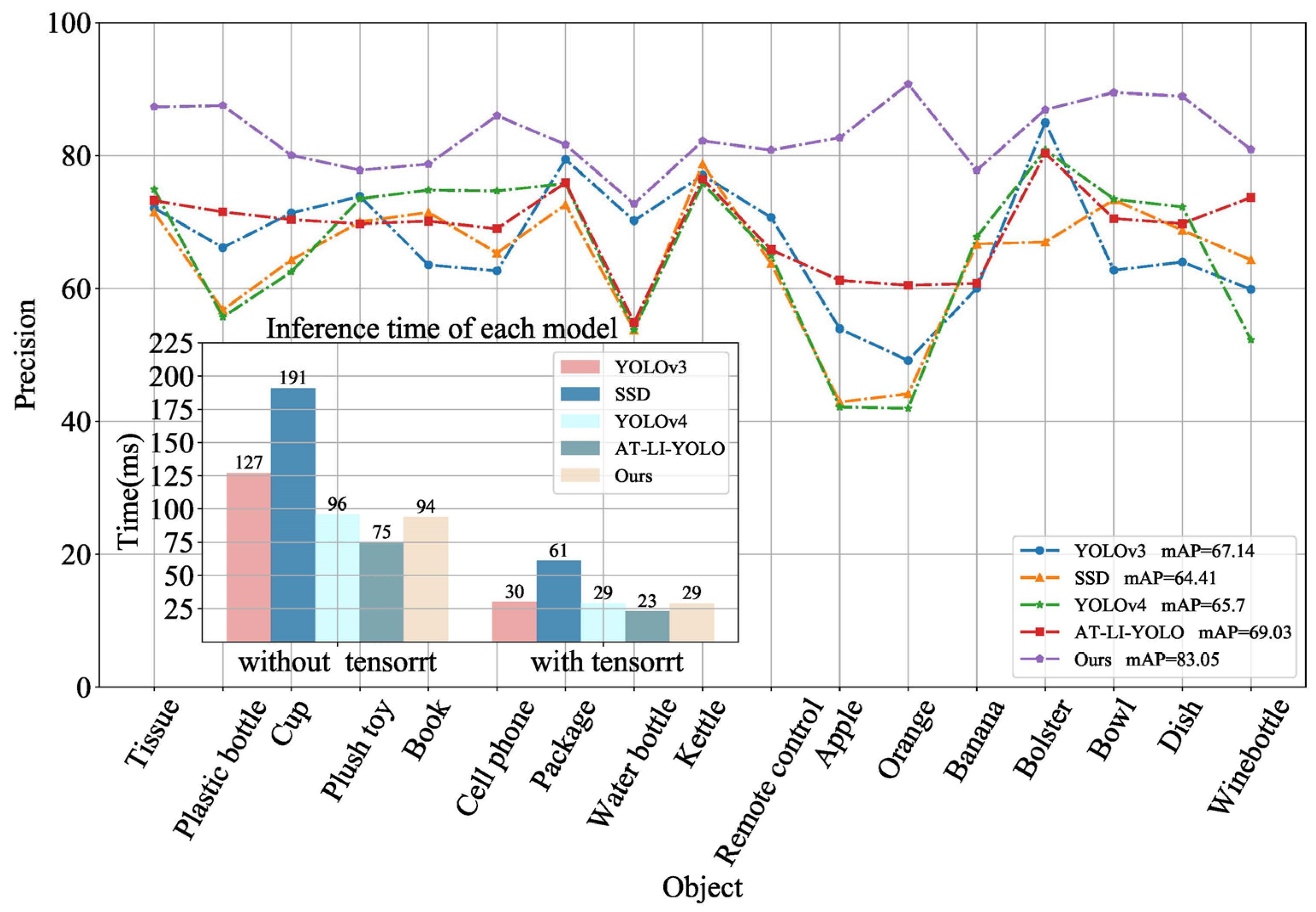
4.2. Object Detection Results
4.3. Experiment of Object Detection during the Motion State of the Service Robot
5. Discussion
6. Conclusions
- (1)
- DA-Multi-DCGAN employs a dynamic adjustment mechanism to filter and sharpen images with different blurriness. The multimodal multiscale fusion structure leverages both robot motion and surrounding environment information to effectively suppress gradient explosion and reduce the randomness of the feature map generation process. Compared with DeblurGAN, our method achieved a 5.07 improvement in PSNR and a 0.022 improvement in SIMM.
- (2)
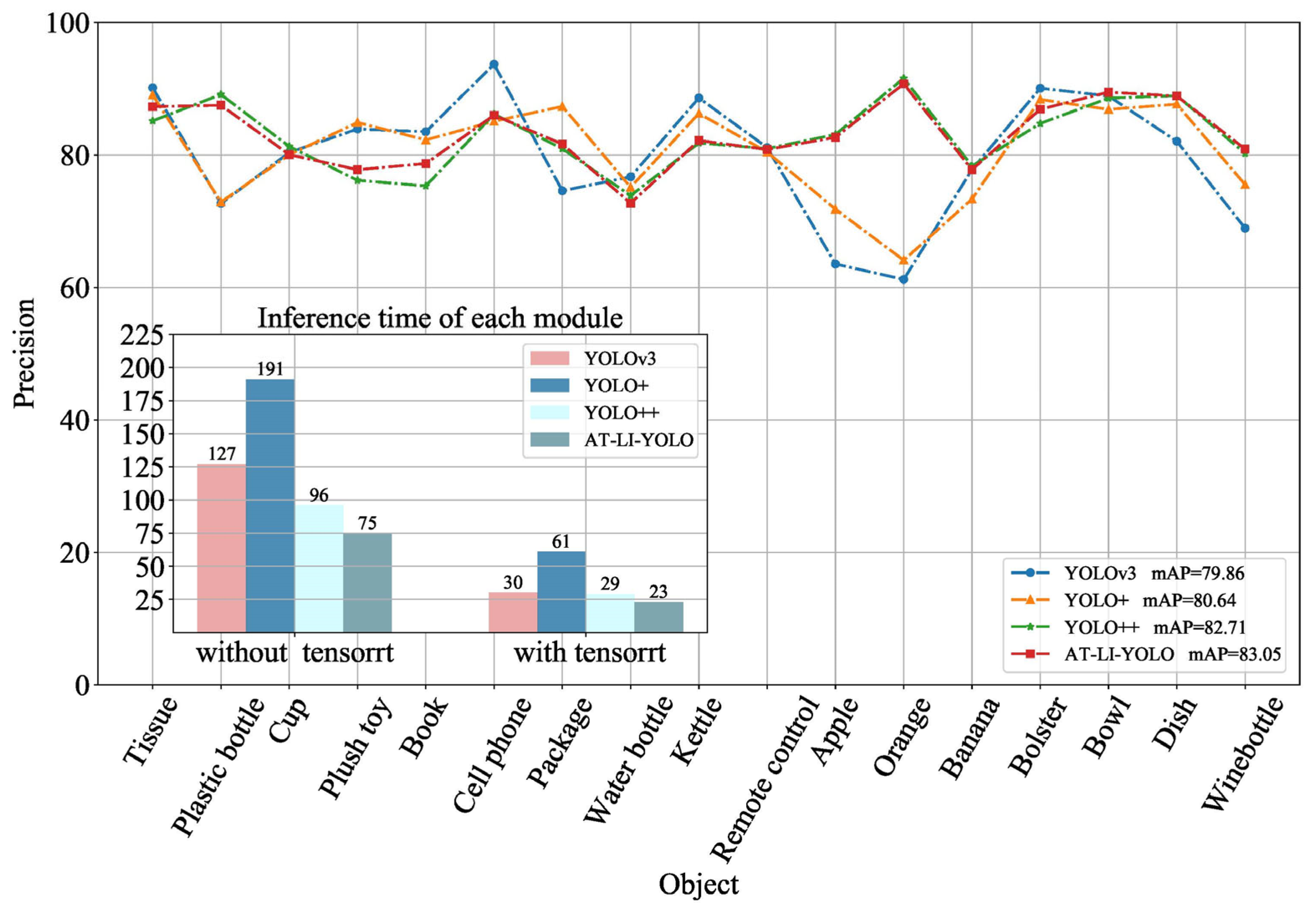
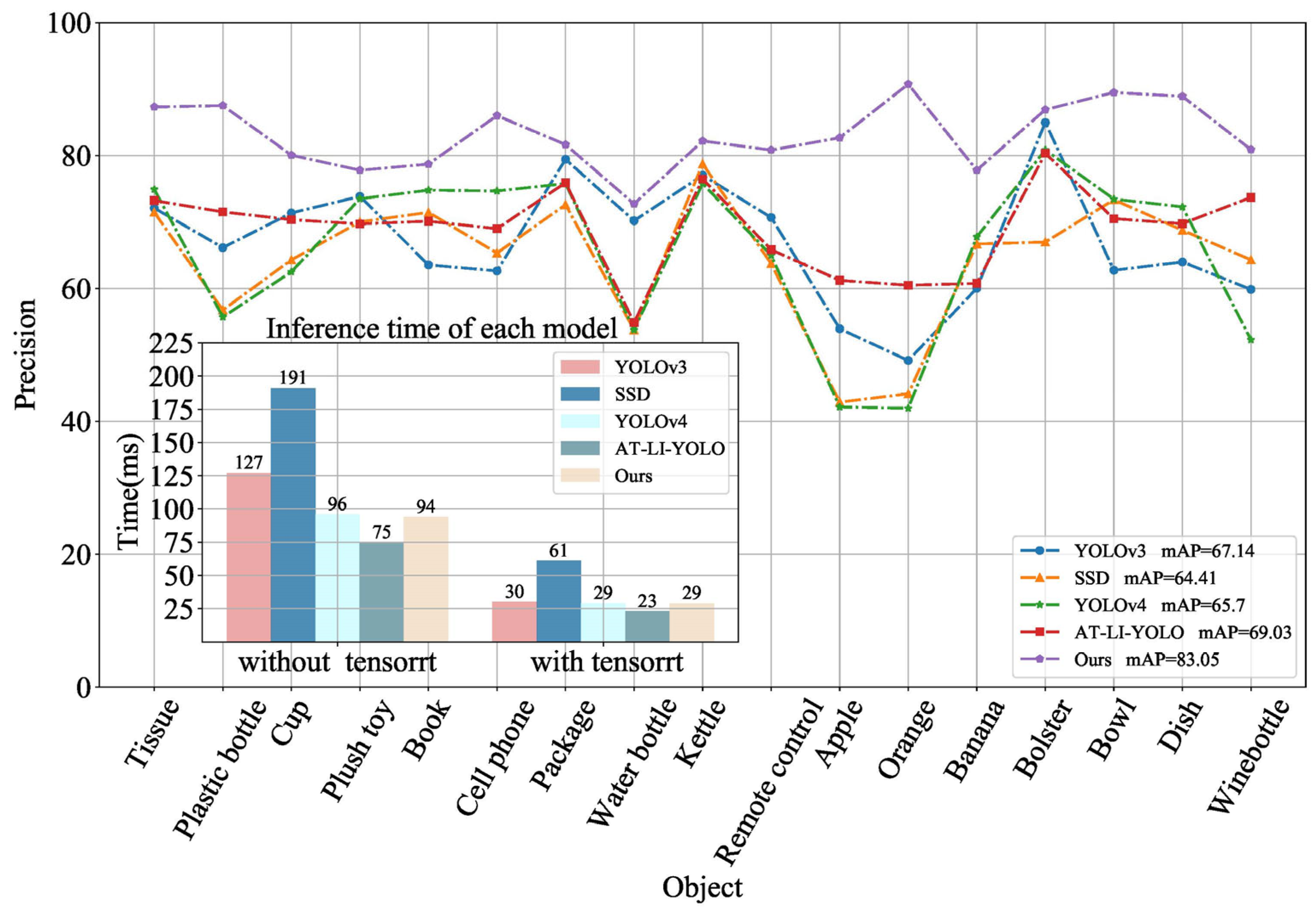
- The proposed AT-LI-YOLO algorithm enhances the precision of detecting small and partially occluded objects by emphasizing important regions and integrating salient features through the attention module embedded in the AT-Resblock. To enhance the detection speed for home service robots, a lightweight network unit Lightblock was designed to reduce the number of parameters and computational complexity of the network. Compared with YOLOv3, the mAP of AT-LI-YOLOs increased by 3.19% and the detection speed was reduced by 7 ms.
- (3)
- The Grasp-17 dataset for home service robots was established based on the habits of elderly people and children. Experiments were conducted using the TensorRT high-performance neural network inference engine in our home service robot prototype. The results demonstrate that our method achieved real-time visual processing for home service robot motion deblurring and object detection, completing the detection process in 29 ms on the NVIDIA Jetson AGX Xavier platform.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Maiettini, E.; Pasquale, G.; Rosasco, L.; Natale, L. On-line object detection: A robotics challenge. Auton. Robot. 2020, 44, 739–757. [Google Scholar] [CrossRef]
- Ito, H.; Yamamoto, K.; Mori, H.; Ogata, T. Efficient multitask learning with an embodied predictive model for door opening and entry with whole-body control. Sci. Robot. 2022, 7, eaax8177. [Google Scholar] [CrossRef]
- Zhang, F.; Demiris, Y. Learning garment manipulation policies toward robot-assisted dressing. Sci. Robot. 2022, 7, eabm6010. [Google Scholar] [CrossRef]
- Liu, Y.; Haridevan, A.; Schofield, H.; Shan, J. Application of Ghost-DeblurGAN to Fiducial Marker Detection. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Kyoto, Japan, 23–27 October 2022; pp. 6827–6832. [Google Scholar]
- Kim, M.D.; Ueda, J. Real-time panoramic image generation and motion deblurring by using dynamics-based robotic vision. IEEE ASME Trans. Mechatron. 2015, 21, 1376–1387. [Google Scholar] [CrossRef]
- Li, Y.; Li, S.; Du, H.; Chen, L.; Zhang, D.; Li, Y. YOLO-ACN: Focusing on small target and occluded object detection. IEEE Access 2020, 8, 227288–227303. [Google Scholar] [CrossRef]
- Lee, J.; Hwang, K. YOLO with adaptive frame control for real-time object detection applications. Multimed. Tools. Appl. 2022, 81, 36375–36396. [Google Scholar] [CrossRef]
- Zhang, H.; Dai, Y.; Li, H.; Koniusz, P. Deep stacked hierarchical multi-patch network for image deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5978–5986. [Google Scholar]
- Cho, S.J.; Ji, S.W.; Hong, J.P.; Jung, S.; Ko, S. Rethinking coarse-to-fine approach in single image deblurring. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 4641–4650. [Google Scholar]
- Kim, K.; Lee, S.; Cho, S. Mssnet: Multi-scale-stage network for single image deblurring. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 524–539. [Google Scholar]
- Chen, L.; Lu, X.; Zhang, J.; Chu, X.; Chen, C. Hinet: Half instance normalization network for image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 182–192. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern. Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Zhang, L.; Zhang, D. A completed modeling of local binary pattern operator for texture classification. IEEE Trans. Image Process. 2010, 19, 1657–1663. [Google Scholar]
- Burges, C.J.C. A tutorial on support vector machines for pattern recognition. Data Min. Knowl. Discov. 1998, 2, 121–167. [Google Scholar] [CrossRef]
- Noble, W.S. What is a support vector machine? Nat. Biotechnol. 2006, 24, 1565–1567. [Google Scholar] [CrossRef] [PubMed]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Tarvas, K.; Bolotnikova, A.; Anbarjafari, G. Edge information based object classification for NAO robots. Cogent. Eng. 2016, 3, 1262571. [Google Scholar] [CrossRef]
- Cao, L.; Kobayashi, Y.; Kuno, Y. Spatial relation model for object recognition in human-robot interaction. In Proceedings of the International Conference on Intelligent Computing, Ulsan, Republic of Korea, 16–19 September 2009; pp. 574–584. [Google Scholar]
- Osorio-Comparan, R.; Vázquez, E.J.; López-Juárez, I.; Peña-Cabrera, M.; Bustamante, M.; Lefranc, G. Object detection algorithms and implementation in a robot of service. In Proceedings of the IEEE International Conference on Automation/XXIII Congress of the Chilean Association of Automatic Control (ICA-ACCA), Concepcion, Chile, 17–19 October 2018; pp. 1–7. [Google Scholar]
- Espinace, P.; Kollar, T.; Roy, N.; Soto, A. Indoor scene recognition by a mobile robot through adaptive object detection. Robot. Auton. Syst. 2013, 61, 932–947. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 8–10 June 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object detection via region-based fully convolutional networks. In Proceedings of the 30th International Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767, 2018. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A. SSD: Single shot multibox detector. In Proceedings of the Computer Vision-ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Martinez-Alpiste, I.; Golcarenarenji, G.; Wang, Q.; Alcaraz-Calero, J.M. A dynamic discarding technique to increase speed and preserve accuracy for YOLOv3. Neural Comput. Appl. 2021, 33, 9961–9973. [Google Scholar] [CrossRef]
- Dos Reis, D.H.; Welfer, D.; De Souza, L.; Cuadros, M.A.; Gamarra, D.F.T. Mobile robot navigation using an object recognition software with RGBD images and the YOLO algorithm. Appl. Artif. Intell. 2019, 33, 1290–1305. [Google Scholar] [CrossRef]
- Szemenyei, M.; Estivill-Castro, V. Fully neural object detection solutions for robot soccer. Neural Comput. Appl. 2022, 34, 21419–21432. [Google Scholar] [CrossRef]
- Xu, Z.F.; Jia, R.S.; Sun, H.M.; Liu, Q.M.; Cui, Z. Light-YOLOv3: Fast method for detecting green mangoes in complex scenes using picking robots. Appl. Intell. 2020, 50, 4670–4687. [Google Scholar] [CrossRef]
- Cui, Z.; Sun, H.M.; Yu, J.T.; Jia, R.S. Fast detection method of green peach for application of picking robot. Appl. Intell. 2022, 52, 1718–1739. [Google Scholar] [CrossRef]
- Zheng, S.; Wu, Y.; Jiang, S.; Liu, C.; Gupta, G. Deblur-yolo: Real-time object detection with efficient blind motion deblurring. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. Deblurgan-v2: Deblurring (orders-of-magnitude) faster and better. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8878–8887. [Google Scholar]
- Tao, X.; Gao, H.; Shen, X.; Wang, J.; Jia, J. Scale-recurrent network for deep image deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8174–8182. [Google Scholar]
- Nah, S.; Kim, T.H.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar]
- Gao, H.; Tao, X.; Shen, X.; Jia, J. Dynamic scene deblurring with parameter selective sharing and nested skip connections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3848–3856. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Li, W.; Saeedi, S.; McCormac, J.; Clark, R.; Tzoumanikas, D.; Ye, Q.; Huang, Y.; Tang, R.; Leutenegger, S. Interiornet: Mega-scale multi-sensor photo-realistic indoor scenes dataset. arXiv 2018, arXiv:1809.00716. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. Deblurgan: Blind motion deblurring using conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8183–8192. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Huang, Z.; Wang, J.; Fu, X.; Yu, T.; Guo, Y.; Wang, R. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Image | Blurred Image | SRN | DeblurGAN | DeblurGANv2-MobileNet | Our Method | |
|---|---|---|---|---|---|---|
| PSNR | - | 23.932 | 22.170 | 24.852 | 22.940 | 29.920 |
| SSIM | - | 0.833 | 0.732 | 0.864 | 0.817 | 0.886 |
| Time(ms) without TensorRT | - | - | 3386 | 32 | 21 | 22 |
| Time(ms) with TensorRT | - | - | 996 | 9 | 6 | 6 |
| SSD | Faster R-CNN | YOLOv3 | Light-YOLOv3 | Fast Detection | YOLOv4 | Mask R-CNN | DC-SPP-YOLO | YOLOv8 | AT-LI-YOLO | |
|---|---|---|---|---|---|---|---|---|---|---|
| Tissue | 80.30 | 89.00 | 90.14 | 80.42 | 80.00 | 82.70 | 62.36 | 73.12 | 91.38 | 87.29 |
| Plastic bottle | 56.25 | 69.40 | 72.66 | 64.40 | 68.85 | 52.24 | 64.00 | 62.10 | 79.05 | 87.50 |
| Cup | 83.33 | 73.70 | 80.36 | 65.30 | 75.70 | 68.66 | 63.63 | 74.26 | 81.33 | 80.04 |
| Plush toy | 70.00 | 83.70 | 83.90 | 73.90 | 75.20 | 80.37 | 73.48 | 65.70 | 90.67 | 77.77 |
| Book | 81.84 | 84.50 | 83.49 | 72.03 | 72.50 | 80.03 | 74.40 | 77.12 | 91.24 | 78.69 |
| Cell phone | 78.95 | 83.70 | 93.69 | 78.04 | 83.98 | 76.45 | 53.80 | 73.21 | 80.34 | 85.99 |
| Package | 88.00 | 89.30 | 74.58 | 76.66 | 88.31 | 84.42 | 73.10 | 81.46 | 92.25 | 81.63 |
| Water bottle | 75.70 | 74.80 | 76.69 | 72.06 | 75.40 | 57.91 | 76.47 | 74.33 | 78.97 | 72.71 |
| Kettle | 87.50 | 83.40 | 88.60 | 78.20 | 75.70 | 80.37 | 73.92 | 81.65 | 92.31 | 82.17 |
| Remote control | 73.60 | 72.40 | 81.10 | 70.06 | 74.20 | 69.38 | 78.94 | 75.82 | 77.00 | 80.81 |
| Apple | 62.40 | 68.70 | 63.53 | 69.30 | 66.48 | 62.30 | 73.30 | 61.48 | 67.25 | 82.65 |
| Orange | 60.80 | 61.10 | 61.20 | 53.70 | 56.40 | 60.50 | 58.70 | 57.69 | 62.57 | 90.72 |
| Banana | 63.10 | 66.80 | 77.78 | 67.10 | 67.79 | 100.00 | 61.74 | 72.30 | 79.32 | 77.77 |
| Bolster | 69.49 | 85.90 | 90.07 | 81.80 | 83.10 | 91.82 | 81.00 | 80.22 | 91.38 | 86.89 |
| Bowl | 90.91 | 77.30 | 88.89 | 80.00 | 83.56 | 76.92 | 60.00 | 67.95 | 83.72 | 89.47 |
| Dish | 93.75 | 62.30 | 82.05 | 75.00 | 80.30 | 85.54 | 65.93 | 79.37 | 88.26 | 88.89 |
| Wine bottle | 90.00 | 78.10 | 68.93 | 61.50 | 78.91 | 53.85 | 55.74 | 67.25 | 85.15 | 80.88 |
| mAP | 76.82 | 76.71 | 79.86 | 71.73 | 75.67 | 74.32 | 67.68 | 72.06 | 83.07 | 83.05 |
| Time(ms) without TensorRT | 191 | 587 | 127 | 85 | 95 | 96 | 604 | 112 | 131 | 75 |
| Time(ms) with TensorRT | 61 | 150 | 30 | 26 | 29 | 29 | 170 | 39 | 33 | 23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, Y.; Ma, X.; Zhou, X.; Bao, G.; Wan, W.; Cai, S. Dynamic and Real-Time Object Detection Based on Deep Learning for Home Service Robots. Sensors 2023, 23, 9482. https://doi.org/10.3390/s23239482
Ye Y, Ma X, Zhou X, Bao G, Wan W, Cai S. Dynamic and Real-Time Object Detection Based on Deep Learning for Home Service Robots. Sensors. 2023; 23(23):9482. https://doi.org/10.3390/s23239482
Chicago/Turabian StyleYe, Yangqing, Xiaolon Ma, Xuanyi Zhou, Guanjun Bao, Weiwei Wan, and Shibo Cai. 2023. "Dynamic and Real-Time Object Detection Based on Deep Learning for Home Service Robots" Sensors 23, no. 23: 9482. https://doi.org/10.3390/s23239482
APA StyleYe, Y., Ma, X., Zhou, X., Bao, G., Wan, W., & Cai, S. (2023). Dynamic and Real-Time Object Detection Based on Deep Learning for Home Service Robots. Sensors, 23(23), 9482. https://doi.org/10.3390/s23239482