Recognition of Arabic Air-Written Letters: Machine Learning, Convolutional Neural Networks, and Optical Character Recognition (OCR) Techniques

 ,
,  , , and
, , and
Abstract
:1. Introduction
2. Related Work
2.1. Air Writing with Numbers and Symbols
2.2. Exploring Air-Written Letters
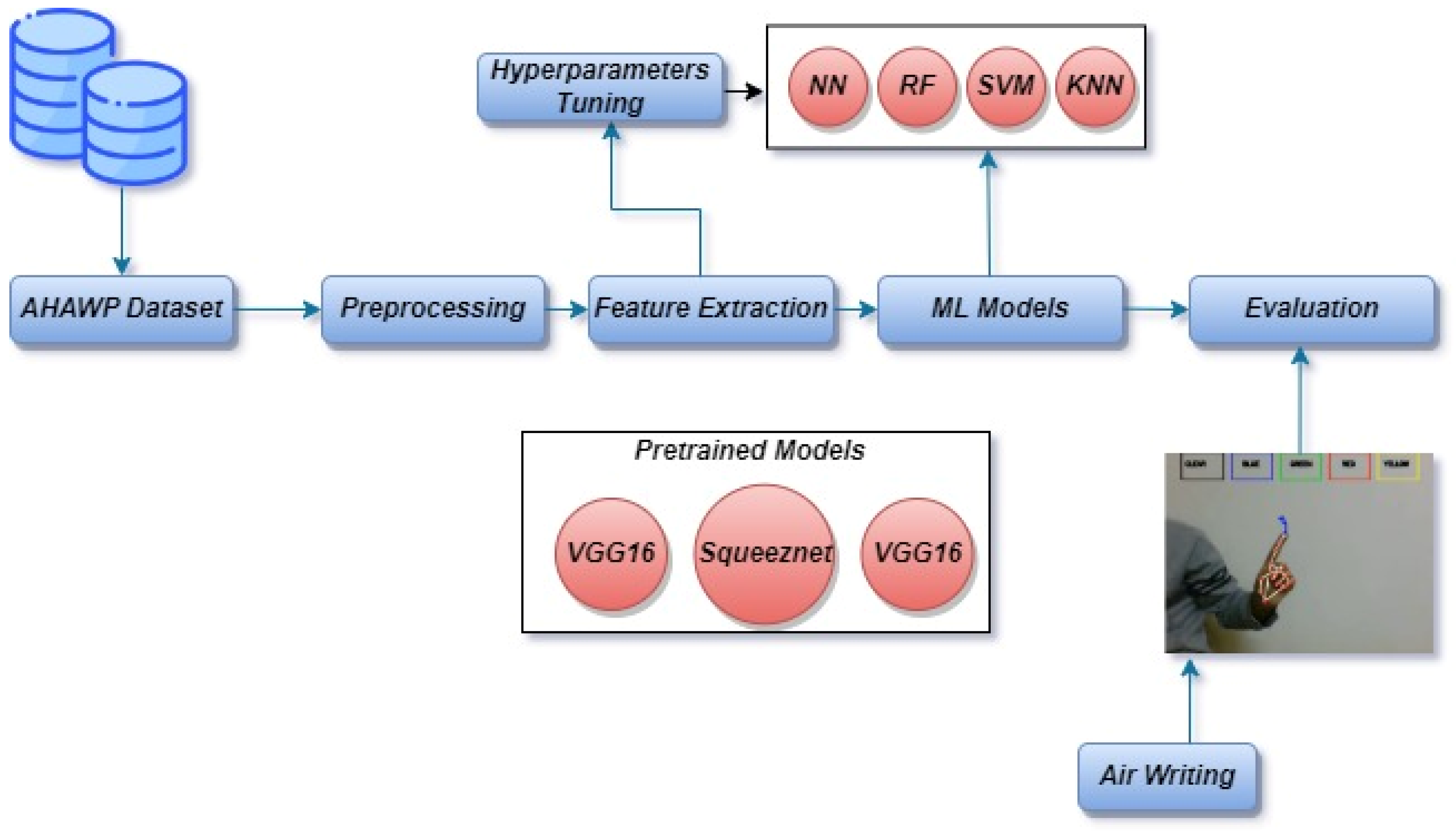
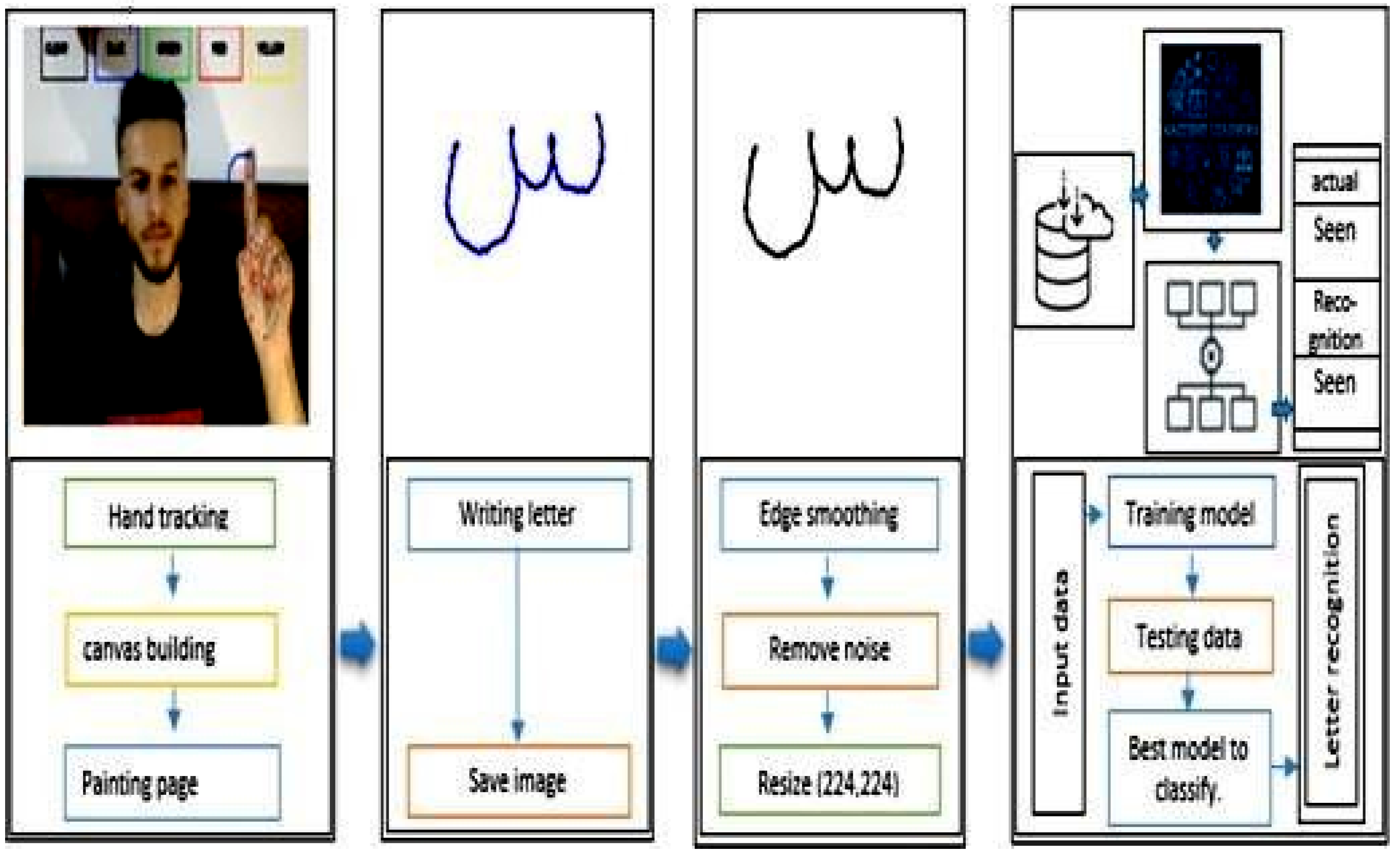
3. Arabic Air Writing to Image Conversion and Recognition: Methodology
3.1. AHAWP Dataset
3.2. Data Preprocessing
3.2.1. Image Prepossessing
3.2.2. Feature Extraction
3.2.3. Dimensionality Reduction
3.2.4. Data Normalization
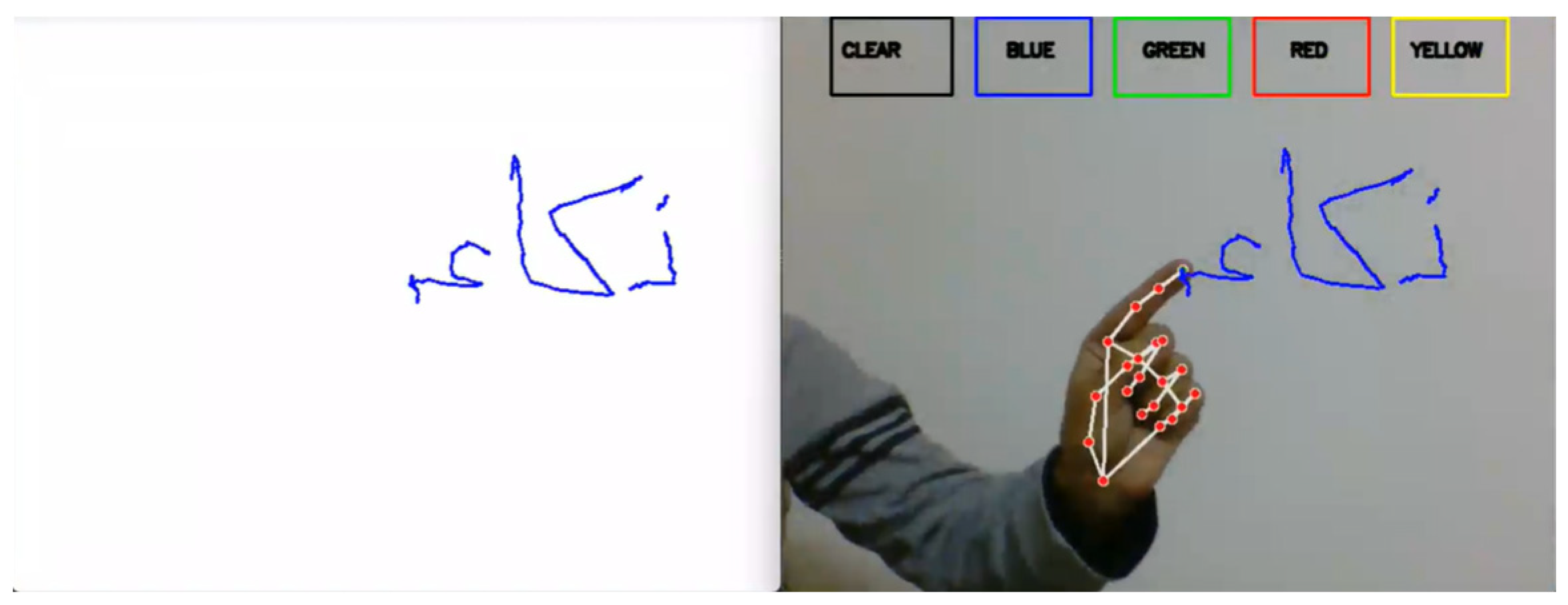
3.3. Building Air Writing Components
Air Writing Tools
3.4. Optical Character Recognition (OCR)
3.5. Arabic Air-Writing Letter Recognition System Using Deep Convolutional Neural
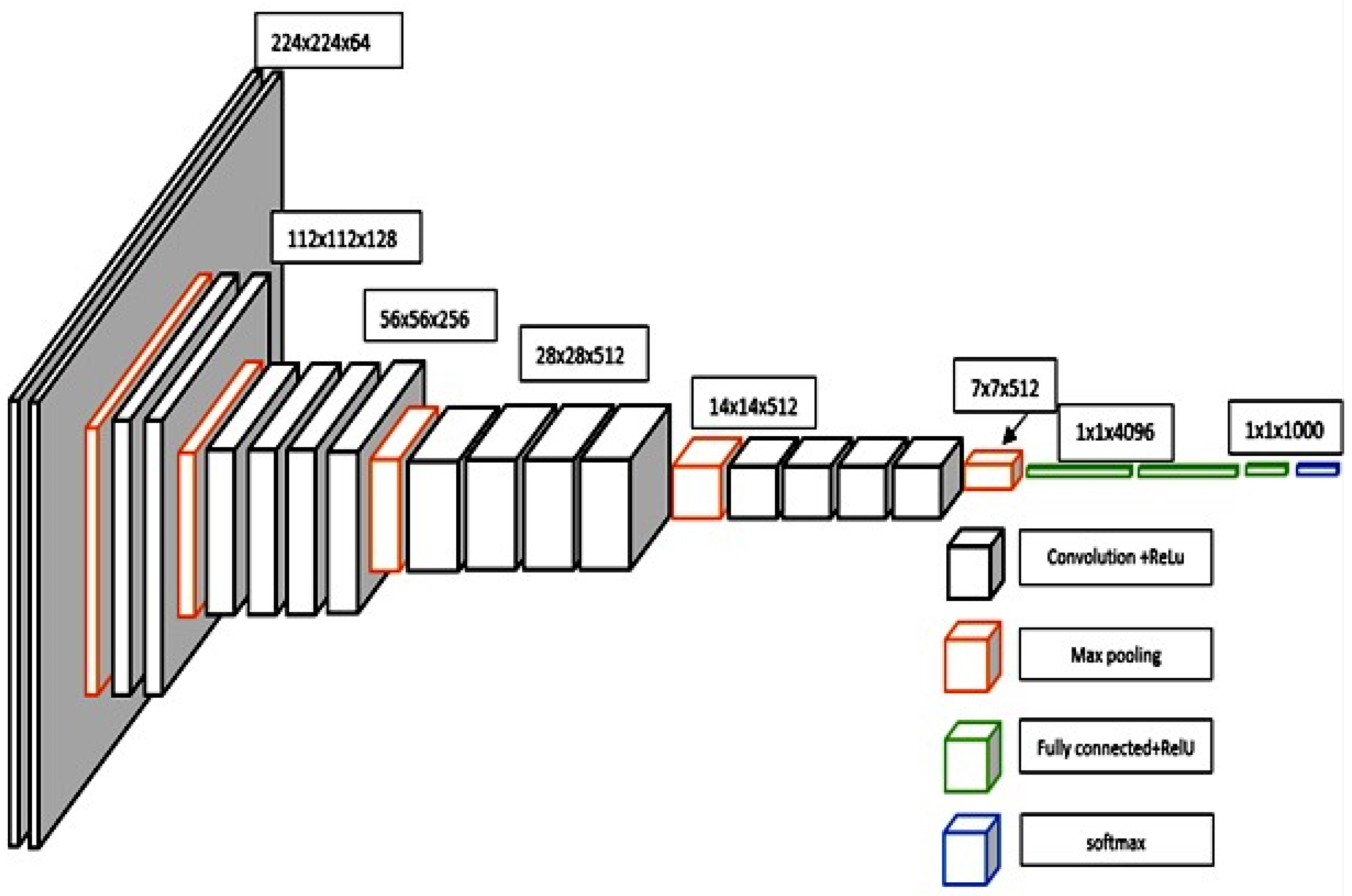
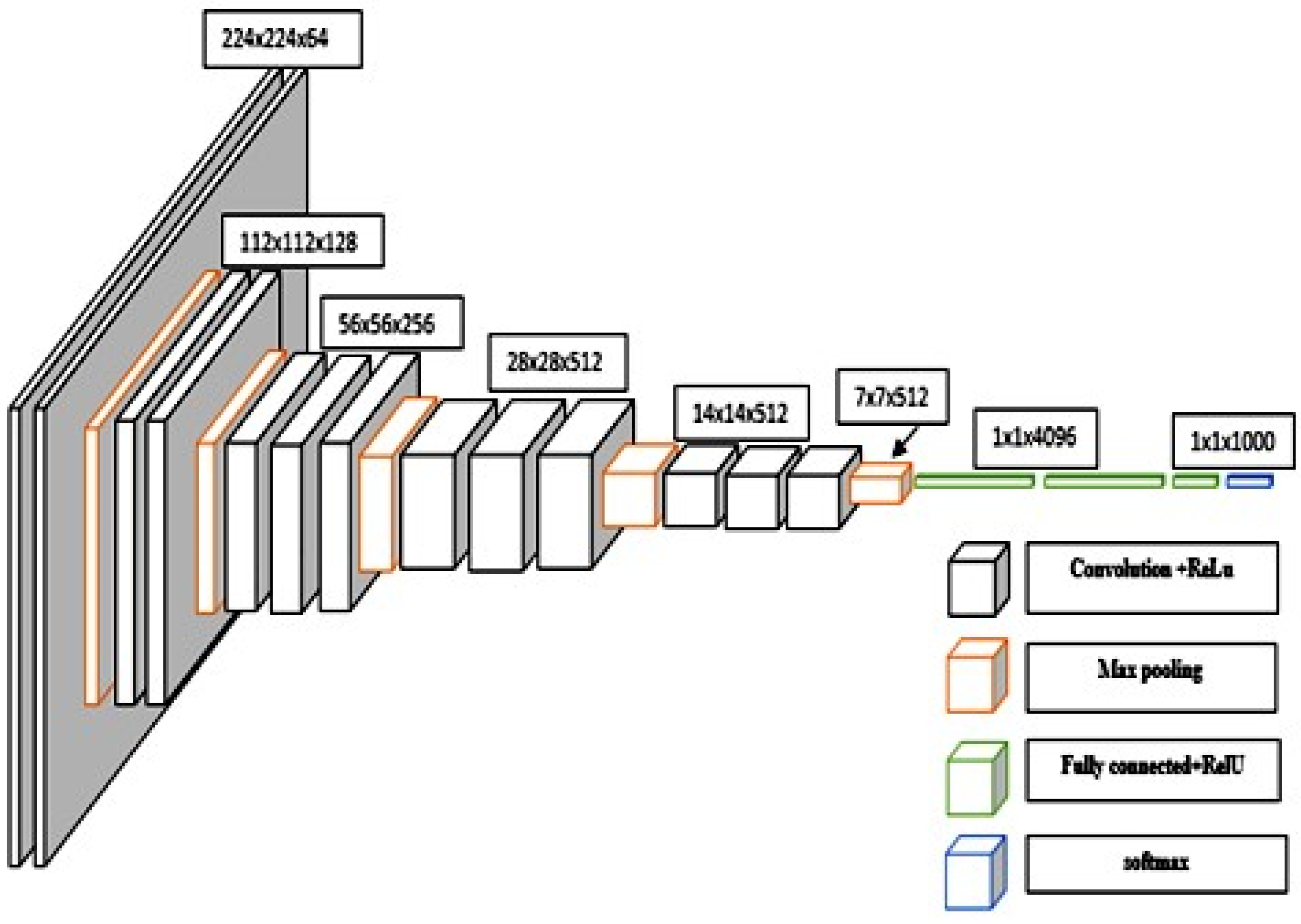
3.5.1. The VGGNet CNN Architecture
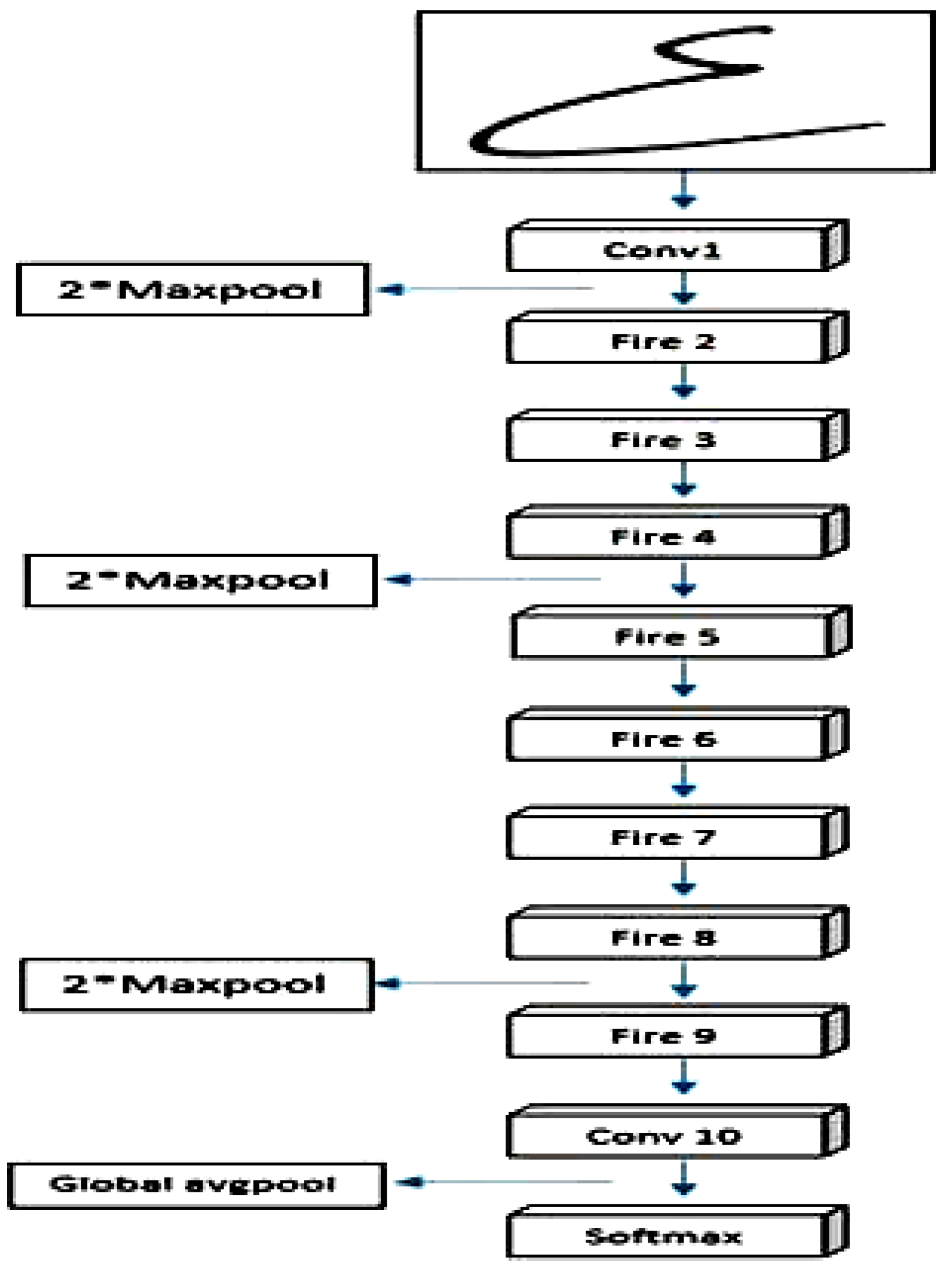
3.5.2. SqueezeNet Architecture
3.6. Hyperparameter Tuning
3.6.1. Grid Search
| Algorithm 1 Pseudo code for grid search |
|
|
|
|
|
|
|
|
|
|
|
|
|
3.6.2. Random Search
3.7. Supervised Machine Learning Models
3.8. Evaluation of Models
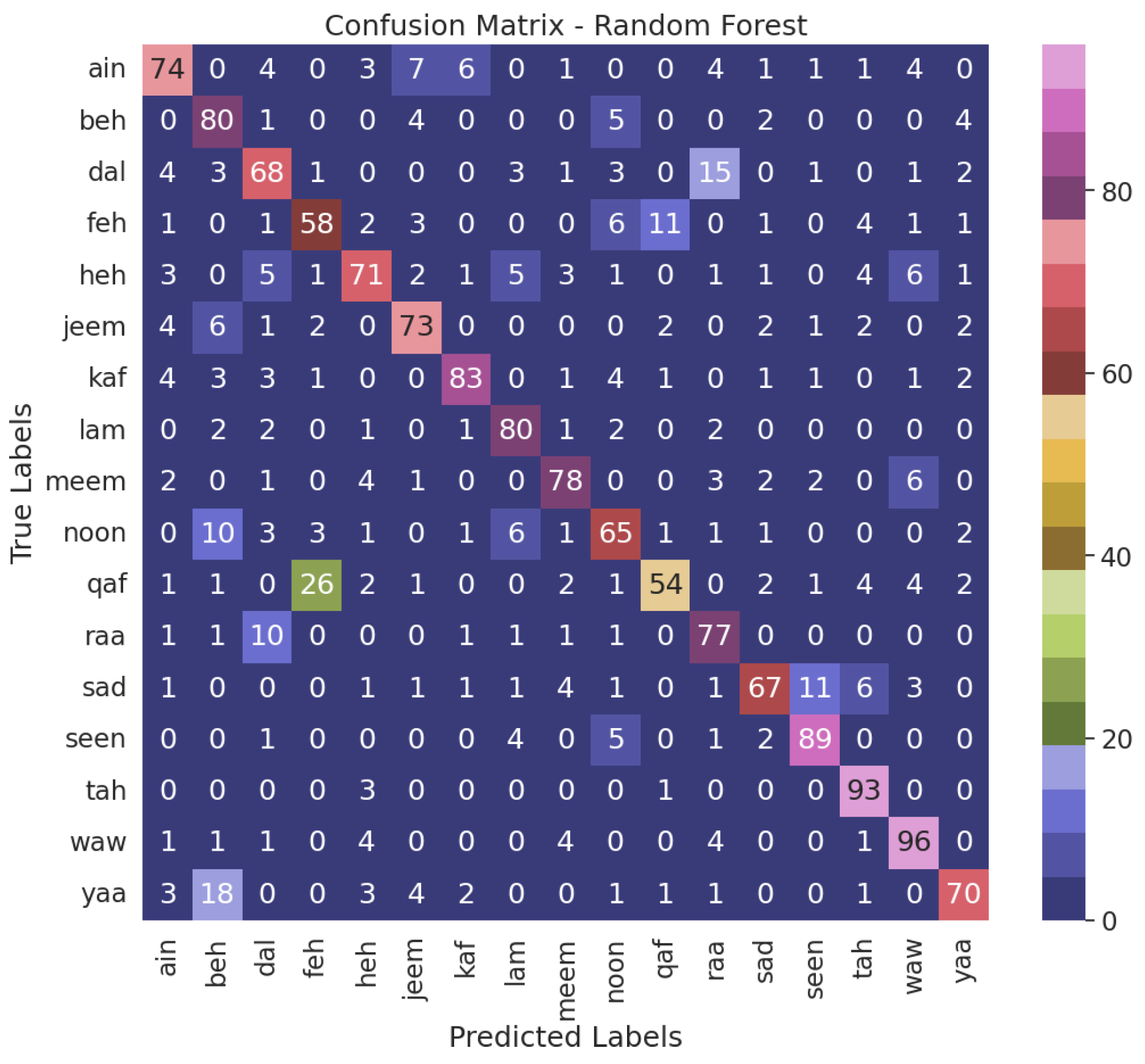
4. Result and Discussion
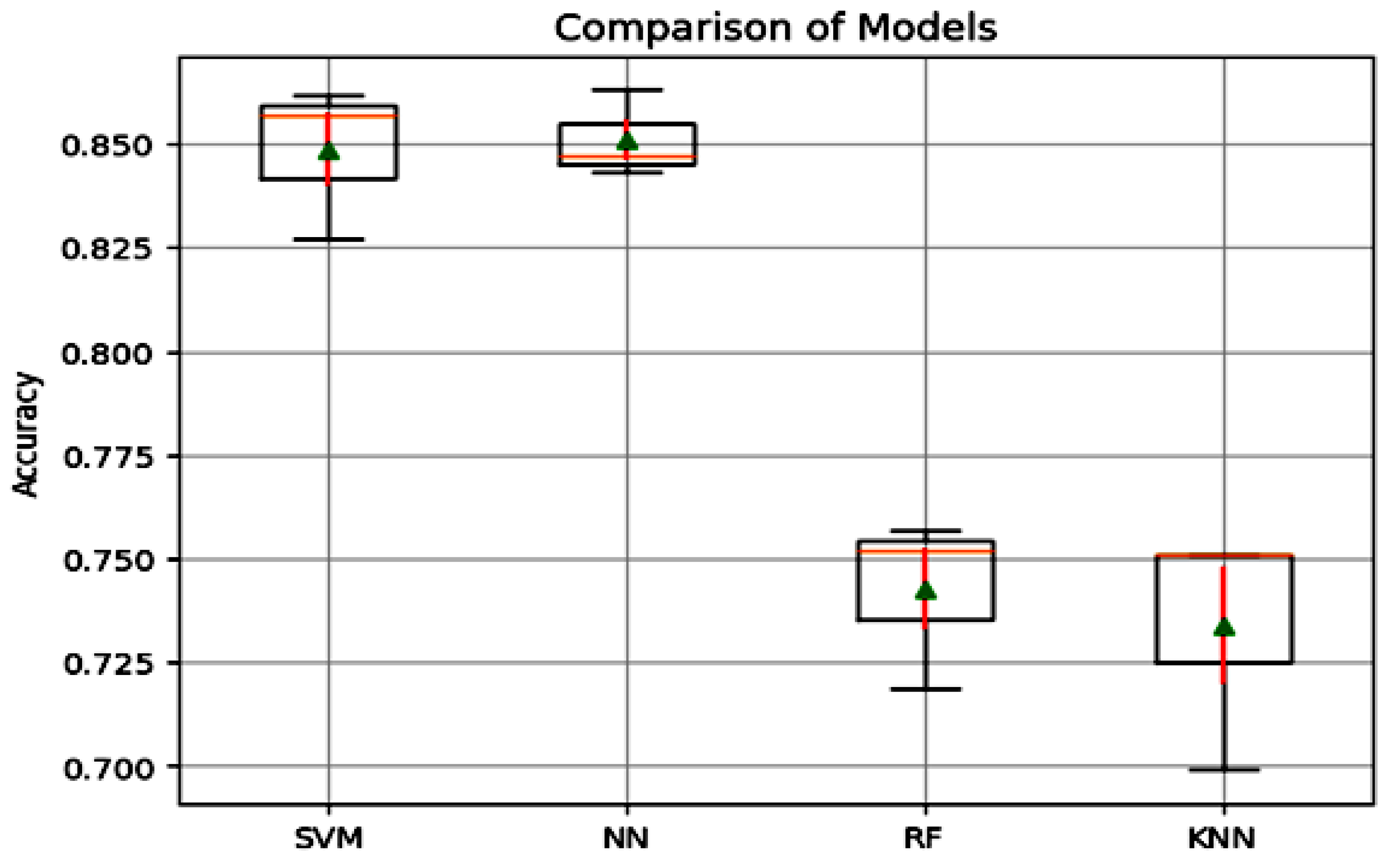
4.1. Performance of Classification Algorithms
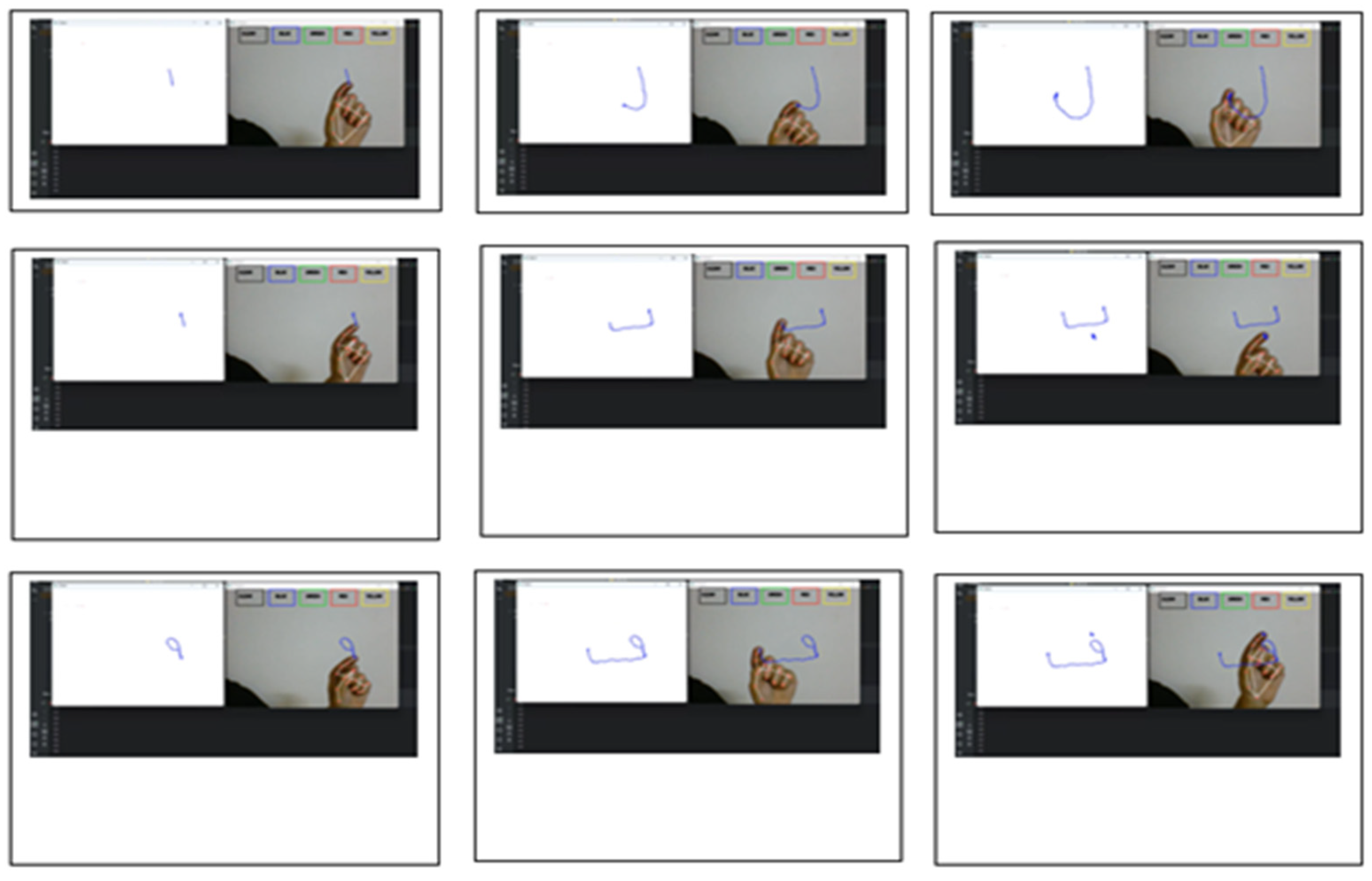
4.2. Samples of Letters Air Writing
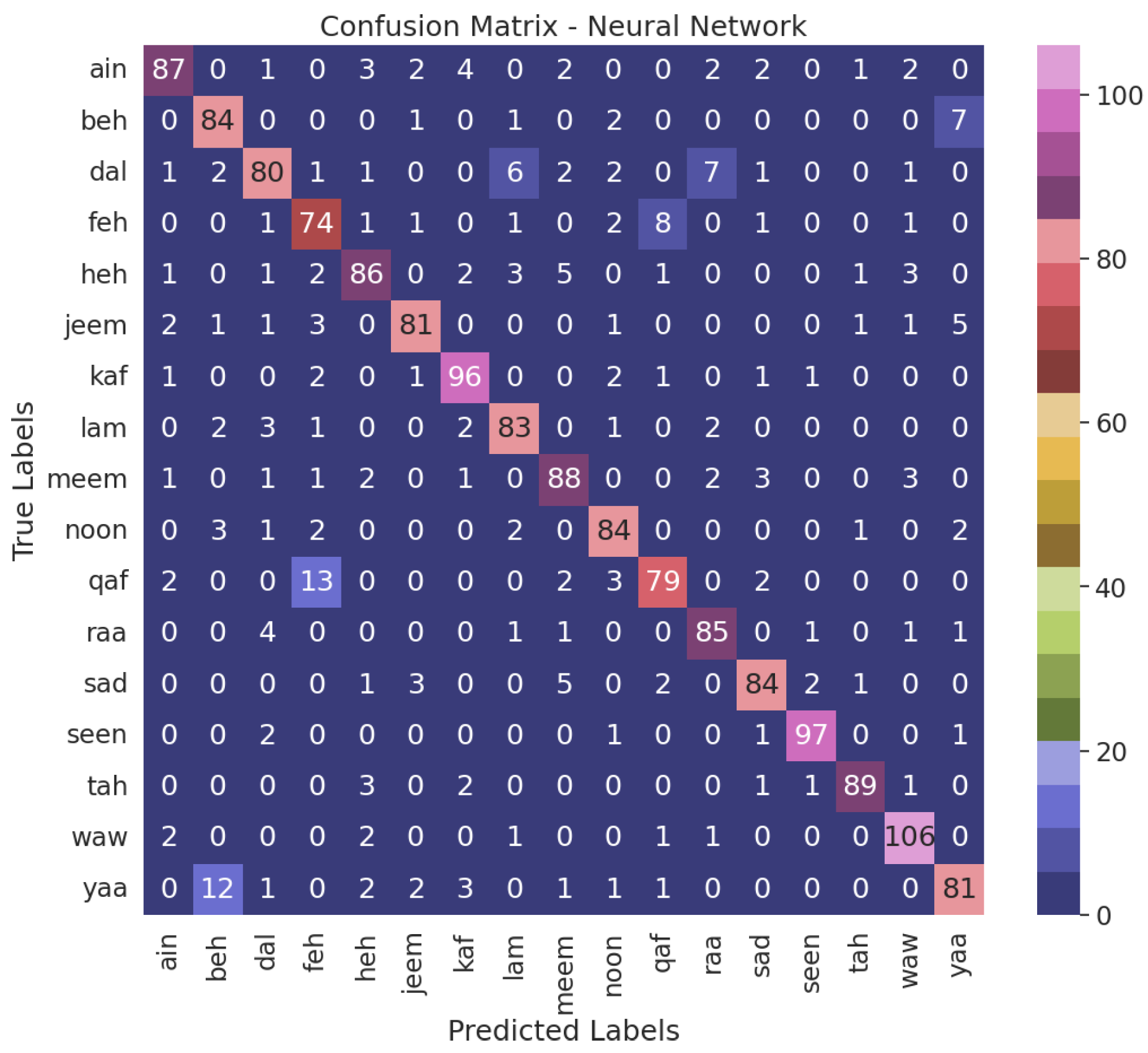
4.3. Model Validation
4.4. A Comparison Study
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abir, F.A.; Siam, M.A.; Sayeed, A.; Hasan, M.A.M.; Shin, J. Deep learning based air-writing recognition with the choice of proper interpolation technique. Sensors 2021, 21, 8407. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, S.; Kim, W.; Park, J.; Cho, S.H. Radar-Based Air-Writing Gesture Recognition Using a Novel Multistream CNN Approach. IEEE Internet Things J. 2022, 9, 23869–23880. [Google Scholar] [CrossRef]
- Alam, M.S.; Kwon, K.C.; Alam, M.A.; Abbass, M.Y.; Imtiaz, S.M.; Kim, N. Trajectory-based air-writing recognition using deep neural network and depth sensor. Sensors 2020, 20, 376. [Google Scholar] [CrossRef]
- Saoji, S.; Dua, N.; Choudhary, A.K.; Phogat, B. Air canvas application using Opencv and numpy in python. Int. Res. J. Eng. Technol. (IRJET) 2021, 8, 1761–1765. [Google Scholar]
- Kim, U.H.; Hwang, Y.; Lee, S.K.; Kim, J.H. Writing in the air: Unconstrained text recognition from finger movement using spatio-temporal convolution. In IEEE Transactions on Artificial Intelligence; IEEE: New York, NY, USA, 2022. [Google Scholar]
- Bouchriha, L.; Zrigui, A.; Mansouri, S.; Berchech, S.; Omrani, S. Arabic Handwritten Character Recognition Based on Convolution Neural Networks. In Proceedings of the International Conference on Computational Collective Intelligence, Hammamet, Tunisia, 28–30 September 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 286–293. [Google Scholar]
- Altwaijry, N.; Al-Turaiki, I. Arabic handwriting recognition system using convolutional neural network. Neural Comput. Appl. 2021, 33, 2249–2261. [Google Scholar] [CrossRef]
- Hsieh, C.H.; Lo, Y.S.; Chen, J.Y.; Tang, S.K. Air-writing recognition based on deep convolutional neural networks. IEEE Access 2021, 9, 142827–142836. [Google Scholar] [CrossRef]
- Khandokar, I.; Hasan, M.; Ernawan, F.; Islam, S.; Kabir, M. Handwritten character recognition using convolutional neural network. In Proceedings of the Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2021; Volume 1918, p. 042152. [Google Scholar]
- Mohd, M.; Qamar, F.; Al-Sheikh, I.; Salah, R. Quranic optical text recognition using deep learning models. IEEE Access 2021, 9, 38318–38330. [Google Scholar] [CrossRef]
- Malik, S.; Sajid, A.; Ahmad, A.; Almogren, A.; Hayat, B.; Awais, M.; Kim, K.H. An efficient skewed line segmentation technique for cursive script OCR. Sci. Program. 2020, 2020, 8866041. [Google Scholar] [CrossRef]
- Mukherjee, S.; Ahmed, S.A.; Dogra, D.P.; Kar, S.; Roy, P.P. Fingertip detection and tracking for recognition of air-writing in videos. Expert Syst. Appl. 2019, 136, 217–229. [Google Scholar] [CrossRef]
- Fadeel, M.A. Off-line optical character recognition system for arabic handwritten text. J. Pure Appl. Sci. 2019, 18. [Google Scholar] [CrossRef]
- Sokar, G.; Hemayed, E.E.; Rehan, M. A generic OCR using deep siamese convolution neural networks. In Proceedings of the 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 1–3 November 2018; IEEE: New York, NY, USA, 2018; pp. 1238–1244. [Google Scholar]
- Misra, S.; Singha, J.; Laskar, R.H. Vision-based hand gesture recognition of alphabets, numbers, arithmetic operators and ASCII characters in order to develop a virtual text-entry interface system. Neural Comput. Appl. 2018, 29, 117–135. [Google Scholar] [CrossRef]
- Zhang, J.; Peng, G.; Yang, H.; Tan, C.; Tan, Y.; Bai, H. Real-Time Finger-Writing Character Recognition via ToF Sensors on Edge Deep Learning. Electronics 2023, 12, 685. [Google Scholar] [CrossRef]
- Khan, M.A. Arabic handwritten alphabets, words and paragraphs per user (AHAWP) dataset. Data Brief 2022, 41, 107947. [Google Scholar] [CrossRef] [PubMed]
- Abdi, H.; Williams, L.J.; Valentin, D. Multiple factor analysis: Principal component analysis for multitable and multiblock data sets. Wiley Interdiscip. Rev. Comput. Stat. 2013, 5, 149–179. [Google Scholar] [CrossRef]
- Jolliffe, I. Principal Component Analysis; Springer: New York, NY, USA, 1986. [Google Scholar]
- Vijayarani, S.; Sakila, A. Performance comparison of OCR tools. Int. J. UbiComp (IJU) 2015, 6, 19–30. [Google Scholar]
- Tang, X.; Wang, C.; Su, J.; Taylor, C. An elevator button recognition method combining yolov5 and ocr. CMC-Comput. Mater. Contin. 2023, 75, 117–131. [Google Scholar] [CrossRef]
- Santamaría, G.; Domínguez, C.; Heras, J.; Mata, E.; Pascual, V. Combining Image Processing Techniques, OCR, and OMR for the Digitization of Musical Books. In Proceedings of the International Workshop on Document Analysis Systems, Wuhan, China, 26–29 July 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 553–567. [Google Scholar]
- Semkovych, V.; Shymanskyi, V. Combining OCR Methods to Improve Handwritten Text Recognition with Low System Technical Requirements. In Proceedings of the International Symposium on Computer Science, Digital Economy and Intelligent Systems, Wuhan, China, 11–13 November 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 693–702. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recogni-tion. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Jaradat, A.S.; Al Mamlook, R.E.; Almakayeel, N.; Alharbe, N.; Almuflih, A.S.; Nasayreh, A.; Gharaibeh, H.; Gharaibeh, M.; Gharaibeh, A.; Bzizi, H. Automated Monkeypox Skin Lesion Detection Using Deep Learning and Transfer Learning Techniques. Int. J. Environ. Res. Public Health 2023, 20, 4422. [Google Scholar] [CrossRef]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Shekar, B.; Dagnew, G. Grid search-based hyperparameter tuning and classification of mi-croarray cancer data. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Sikkim, India, 25–28 February 2019; IEEE: New York, NY, USA, 2019; pp. 1–8. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Al Mamlook, R.E.; Nasayreh, A.; Gharaibeh, H.; Shrestha, S. Classification of Cancer Genome Atlas Glioblastoma Multiform (TCGA-GBM) Using Machine Learning Method. In Proceedings of the 2023 IEEE International Conference on Electro Information Technology (eIT), Romeoville, IL, USA, 18–20 May 2023; IEEE: New York, NY, USA, 2023; pp. 265–270. [Google Scholar]
- Vishwanathan, S.; Murty, M.N. SSVM: A simple SVM algorithm. In Proceedings of the 2002 International Joint Conference on Neural Networks, IJCNN’02 (Cat. No. 02CH37290), Honolulu, HI, USA, 12–17 May 2002; IEEE: New York, NY, USA, 2002; Volume 3, pp. 2393–2398. [Google Scholar]
- Kriegeskorte, N.; Golan, T. Neural network models and deep learning. Curr. Biol. 2019, 29, R231–R236. [Google Scholar] [CrossRef] [PubMed]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Cheng, D. Learning k for knn classification. ACM Trans. Intell. Syst. Technol. (TIST) 2017, 8, 43. [Google Scholar] [CrossRef]
- Chen, M.; AlRegib, G.; Juang, B.H. Air-writing recognition—Part I: Modeling and recognition of characters, words, and connecting motions. IEEE Trans. Hum.-Mach. Syst. 2015, 46, 403–413. [Google Scholar] [CrossRef]
- Sharma, J.K.; Gupta, R.; Sharma, S.; Pathak, V.; Sharma, M. Highly Accurate Trimesh and PointNet based algorithm for Gesture and Hindi air writing recognition. 2023. [Google Scholar] [CrossRef]
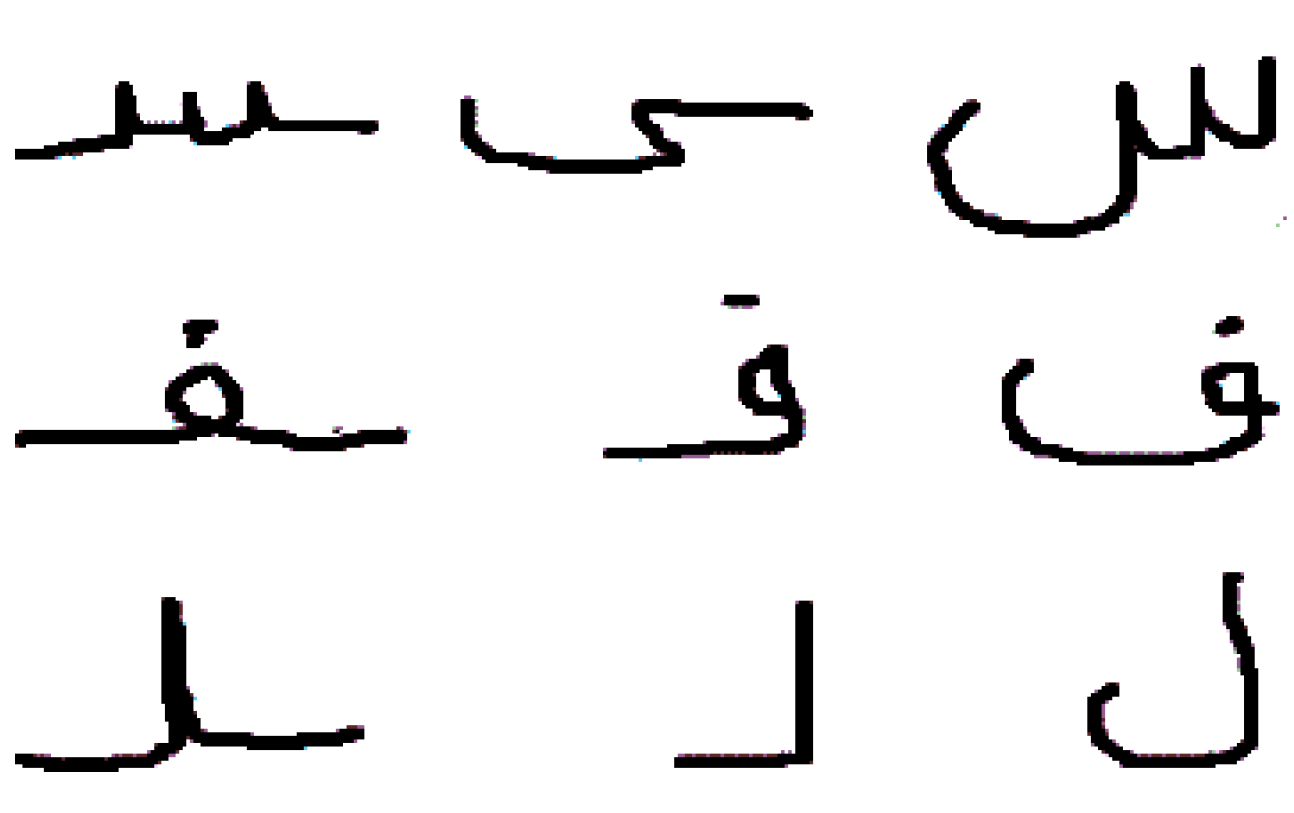







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ML Model | Hyperparameters Search | Best Hyperparameters (Grid Search) |
|---|---|---|
| NN | hidden_layer_sizes: [(50,), (100,), (200,)]; activation: [relu, ‘tanh’]; solver: [adam, sgd]; alpha: [0.0001, 0.001, 0.01]; learning rate: [0.001, 0.01, 0.1]. | hidden_layer_sizes: 200; activation: relu; solver: adam; alpha: 0.001; learning rate: 0.01. |
| SVM | C: [0.1, 1, 10]; kernel: [linear, rbf]; gamma: [0.0001, 0.001, 0.01]. | C: 10; kernel: rbf; gamma: 0.01. |
| RF | n_estimators: [50, 100, 200]; max_depth: [None, 10, 20]; min_samples_split: [2, 5, 10]; min_samples_leaf: [1, 2, 4]. | n_estimators: 200; max_depth: 20; min_samples_split: 5; min_samples_leaf: 1. |
| KNN | n_neighbors: [3, 5, 7]; weights: [uniform, distance], p: [1, 2]. | n_neighbors: 5; weights: distance, p: 1. |
| CNN Model | ML Model | Grid Search | Random Search | Default Parameters |
|---|---|---|---|---|
| VGG19 | SVM | 0.855 | 0.853 | 0.816 |
| NN | 0.847 | 0.851 | 0.825 | |
| RF | 0.744 | 0.735 | 0.706 | |
| KNN | 0.727 | 0.727 | 0.692 | |
| VGG16 | SVM | 0.855 | 0.853 | 0.816 |
| NN | 0.888 | 0.847 | 0.843 | |
| RF | 0.757 | 0.752 | 0.719 | |
| KNN | 0.751 | 0.751 | 0.699 | |
| SqueezeNet | SVM | 0.819 | 0.799 | 0.770 |
| NN | 0.825 | 0.823 | 0.813 | |
| RF | 0.729 | 0.724 | 0.695 | |
| KNN | 0.712 | 0.712 | 0.632 |
| t-Test | p-Value |
|---|---|
| SVM vs. NN | 0.86123788 |
| SVM vs. RF | 0.00280216 |
| SVM vs. KNN | 0.00495305 |
| Reject | Upper | Lower | p-adj | Mean Diff | Group2 | Group1 |
|---|---|---|---|---|---|---|
| True | 0.1728 | 0.0619 | 0.0006 | 0.1173 | NN | KNN |
| True | 0.0644 | −0.0464 | 0.009519 | 0.09 | RF | KNN |
| True | 0.1704 | 0.0596 | 0.0007 | 0.115 | SVM | KNN |
| True | −0.0529 | −0.1638 | 0.0011 | −0.1083 | RF | NN |
| False | 0.531 | −0.0578 | 0.999 | −0.0023 | SVM | NN |
| True | 0.1614 | 0.0506 | 0.0013 | 0.106 | SVM | RF |
| Actual | Prediction | True/False |
|---|---|---|
| Beh (ب) | Beh (ب) | T |
| Dal (د) | Ain (ع) | F |
| Ain (ع) | Ain (ع) | T |
| Feh (ف) | Qaf (ق) | F |
| Heh (ه) | Heh (ه) | T |
| Jeem (ج) | Jeem (ج) | T |
| Kaf (ك) | Kaf (ك) | T |
| Lam (ل) | Da l(د) | F |
| Meem (م) | Meem (م) | T |
| Noon (ن) | Noon (ن) | T |
| Qaf (ق) | Feh (ف) | F |
| Raa (ر) | Raa (ر) | T |
| Sad (ص) | Sad (ص) | T |
| Seen (س) | Seen (س) | T |
| Tah (ت) | Tah (ت) | T |
| Waw (و) | Heh (ه) | F |
| Yaa (ي) | Beh (ب) | F |
| Paper | Languages | Method | Result |
|---|---|---|---|
| [1] | Air writing English | 2D-CNN | Accuracy: 91.24% |
| [2] | Air writing English | MS-CNN | Accuracy: 95% |
| [3] | Air writing English | LSTM | Accuracy: 99.32% |
| [4] | English | Faster RCNN | Accuracy: 94% |
| [5] | Air writing Korean and English | 3D ResNet | Character error rate (CER): Korean: 33.16%, English: 29.24% |
| [8] | Numeric symbols (zero to nine) | 1D-CNN and 2D-CNN | Accuracy: 99% |
| [10] | Diacritics and Ottoman font in Arabic script | CNN and RNN | Accuracy: 98% |
| [12] | Air writing English | Faster RCNN | Mean accuracy: 96.11% |
| [15] | gestures | SVM, kNN, Naïve Bayes, ANN, and ELM | Accuracy of SVM: 96.95 |
| [34] | Air writing English | Error rate: 0.8% | |
| [35] | Air writing Hindi | PointNet | Recognition rate: >97% |
| Our Model | Air writing Arabic | Hybrid Model VGG16 + NN | Accuracy: 88% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nahar, K.M.O.; Alsmadi, I.; Al Mamlook, R.E.; Nasayreh, A.; Gharaibeh, H.; Almuflih, A.S.; Alasim, F. Recognition of Arabic Air-Written Letters: Machine Learning, Convolutional Neural Networks, and Optical Character Recognition (OCR) Techniques. Sensors 2023, 23, 9475. https://doi.org/10.3390/s23239475
Nahar KMO, Alsmadi I, Al Mamlook RE, Nasayreh A, Gharaibeh H, Almuflih AS, Alasim F. Recognition of Arabic Air-Written Letters: Machine Learning, Convolutional Neural Networks, and Optical Character Recognition (OCR) Techniques. Sensors. 2023; 23(23):9475. https://doi.org/10.3390/s23239475
Chicago/Turabian StyleNahar, Khalid M. O., Izzat Alsmadi, Rabia Emhamed Al Mamlook, Ahmad Nasayreh, Hasan Gharaibeh, Ali Saeed Almuflih, and Fahad Alasim. 2023. "Recognition of Arabic Air-Written Letters: Machine Learning, Convolutional Neural Networks, and Optical Character Recognition (OCR) Techniques" Sensors 23, no. 23: 9475. https://doi.org/10.3390/s23239475
APA StyleNahar, K. M. O., Alsmadi, I., Al Mamlook, R. E., Nasayreh, A., Gharaibeh, H., Almuflih, A. S., & Alasim, F. (2023). Recognition of Arabic Air-Written Letters: Machine Learning, Convolutional Neural Networks, and Optical Character Recognition (OCR) Techniques. Sensors, 23(23), 9475. https://doi.org/10.3390/s23239475