
A Privacy and Energy-Aware Federated Framework for Human Activity Recognition

 , , ,
, , ,  and
and
Abstract
:1. Introduction
- We introduce a novel HNFL framework tailored for HAR using wearable sensing technology. The hybrid design of S-LSTM integrates the strengths of both LSTM and SNN seamlessly in a federated setting, offering privacy preservation and computational efficiency.
- A comprehensive analysis is conducted using two distinct publicly available datasets, and the results of the S-LSTM are compared with LSTM, spiking CNN (S-CNN), and simple CNN. This dual-dataset testing approach validates the robustness of the proposed framework and provides valuable insights into its performance in varied environments and scenarios.
- This study addresses a significant issue of client selection within the context of federated HAR applications. We conduct a thorough investigation into the implications of random client selection and its impact on the overall performance of the HAR model. This analysis provides valuable insights into achieving the optimal balance between computation, communication efficiency and model precision, which guides the ideal approach for client selection in federated scenarios.
2. Related Work
2.1. Centralised Learning-Based HAR Systems
2.2. Federated Learning-Based HAR
3. Preliminaries and System Model
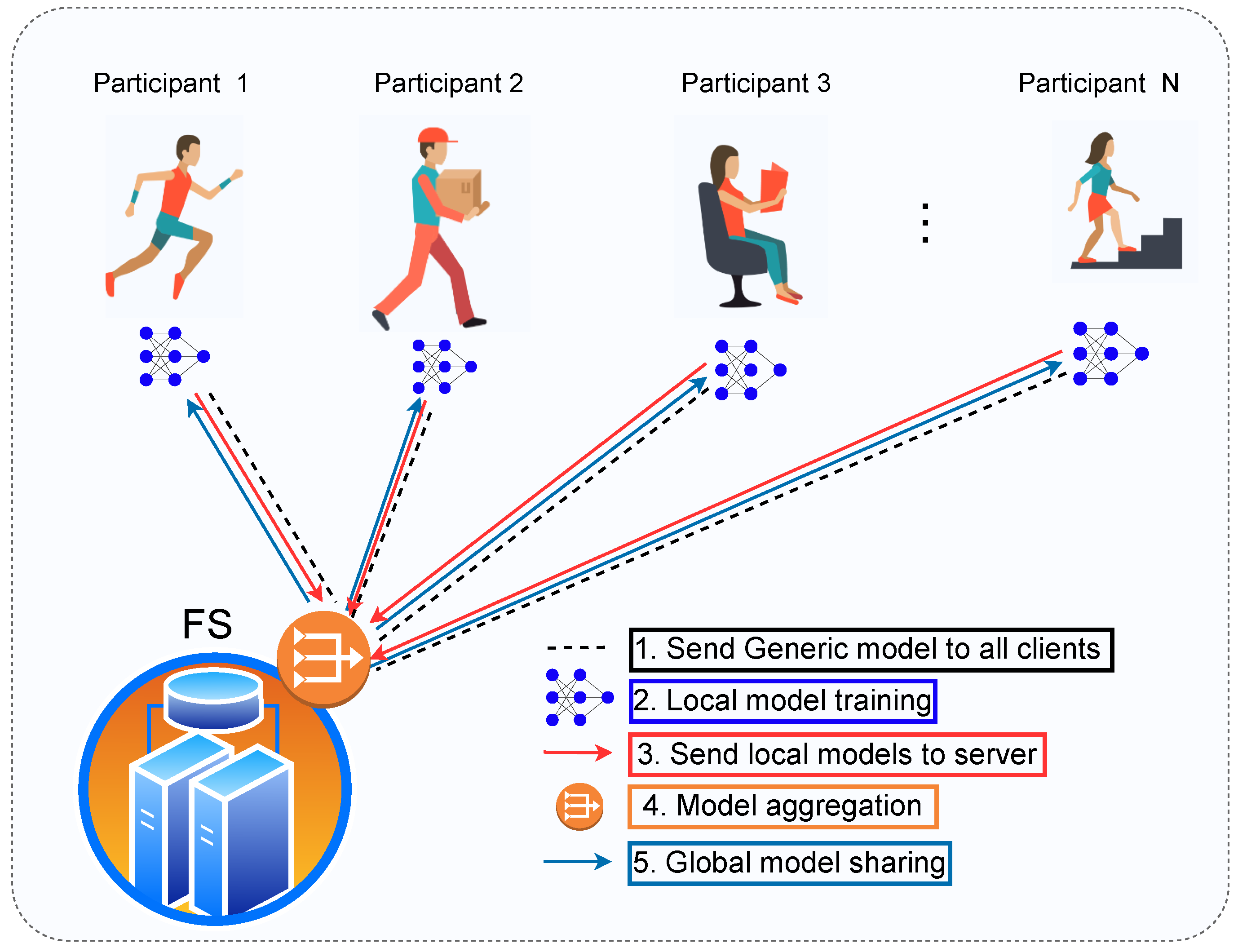
3.1. Federated Learning
3.2. Spiking Neural Network
3.3. Long Short-Term Memory Networks
3.4. Proposed S-LSTM Model
| Algorithm 1 Federated S-LSTM training with surrogate gradient and BPTT. |
|
4. Simulation Setup
4.1. Dataset Description
4.1.1. UCI Dataset
4.1.2. Real-World Dataset
4.2. Performance Metrics
5. Results and Discussion
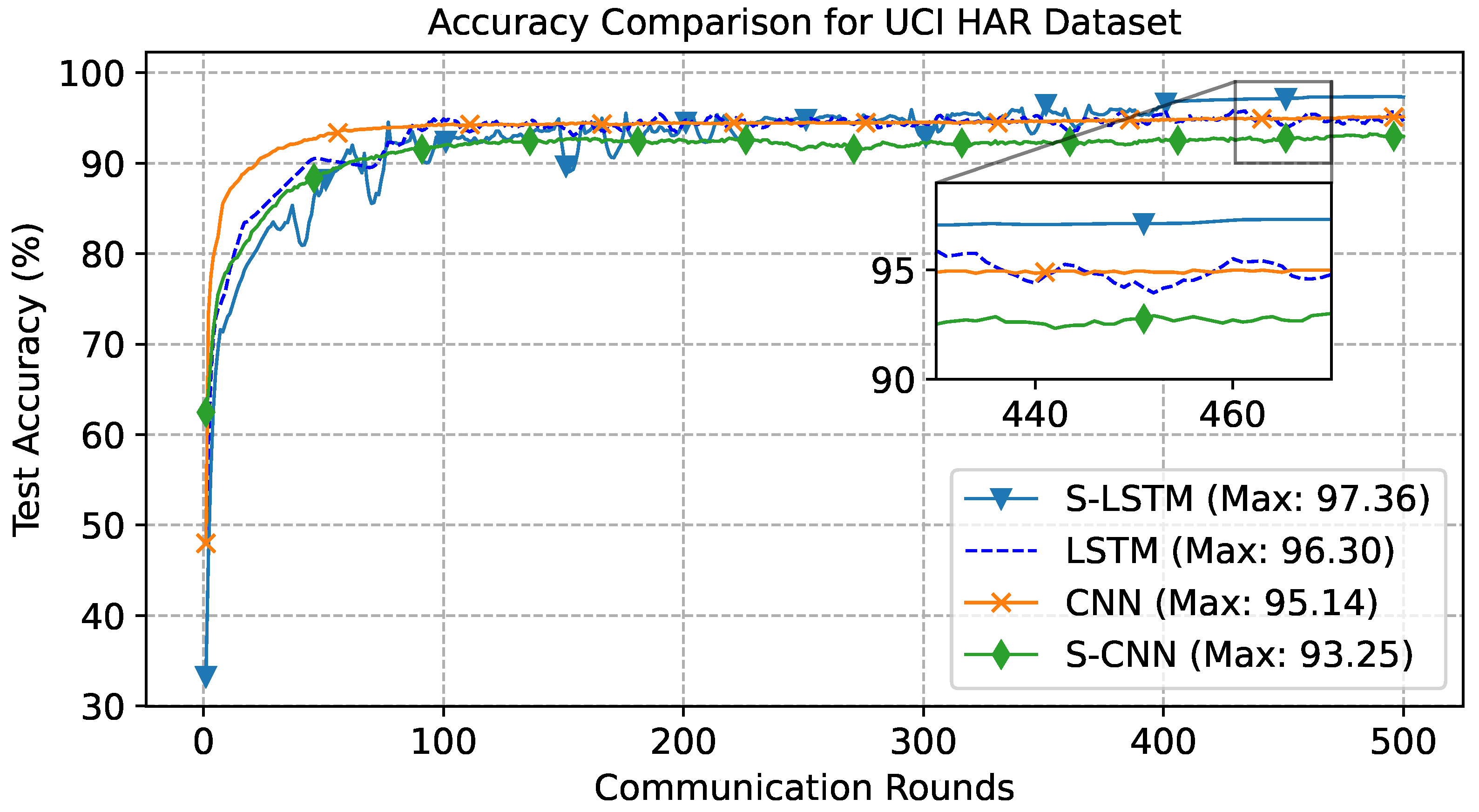
5.1. UCI Results
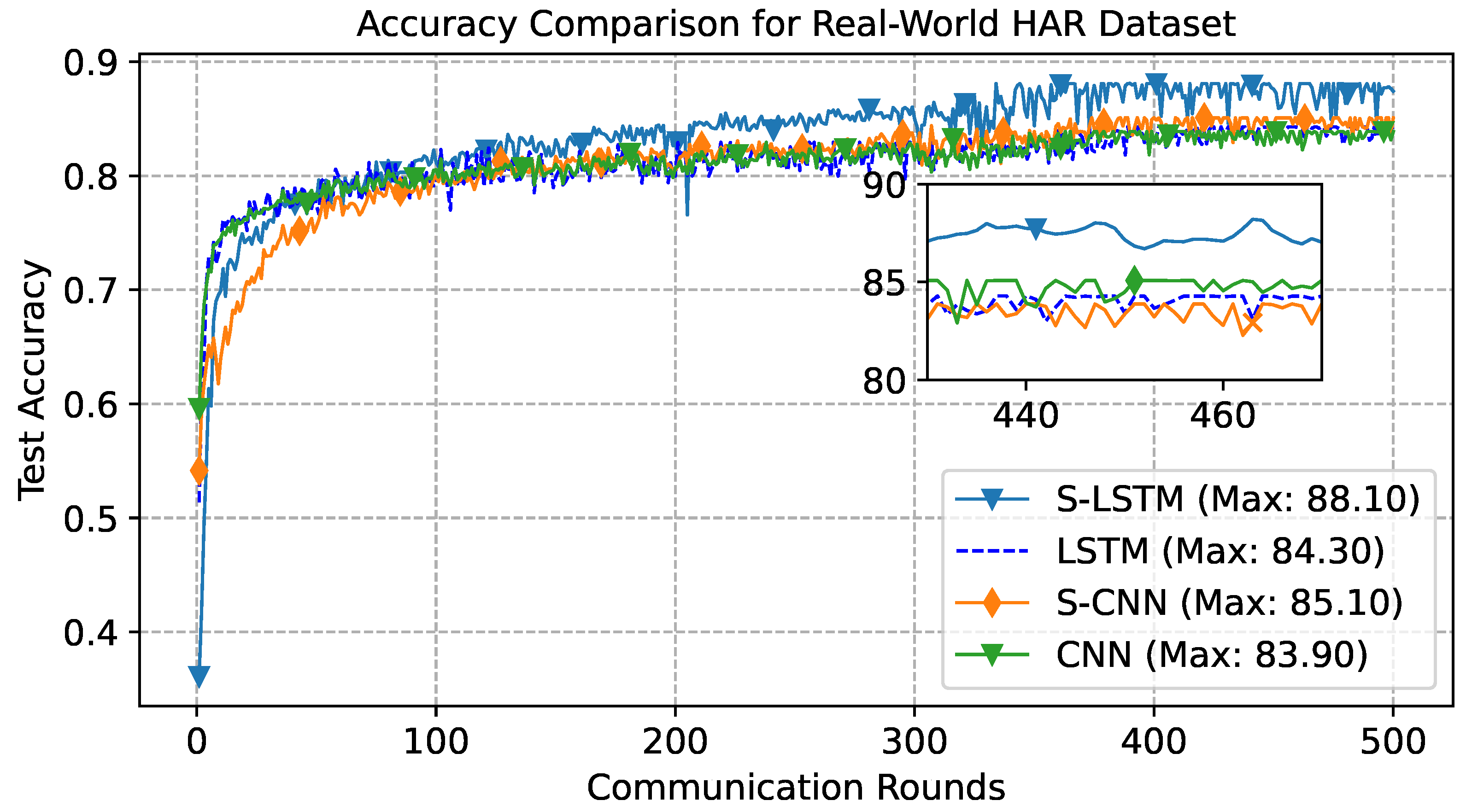
5.2. Real-World Dataset Results
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Diraco, G.; Rescio, G.; Siciliano, P.; Leone, A. Review on Human Action Recognition in Smart Living: Sensing Technology, Multimodality, Real-Time Processing, Interoperability, and Resource-Constrained Processing. Sensors 2023, 23, 5281. [Google Scholar] [CrossRef] [PubMed]
- Kalabakov, S.; Jovanovski, B.; Denkovski, D.; Rakovic, V.; Pfitzner, B.; Konak, O.; Arnrich, B.; Gjoreski, H. Federated Learning for Activity Recognition: A System Level Perspective. IEEE Access 2023, 11, 64442–64457. [Google Scholar] [CrossRef]
- Yu, H.; Chen, Z.; Zhang, X.; Chen, X.; Zhuang, F.; Xiong, H.; Cheng, X. FedHAR: Semi-supervised online learning for personalized federated human activity recognition. IEEE Trans. Mob. Comput. 2021, 22, 3318–3332. [Google Scholar] [CrossRef]
- Bokhari, S.M.; Sohaib, S.; Khan, A.R.; Shafi, M.; Khan, A.u.R. DGRU based human activity recognition using channel state information. Measurement 2021, 167, 108245. [Google Scholar] [CrossRef]
- Ashleibta, A.M.; Taha, A.; Khan, M.A.; Taylor, W.; Tahir, A.; Zoha, A.; Abbasi, Q.H.; Imran, M.A. 5g-enabled contactless multi-user presence and activity detection for independent assisted living. Sci. Rep. 2021, 11, 17590. [Google Scholar] [CrossRef] [PubMed]
- Cheng, X.; Cai, J.; Xu, J.; Gong, D. High-performance strain sensors based on Au/graphene composite films with hierarchical cracks for wide linear-range motion monitoring. ACS Appl. Mater. Interfaces 2022, 14, 39230–39239. [Google Scholar] [CrossRef] [PubMed]
- Islam, M.M.; Nooruddin, S.; Karray, F.; Muhammad, G. Human activity recognition using tools of convolutional neural networks: A state of the art review, data sets, challenges, and future prospects. Comput. Biol. Med. 2022, 149, 106060. [Google Scholar] [CrossRef]
- Sannara, E.; Portet, F.; Lalanda, P.; German, V. A federated learning aggregation algorithm for pervasive computing: Evaluation and comparison. In Proceedings of the 2021 IEEE International Conference on Pervasive Computing and Communications (PerCom), Kassel, Germany, 22–26 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–10. [Google Scholar]
- Yao, S.; Hu, S.; Zhao, Y.; Zhang, A.; Abdelzaher, T. Deepsense: A unified deep learning framework for time-series mobile sensing data processing. In Proceedings of the 26th International Conference on World Wide Web, Perth, WA, Australia, 3–7 April 2017; pp. 351–360. [Google Scholar]
- Wang, J.; Chen, Y.; Hao, S.; Peng, X.; Hu, L. Deep learning for sensor-based activity recognition: A survey. Pattern Recognit. Lett. 2019, 119, 3–11. [Google Scholar] [CrossRef]
- Guan, Y.; Plötz, T. Ensembles of deep lstm learners for activity recognition using wearables. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 1–28. [Google Scholar] [CrossRef]
- Singh, M.S.; Pondenkandath, V.; Zhou, B.; Lukowicz, P.; Liwickit, M. Transforming sensor data to the image domain for deep learning—An application to footstep detection. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2665–2672. [Google Scholar]
- Qi, P.; Chiaro, D.; Piccialli, F. FL-FD: Federated learning-based fall detection with multimodal data fusion. Inf. Fusion 2023, 99, 101890. [Google Scholar] [CrossRef]
- Hafeez, S.; Khan, A.R.; Al-Quraan, M.; Mohjazi, L.; Zoha, A.; Imran, M.A.; Sun, Y. Blockchain-Assisted UAV Communication Systems: A Comprehensive Survey. IEEE Open J. Veh. Technol. 2023, 4, 558–580. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS), Ft. Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Venkatesha, Y.; Kim, Y.; Tassiulas, L.; Panda, P. Federated learning with spiking neural networks. IEEE Trans. Signal Process. 2021, 69, 6183–6194. [Google Scholar] [CrossRef]
- Wang, Y.; Duan, S.; Chen, F. Efficient asynchronous federated neuromorphic learning of spiking neural networks. Neurocomputing 2023, 557, 126686. [Google Scholar] [CrossRef]
- Khatun, M.A.; Yousuf, M.A.; Ahmed, S.; Uddin, M.Z.; Alyami, S.A.; Al-Ashhab, S.; Akhdar, H.F.; Khan, A.; Azad, A.; Moni, M.A. Deep CNN-LSTM with self-attention model for human activity recognition using wearable sensor. IEEE J. Transl. Eng. Health Med. 2022, 10, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Han, C.; Zhang, L.; Tang, Y.; Huang, W.; Min, F.; He, J. Human activity recognition using wearable sensors by heterogeneous convolutional neural networks. Expert Syst. Appl. 2022, 198, 116764. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Soylu, A. Human activity recognition using wearable sensors, discriminant analysis, and long short-term memory-based neural structured learning. Sci. Rep. 2021, 11, 16455. [Google Scholar] [CrossRef] [PubMed]
- Jain, V.; Gupta, G.; Gupta, M.; Sharma, D.K.; Ghosh, U. Ambient intelligence-based multimodal human action recognition for autonomous systems. ISA Trans. 2023, 132, 94–108. [Google Scholar] [CrossRef] [PubMed]
- Qi, W.; Su, H.; Yang, C.; Ferrigno, G.; De Momi, E.; Aliverti, A. A fast and robust deep convolutional neural networks for complex human activity recognition using smartphone. Sensors 2019, 19, 3731. [Google Scholar] [CrossRef]
- Laitrakun, S. Merging-Squeeze-Excitation Feature Fusion for Human Activity Recognition Using Wearable Sensors. Appl. Sci. 2023, 13, 2475. [Google Scholar] [CrossRef]
- Cheng, D.; Zhang, L.; Bu, C.; Wang, X.; Wu, H.; Song, A. ProtoHAR: Prototype Guided Personalized Federated Learning for Human Activity Recognition. IEEE J. Biomed. Health Inform. 2023, 27, 3900–3911. [Google Scholar] [CrossRef]
- Ouyang, X.; Xie, Z.; Zhou, J.; Xing, G.; Huang, J. ClusterFL: A Clustering-based Federated Learning System for Human Activity Recognition. ACM Trans. Sens. Netw. 2022, 19, 1–32. [Google Scholar] [CrossRef]
- Gad, G.; Fadlullah, Z. Federated Learning via Augmented Knowledge Distillation for Heterogenous Deep Human Activity Recognition Systems. Sensors 2022, 23, 6. [Google Scholar] [CrossRef] [PubMed]
- Aouedi, O.; Piamrat, K.; Südholt, M. HFedSNN: Efficient Hierarchical Federated Learning using Spiking Neural Networks. In Proceedings of the 21st ACM International Symposium on Mobility Management and Wireless Access (MobiWac 2023), Montreal, QC, Canada, 30 October–3 November 2023. [Google Scholar]
- Xie, K.; Zhang, Z.; Li, B.; Kang, J.; Niyato, D.; Xie, S.; Wu, Y. Efficient federated learning with spike neural networks for traffic sign recognition. IEEE Trans. Veh. Technol. 2022, 71, 9980–9992. [Google Scholar] [CrossRef]
- Roy, K.; Jaiswal, A.; Panda, P. Towards spike-based machine intelligence with neuromorphic computing. Nature 2019, 575, 607–617. [Google Scholar] [CrossRef] [PubMed]
- Gerstner, W.; Kistler, W.M.; Naud, R.; Paninski, L. Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition; Cambridge University Press: Cambridge, UK, 2014. [Google Scholar]
- Kim, Y.; Panda, P. Optimizing deeper spiking neural networks for dynamic vision sensing. Neural Netw. 2021, 144, 686–698. [Google Scholar] [CrossRef] [PubMed]
- Neftci, E.O.; Mostafa, H.; Zenke, F. Surrogate gradient learning in spiking neural networks: Bringing the power of gradient-based optimization to spiking neural networks. IEEE Signal Process. Mag. 2019, 36, 51–63. [Google Scholar] [CrossRef]
- Wu, Y.; Deng, L.; Li, G.; Zhu, J.; Shi, L. Spatio-temporal backpropagation for training high-performance spiking neural networks. Front. Neurosci. 2018, 12, 331. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Srinivasan, G.; Panda, P.; Roy, K. Deep spiking convolutional neural network trained with unsupervised spike-timing-dependent plasticity. IEEE Trans. Cogn. Dev. Syst. 2018, 11, 384–394. [Google Scholar]
- Tumpa, S.A.; Singh, S.; Khan, M.F.F.; Kandemir, M.T.; Narayanan, V.; Das, C.R. Federated Learning with Spiking Neural Networks in Heterogeneous Systems. In Proceedings of the 2023 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Foz do Iguacu, Brazil, 20–23 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Xia, K.; Huang, J.; Wang, H. LSTM-CNN architecture for human activity recognition. IEEE Access 2020, 8, 56855–56866. [Google Scholar] [CrossRef]
- Li, Y.; Wang, L. Human activity recognition based on residual network and BiLSTM. Sensors 2022, 22, 635. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J. A public domain dataset for human activity recognition using smartphones. In Proceedings of the ESANN, Bruges, Belgium, 24–26 April 2013; Volume 3, p. 3. [Google Scholar]
- Sztyler, T.; Stuckenschmidt, H. On-body localization of wearable devices: An investigation of position-aware activity recognition. In Proceedings of the 2016 IEEE International Conference on Pervasive Computing and Communications (PerCom), Sydney, NSW, Australia, 14–19 March 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–9. [Google Scholar]
- Mian, A.N.; Shah, S.W.H.; Manzoor, S.; Said, A.; Heimerl, K.; Crowcroft, J. A value-added IoT service for cellular networks using federated learning. Comput. Netw. 2022, 213, 109094. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN | S-CNN | LSTM | S-LSTM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| Walking | 0.98 | 0.97 | 0.98 | 0.93 | 0.95 | 0.94 | 0.99 | 0.98 | 0.99 | 0.99 | 0.99 | 0.99 |
| Walking upstairs | 0.98 | 0.98 | 0.98 | 0.93 | 0.96 | 0.95 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 | 0.99 |
| Walking downstairs | 0.98 | 0.99 | 0.98 | 0.93 | 0.88 | 0.91 | 0.99 | 0.99 | 0.99 | 1.00 | 1.00 | 1.00 |
| Sitting | 0.89 | 0.88 | 0.88 | 0.90 | 0.88 | 0.89 | 0.91 | 0.90 | 0.91 | 0.93 | 0.94 | 0.93 |
| Standing | 0.89 | 0.90 | 0.89 | 0.89 | 0.91 | 0.90 | 0.91 | 0.92 | 0.91 | 0.94 | 0.93 | 0.94 |
| Lying | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| CNN | S-CNN | LSTM | S-LSTM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Class | Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score | Precision | Recall | F1-Score |
| Climb down | 0.90 | 0.91 | 0.90 | 0.92 | 0.91 | 0.91 | 0.90 | 0.91 | 0.90 | 0.94 | 0.93 | 0.94 |
| Climb up | 0.90 | 0.88 | 0.89 | 0.92 | 0.89 | 0.90 | 0.90 | 0.88 | 0.89 | 0.93 | 0.92 | 0.93 |
| Jumping | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 0.94 | 0.96 | 1.00 | 1.00 | 1.00 |
| Lying | 0.84 | 0.90 | 0.87 | 0.89 | 0.89 | 0.89 | 0.84 | 0.90 | 0.87 | 0.95 | 0.89 | 0.92 |
| Running | 0.98 | 0.88 | 0.93 | 0.98 | 0.87 | 0.93 | 0.98 | 0.88 | 0.93 | 0.97 | 0.91 | 0.94 |
| Sitting | 0.73 | 0.77 | 0.75 | 0.74 | 0.81 | 0.77 | 0.73 | 0.77 | 0.75 | 0.78 | 0.85 | 0.82 |
| Standing | 0.77 | 0.77 | 0.77 | 0.75 | 0.83 | 0.79 | 0.77 | 0.77 | 0.77 | 0.79 | 0.83 | 0.81 |
| Waling | 0.91 | 0.91 | 0.91 | 0.92 | 0.91 | 0.91 | 0.91 | 0.91 | 0.91 | 0.93 | 0.94 | 0.93 |
| Model |
Model Parameter (KB) |
Computation Time (s) |
Energy Estimate (W) |
|---|---|---|---|
| CNN | 25321 | 258 | 38.24 |
| 143 | 15.73 | ||
| S-CNN | 19418 | 252 | 29.38 |
| 136 | 15.67 | ||
| LSTM | 5231 | 220 | 8.07 |
| 137 | 4.32 | ||
| S-LSTM | 3931 | 208 | 6.10 |
| 121 | 3.27 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, A.R.; Manzoor, H.U.; Ayaz, F.; Imran, M.A.; Zoha, A. A Privacy and Energy-Aware Federated Framework for Human Activity Recognition. Sensors 2023, 23, 9339. https://doi.org/10.3390/s23239339
Khan AR, Manzoor HU, Ayaz F, Imran MA, Zoha A. A Privacy and Energy-Aware Federated Framework for Human Activity Recognition. Sensors. 2023; 23(23):9339. https://doi.org/10.3390/s23239339
Chicago/Turabian StyleKhan, Ahsan Raza, Habib Ullah Manzoor, Fahad Ayaz, Muhammad Ali Imran, and Ahmed Zoha. 2023. "A Privacy and Energy-Aware Federated Framework for Human Activity Recognition" Sensors 23, no. 23: 9339. https://doi.org/10.3390/s23239339
APA StyleKhan, A. R., Manzoor, H. U., Ayaz, F., Imran, M. A., & Zoha, A. (2023). A Privacy and Energy-Aware Federated Framework for Human Activity Recognition. Sensors, 23(23), 9339. https://doi.org/10.3390/s23239339