
Advancing Network Security with AI: SVM-Based Deep Learning for Intrusion Detection


Abstract
:1. Introduction
2. Related Works
3. Proposed Model
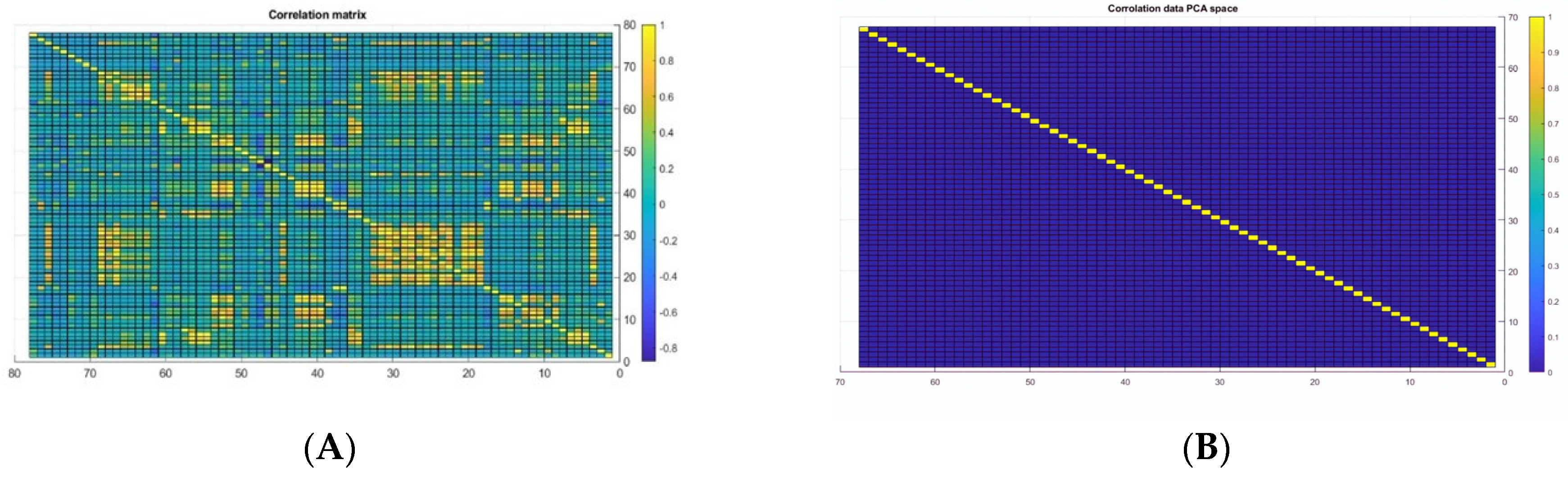
3.1. Data Preprocessing
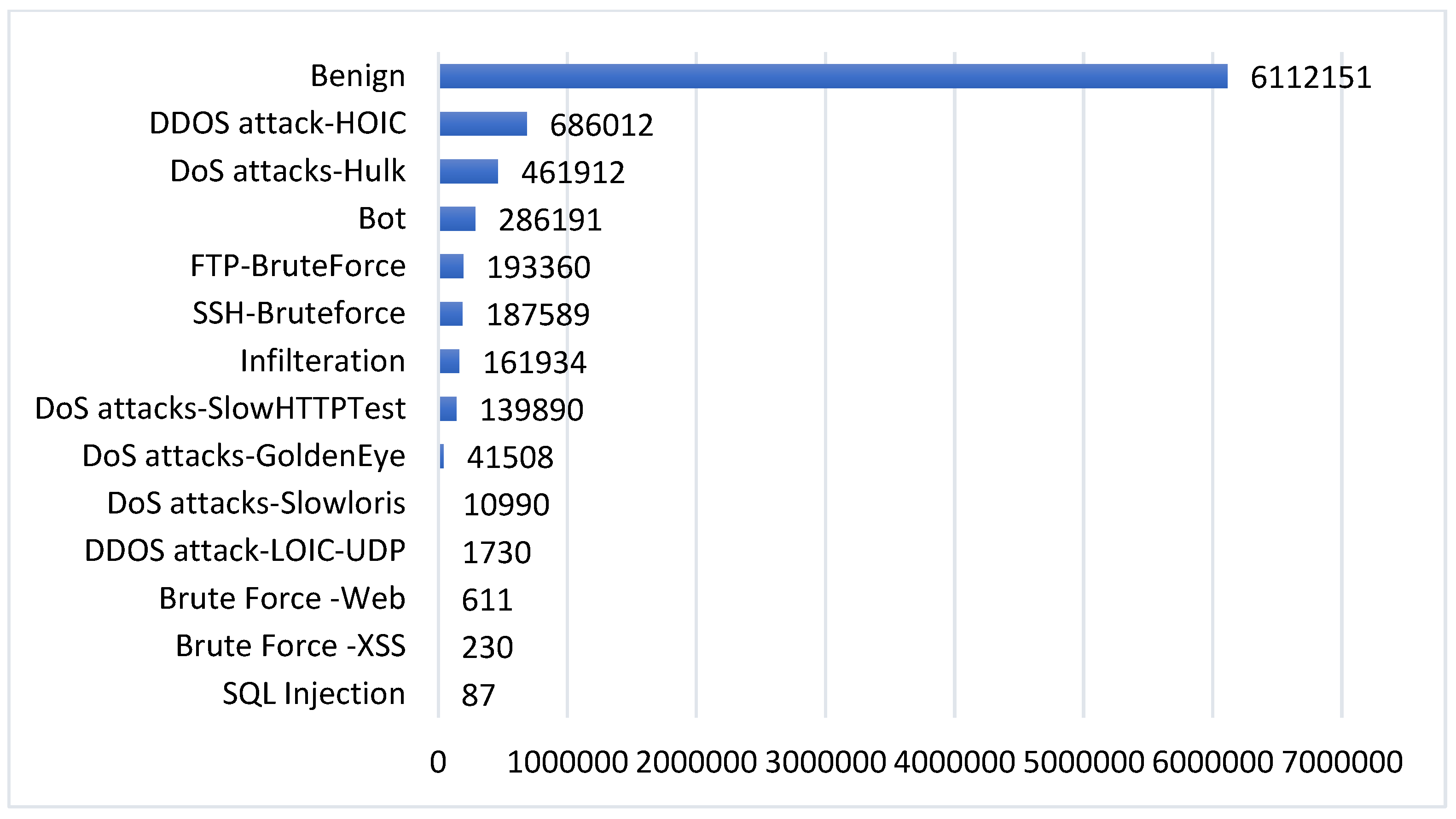
3.1.1. CSE-CIC-IDS 2018 Dataset
3.1.2. Data Preprocessing
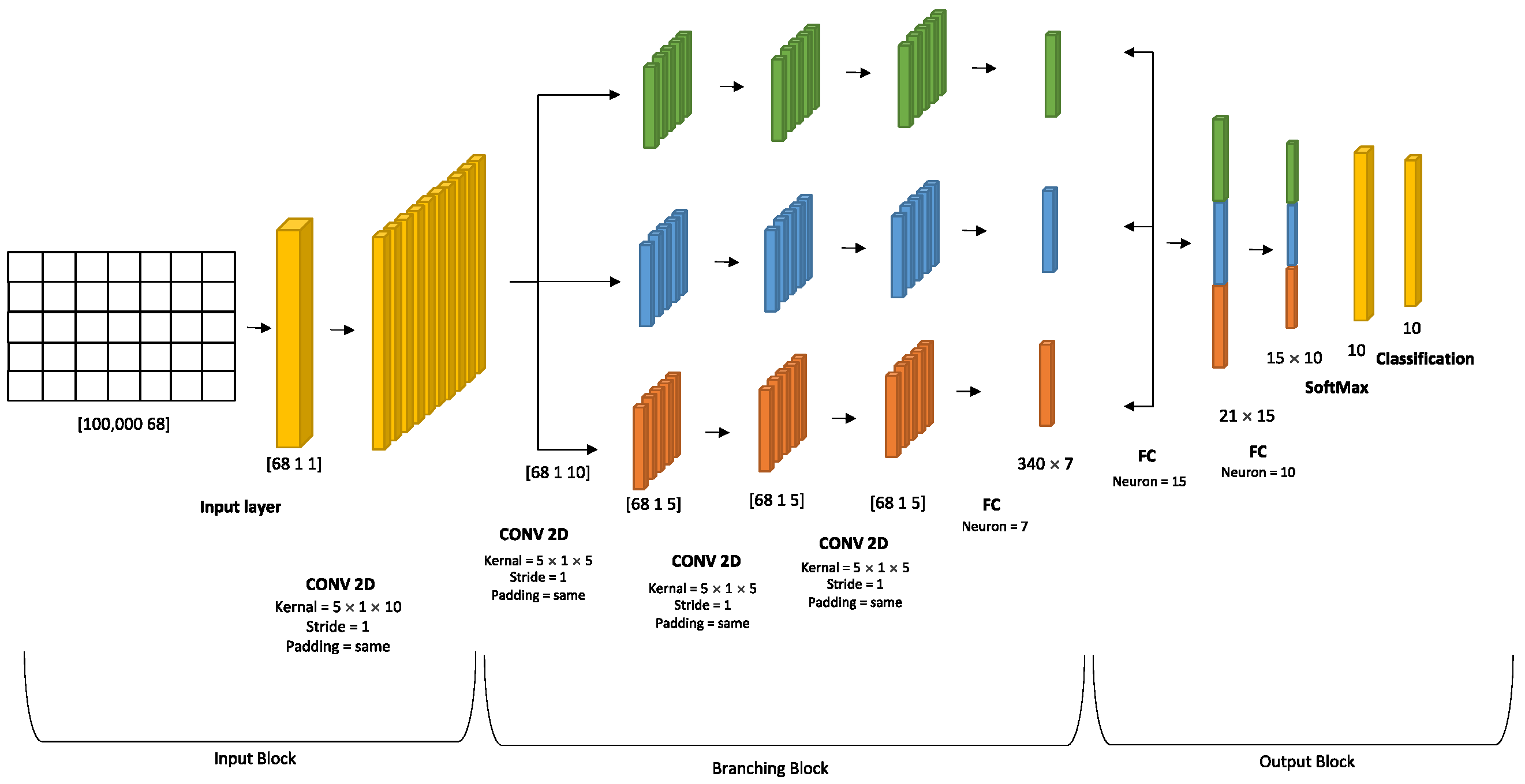
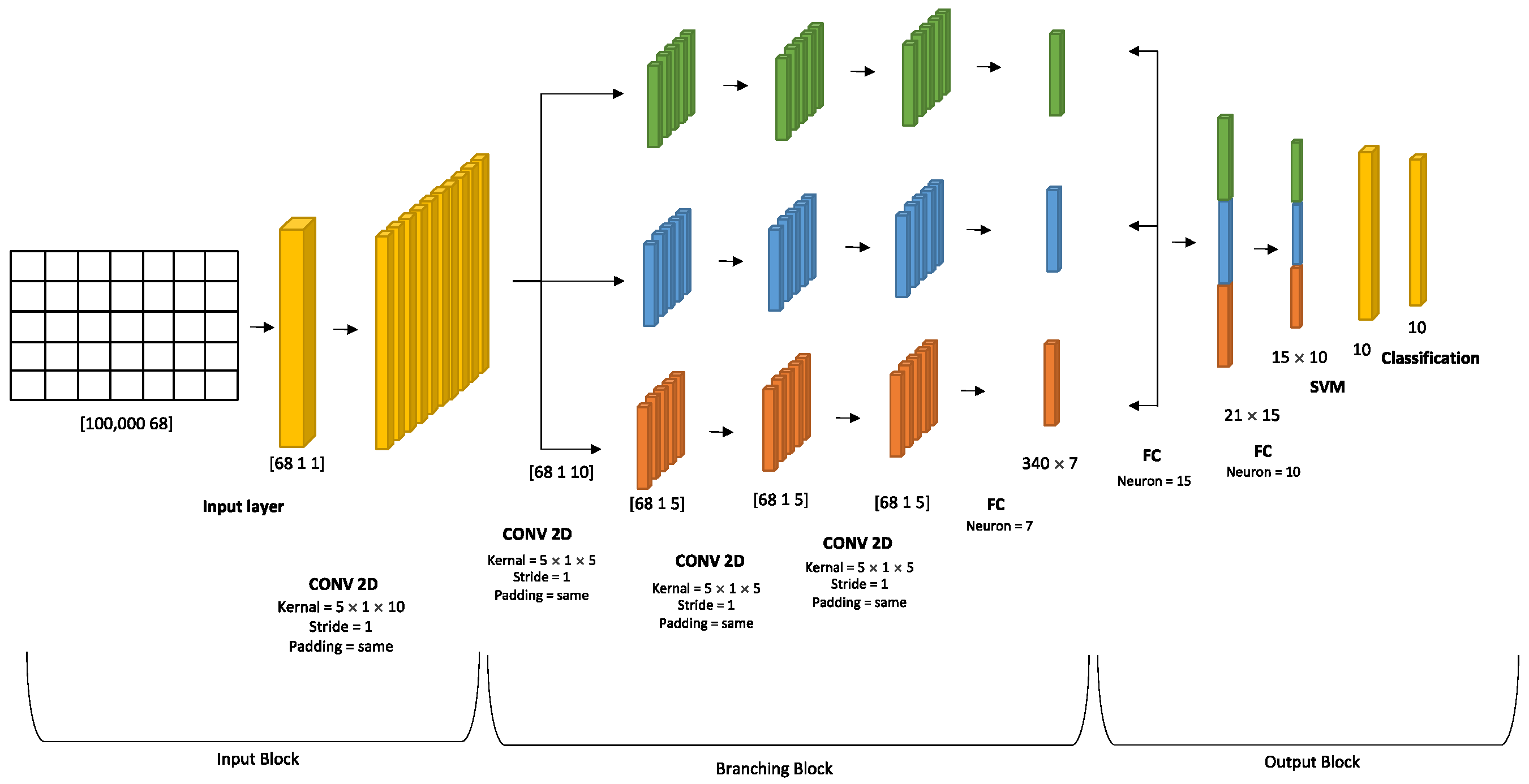
3.2. Deep Neural Network Architecture
DAG SVM Algorithm
4. Experimental Setup
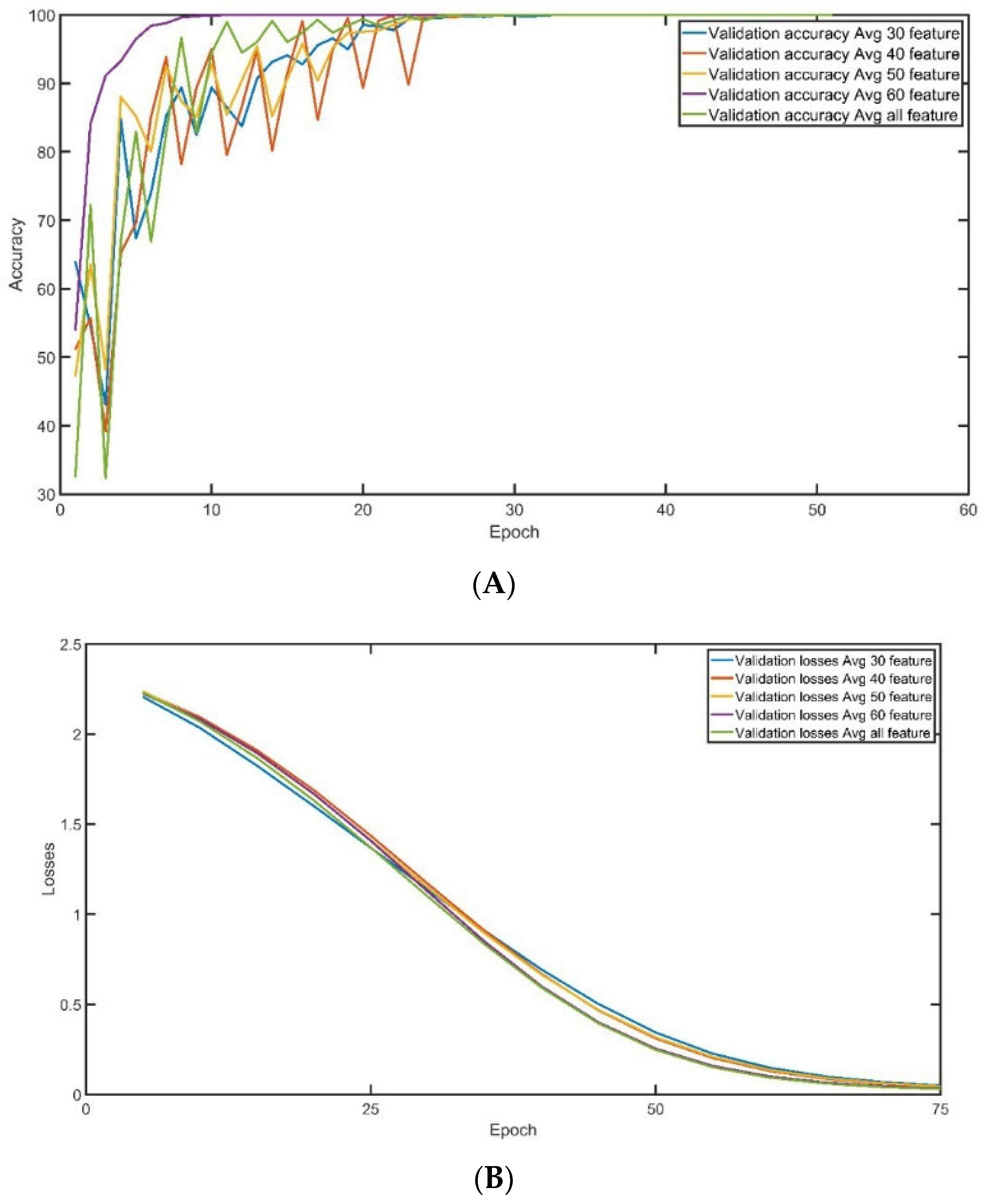
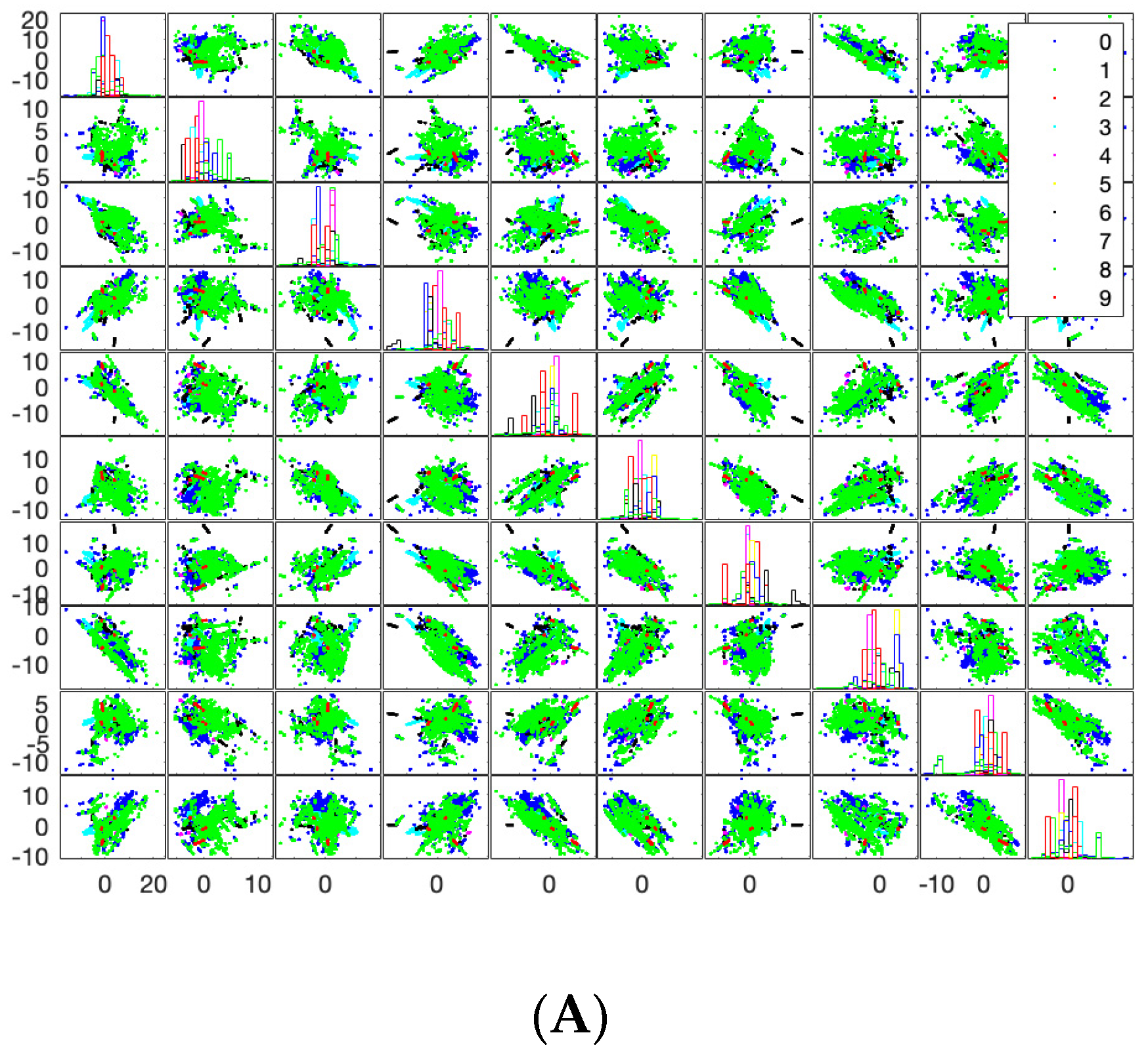
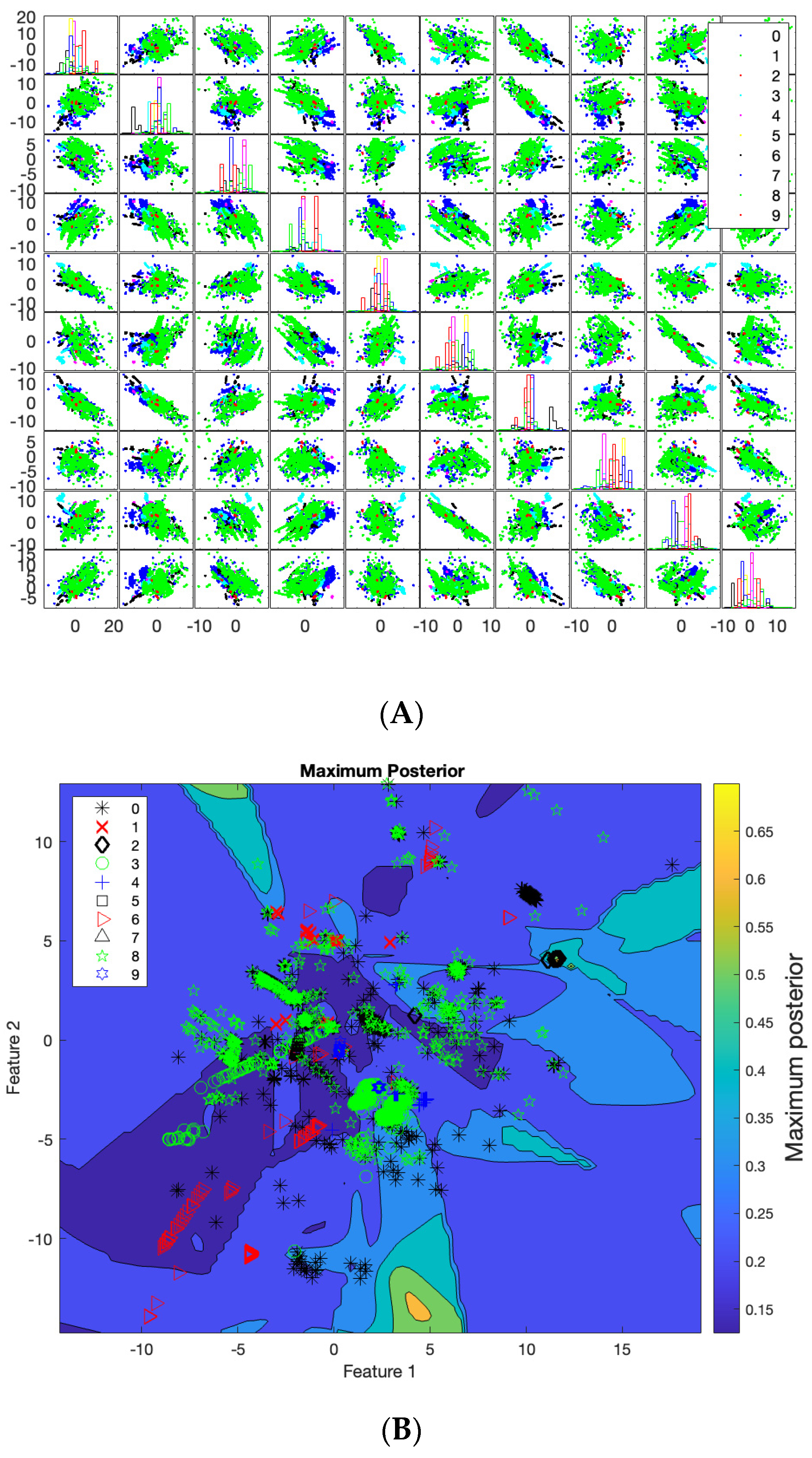
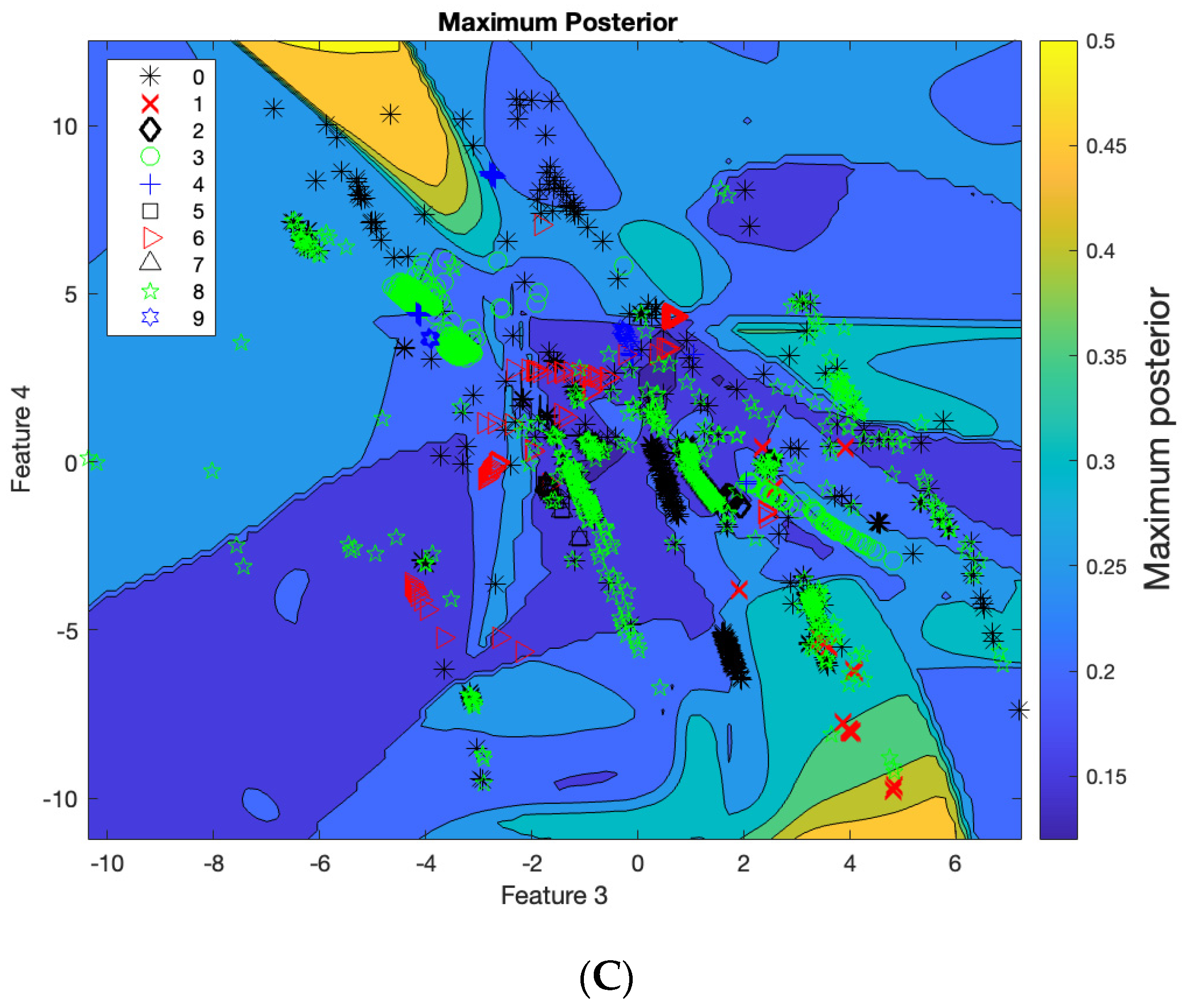
5. Experimental Result
- A.
- Training and Validation Accuracy
- B.
- Classification Accuracy
- C.
- Support Vector Machine (SVM)
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abuali, K.M.; Nissirat, L.; Al-Samawi, A. Intrusion Detection Techniques in Social Media Cloud: Review and Future Directions. Wirel. Commun. Mob. Comput. 2023, 2023, 6687023. [Google Scholar] [CrossRef]
- Kumar, S.A.P.; Kumar, A.; Srinivasan, S. Statistical based intrusion detection framework using six sigma technique. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2007, 7, 333. [Google Scholar]
- Om, H.; Hazra, T. Statistical techniques in anomaly intrusion detection system. Int. J. Adv. Eng. Technol. 2012, 5, 387. [Google Scholar]
- Azad, C.; Jha, V.K. Data mining-based hybrid intrusion detection system. Indian J. Sci. Technol. 2014, 7, 781. [Google Scholar] [CrossRef]
- Jha, J.; Ragha, L. Intrusion detection system using support vector machine. Int. J. Appl. Inf. Syst. IJAIS 2013, 3, 25–30. [Google Scholar]
- Li, J.; Zhao, Z.; Li, R.; Zhang, H. Ai-based two-stage intrusion detection for software defined iot networks. IEEE Internet Things J. 2018, 6, 2093–2102. [Google Scholar] [CrossRef]
- Patgiri, R.; Varshney, U.; Akutota, T.; Kunde, R. An investigation on intrusion detection system using machine learning. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1684–1691. [Google Scholar]
- Ravale, U.; Marathe, N.; Padiya, P. Feature selection based hybrid anomaly intrusion detection system using K means and RBF kernel function. Procedia Comput. Sci. 2015, 45, 428–435. [Google Scholar] [CrossRef]
- Sistla, V.P.K.; Kolli, V.K.K.; Voggu, L.K.; Bhavanam, R.; Vallabhasoyula, S. Predictive Model for Network Intrusion Detection System Using Deep Learning. Rev. D’intelligence Artif. 2020, 34, 323–330. [Google Scholar] [CrossRef]
- Kim, J.; Shin, N.; Jo, S.Y.; Kim, S.H. Method of intrusion detection using deep neural network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju, Republic of Korea, 13–16 February 2017; pp. 313–316. [Google Scholar]
- Nguyen, S.N.; Nguyen, V.Q.; Choi, J.; Kim, K. Design and implementation of intrusion detection system using convolutional neural network for DoS detection. In Proceedings of the 2nd International Conference on Machine Learning and Soft Computing, New York, NY, USA, 2–4 February 2018; pp. 34–38. [Google Scholar]
- Wang, H.; Cao, Z.; Hong, B. A network intrusion detection system based on convolutional neural network. J. Intell. Fuzzy Syst. 2020, 38, 7623–7637. [Google Scholar] [CrossRef]
- Toupas, P.; Chamou, D.; Giannoutakis, K.M.; Drosou, A.; Tzovaras, D. An intrusion detection system for multi-class classification based on deep neural networks. In Proceedings of the 2019 18th IEEE International Conference on Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 1253–1258. [Google Scholar]
- Liu, P. An intrusion detection system based on convolutional neural network. In Proceedings of the 2019 11th International Conference on Computer and Automation Engineering, New York, NY, USA, 23–25 February 2019; pp. 62–67. [Google Scholar]
- Chen, L.; Kuang, X.; Xu, A.; Suo, S.; Yang, Y. A novel network intrusion detection system based on CNN. In Proceedings of the 2020 Eighth International Conference on Advanced Cloud and Big Data (CBD), Taiyuan, China, 5–6 December 2020; pp. 243–247. [Google Scholar]
- Mohammadpour, L.; Ling, T.C.; Liew, C.S.; Chong, C.Y. A convolutional neural network for network intrusion detection system. Proc. Asia-Pac. Adv. Netw. 2018, 46, 50–55. [Google Scholar]
- Kim, J.; Shin, Y.; Choi, E. An intrusion detection model based on a convolutional neural network. J. Multimed. Inf. Syst. 2019, 6, 165–172. [Google Scholar] [CrossRef]
- Maseer, Z.K.; Yusof, R.; Bahaman, N.; Mostafa, S.A.; Foozy, C.F.M. Benchmarking of machine learning for anomaly based intrusion detection systems in the CICIDS2017 dataset. IEEE Access 2021, 9, 22351–22370. [Google Scholar] [CrossRef]
- Ho, S.; Al Jufout, S.; Dajani, K.; Mozumdar, M. A novel intrusion detection model for detecting known and innovative cyberattacks using convolutional neural network. IEEE Open J. Comput. Soc. 2021, 2, 14–25. [Google Scholar] [CrossRef]
- Kilichev, D.; Kim, W. Hyperparameter Optimization for 1D-CNN-Based Network Intrusion Detection Using GA and PSO. Mathematics 2023, 11, 3724. [Google Scholar] [CrossRef]
- Lilhore, U.K.; Manoharan, P.; Simaiya, S.; Alroobaea, R.; Alsafyani, M.; Baqasah, A.M.; Dalal, S.; Sharma, A.; Raahemifar, K. HIDM: Hybrid Intrusion Detection Model for Industry 4.0 Networks Using an Optimized CNN-LSTM with Transfer Learning. Sensors 2023, 23, 7856. [Google Scholar] [CrossRef] [PubMed]
- Oreški, D.; Andročec, D. Genetic algorithm and artificial neural network for network forensic analytics. In Proceedings of the 2020 43rd International Convention on Information, Communication and Electronic Technology (MIPRO), Opatija, Croatia, 28 September–2 October 2020; pp. 1200–1205. [Google Scholar]
- Farhan, R.I.; Maolood, A.T.; Hassan, N.F. Optimized deep learning with binary PSO for intrusion detection on CSE-CIC-IDS2018 dataset. J. Al-Qadisiyah Comput. Sci. Math. 2020, 12, 16. [Google Scholar] [CrossRef]
- Leevy, J.L.; Khoshgoftaar, T.M. A survey and analysis of intrusion detection models based on cse-cic-ids2018 big data. J. Big Data 2020, 7, 104. [Google Scholar] [CrossRef]
- Fatima, A.; Nazir, N.; Khan, M.G. Data cleaning in data warehouse: A survey of data pre-processing techniques and tools. Int. J. Inf. Technol. Comput. Sci. 2017, 9, 50–61. [Google Scholar] [CrossRef]
- Sorzano, C.O.S.; Vargas, J.; Montano, A.P. A survey of dimensionality reduction techniques. arXiv 2014, arXiv:1403.2877. [Google Scholar]
- Joseph, V.R. Optimal ratio for data splitting. Stat. Anal. Data Min. ASA Data Sci. J. 2022, 15, 531–538. [Google Scholar] [CrossRef]
- Ayachi, R.; Afif, M.; Said, Y.; Atri, M. Strided convolution instead of max pooling for memory efficiency of convolutional neural networks. In Proceedings of the 8th International Conference on Sciences of Electronics, Technologies of Information and Telecommunications (SETIT’18); Springer International Publishing: Berlin/Heidelberg, Germany, 2020; Volume 1, pp. 234–243. [Google Scholar]
- Wang, Z.; Li, M.; Wang, H.; Jiang, H.; Yao, Y.; Zhang, H.; Xin, J. Breast cancer detection using extreme learning machine based on feature fusion with CNN deep features. IEEE Access 2019, 7, 105146–105158. [Google Scholar] [CrossRef]
- Shih-Cheng, H.; Anuj, P.; Saeed, S.; Imon, B.; Lungren, M.P. Fusion of medical imaging and electronic health records using deep learning: A systematic review and implementation guidelines. NPJ Digit. Med. 2020, 3, 136. [Google Scholar]
- Sabzekar, M.; GhasemiGol, M.; Naghibzadeh, M.; Yazdi, H.S. Improved DAG SVM: A New Method for Multi-Class SVM Classification. In Proceedings of the International Conference on Artificial Intelligence IC-AI, Las Vegas, NV, USA, 12–15 July 2009; pp. 548–553. [Google Scholar]
- Liu, L.; Wang, P.; Lin, J.; Liu, L. Intrusion detection of imbalanced network traffic based on machine learning and deep learning. IEEE Access 2020, 9, 7550–7563. [Google Scholar] [CrossRef]
- Rizvi, S.; Scanlon, M.; McGibney, J.; Sheppard, J. Deep learning based network intrusion detection system for resource-constrained environments. In Proceedings of the International Conference on Digital Forensics and Cyber Crime, Boston, MA, USA, 6–18 November 2022; Springer Nature: Cham, Switzerland; pp. 355–367. [Google Scholar]
- Hagar, A.A.; Gawali, B.W. Apache Spark and Deep Learning Models for High-Performance Network Intrusion Detection Using CSE-CIC-IDS2018. Comput. Intell. Neurosci. 2022, 2022, 3131153. [Google Scholar] [CrossRef] [PubMed]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class Name | Class Tag |
|---|---|
| Benign | 0 |
| Bot | 1 |
| DDoS attacks-HOIC | 2 |
| DoS Attacks-GoldenEye | 3 |
| DoS attacks-Hulk | 4 |
| DoS attacks-SlowHTTPTest | 5 |
| DoS attacks-Slowlories | 6 |
| FTP-BruteForce | 7 |
| Infiltration | 8 |
| SSH-Bruteforce | 9 |
| Number of Experiments | |||||
|---|---|---|---|---|---|
| Number of Features | Experiment 1 | Experiment 2 | Experiment 3 | Experiment 4 | Experiment 5 |
| 30 | 3 | ||||
| 40 | 3 | ||||
| 50 | 3 | ||||
| 60 | 3 | ||||
| 68 | 3 | ||||
| Total number of Experiments = 15 | |||||
| Items | Specification |
|---|---|
| Manufacturer City Country | MAC Foxconn Designed by California, assembled in China U.S |
| Model | MacBook Pro 2021 |
| Processor Type | Apple M1 Pro chip |
| Installed Memory | Apple M1 Pro Chip, 16GB unified memory |
| Processor Speed | 10-core CPU with 6 performance cores and 2 efficiency cores, 14-core GPU, 16-core Neural Engine, 200 GB/s memory bandwidth |
| Number of Cores | 10-core CPU, 14-core GPU |
| Number of Threads | Single Thread |
| Machine Learning Tool | MATLAB (License Number: 40921045) version R2021b |
| Parameters | Value |
|---|---|
| Algorithm | Adam solver |
| Max Epoach | 50 |
| Mini Batch Size | 1000 |
| ValidationFrequency | 5 |
| ValidartionPatient | 10 |
| ExecutionEnvironment | Parallel Pooling |
| Classes Labels | Accuracy | True-Positive Recall Sensitivity | Predicted Positive Precision | Actual Negative Specificity | False-Positive Recall Sensitivity | F-Score |
|---|---|---|---|---|---|---|
| Benign | 100 | 100 | 100 | 100 | 0 | 100 |
| Bot | 100 | 100 | 100 | 100 | 0 | 100 |
| DDoS attacks-HOIC | 100 | 100 | 100 | 100 | 0 | 100 |
| DoS Attacks-GoldenEye | 100 | 100 | 100 | 100 | 0 | 100 |
| DoS Attacks-Hulk | 100 | 100 | 100 | 100 | 0 | 100 |
| DoS Attacks-SlowHTTPTest | 100 | 100 | 100 | 100 | 0 | 100 |
| DoS Attacks-Slowlories | 100 | 100 | 100 | 100 | 0 | 100 |
| FTP-BrutForce | 100 | 100 | 100 | 100 | 0 | 100 |
| Infiltration | 100 | 100 | 100 | 100 | 0 | 100 |
| SSH-BruteForrce | 100 | 100 | 100 | 100 | 0 | 100 |
| References | Method | Dataset | Accuracy |
|---|---|---|---|
| [23] | Deep Convolution Neural Network (DCNN) | CSE-CIC-IDS2018 | 95% |
| [33] | Deep Convolution Neural Network (DCNN) | CSE-CIC-IDS2018 | 99.98% |
| [34] | Apache Spark, CNN | CSE-CIC-IDS2018 | Apache Spark produced 100% for all classes. The CNN produced 98% for two classes and 100% for the other classes. |
| Proposed System | Deep Convolution Neural Network (DCNN) | CSE-CIC-IDS2018 | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abuali, K.M.; Nissirat, L.; Al-Samawi, A. Advancing Network Security with AI: SVM-Based Deep Learning for Intrusion Detection. Sensors 2023, 23, 8959. https://doi.org/10.3390/s23218959
Abuali KM, Nissirat L, Al-Samawi A. Advancing Network Security with AI: SVM-Based Deep Learning for Intrusion Detection. Sensors. 2023; 23(21):8959. https://doi.org/10.3390/s23218959
Chicago/Turabian StyleAbuali, Khadija M., Liyth Nissirat, and Aida Al-Samawi. 2023. "Advancing Network Security with AI: SVM-Based Deep Learning for Intrusion Detection" Sensors 23, no. 21: 8959. https://doi.org/10.3390/s23218959
APA StyleAbuali, K. M., Nissirat, L., & Al-Samawi, A. (2023). Advancing Network Security with AI: SVM-Based Deep Learning for Intrusion Detection. Sensors, 23(21), 8959. https://doi.org/10.3390/s23218959