1. Introduction
The increasingly serious problem of air pollution has led to a great deal of societal anxiety in recent years [
1]. Environmental management and the control of air pollution depend heavily on pollutant concentration predictions [
2]. An essential element of air pollutants is PM
2.5 (particulate matter with a diameter of less than
) [
3]. Elevated concentrations of PM
2.5 in the atmosphere pose a significant risk of respiratory infections, leading to diseases related to cardiopulmonary dysfunction, which are extremely detrimental to human health [
4]. Predicting air pollution can provide the public and government agencies with effective early warning and support decision-making in response to serious pollution events [
5]. Effective control of PM
2.5 not only protects people’s health but also reduces social and economic losses. Therefore, accurate prediction of PM
2.5 concentrations can provide timely early warning and enable governments to take timely action for the environment. Prediction of air pollutant concentrations, or simply air pollutant forecasting, plays an important role in air pollution prevention and environmental management [
6], and thus it has recently received significant attention in the research community and is recognized as a key challenge in environmental management research.
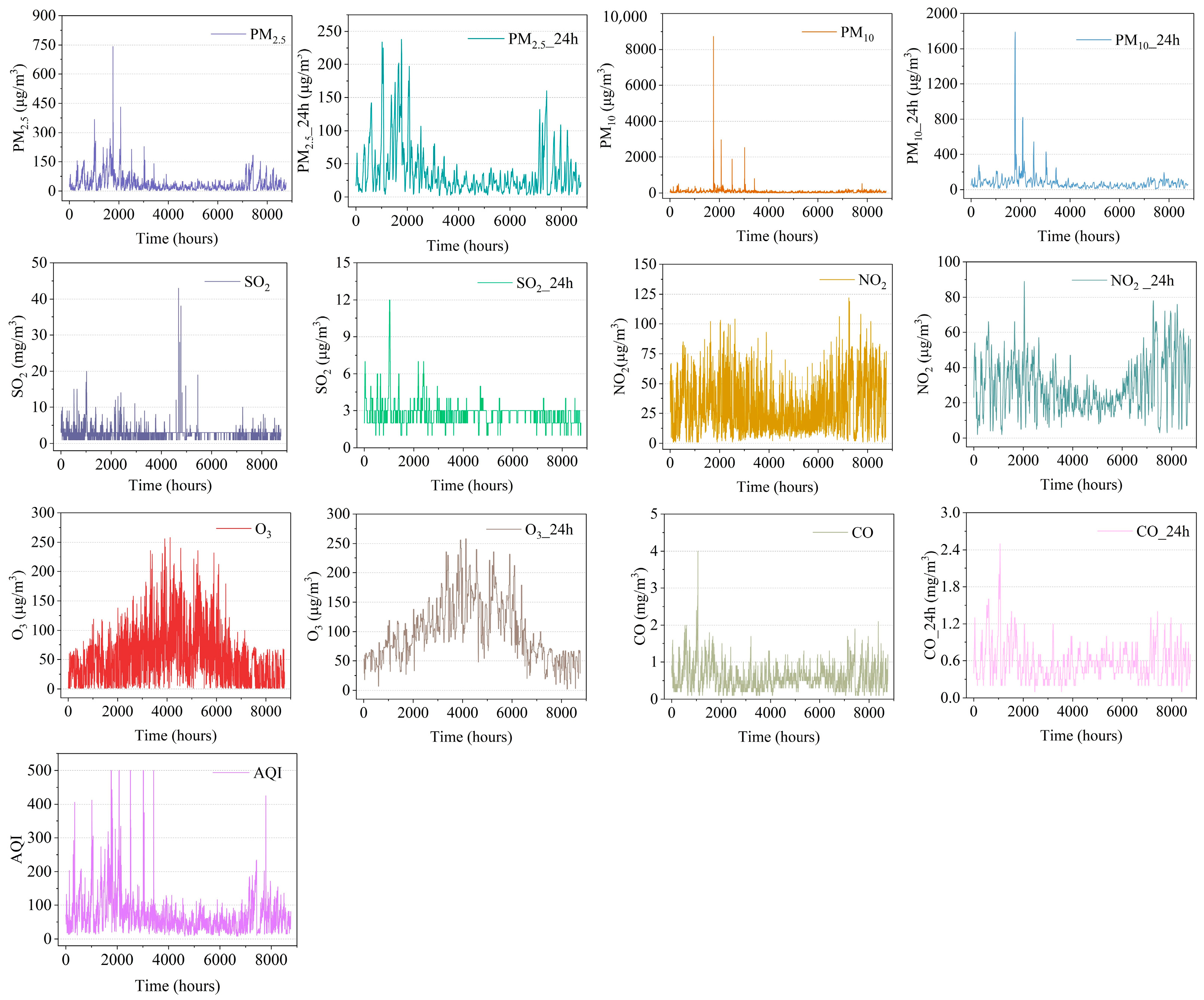
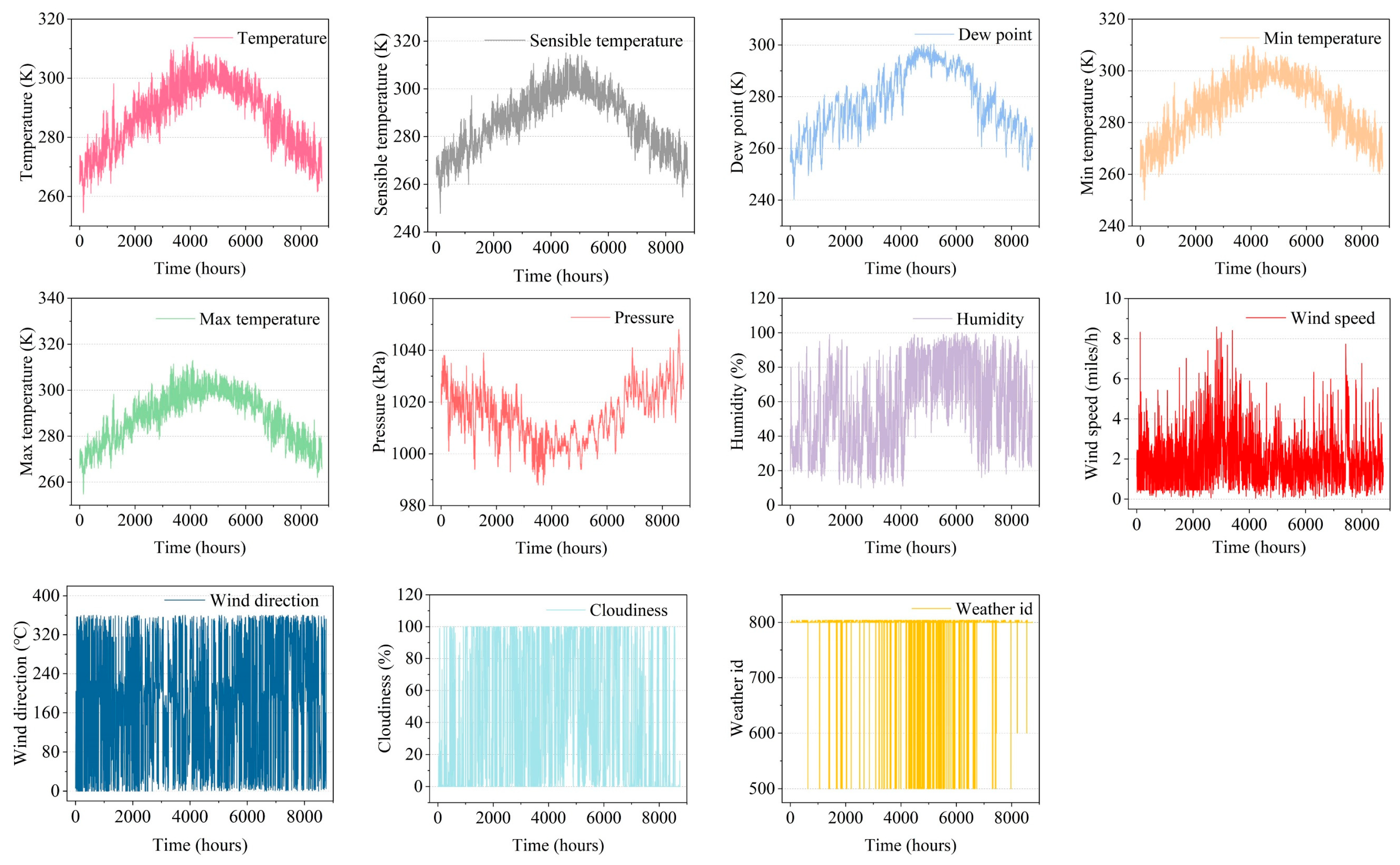
PM
2.5 concentration prediction can be viewed as a time-series processing problem that can be predicted based on past historical correlation data, e.g., meteorological factors such as temperature and humidity, as well as other pollution factors such as PM
10 and O
3 [
7]. At this stage, the research methods are divided into two categories according to the characteristics of the research methods [
8]: numerical model-based prediction methods and data-driven model-based prediction methods. The first is the prediction method of numerical modeling that simulates the process of emission, diffusion, transformation, and removal of air pollutants through meteorological principles and statistical methods so as to achieve the prediction of pollutant concentrations [
9]; the second is the prediction method based on data-driven modeling, which is based on making predictions by learning and analyzing pollutant historical data [
10].
Numerical modeling is mainly based on meteorological principles, knowledge of atmospheric dynamics and statistics, and the construction of equations for atmospheric pollutants and meteorological data to predict short-term pollutant concentrations [
11,
12]. Short-term predictions of pollutants generally refer to predicting pollutant concentrations for the next 1–6 h [
12]. Then, according to the constructed atmospheric conditions, complex differential equations are solved by a computer to simulate the pollutants’ chemical, environmental, and transportation procedures throughout the atmosphere [
13]. There are several commonly used numerical models: the Community Multiscale Air Quality Modeling System (CMAQ) [
14] and the nested air quality prediction modeling system (NAQPMS) [
15]. Despite the fact that numerical models take into account all changes in chemistry and atmospheric pollution transmission pathways, they suffer from the uncertainties of pollution sources, meteorological conditions, and transformation processes, as well as the high complexity of numerical models and the high arithmetic volume [
16].
Compared with numerical modeling, the data-driven learning-based modeling approach is easy, effective, and universally feasible [
6]. The model studies and evaluates historical information, focuses on mapping the relationship between historical data and air pollution concentration values in the predicted time period, and makes a more reasonable prediction of future pollutant concentration levels based on the current state [
17]. Prediction methods based on data-driven models can be further subdivided into two categories: machine learning and deep learning models [
11]. Machine learning models, an important type of artificial intelligence learning, combine the trends of the pollutants themselves and the intrinsic relationship between the pollutants and meteorology to produce predicted concentration values [
18]. The pollutant concentration prediction models in common use today consist of Random Forest (RF) [
19] models, Autoregressive Sliding Average (ARMA) models [
20], and Support Vector Regression (SVR) [
21]. These machine learning models can fully explore the nonlinear relationships between contaminant data with good robustness [
22]. However, machine learning parameters generally rely on manual construction, which relies heavily on personal experience. In addition, they exhibit a lack of ability to reduce redundant data when dealing with larger and larger datasets, which then impacts their capacity for learning and generalization [
23].
Deep learning models are more suitable to be applied within the field of predicting pollutant concentrations than traditional machine learning models [
24]. Deep learning models can obtain better robustness through deeper hidden layers and excellent self-learning ability to explore higher-order nonlinear mapping relationships [
25]. The following are some examples of deep learning models for time-based prediction: Recurrent Neural Networks (RNNs) [
26], Gate Recurrent Units (GRUs) [
27], and long short-term memory networks (LSTMs) [
28]. In most cases, deep learning models outperform machine learning models in terms of effectiveness. Modeling the spatial–temporal interactions between numerous complicated nonsmooth air contaminants and meteorological data is necessary for air pollution prediction [
29]. A single network structure may hinder the model’s ability to forecast accurately, all of which remain deficient when dealing with spatial–temporal big data.
Other deep learning techniques have been utilized by researchers to improve spatial–temporal modeling in order to address the limitations of single structure-based models. The following hybrid models have been employed for the prediction of pollutant concentrations: LSTM-FC [
30], AC-LSTM [
31], and EEMD-GRNN [
32]. Due to shared weights and neighborhood recognition of convolutional processes, convolutional neural networks (CNNs) offer strong feature extraction capabilities [
33]. As a result, using CNNs’ computer vision capabilities, CNN-LSTMs have effectively assessed the geographic dispersion features of atmospheric pollution concentrations [
11]. We analyzed models based on CNNs to thoroughly examine the spatial and temporal correlations between pollutant data and meteorological parameters as a result of these studies [
34].
Additionally, it is commonly acknowledged that attention processes can enhance the accuracy of predictions made by deep learning methods. In recent years, the ideas of attention processes and the processing of natural language and picture evaluation have become increasingly prominent [
35]. Their major goal is to help models concentrate on their more crucial feature data. These are frequently employed in the prediction of time-series tasks related to, among other things, traffic, wind energy, and floods. For instance, to forecast flood events, Ding [
36] designed a novel LSTM that mixes explainable temporal and spatial attention mechanisms (STA-LSTMs). Using spatial and temporal attention, weighting is given to the input data’s pattern of spatial–temporal properties. Additionally, STA-LSTMs fared better than the LSTM and CNN models. Nevertheless, the mechanism of spatial–temporal attention is yet to be investigated or used to forecast pollution. Undoubtedly, a method for bidirectional GRU combining attention was put forth by Zhang [
37]. Studies have shown that the suggested model may outperform its competitors in capturing the most crucial aspects of historical data. Additionally, the prediction performance was significantly better than that of well-known RNN, LSTM and CNN-LSTM, although they did not consider spatial attentional mechanisms when trying to tap into spatial attributes. In order to improve air pollution prediction, it is worthwhile to investigate these potential spatial–temporal attention mechanisms in more detail [
38].
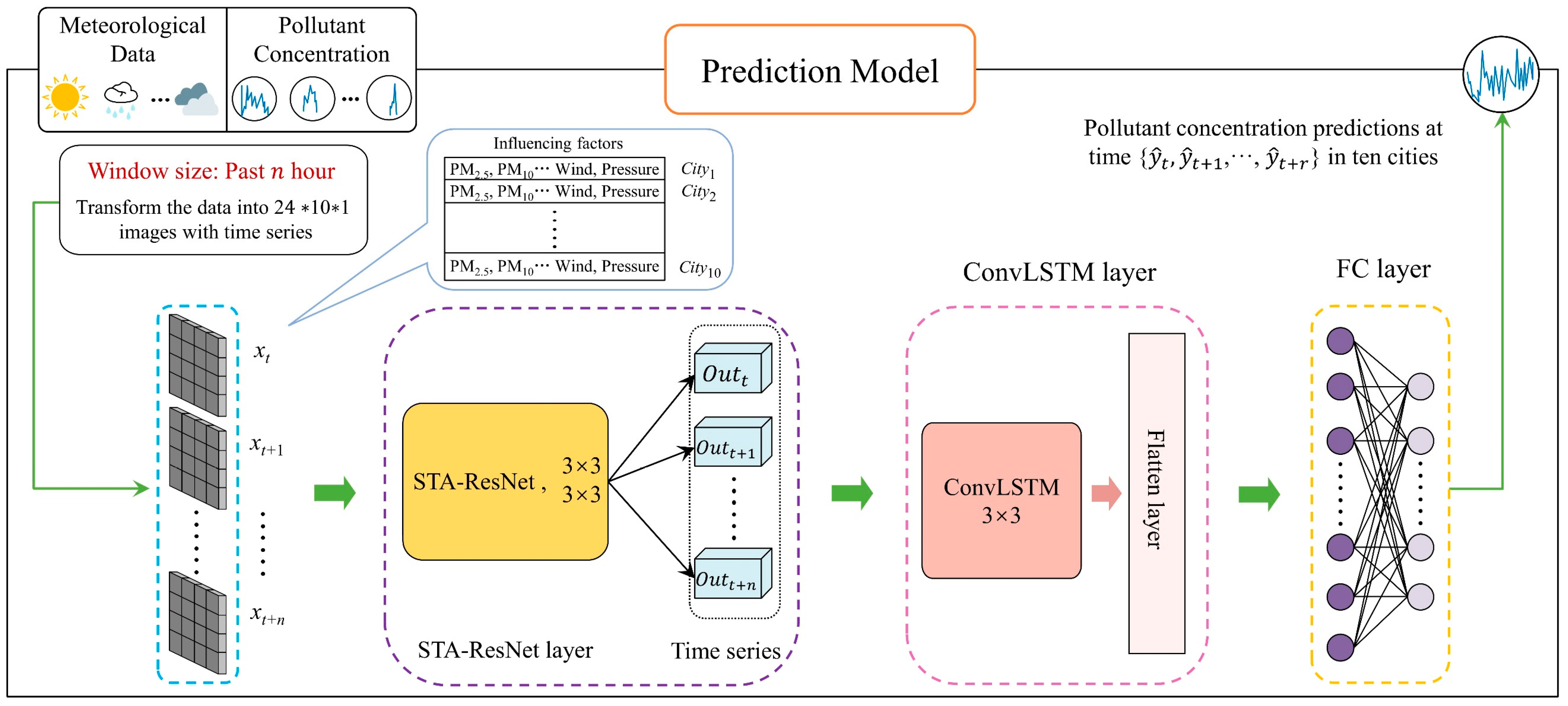
In view of these, the secret to improving the effectiveness of pollution prediction is the efficient mining of spatial–temporal aspects of data. To address this issue and produce a more precise and reliable pollutant concentration forecast, this study provides a hybrid prediction model using spatial–temporal attention, ResNet, and ConvLSTM for pollutant concentration prediction. The contribution of this work is summarized below:
- (1)
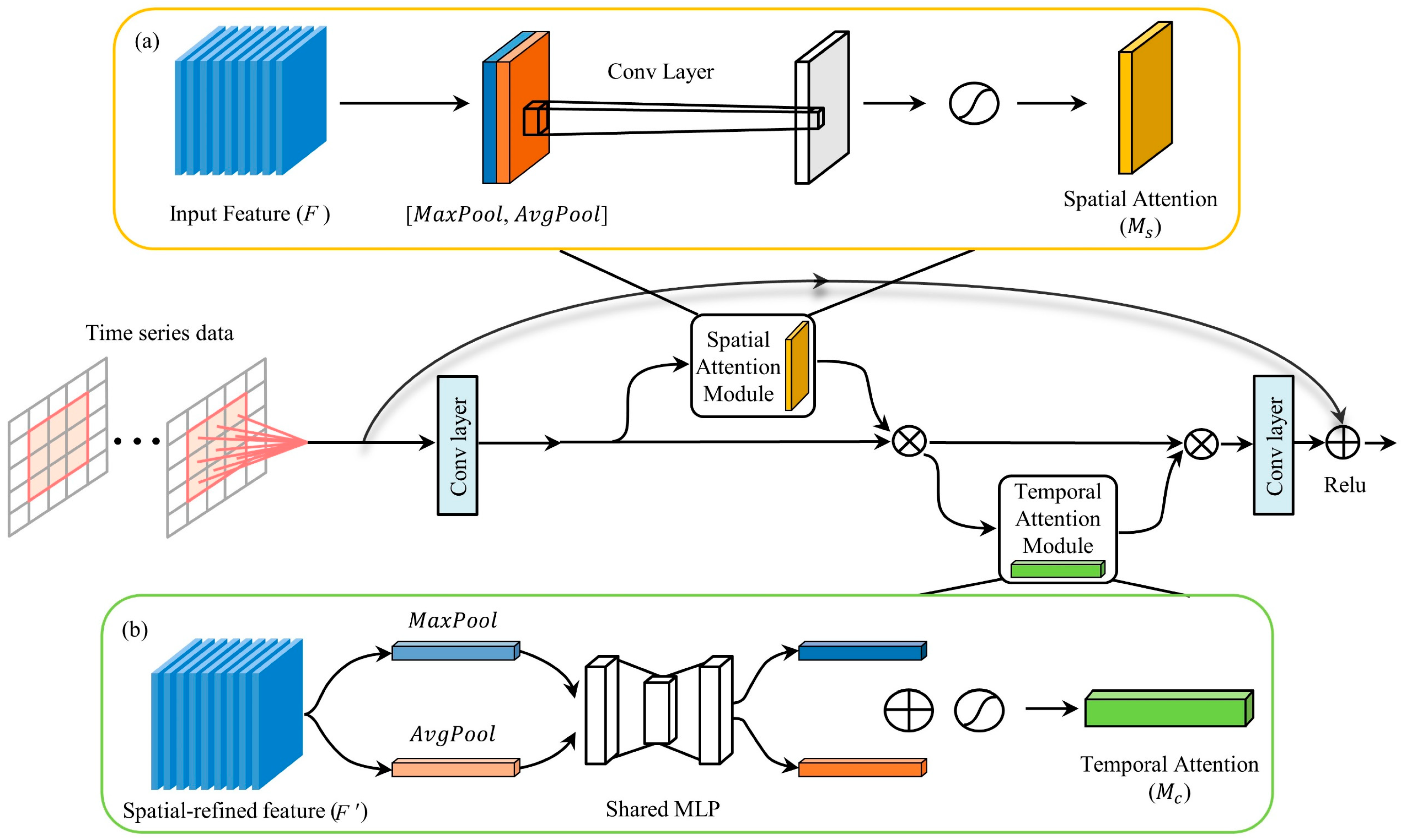
By using ResNet as the foundation layer of STA-ResConvLSTM, we avoid the problem of gradient vanishing or gradient explosion and provide for the removal of the deep network degradation issue and the extraction of spatially important information from meteorological and pollution data from numerous cities.
- (2)
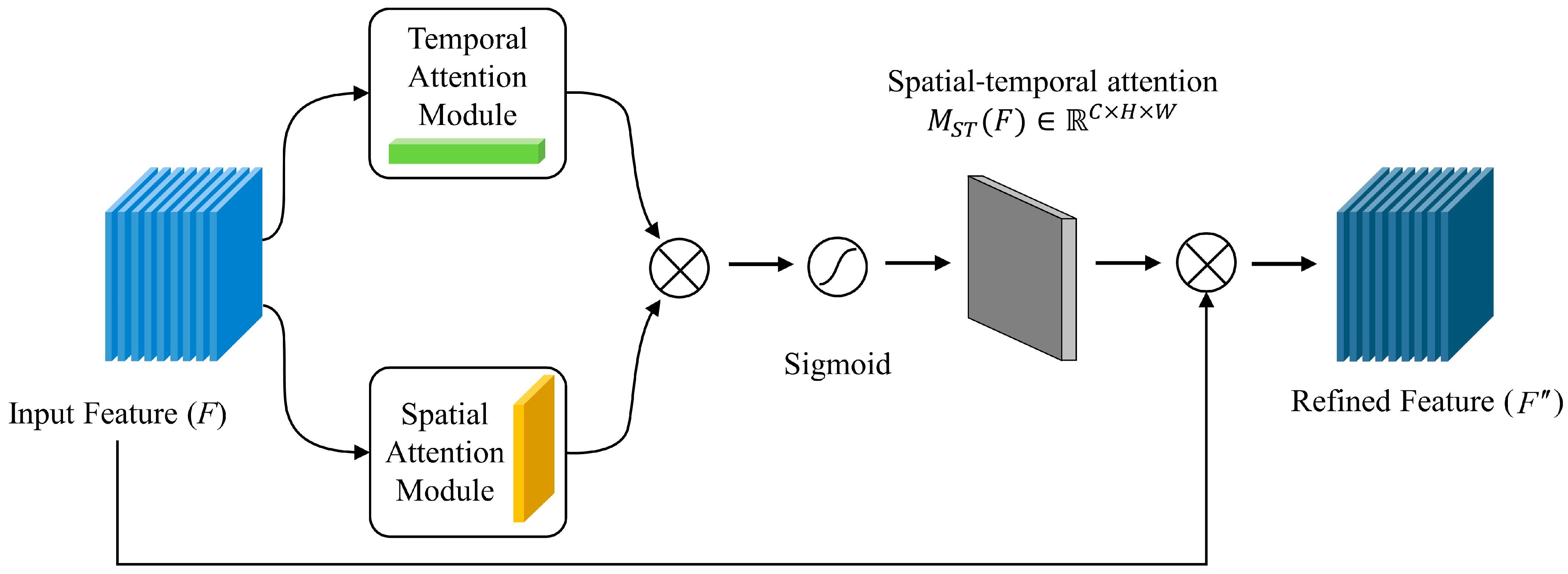
The spatial–temporal attention mechanisms are introduced into the residual block. Features in the temporal and spatial dimensions of pollutants are extracted using spatial–temporal attentional processes. As a result, the temporal and spatial dependencies can be effectively exploited, and the accuracy of pollutant concentration can be improved based on the weight distribution of attention.
- (3)
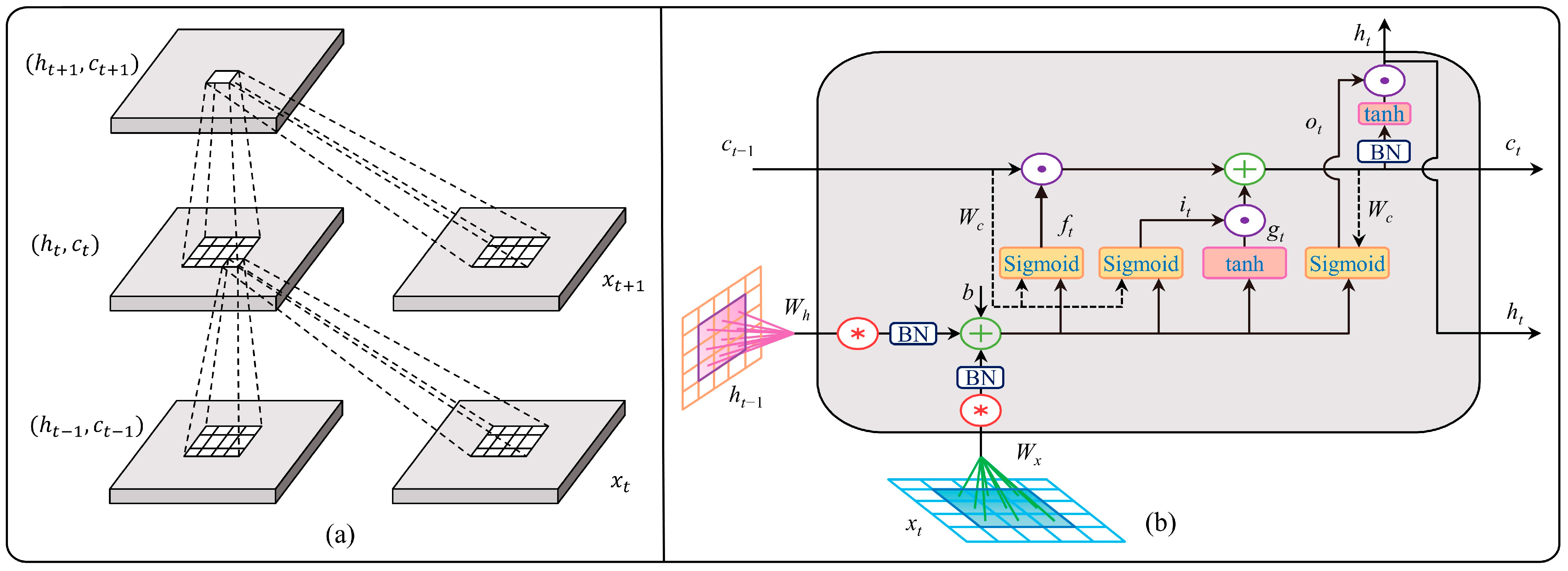
ConvLSTM is used in the model as the final prediction layer. In order to fulfill the aim of mining the spatial–temporal correlation of the data, hidden advanced connection features must be extracted from the complex spatial–temporal sequence data generated via STA-ReNet. ConvLSTM avoids the gradient disappearing issue in addition to gaining from the effectiveness advantages associated with ConvLSTM with regard to time-series forecasting.
5. Discussion
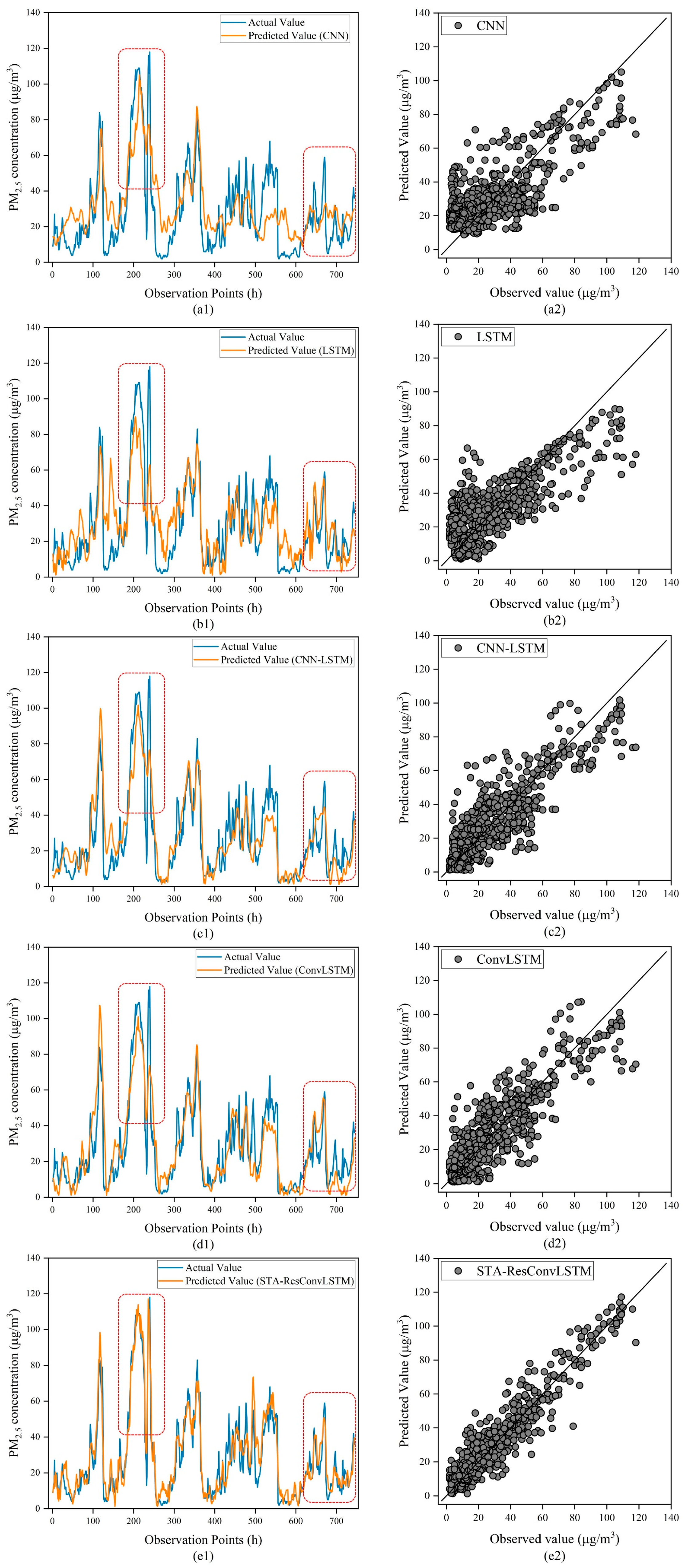
The results show that STA-ResConvLSTM has the best performance among all the tested models for single-step, multi-step, and trend prediction of PM2.5. The hybrid deep learning framework based on spatial–temporal attention mechanisms becomes a more useful tool for processing spatial–temporal data than its deep learning model.
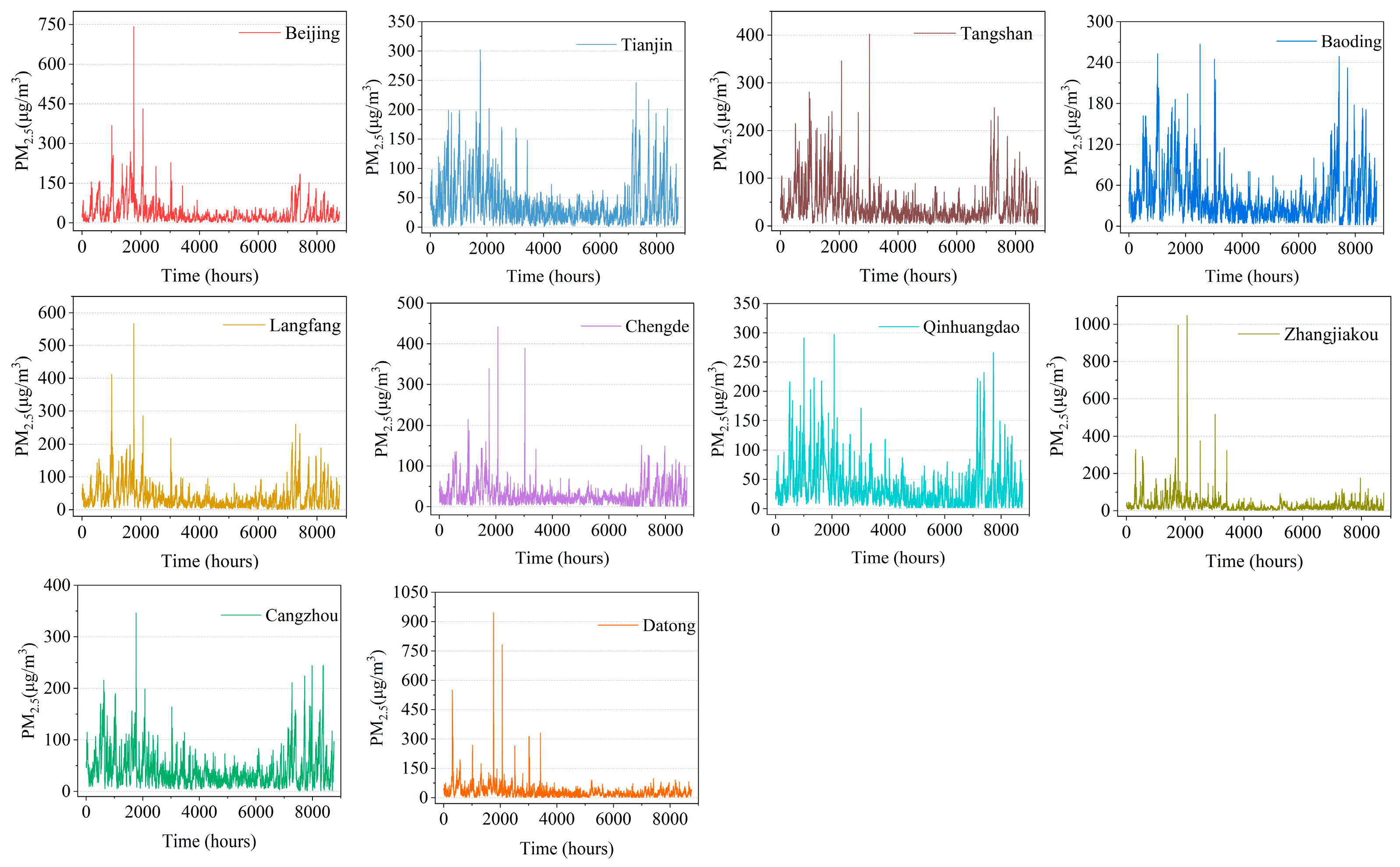
From the temporal dimension, there is a clear cyclical variation in pollutants and meteorological data, which can also be said to be time-dependent. From the spatial dimension, the PM2.5 values of the ten cities are similar, and it can also be said that the pollutants have a spatial correlation.
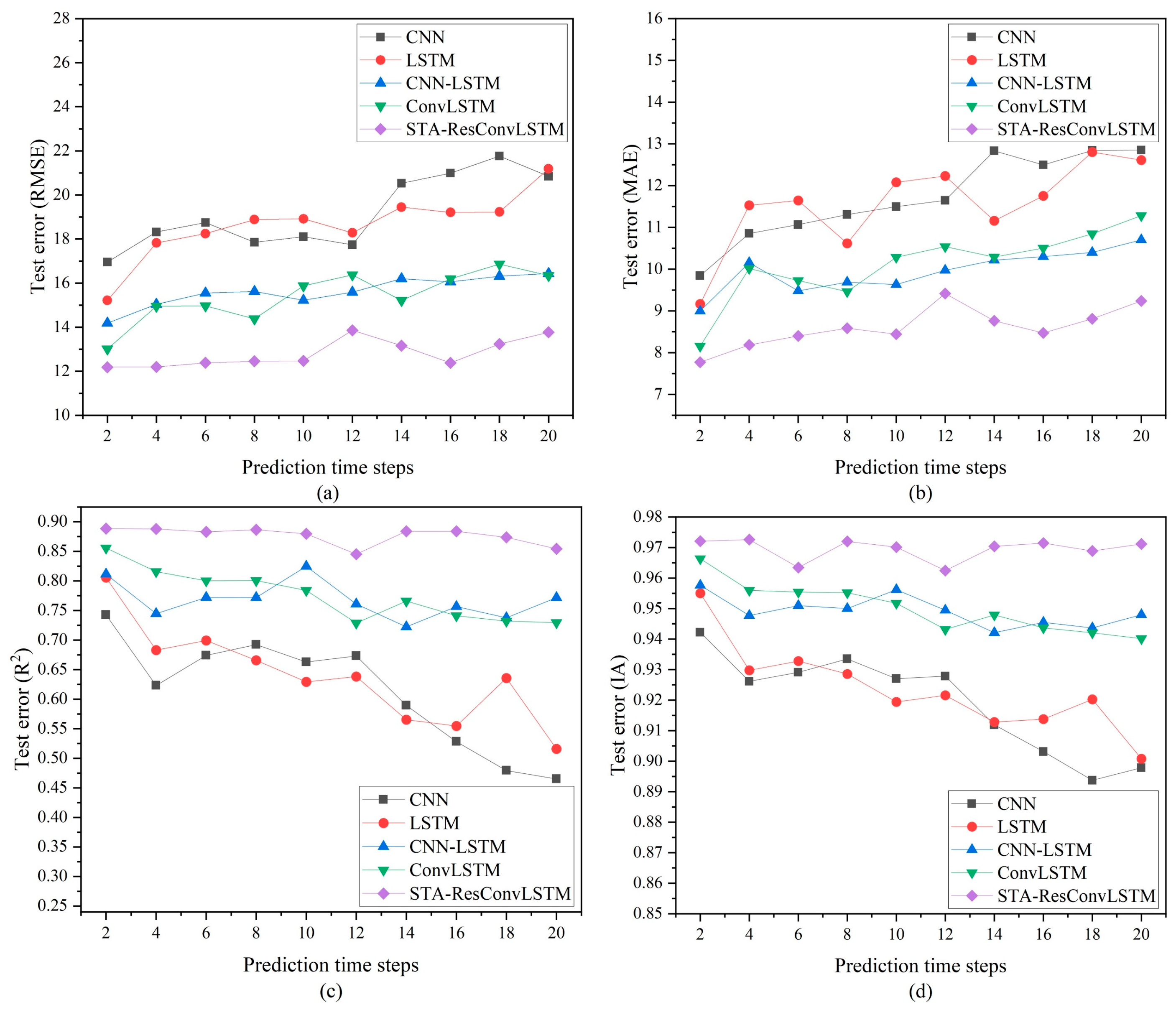
From the results of the PM
2.5 single-step and multi-step prediction experiments, it can be seen in
Table 2 and
Table 3 that CNN-LSTM, ConvLSTM, and STA-ResConvLSTM have better prediction results compared to the CNN and LSTM methods because all three methods can handle pollutant prediction problems. Next, comparing the prediction results of CNN, CNN-LSTM, and ConvLSTM in
Table 2 and
Table 3, it can be concluded that the prediction accuracy of ConvLSTM is higher than that of the other models, which proves that ConvLSTM has a better ability to extract spatial features of pollutants and meteorological data. Finally, comparing the prediction results of ConvLSTM and STA-ResConvLSTM in
Table 2 and
Table 3, it can be seen that the prediction accuracy of STA-ResConvLSTM is higher than that of ConvLSTM, which proves the superiority of the spatial–temporal attention mechanism and residual network for deep feature extraction of spatial–temporal data. The experimental results of the STA-ResConvLSTM model in
Table 2 and
Table 3 also confirm that it is very effective for the prediction of PM
2.5. The optimal values of RMSE are only 9.82 and 12.63, respectively.
From the results of the PM
2.5 trend prediction experiment, as shown in
Figure 11 for CNN and LSTM, the curve fluctuates greatly, and it is difficult to predict the trend in PM
2.5 concentration. CNN-LSTM’s and ConvLSTM’s curves fluctuate little and are stable, but it is difficult to predict the trend in PM
2.5 concentration at the sudden change point. Combining
Table 6 and
Table 7 and
Figure 11, compared to other deep learning models, STA-ResConvLSTM has the least fluctuation in prediction accuracy with the increase in prediction time step and can accurately predict the future trend in pollutant concentration. From the figure, we can see that the trend of the observed and predicted curves in the red box is consistent. Therefore, in the future pollutant prediction process, the STA-ResConvLSTM model can be considered to be combined with state-of-the-art prediction methods so as to improve the accuracy of pollutant prediction more effectively.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}