Scene Uyghur Recognition Based on Visual Prediction Enhancement

 , ,
, ,
Abstract
:1. Introduction
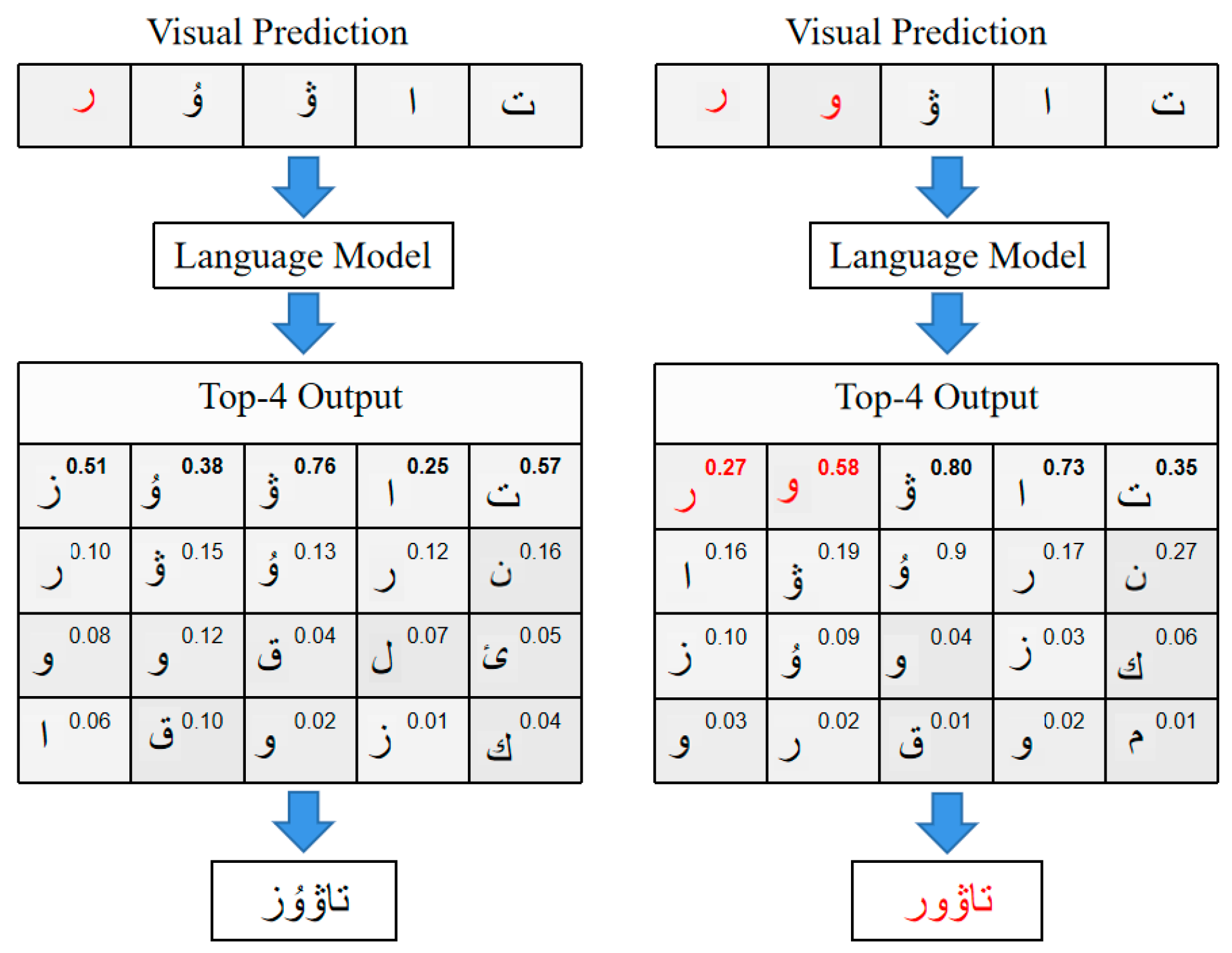
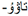 ” is corrected by the language model, and the output “
” is corrected by the language model, and the output “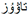 ” is obtained (left side of Figure 2). However, as the number of wrong characters in the input visual prediction increases, the correction of the language model becomes challenging and may lead to wrong corrections (the input word on the right side of Figure 2 is “
” is obtained (left side of Figure 2). However, as the number of wrong characters in the input visual prediction increases, the correction of the language model becomes challenging and may lead to wrong corrections (the input word on the right side of Figure 2 is “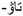 ”, and the corrected word is “
”, and the corrected word is “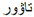 ”).
”).- (1)
- This paper constructs a real scene Uyghur image dataset and a synthetic scene Uyghur image dataset, open at https://github.com/kongfnajie/SUST-and-RUST-datasets-for-Uyghur-STR, accessed on 31 August 2023.
- (2)
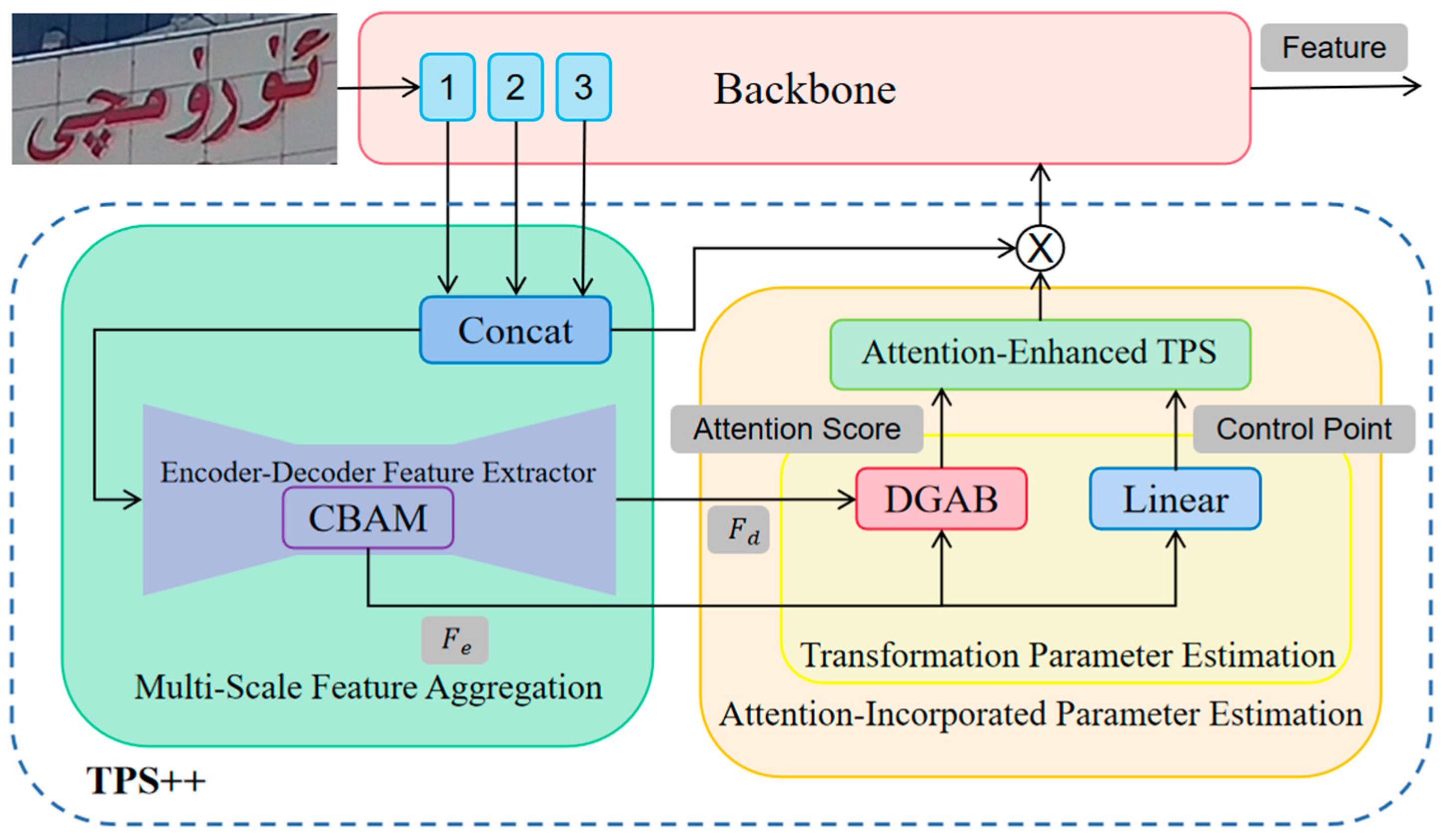
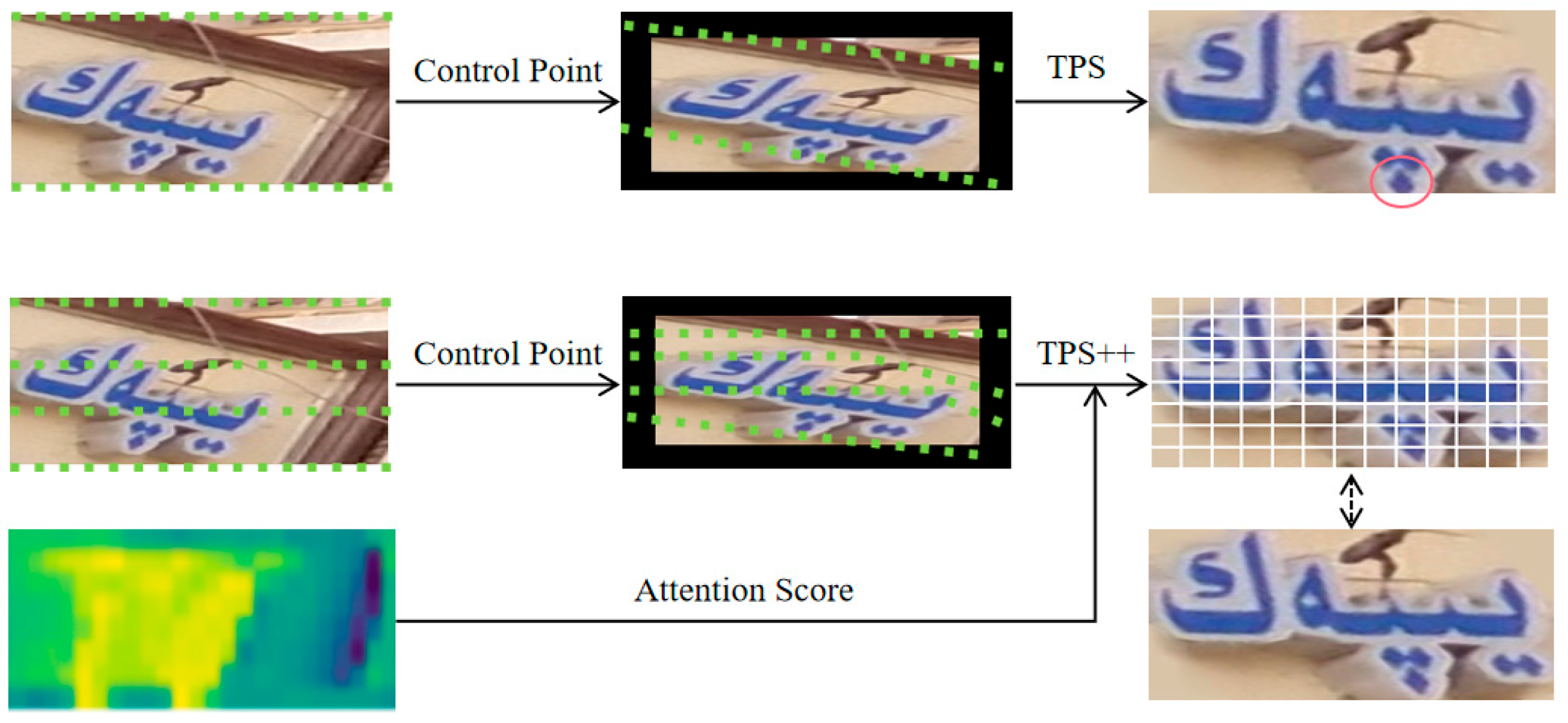
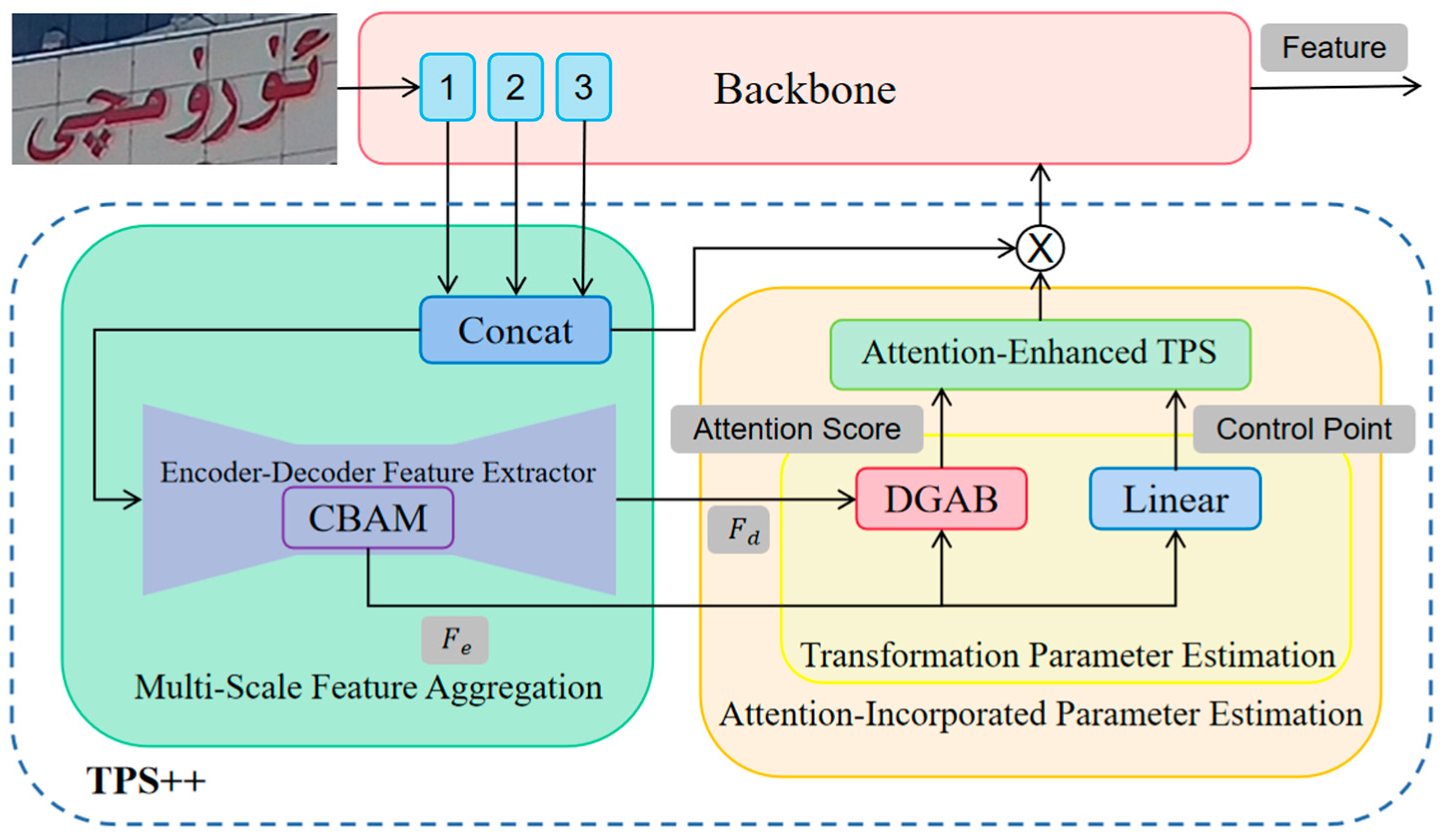
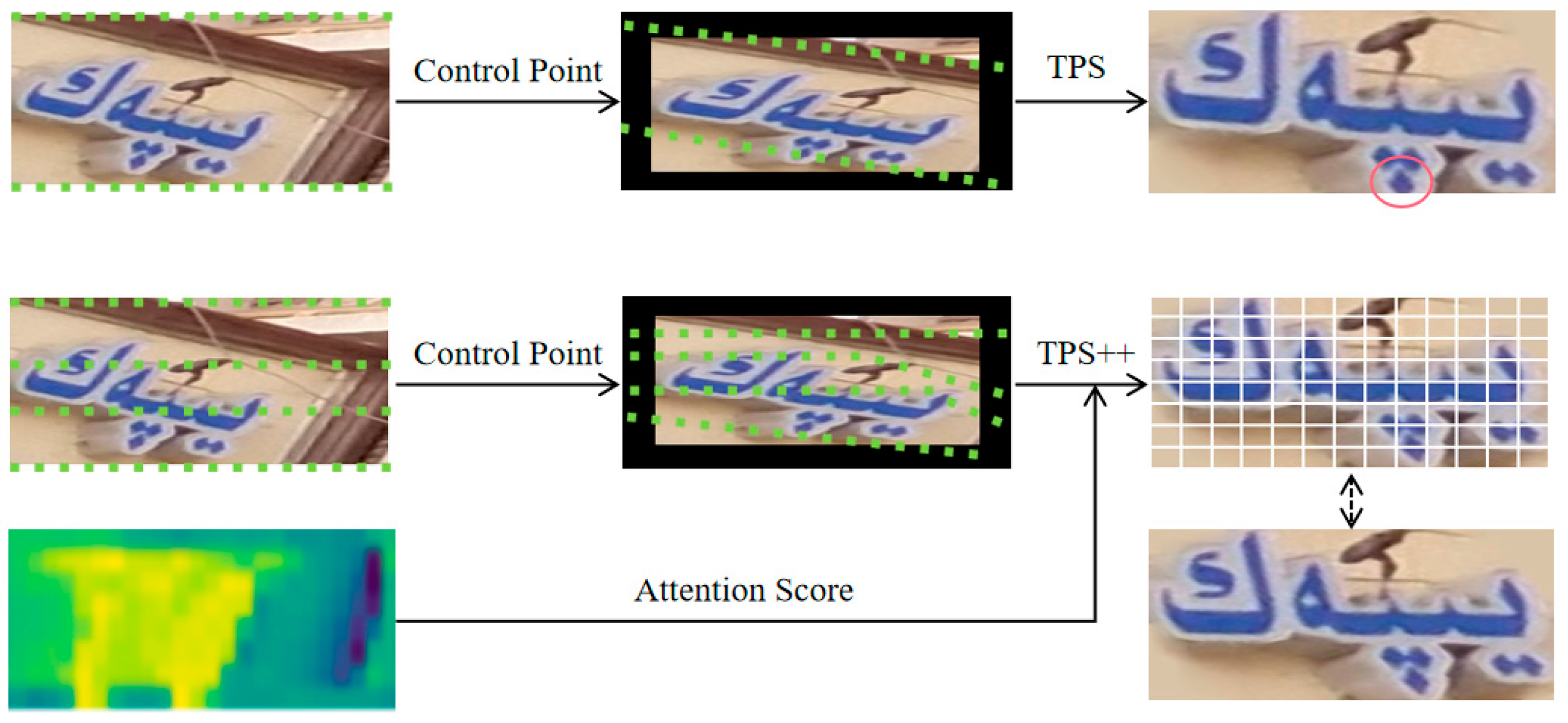
- An attention-enhanced correction network TPS++ is added before the recognition network to correct the inclined Uyghur characters in the scene image into a horizontal form, which is easier to be read by subsequent recognizers.
- (3)
- The vision model of ABINet is improved. A Transformer network is introduced in U-Net to enhance the information flow along the baseline direction, aggregate horizontal features, highlight the spatial features of character positions, and alleviate the problem of character adhesion.
- (4)
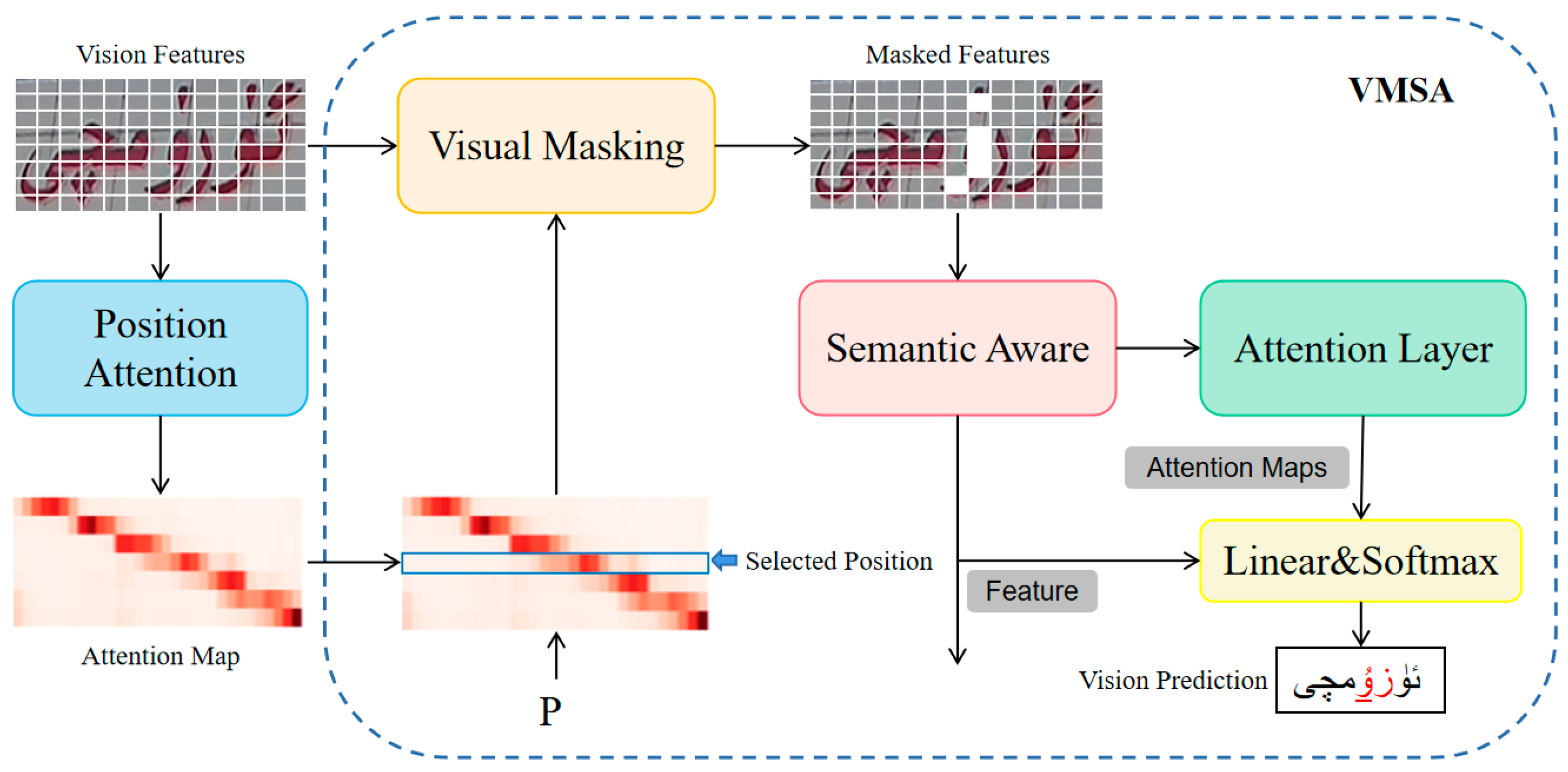
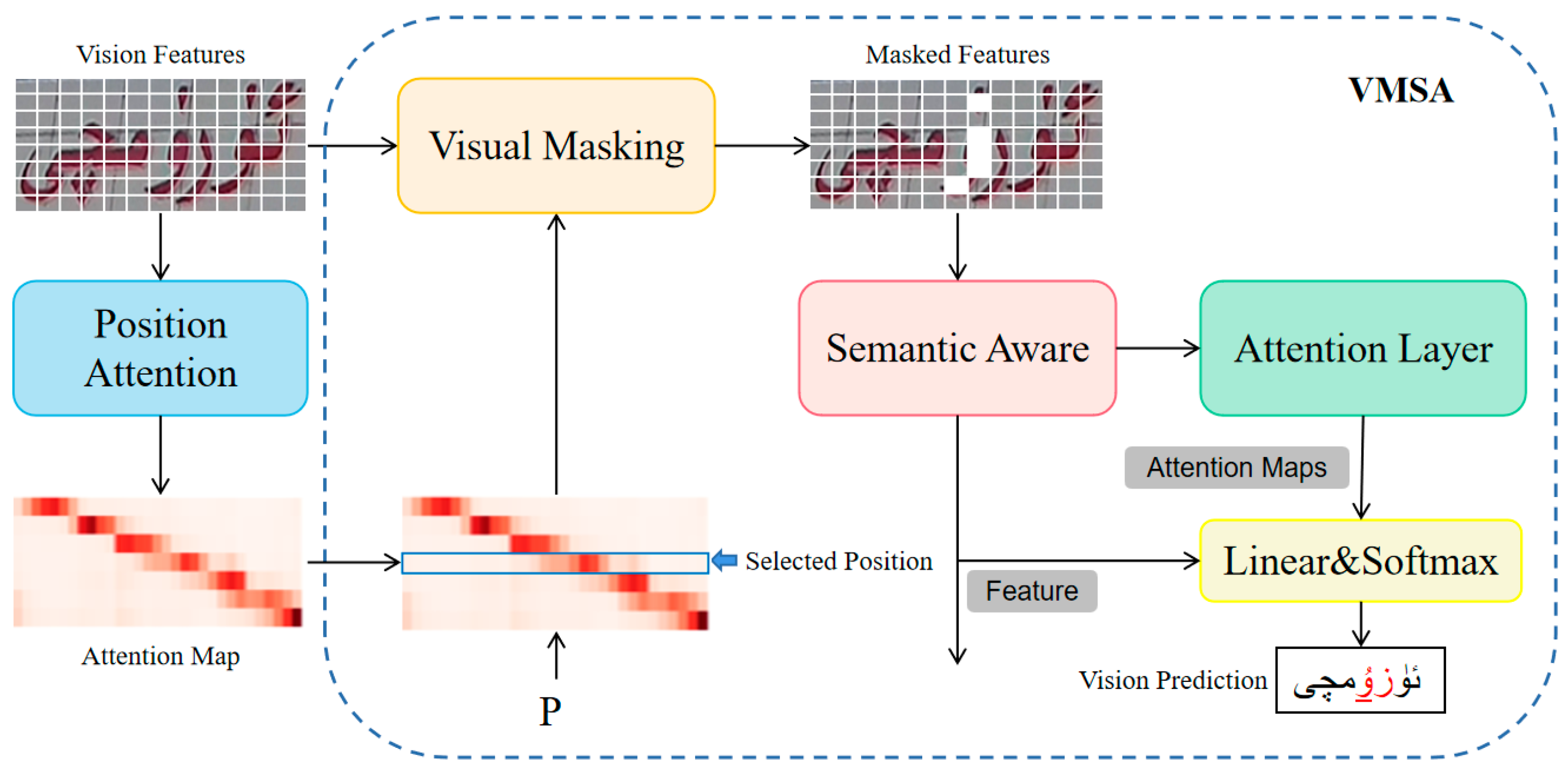
- A visual masking semantic awareness module is proposed to occlude the visual features of the selected character area, and the internal relationship between local visual features is used to guide the vision model to consider the language information in the visual space to reason about the occluded characters, so as to obtain high-precision visual prediction and alleviate the correction load of the language model. When visual cues are confused, language information is used to highlight discriminative visual cues to better distinguish similar characters.
2. Related Work
2.1. Scene Text Recognition
2.1.1. Language-Free Methods
2.1.2. Language-Aware Methods
2.2. Text Correction
2.3. Uyghur Recognition
2.3.1. Uyghur Printing and Handwriting Recognition
2.3.2. Scene Uyghur Recognition
3. Methodology
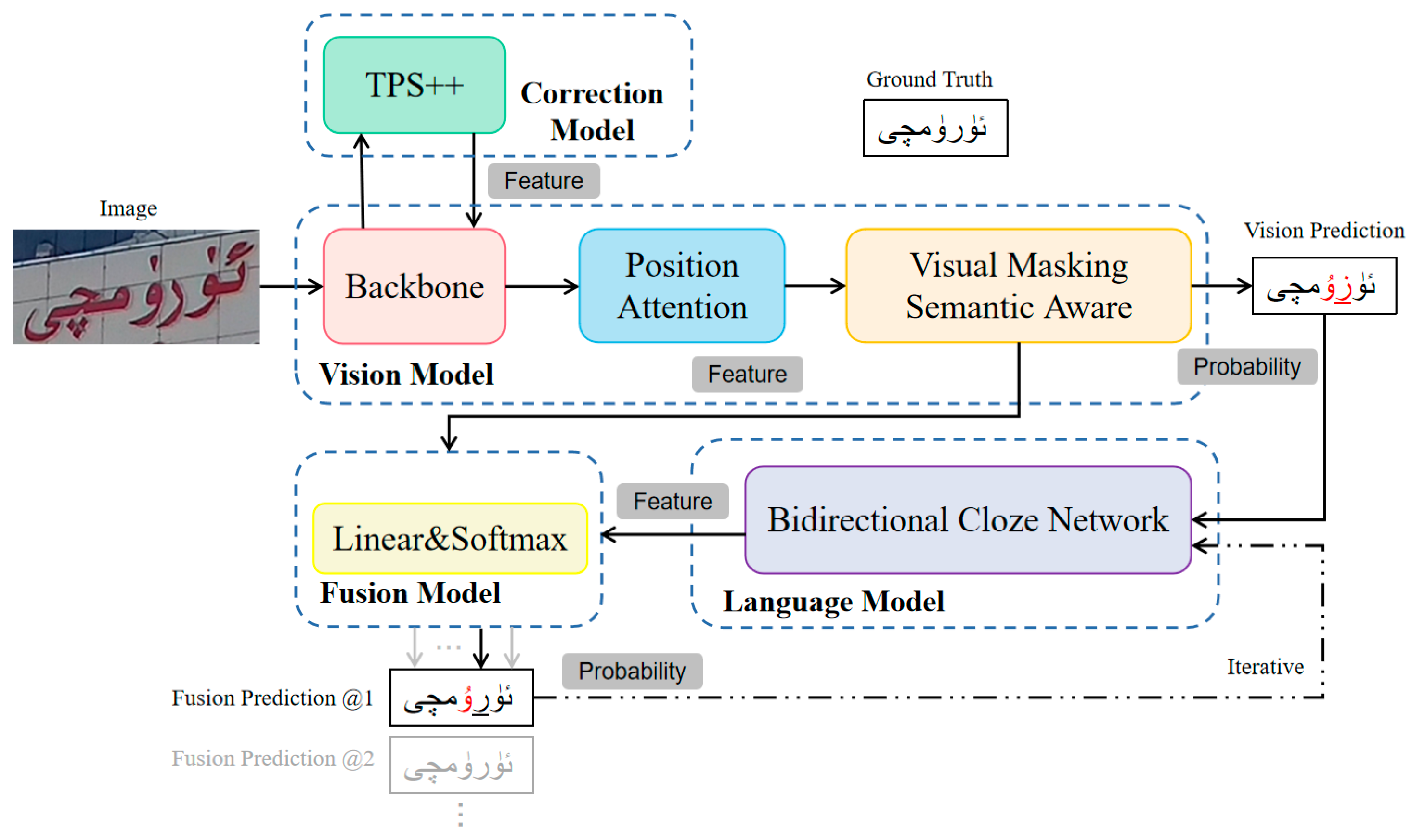
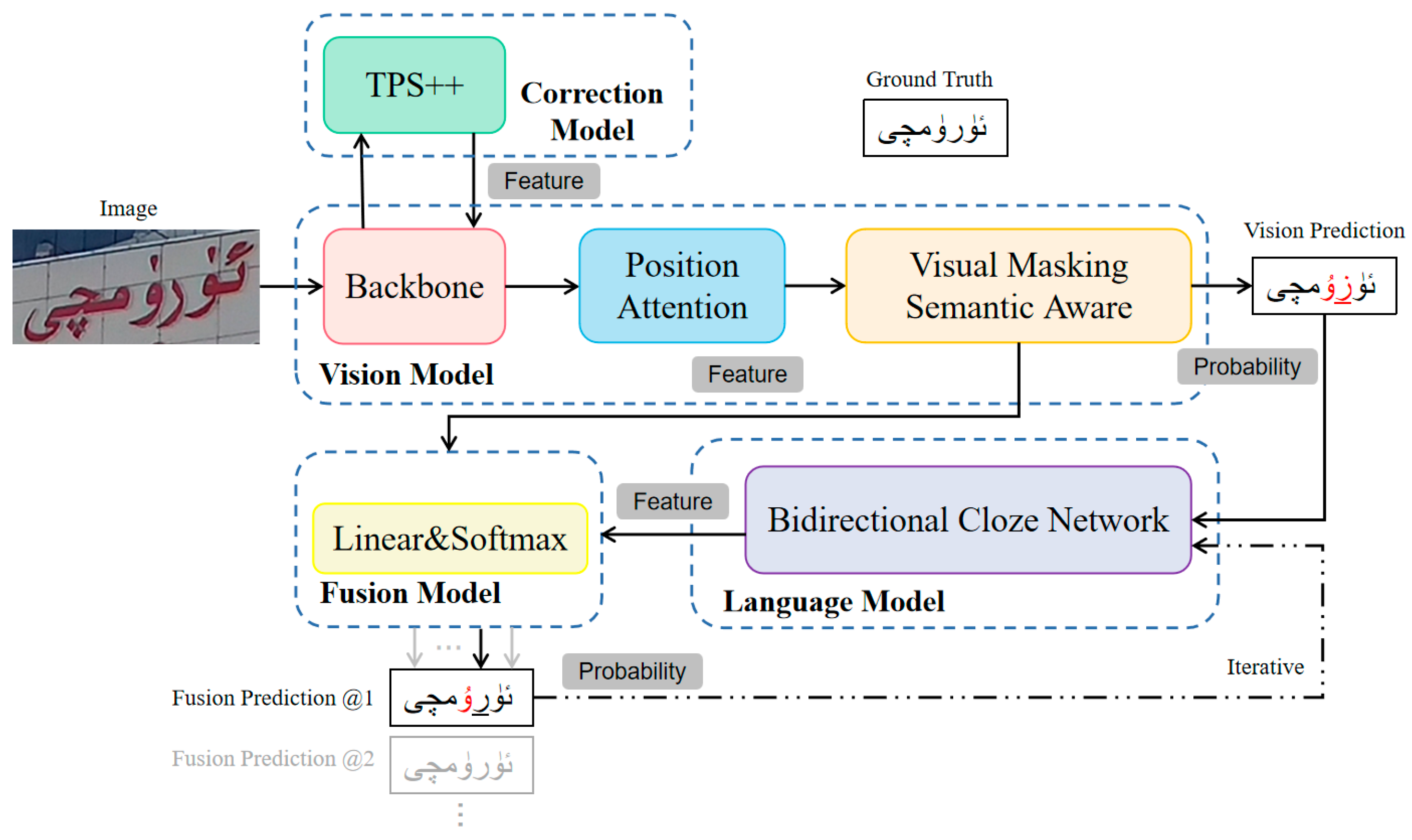
3.1. Process
3.2. Correction Model
3.3. Vision Model
3.4. Language Model
3.5. Fusion Model
3.6. Loss Function
4. Experiments
4.1. Datasets
4.2. Data Augmentation
4.3. Evaluation Criteria
4.4. Experiment Settings
 ”, the labels are “
”, the labels are “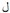 ” and “
” and “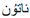 ”, respectively), the label generation process is automatic without human intervention.
”, respectively), the label generation process is automatic without human intervention.4.5. Ablation Study
4.5.1. Effectiveness of TPS++ Correction
4.5.2. Effectiveness of Horizontal Feature Aggregation
4.5.3. Effectiveness of the VMSA Module
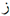 ” and the character “
” and the character “ ” have similar visual cues, the original vision model is wrong, while the vision model guided by VMSA gives the correct prediction of “
” have similar visual cues, the original vision model is wrong, while the vision model guided by VMSA gives the correct prediction of “ ”. In addition, the correct recognition of images with complex backgrounds and poor visibility (rows 3 and 4) also proves the effectiveness of VMSA in improving the accuracy of visual prediction. For example, because the image is blurred, it is difficult to distinguish the character “
”. In addition, the correct recognition of images with complex backgrounds and poor visibility (rows 3 and 4) also proves the effectiveness of VMSA in improving the accuracy of visual prediction. For example, because the image is blurred, it is difficult to distinguish the character “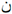 ” from the character “
” from the character “ ”, and the vision model guided by VMSA accurately recognizes the word “
”, and the vision model guided by VMSA accurately recognizes the word “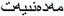 ”.
”.4.5.4. Step by Step Assessment
4.6. Comparative Experiments with Related Methods
4.6.1. Text recognition Algorithm
4.6.2. Scene Uyghur Recognition Algorithm
4.7. Analysis of Failure Samples
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, X.; Meng, G.; Pan, C. Scene text detection and recognition with advances in deep learning: A survey. Int. J. Doc. Anal. Recognit. (IJDAR) 2019, 22, 143–162. [Google Scholar] [CrossRef]
- Sun, W.; Du, Y.; Zhang, X.; Zhang, G. Detection and recognition of text traffic signs above the road. Int. J. Sens. Netw. 2021, 35, 69–78. [Google Scholar] [CrossRef]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. Aster: An attentional scene text recognizer with flexible rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- Fu, Z. Research on Uighur Text Recognition Technology in Scene Images. Master’s Thesis, University of Science and Technology of China, Hefei, China, 2021. [Google Scholar]
- Xiong, L. Research and Application of Uighur Text Detection and Recognition Methods. Master’s Thesis, Xinjiang University, Urumqi, China, 2021. [Google Scholar]
- Wang, Y.; Ao, N.; Guo, R.; Mamat, H.; Ubul, K. Scene Uyghur Recognition with Embedded Coordinate Attention. In Proceedings of the 2022 3rd International Conference on Pattern Recognition and Machine Learning (PRML), Chengdu, China, 22–24 July 2022; pp. 253–260. [Google Scholar]
- Ibrayim, M.; Mattohti, A.; Hamdulla, A. An effective method for detection and recognition of Uyghur texts in images with backgrounds. Information 2022, 13, 332. [Google Scholar] [CrossRef]
- GB 12050–1989; Graphic Character Set for Information Interchange in Uyghur for Information Processing. State Bureau of Quality and Technical Supervision (SBTS): Beijing, China, 1989.
- Jiang, Z.; Ding, X.; Peng, L. Character Model Optimization for Recognition of Unsegmented Uighur Text Lines. J. Tsinghua Univ. (Sci. Technol.) 2015, 55, 873–877. [Google Scholar]
- Yu, D.; Li, X.; Zhang, C.; Liu, T.; Han, J.; Liu, J.; Ding, E. Towards accurate scene text recognition with semantic reasoning networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12113–12122. [Google Scholar]
- Fang, S.; Xie, H.; Wang, Y.; Mao, Z.; Zhang, Y. Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 7098–7107. [Google Scholar]
- Wang, Y.; Xie, H.; Fang, S.; Wang, J.; Zhu, S.; Zhang, Y. From two to one: A new scene text recognizer with visual language modeling network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 14194–14203. [Google Scholar]
- Graves, A.; Fernández, S.; Gomez, F.; Schmidhuber, J. Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd International Conference on Machine Learning, Pittsburgh, PA, USA, 25–29 June 2006; pp. 369–376. [Google Scholar]
- Su, B.; Lu, S. Accurate recognition of words in scenes without character segmentation using recurrent neural network. Pattern Recognit. 2017, 63, 397–405. [Google Scholar] [CrossRef]
- Xie, Z.; Huang, Y.; Zhu, Y.; Jin, L.; Liu, Y.; Xie, L. Aggregation cross-entropy for sequence recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6538–6547. [Google Scholar]
- Hu, W.; Cai, X.; Hou, J.; Yi, S.; Lin, Z. Gtc: Guided training of ctc towards efficient and accurate scene text recognition. AAAI Conf. Artif. Intell. 2020, 34, 11005–11012. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Du, Y.; Chen, Z.; Jia, C.; Yin, X.; Zheng, T.; Li, C.; Du, Y.; Jiang, Y.G. Svtr: Scene text recognition with a single visual model. arXiv 2022, arXiv:2205.00159. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Reading text in the wild with convolutional neural networks. Int. J. Comput. Vis. 2016, 116, 1–20. [Google Scholar] [CrossRef]
- Wan, Z.; He, M.; Chen, H.; Bai, X.; Yao, C. Textscanner: Reading characters in order for robust scene text recognition. AAAI Conf. Artif. Intell. 2020, 34, 12120–12127. [Google Scholar] [CrossRef]
- Xing, L.; Tian, Z.; Huang, W.; Scott, M.R. Convolutional character networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9126–9136. [Google Scholar]
- Fang, S.; Xie, H.; Zha, Z.J.; Sun, N.; Tan, J.; Zhang, Y. Attention and language ensemble for scene text recognition with convolutional sequence modeling. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 248–256. [Google Scholar]
- Cheng, Z.; Xu, Y.; Bai, F.; Niu, Y.; Pu, S.; Zhou, S. Aon: Towards arbitrarily-oriented text recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 5571–5579. [Google Scholar]
- Yang, X.; He, D.; Zhou, Z.; Kifer, D.; Giles, C.L. Learning to read irregular text with attention mechanisms. In Proceedings of the 2017 International Joint Conference on Artificial Intelligence (IJCAI), Melbourne, Australia, 19–25 August 2017; Volume 1, p. 3. [Google Scholar]
- Lee, C.Y.; Osindero, S. Recursive recurrent nets with attention modeling for ocr in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2231–2239. [Google Scholar]
- Yue, X.; Kuang, Z.; Lin, C.; Sun, H.; Zhang, W. Robustscanner: Dynamically enhancing positional clues for robust text recognition. In European Conference on Computer Vision; Springer International Publishing: Cham, Switzerland, 2020; pp. 135–151. [Google Scholar]
- Lyu, P.; Yang, Z.; Leng, X.; Wu, X.; Li, R.; Shen, X. 2d attentional irregular scene text recognizer. arXiv 2019, arXiv:1906.05708. [Google Scholar]
- Sheng, F.; Chen, Z.; Xu, B. NRTR: A no-recurrence sequence-to-sequence model for scene text recognition. In Proceedings of the 2019 International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; pp. 781–786. [Google Scholar]
- Wang, T.; Zhu, Y.; Jin, L.; Luo, C.; Chen, X.; Wu, Y.; Wang, Q.; Cai, M. Decoupled attention network for text recognition. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12216–12224. [Google Scholar] [CrossRef]
- Zheng, T.; Chen, Z.; Fang, S.; Xie, H.; Jiang, Y.G. Cdistnet: Perceiving multi-domain character distance for robust text recognition. arXiv 2021, arXiv:2111.11011. [Google Scholar] [CrossRef]
- Na, B.; Kim, Y.; Park, S. Multi-modal text recognition networks: Interactive enhancements between visual and semantic features. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2022; pp. 446–463. [Google Scholar]
- Chu, X.; Wang, Y. IterVM: Iterative Vision Modeling Module for Scene Text Recognition. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 1393–1399. [Google Scholar]
- Zheng, T.; Chen, Z.; Bai, J.; Xie, H.; Jiang, Y.G. TPS++: Attention-Enhanced Thin-Plate Spline for Scene Text Recognition. arXiv 2023, arXiv:2305.05322. [Google Scholar]
- Bookstein, F.L. Principal warps: Thin-plate splines and the decomposition of deformations. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 567–585. [Google Scholar] [CrossRef]
- Jaderberg, M.; Simonyan, K.; Zisserman, A. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 7–12. [Google Scholar]
- Luo, C.; Jin, L.; Sun, Z. Moran: A multi-object rectified attention network for scene text recognition. Pattern Recognit. 2019, 90, 109–118. [Google Scholar] [CrossRef]
- Ai, L.; Jumai, H.; Halidan, H.; Huang, H. Recognition of Uighur Text in Video Images. Comput. Eng. Appl. 2011, 47, 190–192. [Google Scholar]
- Chen, Q. Research on Classification and Recognition Technology of Printed Uyghur Text Recognition System. Master’s Thesis, Xinjiang University, Urumqi, China, 2012. [Google Scholar]
- Bai, Y. Printed Uighur Word Recognition in Arabic Script. Doctoral Dissertation, Xidian University, Xi’an, China, 2014. [Google Scholar]
- Lang, X. Segmentation-Based Recognition of Printed Uighur Words in Arabic Script. Doctoral Dissertation, Xidian University, Xi’an, China, 2015. [Google Scholar]
- Peng, L. A Recognition Method for Uighur and Arabic Text Based on HMM and Statistical Language Model. Comput. Appl. Softw. 2015, 32, 171–174. [Google Scholar]
- Li, P.; Zhu, J.; Peng, L.; Guo, Y. RNN based Uyghur text line recognition and its training strategy. In Proceedings of the 2016 12th IAPR Workshop on Document Analysis Systems (DAS), Santorini, Greece, 11–14 April 2016; pp. 19–24. [Google Scholar]
- Wang, X. Research and Application of Key Technologies in Recognition of Printed Uighur Text. Doctoral Dissertation, Xidian University, Xi’an, China, 2017. [Google Scholar]
- Li, D. Classifier Design for Recognition of Printed Uighur Word. Doctoral Dissertation, Xidian University, Xi’an, China, 2019. [Google Scholar]
- Chen, Y. Research and Design of Uighur Text Detection and Recognition Based on Deep Learning. Master’s Thesis, Chengdu University of Technology, Chengdu, China, 2020. [Google Scholar]
- Maitituoheti, A. Neural Network-Based Uighur Image Text Detection and Recognition Technology. Master’s Thesis, Xinjiang University, Urumqi, China, 2020. [Google Scholar]
- Tang, J.; Silamu, W.; Xu, M.; Xiong, L.; Wang, M. Scan-based Recognition of Uighur Text Using Deep Learning. J. Northeast. Norm. Univ. (Nat. Sci. Ed.) 2021, 53, 71–76. [Google Scholar]
- Zhang, S. Research on Offline Uighur Handwritten Signature Authentication Technology Based on Local Features. Master’s Thesis, Xinjiang University, Urumqi, China, 2019. [Google Scholar]
- Ibrayim, M.; Simayi, W.; Hamdulla, A. Unconstrained online handwritten Uyghur word recognition based on recurrent neural networks and connectionist temporal classification. Int. J. Biom. 2021, 13, 51–63. [Google Scholar] [CrossRef]
- Li, W.; Mahpirat Kang, W.; Aysa, A.; Ubul, K. Multi-lingual Hybrid Handwritten Signature Recognition Based on Deep Residual Attention Network. In Biometric Recognition: 15th Chinese Conference, CCBR 2021, Shanghai, China, 10–12 September 2021, Proceedings 15; Springer International Publishing: Cham, Switzerland, 2021; pp. 148–156. [Google Scholar]
- Xamxidin, N.; Mahpirat; Yao, Z.; Aysa, A.; Ubul, K. Multilingual Offline Signature Verification Based on Improved Inverse Discriminator Network. Information 2022, 13, 293. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic data for text localisation in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2315–2324. [Google Scholar]
- Atienza, R. Data augmentation for scene text recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1561–1570. [Google Scholar]

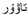 ” in the left image, the input word is “
” in the left image, the input word is “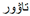 ” in the right image, and the label is “
” in the right image, and the label is “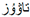 ”. Numbers in the upper right corner indicate the probability of the output character, and red characters indicate incorrect predictions.
” in the left image, the input word is “” in the right image, and the label is “”. Numbers in the upper right corner indicate the probability of the output character, and red characters indicate incorrect predictions.
”. Numbers in the upper right corner indicate the probability of the output character, and red characters indicate incorrect predictions.
” in the left image, the input word is “” in the right image, and the label is “”. Numbers in the upper right corner indicate the probability of the output character, and red characters indicate incorrect predictions.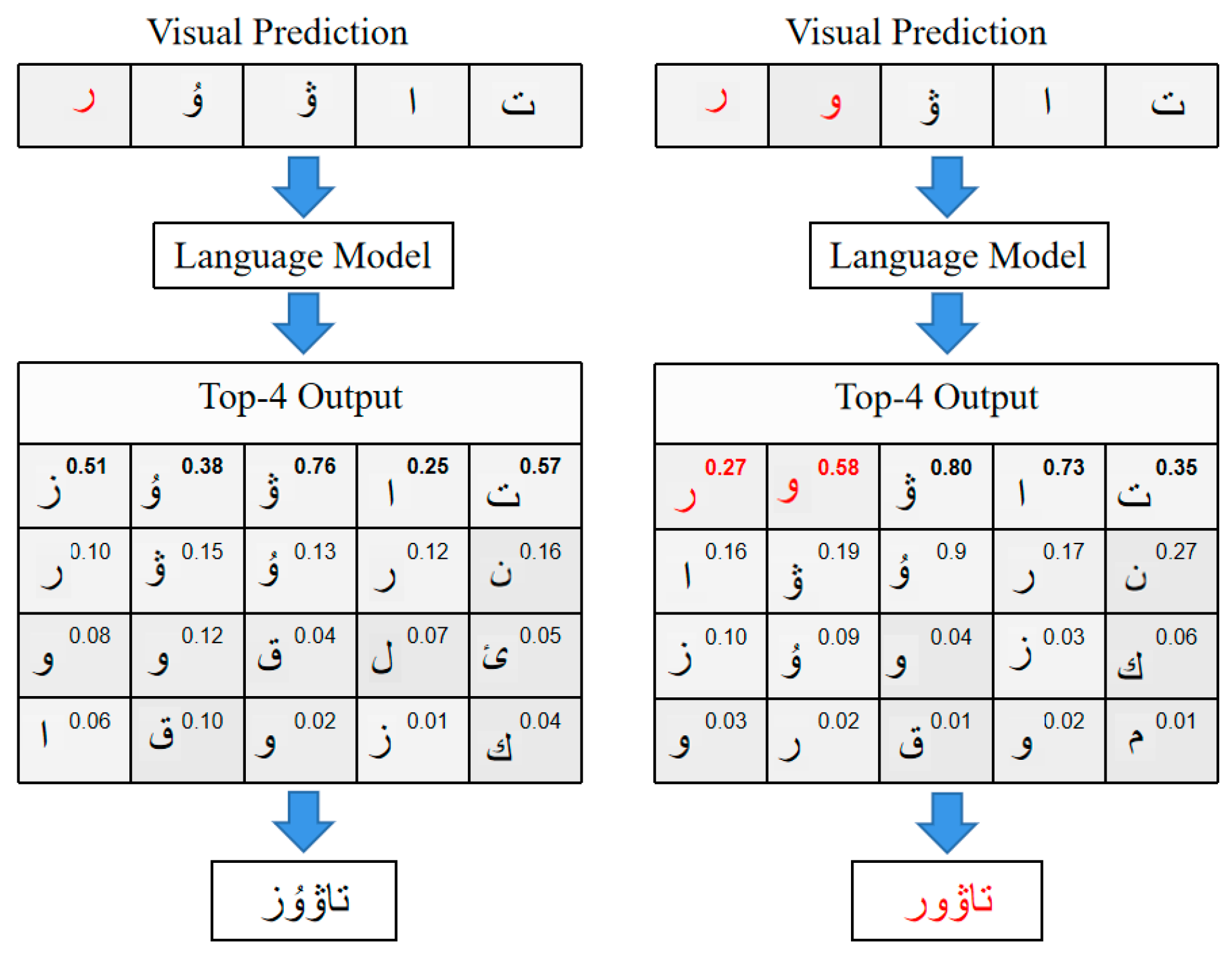






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Parameters (Filters, Strides) | Output (H, W) |
|---|---|---|
| Conv. | [64, (1,2)] × 1 | |
| Conv. | [64, (2,2)] × 1 | |
| Conv. | [64, (2,2)] × 1 | |
| Conv. | [64, (2,2)] × 1 | |
| Trans. | - | - |
| Up + Conv. | [64, (1,1)] × 1 | |
| Up + Conv. | [64, (1,1)] × 1 | |
| Up + Conv. | [64, (1,1)] × 1 | |
| Up + Conv. | [512, (1,1)] × 1 |
| Methods | Attention | Accuracy |
|---|---|---|
| Baseline | - | 85.29 |
| ASTER [4] | - | 78.76 |
| MORAN [37] | - | 75.73 |
| TPS++ | W | 85.36 |
| TPS++ | H | 85.47 |
| TPS++ | W + H | 85.55 |
| Methods | Stride | Aggregation | Accuracy |
|---|---|---|---|
| (a) | (8,16) | - | 85.29 |
| (b) | (8,128) | - | 85.31 |
| (c) | (8,1) | - | 84.80 |
| (d) | (1,128) | - | 85.35 |
| (e) | (1,1) | - | 84.74 |
| (f) | (8,16) | Mean | 85.30 |
| (g) | (8,16) | Conv-1 | 85.34 |
| (h) | (8,16) | Trans-1 | 85.41 |
| (i) | (8,16) | Trans-4 | 85.48 |
| Methods | Accuracy |
|---|---|
| ABINet_V | 74.58 |
| ABINet_V + VMSA | 75.42 |
| ABINet | 85.29 |
| ABINet + VMSA | 85.91 |
| Baseline | TPS++ | U-Net* | VMSA | Accuracy |
|---|---|---|---|---|
| √ | - | - | - | 85.29 |
| √ | √ | - | - | 85.55 |
| √ | √ | √ | - | 85.76 |
| √ | √ | √ | √ | 86.35 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Kong, F.; Xu, M.; Silamu, W.; Li, Y. Scene Uyghur Recognition Based on Visual Prediction Enhancement. Sensors 2023, 23, 8610. https://doi.org/10.3390/s23208610
Liu Y, Kong F, Xu M, Silamu W, Li Y. Scene Uyghur Recognition Based on Visual Prediction Enhancement. Sensors. 2023; 23(20):8610. https://doi.org/10.3390/s23208610
Chicago/Turabian StyleLiu, Yaqi, Fanjie Kong, Miaomiao Xu, Wushour Silamu, and Yanbing Li. 2023. "Scene Uyghur Recognition Based on Visual Prediction Enhancement" Sensors 23, no. 20: 8610. https://doi.org/10.3390/s23208610
APA StyleLiu, Y., Kong, F., Xu, M., Silamu, W., & Li, Y. (2023). Scene Uyghur Recognition Based on Visual Prediction Enhancement. Sensors, 23(20), 8610. https://doi.org/10.3390/s23208610