
Student Behavior Detection in the Classroom Based on Improved YOLOv8

Abstract
:1. Introduction
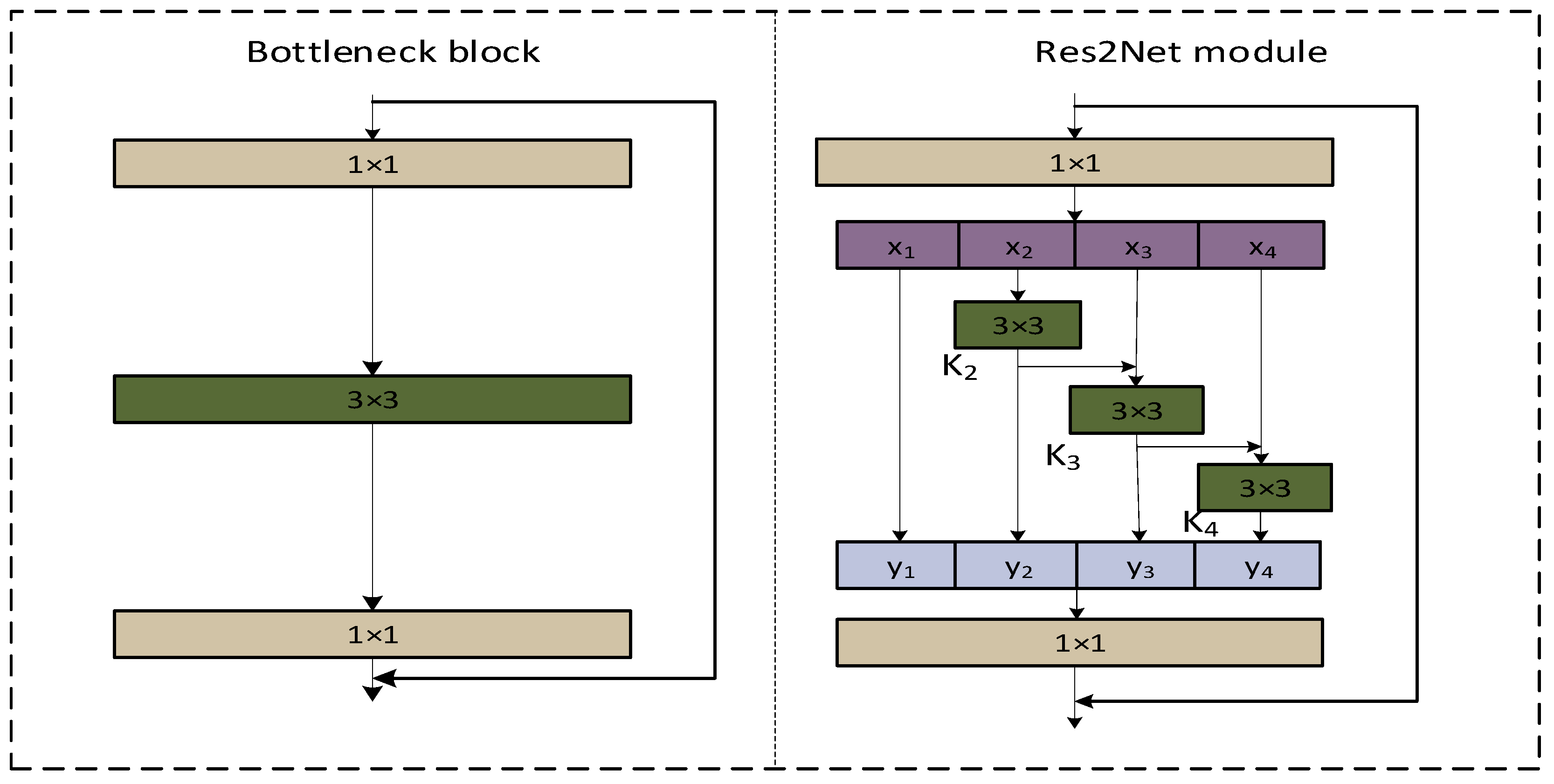
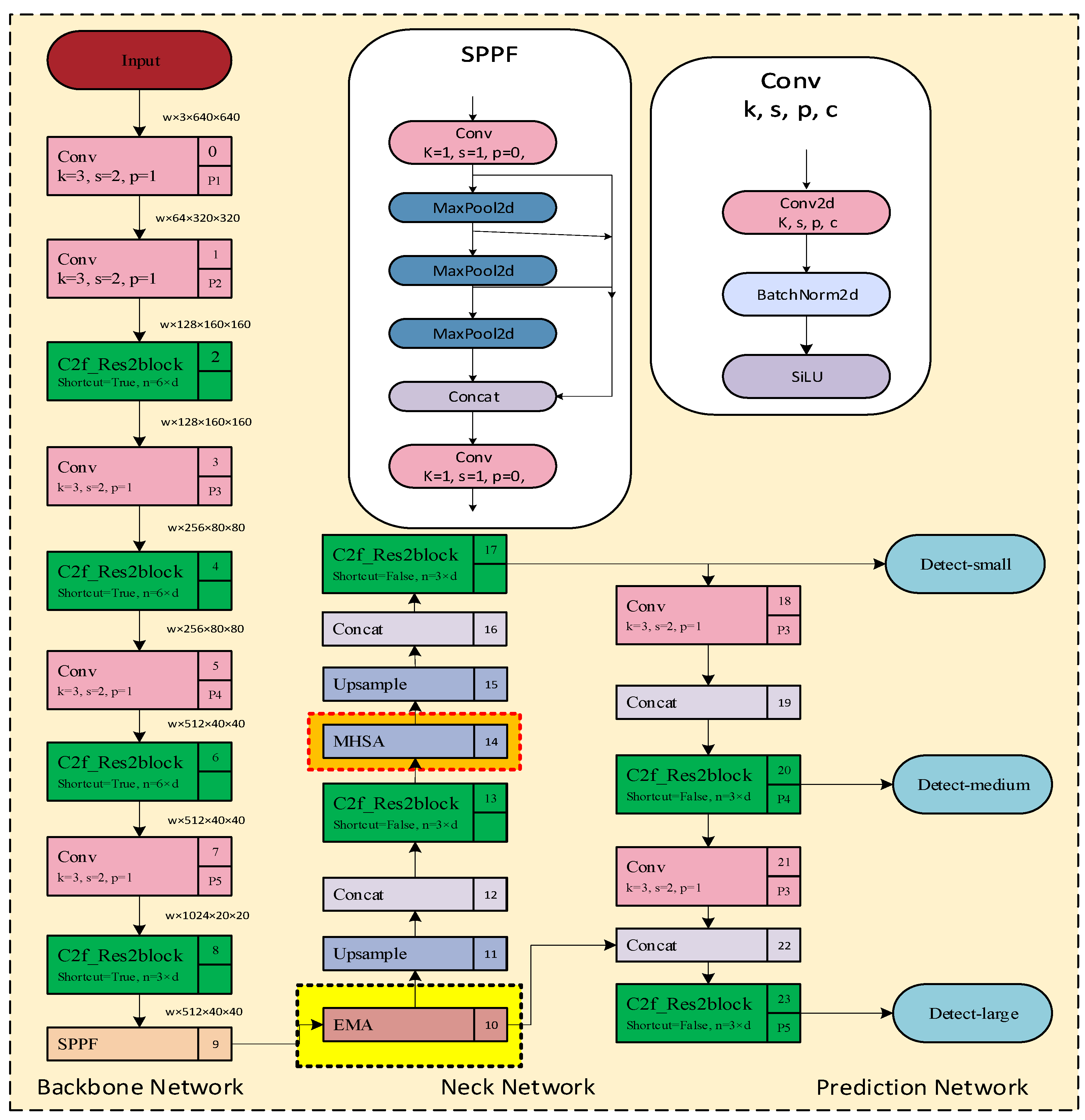
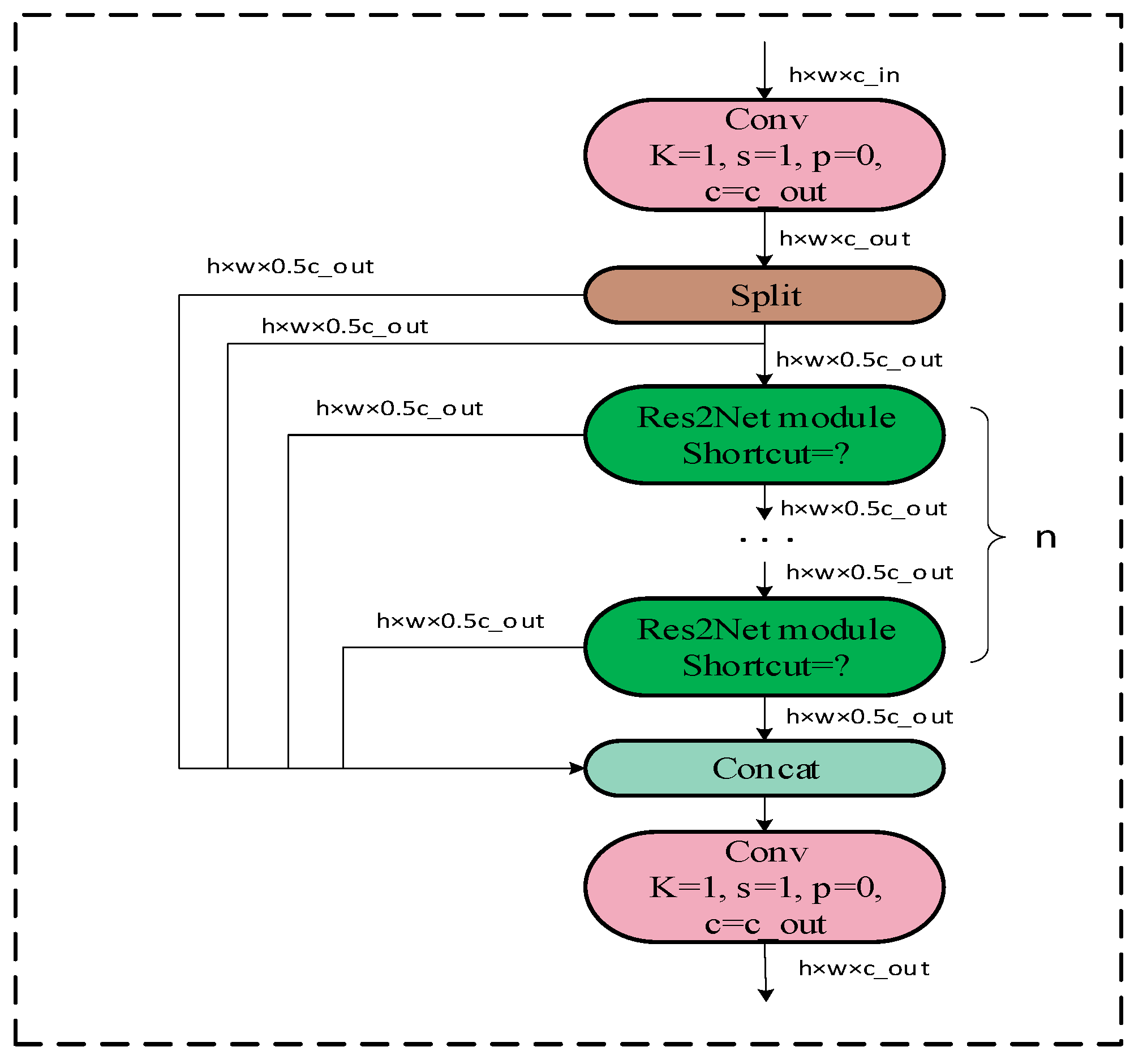
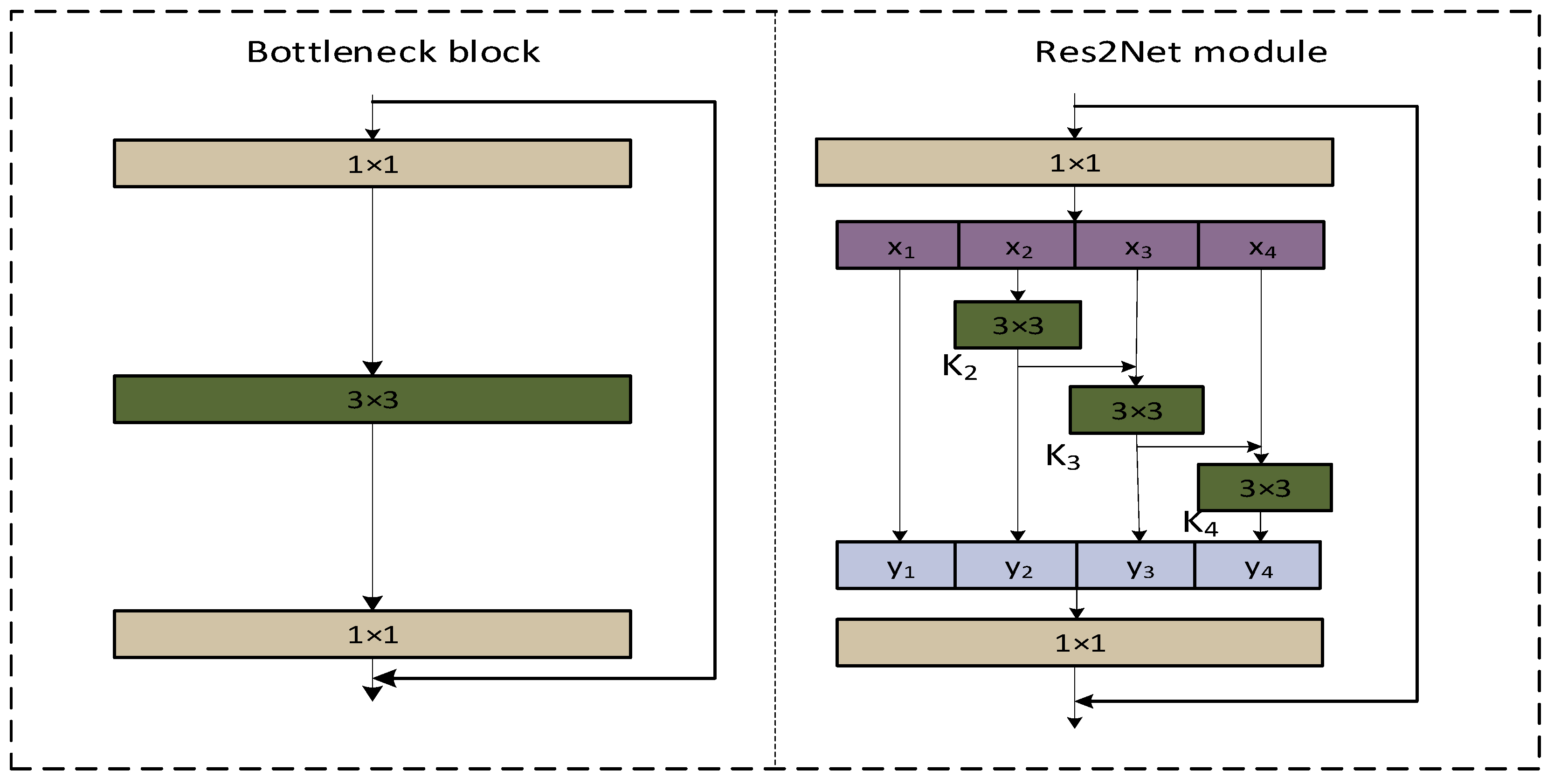
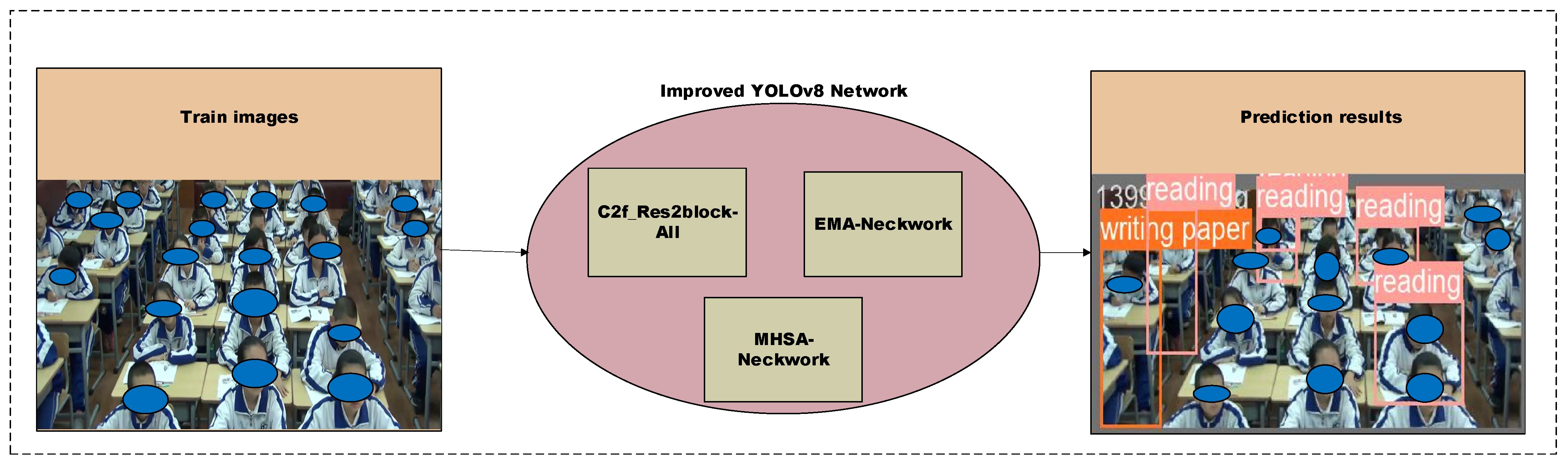
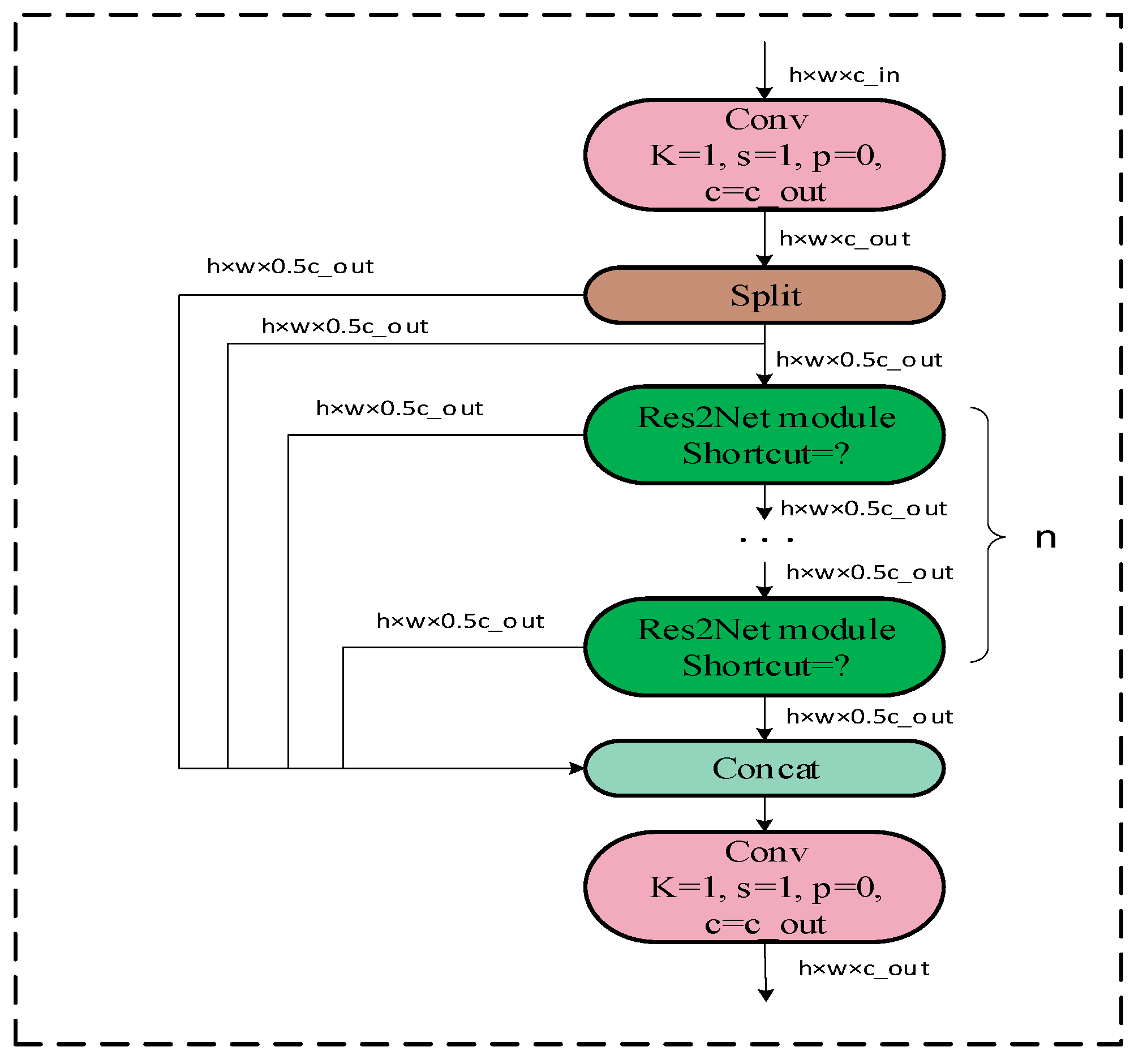
- Based on the idea of multi-scale structure in Res2Net, the C2f_Res2block module is proposed by integrating the Res2Net module therein with the C2f module in YOLOv8 [25]. This module improves the performance and robustness of the whole-target detection model.
- We introduce the newly released multi-scale attention module EMA [26] to merge with the YOLOV8 backbone to further improve the model’s stimulation of targets at different scales.
- Finally, inspired by Transformer, we add a module with the multiple-head self-attention mechanism (MHSA) to the YOLOv8 neck module. MHSA can help the classroom detection model to better capture the key information of the target character in the unobscured region and avoid the information in the occluded region.
- We tested the improved YOLOv8 detection network framework on SCB-Dataset, and its mAp0.5 was improved by 4.2% over the original YOLOv8.
2. Related Work
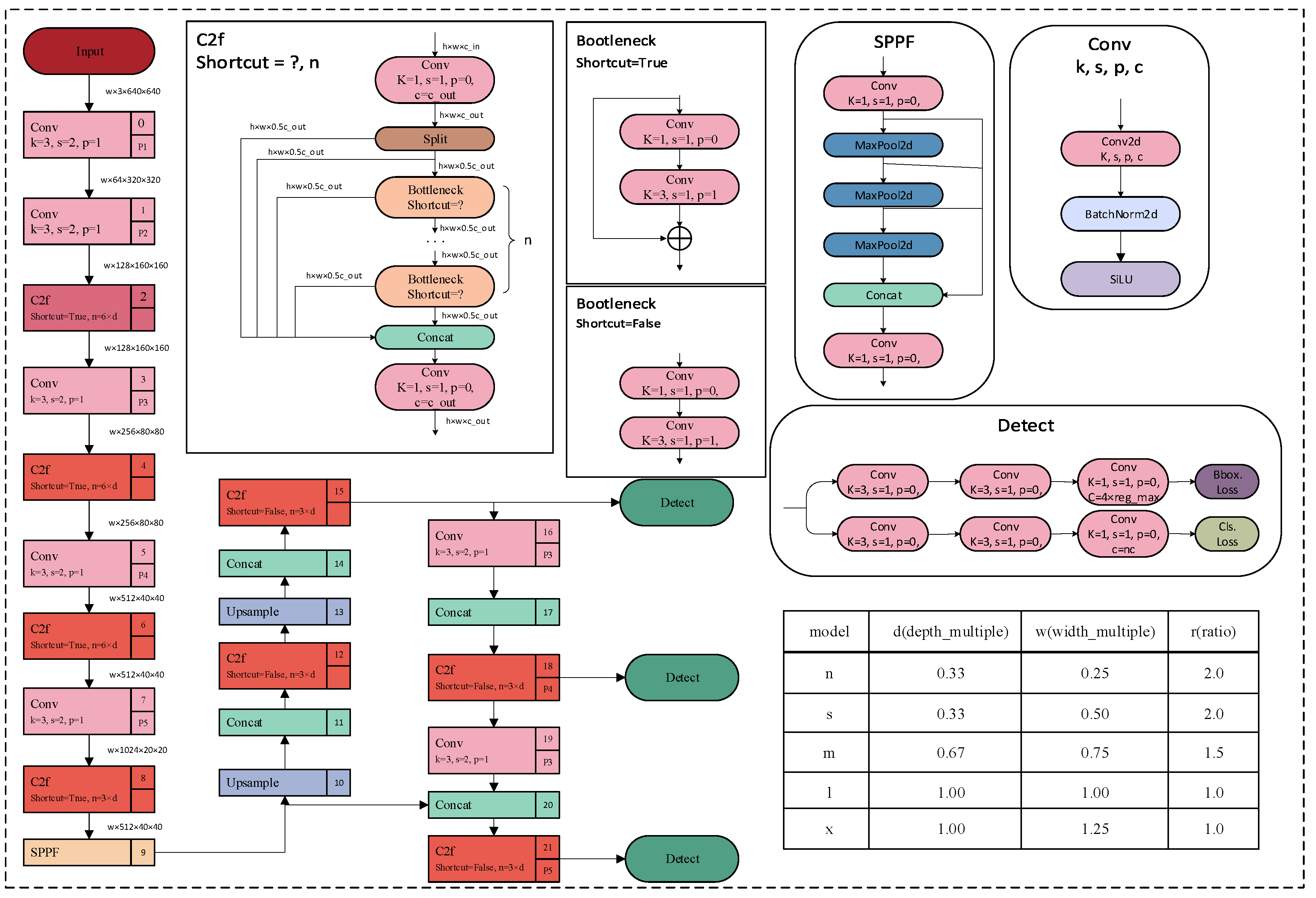
2.1. YOLOv8 Framework Review
2.2. Res2Net
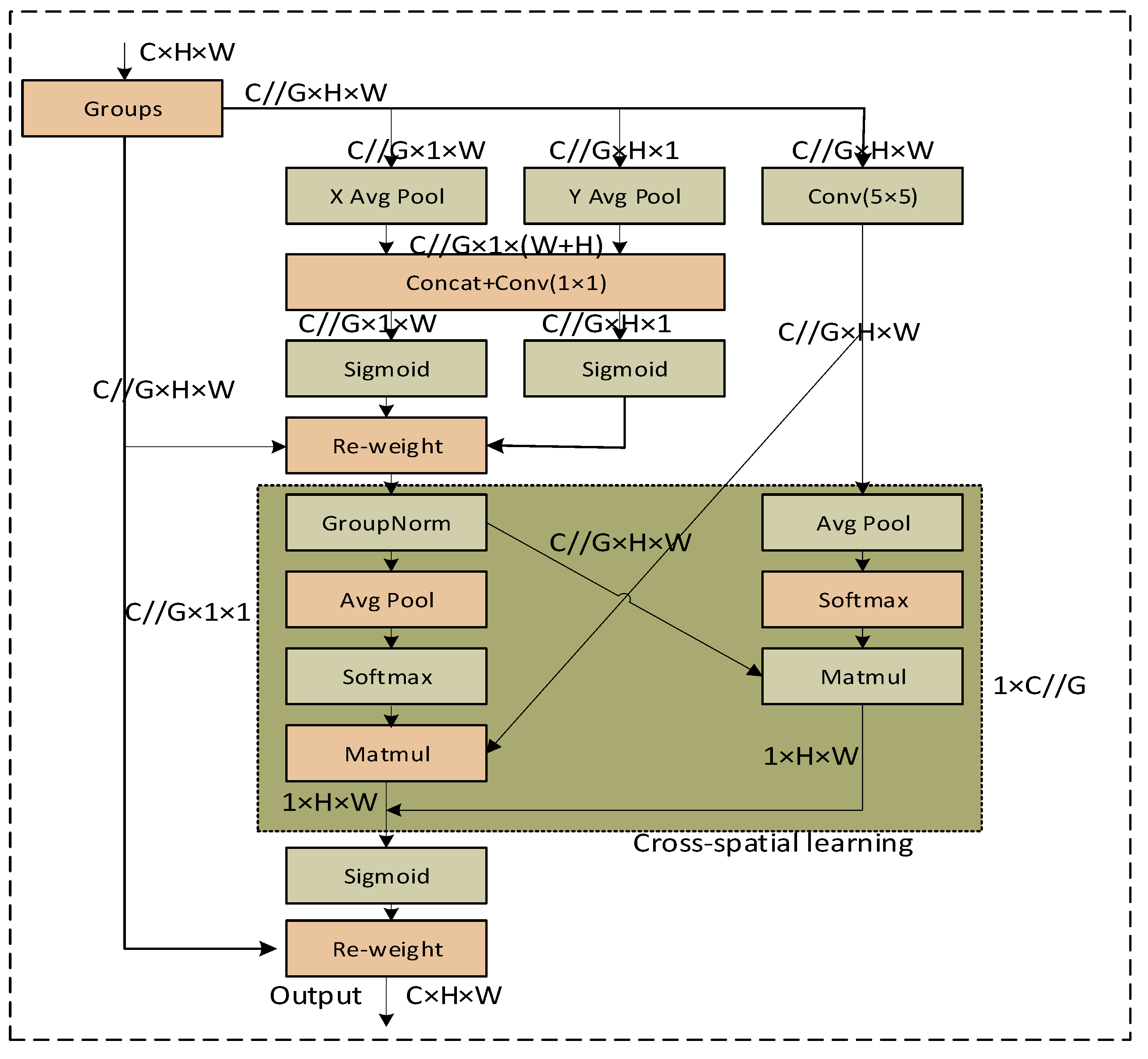
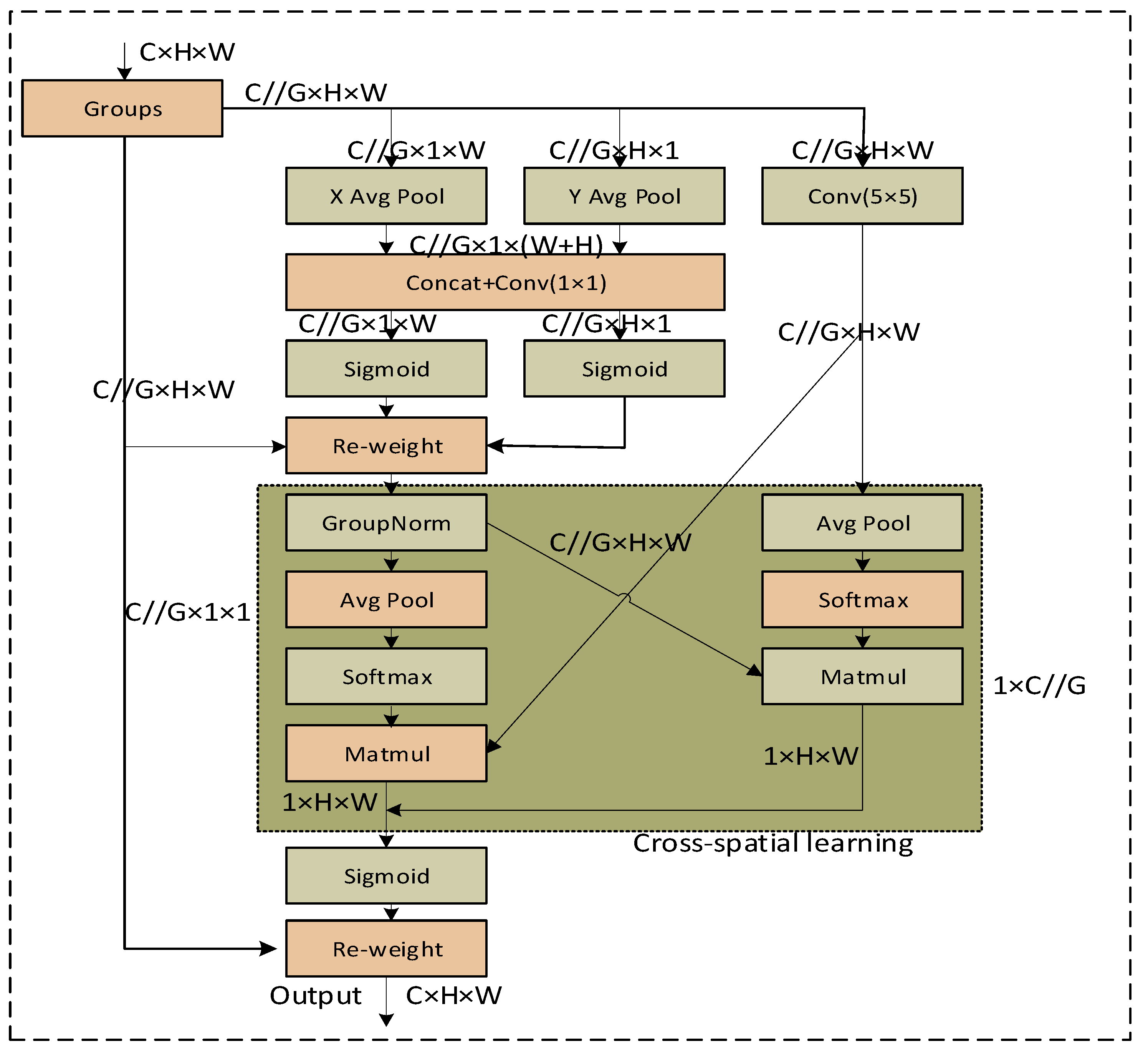
2.3. Efficient Multi-Scale Attention
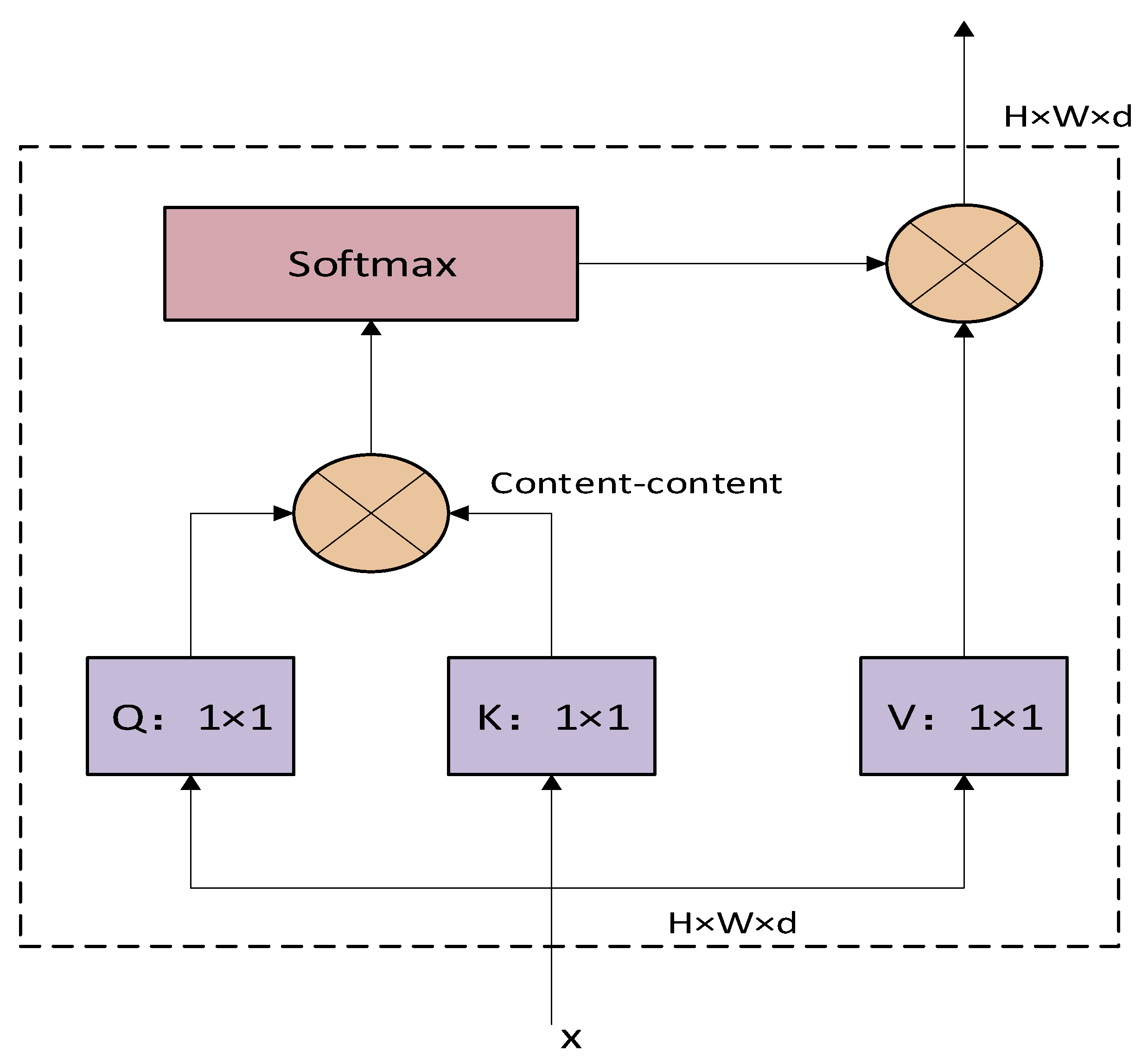
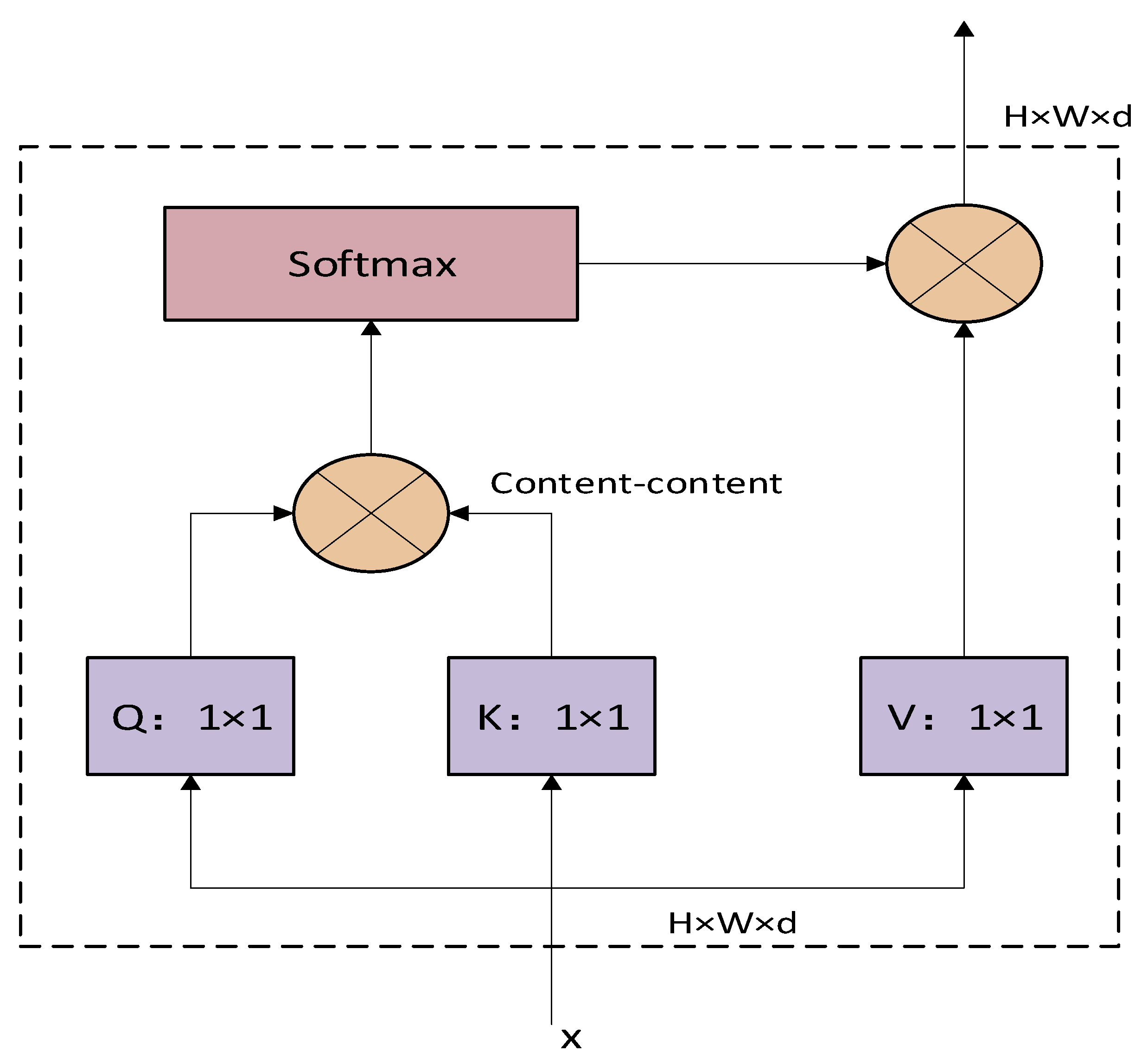
2.4. Transformer Detection Algorithm
3. Methodologies
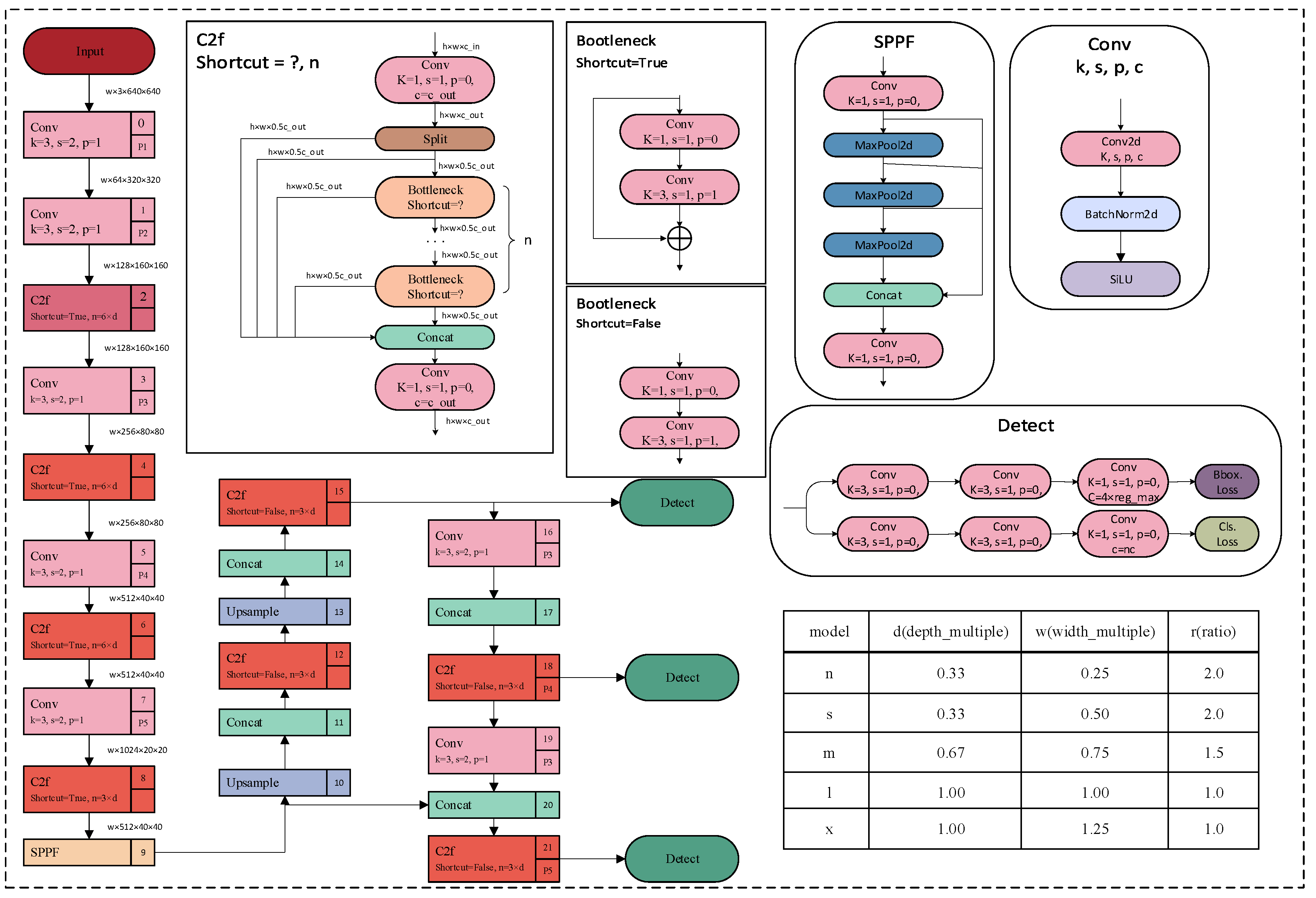
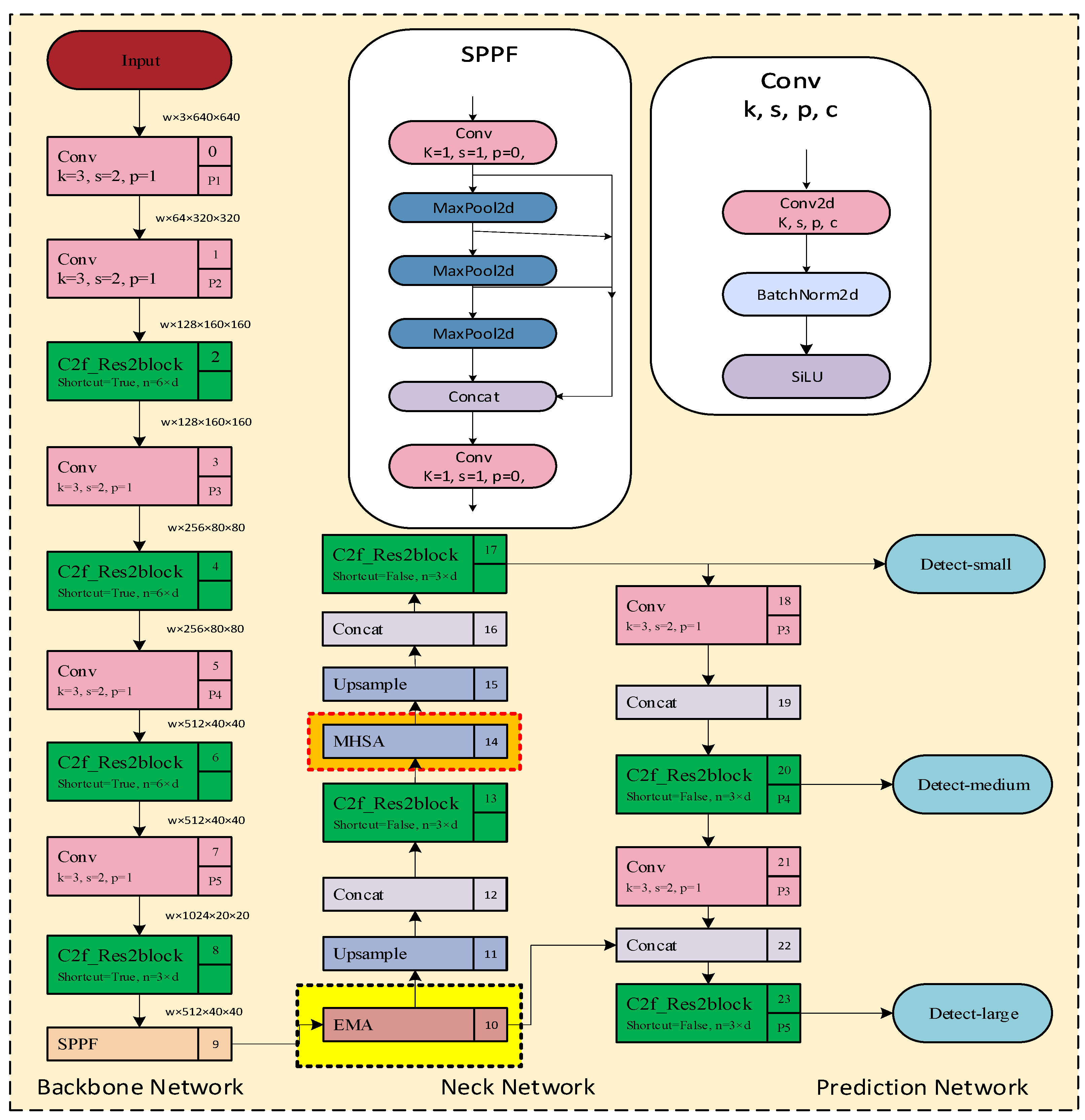
3.1. Overall Framework
3.2. Improved YOLOv8
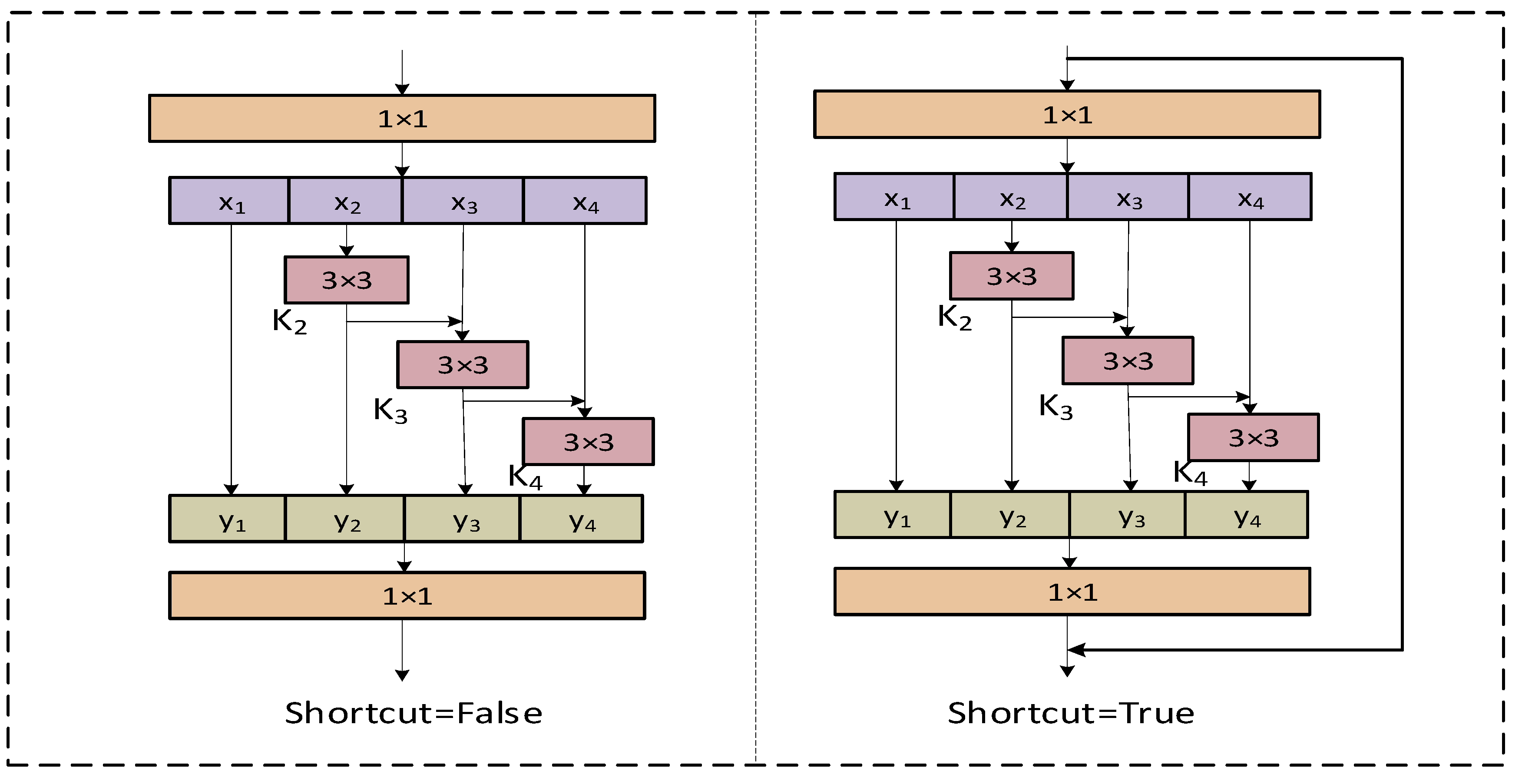
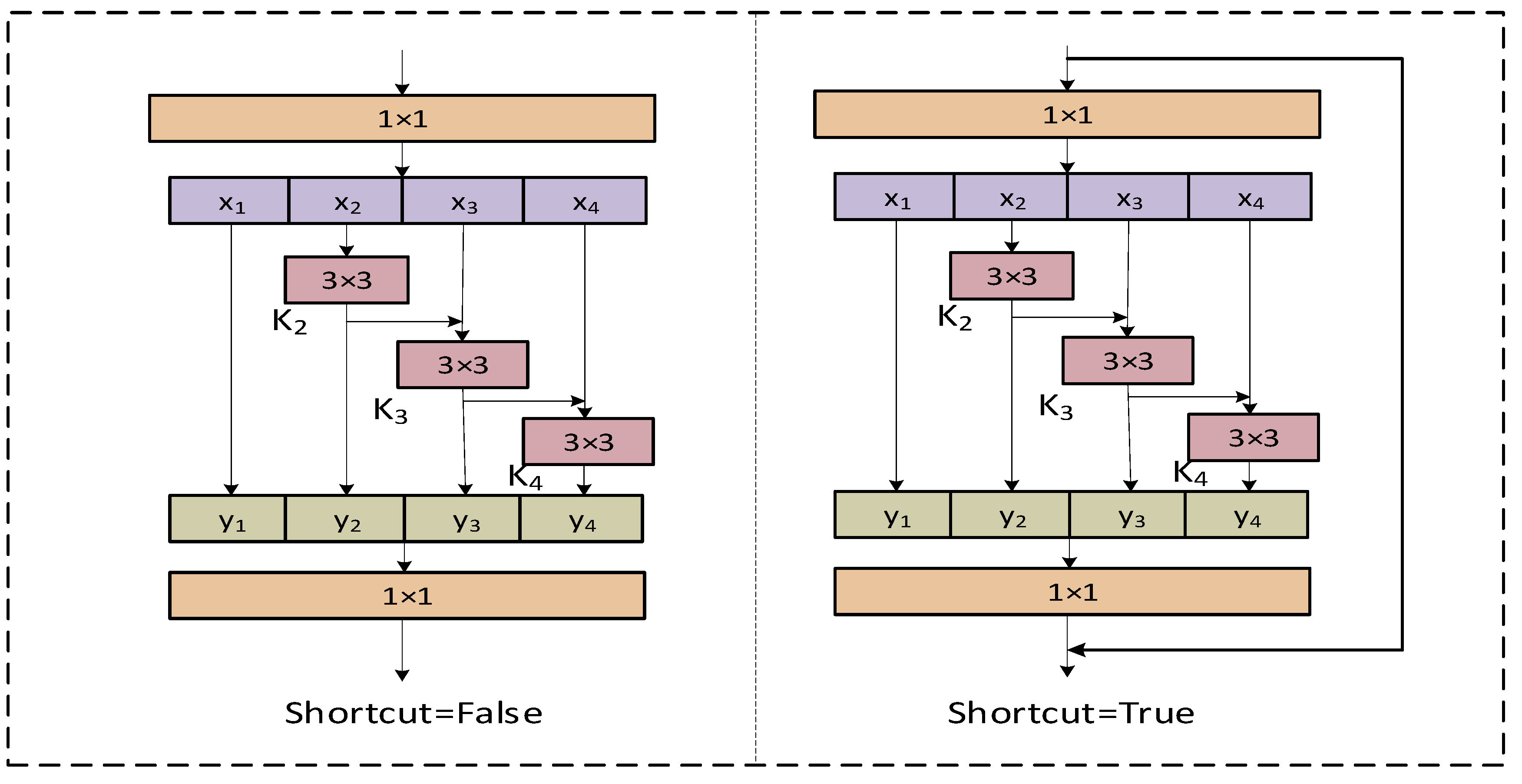
3.2.1. C2f_Res2block Module Proposed in This Study
3.2.2. Neck Network with EMA
3.2.3. Neck Network with MHSA
4. Experiments
4.1. Experimental Details
4.1.1. Datasets
4.1.2. Assessment of Indicators
4.1.3. Experimental Setup
4.2. Experimental Design
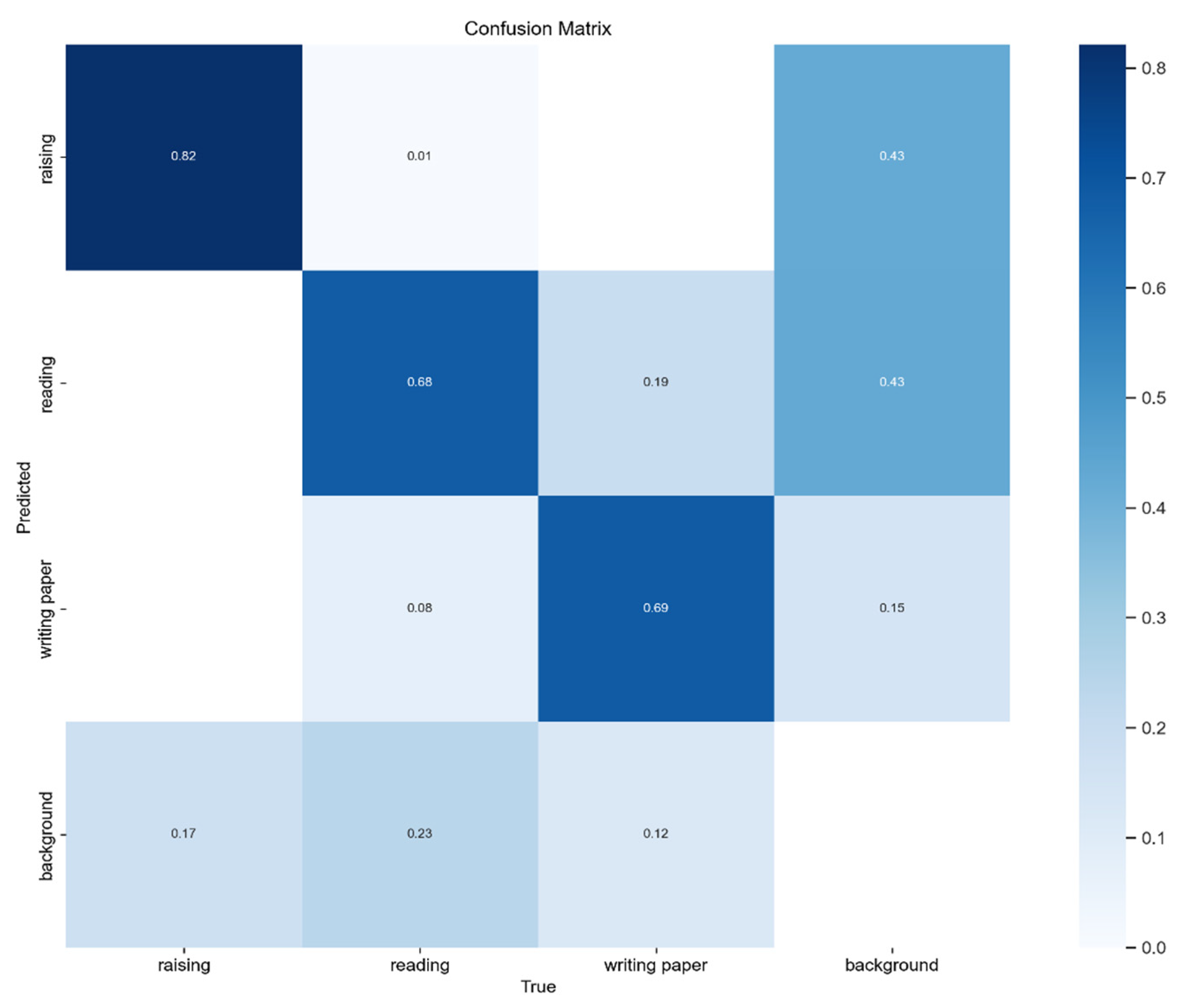
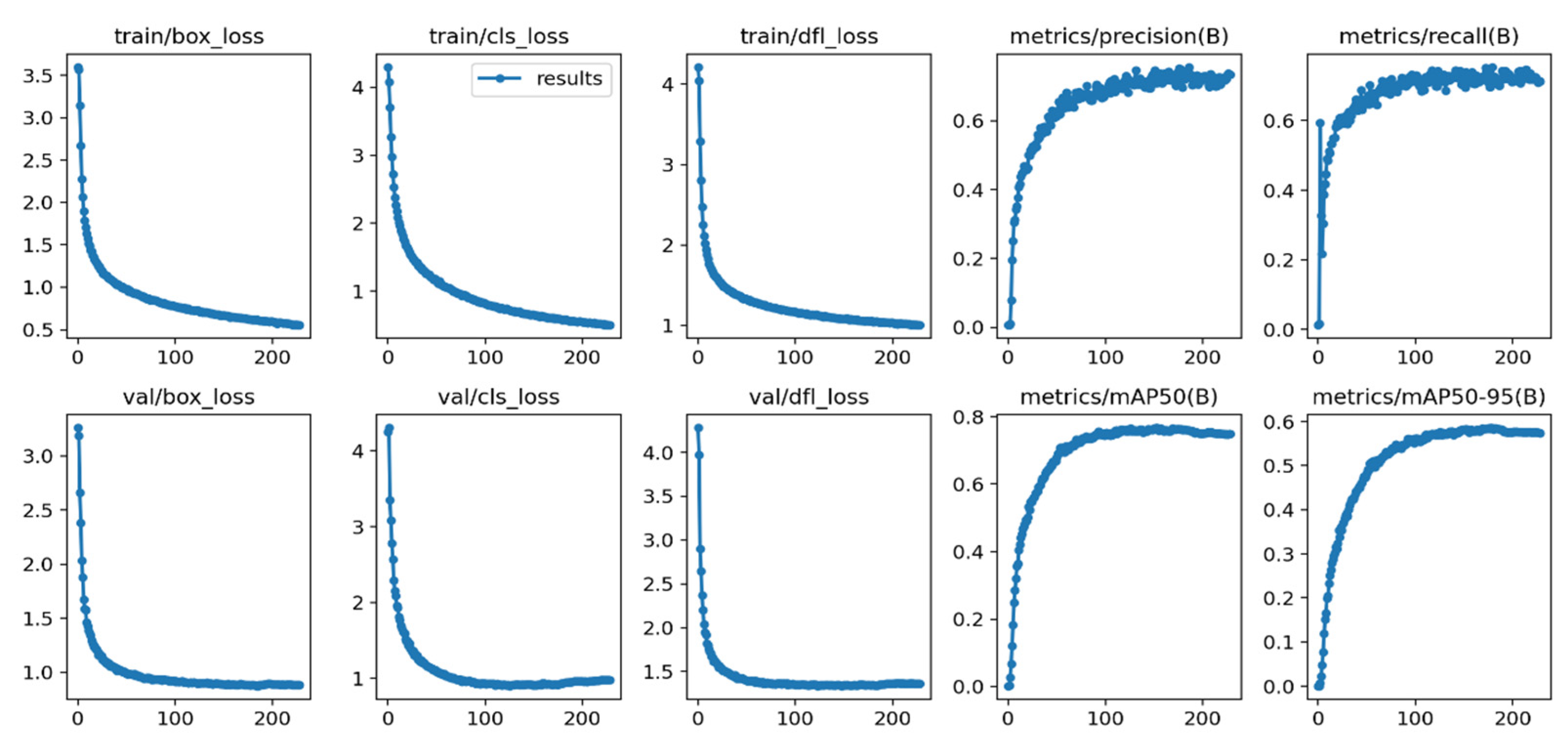
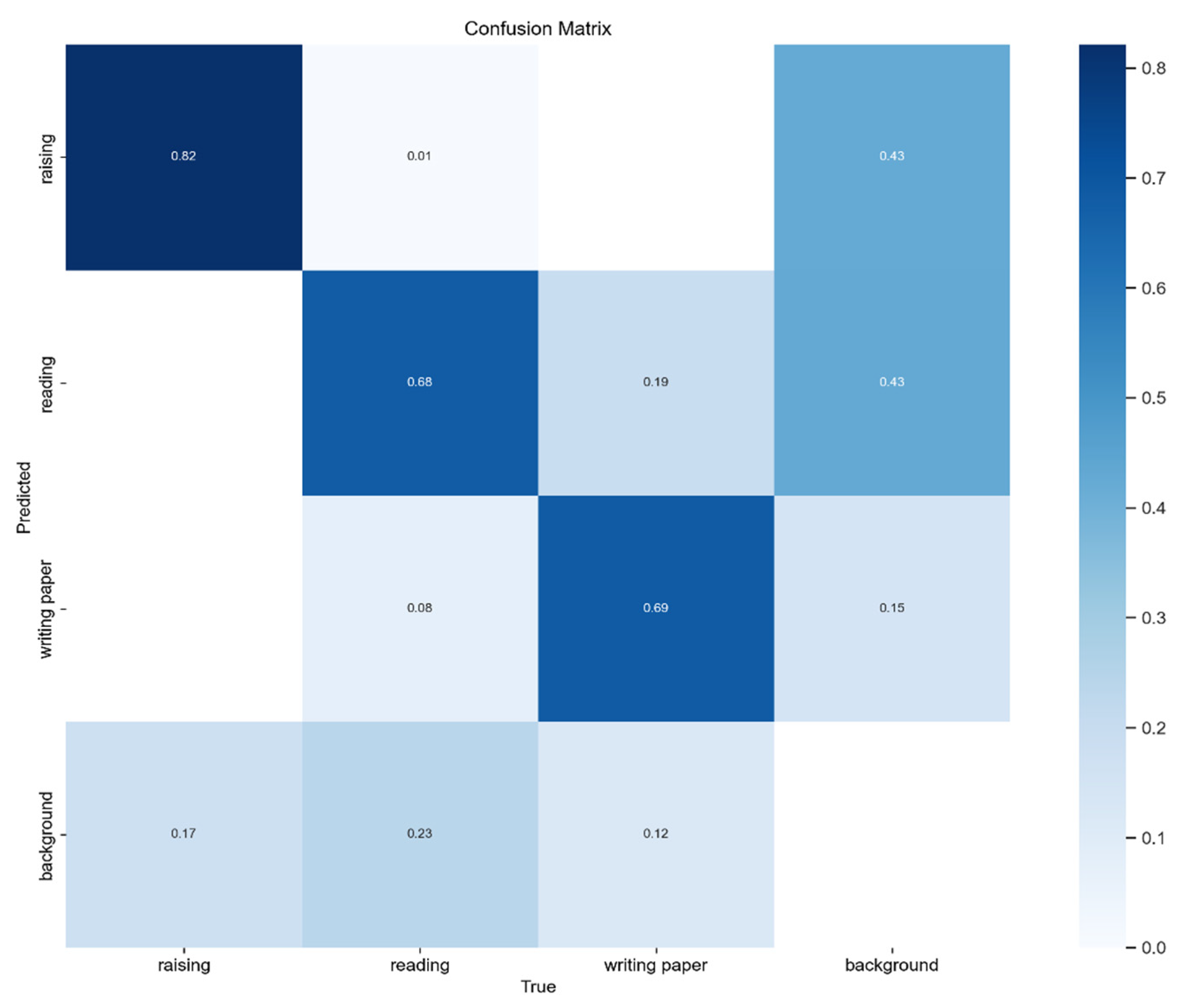
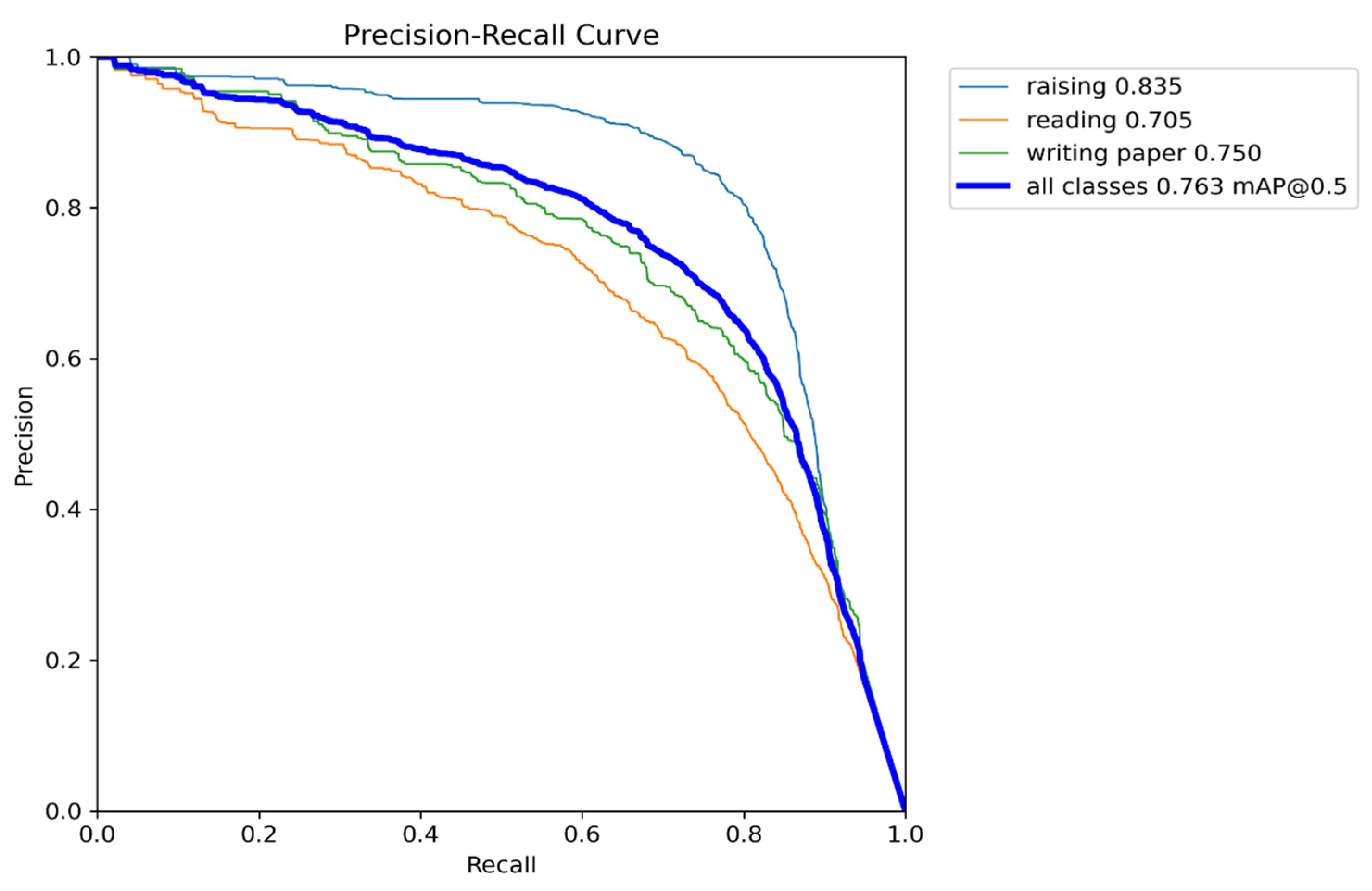
4.3. Experimental Results Obtained on SCB-Dataset Using an Improved Version of YOLOv8
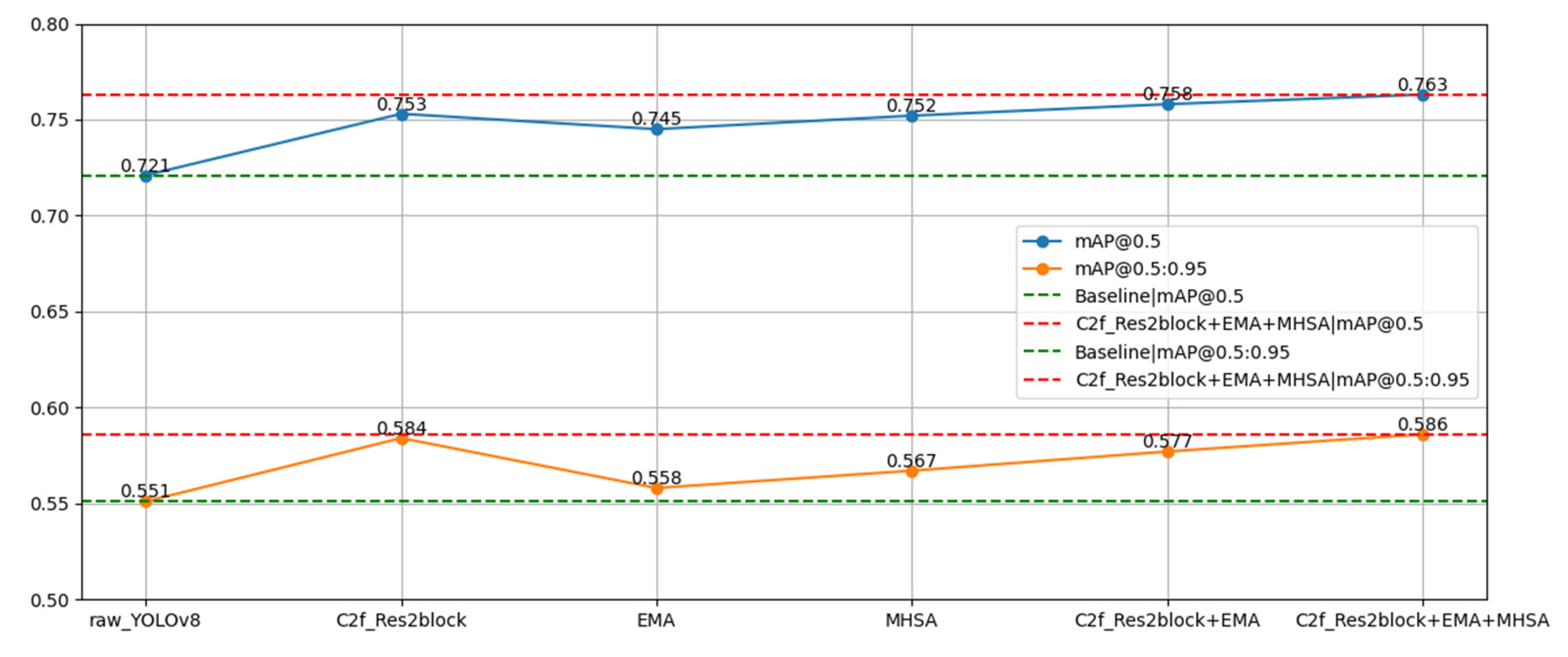
4.4. Ablation Experiments
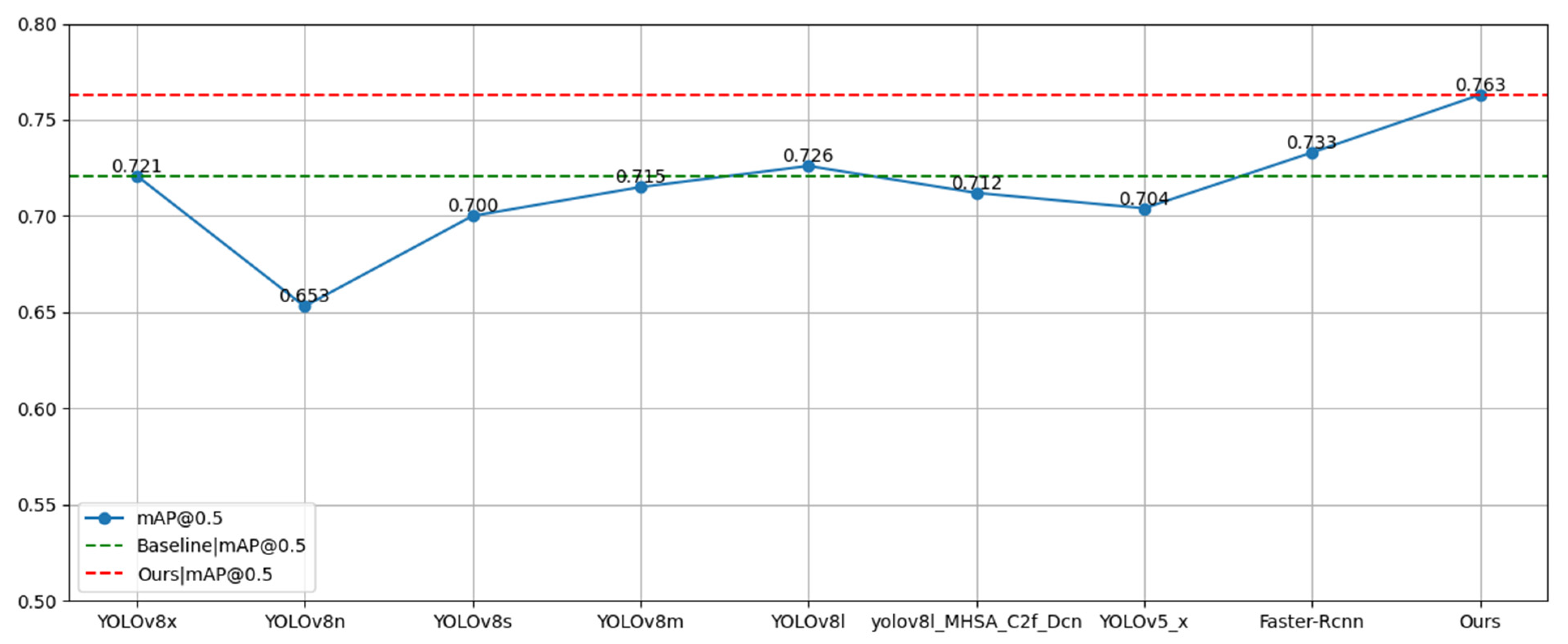
4.5. Comparative Experiments
4.5.1. Comparison of Results of Different Datasets with Experiments
4.5.2. Comparison of Results of Different Models with Experiments
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Singh, H.; Miah, S.J. Smart Education Literature: A Theoretical Analysis. Educ. Inf. Technol. 2020, 25, 3299–3328. [Google Scholar] [CrossRef]
- Zhou, J.; Ran, F.; Li, G.; Peng, J.; Li, K.; Wang, Z. Classroom Learning Status Assessment Based on Deep Learning. Math. Probl. Eng. 2022, 2022, 1–9. [Google Scholar] [CrossRef]
- Hu, M.; Wei, Y.; Li, M.; Yao, H.; Deng, W.; Tong, M.; Liu, Q. Bimodal Learning Engagement Recognition from Videos in the Classroom. Sensors 2022, 22, 5932. [Google Scholar] [CrossRef] [PubMed]
- Yin Albert, C.C.; Sun, Y.; Li, G.; Peng, J.; Ran, F.; Wang, Z.; Zhou, J. Identifying and Monitoring Students’ Classroom Learning Behavior Based on Multisource Information. Mob. Inf. Syst. 2022, 2022, 1–8. [Google Scholar] [CrossRef]
- Lin, C.-M.; Tsai, C.-Y.; Lai, Y.-C.; Li, S.-A.; Wong, C.-C. Visual Object Recognition and Pose Estimation Based on a Deep Semantic Segmentation Network. IEEE Sensors J. 2018, 18, 9370–9381. [Google Scholar] [CrossRef]
- Chen, H.; Guan, J. Teacher–Student Behavior Recognition in Classroom Teaching Based on Improved YOLO-v4 and Internet of Things Technology. Electronics 2022, 11, 3998. [Google Scholar] [CrossRef]
- Gu, C.; Sun, C.; Ross, D.A.; Vondrick, C.; Pantofaru, C.; Li, Y.; Vijayanarasimhan, S.; Toderici, G.; Ricco, S.; Sukthankar, R.; et al. AVA: A Video Dataset of Spatio-Temporally Localized Atomic Visual Actions. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Salt Lake City, UT, USA, 2018; pp. 6047–6056. [Google Scholar]
- Feichtenhofer, C.; Fan, H.; Malik, J.; He, K. SlowFast Networks for Video Recognition. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6201–6210. [Google Scholar]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in Homes: Crowdsourcing Data Collection for Activity Understanding. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 510–526. ISBN 978-3-319-46447-3. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar]
- Ultralytics/Ultralytics: NEW—YOLOv8 in PyTorch > ONNX > OpenVINO > CoreML > TFLite. Available online: https://github.com/ultralytics/ultralytics (accessed on 18 August 2023).
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Jolicoeur-Martineau, A.; Mitliagkas, I. Gradient Penalty from a Maximum Margin Perspective. arXiv 2019, arXiv:1910.06922. [Google Scholar]
- Hu, G.; He, W.; Sun, C.; Zhu, H.; Li, K.; Jiang, L. Hierarchical Belief Rule-Based Model for Imbalanced Multi-Classification. Expert Syst. Appl. 2023, 216, 119451. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Jiang, Y.; Zhu, X.; Wang, X.; Yang, S.; Li, W.; Wang, H.; Fu, P.; Luo, Z. R2CNN: Rotational Region CNN for Orientation Robust Scene Text Detection. arXiv 2017, arXiv:1706.09579. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Chen, Y.; Cai, L.; Ling, H. M2Det: A Single-Shot Object Detector Based on Multi-Level Feature Pyramid Network. AAAI 2019, 33, 9259–9266. [Google Scholar] [CrossRef]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. AugFPN: Improving Multi-Scale Feature Learning for Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12592–12601. [Google Scholar]
- Picouet, V.; Milliard, B.; Kyne, G.; Vibert, D.; Schiminovich, D.; Martin, C.; Hamden, E.; Hoadley, K.; Montel, J.; Melso, N.; et al. End-to-End Ground Calibration and in-Flight Performance of the FIREBall-2 Instrument. J. Astron.Telesc.Instrum. Syst. 2021, 6, 044004. [Google Scholar] [CrossRef]
- Lu, J.; Xiong, C.; Parikh, D.; Socher, R. Knowing When to Look: Adaptive Attention via a Visual Sentinel for Image Captioning. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3242–3250. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Yang, F.; Wang, T.; Wang, X. Student Classroom Behavior Detection Based on YOLOv7-BRA and Multi-Model Fusion. arXiv 2023, arXiv:2305.07825. [Google Scholar]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef] [PubMed]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Liu, H.; Liu, F.; Fan, X.; Huang, D. Polarized Self-Attention: Towards High-Quality Pixel-Wise Regression. arXiv 2021, arXiv:2107.00782. [Google Scholar]
- Fan, Y. SCB-Dataset: A Dataset for Detecting Student Classroom Behavior. arXiv 2023, arXiv:2304.02488. [Google Scholar]
- Shao, S.; Zhao, Z.; Li, B.; Xiao, T.; Yu, G.; Zhang, X.; Sun, J. CrowdHuman: A Benchmark for Detecting Human in a Crowd. arXiv 2018, arXiv:1805.00123. [Google Scholar]
- Wang, W.; Dai, J.; Chen, Z.; Huang, Z.; Li, Z.; Zhu, X.; Hu, X.; Lu, T.; Lu, L.; Li, H.; et al. InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
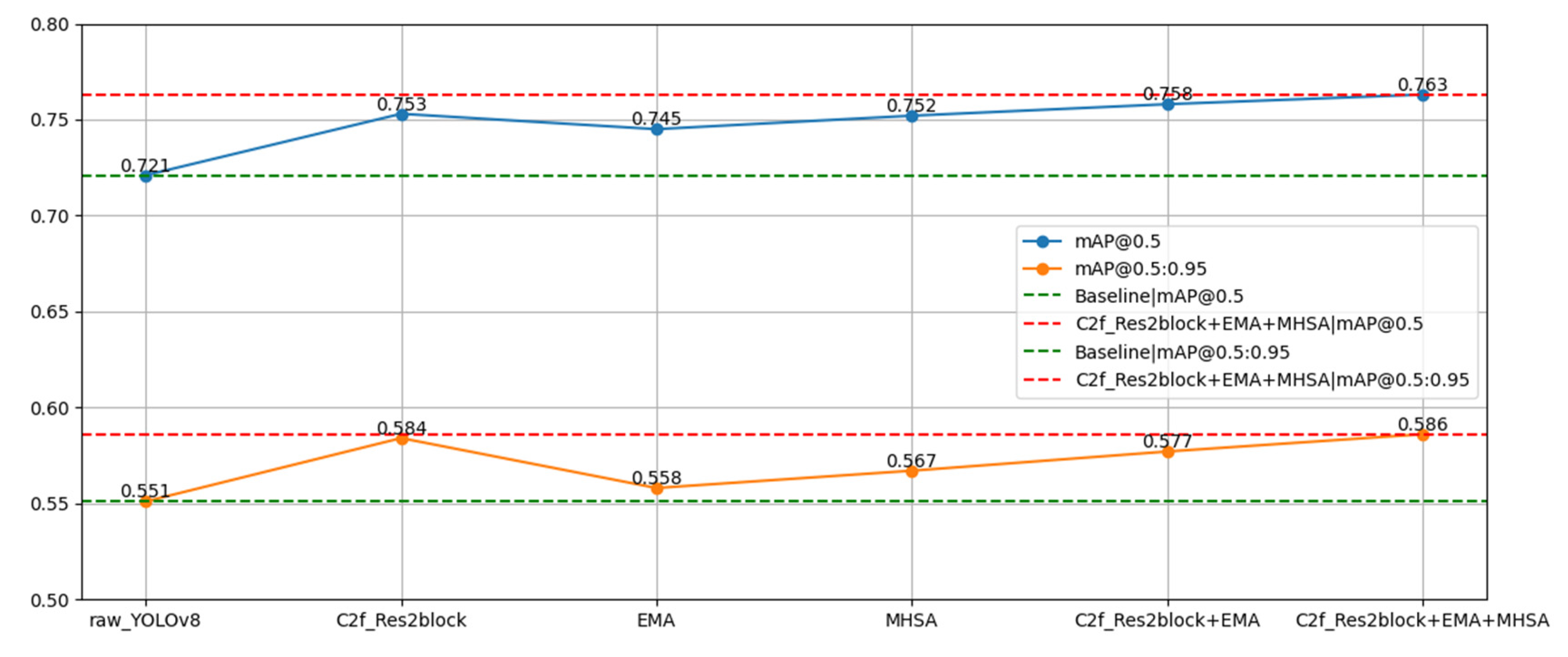
| C2f_Res2block | EMA | MHSA | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|
| 0.721 | 0.551 | |||
| √ | 0.753 | 0.584 | ||
| √ | 0.745 | 0.568 | ||
| √ | 0.752 | 0.567 | ||
| √ | √ | 0.758 | 0.577 | |
| √ | √ | √ | 0.763 | 0.586 |
| Model | Species | mAP@0.5 | mAP@0.95 |
|---|---|---|---|
| YOLOv8_row | Human | 0.746 | 0.492 |
| YOLOv8_improved | Human | 0.767 | 0.512 |
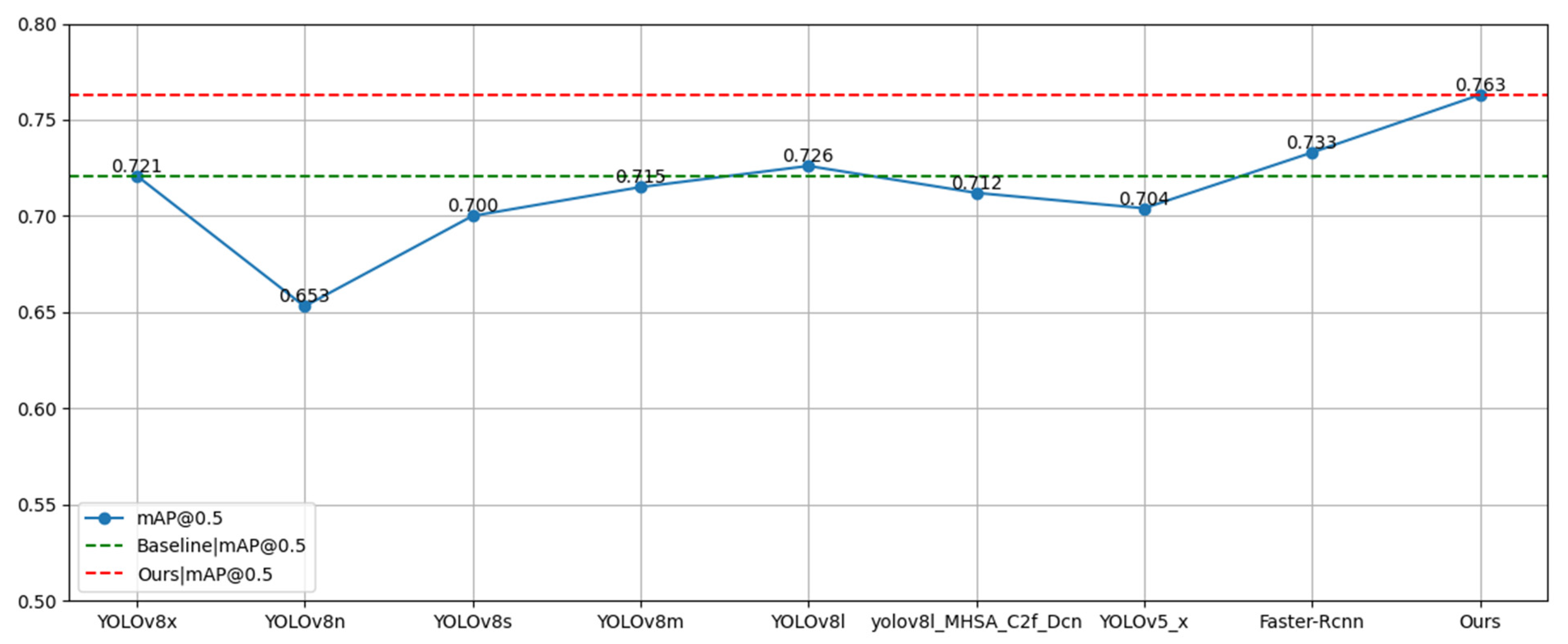
| Method | AP | mAP@0.5 | ||
|---|---|---|---|---|
| Raising | Reading | Writing Paper | ||
| YOLOv8x | 0.822 | 0.645 | 0.696 | 0.721 |
| YOLOv8n | 0.766 | 0.59 | 0.603 | 0.653 |
| YOLOv8s | 0.801 | 0.63 | 0.669 | 0.7 |
| YOLOv8m | 0.815 | 0.643 | 0.687 | 0.715 |
| YOLOv8l | 0.825 | 0.649 | 0.704 | 0.726 |
| YOLOv8l-MHSA-C2f-Cn | 0.814 | 0.644 | 0.679 | 0.712 |
| YOLOv5x | 0.812 | 0.642 | 0.66 | 0.704 |
| Faster-Rcnn | 0.820 | 0.660 | 0.72 | 0.733 |
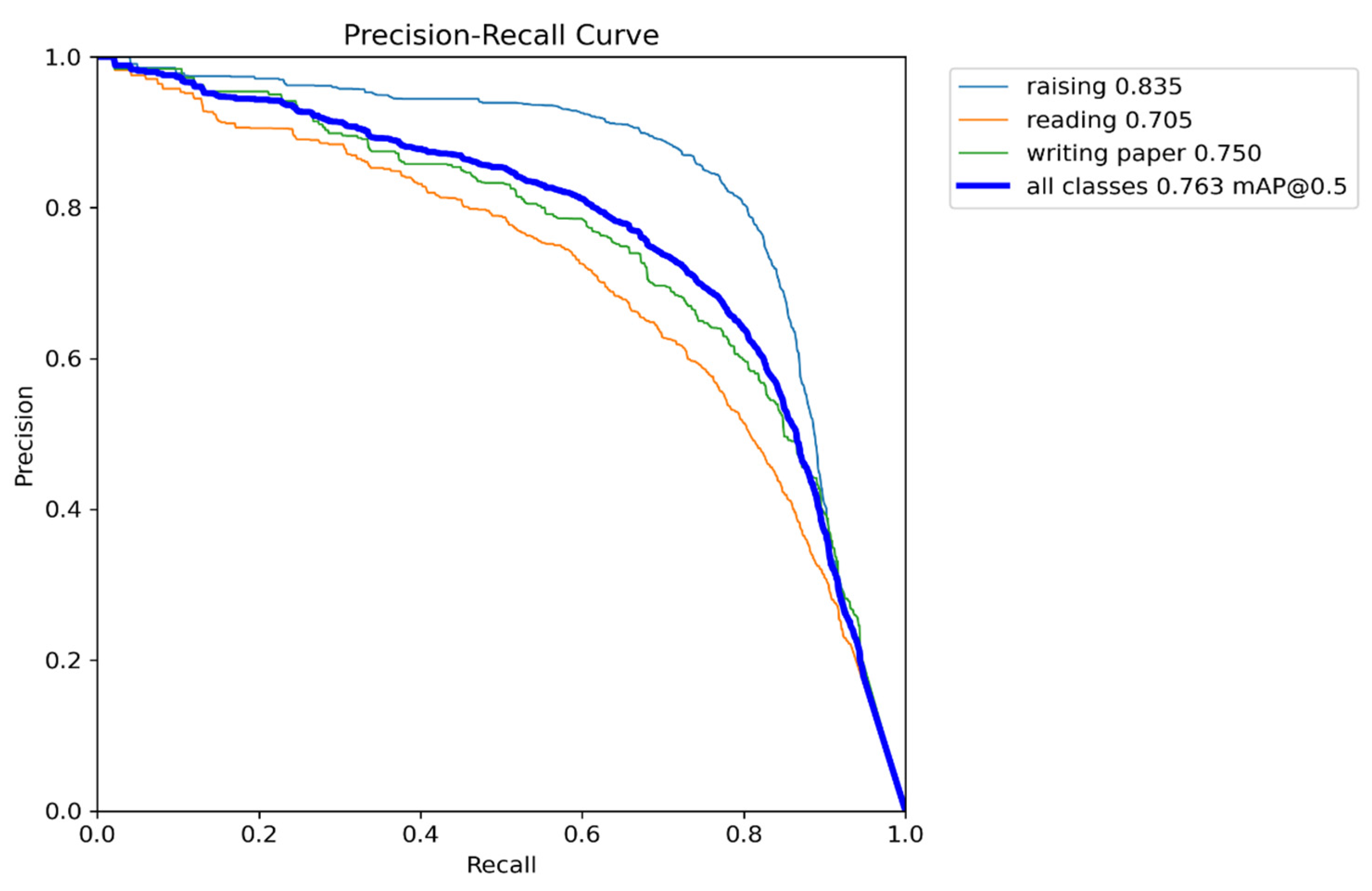
| Ours | 0.835 | 0.705 | 0.75 | 0.763 |
| Real Classroom | Before Improvement | After Improvement | |
|---|---|---|---|
| False positive (8 cases of mistaking one student for multiple students) |  |  |  |
| Missed detection (3 students’ learning statuses detected as 2 learning statuses) |  |  |  |
| The targets are densely packed, and the obscuration effect is not good |  |  |  |
| Low accuracy |  |  |  |
 |  |  |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Zhou, G.; Jiang, H. Student Behavior Detection in the Classroom Based on Improved YOLOv8. Sensors 2023, 23, 8385. https://doi.org/10.3390/s23208385
Chen H, Zhou G, Jiang H. Student Behavior Detection in the Classroom Based on Improved YOLOv8. Sensors. 2023; 23(20):8385. https://doi.org/10.3390/s23208385
Chicago/Turabian StyleChen, Haiwei, Guohui Zhou, and Huixin Jiang. 2023. "Student Behavior Detection in the Classroom Based on Improved YOLOv8" Sensors 23, no. 20: 8385. https://doi.org/10.3390/s23208385
APA StyleChen, H., Zhou, G., & Jiang, H. (2023). Student Behavior Detection in the Classroom Based on Improved YOLOv8. Sensors, 23(20), 8385. https://doi.org/10.3390/s23208385