1. Introduction
The synthetic aperture radar (SAR) is an active sensor system that can acquire high-resolution radar images, regardless of day or night, flight altitude, and weather, using a microwave band [
1,
2,
3].
Figure 1 shows the working principle of the SAR. In the SAR system, a small antenna is mounted on a platform that moves along a flight path. The direction of flight is also called the azimuth direction, and the range direction is perpendicular to the azimuth direction. The direction of the antenna is a range direction, and it moves by illuminating an area called a swath. Two-dimensional data on the azimuth and the range are collected by transmitting and receiving pulses. The central idea of the SAR is based upon matching filtering for both the azimuth and distance directions, which results in high-resolution radar images. In addition, the SAR has the advantage of remote sensing, so it plays a vital role in various fields, such as disaster emergency response, environmental protection, and military applications [
3,
4,
5,
6]. Because the traditional SAR system requires considerable computing resources and high power consumption, it has been mounted on large platforms such as aircraft and satellites. However, recent advances in digital signal processing and complementary metal oxide semiconductor (CMOS) technologies have made it possible to develop small and lightweight SAR systems. Accordingly, research on SAR systems with low power consumption and real-time processing is increasing [
7,
8,
9].
Operations for SAR imaging mainly include the fast Fourier transform (FFT), inverse fast Fourier transform (IFFT), phase compensation, interpolation, etc., and the computational complexity of these operations is very high. Therefore, real-time SAR imaging necessitates accelerating these operations on various computing platforms, such as the central processing unit (CPU), the graphic processing unit (GPU), the field-programmable gate array (FPGA), and application-specific integrated circuits (ASICs) [
9,
10,
11,
12,
13,
14,
15,
16,
17,
18]. CPU and GPU provide high flexibility for software through various instructions and show high performance in single and parallel processing, respectively. However, high power consumption is still a severe challenge. On the other hand, FPGA has latency, throughput, and power consumption advantages compared with CPU or GPU. In addition, it has gained attention as a computing platform that can be used in various fields owing to its high flexibility [
19,
20].
Several studies have been conducted on the implementation of SAR systems using FPGAs. In 2004, Le et al. proposed an FPGA-based hardware architecture for a spaceborne system to process the range-Doppler and space–time adaptive processing (STAP) algorithms [
9]. Greco et al. proposed an HW/SW interface framework to use FPGA resources efficiently through an abstraction layer and verified it in SAR applications and confirmed its performance [
10]. Pfitzner et al. proposed an FPGA-based hardware architecture for airborne, real-time SAR imaging with integrated first-order motion compensation (MoCom) [
11]. Lou et al. proposed a UAVSAR onboard processor for real-time and autonomous operations. They demonstrated the use of UAVSAR data to determine the flood extent, forest fire extent, lava flow, and landslide [
12]. Choi et al. proposed a range-Doppler algorithm (RDA)-based SAR processor for real-time SAR imaging. In the case of RDA, interpolation is performed for range cell migration correction (RCMC). Therefore, all operations of RDA are accelerated by implementing an RCMC unit in addition to the FFT unit. However, the FFT unit adopts a pipelined structure, so there is room for speed improvement [
13].
The most commonly used SAR Imaging algorithms include range-Doppler, chirp scaling, omega-K, polar format, and back projection. The RDA performs efficient imaging through block processing in the range and azimuth frequency domains; however, the complexity of interpolation for RCMC is very high. Therefore, the chirp-scaling algorithm (CSA) was developed by replacing the interpolation of RDA with phase compensation. CSA has a simple algorithm structure comprising FFT and phase compensation operations. In addition, CSA has an advantage of real-time imaging because it has the smallest computational load compared with the RDA and omega-K algorithms [
21].
Several studies have been conducted to implement CSA on various platforms. Zhang et al. proposed a collaborative SAR imaging method that performs efficient task partitioning and scheduling. The entire image can be generated using deep collaborative multiple CPU–GPU computing. It acquired a 32,728 × 32,728-pixel image in 2.8 s [
14]. Tang et al. proposed a simulator for spaceborne SAR onboard imaging on mobile GPUs. It acquired a 4096 × 4096-pixel image in 14.97 s [
15]. Wang et al. proposed a heterogeneous processor consisting of fixed-point PE units and floating-point PE units. It acquired a 32,768 × 32,768-pixel image in 32.9 s at a speed of 200 MHz [
16]. Li et al. proposed a method that employs single-instruction, multiple-data (SIMD) instructions and open multiprocessing (OpenMP) technology on multicore SIMD CPU to realize parallel optimization on CSA [
17]. Di et al. proposed a schedulable and scalable multicore parallel architecture based on FPGA and mapped the fundamental CSA to the system. It acquired a 1024 × 4096-pixel image in 12 s [
18].
Among the CSA operations, FFT/IFFT operations account for the highest proportion. Therefore, it is necessary to implement an FFT/IFFT processor for real-time imaging. The hardware structure of the FFT processor is divided into the butterfly, pipeline, and systolic array structures [
22,
23,
24]. Butterfly and pipeline structures can be implemented with fewer hardware resources but are unsuitable for high-speed operations. Therefore, a systolic array-based FFT processor is suitable for real-time imaging [
25,
26]. Among the various systolic array structures, the base-4 systolic array structure is arithmetically efficient and has a good trade-off between area and speed [
27,
28]. Therefore, We adopted the base-4 systolic array structure.
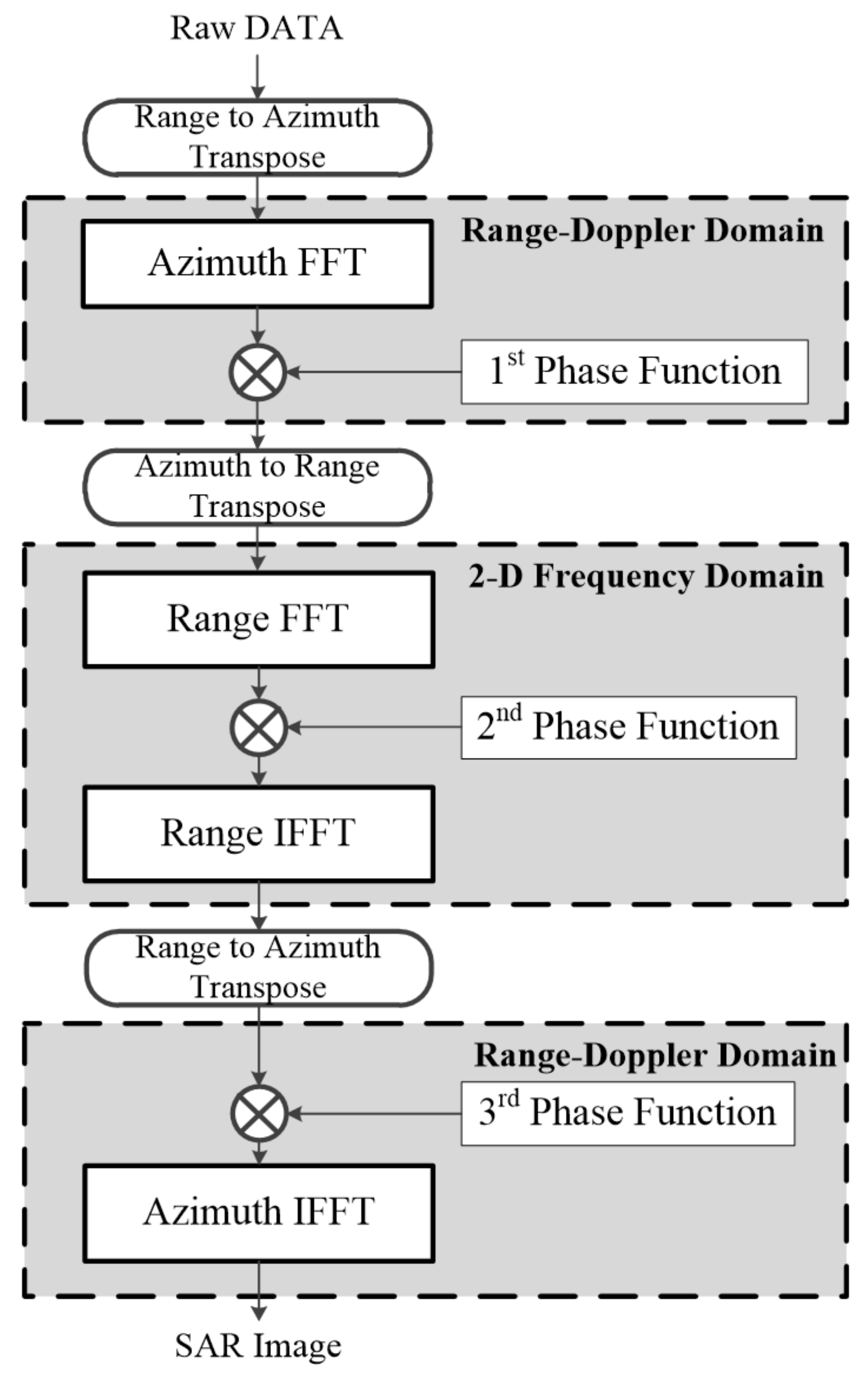
In this paper, we propose a CSA-based SAR processor and present the results of accelerating the modified CSA flow, in which the order of transpose operation is changed in the traditional CSA flow. The proposed CSA-based SAR processor was implemented based on a base-4 systolic array architecture and can only perform FFT or FFT and phase compensation operations simultaneously. Twiddle factor multiplication and phase compensation were designed to share the same multiplier owing to their commonality of element-by-element multiplication, which made it possible to simplify the data flow and achieve area efficiency.
The remainder of this paper is organized as follows:
Section 2 reviews the CSA and base-b FFT algorithm.
Section 3 describes the modified CSA algorithm and the hardware architecture of the proposed CSA-based SAR processor.
Section 4 presents the proposed processor’s implementation and the accelerated CSA results and compares the speed performance with previous studies. Finally,
Section 5 concludes the paper.
3. Proposed HW Architecture
The CSA includes an FFT operation, which is a vector operation, and a phase compensation operation, which is a scalar operation (element-by-element multiplication). Therefore, for phase compensation, the desired result can be obtained by matching the axes of the SAR data and the phase function.
Figure 3 shows the phase compensation operation with transposed data. The first row shows the operation results on the range axis, and the second row shows the operation results on the azimuth axis. The transpose of the result in the second row is the same as that in the first row.
By performing transpose for the phase function, we changed the order in which data is transposed in the traditional CSA flow.
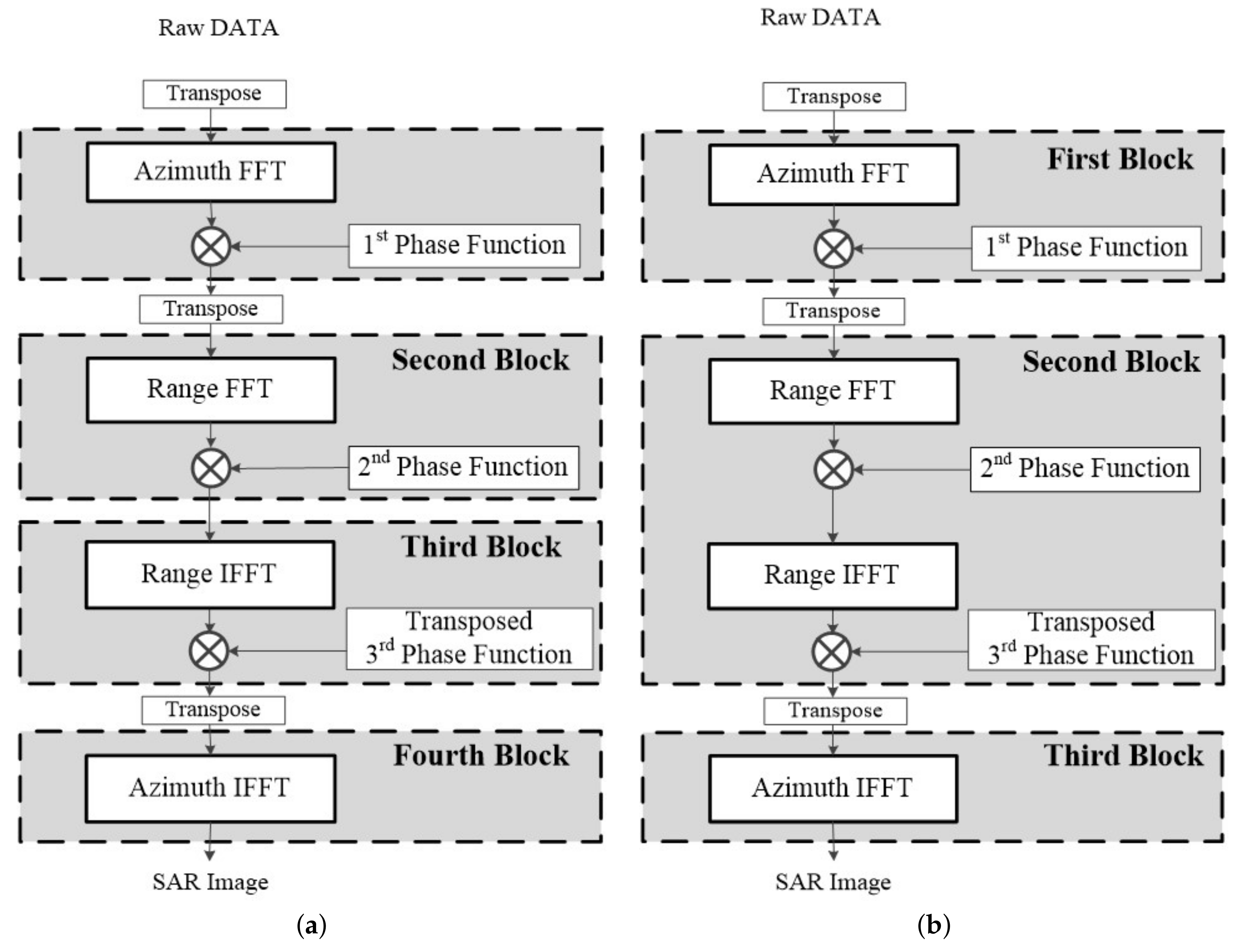
Figure 4 shows the proposed modified CSA flow. We transposed the third-phase function and changed the transpose operation of the data from after range IFFT to after the third-phase compensation. The difference is that the third-phase compensation was performed on the range axis. FFT/IFFT and phase compensation operations were repeated three times as a new operation block, and then azimuth IFFT was performed to obtain SAR images. In the modified CSA flow 2, because the second and third blocks were both processed on the range axis, there was no need to store the data in the external memory to transpose the data. Accordingly, modified flow 2, which integrated the second and third blocks, was determined as the CSA processing flow.
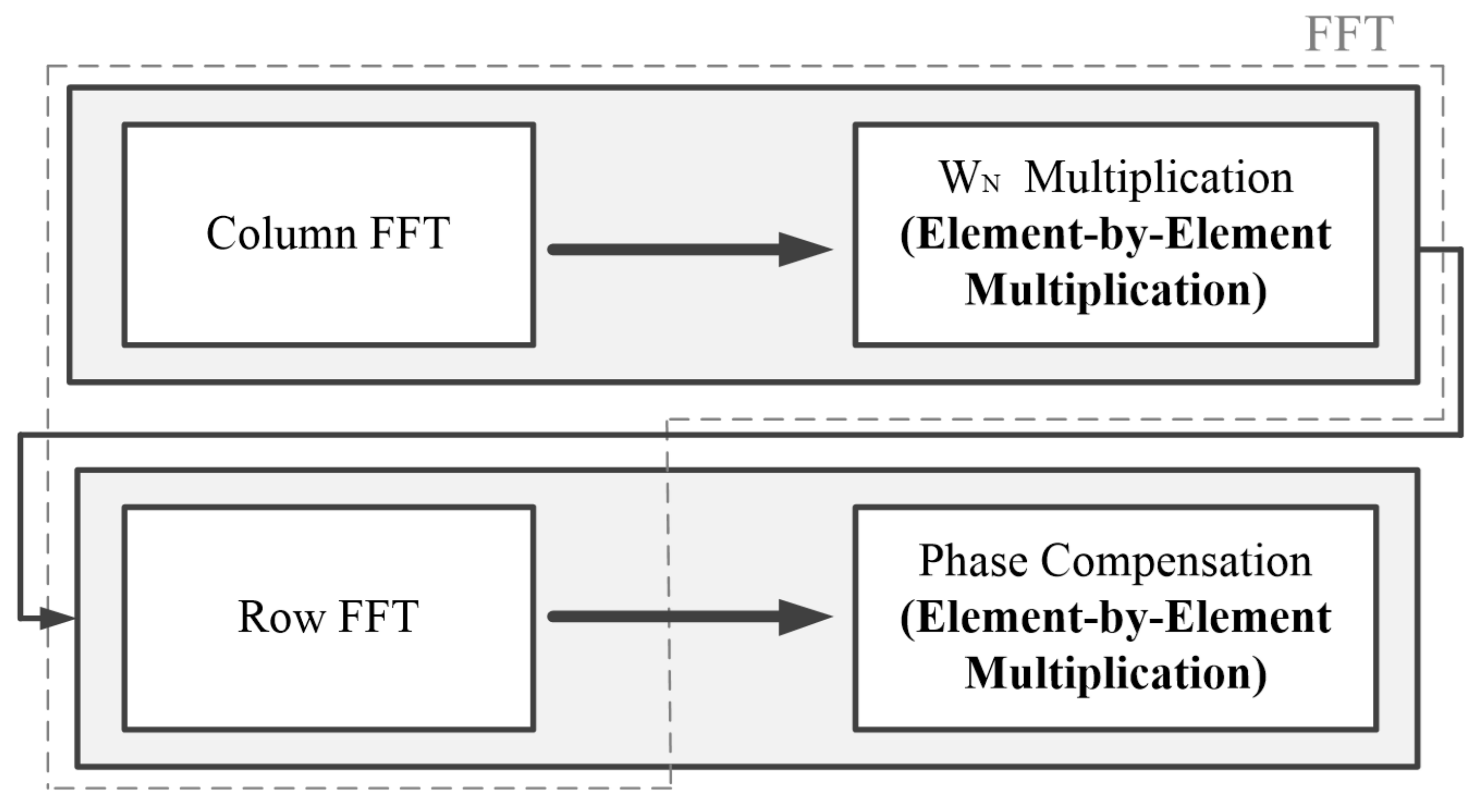
Figure 5 shows the FFT and phase compensation procedure, which is a repeated operation block in the modified CSA flow. The block operation proceeded in the order of column FFT,
multiplication, row FFT, and phase compensation. Both the
multiplication and phase compensation operations were element-by-element multiplications. Therefore, by repeating the row or column FFT and element-by-element multiplication twice, FFT and phase compensation could be performed. Thus, the operation block was accelerated by subdividing the FFT and the phase compensation operations into a row/column FFT and element-by-element multiplications.
Figure 6 shows the hardware architecture of the proposed CSA-based SAR processor. We adopted a base-4 systolic array that best satisfies the trade-off between area and execution time [
27,
28]. On the left, there is a bundle of processing element (PE) cells of size
called left-hand side (LHS), and it is connected to a complex multiplier of size
that multiplies
. On the right, there is a bundle of PE cells of size
called right-hand side, (RHS) and it is connected to four shared multipliers that perform
multiplication or phase compensation operations depending on their input. At the bottom, there are four
-sized memories to store the resulting values. Because both
multiplication and phase compensation operations were element-by-element multiplication, multipliers could be shared. In addition, both operations were performed after the FFT, and the data flow was not disturbed. Therefore, we can achieve area efficiency without using an additional multiplier for the phase compensation operation. Because the proposed hardware supports a maximum of 4096-point operations, the LHS and RHS were PE cells of
size, and the complex multipliers for
had a size of
.
The block operation proceeded in the following order: column FFT,
multiplication, row FFT, and phase compensation. First, the SAR data were transferred to the LHS for column FFT, and matrix multiplication was performed with
in the PE cell. By transmitting this result to the
multiplier, the result of Equation (
15) was obtained. Subsequently, the result was transferred to the RHS, and the result of Equation (
17) was obtained by performing matrix multiplication with
input under the RHS. This result was the same as that for column FFT. The result was transferred to the shared multiplier, and multiplication with the
was performed. Then, the result was stored in the memory. The data stored in the memory were input to the LHS again in the row direction, and the operation was similarly performed up to the RHS. The result of the RHS was the same as that of FFT and transferred to the shared multiplier. However, unlike before, the phase function was input to the shared multiplier to perform phase compensation. Finally, the result for the FFT and phase compensation operation was stored in the memory.
If the phase factor is 1, it is possible to perform only FFT without phase compensation.
In a systolic array, PE cells are locally connected; each PE cell operates simultaneously, and data are delivered to the connected PE cell. It is suitable for algorithms that require a lot of computation because it has a local data flow, and multiple PE cells simultaneously process the computations [
25]. A representative operation that can be accelerated using a systolic array is matrix multiplication.
Figure 7 shows the two types of PE cells used in the proposed CSA-based SAR processor. For LHS, the data were derived from the lower PE cell, and multiplication and addition operations were performed in each PE cell. It passed through all PE cells by passing the input and the resulting values to each connected PE cell. If matrix A is sequentially input from the bottom, and the B matrix value exists inside the PE cell,
can be obtained. For RHS, data were input from the bottom and left cells simultaneously. Similarly, multiplication and addition operations were performed, and the input and the resulting values were transferred to the connected PE cell. After passing through all PE cells,
can be obtained. Using the PE array of these structures, the FFT operation expressed by Equations (
15) and (
17) in a matrix form was performed. Because matrix operations can be performed quickly through systolic arrays, FFT and phase compensation were processed at high speed.
4. Implementation and Acceleration Results
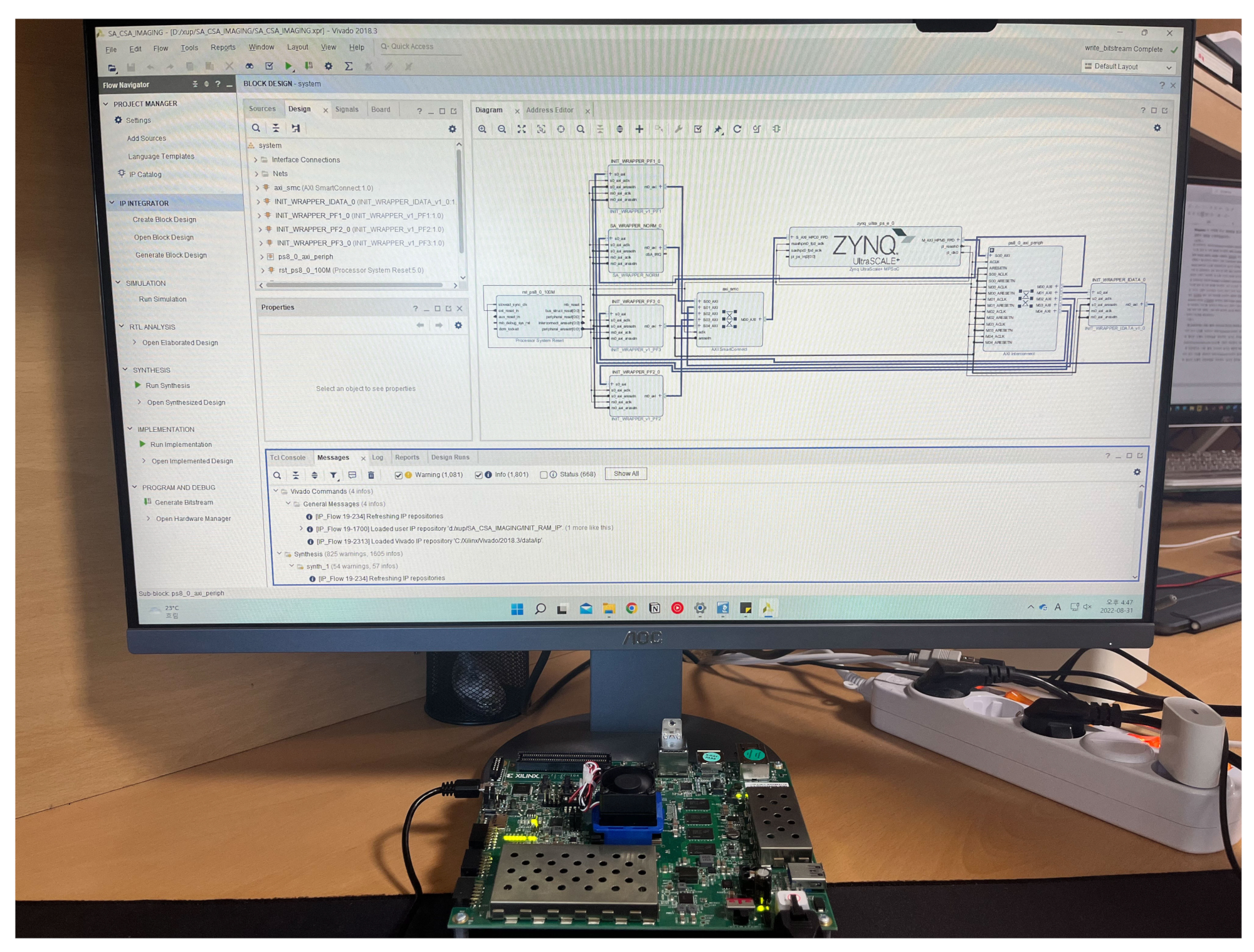
The proposed CSA-based SAR processor was configured on an FPGA platform using an advanced extensible interface (AXI) bus interface for verification.
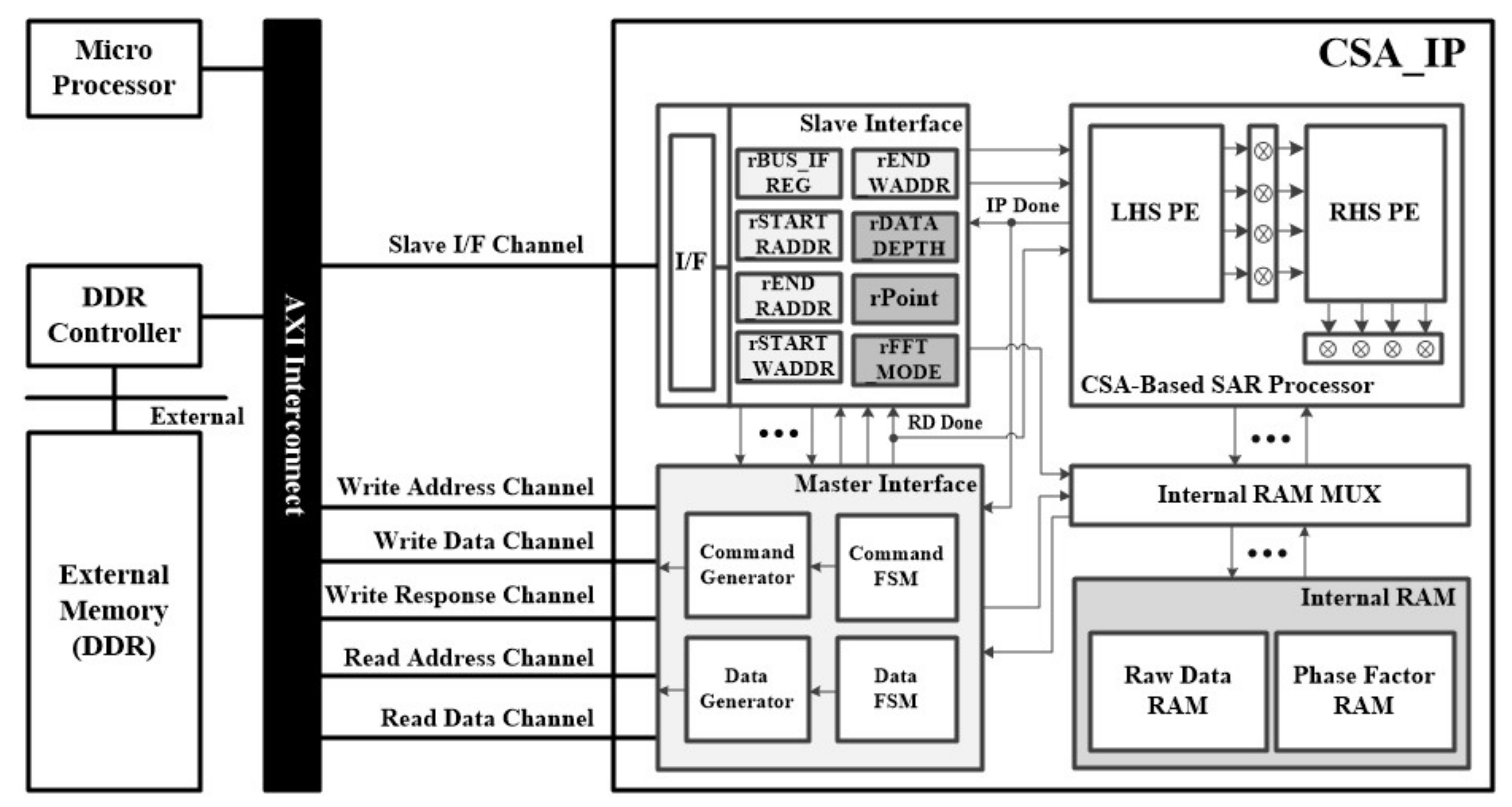
Figure 8 shows the FPGA platform, which includes a CSA-based SAR processor for FFT and phase compensation operations. The system structure comprised a CSA-based SAR processor, master interface to communicate with double data rate (DDR) memory, slave interface to communicate with a microprocessor, and cache RAM to store input/output data and phase functions. In addition, there was a register to change the operation mode because it supported the FFT and IFFT modes and variable lengths from 64 to 4096. The master interface was connected to the DDR memory controller via a 128-bit AXI bus, allowing the transfer of four 32-bit data points per clock cycle. Therefore, it operated efficiently in the base-4 systolic structure, in which four points of data were input in parallel.
The proposed CSA-based SAR processor was implemented using a Verilog HDL on a Xilinx Zynq UltraScale+ FPGA device. The CSA-based SAR processor was implemented with 17,326 CLB registers, 31,025 CLB LUTs, 4 block RAMs, and 78 DSPs, as listed in
Table 1. The CSA-based SAR processor could process at a maximum operating frequency of 235 MHz, and its power consumption was measured to be 1.31 W.
Figure 9 shows the verification environment of the FPGA platform.
When SAR data were loaded into the DDR memory to verify the CSA-based SAR processor, the microprocessor sent a starting signal to the CSA-based SAR processor. The DDR data were then transferred to the cache RAM through the master interface. The CSA-based SAR processor performed azimuth FFT and first-phase compensation operations and stored the result in the cache RAM; the result was transferred back to the DDR via the master interface for the transpose operation. After the transpose operation, the range FFT and second-phase compensation operations were similarly performed. According to the modified CSA flow 2, transposing the result was unnecessary. Therefore, the result was not transmitted to the DDR, and the CSA-based SAR processor performed range IFFT and third-phase compensation operations on the data in the cache RAM and then transmitted the result to the DDR. After performing the transpose operation again, the SAR image was obtained by performing the same operation for the azimuth IFFT. Therefore, SAR images can be obtained by performing four times CSA-based SAR processor operations.
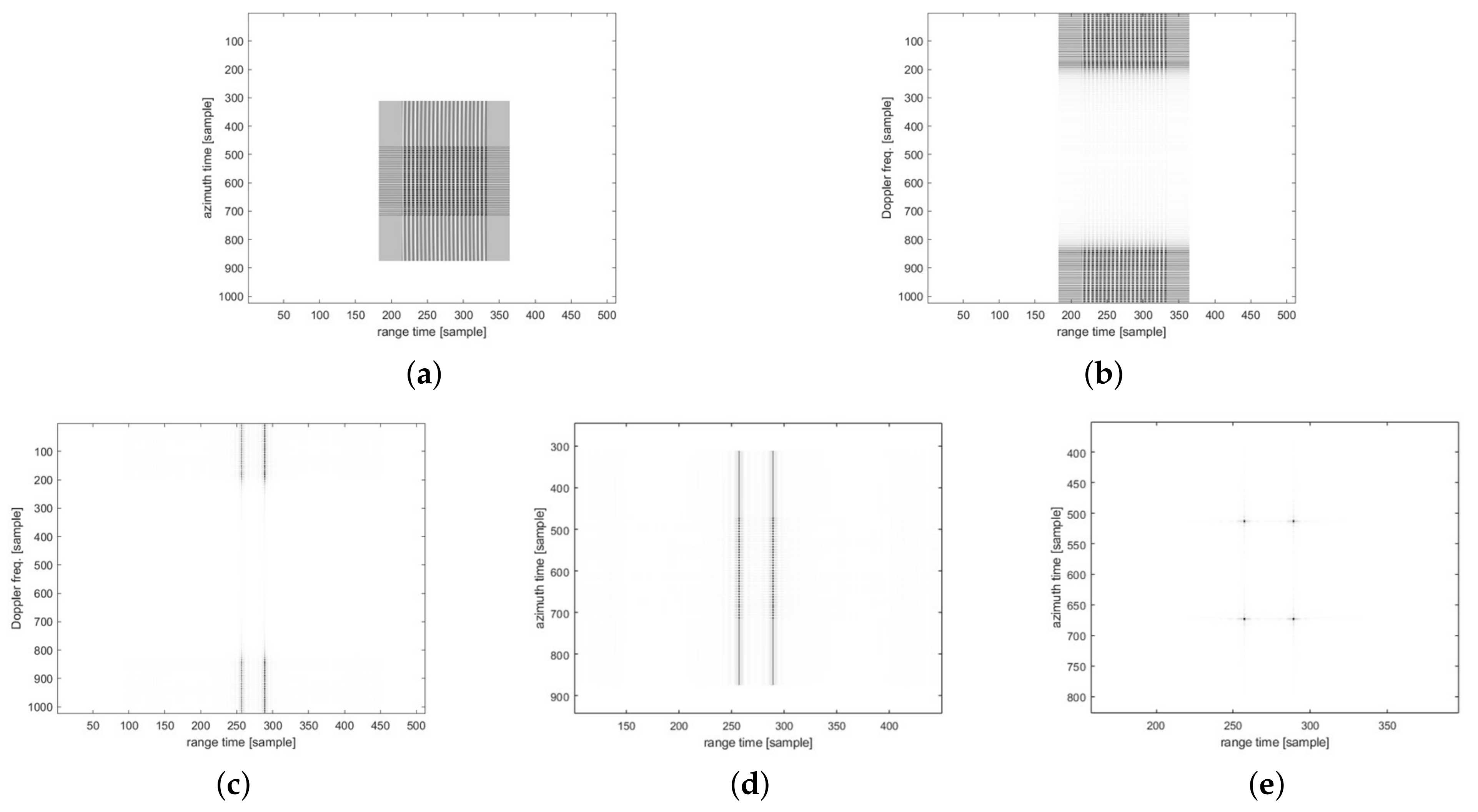
Figure 10 and
Figure 11 show the imaging results for the four-point targets.
Figure 10 shows the results of imaging using the traditional CSA flow, and
Figure 11 shows the results using the modified CSA flow. The third-phase compensation of the modified CSA flow was performed on the range axis, and the result of completing the range axis operation is shown in
Figure 11c. Therefore, as shown in
Figure 11d, the imaging result can be obtained through only the azimuth IFFT. However, for traditional CSA flow, a third-phase compensation operation was performed on the azimuth axis.
Figure 10c shows the result of completing the range-axis operation, and
Figure 10d shows the data of
Figure 10c in the time domain. The operation of the range axis was completed, but the azimuth compression had not yet been performed, which was a distinct difference from the modified CSA flow. We analyzed the peak signal-to-noise ratio (PSNR) [
32] based on the numerical error and structural similarity index map (SSIM) [
33] based on the structural similarity of images as metrics to evaluate the SAR image quality. The PSNR was measured at 35.44 dB, which is higher than 30 dB, and the SSIM was measured at 0.9544.
For validation using actual SAR data, we used the RADARSAR-1 dataset, an image of Vancouver, Canada, from RADARSAT-1’s Fine Beam 2 [
31]. The software processing results using ARM Cortex-A53 were used as references to evaluate the image quality of the proposed hardware results.
Figure 12 shows the SAR images obtained after processing the actual SAR data. The PSNR and SSIM were measured at 33.43 dB and 0.9466, respectively. Compared with the results for point targets, PSNR and SSIM were slightly degraded because actual SAR data contained clutter and interference. However, the image quality was still good, as shown in
Figure 12.
Table 2 presents the evaluation results of the CSA execution time. The acceleration results obtained using the CSA-based SAR processor and ARM Cortex-A53 are presented for various image sizes. According to the modified CSA flow, all CSA operations were accelerated by the CSA-based SAR processor. The experimental results indicate that the execution time decreased from about 267.56 s to 1.96 s for 4096 × 4096-pixel image, resulting in a 136.2-fold acceleration.
Table 3 compares the execution times of the proposed CSA-based SAR processor with previous studies performed on various computing platforms. Because the sizes of the images presented by each study were different, the execution time per pixel is additionally presented for comparison, and the unit is nanoseconds (ns). The authors of [
14] achieved the fastest speed using a combination of a CPU and GPU. However, the power consumption was 345 W, which is unsuitable for small platforms. In [
16], the authors proposed an array-based heterogeneous processor. Each PE cell performed a four-point butterfly operation, and 512 PE cells were used. Furthermore, additional multipliers were used to perform the phase compensation operation. However, the proposed design did not use other resources for phase compensation operations and used 128 PE cells. Assuming that the 4-point butterfly unit used in [
16] used 4 adders and 3 multipliers, 2048 adders and 1536 multipliers were used. In contrast, each PE cell of the proposed design used 1 adder and 1 multiplier; thus, 128 adders and 128 multipliers were used. The difference in the number of calculators used in the PE cell was 16 times for the adder and 12 times the multiplier, which led to a significant difference in execution time (approximately 3.19 times). Therefore, the proposed design could achieve a faster speed per unit area than that in [
16]. A comparison of the results is presented in
Table 4. Compared with [
12,
15,
17], the proposed architecture achieved a higher speed and consumed less power, making it suitable for small SAR platforms.
5. Conclusions
In this study, we proposed a CSA-based SAR processor based on a systolic array. The CSA-based SAR processor supports FFT and phase compensation operations. The multiplier used for the FFT operation was designed to be shared for phase compensation. Therefore, an additional multiplier for phase compensation was not required, and the area efficiency could be achieved. The proposed architecture is suitable for a modified CSA flow, which changes the order of transpose operation from the traditional CSA flow. We confirmed the imaging result using actual SAR data. The proposed processor was implemented using 17,326 CLB registers, 31,025 CLB LUTs, 4 block RAMs, and 78 DSPs on a Xilinx Zynq UltraScale+ FPGA device. Compared with the execution time of the ARM Cortex-A53-based software for an image of 4096 × 4096 pixels, we achieved an approximately 136.2-fold acceleration. We computed the execution time normalized by the number of pixels and compared the results with those of previous studies. Compared with previous studies conducted on various platforms, the CSA-based SAR processor achieved the fastest speed per the number of calculators or power.
Future research will involve the implementation of ASIC usable in small SAR platforms based on the proposed design verified through FPGA. In addition, we expect to implement this model in more power-efficient platforms.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}