1. Introduction
Facial representation has always been a core part of computer vision. One of its applications, face detection, was one of the most successful image analysis tasks in the early years of computer vision [
1]. Since then, facial representation applications have grown to include many security [
2,
3], forensics [
4], and even medical [
5] applications. Facial representation efforts continue to motivate innovations in the computer vision field such as federated learning advancements [
6,
7,
8] or the introduction of angular softmax loss [
9]. The face is a core element of identity and expression. People are identified primarily through their faces and communicate verbally and non-verbally through facial movements. Correspondingly, it is critical for machines attempting to interact with people to have an effective way of representing their faces.
Unexpected changes to the environment often have an adverse effect on computer vision tasks. Implementations that have vastly different background conditions from training data often generalize poorly [
10]. These conditions can include variations in occlusion, lighting, background, pose, and more. Mitigating this by collecting target domain data is often costly or impractical. As a result, many efforts have been made to look for ways to mitigate these conditions without additional data. There have been more generalized attempts to address this domain shift [
11] as well as specific models and methods tailored to specific tasks.
As a result of these challenges, many authors have worked to overcome these difficulties in various facial tasks [
12,
13,
14,
15,
16]. Facial geometry is a representation of the physical layout of the face. This is a complex 3D structure that has some unique properties and can be simplified and represented in a variety of ways. Facial ‘keypoint’ detection is the process of detecting the location of various important parts of the face. The layout of these keypoints can be used to modify, reconstruct, or identify a face [
17,
18,
19], whereas keypoint-based modeling can be useful for many tasks such as facial expression recognition [
20], the lack of fine-grained pixel information makes it unsuitable for such tasks as spoofing or deepfake detection. Another approach uses 3D morphable models to construct a facial geometry representation, where a given face is represented by a combination of various template models [
17,
21,
22,
23]. These models can be further modified for desired deformations. However, morphable models have difficulty when encountering occluded or angled views of the face [
24]. Although not fully symmetric, most faces have a certain degree of symmetry that can be exploited for facial representation tasks. This can be used to compensate for occluded information [
25] or even to perform recognition with half faces [
26]. We seek to capture facial geometry to create a consistent representation irrespective of these changes. Three use cases that can be used to further evaluate the capability of our facial geometry learning are face anti-spoofing, facial expression recognition, and deepfake detection.
The identity component of facial representation corresponds to face recognition and re-identification tasks. These tasks are extensively integrated into biometric security systems [
27]. These systems represent an effective method of limiting access based on identity without the need or vulnerability of physical or password-based systems, whereas current face recognition methods generally operate at a high level of accuracy [
28], these systems present a vulnerability to spoofing attacks. Spoofing attacks come in many forms, but the most common are photo presentation, video replay, and mask attacks. The reason for this vulnerability is that face recognition systems are trained to differentiate between different identities, not to identify false presentations. If an adversary can use a presentation attack to fool systems, the security of face-recognition-dependent systems may be compromised. The threat of these attacks has motivated many works of research into the field of face anti-spoofing (FAS); whereas the facial domain is the same, the focus for FAS shifts from a global identity to looking for subtle liveness cues such as fine-grained texture [
29] or style information [
12].
In addition to recognizing the person’s identity, facial representations are important for understanding the state of a person. People communicate in many more ways than just the words that are spoken. The expressions we present while interacting shape the context and meaning of the words we speak. To understand communication better, computer systems must learn to capture human emotions through expression. In addition, facial expression recognition (FER) can be used for certain medical diagnosis purposes [
30,
31]. The understanding of human emotion is heavily tied to multiple areas of the face: eyes, mouth, and between the eyes [
32]. A facial representation that understands these expressions must be able to capture these small details while having a larger structure to localize and relate these smaller features.
Human perception can be attacked with facial manipulation techniques. This incorporates many techniques through procedures such as face swapping and expression manipulation. We will refer to this category of attacks as deepfakes. Deepfakes present a substantial threat to various facets of our lives. False criminal or civil accusations can be made with fabricated video as proof. Conversely, the utility of video evidence deteriorates if false videos cannot be detected. Similarly, elections can be swayed by conjured footage of politicians engaged in incriminating activity. Detection of these attacks can be done through the examination of regions of abnormal distortion as well as inconsistencies in the face. When facial manipulation algorithms replace or modify facial identities or expressions, there are regions that span the gap between the modified content and the original content. Deepfake algorithms are trained to make these regions as realistic as possible, but such images are still artificial, generated content with the potential for an unnatural distribution of pixels. Examining the image with sufficient resolution makes it possible to detect the artifacts left by deepfake manipulations.
We propose a deep-learning facial representation architecture that uses a multi-level transformer model to capture fine-grained and global facial characteristics. To capture the physical characteristics of the target in each sample, our proposed method uses a Swin transformer [
33] which achieves state-of-the-art results in image classification tasks. The model yields facial embeddings which are used to perform various face-related tasks. Transformer architectures use attention mechanisms to represent relationships between model inputs. These architectures are effective modeling tools, but they suffer from resolution trade-offs due to their large size. The shifted window approach of our selected backbone addresses this problem allowing for better fine-grained modeling which is key for face representation tasks.
Figure 1 shows a high-level representation of the proposed hierarchical architecture compared to a standard ViT transformer model. To further validate this capability, we apply this solution to three facial representation tasks: face anti-spoofing, facial expression recognition, and deepfake detection. Our performance studies show that we are able to robustly detect spoofing, deepfake attacks, and human facial expressions.
Our contributions are summarized as follows:
We propose a hierarchical transformer model to learn multi-scale details of face geometry. We structure this model to capture both fine-grained details and global relationships.
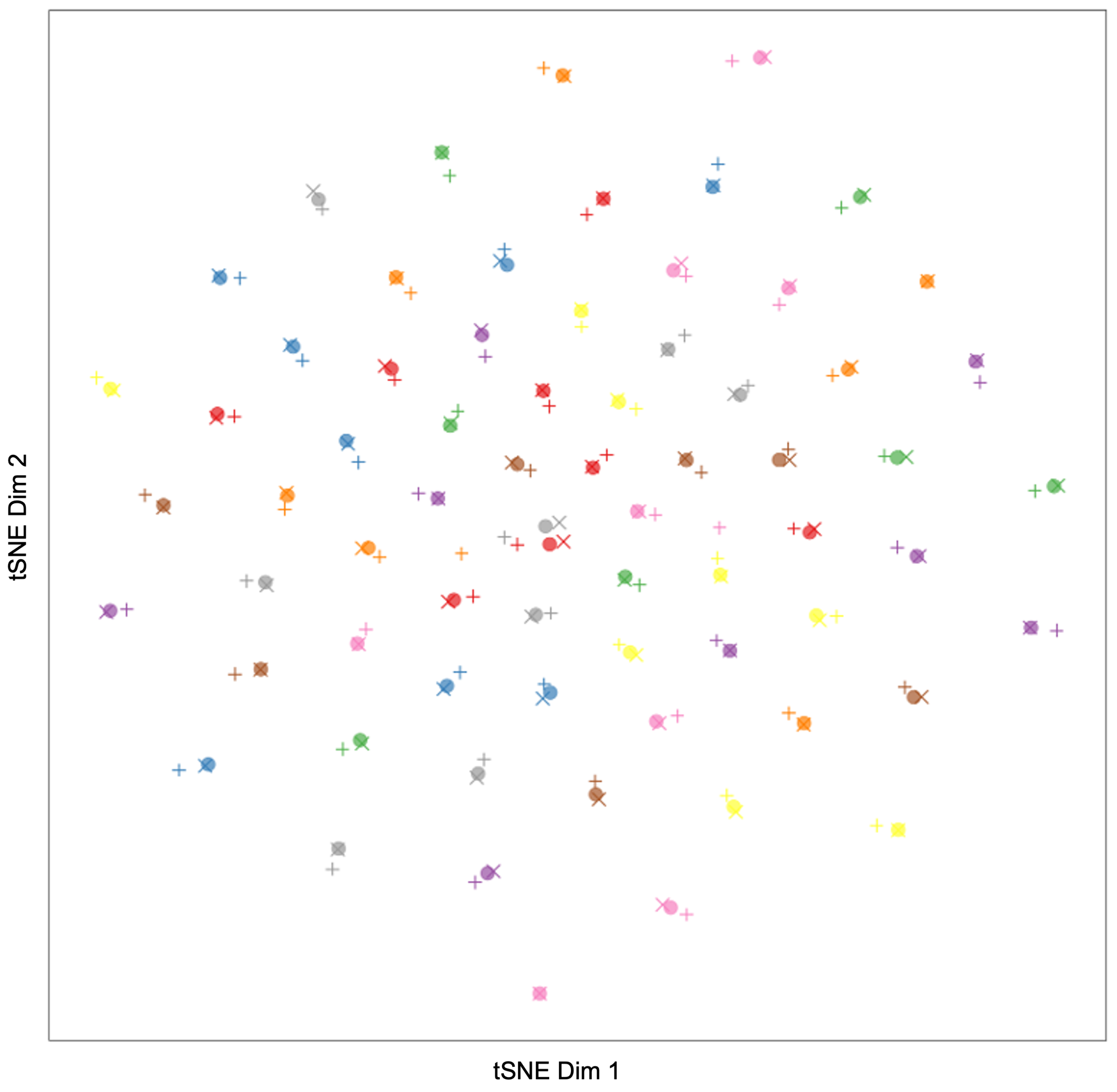
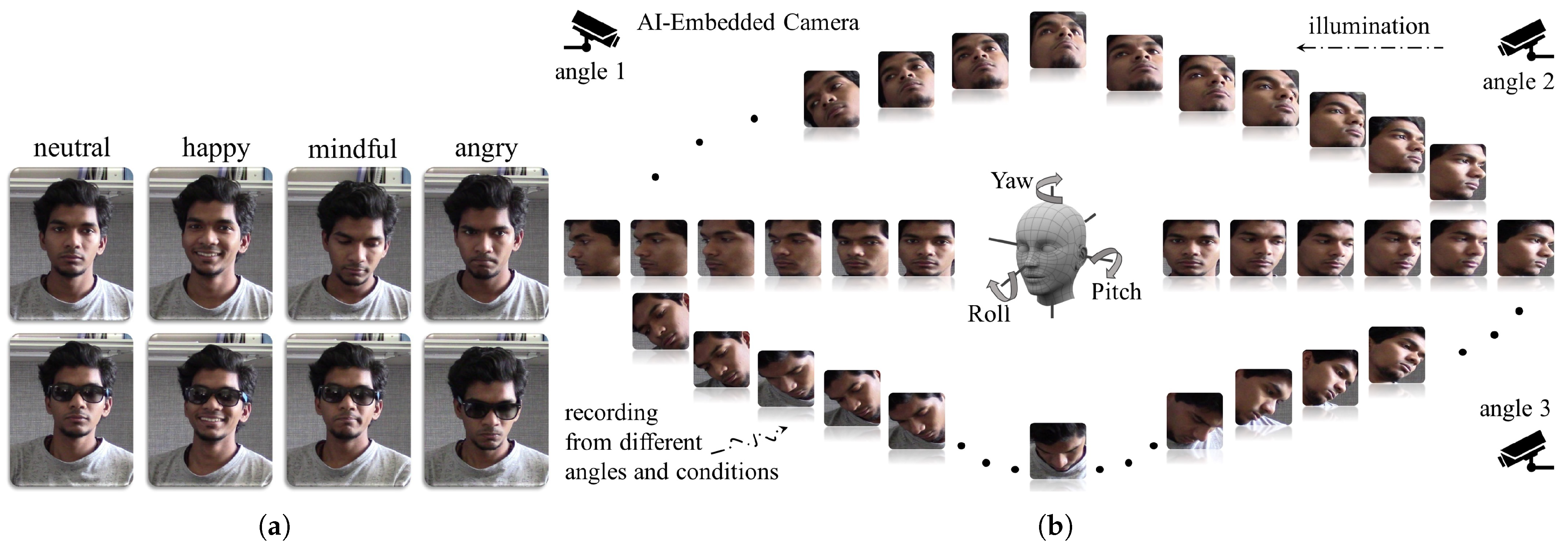
We validate the geometry learning capability of our facial representation approach with various tests. This demonstrates its resilience to rotation, occlusion, pose, and background variation.
We apply and validate the model on three facial representation use cases. The three tasks, face anti-spoofing, facial expression recognition, and deepfake detection, highlight the robustness and versatility of facial geometry representation.
2. Related Work
Various early works involving facial representation used Haar-like features for face detection. The Haar sequence, proposed by Alfred Haar [
34], forms the basis for Haar wavelet functions. These functions, which take the shape of a square wave over the unit interval, have been used to detect transitions such as tool failures [
35]. Papageorgiou et al. and others [
36,
37,
38] use this property on images to find boundaries for object detection. Viola and Jones [
39] use a similar technique with a cascaded model for face detection. Various adaptions have been made on this such as by Mita et al. [
40] which addresses correlated features and Pham et al. [
41] which uses statistics for feature selection.
As convolutional neural network (CNN) models permeated computer vision, various CNN solutions for facial representation emerged [
42,
43,
44,
45]. The increased depth and number of parameters along with CNN strengths of locality and translation invariance have facilitated more sophisticated tasks such as re-identification and face recognition. The increased depth of CNNs allowed for more robust and sophisticated tasks, but tracing gradients through a large number of layers created an exploding/vanishing gradient effect. This effect limited gradient transmission to deeper layers, obstructing training and convergence of models. The introduction of residual connections [
46] between layers alleviated this issue and allowed for deeper, more sophisticated ResNet architectures. However, even with this improvement, CNNs still suffer from some drawbacks. Their pooling layers can be lossy, and the convolutional architecture makes relationships between distant image regions more difficult to model.
In addition to their success in NLP, transformers have shown promising results for image processing. The capability to model image relationships with attention allows the model to focus on key regions and relationships in the image. It also better facilitates the modeling of relationships between more distant image regions. The visual transformer (ViT) [
47] achieved state-of-the-art performance on image classification tasks. Due to the quadratic growth of attention parameters based on the input size, Dosovitskiy et al. structured ViT to accept relatively large patch sizes of
. Various modifications have been made to utilize visual transformers for tasks such as object detection [
48,
49,
50]. Specifically, two problems have emerged to expand the capability of visual transformers. The first is how to create different-scale feature maps to facilitate tasks such as segmentation and detection. The second is how to attend to fine-grained details without losing global relationships or overly increasing the number of parameters. The solution to both of these problems has appeared in multi-level models. Three such models [
33,
51,
52] have appeared and each performs the following tasks in different ways. They attend to fine-grained information locally, while attending to global relationships on a coarser scale.
Structure learning problems in images require learning information from granular-level data. Transformer models provide fine-grained representation learning with attention mechanisms. The quadratic cost of attention parameters inspires many solutions to address the large size and unique challenges of images [
53,
54,
55,
56,
57]. The problem distills to effectively modeling fine-grained details while preserving global relationships.
One of the simplest and most common adaptations has been the ViT model [
47]. This model splits an image into 256 patches and feeds each patch as an input into a transformer encoder. The large patch sizes needed to limit the number of attention parameters deteriorate the model’s effectiveness on finer tasks such as small object detection or FAS. The Swin transformer [
33] is able to shrink the size of these patches by limiting attention to local areas. It then achieves global representation by shifting the boundaries of these areas and gradually merging patches together. These smaller patch sizes make it ideal for more fine-grained tasks as it allows the model’s parameters to attend to smaller details.
Much of the recent literature on FAS has focused on building models that achieve domain generalization, attack type generalization, or both. Jia et al. [
13] use an asymmetric triplet loss to group live embeddings from different domains to facilitate consistent live embeddings in new domains. Wang et al. [
58] use CNN autoencoders with decoders to separate the embedding of live and spoof features to different modules. Wang et al. [
12] also use CNN networks to separate style features and perform contrastive learning to suppress domain-specific features; whereas CNN architectures can capture locality information well, their global representations are limited. Similarly, certain methods such as PatchNet [
29] forgo global information entirely and opt to focus anti-spoofing efforts on texture information from small patches of an image. On the other hand, there are a couple of anti-spoofing methods that make use of transformer architectures for FAS tasks. George et al. [
59] use pretrained vision transformer models for zero-shot FAS capabilities. Similarly, Wang et al. [
60] use a transformer model modified to capture temporal information for spoof detection. The large patch sizes of ViT [
47] limit the fine-grained representation of these ViT-based models.
The challenge of facial expression recognition (FER) comes from two directions. First, models must ensure expression recognition is not tied to the identity of the individual with the expression. Second, models must learn to navigate intra-expression variance and inter-expression similarities. Zhang et al. [
61] separate the identity of the face representation from the facial expression by using a ResNet-based deviation module to subtract out identity features. Ruan et al. [
62] use a feature decomposition network and feature relation modules to model the relationships between expressions and mitigate the challenges related to intra-expression and inter-expression appearance. Similar to previous models, these models lack global connections and are therefore limited in their corresponding modeling ability. Xue et al. [
32] use a CNN network to extract features and relevant patches and then feed them through a transformer encoder to model relations between the features and classify the image. Hong et al. [
63] use a video-modified Swin transformer augmented with optical flow analysis to detect facial microexpressions. The success of this approach on that subset of expression recognition is promising for the broader use of multi-level transformer models in modeling facial expressions.
Zhao et al. [
64] look at the deepfake detection problem as a fine-grained texture classification problem. They use attention with texture enhancement to improve detection. Their work sheds light on the utility of effectively modeling fine-grained image details when performing deepfake detection. This emphasis aligns with multiple other approaches which rely on fine-grained artifacts for detection [
65,
66,
67]. In contrast, Dong et al. [
68] compare identities of inner and outer face regions for their detection. These competing needs highlight the value of a combined representation of fine-grained and global relationships. There has also been some research that relates deepfake detection to expression detection. Mazaheri and Roy-Chowdhury [
69] use FER to localize expression manipulation, whereas Hosler et al. [
70] use discrepancies between detected audio and visual expressions to detect deepfakes. These correlations indicate that a similar model and approach may be appropriate for both problems; whereas Ilyas et al. [
71] performed a combined evaluation on the audio and visual elements of a video with a Swin transformer network, it remains to be seen if the task can be performed effectively solely on image elements.
3. Proposed Method
Facial geometry consists of both smaller local details and larger shape and positioning. To model these well, we implement a multi-level transformer architecture that captures fine-grained details at lower layers and regional relationships at higher layers. These layers are connected hierarchically to combine these features into a complete representation. The structure of the hierarchy is determined by two factors: model depth and window size. The model depth is composed of multiple transformer blocks divided by patch merging layers as shown in
Figure 2. Each transformer block consists of a multi-headed self-attention (MSA) layer and a multi-layer perceptron each with layer normalization and a skip connection. The increasing scale of these layers captures different levels of geometry features throughout the model. The window size is the number of inputs along one dimension which are attended to by each input. For example, with a window size of 7, each input would attend to a
window of inputs. In addition, the window size hyperparameter also determines the number of windows at each layer by virtue of it dividing up the number of inputs at each layer. Thus, if a layer with window size 7 receives a
input, it would contain 64 attention windows arranged in an
pattern. This change in window count affects how quickly the patch merging process achieves global attention since the number of windows is quartered at every patch merging stage.
Figure 3 visualizes the feature scales using a patch size of 7.
As described by Vaswani et al. [
72], MSA can be defined by the expression
where
Q,
K, and
V refer to the query, key, and value vectors derived from each input by matrix multiplication. Each
W variable represents a different set of weights learned during training.
For each of the facial geometry tasks, the initial embeddings are created by dividing the input image into
patches. All three channels of the pixel values for these patches are concatenated into a 48-length vector. Following Dosovitskiy et al. [
47], this vector is embedded linearly and given a positional encoding according to this equation:
Each
x term represents one element of the patch pixel value vector,
is the linear embedding matrix,
is the positional encoding term, and
represents the final patch embedding. After the linear embedding and positional encoding, these patches are input into the transformer. The attention is localized to a
window of patches, where
M is the window size. These windows are connected through a process in which window borders are shifted in subsequent layers. This places previously separated nearby patches into the same window, allowing for representation across patches, as shown in
Figure 4. As the features move through the layers, these patches are gradually merged, reducing the resolution of the features while broadening the scope of the local windows. This continues until the entire representation fits within one window. Algorithm 1 breaks down this process in a step-by-step manner. Finally, the embedding is sent through a classification head according to the task required.
| Algorithm 1 Face geometry representation using hierarchical shifted windows architecture |
- Input:
P = {} where is the nth patch of image x. = learned linear embedding matrix. = positional encoding matrix. MSA, SW-MSA = multiheaded self-attention and shifted window MSA. MLP = multi-layer perceptron LN = layer normalization - Output:
Face Representation Classification - 1:
fordo ▹ For each patch - 2:
flatten(p) - 3:
- 4:
- 5:
end for - 6:
X←P - 7:
for block pair in transformer blocks do - 8:
X← MSA(LN(X)) + X - 9:
X← MLP(LN(X)) + X - 10:
X← SW-MSA(LN(X)) + X - 11:
X← MLP(LN(X)) + X If at block pair 1, 2, 11: - 12:
for do - 13:
merge() - 14:
end for - 15:
end for
|
3.1. Use Cases
For the face anti-spoofing problem, we hypothesize that spoof-related features can be found in both the fine-grained details and the global representations. The fine-grain details include unnatural texture, reflection, or lighting. Global cues involve unnatural bowing or skew. We use our hierarchical architecture as a backbone for binary classification. The detailed representation layers give us the capability to detect based on fine cues, whereas the coarser layers enable the discovery of global spoofing cues. For training and inference, live and spoof images are sampled from their corresponding videos and classified through the model.
Similarly, deepfake detection also makes use of these diverse layers. Deepfake cues can be found both in fine-grained textures as demonstrated by Zhao et al. [
64] or in larger representations, as shown by the regional identity discrepancy work of Dong et al. [
68]. As with the FAS problem, we use a classification of image frames with our hierarchical architecture to detect deepfake attacks.
Facial expression recognition is somewhat different as most of the clues come from certain key regions (eyes, mouth, brow) [
32]. However, these regions are not always located exactly in the same location, and thus localizing representations are needed. Furthermore, the combination of regional expressions is needed as different expressions can exhibit similar facial movements [
62]. By using the aforementioned hierarchical transformer in conjunction with a multi-label classifier, we can use the various layers of features together to address these detection challenges.
3.2. Training
For the FAS, FER, and deepfake experiments, we fine-tuned the Swin transformer using binary and multi-class cross-entropy loss with one additional fully connected layer. Cross-entropy is an entropy-based measurement of the difference between two inputs. Specifically, it refers to the amount of information required to encode one input using the other. The cross-entropy loss for a given class
n can be found by the equation
where
x,
y,
w, and
C represent the input, target, weight, and number of classes, respectively. For binary problems, this simplifies to
We selected the AdamW [
73] optimizer with
= 0.9,
= 0.999 and weight decay = 0.01 for all training purposes.







 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}