

PSNet: A Deep Learning Model-Based Single-Shot Digital Phase-Shifting Algorithm

Abstract
:1. Introduction
- (1)
- The proposed PSNet allows for the generation of N-step PS patterns using only one pattern. Additionally, the relative phases can be retrieved in a pixel-by-pixel fashion with a typical PS algorithm, which thus performs more robustly for regions with phase discontinuity.
- (2)
- Unlike previous works that rely only on image intensity loss (typically regraded as local temporal information), our method incorporates both local and global temporal information in the predicted fringe intensity, which significantly improves the accuracy of relative phase retrieval.
- (3)
- Since a single fringe pattern is sufficient for relative phase retrieval, the efficiency of the PS algorithm can be improved, which will benefit its real-time application.
2. Fundamental Principle of the Proposed Algorithm
2.1. Phase Shifting Technique
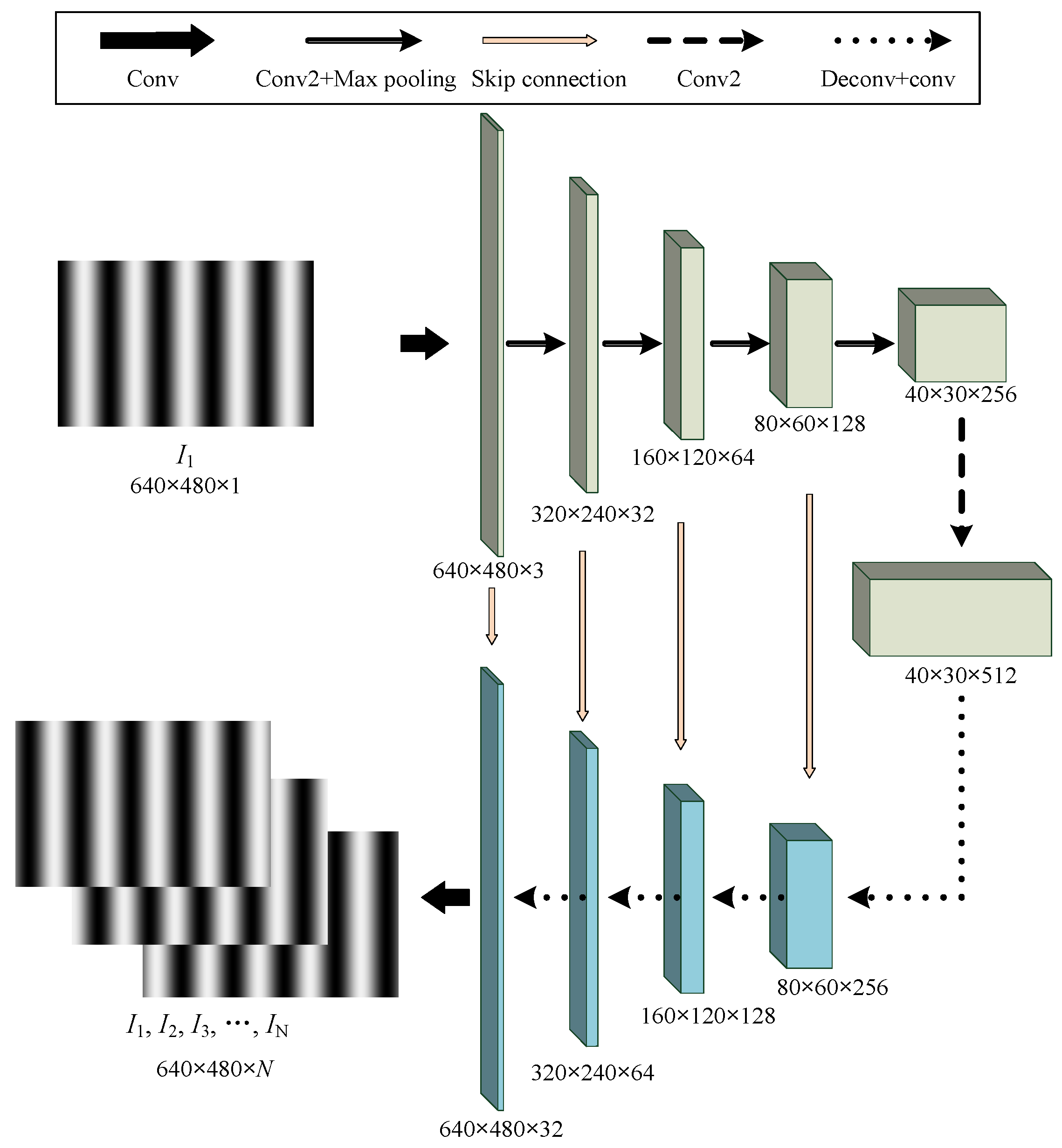
2.2. Architecture of the Proposed PSNet
2.3. Learning Temporal Dependency among the Predicted Sequence
2.4. Phase Unwrapping for Absolute Phase Retrieval
2.5. Dataset and Training
3. Results
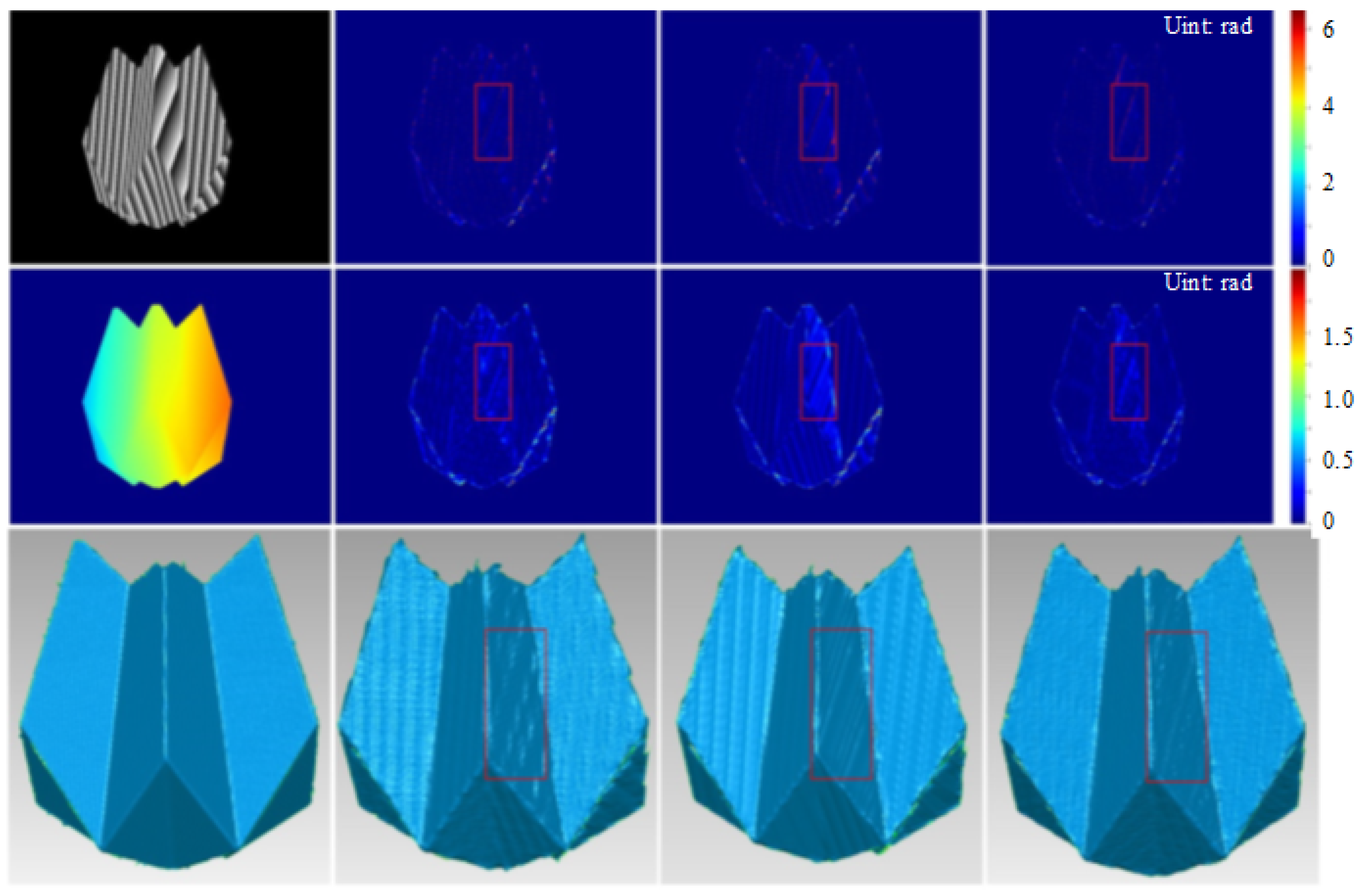
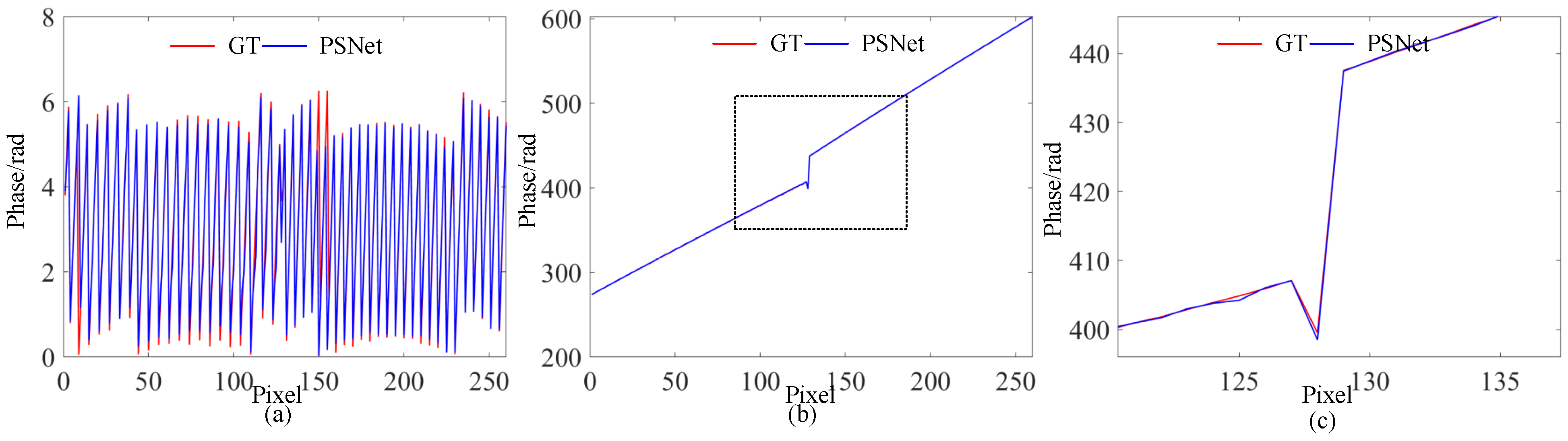
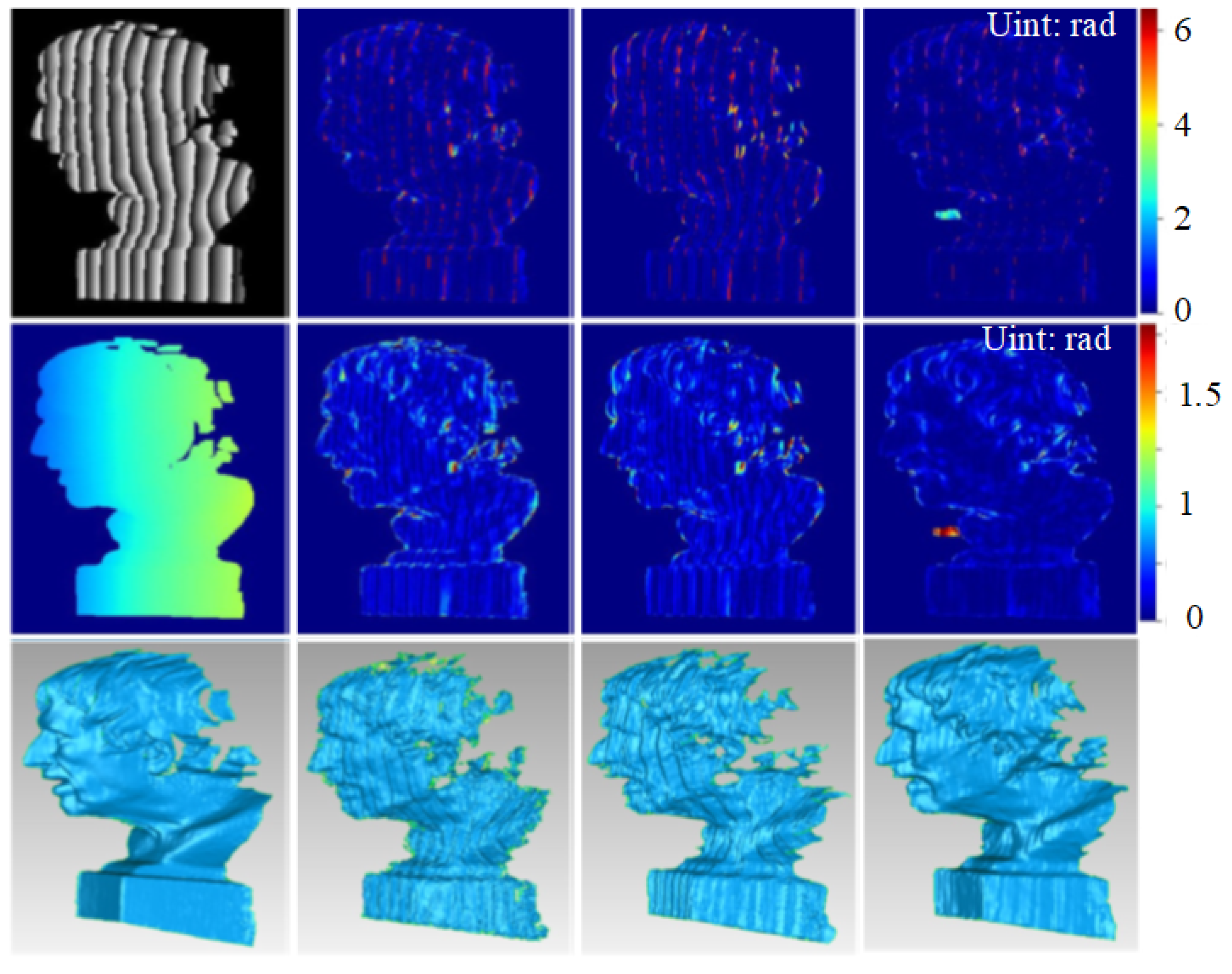
3.1. Evaluation on Simulation Data
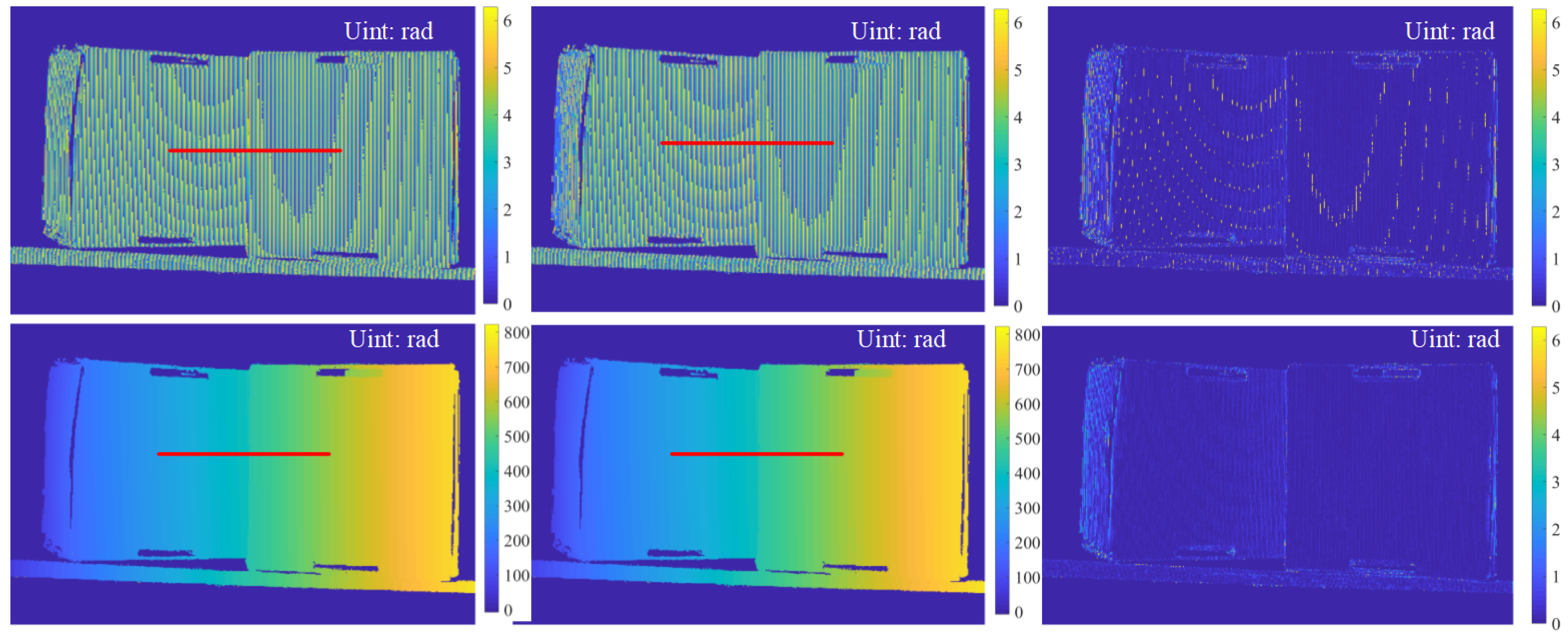
3.2. Evaluation on Real Data
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, Y.; Chen, Y.; Wang, J.; Sun, N.; He, A. Four-step spatial phase-shifting shearing interferometry from moiré configura-tion by triple gratings. Opt. Lett. 2012, 37, 1922–1924. [Google Scholar] [CrossRef] [PubMed]
- Brown, G.M.; Chen, F.; Song, M. Overview of three-dimensional shape measurement using optical methods. Opt. Eng. 2000, 39, 10–22. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, W.; Liu, G.; Song, L.; Qu, Y.; Li, X.; Wei, Z. Overview of the development and application of 3D vision measure-ment technology. J. Image Graph. 2021, 6, 1483–1502. [Google Scholar]
- Lin, S.; Zhu, H.; Guo, H. Harmonics elimination in phase-shifting fringe projection profilometry by use of a non-filtering algorithm in frequency domain. Opt. Express 2023, 31, 25490–25506. [Google Scholar] [CrossRef]
- Yuan, L.; Kang, J.; Feng, L.; Chen, Y.; Wu, B. Accurate Calibration for Crosstalk Coefficient Based on Orthogonal Color Phase-Shifting Pattern. Opt. Express 2023, 31, 23115–23126. [Google Scholar] [CrossRef]
- Wu, Z.; Lv, N.; Tao, W.; Zhao, H. Generic saturation-induced phase-error correction algorithm for phase-measuring profilometry. Meas. Sci. Technol. 2023, 34, 095006. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, H.; Lu, L.; Pan, W.; Su, Z.; Zhang, M.; Lv, P. 3D reconstruction of moving object by double sampling based on phase shifting profilometry. In Proceedings of the Ninth Symposium on Novel Photoelectronic Detection Technology and Applications, Hefei, China, 21–23 April 2023. [Google Scholar] [CrossRef]
- Jiang, H.; He, Z.; Li, X.; Zhao, H.; Li, Y. Deep-learning-based parallel single-pixel imaging for effi-cient 3D shape measurement in the presence of strong interreflections by using sampling Fourier strategy. Opt. Laser Technol. 2023, 159, 109005. [Google Scholar] [CrossRef]
- Srinivasan, V.; Liu, H.C.; Halioua, M. Automated phase-measuring profilometry of 3-D diffuse objects. Appl. Opt. 1984, 23, 3105–3108. [Google Scholar] [CrossRef]
- An, H.; Cao, Y.; Wang, L.; Qin, B. The Absolute Phase Retrieval Based on the Rotation of Phase-Shifting Sequence. IEEE Trans. Instrum. Meas. 2022, 71, 5015910. [Google Scholar] [CrossRef]
- Zeng, J.; Ma, W.; Jia, W.; Li, Y.; Li, H.; Liu, X.; Tan, M. Self-Unwrapping Phase-Shifting for Fast and Accurate 3-D Shape Measurement. IEEE Trans. Instrum. Meas. 2022, 71, 5016212. [Google Scholar] [CrossRef]
- Yu, H.; Chen, X.; Huang, R.; Bai, L.; Zheng, D.; Han, J. Untrained deep learning-based phase retrieval for fringe projection profilometry. Opt. Lasers Eng. 2023, 164, 107483. [Google Scholar] [CrossRef]
- Zhu, X.; Han, Z.; Song, L.; Wang, H.; Wu, Z. Wavelet based deep learning for depth estimation from single fringe pattern of fringe pro-jection profilometry. Optoelectron. Lett. 2022, 18, 699–704. [Google Scholar] [CrossRef]
- Tounsi, Y.; Kumar, M.; Siari, A.; Mendoza-Santoyo, F.; Nassim, A.; Matoba, O. Digital four-step phase-shifting technique from a single fringe pattern using Riesz transform. Opt. Lett. 2019, 44, 3434–3437. [Google Scholar] [CrossRef] [PubMed]
- Xu, C.; Cao, Y.; Yang, N.; Wu, H. Single-shot N-step Phase Measuring Profilometry based on algebraic addition and subtraction. Optik 2023, 276, 170665. [Google Scholar] [CrossRef]
- Feng, S.; Chen, Q.; Gu, G.; Tao, T.; Zhang, L.; Hu, Y.; Yin, W.; Zuo, C. Fringe pattern analysis using deep learning. Adv. Photon- 2019, 1, 025001. [Google Scholar] [CrossRef]
- Qian, J.M.; Feng, S.; Li, Y.; Tao, T.; Han, J.; Chen, Q.; Zuo, C. Single-shot absolute 3D shape measurement with deep-learning-based color fringe projection profilometry. Opt. Lett. 2020, 45, 1842–1845. [Google Scholar] [CrossRef]
- Chen, Y.; Shang, J.; Nie, J. Trigonometric phase net: A robust method for extracting wrapped phase from fringe patterns under non-ideal conditions. Opt. Eng. 2023, 62, 074104. [Google Scholar] [CrossRef]
- Song, Z.; Xue, J.; Xu, Z.; Lu, W. Phase demodulation of single frame projection fringe pattern based on deep learning. In Proceedings of the Vol. 12550: International Conference on Optical and Photonic Engineering (icOPEN 2022), Online, China, 24–27 November 2022; SPIE: Washington, DC, USA, 2022. [Google Scholar]
- Wan, M.; Kong, L.; Peng, X. Single-Shot Three-Dimensional Measurement by Fringe Analysis Network. Photonics 2023, 10, 417. [Google Scholar] [CrossRef]
- Nguyen, A.H.; Ly, K.L.; Li, C.Q.; Wang, Z. Single-shot 3D shape acquisition using a learning-based structured-light tech-nique. Appl. Opt. 2022, 61, 8589–8599. [Google Scholar] [CrossRef]
- Yu, H.; Chen, X.; Zhang, Z.; Zuo, C.; Zhang, Y.; Zheng, D.; Han, J. Dynamic 3-D measurement based on fringe-to-fringe transformation using deep learning. Opt. Express 2020, 28, 9405–9418. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Available online: https://www.autodesk.com/products/3ds-max (accessed on 10 April 2023).
- Wang, F.; Wang, C.; Guan, Q. Single-shot fringe projection profilometry based on deep learning and computer graphics. Opt. Express 2021, 29, 8024–8040. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Wang, S.; Li, Q.; Li, B. Fringe projection profilometry by conducting deep learning from its digital twin. Opt. Express 2020, 28, 36568–36583. [Google Scholar] [CrossRef] [PubMed]
- Qi, Z.; Wang, Z.; Huang, J.; Xing, C.; Duan, Q.; Gao, J. Micro-Frequency Shifting Projection Technique for Inter-reflection Remov-al. Opt. Express 2019, 27, 28293–28312. [Google Scholar] [CrossRef] [PubMed]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 2366–2369. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Image Similarity | Phase Accuracy | |
|---|---|---|---|
| PSNR/dB | SSIM/% | MAE/Rad | |
| FPTNet | 41.3 | 97.2 | 0.217 |
| Ours | 43.5 | 98.2 | 0.133 |
| Methods | Traditional PS | FPTNet | Ours |
|---|---|---|---|
| Processing time/s | 0.03 | 0.04 | 0.07 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, Z.; Liu, X.; Pang, J.; Hao, Y.; Hu, R.; Zhang, Y. PSNet: A Deep Learning Model-Based Single-Shot Digital Phase-Shifting Algorithm. Sensors 2023, 23, 8305. https://doi.org/10.3390/s23198305
Qi Z, Liu X, Pang J, Hao Y, Hu R, Zhang Y. PSNet: A Deep Learning Model-Based Single-Shot Digital Phase-Shifting Algorithm. Sensors. 2023; 23(19):8305. https://doi.org/10.3390/s23198305
Chicago/Turabian StyleQi, Zhaoshuai, Xiaojun Liu, Jingqi Pang, Yifeng Hao, Rui Hu, and Yanning Zhang. 2023. "PSNet: A Deep Learning Model-Based Single-Shot Digital Phase-Shifting Algorithm" Sensors 23, no. 19: 8305. https://doi.org/10.3390/s23198305
APA StyleQi, Z., Liu, X., Pang, J., Hao, Y., Hu, R., & Zhang, Y. (2023). PSNet: A Deep Learning Model-Based Single-Shot Digital Phase-Shifting Algorithm. Sensors, 23(19), 8305. https://doi.org/10.3390/s23198305