
Cluster Content Caching: A Deep Reinforcement Learning Approach to Improve Energy Efficiency in Cell-Free Massive Multiple-Input Multiple-Output Networks



Abstract
:1. Introduction
- In this paper, a new total EE model of a cache-assisted CF-mMIMO system is established, which has the following advantages: the introduction of low-resolution DAC can improve EE; UE-centric cache deployment can provide a better user experience; and considering the influence of different resolution converters on EE, it is more suitable for practical use;
- A deep deterministic policy gradient (DDPG) algorithm is proposed to solve the joint optimization problem of content cache, AP clustering, and DAC resolution, and it can find the global optimal decision for maximizing the EE performance in cache-assisted CF-mMIMO networks;
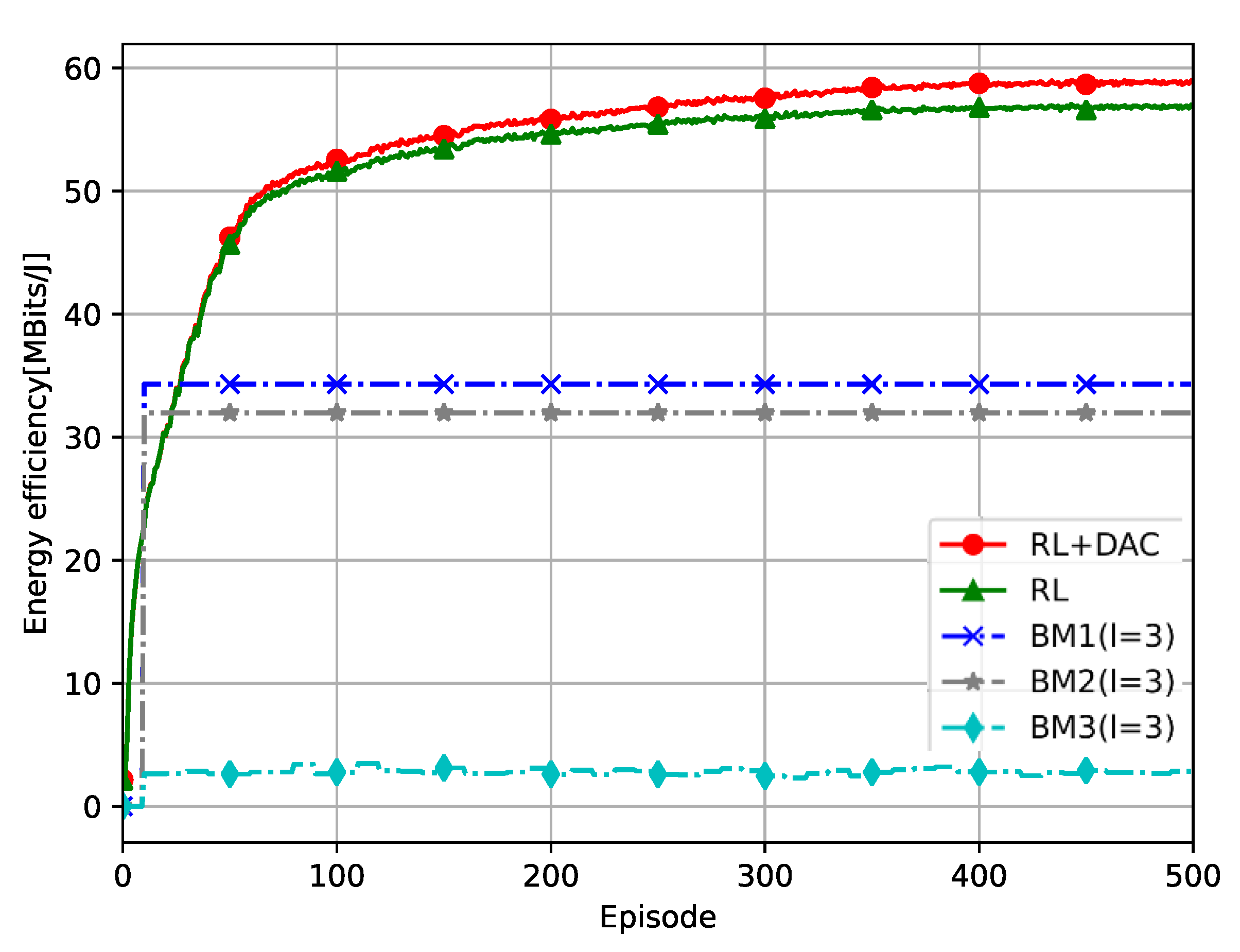
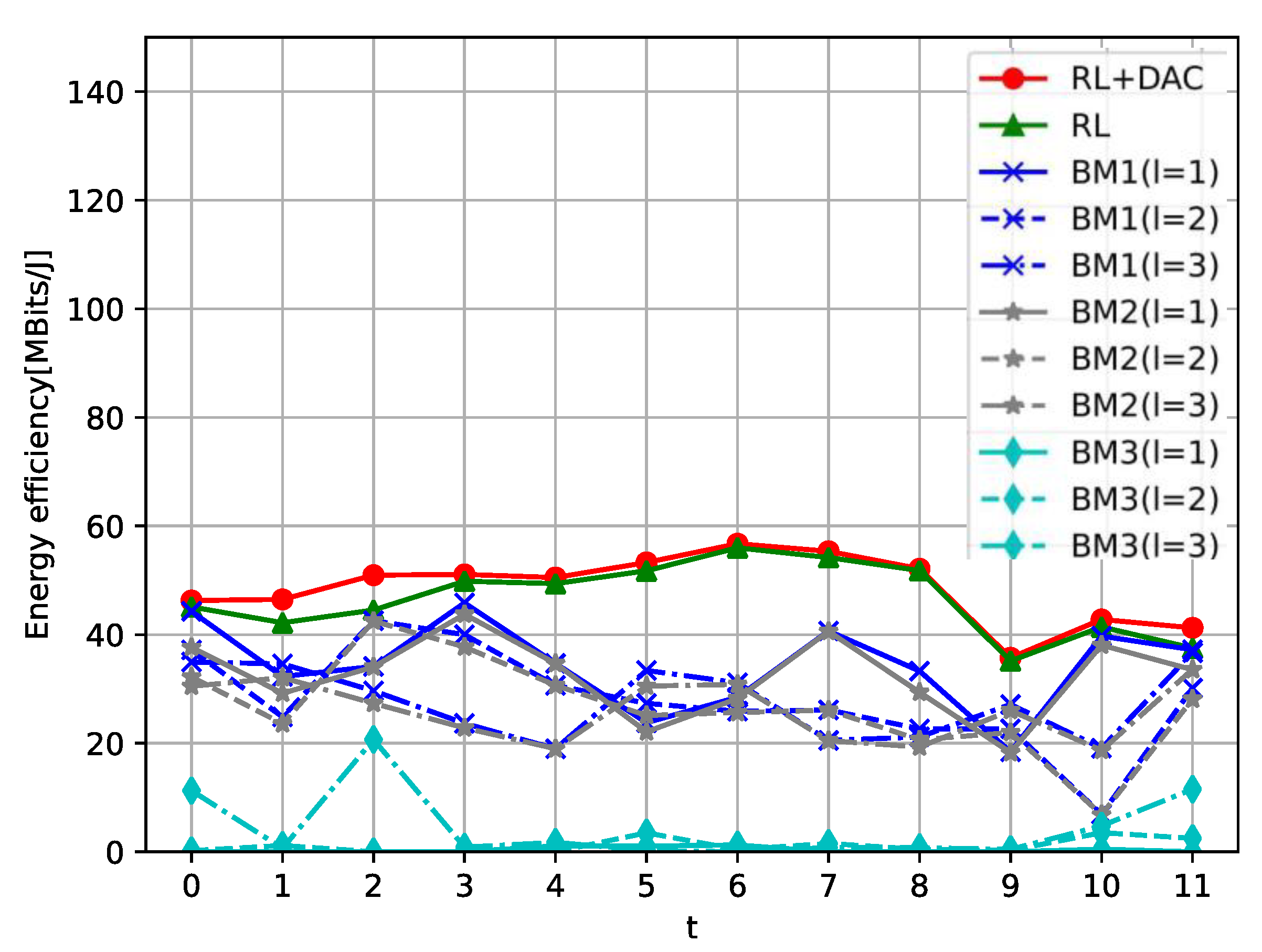
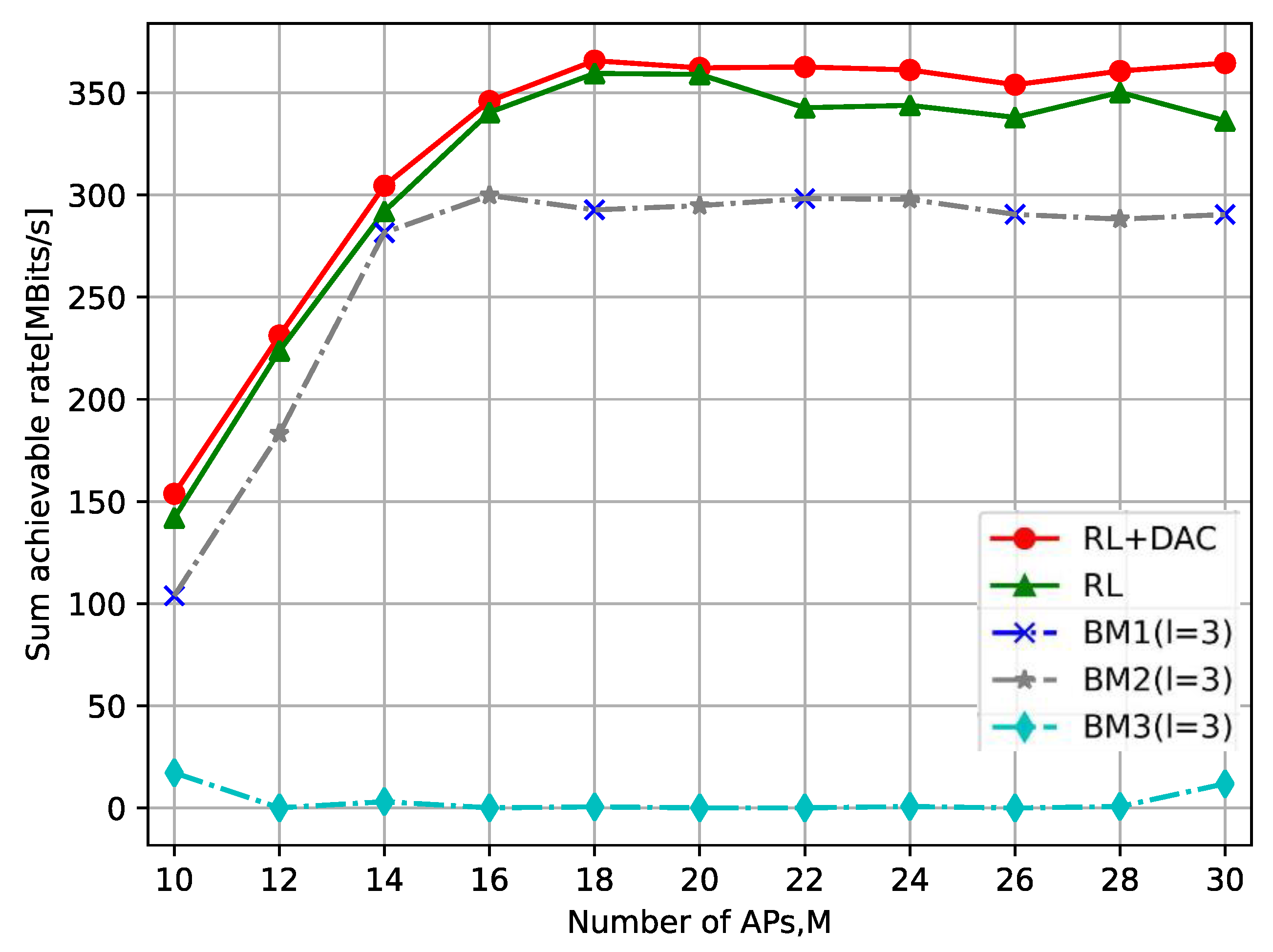
- We compare and discuss the influence of DAC resolutions, the numbers of UEs, and APs on the EE performance. Moreover, the proposed DDPG method is compared with the benchmark methods, such as clustering based on signal-to-interference noise ratio (SINR) and caching strategies based on content popularity. By exploiting the intelligent design, its EE is not only significantly better than the benchmark (BM) methods but also better than the DDPG method based on the joint content cache and AP clustering.
2. System Model
2.1. Signal Model
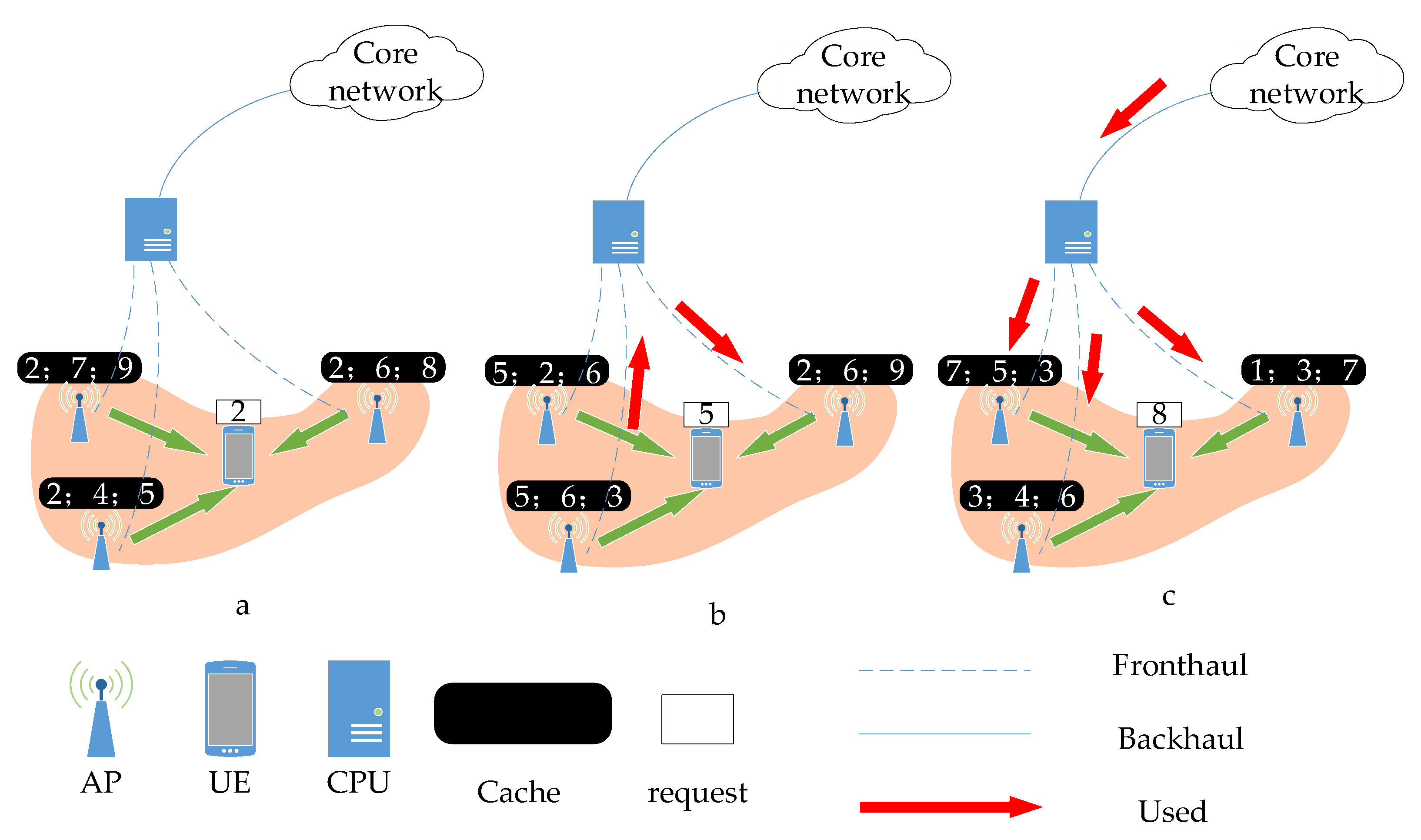
2.2. Caching Model
2.3. Low-Resolution DAC Model
3. The EE Model and Problem Formulation
3.1. The System Sum Rate
3.2. Power Consumption
3.3. Problem Formulation
4. Deep Reinforcement Learning Method
4.1. Action, State, and Reward
4.2. Deep Deterministic Policy Gradient Approach
| Algorithm 1 DDPG Algorithm Procedure |
| initialization |
| in the target network |
| 3: for plot = 1 to Plot do |
| 4: for timeslot = 1 to T do |
| 10: in the network of actors and critics according to the gradient |
| 11: in the target network according to the |
| 12: end for |
| 13: end for |
4.3. Computational Complexity
5. Simulation Results
5.1. Simulation Settings
- BM1: clustering policy based on the SINR ( APs to which the k-th UE is connected is the l with the highest SINR) and caching policy based on local popularity (in the UE served by the m-th AP, the most popular N files are cached on the m-th AP);
- BM2: clustering strategy based on SINR (same as BM1) and caching strategy based on network popularity (caching the N most popular files across all UEs in all APs);
- BM3: cache-based clustering strategy (each UE is connected to APs, and its cache is the content request that best matches each UE in the previous slot) and network-based caching strategy (same as BM2).
5.2. Numerical Results Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AP | Access Point |
| EE | Energy Efficiency |
| mMIMO | Massive Multiple-Input Multiple-Output |
| CF-mMIMO | Cell-free Massive Multiple-Input Multiple-Output |
| DDPG | Deep Deterministic Policy Gradient |
| BS | Base Station |
| DAC | Digital-to-Analog Converter |
| UE | User Equipment |
| CPU | Central Processing Unit |
| BM | Benchmark |
| SE | Spectrum Efficiency |
| DRL | Deep Reinforcement Learning |
| CSI | Channel Statement Information |
References
- Rydning, J. IDC Worldwide Global DataSphere IoT Device and Data Forecast, 2019–2023; IDC: Needham, MA, USA, 2019; p. 3. [Google Scholar]
- Choi, N.; Guan, K.; Kilper, D.C.; Atkinson, G. In-network caching effect on optimal energy consumption in content-centric networking. In Proceedings of the IEEE International Conference on Communications, Ottawa, ON, Canada, 10–15 June 2012; pp. 2889–2894. [Google Scholar]
- Llorca, J.; Tulino, A.M.; Guan, K.; Esteban, J.; Varvello, M.; Choi, N.; Kilper, D.C. Dynamic in-network caching for energy efficient content delivery. In Proceedings of the 32nd IEEE International Conference on Computer Communications, Turin, Italy, 14–19 April 2013; pp. 245–249. [Google Scholar]
- Li, J.; Liu, B.; Wu, H. Energy-efficient in-network caching for content-centric networking. IEEE Commun. Lett. 2013, 17, 797–800. [Google Scholar] [CrossRef]
- Golrezaei, N.; Shanmugam, K.; Dimakis, A.G.; Molisch, A.F.; Caire, G. FemtoCaching: Wireless video content delivery through distributed caching helpers. Proceedings of The 31st Annual IEEE International Conference on Computer Communications, Orlando, FL, USA, 25–30 March 2012; pp. 1107–1115. [Google Scholar]
- Bastug, E.; Bennis, M.; Debbah, M. Living on the edge: The role of proactive caching in 5G wireless networks. IEEE Commun. Mag. 2014, 52, 82–89. [Google Scholar] [CrossRef]
- Xu, Y.; Li, Y.; Wang, Z.; Lin, T.; Zhang, G.; Ci, S. Coordinated caching model for minimizing energy consumption in radio access network. In Proceedings of the IEEE International Conference on Communications, Sydney, Australia, 10–14 June 2014; pp. 2406–2411. [Google Scholar]
- Poularakis, K.; Iosifidis, G.; Sourlas, V.; Tassiulas, L. Multicast-aware caching for small cell networks. In Proceedings of the IEEE Wireless Communications and Networking Conference, Istanbul, Turkey, 6–9 April 2014; pp. 2300–2305. [Google Scholar]
- Rusek, F.; Persson, D.; Lau, B.K.; Larsson, E.G.; Marzetta, T.L.; Edfors, O.; Tufvesson, F. Scaling up MIMO: Opportunities and challenges with very large arrays. IEEE Signal Process. Mag. 2013, 30, 40–60. [Google Scholar] [CrossRef]
- Lopezperez, D.; Roche, G.; Kountouris, M.; Quek, T.; Jie, Z. Enhanced inter-cell interference coordination challenges in heterogeneous networks. IEEE Wirel. Commun. 2011, 18, 22–30. [Google Scholar] [CrossRef]
- Larsson, E.G.; Edfors, O.; Tufvesson, F.; Marzetta, T.L. Massive MIMO for next generation wireless systems. IEEE Commun. Mag. 2014, 52, 186–195. [Google Scholar] [CrossRef]
- Gesbert, D.; Hanly, S.; Huang, H.; Shitz, S.S.; Simeone, O.; Yu, W. Multi-cell MIMO cooperative networks: A new look at interference. IEEE J. Sel. Areas Commun. 2010, 28, 1380–1408. [Google Scholar] [CrossRef]
- Ammar, H.A.; Adve, R.; Shahbazpanahi, S. User-centric cell-free massive MIMO networks: A survey of opportunities, challenges and solutions. IEEE Commun. Surv. Tutor. 2022, 24, 611–652. [Google Scholar] [CrossRef]
- Ngo, H.Q.; Ashikhmin, A.; Yang, H.; Larsson, E.G.; Marzetta, T.L. Cell-free massive MIMO versus small cells. IEEE Trans. Wirel. Commun. 2017, 16, 1834–1850. [Google Scholar] [CrossRef]
- Wang, K.; Chen, Z.; Liu, H. Push-based wireless converged networks for massive multimedia content delivery. IEEE Trans. Wirel. Commun. 2014, 13, 2894–2905. [Google Scholar]
- Peng, M.; Sun, Y.; Li, X.; Mao, Z.; Wang, C. Recent advances in cloud radio access networks: System architectures, key techniques, and open issues. IEEE Commun. Surv. Tutor. 2016, 18, 2282–2308. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, J.; Björnson, E.; Wang, S.; Xing, C.; Ai, B. Wireless caching: Cell-free versus small cells. In Proceedings of the IEEE/CIC International Conference on Communications in China, Xiamen City, China, 28–30 July 2021; pp. 1–6. [Google Scholar]
- Peng, Y.; Tan, F.; Liu, Q. Energy-efficient content caching strategy in cell-free massive MIMO networks with reinforcement learning. In Proceedings of the 2023 IEEE International Symposium on Broadband Multimedia Systems and Broadcasting (BMSB), Beijing, China, 14–16 June 2023; pp. 1–3. [Google Scholar]
- Nguyen, M.-H.T.; Bui, T.T.; Nguyen, L.D. Real-time optimized clustering and caching for 6G satellite-UAV-terrestrial networks. IEEE Trans. Intell. Transp. Syst. 2023, 1–11. [Google Scholar] [CrossRef]
- Chaowei, W.; Ziye, W.; Lexi, X. Collaborative Caching in Vehicular Edge Network Assisted by Cell-Free Massive MIMO. Chin. J. Electron. 2023, 33, 1–13. [Google Scholar]
- Chuang, Y.-C.; Chiu, W.-Y.; Chang, R.Y.; Lai, Y.-C. Deep reinforcement learning for energy efficiency maximization in cache-enabled cell-free massive MIMO networks: Single- and multi-agent approaches. IEEE Trans. Veh. Technol. 2023, 72, 10826–10839. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhou, M.; Qiao, X.; Cao, H.; Yang, L. On the performance of cell-free massive MIMO with low-resolution ADCs. IEEE Access 2019, 7, 117968–117977. [Google Scholar] [CrossRef]
- Chang, R.Y.; Han, S.-F.; Chien, F.-T. Reinforcement learning based joint cooperation clustering and content caching in cell-free massive MIMO networks. In Proceedings of the 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall), Norman, OK, USA, 27–30 September 2021; pp. 1–7. [Google Scholar]
- Cui, S.; Goldsmith, A.J.; Bahai, A. Energy-constrained modulation optimization. IEEE Trans. Wirel. Commun. 2005, 4, 2349–2360. [Google Scholar]
- Ribeiro, L.N.; Schwarz, S.; Rupp, M.; de Almeida, A.L.F. Energy efficiency of mmWave massive MIMO precoding with low-resolution DACs. IEEE J. Sel. Top. Signal Process. 2018, 12, 298–312. [Google Scholar] [CrossRef]
- Zhang, J.; Dai, L.; He, Z.; Jin, S.; Li, X. Performance analysis of mixed-ADC massive MIMO systems over Rician fading channels. IEEE Trans. Wirel. Commun. 2017, 35, 1327–1338. [Google Scholar] [CrossRef]
- Ngo, H.Q.; Tran, L.-N.; Duong, T.Q.; Matthaiou, M.; Larsson, E.G. On the total energy efficiency of cell-free massive MIMO. IEEE Trans. Green Commun. Netw. 2018, 2, 25–39. [Google Scholar] [CrossRef]
- Sadeghi, A.; Sheikholeslami, F.; Giannakis, G.B. Optimal and scalable caching for 5G using reinforcement learning of space-time popularities. IEEE J. Sel. Top. Signal Process. 2018, 12, 180–190. [Google Scholar] [CrossRef]
- Yang, C.; Yao, Y.; Chen, Z.; Xia, B. Analysis on cache-enabled wireless heterogeneous networks. IEEE Trans. Wirel. Commun. 2016, 15, 131–145. [Google Scholar] [CrossRef]
- Zhong, C.; Gursoy, M.C.; Velipasalar, S. Deep multi-agent reinforcement learning based cooperative edge caching in wireless networks. In Proceedings of the IEEE International Conference on Communications, Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Björnson, E.; Sanguinetti, L. Scalable cell-free massive MIMO systems. IEEE Trans. Commun. 2020, 68, 4247–4261. [Google Scholar] [CrossRef]
- Zhang, H.; Li, H.; Liu, T.; Dong, L.; Shi, G.; Gao, X. Lower energy consumption in cache-aided cell-free massive MIMO systems. Digit. Signal Process. 2023, 135, 103936. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Value |
|---|---|
| Bandwidth B | 20 MHz |
| 1000 mW | |
| Joule/Mbit | |
| W | |
| Path-loss exponent α | 2 |
| Zipf distribution factor β | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, F.; Peng, Y.; Liu, Q. Cluster Content Caching: A Deep Reinforcement Learning Approach to Improve Energy Efficiency in Cell-Free Massive Multiple-Input Multiple-Output Networks. Sensors 2023, 23, 8295. https://doi.org/10.3390/s23198295
Tan F, Peng Y, Liu Q. Cluster Content Caching: A Deep Reinforcement Learning Approach to Improve Energy Efficiency in Cell-Free Massive Multiple-Input Multiple-Output Networks. Sensors. 2023; 23(19):8295. https://doi.org/10.3390/s23198295
Chicago/Turabian StyleTan, Fangqing, Yuan Peng, and Qiang Liu. 2023. "Cluster Content Caching: A Deep Reinforcement Learning Approach to Improve Energy Efficiency in Cell-Free Massive Multiple-Input Multiple-Output Networks" Sensors 23, no. 19: 8295. https://doi.org/10.3390/s23198295
APA StyleTan, F., Peng, Y., & Liu, Q. (2023). Cluster Content Caching: A Deep Reinforcement Learning Approach to Improve Energy Efficiency in Cell-Free Massive Multiple-Input Multiple-Output Networks. Sensors, 23(19), 8295. https://doi.org/10.3390/s23198295