
Spatial and Channel Aggregation Network for Lightweight Image Super-Resolution

Abstract
:1. Introduction
- (1)
- The Triple-Scale Spatial Aggregation (TSSA) attention module was innovatively introduced for the first time, enabling the aggregation of triple-scale spatial information.
- (2)
- The Spatial and Channel Aggregation Block (SCAB) is innovatively introduced for the first time, capable of aggregating both multi-scale spatial and channel information.
- (3)
- The Spatial and Channel Aggregation Network (SCAN), a lightweight and efficient pure CNN-based SISR network model that combines the advantages of both CNN and Transformer is proposed.
- (4)
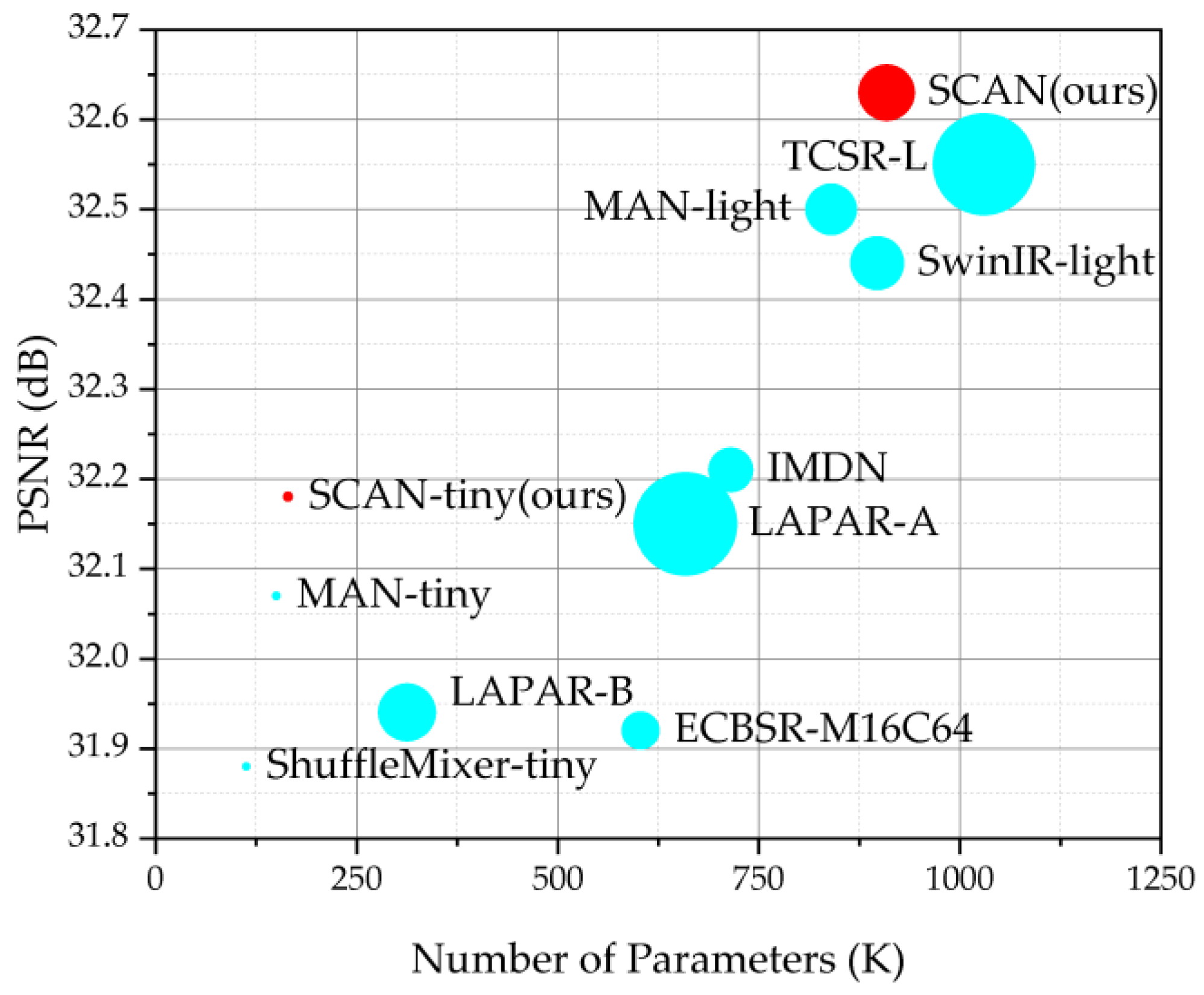
- Quantitative and qualitative evaluations are conducted on benchmark datasets and remote sensing datasets to investigate the proposed SCAN. As shown in Figure 3, the proposed SCAN achieves a good trade-off between model performance and complexity.
2. Related Work
3. Proposed Method
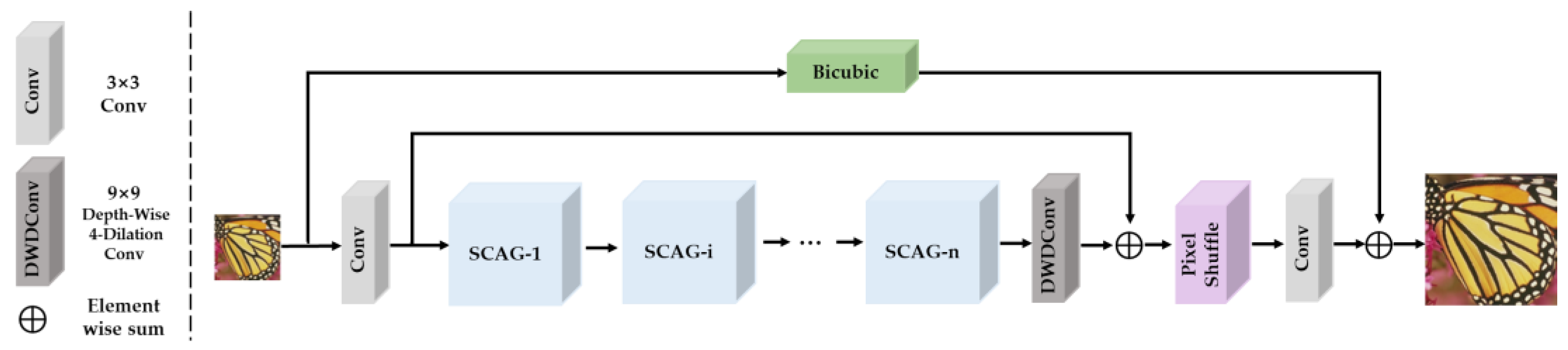
3.1. Network Architecture
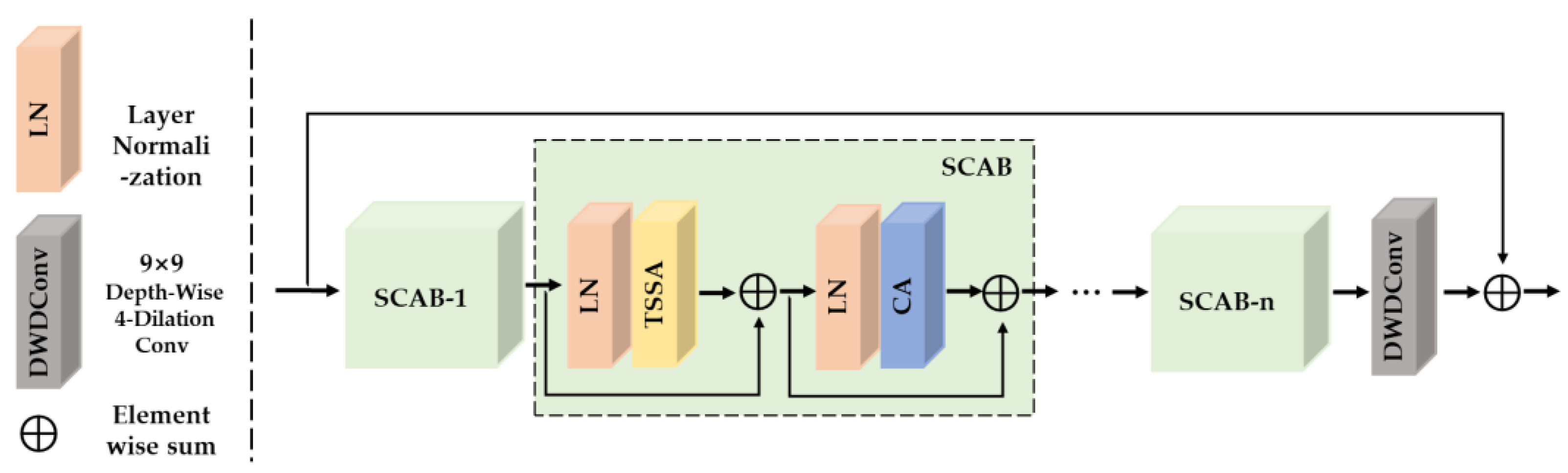
3.2. Spatial and Channel Aggregation Groups (SCAG)
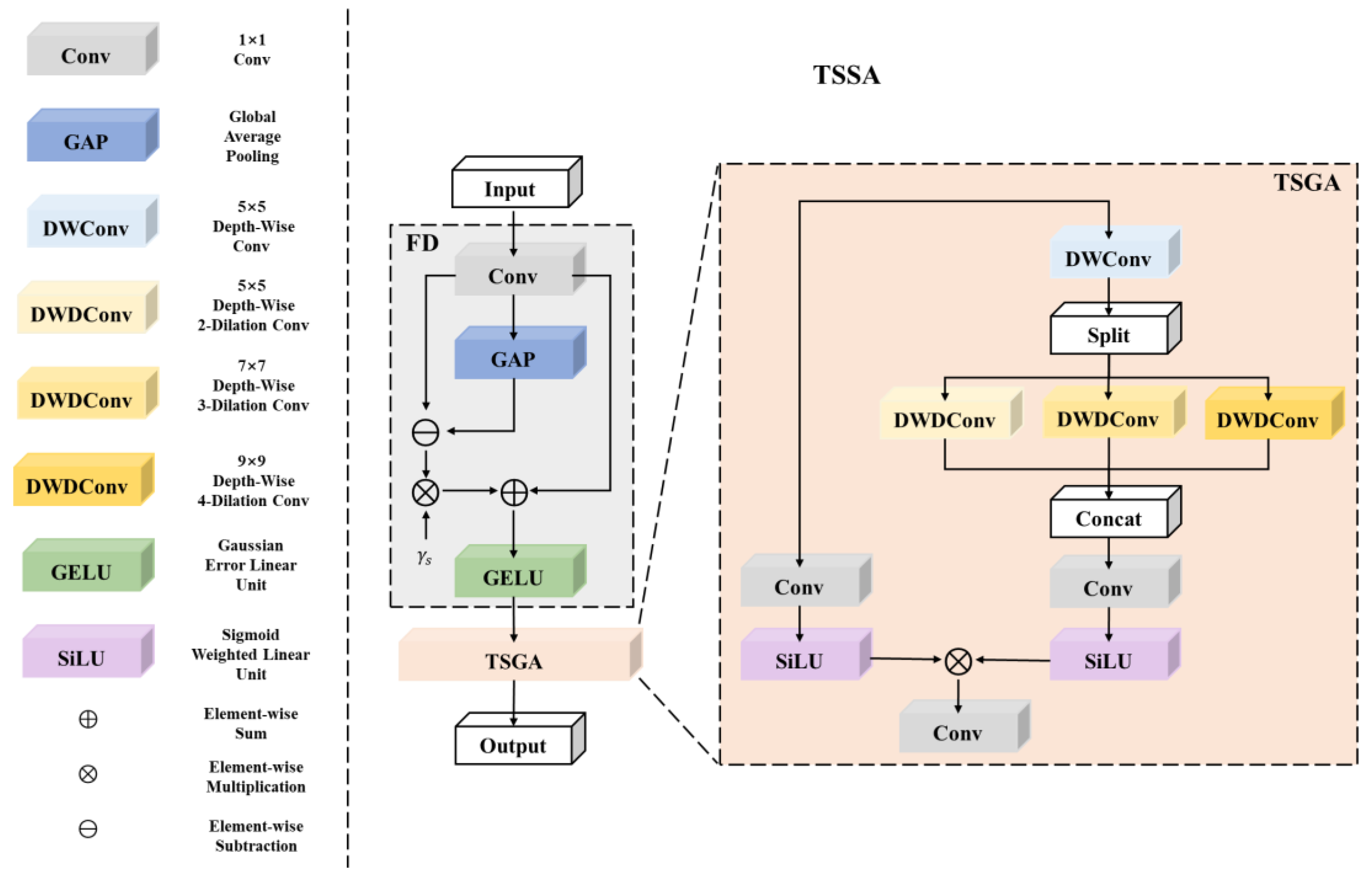
3.2.1. Triple-Scale Spatial Aggregation (TSSA) Attention Module
3.2.2. Channel Aggregation (CA) Module
4. Experiments
4.1. Experimental Setup
4.2. Comparison with SCAN-Tiny SR Method
4.3. Comparison with Light SR Method
4.4. Remote Sensing Image Super-Resolution
4.5. Ablation Studies
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dai, D.; Wang, Y.; Chen, Y.; Van Gool, L. Is image super-resolution helpful for other vision tasks? In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar]
- Bai, Y.; Zhang, Y.; Ding, M.; Ghanem, B. Sod-mtgan: Small object detection via multi-task generative adversarial network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 206–221. [Google Scholar]
- Bei, Y.; Damian, A.; Hu, S.; Menon, S.; Ravi, N.; Rudin, C. New techniques for preserving global structure and denoising with low information loss in single-image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 874–881. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a deep convolutional network for image super-resolution. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part IV 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Lan, R.; Sun, L.; Liu, Z.; Lu, H.; Su, Z.; Pang, C.; Luo, X. Cascading and enhanced residual networks for accurate single-image super-resolution. IEEE Trans. Cybern. 2020, 51, 115–125. [Google Scholar] [CrossRef]
- Tong, T.; Li, G.; Liu, X.; Gao, Q. Image super-resolution using dense skip connections. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4799–4807. [Google Scholar]
- Jiang, K.; Wang, Z.; Yi, P.; Jiang, J.J.P.R. Hierarchical dense recursive network for image super-resolution. Pattern Recognit. 2020, 107, 107475. [Google Scholar] [CrossRef]
- Wei, P.; Xie, Z.; Lu, H.; Zhan, Z.; Ye, Q.; Zuo, W.; Lin, L. Component divide-and-conquer for real-world image super-resolution. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 101–117. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Wu, Z.; Liu, W.; Li, J.; Xu, C.; Huang, D. SFHN: Spatial-Frequency Domain Hybrid Network for Image Super-Resolution. IEEE Trans. Circuits Syst. Video Technol. 2023. early access. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.-T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Wu, H.; Gui, J.; Zhang, J.; Kwok, J.T.; Wei, Z. Feedback pyramid attention networks for single image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2023. early access. [Google Scholar] [CrossRef]
- Imran, A.; Zhu, Q.; Sulaman, M.; Bukhtiar, A.; Xu, M. Electric-Dipole Gated Two Terminal Phototransistor for Charge-Coupled Device. Adv. Opt. Mater. 2023, 2023, 2300910. [Google Scholar] [CrossRef]
- Jang, J.-W.; Lee, S.; Kim, D.; Park, H.; Ardestani, A.S.; Choi, Y.; Kim, C.; Kim, Y.; Yu, H.; Abdel-Aziz, H. Sparsity-aware and re-configurable NPU architecture for Samsung flagship mobile SoC. In Proceedings of the 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 14–18 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 15–28. [Google Scholar]
- Dong, C.; Loy, C.C.; Tang, X. Accelerating the super-resolution convolutional neural network. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 391–407. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.-A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Hui, Z.; Wang, X.; Gao, X. Fast and accurate single image super-resolution via information distillation network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 723–731. [Google Scholar]
- Hui, Z.; Gao, X.; Yang, Y.; Wang, X. Lightweight image super-resolution with information multi-distillation network. In Proceedings of the 27th ACM International Conference on Multimedia, New York, NY, USA, 21–25 October 2019; pp. 2024–2032. [Google Scholar]
- Liu, J.; Tang, J.; Wu, G. Residual feature distillation network for lightweight image super-resolution. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 41–55. [Google Scholar]
- Zhang, X.; Zeng, H.; Zhang, L. Edge-oriented convolution block for real-time super resolution on mobile devices. In Proceedings of the 29th ACM International Conference on Multimedia, New York, NY, USA, 20–24 October 2021; pp. 4034–4043. [Google Scholar]
- Song, D.; Xu, C.; Jia, X.; Chen, Y.; Xu, C.; Wang, Y. Efficient residual dense block search for image super-resolution. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12007–12014. [Google Scholar]
- Huang, F.; Chen, Y.; Wang, X.; Wang, S.; Wu, X. Spectral Clustering Super-Resolution Imaging Based on Multispectral Camera Array. IEEE Trans. Image Process. 2023, 32, 1257–1271. [Google Scholar] [CrossRef] [PubMed]
- Ioannou, Y.; Robertson, D.; Cipolla, R.; Criminisi, A. Deep roots: Improving cnn efficiency with hierarchical filter groups. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1231–1240. [Google Scholar]
- Sifre, L.; Mallat, S. Rigid-motion scattering for texture classification. arXiv 2014, arXiv:1403.1687. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Liu, Y.; Jia, Q.; Fan, X.; Wang, S.; Ma, S.; Gao, W. Cross-SRN: Structure-preserving super-resolution network with cross convolution. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4927–4939. [Google Scholar] [CrossRef]
- Huang, H.; Shen, L.; He, C.; Dong, W.; Liu, W. Differentiable Neural Architecture Search for Extremely Lightweight Image Super-Resolution. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 2672–2682. [Google Scholar] [CrossRef]
- Chu, X.; Zhang, B.; Ma, H.; Xu, R.; Li, Q. Fast, accurate and lightweight super-resolution with neural architecture search. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 59–64. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. Repvgg: Making vgg-style convnets great again. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 11–17 October 2021; pp. 13733–13742. [Google Scholar]
- Zhu, X.; Guo, K.; Ren, S.; Hu, B.; Hu, M.; Fang, H. Lightweight image super-resolution with expectation-maximization attention mechanism. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1273–1284. [Google Scholar] [CrossRef]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Steiner, A.; Keysers, D.; Uszkoreit, J. Mlp-mixer: An all-mlp architecture for vision. Adv. Neural Inf. Process. Syst. 2021, 34, 24261–24272. [Google Scholar]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128. [Google Scholar]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Scaling up your kernels to 31 × 31: Revisiting large kernel design in cnns. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11963–11975. [Google Scholar]
- Guo, M.-H.; Lu, C.-Z.; Liu, Z.-N.; Cheng, M.-M.; Hu, S.-M. Visual attention network. Comput. Vis. Media 2023, 9, 733–752. [Google Scholar] [CrossRef]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. Metaformer is actually what you need for vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10819–10829. [Google Scholar]
- Yu, W.; Si, C.; Zhou, P.; Luo, M.; Zhou, Y.; Feng, J.; Yan, S.; Wang, X. Metaformer baselines for vision. arXiv 2022, arXiv:2210.13452. [Google Scholar]
- Wang, L.; Shen, J.; Tang, E.; Zheng, S.; Xu, L. Multi-scale attention network for image super-resolution. J. Vis. Commun. Image Represent. 2021, 80, 103300. [Google Scholar] [CrossRef]
- Deng, H.; Ren, Q.; Zhang, H.; Zhang, Q. Discovering and explaining the representation bottleneck of dnns. arXiv 2021, arXiv:2111.06236. [Google Scholar]
- Li, S.; Wang, Z.; Liu, Z.; Tan, C.; Lin, H.; Wu, D.; Chen, Z.; Zheng, J.; Li, S. Efficient multi-order gated aggregation network. arXiv 2022, arXiv:2211.03295. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1833–1844. [Google Scholar]
- Gu, J.; Dong, C. Interpreting super-resolution networks with local attribution maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, BC, Canada, 11–17 October 2021; pp. 9199–9208. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-Complexity Single-Image Super-Resolution Based on Nonnegative Neighbor Embedding. In Proceedings of the British Machine Vision Conference, Surrey, UK, 3–7 September 2012. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1637–1645. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, T.; Xu, C.; Deng, Y.; Liu, Z.; Ma, S.; Xu, C.; Xu, C.; Gao, W. Pre-trained image processing transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12299–12310. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.P.; Bishop, R.; Rueckert, D.; Wang, Z. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1874–1883. [Google Scholar]
- Li, W.; Zhou, K.; Qi, L.; Jiang, N.; Lu, J.; Jia, J. Lapar: Linearly-assembled pixel-adaptive regression network for single image super-resolution and beyond. Adv. Neural Inf. Process. Syst. 2020, 33, 20343–20355. [Google Scholar]
- Luo, X.; Xie, Y.; Zhang, Y.; Qu, Y.; Li, C.; Fu, Y. Latticenet: Towards lightweight image super-resolution with lattice block. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 272–289. [Google Scholar]
- Lu, Z.; Liu, H.; Li, J.; Zhang, L. Efficient transformer for single image super-resolution. arXiv 2021, arXiv:2108.11084. [Google Scholar]
- Sun, L.; Pan, J.; Tang, J. ShuffleMixer: An Efficient ConvNet for Image Super-Resolution. Adv. Neural Inf. Process. Syst. 2022, 35, 17314–17326. [Google Scholar]
- Sun, L.; Dong, J.; Tang, J.; Pan, J. Spatially-Adaptive Feature Modulation for Efficient Image Super-Resolution. arXiv 2023, arXiv:2302.13800. [Google Scholar]
- Wu, G.; Jiang, J.; Bai, Y.; Liu, X. Incorporating Transformer Designs into Convolutions for Lightweight Image Super-Resolution. arXiv 2023, arXiv:2303.14324. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Elfwing, S.; Uchibe, E.; Doya, K. Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. 2018, 107, 3–11. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.-P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Agustsson, E.; Timofte, R. NTIRE 2017 Challenge on Single Image Super-Resolution: Dataset and Study. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On Single Image Scale-Up Using Sparse-Representations, Curves and Surfaces. In Proceedings of the 7th International Conference, Avignon, France, 24–30 June 2010. Revised Selected Papers. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the IEEE International Conference on Computer Vision, Vancouver, BC, Canada, 7–14 July 2001. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single Image Super-Resolution from Transformed Self-Exemplars; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Matsui, Y.; Ito, K.; Aramaki, Y.; Fujimoto, A.; Ogawa, T.; Yamasaki, T.; Aizawa, K. Sketch-based Manga Retrieval using Manga109 Dataset. Multimed. Tools Appl. 2017, 76, 21811–21838. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Athiwaratkun, B.; Finzi, M.; Izmailov, P.; Wilson, A.G. There Are Many Consistent Explanations of Unlabeled Data: Why You Should Average. arXiv 2018, arXiv:1806.05594. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Xia, G.-S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A large-scale dataset for object detection in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Scale | Params (K) | Multi-Adds(G) | Set5 PSNR/SSIM | Set14 PSNR/SSIM | BSD100 PSNR/SSIM | Urban100 PSNR/SSIM | Manga109 PSNR/SSIM |
|---|---|---|---|---|---|---|---|---|
| Bicubic | ×2 | - | - | 33.66/0.9299 | 30.24/0.8688 | 29.56/0.8431 | 26.88/0.8403 | 30.80/0.9339 |
| SRCNN [4] | 57 | 53 | 36.66/0.9542 | 32.42/0.9063 | 31.36/0.8879 | 29.50/0.8946 | 35.74/0.9661 | |
| FSRCNN [20] | 13 | 6.0 | 37.00/0.9558 | 32.63/0.9088 | 31.53/0.8920 | 29.88/0.9020 | 36.67/0.9694 | |
| ShuffleMixer-tiny [56] | 180 | 25.0 | 37.85/0.9600 | 33.33/0.9153 | 31.99/0.8972 | 31.22/0.9183 | 38.25/0.9761 | |
| LAPAR-B [53] | 250 | 85.0 | 37.87/0.9600 | 33.39/0.9162 | 32.10/0.8987 | 31.62/0.9235 | 38.27/0.9764 | |
| MAN-tiny [42] | 134 | 7.7 | 37.91/0.9603 | 33.47/0.9170 | 32.12/0.8991 | 31.74/0.9247 | 38.62/0.9770 | |
| SAFMN [57] | 228 | 52.0 | 38.00/0.9605 | 33.54/0.9177 | 32.16/0.8995 | 31.84/0.9256 | 38.71/0.9771 | |
| SCAN-tiny (ours) | 150 | 30.4 | 37.96/0.9604 | 33.56/0.9184 | 32.16/0.8996 | 31.89/0.9266 | 38.72/0.9772 | |
| Bicubic | ×3 | - | - | 30.39/0.8682 | 27.55/0.7742 | 27.21/0.7385 | 24.46/0.7349 | 26.95/0.8556 |
| SRCNN [4] | 57 | 53.0 | 32.75/0.9090 | 29.28/0.8290 | 28.41/0.7863 | 26.24/0.7989 | 30.59/0.9107 | |
| FSRCNN [20] | 12 | 5.0 | 33.16/0.9140 | 29.43/0.8242 | 28.53/0.7910 | 26.43/0.8080 | 30.98/0.9212 | |
| ShuffleMixer-tiny [56] | 114 | 12.0 | 34.07/0.9250 | 30.14/0.8382 | 28.94/0.8009 | 27.54/0.8373 | 33.03/0.9400 | |
| LAPAR-B [53] | 276 | 61.0 | 34.20/0.9256 | 30.17/0.8387 | 29.03/0.8032 | 27.85/0.8459 | 33.15/0.9417 | |
| MAN-tiny [42] | 141 | 8.0 | 34.23/0.9258 | 30.25/0.8404 | 29.03/0.8039 | 27.85/0.8463 | 33.32/0.9427 | |
| SAFMN [57] | 233 | 23.0 | 34.34/0.9267 | 30.33/0.8418 | 29.08/0.8048 | 27.95/0.8474 | 33.52/0.9437 | |
| SCAN-tiny (ours) | 156 | 15.8 | 34.34/0.9265 | 30.30/0.8414 | 29.07/0.8043 | 27.95/0.8483 | 33.48/0.9436 | |
| Bicubic | ×4 | - | - | 28.42/0.8104 | 26.00/0.7027 | 25.96/0.6675 | 23.14/0.6577 | 24.89/0.7866 |
| SRCNN [4] | 57 | 53.0 | 30.48/0.8628 | 27.49/0.7503 | 26.90/0.7101 | 24.52/0.7221 | 27.66/0.8505 | |
| FSRCNN [20] | 12 | 4.6 | 30.71/0.8657 | 27.59/0.7535 | 26.98/0.7150 | 24.62/0.7280 | 27.90/0.8517 | |
| ECBSR-M16C64 [25] | 603 | 34.7 | 31.87/0.8901 | 28.39/0.7768 | 27.44/0.7316 | 25.63/0.7710 | 29.80/0.8986 | |
| ShuffleMixer-tiny [56] | 113 | 8.0 | 31.88/0.8912 | 28.46/0.7779 | 27.45/0.7313 | 25.66/0.7690 | 29.96/0.9006 | |
| LAPAR-B [53] | 313 | 53.0 | 31.94/0.8917 | 28.46/0.7784 | 27.52/0.7335 | 25.84/0.7772 | 30.03/0.9025 | |
| MAN-tiny [42] | 150 | 8.4 | 32.07/0.8930 | 28.53/0.7801 | 27.51/0.7345 | 25.84/0.7786 | 30.18/0.9047 | |
| SAFMN [57] | 240 | 14.0 | 32.18/0.8948 | 28.60/0.7813 | 27.58/0.7359 | 25.97/0.7809 | 30.43/0.9063 | |
| SCAN-tiny (ours) | 165 | 9.5 | 32.18/0.8946 | 28.59/0.7816 | 27.55/0.7358 | 25.97/0.7829 | 30.34/0.9068 |
| Method | Scale | Params (K) | FLOPs (G) | Set5 PSNR/SSIM | Set14 PSNR/SSIM | BSD100 PSNR/SSIM | Urban100 PSNR/SSIM | Manga109 PSNR/SSIM |
|---|---|---|---|---|---|---|---|---|
| CARN [21] | ×2 | 1592 | 222.8 | 37.76/0.9590 | 33.52/0.9166 | 32.09/0.8978 | 31.92/0.9256 | 38.36/0.9765 |
| LatticeNet [54] | 756 | 169.5 | 38.06/0.9607 | 33.70/0.9187 | 32.20/0.8999 | 32.25/0.9288 | 39.00/0.9774 | |
| LAPAR-A [53] | 548 | 171.1 | 38.01/0.9605 | 33.62/0.9183 | 32.19/0.8999 | 32.10/0.9283 | 38.67/0.9772 | |
| IMDN [23] | 694 | 158.8 | 38.00/0.9605 | 33.63/0.9177 | 32.19/0.8996 | 32.17/0.9283 | 38.88/0.9774 | |
| ESRT [55] | 677 | 208.4 | 38.03/0.9600 | 33.75/0.9184 | 32.25/0.9001 | 32.58/0.9318 | 39.12/0.9774 | |
| SwinIR-light [45] | 878 | 195.6 | 38.14/0.9611 | 33.86/0.9206 | 32.31/0.9012 | 32.76/0.9340 | 39.12/0.9783 | |
| MAN-light [42] | 820 | 180.4 | 38.18/0.9612 | 33.93/0.9213 | 32.36/0.9022 | 32.92/0.9364 | 39.44/0.9786 | |
| SCAN (ours) | 889 | 204.7 | 38.23/0.9614 | 34.22/0.9233 | 32.38/0.9022 | 33.05/0.9368 | 39.50/0.9788 | |
| CARN [21] | ×3 | 1592 | 118.8 | 32.29/0.9255 | 30.29/0.8407 | 29.06/0.8034 | 28.06/0.8493 | 33.50/0.9440 |
| LatticeNet [54] | 765 | 76.3 | 34.40/0.9272 | 30.32/0.8416 | 29.10/0.8049 | 28.19/0.8513 | 33.66/0.9440 | |
| LAPAR-A [53] | 544 | 114.1 | 34.36/0.9267 | 30.34/0.8421 | 29.11/0.8054 | 28.15/0.8523 | 33.51/0.9441 | |
| IMDN [23] | 703 | 71.5 | 34.36/0.9270 | 30.32/0.8417 | 29.09/0.8046 | 28.17/0.8519 | 33.61/0.9445 | |
| ESRT [55] | 770 | 102.3 | 34.42/0.9268 | 30.43/0.8433 | 29.15/0.8063 | 28.46/0.8574 | 33.95/0.9455 | |
| SwinIR-light [45] | 886 | 87.2 | 34.62/0.9289 | 30.54/0.8463 | 29.20/0.8082 | 28.66/0.8624 | 33.89/0.9464 | |
| MAN-light [42] | 829 | 82.5 | 34.65/0.9292 | 30.60/0.8476 | 29.29/0.8101 | 28.87/0.8671 | 34.40/0.9434 | |
| SCAN (ours) | 897 | 91.1 | 34.81/0.9302 | 30.65/0.8486 | 29.31/0.8107 | 28.80/0.8691 | 34.62/0.9505 | |
| CARN [21] | ×4 | 1592 | 90.9 | 32.13/0.8937 | 28.60/0.7806 | 27.58/0.7349 | 26.07/0.7837 | 30.42/0.9070 |
| LatticeNet [54] | 777 | 43.6 | 32.18/0.8943 | 28.61/0.7812 | 27.57/0.7355 | 26.14/0.7844 | 30.46/0.9601 | |
| LAPAR-A [53] | 659 | 94.0 | 32.15/0.8944 | 28.61/0.7818 | 27.61/0.7366 | 26.14/0.7871 | 30.42/0.9074 | |
| IMDN [23] | 715 | 40.9 | 32.21/0.8948 | 28.58/0.7811 | 27.56/0.7353 | 26.04/0.7838 | 30.45/0.9075 | |
| ESRT [55] | 777 | 67.7 | 32.19/0.8947 | 28.69/0.7833 | 27.69/0.7379 | 26.39/0.7962 | 30.75/0.9100 | |
| SwinIR-light [45] | 897 | 49.6 | 32.44/0.8976 | 28.77/0.7858 | 27.69/0.7406 | 26.47/0.7980 | 30.92/0.9151 | |
| TCSR-L [58] | 1030 | 93.0 | 32.55/0.8992 | 28.89/0.7886 | 27.75/0.7423 | 26.67/0.8039 | 31.17/0.9107 | |
| MAN-light [42] | 840 | 47.1 | 32.50/0.8988 | 28.87/0.7885 | 27.77/0.7429 | 26.70/0.8052 | 31.25/0.9170 | |
| SCAN (ours) | 909 | 51.8 | 32.63/0.9001 | 28.91/0.7890 | 27.80/0.7429 | 26.79/0.8065 | 31.38/0.9148 |
| Method | Scale | Params (K) | FLOPs (G) | Dior PSNR/SSIM | Dota PSNR/SSIM |
|---|---|---|---|---|---|
| RFDN [24] | ×4 | 555 | 23.9 | 25.95/0.6430 | 24.79/0.5975 |
| SwinIR-light [45] | 840 | 47.1 | 27.50/0.6786 | 26.00/0.7400 | |
| IMDN [23] | 703 | 71.5 | 27.52/0.6778 | 26.04/0.7381 | |
| LAPAR-A [53] | 659 | 94.0 | 27.55/0.6799 | 26.01/0.7402 | |
| MAN-light [42] | 840 | 47.1 | 27.59/0.6805 | 26.19/0.7453 | |
| SCAN (ours) | 909 | 51.8 | 28.29/0.7037 | 26.30/0.7486 |
| Module | Params (K) | FLOPs (G) | Set5 | Set14 | BSD100 | Urban100 | Manga109 | |
|---|---|---|---|---|---|---|---|---|
| FD | TSGA | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||
| × | × | 99.27 | 5.63 | 30.79/0.8654 | 27.62/0.7584 | 26.91/0.7178 | 24.67/0.7359 | 28.12/0.8610 |
| × | √ | 153.43 | 8.75 | 32.01/0.8922 | 28.48/0.7786 | 27.48/0.7332 | 25.75/0.7755 | 30.05/0.9032 |
| √ | √ | 165.43 | 9.45 | 32.13/0.8937 | 28.53/0.7800 | 27.52/0.7344 | 25.87/0.7790 | 30.17/0.9046 |
| Convolution Type | Params (K) | FLOPs (G) | Set5 PSNR/SSIM | Set14 PSNR/SSIM | BSD100 PSNR/SSIM | Urban100 PSNR/SSIM | Manga109 PSNR/SSIM |
|---|---|---|---|---|---|---|---|
| 159.03 | 9.08 | 32.08/0.8931 | 28.49/0.7792 | 27.52/0.7339 | 25.82/0.7774 | 30.15/0.9043 | |
| 164.79 | 9.41 | 32.11/0.8933 | 28.51/0.7795 | 27.53/0.7344 | 25.86/0.7786 | 30.21/0.9050 | |
| 172.47 | 9.85 | 32.10/0.8936 | 28.52/0.7798 | 27.52/0.7346 | 25.88/0.7797 | 30.18/0.9048 | |
| Triple-scale | 165.43 | 9.45 | 32.13/0.8937 | 28.53/0.7800 | 27.52/0.7344 | 25.87/0.7790 | 30.17/0.9046 |
| Activation Function Type | Params (K) | FLOPs (G) | Set5 PSNR/SSIM | Set14 PSNR/SSIM | BSD100 PSNR/SSIM | Urban100 PSNR/SSIM | Manga109 PSNR/SSIM |
|---|---|---|---|---|---|---|---|
| ReLU | 165.43 | 9.47 | 32.06/0.7796 | 28.52/0.7796 | 27.51/0.7339 | 25.84/0.7779 | 30.14/0.9041 |
| PReLU | 165.43 | 9.47 | 32.09/0.8932 | 28.54/0.7798 | 27.51/0.7341 | 25.86/0.7788 | 30.15/0.9045 |
| GELU | 165.43 | 9.45 | 32.09/0.8933 | 28.53/0.7796 | 27.51/0.7341 | 25.87/0.7786 | 30.17/0.9048 |
| SiLU | 165.43 | 9.45 | 32.13/0.8937 | 28.53/0.7800 | 27.52/0.7344 | 25.87/0.7790 | 30.17/0.9046 |
| Module | Params (K) | FLOPs (G) | Set5 | Set14 | BSD100 | Urban100 | Manga109 | |
|---|---|---|---|---|---|---|---|---|
| MSFR | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | |||
| × | × | 160.15 | 9.14 | 32.03/0.8926 | 28.47/0.7785 | 27.49/0.7331 | 25.76/0.7756 | 30.03/0.9025 |
| × | √ | 160.63 | 9.17 | 31.35/0.8767 | 27.89/0.7597 | 27.11/0.7109 | 24.97/0.7400 | 28.46/0.8563 |
| √ | × | 164.46 | 9.42 | 32.08/0.8933 | 28.52/0.7797 | 27.51/0.7342 | 25.86/0.7789 | 30.17/0.9045 |
| √ | √ | 165.43 | 9.45 | 32.13/0.8937 | 28.53/0.7800 | 27.52/0.7344 | 25.87/0.7790 | 30.17/0.9046 |
| Tail Type | Params (K) | FLOPs (G) | Set5 PSNR/SSIM | Set14 PSNR/SSIM | BSD100 PSNR/SSIM | Urban100 PSNR/SSIM | Manga109 PSNR/SSIM |
|---|---|---|---|---|---|---|---|
| None | 141.81 | 8.09 | 31.96/0.8915 | 28.44/0.7783 | 27.48/0.7329 | 25.72/0.7741 | 29.99/0.9020 |
| 149.30 | 8.52 | 32.09/0.8936 | 28.52/0.7796 | 27.52/0.7343 | 25.88/0.7792 | 30.20/0.9050 | |
| 156.21 | 8.91 | 32.08/0.7796 | 28.51/0.7796 | 27.52/0.7344 | 25.85/0.7786 | 30.18/0.9048 | |
| 165.43 | 9.45 | 32.13/0.8937 | 28.53/0.7800 | 27.52/0.7344 | 25.87/0.7790 | 30.17/0.9046 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Zuo, L.; Huang, F. Spatial and Channel Aggregation Network for Lightweight Image Super-Resolution. Sensors 2023, 23, 8213. https://doi.org/10.3390/s23198213
Wu X, Zuo L, Huang F. Spatial and Channel Aggregation Network for Lightweight Image Super-Resolution. Sensors. 2023; 23(19):8213. https://doi.org/10.3390/s23198213
Chicago/Turabian StyleWu, Xianyu, Linze Zuo, and Feng Huang. 2023. "Spatial and Channel Aggregation Network for Lightweight Image Super-Resolution" Sensors 23, no. 19: 8213. https://doi.org/10.3390/s23198213
APA StyleWu, X., Zuo, L., & Huang, F. (2023). Spatial and Channel Aggregation Network for Lightweight Image Super-Resolution. Sensors, 23(19), 8213. https://doi.org/10.3390/s23198213