
Display-Semantic Transformer for Scene Text Recognition

Abstract
:1. Introduction
2. Related Work
2.1. Semantic-Free Methods
2.2. Semantic-Aware Methods
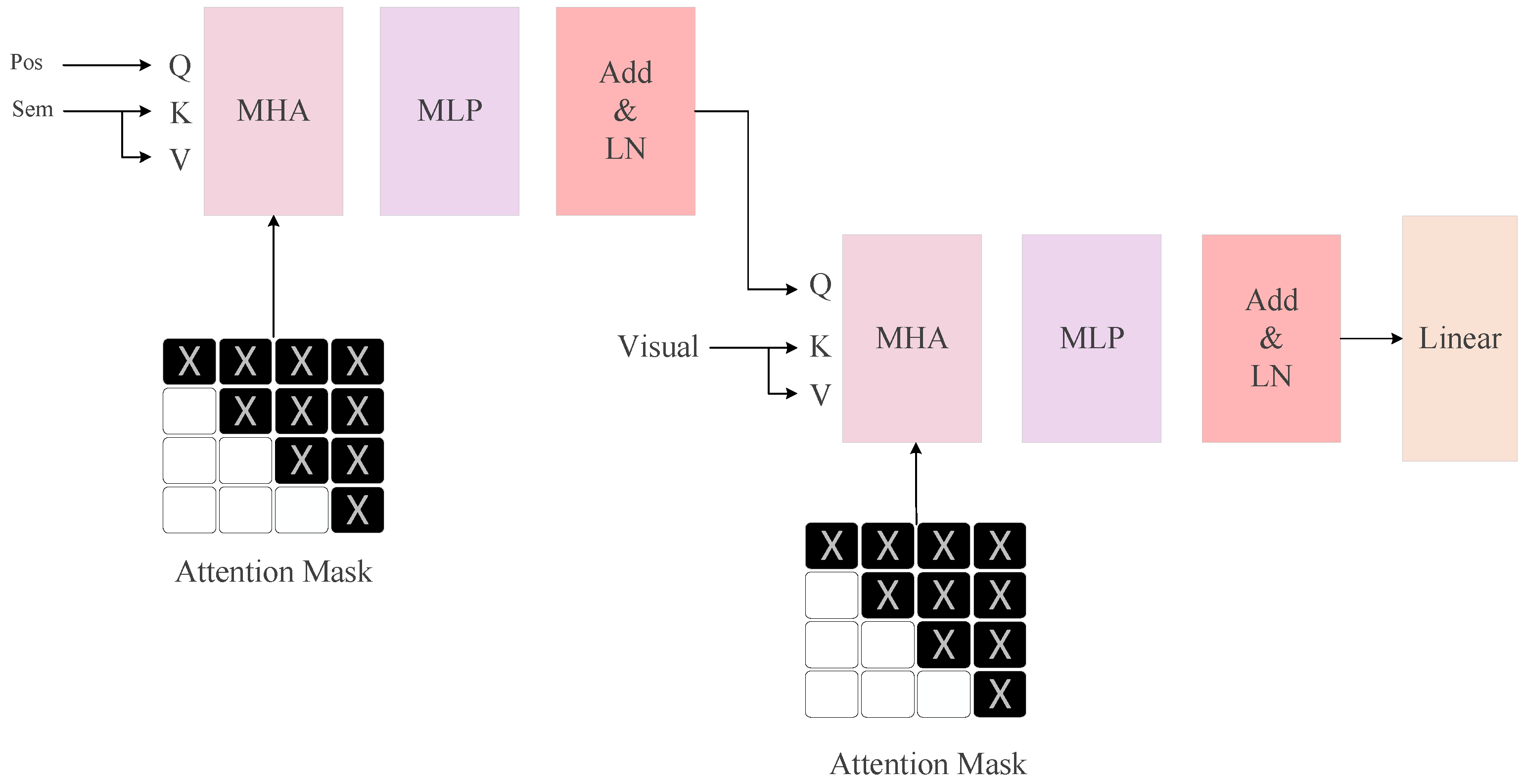
3. DST Model
3.1. Image Processing
3.2. Visual Model
3.3. Masked Language Model
3.4. Semantic-Visual Interaction Module (SVIM)
3.5. Character Prediction and Loss Calculation
3.6. Methodology
3.6.1. Datasets
3.6.2. Experimental Setup
4. Experiment
4.1. Proof of Concept for the DST Model
4.2. Comparison of Accuracy with Existing Methods on Six Standard Benchmarks
4.3. Ablation Study
4.4. Comparison of Inference Times and Model Parameters
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Long, S.; He, X.; Yao, C. Scene text detection and recognition: The deep learning era. Int. J. Comput. Vis. 2021, 129, 161–184. [Google Scholar] [CrossRef]
- Zhu, Y.; Yao, C.; Bai, X. Scene text detection and recognition: Recent advances and future trends. Front. Comput. Sci. 2016, 10, 19–36. [Google Scholar] [CrossRef]
- Bautista, D.; Atienza, R. Scene text recognition with permuted autoregressive sequence models. In Proceedings of the European Conference on Computer Vision, Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 178–196. [Google Scholar]
- Yu, D.; Li, X.; Zhang, C.; Liu, T.; Han, J.; Liu, J.; Ding, E. Towards accurate scene text recognition with semantic reasoning networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12113–12122. [Google Scholar]
- Wang, P.; Da, C.; Yao, C. Multi-granularity prediction for scene text recognition. In Proceedings of the European Conference on Computer Vision, Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 339–355. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Qiao, Z.; Zhou, Y.; Yang, D.; Zhou, Y.; Wang, W. Seed: Semantics enhanced encoder-decoder framework for scene text recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13528–13537. [Google Scholar]
- Yue, X.; Kuang, Z.; Lin, C.; Sun, H.; Zhang, W. Robustscanner: Dynamically enhancing positional clues for robust text recognition. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 135–151. [Google Scholar]
- Zhan, F.; Lu, S. Esir: End-to-end scene text recognition via iterative image rectification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2059–2068. [Google Scholar]
- Wang, Y.; Xie, H.; Fang, S.; Wang, J.; Zhu, S.; Zhang, Y. From two to one: A new scene text recognizer with visual language modeling network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14194–14203. [Google Scholar]
- Shi, B.; Yang, M.; Wang, X.; Lyu, P.; Yao, C.; Bai, X. Aster: An attentional scene text recognizer with flexible rectification. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2035–2048. [Google Scholar] [CrossRef] [PubMed]
- Fang, S.; Xie, H.; Zha, Z.J.; Sun, N.; Tan, J.; Zhang, Y. Attention and language ensemble for scene text recognition with convolutional sequence modeling. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 26 October 2018; pp. 248–256. [Google Scholar]
- Wang, T.; Zhu, Y.; Jin, L.; Luo, C.; Chen, X.; Wu, Y.; Wang, Q.; Cai, M. Decoupled attention network for text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–8 February 2020; Volume 34, pp. 12216–12224. [Google Scholar]
- Chen, X.; Jin, L.; Zhu, Y.; Luo, C.; Wang, T. Text recognition in the wild: A survey. ACM Comput. Surv. (CSUR) 2021, 54, 1–35. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Lee, C.Y.; Osindero, S. Recursive recurrent nets with attention modeling for ocr in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2231–2239. [Google Scholar]
- Bai, J.; Chen, Z.; Feng, B.; Xu, B. Chinese image text recognition on grayscale pixels. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; IEEE: Toulouse, France, 2014; pp. 1380–1384. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Reading text in the wild with convolutional neural networks. Int. J. Comput. Vis. 2016, 116, 1–20. [Google Scholar] [CrossRef]
- Shi, B.; Bai, X.; Yao, C. An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 2298–2304. [Google Scholar] [CrossRef] [PubMed]
- He, P.; Huang, W.; Qiao, Y.; Loy, C.; Tang, X. Reading scene text in deep convolutional sequences. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Su, B.; Lu, S. Accurate recognition of words in scenes without character segmentation using recurrent neural network. Pattern Recognit. 2017, 63, 397–405. [Google Scholar] [CrossRef]
- Hu, W.; Cai, X.; Hou, J.; Yi, S.; Lin, Z. Gtc: Guided training of ctc towards efficient and accurate scene text recognition. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11005–11012. [Google Scholar]
- Liao, M.; Zhang, J.; Wan, Z.; Xie, F.; Liang, J.; Lyu, P.; Yao, C.; Bai, X. Scene text recognition from two-dimensional perspective. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 1–27 January 2019; Volume 33, pp. 8714–8721. [Google Scholar]
- Xing, L.; Tian, Z.; Huang, W.; Scott, M.R. Convolutional character networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Toulouse, France, 2019; pp. 9126–9136. [Google Scholar]
- Cheng, Z.; Xu, Y.; Bai, F.; Niu, Y.; Pu, S.; Zhou, S. Aon: Towards arbitrarily-oriented text recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Toulouse, France, 2018; pp. 5571–5579. [Google Scholar]
- Li, H.; Wang, P.; Shen, C.; Zhang, G. Show, attend and read: A simple and strong baseline for irregular text recognition. In Proceedings of the AAAI conference on artificial intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8610–8617. [Google Scholar]
- Yang, M.; Guan, Y.; Liao, M.; He, X.; Bian, K.; Bai, S.; Yao, C.; Bai, X. Symmetry-constrained rectification network for scene text recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Toulouse, France, 2019; pp. 9147–9156. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]
- Bhunia, A.K.; Sain, A.; Kumar, A.; Ghose, S.; Chowdhury, P.N.; Song, Y.Z. Joint visual semantic reasoning: Multi-stage decoder for text recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 14940–14949. [Google Scholar]
- Na, B.; Kim, Y.; Park, S. Multi-modal text recognition networks: Interactive enhancements between visual and semantic features. In Proceedings of the European Conference on Computer Vision, Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 446–463. [Google Scholar]
- Da, C.; Wang, P.; Yao, C. Levenshtein OCR. In Proceedings of the European Conference on Computer Vision, Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 322–338. [Google Scholar]
- Yang, X.; Qiao, Z.; Wei, J.; Zhou, Y.; Yuan, Y.; Ji, Z.; Yang, D.; Wang, W. Masked and Permuted Implicit Context Learning for Scene Text Recognition. arXiv 2023, arXiv:2305.16172. [Google Scholar]
- Zhang, B.; Xie, H.; Wang, Y.; Xu, J.; Zhang, Y. Linguistic More: Taking a Further Step toward Efficient and Accurate Scene Text Recognition. arXiv 2023, arXiv:2305.05140. [Google Scholar]
- Fang, S.; Xie, H.; Wang, Y.; Mao, Z.; Zhang, Y. Read like humans: Autonomous, bidirectional and iterative language modeling for scene text recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7098–7107. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Synthetic data and artificial neural networks for natural scene text recognition. arXiv 2014, arXiv:1406.2227. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic data for text localisation in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2315–2324. [Google Scholar]
- Mishra, A.; Alahari, K.; Jawahar, C. Scene text recognition using higher order language priors. In Proceedings of the BMVC-British Machine Vision Conference, Surrey, UK, 3–7 September 2012; BMVA: Surrey, UK, 2012. [Google Scholar]
- Wang, K.; Babenko, B.; Belongie, S. End-to-end scene text recognition. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Toulouse, France, 2011; pp. 1457–1464. [Google Scholar]
- Karatzas, D.; Shafait, F.; Uchida, S.; Iwamura, M.; i Bigorda, L.G.; Mestre, S.R.; Mas, J.; Mota, D.F.; Almazan, J.A.; De Las Heras, L.P. ICDAR 2013 robust reading competition. In Proceedings of the 2013 12th International Conference on Document Analysis and Recognition, Washington, DC, USA, 25–28 August 2013; IEEE: Toulouse, France, 2013; pp. 1484–1493. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Bagdanov, A.; Iwamura, M.; Matas, J.; Neumann, L.; Chandrasekhar, V.R.; Lu, S.; et al. ICDAR 2015 competition on robust reading. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; IEEE: Toulouse, France, 2015; pp. 1156–1160. [Google Scholar]
- Phan, T.Q.; Shivakumara, P.; Tian, S.; Tan, C.L. Recognizing text with perspective distortion in natural scenes. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 2–8 December 2013; pp. 569–576. [Google Scholar]
- Risnumawan, A.; Shivakumara, P.; Chan, C.S.; Tan, C.L. A robust arbitrary text detection system for natural scene images. Expert Syst. Appl. 2014, 41, 8027–8048. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR: Sydney, Australia, 2021; pp. 10347–10357. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. Randaugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- Zeiler, M.D. Adadelta: An adaptive learning rate method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Loshchilov, I.; Hutter, F. Sgdr: Stochastic gradient descent with warm restarts. arXiv 2016, arXiv:1608.03983. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Year | Datasets | IC13 | SVT | III5K | IC15 | SVTP | CUTE80 | Avg |
|---|---|---|---|---|---|---|---|---|---|
| TRBA | 2019 | MJ+ST | 93.6 | 87.5 | 87.9 | 77.6 | 79.2 | 74 | 84.6 |
| TextScanner | 2019 | MJ+ST | 92.9 | 90.1 | 93.9 | 79.4 | 84.3 | 83.3 | 88.5 |
| DAN | 2020 | MJ+ST | 93.9 | 89.2 | 94.3 | 74.5 | 80 | 84.4 | 87.2 |
| SRN | 2020 | MJ+ST | 95.5 | 91.5 | 94.8 | 82.7 | 85.1 | 87.8 | 90.4 |
| RobustScanner | 2020 | MJ+ST | 94.8 | 88.1 | 95.3 | 77.1 | 79.5 | 90.3 | 88.4 |
| SAM | 2021 | MJ+ST | 95.3 | 90.6 | 93.9 | 77.3 | 82.2 | 87.8 | 88.3 |
| ViTSTR | 2021 | MJ+ST | 93.2 | 87.7 | 88.4 | 78.5 | 81.8 | 81.3 | 85.6 |
| VisionLAN | 2021 | MJ+ST | 95.7 | 91.7 | 95.8 | 83.7 | 86 | 88.5 | 90.23 |
| PIMNet | 2021 | MJ+ST | 95.2 | 91.2 | 95.2 | 83.5 | 84.3 | 84.4 | 90.5 |
| MGP-STR | 2022 | MJ+ST | 95.7 | 93 | 95.6 | 83.6 | 89 | 88.5 | 91.3 |
| PARSeq | 2022 | MJ+ST | 95.7 | 92.4 | 96 | 83.1 | 88.7 | 90.6 | 91.4 |
| baseline | - | MJ+ST | 95.799 | 91.499 | 91.333 | 82.827 | 85.116 | 81.597 | 88.811 |
| DST | - | MJ+ST | 97.316 | 93.045 | 92.8 | 84.539 | 87.752 | 83.681 | 90.68 |
| IC13 | SVT | IIIT5K | IC15 | SVTP | CUTE80 | Avg | |
|---|---|---|---|---|---|---|---|
| baseline | 95.799 | 91.499 | 91.333 | 82.827 | 85.116 | 81.597 | 88.811 |
| +MLM | 96.266 | 92.382 | 92.26 | 83.821 | 86.822 | 81.944 | 89.804 |
| +MLM+SVIM | 97.316 | 93.045 | 92.8 | 84.539 | 87.752 | 83.681 | 90.68 |
| Methods | Year | IC13 | SVT | IIIT5k | IC15 | SVTP | CUTE80 | Avg | Parm (m) | Speed (ms) | FLOPs (G) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SRN | 2020 | 95.5 | 91.5 | 94.8 | 82.7 | 85.1 | 87.8 | 90.4 | 54.7 | 25.4 | 11.36 |
| VisionLAN | 2021 | 95.7 | 91.7 | 95.8 | 83.7 | 86 | 88.5 | 90.23 | 32.8 | 28 | - |
| ABINet | 2021 | 95.2 | 93.4 | 97 | 83.4 | 89.6 | 89.2 | 91.9 | 36.7 | 51.3 | 10.94 |
| MGPSTR | 2022 | 95.7 | 93 | 95.6 | 83.6 | 89 | 88.5 | 91.3 | 52.6 | 9.37 | 25.4 |
| PARSeq | 2022 | 95.7 | 92.4 | 96 | 83.1 | 88.7 | 90.6 | 91.4 | 23.8 | 11.7 | 3.25 |
| ours | - | 97.316 | 93.045 | 92.8 | 84.539 | 87.752 | 83.681 | 90.68 | 8.57 | 15.9 | 5.919 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, X.; Silamu, W.; Xu, M.; Li, Y. Display-Semantic Transformer for Scene Text Recognition. Sensors 2023, 23, 8159. https://doi.org/10.3390/s23198159
Yang X, Silamu W, Xu M, Li Y. Display-Semantic Transformer for Scene Text Recognition. Sensors. 2023; 23(19):8159. https://doi.org/10.3390/s23198159
Chicago/Turabian StyleYang, Xinqi, Wushour Silamu, Miaomiao Xu, and Yanbing Li. 2023. "Display-Semantic Transformer for Scene Text Recognition" Sensors 23, no. 19: 8159. https://doi.org/10.3390/s23198159
APA StyleYang, X., Silamu, W., Xu, M., & Li, Y. (2023). Display-Semantic Transformer for Scene Text Recognition. Sensors, 23(19), 8159. https://doi.org/10.3390/s23198159