
Explainable Risk Prediction of Post-Stroke Adverse Mental Outcomes Using Machine Learning Techniques in a Population of 1780 Patients

 ,
,  , ,
, ,
Abstract
:1. Introduction
1.1. Background
1.2. Literature Review
1.3. Motivation and Proposed Method

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author | Dataset | Features | Outcome | Techniques | Best Performance |
|---|---|---|---|---|---|
| Ryu et al. [24], 2022 | 31 PSD and 34 non-PSD cases | Medical history, demographics, neurological, cognitive, and functional test data | PSD | SVM, KNN, RF | SVM: AUC 0.711; Acc 0.70; Sens 0.742; Spec 0.517 |
| Fast et al. [25], 2023 | 49 PSD and 258 non-PSD cases | Demographics, clinical, serological, and MRI data | PSD * | GBT, SVM | GBT: Balanced Acc 0.63; AUC 0.70 |
| Wang et al. [26], 2021 | 395 cases | Demographics, lab results, vascular risk factors | PSA | RF, DT, SVM, stochastic gradient descent, multi-layer perceptron | RF: 18.625 Euclidean distance between anxiety scores |
| Current study | 285 PSAMO and 1495 no PSAMO cases | Demographics, stroke-related data, surgical and medical history, etc. | PSAMO * | Logistic regression, DT, GBT, RF, XGBoost, CatBoost, AdaBoost, LightGBM | GBT: AUC 0.620; Acc 0.747; F1-score 0.341 |
1.4. Main Contributions
2. Methods
2.1. Data Collection and Study Design
2.2. Identification of PSAMO
2.3. Statistical Analysis
2.4. Data Preprocessing and Engineering
2.5. Model Development
2.5.1. Recursive Feature Elimination (RFE)
2.5.2. Synthetic Minority Oversampling Technique (SMOTE)
2.5.3. Application of Machine Learning Algorithms
2.5.4. Bayesian Optimization and Cross-Validation
2.6. Model Evaluation
2.7. Model Explanation
2.8. Packages Used
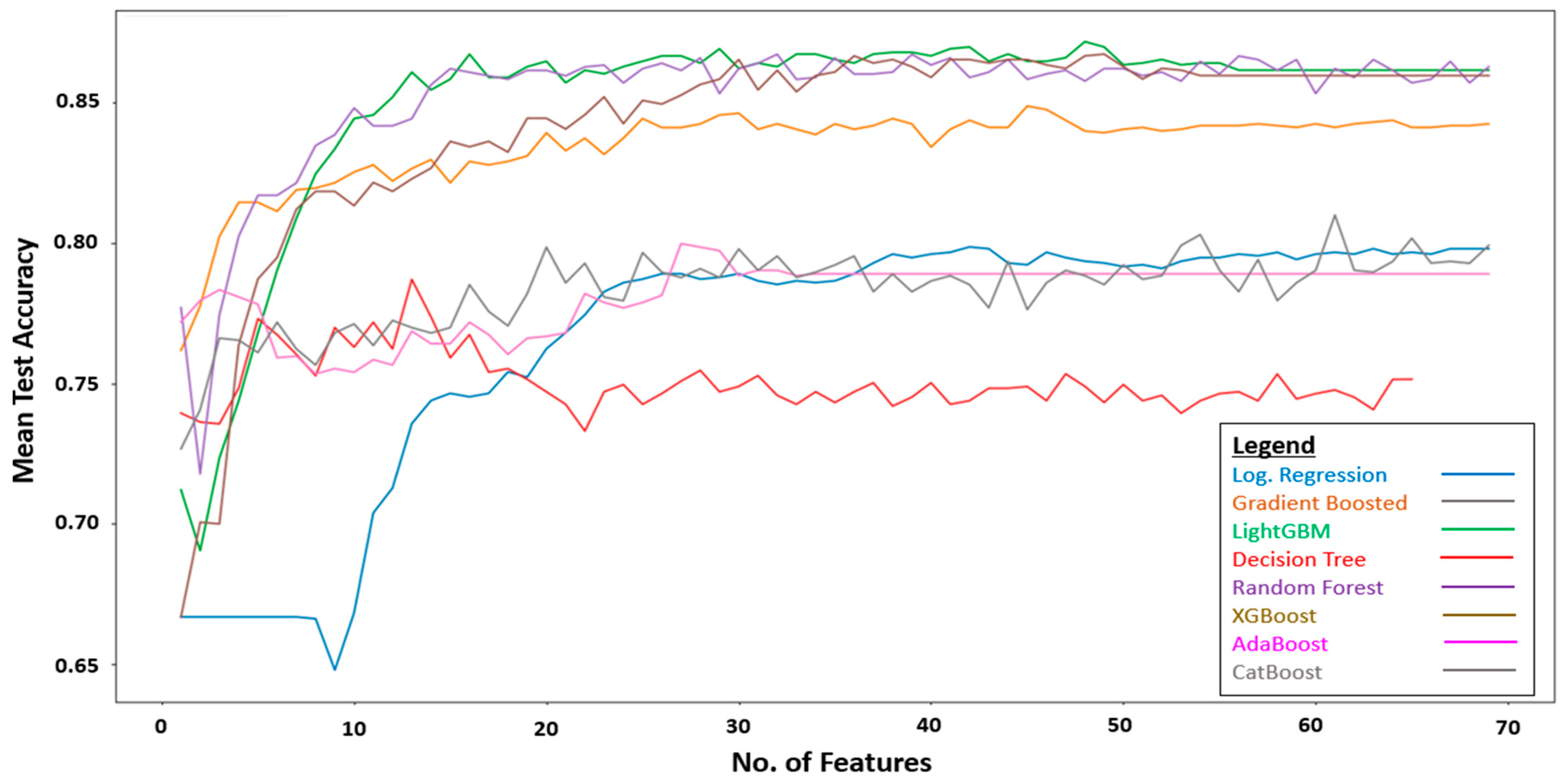
3. Results
SHAP Explanation of the Gradient-Boosted Tree Model
4. Discussion
4.1. Model Performance
4.2. Explainable Features
4.3. Study Advantages and Limitations
4.3.1. Advantages
- To the best of our knowledge, this is the first ML model that has been designed to predict the risk of PSAMO, a composite of PSD and PSA.
- The model predicted the risk of PSAMO with good accuracy (i.e., 74.7%).
- Trained on the largest PSAMO dataset to date, our model results are less susceptible to the influence of outliers, and therefore are representative of the broader stroke population.
- XAI-enabled model interpretability allows doctors to develop intervention plans for important risk factors for PSAMO.
4.3.2. Limitations
- This is a cross-sectional study and the observed associations cannot infer causality. Future expansion of this study to longitudinal data may offer stronger insights.
- Deep learning methods such as neural networks can be investigated in the future, which may produce better results.
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
| Package Name | Functions |
|---|---|
| Pandas | Data pre-processing and engineering |
| Numpy | |
| Scipy | Conducting statistical tests and descriptive statistics |
| Statsmodels | |
| fancyimpute | Implementation of Multiple Imputation-Chained Equations (MICE) imputation |
| Imblearn | Implementation of SMOTE |
| scikit-learn | Training and cross validation of Machine Learning Models such as “Logistic Regression”, “Support Vector Machine”, “Decision Tree”, “Random Forest” and “AdaBoost” |
| Xgboost | Training of “XGBoost” algorithm |
| Catboost | Training of “CatBoost” algorithm |
| Lightgbm | Training of “LightGBM” algorithm |
| bayes_opt | Bayesian Optimization for hyperparameter tuning |
| SHAP | SHAP values |
| Matplotlib | Display of graphs and charts |
References
- The Top 10 Causes of Death. Available online: https://www.who.int/news-room/fact-sheets/detail/the-top-10-causes-of-death (accessed on 4 August 2023).
- Sun, Y.; Lee, S.H.; Heng, B.H.; Chin, V.S. 5-Year Survival and Rehospitalization Due to Stroke Recurrence among Patients with Hemorrhagic or Ischemic Strokes in Singapore. BMC Neurol. 2013, 13, 133. [Google Scholar] [CrossRef]
- Ellis, C.; Zhao, Y.; Egede, L.E. Depression and Increased Risk of Death in Adults with Stroke. J. Psychosom. Res. 2010, 68, 545–551. [Google Scholar] [CrossRef] [PubMed]
- Schöttke, H.; Giabbiconi, C.-M. Post-Stroke Depression and Post-Stroke Anxiety: Prevalence and Predictors. Int. Psychogeriatr. 2015, 27, 1805–1812. [Google Scholar] [CrossRef]
- Burton, C.A.C.; Murray, J.; Holmes, J.; Astin, F.; Greenwood, D.; Knapp, P. Frequency of Anxiety after Stroke: A Systematic Review and Meta-Analysis of Observational Studies. Int. J. Stroke 2013, 8, 545–559. [Google Scholar] [CrossRef]
- De Mello, R.F.; Santos, I.d.S.; Alencar, A.P.; Benseñor, I.M.; Lotufo, P.A.; Goulart, A.C. Major Depression as a Predictor of Poor Long-Term Survival in a Brazilian Stroke Cohort (Study of Stroke Mortality and Morbidity in Adults) EMMA Study. J. Stroke Cerebrovasc. Dis. 2016, 25, 618–625. [Google Scholar] [CrossRef] [PubMed]
- Cai, W.; Mueller, C.; Li, Y.-J.; Shen, W.-D.; Stewart, R. Post Stroke Depression and Risk of Stroke Recurrence and Mortality: A Systematic Review and Meta-Analysis. Ageing Res. Rev. 2019, 50, 102–109. [Google Scholar] [CrossRef]
- Astuti, P.; Kusnanto, K.; Dwi Novitasari, F. Depression and Functional Disability in Stroke Patients. J. Public Health Res. 2020, 9, 1835. [Google Scholar] [CrossRef] [PubMed]
- Lee, E.-H.; Kim, J.-W.; Kang, H.-J.; Kim, S.-W.; Kim, J.-T.; Park, M.-S.; Cho, K.-H.; Kim, J.-M. Association between Anxiety and Functional Outcomes in Patients with Stroke: A 1-Year Longitudinal Study. Psychiatry Investig. 2019, 16, 919–925. [Google Scholar] [CrossRef] [PubMed]
- Wright, F.; Wu, S.; Chun, H.-Y.Y.; Mead, G. Factors Associated with Poststroke Anxiety: A Systematic Review and Meta-Analysis. Stroke Res. Treat. 2017, 2017, e2124743. [Google Scholar] [CrossRef]
- Sanner Beauchamp, J.E.; Casameni Montiel, T.; Cai, C.; Tallavajhula, S.; Hinojosa, E.; Okpala, M.N.; Vahidy, F.S.; Savitz, S.I.; Sharrief, A.Z. A Retrospective Study to Identify Novel Factors Associated with Post-Stroke Anxiety. J. Stroke Cerebrovasc. Dis. 2020, 29, 104582. [Google Scholar] [CrossRef]
- Fang, Y.; Mpofu, E.; Athanasou, J. Reducing Depressive or Anxiety Symptoms in Post-Stroke Patients: Pilot Trial of a Constructive Integrative Psychosocial Intervention. Int. J. Health Sci. 2017, 11, 53–58. [Google Scholar]
- Shi, Y.; Yang, D.; Zeng, Y.; Wu, W. Risk Factors for Post-Stroke Depression: A Meta-Analysis. Front. Aging Neurosci. 2017, 9, 218. [Google Scholar] [CrossRef]
- Li, X.; Wang, X. Relationships between Stroke, Depression, Generalized Anxiety Disorder and Physical Disability: Some Evidence from the Canadian Community Health Survey-Mental Health. Psychiatry Res. 2020, 290, 113074. [Google Scholar] [CrossRef]
- Castillo, C.S.; Schultz, S.K.; Robinson, R.G. Clinical Correlates of Early-Onset and Late-Onset Poststroke Generalized Anxiety. Am. J. Psychiatry 1995, 152, 1174–1179. [Google Scholar] [CrossRef]
- Starkstein, S.E.; Cohen, B.S.; Fedoroff, P.; Parikh, R.M.; Price, T.R.; Robinson, R.G. Relationship between Anxiety Disorders and Depressive Disorders in Patients with Cerebrovascular Injury. Arch. Gen. Psychiatry 1990, 47, 246–251. [Google Scholar] [CrossRef] [PubMed]
- Chemerinski, E.; Robinson, R.G. The Neuropsychiatry of Stroke. Psychosomatics 2000, 41, 5–14. [Google Scholar] [CrossRef] [PubMed]
- Woranush, W.; Moskopp, M.L.; Sedghi, A.; Stuckart, I.; Noll, T.; Barlinn, K.; Siepmann, T. Preventive Approaches for Post-Stroke Depression: Where Do We Stand? A Systematic Review. Neuropsychiatr. Dis. Treat. 2021, 17, 3359–3377. [Google Scholar] [CrossRef]
- Mikami, K.; Jorge, R.E.; Moser, D.J.; Arndt, S.; Jang, M.; Solodkin, A.; Small, S.L.; Fonzetti, P.; Hegel, M.T.; Robinson, R.G. Prevention of Post-Stroke Generalized Anxiety Disorder, Using Escitalopram or Problem-Solving Therapy. J. Neuropsychiatry Clin. Neurosci. 2014, 26, 323–328. [Google Scholar] [CrossRef]
- Eack, S.M.; Greeno, C.G.; Lee, B.-J. Limitations of the Patient Health Questionnaire in Identifying Anxiety and Depression: Many Cases Are Undetected. Res. Soc. Work Pract. 2006, 16, 625–631. [Google Scholar] [CrossRef]
- Maters, G.A.; Sanderman, R.; Kim, A.Y.; Coyne, J.C. Problems in Cross-Cultural Use of the Hospital Anxiety and Depression Scale: “No Butterflies in the Desert”. PLoS ONE 2013, 8, e70975. [Google Scholar] [CrossRef]
- Premsagar, P.; Aldous, C.; Esterhuizen, T.M.; Gomes, B.J.; Gaskell, J.W.; Tabb, D.L. Comparing Conventional Statistical Models and Machine Learning in a Small Cohort of South African Cardiac Patients. Inform. Med. Unlocked 2022, 34, 101103. [Google Scholar] [CrossRef]
- Desai, R.J.; Wang, S.V.; Vaduganathan, M.; Evers, T.; Schneeweiss, S. Comparison of Machine Learning Methods With Traditional Models for Use of Administrative Claims With Electronic Medical Records to Predict Heart Failure Outcomes. JAMA Netw. Open 2020, 3, e1918962. [Google Scholar] [CrossRef] [PubMed]
- Ryu, Y.H.; Kim, S.Y.; Kim, T.U.; Lee, S.J.; Park, S.J.; Jung, H.-Y.; Hyun, J.K. Prediction of Poststroke Depression Based on the Outcomes of Machine Learning Algorithms. J. Clin. Med. 2022, 11, 2264. [Google Scholar] [CrossRef]
- Fast, L.; Temuulen, U.; Villringer, K.; Kufner, A.; Ali, H.F.; Siebert, E.; Huo, S.; Piper, S.K.; Sperber, P.S.; Liman, T.; et al. Machine Learning-Based Prediction of Clinical Outcomes after First-Ever Ischemic Stroke. Front. Neurol. 2023, 14, 1114360. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Zhao, D.; Lin, M.; Huang, X.; Shang, X. Post-Stroke Anxiety Analysis via Machine Learning Methods. Front. Aging Neurosci. 2021, 13, 657937. [Google Scholar] [CrossRef]
- Chen, Y.-M.; Chen, P.-C.; Lin, W.-C.; Hung, K.-C.; Chen, Y.-C.B.; Hung, C.-F.; Wang, L.-J.; Wu, C.-N.; Hsu, C.-W.; Kao, H.-Y. Predicting New-Onset Post-Stroke Depression from Real-World Data Using Machine Learning Algorithm. Front. Psychiatry 2023, 14, 1195586. [Google Scholar] [CrossRef] [PubMed]
- Zhanina, M.Y.; Druzhkova, T.A.; Yakovlev, A.A.; Vladimirova, E.E.; Freiman, S.V.; Eremina, N.N.; Guekht, A.B.; Gulyaeva, N.V. Development of Post-Stroke Cognitive and Depressive Disturbances: Associations with Neurohumoral Indices. Curr. Issues Mol. Biol. 2022, 44, 6290–6305. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Oakley, L.D.; Brown, R.L.; Li, Y.; Luo, Y. Properties of the Early Symptom Measurement of Post-Stroke Depression: Concurrent Criterion Validity and Cutoff Scores. J. Nurs. Res. 2020, 28, e107. [Google Scholar] [CrossRef]
- Khazaal, W.; Taliani, M.; Boutros, C.; Abou-Abbas, L.; Hosseini, H.; Salameh, P.; Sadier, N.S. Psychological Complications at 3 Months Following Stroke: Prevalence and Correlates among Stroke Survivors in Lebanon. Front. Psychol. 2021, 12, 663267. [Google Scholar] [CrossRef]
- Stern, A.F. The Hospital Anxiety and Depression Scale. Occup. Med. 2014, 64, 393–394. [Google Scholar] [CrossRef]
- Kroenke, K.; Spitzer, R.L.; Williams, J.B.W. The PHQ-9. J. Gen. Intern. Med. 2001, 16, 606–613. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Levis, B.; Sun, Y.; He, C.; Krishnan, A.; Neupane, D.; Bhandari, P.M.; Negeri, Z.; Benedetti, A.; Thombs, B.D. Accuracy of the Hospital Anxiety and Depression Scale Depression Subscale (HADS-D) to Screen for Major Depression: Systematic Review and Individual Participant Data Meta-Analysis. BMJ 2021, 373, n972. [Google Scholar] [CrossRef]
- Burton, L.-J.; Tyson, S. Screening for Mood Disorders after Stroke: A Systematic Review of Psychometric Properties and Clinical Utility. Psychol. Med. 2015, 45, 29–49. [Google Scholar] [CrossRef]
- Urtasun, M.; Daray, F.M.; Teti, G.L.; Coppolillo, F.; Herlax, G.; Saba, G.; Rubinstein, A.; Araya, R.; Irazola, V. Validation and Calibration of the Patient Health Questionnaire (PHQ-9) in Argentina. BMC Psychiatry 2019, 19, 291. [Google Scholar] [CrossRef]
- Kroenke, K.; Spitzer, R.L.; Williams, J.B.W. The Patient Health Questionnaire-2: Validity of a Two-Item Depression Screener. Med. Care 2003, 41, 1284–1292. [Google Scholar] [CrossRef] [PubMed]
- Jakobsen, J.C.; Gluud, C.; Wetterslev, J.; Winkel, P. When and How Should Multiple Imputation Be Used for Handling Missing Data in Randomised Clinical Trials—A Practical Guide with Flowcharts. BMC Med. Res. Methodol. 2017, 17, 162. [Google Scholar] [CrossRef]
- Blagus, R.; Lusa, L. Class Prediction for High-Dimensional Class-Imbalanced Data. BMC Bioinform. 2010, 11, 523. [Google Scholar] [CrossRef]
- Blagus, R.; Lusa, L. SMOTE for High-Dimensional Class-Imbalanced Data. BMC Bioinform. 2013, 14, 106. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R. Regression Shrinkage and Selection via the Lasso. J. R. Stat. Soc. Ser. B Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Fürnkranz, J. Decision Tree. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; pp. 263–267. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Bühlmann, P.; Hothorn, T. Boosting Algorithms: Regularization, Prediction and Model Fitting. Stat. Sci. 2007, 22, 477–505. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient Boosting with Categorical Features Support. arXiv 2018, arXiv:1810.11363. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2017. [Google Scholar]
- Martinez-Cantin, R. BayesOpt: A Bayesian Optimization Library for Nonlinear Optimization, Experimental Design and Bandits. arXiv 2014, arXiv:1405.7430. [Google Scholar] [CrossRef]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical Bayesian Optimization of Machine Learning Algorithms. arXiv 2012, arXiv:1206.2944. [Google Scholar] [CrossRef]
- Youden, W.J. Index for Rating Diagnostic Tests. Cancer 1950, 3, 32–35. [Google Scholar] [CrossRef]
- Lundberg, S.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar] [CrossRef]
- McKinney, W. Pandas: A Foundational Python Library for Data Analysis and Statistics; Academic Publishers: Singapore, 2011. [Google Scholar]
- Array Programming with NumPy|Nature. Available online: https://www.nature.com/articles/s41586-020-2649-2 (accessed on 20 June 2023).
- SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python|Nature Methods. Available online: https://www.nature.com/articles/s41592-019-0686-2 (accessed on 20 June 2023).
- Seabold, S.; Perktold, J. Statsmodels: Econometric and Statistical Modeling with Python; SCIPY: Austin, TX, USA, 2010; pp. 92–96. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Droettboom, M.; Hunter, J.; Firing, E.; Caswell, T.A.; Dale, D.; Lee, J.-J.; Elson, P.; McDougall, D.; Straw, A.; Root, B.; et al. Matplotlib, version 1.4.0; CERN Data Center: Meyrin, Switzerland, 2014. [Google Scholar] [CrossRef]
- Pinto-Meza, A.; Serrano-Blanco, A.; Peñarrubia, M.T.; Blanco, E.; Haro, J.M. Assessing Depression in Primary Care with the PHQ-9: Can It Be Carried Out over the Telephone? J. Gen. Intern. Med. 2005, 20, 738–742. [Google Scholar] [CrossRef] [PubMed]
- Lyu, Y.; Li, W.; Tang, T. Prevalence Trends and Influencing Factors of Post-Stroke Depression: A Study Based on the National Health and Nutrition Examination Survey. Med. Sci. Monit. Int. Med. J. Exp. Clin. Res. 2022, 28, e933367-e1–e933367-e8. [Google Scholar] [CrossRef]
- Wang, Z.; Zhu, M.; Su, Z.; Guan, B.; Wang, A.; Wang, Y.; Zhang, N.; Wang, C. Post-Stroke Depression: Different Characteristics Based on Follow-up Stage and Gender–A Cohort Perspective Study from Mainland China. Neurol. Res. 2017, 39, 996–1005. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Ma, J.; Sun, Y.; Xiao, L.D.; Yan, F.; Tang, S. Anxiety Subtypes in Rural Ischaemic Stroke Survivors: A Latent Profile Analysis. Nurs. Open 2023, 10, 4083–4092. [Google Scholar] [CrossRef] [PubMed]
- Park, E.-Y.; Kim, J.-H. An Analysis of Depressive Symptoms in Stroke Survivors: Verification of a Moderating Effect of Demographic Characteristics. BMC Psychiatry 2017, 17, 132. [Google Scholar] [CrossRef] [PubMed]
- Lin, F.-H.; Yih, D.N.; Shih, F.-M.; Chu, C.-M. Effect of Social Support and Health Education on Depression Scale Scores of Chronic Stroke Patients. Medicine 2019, 98, e17667. [Google Scholar] [CrossRef]
- Egan, M.; Kubina, L.-A.; Dubouloz, C.-J.; Kessler, D.; Kristjansson, E.; Sawada, M. Very Low Neighbourhood Income Limits Participation Post Stroke: Preliminary Evidence from a Cohort Study. BMC Public Health 2015, 15, 528. [Google Scholar] [CrossRef]
- Bi, H.; Wang, M. Role of Social Support in Poststroke Depression: A Meta-Analysis. Front. Psychiatry 2022, 13, 924277. [Google Scholar] [CrossRef]
- Kruithof, W.J.; van Mierlo, M.L.; Visser-Meily, J.M.A.; van Heugten, C.M.; Post, M.W.M. Associations between Social Support and Stroke Survivors’ Health-Related Quality of Life—A Systematic Review. Patient Educ. Couns. 2013, 93, 169–176. [Google Scholar] [CrossRef]
- Knapp, P.; Hewison, J. The Protective Effects of Social Support against Mood Disorder after Stroke. Psychol. Health Med. 1998, 3, 275–283. [Google Scholar] [CrossRef]


| Train Set | Test Set (after Youden’s J Adjustment) | |||||
|---|---|---|---|---|---|---|
| Accuracy | AUROC | F1-Score | Accuracy | AUROC | F1-Score | |
| Logistic Regression | 0.696 (0.647–0.738) | 0.870 (0.864–0.877) | 0.658 (0.646–0.673) | 0.640 | 0.573 | 0.304 |
| Gradient-boosted tree | 0.973 (0.958–0.982) | 0.946 (0.932–0.957) | 0.950 (0.924–0.964) | 0.747 | 0.620 | 0.341 |
| Light GBM | 0.905 (0.878–0.922) | 0.942 (0.924–0.964) | 0.882 (0.872–0.894) | 0.659 | 0.646 | 0.355 |
| Decision tree | 0.729 (0.660–0.760) | 0.831 (0.810–0.844) | 0.705 (0.656–0.729) | 0.713 | 0.622 | 0.338 |
| Random forest | 0.800 (0.779–0.820) | 0.911 (0.906–0.915) | 0.779 (0.770–0.787) | 0.506 | 0.671 | 0.359 |
| XGBoost | 0.899 (0.874–0.920) | 0.956 (0.934–0.968) | 0.877 (0.868–0.889) | 0.539 | 0.641 | 0.346 |
| AdaBoost | 0.843 (0.825–0.860) | 0.946 (0.939–0.948) | 0.828 (0.811–0.841) | 0.727 | 0.634 | 0.354 |
| CatBoost | 0.966 (0.950–0.980) | 0.966 (0.952–0.970) | 0.957 (0.945–0.971) | 0.631 | 0.592 | 0.318 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oei, C.W.; Ng, E.Y.K.; Ng, M.H.S.; Tan, R.-S.; Chan, Y.M.; Chan, L.G.; Acharya, U.R. Explainable Risk Prediction of Post-Stroke Adverse Mental Outcomes Using Machine Learning Techniques in a Population of 1780 Patients. Sensors 2023, 23, 7946. https://doi.org/10.3390/s23187946
Oei CW, Ng EYK, Ng MHS, Tan R-S, Chan YM, Chan LG, Acharya UR. Explainable Risk Prediction of Post-Stroke Adverse Mental Outcomes Using Machine Learning Techniques in a Population of 1780 Patients. Sensors. 2023; 23(18):7946. https://doi.org/10.3390/s23187946
Chicago/Turabian StyleOei, Chien Wei, Eddie Yin Kwee Ng, Matthew Hok Shan Ng, Ru-San Tan, Yam Meng Chan, Lai Gwen Chan, and Udyavara Rajendra Acharya. 2023. "Explainable Risk Prediction of Post-Stroke Adverse Mental Outcomes Using Machine Learning Techniques in a Population of 1780 Patients" Sensors 23, no. 18: 7946. https://doi.org/10.3390/s23187946
APA StyleOei, C. W., Ng, E. Y. K., Ng, M. H. S., Tan, R.-S., Chan, Y. M., Chan, L. G., & Acharya, U. R. (2023). Explainable Risk Prediction of Post-Stroke Adverse Mental Outcomes Using Machine Learning Techniques in a Population of 1780 Patients. Sensors, 23(18), 7946. https://doi.org/10.3390/s23187946