



Accurate Visual Simultaneous Localization and Mapping (SLAM) against Around View Monitor (AVM) Distortion Error Using Weighted Generalized Iterative Closest Point (GICP)

Abstract
:1. Introduction
2. Background
2.1. Related Work
2.1.1. Visual SLAM
Front-Camera-Based Visual SLAM
AVM-Based Visual SLAM
2.1.2. AVM Image Enhancement Techniques
AVM Image Modification Using Automatic Calibration
AVM Image Generation Using Deep Learning
2.2. Limitation of Hybrid Bird’s-Eye Edge-Based Semantic Visual SLAM
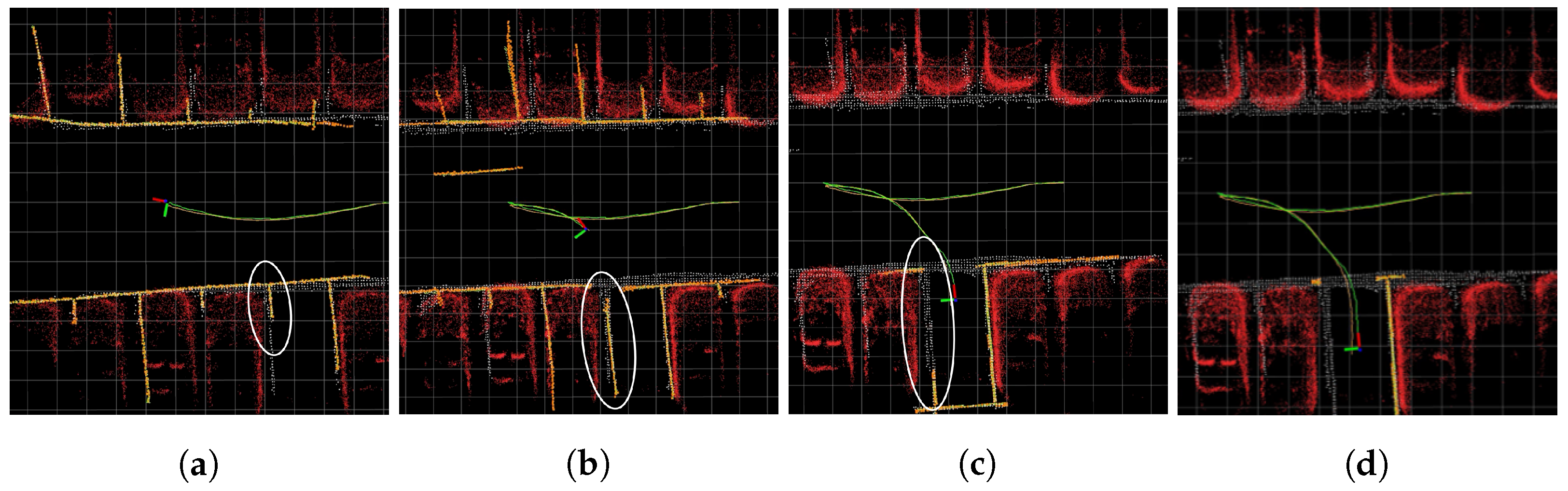
2.2.1. Avm Distortion Error
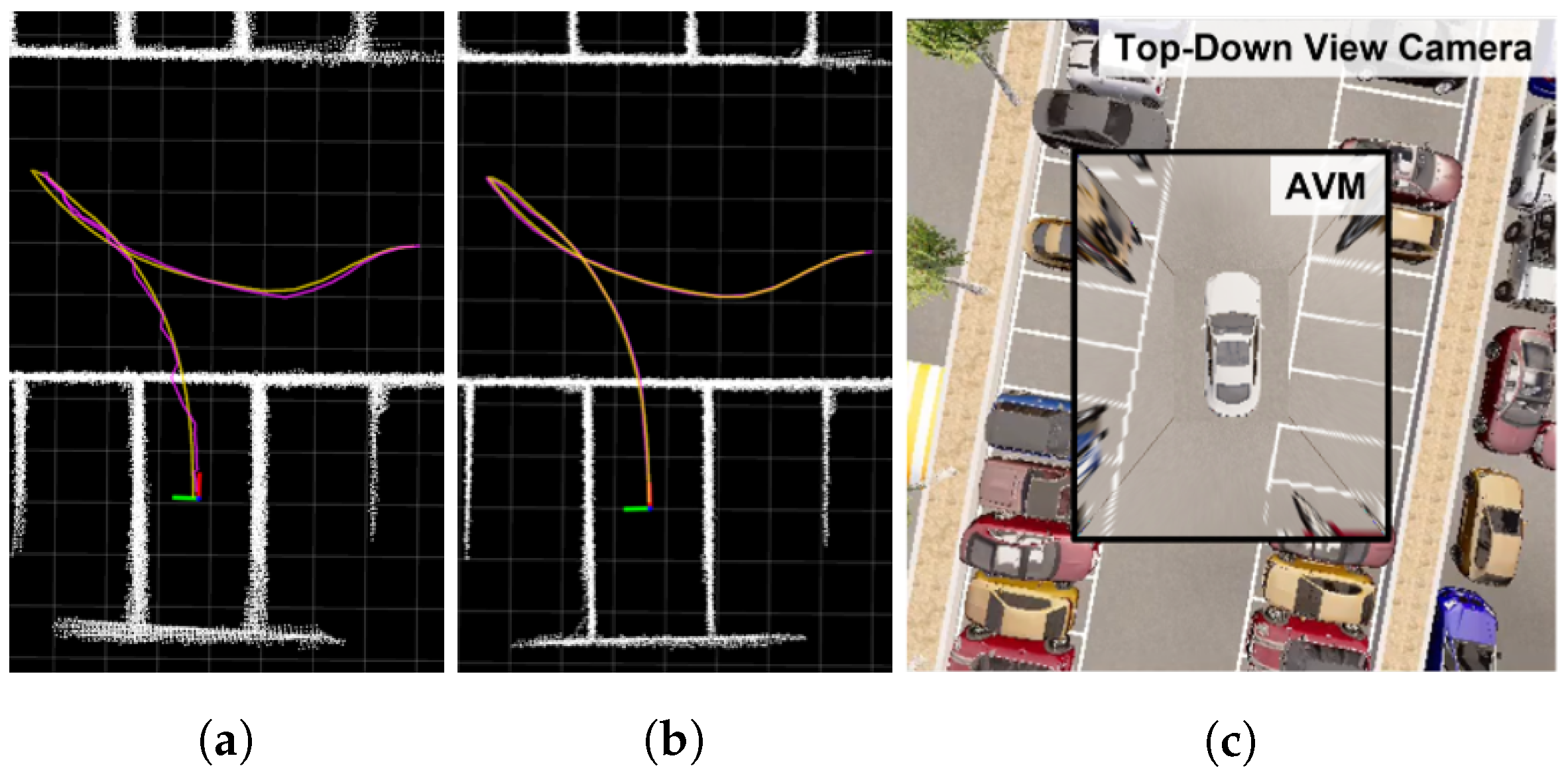
2.2.2. SLAM Performance Comparison in Simulation Environment and the Real World
3. Proposed Method
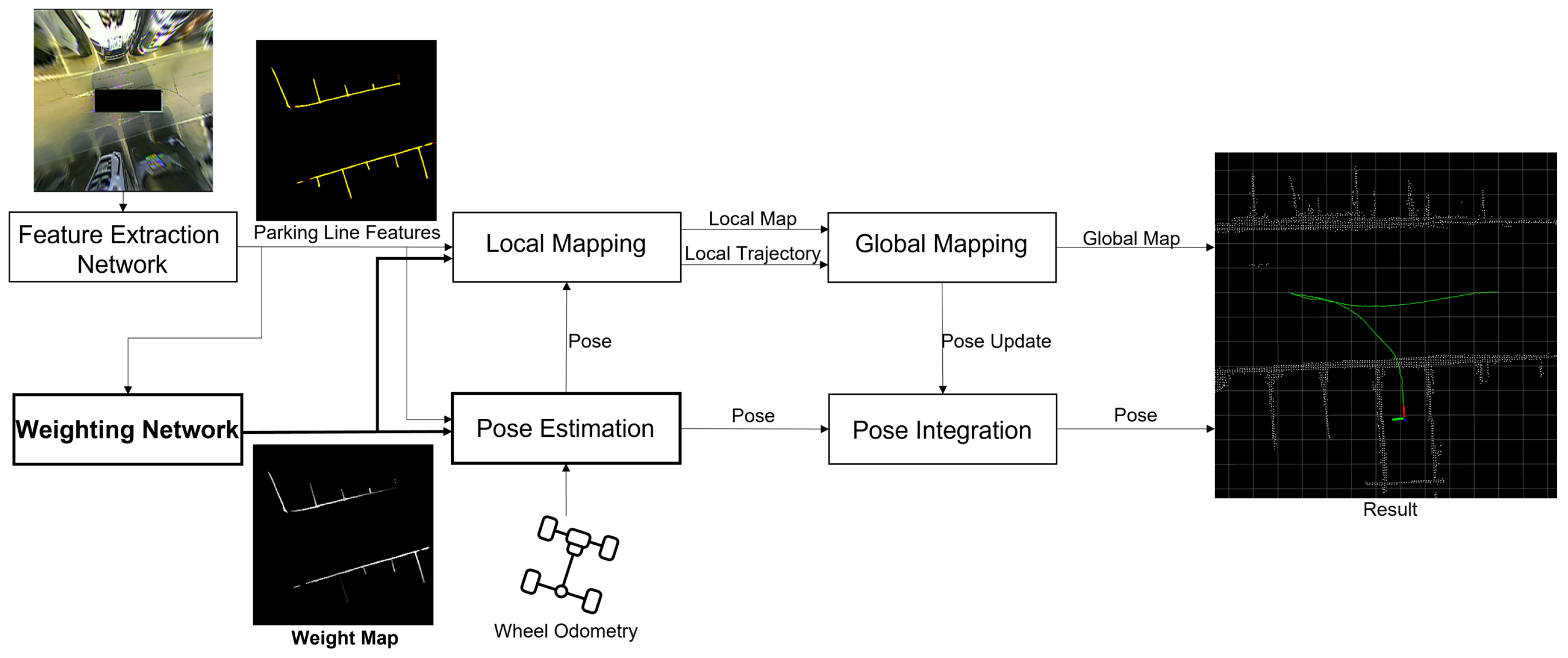
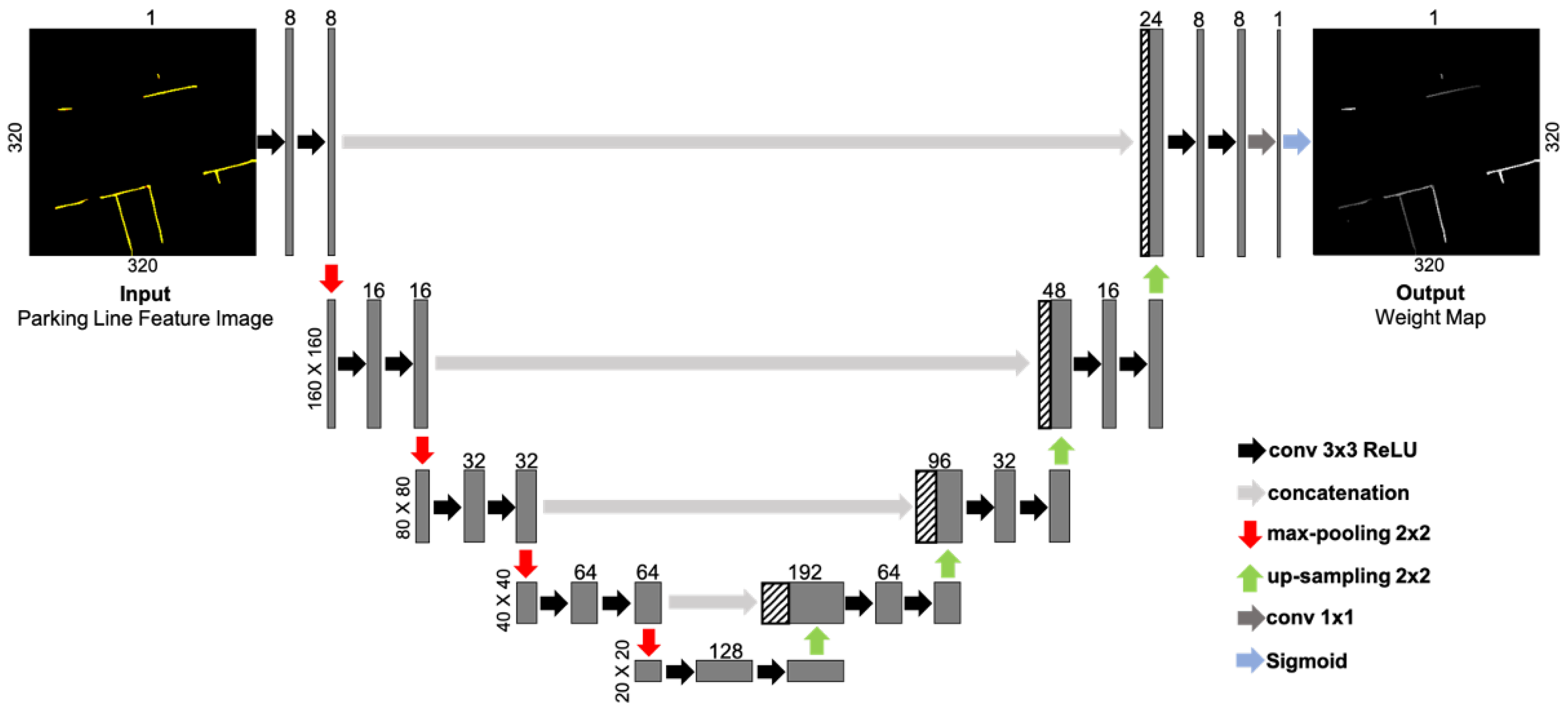
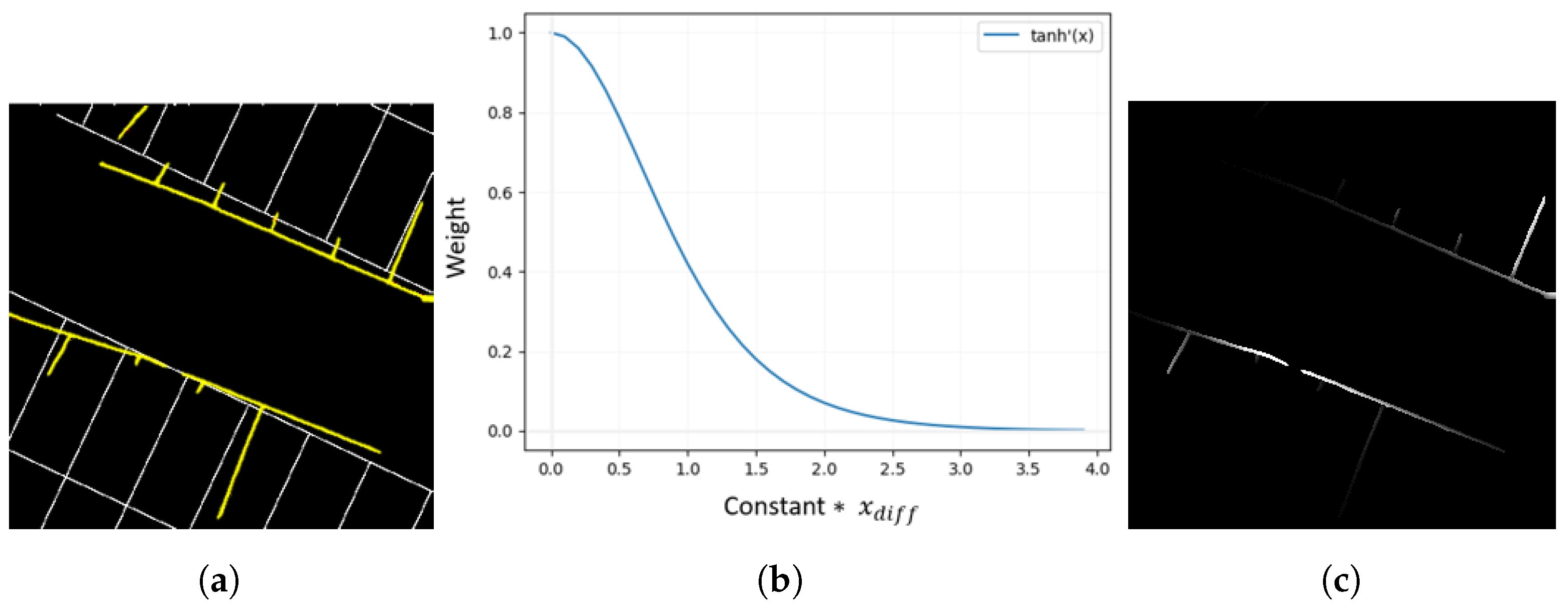
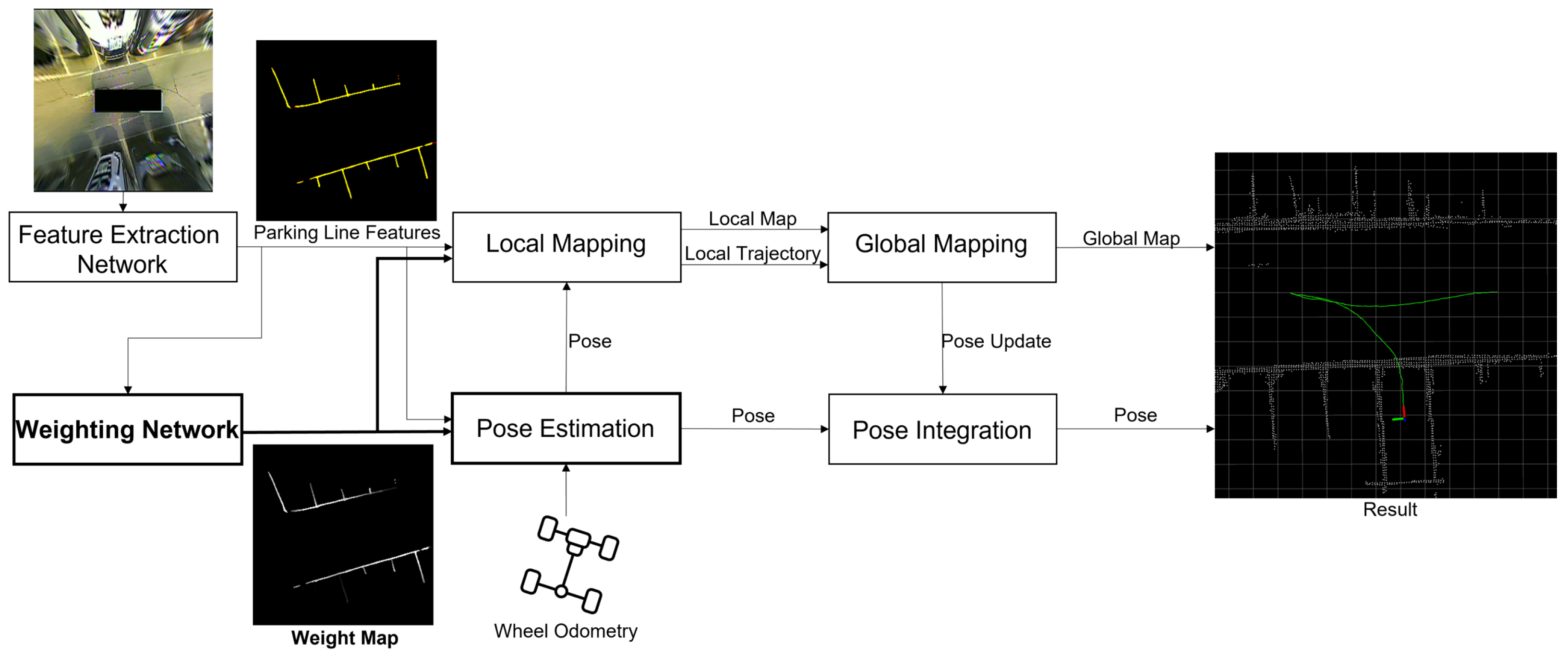
3.1. Framework of AVM-Based Visual SLAM Using Weight Map
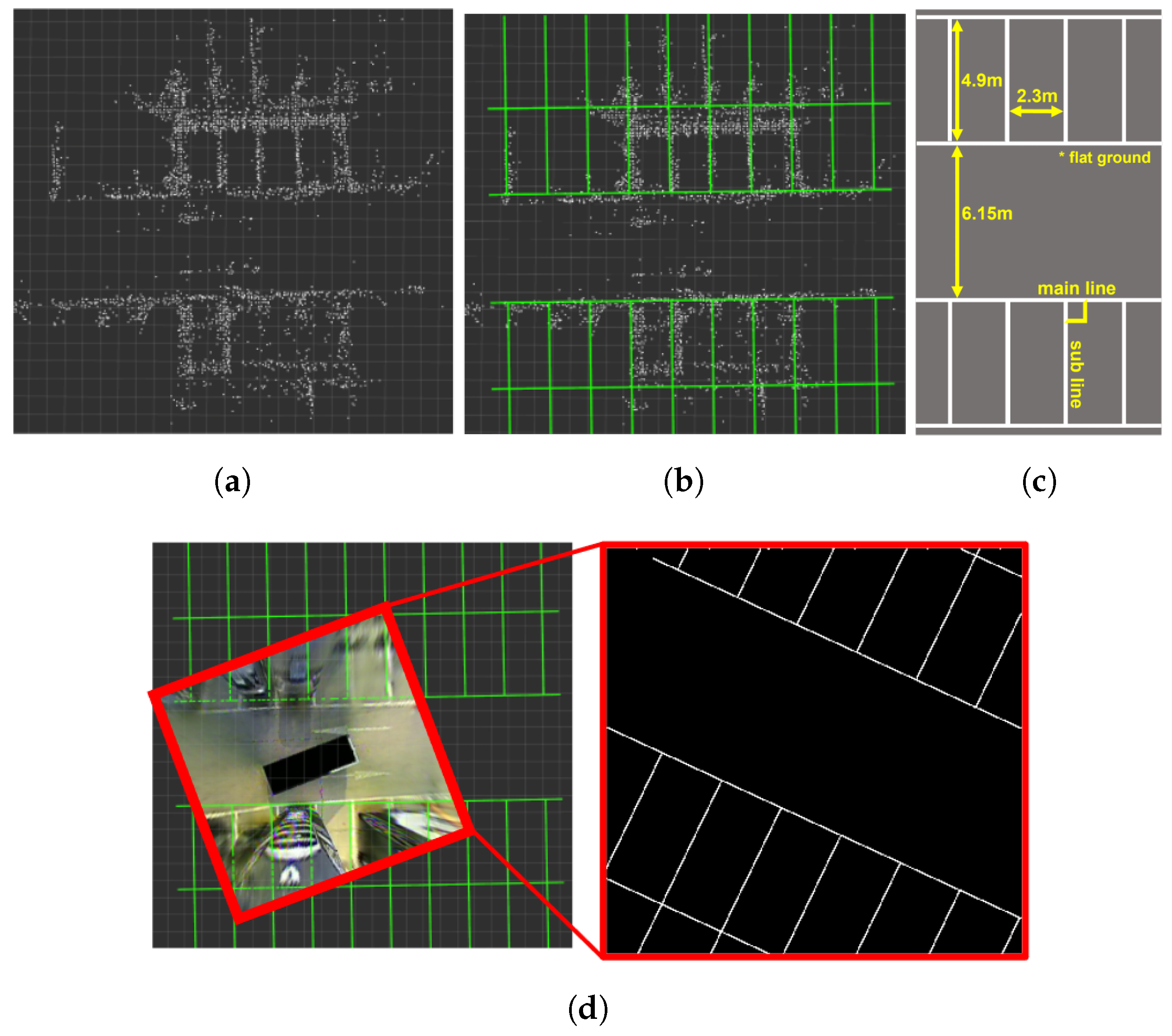
3.2. Dataset Creation
4. Experiment and Discussion
4.1. Experimental Setup
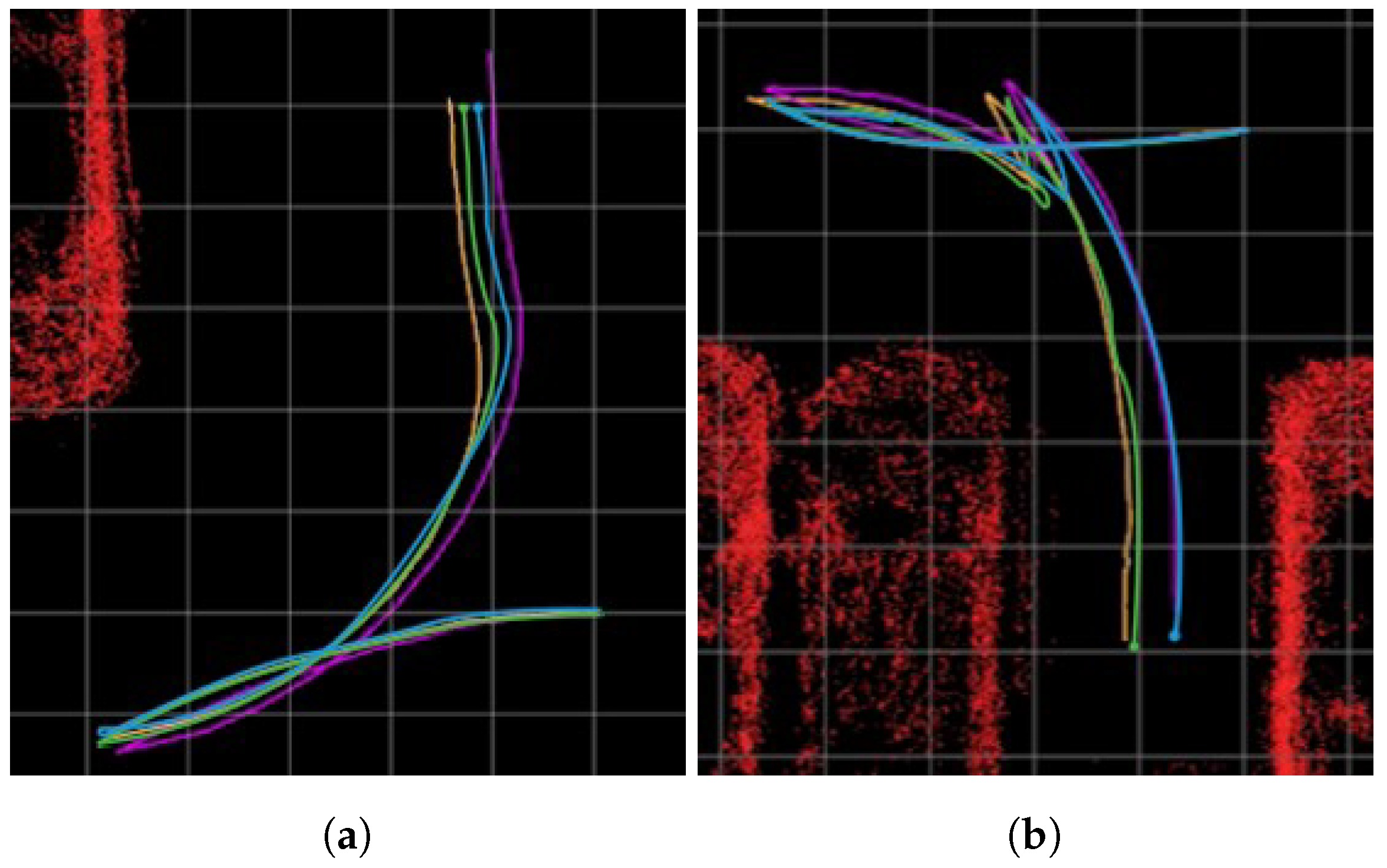
4.2. Quantitative Comparison between CARLA Simulation and Real Environments
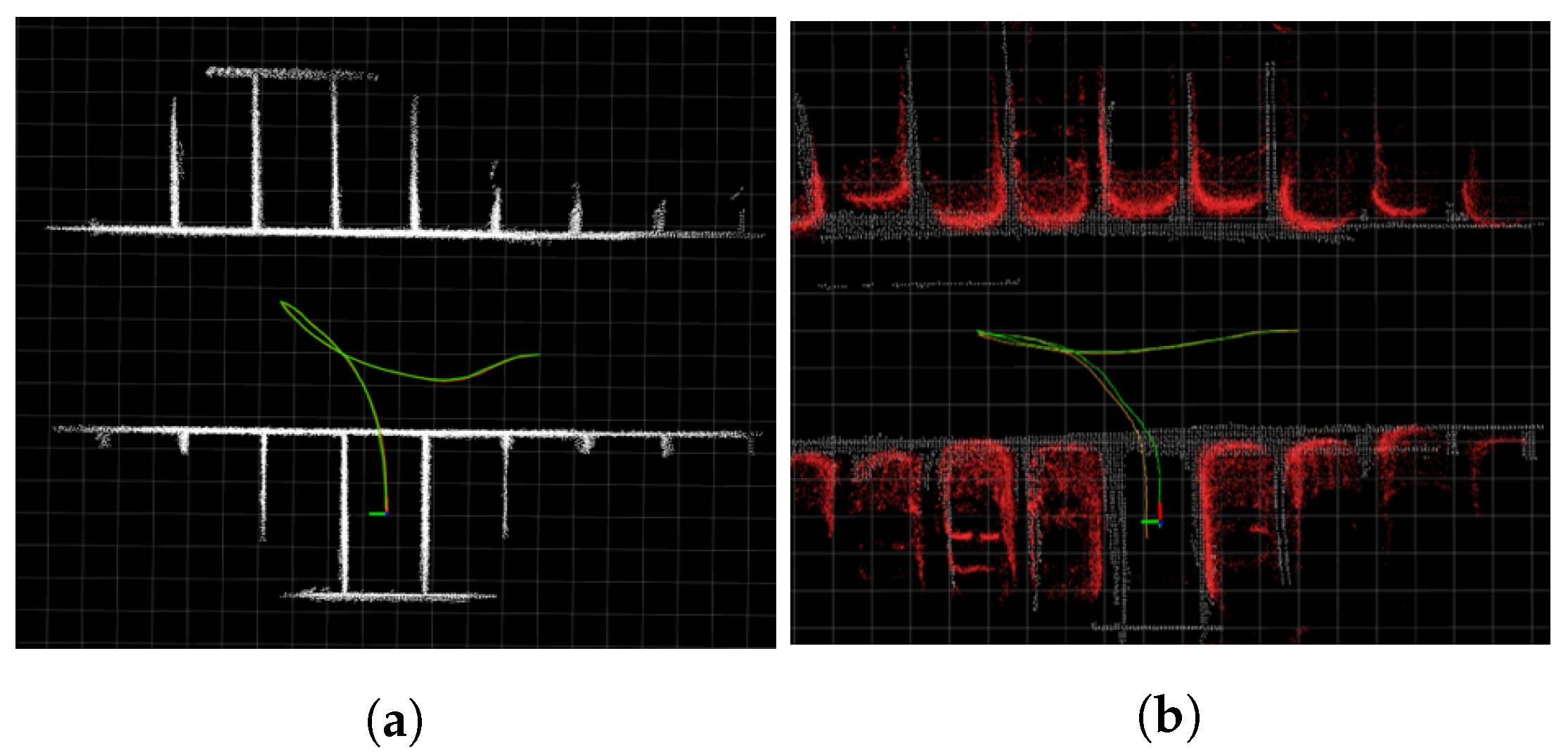
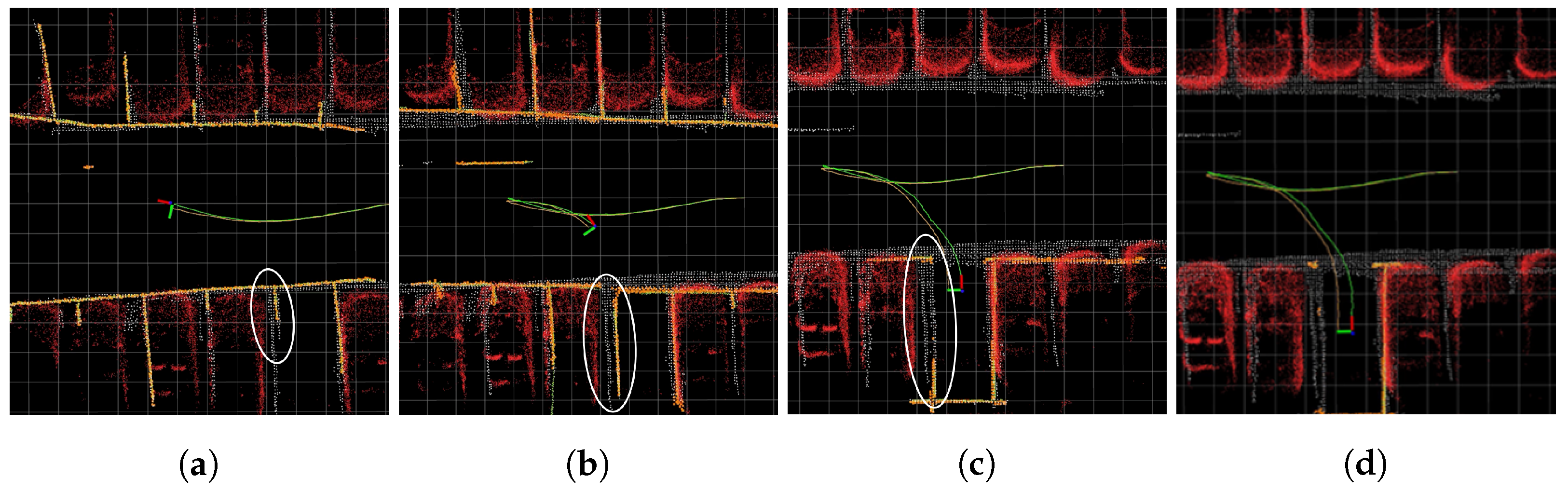
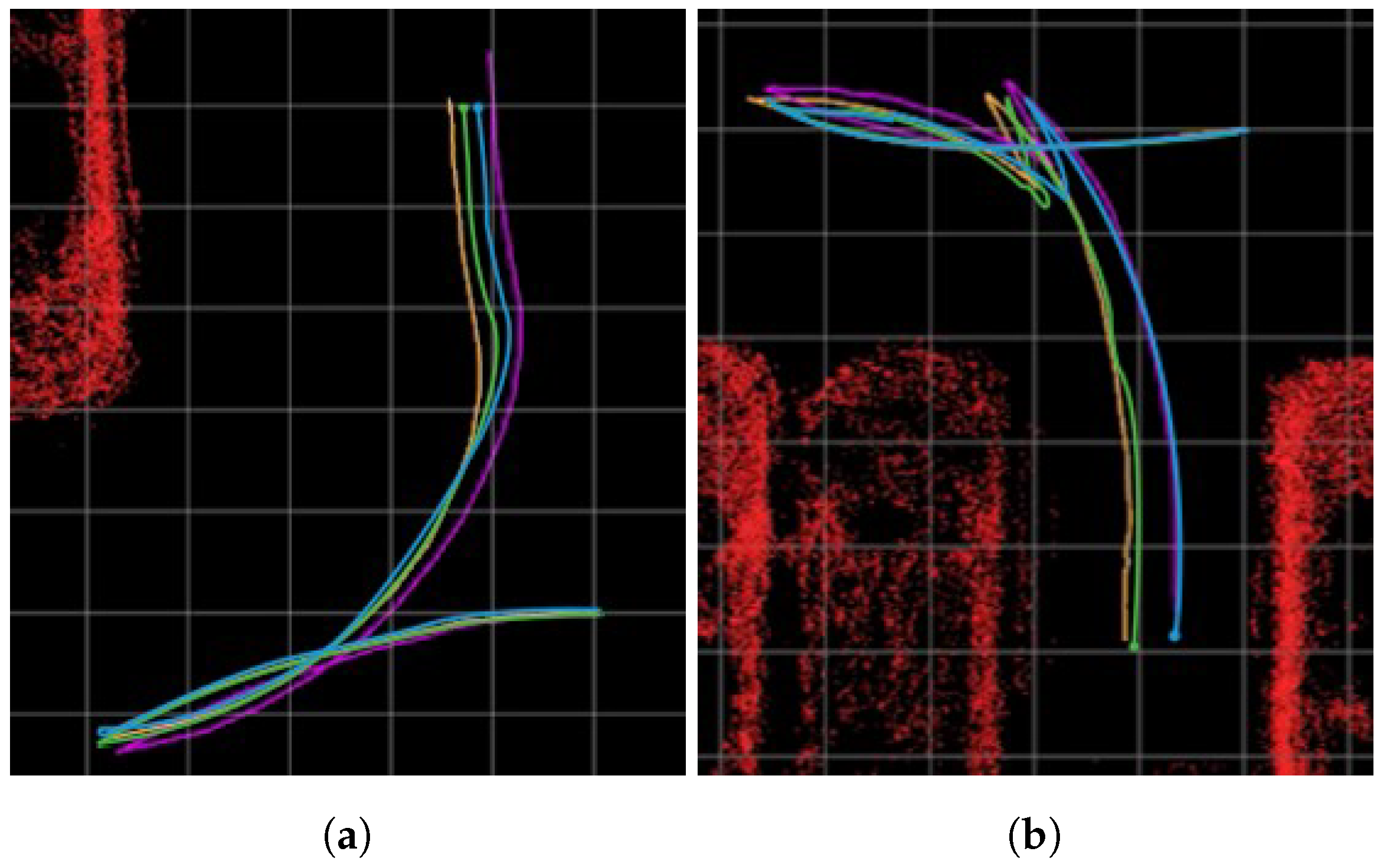
4.3. Proposed Method Evaluation and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Smith, R.C.; Cheeseman, P. On the representation and estimation of spatial uncertainty. Int. J. Robot. Res. 1986, 5, 56–68. [Google Scholar] [CrossRef]
- Karlsson, N.; Di Bernardo, E.; Ostrowski, J.; Goncalves, L.; Pirjanian, P.; Munich, M.E. The vSLAM algorithm for robust localization and mapping. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; IEEE: New York, NY, USA, 2005; pp. 24–29. [Google Scholar]
- Chen, W.; Shang, G.; Ji, A.; Zhou, C.; Wang, X.; Xu, C.; Li, Z.; Hu, K. An overview on visual slam: From tradition to semantic. Remote Sens. 2022, 14, 3010. [Google Scholar] [CrossRef]
- Yang, N.; Wang, R.; Gao, X.; Cremers, D. Challenges in monocular visual odometry: Photometric calibration, motion bias, and rolling shutter effect. IEEE Robot. Autom. Lett. 2018, 3, 2878–2885. [Google Scholar] [CrossRef]
- Qin, T.; Chen, T.; Chen, Y.; Su, Q. Avp-slam: Semantic visual mapping and localization for autonomous vehicles in the parking lot. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; IEEE: New York, NY, USA, 2020; pp. 5939–5945. [Google Scholar]
- Zhang, C.; Liu, H.; Xie, Z.; Yang, K.; Guo, K.; Cai, R.; Li, Z. AVP-Loc: Surround View Localization and Relocalization Based on HD Vector Map for Automated Valet Parking. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: New York, NY, USA, 2021; pp. 5552–5559. [Google Scholar]
- Xiang, Z.; Bao, A.; Su, J. Hybrid bird’s-eye edge based semantic visual SLAM for automated valet parking. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: New York, NY, USA, 2021; pp. 11546–11552. [Google Scholar]
- Natroshvili, K.; Scholl, K.U. Automatic extrinsic calibration methods for surround view systems. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; IEEE: New York, NY, USA, 2017; pp. 82–88. [Google Scholar]
- Choi, K.; Jung, H.G.; Suhr, J.K. Automatic calibration of an around view monitor system exploiting lane markings. Sensors 2018, 18, 2956. [Google Scholar] [CrossRef]
- Lee, Y.H.; Kim, W.Y. An automatic calibration method for AVM cameras. IEEE Access 2020, 8, 192073–192086. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Y.; Wang, Y.; Zhao, H. Hdmapnet: An online hd map construction and evaluation framework. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: New York, NY, USA, 2022; pp. 4628–4634. [Google Scholar]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Qiao, Y.; Dai, J. Bevformer: Learning bird’s-eye-view representation from multi-camera images via spatiotemporal transformers. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Proceedings, Part IX. Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–18. [Google Scholar]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Forster, C.; Pizzoli, M.; Scaramuzza, D. SVO: Fast semi-direct monocular visual odometry. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; IEEE: New York, NY, USA, 2014; pp. 15–22. [Google Scholar]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Sensor Fusion IV: Control Paradigms and Data Structures; SPIE: Bellingham, WA, USA, 1992; Volume 1611, pp. 586–606. [Google Scholar]
- Segal, A.; Haehnel, D.; Thrun, S. Generalized-icp. In Proceedings of the Robotics: Science and Systems, Seattle, WA, USA, 28 June–1 July 2009; Volume 2, p. 435. [Google Scholar]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; Lopez, A.; Koltun, V. CARLA: An open urban driving simulator. In Proceedings of the Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Wang, Z.; Ren, W.; Qiu, Q. Lanenet: Real-time lane detection networks for autonomous driving. arXiv 2018, arXiv:1807.01726. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- De Maesschalck, R.; Jouan-Rimbaud, D.; Massart, D.L. The mahalanobis distance. Chemom. Intell. Lab. Syst. 2000, 50, 1–18. [Google Scholar] [CrossRef]
- Peterson, L.E. K-nearest neighbor. Scholarpedia 2009, 4, 1883. [Google Scholar] [CrossRef]
- Shan, T.; Englot, B. Lego-loam: Lightweight and ground-optimized lidar odometry and mapping on variable terrain. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: New York, NY, USA, 2018; pp. 4758–4765. [Google Scholar]
- Zhang, Z.; Scaramuzza, D. A tutorial on quantitative trajectory evaluation for visual (-inertial) odometry. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: New York, NY, USA, 2018; pp. 7244–7251. [Google Scholar]
- Jang, C.; Kim, C.; Lee, S.; Kim, S.; Lee, S.; Sunwoo, M. Re-plannable automated parking system with a standalone around view monitor for narrow parking lots. IEEE Trans. Intell. Transp. Syst. 2019, 21, 777–790. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Max [m] | Mean [m] | RMSE [m] |
|---|---|---|---|
| CARLA | 0.117 | 0.053 | 0.061 |
| Real | 0.549 | 0.260 | 0.299 |
| Case | Experiment Place | The Number of Adjacent Vehicles | The Location of the Goal Position | The Number of Cusps |
|---|---|---|---|---|
| 1 | Parking Lot 1 | 0 | right | 1 |
| 2 | Parking Lot 1 | 0 | left | 1 |
| 3 | Parking Lot 1 | 0 | left | 3 |
| 4 | Parking Lot 1 | 1 | left | 1 |
| 5 | Parking Lot 1 | 1 | left | 3 |
| 6 | Parking Lot 1 | 2 | left | 1 |
| 7 | Parking Lot 2 | 1 | right | 1 |
| 8 | Parking Lot 2 | 2 | left | 3 |
| 9 | Parking Lot 3 | 2 | right | 3 |
| 10 | Parking Lot 3 | 2 | left | 3 |
| Case | Method | ATE Max [m] | ATE Mean [m] | ATE RMSE [m] | FPLE [m] |
|---|---|---|---|---|---|
| 1 | PF | 0.667 | 0.326 | 0.378 | 0.647 |
| Modified | 0.421 | 0.164 | 0.193 | 0.285 | |
| Proposed | 0.299 | 0.107 | 0.124 | 0.137 | |
| 2 | PF | 0.954 | 0.284 | 0.410 | 0.851 |
| Modified | 0.431 | 0.239 | 0.259 | 0.155 | |
| Proposed | 0.362 | 0.150 | 0.174 | 0.056 | |
| 3 | PF | 1.253 | 0.485 | 0.545 | 1.017 |
| Modified | 0.563 | 0.250 | 0.271 | 0.482 | |
| Proposed | 0.394 | 0.183 | 0.201 | 0.394 | |
| 4 | PF | 0.802 | 0.222 | 0.296 | 0.790 |
| Modified | 0.807 | 0.334 | 0.407 | 0.613 | |
| Proposed | 0.446 | 0.132 | 0.169 | 0.224 | |
| 5 | PF | 0.941 | 0.413 | 0.459 | 0.771 |
| Modified | 0.784 | 0.317 | 0.373 | 0.572 | |
| Proposed | 0.423 | 0.142 | 0.161 | 0.198 | |
| 6 | PF | 0.686 | 0.260 | 0.308 | 0.686 |
| Modified | 0.563 | 0.282 | 0.320 | 0.509 | |
| Proposed | 0.301 | 0.164 | 0.201 | 0.270 | |
| 7 | PF | 0.830 | 0.245 | 0.328 | 0.648 |
| Modified | 0.513 | 0.230 | 0.257 | 0.361 | |
| Proposed | 0.300 | 0.159 | 0.174 | 0.121 | |
| 8 | PF | 0.708 | 0.295 | 0.349 | 0.688 |
| Modified | 0.561 | 0.332 | 0.378 | 0.495 | |
| Proposed | 0.235 | 0.102 | 0.111 | 0.234 | |
| 9 | PF | 0.865 | 0.265 | 0.312 | 0.470 |
| Modified | 0.457 | 0.193 | 0.214 | 0.443 | |
| Proposed | 0.388 | 0.161 | 0.189 | 0.379 | |
| 10 | PF | 1.047 | 0.537 | 0.602 | 1.005 |
| Modified | 0.492 | 0.173 | 0.212 | 0.427 | |
| Proposed | 0.430 | 0.143 | 0.175 | 0.416 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.; Kim, M.; Ahn, J.; Park, J. Accurate Visual Simultaneous Localization and Mapping (SLAM) against Around View Monitor (AVM) Distortion Error Using Weighted Generalized Iterative Closest Point (GICP). Sensors 2023, 23, 7947. https://doi.org/10.3390/s23187947
Lee Y, Kim M, Ahn J, Park J. Accurate Visual Simultaneous Localization and Mapping (SLAM) against Around View Monitor (AVM) Distortion Error Using Weighted Generalized Iterative Closest Point (GICP). Sensors. 2023; 23(18):7947. https://doi.org/10.3390/s23187947
Chicago/Turabian StyleLee, Yangwoo, Minsoo Kim, Joonwoo Ahn, and Jaeheung Park. 2023. "Accurate Visual Simultaneous Localization and Mapping (SLAM) against Around View Monitor (AVM) Distortion Error Using Weighted Generalized Iterative Closest Point (GICP)" Sensors 23, no. 18: 7947. https://doi.org/10.3390/s23187947
APA StyleLee, Y., Kim, M., Ahn, J., & Park, J. (2023). Accurate Visual Simultaneous Localization and Mapping (SLAM) against Around View Monitor (AVM) Distortion Error Using Weighted Generalized Iterative Closest Point (GICP). Sensors, 23(18), 7947. https://doi.org/10.3390/s23187947