



SFPFusion: An Improved Vision Transformer Combining Super Feature Attention and Wavelet-Guided Pooling for Infrared and Visible Images Fusion


Abstract
:1. Introduction
- An improved Transformer architecture combined with wavelet-guided pooling and attention mechanism (super feature) is proposed, which preserves global features while enhancing detail information.
- A simple yet efficient fusion network is proposed, which only employs a simple -norm and the softmax-like fusion strategy to achieve better fusion performance.
- The qualitative and quantitative experiments on several public image fusion datasets demonstrate the superiority of the proposed fusion method.
2. Related Work
2.1. Deep Learning Model for Image Fusion
2.2. Transformer for Image Fusion
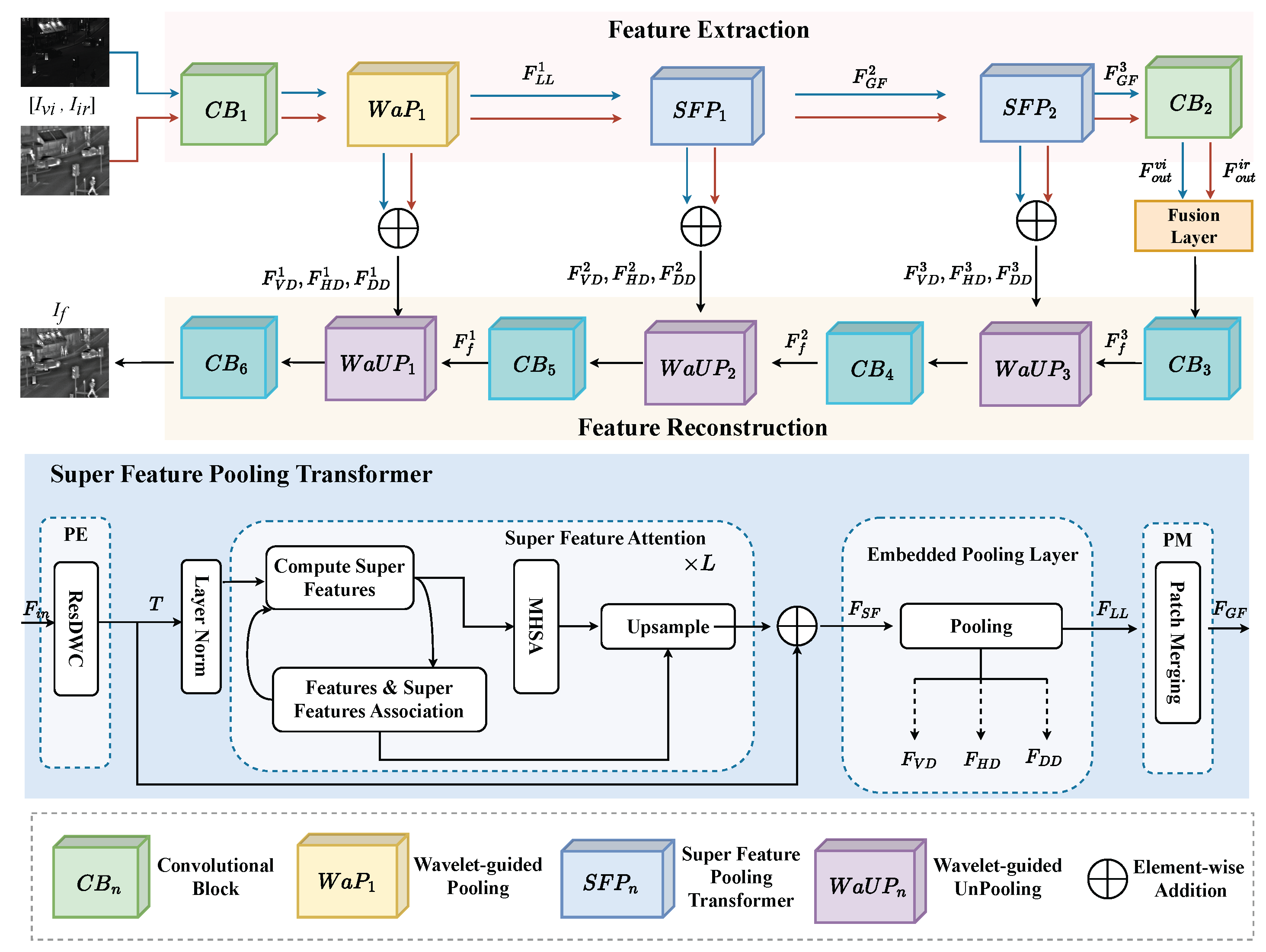
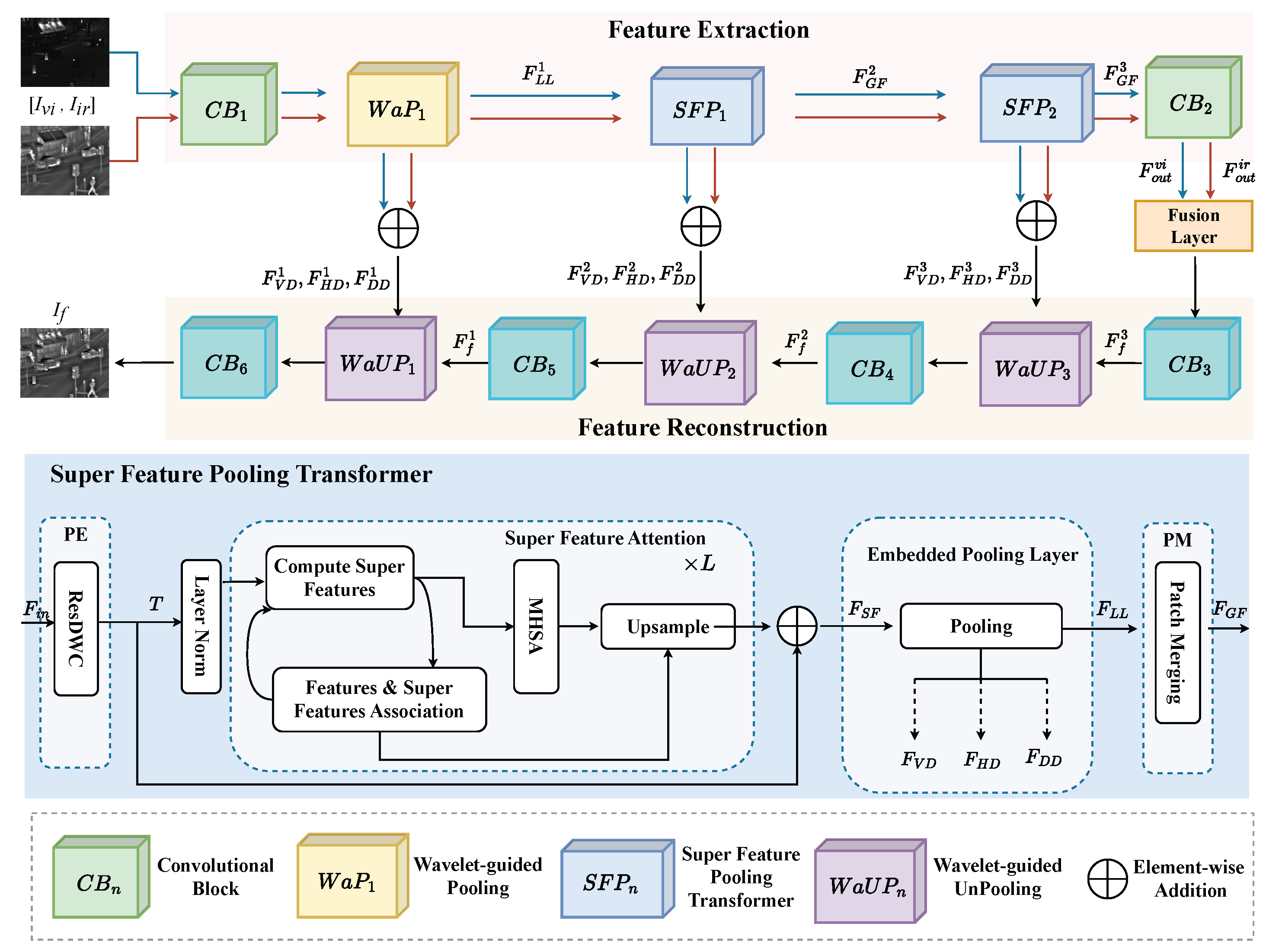
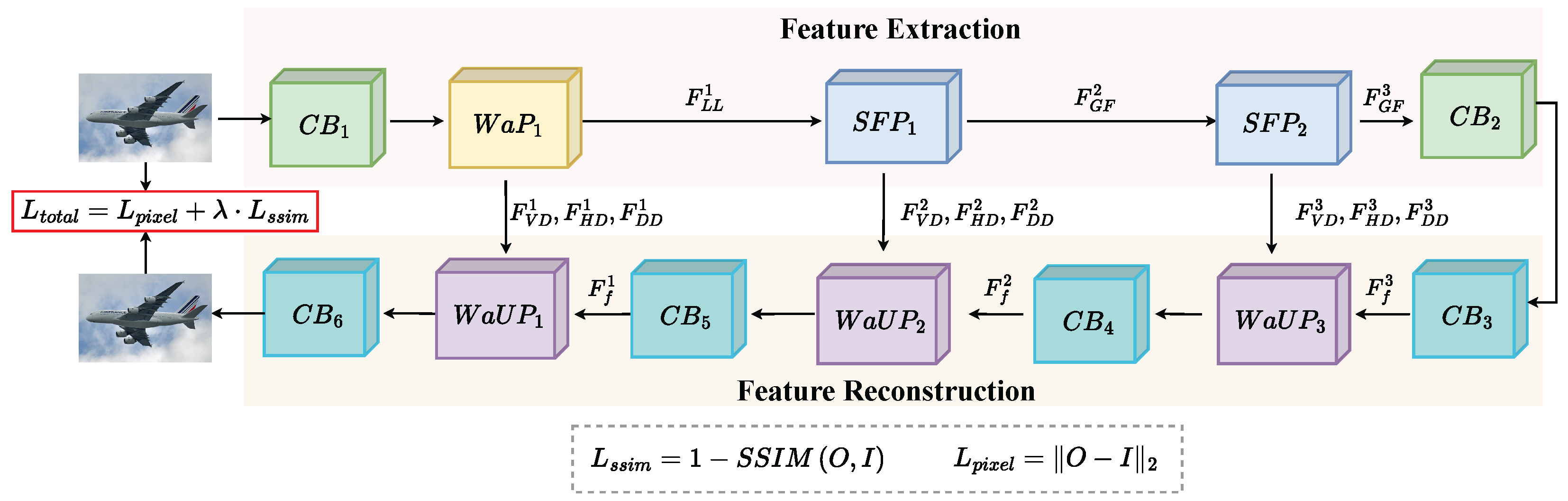
3. Proposed Fusion Method
3.1. Overall Framework
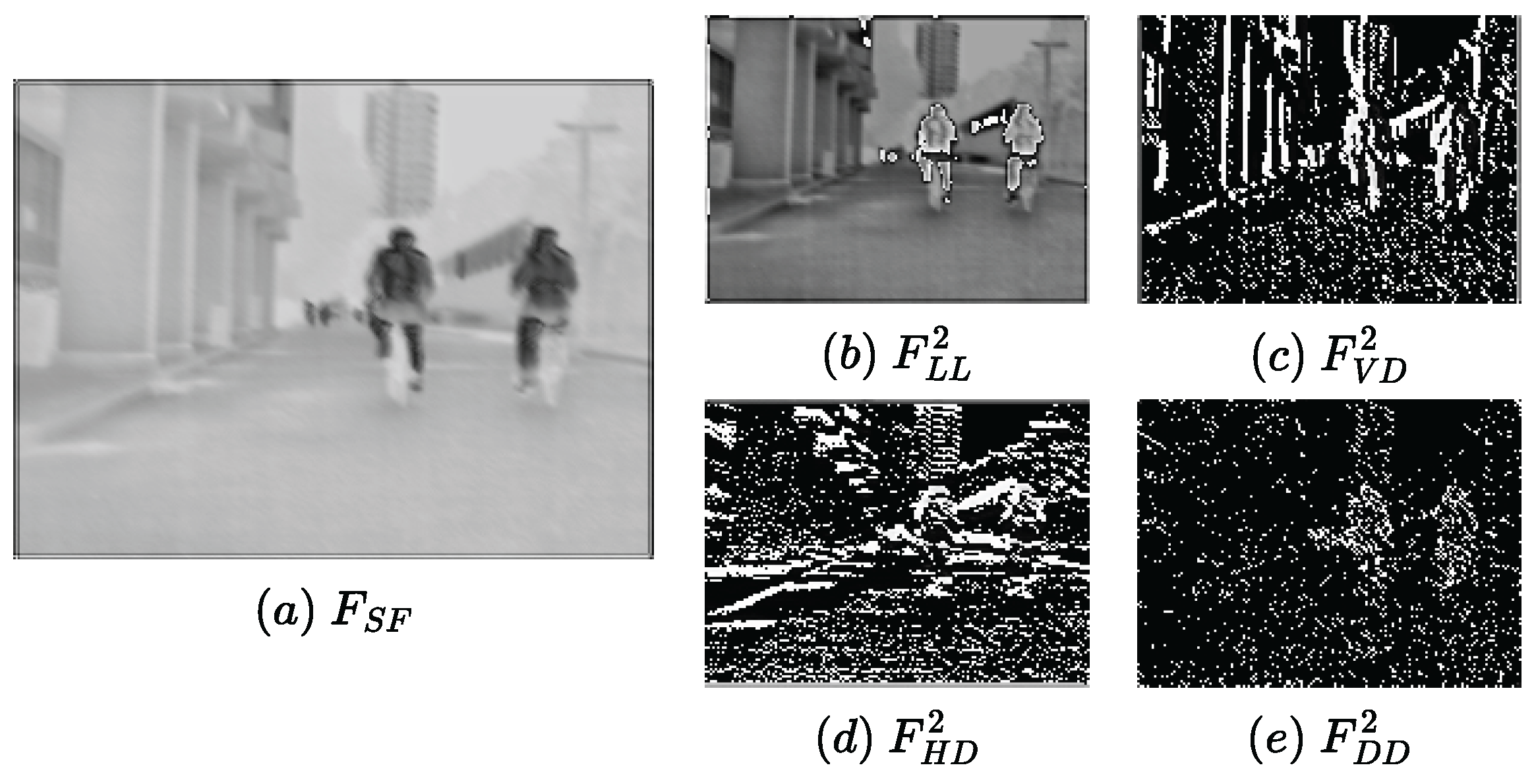
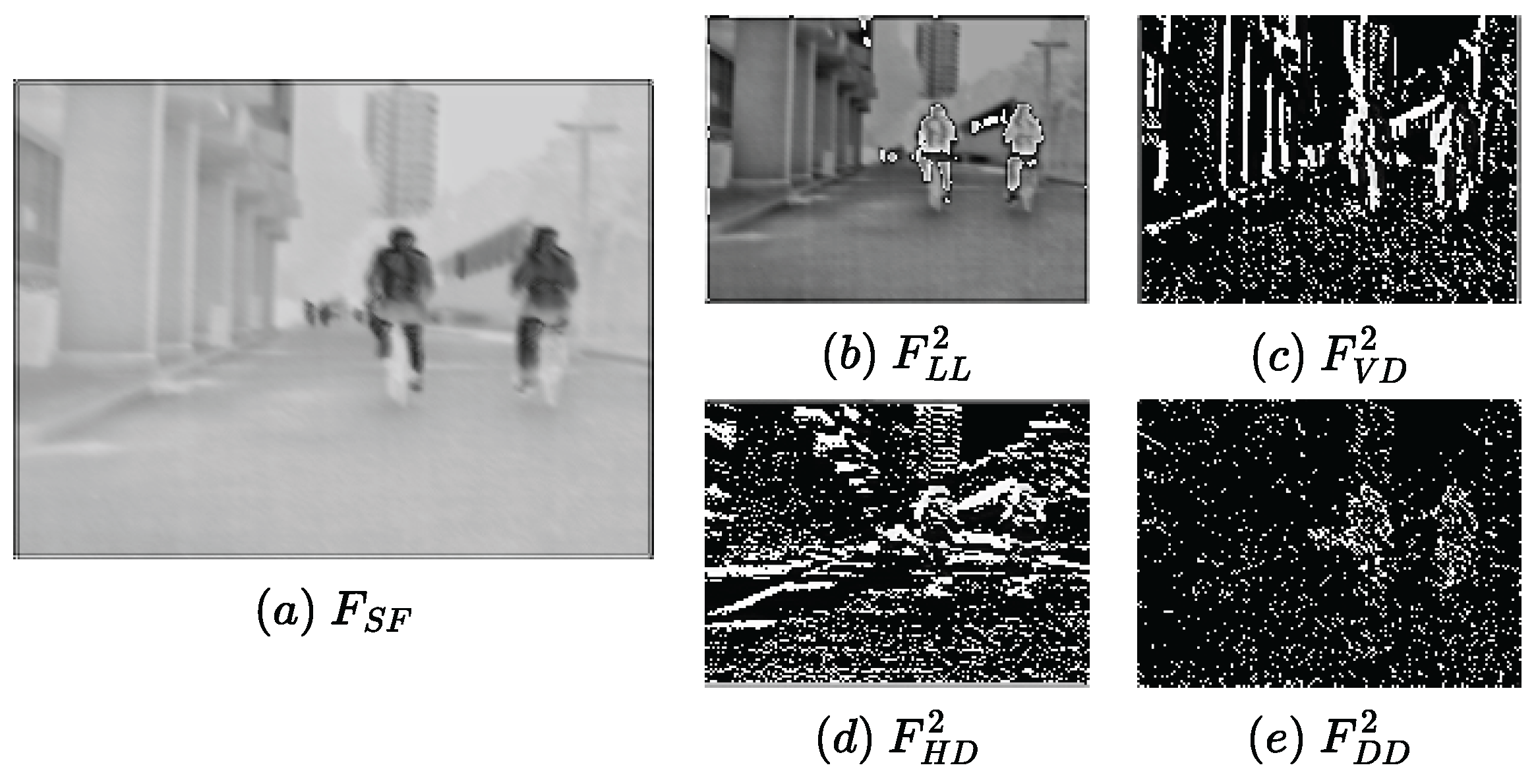
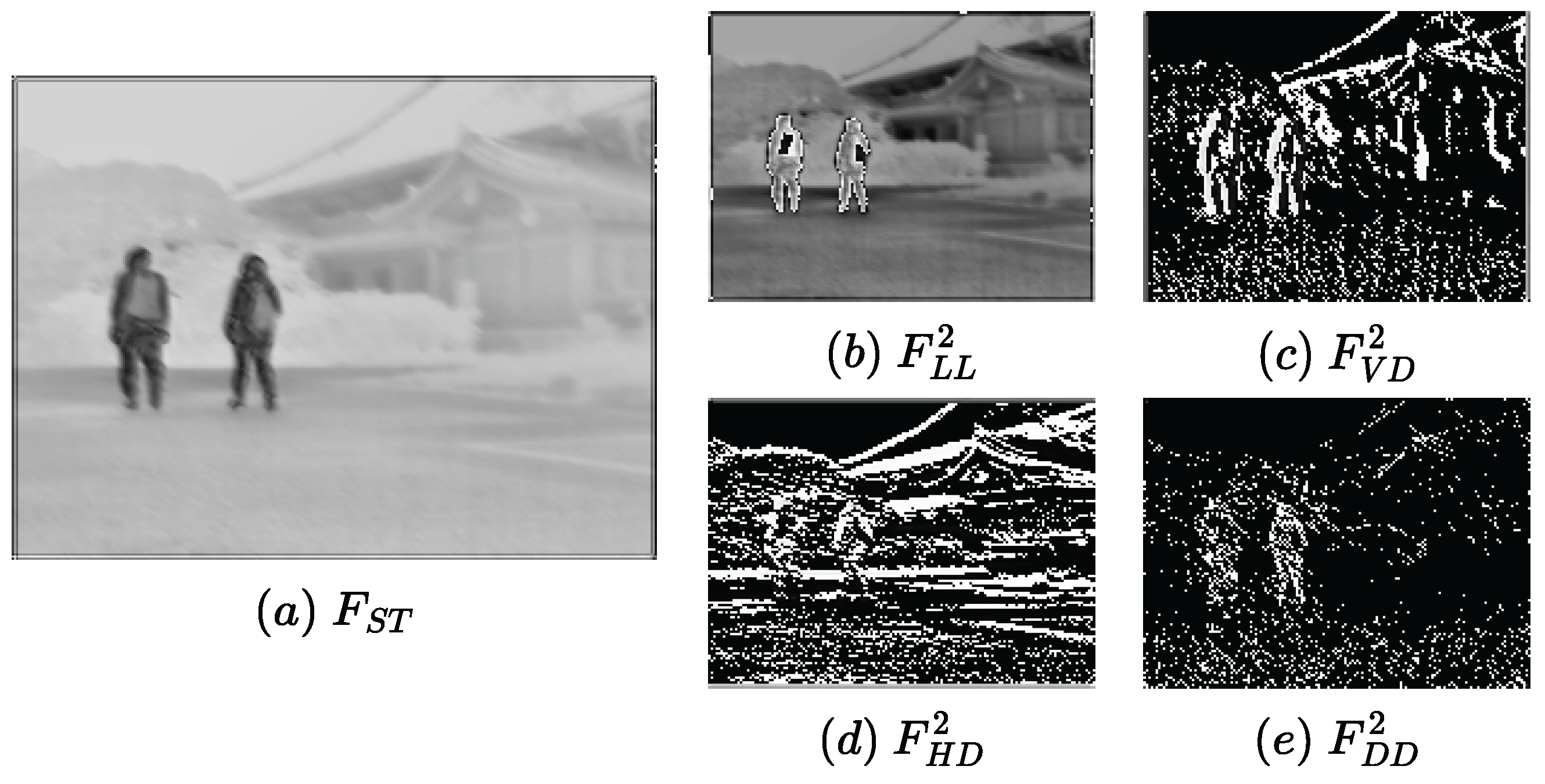
3.1.1. Feature Extraction
3.1.2. Fusion Strategy
| Algorithm 1 Procedure for fusion strategy. |
|
3.1.3. Feature Reconstruction
3.2. Training Phase
4. Experimental Results and Analysis
4.1. Experimental Settings
4.2. Comparative Experiments
4.2.1. Fusion Results on MSRS Dataset
4.2.2. Fusion Results on LLVIP Dataset
4.2.3. Fusion Results on TNO Dataset
4.3. Comparison of the Efficiency
4.4. Ablation Studies
4.4.1. Analysis of Transformer
4.4.2. Analysis of CNN
4.4.3. Analysis of Structure
4.4.4. Analysis of Global Features Fusion Strategy
4.4.5. Analysis of Detail Features Fusion Strategy
4.4.6. Analysis of Different
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Guo, R.; Li, D.; Han, Y. Deep multi-scale and multi-modal fusion for 3D object detection. Pattern Recognit. Lett. 2021, 151, 236–242. [Google Scholar] [CrossRef]
- Gao, W.; Liao, G.; Ma, S.; Li, G.; Liang, Y.; Lin, W. Unified information fusion network for multi-modal RGB-D and RGB-T salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2091–2106. [Google Scholar] [CrossRef]
- Zhang, L.; Danelljan, M.; Gonzalez-Garcia, A.; Van De Weijer, J.; Shahbaz Khan, F. Multi-modal fusion for end-to-end rgb-t tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhu, J.; Lai, S.; Chen, X.; Wang, D.; Lu, H. Visual prompt multi-modal tracking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 9516–9526. [Google Scholar]
- Tang, L.; Yuan, J.; Ma, J. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Inf. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Tang, W.; He, F.; Liu, Y.; Duan, Y.; Si, T. DATFuse: Infrared and Visible Image Fusion via Dual Attention Transformer. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3159–3172. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Inf. Fusion 2022, 83, 79–92. [Google Scholar] [CrossRef]
- Kong, W.; Lei, Y.; Zhao, H. Adaptive fusion method of visible light and infrared images based on non-subsampled shearlet transform and fast non-negative matrix factorization. Infrared Phys. Technol. 2014, 67, 161–172. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Nencini, F.; Garzelli, A.; Baronti, S.; Alparone, L. Remote sensing image fusion using the curvelet transform. Inf. Fusion 2007, 8, 143–156. [Google Scholar] [CrossRef]
- Lewis, J.J.; O’Callaghan, R.J.; Nikolov, S.G.; Bull, D.R.; Canagarajah, N. Pixel-and region-based image fusion with complex wavelets. Inf. Fusion 2007, 8, 119–130. [Google Scholar] [CrossRef]
- Pati, Y.C.; Rezaiifar, R.; Krishnaprasad, P.S. Orthogonal matching pursuit: Recursive function approximation with applications to wavelet decomposition. In Proceedings of the 27th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 1–3 November 1993; pp. 40–44. [Google Scholar]
- Li, S.; Yin, H.; Fang, L. Group-sparse representation with dictionary learning for medical image denoising and fusion. IEEE Trans. Biomed. Eng. 2012, 59, 3450–3459. [Google Scholar] [CrossRef]
- Chen, C.; Li, Y.; Liu, W.; Huang, J. Image fusion with local spectral consistency and dynamic gradient sparsity. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 2760–2765. [Google Scholar]
- Yang, B.; Li, S. Pixel-level image fusion with simultaneous orthogonal matching pursuit. Inf. Fusion 2012, 13, 10–19. [Google Scholar] [CrossRef]
- Zhou, Y.; Mayyas, A.; Omar, M.A. Principal component analysis-based image fusion routine with application to automotive stamping split detection. Res. Nondestruct. Eval. 2011, 22, 76–91. [Google Scholar] [CrossRef]
- Bavirisetti, D.P.; Xiao, G.; Liu, G. Multi-sensor image fusion based on fourth order partial differential equations. In Proceedings of the 2017 20th International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017; pp. 1–9. [Google Scholar]
- Li, H.; Wu, X.J.; Kittler, J. Infrared and visible image fusion using a deep learning framework. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2705–2710. [Google Scholar]
- Gao, C.; Song, C.; Zhang, Y.; Qi, D.; Yu, Y. Improving the performance of infrared and visible image fusion based on latent low-rank representation nested with rolling guided image filtering. IEEE Access 2021, 9, 91462–91475. [Google Scholar] [CrossRef]
- Bhavana, D.; Kishore Kumar, K.; Ravi Tej, D. Infrared and visible image fusion using latent low rank technique for surveillance applications. Int. J. Speech Technol. 2022, 25, 551–560. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Kittler, J. MDLatLRR: A novel decomposition method for infrared and visible image fusion. IEEE Trans. Image Process. 2020, 29, 4733–4746. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.j.; Durrani, T.S. Infrared and visible image fusion with ResNet and zero-phase component analysis. Infrared Phys. Technol. 2019, 102, 103039. [Google Scholar] [CrossRef]
- Xu, H.; Gong, M.; Tian, X.; Huang, J.; Ma, J. CUFD: An encoder–decoder network for visible and infrared image fusion based on common and unique feature decomposition. Comput. Vis. Image Underst. 2022, 218, 103407. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Durrani, T. NestFuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, Y.; Shao, W.; Li, H.; Zhang, L. SwinFuse: A residual swin transformer fusion network for infrared and visible images. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Zhang, Y.; Liu, Y.; Sun, P.; Yan, H.; Zhao, X.; Zhang, L. IFCNN: A general image fusion framework based on convolutional neural network. Inf. Fusion 2020, 54, 99–118. [Google Scholar] [CrossRef]
- Li, H.; Xu, T.; Wu, X.J.; Lu, J.; Kittler, J. LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11040–11052. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Neural Information Processing Systems, Montreal, BC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Neural Information Processing Systems 30 (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vs, V.; Valanarasu, J.M.J.; Oza, P.; Patel, V.M. Image fusion transformer. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3566–3570. [Google Scholar]
- Chen, J.; Ding, J.; Yu, Y.; Gong, W. THFuse: An infrared and visible image fusion network using transformer and hybrid feature extractor. Neurocomputing 2023, 527, 71–82. [Google Scholar] [CrossRef]
- Tang, W.; He, F.; Liu, Y. TCCFusion: An infrared and visible image fusion method based on transformer and cross correlation. Pattern Recognit. 2023, 137, 109295. [Google Scholar] [CrossRef]
- Yi, S.; Jiang, G.; Liu, X.; Li, J.; Chen, L. TCPMFNet: An infrared and visible image fusion network with composite auto encoder and transformer–convolutional parallel mixed fusion strategy. Infrared Phys. Technol. 2022, 127, 104405. [Google Scholar] [CrossRef]
- Yang, X.; Huo, H.; Wang, R.; Li, C.; Liu, X.; Li, J. DGLT-Fusion: A decoupled global–local infrared and visible image fusion transformer. Infrared Phys. Technol. 2023, 128, 104522. [Google Scholar] [CrossRef]
- Rao, D.; Xu, T.; Wu, X.J. Tgfuse: An infrared and visible image fusion approach based on transformer and generative adversarial network. arXiv 2023, arXiv:2201.10147. [Google Scholar] [CrossRef] [PubMed]
- Yao, T.; Pan, Y.; Li, Y.; Ngo, C.W.; Mei, T. Wave-vit: Unifying wavelet and transformers for visual representation learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–24 October 2022; pp. 328–345. [Google Scholar]
- Yoo, J.; Uh, Y.; Chun, S.; Kang, B.; Ha, J.W. Photorealistic style transfer via wavelet transforms. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9036–9045. [Google Scholar]
- Huang, H.; Zhou, X.; Cao, J.; He, R.; Tan, T. Vision Transformer with Super Token Sampling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22690–22699. [Google Scholar]
- Shaw, P.; Uszkoreit, J.; Vaswani, A. Self-attention with relative position representations. arXiv 2018, arXiv:1803.02155. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A visible-infrared paired dataset for low-light vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3496–3504. [Google Scholar]
- Toet, A. The TNO multiband image data collection. Data Brief 2017, 15, 249–251. [Google Scholar] [CrossRef] [PubMed]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2Fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 502–518. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, S.; Zhang, J.; Liang, C.; Zhang, C.; Liu, J. Efficient and model-based infrared and visible image fusion via algorithm unrolling. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 1186–1196. [Google Scholar] [CrossRef]
- Cheng, C.; Xu, T.; Wu, X.J. MUFusion: A general unsupervised image fusion network based on memory unit. Inf. Fusion 2023, 92, 80–92. [Google Scholar] [CrossRef]
- Li, B.; Lu, J.; Liu, Z.; Shao, Z.; Li, C.; Du, Y.; Huang, J. AEFusion: A multi-scale fusion network combining Axial attention and Entropy feature Aggregation for infrared and visible images. Appl. Soft Comput. 2023, 132, 109857. [Google Scholar] [CrossRef]
- Rao, Y.J. In-fibre Bragg grating sensors. Meas. Sci. Technol. 1997, 8, 355. [Google Scholar] [CrossRef]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A new image fusion performance metric based on visual information fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Cui, G.; Feng, H.; Xu, Z.; Li, Q.; Chen, Y. Detail preserved fusion of visible and infrared images using regional saliency extraction and multi-scale image decomposition. Opt. Commun. 2015, 341, 199–209. [Google Scholar] [CrossRef]
- Roberts, J.W.; Van Aardt, J.A.; Ahmed, F.B. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. Appl. Remote Sens. 2008, 2, 023522. [Google Scholar]
- Xydeas, C.S.; Petrovic, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef]
- Kelishadrokhi, M.K.; Ghattaei, M.; Fekri-Ershad, S. Innovative local texture descriptor in joint of human-based color features for content-based image retrieval. Signal Image Video Process. 2023, 17, 4009–4017. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Block | Layer Name | Kernel | Input | Output | Size | Activation | |
|---|---|---|---|---|---|---|---|---|
| Extraction | Stage1 | Layer1 | 1 | 3 | ReLU | |||
| Layer2 | 3 | 64 | ReLU | |||||
| Layer3 | 64 | 64 | ReLU | |||||
| Pooling | 64 | 64 | ||||||
| Stage2 | CPE | |||||||
| SFA | ||||||||
| Pooling | ||||||||
| PM | ||||||||
| Stage3 | CPE | |||||||
| SFA | ||||||||
| Pooling | ||||||||
| PM | ||||||||
| Stage4 | Layer1 | 320 | 512 | ReLU | ||||
| Blocks | Layers | Kernel | Input | Output | Activation | |
|---|---|---|---|---|---|---|
| Reconstruction | Layer1 | 512 | 256 | ReLU | ||
| Layer1 | 256 | 256 | ReLU | |||
| Layer2 | 256 | 256 | ReLU | |||
| Layer3 | 256 | 256 | ReLU | |||
| Layer4 | 256 | 128 | ReLU | |||
| Layer1 | 128 | 128 | ReLU | |||
| Layer2 | 128 | 64 | ReLU | |||
| Layer1 | 64 | 64 | ReLU | |||
| Layer2 | 64 | 1 | Sigmoid |
| Methods | SD | VIF | AG | EN | |
|---|---|---|---|---|---|
| DenseFuse [24] | 7.4237 | 0.6999 | 2.0873 | 0.3572 | 5.9340 |
| FusionGAN [26] | 7.1758 | 0.8692 | 3.1193 | 0.2110 | 5.9937 |
| SwinFuse [29] | 4.9246 | 0.4102 | 1.9673 | 0.1720 | 4.4521 |
| U2Fusion [50] | 6.8217 | 0.5863 | 2.0694 | 0.2972 | 5.5515 |
| AUIF [51] | 5.2622 | 0.3981 | 1.8238 | 0.1970 | 4.6460 |
| CUFD [23] | 7.6384 | 0.6488 | 2.9003 | 0.4397 | 6.0652 |
| MUFusion [52] | 6.9233 | 0.6086 | 3.1474 | 0.4110 | 5.9682 |
| AEFusion [53] | 8.2104 | 0.8548 | 2.6968 | 0.4239 | 6.5374 |
| Ours | 8.2650 | 0.9214 | 3.8950 | 0.5361 | 6.5636 |
| Methods | SD | VIF | AG | EN | |
|---|---|---|---|---|---|
| DenseFuse | 9.2963 | 0.7503 | 2.6714 | 0.3458 | 6.8287 |
| FusionGAN | 10.0823 | 1.0263 | 2.1706 | 0.2765 | 7.1741 |
| SwinFuse | 7.5469 | 0.6290 | 2.9580 | 0.3392 | 6.0825 |
| U2Fusion | 9.4256 | 0.7212 | 2.3685 | 0.3425 | 6.7588 |
| AUIF | 7.5433 | 0.5877 | 2.8790 | 0.3348 | 6.1555 |
| CUFD | 9.1701 | 0.7187 | 2.5198 | 0.3264 | 6.8448 |
| MUFusion | 8.7452 | 0.7875 | 3.5412 | 0.4128 | 6.9242 |
| AEFusion | 9.8400 | 0.6302 | 2.0397 | 0.1477 | 7.2764 |
| Ours | 9.8103 | 0.9671 | 4.7353 | 0.6088 | 7.3006 |
| Methods | SD | VIF | AG | EN | |
|---|---|---|---|---|---|
| DenseFuse | 9.2203 | 0.7349 | 3.8804 | 0.4465 | 6.8256 |
| FusionGAN | 8.1234 | 0.6197 | 2.8120 | 0.2260 | 6.4629 |
| SwinFuse | 9.2633 | 0.7982 | 5.5986 | 0.4542 | 6.9484 |
| U2Fusion | 9.3869 | 0.7200 | 5.4456 | 0.4653 | 6.9395 |
| AUIF | 9.2805 | 0.7482 | 5.2820 | 0.4513 | 7.0402 |
| CUFD | 9.4136 | 0.8781 | 4.5178 | 0.3782 | 7.0743 |
| MUFusion | 9.5379 | 0.7851 | 5.5756 | 0.3818 | 7.3032 |
| AEFusion | 9.4655 | 0.7803 | 3.4114 | 0.3074 | 7.0716 |
| Ours | 9.4400 | 0.8021 | 6.2300 | 0.4802 | 7.1578 |
| Method | DenseFuse | FusionGAN | SwinFuse | U2Fusion | AUIF | CUFD | MUFusion | AEFusion | Ours |
|---|---|---|---|---|---|---|---|---|---|
| Inference time | 0.1813 | 0.0677 | 0.2592 | 0.0342 | 0.1158 | 72.6157 | 0.7045 | 0.2244 | 0.0739 |
| Strategies | SD | VIF | AG | EN | |
|---|---|---|---|---|---|
| Ours | 9.4400 | 0.8021 | 6.2300 | 0.4802 | 7.1578 |
| Original-SFT | 9.4101 | 0.8451 | 6.1572 | 0.4696 | 7.0922 |
| Original-ViT | 8.9065 | 0.6971 | 5.6691 | 0.4040 | 6.6331 |
| CNN-Pooling | 8.9091 | 0.7100 | 5.8372 | 0.4652 | 6.7445 |
| W/O | 9.3070 | 0.7713 | 5.9607 | 0.4712 | 6.9916 |
| One-SFP | 9.3145 | 0.7935 | 6.0023 | 0.4697 | 7.0172 |
| GF-Add | 10.1152 | 0.7116 | 4.4128 | 0.3714 | 6.7826 |
| GF-Avg | 9.1915 | 0.7884 | 6.5182 | 0.4772 | 7.0576 |
| Detail-Avg | 9.1556 | 0.6812 | 3.3329 | 0.3809 | 6.9184 |
| SD | VIF | AG | EN | ||
|---|---|---|---|---|---|
| Ours ( = 10) | 9.4400 | 0.8021 | 6.2300 | 0.4802 | 7.1578 |
| = 1 | 9.5901 | 0.7964 | 6.2220 | 0.4768 | 7.2029 |
| = 100 | 9.4001 | 0.7999 | 6.1762 | 0.4820 | 7.1582 |
| = 1000 | 9.4644 | 0.7907 | 6.0682 | 0.4800 | 7.1623 |
| = 10,000 | 9.5537 | 0.8010 | 6.1070 | 0.4763 | 7.1716 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Xiao, Y.; Cheng, C.; Song, X. SFPFusion: An Improved Vision Transformer Combining Super Feature Attention and Wavelet-Guided Pooling for Infrared and Visible Images Fusion. Sensors 2023, 23, 7870. https://doi.org/10.3390/s23187870
Li H, Xiao Y, Cheng C, Song X. SFPFusion: An Improved Vision Transformer Combining Super Feature Attention and Wavelet-Guided Pooling for Infrared and Visible Images Fusion. Sensors. 2023; 23(18):7870. https://doi.org/10.3390/s23187870
Chicago/Turabian StyleLi, Hui, Yongbiao Xiao, Chunyang Cheng, and Xiaoning Song. 2023. "SFPFusion: An Improved Vision Transformer Combining Super Feature Attention and Wavelet-Guided Pooling for Infrared and Visible Images Fusion" Sensors 23, no. 18: 7870. https://doi.org/10.3390/s23187870
APA StyleLi, H., Xiao, Y., Cheng, C., & Song, X. (2023). SFPFusion: An Improved Vision Transformer Combining Super Feature Attention and Wavelet-Guided Pooling for Infrared and Visible Images Fusion. Sensors, 23(18), 7870. https://doi.org/10.3390/s23187870