
Cryptographic Algorithms with Data Shorter than the Encryption Key, Based on LZW and Huffman Coding

 , , and
, , and
Abstract
:1. Introduction
2. Related Work
3. Overview of the Proposed Solution
4. Materials and Methods
4.1. The LZW Algorithm
4.2. Huffman Algorithm
4.3. Combination of LZW and Huffman Algorithms
4.4. Application of the Algorithms
5. Sample Application Procedure
5.1. Analysis of an Example of Huffman Algorithm Application
5.2. Analysis of an Example of LZW Algorithm Application
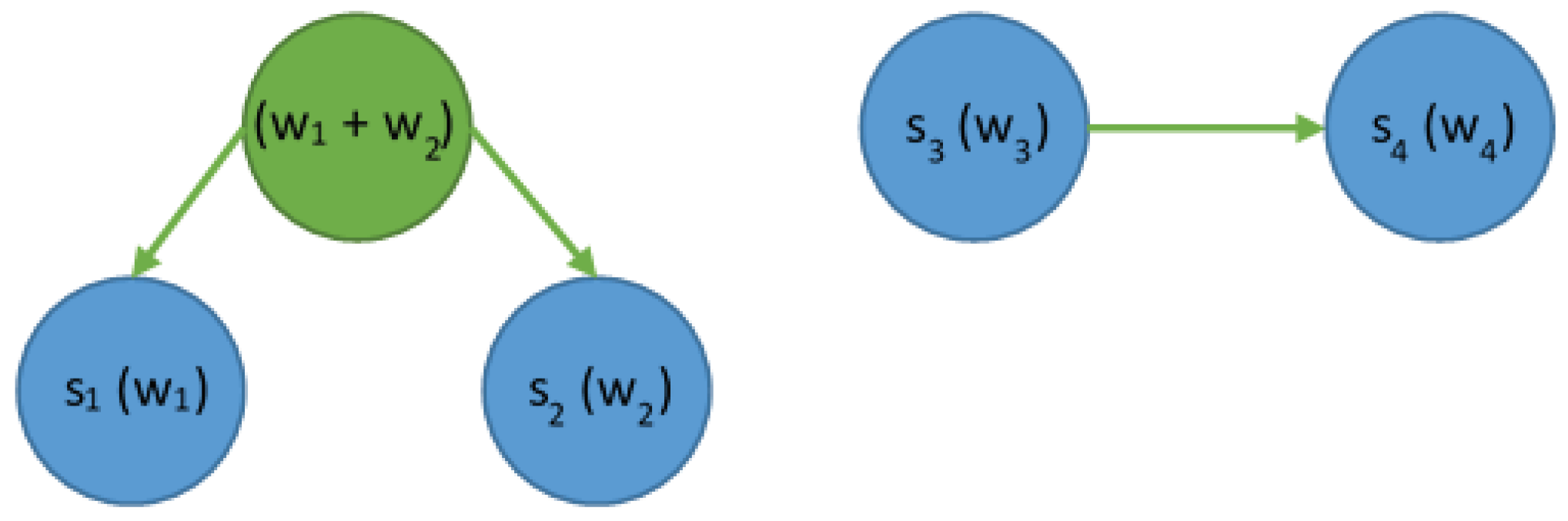
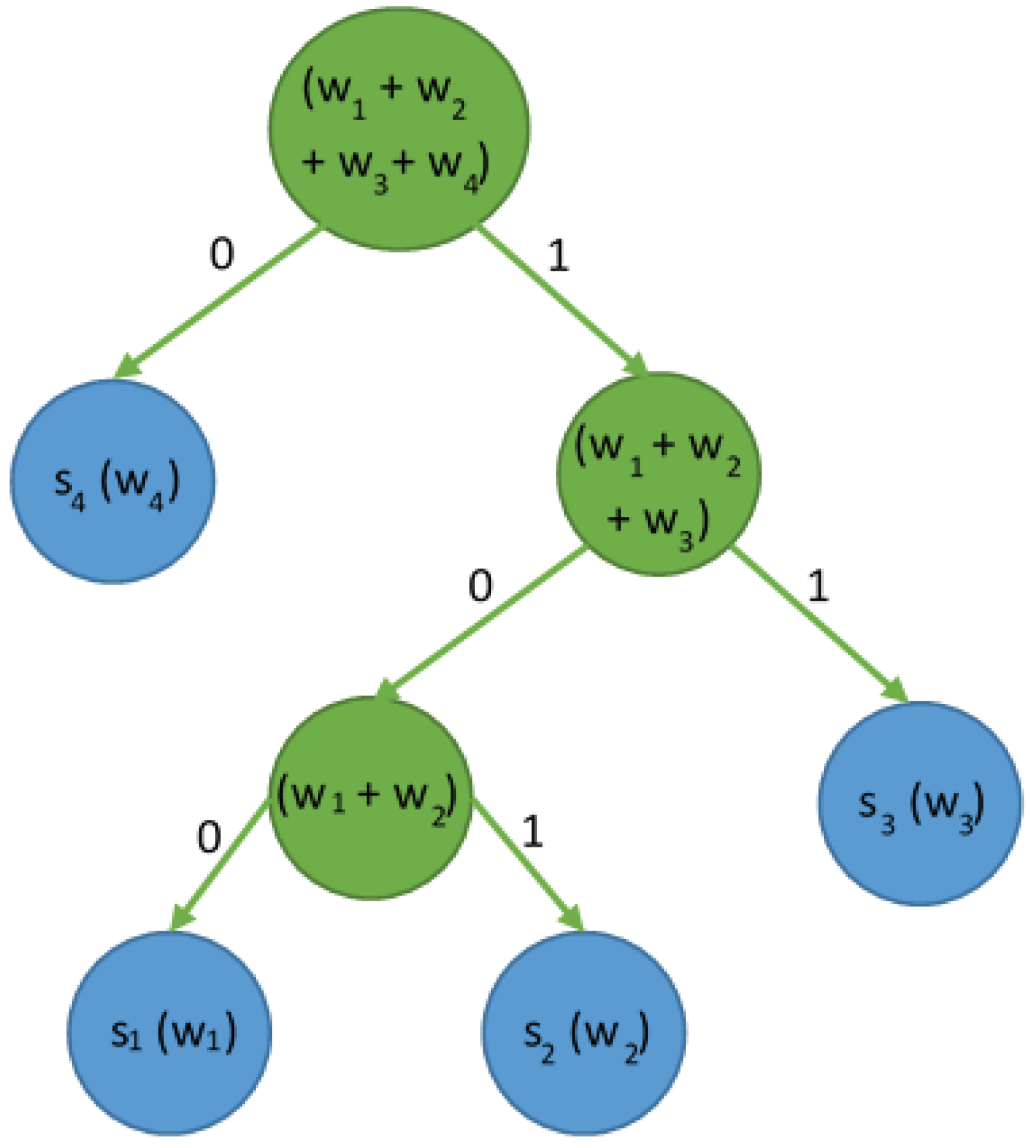
5.3. Huffman and LZW Algorithms Combined
- Move all elements of the LZW array to a temporary repository marking them as “final” in the Huffman tree. The repository should be organized as an array.
- Repeat steps 3–4 below until the temporary repository contains only one item.
- Find the pair of two items in the temporary repository that have the lowest repeat count values. If several items have the same count value, select the item that is closer to the top of the table.
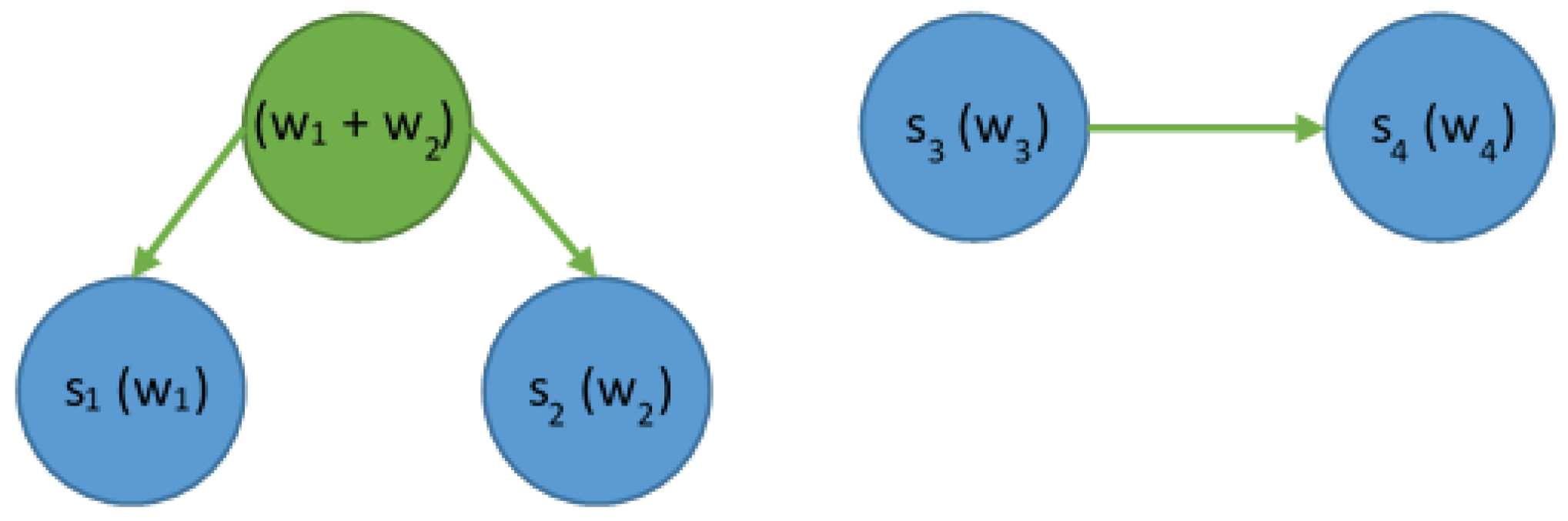
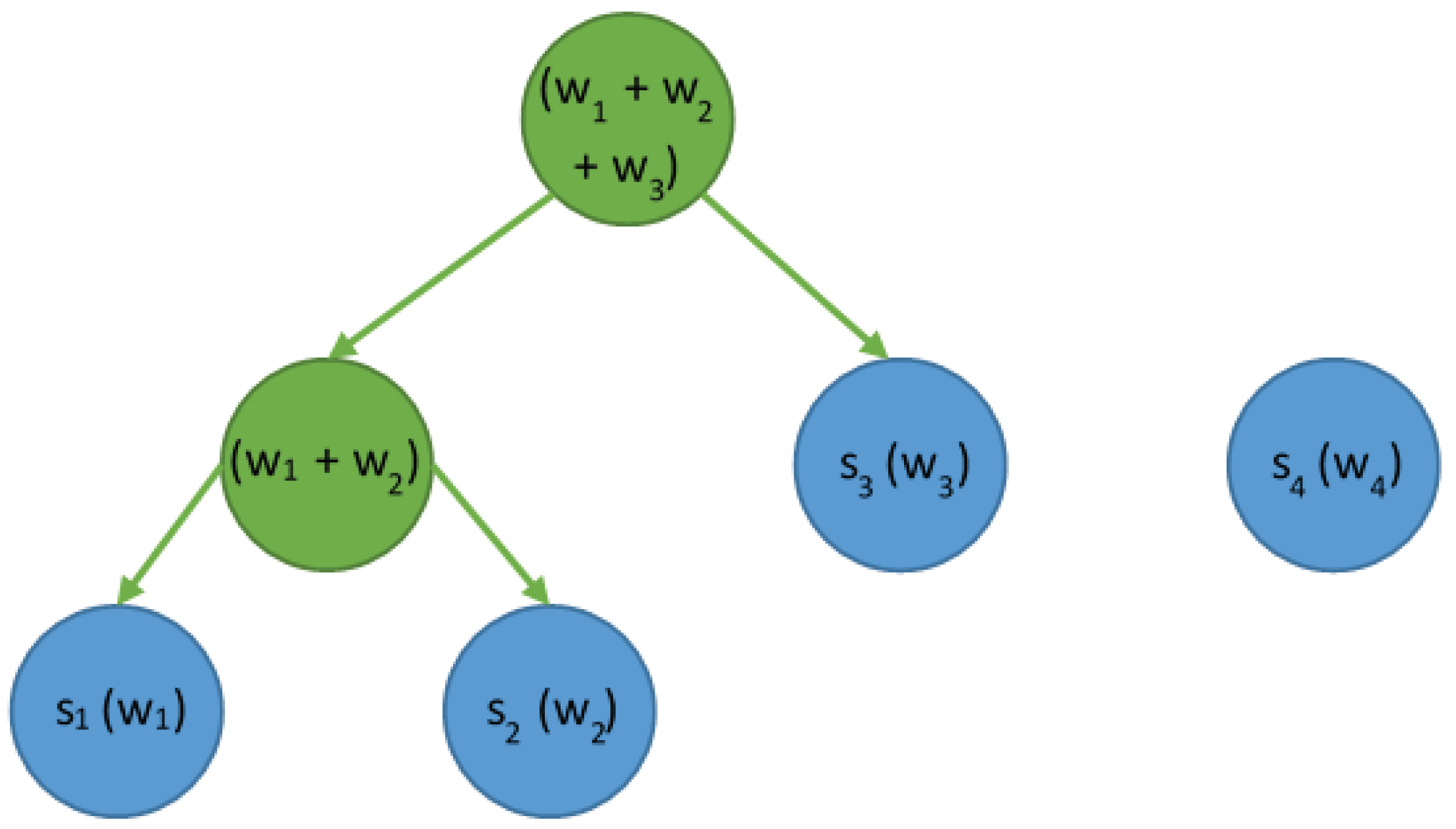
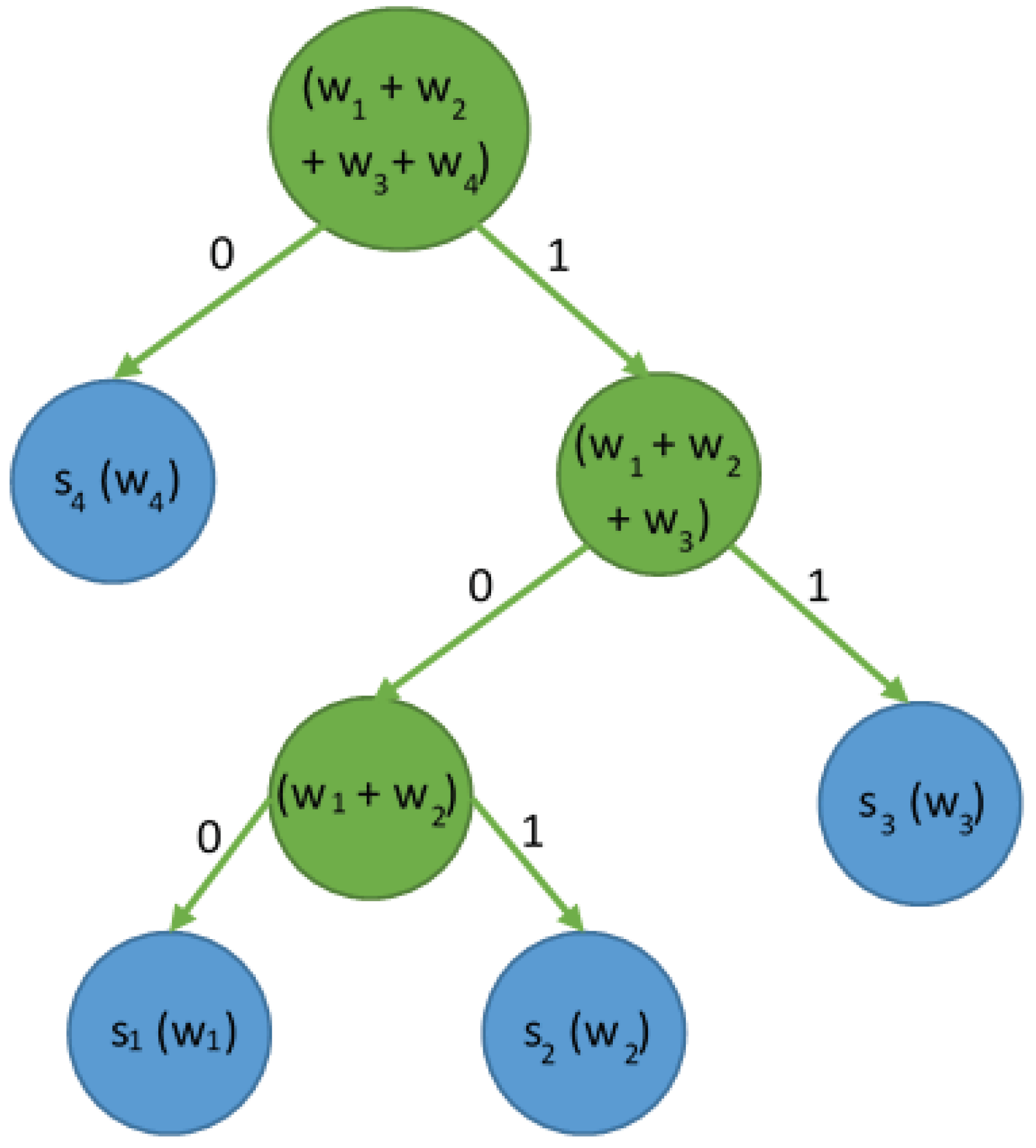
- For each pair found, add the elements of that pair to the final array. In the temporary repository, generate a new item that is the “parent” of this pair. This parent element, which is described by the sum of occurrences of both elements, also contains the identifiers of these elements as “left” and “right” children. Remove both members of the pair from the temporary repository.
- The last item from the temporary repository is the root of the Huffman tree. Add it to the end array and mark it as the start element of that array.
- Set the current input string buffer position to zero.
- If at least two characters are remaining, starting at the current position to the end of the input string, form a temporary substring composed of a pair of the next two characters and advance the position by two; otherwise, form the substring of the last character in the input string.
- Find the Huffman + LZW tree node connected to the substring and generate output based on this node by adding the node-represented set of bits.
- Continue steps 2–3 until the whole input string is processed, and the current position in the input buffer points to the string’s end.
- If the number of output bits is not a multiple of eight, add a certain number of 0 bits to complement the output.
- Group each 8-bit part to represent it as a byte.
- If the output is to be sent by a text channel, convert the bytes to some printable characters using some well-known algorithms such as Base64; otherwise, send the output as a binary string.
- Convert received string to a bit array, using Base64 text-to-binary decoding if necessary.
- Set the current input position to zero.
- Set the current tree node to the root.
- Read the bit value from the current input position. Find a direct child of the current node based on this bit value. If the selected child is a leaf of the tree, add the set of two characters (a single character for some nodes) to the output and return to step 3; otherwise, advance the input position by one and repeat step 4.
- Execute steps 3–4 until the current input position points to the end of the input string, or less than 8 bits remain at the input and are all zeros.
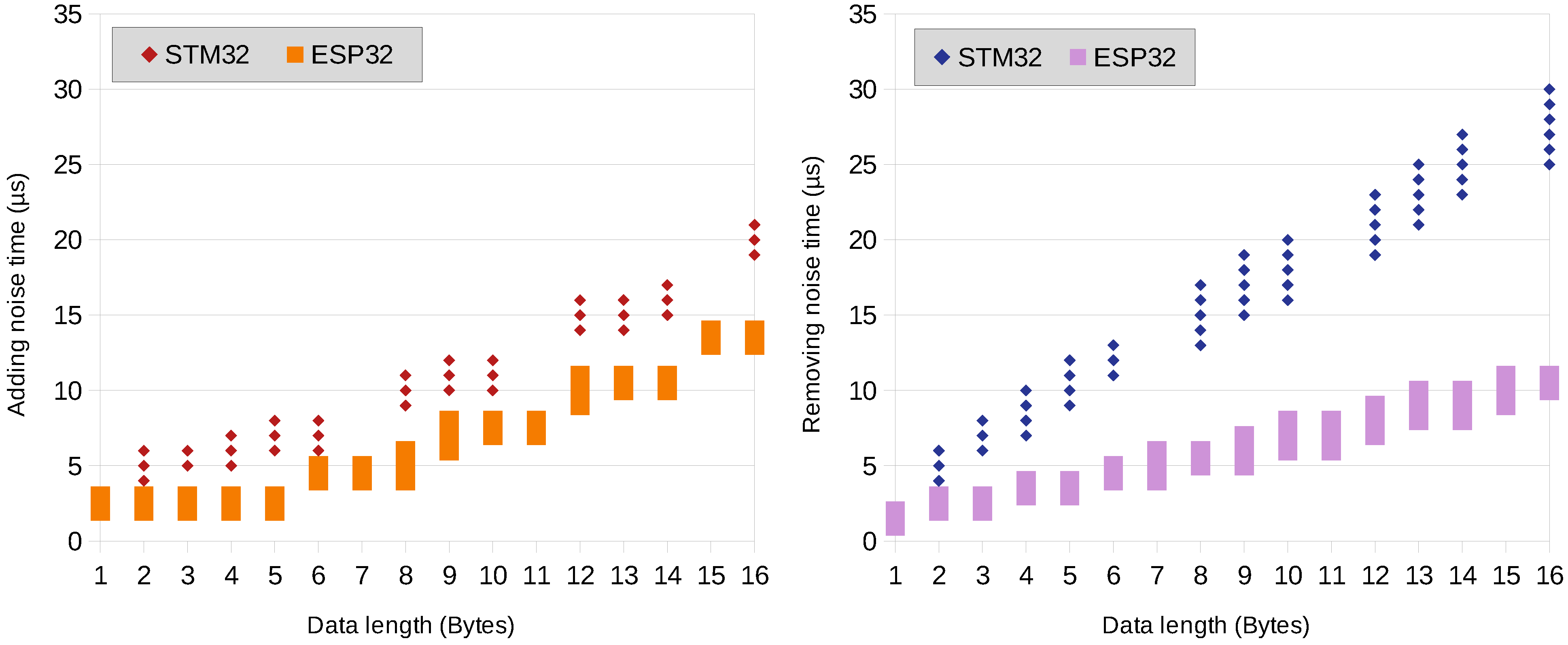
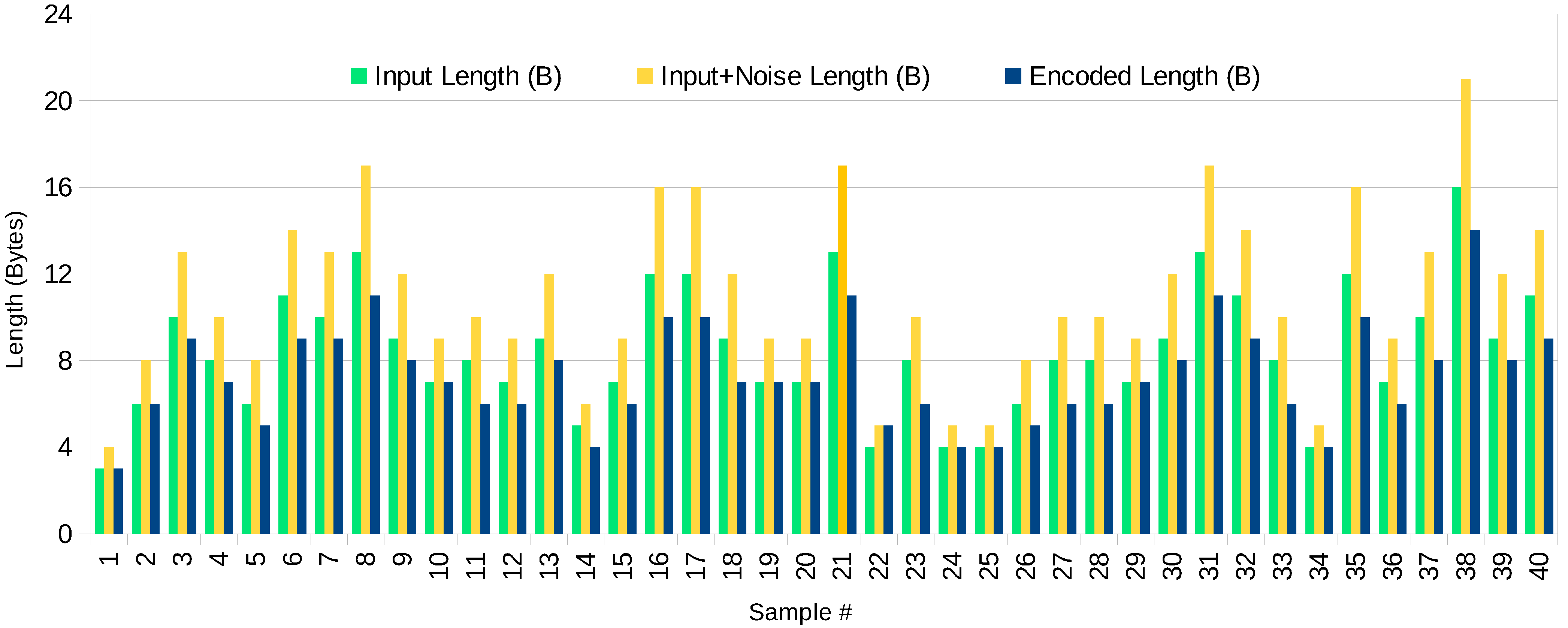
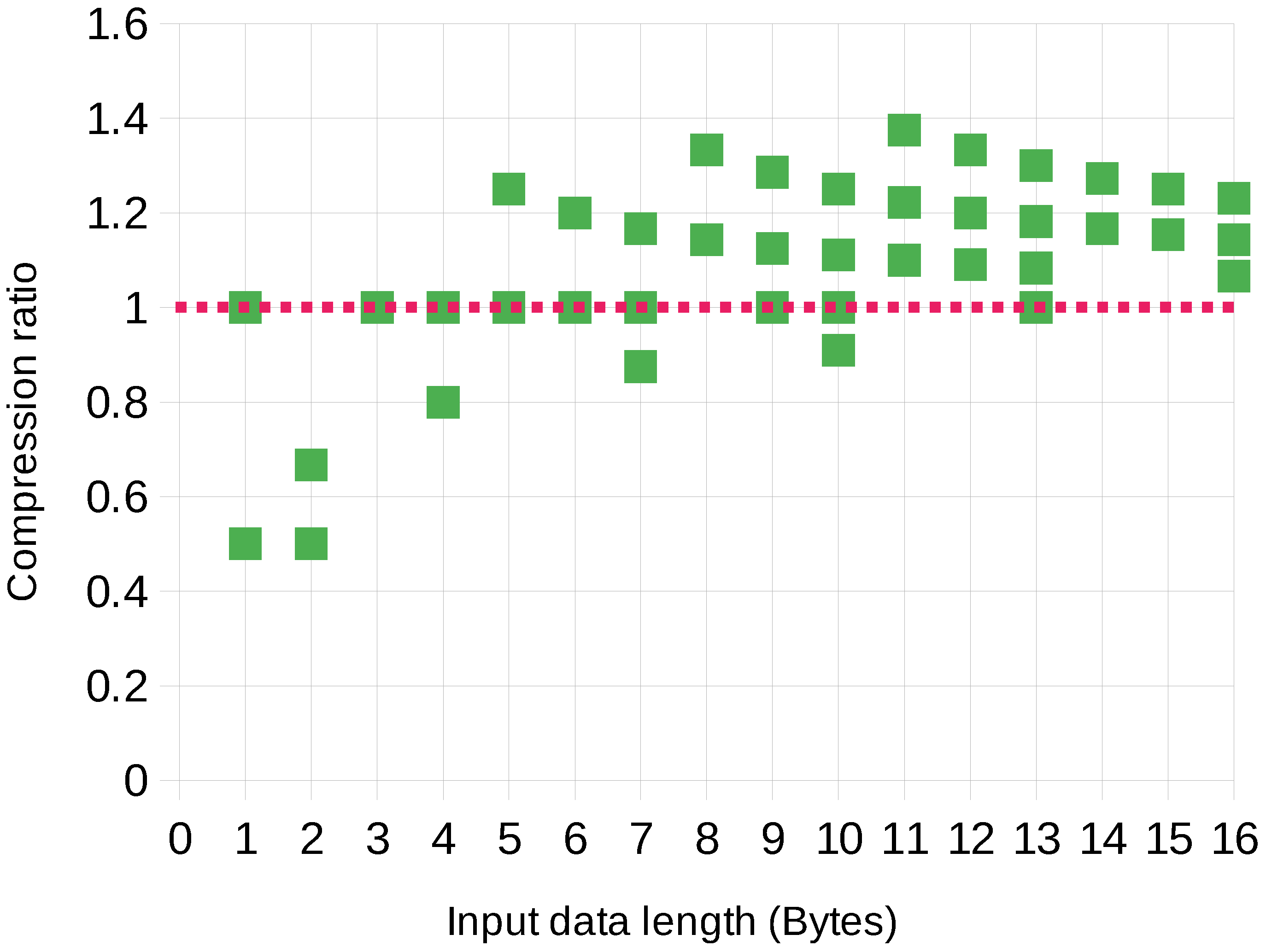
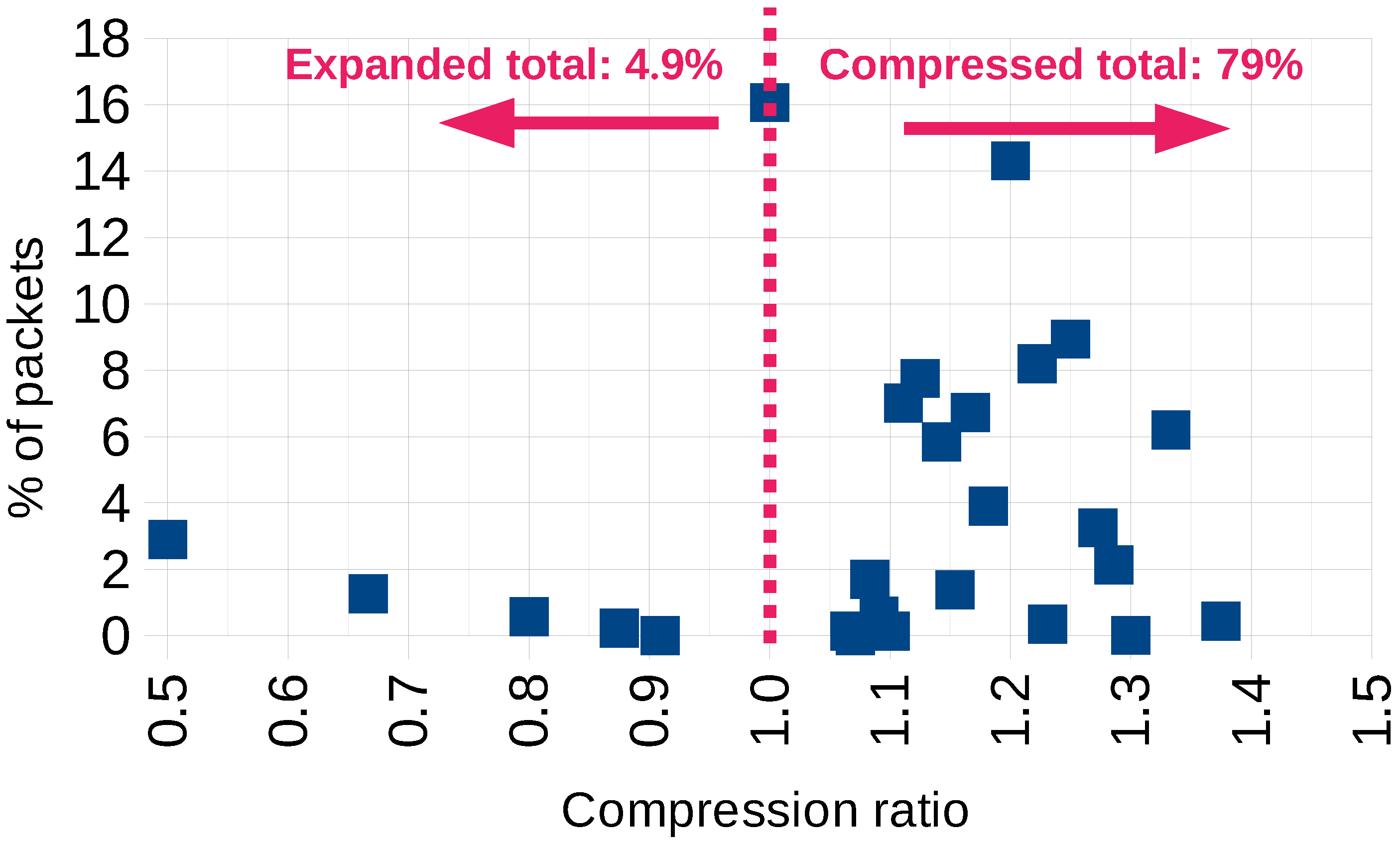
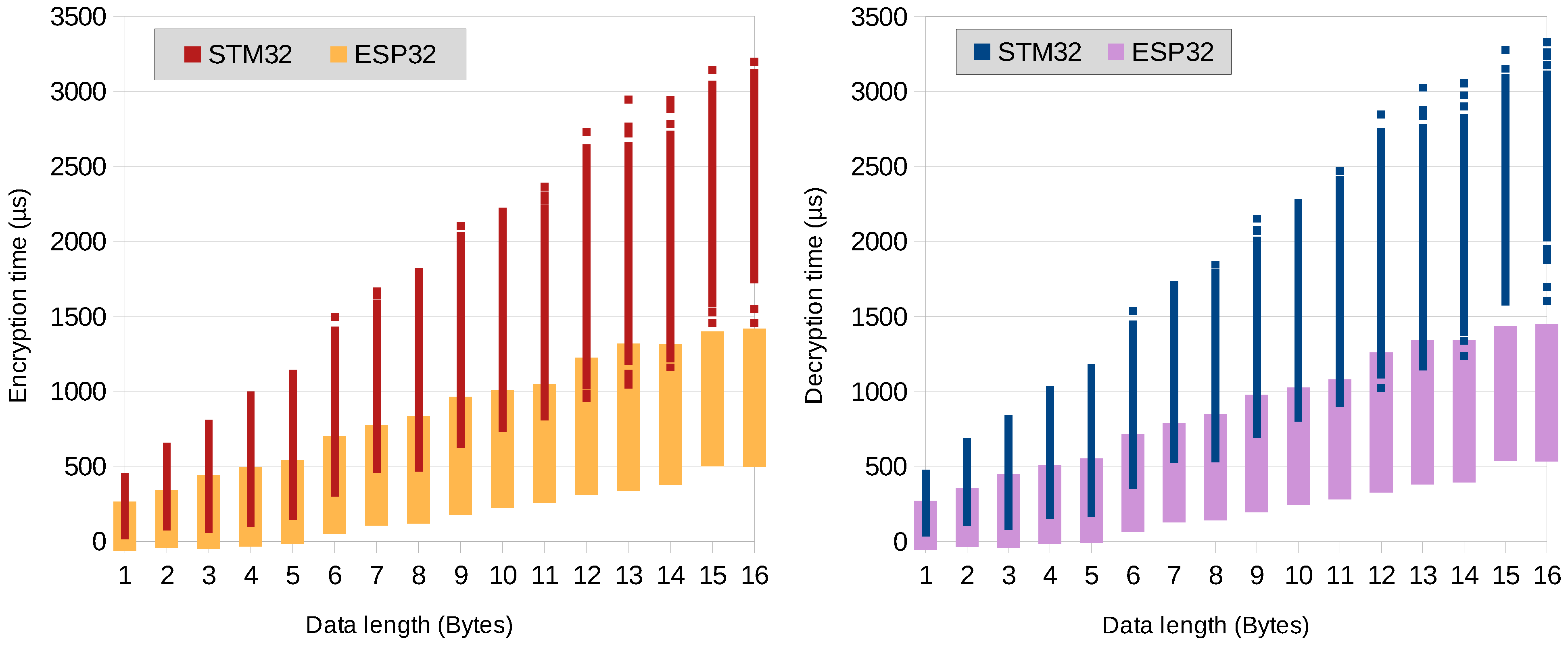
6. Evaluation and Results
- Generating an ASCII-encoded data stream or packet which is 1 to 16 bytes (characters) long.
- Applying noise to the stream according to the description in Section 5.3.
- Encoding–encrypting the stream with the proposed combination of Huffman and LZW algorithms using the previously generated binary tree as a key.
- Decrypting the stream.
- Removing the noise from the stream.
- Formatting a line of output data in CSV format, including the information of measured times and effects of noise application as well as encryption and decryption, then printing the information using a hardware serial port.
| Listing 1. A sample output from the terminal while running the test program—a header and the first 3 records of raw data are shown; new lines were added for readability. |
| No; String; Length[B]; String_noised; Length[B]; String_encoded_bin; String_encoded_hex; Length[B]; Add_noise_time[us]; Encryption_time[us]; Decryption_time[us]; Remove_noise_time[us]; Total_time[us] 0; 390; 3; =390; 4; 101111100110010001110000; EB4607; 3; 3; 135; 156; 2; 296 1; 2.3583; 6; (!2.3583; 8; 011111000101111110101001101111011110010000000000; C7F59ADB4E00; 6; 4; 366; 389; 5; 764 2; 2803924.91; 10; #_2803*924.91; 13; 111000001011110111110111110101000100001001000110000110001001010000000000; 0EDB7F4D2464814900; 9; 7; 599; 629; 7; 1242 |
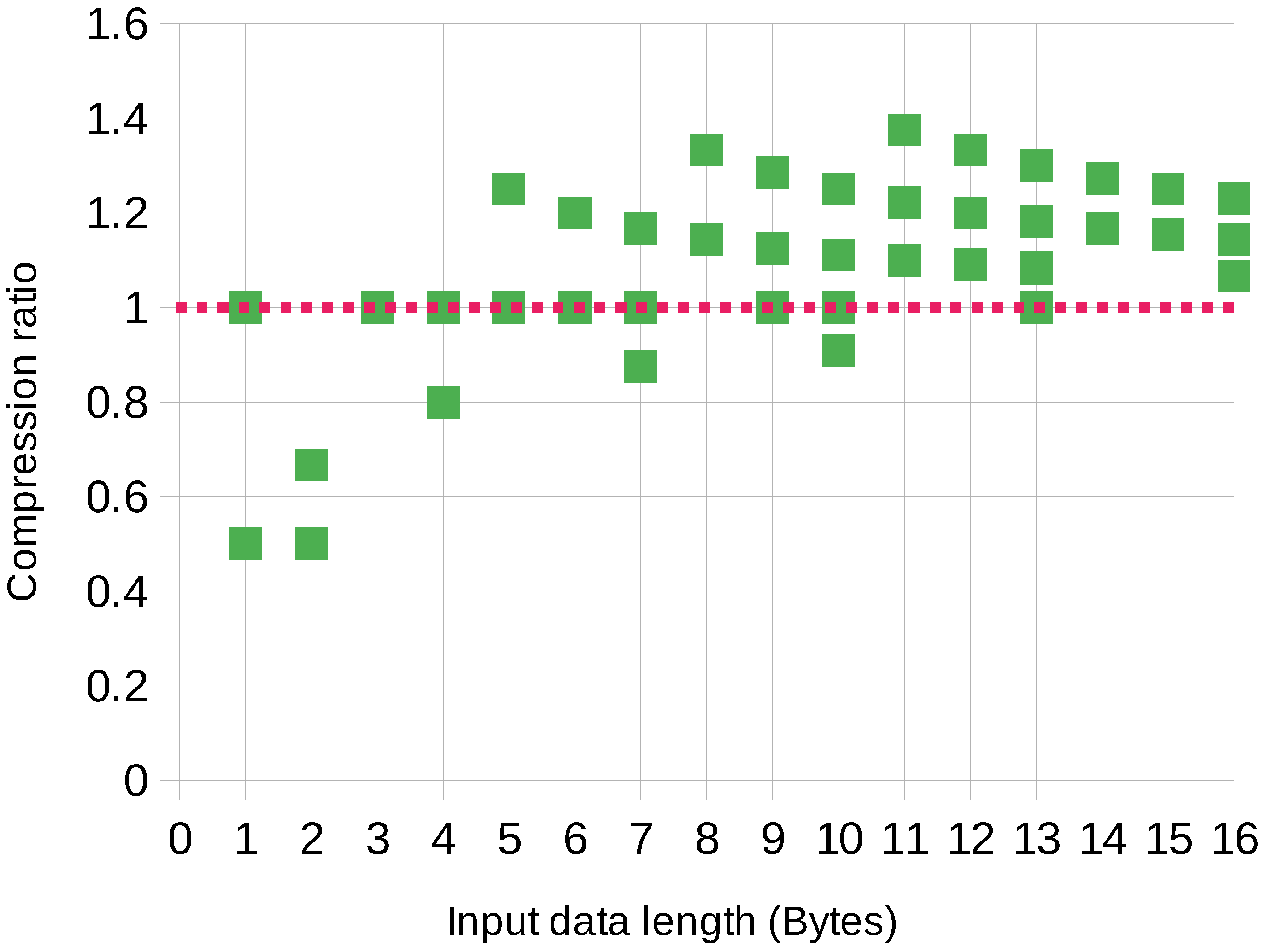
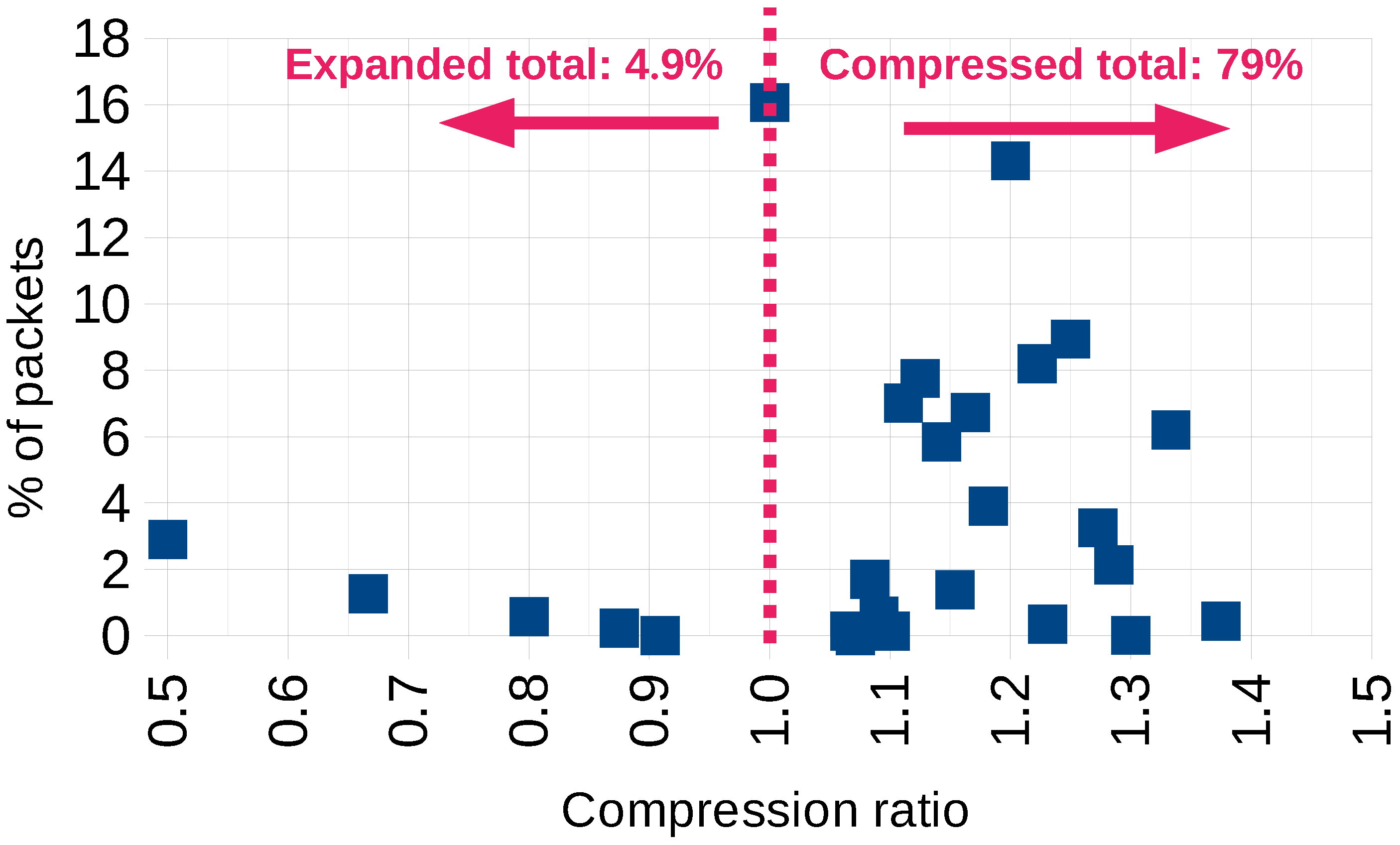
6.1. Compression Ratio Analysis
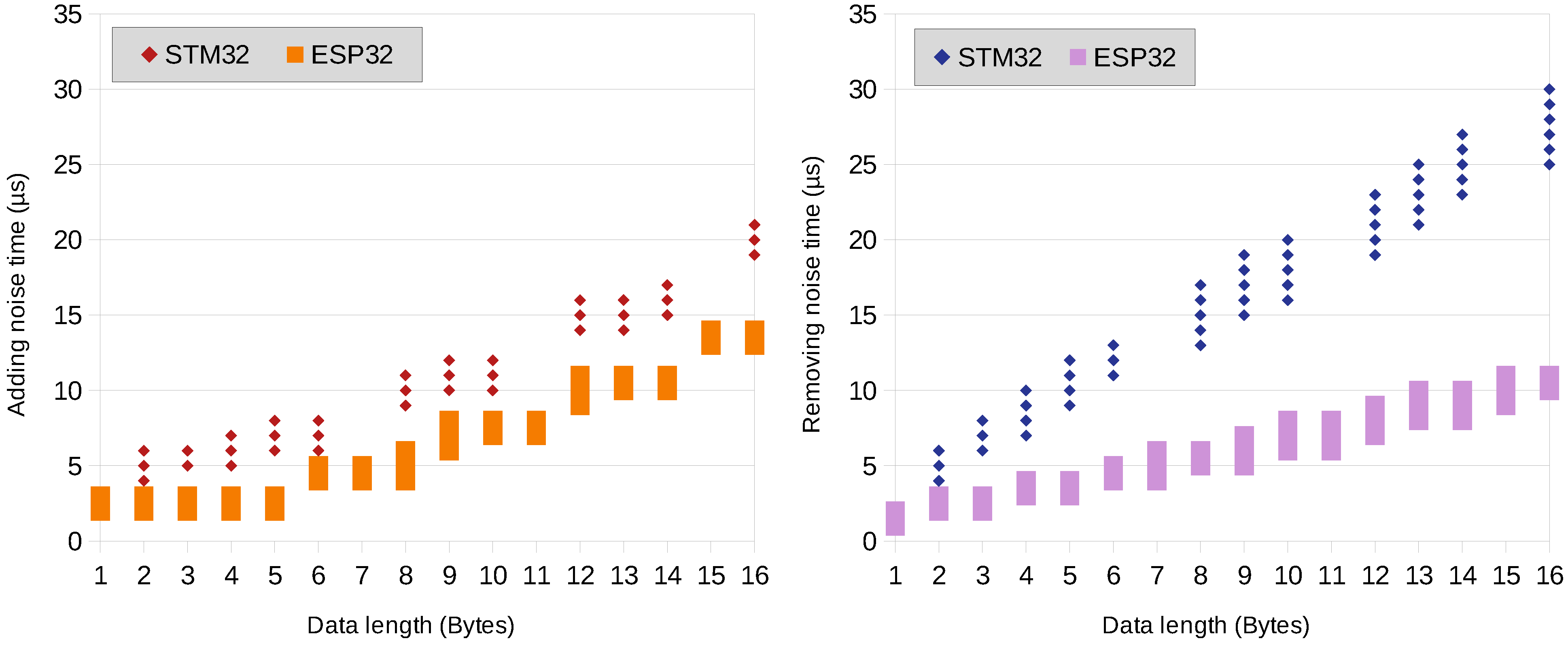
6.2. Encryption and Decryption Time
6.3. MCU Resource Usage
7. Discussion
7.1. Security Considerations
7.1.1. Brute-Force Attack Considerations
- Guess the alphabet which is a subset of letters of N elements.
- Guess the noise which is a subset of letters of M elements.
- Generate a set of all possible ordered lists of subsets of one- and two-character substrings.
- For each list from the set:
- (a)
- Generate Huffman + LZW tree using the algorithm from Section 5.3
- (b)
- Try to decode the message using the algorithm from Section 5.3
- (c)
- If failed, take the next element from the list
7.1.2. Features which Make the Brute-Force Attacks More Difficult
7.1.3. Security Improvements
7.2. Solution Scalability Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ASCII | American Standard Code for Information Interchange |
| CSV | Comma-separated values |
| DCR | Data compression ratio |
| LZ77 | Lempel-Ziv 1977 |
| LZW | Lempel–Ziv–Welch |
| MCU | Microcontroller unit |
| RAM | Random Access Memory |
References
- Nair, A.K.; Sahoo, J.; Raj, E.D. Privacy preserving Federated Learning framework for IoMT based big data analysis using edge computing. Comput. Stand. Interfaces 2023, 7, 103720. [Google Scholar] [CrossRef]
- Zarour, M.; Alenezi, M.; Ansari, M.T.J.; Pandey, A.K.; Ahmad, M.; Agrawal, A.; Kumar, R.; Khan, R.A. Ensuring data integrity of healthcare information in the era of digital health. Healthc. Technol. Lett. 2021, 8, 66–77. [Google Scholar] [CrossRef] [PubMed]
- Li, G.; Chen, Y.; Wang, Y.; Nie, P.; Yu, Z.; He, Z. City-scale synthetic individual-level vehicle trip data. Sci. Data 2023, 10, 96. [Google Scholar] [CrossRef] [PubMed]
- Lin, H.Y. Secure Data Transfer Based on a Multi-Level Blockchain for Internet of Vehicles. Sensors 2023, 23, 2664. [Google Scholar] [CrossRef] [PubMed]
- Rejeb, A.; Rejeb, K.; Treiblmaier, H.; Appolloni, A.; Alghamdi, S.; Alhasawi, Y.; Iranmanesh, M. The Internet of Things (IoT) in healthcare: Taking stock and moving forward. Internet Things 2023, 10, 100721. [Google Scholar] [CrossRef]
- Gupta, S.; Maple, C.; Crispo, B.; Raja, K.; Yautsiukhin, A.; Martinelli, F. A survey of human–computer interaction (HCI) & natural habits-based behavioural biometric modalities for user recognition schemes. Pattern Recognit. 2023, 25, 109453. [Google Scholar]
- Kyeong, N.; Nam, K. Mechanism design for data reliability improvement through network-based reasoning model. Expert Syst. Appl. 2022, 205, 117660. [Google Scholar] [CrossRef]
- Chowdhury, A.; Raut, S.A. A survey study on internet of things resource management. J. Netw. Comput. Appl. 2018, 120, 42–60. [Google Scholar] [CrossRef]
- Petitcolas, F.A.P. Kerckhoffs’ Principle. In Encyclopedia of Cryptography and Security; van Tilborg, H.C.A., Jajodia, S., Eds.; Springer: Boston, MA, USA, 2011; p. 675. [Google Scholar] [CrossRef]
- Patil, P.; Narayankar, P.; Narayan, D.; Meena, S.M. A comprehensive evaluation of cryptographic algorithms: DES, 3DES, AES, RSA and Blowfish. Procedia Comput. Sci. 2016, 78, 617–624. [Google Scholar] [CrossRef]
- Mathur, N.; Bansode, R. AES based text encryption using 12 rounds with dynamic key selection. Procedia Comput. Sci. 2016, 79, 1036–1043. [Google Scholar] [CrossRef]
- Tan, W.; Wang, X.; Lou, X.; Pan, M. Analysis of RSA based on quantitating key security strength. Procedia Eng. 2011, 15, 1340–1344. [Google Scholar] [CrossRef]
- Peyrin, T.; Sasaki, Y.; Wang, L. Generic Related-Key Attacks for HMAC. In Proceedings of the ASIACRYPT, Beijing, China, 2–6 December 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7658, pp. 580–597. [Google Scholar]
- Glabb, R.; Imbert, L.; Jullien, G.; Tisserand, A.; Veyrat-Charvillon, N. Multi-mode operator for SHA-2 hash functions. J. Syst. Archit. 2007, 53, 127–138. [Google Scholar] [CrossRef]
- De Canniere, C.; Biryukov, A.; Preneel, B. An introduction to block cipher cryptanalysis. Proc. IEEE 2006, 94, 346–356. [Google Scholar] [CrossRef]
- Rong, C.; Zhao, G.; Yan, L.; Cayirci, E.; Cheng, H. Wireless Network Security. In Computer and Information Security Handbook; Elsevier: Amsterdam, The Netherlands, 2013; pp. 301–316. [Google Scholar]
- Sinha, S.; Islam, S.H.; Obaidat, M.S. A comparative study and analysis of some pseudorandom number generator algorithms. Secur. Priv. 2018, 1, e46. [Google Scholar] [CrossRef]
- Pu, I.M. Fundamental Data Compression; Butterworth-Heinemann: Oxford, UK, 2005. [Google Scholar]
- Capocelli, R.; Giancarlo, R.; Taneja, I. Bounds on the redundancy of Huffman codes (Corresp.). IEEE Trans. Inf. Theory 1986, 32, 854–857. [Google Scholar] [CrossRef]
- Welch, T.A. A Technique for High-Performance Data Compression. Computer 1984, 17, 8–19. [Google Scholar] [CrossRef]
- Dheemanth, H. LZW data compression. Am. J. Eng. Res. 2014, 3, 22–26. [Google Scholar]
- Sayood, K. Data Compression. In Encyclopedia of Information Systems; Bidgoli, H., Ed.; Elsevier: New York, NY, USA, 2003; pp. 423–444. [Google Scholar]
- Huffman, D.A. A method for the construction of minimum-redundancy codes. Proc. IRE 1952, 40, 1098–1101. [Google Scholar] [CrossRef]
- Van Leeuwen, J. On the Construction of Huffman Trees. In Proceedings of the ICALP, University of Edinburgh, Edinburgh, UK, 20–23 July 1976; pp. 382–410. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Input | Output |
|---|---|---|
| 0 | - | |
| 1 | - | |
| 2 | - | |
| 3 | - | |
| 4 | 1 | |
| 5 | 2 | |
| 6 | 1 | |
| 7 | 0 | |
| 8 | 4 | |
| 9 | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krokosz, T.; Rykowski, J.; Zajęcka, M.; Brzoza-Woch, R.; Rutkowski, L. Cryptographic Algorithms with Data Shorter than the Encryption Key, Based on LZW and Huffman Coding. Sensors 2023, 23, 7408. https://doi.org/10.3390/s23177408
Krokosz T, Rykowski J, Zajęcka M, Brzoza-Woch R, Rutkowski L. Cryptographic Algorithms with Data Shorter than the Encryption Key, Based on LZW and Huffman Coding. Sensors. 2023; 23(17):7408. https://doi.org/10.3390/s23177408
Chicago/Turabian StyleKrokosz, Tomasz, Jarogniew Rykowski, Małgorzata Zajęcka, Robert Brzoza-Woch, and Leszek Rutkowski. 2023. "Cryptographic Algorithms with Data Shorter than the Encryption Key, Based on LZW and Huffman Coding" Sensors 23, no. 17: 7408. https://doi.org/10.3390/s23177408
APA StyleKrokosz, T., Rykowski, J., Zajęcka, M., Brzoza-Woch, R., & Rutkowski, L. (2023). Cryptographic Algorithms with Data Shorter than the Encryption Key, Based on LZW and Huffman Coding. Sensors, 23(17), 7408. https://doi.org/10.3390/s23177408