

Global Guided Cross-Modal Cross-Scale Network for RGB-D Salient Object Detection

Abstract
:1. Introduction
- We exploit cross-modal cross-scale feature fusion under the guidance of global context information to suppress distractors in lower layers. This strategy is based on the observation that high-level features contain global context information, which is helpful to eliminate distractors in lower layers.
- To fully capture the complementary information in the depth map and effectively fuse RGB features and depth features, we introduce a depth enhancement module (DEM), which utilizes the complementarity between RGB features and depth features, and an RGB enhancement module (REM) which utilizes the information of RGB features to improve the details of salient object detection.
- We propose a Global Guided Cross-Modal Cross-Scale Network (G2CMCSNet) to detect RGB-D salient objects, which exceed 12 SOTAs on five public datasets. Different from other models, our model not only considers feature continuity but also exploits the intrinsic structure of the RGB features and the global context information of high-level features. The performance of the proposed method is evaluated on five popular public datasets under four evaluation metrics, and compared with 12 state-of-the-art RGB-D SOD methods.
2. Related Work
3. Methodologies
3.1. The Overall Architecture and Motivation
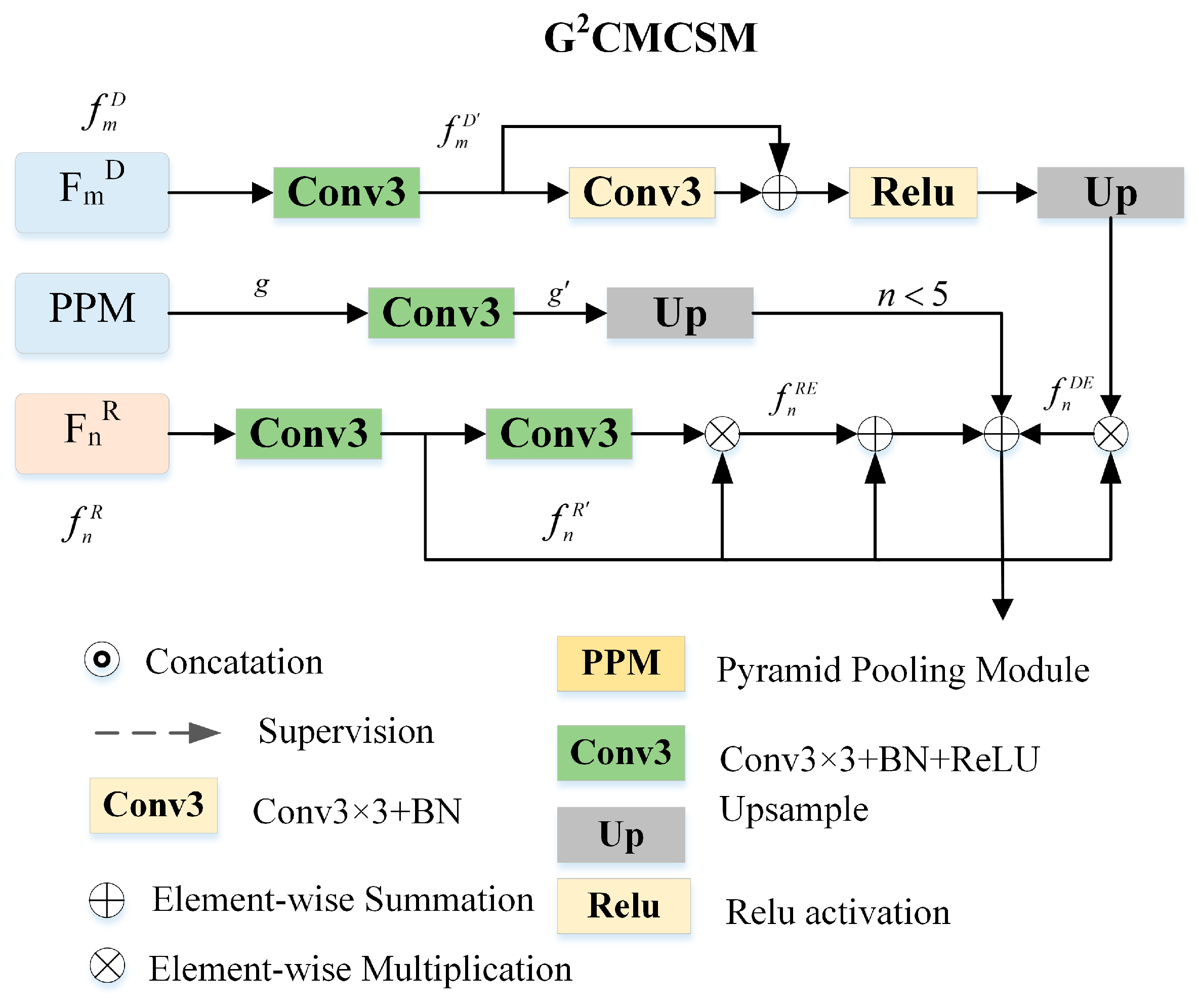
3.2. Global Guided Cross-Modal Cross-Scale Module
3.3. Cascaded Decoder
3.4. Loss Function
4. Experiments
4.1. Datasets and Evaluation Metrics
4.2. Implementation Details
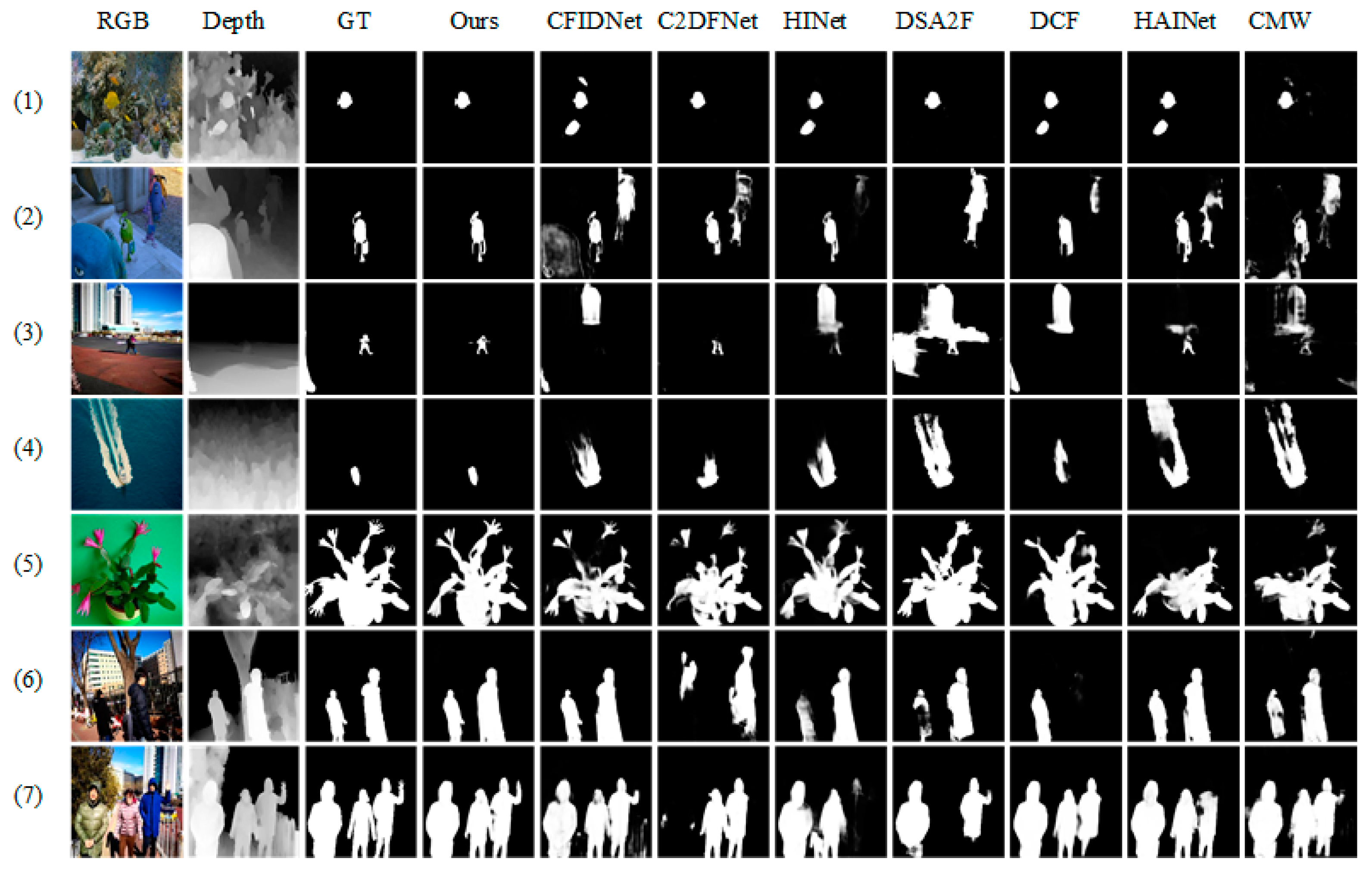
4.3. Comparison with State-of-the-Art
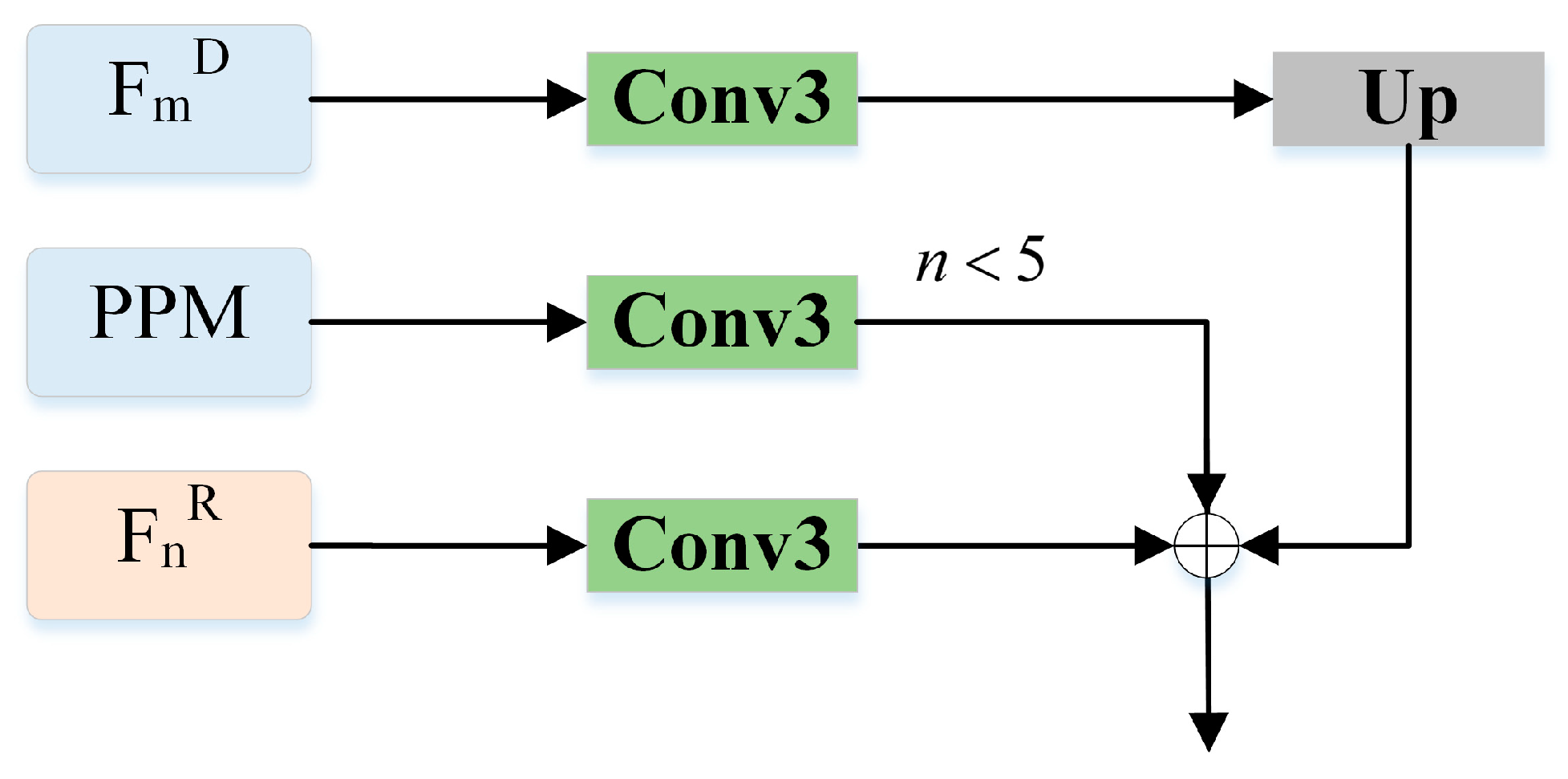
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, J.Y.; Wu, J.; Xu, Y.; Chang, E.; Tu, Z. Unsupervised object class discovery via saliency-guided multiple class learning. In Proceedings of the 2012 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Fan, D.P.; Wang, W.; Cheng, M.M.; Shen, J. Shifting more attention to video salient object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Shimoda, W.; Yanai, K. Distinct class-specific saliency maps for weakly supervised semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Mahadevan, V.; Vasconcelos, N. Saliency-based discriminant tracking. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Li, N.; Ye, J.; Ji, Y.; Ling, H.; Yu, J. Saliency detection on light field. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, X.; Ma, H.; Chen, X.; You, S. Edge preserving and multiscale contextual neural network for salient object detection. IEEE Trans. Image Process. 2018, 27, 121–134. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Huang, D.; Wang, Y. Receptive field block net for accurate and fast object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 385–400. [Google Scholar]
- Liu, J.J.; Hou, Q.; Cheng, M.M.; Feng, J.; Jiang, J. A simple pooling-based design for real-time salient object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhao, J.X.; Cao, Y.; Fan, D.P.; Cheng, M.M.; Li, X.Y.; Zhang, L. Contrast prior and fluid pyramid integration for RGBD salient object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Piao, Y.; Rong, Z.; Zhang, M.; Ren, W.; Lu, H. A2dele: Adaptive and attentive depth distiller for efficient RGB-D salient object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Chen, S.; Fu, Y. Progressively guided alternate refinement network for RGB-D salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Virtual, 23–28 August 2020; pp. 520–538. [Google Scholar]
- Fan, D.P.; Zhai, Y.; Borji, A.; Yang, J.; Shao, L. BBS-Net: RGB-D salient object detection with a bifurcated backbone strategy network. In Proceedings of the European Conference on Computer Vision (ECCV), Virtual, 23–28 August 2020; pp. 275–292. [Google Scholar]
- Li, G.Y.; Liu, Z.; Ye, L.W.; Wang, Y.; Ling, H.B. Cross-modal weighting network for RGB-D salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Virtual, 23–28 August 2020; pp. 665–681. [Google Scholar]
- Li, G.Y.; Liu, Z.; Chen, M.Y.; Bai, Z.; Lin, W.S.; Ling, H.B. Hierarchical Alternate Interaction Network for RGB-D Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 3528–3542. [Google Scholar] [CrossRef] [PubMed]
- Zhou, T.; Fu, H.Z.; Chen, G.; Zhou, Y.; Fan, D.P.; Shao, L. Specificity-preserving RGB-D Saliency Detection. In Proceedings of the 2021 IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 4681–4691. [Google Scholar]
- Zhao, H.S.; Shi, J.P.; Qi, X.J.; Wang, X.G.; Jia, J.Y. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, L.Z.; Wang, L.J.; Lu, H.C.; Zhang, P.P.; Ruan, X. Saliency detection with recurrent fully convolutional networks. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 825–841. [Google Scholar]
- Qu, L.Q.; He, S.F.; Zhang, J.W.; Tian, J.D.; Tang, Y.D.; Yang, Q.X. RGBD salient object detection via deep fusion. IEEE Trans. Image Process. 2017, 26, 2274–2285. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Han, J.W. Dhsnet: Deep hierarchical saliency network for salient object detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Chen, S.; Tan, X.; Wang, B.; Hu, X. Reverse attention for salient object detection. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 234–250. [Google Scholar]
- Wang, W.; Shen, J.; Cheng, M.M.; Shao, L. An iterative and cooperative top-down and bottom-up inference network for salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5968–5977. [Google Scholar]
- Wu, Z.; Su, L.; Huang, Q. Cascaded partial decoder for fast and accurate salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3907–3916. [Google Scholar]
- Zhang, L.; Zhang, J.; Lin, Z.; Lu, H.; He, Y. Capsal: Leveraging captioning to boost semantics for salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6024–6033. [Google Scholar]
- Chen, H.; Li, Y.F.; Su, D. Multi-modal fusion network with multi-scale multi-path and cross-modal interactions for RGB-D salient object detection. Pattern Recognit. 2019, 86, 376–385. [Google Scholar] [CrossRef]
- Zhang, J.; Fan, D.P.; Dai, Y.C.; Yu, X.; Zhong, Y.Z.; Barnes, N.; Shao, L. RGB-D saliency detection via cascaded mutual information minimization. In Proceedings of the 2021 IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 4318–4327. [Google Scholar]
- Ji, W.; Li, J.; Yu, S.; Zhang, M.; Piao, Y.; Yao, S.; Bi, Q.; Ma, K.; Zheng, Y.; Lu, H.; et al. Calibrated rgb-d salient object detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 9471–9481. [Google Scholar]
- Lee, M.Y.; Park, C.W.; Cho, S.W.; Lee, S.Y. SPSN: Superpixel prototype sampling network for RGB-D salient object detection. In Proceedings of the ECCV, Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Sun, P.; Zhang, W.H.; Wang, H.Y.; Li, S.Y.; Li, X. Deep RGB-D Saliency Detection with Depth-Sensitive Attention and Automatic Multi-Modal Fusion. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Zhang, C.; Cong, R.; Lin, Q.; Ma, L.; Li, F.; Zhao, Y.; Kwong, S. Cross-modality discrepant interaction network for RGB-D salient object detection. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 2094–2102. [Google Scholar]
- Wu, Z.; Gobichettipalayam, S.; Tamadazte, B.; Allibert, G.; Paudel, D.P.; Demonceaux, C. Robust rgb-d fusion for saliency detection. In Proceedings of the International Conference on 3D Vision (3DV), Prague, Czech Republic, 12–15 September 2022; pp. 403–413. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. BASNet: Boundary-aware salient object detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Fu, K.; Fan, D.P.; Ji, G.P.; Zhao, Q. JL-DCF: Joint learning and densely-cooperative fusion framework for rgb-d salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3052–3062. [Google Scholar]
- Wang, F.; Pan, J.; Xu, S.; Tang, J. Learning Discriminative Cross-modality Features for RGB-D Saliency Detection. IEEE Trans. Image Process. 2022, 31, 1285–1297. [Google Scholar] [CrossRef] [PubMed]
- Bi, H.B.; Wu, R.W.; Liu, Z.Q.; Zhu, H.H. Cross-modal Hierarchical Interaction Network for RGB-D Salient Object Detection. Pattern Recognit. 2023, 136, 109194. [Google Scholar] [CrossRef]
- Chen, T.Y.; Hu, X.G.; Xiao, J.; Zhang, G.F.; Wang, S.J. CFIDNet: Cascaded Feature Interaction Decoder for RGB-D Salient Object Detection. Neural Comput. Appl. 2022, 34, 7547–7563. [Google Scholar] [CrossRef]
- Zhang, M.; Yao, S.Y.; Hu, B.Q.; Piao, Y.R.; Ji, W. C2DFNet: Criss-Cross Dynamic Filter Network for RGB-D Salient Object Detection. IEEE Trans. Multimed. 2022; early access. [Google Scholar] [CrossRef]
- Ju, R.; Ge, L.; Geng, W.J.; Ren, T.W.; Wu, G.S. Depth saliency based on anisotropic center-surround difference. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 1115–1119. [Google Scholar]
- Niu, Y.Z.; Geng, Y.J.; Li, X.Q.; Liu, F. Leveraging stereopsis for saliency analysis. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Province, RI, USA, 16–21 June 2012; pp. 454–461. [Google Scholar]
- Peng, H.W.; Li, B.; Xiong, W.H.; Hu, W.M.; Ji, R.R. RGBD salient object detection: A benchmark and algorithms. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 5–12 September 2014; pp. 92–109. [Google Scholar]
- Zhu, C.B.; Li, G. A three-pathway psychobiological framework of salient object detection using stereoscopic technology. In Proceedings of the IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017; pp. 3008–3014. [Google Scholar]
- Fan, D.P.; Lin, Z.; Zhang, Z.; Zhu, M.; Cheng, M.M. Rethinking RGB-D salient object detection: Models, data sets, and large-scale benchmarks. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 2075–2089. [Google Scholar] [CrossRef] [PubMed]
- Achanta, R.; Hemami, S.; Estrada, F.; Susstrunk, S. Frequency-tuned salient region detection. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 1597–1604. [Google Scholar]
- Perazzi, F.; Krähenbühl, P.; Pritch, Y.; Hornung, A. Saliency filters: Contrast based filtering for salient region detection. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 733–740. [Google Scholar]
- Fan, D.P.; Cheng, M.M.; Liu, Y.; Li, T.; Borji, A. Structure-measure: A new way to evaluate foreground maps. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4548–4557. [Google Scholar]
- Fan, D.P.; Gong, C.; Cao, Y.; Ren, B.; Cheng, M.M.; Borji, A. Enhanced-alignment measure for binary foreground map evaluation. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Stockholm, Sweden, 13–19 July; pp. 698–704.
- Piao, Y.R.; Ji, W.; Li, J.J.; Zhang, M.; Lu, H.C. Depth-induced multi-scale recurrent attention network for saliency detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7254–7263. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | DMRA | CMW | PGAR | HAINet | JLDCF | DCF | DSA2F | DCMF | HINet | CFIDNet | SPSNet | C2DFNet | Ours | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NLPR | M↓ | 0.031 | 0.03 | 0.025 | 0.024 | 0.022 | 0.024 | 0.024 | 0.029 | 0.026 | 0.026 | 0.024 | 0.021 | 0.021 |
| Sm↑ | 0.899 | 0.917 | 0.93 | 0.924 | 0.925 | 0.922 | 0.918 | 0.922 | 0.923 | 0.922 | 0.923 | 0.928 | 0.928 | |
| Fm↑ | 0.888 | 0.912 | 0.925 | 0.922 | 0.916 | 0.917 | 0.917 | 0.913 | 0.915 | 0.914 | 0.918 | 0.926 | 0.927 | |
| Em↑ | 0.941 | 0.94 | 0.953 | 0.956 | 0.962 | 0.954 | 0.951 | 0.939 | 0.948 | 0.95 | 0.956 | 0.957 | 0.960 | |
| SSD | M↓ | 0.058 | 0.052 | - | 0.052 | 0.053 | 0.054 | 0.047 | 0.054 | 0.049 | 0.051 | - | 0.047 | 0.043 |
| Sm↑ | 0.857 | 0.875 | - | 0.857 | 0.861 | 0.852 | 0.876 | 0.882 | 0.865 | 0.879 | - | 0.871 | 0.880 | |
| Fm↑ | 0.858 | 0.883 | - | 0.859 | 0.862 | 0.858 | 0.878 | 0.88 | 0.874 | 0.882 | - | 0.883 | 0.892 | |
| Em↑ | 0.898 | 0.909 | - | 0.895 | 0.889 | 0.892 | 0.911 | 0.905 | 0.903 | 0.916 | - | 0.912 | 0.917 | |
| STEREO | M↓ | 0.047 | 0.042 | 0.04 | 0.039 | 0.042 | 0.036 | 0.038 | 0.042 | 0.048 | 0.042 | 0.035 | 0.037 | 0.039 |
| Sm↑ | 0.886 | 0.913 | 0.914 | 0.915 | 0.905 | 0.915 | 0.904 | 0.917 | 0.900 | 0.91 | 0.914 | 0.911 | 0.910 | |
| Fm↑ | 0.895 | 0.909 | 0.909 | 0.914 | 0.901 | 0.913 | 0.91 | 0.914 | 0.895 | 0.906 | 0.908 | 0.91 | 0.909 | |
| Em↑ | 0.93 | 0.93 | 0.93 | 0.938 | 0.946 | 0.943 | 0.939 | 0.929 | 0.921 | 0.935 | 0.941 | 0.938 | 0.935 | |
| NJU2K | M↓ | - | 0.046 | 0.043 | 0.038 | 0.043 | 0.042 | - | 0.043 | 0.039 | 0.038 | 0.033 | 0.039 | 0.032 |
| Sm↑ | - | 0.903 | 0.909 | 0.912 | 0.903 | 0.895 | - | 0.913 | 0.915 | 0.914 | 0.918 | 0.908 | 0.919 | |
| Fm↑ | - | 0.913 | 0.917 | 0.925 | 0.903 | 0.908 | - | 0.922 | 0.925 | 0.923 | 0.927 | 0.918 | 0.929 | |
| Em↑ | - | 0.925 | 0.931 | 0.94 | 0.944 | 0.932 | - | 0.932 | 0.936 | 0.938 | 0.949 | 0.937 | 0.949 | |
| SIP | M↓ | - | 0.063 | 0.056 | 0.053 | 0.051 | 0.053 | 0.057 | - | 0.066S | 0.051 | 0.044 | 0.052 | 0.044 |
| Sm↑ | - | 0.867 | 0.876 | 0.879 | 0.879 | 0.872 | 0.861 | - | 0.856 | 0.881 | 0.892 | 0.871 | 0.890 | |
| Fm↑ | - | 0.889 | 0.892 | 0.906 | 0.885 | 0.899 | 0.891 | - | 0.880 | 0.9 | 0.91 | 0.895 | 0.912 | |
| Em↑ | - | 0.9 | 0.904 | 0.923 | 0.915 | 0.909 | - | 0.887 | 0.918 | 0.931 | 0.913 | 0.927 |
| Models | RGBD135 | SSD | SIP | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| M↓ | Sm↑ | Fm↑ | Em↑ | M↓ | Sm↑ | Fm↑ | Em↑ | M↓ | Sm↑ | Fm↑ | Em↑ | |
| Ours | 0.020 | 0.920 | 0.931 | 0.959 | 0.043 | 0.880 | 0.892 | 0.916 | 0.044 | 0.890 | 0.912 | 0.927 |
| A1 | 0.025 | 0.907 | 0.925 | 0.939 | 0.048 | 0.860 | 0.859 | 0.90 | 0.051 | 0.877 | 0.900 | 0.915 |
| A2 | 0.025 | 0.921 | 0.917 | 0.952 | 0.058 | 0.845 | 0.847 | 0.891 | 0.063 | 0.851 | 0.878 | 0.897 |
| A3 | 0.024 | 0.905 | 0.919 | 0.936 | 0.047 | 0.868 | 0.881 | 0.902 | 0.045 | 0.888 | 0.912 | 0.926 |
| A4 | 0.022 | 0.913 | 0.927 | 0.948 | 0.049 | 0.862 | 0.875 | 0.899 | 0.047 | 0.885 | 0.909 | 0.921 |
| A5 | 0.021 | 0.915 | 0.929 | 0.951 | 0.053 | 0.865 | 0.868 | 0.898 | 0.046 | 0.885 | 0.913 | 0.922 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, S.; Jiang, F.; Xu, B. Global Guided Cross-Modal Cross-Scale Network for RGB-D Salient Object Detection. Sensors 2023, 23, 7221. https://doi.org/10.3390/s23167221
Wang S, Jiang F, Xu B. Global Guided Cross-Modal Cross-Scale Network for RGB-D Salient Object Detection. Sensors. 2023; 23(16):7221. https://doi.org/10.3390/s23167221
Chicago/Turabian StyleWang, Shuaihui, Fengyi Jiang, and Boqian Xu. 2023. "Global Guided Cross-Modal Cross-Scale Network for RGB-D Salient Object Detection" Sensors 23, no. 16: 7221. https://doi.org/10.3390/s23167221
APA StyleWang, S., Jiang, F., & Xu, B. (2023). Global Guided Cross-Modal Cross-Scale Network for RGB-D Salient Object Detection. Sensors, 23(16), 7221. https://doi.org/10.3390/s23167221