
A Depth-Based Hybrid Approach for Safe Flight Corridor Generation in Memoryless Planning

 , ,
, ,  , ,
, ,  and
and 
Abstract
:1. Introduction
- (1)
- We propose a hybrid safe flight corridor generation technique that utilizes only depth images. It produces less-overlapping corridors compared to a depth-based inflating method.
- (2)
- We propose a memoryless planner employing the above-generated corridors to navigate a quadrotor autonomously through an obstacle-dense environment to a destination without employing any map or external global planners. The entire planning system can run in real time with fully onboard sensing and computation.
- (3)
- We implemented and validated the proposed method on an actual fully autonomous quadrotor system. Real-world flight tests show that our methods can effectively navigate a quadrotor through cluttered scenarios.
2. Related Works
2.1. Corridor-Based Trajectory Planning
2.2. Learning-Based Local Planning Limitation
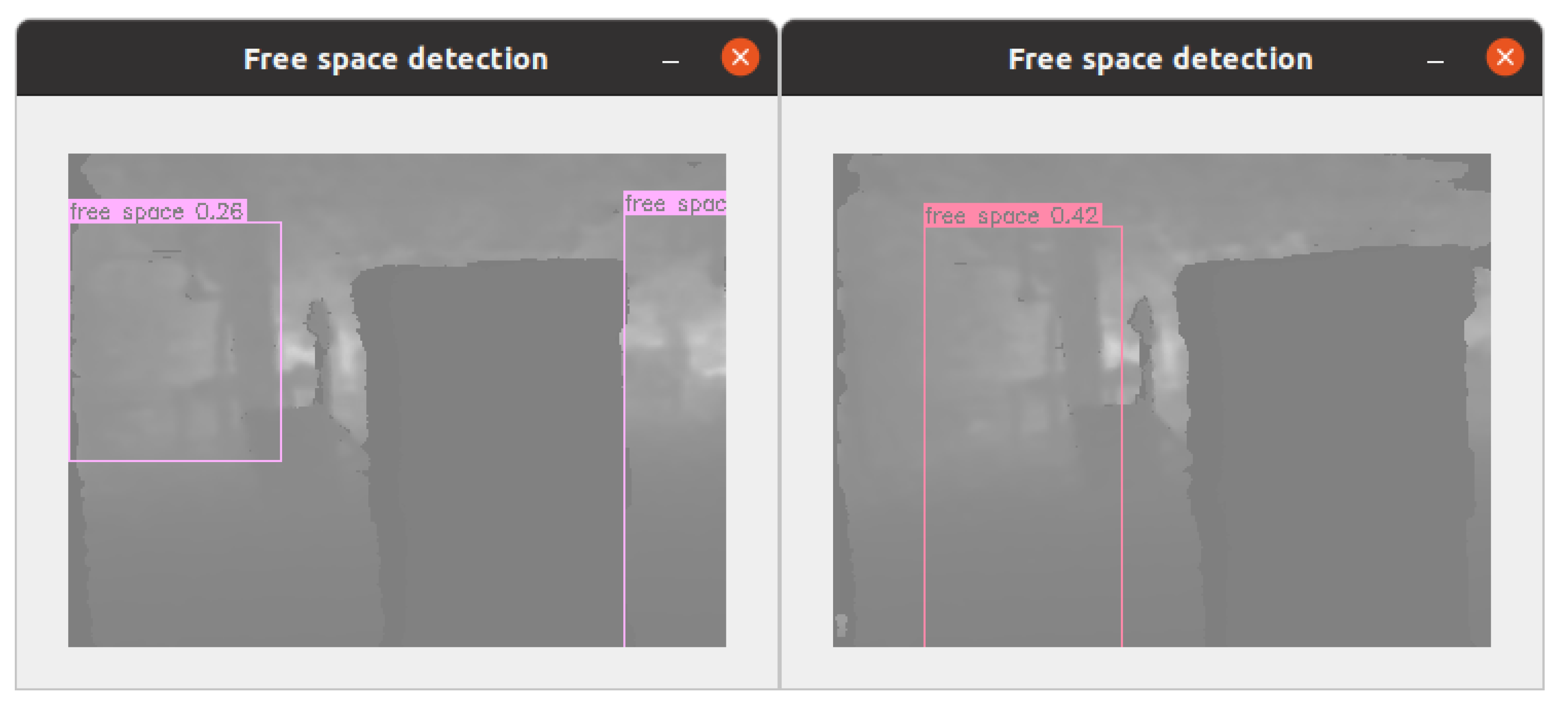
2.3. Free Space Segmentation
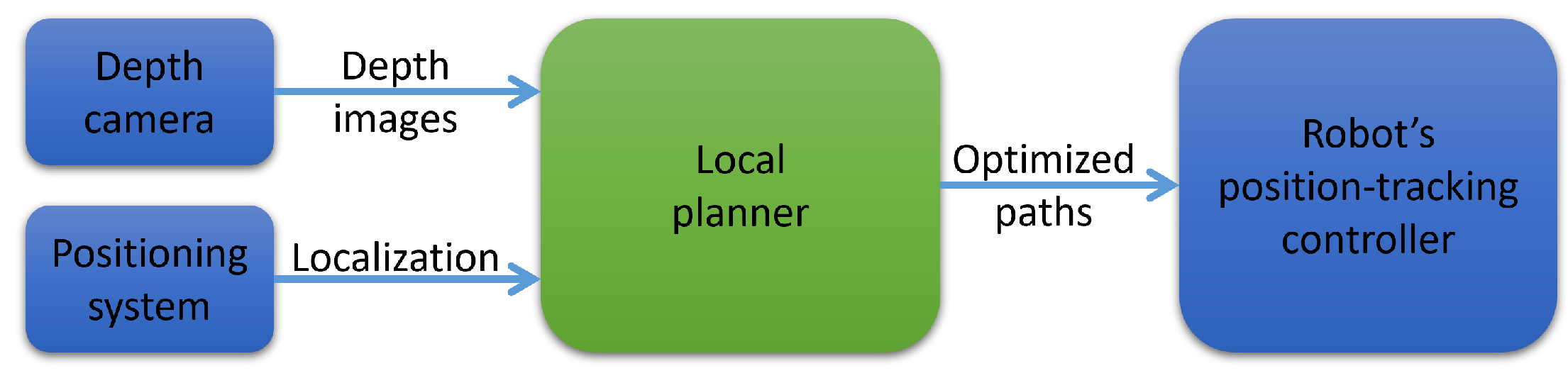
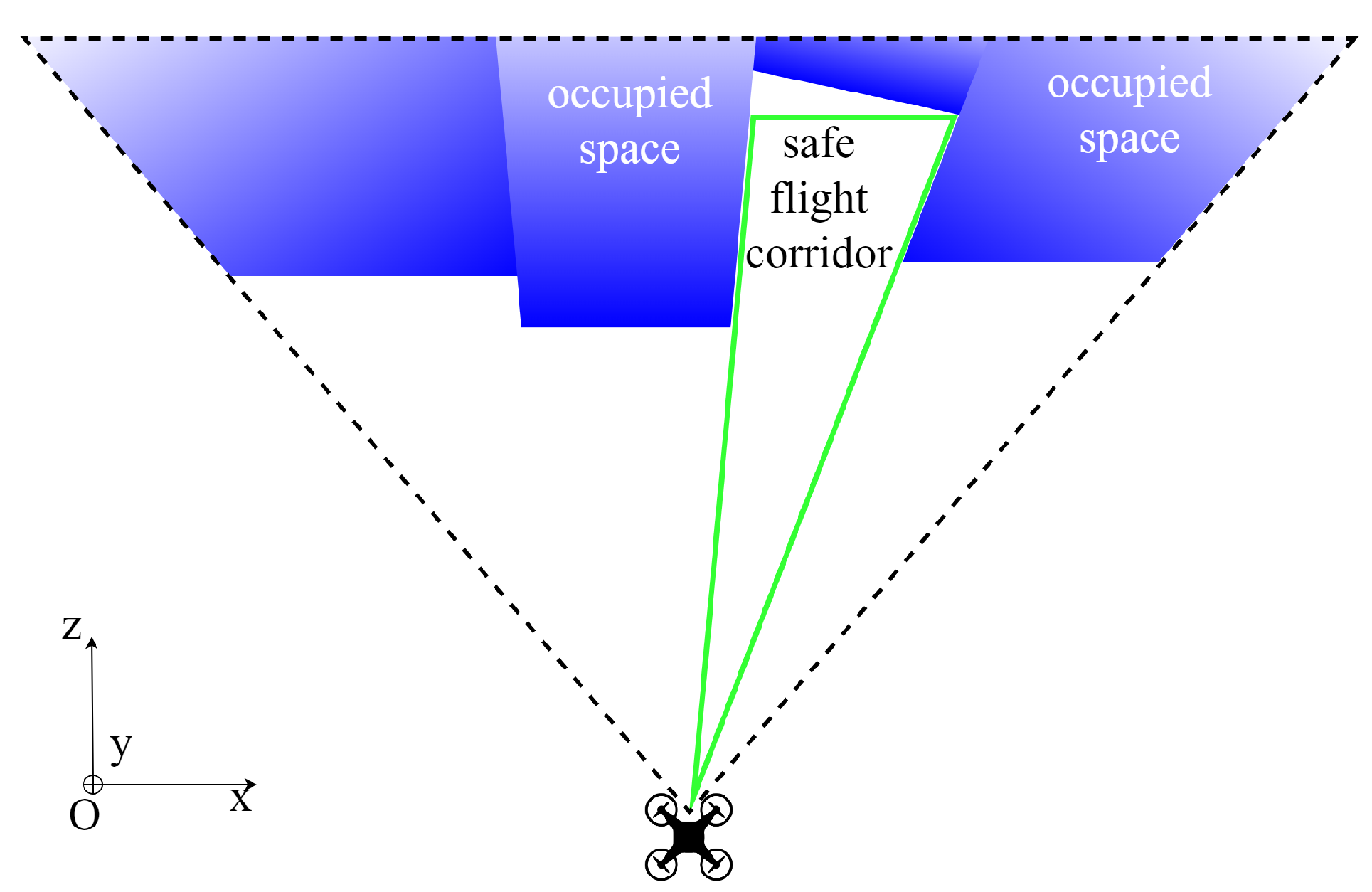
3. Problem Formulation
4. Free Space Detection
4.1. A Hybrid Approach
4.2. Safe Flight Corridor Constitution
4.3. Supervised Learning and Conservativeness
4.4. Data Collection and Training
4.5. Free Space Prediction and Verification
5. Local Planning Algorithm
5.1. Local Planner
5.2. Best Direction Path
- (a)
- If g falls into one of four corner areas, p is the nearest corner.
- (b)
- If g falls into one of the four edge areas, p will lie on the nearest edge, specified by a perpendicular line drawn from g to the edge.
- (c)
- If g falls into the bounding box, the solution is g itself.
6. Implementations and Results
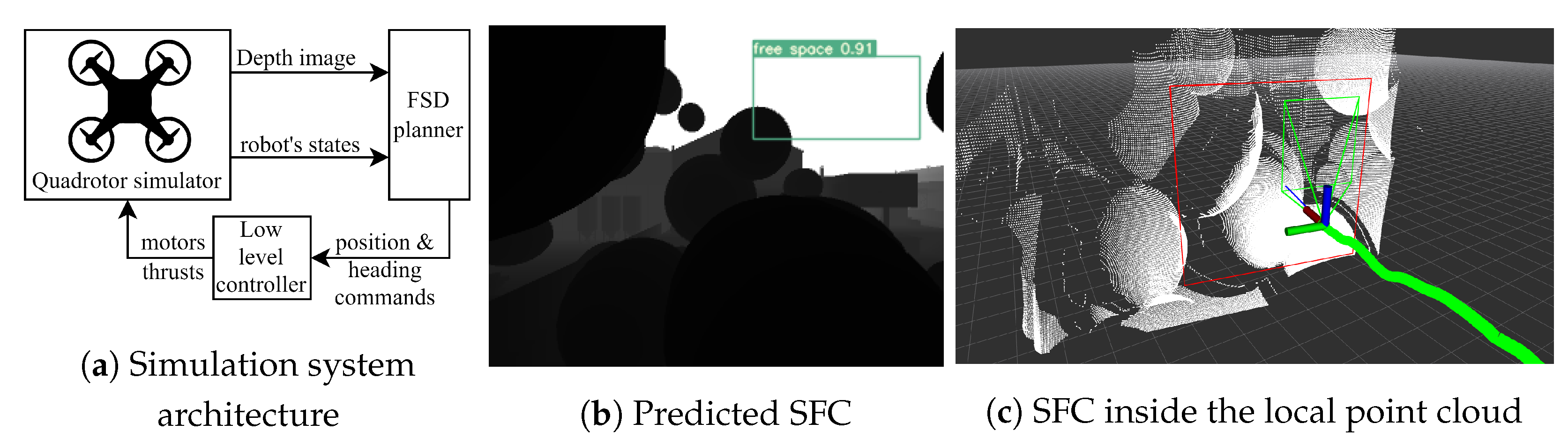
6.1. Simulation
6.2. Flight Tests
6.3. Results
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SFC | Safe flight corridor |
| FSD | Free space detection |
| IoU | Intersection over union |
| FoV | Field of view |
References
- Chung, T.H.; Orekhov, V.; Maio, A. Into the Robotic Depths: Analysis and Insights from the DARPA Subterranean Challenge. Annu. Rev. Control. Robot. Auton. Syst. 2023, 6, 477–502. [Google Scholar] [CrossRef]
- Maghazei, O.; Lewis, M.A.; Netland, T.H.; Heim, G.; Peng, X. Emerging technologies and the use case: A multi-year study of drone adoption. J. Oper. Manag. 2022, 68, 560–591. [Google Scholar] [CrossRef]
- Damigos, G.; Lindgren, T.; Sandberg, S.; Nikolakopoulos, G. Performance of Sensor Data Process Offloading on 5G-Enabled UAVs. Sensors 2023, 23, 864. [Google Scholar] [CrossRef] [PubMed]
- Lai, W.C.; Chao, H.C.; Skorek, A.W.; Kujawska, M.; Dobrescu, L.; Jang, S.L.; Wu, Y.; Varadarajan, V.; Wang, H.; Bhardwaj, R.; et al. An Edge-Based Architecture for Offloading Model Predictive Control for UAVs. Robotics 2022, 11, 80. [Google Scholar] [CrossRef]
- Khattak, S.; Nguyen, H.; Mascarich, F.; Dang, T.; Alexis, K. Complementary Multi-Modal Sensor Fusion for Resilient Robot Pose Estimation in Subterranean Environments. In Proceedings of the 2020 International Conference on Unmanned Aircraft Systems, ICUAS 2020, Athens, Greece, 1–4 September 2020; pp. 1024–1029. [Google Scholar] [CrossRef]
- Zhao, S.; Wang, P.; Zhang, H.; Fang, Z.; Scherer, S. TP-TIO: A robust thermal-inertial odometry with deep thermalpoint. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 4505–4512. [Google Scholar] [CrossRef]
- Palieri, M.; Morrell, B.; Thakur, A.; Ebadi, K.; Nash, J.; Chatterjee, A.; Kanellakis, C.; Carlone, L.; Guaragnella, C.; Agha-Mohammadi, A.A. LOCUS: A Multi-Sensor Lidar-Centric Solution for High-Precision Odometry and 3D Mapping in Real-Time. IEEE Robot. Autom. Lett. 2021, 6, 421–428. [Google Scholar] [CrossRef]
- Han, L.; Gao, F.; Zhou, B.; Shen, S. FIESTA: Fast Incremental Euclidean Distance Fields for Online Motion Planning of Aerial Robots. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems, Macau, China, 3–8 November 2019; pp. 4423–4430. [Google Scholar] [CrossRef]
- Ji, J.; Wang, Z.; Wang, Y.; Xu, C.; Gao, F. Mapless-Planner: A Robust and Fast Planning Framework for Aggressive Autonomous Flight without Map Fusion. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–June 2021; pp. 6315–6321. [Google Scholar] [CrossRef]
- Grando, R.B.; de Jesus, J.C.; Kich, V.A.; Kolling, A.H.; Drews, P.L.J., Jr. Double Critic Deep Reinforcement Learning for Mapless 3D Navigation of Unmanned Aerial Vehicles. J. Intell. Robot. Syst. 2022, 104, 29. [Google Scholar] [CrossRef]
- Yoon, D.; Tang, T.; Barfoot, T. Mapless online detection of dynamic objects in 3D lidar. In Proceedings of the 2019 16th Conference on Computer and Robot Vision, CRV 2019, Kingston, QC, Canada, 29–31 May 2019; pp. 113–120. [Google Scholar] [CrossRef]
- Bucki, N.; Lee, J.; Mueller, M.W. Rectangular Pyramid Partitioning Using Integrated Depth Sensors (RAPPIDS): A Fast Planner for Multicopter Navigation. IEEE Robot. Autom. Lett. 2020, 5, 4626–4633. [Google Scholar] [CrossRef]
- Lee, J.; Wu, X.; Lee, S.J.; Mueller, M.W. Autonomous flight through cluttered outdoor environments using a memoryless planner. In Proceedings of the 2021 International Conference on Unmanned Aircraft Systems, ICUAS 2021, Athens, Greece, 15–18 June 2021; pp. 11131–11138. [Google Scholar] [CrossRef]
- Kamon, I.; Rivlin, E. Sensory-based motion planning with global proofs. IEEE Trans. Robot. Autom. 1997, 13, 814–822. [Google Scholar] [CrossRef]
- Choset, H.; Walker, S.; Eiamsa-Ard, K.; Burdick, J. Sensor-Based Exploration: Incremental Construction of the Hierarchical Generalized Voronoi Graph. Int. J. Robot. Res. 2000, 19, 126–148. [Google Scholar] [CrossRef]
- Nguyen, H.; Fyhn, S.H.; Petris, P.D.; Alexis, K. Motion Primitives-based Navigation Planning using Deep Collision Prediction. In Proceedings of the IEEE International Conference on Robotics and Automation, Philadelphia, PA, USA, 23–27 May 2022; pp. 9660–9667. [Google Scholar] [CrossRef]
- Kahn, G.; Abbeel, P.; Levine, S. BADGR: An Autonomous Self-Supervised Learning-Based Navigation System. IEEE Robot. Autom. Lett. 2020, 6, 1312–1319. [Google Scholar] [CrossRef]
- Kahn, G.; Abbeel, P.; Levine, S. LaND: Learning to Navigate from Disengagements. IEEE Robot. Autom. Lett. 2020, 6, 1872–1879. [Google Scholar] [CrossRef]
- Loquercio, A.; Kaufmann, E.; Ranftl, R.; Müller, M.; Koltun, V.; Scaramuzza, D. Learning high-speed flight in the wild. Sci. Robot. 2021, 6, eabg5810. [Google Scholar] [CrossRef] [PubMed]
- Florence, P.; Carter, J.; Tedrake, R. Integrated Perception and Control at High Speed: Evaluating Collision Avoidance Maneuvers Without Maps. In Springer Proceedings in Advanced Robotics; Springer: Cham, Switzerland, 2020; Volume 13, pp. 304–319. [Google Scholar] [CrossRef]
- Ryll, M.; Ware, J.; Carter, J.; Roy, N. Efficient trajectory planning for high speed flight in unknown environments. In Proceedings of the IEEE International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 732–738. [Google Scholar] [CrossRef]
- Chen, J.; Liu, T.; Shen, S. Online generation of collision-free trajectories for quadrotor flight in unknown cluttered environments. In Proceedings of the IEEE International Conference on Robotics and Automation, Stockholm, Sweden, 16–21 May 2016; pp. 1476–1483. [Google Scholar] [CrossRef]
- Liu, S.; Watterson, M.; Mohta, K.; Sun, K.; Bhattacharya, S.; Taylor, C.J.; Kumar, V. Planning dynamically feasible trajectories for quadrotors using safe flight corridors in 3-D complex environments. IEEE Robot. Autom. Lett. 2017, 2, 1688–1695. [Google Scholar] [CrossRef]
- Gao, F.; Wu, W.; Gao, W.; Shen, S. Flying on point clouds: Online trajectory generation and autonomous navigation for quadrotors in cluttered environments. J. Field Robot. 2019, 36, 710–733. [Google Scholar] [CrossRef]
- Hornung, A.; Wurm, K.M.; Bennewitz, M.; Stachniss, C.; Burgard, W. OctoMap: An efficient probabilistic 3D mapping framework based on octrees. Auton. Robot. 2013, 34, 189–206. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, F.; Liu, W.; Wang, Z.; Lin, Y.; Gao, F.; Zhang, F. Bubble Planner: Planning High-speed Smooth Quadrotor Trajectories using Receding Corridors. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 6332–6339. [Google Scholar] [CrossRef]
- Ahmad, S.; Sunberg, Z.N.; Humbert, J.S. End-to-End Probabilistic Depth Perception and 3D Obstacle Avoidance using POMDP. J. Intell. Robot. Syst. 2021, 103, 33. [Google Scholar] [CrossRef]
- Amini, A.; Paull, L.; Balch, T.; Karaman, S.; Rus, D. Learning Steering Bounds for Parallel Autonomous Systems. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 4717–4724. [Google Scholar] [CrossRef]
- Watson, J.; Firman, M.; Monszpart, A.; Brostow, G.J. Footprints and Free Space From a Single Color Image. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11–20. [Google Scholar] [CrossRef]
- Tsutsui, S.; Kerola, T.; Saito, S.; Crandall, D.J. Minimizing Supervision for Free-Space Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1101–1109. [Google Scholar] [CrossRef]
- Shao, M.E.; Haq, M.A.; Gao, D.Q.; Chondro, P.; Ruan, S.J. Semantic Segmentation for Free Space and Lane Based on Grid-Based Interest Point Detection. IEEE Trans. Intell. Transp. Syst. 2022, 23, 8498–8512. [Google Scholar] [CrossRef]
- Messiou, C.; Fusaro, D.; Beraldo, G.; Tonin, L. Real-Time Free Space Semantic Segmentation for Detection of Traversable Space for an Intelligent Wheelchair. In Proceedings of the IEEE International Conference on Rehabilitation Robotics, Rotterdam, The Netherlands, 25–29 July 2022. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Fabio, C.; Ira, C. Risks of Semi-Supervised Learning: How Unlabeled Data Can Degrade Performance of Generative Classifiers. In Semi-Supervised Learning; MIT Press: Cambridge, UK, 2006; pp. 56–72. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022. [Google Scholar] [CrossRef]
- Nguyen, T.B.; Nguyen, L.; Choudhury, T.; Keogh, K.; Murshed, M. Depth-based Sampling and Steering Constraints for Memoryless Local Planners. arXiv 2022. [Google Scholar] [CrossRef]
- Song, Y.; Kaufmann, E.; Bauersfeld, L.; Loquercio, A.; Scaramuzza, D. ICRA 2022 DodgeDrone Challenge: Vision-Based Agile Drone Flight. Github Online Repository. Available online: https://uzh-rpg.github.io/icra2022-dodgedrone/ (accessed on 1 June 2023).
- Michael, N.; Mellinger, D.; Lindsey, Q.; Kumar, V. The GRASP multiple micro-UAV testbed. IEEE Robot. Autom. Mag. 2010, 17, 56–65. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Platform | SFC Generator | Overall IoU | Number of SFCs Generated per Frame | Average Planning Time | Average Direction Reward |
|---|---|---|---|---|---|
| Xavier NX | Exhaustive inflating | 42.27% | 16.53 | 78.16 ms | 0.97 |
| Proposed FSD | 1.35% | 5.88 | 26.73 ms | 0.97 | |
| i7 laptop | Exhaustive inflating | 51.78% | 56 | 4.05 ms | 0.97 |
| Proposed FSD | 1.35% | 5.88 | 0.44 ms | 0.97 |
| Success Rate | Average Flight Time | |
|---|---|---|
| Easy | 99.9% | 23.8 s |
| Medium | 99.8% | 22.8 s |
| Hard | 99.6% | 23.9 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.B.; Murshed, M.; Choudhury, T.; Keogh, K.; Kahandawa Appuhamillage, G.; Nguyen, L. A Depth-Based Hybrid Approach for Safe Flight Corridor Generation in Memoryless Planning. Sensors 2023, 23, 7206. https://doi.org/10.3390/s23167206
Nguyen TB, Murshed M, Choudhury T, Keogh K, Kahandawa Appuhamillage G, Nguyen L. A Depth-Based Hybrid Approach for Safe Flight Corridor Generation in Memoryless Planning. Sensors. 2023; 23(16):7206. https://doi.org/10.3390/s23167206
Chicago/Turabian StyleNguyen, Thai Binh, Manzur Murshed, Tanveer Choudhury, Kathleen Keogh, Gayan Kahandawa Appuhamillage, and Linh Nguyen. 2023. "A Depth-Based Hybrid Approach for Safe Flight Corridor Generation in Memoryless Planning" Sensors 23, no. 16: 7206. https://doi.org/10.3390/s23167206
APA StyleNguyen, T. B., Murshed, M., Choudhury, T., Keogh, K., Kahandawa Appuhamillage, G., & Nguyen, L. (2023). A Depth-Based Hybrid Approach for Safe Flight Corridor Generation in Memoryless Planning. Sensors, 23(16), 7206. https://doi.org/10.3390/s23167206