1. Introduction
Animal behaviour can provide a reliable and non-invasive indication of animal health and welfare. In domestic cats (
Felis catus), behavioural changes can indicate the presence of illness, pain, or distress [
1]. Behavioural monitoring of pet cats is often carried out by their owner(s). However, owner observation is subjective, and they cannot monitor their pets continuously, and they may therefore miss early and subtle signs of illness. This is exacerbated by the fact that changes in behaviour in response to illness and/or pain can often be subtle and well disguised by the cat [
1]. In addition, any behavioural research trial using traditional methods, scoring behaviour manually either directly or from video recordings, is labour-intensive. Accelerometers are a promising tool to help continuously monitor the behaviour of animals, including domestic cats.
To date, few studies in domestic cats have used accelerometer data from non-commercial triaxial accelerometers to distinguish between or identify specific behaviours [
2,
3]. Accelerometers can measure body movement in terms of acceleration in one to three orthogonal planes: craniocaudal (surge; forwards/backwards), mediolateral (sway; left/right), and dorsoventral (up/down) [
4]. Measuring these accelerations in multiple directions allows detection of both dynamic (motion) and static (gravity) accelerations [
4,
5]. Watanabe et al. [
3] were able to successfully distinguish drinking (100% accuracy), eating (68% accuracy), trotting (78% accuracy), and galloping (71% accuracy) in a single domestic cat using only acceleration data along the craniocaudal plane (forwards/backwards). Galea et al. [
2] successfully built two identifying models for twelve different behaviours from triaxial acceleration data from ten domestic cats, using random forest (RF) and self-organizing maps (SOM).
The location of the accelerometer on the animal is an important factor to consider. Aspects to consider when determining the attachment site include the animal species, potential effects of attachment site on behaviour, behaviours that are of interest in the study, and rigidity of the attachment of the accelerometer on a site [
4,
6]. For example, an accelerometer attached to the back of an animal is less likely to register fine-scale head movements involved in eating behaviour which may be detectable by a collar-mounted accelerometer [
4]. In domestic cats, the most commonly used site of accelerometer attachment is a collar with the device positioned ventrally. Attachment to a collar, however, can result in rotation of the accelerometer and residual movement (i.e., movement of the device after the physical movement stops) which is dependent on the looseness of the collar, weight of the accelerometer, and the animal’s behaviour [
4,
6]. A greater model accuracy was found in dogs for accelerometers attached to a harness than a collar [
7]. It is therefore important to identify behaviours of interest before determining the accelerometer placement location.
To be able to identify behaviours using accelerometer data, machine learning (ML) techniques are often used to build classifier models. Depending on the dataset, some ML techniques might be a better fit than others. Nathan et al. [
8] reported that the random forest (RF) ML technique had the highest accuracies for identifying behaviour of free ranging griffon vultures from accelerometer data. In that study, the accuracies of five frequently used supervised ML techniques were compared: linear discriminant analysis (LDA), support vector machines (SVM), classification and regression trees (CART), random forests (RF), and an artificial neural network (ANN) [
8]. Galea et al. [
2] compared SOM with RF and found that SOM had a higher overall accuracy than RF (99.6% vs. 98.9%, respectively) for behaviour classification of domestic cats wearing a harness-mounted accelerometer.
In the present study, commercially available accelerometers were attached to domestic cats on both a collar and a harness, to capture movement data needed to build behaviour identifier models. The aim of the current study was to compare model performance between the two sites of attachment, (collar and harness) and two machine learning techniques (RF and supervised SOM). It was hypothesised that both RF and SOM models of harness-mounted accelerometer data would have better overall performance, or ability to identify behaviour, when compared with models of the collar-mounted accelerometer, due to the greater rigidity of the harness-mounted accelerometer reducing the risk of individual and residual device movement. However, given that the collar-mounted accelerometer was expected to be more likely to detect finer-scale head movements, it was expected that the model of the collar-mounted accelerometer would have higher accuracy in detecting eating behaviour than harness-mounted accelerometer models. Furthermore, as the SOM model had higher overall performance compared with the RF model in the study by Galea et al. [
2], it was also hypothesised that in the current study SOM models would have higher overall performance compared with the RF model.
4. Discussion
The current study aimed to build a model to identify cat behaviour using accelerometer data. Generally, the more classes that were included in a model, the lower the accuracy of it. In the current study, the models for three behavioural classes (active, inactive, and maintenance) had the highest accuracy (
Table 3). In the current study, similar behaviours that were often misclassified were merged (e.g., trotting and walking) or removed from the model (e.g., digging). This reduction of behaviour classes lowers the risk of misclassification, resulting in fewer false positives and false negatives, thereby increasing the accuracy. Similar results were found in a study on cheetahs (
Acinonyx jubatus), where merging of similar behaviours resulted in models with higher accuracy [
13]. Another study, modelling behaviour using accelerometer data of oystercatchers (
Haematopus ostralegus), found that a model with three behaviour classes had a lower absolute cross-validation error than a model with eight behaviour classes [
26]. These results show that there is a trade-off between a more representative model, including more behaviours, and accuracy. Despite decreasing accuracy with increasing classes, all models in the current study had an accuracy ≥0.70.
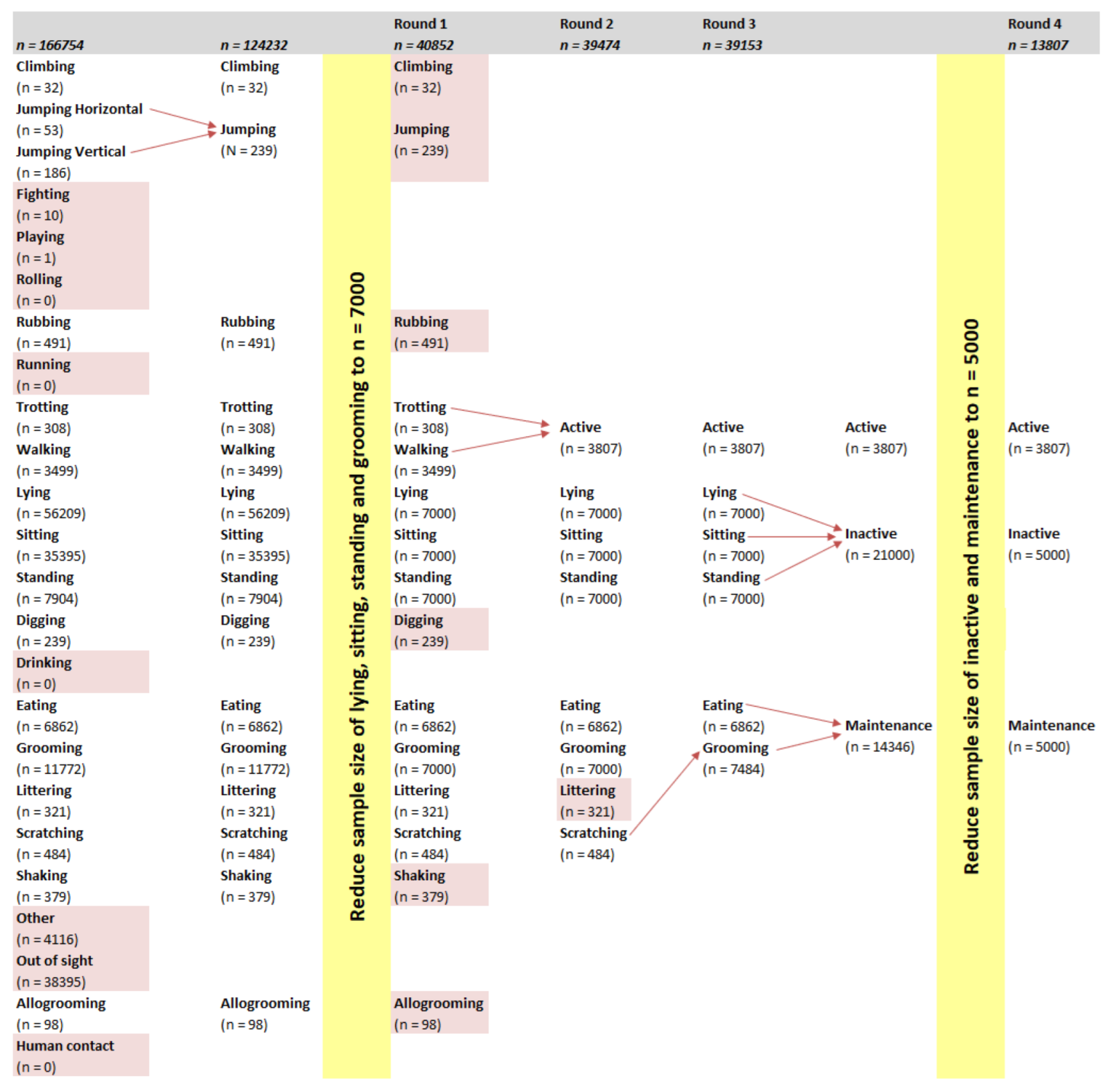
Two modelling techniques, RF and SOM, and two mounting locations, collar and harness, were compared. Early models (data not shown) were able to identify behaviours that had relatively large sample sizes (e.g., lying), but had difficulty with behaviours with a sample size lower than 500 (e.g., climbing). In order to balance the dataset from which the models were built, behaviours with a large sample size were limited to 7000 datapoints. Despite this limit, the models from the first round of modelling had difficulty identifying behaviours with a low sample size such as climbing (n = 32), jumping (n = 239), and trotting (n = 308). Galea et al. [
2] reported that SOM models of behaviours with a sample size less than 2000 datapoints had lower accuracy, sensitivity, and precision compared with behaviours with a sample size larger than 2000. Low sample sizes were the result of a behaviour being displayed infrequently.
In the current study, most behaviours with low sensitivity and precision were those that consisted of swift movements and/or behaviours of short duration (<one second). This is in agreement with [
27] who reported that models of data derived from collar-mounted accelerometers attached to captive dingoes (
Canis lupus dingo) had more difficulty identifying active behaviours consisting of swift movements performed over a short period of time. Capturing swift and short duration movements is a challenge especially encountered in small animal species, as movements are generally quicker than in larger animals [
4]. A study using data from accelerometers attached to chipmunks (
Tamias), a small-bodied animal (<100 g), found the lowest sampling frequency that resulted in negligible decrease in accuracy was 20 Hz [
28]. In the current study, jumping was often misidentified as walking, a behaviour that was often observed and identified immediately before and after the jump. In the current study, the shortest lasting behaviour (jumping) lasted for an average of 0.89 s (results not shown). Accelerometer data were collected at 30 Hz and summarised into one-second epochs, which could have led to the acceleration signature of very short-lasting behaviours being lost in the signature of the behaviour immediately before or after they occurred. Choosing an epoch length that resembled the length of these shorter behaviours might help in the ability of models to identify them more accurately. In addition, a shorter epoch could also increase the sample size of infrequent behaviours. While a smaller epoch length can increase the sample size, it will increase the computational time to train and test the models [
27]. In the current study, the total number of observations (
Appendix A) for each short-lasting behaviour was very close to the total amount of time it was observed in the video recordings. A one-second epoch is therefore thought to be small enough when considering the behaviours included in the current study.
It was hypothesised that the harness-mounted accelerometer would have better performance values compared with the collar. There was little difference in Kappa and overall accuracy between the CSOM and HSOM models within each modelling round. However, the majority of the RF models had higher performance values when data from devices attached to a harness were compared with the collar. These results are in agreement with a study with domestic dogs, where harness-mounted accelerometers resulted in models where accuracy was higher (87–91%) than collar-mounted accelerometers (69–76%) [
7]. One of the reasons cited for the higher accuracy of harness-mounted accelerometers compared with collar-mounted ones was the firmer attachment the harness provided for the device [
7]. Collar attachment, in contrast, resulted in changes in device orientation and residual movement [
7]. For cats, it is challenging to obtain a firmer device attachment with a collar, as securing the collar tightly might result in discomfort or injury [
29]. Despite the harness models generally having better performance compared with the collar models when considering the RF modelling technique, the collar and harness models identified similar percentages of each behaviour within each behavioural round (
Table 4,
Table 5,
Table 6 and
Table 7).
In the current study, it was hypothesised that the models from the collar-mounted accelerometers would be better for identifying more subtle behaviours such as eating and drinking, as these behaviours are associated with head movement rather than body movement. While drinking and eating behaviours have been successfully distinguished using data from only one axis of an accelerometer attached to a collar on a single domestic cat [
3], different attachment methods (harness vs. collar) have not been compared for these fine-scale behaviours in domestic cats. In the current study, the differences in performance values between the CSOM and HSOM models were very small, on average <1%. For the RF models, however, the performance values of the harness model for eating behaviour were always higher than those of the RF collar models. This could be the result of the design of the feeding area in the colony cages (
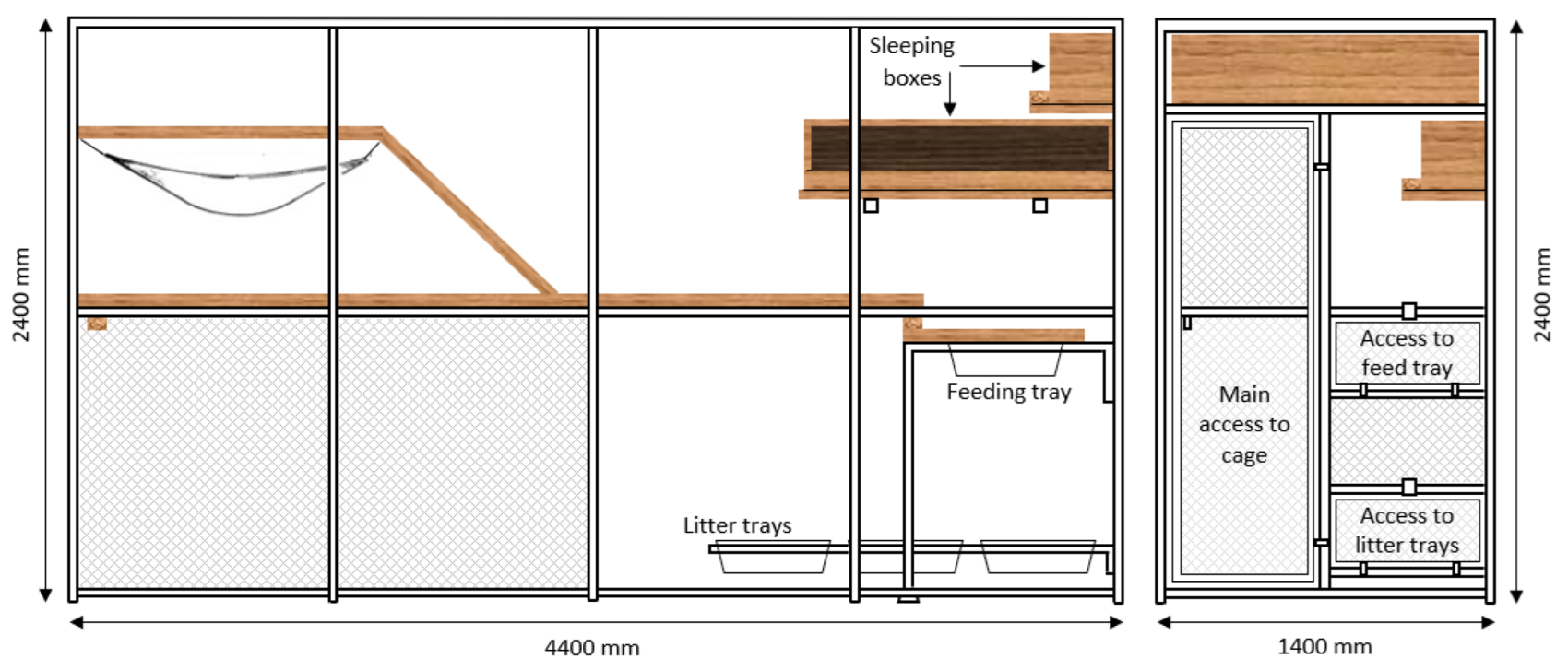
Figure 1). Cats were often observed to place their front paws in the feeding tray, while their hind paws remained on the wooden walkway surrounding the feeding tray, resulting in a forward tilted posture where the head and shoulders were lower than their hips. This change in posture during eating is likely to have resulted in a greater change in the orientation of the harness-mounted accelerometer compared with the collar [
7]. In a home situation it would be expected that food bowls would be on the ground or slightly elevated and thus will not result in the cat being tilted forward [
30,
31].
As hypothesised, in the current study the SOM models had higher Kappa and overall accuracy values compared with the RF models. These results are in agreement with previous findings reported on domestic cats by [
2], where the SOM model had a mean accuracy of 99.6%, compared with the RF model of 98.9%. The mean accuracy of the RF model as reported by [
2] was higher than the overall accuracy reported in the current study (70–83%). It should be noted, however, that mean accuracy and overall accuracy were calculated differently, and cannot therefore be directly compared.
In addition to Kappa and overall accuracy to determine model performance, the current study further evaluated the performance of the models. To date, rather than using models on a new dataset and then comparing the results, the ability of models to identify behaviours has been based on performance results, such as measures of accuracy [
8,
27]. In the current study, all models were used to identify the behaviour of the same 12 domestic cats, using accelerometer data that were not used in the training and testing of the model. The results showed that the identified behaviours, expressed as a percentage of total behaviour, were identified more consistently with the RF models between mounting locations and across modelling rounds than the SOM models.
A possible explanation for the seemingly poorer performance of the SOM models when presented with a new dataset is overfitting. Overfitting occurs when a model fits the training data so well, it memorises noise in the dataset, leading to a model that does not perform well on a new dataset [
32]. There are different reasons why overfitting might occur, including a dataset that is too small and/or the presence of too many predictor variables, making the model overcomplicated [
32,
33]. Galea et al. [
2] tested how the accuracy of the SOM changed with different sample sizes for the training dataset and reported that the accuracy of the SOM plateaued after 20,000 samples. With the exception of the fourth modelling round, the training dataset (70%) contained more than 20,000 samples, making the size of the dataset sufficient according to results reported by [
2]. Since the sample size of the current study was probably sufficient, the most likely explanation for the overfitting of the SOM models is overcomplication of the models due to many predictor variables. Overfitting due to too many predictor variables can be avoided by either selecting fewer predictor variables, or by increasing the sample size [
32]. The predictor variables included in the current study were based on the 26 predictor variables identified as most effective by [
27] and the 31 used by [
2]. The SOM models were simplified to as few as four predictor variables (mean for X, Y and Z, and ODBA), but this did not improve the results (results not shown).
A supervised SOM is a type of artificial neural network that consists of an input layer, a single hidden layer, and an output layer in the form of a grid map consisting of neurons [
34]. There is a neighbourhood relationship between the neurons on the output grid map [
34]. The neurons of the hidden layer are connected to the samples in the input layer through weights, and weights are updated with each iteration [
35]. Due to the neighbourhood relationship between neurons, changes in the weight of one neuron will affect other neurons in its neighbourhood [
34]. Allende et al. [
36] reported that SOMs are sensitive to outliers because of how the changing weight of one neuron affects the neighbouring neurons. It is reasonable to expect outliers in behavioural datasets, as behaviour can be very dynamic. A cat sitting, for example, can sit completely stationary, but it might suddenly turn its head back when it hears a noise, triggering the accelerometer due to the movement. In both cases, the cat is identified simply as sitting but will result in different accelerometer traces where one might be identified as an outlier. It is possible that the outliers of the dataset not used to build the model included outliers that were different than those contained in the training dataset. This could have led to the SOM being able to identify behaviours in the training dataset with high accuracy but having problems with identifying behaviours in a novel dataset. The SOM models could possibly be improved by distinguishing more subtle differences in behaviour and posture, e.g., separately annotating sitting completely stationary and moving the head around while sitting. It was decided not to re-watch the video recordings to separately identify more subtle differences within a single behaviour, as scoring behaviour is very labour-intensive, and the results show that the RF models identify behaviours consistently across mounting locations and are the best fit for the dataset generated in this study.
Literature on the activity budget of domestic cats is limited and results cannot be compared directly due to differences in housing conditions, behaviours, and sampling method. Despite these differences, the time domestic cats spent on eating behaviours was surprisingly consistent, with daily time spent eating being approximately 2–3% [
37,
38,
39,
40]. The RF models showed that in the current study cats spent between ~3% and ~4% of their time eating, whereas this ranged between ~13% and ~28% when identified with the SOM models. Not only did the RF models identify behaviour more consistently between mounting locations, but they also identified eating behaviour with a similar percentage as reported in the literature. This further supports the choice of RF models for the dataset generated in the current study.
The present study provided an insight into the activity budgets of colony-housed cats. Irrespective of modelling technique used or mounting location, cats spent the majority of their time inactive. The RF models identified that inactive behaviours accounted for between ~83% and ~86% of all behaviours. This was greater than the ~62% observed in farm cats [
40], but comparable to that observed in privately owned cats (~84%) [
39]. The difference in the percentage of inactive behaviours between these studies is probably due to the farm cats having the ability to roam around the farm and hunt for prey, whereas the cats in the current study had limited opportunity to roam and had a consistent
ad libitum food source. Panaman [
40] reported that four of the five farm cats were active hunters, which resulted in active behaviours (hunting and travelling) being observed for ~18% of their day, whereas the colony-housed cats were active (walking, trotting) for only ~3–5% of their time when the RF models were used.


 ,
, 



{kind=link}
{kind=link}
{kind=link}