
A Bio-Inspired Chaos Sensor Model Based on the Perceptron Neural Network: Machine Learning Concept and Application for Computational Neuro-Science





Abstract
1. Introduction
- Optimal FuzzyEn parameters were determined, allowing to reach maximum sensitivity of the chaos sensor for SFU and SPE models;
- Time series datasets for training and testing the perceptron model based on the Hindmarsh–Rose spike model and FuzzyEn were created.
- A bio-inspired model of a chaos sensor based on a multilayer perceptron, approximating FuzzyEn, is proposed.
- The proposed perceptron model with 1 neuron in the hidden layer reaches high degree of similarity between SFU and SPE models with an accuracy in the range R2~0.5 ÷ 0.8, depending on the combination of datasets.
- The proposed perceptron model with 50 neurons in the hidden layer reaches an extremely high degree of similarity between SFU and SPE models with an accuracy of R2~0.9.
- An example of using the chaos sensor on spike train of action potentials recordings from the L5 dorsal rootlet of rat is given.
2. Materials and Methods
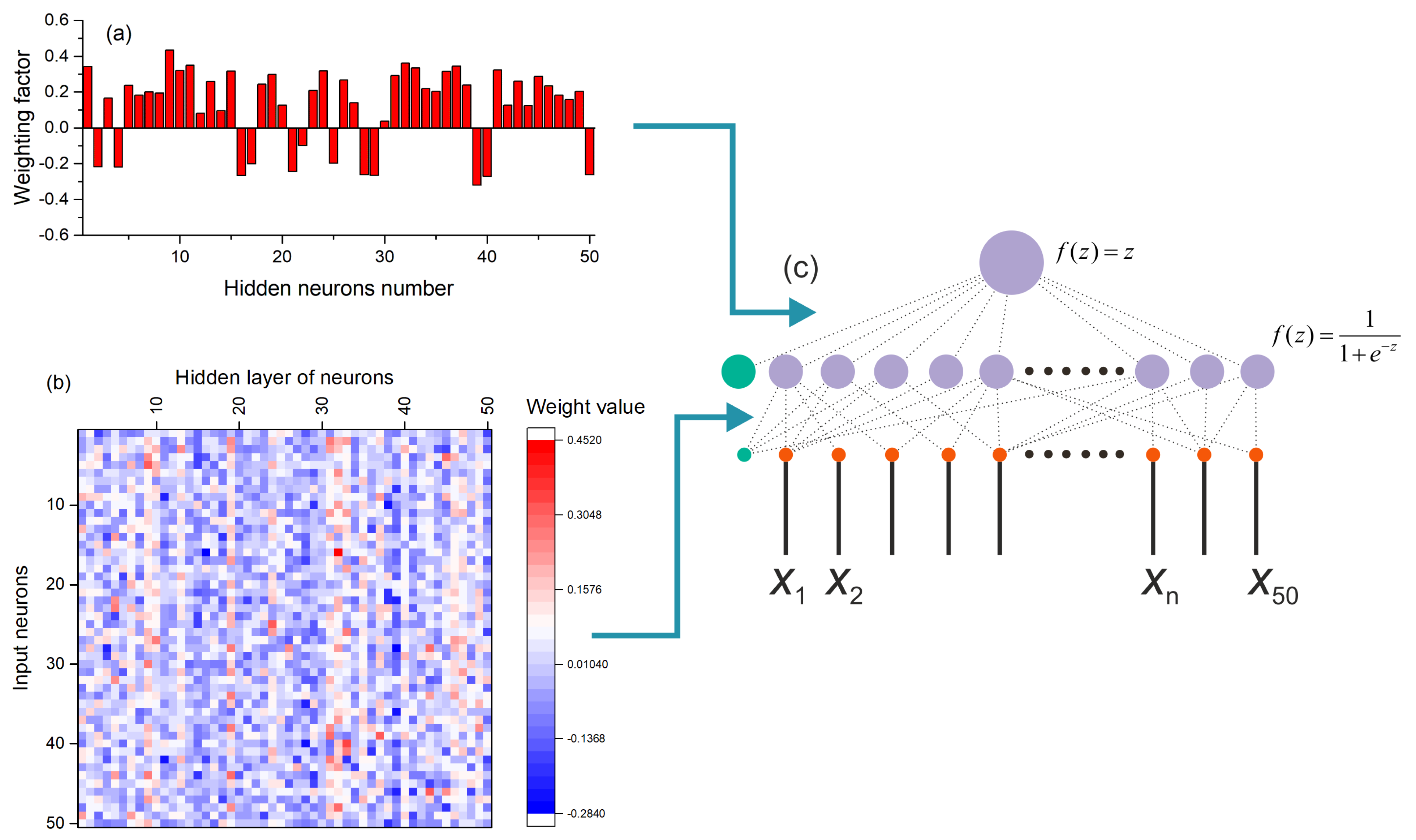
2.1. Multilayer Perceptron Neural Network Model
2.2. Modeling the Hindmarsh-Rose System
2.3. Method for Generating Time Series of Various Lengths
2.4. Datasets for Training and Testing the Perceptron Using HR System
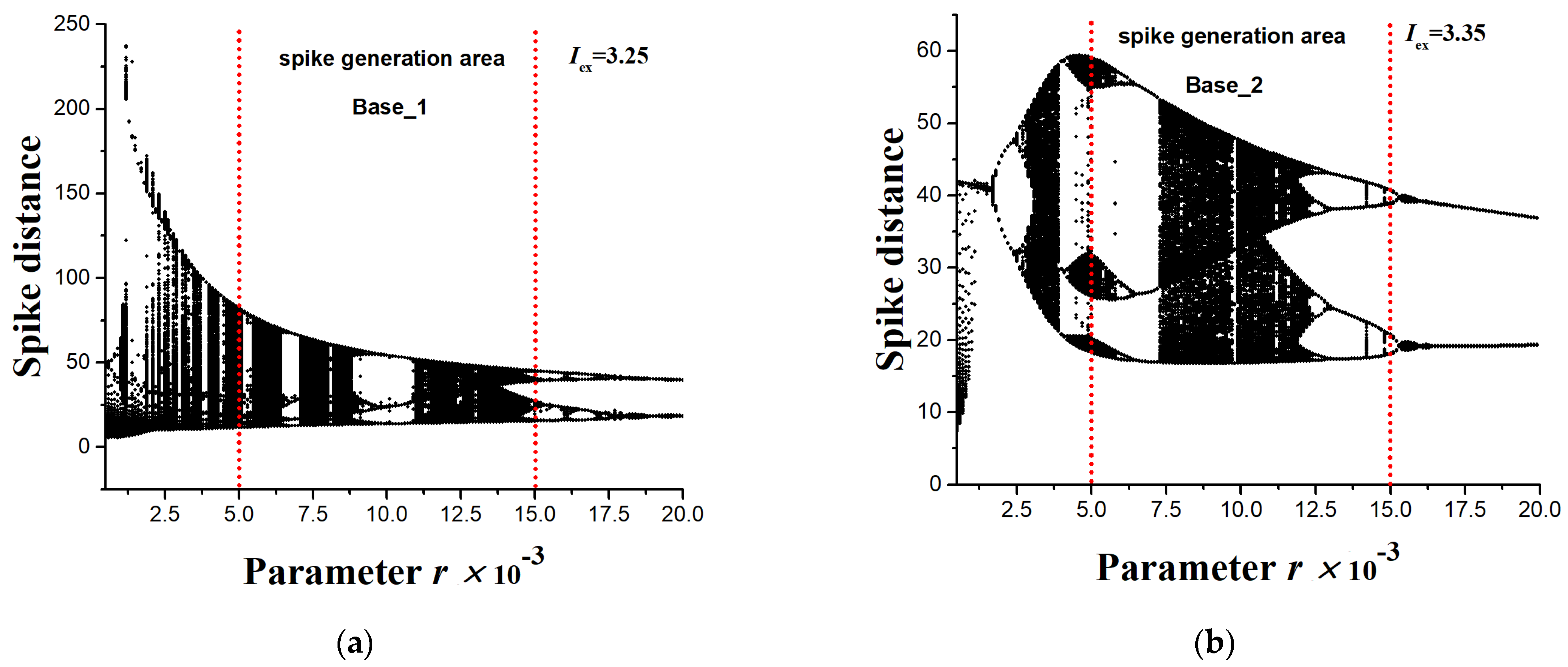
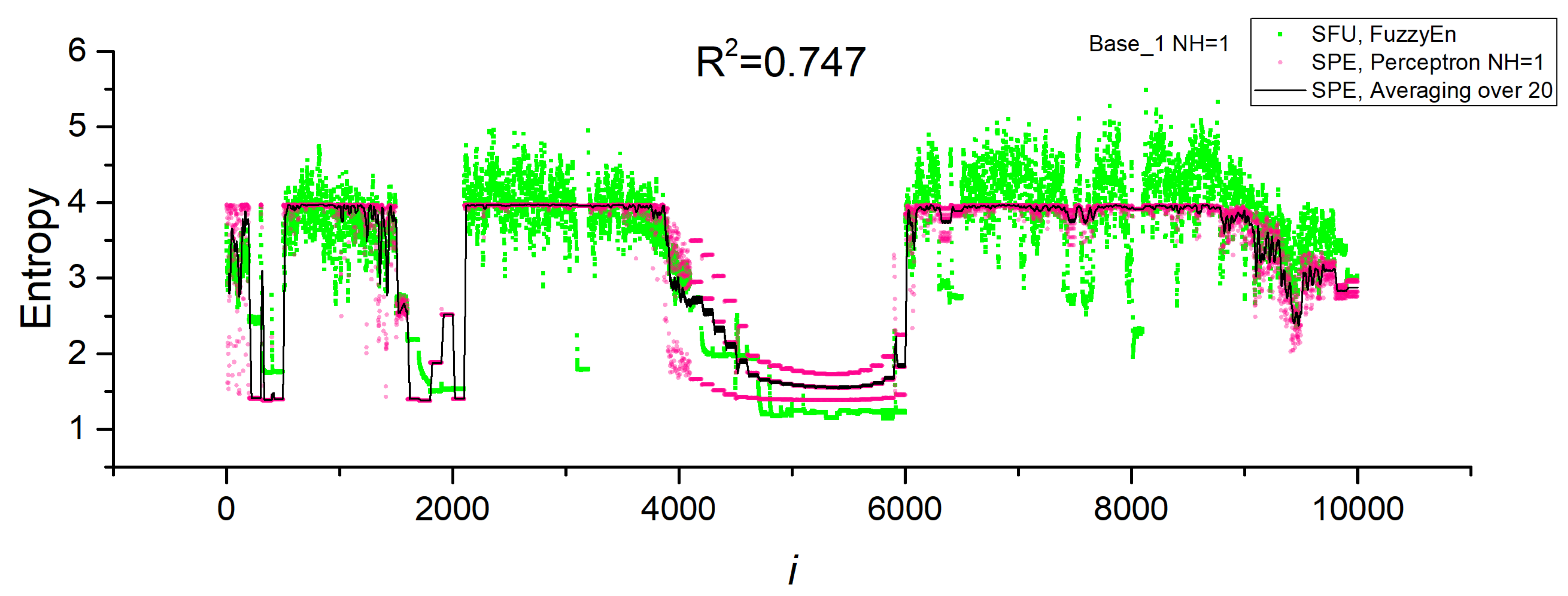
- The Base_1 dataset consisted of 10,000 time series with a length of NL = 50, which were obtained by modeling the HR system with Iex = 3.25 (Figure 4a). The range of r was {5 × 10−3 ÷ 1.5 × 10−2} and it was divided into 100 values. One-hundred short time series for each r were generated according to the algorithm from Section 2.3. The target value of the entropy of all series was estimated through FuzzyEn using the method from Section 2.6.
- The Base_2 dataset consisted of 10,000 time series with a length of NL = 50, which were obtained by modeling the HR system with Iex = 3.35 (Figure 4a). The range of r was {5 × 10−3 ÷ 1.5 × 10−2} and it was divided into 100 values. The generation of 100 short time series for each r was performed according to the algorithm from Section 2.3. The target value of the entropy of all series was estimated through FuzzyEn using the method from Section 2.6.
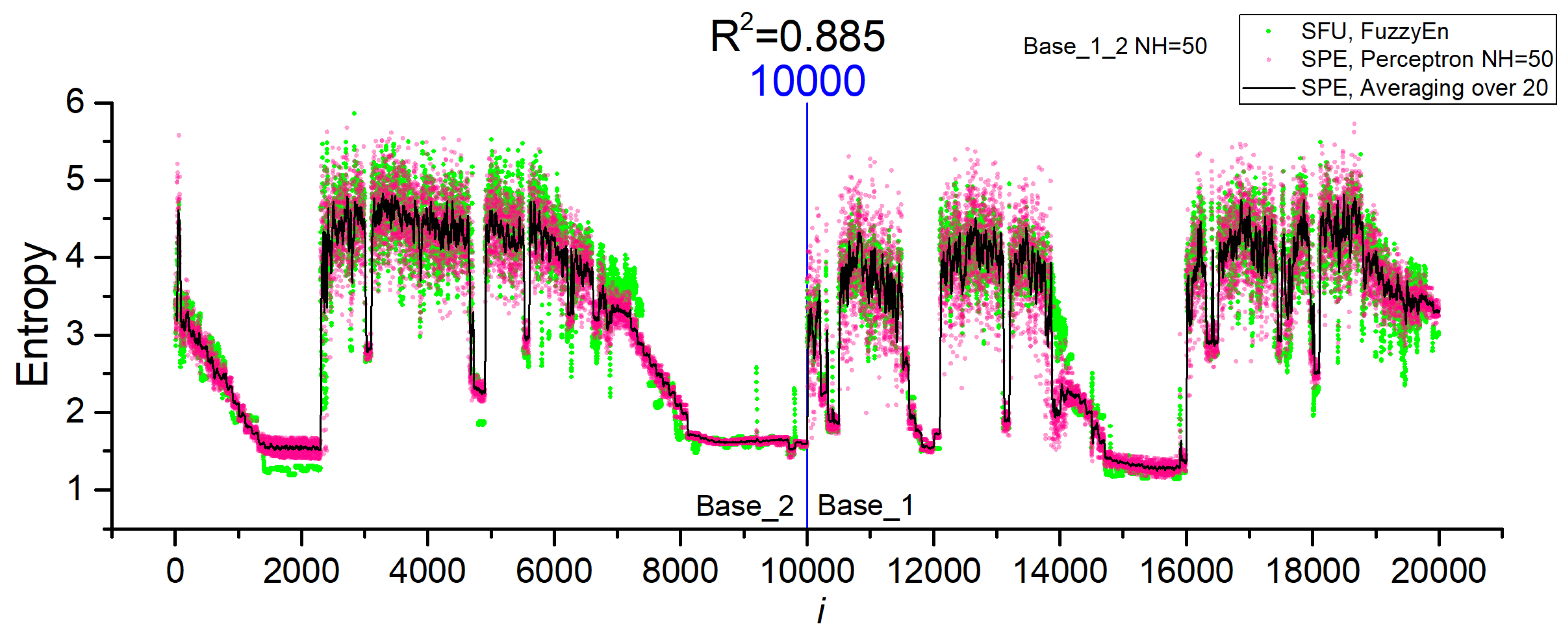
- Dataset Base_1_2 was a combination of Base_1 and Base_2.
2.5. Datasets for Training and Testing the Perceptron Using Experimental Data
2.6. Entropy Calculation Method
2.7. Perceptron Training and Testing Method
2.8. Sensor Characteristics
- Enav(chaos): average value of entropy over five chaotic series, at r = 0.0056, 0.0076, 0.0082, 0.0119, 0.0141 in HR model; Averaging within each series was performed over 100 short series.
- Enav(order): average entropy value over five regular series, at r = 0.0068, 0.0070, 0.0099, 0.0105, 0.0108 in HR model; Averaging within each series was performed over 100 short series.
- EnR = Enav(chaos) − Enav(order): range of entropy change at the output of the sensor.
- Std_En(chaos): entropy mean square deviation over five chaotic series;
- Std_En(order): entropy mean square deviation over five regular series;
- EnSens = EnR/Std_En(chaos): chaos sensor sensitivity.
- EnErr = (Std_En(chaos)/EnR) × 100%: relative entropy measurement error in percent.
3. Results
3.1. Dependence of Sensor Characteristics on the Series Length in the SFU Model
3.2. Results of Entropy Approximation in Perceptron SPE Model
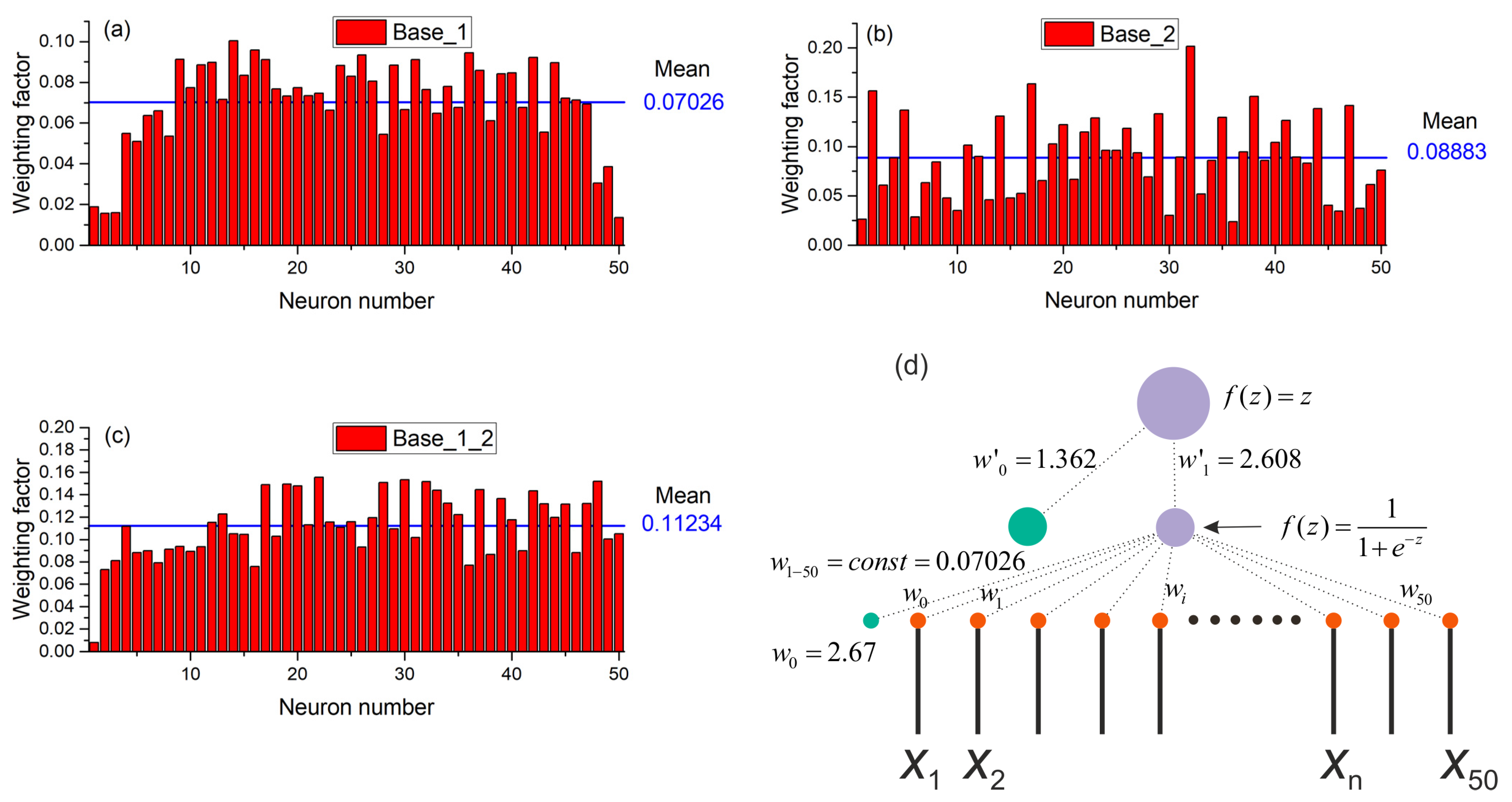
3.3. Operating Principles of the Perspectron Sensor Model
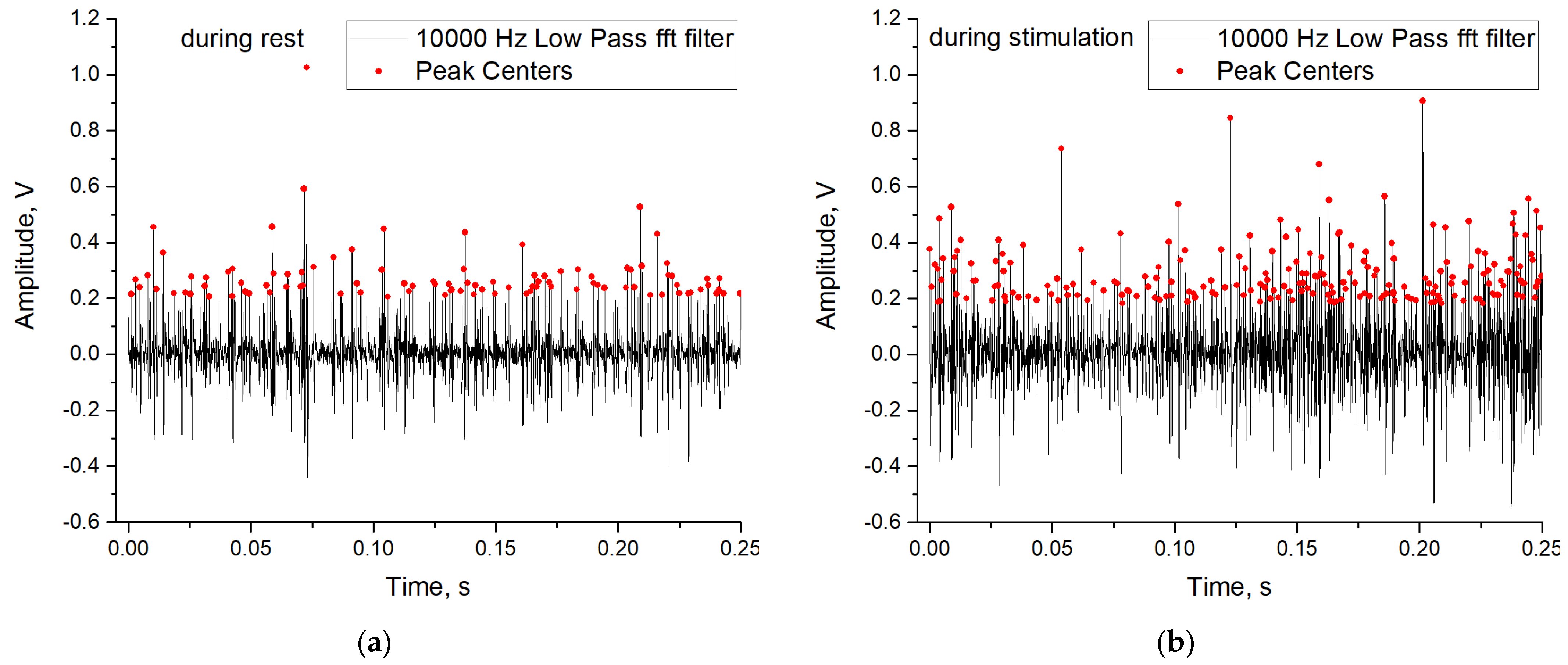
3.4. The Results of Training the Perceptron Sensor of Chaos on Experimental Data
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ANN | artificial neural network; |
| CNS | central (cortical) nervous system; |
| ECG | electrocardiography; |
| EEG | electroencephalography; |
| Enav | average value of entropy; |
| EnErr | relative entropy measurement error; |
| EnR | range of entropy change; |
| EnSens | chaos sensor sensitivity; |
| FuzzyEn | fuzzy entropy; |
| HR | Hindmarsh-Rose; |
| Mean | average value for all elements of the time series in the dataset; |
| Mean50_max | maximum value of the average value of the time series; |
| Mean50_min | minimum value of the average value of the time series; |
| Max_X | maximum value of all elements in the dataset; |
| Min_X | minimum value of all elements in the dataset; |
| MLP | Multilayer perceptrons; |
| ML | machine learning; |
| NH | number of neurons in the hidden layer; |
| NL | number of elements of the time series; |
| NNetEn | Neural Network Entropy; |
| PermEn | permutation entropy; |
| SampEn | sample entropy; |
| SPE | Sensor on Perceptron; |
| SFU | Sensor on fuzzy entropy; |
| Std_En | entropy mean square deviation; |
| SvdEn | singular value decomposition entropy. |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Neurons in the Hidden Layer, NH | Cross-Validation Accuracy, RMSE | Approximation Accuracy When Training on One Set and Testing on Another Set, RMSE | |||
|---|---|---|---|---|---|
| Base_1 | Base_2 | Base_1_2 | Base_1-Training Base_2-Testing | Base_1-Testing Base_2-Training | |
| 1 | 1.12 | 1.25 | 1.2 | 1.27 | 1.14 |
| 50 | 0.462 | 0.452 | 0.52 | 1.25 | 1.16 |
| 150 | 0.434 | 0.426 | 0.473 | 1.16 | 1.51 |
| Number of Neurons in the Hidden Layer, NH | Cross-Validation Accuracy, MAPE (%) | Approximation Accuracy When Training on One Set and Testing on Another Set, MAPE (%) | |||
|---|---|---|---|---|---|
| Base_1 | Base_2 | Base_1_2 | Base_1-Training Base_2-Testing | Base_1-Testing Base_2-Training | |
| 1 | 43.9 | 48.5 | 46.9 | 52.2 | 43.1 |
| 50 | 11.7 | 11 | 14.8 | 51.3 | 38.1 |
| 150 | 10.8 | 10.9 | 12.4 | 44 | 52.3 |
| Number of Neurons in The Hidden Layer, NH | Cross-Validation Accuracy, RMSE | Approximation Accuracy When Training on One Set and Testing on Another Set, RMSE | |||
|---|---|---|---|---|---|
| Base_1 | Base_2 | Base_1_2 | Base_1-Training Base_2-Testing | Base_1-Testing Base_2-Training | |
| 1 | 0.486 | 0.788 | 0.85 | 1.18 | 0.914 |
| 50 | 0.351 | 0.335 | 0.4 | 1.38 | 0.654 |
| 150 | 0.331 | 0.321 | 0.388 | 1.6 | 0.732 |
| Number of Neurons in the Hidden Layer, NH | Cross-Validation Accuracy, MAPE (%) | Approximation Accuracy When Training on One Set and Testing on Another Set, MAPE (%) | |||
|---|---|---|---|---|---|
| Base_1 | Base_2 | Base_1_2 | Base_1-Training Base_2-Testing | Base_1-Testing Base_2-Training | |
| 1 | 13.5 | 22.3 | 26.7 | 42.6 | 28 |
| 50 | 8.4 | 7.1 | 9.9 | 48.6 | 19.5 |
| 150 | 8.1 | 7 | 9.3 | 55.9 | 21 |
References
- Hänggi, P. Stochastic Resonance in Biology: How Noise Can Enhance Detection of Weak Signals and Help Improve Biological Information Processing. ChemPhysChem 2002, 3, 285–290. [Google Scholar] [CrossRef] [PubMed]
- McDonnell, M.D.; Ward, L.M. The Benefits of Noise in Neural Systems: Bridging Theory and Experiment. Nat. Rev. Neurosci. 2011, 12, 415–425. [Google Scholar] [CrossRef]
- Takahashi, T. Complexity of Spontaneous Brain Activity in Mental Disorders. Prog. Neuro-Psychopharmacol. Biol. Psychiatry 2013, 45, 258–266. [Google Scholar] [CrossRef] [PubMed]
- Vd Groen, O.; Tang, M.; Wenderoth, N.; Mattingley, J. Stochastic Resonance Enhances the Rate of Evidence Accumulation during Combined Brain Stimulation and Perceptual Decision-Making. PLOS Comput. Biol. 2018, 14, e1006301. [Google Scholar] [CrossRef]
- Freeman, W.J. Simulation of Chaotic EEG Patterns with a Dynamic Model of the Olfactory System. Biol. Cybern. 1987, 56, 139–150. [Google Scholar] [CrossRef]
- Moss, F.; Ward, L.M.; Sannita, W.G. Stochastic Resonance and Sensory Information Processing: A Tutorial and Review of Application. Clin. Neurophysiol. 2004, 115, 267–281. [Google Scholar] [CrossRef] [PubMed]
- Garrett, D.; Samanez-Larkin, G.; MacDonald, S.; Lindenberger, U.; McIntosh, A.; Grady, C. Moment-to-Moment Brain Signal Variability: A next Frontier in Human Brain Mapping? Neurosci. Biobehav. Rev. 2013, 37, 610–624. [Google Scholar] [CrossRef]
- Hindmarsh, J.; Rose, R. A Model of Neuronal Bursting Using Three Coupled First Order Differential Equations. Proc. R. Soc. Lond. B. Biol. Sci. 1984, 221, 87–102. [Google Scholar] [CrossRef]
- Malik, S.A.; Mir, A.H. Synchronization of Hindmarsh Rose Neurons. Neural Netw. 2020, 123, 372–380. [Google Scholar] [CrossRef]
- Shilnikov, A.; Kolomiets, M. Methods of the Qualitative Theory for the Hindmarsh-Rose Model: A Case Study—A Tutorial. I. J. Bifurc. Chaos 2008, 18, 2141–2168. [Google Scholar] [CrossRef]
- Kumar, A. Chaos Theory: Impact on and Aplication Medicine. J. Health Allied Sci. NU 2012, 2, 93–99. [Google Scholar] [CrossRef]
- Pappalettera, C.; Miraglia, F.; Cotelli, M.; Rossini, P.M.; Vecchio, F. Analysis of Complexity in the EEG Activity of Parkinson’s Disease Patients by Means of Approximate Entropy. GeroScience 2022, 44, 1599–1607. [Google Scholar] [CrossRef] [PubMed]
- Morabito, F.C.; Labate, D.; La Foresta, F.; Bramanti, A.; Morabito, G.; Palamara, I. Multivariate Multi-Scale Permutation Entropy for Complexity Analysis of Alzheimer’s Disease EEG. Entropy 2012, 14, 1186–1202. [Google Scholar] [CrossRef]
- Acharya, U.R.; Fujita, H.; Sudarshan, V.K.; Bhat, S.; Koh, J.E.W. Application of Entropies for Automated Diagnosis of Epilepsy Using EEG Signals: A Review. Knowl.-Based Syst. 2015, 88, 85–96. [Google Scholar] [CrossRef]
- Xu, X.; Nie, X.; Zhang, J.; Xu, T. Multi-Level Attention Recognition of EEG Based on Feature Selection. Int. J. Environ. Res. Public Health 2023, 20, 3487. [Google Scholar] [CrossRef] [PubMed]
- Stancin, I.; Cifrek, M.; Jovic, A. A Review of EEG Signal Features and Their Application in Driver Drowsiness Detection Systems. Sensors 2021, 21, 3786. [Google Scholar] [CrossRef]
- Richer, R.; Zhao, N.; Amores, J.; Eskofier, B.M.; Paradiso, J.A. Real-Time Mental State Recognition Using a Wearable EEG. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 5495–5498. [Google Scholar] [CrossRef]
- Duan, R.-N.; Zhu, J.-Y.; Lu, B.-L. Differential Entropy Feature for EEG-Based Emotion Classification. In Proceedings of the 2013 6th International IEEE/EMBS Conference on Neural Engineering (NER), San Diego, CA, USA, 6–8 November 2013; pp. 81–84. [Google Scholar] [CrossRef]
- Lu, Y.; Wang, M.; Wu, W.; Han, Y.; Zhang, Q.; Chen, S. Dynamic Entropy-Based Pattern Learning to Identify Emotions from EEG Signals across Individuals. Measurement 2020, 150, 107003. [Google Scholar] [CrossRef]
- Mu, Z.; Hu, J.; Min, J. EEG-Based Person Authentication Using a Fuzzy Entropy-Related Approach with Two Electrodes. Entropy 2016, 18, 432. [Google Scholar] [CrossRef]
- Thomas, K.P.; Vinod, A.P. Biometric Identification of Persons Using Sample Entropy Features of EEG during Rest State. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016; pp. 003487–003492. [Google Scholar] [CrossRef]
- Churchland, P.S.; Sejnowski, T.J. The Computational Brain; MIT Press: Cambridge, MA, USA, 1992; ISBN 0262031884. [Google Scholar]
- Maass, W.; Legenstein, R.; Markram, H.; Bülthoff, H.; Lee, S.-W.; Poggio, T.; Wallraven, C. A New Approach towards Vision Suggested by Biologically Realistic Neural Microcircuit Models. In Proceedings of the Biologically Motivated Computer Vision Second International Workshop (BMCV 2002), Tübingen, Germany, 22–24 November 2002. [Google Scholar] [CrossRef]
- Bahmer, A.; Gupta, D.; Effenberger, F. Modern Artificial Neural Networks: Is Evolution Cleverer? Neural Comput. 2023, 35, 763–806. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; McClelland, J.L. Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Foundations; MIT Press: Cambridge, MA, USA, 1987; ISBN 9780262291408. [Google Scholar]
- Plaut, D.C.; McClelland, J.L.; Seidenberg, M.S.; Patterson, K. Understanding Normal and Impaired Word Reading: Computational Principles in Quasi-Regular Domains. Psychol. Rev. 1996, 103, 56–115. [Google Scholar] [CrossRef]
- Bates, E.; Elman, J.; Johnson, M.; Karmiloff-Smith, A.; Parisi, D.; Plunkett, K. Rethinking Innateness: A Connectionist Perspective on Development; MIT Press: Cambridge, MA, USA, 1996; ISBN 9780262272292. [Google Scholar]
- Marcus, G. The Algebraic Mind: Integrating Connectionism and Cognitive Science; MIT Press: Cambridge, MA, USA, 2001; ISBN 9780262279086. [Google Scholar]
- Rosenblatt, F. The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [PubMed]
- Rumelhart, D.; McClelland, J.L. Learning Internal Representation by Error Propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Foundations; MIT Press: Cambridge, MA, USA, 1987; ISBN 9780262291408. [Google Scholar]
- Valaitis, V.; Luneckas, T.; Luneckas, M.; Udris, D. Minimizing Hexapod Robot Foot Deviations Using Multilayer Perceptron. Int. J. Adv. Robot. Syst. 2015, 12, 182. [Google Scholar] [CrossRef]
- Cazenille, L.; Bredeche, N.; Halloy, J. Evolutionary Optimisation of Neural Network Models for Fish Collective Behaviours in Mixed Groups of Robots and Zebrafis. In Biomimetic and Biohybrid Systems; Vouloutsi, V., Mura, A., Tauber, F., Speck, T., Prescott, T.J., Verschure, P.F.M.J., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 85–96. ISBN 978-3-319-95972-6. [Google Scholar]
- Mano, M.; Capi, G.; Tanaka, N.; Kawahara, S. An Artificial Neural Network Based Robot Controller That Uses Rat’s Brain Signals. Robotics 2013, 2, 54–65. [Google Scholar] [CrossRef]
- Lindner, T.; Wyrwał, D.; Milecki, A. An Autonomous Humanoid Robot Designed to Assist a Human with a Gesture Recognition System. Electronics 2023, 12, 2652. [Google Scholar] [CrossRef]
- Romano, D.; Wahi, A.; Miraglia, M.; Stefanini, C. Development of a Novel Underactuated Robotic Fish with Magnetic Transmission System. Machines 2022, 10, 755. [Google Scholar] [CrossRef]
- López-González, A.; Tejada, J.C.; López-Romero, J. Review and Proposal for a Classification System of Soft Robots Inspired by Animal Morphology. Biomimetics 2023, 8, 192. [Google Scholar] [CrossRef]
- Velichko, A. Neural Network for Low-Memory IoT Devices and MNIST Image Recognition Using Kernels Based on Logistic Map. Electronics 2020, 9, 1432. [Google Scholar] [CrossRef]
- Yang, G.; Zhu, T.; Yang, F.; Cui, L.; Wang, H. Output Feedback Adaptive RISE Control for Uncertain Nonlinear Systems. Asian J. Control 2023, 25, 433–442. [Google Scholar] [CrossRef]
- Yang, G. Asymptotic Tracking with Novel Integral Robust Schemes for Mismatched Uncertain Nonlinear Systems. Int. J. Robust Nonlinear Control 2023, 33, 1988–2002. [Google Scholar] [CrossRef]
- Peron, S.P.; Gabbiani, F. Role of Spike-Frequency Adaptation in Shaping Neuronal Response to Dynamic Stimuli. Biol. Cybern. 2009, 100, 505–520. [Google Scholar] [CrossRef]
- Metcalfe, B.W.; Hunter, A.J.; Graham-Harper-Cater, J.E.; Taylor, J.T. Array Processing of Neural Signals Recorded from the Peripheral Nervous System for the Classification of Action Potentials. J. Neurosci. Methods 2021, 347, 108967. [Google Scholar] [CrossRef] [PubMed]
- Izotov, Y.A.; Velichko, A.A.; Ivshin, A.A.; Novitskiy, R.E. Recognition of Handwritten MNIST Digits on Low-Memory 2 Kb RAM Arduino Board Using LogNNet Reservoir Neural Network. IOP Conf. Ser. Mater. Sci. Eng. 2021, 1155, 12056. [Google Scholar] [CrossRef]
- Izotov, Y.A.; Velichko, A.A.; Boriskov, P.P. Method for Fast Classification of MNIST Digits on Arduino UNO Board Using LogNNet and Linear Congruential Generator. J. Phys. Conf. Ser. 2021, 2094, 32055. [Google Scholar] [CrossRef]
- Ballard, Z.; Brown, C.; Madni, A.M.; Ozcan, A. Machine Learning and Computation-Enabled Intelligent Sensor Design. Nat. Mach. Intell. 2021, 3, 556–565. [Google Scholar] [CrossRef]
- Chinchole, S.; Patel, S. Artificial Intelligence and Sensors Based Assistive System for the Visually Impaired People. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 7–8 December 2017; pp. 16–19. [Google Scholar] [CrossRef]
- Gulzar Ahmad, S.; Iqbal, T.; Javaid, A.; Ullah Munir, E.; Kirn, N.; Ullah Jan, S.; Ramzan, N. Sensing and Artificial Intelligent Maternal-Infant Health Care Systems: A Review. Sensors 2022, 22, 4362. [Google Scholar] [CrossRef] [PubMed]
- Warden, P.; Stewart, M.; Plancher, B.; Banbury, C.; Prakash, S.; Chen, E.; Asgar, Z.; Katti, S.; Reddi, V.J. Machine Learning Sensors. arXiv 2022, arXiv:2206.03266. [Google Scholar] [CrossRef]
- Machine Learning Sensors: Truly Data-Centric AI|Towards Data Science. Available online: https://towardsdatascience.com/machine-learning-sensors-truly-data-centric-ai-8f6b9904633a (accessed on 1 August 2023).
- Tan, H.; Zhou, Y.; Tao, Q.; Rosen, J.; van Dijken, S. Bioinspired Multisensory Neural Network with Crossmodal Integration and Recognition. Nat. Commun. 2021, 12, 1120. [Google Scholar] [CrossRef]
- del Valle, M. Bioinspired Sensor Systems. Sensors 2011, 11, 10180–10186. [Google Scholar] [CrossRef]
- Liao, F.; Zhou, Z.; Kim, B.J.; Chen, J.; Wang, J.; Wan, T.; Zhou, Y.; Hoang, A.T.; Wang, C.; Kang, J.; et al. Bioinspired In-Sensor Visual Adaptation for Accurate Perception. Nat. Electron. 2022, 5, 84–91. [Google Scholar] [CrossRef]
- Lee, W.W.; Tan, Y.J.; Yao, H.; Li, S.; See, H.H.; Hon, M.; Ng, K.A.; Xiong, B.; Ho, J.S.; Tee, B.C.K. A Neuro-Inspired Artificial Peripheral Nervous System for Scalable Electronic Skins. Sci. Robot. 2019, 4, eaax2198. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, Y.; Zhou, Y.; Man, Q.; Hu, C.; Asghar, W.; Li, F.; Yu, Z.; Shang, J.; Liu, G.; et al. A Skin-Inspired Tactile Sensor for Smart Prosthetics. Sci. Robot. 2018, 3, eaat0429. [Google Scholar] [CrossRef]
- Goldsmith, B.R.; Mitala, J.J.J.; Josue, J.; Castro, A.; Lerner, M.B.; Bayburt, T.H.; Khamis, S.M.; Jones, R.A.; Brand, J.G.; Sligar, S.G.; et al. Biomimetic Chemical Sensors Using Nanoelectronic Readout of Olfactory Receptor Proteins. ACS Nano 2011, 5, 5408–5416. [Google Scholar] [CrossRef]
- Wei, X.; Qin, C.; Gu, C.; He, C.; Yuan, Q.; Liu, M.; Zhuang, L.; Wan, H.; Wang, P. A Novel Bionic in Vitro Bioelectronic Tongue Based on Cardiomyocytes and Microelectrode Array for Bitter and Umami Detection. Biosens. Bioelectron. 2019, 145, 111673. [Google Scholar] [CrossRef] [PubMed]
- Guo, H.; Pu, X.; Chen, J.; Meng, Y.; Yeh, M.-H.; Liu, G.; Tang, Q.; Chen, B.; Liu, D.; Qi, S.; et al. A Highly Sensitive, Self-Powered Triboelectric Auditory Sensor for Social Robotics and Hearing Aids. Sci. Robot. 2018, 3, eaat2516. [Google Scholar] [CrossRef] [PubMed]
- Jung, Y.H.; Park, B.; Kim, J.U.; Kim, T.-I. Bioinspired Electronics for Artificial Sensory Systems. Adv. Mater. 2019, 31, e1803637. [Google Scholar] [CrossRef] [PubMed]
- Al-sharhan, S.; Karray, F.; Gueaieb, W.; Basir, O. Fuzzy Entropy: A Brief Survey. In Proceedings of the 10th IEEE International Conference on Fuzzy Systems. (Cat. No.01CH37297), Melbourne, Australia, 2–5 December 2001; Volume 2, pp. 1135–1139. [Google Scholar] [CrossRef]
- Chanwimalueang, T.; Mandic, D.P. Cosine Similarity Entropy: Self-Correlation-Based Complexity Analysis of Dynamical Systems. Entropy 2017, 19, 652. [Google Scholar] [CrossRef]
- Rohila, A.; Sharma, A. Phase Entropy: A New Complexity Measure for Heart Rate Variability. Physiol. Meas. 2019, 40, 105006. [Google Scholar] [CrossRef]
- Varshavsky, R.; Gottlieb, A.; Linial, M.; Horn, D. Novel Unsupervised Feature Filtering of Biological Data. Bioinformatics 2006, 22, e507–e513. [Google Scholar] [CrossRef]
- Velichko, A.; Belyaev, M.; Izotov, Y.; Murugappan, M.; Heidari, H. Neural Network Entropy (NNetEn): Entropy-Based EEG Signal and Chaotic Time Series Classification, Python Package for NNetEn Calculation. Algorithms 2023, 16, 255. [Google Scholar] [CrossRef]
- Heidari, H.; Velichko, A.; Murugappan, M.; Chowdhury, M.E.H. Novel Techniques for Improving NNetEn Entropy Calculation for Short and Noisy Time Series. Nonlinear Dyn. 2023, 111, 9305–9326. [Google Scholar] [CrossRef]
- Velichko, A.; Heidari, H. A Method for Estimating the Entropy of Time Series Using Artificial Neural Networks. Entropy 2021, 23, 1432. [Google Scholar] [CrossRef] [PubMed]
- Velichko, A.; Belyaev, M.; Wagner, M.P.; Taravat, A. Entropy Approximation by Machine Learning Regression: Application for Irregularity Evaluation of Images in Remote Sensing. Remote Sens. 2022, 14, 5983. [Google Scholar] [CrossRef]
- Guckenheimer, J.; Oliva, R.A. Chaos in the Hodgkin--Huxley Model. SIAM J. Appl. Dyn. Syst. 2002, 1, 105–114. [Google Scholar] [CrossRef]
- Gonzàlez-Miranda, J.M. Complex Bifurcation Structures in the Hindmarsh–Rose Neuron Model. Int. J. Bifurc. Chaos 2007, 17, 3071–3083. [Google Scholar] [CrossRef]
- Kuznetsov, S.P.; Sedova, Y.V. Hyperbolic Chaos in Systems Based on FitzHugh—Nagumo Model Neurons. Regul. Chaotic Dyn. 2018, 23, 458–470. [Google Scholar] [CrossRef]
- Nobukawa, S.; Nishimura, H.; Yamanishi, T.; Liu, J.-Q. Chaotic States Induced by Resetting Process in Izhikevich Neuron Model. J. Artif. Intell. Soft Comput. Res. 2015, 5, 109–119. [Google Scholar] [CrossRef]
- Hindmarsh, J.L.; Rose, R.M. A Model of the Nerve Impulse Using Two First-Order Differential Equations. Nature 1982, 296, 162–164. [Google Scholar] [CrossRef]
- Rajagopal, K.; Khalaf, A.J.M.; Parastesh, F.; Moroz, I.; Karthikeyan, A.; Jafari, S. Dynamical Behavior and Network Analysis of an Extended Hindmarsh–Rose Neuron Model. Nonlinear Dyn. 2019, 98, 477–487. [Google Scholar] [CrossRef]
- Zheng, Q.; Shen, J.; Zhang, R.; Guan, L.; Xu, Y. Spatiotemporal Patterns in a General Networked Hindmarsh-Rose Model. Front. Physiol. 2022, 13, 936982. [Google Scholar] [CrossRef]
- Velasco Equihua, G.G.; Ramirez, J.P. Synchronization of Hindmarsh-Rose Neurons via Huygens-like Coupling. IFAC-PapersOnLine 2018, 51, 186–191. [Google Scholar] [CrossRef]
- Shi, X.; Wang, Z.; Zhou, Y.; Xin, L. Synchronization of Fractional-Order Hindmarsh-Rose Neurons with Hidden Attractor via Only One Controller. Math. Probl. Eng. 2022, 2022, 3157755. [Google Scholar] [CrossRef]
- Shilnikov, L.P.; Shilnikov, A.; Turaev, D.; Chua, L. Methods of Qualitative Theory in Nonlinear Dynamics; World Scientific Publishing: Singapore, 1998; Volume 5, ISBN 978-981-02-3382-2. [Google Scholar]
- Metcalfe, B.; Hunter, A.; Graham-Harper-Cater, J.; Taylor, J. A Dataset of Action Potentials Recorded from the L5 Dorsal Rootlet of Rat Using a Multiple Electrode Array. Data Br. 2020, 33, 106561. [Google Scholar] [CrossRef] [PubMed]
- Chen, W.; Wang, Z.; Xie, H.; Yu, W. Characterization of Surface EMG Signal Based on Fuzzy Entropy. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 266–272. [Google Scholar] [CrossRef] [PubMed]
- Flood, M.W.; Grimm, B. EntropyHub: An Open-Source Toolkit for Entropic Time Series Analysis. PLoS ONE 2021, 16, e0259448. [Google Scholar] [CrossRef] [PubMed]
- Di Bucchianico, A. Coefficient of Determination (R2). In Encyclopedia of Statistics in Quality and Reliability; Wiley: New York, NY, USA, 2007. [Google Scholar]
- Apicella, A.; Donnarumma, F.; Isgrò, F.; Prevete, R. A Survey on Modern Trainable Activation Functions. Neural Netw. 2021, 138, 14–32. [Google Scholar] [CrossRef]
















| Datasets | Mean | Mean50_min | Mean50_max | Min_X | Max_X |
|---|---|---|---|---|---|
| Base_1 | 32.26571 | 30.09417 | 36.30281 | 11.686 | 81.764 |
| Base_2 | 32.28749 | 29.70656 | 36.25960 | 16.744 | 59.124 |
| Base_1_2 | 32.27660 | 29.70656 | 36.30281 | 11.686 | 81.764 |
| Number of Neurons in the Hidden Layer, NH | Cross-Validation Accuracy, R2 | Approximation Accuracy When Training on One Set and Testing on Another Set, R2 | |||
|---|---|---|---|---|---|
| Base_1 | Base_2 | Base_1_2 | Base_1-Training Base_2-Testing | Base_1-Testing Base_2-Training | |
| 1 | −0.001 | −0.001 | −0.001 | −0.013 | −0.047 |
| 50 | 0.827 | 0.868 | 0.810 | 0.030 | −0.084 |
| 150 | 0.846 | 0.888 | 0.842 | 0.159 | −0.831 |
| Number of Neurons in the Hidden Layer, NH | Cross-Validation Accuracy, R2 | Approximation Accuracy When Training on One Set and Testing on Another Set, R2 | |||
|---|---|---|---|---|---|
| Base_1 | Base_2 | Base_1_2 | Base_1-Training Base_2-Testing | Base_1-Testing Base_2-Training | |
| 1 | 0.812 | 0.617 | 0.498 | 0.128 | 0.326 |
| 50 | 0.904 | 0.928 | 0.885 | −0.180 | 0.655 |
| 150 | 0.912 | 0.937 | 0.897 | −0.729 | 0.568 |
| Enav (Order) | Enav (Chaos) | Std_En (Chaos) | EnSens | EnErr | |
|---|---|---|---|---|---|
| Sensor on FuzzyEn | 1.33 | 3.98 | 0.29 | 9 | 11% |
| Sensor on Perceptron | 1.48 | 4 | 0.28 | 9 | 11% |
| Sensor on Perceptron Averaging over 20 | 1.34 | 4.1 | 0.11 | 25 | 4% |
| Number of Neurons in the Hidden Layer, NH | Cross-Validation Accuracy for Base_1_exp | Approximation Accuracy When Training on Base_1_exp and Testing on Base_2_exp | ||||
|---|---|---|---|---|---|---|
| R2 | RMSE | MAPE, % | R2 | RMSE | MAPE, % | |
| 1 | 0.781 | 0.219 | 4.9 | 0.849 | 0.189 | 4.3 |
| 50 | 0.781 | 0.219 | 4.9 | 0.85 | 0.188 | 4.3 |
| 150 | 0.778 | 0.221 | 4.9 | 0.852 | 0.187 | 4.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Velichko, A.; Boriskov, P.; Belyaev, M.; Putrolaynen, V. A Bio-Inspired Chaos Sensor Model Based on the Perceptron Neural Network: Machine Learning Concept and Application for Computational Neuro-Science. Sensors 2023, 23, 7137. https://doi.org/10.3390/s23167137
Velichko A, Boriskov P, Belyaev M, Putrolaynen V. A Bio-Inspired Chaos Sensor Model Based on the Perceptron Neural Network: Machine Learning Concept and Application for Computational Neuro-Science. Sensors. 2023; 23(16):7137. https://doi.org/10.3390/s23167137
Chicago/Turabian StyleVelichko, Andrei, Petr Boriskov, Maksim Belyaev, and Vadim Putrolaynen. 2023. "A Bio-Inspired Chaos Sensor Model Based on the Perceptron Neural Network: Machine Learning Concept and Application for Computational Neuro-Science" Sensors 23, no. 16: 7137. https://doi.org/10.3390/s23167137
APA StyleVelichko, A., Boriskov, P., Belyaev, M., & Putrolaynen, V. (2023). A Bio-Inspired Chaos Sensor Model Based on the Perceptron Neural Network: Machine Learning Concept and Application for Computational Neuro-Science. Sensors, 23(16), 7137. https://doi.org/10.3390/s23167137