


High-Speed Tracking with Mutual Assistance of Feature Filters and Detectors


Abstract
1. Introduction
2. Related Work
2.1. Object Detection
2.1.1. Manual Feature Extraction
2.1.2. Motion Detection
2.1.3. Deep Learning-Based Detection
2.2. Inter-Frame Tracking
2.2.1. Template Matching
2.2.2. Deep Learning-Based Tracking
2.3. Hybrid Method
2.4. Challenges of Previous Studies
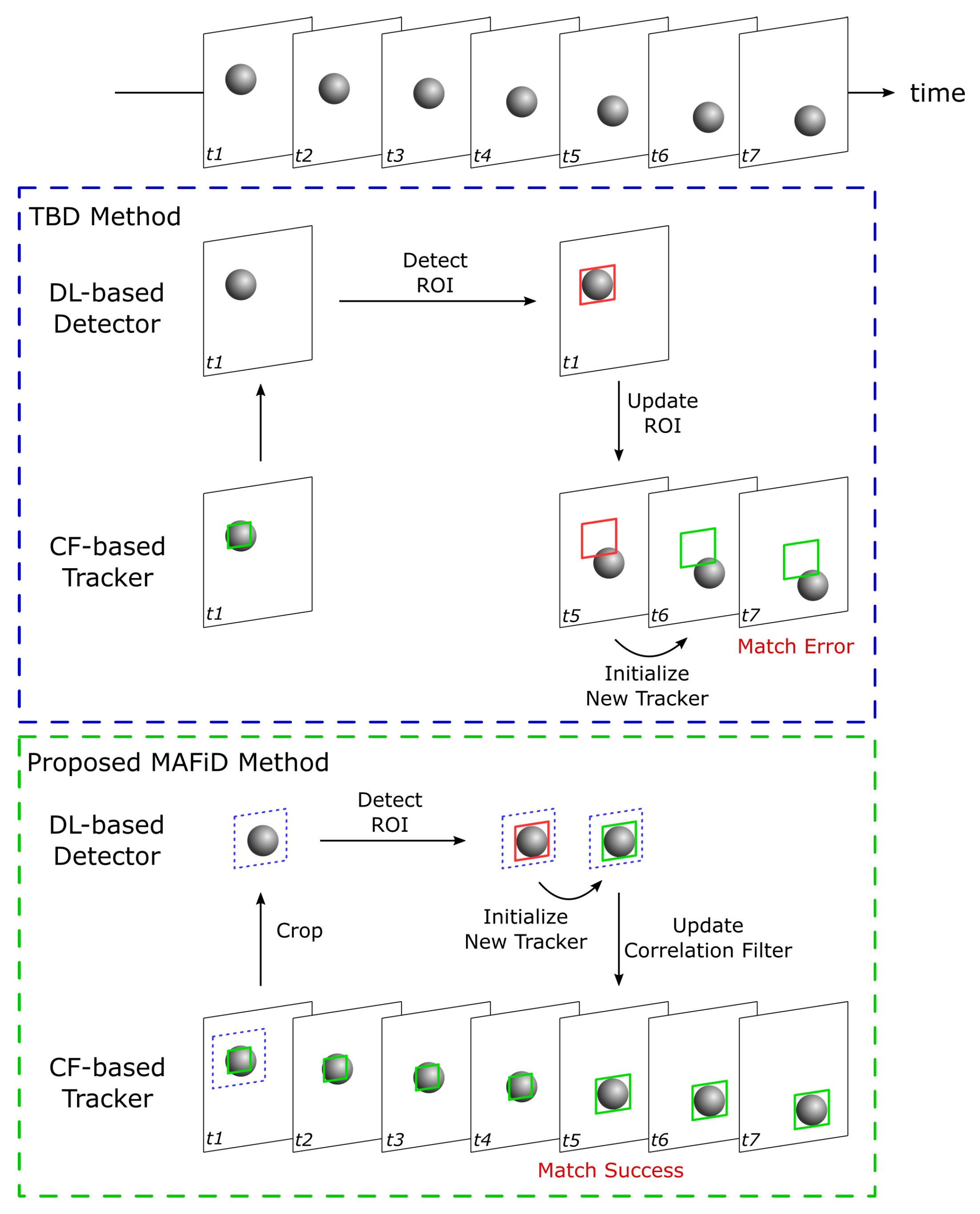
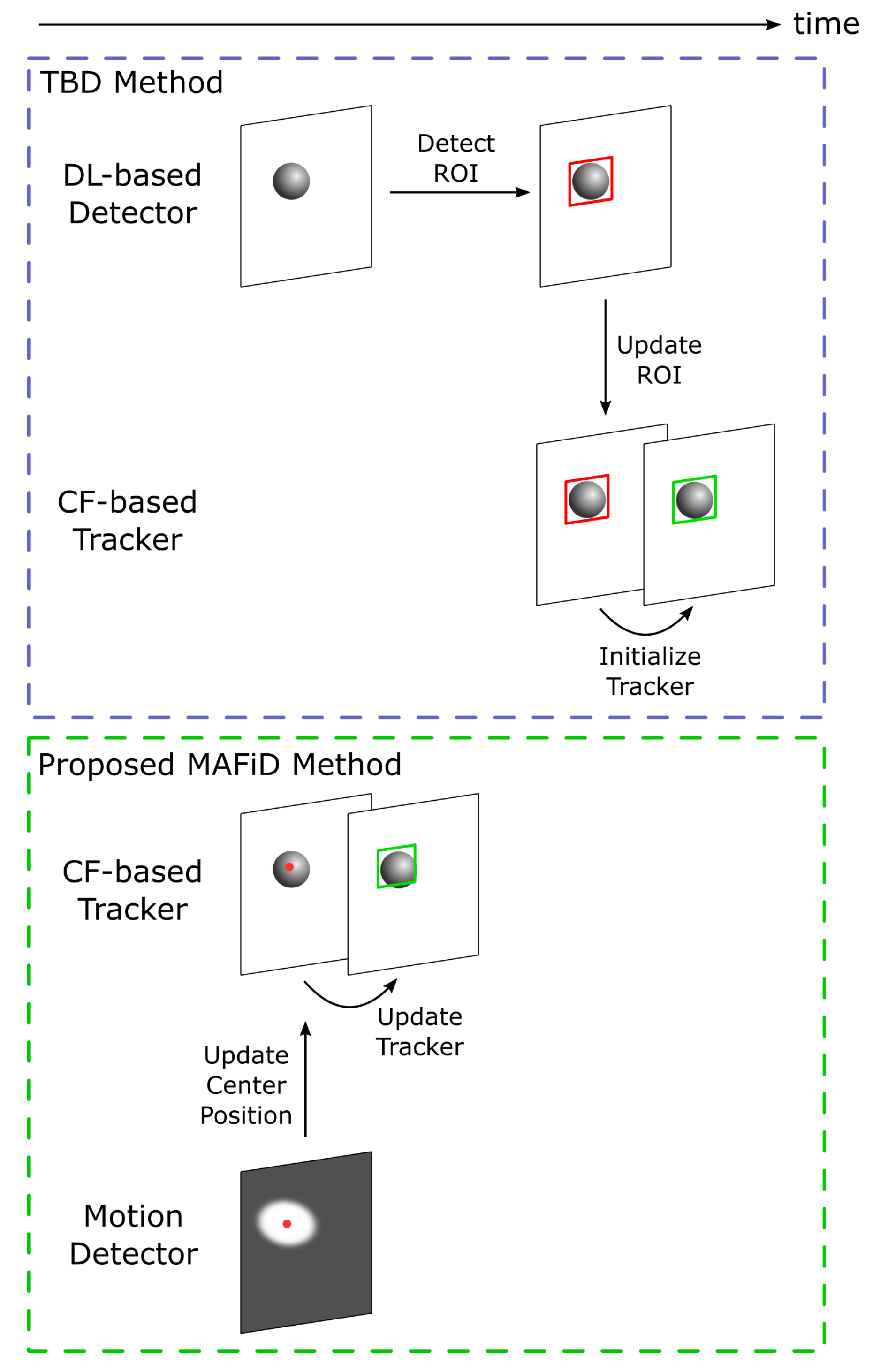
3. Proposed Methodology
3.1. Overview of the Tracking Method
3.2. Tracking Process
3.3. Detection Process
3.4. Algorithms
4. Experiments and Discussion
4.1. Experimental System
4.2. Training of DL-Based Detector Model
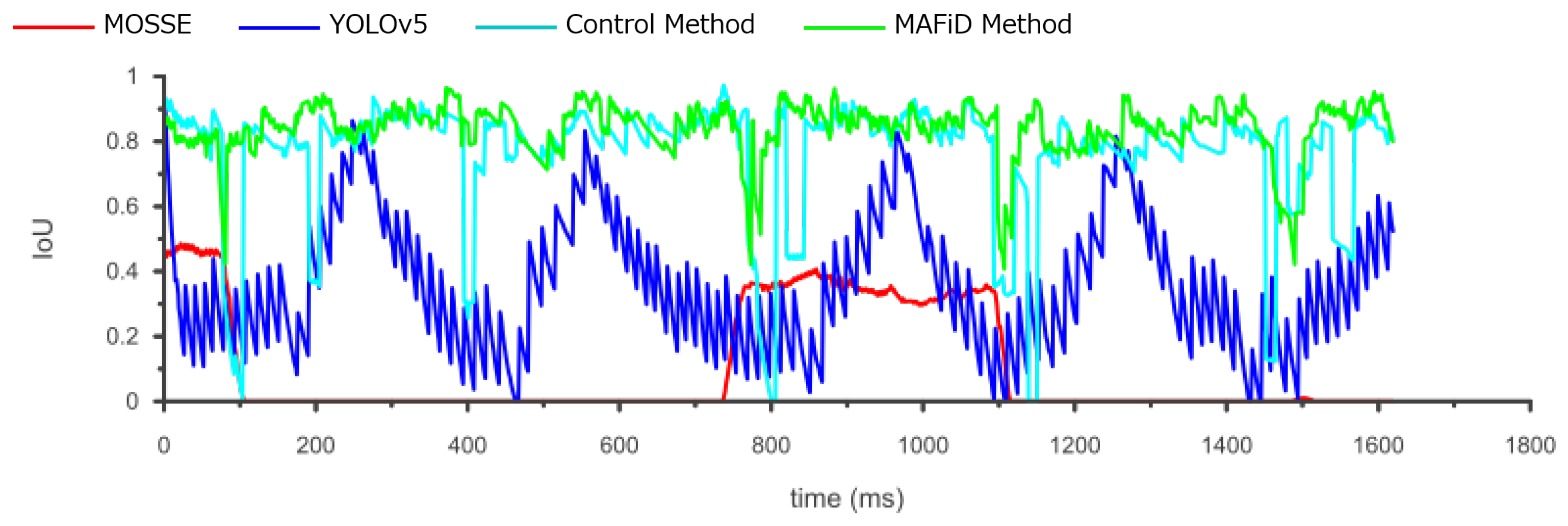
4.3. Tracking Experiment
- Proposed MAFiD MethodMOSSE tracker + YOLOv5 detector + Motion detector
- CF-based tracking methodMOSSE tracker
- DL-based detection methodYOLOv5 detector
- Control methodMOSSE tracker + YOLOv5 detector (Global detection)
4.4. Detection Experiment
- Proposed MAFiD MethodMOSSE tracker + YOLOv5 detector + Motion detector
- DL-based detection methodYOLOv5 detector
- ROI-based TBD methodMOSSE tracker + YOLOv5 detector
- Control methodMOSSE tracker + YOLOv5 detector (Global detection)
4.4.1. Slow Object Detection
4.4.2. Fast Object Detection
4.4.3. Detection Latency
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bütepage, J.; Cruciani, S.; Kokic, M.; Welle, M.; Kragic, D. From Visual Understanding to Complex Object Manipulation. Annu. Rev. Control. Robot. Auton. Syst. 2019, 2, 161–179. [Google Scholar] [CrossRef]
- Ishikawa, M.; Namiki, A.; Senoo, T.; Yamakawa, Y. Ultra High-Speed Robot Based on 1 kHz Vision System. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Algarve, Portugal, 7–12 October 2012; pp. 5460–5461. [Google Scholar] [CrossRef]
- Balaji, S.R.; Karthikeyan, S. A Survey on Moving Object Tracking Using Image Processing. In Proceedings of the 2017 11th International Conference on Intelligent Systems and Control (ISCO), Coimbatore, India, 5–6 January 2017; pp. 469–474. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef]
- Lindeberg, T. Scale Invariant Feature Transform. Scholarpedia 2012, 7, 10491. [Google Scholar] [CrossRef]
- Chen, Z.; Hong, Z.; Tao, D. An Experimental Survey on Correlation Filter-based Tracking. arXiv 2015, arXiv:1509.05520. [Google Scholar]
- Li, K.; Cao, L. A Review of Object Detection Techniques. In Proceedings of the 2020 5th International Conference on Electromechanical Control Technology and Transportation (ICECTT), Nanchang, China, 15–17 May 2020; pp. 385–390. [Google Scholar] [CrossRef]
- Sharifara, A.; Mohd Rahim, M.S.; Anisi, Y. A General Review of Human Face Detection Including a Study of Neural Networks and Haar Feature-Based Cascade Classifier in Face Detection. In Proceedings of the 2014 International Symposium on Biometrics and Security Technologies (ISBAST), Kuala Lumpur, Malaysia, 26–27 August 2014; pp. 73–78. [Google Scholar] [CrossRef]
- Harris, C.; Stephens, M. A Combined Corner and Edge Detector. In Proceedings of the Alvey Vision Conference. British Machine Vision Association and Society for Pattern Recognition, Manchester, UK, 10–13 September 1988; pp. 147–151. [Google Scholar] [CrossRef]
- Garcia-Garcia, B.; Bouwmans, T.; Rosales Silva, A.J. Background Subtraction in Real Applications: Challenges, Current Models and Future Directions. Comput. Sci. Rev. 2020, 35, 100204. [Google Scholar] [CrossRef]
- Lucas, B.D.; Kanade, T. An Iterative Image Registration Technique with an Application to Stereo Vision. In Proceedings of the 7th International Joint Conference on Artificial Intelligence, IJCAI’81, Vancouver, BC, Canada, 24–28 August 1981; Volume 2, pp. 674–679. [Google Scholar]
- Zou, Z.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. arXiv 2019, arXiv:1905.05055. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. arXiv 2014, arXiv:1311.2524. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. arXiv 2015, arXiv:1504.08083. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. arXiv 2016, arXiv:1506.01497. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. arXiv 2017, arXiv:1612.03144. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9905, pp. 21–37. [Google Scholar] [CrossRef]
- Bolme, D.; Beveridge, J.R.; Draper, B.A.; Lui, Y.M. Visual Object Tracking Using Adaptive Correlation Filters. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2544–2550. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, L.; Liu, Q.; Zhang, D.; Yang, M.H. Fast Visual Tracking via Dense Spatio-temporal Context Learning. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; Volume 8693, pp. 127–141. [Google Scholar] [CrossRef]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-Speed Tracking with Kernelized Correlation Filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Danelljan, M.; Häger, G.; Khan, F.S.; Felsberg, M. Discriminative Scale Space Tracking. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1561–1575. [Google Scholar] [CrossRef] [PubMed]
- Ma, C.; Yang, X.; Zhang, C.; Yang, M.H. Long-Term Correlation Tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5388–5396. [Google Scholar]
- Hong, Z.; Chen, Z.; Wang, C.; Mei, X.; Prokhorov, D.; Tao, D. MUlti-Store Tracker (MUSTer): A Cognitive Psychology Inspired Approach to Object Tracking. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 749–758. [Google Scholar] [CrossRef]
- Held, D.; Thrun, S.; Savarese, S. Learning to Track at 100 FPS with Deep Regression Networks. In Proceedings of the Computer Vision—ECCV 2016; Lecture Notes in Computer Science; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 749–765. [Google Scholar] [CrossRef]
- Nam, H.; Han, B. Learning Multi-domain Convolutional Neural Networks for Visual Tracking. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4293–4302. [Google Scholar] [CrossRef]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H.S. Fully-Convolutional Siamese Networks for Object Tracking. arXiv 2016, arXiv:1606.09549. [Google Scholar]
- Valmadre, J.; Bertinetto, L.; Henriques, J.; Vedaldi, A.; Torr, P.H.S. End-to-End Representation Learning for Correlation Filter Based Tracking. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5000–5008. [Google Scholar] [CrossRef]
- Li, B.; Yan, J.; Wu, W.; Zhu, Z.; Hu, X. High Performance Visual Tracking with Siamese Region Proposal Network. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8971–8980. [Google Scholar] [CrossRef]
- Li, B.; Wu, W.; Wang, Q.; Zhang, F.; Xing, J.; Yan, J. SiamRPN++: Evolution of Siamese Visual Tracking With Very Deep Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4277–4286. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, Z.; Li, Z.; Yuan, Y.; Yu, G. SiamFC++: Towards Robust and Accurate Visual Tracking with Target Estimation Guidelines. arXiv 2020, arXiv:1911.06188. [Google Scholar] [CrossRef]
- Ma, C.; Huang, J.B.; Yang, X.; Yang, M.H. Hierarchical Convolutional Features for Visual Tracking. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3074–3082. [Google Scholar] [CrossRef]
- Sun, Z.; Chen, J.; Chao, L.; Ruan, W.; Mukherjee, M. A Survey of Multiple Pedestrian Tracking Based on Tracking-by-Detection Framework. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 1819–1833. [Google Scholar] [CrossRef]
- Liu, F.; Mao, K.; Qi, H.; Liu, S. Real-Time Long-Term Correlation Tracking by Single-Shot Multibox Detection. Opt. Eng. 2019, 58, 013105. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, K.; Li, S.; Hu, Y.; Yan, J. An Optimal Long-Term Aerial Infrared Object Tracking Algorithm With Re-Detection. IEEE Access 2019, 7, 114320–114333. [Google Scholar] [CrossRef]
- Jiang, M.; Gu, Y.; Takaki, T.; Ishii, I. High-Frame-Rate Target Tracking with CNN-based Object Recognition. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 599–606. [Google Scholar] [CrossRef]
- Ultralytics/Yolov5. Ultralytics, 2022. Available online: https://docs.ultralytics.com/yolov5/ (accessed on 5 October 2022).
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Image Size of Dataset | mAP (0.5) | mAP (0.5–0.95) |
|---|---|---|
| 544 × 438 | 0.99 | 0.89 |
| 128 × 128 | 0.99 | 0.86 |
| Method | FPS | RMSE (Pixels) | Average IoU |
|---|---|---|---|
| MOSSE tracker | 618 | 141.0 | 0.10 |
| YOLOv5 detector | 70 | 35.1 | 0.36 |
| Control method | 618 (Thread 2: 65) 1 | 14.5 | 0.76 |
| MAFiD method | 618 (Thread 2: 98) 1 | 4.9 | 0.84 |
| Method | RMSE (Pixels) | Average IoU |
|---|---|---|
| YOLOv5 detector | 39.2 | 0.40 |
| TBD method | 25.8 | 0.52 |
| Control method | 17.9 | 0.81 |
| MAFiD method | 27.3 | 0.83 |
| Method | RMSE (Pixels) | Average IoU |
|---|---|---|
| YOLOv5 detector | 89.1 | 0.07 |
| TBD method | 60.6 | 0.07 |
| Control method | 92.0 | 0.01 |
| MAFiD method | 53.1 | 0.78 |
| Method | Detection Latency (ms) |
|---|---|
| YOLOv5 detector | 14.3 |
| TBD method | 15.4 |
| Control method | 15.4 |
| MAFiD method | 3.48 (ROI: 11.94) 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matsuo, A.; Yamakawa, Y. High-Speed Tracking with Mutual Assistance of Feature Filters and Detectors. Sensors 2023, 23, 7082. https://doi.org/10.3390/s23167082
Matsuo A, Yamakawa Y. High-Speed Tracking with Mutual Assistance of Feature Filters and Detectors. Sensors. 2023; 23(16):7082. https://doi.org/10.3390/s23167082
Chicago/Turabian StyleMatsuo, Akira, and Yuji Yamakawa. 2023. "High-Speed Tracking with Mutual Assistance of Feature Filters and Detectors" Sensors 23, no. 16: 7082. https://doi.org/10.3390/s23167082
APA StyleMatsuo, A., & Yamakawa, Y. (2023). High-Speed Tracking with Mutual Assistance of Feature Filters and Detectors. Sensors, 23(16), 7082. https://doi.org/10.3390/s23167082