Figure 1.
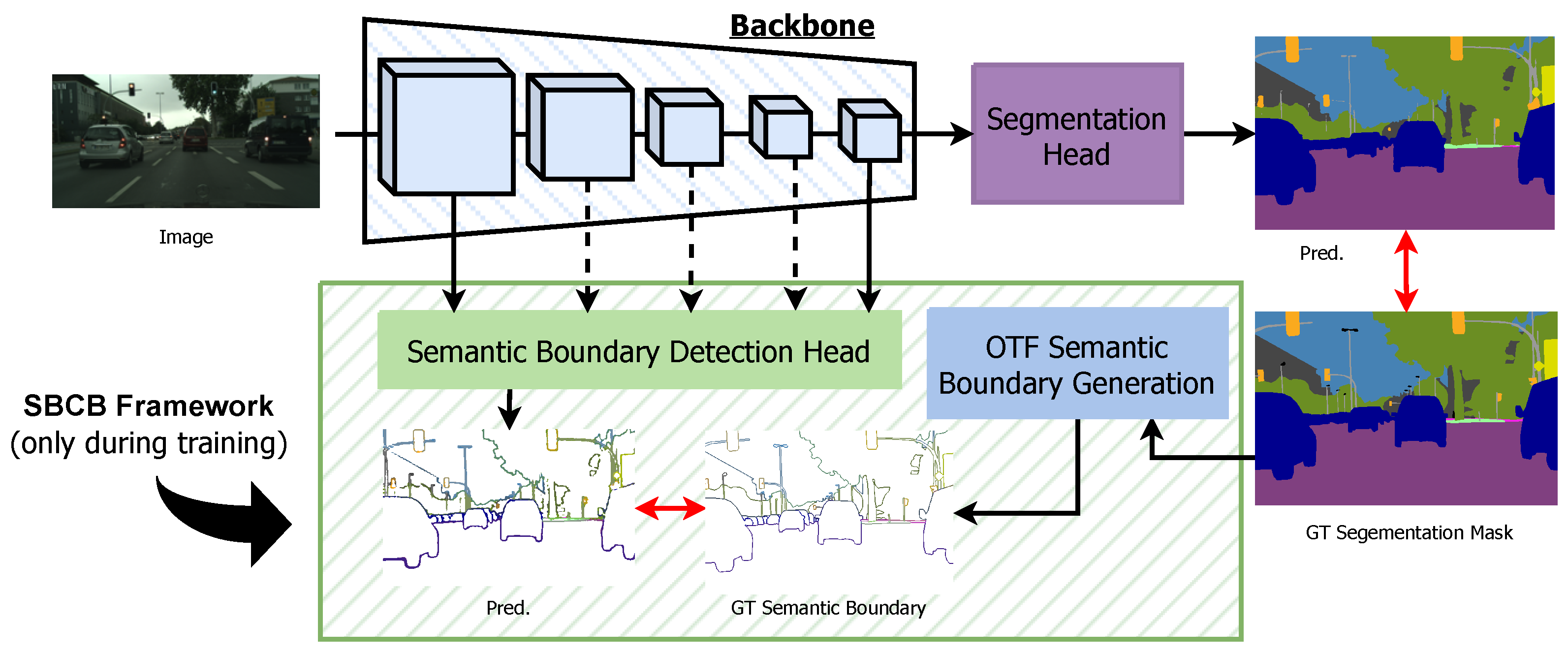
Overview of the Semantic-Boundary-Conditioned Backbone (SBCB) framework. During training, the semantic boundary detection (SBD) head is integrated into the backbone of the semantic segmentation head. Ground-truth (GT) semantic boundaries are generated on the fly (OTF) by the semantic boundary generation module to train the SBD head. This straightforward framework enhances segmentation quality by encouraging the backbone network to explicitly and jointly model boundaries and their relation with semantics, as the SBD task is complementary yet more challenging than the main task.
Figure 1.
Overview of the Semantic-Boundary-Conditioned Backbone (SBCB) framework. During training, the semantic boundary detection (SBD) head is integrated into the backbone of the semantic segmentation head. Ground-truth (GT) semantic boundaries are generated on the fly (OTF) by the semantic boundary generation module to train the SBD head. This straightforward framework enhances segmentation quality by encouraging the backbone network to explicitly and jointly model boundaries and their relation with semantics, as the SBD task is complementary yet more challenging than the main task.
Figure 2.
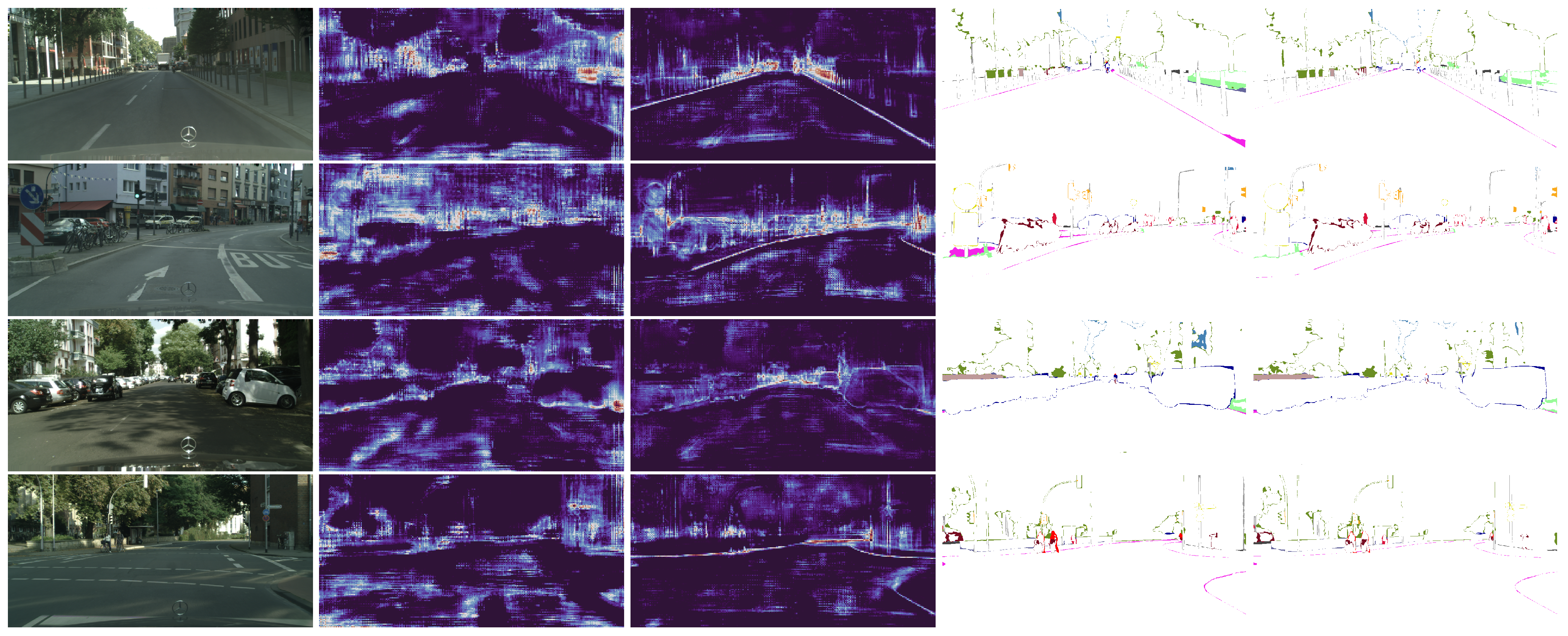
Visualization of the backbone features and segmentation errors of DeepLabV3+ with and without the SBCB framework. Starting from the left, the columns represent the input image, last-stage features without the SBCB, last-stage features with the SBCB, segmentation errors without the SBCB, and segmentation errors with the SBCB. Backbone features conditioned on semantic boundaries exhibit boundary-aware characteristics. Consequently, this results in better segmentation, especially around the mask boundaries. Best seen in color and zoomed in.
Figure 2.
Visualization of the backbone features and segmentation errors of DeepLabV3+ with and without the SBCB framework. Starting from the left, the columns represent the input image, last-stage features without the SBCB, last-stage features with the SBCB, segmentation errors without the SBCB, and segmentation errors with the SBCB. Backbone features conditioned on semantic boundaries exhibit boundary-aware characteristics. Consequently, this results in better segmentation, especially around the mask boundaries. Best seen in color and zoomed in.
Figure 4.
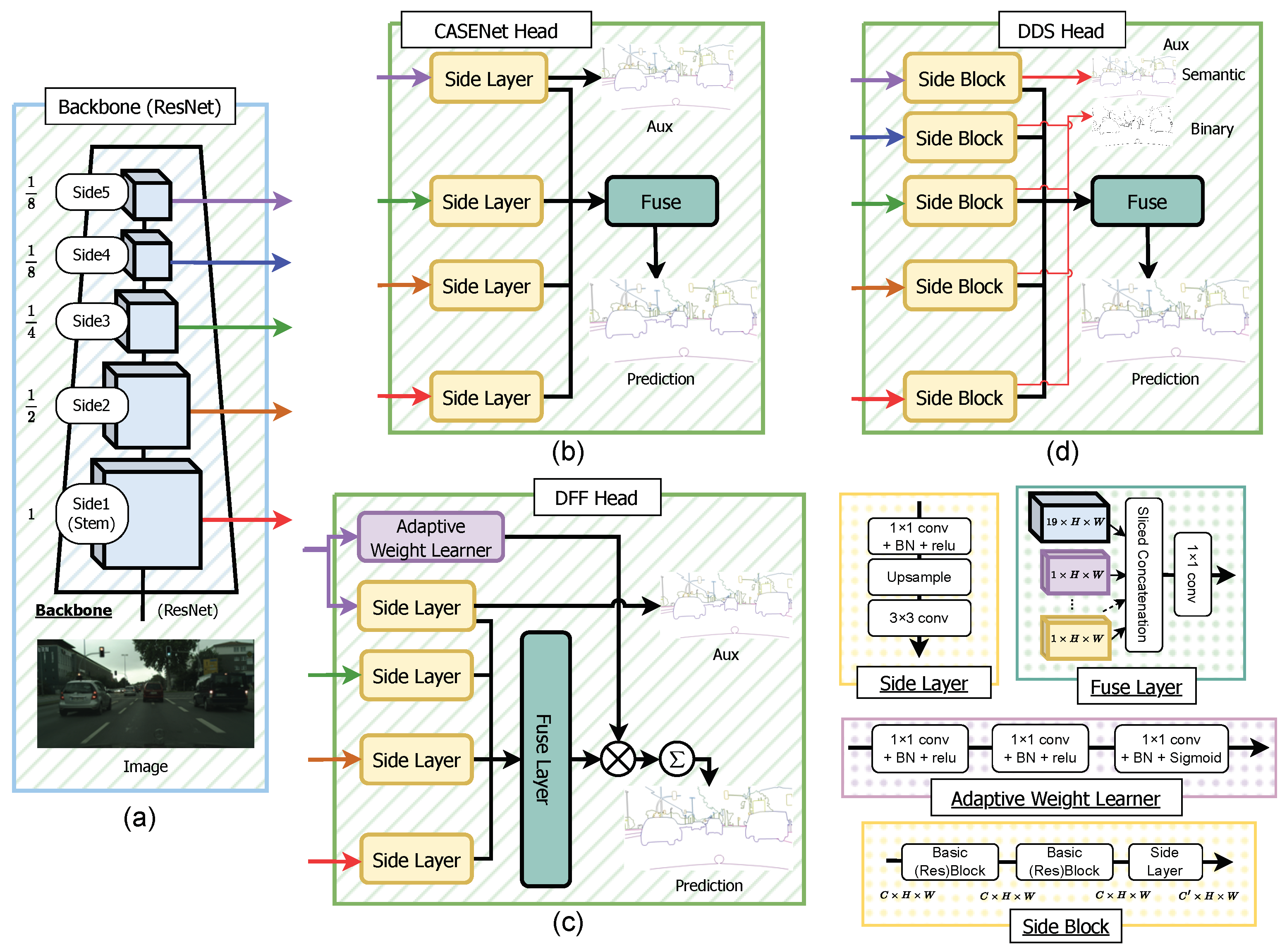
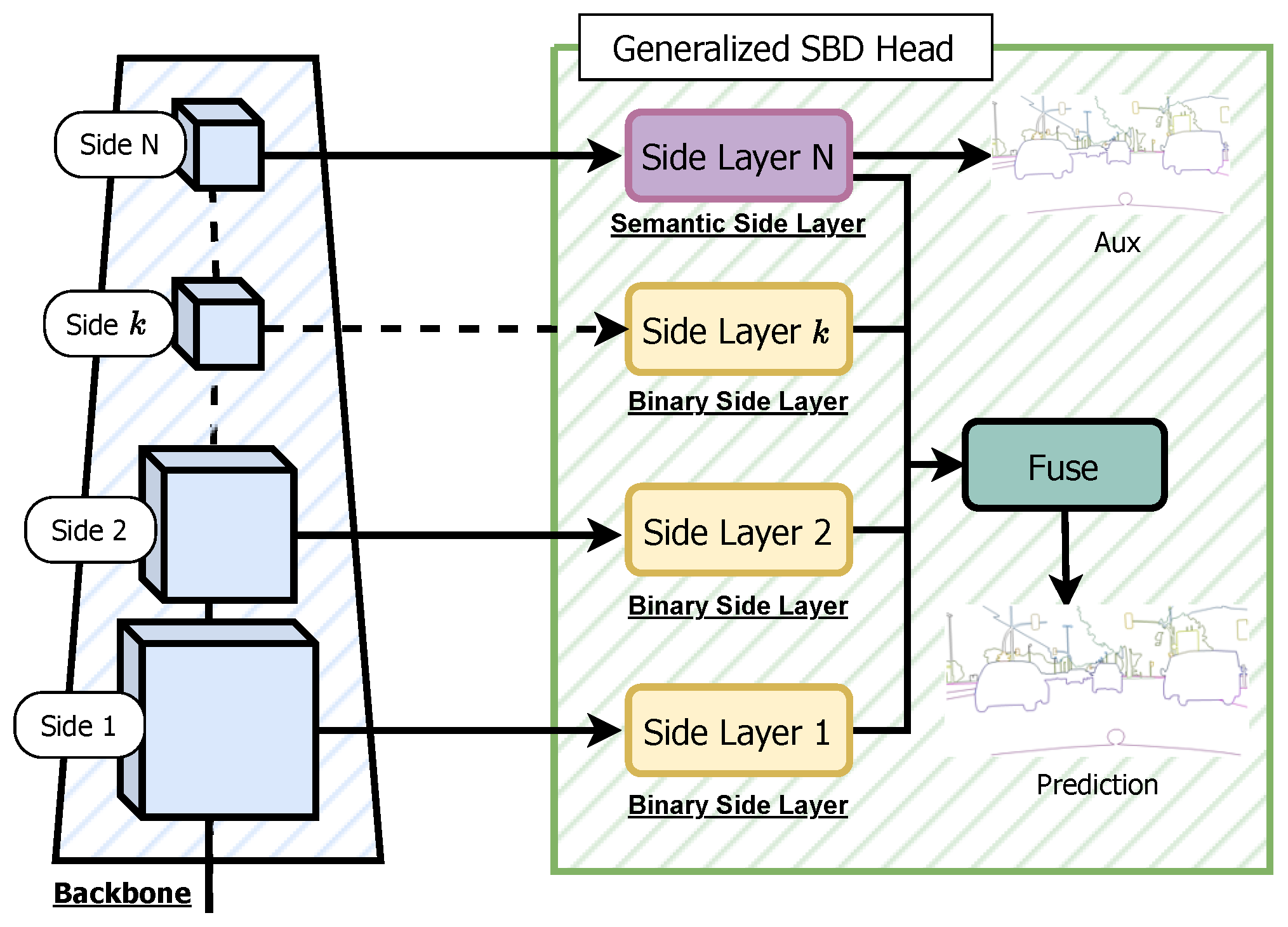
Overview of the Generalized SBD head. The Generalized CASENet Architecture is an extended version of the original CASENet architecture shown in
Figure 3. In this generalized version, the last (
Nth) Side Layer is referred to as the Semantic-Side Layer, and its corresponding input feature is called the Semantic Side. Conversely, the
th Side Layer is termed the Binary-Side Layer, with the input side feature denoted as the Binary Side, having a single channel like other SBD architectures. This generalization allows for the flexibility of accommodating an unrestricted number of Sides and Side Layers, enabling the application of this SBD head to various backbone networks. Moreover, this generalization can be extended to work with DFF and DDS architectures.
Figure 4.
Overview of the Generalized SBD head. The Generalized CASENet Architecture is an extended version of the original CASENet architecture shown in
Figure 3. In this generalized version, the last (
Nth) Side Layer is referred to as the Semantic-Side Layer, and its corresponding input feature is called the Semantic Side. Conversely, the
th Side Layer is termed the Binary-Side Layer, with the input side feature denoted as the Binary Side, having a single channel like other SBD architectures. This generalization allows for the flexibility of accommodating an unrestricted number of Sides and Side Layers, enabling the application of this SBD head to various backbone networks. Moreover, this generalization can be extended to work with DFF and DDS architectures.
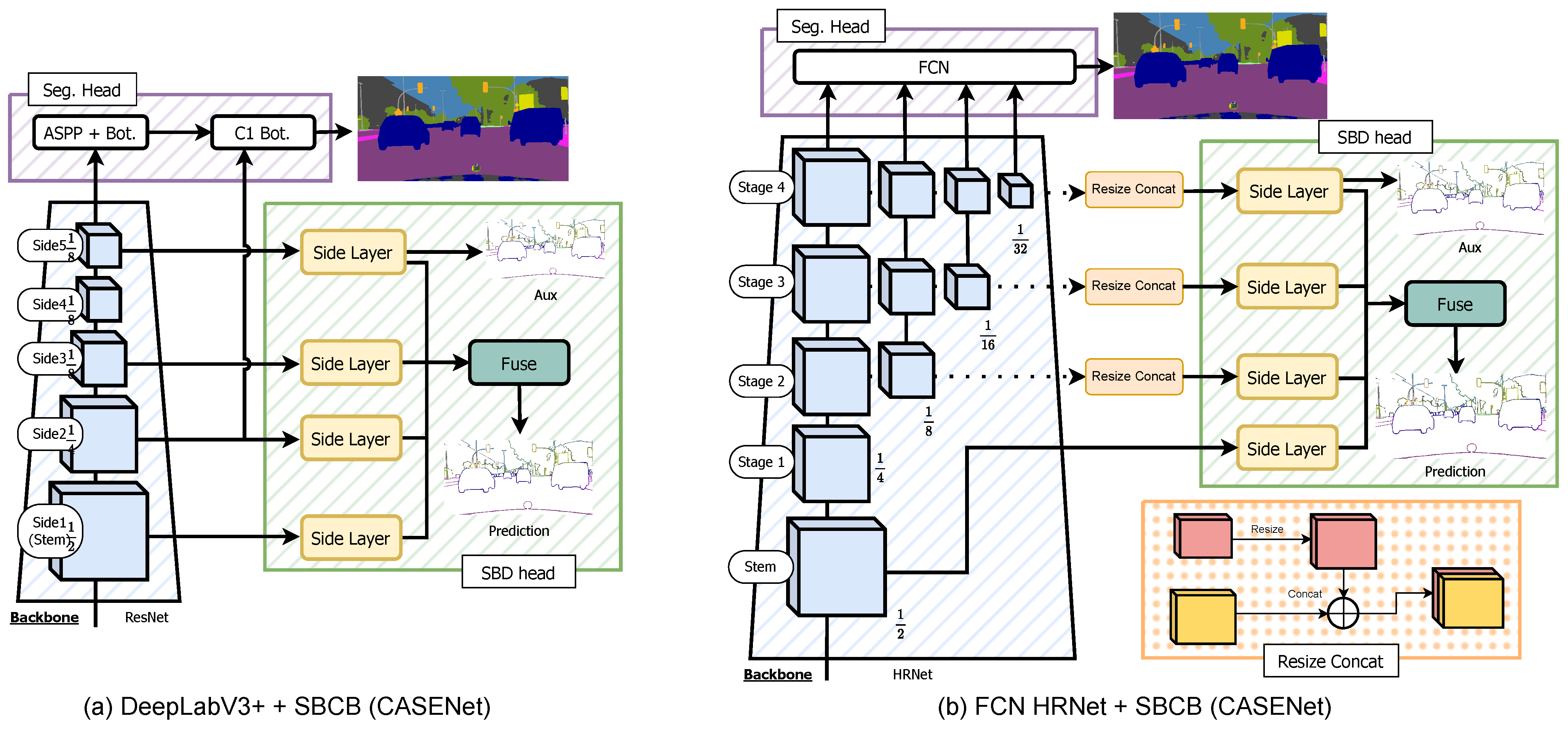
Figure 5.
A diagram showcasing how the SBCB framework is applied to a DeepLabV3+ segmentation head is shown in (a). A diagram showcasing how the SBCB framework is applied to the HRNet backbone with an FCN segmentation head is shown in (b).
Figure 5.
A diagram showcasing how the SBCB framework is applied to a DeepLabV3+ segmentation head is shown in (a). A diagram showcasing how the SBCB framework is applied to the HRNet backbone with an FCN segmentation head is shown in (b).
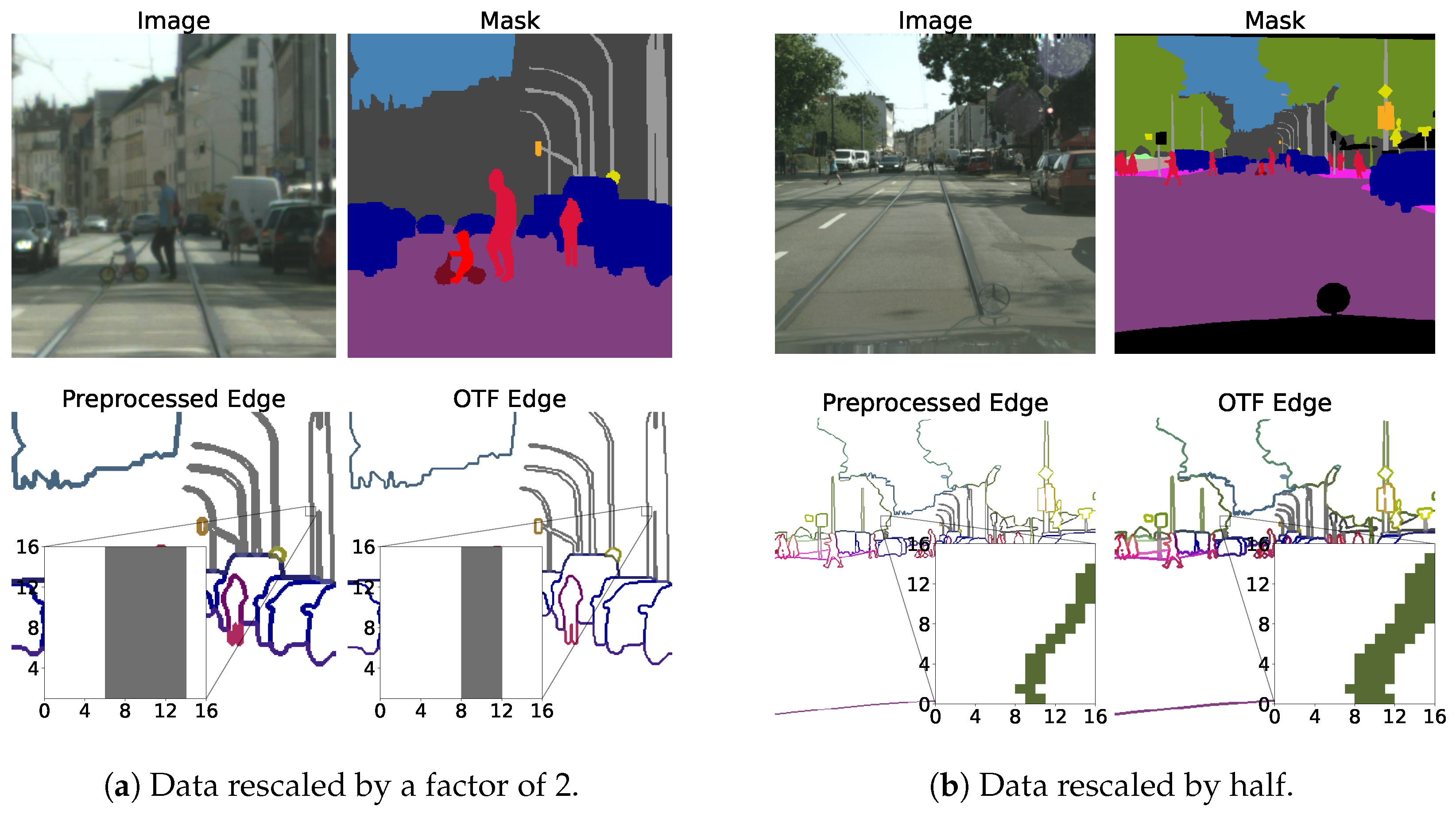
Figure 6.
The two figures represent sample validation images, masks, and boundaries from the Cityscapes validation split, which we rescaled and cropped to . In each figure, we compare the two methods of preprocessing. The one on the left uses preprocessed boundaries, and the one on the right uses OTFGT boundaries. We can observe that OTFGT boundaries have consistent boundary widths, while preprocessed boundaries vary depending on the rescale value.
Figure 6.
The two figures represent sample validation images, masks, and boundaries from the Cityscapes validation split, which we rescaled and cropped to . In each figure, we compare the two methods of preprocessing. The one on the left uses preprocessed boundaries, and the one on the right uses OTFGT boundaries. We can observe that OTFGT boundaries have consistent boundary widths, while preprocessed boundaries vary depending on the rescale value.
Figure 7.
Overview of the OTFGT module. We apply distance transforms to segmentation masks to obtain category-specific distance maps. We then threshold the distances by the radius of the boundaries to obtain category-specific boundaries. The boundaries are concatenated to form a semantic boundary tensor for supervision.
Figure 7.
Overview of the OTFGT module. We apply distance transforms to segmentation masks to obtain category-specific distance maps. We then threshold the distances by the radius of the boundaries to obtain category-specific boundaries. The boundaries are concatenated to form a semantic boundary tensor for supervision.
Figure 8.
The three main datasets that we used for the experiments. We show a sample input image, segmentation GT, and the result of OTF semantic boundary generation for each dataset. The color of the segmentation masks and boundaries corresponds to the colors used in the Cityscapes dataset. For Synthia, the visualization contains separate colors for each mask instances. Humans annotated the Cityscapes and BDD100K datasets, and the segmentation masks are clean but tend to have imperfections around the boundaries and exhibit “polygon” masks. On the other hand, the Synthia dataset is data from a game engine, and the annotations are pixel-perfect, making this a challenging dataset for semantic segmentation. The segmentation mask for Synthia also contains instance segmentation, which is used for OTF semantic boundary generation but not for the segmentation task. The BDD100K and Synthia datasets are less widely used than the Cityscapes dataset. However, the BDD100K and Synthia datasets contain more variations in natural noise and corruption (weather, heavy light reflections, etc.), which will help benchmark the methods fairly. The images are best seen in color and zoomed in.
Figure 8.
The three main datasets that we used for the experiments. We show a sample input image, segmentation GT, and the result of OTF semantic boundary generation for each dataset. The color of the segmentation masks and boundaries corresponds to the colors used in the Cityscapes dataset. For Synthia, the visualization contains separate colors for each mask instances. Humans annotated the Cityscapes and BDD100K datasets, and the segmentation masks are clean but tend to have imperfections around the boundaries and exhibit “polygon” masks. On the other hand, the Synthia dataset is data from a game engine, and the annotations are pixel-perfect, making this a challenging dataset for semantic segmentation. The segmentation mask for Synthia also contains instance segmentation, which is used for OTF semantic boundary generation but not for the segmentation task. The BDD100K and Synthia datasets are less widely used than the Cityscapes dataset. However, the BDD100K and Synthia datasets contain more variations in natural noise and corruption (weather, heavy light reflections, etc.), which will help benchmark the methods fairly. The images are best seen in color and zoomed in.

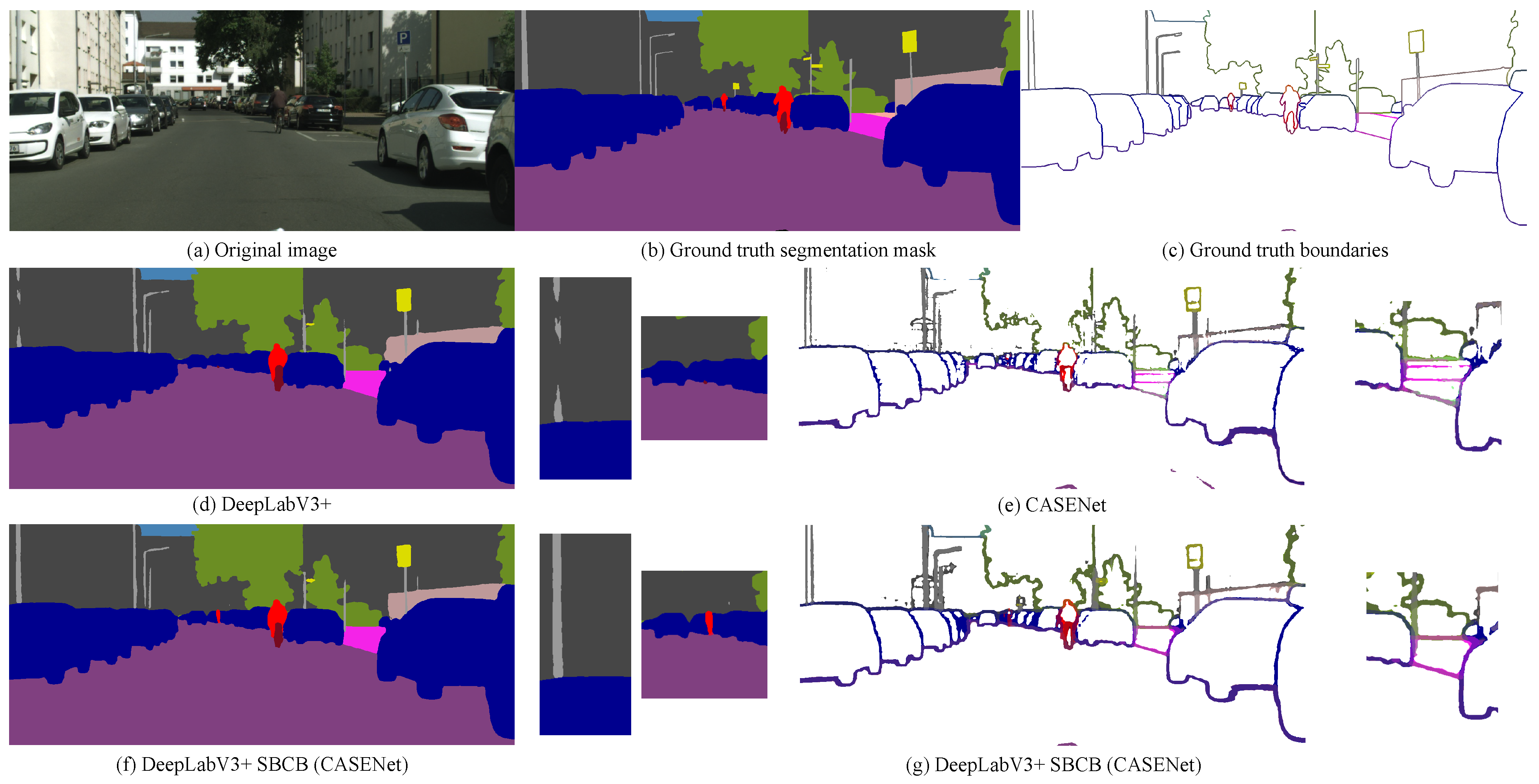
Figure 9.
Visualizations of the GT and predictions on the Cityscapes dataset. Depicted in (a–c) are the input image, ground-truth (GT) segmentation map, and GT semantic boundary map. Note that because the task of SBD is pixel-wise multi-label classification, the visualized semantic boundary maps have overlapped boundaries. The color of the segmentation and boundaries represents categories following the visualization format used in Cityscapes. In (d), we show the output of DeepLabV3+, a popular semantic segmentation model. The semantic boundary detection (SBD) baseline is CASENet, which we show in (e). The output of DeepLabV3+ trained with the SBCB framework using the CASENet head is shown in (f,g). We can see that small and thin objects are recognized better using the framework and smoother boundaries with fewer artifacts. We can also notice improvements in over-segmentation for both the segmentation mask and semantic boundary results.
Figure 9.
Visualizations of the GT and predictions on the Cityscapes dataset. Depicted in (a–c) are the input image, ground-truth (GT) segmentation map, and GT semantic boundary map. Note that because the task of SBD is pixel-wise multi-label classification, the visualized semantic boundary maps have overlapped boundaries. The color of the segmentation and boundaries represents categories following the visualization format used in Cityscapes. In (d), we show the output of DeepLabV3+, a popular semantic segmentation model. The semantic boundary detection (SBD) baseline is CASENet, which we show in (e). The output of DeepLabV3+ trained with the SBCB framework using the CASENet head is shown in (f,g). We can see that small and thin objects are recognized better using the framework and smoother boundaries with fewer artifacts. We can also notice improvements in over-segmentation for both the segmentation mask and semantic boundary results.
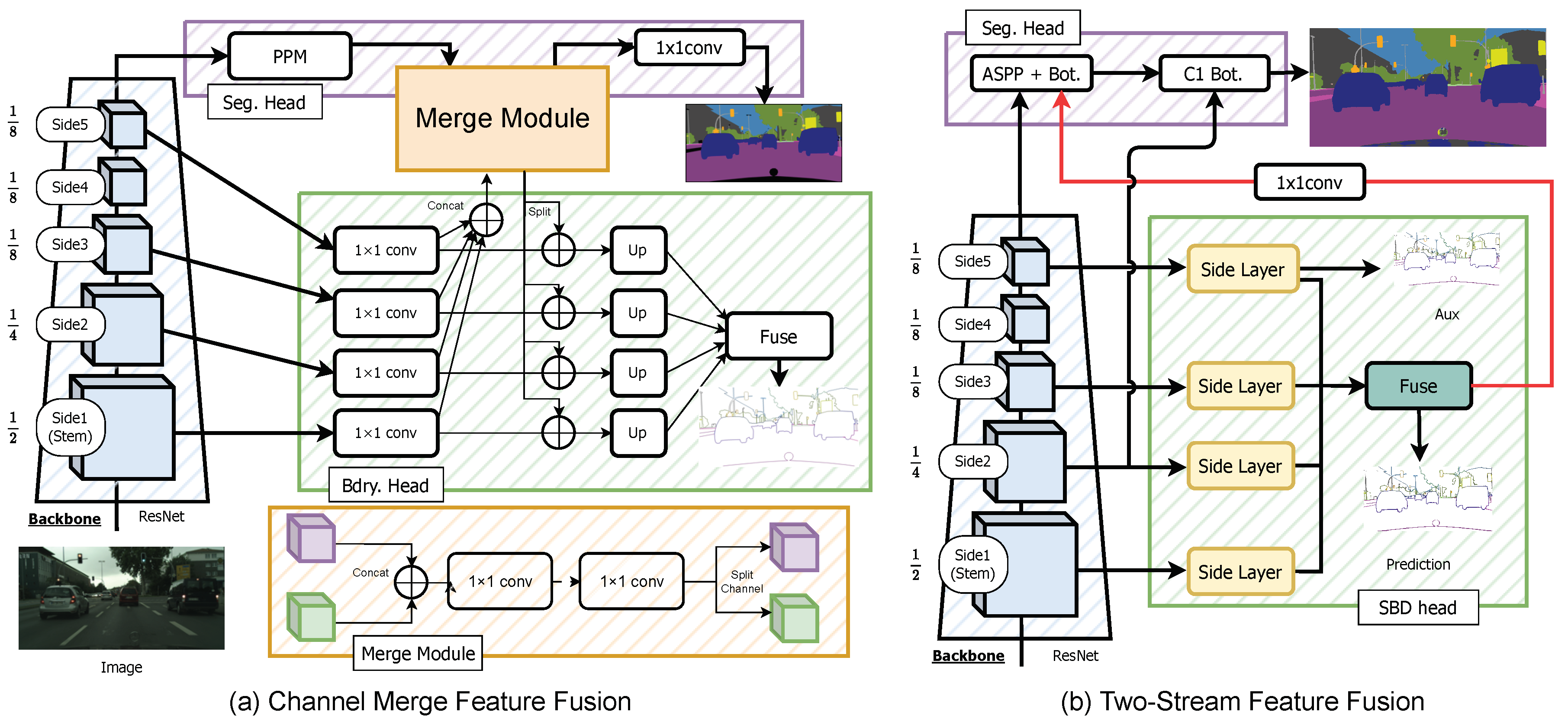
Figure 10.
In (a), we show how to apply the Channel-Merge module for explicit feature fusion based on the SBCB framework. In (b), we show how to apply the Two-Stream approach for explicit feature fusion modeled after the GSCNN architecture.
Figure 10.
In (a), we show how to apply the Channel-Merge module for explicit feature fusion based on the SBCB framework. In (b), we show how to apply the Two-Stream approach for explicit feature fusion modeled after the GSCNN architecture.
Table 1.
Results for Cityscapes. The best performant metrics are shown in bold.
Table 1.
Results for Cityscapes. The best performant metrics are shown in bold.
| Head | mIoU | mF (ODS) | Param. | GFLOPs |
|---|
| DeepLabV3+ | 79.5 | - | 60.2 M | 506 |
| CASENet | - | 63.7 | 42.5 M | 357 |
| DFF | | 65.5 | 42.8 M | 395 |
| DDS | | 73.4 | 243.3 M | 2079 |
| SBCB (CASENet) | 80.3 | 74.4 | 60.2 M | 508 |
| SBCB (DFF) | 80.2 | 74.6 | 60.5 M | 545 |
| SBCB (DDS) | 80.6 | 75.8 | 261.0 M | 2228 |
Table 2.
Results for Cityscapes with input crop size of . The best performant metrics are shown in bold.
Table 2.
Results for Cityscapes with input crop size of . The best performant metrics are shown in bold.
| Head | mIoU | mF (ODS) | Param. | GFLOPs |
|---|
| DeepLabV3+ | 78.9 | – | 60.2 M | 506 |
| CASENet | - | 68.6 | 42.5 M | 357 |
| DFF | | 68.9 | 42.8 M | 395 |
| DDS | | 75.5 | 243.3 M | 2079 |
| SBCB (CASENet) | 80.3 | 74.0 | 60.2 M | 508 |
| SBCB (DFF) | 80.0 | 74.8 | 60.5 M | 545 |
| SBCB (DDS) | 80.4 | 75.6 | 261.0 M | 2228 |
Table 3.
Results for Cityscapes using the HRNet-48 (HR48) backbone. The best performant metrics are shown in bold.
Table 3.
Results for Cityscapes using the HRNet-48 (HR48) backbone. The best performant metrics are shown in bold.
| Head | mIoU | mF (ODS) | Param. | GFLOPs |
|---|
| FCN | 80.5 | – | 65.9 M | 187 |
| CASENet | - | 75.7 | 65.3 M | 172 |
| DFF | | 75.3 | 65.5 M | 210 |
| DDS | | 78.9 | 89.0 M | 946 |
| SBCB (CASENet) | 82.0 | 78.9 | 65.9 M | 187 |
| SBCB (DFF) | 81.5 | 78.8 | 66.0 M | 221 |
| SBCB (DDS) | 81.0 | 79.3 | 89.5 M | 1012 |
Table 4.
Results for BDD100K. The best performant metrics are shown in bold.
Table 4.
Results for BDD100K. The best performant metrics are shown in bold.
| Head | mIoU | mF (ODS) |
|---|
| DeepLabV3+ | 60.0 | - |
| CASENet | - | 55.7 |
| DFF | | 57.3 |
| DDS | | 59.9 |
| SBCB (CASENet) | 61.4 | 56.6 |
| SBCB (DFF) | 62.0 | 58.1 |
| SBCB (DDS) | 64.1 | 60.2 |
Table 5.
Results for Synthia. The best performant metrics are shown in bold.
Table 5.
Results for Synthia. The best performant metrics are shown in bold.
| Head | mIoU | mF (ODS) |
|---|
| DeepLabV3+ | 74.5 | - |
| CASENet | - | 61.0 |
| DFF | | 64.8 |
| DDS | | 67.6 |
| SBCB (CASENet) | 75.9 | 65.2 |
| SBCB (DFF) | 75.3 | 66.5 |
| SBCB (DDS) | 75.7 | 67.0 |
Table 6.
Results using ResNet-101 backbone with different side configurations on the Cityscapes validation split.
Table 6.
Results using ResNet-101 backbone with different side configurations on the Cityscapes validation split.
| Head | Sides | mIoU | |
|---|
| PSPNet | | 77.6 | |
| 1 + 5 | 78.5 | +0.9 |
| 1 + 2 + 5 | 78.6 | +1.0 |
| 1 + 2 + 3 + 5 | 78.7 | +1.1 |
| 1 + 2 + 3 + 4 + 5 | 78.5 | +0.9 |
| DeepLabV3 | | 79.2 | |
| 1 + 5 | 79.8 | +0.6 |
| 1 + 2 + 5 | 79.9 | +0.7 |
| 1 + 2 + 3 + 5 | 79.9 | +0.7 |
| 1 + 2 + 3 + 4 + 5 | 79.4 | +0.2 |
| DeepLabV3+ | | 79.5 | |
| 1 + 5 | 80.1 | +0.6 |
| 1 + 2 + 5 | 80.1 | +0.6 |
| 1 + 2 + 3 + 5 | 80.3 | +0.8 |
| 1 + 2 + 3 + 4 + 5 | 80.5 | +1.0 |
Table 7.
Per-category IoU for the Cityscapes validation split. Red and Blue represents improvements and degradation.
Table 7.
Per-category IoU for the Cityscapes validation split. Red and Blue represents improvements and degradation.
| Method | SBCB | mIoU | Road | Swalk | Build. | Wall | Fence | Pole | Tlight | Sign | Veg | Terrain | Sky | Person | Rider | Car | Truck | Bus | Train | Motor | Bike |
|---|
| PSPNet | ✓ | 77.6 | 98.0 | 83.9 | 92.4 | 49.5 | 59.3 | 64.5 | 71.7 | 79.0 | 92.4 | 64.2 | 94.7 | 81.8 | 60.5 | 95.0 | 77.8 | 89.1 | 80.1 | 63.4 | 77.9 |
| 78.7 | 98.3 | 85.7 | 92.7 | 52.7 | 60.7 | 66.3 | 72.7 | 80.8 | 92.8 | 64.3 | 94.6 | 82.4 | 62.7 | 95.3 | 79.5 | 88.6 | 81.4 | 66.0 | 78.7 |
| +1.1 | +0.3 | +1.8 | +0.3 | +3.2 | +1.4 | +1.8 | +1.0 | +1.8 | +0.4 | +0.1 | −0.1 | +0.6 | +2.2 | +0.3 | +1.7 | −0.5 | +1.3 | +2.6 | +0.8 |
| DeepLabV3 | ✓ | 79.2 | 98.1 | 84.6 | 92.6 | 54.5 | 61.7 | 64.6 | 71.7 | 79.3 | 92.6 | 64.6 | 94.6 | 82.4 | 63.8 | 95.4 | 83.2 | 90.9 | 84.2 | 67.7 | 78.1 |
| 79.9 | 98.4 | 86.4 | 93.0 | 55.3 | 63.7 | 66.8 | 72.9 | 80.4 | 94.9 | 65.4 | 94.9 | 83.3 | 65.9 | 95.5 | 81.9 | 92.3 | 81.3 | 68.2 | 78.9 |
| +0.7 | +0.3 | +1.8 | +0.4 | +0.8 | +2.0 | +2.2 | +1.2 | +1.1 | +2.3 | +0.8 | +0.3 | +0.9 | +2.1 | +0.1 | −1.3 | +1.4 | −2.9 | +0.5 | +0.8 |
| DeepLabV3+ | ✓ | 79.5 | 98.1 | 85.0 | 92.9 | 53.2 | 62.8 | 66.5 | 72.1 | 80.4 | 92.7 | 64.9 | 94.7 | 82.8 | 63.6 | 95.5 | 85.1 | 90.9 | 82.2 | 69.4 | 78.4 |
| 80.3 | 98.3 | 85.9 | 93.4 | 65.7 | 65.6 | 68.5 | 73.0 | 81.4 | 92.8 | 66.1 | 95.3 | 83.3 | 65.6 | 95.5 | 81.3 | 88.3 | 78.1 | 68.7 | 78.8 |
| +0.8 | +0.2 | +0.9 | +0.5 | +12.5 | +2.8 | +2.0 | +0.9 | +1.0 | +0.1 | +1.2 | +0.6 | +0.5 | +2.0 | 0 | −3.8 | −2.6 | −4.1 | −0.7 | +0.4 |
Table 8.
Tables that compare different backbone-conditioning methods on the Cityscapes validation split. We investigated the effects on three popular segmentation heads: PSPNet, DeepLabV3, and DeepLabV3+. Note that all methods use ResNet-101 as the backbone. Also, note that we show the number of parameters (Params.) during training.
Table 8.
Tables that compare different backbone-conditioning methods on the Cityscapes validation split. We investigated the effects on three popular segmentation heads: PSPNet, DeepLabV3, and DeepLabV3+. Note that all methods use ResNet-101 as the backbone. Also, note that we show the number of parameters (Params.) during training.
| Head | FCN | BBCB | SBCB | Param. | mIoU | |
|---|
| PSPNet | | | | 65.58 M | 77.6 | |
| ✓ | | | +2.37 M | 78.3 | +0.7 |
| | ✓ | | +0.01 M | 78.1 | +0.5 |
| | | ✓ | +0.05 M | 78.7 | +1.1 |
| ✓ | ✓ | | +2.37 M | 79.1 | +1.5 |
| ✓ | | ✓ | +2.41 M | 79.4 | +1.8 |
| DeepLabV3 | | | | 84.72 M | 79.2 | |
| ✓ | | | +2.37 M | 79.3 | +0.1 |
| | ✓ | | +0.01 M | 79.6 | +0.4 |
| | | ✓ | +0.05 M | 79.9 | +0.7 |
| ✓ | ✓ | | +2.37 M | 80.1 | +0.9 |
| ✓ | | ✓ | +2.41 M | 80.1 | +0.9 |
| DeepLabV3+ | | | | 60.2 M | 79.5 | |
| ✓ | | | +2.37 M | 79.7 | +0.2 |
| ✓ | | +0.01 M | 79.9 | +0.4 |
| | | ✓ | +0.05 M | 80.3 | +0.8 |
| ✓ | ✓ | | +2.37 M | 80.6 | +1.1 |
| ✓ | | ✓ | +2.41 M | 80.5 | +1.0 |
Table 9.
Tables that compare different backbone-conditioning methods on Synthia.
Table 9.
Tables that compare different backbone-conditioning methods on Synthia.
| Head | FCN | BBCB | SBCB | mIoU | |
|---|
| PSPNet | | | | 70.5 | |
| ✓ | | | 70.1 | −0.4 |
| | ✓ | | 70.7 | +0.2 |
| | | ✓ | 71.7 | +1.2 |
| ✓ | ✓ | | 70.7 | +0.2 |
| ✓ | | ✓ | 71.6 | +1.1 |
| DeepLabV3 | | | | 70.9 | |
| ✓ | | | 70.6 | −0.3 |
| | ✓ | | 70.7 | −0.2 |
| | | ✓ | 71.9 | +1.0 |
| ✓ | ✓ | | 70.5 | −0.4 |
| ✓ | | ✓ | 71.0 | +0.1 |
| DeepLabV3+ | | | | 72.4 | |
| ✓ | | | 72.0 | −0.4 |
| | ✓ | | 72.1 | −0.3 |
| | | ✓ | 73.5 | +1.1 |
| ✓ | ✓ | | 72.3 | −0.1 |
| ✓ | | ✓ | 73.5 | +1.1 |
Table 10.
Comparison of the use of SegFix with auxiliary heads (SBCB and FCN) on the Cityscapes validation split.
Table 10.
Comparison of the use of SegFix with auxiliary heads (SBCB and FCN) on the Cityscapes validation split.
| Model | mIoU | |
|---|
| PSPNet | | 77.6 | |
| + SegFix | 78.8 | +1.2 |
| + SBCB | 78.7 | +1.1 |
| + SBCB + FCN | 79.4 | +1.8 |
| + SBCB + SegFix | 79.7 | +2.1 |
| + SBCB + FCN + SegFix | 80.3 | +2.8 |
| DeepLabV3 | | 79.2 | |
| + SegFix | 80.3 | +1.1 |
| + SBCB | 79.9 | +0.7 |
| + SBCB + FCN | 80.1 | +0.9 |
| + SBCB + SegFix | 80.8 | +1.6 |
| + SBCB + FCN + SegFix | 81.0 | +1.8 |
| DeepLabV3+ | | 79.5 | |
| + SegFix | 80.4 | +0.9 |
| + SBCB | 80.3 | +0.8 |
| + SBCB + FCN | 80.6 | +1.1 |
| + SBCB + SegFix | 81.0 | +1.5 |
| + SBCB + FCN + SegFix | 81.2 | +1.7 |
Table 11.
Comparisons of DeepLabV3+ and GSCNN on the Cityscapes validation split. We show that the SBCB framework can be applied to train GSCNN.
Table 11.
Comparisons of DeepLabV3+ and GSCNN on the Cityscapes validation split. We show that the SBCB framework can be applied to train GSCNN.
| Model | mIoU | |
|---|
| DeepLabV3+ | | 79.5 | |
| +SBCB (CASENet) | 80.3 | +0.8 |
| +SBCB (DDS) | 80.6 | +1.1 |
| GSCNN | | 80.5 | +1.0 |
| +Canny | 80.6 | +1.1 |
| SBD | 80.0 | +0.5 |
| +SBCB (CASENet) | 80.9 | +1.4 |
Table 12.
This table shows the configurations of the two common types of modifications to the ResNet backbone. Note that the output feature resolutions are in the order of Stem, Stages 1, Stage 2, Stage 3, and Stage 4.
Table 12.
This table shows the configurations of the two common types of modifications to the ResNet backbone. Note that the output feature resolutions are in the order of Stem, Stages 1, Stage 2, Stage 3, and Stage 4.
| Task | Stem Stride | Strides | Dilations | Resolutions |
|---|
| Original | 2 | (1, 2, 2, 2) | (1, 1, 1, 1) | (1/2, 1/4, 1/8, 1/16, 1/32) |
| Segmentation | 2 | (1, 2, 1, 1) | (1, 1, 2, 4) | (1/2, 1/4, 1/8, 1/8, 1/8) |
| Edge Det. | 1 | (1, 2, 2, 1) | (2, 2, 2, 4) | (1, 1/2, 1/4, 1/8, 1/8) |
Table 13.
Results of the “Backbone Trick” validated on Cityscapes. We modified the ResNet-101 backbone’s stride and dilation at each stage to keep the number of parameters the same but generate larger feature maps. The authors of [
33] introduced this technique, and we prepend “HED” to the backbone that uses this trick.
Table 13.
Results of the “Backbone Trick” validated on Cityscapes. We modified the ResNet-101 backbone’s stride and dilation at each stage to keep the number of parameters the same but generate larger feature maps. The authors of [
33] introduced this technique, and we prepend “HED” to the backbone that uses this trick.
| Head | mIoU | mF (ODS) | Param. | GFLOPs |
|---|
| DeepLabV3+ | 79.8 | - | 60.2 M | 506 |
| CASENet | - | 68.6 | 42.5 M | 417 |
| DFF | | 70.0 | 42.8 M | 455 |
| DDS | | 76.3 | 243.3 M | 2661 |
| SBCB (CASENet) | 81.0 | 75.1 | 60.2 M | 508 |
| SBCB (DFF) | 80.8 | 75.4 | 60.5 M | 545 |
| SBCB (DDS) | 80.8 | 76.5 | 261.0 M | 2228 |
Table 14.
Results of the “Backbone Trick” validated on BDD100K.
Table 14.
Results of the “Backbone Trick” validated on BDD100K.
| Head | mIoU | mF (ODS) |
|---|
| DeepLabV3+ | 59.8 | - |
| CASENet | - | 56.6 |
| DFF | | 58.1 |
| DDS | | 60.1 |
| SBCB (CASENet) | 62.4 | 59.3 |
| SBCB (DFF) | 62.0 | 58.9 |
| SBCB (DDS) | 63.5 | 60.5 |
Table 15.
Results of the “Backbone Trick” validated on Synthia.
Table 15.
Results of the “Backbone Trick” validated on Synthia.
| Head | mIoU | mF (ODS) |
|---|
| DeepLabV3+ | 77.0 | - |
| CASENet | - | 64.0 |
| DFF | | 65.6 |
| DDS | | 68.5 |
| SBCB (CASENet) | 78.0 | 67.5 |
| SBCB (DFF) | 77.8 | 68.9 |
| SBCB (DDS) | 78.6 | 68.4 |
Table 16.
Comparison of SBD models on the Cityscapes validation split using the instance-sensitive “thin” evaluation protocol.
†: Performance reported in [
38].
Table 16.
Comparison of SBD models on the Cityscapes validation split using the instance-sensitive “thin” evaluation protocol.
†: Performance reported in [
38].
| Method | Backbone | mF (ODS) |
|---|
| CASENet † | HED ResNet-101 | 68.1 |
| SEAL † | HED ResNet-101 | 69.1 |
| STEAL † | HED ResNet-101 | 69.7 |
| DDS † | HED ResNet-101 | 73.8 |
| CSEL [5] | HED ResNet-101 | 78.1 |
| DeepLabV3+ + SBCB (CASENet) | ResNet-101 | 77.8 |
| DeepLabV3+ + SBCB (CASENet) | HED ResNet-101 | 78.4 |
| DeepLabV3+ + SBCB (DDS) | ResNet-101 | 78.8 |
| DeepLabV3+ + SBCB (DDS) | HED ResNet-101 | 78.8 |
Table 17.
Comparison of the boundary F-score, evaluated on the Cityscapes validation split. The models were trained using the same hyperparameters and ResNet-101 backbone.
Table 17.
Comparison of the boundary F-score, evaluated on the Cityscapes validation split. The models were trained using the same hyperparameters and ResNet-101 backbone.
| Head | SBCB | 12 px | | 9 px | | 5 px | | 3 px | |
|---|
| PSPNet | | 80.9 | | 79.6 | | 75.7 | | 70.2 | |
| ✓ | 83.3 | +2.4 | 82.1 | +2.5 | 78.5 | +2.8 | 73.3 | +3.1 |
| DeepLabV3 | | 81.8 | | 80.6 | | 76.7 | | 71.2 | |
| ✓ | 83.4 | +1.6 | 82.2 | +1.6 | 78.7 | +2.0 | 73.4 | +2.2 |
| DeepLabV3+ | | 81.2 | | 80.0 | | 76.4 | | 71.4 | |
| ✓ | 83.0 | +1.8 | 81.8 | +1.8 | 78.5 | +2.1 | 73.7 | +2.3 |
Table 18.
Comparison of region-based over-segmentation measure (ROM) and region-based under-segmentation measure (RUM) on the Cityscapes validation split. The models are trained using the same hyperparameters and ResNet-101 backbone.
Table 18.
Comparison of region-based over-segmentation measure (ROM) and region-based under-segmentation measure (RUM) on the Cityscapes validation split. The models are trained using the same hyperparameters and ResNet-101 backbone.
| Head | SBCB | ROM ↓ | | RUM ↓ | |
|---|
| PSPNet | | 0.078 | | 0.102 | |
| ✓ | 0.061 | | 0.098 | |
| DeepLabV3 | | 0.072 | | 0.104 | |
| ✓ | 0.060 | | 0.1 | |
| DeepLabV3+ | | 0.08 | | 0.094 | |
| ✓ | 0.065 | | 0.086 | |
Table 19.
Effect of using SBCB for different CNN-based backbones on Cityscapes.
Table 19.
Effect of using SBCB for different CNN-based backbones on Cityscapes.
| Head | Backbone | SBCB | mIoU ↑ | | F-Score ↑ | | ROM ↓ | | RUM ↓ | |
|---|
| DenseASPP | ResNet-50 | | 77.5 | | 69.0 | | 0.108 | | 0.096 | |
| ✓ | 78.3 | +0.8 | 70.6 | +1.6 | 0.1 | −0.008 | 0.093 | −0.003 |
| DenseASPP | DenseNet-169 | | 76.6 | | 69.0 | | 0.077 | | 0.102 | |
| ✓ | 78.2 | +1.6 | 72.1 | +3.1 | 0.072 | −0.005 | 0.101 | −0.001 |
| ASPP | ResNeSt-101 | | 79.5 | | 72.3 | | 0.079 | | 0.102 | |
| ✓ | 80.3 | +0.8 | 75.2 | +2.9 | 0.065 | −0.014 | 0.094 | −0.008 |
| OCR | HR18 | | 78.9 | | 71.9 | | 0.074 | | 0.093 | |
| ✓ | 79.7 | +0.8 | 74.0 | +2.1 | 0.066 | −0.008 | 0.092 | −0.001 |
| OCR | HR48 | | 80.7 | | 74.4 | | 0.073 | | 0.09 | |
| ✓ | 82.0 | +1.3 | 77.7 | +3.7 | 0.069 | −0.004 | 0.083 | −0.007 |
| ASPP | MobileNetV2 | | 73.9 | | 66.2 | | 0.074 | | 0.1 | |
| ✓ | 74.4 | +0.5 | 68.3 | +2.1 | 0.07 | −0.004 | 0.095 | −0.005 |
| LRASPP | MobileNetV3 | | 64.5 | | 58.0 | | 0.128 | | 0.082 | |
| ✓ | 67.5 | +3.0 | 62.1 | +4.1 | 0.115 | −0.013 | 0.08 | −0.002 |
Table 20.
Effect of using SBCB for different CNN-based backbones on Synthia.
Table 20.
Effect of using SBCB for different CNN-based backbones on Synthia.
| Head | Backbone | SBCB | mIoU ↑ | |
|---|
| DenseASPP | ResNet-50 | | 69.6 | |
| ✓ | 70.5 | +0.9 |
| DenseASPP | DenseNet-169 | | 71.3 | |
| ✓ | 72.0 | +0.7 |
| ASPP | ResNeSt-101 | | 72.3 | |
| ✓ | 73.8 | +1.5 |
| OCR | HR18 | | 70.1 | |
| ✓ | 70.9 | +0.8 |
| OCR | HR48 | | 74.3 | |
| ✓ | 76.0 | +1.7 |
| ASPP | MobileNetV2 | | 65.3 | |
| ✓ | 67.0 | +1.7 |
| LRASPP | MobileNetV3 | | 60.8 | |
| ✓ | 64.8 | +4.0 |
Table 21.
Effect of using SBCB with different segmentation heads on Cityscapes. Note that the backbones for all models are set to ResNet-101.
Table 21.
Effect of using SBCB with different segmentation heads on Cityscapes. Note that the backbones for all models are set to ResNet-101.
| Head | SBCB | mIoU ↑ | | F-Score ↑ | | ROM ↓ | | RUM ↓ | |
|---|
| FCN | | 74.6 | | 69.3 | | 0.072 | | 0.104 | |
| ✓ | 76.3 | +1.7 | 71.6 | +2.3 | 0.058 | −0.014 | 0.096 | −0.008 |
| PSPNet | | 77.6 | | 70.2 | | 0.078 | | 0.102 | |
| ✓ | 78.7 | +1.1 | 73.3 | +3.1 | 0.061 | −0.017 | 0.098 | −0.004 |
| ANN | | 77.4 | | 70.1 | | 0.074 | | 0.1 | |
| ✓ | 79.0 | +1.6 | 72.8 | +2.7 | 0.059 | −0.015 | 0.091 | −0.009 |
| GCNet | | 77.8 | | 70.2 | | 0.07 | | 0.103 | |
| ✓ | 78.9 | +1.1 | 73.0 | +2.8 | 0.058 | −0.012 | 0.092 | −0.011 |
| ASPP | | 79.2 | | 71.2 | | 0.072 | | 0.104 | |
| ✓ | 79.9 | +0.7 | 73.4 | +2.2 | 0.06 | −0.012 | 0.1 | −0.004 |
| DNLNet | | 78.7 | | 71.2 | | 0.07 | | 0.101 | |
| ✓ | 79.7 | +1.0 | 73.6 | +2.4 | 0.052 | −0.018 | 0.093 | −0.008 |
| CCNet | | 79.2 | | 71.9 | | 0.068 | | 0.102 | |
| ✓ | 80.1 | +0.9 | 73.9 | +2.0 | 0.053 | −0.015 | 0.089 | −0.013 |
| UPerNet | | 78.1 | | 71.9 | | 0.082 | | 0.091 | |
| ✓ | 78.9 | +0.8 | 73.9 | +2.0 | 0.068 | −0.014 | 0.087 | −0.004 |
| OCR | | 78.2 | | 70.6 | | 0.071 | | 0.096 | |
| ✓ | 80.2 | +2.0 | 74.4 | +3.8 | 0.064 | −0.007 | 0.1 | +0.004 |
Table 22.
Effect of using SBCB with different segmentation heads on Synthia. Note that the backbones for all models are set to ResNet-101.
Table 22.
Effect of using SBCB with different segmentation heads on Synthia. Note that the backbones for all models are set to ResNet-101.
| Head | SBCB | mIoU | |
|---|
| FCN | | 70.0 | |
| ✓ | 70.9 | +0.9 |
| PSPNet | | 70.5 | |
| ✓ | 71.7 | +1.2 |
| ANN | | 70.4 | |
| ✓ | 71.8 | +1.4 |
| GCNet | | 70.8 | |
| ✓ | 71.4 | +0.6 |
| ASPP | | 70.9 | |
| ✓ | 71.9 | +1.0 |
| DNLNet | | 70.5 | |
| ✓ | 71.9 | +1.4 |
| CCNet | | 70.8 | |
| ✓ | 71.3 | +0.5 |
| UPerNet | | 72.4 | |
| ✓ | 73.1 | +0.7 |
| OCR | | 69.7 | |
| ✓ | 72.4 | +2.7 |
Table 23.
Comparison of our method and state-of-the-art methods on the Cityscapes validation split. The methods were only trained with fine-annotation data and without additional coarse training data and Mapillary Vistas pre-training. The sections are divided into three categories: models without boundary auxiliary, with boundary auxiliary, and with SBCB auxiliary.
Table 23.
Comparison of our method and state-of-the-art methods on the Cityscapes validation split. The methods were only trained with fine-annotation data and without additional coarse training data and Mapillary Vistas pre-training. The sections are divided into three categories: models without boundary auxiliary, with boundary auxiliary, and with SBCB auxiliary.
| Method | Backbone | mIoU |
|---|
| PSPNet [12] | ResNet-101 | 78.8 |
| DeepLabV3+ [64] | ResNet-101 | 78.8 |
| CCNet [16] | ResNet-101 | 80.5 |
| DANet [13] | ResNet-101 | 81.5 |
| SegFix [6] | ResNet-101 | 81.5 |
| GSCNN [2] | ResNet-38 | 80.8 |
| RPCNet [4] | ResNet-101 | 82.1 |
| CSEL [5] | HED ResNet-101 | 83.7 |
| BANet [41] | HED ResNet-101 | 82.5 |
| DeepLabV3+ SBCB | ResNet-101 | 82.2 |
| DeepLabV3+ SBCB | HED ResNet-101 | 82.6 |
Table 24.
Comparison of our method and state-of-the-art methods on the Cityscapes test split. The methods were only trained with fine-annotation data and without additional coarse training data and Mapillary Vistas pre-training.
Table 24.
Comparison of our method and state-of-the-art methods on the Cityscapes test split. The methods were only trained with fine-annotation data and without additional coarse training data and Mapillary Vistas pre-training.
| Method | Backbone | mIoU |
|---|
| PSPNet [12] | ResNet-101 | 78.4 |
| PSANet [65] | ResNet-101 | 80.1 |
| SeENet [15] | ResNet-101 | 81.2 |
| ANNNet [14] | ResNet-101 | 81.3 |
| CCNet [16] | ResNet-101 | 81.4 |
| DANet [13] | ResNet-101 | 81.5 |
| RPCNet [4] | ResNet-101 | 81.8 |
| CSEL [5] | HED ResNet-101 | 82.1 |
| DeepLabV3+ SBCB | ResNet-101 | 81.4 |
| DeepLabV3+ SBCB | HED ResNet-101 | 81.0 |
Table 25.
Results using ResNet backbones on the ADE20k validation split.
Table 25.
Results using ResNet backbones on the ADE20k validation split.
| Head | Backbone | Batch | SBCB | mIoU | |
|---|
| PSPNet | 50 | 8 | | 39.9 | |
| 50 | 8 | ✓ | 40.6 | +0.7 |
| 101 | 4 | | 38.2 | |
| 101 | 4 | ✓ | 38.7 | +0.5 |
| DeepLabV3+ | 50 | 8 | | 41.5 | |
| 50 | 8 | ✓ | 42.0 | +0.5 |
| 101 | 4 | | 37.7 | |
| 101 | 4 | ✓ | 38.2 | +0.5 |
Table 26.
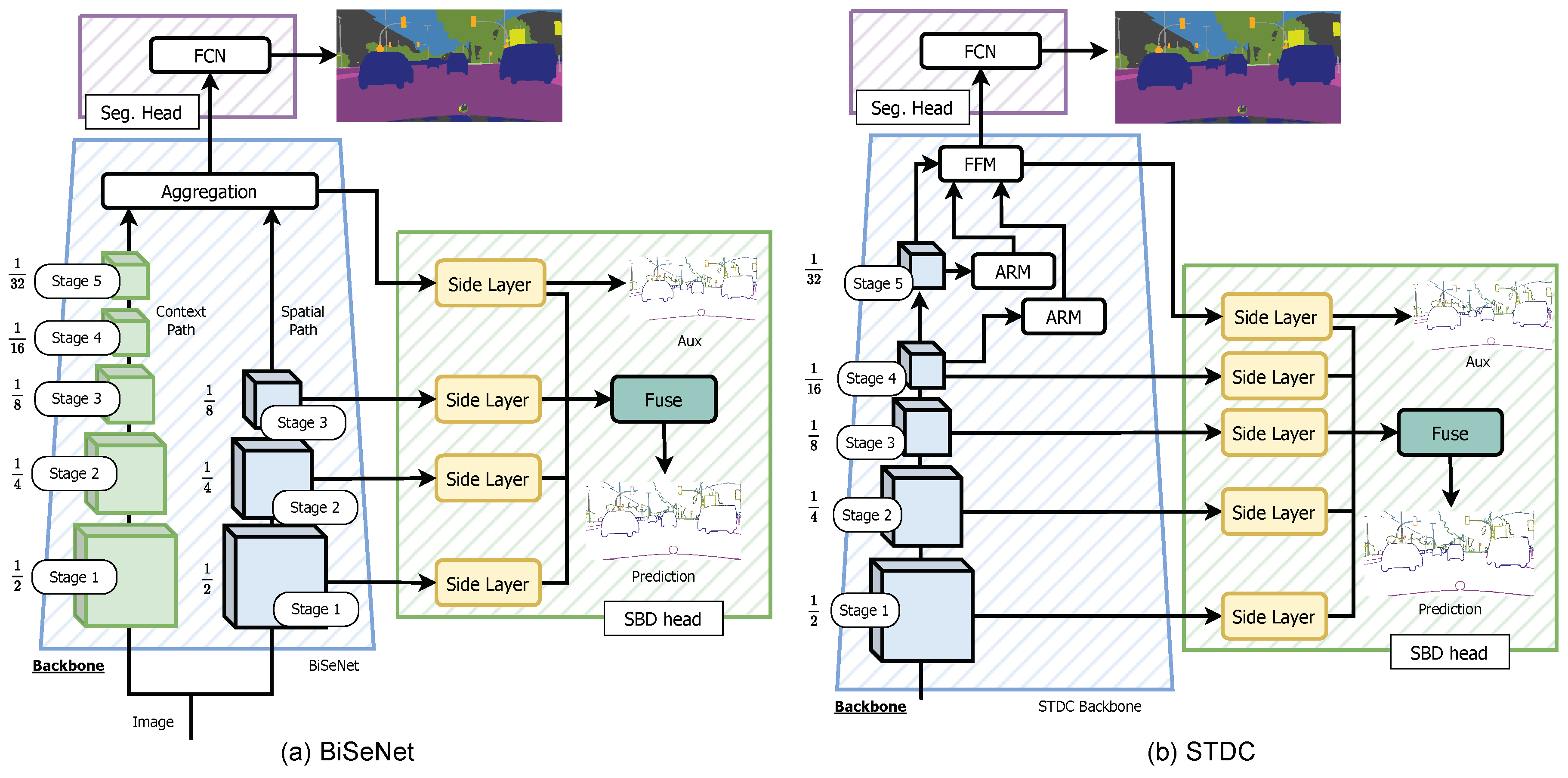
Results for BiSeNet and STDC on Cityscapes validation split.
Table 26.
Results for BiSeNet and STDC on Cityscapes validation split.
| Model | SBCB | mIoU | | F-Score | |
|---|
| BiSeNetV1 R50 | | 74.3 | | 66.0 | |
| ✓ | 75.4 | +1.1 | 69.9 | +3.9 |
| BiSeNetV2 | | 70.7 | | 63.8 | |
| ✓ | 71.6 | +0.9 | 66.2 | +2.4 |
| STDC V1 FCN (+Detail Head) | | 73.7 | | 66.5 | |
| STDC V1 FCN | ✓ | 75.4 | +1.7 | 67.9 | +1.4 |
Table 27.
Results of the SBCB framework on modern backbones/architectures on the Cityscapes validation split.
Table 27.
Results of the SBCB framework on modern backbones/architectures on the Cityscapes validation split.
| Head | Backbone | SBCB | mIoU | | F-Score | |
|---|
| | ConvNeXt-base | | 81.8 | | 74.4 | |
| | ✓ | 82.0 | +0.2 | 75.5 | +1.1 |
| UPerNet | Mod ConvNeXt-base | ✓ | 82.2 | +0.4 | 76.5 | +2.1 |
| | MiT-b0 | | 75.5 | | 66.9 | |
| SegFormer | ✓ | 76.5 | +1.0 | 68.1 | +1.2 |
| Mod MIT-b0 | ✓ | 76.8 | +1.3 | 69.7 | +2.8 |
| | MiT-b2 | | 80.9 | | 73.2 | |
| SegFormer | ✓ | 81.1 | +0.2 | 74.7 | +1.5 |
| Mod MIT-b2 | ✓ | 81.6 | +0.7 | 76.0 | +2.8 |
| SegFormer | MiT-b4 | | 81.6 | | 75.5 | |
| ✓ | 82.2 | +0.6 | 76.7 | +1.2 |
Table 28.
Comparison of feature fusion methods with baseline methods on Cityscapes.
Table 28.
Comparison of feature fusion methods with baseline methods on Cityscapes.
| Model | mIoU | | F-Score | |
|---|
| | | 77.6 | | 70.2 | |
| | +SBCB | 78.7 | +1.1 | 73.3 | +3.1 |
| PSPNet | Two-Stream Merge | 78.7 | +1.0 | 73.0 | +2.8 |
| | Channel-Merge | 79.1 | +1.5 | 73.2 | +3.0 |
| | | 79.5 | | 71.4 | |
| | +SBCB | 80.2 | +0.7 | 73.7 | +2.3 |
| DeepLabV3+ | Two-Stream Merge | 80.5 | +1.0 | 73.6 | +2.2 |
| | Channel-Merge | 80.5 | +1.0 | 74.5 | +3.1 |
Table 29.
Comparison of feature fusion methods with baseline methods on Synthia.
Table 29.
Comparison of feature fusion methods with baseline methods on Synthia.
| Model | mIoU | | F-Score | |
|---|
| | | 70.5 | | 63.7 | |
| | +SBCB | 71.7 | +1.2 | 65.9 | +2.2 |
| PSPNet | Two-Stream Merge | 71.3 | +0.8 | 65.5 | +1.8 |
| | Channel-Merge | 72.5 | +2.0 | 67.2 | +3.5 |
| | | 72.4 | | 67.2 | |
| | +SBCB | 73.5 | +1.1 | 69.1 | +1.9 |
| DeepLabV3+ | Two-Stream Merge | 73.8 | +1.4 | 69.2 | +2.0 |
| | Channel-Merge | 74.0 | +1.6 | 69.9 | +2.7 |






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











