Survey of Time Series Data Generation in IoT


Abstract
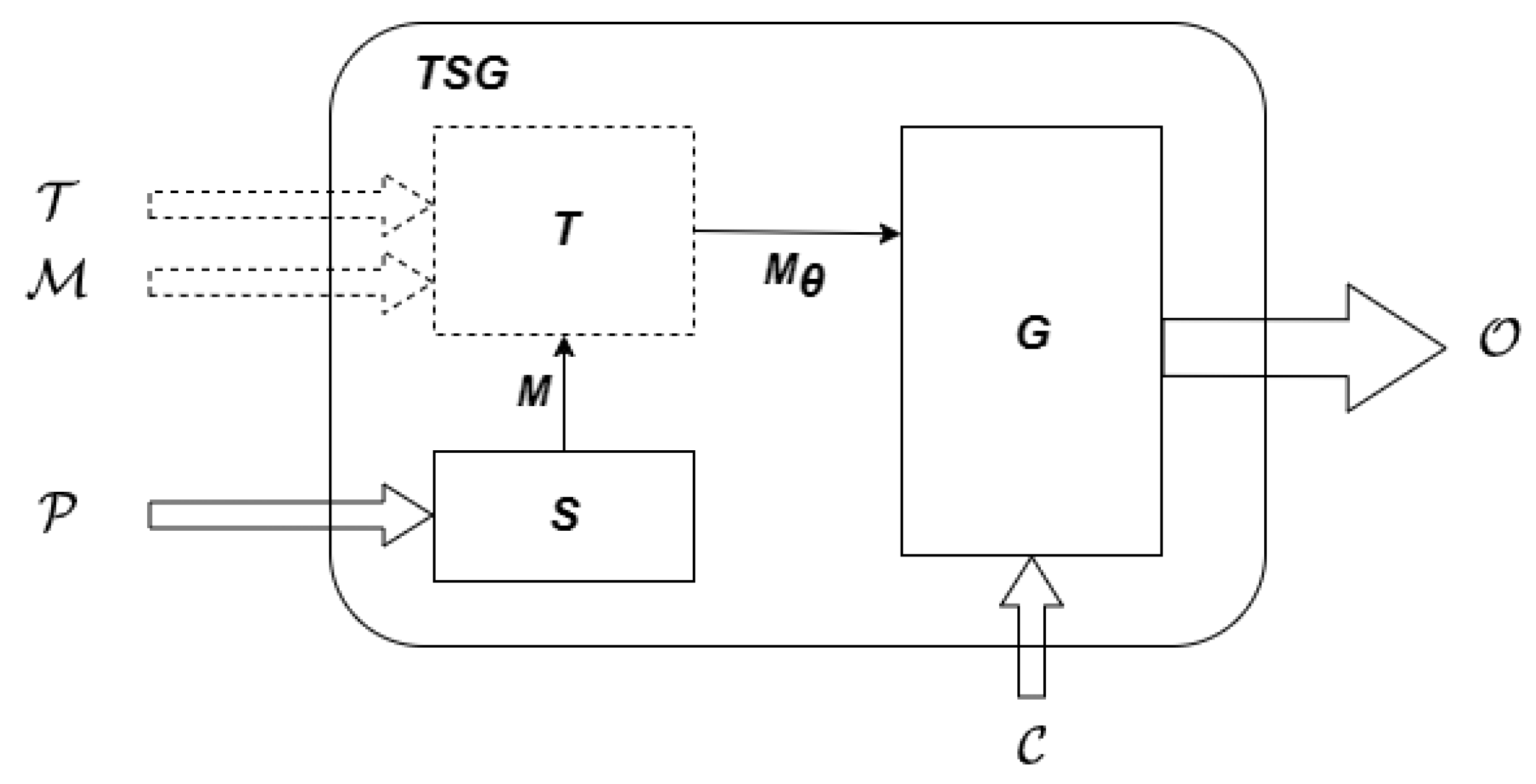
1. Introduction
- 1.
- The time series data generation methods are classified into four categories based on their underlying algorithms and models.
- 2.
- The characteristics, mechanisms and application scenarios of each category are illustrated.
- 3.
- The challenges and future directions of time series data generation are summarized.
2. Four Categories of Time Series Data Generation Methods
3. Rule-Based Methods
- 1.
- Simplicity and speed: Rule-based methods are simple, only need to define rules and parameters, and use random number generation. Therefore, the generation speed is fast, which can meet some scenarios with high real-time requirements.
- 2.
- Strong controllability: The properties of generating time series data can be easily controlled and adjusted using rule-based methods. By modifying the rules and parameters, data that meet specific needs can be easily generated.
- 3.
- Low reliance on historical data: Rule-based methods do not require a large amount of historical data to generate new data. This makes them useful in situations where historical data are scarce.
- 4.
- Lack of authenticity: Since the generated data are based on fixed rules and parameters, without considering the actual system behavior, they may be different from the actual data and lack authenticity.
- 5.
- Inability to simulate complex system behavior: These methods are generally unable to simulate complex system behavior, because the actual system behavior is often very complex and cannot be well described and simulated by simple rules and parameters.
3.1. Common Time Series Models
3.1.1. Autoregressive (AR) Model [66]
3.1.2. Moving-Average (MA) Model [67]
3.1.3. Autoregressive Moving-Average (ARMA) Model [68]
3.1.4. Autoregressive Integrated Moving-Average (ARIMA) Model [69]
3.2. Rule-Based Methods
3.2.1. FDG [51]
3.2.2. SRDG [52]
3.2.3. GRATIS [53]
4. Simulation-Model-Based Methods
- 1.
- Ability to simulate actual system behavior: Compared with the rule-based methods, simulation-model-based methods can simulate the behavior of actual systems more accurately, because the simulation models can analyze and model the actual system behavior and simulate the dynamic evolution of the system.
- 2.
- Interpretability of generated data: Through the analysis and adjustment of the simulation model, the reasons and rules of the generated data can be well explained, making the generated data more reliable and interpretable.
- 3.
- Reliance on model accuracy: The accuracy of the generated data is closely related to the accuracy of the model. If the accuracy of the model is not high, errors and deviations may also exist in the generated data.
- 4.
- Slow data generation speed: Compared with the rule-based random generation methods, simulation-model-based methods require model building, so the generation speed is relatively slow and cannot meet the high real-time requirements of the scene.
- 5.
- Limited data quantity: Due to the need of model building, a certain amount of historical data are required for training and adjustment of the model. Therefore, when the amount of data is insufficient, the accuracy and reliability of the generated data will be affected.
5. Traditional Machine-Learning-Based Methods
- 1.
- Ability to process data with more complex patterns: Traditional machine-learning-based methods can process data with more complex patterns, enabling them to better capture the complex relationships between data and generate more realistic data.
- 2.
- Fast data generation: The methods have fast data generation speeds, so they can produce large amounts of data in a short period of time.
- 3.
- Rely on model accuracy: The accuracy of the generated data is closely related to the accuracy of the model. If the accuracy of the model is not high, errors and deviations may exist in the generated data.
- 4.
- Sufficient historical data required: Due to the need to train the model, a certain amount of historical data are necessary for the training and adjustment of the model. Therefore, when the amount of data is insufficient, the accuracy and reliability of the generated data will be affected.
5.1. Markov Model
5.1.1. Discrete-Time Markov Chain [72]
5.1.2. Hidden Markov Model (HMM) [73]
5.2. Traditional Machine-Learning-Based Methods
6. Deep-Learning-Based Methods
- 1.
- Learning higher-level features: The deep generative models can learn higher-level features and can automatically capture nonlinear and complex relationships in the data, thereby generating more realistic and complex data.
- 2.
- Generating more diverse data: The methods can not only generate data with similar characteristics, but also generate more diverse data, which allows patterns of data to be shown from various angles. This enables a better data generalization ability.
- 3.
- Generating more realistic data: The deep generative models can learn the high-order statistical features of data, thereby generating more realistic data, and the differences between the data generated by the model and the real data are becoming smaller and smaller.
- 4.
- Difficulty in training: Compared with traditional machine learning models, the training processes of deep generative models are more complicated and require more computing resources and time.
- 5.
- High data volume: Deep generation models require large amounts of data for training. If the amount of training data is insufficient, the generalization ability of the model and the accuracy of the generated data will be affected.
6.1. GAN-Based Methods
6.1.1. C-RNN-GAN [44]
6.1.2. RCGAN [7]
6.1.3. SeqGAN [54]
6.1.4. T-CGAN [55]
6.1.5. TimeGAN [56]
6.1.6. DoppelGANger [57]
6.1.7. COT-GAN [58]
6.1.8. TS-Benchmark [30]
6.1.9. RTSGAN [59]
6.2. VAE-Based Methods
6.2.1. Variational Autoencoder
6.2.2. FSTS [60]
6.2.3. VRNN [61]
6.2.4. SRNN [62]
6.2.5. DSAE [63]
7. Challenges and Future Directions
- 1.
- High dimensionality of time series: Time series data usually have high dimensionality, which increases the difficulty of training the time series data generation model. Generative models need to have sufficient memory capacity while avoiding overfitting to handle noise and discontinuities in the generation processes.
- 2.
- Long-term dependencies: Time series data usually have long-term dependencies, that is, previous data points may have an impact on the generation of subsequent data points. Many traditional generative models do not handle such long-term dependencies well, and for some time series data, such dependencies can be very important.
- 3.
- Insufficient data samples: In some fields, such as healthcare and finance, the data may be very limited and rarely labeled. Therefore, how to efficiently train generative models to generate high-quality time series data remains a challenging problem.
- 1.
- More efficient model design: At present, many time series data generation models have been proposed, but most of them require long training times and large amounts of computing resources. Future directions may include designing more efficient models to reduce the training time and computational cost.
- 2.
- Better long-term dependency modeling: Time series data usually exhibit long-term dependencies, where previous data points may have an impact on the generation of subsequent data points. Future directions may include designing better generative models that can efficiently handle long-term dependencies and maintain data continuity and smoothness during generation.
- 3.
- Time series data generation applications based on deep learning and advanced technologies: With the development of deep learning and other advanced technologies, future development directions may include the development of more time series data generation applications, such as speech synthesis, music generation, video generation, machine translation, natural language generation, etc. These applications can be combined with other technologies, such as automation, augmented reality, and virtual reality, etc., to create more intelligent, natural, and real time series data generation applications.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, S.; Xu, L.D.; Zhao, S. The internet of things: A survey. Inf. Syst. Front. 2015, 17, 243–259. [Google Scholar]
- Mobaraki, B.; Pascual, F.J.C.; Garcia, A.M.; Mascaraque, M.Á.M.; Vázquez, B.F.; Alonso, C. Studying the impacts of test condition and nonoptimal positioning of the sensors on the accuracy of the in-situ U-value measurement. Heliyon 2023, 9, 17282. [Google Scholar] [CrossRef]
- Mobaraki, B.; Castilla Pascual, F.J.; Lozano-Galant, F.; Lozano-Galant, J.A.; Porras Soriano, R. In situ U-value measurement of building envelopes through continuous low-cost monitoring. Case Stud. Therm. Eng. 2023, 43, 102778. [Google Scholar] [CrossRef]
- Coxon, G.; Addor, N.; Bloomfield, J.P.; Freer, J.; Fry, M.; Hannaford, J.; Howden, N.J.; Lane, R.; Lewis, M.; Robinson, E.L.; et al. CAMELS-GB: Hydrometeorological time series and landscape attributes for 671 catchments in Great Britain. Earth Syst. Sci. Data 2020, 12, 2459–2483. [Google Scholar]
- Sezer, O.B.; Gudelek, M.U.; Ozbayoglu, A.M. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Appl. Soft Comput. 2020, 90, 106181. [Google Scholar]
- Feyrer, J. Trade and income—Exploiting time series in geography. Am. Econ. J. Appl. Econ. 2019, 11, 1–35. [Google Scholar] [CrossRef]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-valued (medical) time series generation with recurrent conditional gans. arXiv 2017, arXiv:1706.02633. [Google Scholar]
- Haradal, S.; Hayashi, H.; Uchida, S. Biosignal data augmentation based on generative adversarial networks. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 368–371. [Google Scholar]
- Li, H.; Xu, X.L.; Dai, D.W.; Huang, Z.Y.; Ma, Z.; Guan, Y.J. Air pollution and temperature are associated with increased COVID-19 incidence: A time series study. Int. J. Infect. Dis. 2020, 97, 278–282. [Google Scholar] [CrossRef]
- Liu, F.; Elliott, J.; Craig, T.; Hooper, A.; Wright, T. Improving the resolving power of InSAR for earthquakes using time series: A case study in Iran. Geophys. Res. Lett. 2021, 48, e2021GL093043. [Google Scholar] [CrossRef]
- Jensen, S.K.; Pedersen, T.B.; Thomsen, C. Time series management systems: A survey. IEEE Trans. Knowl. Data Eng. 2017, 29, 2581–2600. [Google Scholar] [CrossRef]
- Wang, C.; Huang, X.; Qiao, J.; Jiang, T.; Rui, L.; Zhang, J.; Kang, R.; Feinauer, J.; McGrail, K.A.; Wang, P.; et al. Apache iotdb: Time-series database for internet of things. Proc. Vldb Endow. 2020, 13, 2901–2904. [Google Scholar] [CrossRef]
- Ghaderpour, E.; Pagiatakis, S.D.; Hassan, Q.K. A survey on change detection and time series analysis with applications. Appl. Sci. 2021, 11, 6141. [Google Scholar] [CrossRef]
- Mudelsee, M. Trend analysis of climate time series: A review of methods. Earth-Sci. Rev. 2019, 190, 310–322. [Google Scholar]
- Feng, C.; Liu, Y.; Zhao, H. Periodic measures and Wasserstein distance for analysing periodicity of time series datasets. Commun. Nonlinear Sci. Numer. Simul. 2023, 120, 107166. [Google Scholar] [CrossRef]
- Puech, T.; Boussard, M.; D’Amato, A.; Millerand, G. A fully automated periodicity detection in time series. In Proceedings of the Advanced Analytics and Learning on Temporal Data: 4th ECML PKDD Workshop, AALTD 2019, Würzburg, Germany, 20 September 2019; Revised Selected Papers 4. Springer: Berlin/Heidelberg, Germany, 2020; pp. 43–54. [Google Scholar]
- Zhou, S.; Wang, X.; Zhou, W.; Zhang, C. Recognition of the scale-free interval for calculating the correlation dimension using machine learning from chaotic time series. Phys. Stat. Mech. Its Appl. 2022, 588, 126563. [Google Scholar] [CrossRef]
- Edelmann, D.; Fokianos, K.; Pitsillou, M. An updated literature review of distance correlation and its applications to time series. Int. Stat. Rev. 2019, 87, 237–262. [Google Scholar] [CrossRef]
- Park, M.H.; Chakraborty, S.; Vuong, Q.D.; Noh, D.H.; Lee, J.W.; Lee, J.U.; Choi, J.H.; Lee, W.J. Anomaly Detection Based on Time Series Data of Hydraulic Accumulator. Sensors 2022, 22, 9428. [Google Scholar] [CrossRef]
- Kim, B.; Alawami, M.A.; Kim, E.; Oh, S.; Park, J.; Kim, H. A Comparative Study of Time Series Anomaly Detection Models for Industrial Control Systems. Sensors 2023, 23, 1310. [Google Scholar] [CrossRef]
- Wang, C.; Xing, S.; Gao, R.; Yan, L.; Xiong, N.; Wang, R. Disentangled Dynamic Deviation Transformer Networks for Multivariate Time Series Anomaly Detection. Sensors 2023, 23, 1104. [Google Scholar] [CrossRef]
- Karim, F.; Majumdar, S.; Darabi, H.; Chen, S. LSTM fully convolutional networks for time series classification. IEEE Access 2017, 6, 1662–1669. [Google Scholar] [CrossRef]
- Wang, Z.; Yan, W.; Oates, T. Time series classification from scratch with deep neural networks: A strong baseline. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1578–1585. [Google Scholar]
- Ismail Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.A. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef]
- Bandara, K.; Bergmeir, C.; Smyl, S. Forecasting across time series databases using recurrent neural networks on groups of similar series: A clustering approach. Expert Syst. Appl. 2020, 140, 112896. [Google Scholar] [CrossRef]
- Maharaj, E.A.; D’Urso, P.; Caiado, J. Time Series Clustering and Classification; CRC Press: Boca Raton, FL, USA, 2019. [Google Scholar]
- Lin, H.; Bergmann, N.W. IoT privacy and security challenges for smart home environments. Information 2016, 7, 44. [Google Scholar] [CrossRef]
- Tawalbeh, L.; Muheidat, F.; Tawalbeh, M.; Quwaider, M. IoT Privacy and security: Challenges and solutions. Appl. Sci. 2020, 10, 4102. [Google Scholar] [CrossRef]
- Arlitt, M.; Marwah, M.; Bellala, G.; Shah, A.; Healey, J.; Vandiver, B. Iotabench: An internet of things analytics benchmark. In Proceedings of the 6th ACM/SPEC International Conference on Performance Engineering, Austin, TX, USA, 28 January–4 February 2015; pp. 133–144. [Google Scholar]
- Hao, Y.; Qin, X.; Chen, Y.; Li, Y.; Sun, X.; Tao, Y.; Zhang, X.; Du, X. Ts-benchmark: A benchmark for time series databases. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 588–599. [Google Scholar]
- Zhang, C.; Kuppannagari, S.R.; Kannan, R.; Prasanna, V.K. Generative adversarial network for synthetic time series data generation in smart grids. In Proceedings of the 2018 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), Aalborg, Denmark, 29–31 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Shamshad, A.; Bawadi, M.; Hussin, W.W.; Majid, T.A.; Sanusi, S. First and second order Markov chain models for synthetic generation of wind speed time series. Energy 2005, 30, 693–708. [Google Scholar] [CrossRef]
- Chen, P.; Pedersen, T.; Bak-Jensen, B.; Chen, Z. ARIMA-based time series model of stochastic wind power generation. IEEE Trans. Power Syst. 2009, 25, 667–676. [Google Scholar] [CrossRef]
- Shi, J.; Guo, J.; Zheng, S. Evaluation of hybrid forecasting approaches for wind speed and power generation time series. Renew. Sustain. Energy Rev. 2012, 16, 3471–3480. [Google Scholar] [CrossRef]
- Kardakos, E.G.; Alexiadis, M.C.; Vagropoulos, S.I.; Simoglou, C.K.; Biskas, P.N.; Bakirtzis, A.G. Application of time series and artificial neural network models in short-term forecasting of PV power generation. In Proceedings of the 2013 48th International Universities’ Power Engineering Conference (UPEC), Dublin, Ireland, 2–5 September 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–6. [Google Scholar]
- Bright, J.; Smith, C.; Taylor, P.; Crook, R. Stochastic generation of synthetic minutely irradiance time series derived from mean hourly weather observation data. Sol. Energy 2015, 115, 229–242. [Google Scholar] [CrossRef]
- Bokde, N.D.; Feijoo, A.; Al-Ansari, N.; Yaseen, Z.M. A comparison between reconstruction methods for generation of synthetic time series applied to wind speed simulation. IEEE Access 2019, 7, 135386–135398. [Google Scholar] [CrossRef]
- Talbot, P.W.; Rabiti, C.; Alfonsi, A.; Krome, C.; Kunz, M.R.; Epiney, A.; Wang, C.; Mandelli, D. Correlated synthetic time series generation for energy system simulations using Fourier and ARMA signal processing. Int. J. Energy Res. 2020, 44, 8144–8155. [Google Scholar] [CrossRef]
- Li, Y.; Hu, B.; Niu, T.; Gao, S.; Yan, J.; Xie, K.; Ren, Z. GMM-HMM-based medium-and long-term multi-wind farm correlated power output time series generation method. IEEE Access 2021, 9, 90255–90267. [Google Scholar] [CrossRef]
- Bogárdi, J.J.; Duckstein, L.; Rumambo, O.H. Practical generation of synthetic rainfall event time series in a semi-arid climatic zone. J. Hydrol. 1988, 103, 357–373. [Google Scholar] [CrossRef]
- Smakhtin, V.Y. Generation of natural daily flow time-series in regulated rivers using a non-linear spatial interpolation technique. Regul. Rivers Res. Manag. Int. J. Devoted River Res. Manag. 1999, 15, 311–323. [Google Scholar] [CrossRef]
- Efstratiadis, A.; Dialynas, Y.G.; Kozanis, S.; Koutsoyiannis, D. A multivariate stochastic model for the generation of synthetic time series at multiple time scales reproducing long-term persistence. Environ. Model. Softw. 2014, 62, 139–152. [Google Scholar] [CrossRef]
- Wiese, M.; Knobloch, R.; Korn, R.; Kretschmer, P. Quant GANs: Deep generation of financial time series. Quant. Financ. 2020, 20, 1419–1440. [Google Scholar] [CrossRef]
- Mogren, O. C-RNN-GAN: Continuous recurrent neural networks with adversarial training. arXiv 2016, arXiv:1611.09904. [Google Scholar]
- Koltuk, F.; Schmidt, E.G. A novel method for the synthetic generation of non-iid workloads for cloud data centers. In Proceedings of the 2020 IEEE Symposium on Computers and Communications (ISCC), Rennes, France, 7–10 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Manunta, M.; De Luca, C.; Zinno, I.; Casu, F.; Manzo, M.; Bonano, M.; Fusco, A.; Pepe, A.; Onorato, G.; Berardino, P.; et al. The parallel SBAS approach for Sentinel-1 interferometric wide swath deformation time-series generation: Algorithm description and products quality assessment. IEEE Trans. Geosci. Remote. Sens. 2019, 57, 6259–6281. [Google Scholar] [CrossRef]
- Chuvieco, E.; Englefield, P.; Trishchenko, A.P.; Luo, Y. Generation of long time series of burn area maps of the boreal forest from NOAA–AVHRR composite data. Remote. Sens. Environ. 2008, 112, 2381–2396. [Google Scholar] [CrossRef]
- Hilker, T.; Wulder, M.A.; Coops, N.C.; Seitz, N.; White, J.C.; Gao, F.; Masek, J.G.; Stenhouse, G. Generation of dense time series synthetic Landsat data through data blending with MODIS using a spatial and temporal adaptive reflectance fusion model. Remote. Sens. Environ. 2009, 113, 1988–1999. [Google Scholar] [CrossRef]
- Bonano, M.; Manunta, M.; Marsella, M.; Lanari, R. Long-term ERS/ENVISAT deformation time-series generation at full spatial resolution via the extended SBAS technique. Int. J. Remote. Sens. 2012, 33, 4756–4783. [Google Scholar] [CrossRef]
- Alzantot, M.; Chakraborty, S.; Srivastava, M. Sensegen: A deep learning architecture for synthetic sensor data generation. In Proceedings of the 2017 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kona, HI, USA, 13–17 March 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 188–193. [Google Scholar]
- Bruno, N.; Chaudhuri, S. Flexible database generators. In Proceedings of the 31st International Conference on Very Large Data Bases, Trondheim, Norway, 30 August–2 September 2005; pp. 1097–1107. [Google Scholar]
- Houkjær, K.; Torp, K.; Wind, R. Simple and realistic data generation. In Proceedings of the 32nd International Conference on Very Large Data Bases, Seoul, Republic of Korea, 12–15 September 2006; pp. 1243–1246. [Google Scholar]
- Kang, Y.; Hyndman, R.J.; Li, F. GRATIS: GeneRAting TIme Series with diverse and controllable characteristics. Stat. Anal. Data Mining ASA Data Sci. J. 2020, 13, 354–376. [Google Scholar] [CrossRef]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. Seqgan: Sequence generative adversarial nets with policy gradient. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Ramponi, G.; Protopapas, P.; Brambilla, M.; Janssen, R. T-cgan: Conditional generative adversarial network for data augmentation in noisy time series with irregular sampling. arXiv 2018, arXiv:1811.08295. [Google Scholar]
- Yoon, J.; Jarrett, D.; Van der Schaar, M. Time-series generative adversarial networks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Lin, Z.; Jain, A.; Wang, C.; Fanti, G.; Sekar, V. Using gans for sharing networked time series data: Challenges, initial promise, and open questions. In Proceedings of the ACM Internet Measurement Conference, Virtual Event, 27–29 October 2020; pp. 464–483. [Google Scholar]
- Xu, T.; Wenliang, L.K.; Munn, M.; Acciaio, B. Cot-gan: Generating sequential data via causal optimal transport. Adv. Neural Inf. Process. Syst. 2020, 33, 8798–8809. [Google Scholar]
- Pei, H.; Ren, K.; Yang, Y.; Liu, C.; Qin, T.; Li, D. Towards generating real-world time series data. In Proceedings of the 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 7–10 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 469–478. [Google Scholar]
- Zheng, Y.; Zhang, Z.; Cui, R. Few-Shot Learning for Time Series Data Generation Based on Distribution Calibration. In Proceedings of the Web Information Systems and Applications: 18th International Conference, WISA 2021, Kaifeng, China, 24–26 September 2021; Proceedings 18. Springer: Berlin/Heidelberg, Germany, 2021; pp. 198–206. [Google Scholar]
- Chung, J.; Kastner, K.; Dinh, L.; Goel, K.; Courville, A.C.; Bengio, Y. A recurrent latent variable model for sequential data. Adv. Neural Inf. Process. Syst. 2015, 28. Available online: https://github.com/jych/nips2015_vrnn (accessed on 1 July 2023).
- Fraccaro, M.; Sønderby, S.K.; Paquet, U.; Winther, O. Sequential neural models with stochastic layers. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Li, Y.; Mandt, S. Disentangled sequential autoencoder. arXiv 2018, arXiv:1803.02991. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. Acm 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Doersch, C. Tutorial on variational autoencoders. arXiv 2016, arXiv:1606.05908. [Google Scholar]
- Lewis, R.; Reinsel, G.C. Prediction of multivariate time series by autoregressive model fitting. J. Multivar. Anal. 1985, 16, 393–411. [Google Scholar] [CrossRef]
- Durbin, J. Efficient estimation of parameters in moving-average models. Biometrika 1959, 46, 306–316. [Google Scholar] [CrossRef]
- Kashyap, R.L. Optimal choice of AR and MA parts in autoregressive moving average models. IEEE Trans. Pattern Anal. Mach. Intell. 1982, PAMI-4, 99–104. [Google Scholar] [CrossRef] [PubMed]
- Nelson, B.K. Time series analysis using autoregressive integrated moving average (ARIMA) models. Acad. Emerg. Med. 1998, 5, 739–744. [Google Scholar] [CrossRef]
- Wong, C.S.; Li, W.K. On a mixture autoregressive model. J. R. Stat. Soc. Ser. (Stat. Methodol.) 2000, 62, 95–115. [Google Scholar] [CrossRef]
- Rinne, H. The Weibull Distribution: A Handbook; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Norris, J.R. Markov Chains; Number 2; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Rabiner, L.; Juang, B. An introduction to hidden Markov models. IEEE Assp Mag. 1986, 3, 4–16. [Google Scholar] [CrossRef]
- Xuan, G.; Zhang, W.; Chai, P. EM algorithms of Gaussian mixture model and hidden Markov model. In Proceedings of the 2001 International Conference on Image Processing (Cat. No. 01CH37205), Thessaloniki, Greece, 7–10 October 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 1, pp. 145–148. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Browne, C.B.; Powley, E.; Whitehouse, D.; Lucas, S.M.; Cowling, P.I.; Rohlfshagen, P.; Tavener, S.; Perez, D.; Samothrakis, S.; Colton, S. A survey of monte carlo tree search methods. IEEE Trans. Comput. Intell. Games 2012, 4, 1–43. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Villani, C. Optimal Transport: Old and New; Springer: Berlin/Heidelberg, Germany, 2009; Volume 338. [Google Scholar]


{kind=link}
| Method | References | The Need for Real Data | The Need for Domain-Specific Knowledge | Controllability of Results | Authenticity of Results | Simulating Complex IoT System Behavior |
|---|---|---|---|---|---|---|
| Rule-based methods | [51,52,53] | × | × | Strong | Weak | Weak |
| Simulation-model-based methods | [37,45] | ✓ | ✓ | Strong | Depends on the model | Depends on the model |
| Traditional machine-learning-based methods | [29,32,39] | ✓ | × | Weak | Depends on the model | Strong |
| Deep-learning-based methods | [7,30,44,54,55,56,57,58,59,60,61,62,63] | ✓ | × | Weak | Strong | Strong |
| Method | Reference | Support Condition/Metadata | Has Embedding | Other Features |
|---|---|---|---|---|
| C-RNN-GAN | [44] | × | × | |
| RCGAN | [7] | ✓ | × | ”Train on synthetic data, test on real data“ strategy |
| SeqGAN | [54] | × | × | Modeling the generator as a RL policy |
| T-CGAN | [55] | ✓(timestamp only) | × | Support for input data with missing value |
| TimeGAN | [56] | ✓ | ✓ | Combination of supervised and unsupervised loss |
| DoppelGANger | [57] | ✓ | × | Separating the generation and discrimination of metadata from time series data |
| COT-GAN | [58] | × | × | Utilization of causal optimal transport theory |
| TS-Benchmark | [30] | ✓ | × | Generating pieces of time series data and splicing them together |
| RTSGAN | [59] | ✓ | ✓ | Fixed length vector in the latent space; support for input data with missing value |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, C.; Sun, Z.; Li, C.; Zhang, Y.; Xing, C. Survey of Time Series Data Generation in IoT. Sensors 2023, 23, 6976. https://doi.org/10.3390/s23156976
Hu C, Sun Z, Li C, Zhang Y, Xing C. Survey of Time Series Data Generation in IoT. Sensors. 2023; 23(15):6976. https://doi.org/10.3390/s23156976
Chicago/Turabian StyleHu, Chaochen, Zihan Sun, Chao Li, Yong Zhang, and Chunxiao Xing. 2023. "Survey of Time Series Data Generation in IoT" Sensors 23, no. 15: 6976. https://doi.org/10.3390/s23156976
APA StyleHu, C., Sun, Z., Li, C., Zhang, Y., & Xing, C. (2023). Survey of Time Series Data Generation in IoT. Sensors, 23(15), 6976. https://doi.org/10.3390/s23156976