1. Introduction
The rapid development of autonomous vehicles requires continuous improvement in the ability to perceive the environment around the vehicle. One of the main perception modules is vision-based lane detection. Traditionally, the task of lane detection has been attempted by using hand-crafted algorithms, such as color-based [
1,
2] or Hough Transform [
3,
4]. Despite being able to detect at rapid speed, these methods prove to be limited as they are not robust enough against the vast variations in real-world road scenes, such as poorly marked lanes, shadows, low illumination, or occlusion. More recently, this problem has been mainly shifted towards the field of deep learning, more specifically Convolutional Neural Networks (CNNs), as they are capable of outstanding accuracy across numerous applications. Wen et al. [
5] propose a unified viewpoint transformation (UVT) method that transforms the camera viewpoints of different datasets into a common virtual world coordinate system to tackle the dataset bias between the training and test datasets to improve lane detection performance. Li et al. [
6] presents a framework of two types of deep neural networks to learn the structures for visual analytics. The first is the convolutional neural network (CNN) to build global objects (location and orientation). The second is the recurrent neural network (RNN) to detect local visual lanes in a traffic scene. This work leads to superior recognition performance. Kim et al. [
7] present a method that combines the random sample consensus (RANSAC) algorithm with the convolutional neural network (CNN) to improve the accuracy of traffic lane detections. RetinaNet [
8] proposes a detection and classification method for various types of arrow markings and bike markings on the road in various complex environments using a one-stage deep convolutional neural network (CNN). LkLaneNet [
9] proposes a novel multi-lane detection method called Large Kernel Lane Network to detect multiple lanes accurately and efficiently in challenging scenarios. ZF-VPGNet [
10] builds a multi-task learning network consisting of multi-label classification, grid box regression, and object mask. This work obtains the correct results and achieves high accuracy and robustness. Alam et al. [
11] propose a lane detection method using the microlens array-based light field camera image that uses the additional angular information. This approach increases accuracy in challenging conditions, such as illumination variation, shadows, false lane lines, and worn lane markings. Chao et al. [
12] combine a deep convolutional neural network to classify the lane images at the pixel level with the Hough transform to determine the interval and the least square method to fit lane marking. This approach helps to improve the accuracy performance to 98.74 %. Zhang et al. [
13] use a monocular camera to study a lane-changing warning algorithm for highway vehicles based on deep learning image processing. This system improves vehicle driving safety in a low-cost manner. SUPER [
14] proposes a novel lane detection system consisting of a hierarchical semantic segmentation network as the scene feature extractor and a physics-enhanced multi-lane parameter optimization module for lane inference. This approach provides better accuracy.
These above approaches show their effectiveness in improving the accuracy performance; however, the calculation costs are incredibly high because they utilize a heavy deep learning network. These networks need to be simplified to apply this application on embedded devices with limited resources. LLDNet [
15] introduced a lightweight CNN model based on an encoder–decoder architecture that makes it suitable for being implemented in embedded devices. Podbucki et al. [
16] present an NVIDIA Jetson Xavier AGX embedded system to process video sequences for lane detection. Jayasinghe et al. [
17] propose a simple, lightweight, end-to-end deep learning-based framework coupled with the row-wise classification formulation for fast and efficient lane detection. This system is implemented on an Nvidia Jetson AGX Xavier embedded system to achieve a high inference speed of 56 frames per second (FPS). Liu et al. [
18] propose a lightweight network, named as LaneFCNet, combined with the conditional random field for lane detection to reduce processing time. Hassan et al. [
19] discuss an improved CNN-based detection system for autonomous roads to identify potholes, cracks, and yellow lanes. This system is implemented and verified on the Jetson TX2 embedded system. Due to the limitations of processing power, memory, and other resources of the embedded devices, these approaches are hard to reach in real-time for their processing.
To speed up processing for real-time applications, the hardware platforms are used to design and implement. Martin et al. [
20] present an algorithm for detecting lane markings from images. It is designed and implemented in Field Programmable Gate Arrays (FPGA) technology on Zynq-7000 System-on-Chip (SoC). The algorithm uses traditional computer vision techniques to obtain lane markings and detect driving lanes. Kojima et al. [
21] presents an autonomous driving system consisting of lane-keeping, localization, driving planning, and obstacle avoidance that are implemented as software in the embedded processor on FPGA. Wang et al. [
22] propose a detailed procedure that helps guide the performance optimization of parallelized ADAS applications in an FPGA-Graphics Processing Unit (GPU) combined heterogeneous system. Kamimae et al. [
23] develop an SoC FPGA based on the Helmholtz Principle to control unmanned mobile vehicles for the FPGA design competition. Peng et al. [
24] build a multi-task learning framework for lane detection, semantic segmentation, 2D object detection, and orientation prediction on FPGA. The performance on FPGA is optimized by software and hardware co-design to achieve 55 FPS. A CNN for drivable region segmentation from a LiDAR sensor called ChipNet [
25,
26] is designed and implemented on FPGA, which achieves 79.43 FPS. Utilizing the scheme presented in [
27], RoadNet-RT [
28] designs and implements a CNN on FPGA using 8-bit quantization. Their FPGA implementation achieves 197.7 FPS. These approaches obtain good performance in processing speed; however, the trade-off among processing speed, accuracy, hardware resources, and power consumption is not fully discussed in these studies.
The segmentation is a common strategy for lane detection works. This strategy typically outputs a pixel map with an identical size to the input RGB image, where each pixel is classified into a different class, such as roads, cars, pedestrians, etc. U-Net [
29] presents a full convolution network and training strategy that relies on the strong use of data augmentation to work with very few training images and yields more precise segmentations in the biomedical field. ENet [
30] proposes a novel deep neural network architecture on embedded systems to perform real-time semantic segmentation. SegNet [
31] presents a segmentation engine consisting of an encoder network and a corresponding decoder network followed by a pixel-wise classification layer. The decoder uses pooling indices computed in the max-pooling step of the corresponding encoder to perform non-linear upsampling. This eliminates the need for learning to upsample. The upsampled maps are sparse and are then convolved with trainable filters to produce dense feature maps. This design achieves good segmentation performance. Zou et al. [
32] propose a hybrid deep architecture by combining the convolutional neural network (DCNN) and the recurrent neural network (DRNN), where the DCNN consists of an encoder and a decoder with fully-convolution layers, and the DRNN is implemented as a long short-term memory (LSTM) network. The DCNN abstracts each frame into a low-dimension feature map, and the LSTM takes each feature map as a full-connection layer in the timeline and recursively predicts the lane. The LSTM is found to be very effective for information prediction and significantly improves the performance of lane detection in the semantic segmentation framework. Davy et al. [
33] design a branched, multi-task network for lane instance segmentation, consisting of a lane segmentation branch and a lane embedding branch that can be trained end-to-end. The lane segmentation branch has two output classes, background or lane, while the lane embedding branch further disentangles the segmented lane pixels into different lane instances. This approach can handle various lanes and cope with lane changes.
While methods utilizing the segmentation technique yield accurate results, they suffer from low efficiency. For example, lane markings are slim and continuous lines that do not require clusters of dense pixels to represent. Moreover, segmentation requires significant post-processing to extract geometric information about the lane lines, which introduces further inefficiency.
Figure 1 illustrates lane segmentation. Recent studies attempted to solve this problem by substituting dense pixel segmentation for sparser or more descriptive representations. Inspired by the Region Proposal Network (RPN) of Faster R-CNN [
34], Line-CNN [
35] utilizes the line proposal unit (LRU) to predict lanes using predefined straight rays. PolyLaneNet [
36] attempts to frame lane detection as a polynomial regression problem. UFAST [
37] proposes a row-wise formulation, where the output is a series of horizontal locations corresponding to predefined row anchors. This work puts emphasis on obtaining real-time speed. Later, CondLaneNet [
38] adds a vertical range and offset map to improve the row-wise formulation. Another approach is PINet [
39], which predicts sparse key points from the input image, which is then clustered into different instances by an embedding branch. However, the runtime results of these models are evaluated on power-hungry GPUs. Despite obtaining state-of-the-art accuracy, the massive power consumption of these GPUs proves impractical for power-constrained systems on cars.
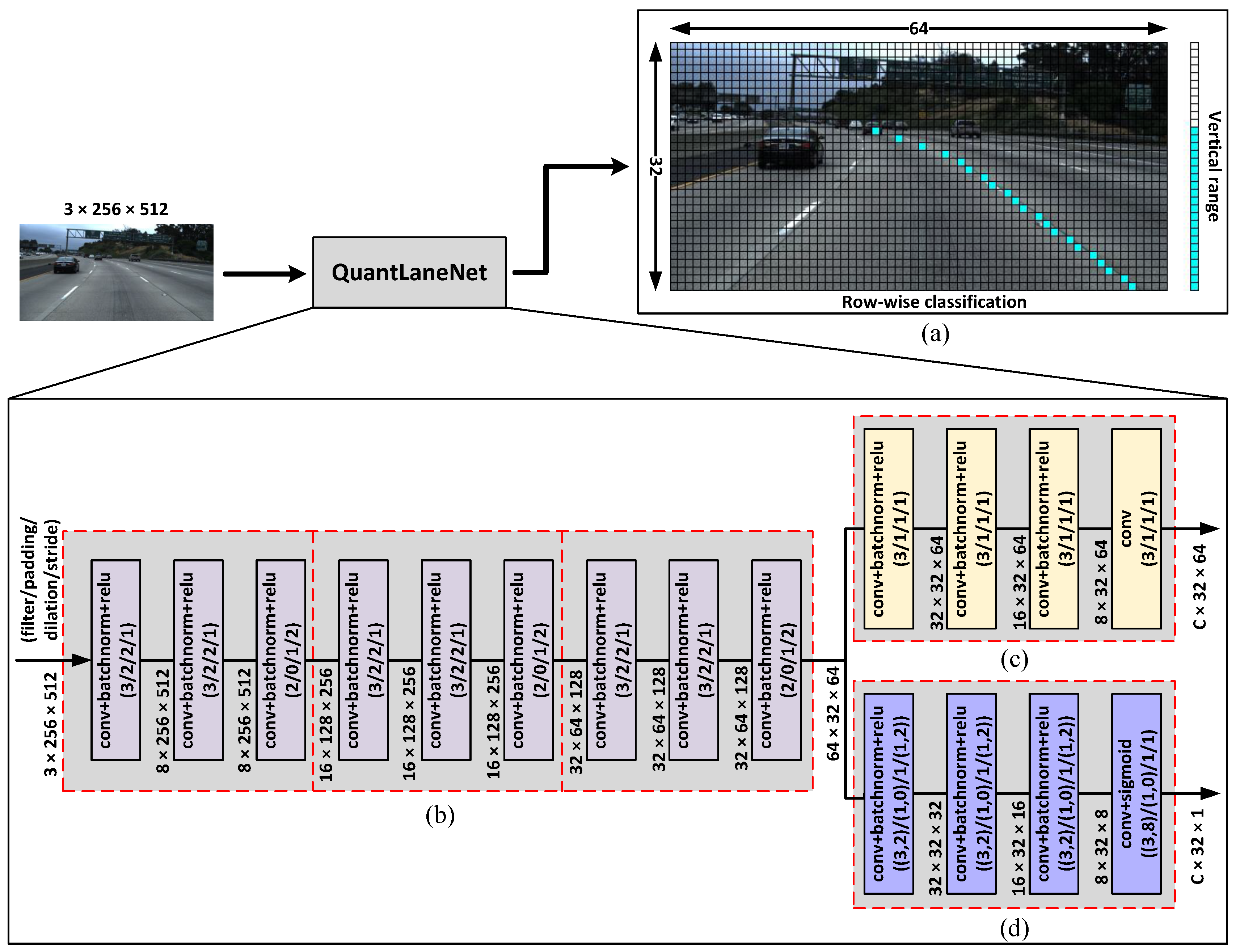
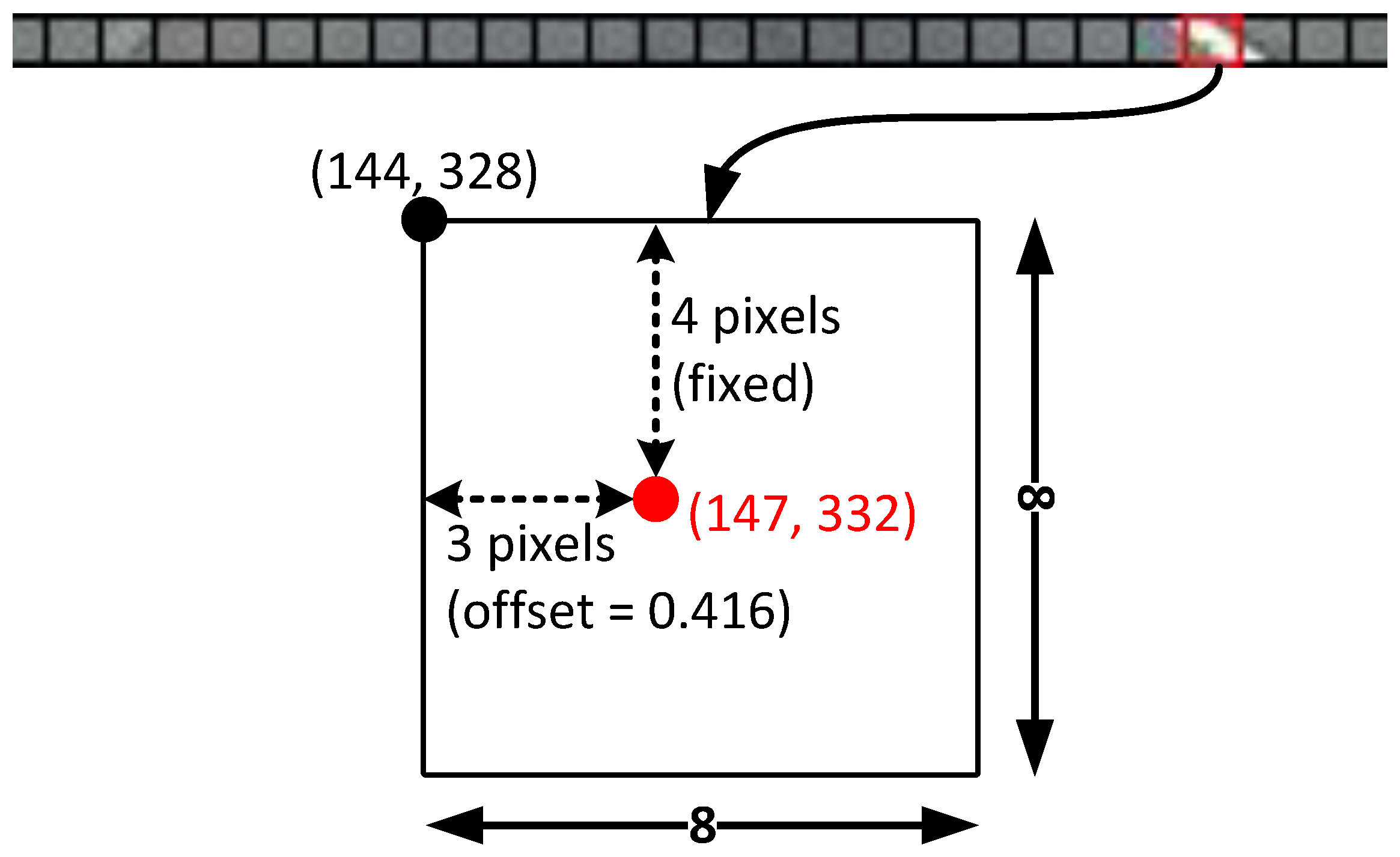
In this work, we propose a simple and efficient lane representation format alongside a lightweight lane detection CNN, named QuantLaneNet, to achieve real-time processing at the low cost of hardware design resources and power consumption. Meanwhile, the accuracy of traffic lane detection is relatively close to the related works. The contributions of this paper are summarized as follows:
To efficiently represent the geometric information of lane markings, we propose a lightweight format that only requires two small arrays for minimum post-processing instead of segmentation maps. Using our format as the shape for the output, we propose a simple and lightweight CNN for the task of lane detection. The model consists of three encoder stages to extract features from the input image and two output branches that produce the two matrices which make up our proposed lane representation format. Our model only contains 102k parameters and achieves 348.34 FPS on the NVIDIA Tesla T4 GPU.
To optimize processing speed and power consumption, a corresponding hardware accelerator is designed and implemented on Xilinx Virtex-7 VC707 FPGA as a Peripheral Component Interconnect Express (PCIe) device. By optimizing the techniques, such as data quantization to reduce data width down to 8-bit and exploring various loop-unrolling strategies for different convolution layers, and pipelined computation across layers, our architecture achieves very high throughput while consuming very little power compared to other studies. Using the verification system described in
Section 5.2, our FPGA system achieves 640 FPS while consuming only 10.309 Watts (W), which equates to a throughput of 345.6 giga operations per second (GOPS) and an energy efficiency of 33.52 GOPS/W. The trade-off in accuracy due to data quantization is negligible, and the overall accuracy is relatively close to that of the related works.
The rest of the paper is organized as follows.
Section 2 presents the background of this work.
Section 3 presents the proposed lane representation format and CNN model, along with training and evaluation details.
Section 4 describes several optimizations for designing a hardware accelerator, and the implementation of the final design is presented in
Section 5. Finally,
Section 6 concludes this paper.
2. Background
2.1. Convolutional Neural Networks
Convolutional neural networks (CNNs) have gained prominence in the field of computer vision due to their ability to capture spatial patterns in images. For images, their visual meaning comes from local and global patterns instead of the values of each individual pixel that makes up the image. By applying sliding windows (called kernels) on the input image, CNNs can capture local patterns from each group of pixels. During training, the values of the kernels (called parameters or weights) can be “learned” so that each convolutional layer can extract the correct features relative to its purpose, as opposed to handcrafted kernels that can be susceptible to variations in the environment.
Each convolutional layer can be configured differently by changing its kernel size, padding, stride, and dilation. A larger kernel size can give the layer a bigger depth of field but will increase the number of parameters dramatically. Padding is used to add border pixels to the input to preserve the output size. Stride determines the step size of the sliding kernel. It affects the receptive field of the layer and will typically reduce the size of the output, unless padding is applied. Dilation adds gaps in the kernel so that the kernel’s depth of field can be increased without adding more parameters. All of these values can be used in combination with each other for many reasons, such as manipulating the size of the output or emphasizing local or global patterns, among others.
A convolutional layer is typically followed by a non-linear activation function, such as ReLU or sigmoid. In a supervised training context, a dataset with inputs and human-labeled correct outputs is used. The inputs are fed through the model, and a “score”, formally referred to as the loss, is calculated from the outputs and the labels using the loss function. Through backpropagation, the parameters within the model are incrementally adjusted to minimize the loss value through many training iterations. Based on many elements such as purpose, the shape of the output, model’s architecture, etc., the loss function will have to be carefully chosen, or in many cases, developed, to achieve the best accuracy.
2.2. Data Quantization
Data quantization is a commonly used technique with the main aim of decreasing the quantity of discrete values present in a given system. The method involves representing a continuous or high-resolution range of values with a limited range of discrete values, typically in a much lower bit width. The utilization of this technique extends to diverse fields, including signal processing, data compression, and machine learning. Within the domain of machine learning, it assumes a pivotal role in the optimization of neural network inference. Instead of retaining the floating-point values used in training, the technique converts these values into a low-precision representation to use in inference. This not only reduces the memory footprint of the system but also decreases processing time and complexity significantly.
Despite the numerous advantages of quantization, the data precision of the system will inevitably be compromised. The amount of memory/speed to precision trade-off will have to be evaluated by the designer to best fit the requirements of each specific system.
2.3. Dataset and Accuracy Formulation
The open-source TuSimple dataset [
40], which annotates lanes as the sets of horizontal coordinates corresponding to fixed vertical coordinates. TuSimple dataset includes 3626 video clips, 3626 annotated frames for the training phase, and 2782 video clips for the testing phase. These videos cover the good and medium weather conditions at different daytime. They include 2-lane, 3-lane, and 4-lane roads in different traffic conditions. The main evaluation metrics for TuSimple are accuracy, false positive, and false negative. Accuracy is defined by Equation (
1), where
is the number of correct points in the frame and
is the number of requested points:
False positive (FP) and false negative (FN) are defined by Equations (
2) and (
3), respectively, where
is the number of wrongly predicted lanes,
is the number of all predicted lanes,
is the number of missed ground-truth lanes in the prediction and
is the number of all ground-truth lanes:

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}