
Evaluation of Open-Source Tools for Differential Privacy

 and
and
Abstract
1. Introduction
1.1. Differential Privacy
1.2. A Brief Review of Open-Source Tools with DP Services
1.2.1. OpenDP Smartnoise
1.2.2. Google DP
1.2.3. Opacus
1.2.4. Tensorflow Privacy
1.2.5. Diffprivlib
1.2.6. Chorus
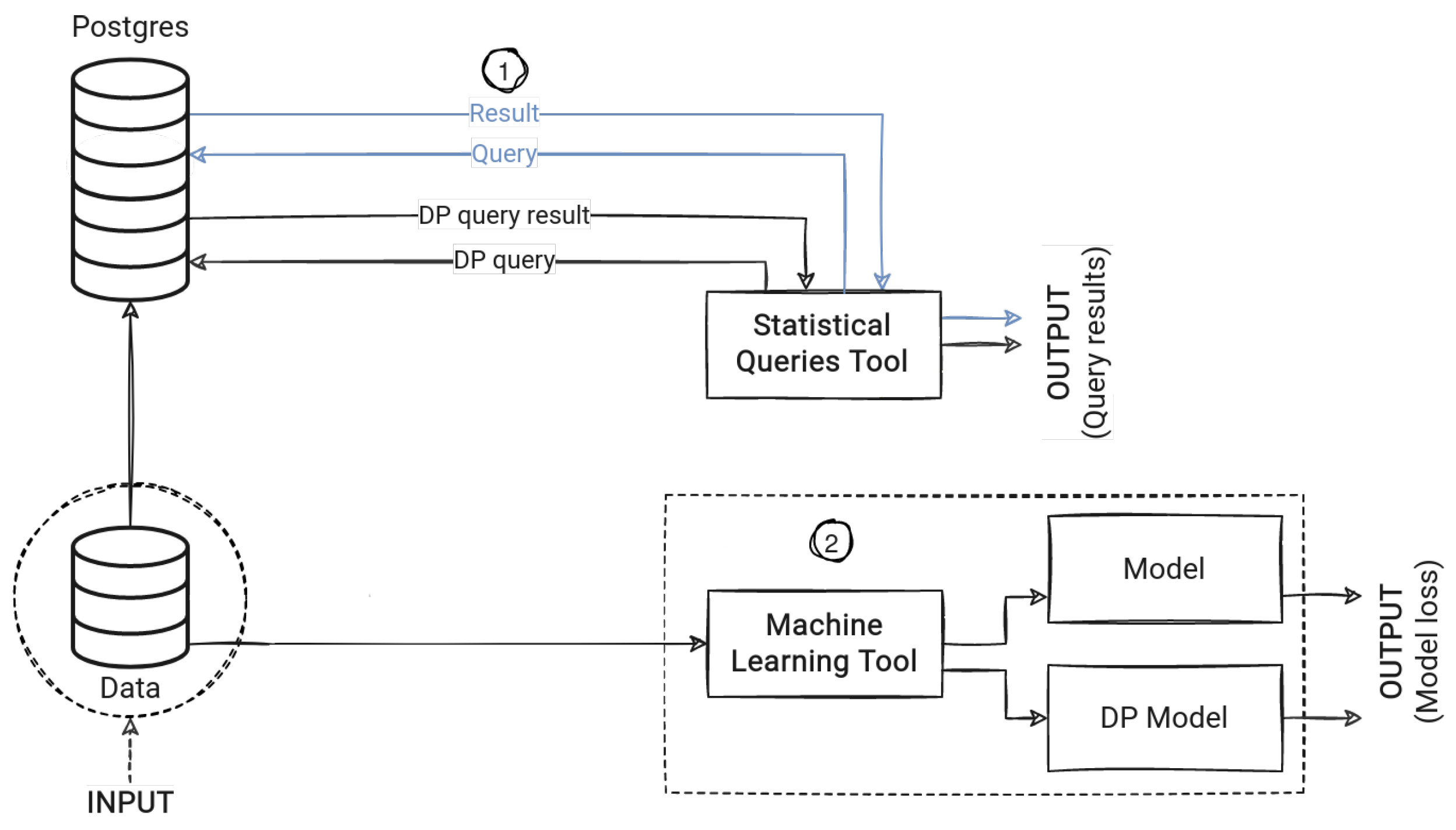
1.3. Evaluation Approach
1.3.1. The United States Health Reform Monitoring Survey Data
1.3.2. The UCI Parkinson Dataset
1.4. Our Contribution
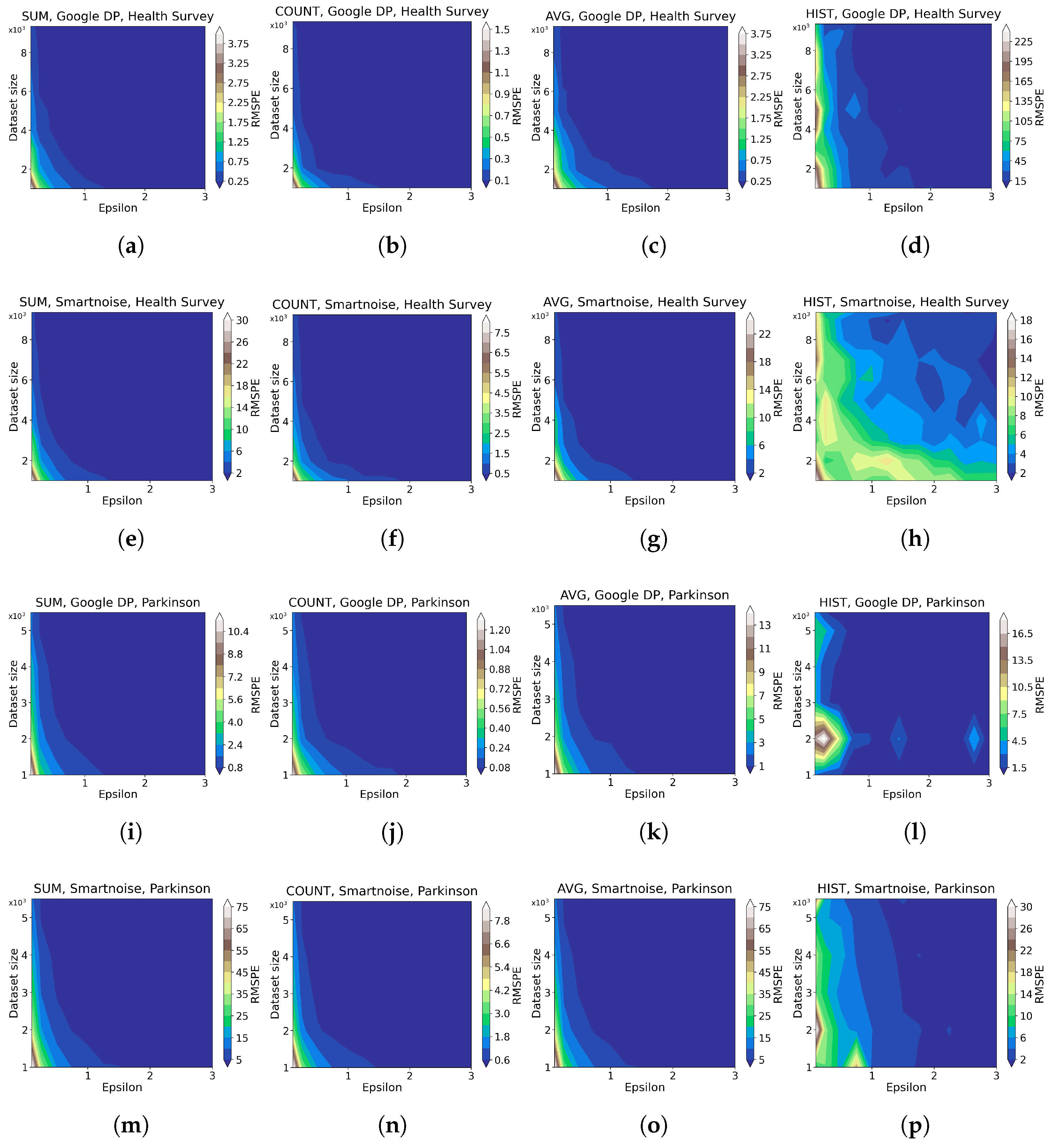
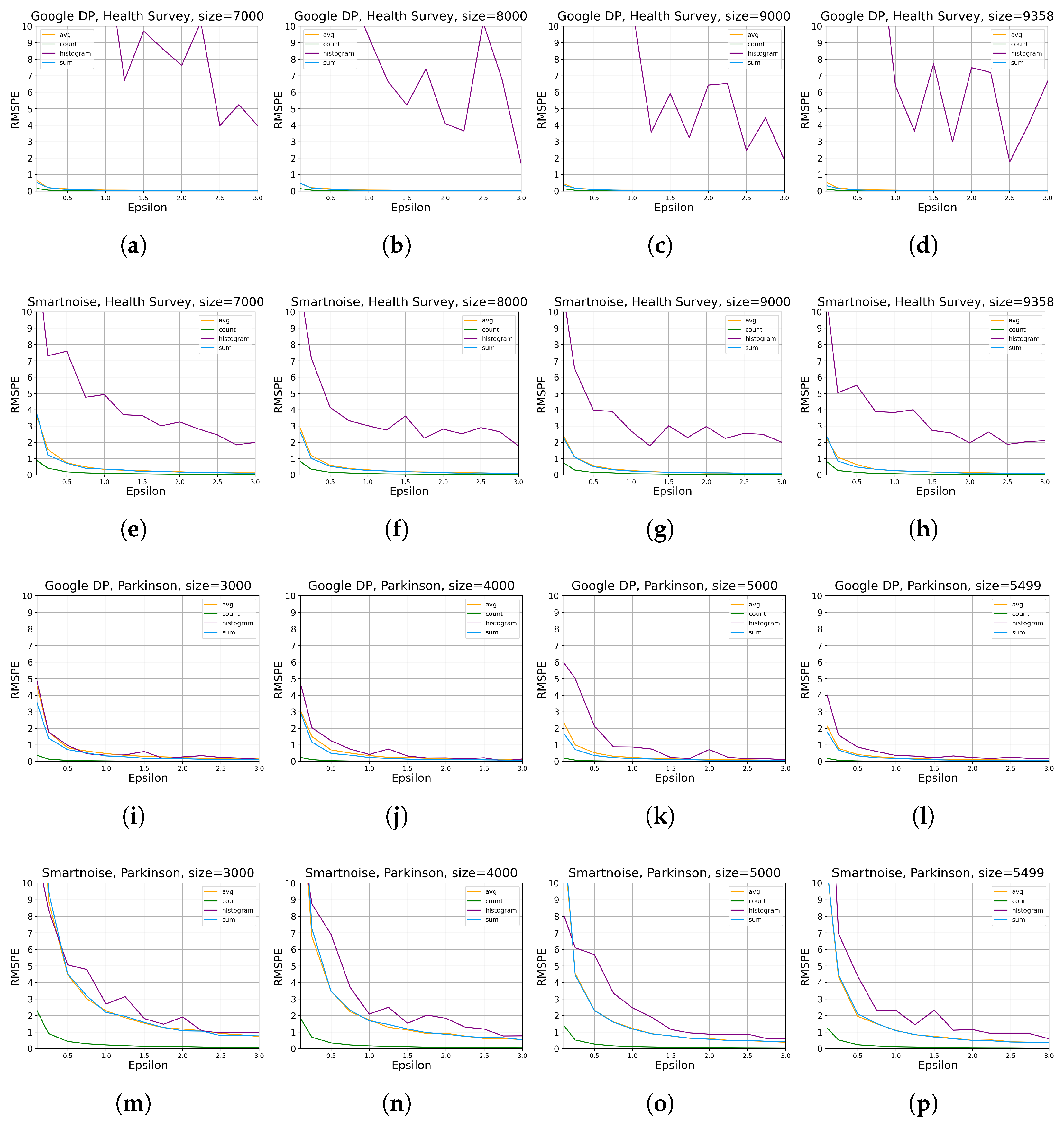
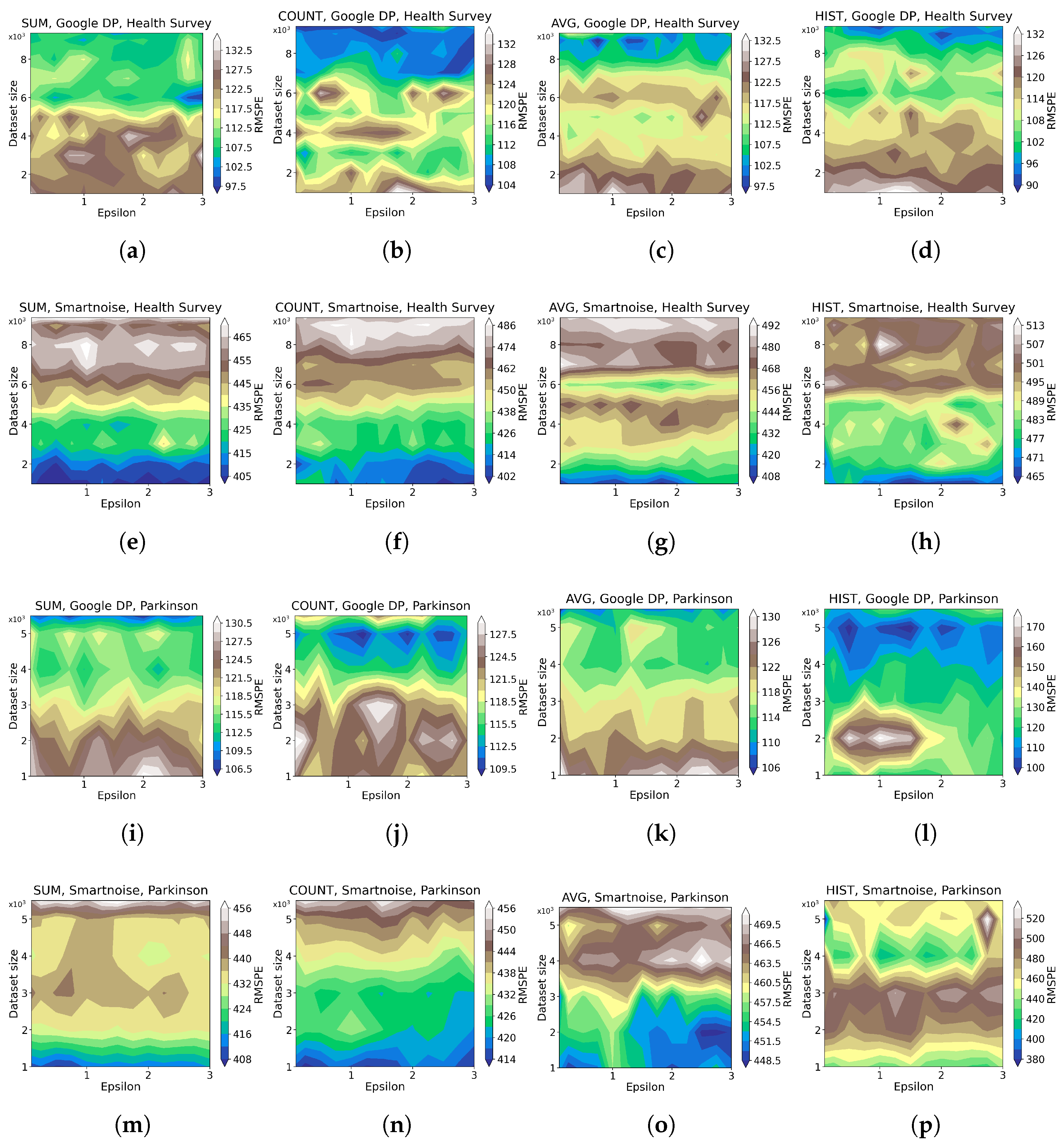
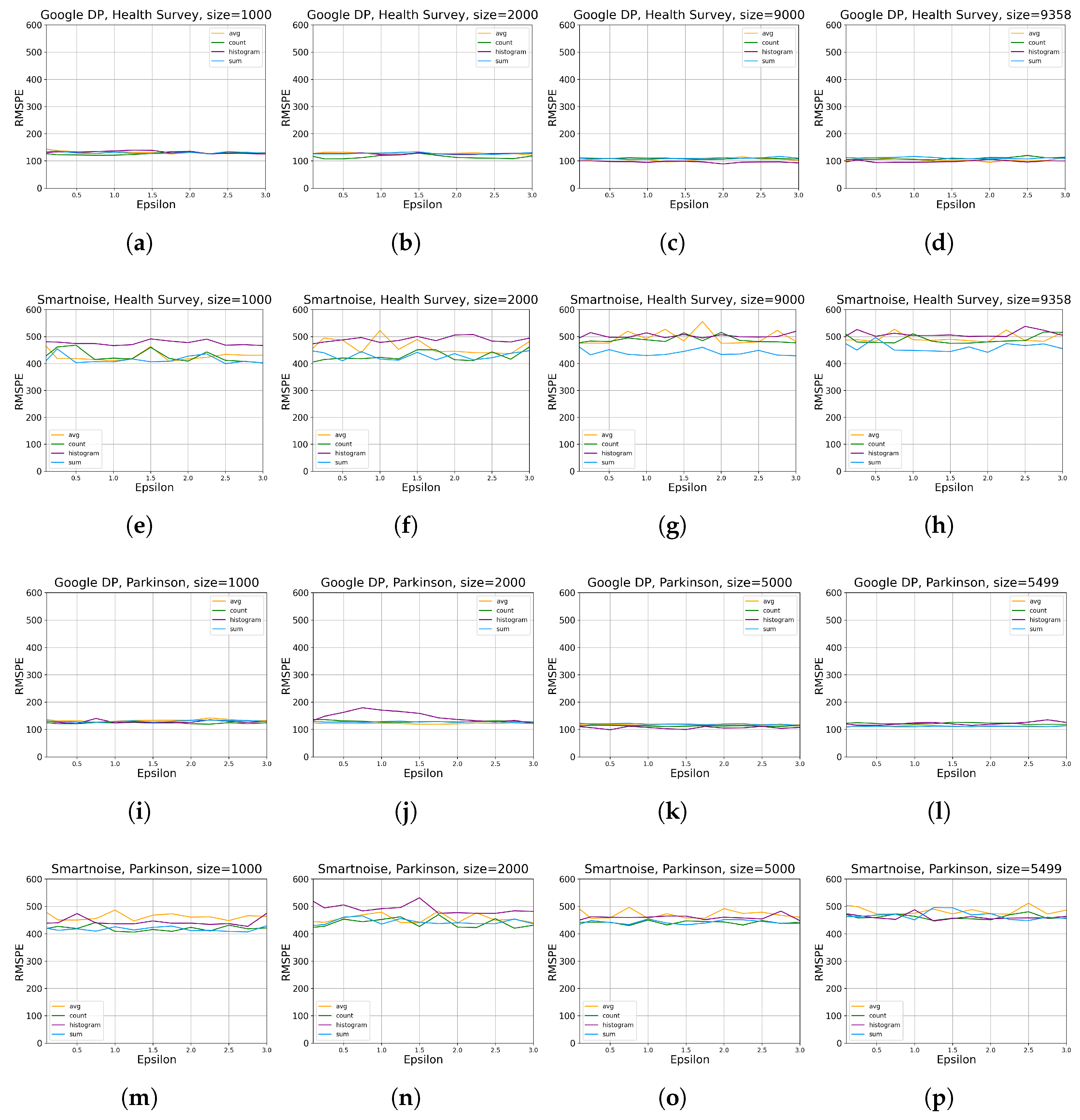
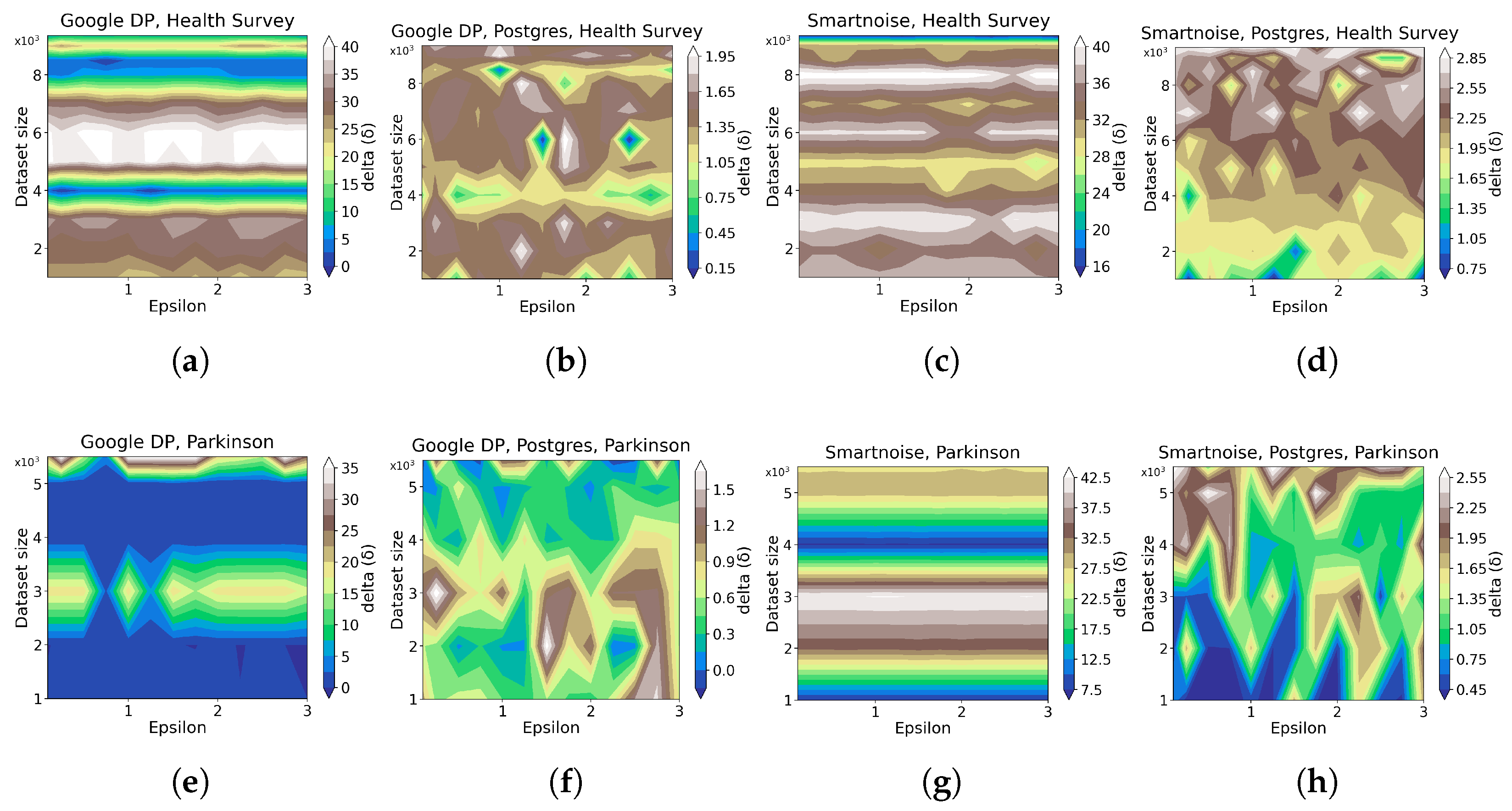
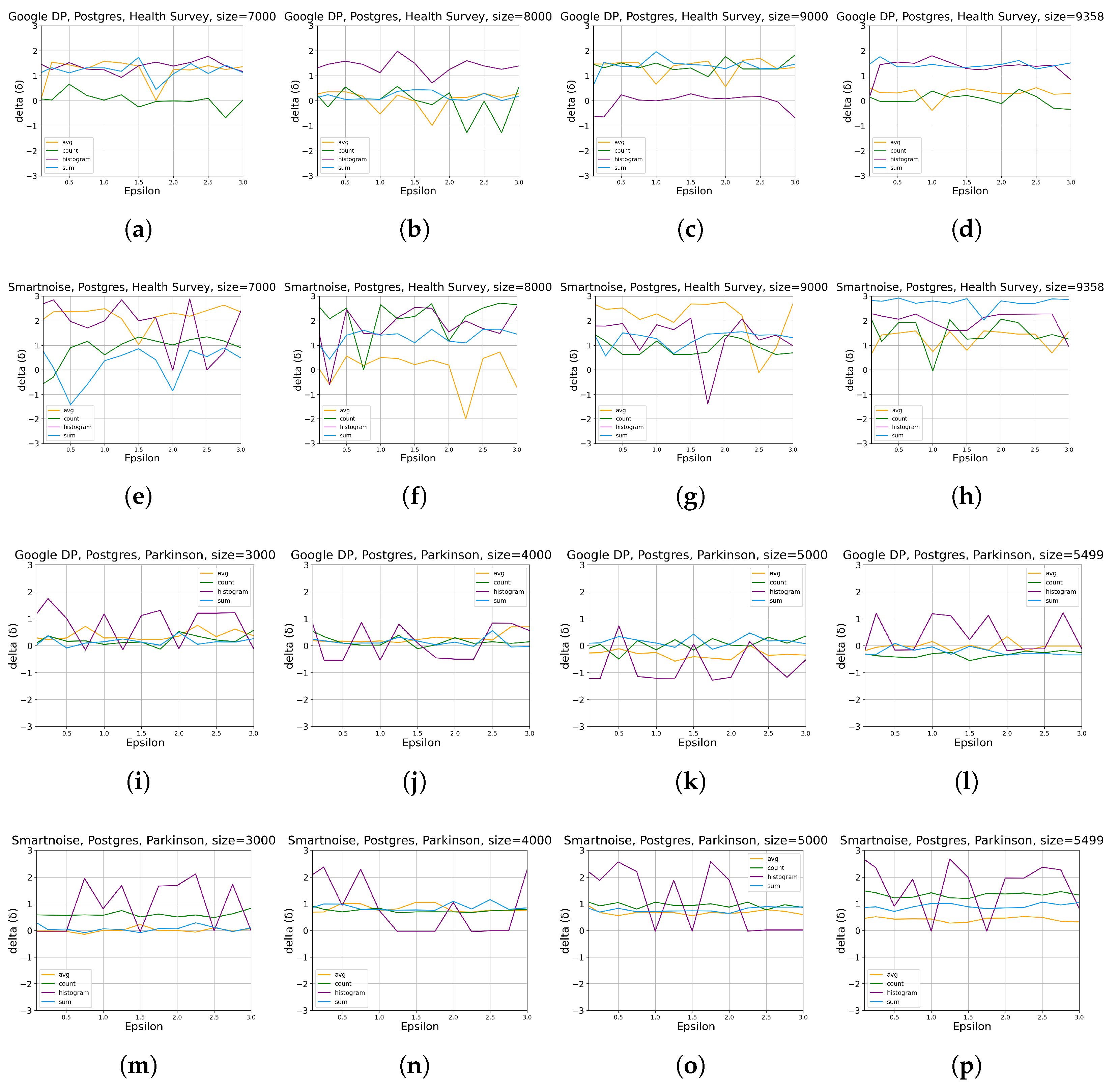
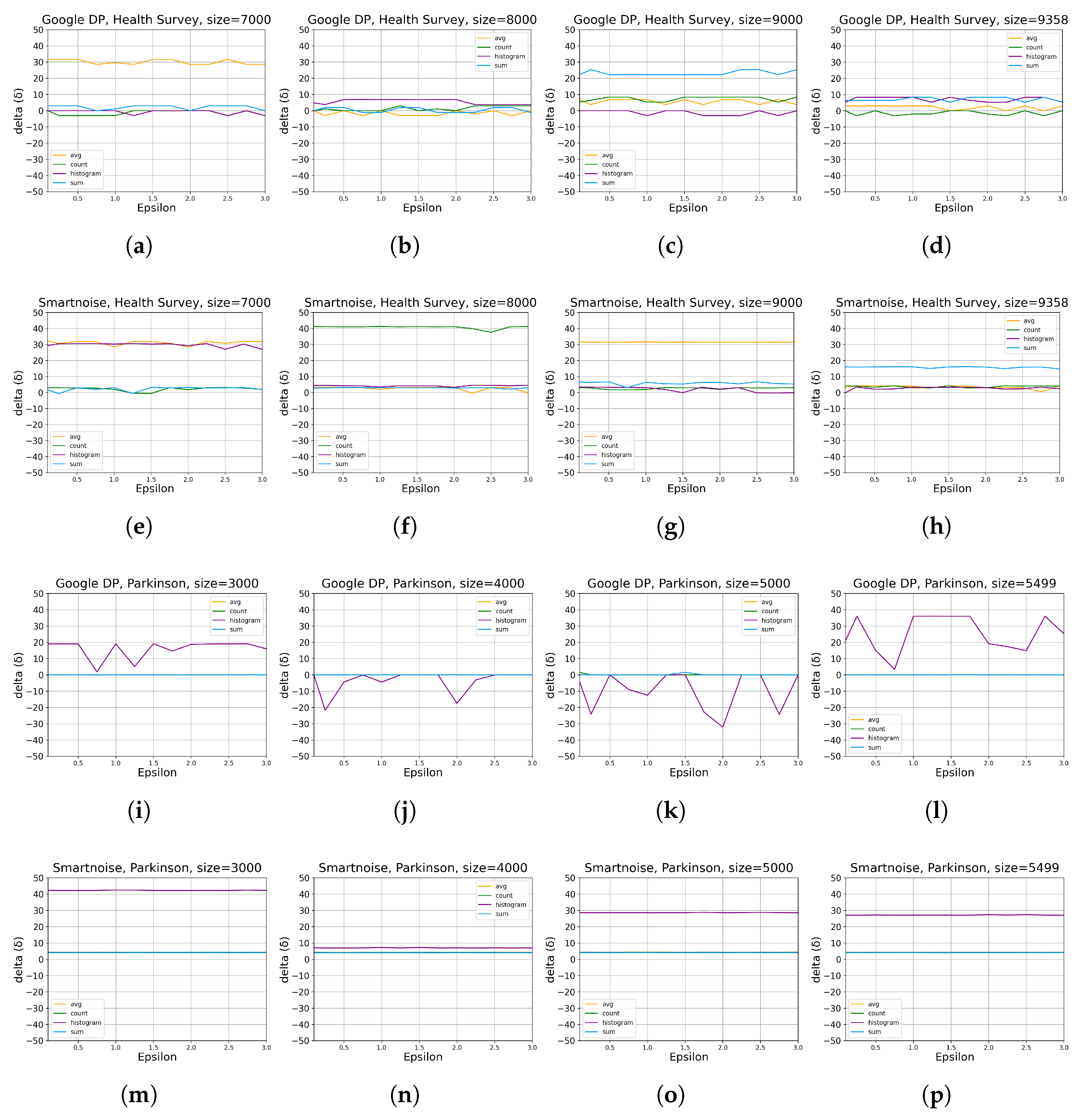
- For developers looking at accumulating general statistics about categorical or continuous datasets, Google DP seems promising, with a margin of error from about 0.1% to 2% for simple queries (SUM, COUNT, AVG) with . Given the same set of queries and values, Smartnoise provides an error of about 0.5% to 5%. We also note that Smartnoise offers better accuracy for HISTOGRAM queries, with an error below ca. 10% compared to Google DP’s about 15%, on Health Survey.
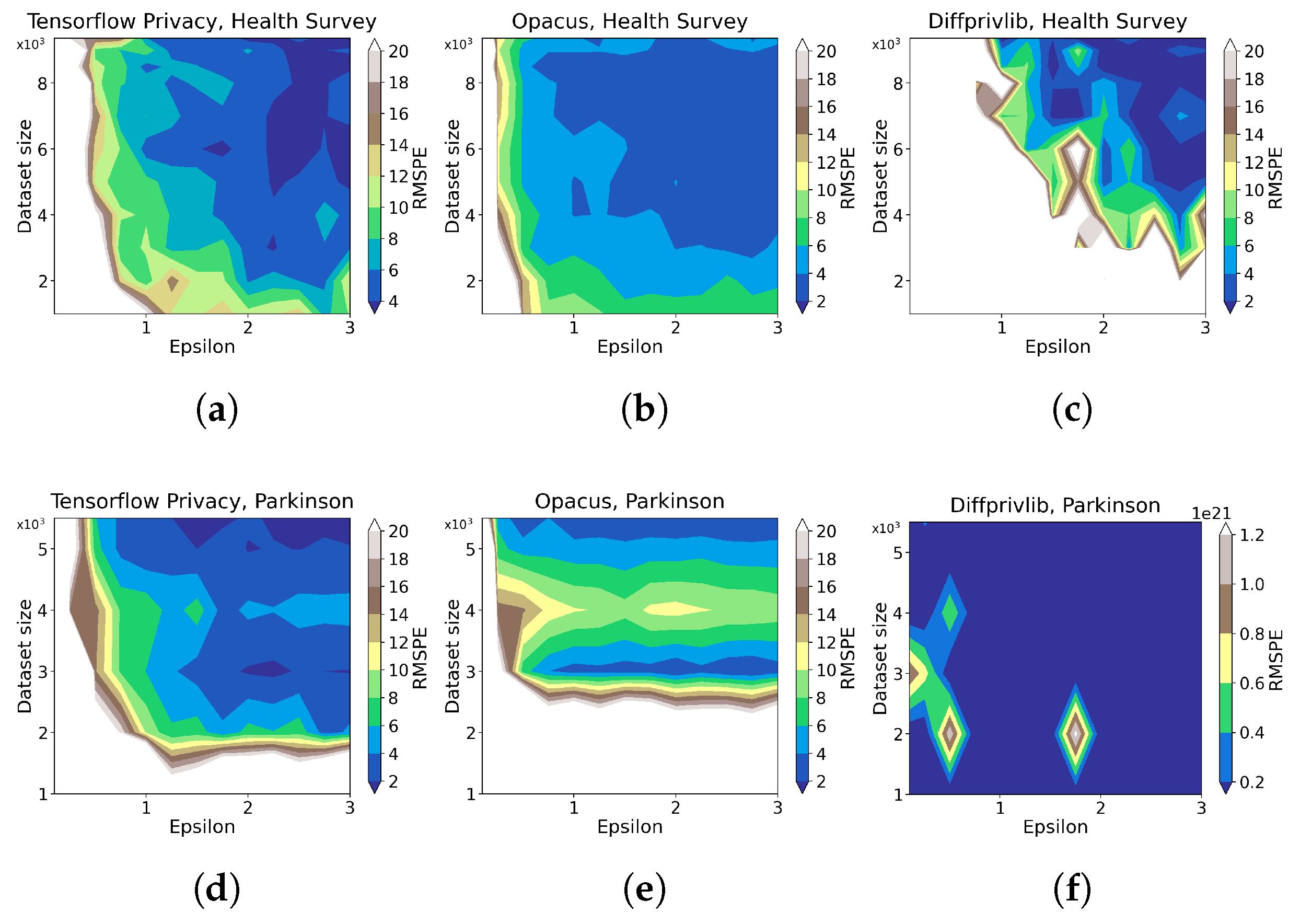
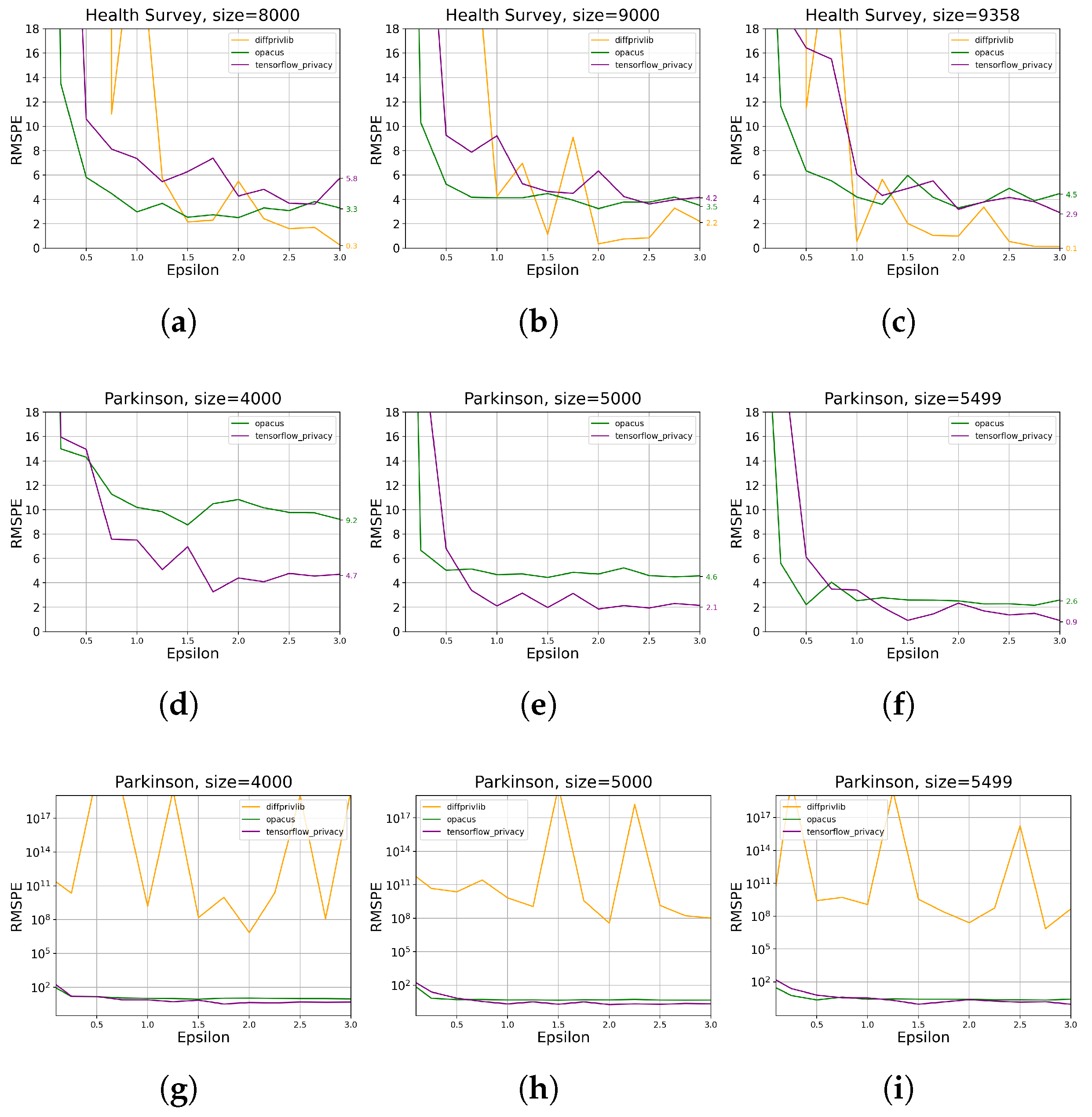
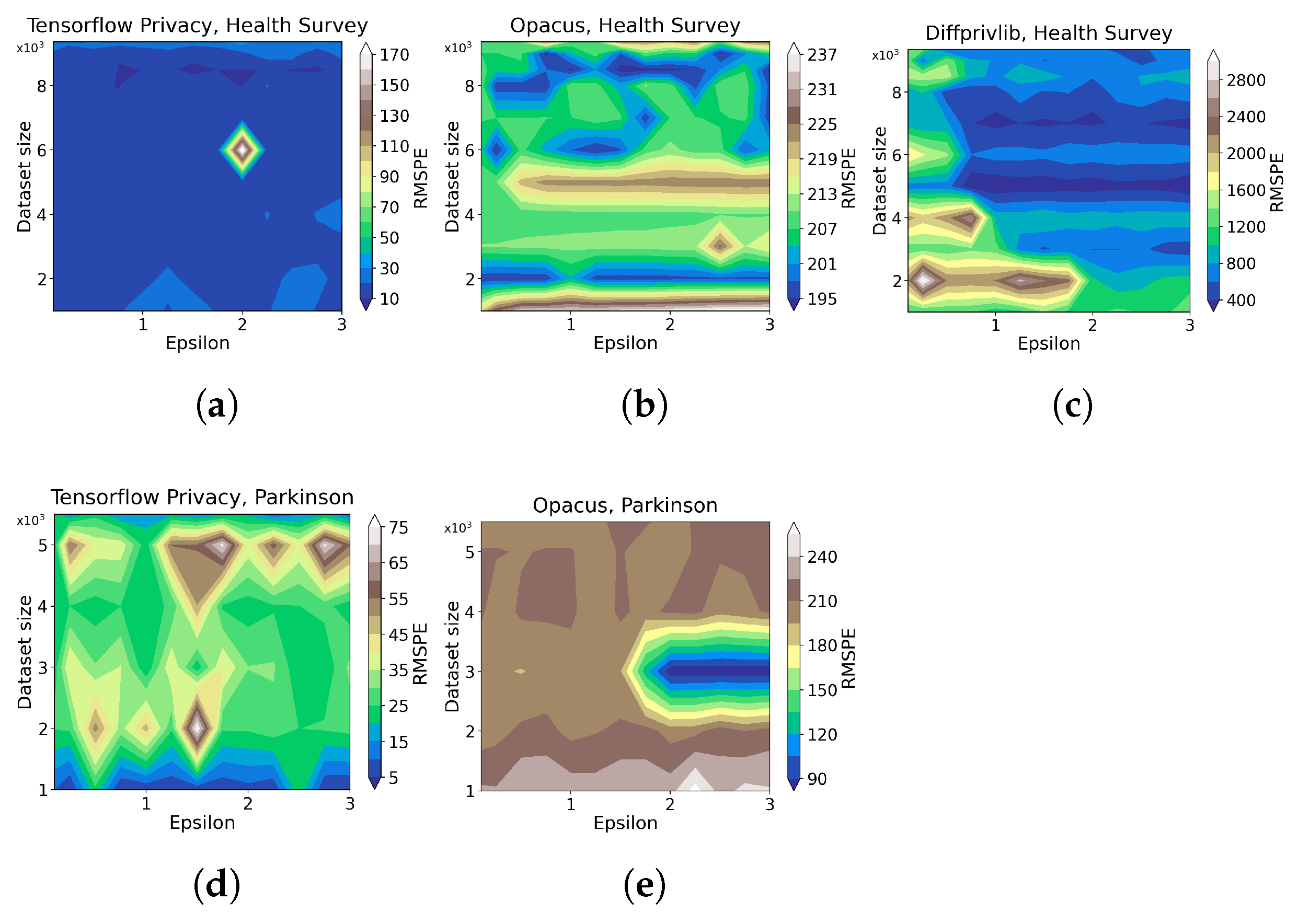
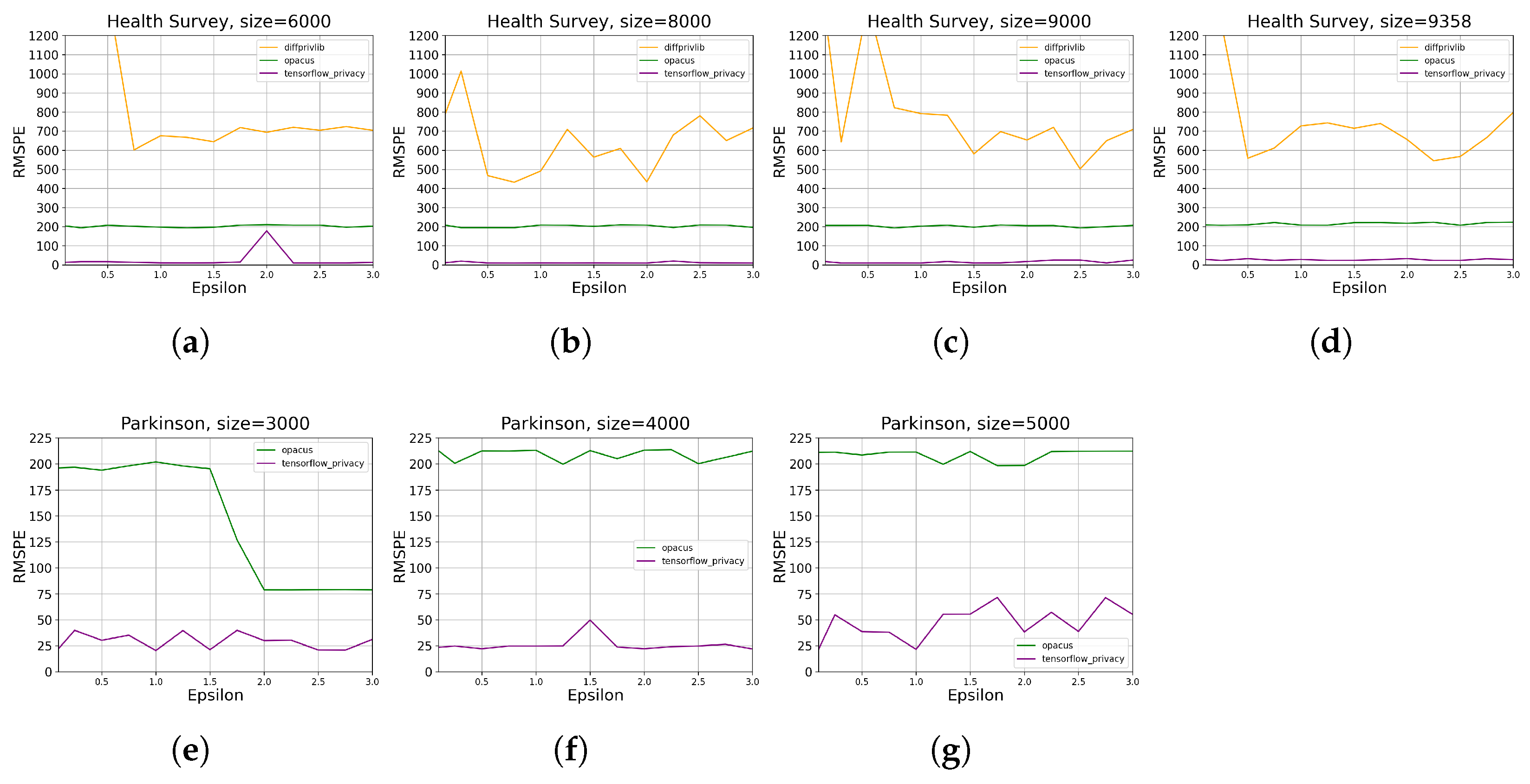
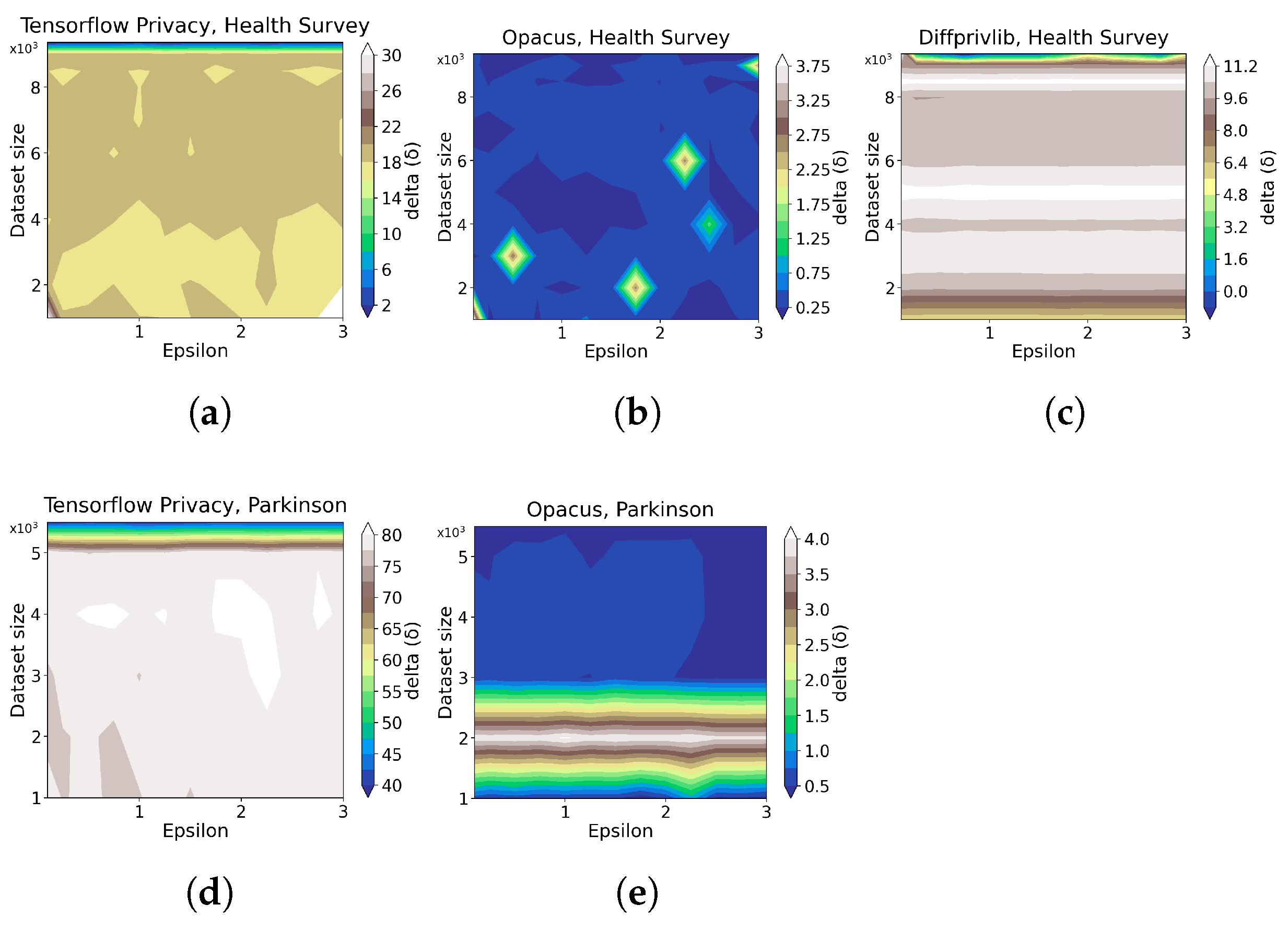
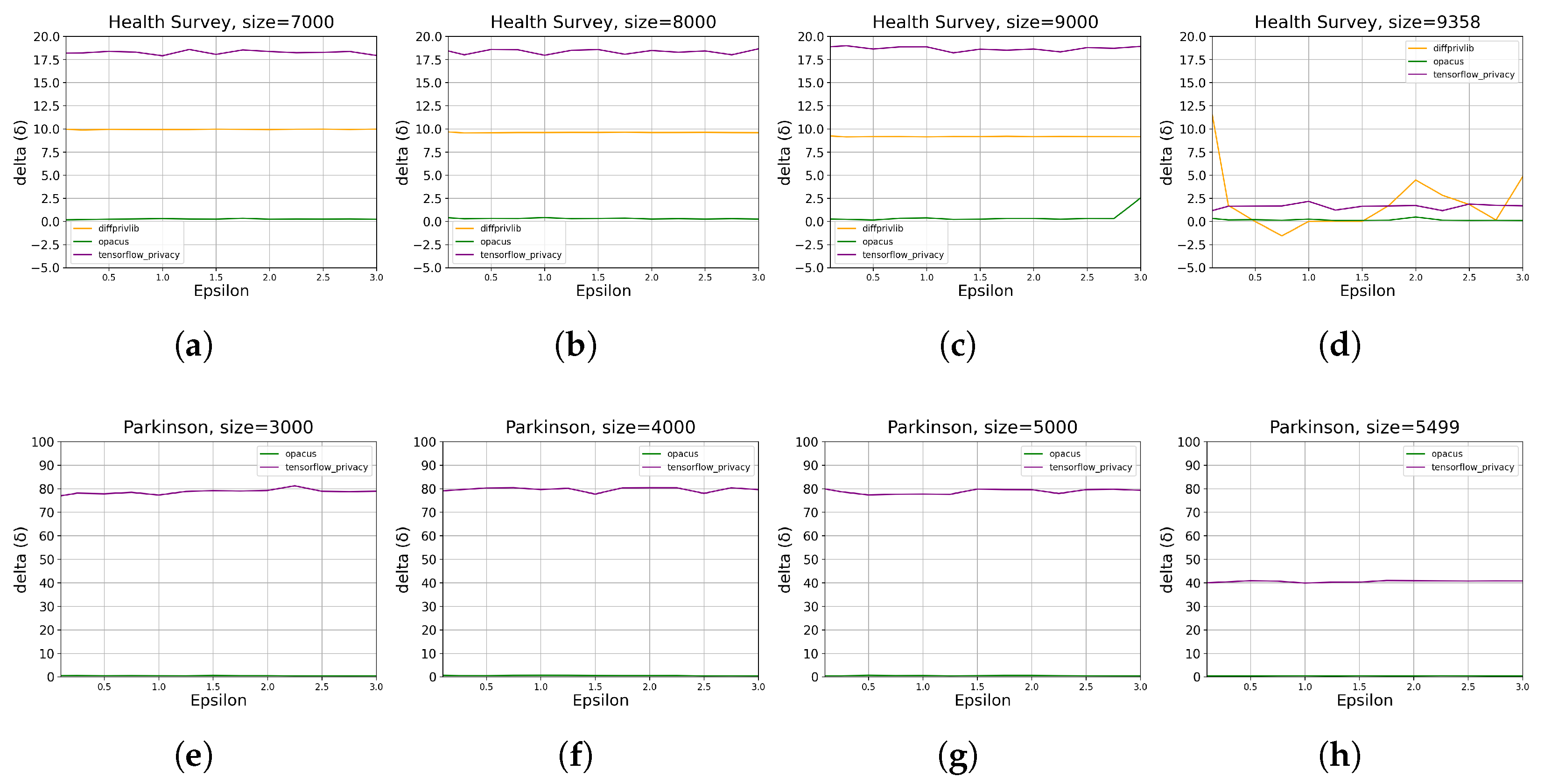
- For developers looking at building DP machine learning models, both Opacus and Tensorflow Privacy (TFP) show promising results, obtaining data utility below around 6% error for on Parkinson and Health Survey. Nevertheless, TFP manages to obtain around two times better data utility than Opacus given maximum data size and . Diffprivlib, on the other hand, outperforms both tools on Health Survey given maximum data size and . It should, however, be noted that Diffprivlib did not manage to generate any useful results on continuous data and is also limited to linear regression and logistic regression models, while TFP and Opacus offer building custom neural networks, allowing developers to build complex models for a variety of problems.
1.5. Document Structure
2. Evaluation Settings
2.1. Evaluation Criterion
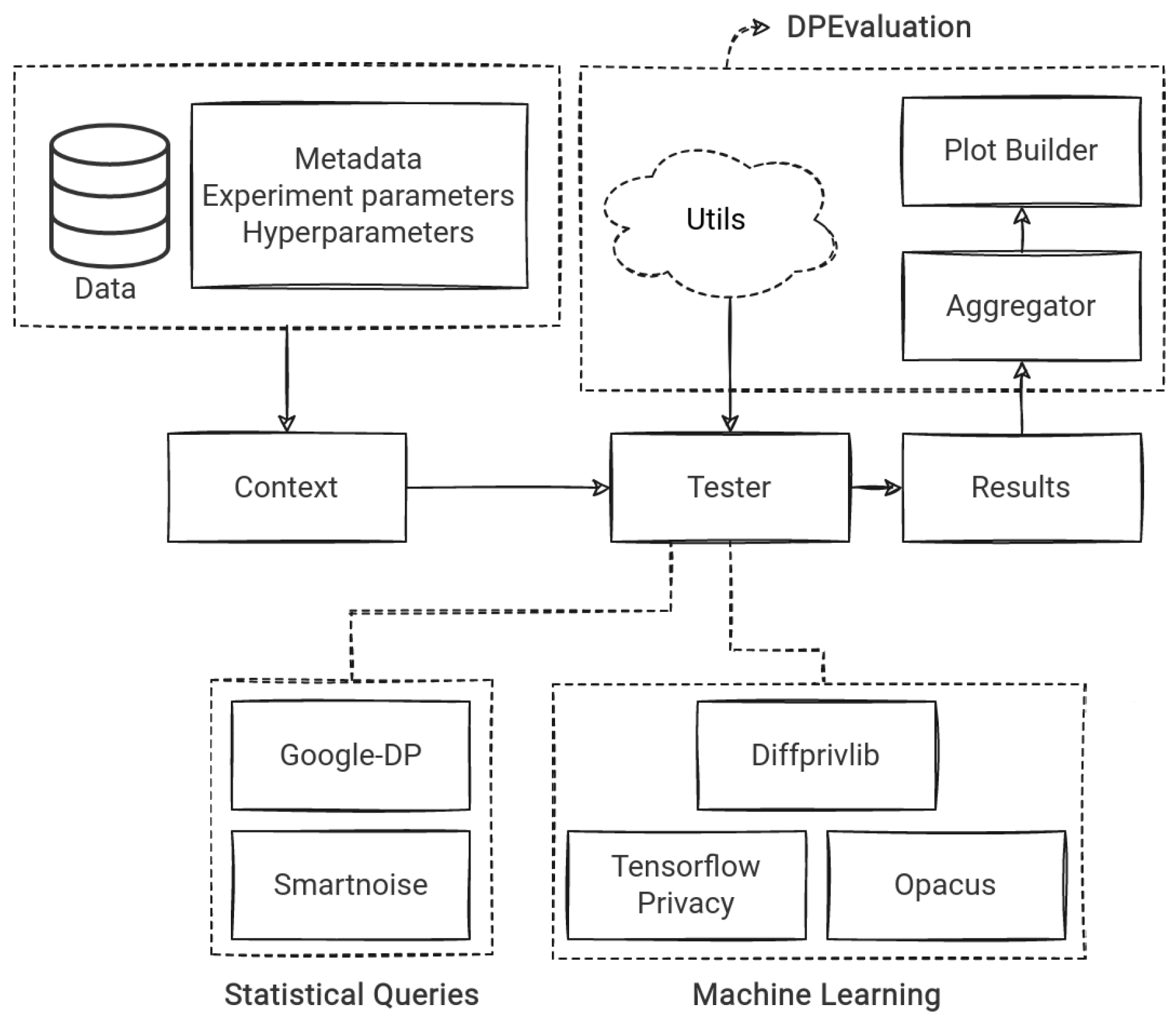
2.2. Evaluating Framework
2.3. Experiment Implementation
3. Evaluation Results
3.1. Statistical Tools Assessment
3.1.1. Data Utility
3.1.2. Runtime Overhead
3.1.3. Memory Overhead
3.2. Machine Learning Tools Assessment
3.2.1. Data Utility
3.2.2. Runtime Overhead
3.2.3. Memory Overhead
3.3. Summary of Results
4. Related Work
4.1. Statistical Queries
4.2. Machine Learning
4.3. Bibliographical Note
5. Conclusions
5.1. Limitations
5.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DBMS | Database Management Systems |
| DP | Differential Privacy |
| FES | Favorable Experiment Settings |
| GDPR | General Data Protection Regulation |
| Google DP | Google Differential Privacy |
| HIPAA | Health Insurance Portability and Accountability Act |
| MHRS | Massachusetts Health Reform Survey |
| ML | Machine Learning |
| NP | Non-privacy-protected |
| PD | Parkinson’s Disease |
| PinQ | Privacy-integrated Queries |
| RES | Restrictive Experiment Settings |
| RMSPE | Root Mean Square Percentage Error |
| SGD | Stochastic Gradient Descent |
| SQ | Statistical Query |
| TFP | TensorFlow Privacy |
| UPDRS | Unified Parkinson’s Disease Rating Scale |
References
- Scherer, J.; Kiparski, G. Buchbesprechungen. Feiler, Lukas/Forgó, Nikolaus/Weigl, Michaela: The EU General Data Protection Regulation (GDPR): A Commentary; German Law Publishers: Frankfurt, Germany, 2018; Volume 34, pp. 69–70. [Google Scholar]
- Mbonihankuye, S.; Nkunzimana, A.; Ndagijimana, A. Healthcare Data Security Technology: HIPAA Compliance. Wirel. Commun. Mob. Comput. 2019, 2019, 1927495:1–1927495:7. [Google Scholar] [CrossRef]
- Goldman, E. An Introduction to the California Consumer Privacy Act (CCPA); Santa Clara University Legal Studies Research Paper: Santa Clara, CA, USA, 2020. [Google Scholar]
- Dwork, C. Differential Privacy: A Survey of Results. In Proceedings of the Theory and Applications of Models of Computation, 5th International Conference, TAMC 2008, Xi’an, China, 25–29 April 2008; Agrawal, M., Du, D., Duan, Z., Li, A., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2008; Volume 4978, pp. 1–19. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A.D. Calibrating Noise to Sensitivity in Private Data Analysis. J. Priv. Confidentiality 2016, 7, 17–51. [Google Scholar] [CrossRef]
- Harvard University Privacy Tools Project. Available online: https://privacytools.seas.harvard.edu/ (accessed on 7 July 2023).
- Hsu, J.; Gaboardi, M.; Haeberlen, A.; Khanna, S.; Narayan, A.; Pierce, B.C.; Roth, A. Differential Privacy: An Economic Method for Choosing Epsilon. In Proceedings of the IEEE 27th Computer Security Foundations Symposium, CSF 2014, Vienna, Austria, 19–22 July 2014; IEEE Computer Society: Washington, DC, USA, 2014; pp. 398–410. [Google Scholar]
- McSherry, F. Privacy integrated queries: An extensible platform for privacy-preserving data analysis. Commun. ACM 2010, 53, 89–97. [Google Scholar] [CrossRef]
- Zhang, D.; McKenna, R.; Kotsogiannis, I.; Hay, M.; Machanavajjhala, A.; Miklau, G. EKTELO: A Framework for Defining Differentially-Private Computations. In Proceedings of the International Conference on Management of Data, SIGMOD, Houston, TX, USA, 10–15 June 2018; ACM: New York, NY, USA, 2018; pp. 115–130. [Google Scholar]
- Kotsogiannis, I.; Tao, Y.; Machanavajjhala, A.; Miklau, G.; Hay, M. Architecting a Differentially Private SQL Engine. In Proceedings of the CIDR, Asilomar, CA, USA, 13–16 January 2019; Available online: www.cidrdb.org (accessed on 7 July 2023).
- Haeberlen, A.; Pierce, B.C.; Narayan, A. Differential Privacy Under Fire. In Proceedings of the 20th USENIX Security Symposium, San Francisco, CA, USA, 8–12 August 2011; USENIX Association: Berkeley, CA, USA, 2011. [Google Scholar]
- Zhang, D.; Kifer, D. LightDP: Towards automating differential privacy proofs. In Proceedings of the POPL, Paris, France, 15–21 January 2017; ACM: New York, NY, USA, 2017; pp. 888–901. [Google Scholar]
- Miguel Guevara Enabling Developers and Organizations to Use Differential Privacy. Available online: https://developers.googleblog.com/2019/09/enabling-developers-and-organizations.html (accessed on 4 June 2021).
- Openminded. Available online: https://www.openminded.org/ (accessed on 7 July 2023).
- Subramani, P.; Vadivelu, N.; Kamath, G. Enabling Fast Differentially Private SGD via Just-in-Time Compilation and Vectorization. arXiv 2020, arXiv:abs/2010.09063. [Google Scholar]
- Abadi, M.; Chu, A.; Goodfellow, I.J.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep Learning with Differential Privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; ACM: New York, NY, USA, 2016; pp. 308–318. [Google Scholar]
- Holohan, N.; Braghin, S.; Aonghusa, P.M.; Levacher, K. Diffprivlib: The IBM Differential Privacy Library. arXiv 2019, arXiv:abs/1907.02444. [Google Scholar]
- Diffprivlib. Available online: https://github.com/IBM/differential-privacy-library (accessed on 2 June 2021).
- Johnson, N.M.; Near, J.P.; Hellerstein, J.M.; Song, D. Chorus: Differential Privacy via Query Rewriting. arXiv 2018, arXiv:abs/1809.07750. [Google Scholar]
- Johnson, N.M.; Near, J.P.; Hellerstein, J.M.; Song, D. Chorus: A Programming Framework for Building Scalable Differential Privacy Mechanisms. In Proceedings of the IEEE European Symposium on Security and Privacy, EuroS&P 2020, Genoa, Italy, 7–11 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 535–551. [Google Scholar]
- Wilson, R.J.; Zhang, C.Y.; Lam, W.; Desfontaines, D.; Simmons-Marengo, D.; Gipson, B. Differentially Private SQL with Bounded User Contribution. Proc. Priv. Enhancing Technol. 2020, 2020, 230–250. [Google Scholar] [CrossRef]
- Haney, S.; Desfontaines, D.; Hartman, L.; Shrestha, R.; Hay, M. Precision-based attacks and interval refining: How to break, then fix, differential privacy on finite computers. arXiv 2022, arXiv:abs/2207.13793. [Google Scholar]
- Long, S.K. Massachusetts Health Reform Survey, 2018; Inter-University Consortium for Political and Social Research: Ann Harbor, MI, USA, 2019. [Google Scholar] [CrossRef]
- Tsanas, A.; Little, M.A.; McSharry, P.E.; Ramig, L.O. Accurate Telemonitoring of Parkinson’s Disease Progression by Noninvasive Speech Tests. IEEE Trans. Biomed. Eng. 2010, 57, 884–893. [Google Scholar] [CrossRef] [PubMed]
- Boettiger, C. An introduction to Docker for reproducible research. ACM SIGOPS Oper. Syst. Rev. 2015, 49, 71–79. [Google Scholar] [CrossRef]
- Kopp, A. Microsoft SmartNoise Differential Privacy Machine Learning Case Studies. Microsoft Azure White Papers, 14 February 2021. [Google Scholar]
- Rosenblatt, L.; Liu, X.; Pouyanfar, S.; de Leon, E.; Desai, A.; Allen, J. Differentially Private Synthetic Data: Applied Evaluations and Enhancements. arXiv 2020, arXiv:abs/2011.05537. [Google Scholar]
- Johnson, N.; Near, J.P.; Song, D. Towards Practical Differential Privacy for SQL Queries. Proc. VLDB Endow. 2018, 11, 526–539. [Google Scholar] [CrossRef]
- Garrido, G.M.; Near, J.P.; Muhammad, A.; He, W.; Matzutt, R.; Matthes, F. Do I Get the Privacy I Need? Benchmarking Utility in Differential Privacy Libraries. arXiv 2021, arXiv:abs/2109.10789. [Google Scholar]
- Hay, M.; Machanavajjhala, A.; Miklau, G.; Chen, Y.; Zhang, D. Principled Evaluation of Differentially Private Algorithms using DPBench. In Proceedings of the International Conference on Management of Data, SIGMOD, San Francisco, CA, USA, 26 June–1 July 2016; Özcan, F., Koutrika, G., Madden, S., Eds.; ACM: New York, NY, USA, 2016; pp. 139–154. [Google Scholar] [CrossRef]
- Bu, Z.; Gopi, S.; Kulkarni, J.; Lee, Y.T.; Shen, J.H.; Tantipongpipat, U. Fast and Memory Efficient Differentially Private-SGD via JL Projections. arXiv 2021, arXiv:abs/2102.03013. [Google Scholar]
- Xu, J.; Zhang, Z.; Xiao, X.; Yang, Y.; Yu, G.; Winslett, M. Differentially private histogram publication. VLDB J. 2013, 22, 797–822. [Google Scholar] [CrossRef]
- Jayaraman, B.; Evans, D. Evaluating Differentially Private Machine Learning in Practice. In Proceedings of the 28th USENIX Security Symposium, USENIX Security 2019, Santa Clara, CA, USA, 14–16 August 2019; Heninger, N., Traynor, P., Eds.; USENIX Association: Berkeley, CA, USA, 2019; pp. 1895–1912. [Google Scholar]
- Mironov, I. Rényi Differential Privacy. In Proceedings of the 30th IEEE Computer Security Foundations Symposium, CSF 2017, Santa Barbara, CA, USA, 21–25 August 2017; IEEE Computer Society: Washington, DC, USA, 2017; pp. 263–275. [Google Scholar]
- Tramèr, F.; Boneh, D. Differentially Private Learning Needs Better Features (or Much More Data). arXiv 2021, arXiv:2011.11660. [Google Scholar]
- Zhang, S.; Hagermalm, A.; Slavnic, S.; Schiller, E.M.; Almgren, M. Evaluation of Open-source Tools for Differential Privacy. arXiv 2022, arXiv:abs/2202-09587. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Machine Learning Domain | Statistical Query Domain | ||
|---|---|---|---|
| Environment | • Docker | ||
| Task to evaluate | • Regression |
| |
| Influencing factors |
| ||
| Evaluation criterion | Utility | Prediction accuracy reduction compared with non-private machine learning. | Decreased query accuracy due to privacy measures. |
| Overhead | Extra resource consumption induced by differential privacy, including
| ||
| Database to evaluate on |
| ||
| Dataset Sizes |
|---|
| Health Survey size ∈ {1000, 2000, 3000, 4000, 5000, 6000, 7000, 8000, 9000, 9358} |
| Parkinson size ∈ {1000, 2000, 3000, 4000, 5000, 5499} |
| Values |
|---|
| {0.1, 0.25, 0.5, 0.75, 1.0, 1.25, 1.5, 1.75, 2.0, 2.25, 2.5, 2.75, 3.0} |
| QUERIES |
|---|
| Queries {SUM, AVG, COUNT, HISTOGRAM} |
| Tool Name | Patterns Revealed | |
|---|---|---|
| ML | Diffprivlib | • utility and runtime overhead grow with and data size on categorical data |
| PyTorch Opacus |
| |
| TensorFlow Privacy |
| |
| SQ | Google Differential Privacy |
|
| OpenDP SmartNoise |
| |
| Performance Criteria (RMPSE) | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Categorical Data | Continuous Data | ||||||||||||||||||
| Utility FES | Runtime FES | Memory FES | Utility RES | Runtime RES | Memory RES | Utility DFC | Runtime DFC | Memory DFC | Utility FES | Runtime FES | Memory FES | Utility RES | Runtime RES | Memory RES | Utility DFC | Runtime DFC | Memory DFC | ||
| machine learning | Diffprivlib | 1st 0.15 | 3rd 797.86 | 3rd 6.35 | 3rd 6.4 | 3rd 1176.20 | 3rd 46.21 | 3rd 2.76 to 1.21 | 3rd 603.17 to 1.15 | 3rd 9.11 to 16.64 | Results far away from usable | ||||||||
| 4.6 | 2323.46 | 35.64 | 1.96 | 856.53 | 31.54 | 1.53 to 1.89 | 603.17 to 1.15 | 40.88 to 45.38 | |||||||||||
| PyTorch Opacus | 3rd 4.47 | 2nd 221.13 | 2nd 0.72 | 1st 1283.47 | 2nd 217.85 | 1st 2.35 | 1st 3.44 to 7.10 | 2nd 197.67 to 211.96 | 1st 0.11 to 0.16 | 2nd 2.59 | 2nd 213.23 | 1st 1.77 | 1st 5122.05 | 2nd 224.95 | 1st 1.81 | 2nd 3.99 to 38.21 | 2nd 199.77 to 213.90 | 1st 0.55 to 1.68 | |
| TensorFlow Privacy | 2nd 2.91 | 1st 22.52 | 1st 6.1 | 2nd 6960.15 | 1st 17.25 | 2rd 9.74 | 2rd 4.65 to 12.73 | 1st 10.30 to 14.23 | 2nd 0.64 to 7.06 | 1st 0.90 | 1st 35.69 | 2nd 15.77 | 2nd 6177.35 | 1st 1.57 | 2nd 28.32 | 1st 2.32 to 26.37 | 1st 21.01 to 35.25 | 2nd 13.48 to 26.88 | |
| statistical query | Google Differential Privacy | 1st 0.61 | 1st 115.63 | 1st 8.12 | 1st 74.3 | 1st 137.37 | 1st 25.19 | 1st 0.016 to 0.31 | 1st 108.25 to 129.35 | 1st 0.05 to 1.88 | 1st 0.5 | 1st 120.32 | 1st 4.6 | 1st 75.9 | 1st 126.63 | 1st 7.6 | 1st 0.02 to 0.36 | 1st 115.11 to 137.43 | 1st 0 to 2.16 |
| OpenDP SmartNoise | 2rd 2.9 | 2rd 481.11 | 2rd 14.08 | 2nd 801 | 2rd 413.96 | 2rd 29.27 | 2rd 0.11 to 2.08 | 2rd 408.74 to 466.23 | 2rd 0.50 to 2.75 | 2rd 3.9 | 2rd 473.63 | 2rd 4.56 | 2nd 746 | 2rd 558.16 | 2rd 4.67 | 2rd 0.19 to 2.24 | 2rd 427.19 to 465.05 | 2rd 5.06 to 6.47 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Hagermalm, A.; Slavnic, S.; Schiller, E.M.; Almgren, M. Evaluation of Open-Source Tools for Differential Privacy. Sensors 2023, 23, 6509. https://doi.org/10.3390/s23146509
Zhang S, Hagermalm A, Slavnic S, Schiller EM, Almgren M. Evaluation of Open-Source Tools for Differential Privacy. Sensors. 2023; 23(14):6509. https://doi.org/10.3390/s23146509
Chicago/Turabian StyleZhang, Shiliang, Anton Hagermalm, Sanjin Slavnic, Elad Michael Schiller, and Magnus Almgren. 2023. "Evaluation of Open-Source Tools for Differential Privacy" Sensors 23, no. 14: 6509. https://doi.org/10.3390/s23146509
APA StyleZhang, S., Hagermalm, A., Slavnic, S., Schiller, E. M., & Almgren, M. (2023). Evaluation of Open-Source Tools for Differential Privacy. Sensors, 23(14), 6509. https://doi.org/10.3390/s23146509