1. Introduction
Speech captured by microphone in the real-world environment is prone to being corrupted by background noise. In order to reduce listener fatigue and the loss of intelligibility, speech enhancement which aims at removing the background noise and improving intelligibility has been an important and active field for many years.
The established statistical speech enhancement methods, the minimum mean-square error (MMSE), short-time spectral amplitude (STSA) estimator [
1], and the MMSE-log spectral amplitude (MMSE-LSA) [
2], require an initial estimate of a priori SNR and a posteriori SNR derived from the spectral density power estimates of the clean speech and the background noise. On top of that, the decision-directed (DD) approach—a recursive smoothing procedure for the a priori SNR—is proposed in combination with these estimators to reduce the residual musical tones and improve the naturalness of the processed audio. However, this technique also introduces an estimation bias in the SNRs and leads to an annoying reverberation effect [
3]. Therefore, a two-stage framework has been proposed in Reference [
3] to avoid the speech distortion from this bias. In the two-stage framework, a better speech estimate is refined from the initial one so that a priori SNR can be calculated
without recursive smoothing. Additional prior knowledge on speech can also be introduced during the procedure.
In our recent work [
4], for example, we improve the speech harmonic recovery method termed cepstral excitation manipulation (CEM) [
5] using the source-filter model of speech production to highlight its periodic structure. In this model, the speech signal is decomposed into an excitation and an envelope component in order to represent the excitation source and the vocal tract filter, respectively. It is proposed to amplify the quefrency related to the fundamental frequency and its harmonics in order to highlight the periodic structure of the voiced speech in the cepstral domain. To maintain the fine structure of the speech, the excitation signal in high quefrencies is smoothed with a quefrency-dependent window. In this work, we investigate the contribution of enhancing the other component of the source-filter decomposition result, the spectral envelope, for speech enhancement.
It has been shown that there is a strong correlation between the speech envelope and its intelligibility [
6]. Consequently, the short-time spectral envelope of speech has been widely exploited in many areas such as automatic speech recognition (ASR) [
7], artificial bandwidth extension [
8], and speech intelligibility prediction [
6,
7]. The well-known and widely used short-time objective intelligibility (STOI) [
9] is based on the linear correlation between the envelopes of the processed noisy speech signal and those of the clean reference. One well-known problem of speech enhancement is that many methods hardly improve (and, sometimes, even degrade) speech intelligibility, although they perform well on noise reduction. Given the relationship between the speech envelope and intelligibility, it is possible to improve speech quality as well as its intelligibility by refining the spectral envelope of the clean speech estimate.
For a given language, the possible patterns of speech spectral envelope are limited because the number of phonemes is limited, which makes the codebook technique an efficient solution to capture a priori information about speech envelopes. Thereby, a good estimate of the codebook entries integrates this prior knowledge into the following tasks. For example, [
10] trained two sets of codebooks for speech and noise, respectively. Then, the gain function was estimated by the codebook-constrained Wiener filter, with optimal codebook entries being searched for in a maximum likelihood framework.
As speech has temporal dependency, a combination of the Gaussian mixture model (GMM) and hidden Markov model (HMM), GMM-HMM, was widely used in classical ASR systems as the back-end to recognise phonemes [
7]. This statistical approach models the distribution of phonemes and their temporal dependency through two individual components: the GMMs, which learn the feature distribution, and the HMM, which imposes temporal dependencies on the hidden state sequences inferred from the GMMs. A similar pre-trained codebook with a GMM-HMM back-end also serves as the baseline in the speech envelope enhancement research of Reference [
11] using the aforementioned two-stage framework. Therein, only the speech envelope codebook is generated, and the speech envelope is estimated from it in an MMSE manner. This envelope is introduced to update the a priori SNR for a second-stage estimate of the clean speech. In Reference [
12], noisy signals are enhanced by resynthesising the clean speech from the inferred acoustic cues (e.g., pitch and spectral envelope). The underlying clean speech envelope is, again, estimated with a codebook-aided Kalman filter, the codebook having been designed to capture not only the envelope shapes, but also the evolution of the envelopes in a given number of consecutive frames.
The classifier for such codebook-based methods can, of course, be replaced by deep learning models. In Reference [
13], using two separate sets of codebooks for speech and noise, the codebook entries corresponding to the envelopes of both components are estimated by a feedforward deep neural network (DNN). These codebook entries are used to update the time-smoothed Wiener filter which performs the final speech enhancement. The work in Reference [
11] also investigates the utilisation of DNN-based classifiers for codebook-based speech envelope estimation. Compared to the GMM-HMM baseline, the trained DNN classifier, with a similar computational cost, shows an advantage in both the classification accuracy and the instrumental metrics for speech enhancement. Compared to its regression counterpart, in which the network architecture is kept but the model is repurposed to predict the envelope coefficients directly from the initial estimation, it is shown that this architecture benefits from the codebook.
There are different ways to extract and represent speech envelope. Subband representation is a popular approach. For example, in STOI, the spectro-temporal envelope is calculated as the average of one-third octave decomposition results of 30 consecutive frames [
9]. The STOI loss function to optimise speech enhancement DNN adopts, naturally, the same features [
14]. Analogously, Reference [
15] uses equivalent rectangular bandwidth (ERB) to compress the spectrum and Reference [
16] uses the auditory filterbank. It should be noted there is no direct inverse from these subband presentations to spectra. Applying the subband gain directly to the spectrum yields a ‘rougher’ signal, as the processed signal is less harmonic [
15]. Therefore, the subband gain function is combined with a comb filter to restore the distorted harmonics in Reference [
15].
The envelope can also be obtained from the auto-regressive (AR) filter applied, e.g., in linear predictive coding (LPC). For stability reasons, instead of directly using the AR filter coefficients, the equivalent line spectral frequencies (LSF) are adopted for speech enhancement in References [
12,
13]. Another equivalent representation of the AR filter coefficients is given by linear prediction cepstral coefficients (LPCCs). These are employed in Reference [
11] to define the spectral codebook and to estimate the enhanced envelope within the two-stage framework. However, LPCCs can suffer from quantisation issues [
17], which can cause degradation in codebook-based approaches. Another alternative envelope representation is based on the cepstral representation of the signal, which also implicitly describes the spectral envelope. Based on the relationship between the spectrum and the cepstrum, the first few cepstral coefficients (CCs) of a signal frame can be regarded as the description of its spectral shape. This is exploited in cepstral smoothing approaches [
18,
19,
20] in order to remove musical noise. By preserving the first few cepstral coefficients, and strongly smoothing the rest, instantaneous temporal spectral fluctuations in the signal are suppressed while the principal structure (i.e., the spectral envelope) of the processed speech is maintained. Of the aforementioned envelope representations, we focus on the LPCCs and CCs in this work due to the convenience of their transformations between the domains and the easy fitting of the decomposition results to the source-filter model.
While data-driven, deep-learning-based end-to-end speech enhancement offers a powerful solution, the computational cost of such a system is still relatively high. Furthermore, a drawback of such systems is the black-box nature of the enhancement, which makes interpretability and control difficult. Data-driven envelope estimation, incorporated into classical speech enhancement, can provide us a compromise, and at a low computational complexity. This work is developed from the idea of cepstral envelope estimation (CEE) using the pre-trained codebook in [
11]. We further explore its potential and investigate the achievable results of this method. Specifically, the following questions will be answered by our investigation: what is the maximum benefit of such data-driven two-stage enhancement? How (much) does the quantisation of the envelopes affect the quality of the enhanced audio quality? What is the optimal cepstral speech envelope representation for the purpose of speech enhancement? Will the speech envelope classifier benefit from temporal modeling?
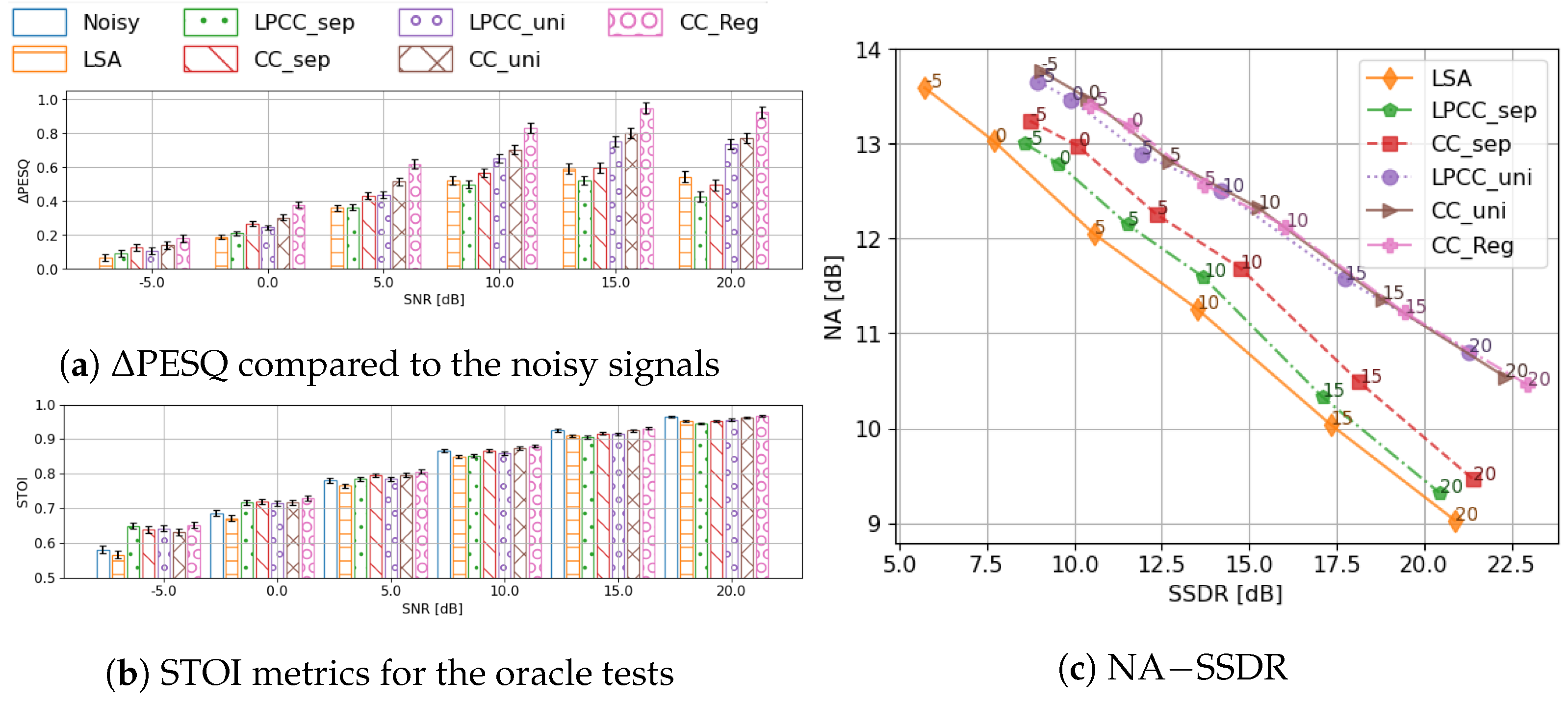
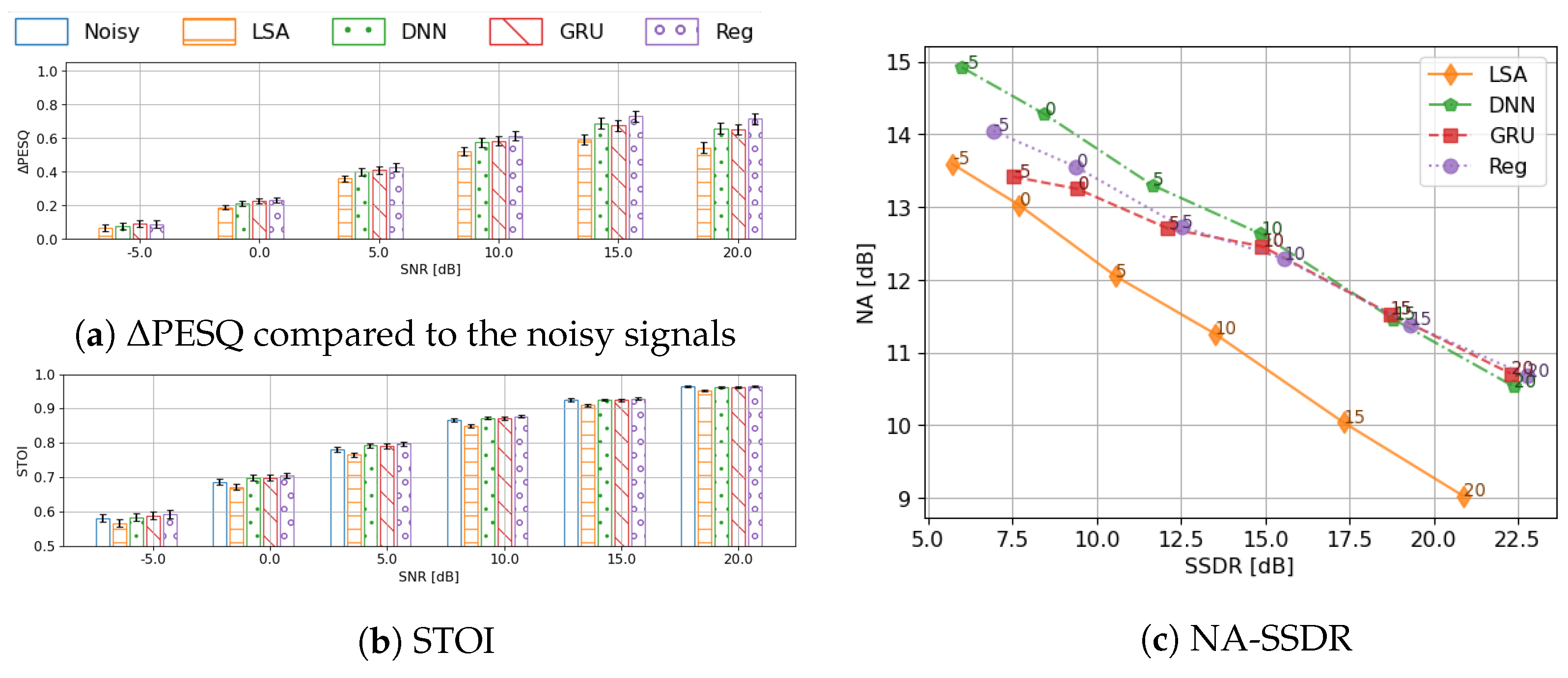
Below, we start from a series of oracle tests to investigate the potential and the limitation of the codebook method, in which different envelope representations are compared and benchmarked against each other in the two-stage framework. Then, several practical systems are trained and evaluated.
The temporal dependency of speech is usually taken into consideration in the aforementioned envelope enhancement methods via explicit temporal models or components such as Kalman filters and HMMs in the frameworks. For the DNN structure, however, including an HMM is counterproductive, as reported in Reference [
11]. Therefore, we will investigate other possibilities to enable temporal modeling within the neural network. Literature shows that recurrent layers are powerful to this end. For instance, the long-short term memory (LSTM) layer is widely used in end-to-end speech enhancement systems due to its effective usage of long-term information granted by the gate mechanism. Recent research [
21] shows that gated recurrent units (GRU) can achieve comparable performance with less complexity, which is also verified in the speech enhancement tasks [
22]. Therefore, in this contribution, we will investigate the performance of the GRU-based classifier for the speech envelope estimation using codebooks.
Furthermore, we will explore the usage of the more recent network architecture, convolutional recurrent neural network (CRNN), as the regression estimator. It is hypothesised in Reference [
11] that the repurposed feedforward DNN is too small for the regression problem. Yet, fully connected neural networks have been gradually replaced by the convolutional layers and convolutional neural networks (CNN) have been reported to yield high performance on many tasks and to do so with fewer parameters than feedforward DNNs. For a deep or complex network, CNNs can be easily trained in an end-to-end style. By inserting the recurrent layers into CNN, the network benefits from both the strong feature extraction ability of convolutional layers and the temporal modeling ability of the recurrent layers. Therefore, we propose to make use of the CRNN architecture for the regression problem.
The remainder of this paper is organised as follows. We provide an overview of the two-stage speech enhancement framework in
Section 2, so that the purpose and the target of CEE are clear.
Section 3 introduces the cepstral envelope estimation in a systematic manner, followed by its use in the two-stage enhancement framework. We report and discuss the evaluation results of the oracle tests and the practical systems in
Section 4 and answer the core questions raised above. The paper is summarised and concluded in
Section 5.
2. Speech Enhancement Framework
We consider the noisy observation , which consists of the target speech corrupted by noise in an additive way: , with k being the discrete time sample index. The microphone signal can then be transformed using the short-time Fourier transformation (STFT) with an M-point windowed discrete Fourier transform (DFT). This yields , where m is the frequency bin index and l is the frame index.
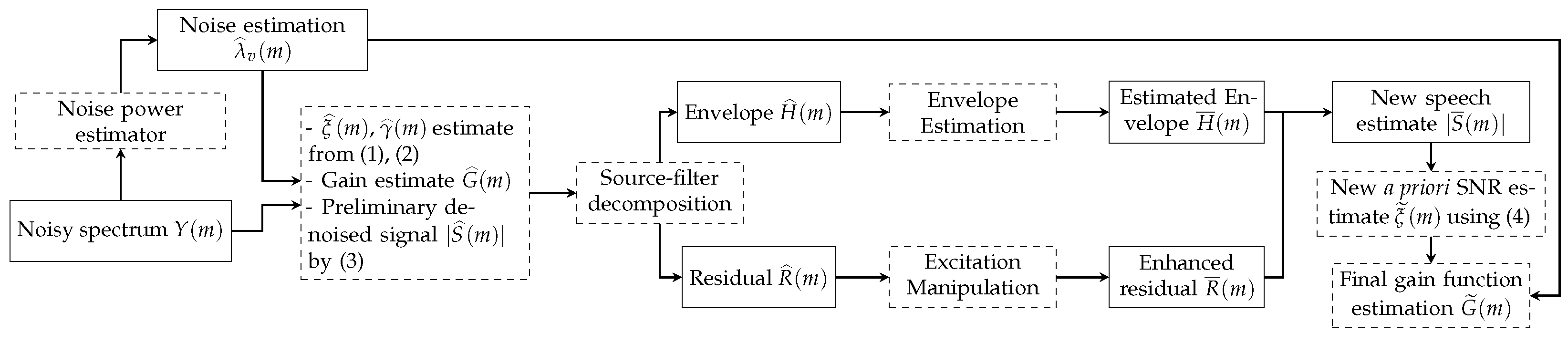
As summarised in
Figure 1, we adopt the same two-stage speech enhancement framework in Reference [
11]. A preliminary denoising is performed in the first stage. The MMSE-LSA gain function is employed to obtain the initial speech estimate
. As with the majority of the gain functions, this estimator
is expressed as a function of two crucial parameters: a priori SNR
and a posteriori SNR
. They are defined as:
and
where
and
are the power spectral densities (PSDs) of the speech and noise signals, respectively. Since the true values of these PSDs cannot be obtained in practice,
is approximated using the estimated noise PSD
from the noise floor estimator, and
is obtained from the decision-directed (DD) approach. The clean speech amplitude estimate is then obtained by applying the gain function to the amplitude of the noisy observation:
Then, according to the source-filter model, the enhanced signal is decomposed into the excitation signal
and the envelope
, and each component can be enhanced individually. The enhancement of the speech excitation signal has been discussed in References [
4,
5,
23], showing that the idealised excitation signal
brings the benefit of recovering the weak or lost harmonics in the initial speech estimate.
While the excitation signal can be modeled by straightforward mathematical equations due to its periodic nature in the voiced frames with the largest energy [
4,
5,
23], data-driven methods are more common in the estimation of the speech envelopes as in References [
10,
11,
12,
13]. If the underlying clean-speech envelope can be accurately estimated from the distorted or noisy signal envelope, it should improve the final speech estimate. One option to introduce prior knowledge of speech envelopes is to use codebooks. Thereby, the envelope estimation problem is converted into a classification problem. First, we create a codebook representing the different speech envelope patterns. Next, we train a suitable classifier to estimate the correct codebook entry for each frame, conditioned on the initial estimate
. The other perspective is to regard the envelope estimation problem as a regression, which predicts the underlying clean-speech envelope from the noisy observation.
The improved speech envelope
is subsequently combined with the refined speech excitation signal
, yielding an improved speech estimate
. However, this synthetic speech estimate sounds less natural than the initial speech estimate, as the excitation signal and the envelope are artificially imposed. Thus, instead of using
to recover the speech, we use
to update the a priori SNR:
This is then used to compute a new gain function:
. The final speech estimate
is given by applying this new gain
to the microphone signal
:
The enhanced time-domain signal can be obtained from by over-lap add.
5. Conclusions
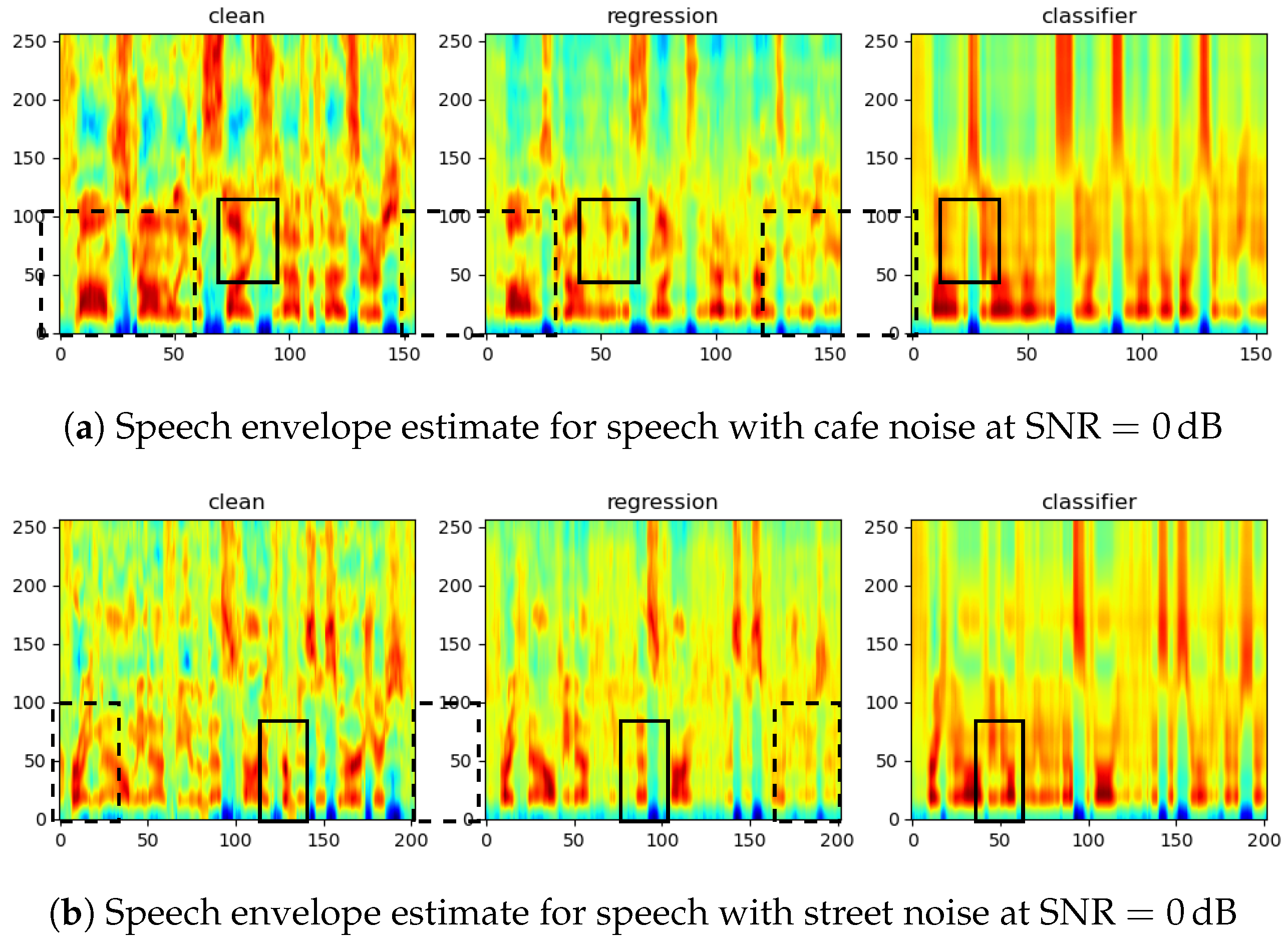
In this paper, we investigated and optimised the cepstral envelope estimation for speech enhancement using the two-stage framework. Through oracle tests, we conclusively demonstrated that cepstral coefficients provide a better envelope representation compared to linear prediction cepstral coefficients. Furthermore, the manual division of the speech/non-speech frames for codebook creation was shown to be unnecessary and even detrimental to the system performance. Using the optimal envelope feature representation, the GRU-based classifier achieved better performance than the baseline feedforward DNN-based classifier. This performance improvement was, additionally, obtained with fewer parameters and lower computational cost. Envelope estimation could be further improved by performing a regression onto the envelope coefficients instead of utilising a codebook-based template. The CRNN network designed for the regression took the noisy input spectrum and initial gain function estimate as input and performed better with a lower computational cost in comparison with the codebook-based estimator. Compared to the initial speech estimate (preliminary denoising), all of the evaluated methods brought benefits to the quality of the enhanced signal without reducing the intelligibility.
More importantly, the oracle tests revealed that the fundamental shortcoming of the two-stage framework lay not in the envelope estimation, but in limitations resulting from other components, such as the noise floor estimate and the statistical-model-based gain function, which performed poorly in very dynamic noise conditions.
Given a better initial estimate of the underlying speech signal, the proposed envelope estimators could be integrated into the signal processing pipeline in post-processing or as a second neural network focusing on the envelope estimation.
In summary, if the goal is to have improved single-microphone noise suppression within an interpretable, controllable, low-cost framework, then the work presented in this paper may be a good option. On the other hand, end-to-end enhancement can yield better noise suppression and speech quality, but at the cost of higher computational expense, poorer interpretability, and lack of control possibilities.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}