In this section, we first overview the architecture of the proposed network. Then, the design details of the main components of the network, the separate asymmetric reinforcement non-bottleneck (SAR-nbt) module and the feature adaptive fusion module (FAFM) are presented.
3.1. Network Overview
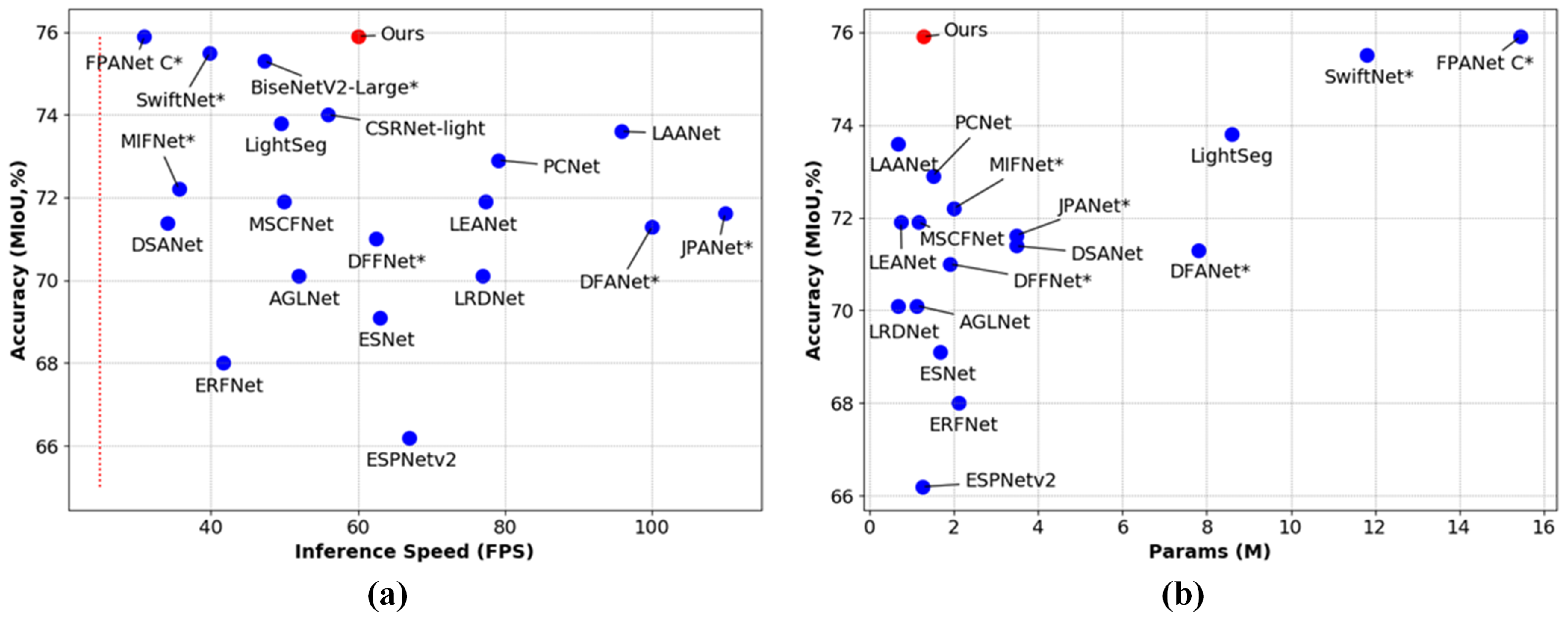
The overall network architecture of MFAFNet is shown in
Figure 2, which is an asymmetric encoder–decoder structure. The encoder contains four down-sampling operations, decreasing the resolution to 1/16 to reduce the computational overhead of the feature extraction process. The decoder contains a feature adaptive fusion module (FAFM), which fuses the output features of multi-levels in the encoding stage to reduce the loss of spatial detail information and improve the segmentation accuracy.
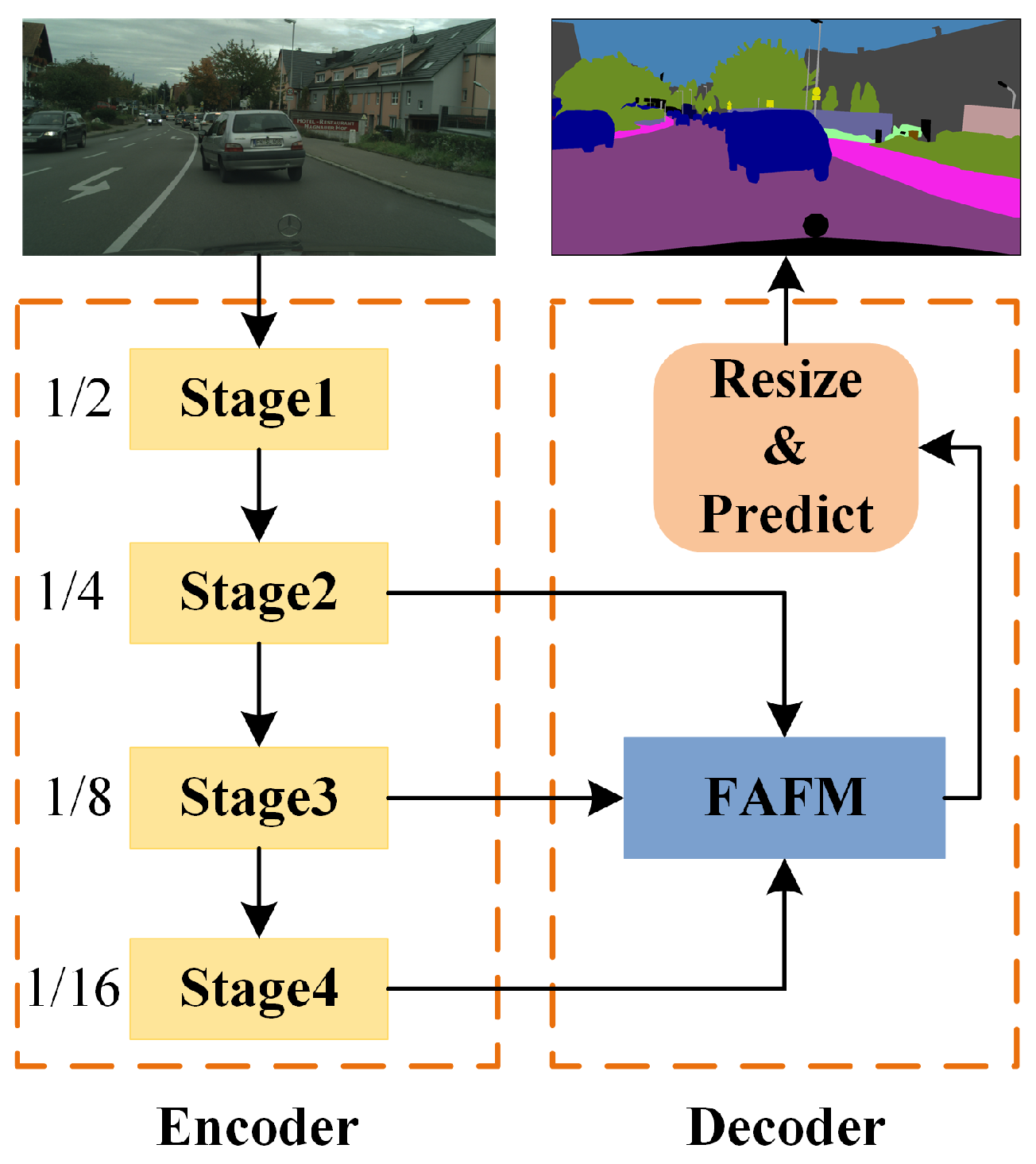
The design details of the encoder are shown in
Figure 3, which consists of four stages. Stage 1 uses a
standard convolution with stride of 2 to achieve the first down-sampling, which quickly reduces the resolution of the input features and reduces the computational complexity. The 2nd, 3rd and 4th stages are composed of SAR-nbt modules, containing 2, 3, 9 SAR-nbt modules, respectively, and down-sampling only happens in the first SAR-nbt module of each stage. To avoid weakening the feature-extraction capability of the network due to the use of depth-wise convolution, the channel expansion is added to the SAR-nbt module, and the expansion factor is 4 only for the last one in stage 3 and stage 4, and 2 for the others so as to avoid a too-wide channel dimension that would substantially increase the computational cost. In addition, in order to expand the receptive field to extract context information at a distance and to avoid losing semantic information by introducing dilated convolution prematurely, dilated convolution is introduced in the middle layer of the network. The SAR-nbt module in stage 4 introduces dilated convolution to gradually expand the receptive field, and the dilation rates are set to 2, 4, 6, 8, 10, 12, 12, 12, and 12, respectively.
For faster reasoning speed, many networks directly use bilinear interpolation methods to recover deep semantic features to the original image resolution, and although this operation improves efficiency, it leads to the loss of spatial detail information and loss of accuracy. While the decoder structure of the progressive layer-by-layer fusion of shallow features performs better in terms of segmentation accuracy, the negative effects, such as slower inference and increased computational cost, are also evident. Therefore, we design a feature adaptive fusion module in the decoder, as shown in
Figure 5, to efficiently fuse multi-level features to compensate for the loss of spatial information caused by the high abstraction of deep features and multiple down-sampling, and to significantly improve the segmentation accuracy with only a small computational overhead. Finally, we use
convolution and bilinear interpolation to recover the features to the original input size to predict the final segmentation result.
3.2. Separable Asymmetric Reinforcement Non-Bottleneck Module
In recent years, many lightweight real-time semantic segmentation networks [
14] have adopted the residual structure when designing bottleneck blocks and used optimized convolution to replace the standard convolution of the original residual blocks to reduce the number of network parameters and computational overhead.
Optimized convolution includes two categories: factorized convolution and dilated convolution. Among them, factorized convolution is mainly used to reduce the number of parameters and the computational overhead, such as group convolution [
26], asymmetric convolution [
16], and depth-wise separable convolution [
27]. Dilated convolution [
23] can effectively expand the receptive field of the convolution kernel to capture more contextual information without increasing the number of parameters. In addition, there are many works that combine multiple optimized convolutions to further improve the performance of convolution, such as dilated depth-wise separable convolution [
11], asymmetric depth-wise separable convolution [
14], and asymmetric dilated depth-wise separable convolution [
15]. Assuming that the size of the input feature map is
, the size of the convolution kernel is
, the size of the output feature map is
, and the dilation rate is
d, regardless of bias. The comparison of the parameters and receptive fields between several common optimized convolutions and standard convolutions is shown in
Table 1. Obviously, the optimized convolution can effectively reduce the number of parameters of the residual blocks, and obtain a larger receptive field. Inspired by the success of aforementioned works, we take advantage of asymmetric dilated depth-wise separable convolution to design a separable asymmetric reinforcement non-bottleneck (SAR-nbt) module as shown in
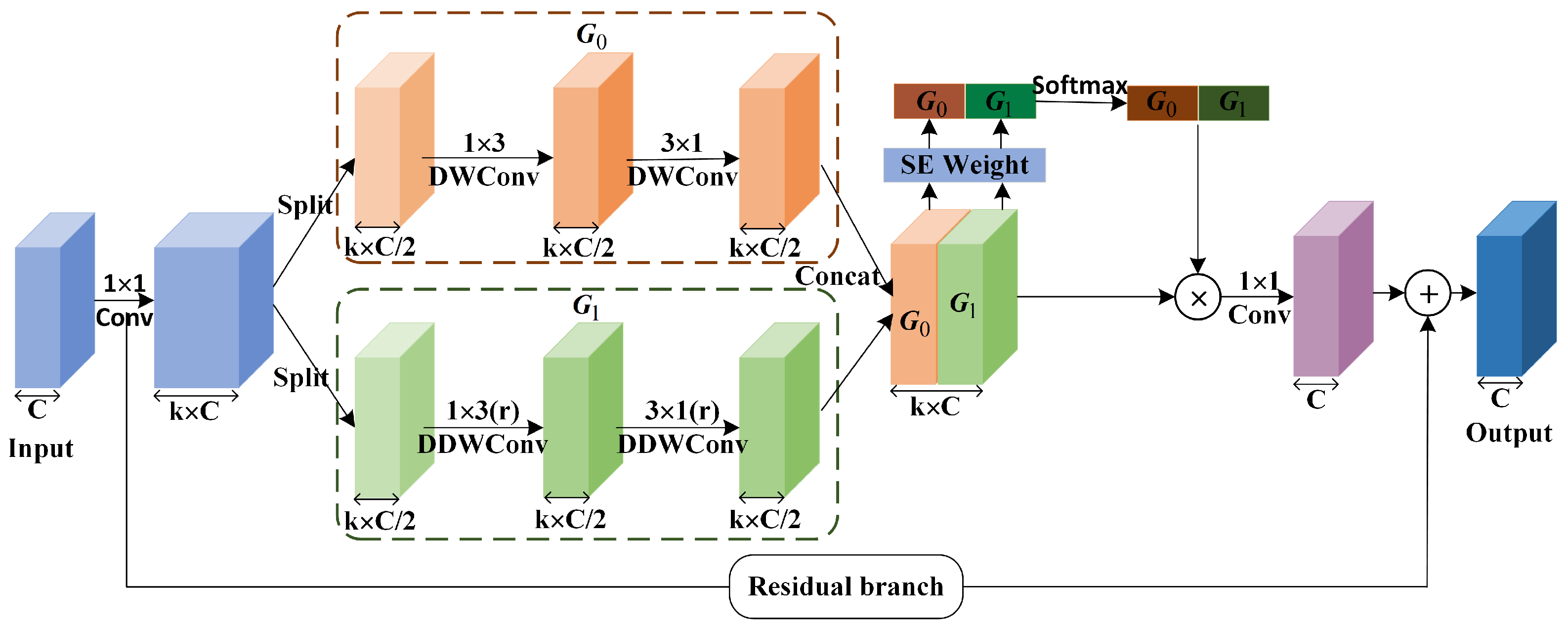
Figure 4.
Figure 4.
The structure of the proposed separable asymmetric reinforcement non-bottleneck (SAR-nbt) module. “DWConv” indicates depth-wise convolution. “DDWConv” indicates dilated depth-wise convolution.
Figure 4.
The structure of the proposed separable asymmetric reinforcement non-bottleneck (SAR-nbt) module. “DWConv” indicates depth-wise convolution. “DDWConv” indicates dilated depth-wise convolution.
The SAR-nbt module is mainly implemented in six steps. Each convolutional layer in the SAR-nbt module is followed by one batch normalization layer and one PReLU activation layer (the PReLU activation function has been demonstrated in many works to perform excellent in lightweight networks). First, to avoid the problem of feature encoding capability degradation due to the use of depth-wise convolution in the network, the SAR-nbt module first uses convolution to expand the number of channels, expanding the channels to k times the original channels to improve the feature extraction capability. Second, in order to reduce the computational complexity of the network, a channel-splitting operation is used to divide the boosted feature maps into two equal groups along the channels: and . Third, multi-scale features are extracted by two parallel groups. Many works demonstrated that fusing multi-scale features can effectively improve segmentation accuracy, so different scale features are extracted from two groups separately. uses an asymmetric depth-wise convolution to capture short-range context information. Specifically, a standard depth-wise convolution is decomposed into a convolution and a convolution, an operation that reduces the number of network parameters without reducing the receptive field. further incorporates dilated convolution to effectively expand the receptive field and extract long-range context information without increasing the computational overhead. Specially, when the stride of the SAR-nbt module is set to 2, it indicates that the stride of the convolution in and is 2, which achieves down-sampling of the input feature maps. After that, the features of the two groups are fused using the channel concatenate operation to obtain rich multi-scale features and adapt to the recognition of objects of different sizes.
Fourth, the multi-scale feature maps are enhanced by using channel attention SENet. Specifically, the channel-wise attention vector is obtained by using the SEWeight module to extract the attention of the feature maps with different scales, and the attention vector is re-calibrated by using the Softmax. Then, the re-calibrated weights are multiplied with the corresponding feature maps to achieve the enhancement of key features and obtain the refined feature maps. Fifth, the number of channels of the refined feature maps is compressed using a point-wise convolution to keep the same number of channels as the input feature maps. Finally, a residual branch is constructed to fuse the initial input with the output to solve the problem of gradient disappearance and explosion during the training process. Specifically, when the stride of the SAR-nbt module is 1, the residual branch represents the input feature map. When the stride = 2, the residual branch contains an average pooling layer, a convolutional layer, and a batch normalization layer to act on the input to keep the resolution of the residual branch consistent with the output feature map.
3.3. Feature Adaptive Fusion Module
High-level features contain rich semantic information and have high abstract generalization; low-level features have rich spatial detail information and can guide object position features. Making full use of the deep semantic information and the shallow spatial detail information can effectively improve the segmentation accuracy. Most existing real-time semantic segmentation methods use element addition or channel concatenation operations when performing feature fusion, ignoring the existence of semantic gaps in features at different levels. To effectively fuse information from multi-levels, we propose a feature adaptive fusion module (FAFM), which adaptively enhances features at different levels through an attention mechanism to reduce the semantic gap existing between low-level and high-level features.
The FAFM module is shown in
Figure 5.
H and
W represent the height and width of the input RGB image. The output features of stage 2, stage 3, and stage 4 are used in the fusion process, corresponding to the low-level feature
, the mid-level feature
, and the high-level feature
, and the feature map sizes are
,
, and
, respectively. To avoid excessive computational overhead, an element addition operation is used to fuse multi-level features. And the number of channels and resolution of each level feature maps are different; therefore, the consistency processing of each level feature is needed before feature fusion. Considering that the mid-level features have better semantic information and also retain spatial information, the number of channels and resolution of the middle-level features are chosen as the benchmark. The low-level features are down-sampled using the averaging pooling operation, and the number of channels is expanded using
point-wise convolution, while the high-level features are up-sampled using the bilinear interpolation method. The number of channels is compressed using
point-wise convolution, and the processed low-level feature
and high-level feature
are obtained in turn, both with feature map size
. The above operations can be expressed as follows:
where
and
indicate the down-sampling and up-sampling operations, respectively.
refers to the standard convolution with a kernel size of
k, with the same meaning for subsequent references.
Figure 5.
Design details of feature adaptive fusion module.
Figure 5.
Design details of feature adaptive fusion module.
Then, to reduce the semantic gaps existing in different level features, the channel attention weights
and spatial attention weights
of mid-level features are obtained to enhance the representations of other level features. The attention weights
and
are calculated as follows:
where
and
, and
and
represent the two sets of max-pooling and average-pooling operations along the spatial and channel axes, respectively.
represents the channel concatenation operation.
R and
represent the ReLU activation function and the sigmoid activation function, respectively. The ReLU and sigmoid activation functions are simple to implement and easy to optimize, and are still used by most attention mechanisms to compute attention weights.
Then, both channel attention weights
and spatial attention weights
are multiplied with low-level features and high-level features to achieve the adaptive adjustment of features at different levels. Finally, the multi-level features are element-wise added and fused, and the 3 × 3 convolutional layer is used to make the feature fusion more fully, and the final output of the FAFM module is obtained. The final features
can be obtained according to the following formula:
Obviously, the proposed FAFM module uses an attention mechanism to reduce the semantic gaps that exist between multi-levels, effectively balances feature maps with multiple resolutions, and improves segmentation accuracy.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}