3.1. Equally Proportional Center Prior
The center region containing anchors is the area that is in the center of the GT box. The general sample assignment algorithms use the anchors of the center region as positive samples directly or as candidate positive samples for the next filtering step. In this paper, this step is referred to as center prior (CP). FCOS [
2] directly selects anchors in the center region of a square as positive samples; ATSS [
3] selects candidate positive samples based on L2 distance, so its center region is close to circular. However, instead of directly using anchors within the center region as positive samples, ATSS processes them further, and considers anchors outside the GT box to be poorer anchors. Both FCOS and ATSS, as well as the EPCP proposed in this paper, ensure that the positive anchors are inside the GT box.
In theory, all anchors within the GT box have the potential to be positive samples. However, in most cases, especially in the early stages of training, the anchors in the center of the object are more conducive to the training of the model, so the choice of the center region should be as reasonable as possible. FCOS directly selects the anchors in the small center region as positive samples, which leads to the model focusing too much on the central anchors; ATSS selects candidate samples at L2 distance in each feature layer, which also only selects samples that are more clustered in the center region of the GT box. For some objects that are not completely in the center, it is difficult for these two methods to assign better anchors. However, if the center region is simply expanded, many anchors containing a lot of noise will be introduced, which will affect the performance of the detection model to some extent. In addition, FCOS and ATSS select candidate samples without considering the GT box’s shape at all. For some GT boxes with a large difference in length and width, the selection of anchors by FCOS or ATSS is not suitable.
To solve this problem, this paper proposes the EPCP. Different from the traditional center prior, EPCP determines the center region according to the aspect ratio of each GT box. For objects with similar length and width, the center region using EPCP is close to square, which is not much different from the center region using the traditional center prior. However, for objects with a large difference in length and width, the center region is rectangular and contains most of the anchor points that can represent the features of the object because the aspect ratio of the center region is the same as that of the GT box.
Specifically, the process of using EPCP to determine the center region is as follows: assume that all GT boxes in an image are the set
, and
is one of the GT boxes, i.e.,
. The length and width of
are
and
, respectively, the center coordinates are
, and the stride from the feature layer to the original image is
, so the two distances from the center of the GT box to the left boundary and the upper boundary of the central area can be determined as shown in Equations (1) and (2), respectively:
In these equations,
is a hyperparameter, and
. From these two distances, the coordinates of the four vertices of the center region with EPCP can be determined as
,
,
, and
, respectively. Through EPCP, the short side of the center region of each GT box is
, and the center region maintains the same aspect ratio as the GT box.
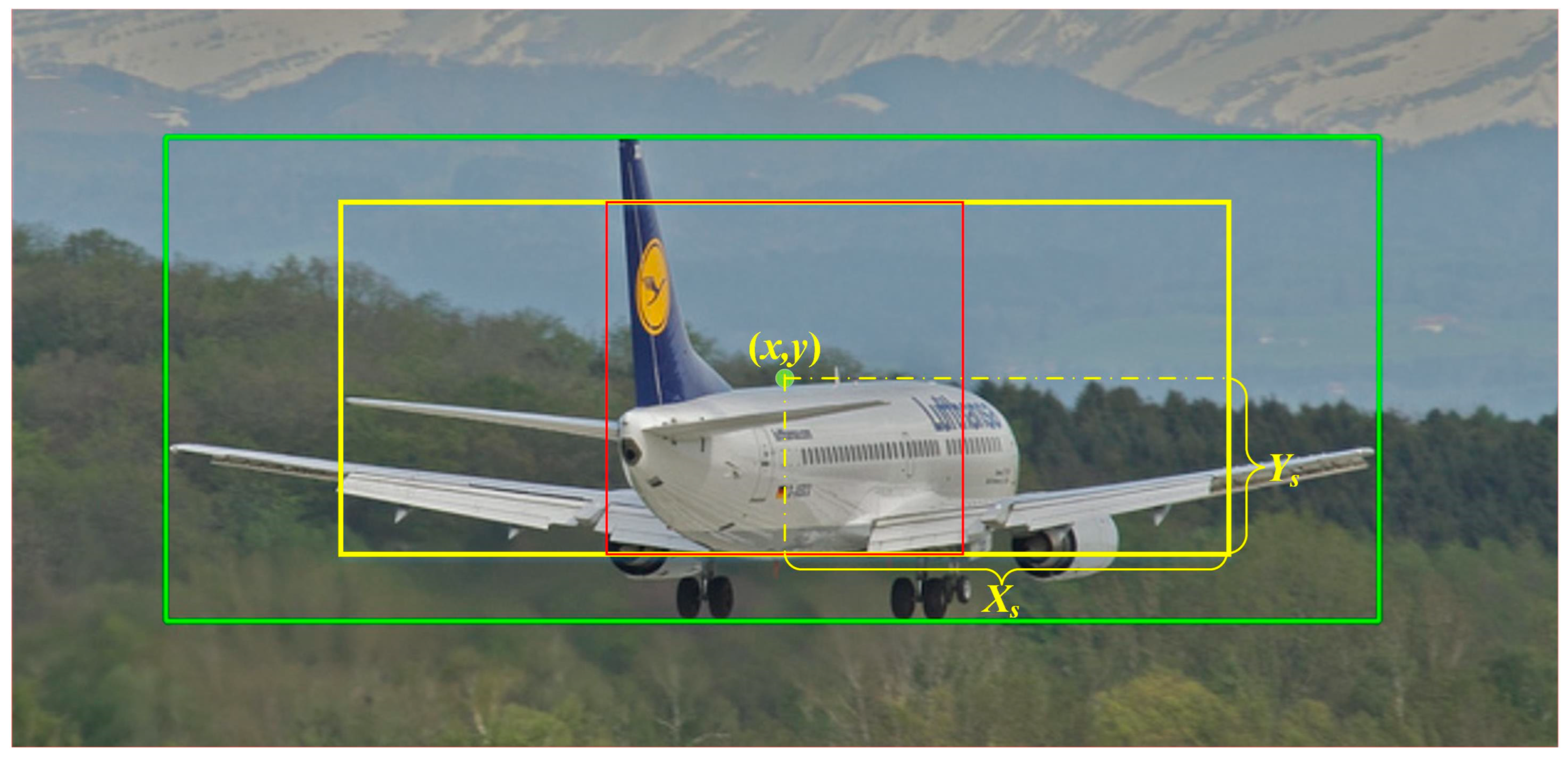
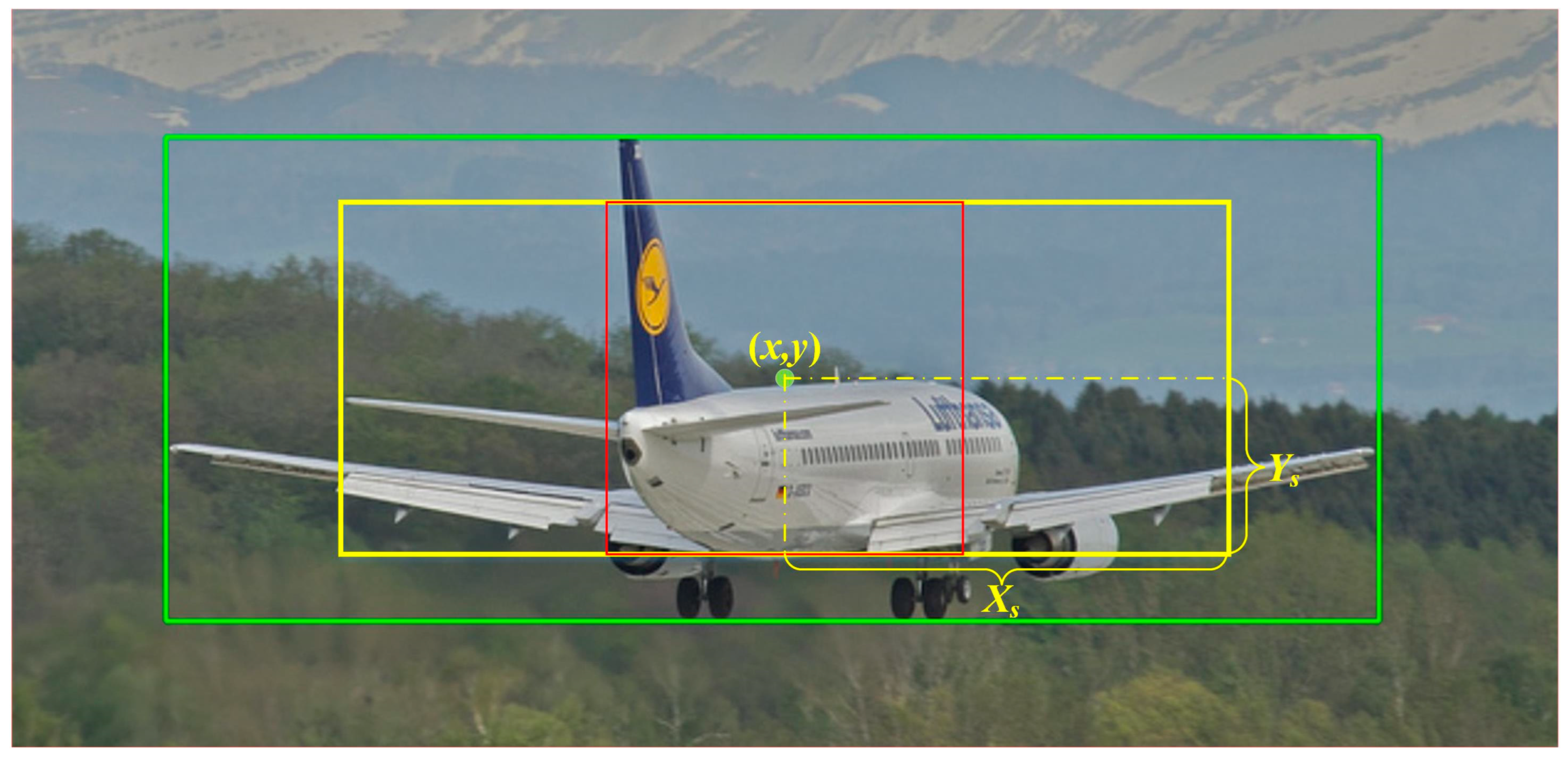
Figure 2 shows the center region obtained from EPCP; in this figure, the green box is the GT box, the yellow box is the center region of EPCP with the same aspect ratio as the GT box, and the red box is the center region of CP. The red box is still square when the GT differs greatly in length and width.
To ensure that the center region can cover all anchors suitable as positive samples as much as possible, this paper sets the hyperparameter of the center region to 2.5, which is only 1.5 in the center sampling of FCOS. The area of the center region of FCOS is , while the shortest side of the central area of EPCP is , so its minimum area is . By increasing the area of the center region, most of the anchors that may become positive samples are in the center region. In addition, better positive anchors will not be missed for some objects with a large difference in length and width, such as buses, giraffes, tennis rackets, toothbrushes, etc. Through EPCP, the potential positive anchors are selected as much as possible, which are called the first round of candidate positive samples, , in this paper. However, it also brings a new problem, that is, how to select high-quality anchors from the many anchors in this center region. Therefore, this paper proposes the CLA for evaluating the quality of anchors in the next section.
3.2. Combined Loss of Anchor
Using a fixed IoU threshold or other fixed hyperparameters as the basis for assignment often fails to assign the more suitable anchors to the GT box. For example, RetinaNet [
1] uses a fixed IoU threshold and considers that the anchor boxes with larger IoUs with the GT box are positive samples. In
Figure 3, the green box is the GT box, the blue box is one of the anchor boxes (only the anchor box with an aspect ratio of 1:1 is drawn), and the blue point in the center of the anchor box is the corresponding anchor point. The anchor point in
Figure 3a is in the center region of the GT box, and the IoU between the anchor box and the GT box, which is 0.66, is also relatively large. This IoU value is higher than most anchor boxes. According to RetinaNet’s method, this anchor box will be assigned as a positive sample for training. However, most of the area where the anchor box intersects with the GT box is the background, and even the central area of the anchor box is mostly the background rather than the object, so it is difficult for the model to learn useful information from the content that is largely background noise. The prediction box obtained based on this anchor box is unlikely to have a high IoU with the GT box, and thus, ideal prediction results cannot be obtained. Therefore, although the IoU of this anchor box with the GT box is higher than most anchor boxes, it is not a suitable positive sample. From this example, it can be seen that the IoU between the anchor box and the GT box cannot be used as the only basis for evaluating the quality of the anchor box or anchor point.
ATSS [
3] tiles only a square anchor box at each location and uses dynamic IoU as a threshold to distinguish between positive and negative samples. Although this approach can alleviate the problem caused by the fixed IoU threshold, there are still notable issues. On the one hand, since the IoU of the anchor boxes and the GT box is not the best metric to assess the quality of anchor boxes, using the sum of the mean and standard deviation of the IoU as the threshold is also not optimal; on the other hand, these tiled anchor boxes do not change in any way during the training process, so the IoUs of the GT box and anchor boxes do not change and the IoU threshold does not change with the training process, so the positive samples will not change and the model still cannot participate in the process of anchor assignment. In addition, both RetinaNet and ATSS do not consider the aspect ratio of the GT box. For example, the anchor box in
Figure 3b has a high IoU with the GT box, but the intersection area is mostly background. Moreover, the length and width of the GT differ greatly, so it is difficult to satisfy all kinds of aspect ratios of GT boxes by only tiling one scale and aspect ratio of anchor boxes. Furthermore, tiling multiple scales and aspect ratios of anchor boxes not only requires setting the scales and aspect ratios of anchor boxes according to the dataset, but also greatly increases the computational effort.
Since the IoU between the best positive anchor box and the GT box is not necessarily higher than that of a negative anchor box, for the reasonableness of the sample assignment, the anchor needs a more appropriate evaluation metric to define whether the anchor is a positive sample or a negative sample. Furthermore, this metric needs to be relevant to the model to avoid the situation where the IoU of the anchor and the GT box is large during the assignment process, but the model still predicts poorly. The anchor assigned by this metric is not necessarily near the center of the GT box, and the corresponding IoU of the anchor box to the GT box is not necessarily high, but it can well represent the characteristics of the objects in the GT box, allowing the model to learn better. In summary, this paper proposes the CLA, which satisfies the above conditions, as shown in Equation (3):
where
,
, and
are the classification loss, regression loss, and deviation loss of the prediction results of candidate anchors, respectively.
and
are hyperparameters to balance the weights of each loss. In the experiments of this paper,
and
are used.
The CLA takes into account both the classification quality and regression quality of the anchors, as well as the degree of deviation within the GT box. The classification loss and regression loss of anchors in CLA are similar to the anchor scores used in the PAA algorithm [
4], which will be smaller for anchors that are suitable as positive anchors and, conversely, will be larger for negative anchors. In particular, the classification loss and regression loss will be larger for anchors that contain a large amount of background because it is almost impossible for the model to correctly predict the bounding box and the corresponding category based on the background without clues. In addition, since the center region where the
are located is related to the stride
, this center region is large on the higher feature layers, leading to the selection of all anchors within some small and medium-sized objects on these feature layers. Therefore, this paper proposes the use of deviation loss. Anchors in
at the edge of the GT box have different deviation loss from those at the center range of the GT box, but exactly which anchors are eventually selected as positive samples is determined by the CLA. The smaller the CLA, the better the prediction of the correct category and bounding box. The calculation of each loss is described below.
After the screening of the EPCP in the previous step, the corresponding candidate positive samples can be obtained on different feature layers, and the candidate positive samples in each layer together form the first round of candidate positive samples . Suppose one of the anchors , whose coordinates are . obtains the prediction value after forward propagation of the mode, where and represent the classification vector and the coordinate vector of the regression box predicted by the model, respectively. If is assigned to the GT box, then , where and denote the coordinates of the vertices of the upper left and lower right corners of the GT box, and corresponds to the class of the objects in the GT box.
The classification loss of the anchors uses Focal Loss [
1]. The vector
obtained from the forward propagation of the anchor
is a vector with the dimensionality of the number of categories
, and its classification loss can be calculated as shown in Equation (4):
The regression loss of the anchors uses GIoU loss [
27]. The prediction box’s coordinate vector
obtained from the forward propagation of the anchor
is a vector of 4 dimensions which can be expressed as
, representing the position information of the prediction box relative to the anchor
in the FCOS detector [
2]. The values of the four components represent the distances from the anchor point to the left, top, right, and bottom boundaries of the prediction box, respectively. The regression loss can be calculated as shown in Equation (5):
The deviation loss of the anchors is calculated by the center deviation. Suppose the distances from the anchor
to the left, top, right, and bottom boundaries of the GT box
are
, respectively, and since the first round of screening ensures that the anchor
is inside the GT box
, all 4 of these distances are positive. Based on these 4 distances, this paper defines the center deviation, denoted as
, as shown in Equation (6). The smaller the absolute value of the difference
, the more this anchor is in the center of the GT box horizontally, and the same goes for the difference
. In addition, considering the different potential lengths and widths of the GT box, the absolute value of this difference is divided by the corresponding side length of the GT box and normalized to
.
The deviation loss proposed in this paper is shown in Equation (7), and the deviation loss is set to 0 for anchors whose center deviation is within the threshold value, i.e., this anchor is considered to be within the acceptable range of deviation; the deviation loss is calculated for each anchor whose center deviation is greater than the threshold value, and the specific value is calculated by the
.
The above three losses together form the CLA, which takes into account the actual distribution of objects inside the GT box and the aspect ratio of the GT box. This metric is more reasonable for the anchor assignment of eccentric objects and objects with a large difference in length and width.
3.3. Dynamic Loss Threshold
After calculating the CLA of
, we need to divide the positive and negative samples in
. To further divide the positive and negative samples, a fixed number of positive samples is directly used in LLA [
28] without considering the specific value of anchor loss, and only the
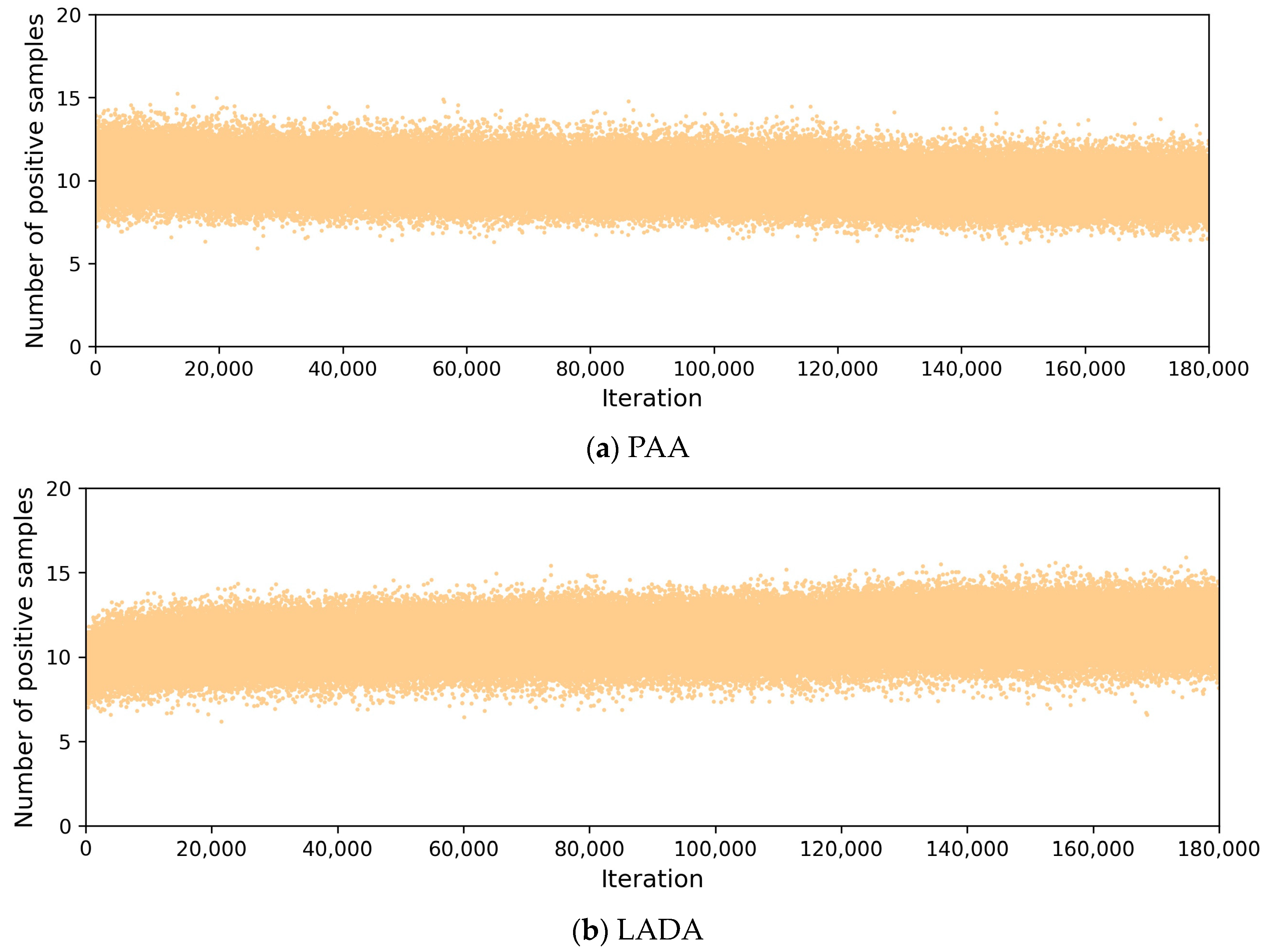
anchors with smaller losses are selected as the positive samples. Although this approach does not require additional calculations, it introduces hyperparameters and cannot use the specific value of the loss to judge the number of positive samples. Moreover, the number of positive samples is not necessarily the same for objects of different sizes. A complex GMM is used in PAA [
4] to cluster the candidate positive samples according to the value of the anchor score (calculated by the anchor loss) into two categories of positive and negative samples. PAA greatly reduces the training speed of the model; for each GT box, it needs to be re-iterated once, and this iteration needs to be performed on the CPU.
To solve the above problems and better use anchor loss to dynamically divide the positive and negative samples without using additional models, this paper proposes a simpler and more effective division method, called the DLT. After calculating the CLA of , the process of using DLT is as follows:
Select anchors with smaller CLAs in each feature layer to obtain the second round of candidate positive samples .
Select anchors with smaller CLAs in as the third round candidate positive samples , and calculate the mean value of the CLAs of these candidate positive samples.
The anchors in with CLAs lower than are taken as positive samples , and the rest are negative samples .
Since the LADA algorithm does not focus on which feature layer is more suitable for predicting the current GT box in the first round using EPCP screening, may come from all feature layers, and some feature layers are not suitable for predicting the GT box at the current scale. To find suitable positive samples, DLT in LADA first selects anchors in each feature layer to form the second round of candidate positive samples . However, there are some candidate anchors on feature layers that are not suitable for predicting the current GT box (e.g., anchors on the lowest feature layer are not suitable as their candidate anchors were placed when the GT box was larger), these poorer candidate anchors have larger losses and are not suitable as positive samples, and there is no need to continue to retain these anchors. However, PAA retains these poorer anchors and clusters them as well. Since these poor candidate anchors have larger losses, they are also assigned as negative samples after clustering. Therefore, anchors in all participating in clustering is not the most appropriate approach, because some anchors with larger losses and low rankings will hardly be positive samples. In addition, the cost of GMM iteration is large, and the same process has to be performed for each GT box. Furthermore, an image often has more than one GT box, which leads to the training time being greatly prolonged.
Therefore, the DLT proposed in this paper does further screening on before dividing it. The experimental part of this paper demonstrates that compared with the PAA algorithm, the LADA algorithm reduces the training time by about 26.8%.
3.4. Algorithm Realization
As shown in Algorithm 1, the process of positive and negative sample assignment by LADA is described. A preliminary matching is performed before the assignment, referring to the practice in PAA [
4] that assigns the anchors to the GT box with the largest IoU. Meanwhile, the anchor-free detector refers to the practice in ATSS [
3] that gives each anchor a flat
anchor box before the preliminary IoU matching. When an anchor is assigned to more than one GT box, the GT box with the largest IoU of the anchor will be selected. The IoU threshold here is consistent with that in PAA, set to 0.1. The anchors containing too much background are omitted, and the most original positive sample candidate set is constructed. The anchors both in the GT box and the center region of EPCP are the first round of candidate positive samples
. Then, the CLA of
is calculated, and
anchors with smaller CLAs are selected in each layer as the second round of candidate positive samples
. Finally,
anchors with smaller CLAs are selected as the third candidate positive samples
. The mean CLA value of
is calculated as the DLT to distinguish the positive and negative anchors, so the positive anchors
and negative samples
are obtained.
| Algorithm 1 Lightweight Anchor Dynamic Assignment (LADA) |
Input: , , , , , . is a set of GT boxes, is a set of anchors, is a set of anchors from pyramid level, is the number of pyramid levels, is the number of the second round of candidate positive samples for each pyramid, is the number of the third round of candidate positive samples .
Output: . is a set of positive samples, is a set of negative samples.
- 1.
- 4.
do Iterate through each GT box in the current image - 5.
is the round of candidate positive samples - 6.
Select the anchors using EPCP - 7.
do - 8.
Calculate the CLA of this layer from Equation (3) - 9.
The CLAs of each layer of anchors together form - 10.
Select anchors with smaller CLAs as - 11.
end for - 12.
Select anchors with smaller CLAs - 13.
Calculate the mean of CLA as DLT - 14.
do - 15.
if then - 16.
Anchors with CLAs lower than are positive anchors - 17.
end if - 18.
end for - 19.
end for - 20.
- 21.
return
|
The assignment process is schematically shown in
Figure 4. To illustrate the assignment of different feature layers, three of them,
,
and
, are selected and the positions of the assignment results of these feature layers on the original figure are drawn. Anchors in
Figure 4a are the first round of candidate positive samples that satisfied EPCP. Anchors in
Figure 4b are candidate samples with smaller CLAs in each layer. Anchors in
Figure 4c are candidate samples with smaller CLAs in all layers, and it can be seen that there are almost no anchors retained in the feature layer
, which is not suitable for prediction. Anchors in
Figure 4d are positive samples with CLAs smaller than the threshold, and the positive samples are only distributed in
and
.
The LADA algorithm proposed in this paper is used in the training phase, as shown in
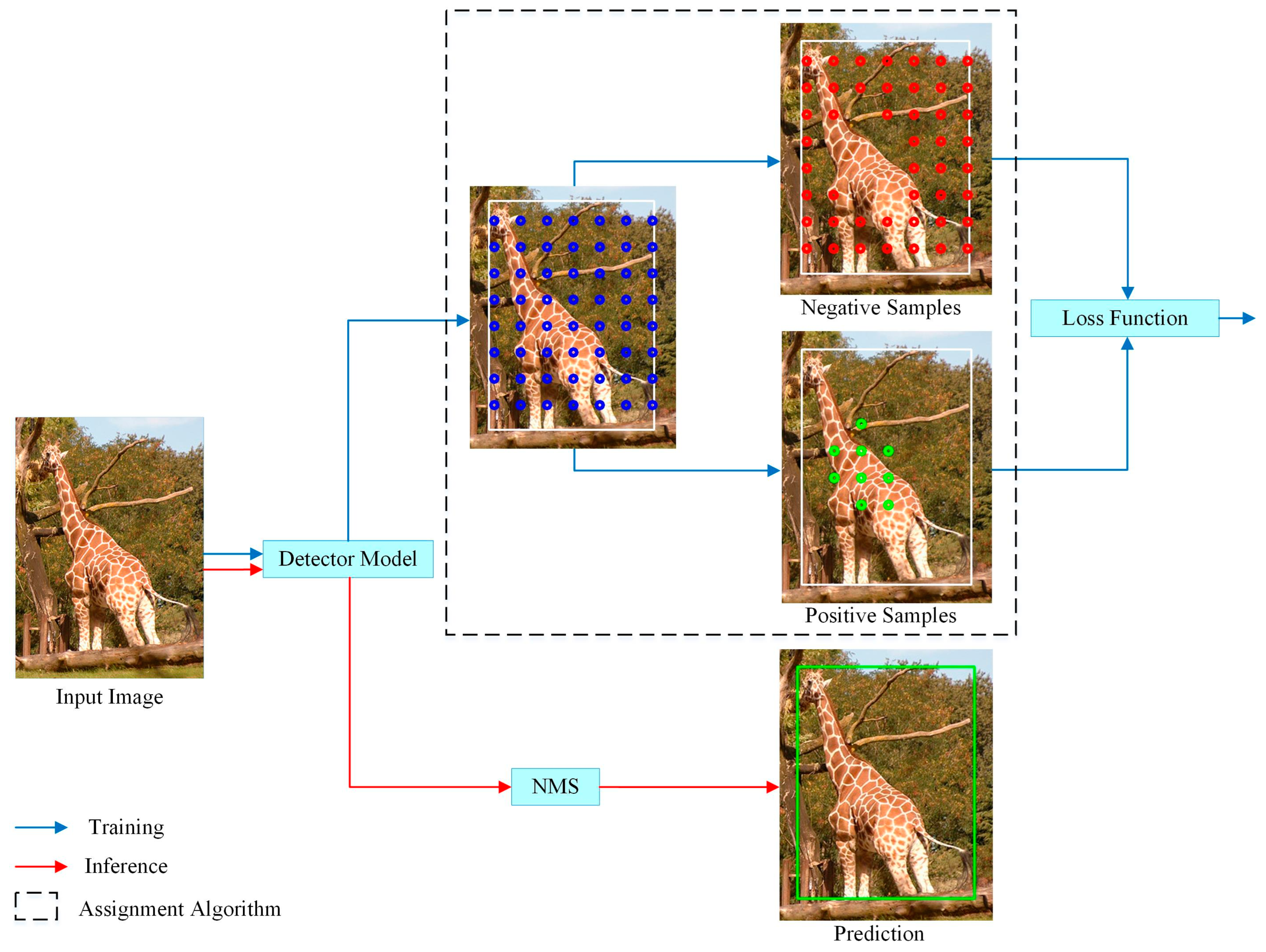
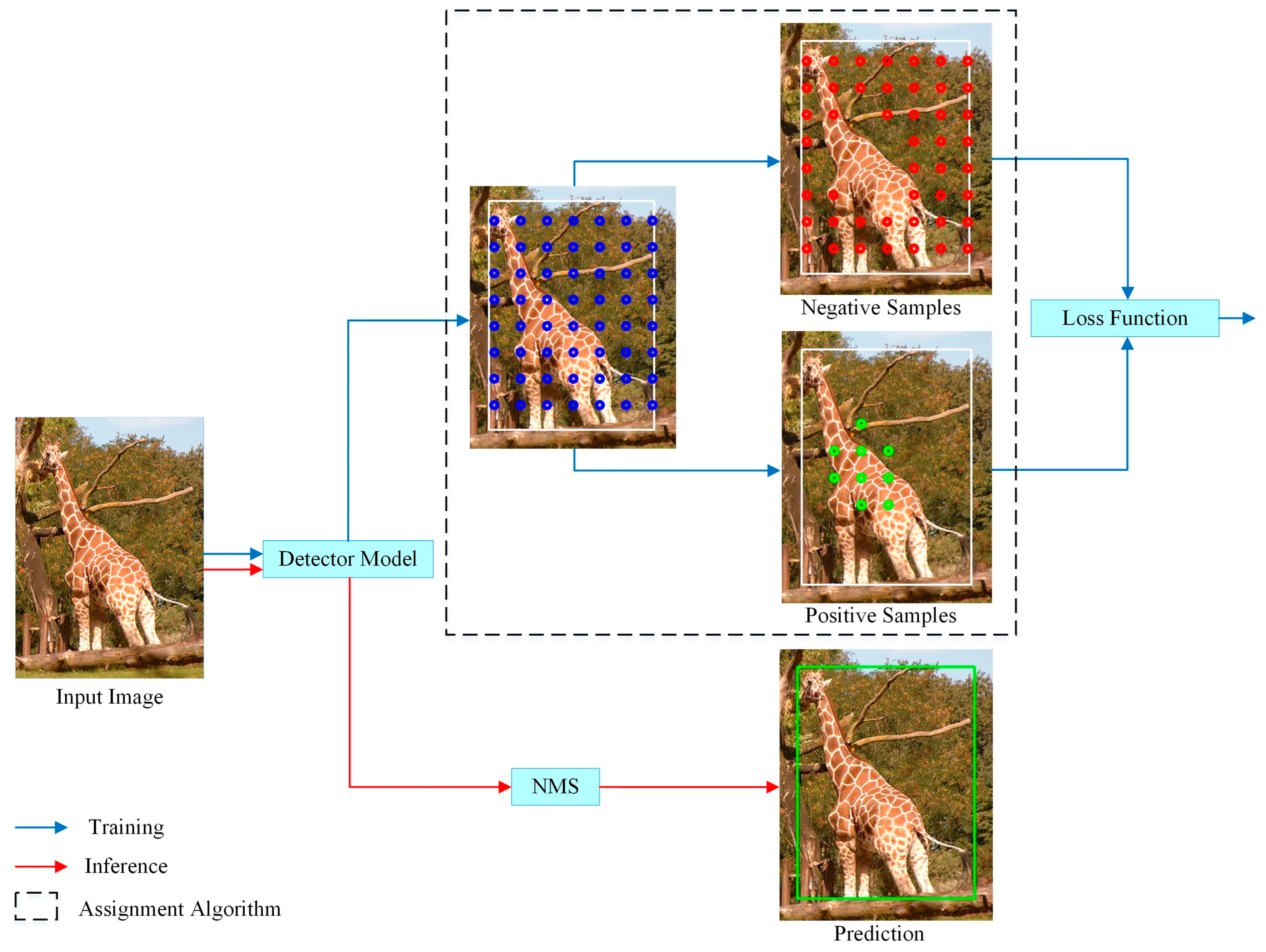
Figure 5. In the training process, the positive and negative samples are determined by LADA, and then the losses, such as classification and regression, of the model prediction results are calculated and back-propagated to update the parameters of the detection model. The inference process, on the other hand, does not require the involvement of the LADA algorithm and only requires Non-Maximum Suppression (NMS) as post-processing of the model output vectors to obtain the detection results. Since the LADA algorithm only changes the positive and negative sample assignment results, it does not change the model structure.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}