1. Introduction
In recent years, the rapid development of technologies such as the Internet of Things, micro-sensors and 5G, and the increased demand for smart city sensing has contributed to the boom of a new sensing paradigm known as mobile crowd sensing (MCS) [
1,
2]. Mobile crowd sensing is a new large-scale sensing paradigm that mainly operates through the participation of a large number of users to obtain sensing data. People can use their mobile phones or smart devices to perform complex and large-scale sensing tasks [
3], thus forming a large-scale, anytime, anywhere sensing system which is closely related to people’s daily lives. A typical crowd-sensing system usually consists of workers, users and the platform. The user posts tasks on the platform and the platform distributes the collected sensing tasks to the workers, who complete the sensing tasks and get paid. MCS research mainly includes data quality management [
4,
5], privacy protection [
6,
7], incentive design [
8,
9], worker selection, task assignment [
10,
11], etc. MCS also has a wide range of application scenarios, such as traffic planning [
12], indoor positioning [
13,
14], energy management [
15], air monitoring [
16], public safety [
17], etc. Mobile crowd sensing has now become an effective method for meeting the needs of large-scale sensing applications [
18], such as sensor networks for detecting bridge vibrations on mobile vehicles [
19], Creekwatch for monitoring the condition of river basins [
20] and crowd engagement systems for public transport arrival time prediction [
21].
One of the central issues in mobile crowd sensing is task allocation. Assigning tasks to specific workers under certain conditions not only increases the effectiveness of the platform, but also reduces worker consumption. Hence, ensuring appropriate task allocation is a mutually beneficial strategy for both participants and the platform. At this stage, task assignment studies can be divided into two categories based on the degree of worker participation: participatory sensing task assignment [
22] and opportunistic sensing task assignment [
23]. In the context of opportunistic sensing task assignment, workers perform sensing tasks along a predetermined route. However, in the case of participatory perception, workers are required to generate their own movement routes based on the tasks assigned by the platform. The strategies for task assignment heavily rely on the temporal and spatial information associated with both the workers and the tasks. This poses a challenge in dynamically assigning tasks to workers while considering spatio-temporal aspects.
In addition, for task assignment issue, it can be divided into user-centric [
24] and platform-centric modes [
25] according to different task assignment methods. In the user-centric model, workers are more autonomous and can choose which tasks to complete themselves by browsing tasks posted on the server and then uploading the collected data through their smart devices. As it relies mainly on workers’ autonomy to select tasks, the worker-centric model has some drawbacks, such as that individual workers tend to consider only their own interests and select only high-value tasks, and there may even be a situation where pending selection of tasks can go to completion but multiple workers compete for a high-value task, resulting in an unbalanced distribution of sensing tasks, making it difficult to maximise worker resources to complete more tasks and improve the quality of task execution. In contrast, in the platform-centric model, the platform collects all information from the demand of sensing tasks (such as response time and completion quality) and workers, and can use global optimisation algorithms to allocate tasks to different workers according to different strategies, making good use of worker resources while completing the task assignment in a global manner.
In MCS applications, excluding tasks with complex requirements, sensing tasks can be divided into two types: area tasks and point tasks, depending on the size of the sensing range [
26]. Therefore, workers must reach these locations in order to perform their assigned tasks. For each worker, the reward received is related to the path taken to perform the task, and the order in which the tasks are performed directly affects the worker’s travel path, so the task assignment problem can be considered as a path planning problem. However, even if there is only one worker, the path planning problem without various constraints is computationally intractable, similar to the travelling salesman problem [
27]. To plan the worker’s travel path, the platform makes decisions on the worker’s sensing task assignment process sequentially. Since reinforcement learning [
28] has a long-term perspective, considers long-term payoffs and is particularly suited to making sequential decisions, it is promising for RL to be applied to task assignment problems.
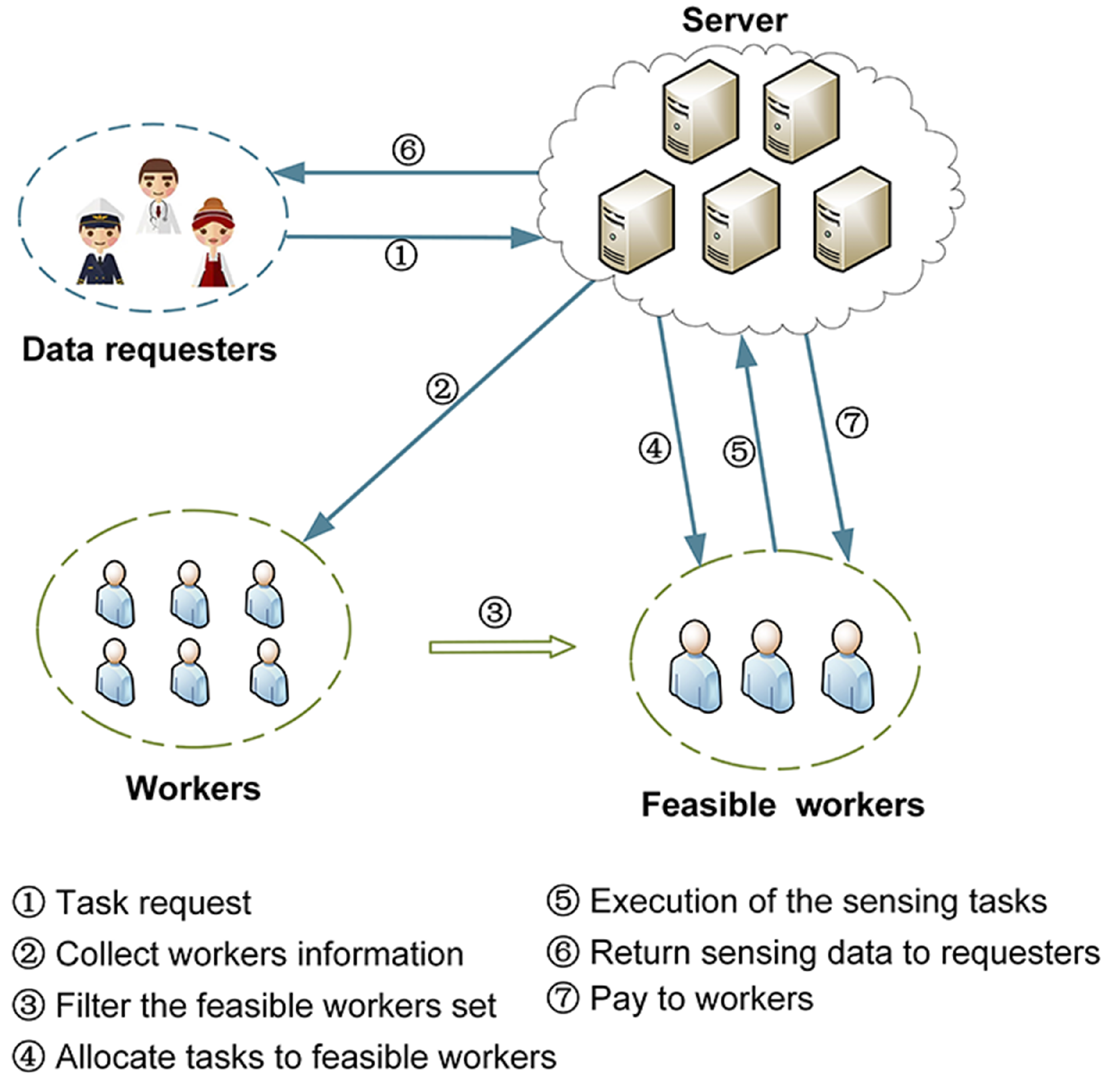
Thus, since the platform is seen as an agent for RL, the status of sensing tasks and workers is regarded as the environment of RL. However, when the state and action space is large, traditional RL methods (e.g., Q-learning [
29]) suffer from slow convergence and dimensional disasters. To address this problem, deep reinforcement learning (DRL) has introduced deep learning methods to RL and has already made great progress in several areas, such as natural language processing [
30] and recommender systems [
31]. In this paper, an MCS framework is proposed with five phases. Initially, data requesters (platform users) post their sensing tasks and relevant information (e.g., location, time window and budget) in the platform. Secondly, the platform announces the reward rules to the workers and filters the set of optional workers. Thirdly, the platform solves the task allocation problem and plans the travel path for the recruited workers. Then, the recruited workers move along the planned path to perform their assigned tasks and then upload their information (e.g., location, estimated completion time, etc.) to the platform, which feeds the information back to the user. Finally, the platform validates the data collected and sends it to the corresponding user. At the same time, the platform distributes rewards to the recruited workers. In existing studies, usually the platform-centric task allocation model only considers the interests of the platform [
32], ignoring the feelings of other participants, which is not conducive to the development of the platform. Therefore, a weighted multi-objective approach was adopted, taking into account both the participants’ experience and the platform’s profit. To achieve this goal, we proposed a D3QN solution with a double deep Q network (DDQN) structure and a Dueling architecture for the task allocation problem. In addition, three baseline solutions are considered for performance comparison, namely DQN,
–greedy and random solutions. Finally, we evaluate our proposal experimentally.
In brief, the main contributions of this paper are summarised as follows:
We propose a time-sensitive dynamic multi-objective task assignment problem and use a new MCS framework to efficiently recruit workers and have them complete their assigned sensing tasks within a specified time;
We propose an MCS task assignment strategy based on a modified version of DQN. Considering the location of workers, time constraints of tasks and other factors, it is closer to realistic scenarios. To our knowledge, we are the first to use D3QN to solve the task allocation problem for MCS;
We use three baseline solutions (i.e., DQN, –greedy and random solutions) and conducted various simulations with different numbers of workers to evaluate the performance of the algorithm. The results show that our proposed D3QN solution outperforms the baseline solutions;
We use weighted multi-objectives to optimise multiple objectives, comprehensively consider platform’s profit and participants’ experience and achieve good results, improving the practicability of the platform.
The remainder of this paper is organised as follows.
Section 2 presents related work,
Section 3 describes the structure of the task allocation framework and the formulation of the task allocation problem, and
Section 4 details the D3QN solution and the three baseline solutions.
Section 5 presents the simulation scenarios and results. Finally,
Section 6 concludes the paper.
4. Solutions of Formulated Problem
4.1. Markov Decision Process and Reinforcement Learning
In this section, first, the task assignment problem of MCS is considered from a reinforcement learning perspective, and then a D3QN-based solution is proposed. To evaluate the proposed solution, we also provide three baseline solutions as benchmarks, including DQN, –greedy and random solutions.
Reinforcement learning studies the sequential decision process by which an agent as the subject interacts with the environment as the object. Mathematically, it is generally normalised as a Markov decision Process (MDP), described by the current state and the action taken on it. A Markov decision Process can be described, where the next state is determined as
. In this case,
S and
A denote the finite state space and action space, respectively, and
is the reward function.
is the state transfer probability of obtaining the corresponding reward
r from a given state and action to the next state.
is the discount rate that responds to the importance of the current reward to future rewards. The goal of reinforcement learning is to maximise the cumulative reward
, where
T is the number of steps for state
s to reach the terminal state.
is then computed from the action-value function, which is defined as follows:
Through the function
, it can be judged whether the policy function
performs the action
under the state
at time t. When maximising
with respect to
, the optimal action value function can be obtained:
Next, we treat the task assignment problem as a Markov decision process, represented by a five-tuple
, based on an interaction model between the MCS server and the environment, where the platform is considered as the agent and
S is a finite set of states, each consisting of the set of tasks observed by the current agent.
A is a finite set of actions, with each action representing an assignment between a sensing task and a worker.
P is the probability that the current agent will move to state s’ after taking action a in state
s.
R is the reward function, from which the value of the reward that can be obtained by moving from the current state to the next state is returned.
is the discount rate. It is worth noting that, for faster learning, we added penalties to all failed decisions. Thus, the reward function
r for a round is defined as: follows
where
K1 and
K2 correspond to the constants of the variables
d and
t, respectively, with the aim of transforming the minimisation problem into a maximisation one.
d is the distance travelled by the performing worker,
t is the workers’ response time for the current task, and
p is the profit that the platform can obtain from the current task.
,
and
are weighting factors that sum to 1.
z is a negative constant that is the penalty constant added for failed task assignment rounds.
Reinforcement learning problems can be solved in various ways, such as dynamic programming, Monte Carlo methods and temporal difference methods. Among them, the time difference method is favored because of its model-free characteristics. Q-learning is a typical algorithm of temporal difference methods and a widely used reinforcement learning method, which mainly focuses on estimating the value function of each state–action pair. For any state
and action
acquired at time
t, Q-learning predicts the value of the state–action pair
by iteratively updating:
where
is the learning rate,
is the discount factor and
is the reward obtained for the transition of the state from
to
after action
.
is the largest Q-value function of all possible actions in the new state
.
4.2. DQN Solution
DQN (Deep Q Network) is an approach that combines neural networks and Q-learning. The core of Q-learning is the Q-table, which is built to guide actions. However, this applies when the state and action space is discrete and not high dimensional. When the state and action space is high-dimensional, the Q-table will become very large and the amount of computer memory required to store the Q-table and the time consumed to find the state are both unacceptable.
Therefore, neural networks in machine learning were introduced to solve this problem. The neural network receives input from the state
and, after analysis, outputs a Q-value vector of actions
.
is a parameter of the neural network and represents the weight between neurons. The DQN also uses two means of improving learning efficiency, namely, the experience replay mechanism and Fixed Q-targets. Experience replay refers to the use of buffer to store past and current experience, and, when the neural network parameters need to be updated, some random samples can be taken for learning. Thus, experience replay makes samples reusable and improves learning efficiency. The principle of Fixed Q-targets is to use two neural networks with the same structure but different parameters, where the parameters of the target network are
. Every certain number of steps, the parameters of the replicated neural network are used to update the target network. The Q values in the DQN are then updated by the following:
We then define the loss function in terms of the mean squared error as follows:
where
is the target action value function based on the action distribution of the output of the target Q-network. All parameters of the evaluated Q-network are denoted as
at iteration generation
i and are updated at each iteration.
values come from the target Q-network; they are fixed and are only updated with
every certain number of steps.
is the discount factor, which determines the weights for considering long-term rewards.
4.3. D3QN Solution
Furthermore, the DQN algorithm itself is prone to overestimation. To address this issue, we adopted the double DQN approach, which involves training two Q-networks: the original Q-network and the target Q-network. The Q-network is responsible for action selection using parameter , while the target Q-network evaluates the action values using parameter . Unlike the DQN method that directly selects the action with the highest value from the target Q-network for updating, the double DQN approach considers that the action with the highest value in the Q-network may not necessarily be the one with the highest value in the Dueling DQN target Q-network. This distinction allows for more effective mitigation of the overestimation problem while maintaining the algorithm’s performance.
Then, Dueling is used to optimise the network architecture, as shown in
Figure 2. The above is the traditional DQN, and the bottom is the Dueling DQN. In the original DQN, the neural network directly outputs the Q-value of each action. In contrast, the Dueling DQN decomposes the Q-value of each action into a V-value and a dominance function A(s,a), which can distinguish between what is rewarded by the state and what is rewarded by the action. The value function is then re-represented as follows:
where
is the network parameter of the common part,
is the network parameter of the unique part of the value function and
is the network parameter of the unique part of the dominance function. In addition, in practice, for better stability, we replace the maximum operator with the average operator:
Finally, D3QN updates the Q-value:
Based on the above improvements, we propose a D3QN solution for the dynamic task allocation problem in crowd sensing. The algorithmic time complexity of the D3QN solution with experience replay, considering the training process, can be expressed as O(M*(N*(|U| + |V| + ))), where M is the maximum number of episodes, N is the number of samples in the experience replay, |U| denotes the size of the input state space, |V| denotes the number of actions and is the time spent processing a neural network layer for one worker and one task. The complexity of the algorithm mainly focuses on steps such as policy selection, action execution, experience playback, network update and task assignment. It should be noted that this complexity analysis is based on the training and update times of neural networks being far longer than other operations and may be affected by specific implementation details. Then, the pseudo-code for the D3QN-based dynamic task assignment algorithm is as described in Algorithm 1.
| Algorithm 1: D3QN Solution with Experience Replay Solution |
- Input:
V (tasks), W (users), N (capacity of replaymemory), (probability of random selection), M (maximum number of episodes), (discount factor), C (frequency of updating target network) - Output:
R (greward of all episodes), {} (profit of platform, travel distance of workers and workers’ response time), {} (travelling trajectory of workers)
- 1:
Initialise policy network Q with parameters - 2:
Initialise target network with parameters = - 3:
Initialise replay memory D with capacity of N - 4:
// global maximum greward - 5:
// profit, distance and response time - 6:
for k = 1,M do - 7:
; // local greward in current episode - 8:
; // initialise state - 9:
while do - 10:
Select with probability ; otherwise, randomly select - 11:
Execute to observe and - 12:
Store in D - 13:
Sample minibatch transitions from D - 14:
if then - 15:
- 16:
else - 17:
- 18:
end if - 19:
Perform a gradient descent step on the loss value computed according to Equation (13) and update the parameters - 20:
Reset every C steps - 21:
; // go to next step - 22:
; // update local greward - 23:
if the task cannot be completed then - 24:
Tasks are not assigned to workers, update status of tasks and workers’set - 25:
else - 26:
Assign the task to worker, update status of tasks and workers’ set - 27:
end if - 28:
if then - 29:
; // update global maximum greward - 30:
Record - 31:
Record paths - 32:
end if - 33:
end while - 34:
end for - 35:
return R, {} and
|
Algorithm 1 shows the implementation details of the D3QN solution. The initialisation of the Q-network, target network and experience pool is performed in lines 1–3, respectively. Line 4 establishes a variable to track the global maximum reward. Platform profit, worker travel distance and worker response time are initialised in line 5. The variable ‘k’ in line 6 keeps track of the current episode count, and learning continues until a termination condition is met. In each episode, the local variables ‘greward’ and the start state are initialised (lines 7–8). If the current state is not a terminal state within the episode (line 9), an –greedy strategy is employed to select an action (line 10). The –greedy policy chooses the action with the highest Q-value greedily with probability ; otherwise, a random action is chosen. Upon executing the selected action, the platform observes the reward and the next state (line 11). To reduce data sample correlation, the agents’ experience is stored in the experience pool (line 12). At each learning step, the platform randomly selects small batches of samples from the experience pool (line 13) and updates the Q-network parameters by minimising the mean-squared loss function as defined in Equation (13) (lines 14–19). After a certain number of learning steps, the target network is periodically updated with the parameters from the Q-network (line 20). Line 21 denotes the update of the current state, while line 22 credits the reward to the local agent. The server then evaluates whether the task can be completed and updates the environment (lines 23–27). If the local reward exceeds the global reward (line 29), the global reward is updated (line 30). Profit, driving distance and response time are recorded in line 31, and the worker’s trajectory is stored in line 32. Finally, the function returns the final result in line 35.
4.4. Baseline Solutions
For the performance comparison of D3QN, we consider three baseline solutions for the task allocation problem: DQN, –greedy, and random solutions. DQN is a well-known algorithm in deep reinforcement learning that has been successfully applied to various combinatorial optimisation problems. It leverages neural networks and Q-learning to interact with the environment and make decisions in order to discover the optimal strategy.
Additionally, greedy-based solutions are commonly employed in previous studies. Hence, the –greedy solution serves as a baseline approach. In this solution, the platform selects the worker with the highest greward with probability , while random selection is used otherwise. Algorithm 2 illustrates the -greedy solution. Furthermore, the random solution corresponds to the scenario where is set to 0, implying completely random worker selection.
| Algorithm 2: –Greedy Solution |
- Input:
V (tasks), W (users), (probability of random selection), M (maximum number of episodes with no improvement) - Output:
R (greward of all episodes), {} (profit of platform, travel distance of workers and workers’ response time), {} (travelling trajectory of workers)
- 1:
// global maximum greward - 2:
// profit, distance and response time - 3:
; // number of episodes with no improvement - 4:
while do - 5:
; // local greward in current episode - 6:
for do - 7:
if there exist feasible users for task then - 8:
Random selection with probability ; otherwise, greedy selection (reward) - 9:
Get reward of this assignment as - 10:
; // update local greward - 11:
if the task cannot be completed then - 12:
Tasks are not assigned to workers, update status of tasks and workers’ set - 13:
else - 14:
Assign the task to worker, update status of tasks and workers’ set - 15:
end if - 16:
end if - 17:
end for - 18:
if then - 19:
R = ; // update global maximum greward - 20:
Record - 21:
Record paths - 22:
k = 0; // reset k with improvement - 23:
else - 24:
k = k + 1; // increase k without improvement - 25:
end if - 26:
end while - 27:
return R, {} and
|
5. Numerical Results and Discussion
In this section, the experimental scenario and the parameters of the neural network are set. Additionally, we experimentally evaluate the performance of the D3QN-based solution and the baseline solution. More specifically, the performance of the D3QN-based solution is demonstrated in three scenarios with different numbers of workers.
5.1. Simulation Settings
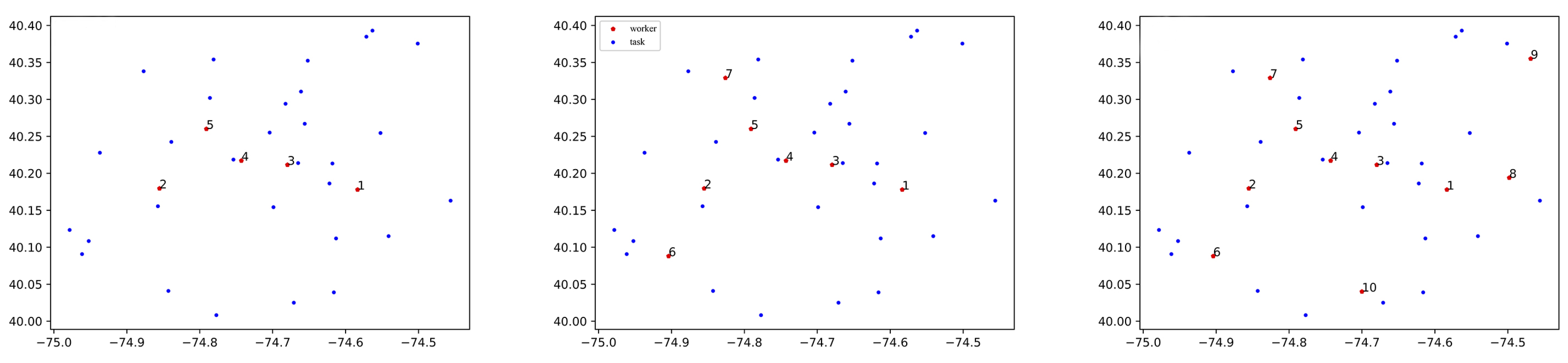
In our simulations, we used a real dataset from an existing application: Foursquare [
60]. Specifically, two files from this data subset were used: (1) the venues’ file representing the location of the tasks and (2) a users’ file corresponding to the location of the workers. The dataset contains 1,021,966 check-in records for 2,153,469 users at 1,143,090 venues over a given time period. To facilitate data processing, the coordinate ranges of the dataset were narrowed down to [−74.9831° W, −74.4322° W] and [40.0023° N, 40.4128° N]. In the simulation setup, the sensing area was set as a rectangular area. Then, 30 sensing tasks and some workers were evenly distributed in the area. There were three different scenarios with 5, 7 and 10 workers, as shown in
Figure 3. Euclidean distances were used. Each worker’s travel speed was randomly generated from 10 to 50 km/h, with a reward value set to 1 per unit of travel distance and a maximum travel distance set to 30 km. For each sensing task, the time window started from 0 to 30 and ended at 60 (in minutes). The average user budget for a sensing task submission was 50. Finally, all simulation parameters were set as shown in
Table 2.
5.2. Parameter Settings of DQN and D3QN Neural Networks
It is particularly important to construct DQN or D3QN networks in order to obtain the best results. The key to optimising the performance of the network is to tune the hyperparameters, such as , the exploration rate, the number of neurons in each layer of the Q-network and the learning rate. It is worth mentioning that we performed a moving average with a window size of 20 on the 1D data. This technique helps to reduce noise and smooth out fluctuations in the data, providing a clearer representation of the underlying trends or patterns. By using a sliding average window of size 20, the data are effectively averaged over a specific interval, resulting in a more reliable analysis and interpretation of the experimental results.
As shown in
Figure 4, the number of neurons was chosen in the range of [16–512]. As shown in
Figure 4a, when the number of neurons of the DQN was 16 and 32, the network did not have good learning ability due to the relatively small number of neurons. When greater than or equal to 128, as shown in
Figure 4c, the complexity of the network structure increased greatly, resulting in slower learning of the network and much higher running time of the platform. This was similar for D3QN, as seen in
Figure 4e–g. When the number of neurons is 128, the platform has the shortest running time, the fastest network convergence and can maintain better stability after convergence. Thus, the number of neurons for both networks was chosen to be 128.
As shown in
Figure 5, the learning rate increases from 0.0001 to 0.002. As shown in
Figure 5a, when the learning rate is 0.0001 or 0.0005, the DQN network structure is relatively simple and the learning rate is low. The network, in this case, does not have good learning ability. Once the learning rate increases to 0.002, the learning effect and convergence speed are accelerated. Moreover, when the learning rate is greater than or equal to 0.0005, the running time of the platforms is shorter and the difference is not significant. For D3QN, as shown in
Figure 5d, the convergence effect is best and the platform running time is shortest when the learning rate is 0.0005. Therefore, the learning rates for DQN and D3QN were chosen to be 0.002 and 0.0005, respectively.
Due to space limitations, other parameters are not described. In short, when the replay memory capacity is 50,000, the initial exploration rates are 0.75 and 0.90, the final exploration rate is 0.999, the learning rates are 0.002 and 0.0005, the number of Q-network layers is 2 and the number of neurons in the hidden layer of the Q network is 128, the DQN and D3QN networks tend to be stable and have the best effect. The target network is replaced by the Q-network every 200 learning steps. The discount factor is set to 0.9. Both the Q-network and the target network are DNNs with one hidden layer. Here, Rectified Linear Unit (ReLU) is used in DNN. Finally, the setting of neural network parameters is shown in
Table 2.
5.3. Ablation Study
To further understand how networks compete with each other in D3QN, we conduct a deeper ablation study of the D3QN algorithm, investigating the true role played by Double DQN, Dueling DQN, and D3QN network structures. In this process, the hyperparameters of the neural network are fixed, the learning rate is 0.0005, the number of neurons is 128, the replay memory capacity is 50,000, the initial exploration rate is 0.90, the final exploration rate is 0.999 and the number of Q-network layers is 2. The number of tasks to be completed is 30 and the number of workers is 5.
The experimental results are shown in
Table 3. Compared with the baseline network, the neural network with Dueling DQN increased the Reward value by 27.54%, reaching 600.41; the task completion rate increased by 3.34%, reaching 66.67% and the platform profit increased by 8.99%, reaching 900.88. Response time decreased by 19.42% to 2.99. Compared with the baseline network, the neural network with Double DQN increased the Reward value by 29.36%, reaching 608.99; the task completion rate increased to 66.67%. Platform profits increased by 5.26 to 869.64. The response time decreased by 45.85% to 2.01. Finally, compared with the baseline network, the D3QN neural network using Double DQN and Dueling DQN improved in four indicators, among which, Reward, task completion rate, profit and response time reached 825.24, 76.67%, 986.95 and 1.94, respectively. Experimental results show that Double DQN and Dueling DQN improve the learning efficiency of the neural network, suppress the interference of noise and improve the performance of the neural network.
5.4. Result of Greward
Greward is the target of the task allocation problem in (7a)–(7f) and is, therefore, the most important indicator of effectiveness.
Figure 6 shows the maximum greward value under all episodes, i.e., the cumulative maximum reward value found before the current episode. From
Figure 6, we can observe that the greward of the random solution is the smallest of all the solutions, due to the fact that it does not take into account the suitability of the workers. The traditional greedy-based algorithm is also obviously inferior to deep reinforcement learning methods in terms of learning speed and effectiveness. Ultimately, the D3QN solution achieves the largest greward in all three scenarios. The D3QN solution rapidly increases the greward value of the platform at the initial time and then gradually converges to the final result, demonstrating its excellent learning capability. The curves in
Figure 6 clearly show when the D3QN solution outperforms the baseline solution, and the growth curve of the D3QN solution demonstrates its ability to solve the task allocation problem.
5.5. Result of Completed Tasks
The completion rate of tasks is an important evaluation metric for platform performance and directly affects the platform’s profit and ability to attract users. Here, some tasks were left incomplete. This failure was due to either platform response timeout or the platform algorithm’s inability to select suitable workers who could complete the tasks within the tasks’ response time. Additionally, objective factors such as worker speed or distance between workers and tasks could prevent task completion within the tasks’ response time. In such cases, the server does not actually assign the tasks to the workers but instead marks them as idle, and the tasks are marked as failed. The system then proceeds to the next round of task assignment. This means that task execution failures are not taken into account, and, once a worker accepts a task, they are considered available for task completion.
Figure 7 shows the number of tasks completed in the three scenarios. It can be seen that, although the number of tasks completed by all algorithms increases with the number of workers, in the three simulation scenarios with the same number of workers, the random algorithm has the least number of tasks due to its randomness, and the task completion rate of the
–greedy algorithm is much lower than that of the DQN and D3QN schemes of deep reinforcement learning due to insufficient algorithm capabilities. Among them, the performance of the D3QN algorithm is higher than that of DQN, and the number of completed tasks is also more than that of DQN. Among all algorithms, the number of tasks completed by the D3QN algorithm is the largest. In the D3QN solution, 5, 7 and 10 workers completed 23, 25 and 26 sensing tasks, respectively. Although not all tasks can be completed, many constraints are taken into account, such as randomness of task locations, constraints on worker travel distance and speed, time constraints in completing tasks, etc. Under the constraints of various conditions, the solution of the algorithm may already be the optimal solution of the problem. Finally, it can be seen that the D3QN-based solution accomplishes the most tasks in all simulated scenarios. Therefore, the D3QN-based solution outperforms other solutions in terms of task completion rate.
5.6. Result of Platform Profit
Platform profit is often an important objective in the task allocation problem, and
Figure 8 shows the platform profit for three scenarios with different algorithms. As can be seen, the platform profit increases as the number of workers increases. This is due to the fact that more workers are involved, more paths can be planned and workers’ previous travel paths are optimised, allowing more tasks to be completed while the platform gains more profit. Finally, our proposed D3QN solution achieves maximum profit in all three cases with 986.9, 1091.46 and 1141.23. However, the number of workers has little effect on the random solution with profits of 449.22, 545.31 and 582.82 for the three cases. We also observe that the gap between the DQN and D3QN solutions becomes smaller as the number of workers increases, with 127.32 (5 workers), 79.25 (7 workers) and 44.74 (10 workers). The reason for this is that redundant workers make it less difficult to find a satisfactory solution and the platform can easily find the right workers for the sensing task at a lower cost. Therefore, the DQN solution with the slightly weaker learning ability is close to the D3QN solution in terms of profit as the number of workers increases.
5.7. Result of Average Response Time of Workers
The workers’ response time is an important part of the performance of the task allocation framework. On the one hand, workers’ response time can be saved, allowing for more tasks to be completed and greater profits to be made. On the other hand, when data requesters experience shorter response time for their tasks, it helps to improve their experience and, thus, attract more users to the platform. Here, due to the different number of tasks completed by each method, the time spent is also different. To illustrate,
Figure 9 shows the average response time in minutes for workers in the three scenarios. Using the average response time to judge the effectiveness of the methods, we observe that the random algorithm has the smallest response value in all three scenarios, due to the fact that it completes the least number of tasks and does not need to pick the right worker in the random case. Furthermore, the average response time of the DQN solution is the longest among the solutions. In addition, compared to other algorithms, the D3QN solution achieves a shorter response time value in all scenarios.
5.8. Result of Average Traveling Distances of Workers
Regarding travel distance, the platform and the workers have the same objective and want shorter travel distances.
Figure 10 shows the average travel distance of workers in the three scenarios. Overall, the average travel distance decreases with the number of workers. However, it is clear that the decrease is greater for D3QN, with the average travel distance of the D3QN solutions for the three scenarios being 32.61, 22.64 and 15.87. This is due to the fact that, in scenarios with a smaller number of workers, a single worker needs to perform a larger number of tasks, which can easily lead to a situation where the optimal solution worker for a task is performing other tasks. This situation is gradually alleviated as the number of workers increases, and, when more workers are involved, fewer sensing tasks are assigned to each worker on average, and then workers can use shorter paths to perform the assigned tasks. As can be seen from the figure, D3QN has the largest decline, and, when the number of workers increases to 10, the D3QN scheme works best. It is worth noting that the D3QN solution achieves the highest profit and task completion numbers as well as a short response time in all scenarios, which shows that D3QN is significantly better than the other comparison algorithms.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}