

DenseTextPVT: Pyramid Vision Transformer with Deep Multi-Scale Feature Refinement Network for Dense Text Detection


Abstract
:1. Introduction
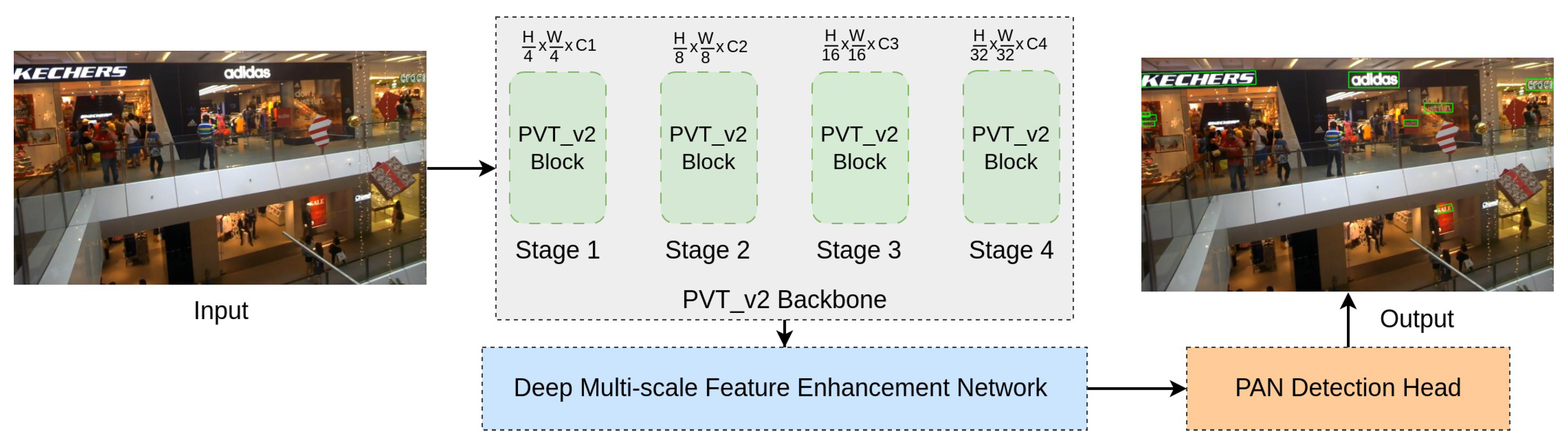
- We propose an effective approach, called DenseTextPVT, which incorporates the advantages of dense prediction backbone in object detection tasks, Pyramid Vision Transformer (PvTv2) [26], with a channel attention module (CAM) [27] and spatial attention module (SAM) [27] to obtain high-resolution features that make our model well suited for dense text prediction in natural scene images.
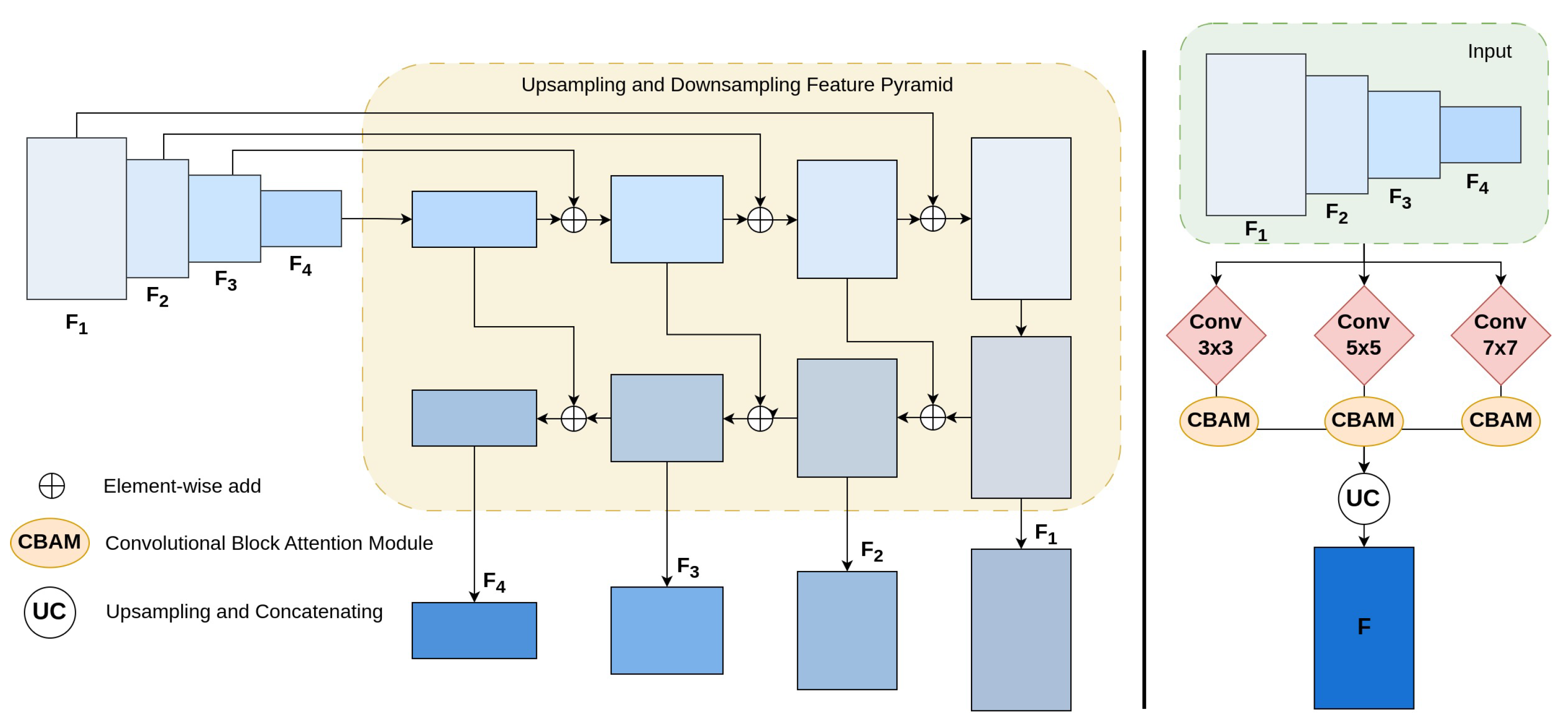
- We employed a Deep Multi-scale Feature Refinement Network (DMFRN) using three kernel filters simultaneously (, , ) with CBAM [27] at each feature. This allows for adaptive feature refinement, enabling our model to enrich feature representations with different scales, including small representations.
2. Related Work
2.1. Scene Text Detection
2.2. Transformer
3. Methodology
3.1. Overall Architecture
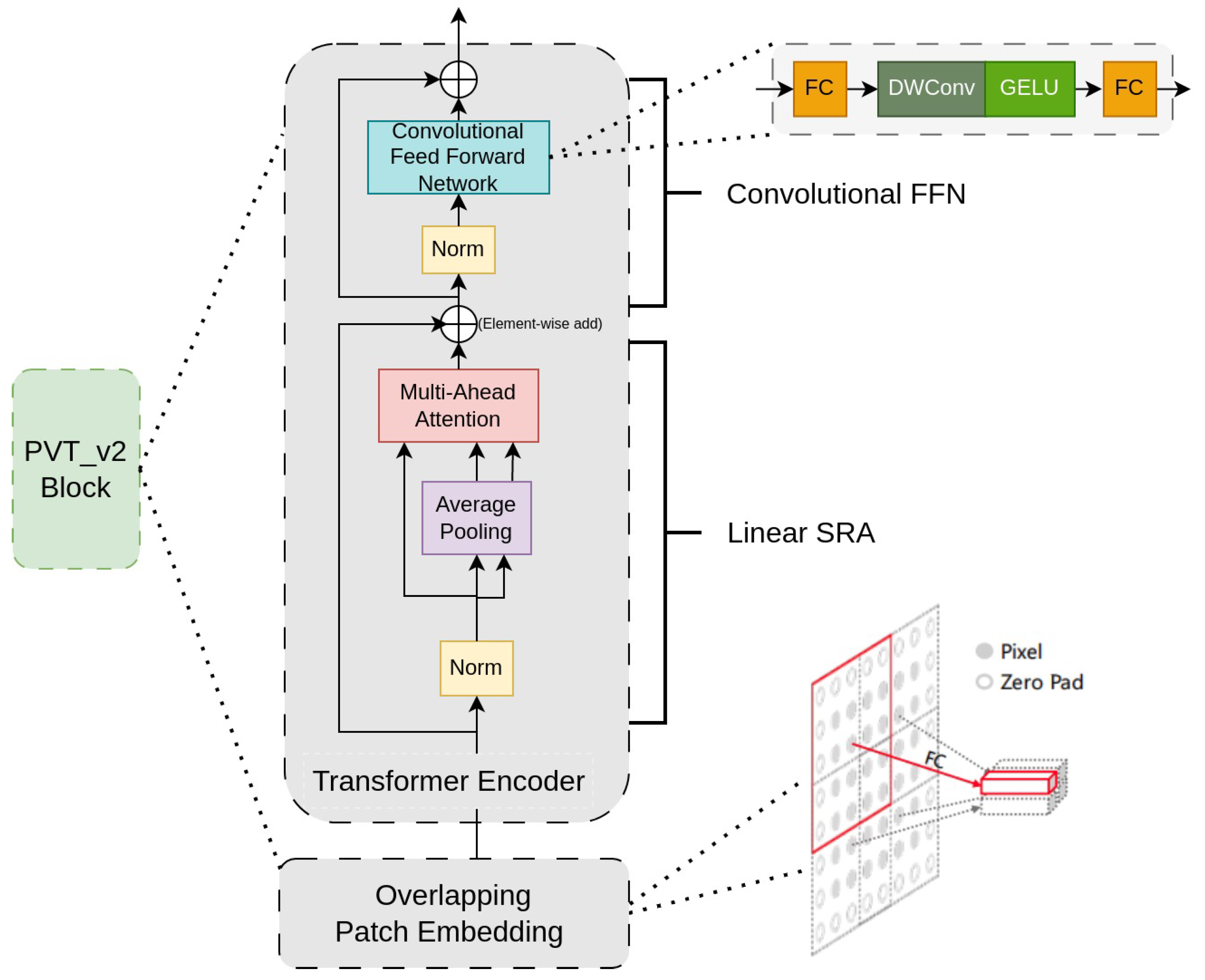
3.2. PvTv2 Backbone
3.3. Deep Multi-Scale Feature Refinement Network
3.4. Loss Function
4. Experiments and Results
4.1. Dataset
4.2. Implementations
4.3. Evaluation Metrics
4.4. Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PvTv2 | Pyramid Vision Transformer |
| CAM | Channel Attention Module |
| SAM | Spatial Attention Module |
| CBAM | Convolutional Block Attention |
| DNNs | Deep Neural Networks |
| DMFRN | Deep Multi-scale Feature Refinement Network |
| PA | Pixel Aggregation |
| PAN | Pixel Aggregation Network |
| LinearSRA | Linear Shifted Row Attention |
| FC | Fully Connected |
| FFN | Feed Forward Network |
| P | Precision |
| R | Recall |
| F | F-measure |
References
- Wang, W.; Xie, E.; Song, X.; Zang, Y.; Wang, W.; Lu, T.; Yu, G.; Shen, C. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 19–20 June 2019; pp. 8440–8449. [Google Scholar]
- Liao, M.; Wan, Z.; Yao, C.; Chen, K.; Bai, X. Real-time scene text detection with differentiable binarization and adaptive scale fusion. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 919–931. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.X.; Zhu, X.; Chen, L.; Hou, J.B.; Yin, X.C. Arbitrary Shape Text Detection via Segmentation with Probability Map. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2736–2750. [Google Scholar] [CrossRef] [PubMed]
- Tang, J.; Zhang, W.; Liu, H.; Yang, M.; Jiang, B.; Hu, G.; Bai, X. Few Could Be Better Than All: Feature Sampling and Grouping for Scene Text Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 20–25 June 2022; pp. 4563–4572. [Google Scholar]
- Yin, X.-C.; Yin, X.; Huang, K.; Hao, H.-W. Robust text detection in natural scene images. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 970–983. [Google Scholar]
- Chen, Z.; Wang, J.; Wang, W.; Chen, G.; Xie, E.; Luo, P.; Lu, T. FAST: Searching for a Faster Arbitrarily-Shaped Text Detector with Minimalist Kernel Representation. arXiv 2021, arXiv:2111.02394. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Hou, W.; Lu, T.; Yu, G.; Shao, S. Shape robust text detection with progressive scale expansion network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 19–20 June 2019; pp. 9336–9345. [Google Scholar]
- Zhou, X.; Yao, C.; Wen, H.; Wang, Y.; Zhou, S.; He, W.; Liang, J. East: An efficient and accurate scene text detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5551–5560. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2921–2929. [Google Scholar]
- Dai, P.; Zhang, S.; Zhang, H.; Cao, X. Progressive contour regression for arbitrary-shape scene text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 20–25 June 2021; pp. 7393–7402. [Google Scholar]
- Baek, Y.; Lee, B.; Han, D.; Yun, S.; Lee, H. Character region awareness for text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9365–9374. [Google Scholar]
- Sheng, T.; Chen, J.; Lian, Z. Centripetaltext: An efficient text instance representation for scene text detection. Adv. Neural Inf. Process. Syst. 2021, 34, 335–346. [Google Scholar]
- Shi, B.; Xiang, B.; Serge, B. Detecting oriented text in natural images by linking segments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Zhang, C.; Borong, L.; Zuming, H.; Mengyi, E.; Junyu, H.; Errui, D.; Xinghao, D. Look more than once: An accurate detector for text of arbitrary shapes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10552–10561. [Google Scholar]
- He, W.; Zhang, X.-Y.; Yin, F.; Liu, C.-L. Deep direct regression for multi-oriented scene text detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 745–753. [Google Scholar]
- Kheng, C.C.; Chan, C.S. TotalText: A comprehensive dataset for scene text detection and recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 1. [Google Scholar]
- Liu, Y.; Jin, L.; Zhang, S.; Zhang, S. Detecting curve text in the wild: New dataset and new solution. arXiv 2017, arXiv:1712.02170. [Google Scholar]
- Karatzas, D.; Gomez-Bigorda, L.; Nicolaou, A.; Ghosh, S.; Bagdanov, A.; Iwamura, M.; Matas, J.; Neumann, L.; Chandrasekhar, V.R.; Lu, S.; et al. ICDAR 2015 competition on robust reading. In Proceedings of the 2015 13th International Conference on Document Analysis and Recognition (ICDAR), Tunis, Tunisia, 23–26 August 2015; pp. 1156–1160. [Google Scholar]
- Xue, C.; Shijian, L.; Wei, Z. MSR: Multi-scale shape regression for scene text detection. arXiv 2019, arXiv:1901.02596. [Google Scholar]
- Long, S.; Jiaqiang, R.; Wenjie, Z.; Xin, H.; Wenhao, W.; Cong, Y. Textsnake: A flexible representation for detecting text of arbitrary shapes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 20–36. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, l30, 5998–6008. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 213–229. [Google Scholar]
- Ze, L.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 20–25 June 2021; pp. 10012–10022. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations, Virtual Event, 3–7 May 2021. [Google Scholar]
- Hugo, T.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. Int. Conf. Mach. Learn. 2021, 139, 10347–10357. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhu, Y.; Chen, J.; Liang, L.; Kuang, Z.; Jin, L.; Zhang, W. Fourier contour embedding for arbitrary-shaped text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 20–25 June 2021; pp. 3123–3131. [Google Scholar]
- Liao, M.; Wan, Z.; Yao, C.; Chen, K.; Bai, X. Real-time scene text detection with differentiable binarization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11474–11481. [Google Scholar]
- Wang, F.; Chen, Y.; Wu, F.; Li, X. Textray: Contour-based geometric modeling for arbitrary-shaped scene text detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 111–119. [Google Scholar]
- Dang, Q.-V.; Lee, G.-S. Document image binarization with stroke boundary feature guided network. IEEE Access 2021, 9, 36924–36936. [Google Scholar] [CrossRef]
- Jiang, X.; Xu, S.; Zhang, S.; Cao, S. Arbitrary-shaped text detection with adaptive text region representation. IEEE Access 2020, 8, 102106–102118. [Google Scholar] [CrossRef]
- Zobeir, R.; Naiel, M.A.; Younes, G.; Wardell, S.; Zelek, J.S. Transformer-based text detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 20–25 June 2021; pp. 3162–3171. [Google Scholar]
- Zobeir, R.; Younes, G.; Zelek, J. Arbitrary shape text detection using transformers. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; pp. 3238–3245. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 20–25 June 2021; pp. 568–578. [Google Scholar]
- Dinh, M.-T.; Lee, G.-S. Arbitrary-shaped Scene Text Detection based on Multi-scale Feature Enhancement Network. In Proceedings of the Korean Information Science Society Conference, Jeju, Korea, 29 June–1 July 2022. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support: Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, Held in Conjunction with MICCAI 2017, Québec City, QC, Canada, 14 September 2017; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 240–248. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Shrivastava, A.; Gupta, A.; Girshick, R. Training region-based object detectors with online hard example mining. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 761–769. [Google Scholar]
- Enze, X.; Zang, Y.; Shao, S.; Yu, G.; Yao, C.; Li, G. Scene text detection with supervised pyramid context network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9038–9045. [Google Scholar]
- Lin, J.; Jiang, J.; Yan, Y.; Guo, C.; Wang, H.; Liu, W.; Wang, H. DPTNet: A Dual-Path Transformer Architecture for Scene Text Detection. arXiv 2022, arXiv:2208.09878. [Google Scholar]
- Deng, D.; Liu, H.; Li, X.; Cai, D. Pixellink: Detecting scene text via instance segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–3 February 2018. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Ext | P | R | F |
|---|---|---|---|---|
| EAST [8] | - | 80.9 | 76.2 | 78.5 |
| TextSnake [20] | ✓ | 82.7 | 74.5 | 78.4 |
| MSC [19] | ✓ | 83.8 | 74.8 | 79.0 |
| PSENet [7] | - | 84.0 | 78.0 | 80.9 |
| PAN [1] | - | 88.0 | 79.4 | 83.5 |
| TextRay [30] | - | 83.5 | 77.9 | 80.6 |
| SegLink++ [13] | ✓ | 82.1 | 80.9 | 81.5 |
| LOMO [14] | ✓ | 87.6 | 79.3 | 83.3 |
| SPCNet [40] | ✓ | 83.0 | 82.8 | 82.9 |
| PCR [10] | - | 86.4 | 81.5 | 83.9 |
| CRAFT [27] | ✓ | 87.6 | 79.9 | 83.6 |
| Ours_DenseTextPVT | - | 89.4 | 80.1 | 84.7 |
| Method | Ext | P | R | F |
|---|---|---|---|---|
| EAST [8] | - | 78.7 | 49.1 | 60.4 |
| PSENet [7] | - | 80.6 | 75.6 | 78.0 |
| PAN [1] | - | 84.6 | 77.7 | 81.0 |
| SegLink++ [13] | ✓ | 82.8 | 79.8 | 81.3 |
| LOMO [14] | ✓ | 85.7 | 76.5 | 80.8 |
| CT [12] | - | 85.5 | 79.2 | 82.2 |
| MSC [19] | ✓ | 85.0 | 78.3 | 81.5 |
| PCE [10] | - | 85.3 | 79.8 | 82.4 |
| TextRay [30] | - | 82.8 | 80.4 | 81.6 |
| DB [29] | ✓ | 86.9 | 80.2 | 83.4 |
| PAN [1] | ✓ | 86.4 | 81.2 | 83.7 |
| CRAFT [27] | ✓ | 86.0 | 81.1 | 83.5 |
| Xiufeng et al. [32] | ✓ | 84.9 | 80.3 | 82.5 |
| Ours_DenseTextPVT | - | 88.3 | 79.8 | 83.9 |
| Method | Ext | P | R | F |
|---|---|---|---|---|
| EAST [8] | - | 83.6 | 73.5 | 78.2 |
| PSENet [7] | - | 81.5 | 79.7 | 80.6 |
| DPTNet-Tiny [41] | ✓ | 90.3 | 77.4 | 83.3 |
| LOMO [14] | ✓ | 83.7 | 80.3 | 82.0 |
| TextSnake [20] | ✓ | 84.9 | 80.4 | 82.6 |
| Xiufeng et al. [32] | - | 85.8 | 79.7 | 82.6 |
| MFEN [38] | - | 84.5 | 79.7 | 82.0 |
| SegLink++ [13] | ✓ | 83.7 | 80.3 | 82.0 |
| MSC [19] | ✓ | 86.6 | 78.4 | 82.3 |
| PAN [1] | - | 82.9 | 77.8 | 80.3 |
| PAN [1] | ✓ | 84.0 | 81.9 | 82.9 |
| Ours_DenseTextPVT | - | 87.8 | 79.4 | 83.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dinh, M.-T.; Choi, D.-J.; Lee, G.-S. DenseTextPVT: Pyramid Vision Transformer with Deep Multi-Scale Feature Refinement Network for Dense Text Detection. Sensors 2023, 23, 5889. https://doi.org/10.3390/s23135889
Dinh M-T, Choi D-J, Lee G-S. DenseTextPVT: Pyramid Vision Transformer with Deep Multi-Scale Feature Refinement Network for Dense Text Detection. Sensors. 2023; 23(13):5889. https://doi.org/10.3390/s23135889
Chicago/Turabian StyleDinh, My-Tham, Deok-Jai Choi, and Guee-Sang Lee. 2023. "DenseTextPVT: Pyramid Vision Transformer with Deep Multi-Scale Feature Refinement Network for Dense Text Detection" Sensors 23, no. 13: 5889. https://doi.org/10.3390/s23135889
APA StyleDinh, M.-T., Choi, D.-J., & Lee, G.-S. (2023). DenseTextPVT: Pyramid Vision Transformer with Deep Multi-Scale Feature Refinement Network for Dense Text Detection. Sensors, 23(13), 5889. https://doi.org/10.3390/s23135889