
Quantum Neural Network Based Distinguisher on SPECK-32/64


Abstract
1. Introduction
1.1. Our Contribution
1.1.1. Quantum Neural Network Based Distinguisher for 5-Round SPECK-32 in NISQ
1.1.2. In-Depth Analysis of Factors Affecting the Performance of the Quantum Neural Distinguisher
2. Background
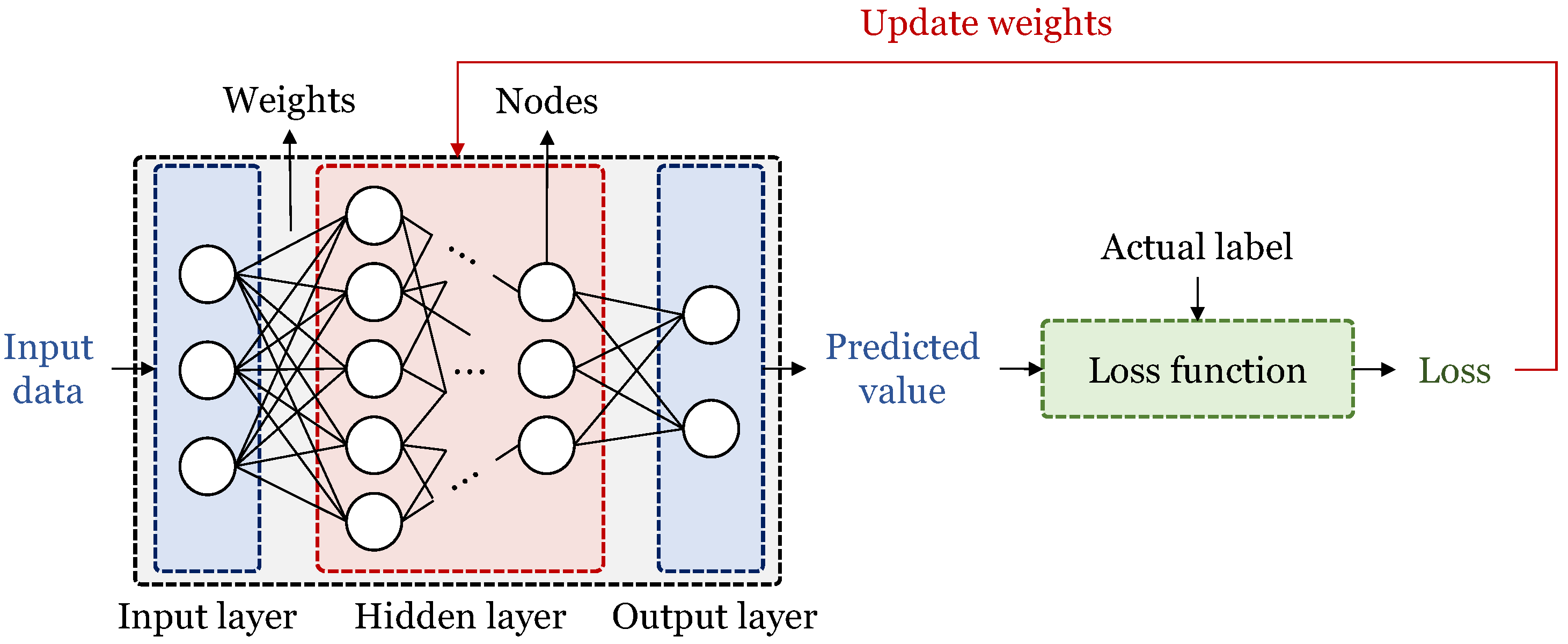
2.1. Classical Neural Networks
2.2. Quantum Neural Networks
2.2.1. Quantum Circuit
2.2.2. Quantum Neural Network
2.3. Differential Characteristics
2.4. Neural-Network-Based Distinguisher for Differential Cryptanalysis
2.4.1. Basic Design of Neural Distinguisher
2.4.2. Related Works
3. Design of Quantum Neural Distinguisher for SPECK-32
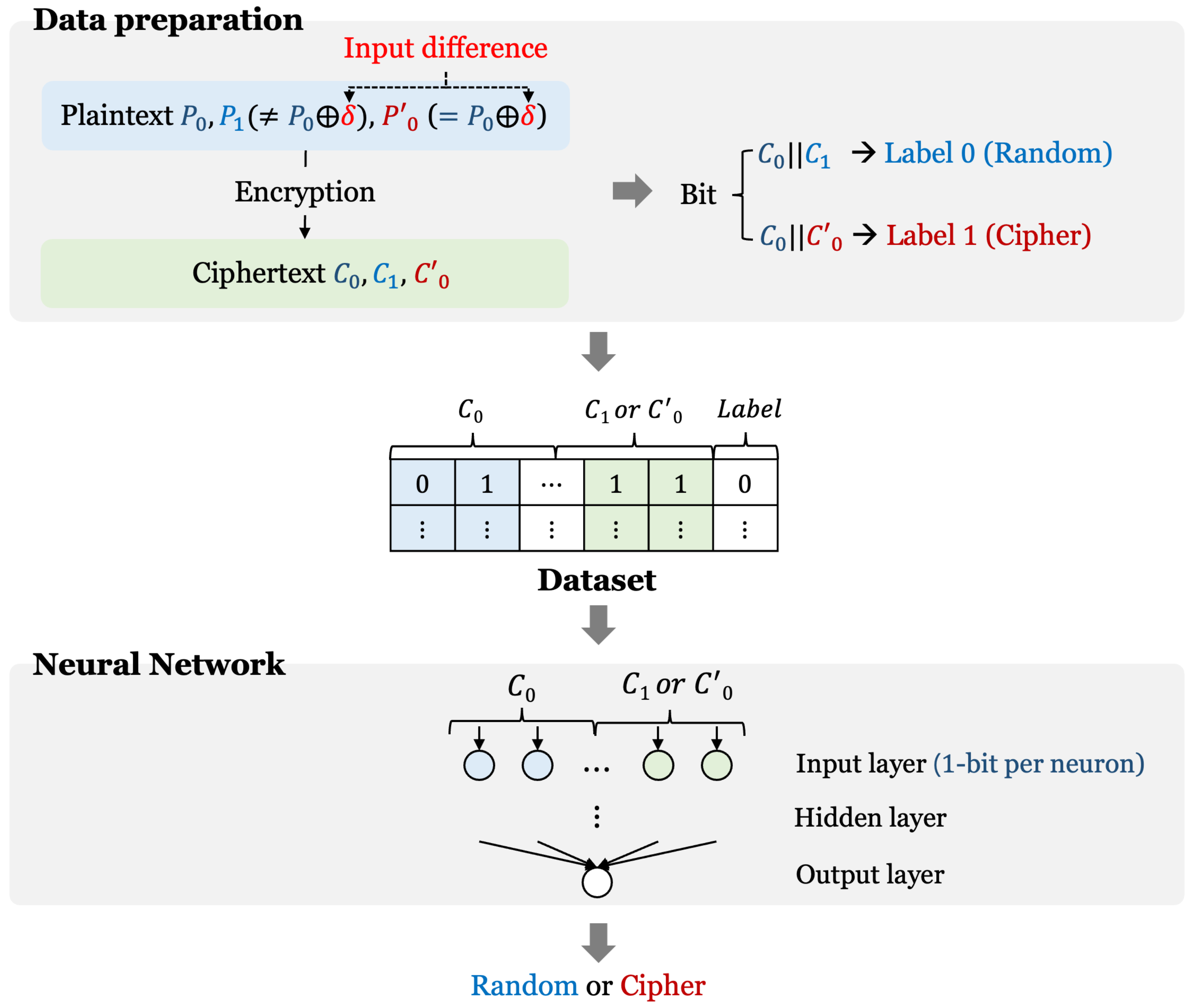
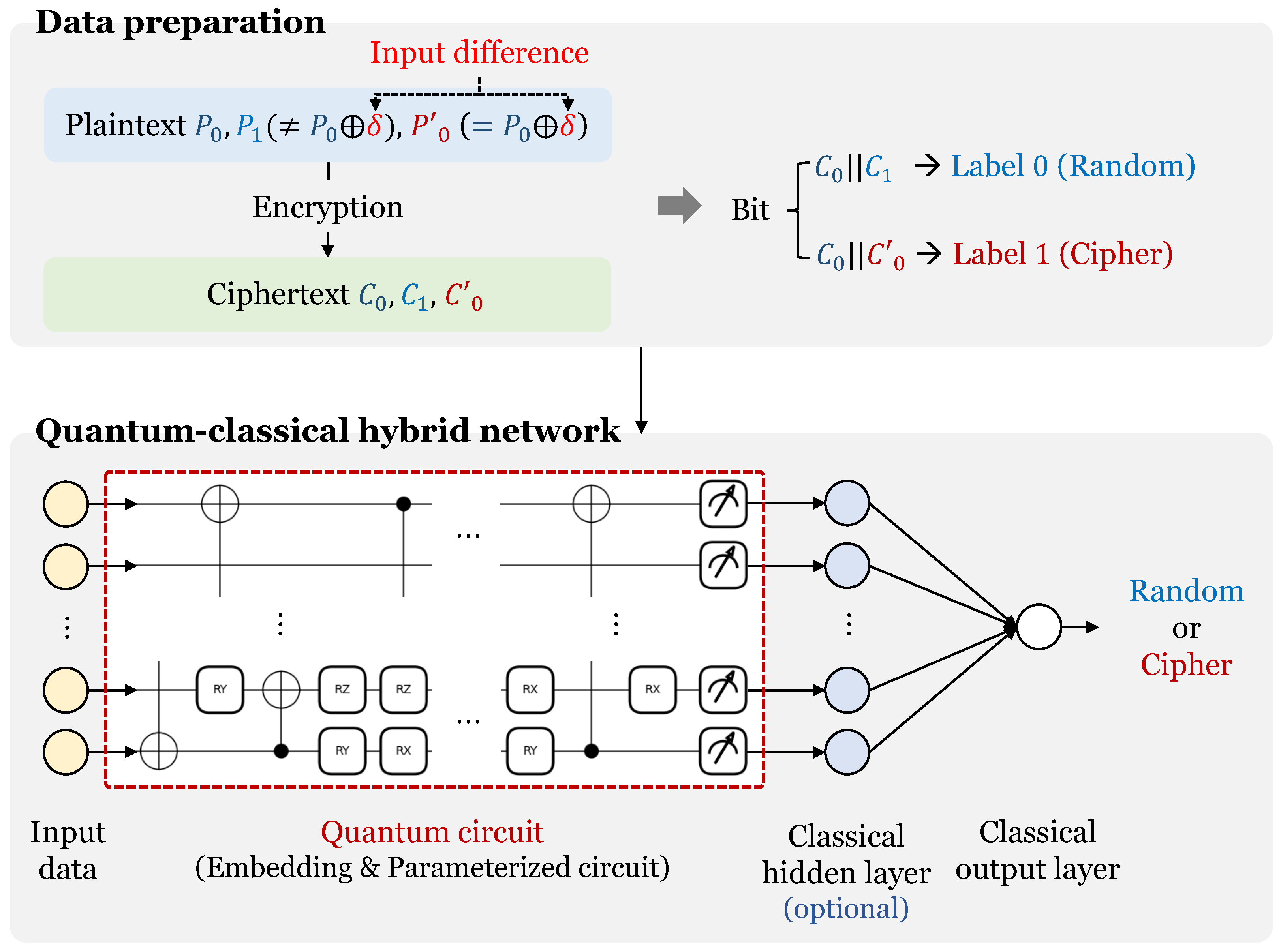
3.1. Data Set Preparation
3.2. Structure of Quantum Neural Distinguisher
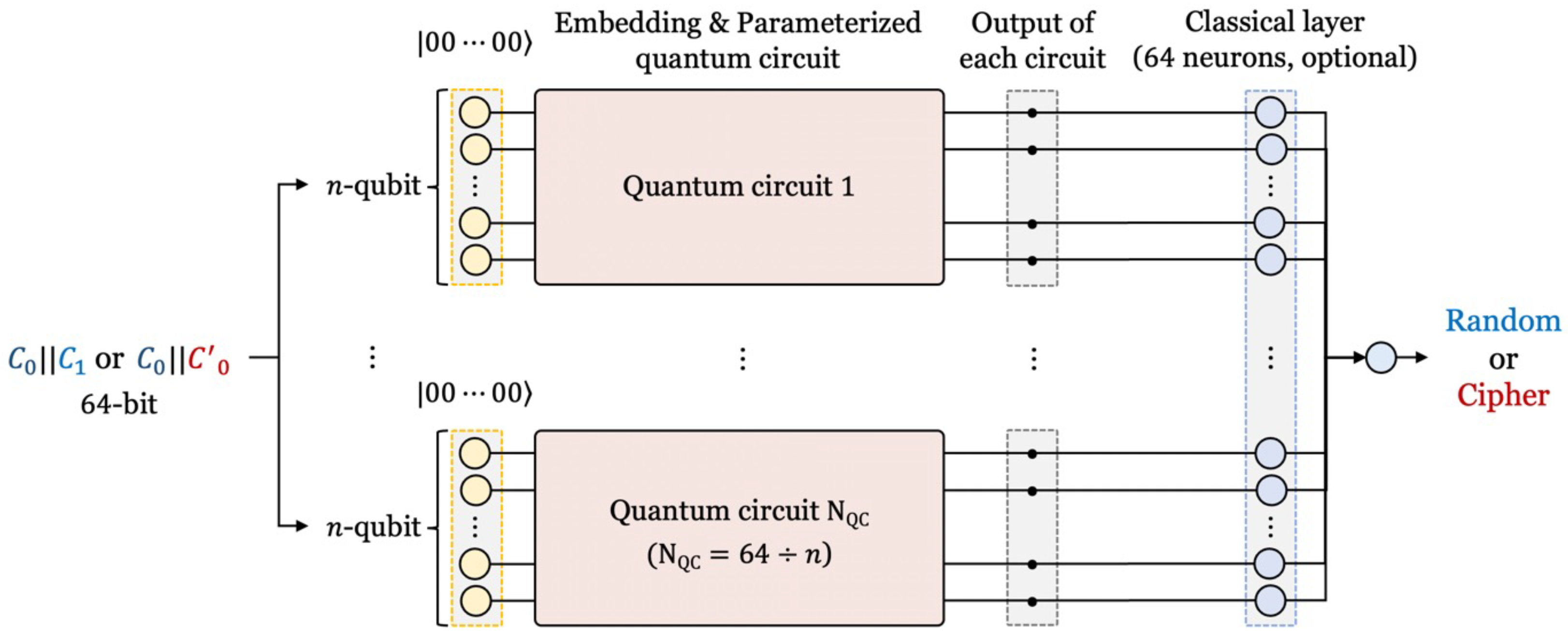
3.2.1. Overall Network Structure
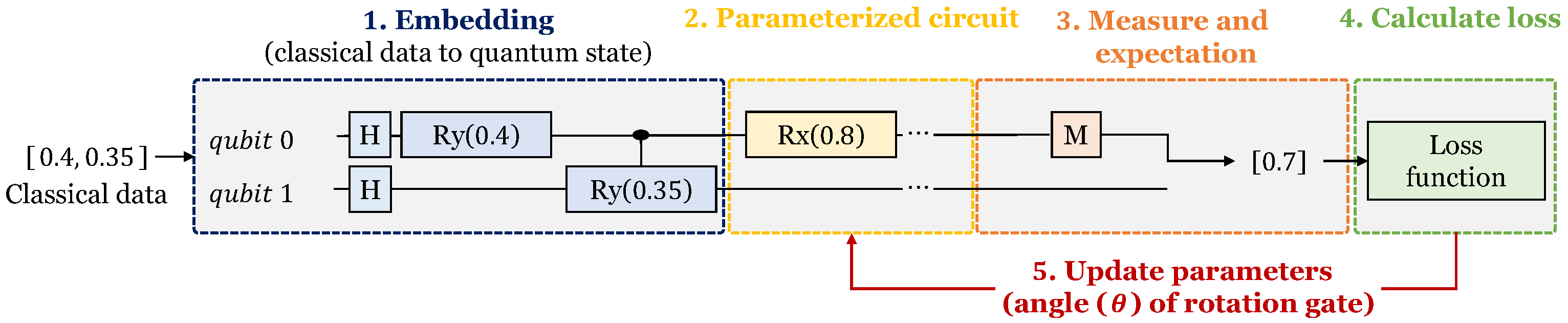
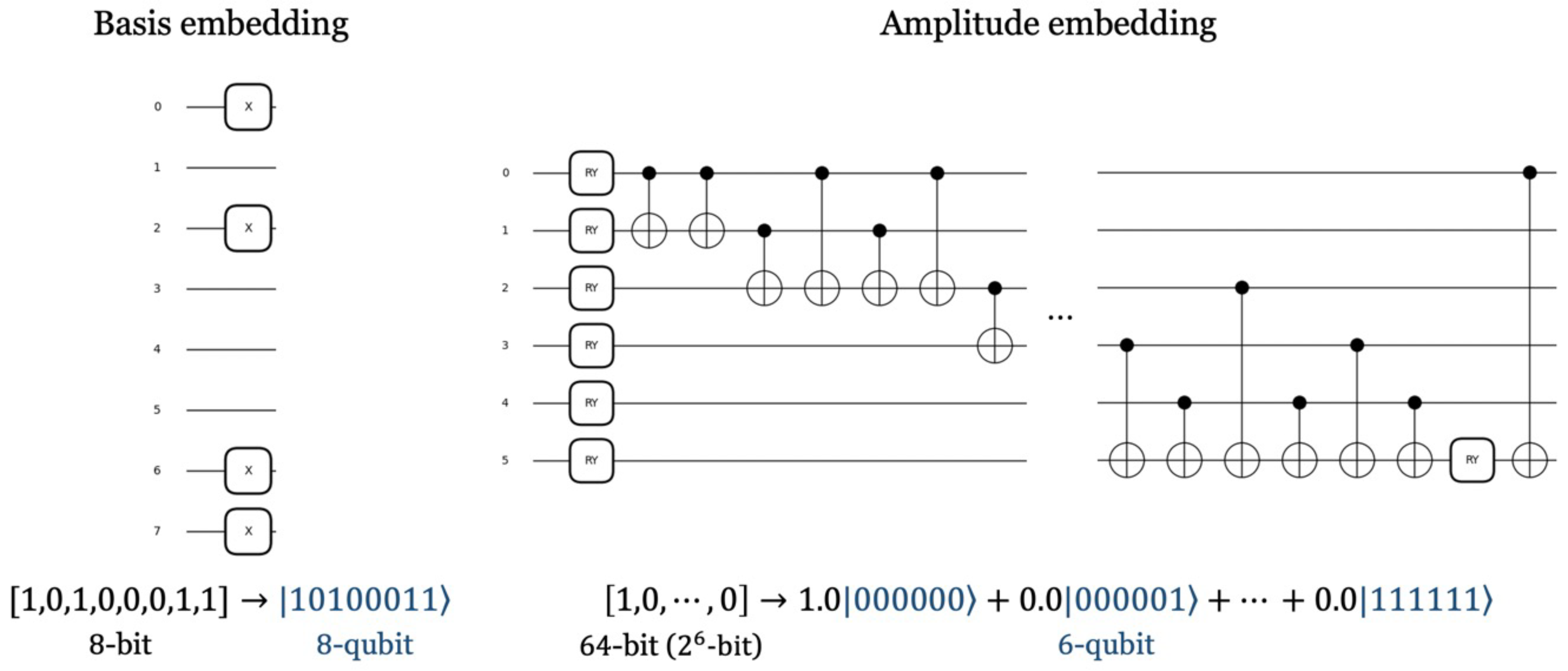
3.2.2. Data Embedding
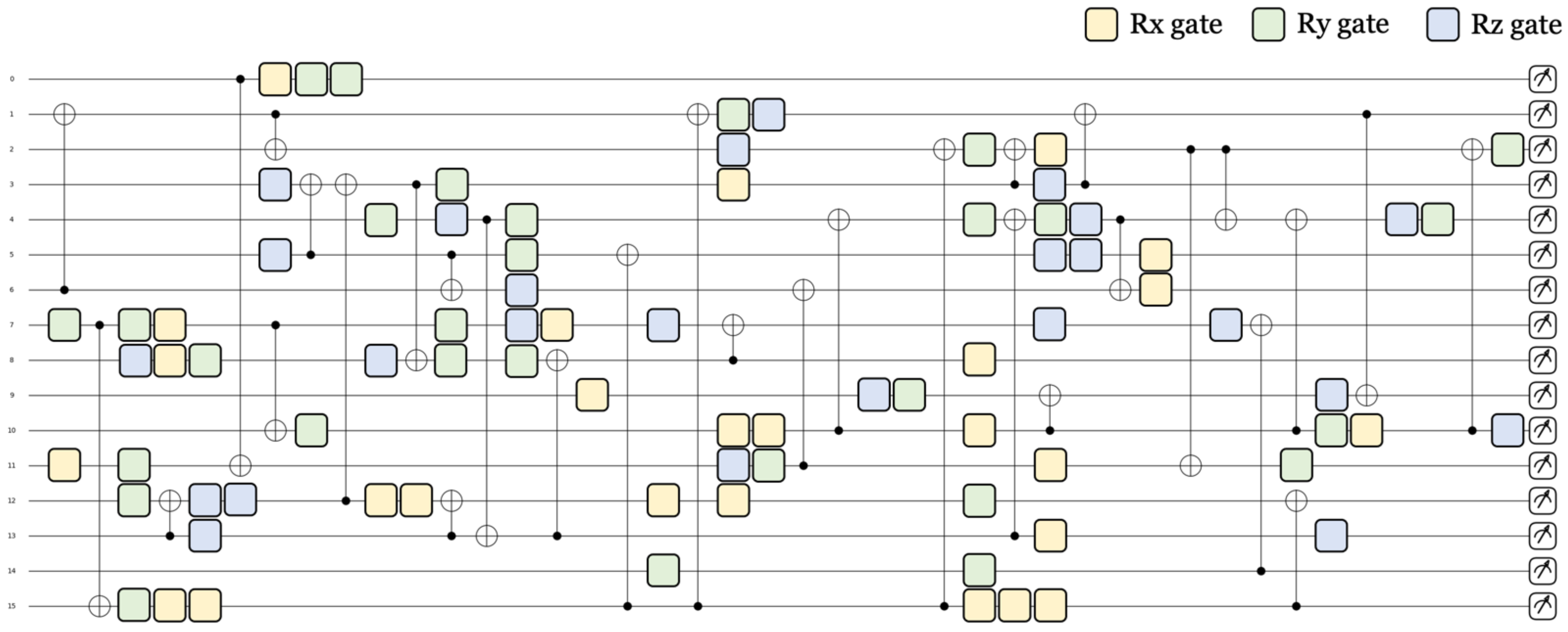
3.2.3. Parameterized Quantum Circuit
4. Experiment and Evaluation
4.1. Numerical Experiments and Results
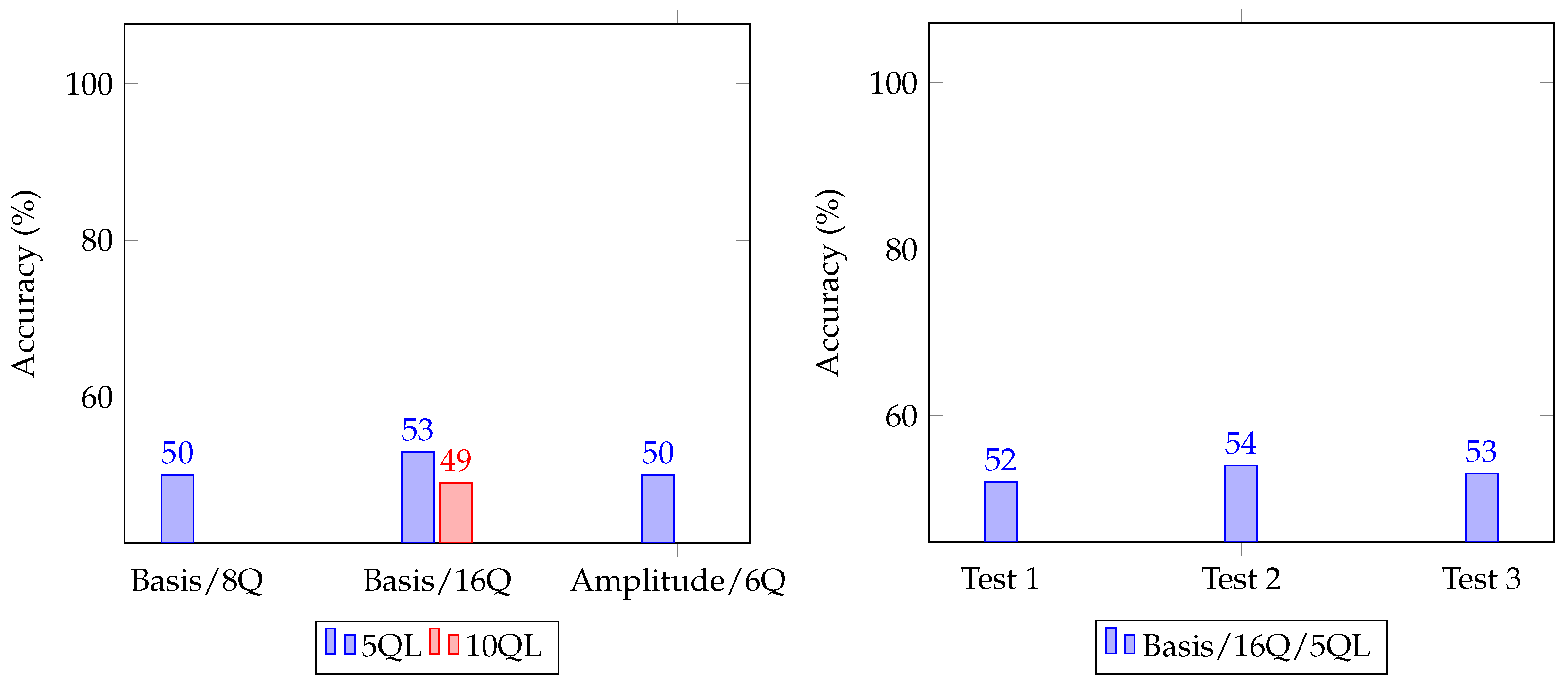
4.1.1. Accuracy According to Data Embedding
4.1.2. Accuracy According to the Number of Quantum Layers
4.1.3. Accuracy According to the Number of Qubits
4.2. The Best Model of Our Quantum Neural Distinguisher
4.3. Comparison of Quantum and Classical Neural Distinguisher
4.4. Quantum Neural Distinguisher in NISQ
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chanal, P.M.; Kakkasageri, M.S. Security and privacy in IOT: A survey. Wirel. Pers. Commun. 2020, 115, 1667–1693. [Google Scholar] [CrossRef]
- Beaulieu, R.; Shors, D.; Smith, J.; Treatman-Clark, S.; Weeks, B.; Wingers, L. SIMON and SPECK: Block Ciphers for the Internet of Things. Cryptol. Eprint Arch. 2015. [Google Scholar]
- Dwivedi, A.D.; Morawiecki, P.; Srivastava, G. Differential cryptanalysis of round-reduced speck suitable for internet of things devices. IEEE Access 2019, 7, 16476–16486. [Google Scholar] [CrossRef]
- Gohr, A. Improving attacks on round-reduced speck32/64 using deep learning. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 150–179. [Google Scholar]
- Chen, Y.; Yu, H. A New Neural Distinguisher Model Considering Derived Features from Multiple Ciphertext Pairs. IACR Cryptol. ePrint Arch. 2021, 2021, 310. [Google Scholar]
- Benamira, A.; Gerault, D.; Peyrin, T.; Tan, Q.Q. A deeper look at machine learning-based cryptanalysis. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Zagreb, Croatia, 17–21 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 805–835. [Google Scholar]
- Baksi, A. Machine learning-assisted differential distinguishers for lightweight ciphers. In Classical and Physical Security of Symmetric Key Cryptographic Algorithms; Springer: Berlin/Heidelberg, Germany, 2022; pp. 141–162. [Google Scholar]
- Hou, Z.; Ren, J.; Chen, S. Cryptanalysis of round-reduced Simon32 based on deep learning. Cryptol. Eprint Arch. 2021. [Google Scholar]
- Yadav, T.; Kumar, M. Differential-ml distinguisher: Machine learning based generic extension for differential cryptanalysis. In Proceedings of the International Conference on Cryptology and Information Security in Latin America, Bogotá, Colombia, 6–8 October 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 191–212. [Google Scholar]
- Lu, J.; Liu, G.; Sun, B.; Li, C.; Liu, L. Improved (Related-key) Differential-based Neural Distinguishers for SIMON and SIMECK Block Ciphers. Cryptol. Eprint Arch. 2022. [Google Scholar] [CrossRef]
- Rajan, R.; Roy, R.K.; Sen, D.; Mishra, G. Deep Learning-Based Differential Distinguisher for Lightweight Cipher GIFT-COFB. In Machine Intelligence and Smart Systems: Proceedings of MISS 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 397–406. [Google Scholar]
- Haykin, S. Neural Networks and Learning Machines, 3/E; Pearson Education India: Noida, India, 2009. [Google Scholar]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Petneházi, G. Recurrent neural networks for time series forecasting. arXiv 2019, arXiv:1901.00069. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. Acm 2020, 63, 139–144. [Google Scholar] [CrossRef]
- DiVincenzo, D.P. Quantum gates and circuits. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1998, 454, 261–276. [Google Scholar] [CrossRef]
- Fingerhuth, M.; Babej, T.; Wittek, P. Open source software in quantum computing. PLoS ONE 2018, 13, e0208561. [Google Scholar] [CrossRef]
- Killoran, N.; Bromley, T.R.; Arrazola, J.M.; Schuld, M.; Quesada, N.; Lloyd, S. Continuous-variable quantum neural networks. Phys. Rev. Res. 2019, 1, 033063. [Google Scholar] [CrossRef]
- Beer, K.; Bondarenko, D.; Farrelly, T.; Osborne, T.J.; Salzmann, R.; Scheiermann, D.; Wolf, R. Training deep quantum neural networks. Nat. Commun. 2020, 11, 808. [Google Scholar] [CrossRef]
- Farhi, E.; Neven, H. Classification with quantum neural networks on near term processors. arXiv 2018, arXiv:1802.06002. [Google Scholar]
- Bergholm, V.; Izaac, J.; Schuld, M.; Gogolin, C.; Alam, M.S.; Ahmed, S.; Arrazola, J.M.; Blank, C.; Delgado, A.; Jahangiri, S.; et al. Pennylane: Automatic differentiation of hybrid quantum-classical computations. arXiv 2018, arXiv:1811.04968. [Google Scholar]
- Schuld, M.; Killoran, N. Is quantum advantage the right goal for quantum machine learning? Prx Quantum 2022, 3, 030101. [Google Scholar] [CrossRef]
- Henderson, M.; Shakya, S.; Pradhan, S.; Cook, T. Quanvolutional neural networks: Powering image recognition with quantum circuits. Quantum Mach. Intell. 2020, 2, 2. [Google Scholar] [CrossRef]
- Huang, H.L.; Du, Y.; Gong, M.; Zhao, Y.; Wu, Y.; Wang, C.; Li, S.; Liang, F.; Lin, J.; Xu, Y.; et al. Experimental quantum generative adversarial networks for image generation. Phys. Rev. Appl. 2021, 16, 024051. [Google Scholar] [CrossRef]
- Kwak, Y.; Yun, W.J.; Jung, S.; Kim, J.K.; Kim, J. Introduction to quantum reinforcement learning: Theory and pennylane-based implementation. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 20–22 October 2021; pp. 416–420. [Google Scholar]
- Mangini, S.; Marruzzo, A.; Piantanida, M.; Gerace, D.; Bajoni, D.; Macchiavello, C. Quantum neural network autoencoder and classifier applied to an industrial case study. Quantum Mach. Intell. 2022, 4, 13. [Google Scholar] [CrossRef]
- Mari, A.; Bromley, T.R.; Izaac, J.; Schuld, M.; Killoran, N. Transfer learning in hybrid classical-quantum neural networks. Quantum 2020, 4, 340. [Google Scholar] [CrossRef]
- Schuld, M.; Petruccione, F. Quantum ensembles of quantum classifiers. Sci. Rep. 2018, 8, 2772. [Google Scholar] [CrossRef]
- Pérez-Salinas, A.; Cervera-Lierta, A.; Gil-Fuster, E.; Latorre, J.I. Data re-uploading for a universal quantum classifier. Quantum 2020, 4, 226. [Google Scholar] [CrossRef]
- Heys, H.M. A tutorial on linear and differential cryptanalysis. Cryptologia 2002, 26, 189–221. [Google Scholar] [CrossRef]
- Tacchino, F.; Macchiavello, C.; Gerace, D.; Bajoni, D. An artificial neuron implemented on an actual quantum processor. NPJ Quantum Inf. 2019, 5, 26. [Google Scholar] [CrossRef]
- Havlíček, V.; Córcoles, A.D.; Temme, K.; Harrow, A.W.; Kandala, A.; Chow, J.M.; Gambetta, J.M. Supervised learning with quantum-enhanced feature spaces. Nature 2019, 567, 209–212. [Google Scholar] [CrossRef]
- Schuld, M.; Fingerhuth, M.; Petruccione, F. Implementing a distance-based classifier with a quantum interference circuit. Europhys. Lett. 2017, 119, 60002. [Google Scholar] [CrossRef]
- Mitarai, K.; Negoro, M.; Kitagawa, M.; Fujii, K. Quantum circuit learning. Phys. Rev. A 2018, 98, 032309. [Google Scholar] [CrossRef]
- Grant, E.; Benedetti, M.; Cao, S.; Hallam, A.; Lockhart, J.; Stojevic, V.; Green, A.G.; Severini, S. Hierarchical quantum classifiers. npj Quantum Inf. 2018, 4, 65. [Google Scholar] [CrossRef]
- Benedetti, M.; Lloyd, E.; Sack, S.; Fiorentini, M. Parameterized quantum circuits as machine learning models. Quantum Sci. Technol. 2019, 4, 043001. [Google Scholar] [CrossRef]
- Sim, S.; Johnson, P.D.; Aspuru-Guzik, A. Expressibility and entangling capability of parameterized quantum circuits for hybrid quantum-classical algorithms. Adv. Quantum Technol. 2019, 2, 1900070. [Google Scholar] [CrossRef]
- Anand, R.; Maitra, A.; Mukhopadhyay, S. Evaluation of quantum cryptanalysis on speck. In Proceedings of the Progress in Cryptology–INDOCRYPT 2020: 21st International Conference on Cryptology in India, Bangalore, India, 13–16 December 2020; Proceedings 21. Springer: Berlin/Heidelberg, Germany, 2020; pp. 395–413. [Google Scholar]
- Lloyd, S.; Schuld, M.; Ijaz, A.; Izaac, J.; Killoran, N. Quantum embeddings for machine learning. arXiv 2020, arXiv:2001.03622. [Google Scholar]










{kind=link}
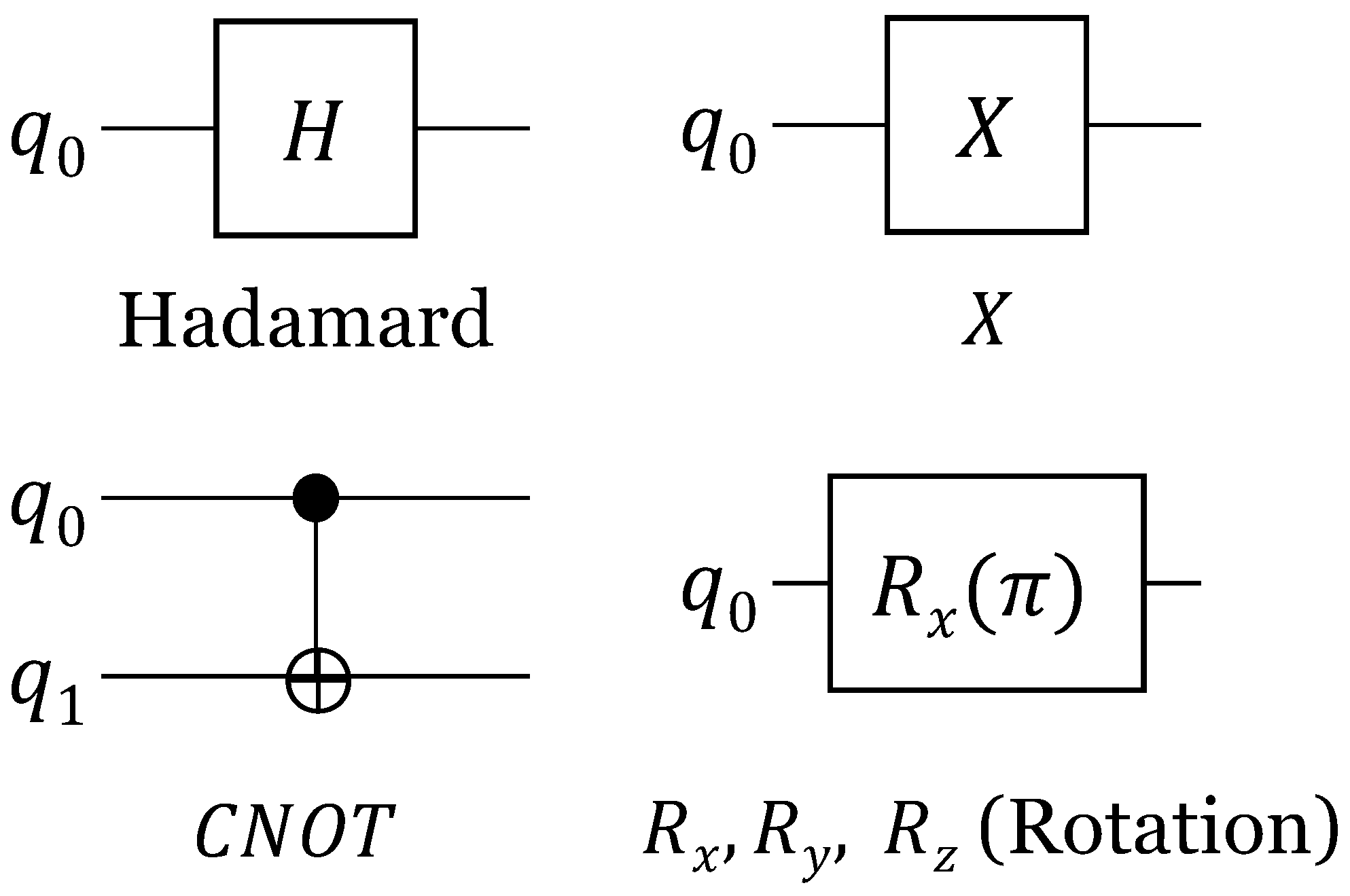{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Embedding Method | Basis | Amplitude |
|---|---|---|
| Qubits | 16 | 6 |
| Training accuracy | 0.52 | 0.51 |
| Test accuracy | 0.53 | 0.50 |
| Quantum layer | 5 | 10 |
| Qubit | 16 | |
| Depth | 22 | 42 |
| Quantum parameters | 80 | 160 |
| Training accuracy | 0.52 | 0.53 |
| Test accuracy | 0.53 | 0.49 |
| Qubit | Quantum Layers | Quantum Parameters | Parameters Per Single Qubit |
|---|---|---|---|
| 8 | 5 | 40 | 5 |
| 8 | 10 | 80 | 10 |
| 16 | 5 | 80 | 5 |
| 16 | 10 | 160 | 10 |
| Qubits | 8 | 16 |
| Gates () | 12, 16, 12, 16 | 26, 29, 25, 31 |
| Quantum parameters | 40 | 80 |
| Depth | 14 | 22 |
| Quantum layers | 5 | 5 |
| Quantum circuit size | 112 | 352 |
| Connectivity | 5.00 | 7.93 |
| Training accuracy | 0.52 | 0.52 |
| Test accuracy | 0.50 | 0.53 |
| Method | Only Q | Constrained C | C1 [4] | C2 [5] |
|---|---|---|---|---|
| Qubits | 16 | - | ||
| Quantum layers | 5 | - | ||
| Embedding method | Basis | - | ||
| Parameters | 385 | 4353 | 100897 | Can be adjusted adaptively |
| Data size (Training, Test) | , | , | ||
| Epoch | 10 | 200 | 10 | |
| Batch size | 32 | 5000 | 500 | |
| Training accuracy | 0.52 | 0.79 | 0.93 | 0.99 (Max) |
| Test accuracy | 0.53 | 0.76 | 0.93 | 0.99 (Max) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.; Jang, K.; Lim, S.; Kang, Y.; Kim, W.; Seo, H. Quantum Neural Network Based Distinguisher on SPECK-32/64. Sensors 2023, 23, 5683. https://doi.org/10.3390/s23125683
Kim H, Jang K, Lim S, Kang Y, Kim W, Seo H. Quantum Neural Network Based Distinguisher on SPECK-32/64. Sensors. 2023; 23(12):5683. https://doi.org/10.3390/s23125683
Chicago/Turabian StyleKim, Hyunji, Kyungbae Jang, Sejin Lim, Yeajun Kang, Wonwoong Kim, and Hwajeong Seo. 2023. "Quantum Neural Network Based Distinguisher on SPECK-32/64" Sensors 23, no. 12: 5683. https://doi.org/10.3390/s23125683
APA StyleKim, H., Jang, K., Lim, S., Kang, Y., Kim, W., & Seo, H. (2023). Quantum Neural Network Based Distinguisher on SPECK-32/64. Sensors, 23(12), 5683. https://doi.org/10.3390/s23125683